
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:YY1AP1-CCDC53 (FusionGDB2 ID:100238) |
Fusion Gene Summary for YY1AP1-CCDC53 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: YY1AP1-CCDC53 | Fusion gene ID: 100238 | Hgene | Tgene | Gene symbol | YY1AP1 | CCDC53 | Gene ID | 55249 | 51019 |
| Gene name | YY1 associated protein 1 | WASH complex subunit 3 | |
| Synonyms | GRNG|HCCA1|HCCA2|YY1AP | CCDC53|CGI-116 | |
| Cytomap | 1q22 | 12q23.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | YY1-associated protein 1hepatocellular carcinoma susceptibility proteinhepatocellular carcinoma-associated protein 2 | WASH complex subunit 3WASH complex subunit CCDC53coiled-coil domain containing 53coiled-coil domain-containing protein 53 | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000295566, ENST00000311573, ENST00000347088, ENST00000355499, ENST00000359205, ENST00000361831, ENST00000368330, ENST00000368339, ENST00000368340, ENST00000404643, ENST00000405763, ENST00000407221, ENST00000535662, ENST00000438245, ENST00000476093, | ENST00000539515, ENST00000240079, ENST00000545679, | |
| Fusion gene scores | * DoF score | 10 X 12 X 6=720 | 6 X 3 X 6=108 |
| # samples | 14 | 6 | |
| ** MAII score | log2(14/720*10)=-2.36257007938471 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/108*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: YY1AP1 [Title/Abstract] AND CCDC53 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | YY1AP1(155638417)-CCDC53(102406970), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | YY1AP1-CCDC53 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | YY1AP1 | GO:0051726 | regulation of cell cycle | 17541814 |
| Fusion gene breakpoints across YY1AP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
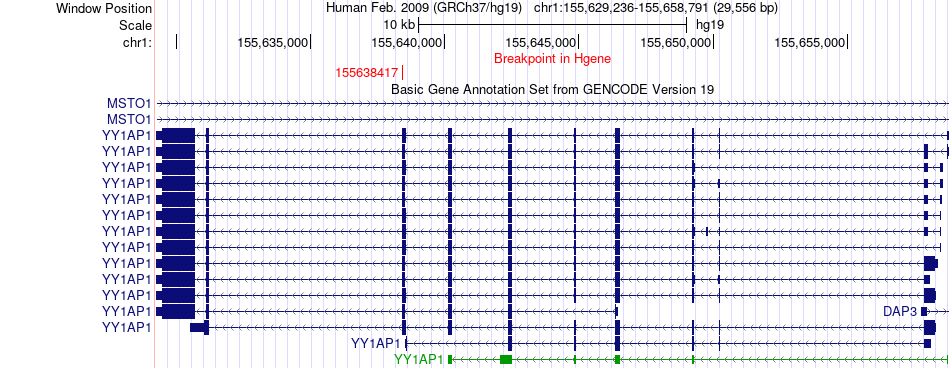 |
| Fusion gene breakpoints across CCDC53 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-L5-A43E | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
Top |
Fusion Gene ORF analysis for YY1AP1-CCDC53 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000295566 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000311573 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000347088 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000355499 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000359205 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000361831 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000368330 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000368339 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000368340 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000404643 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000405763 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000407221 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| 5CDS-intron | ENST00000535662 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000311573 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000311573 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000355499 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000355499 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000361831 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000361831 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000368330 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000368330 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000404643 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| Frame-shift | ENST00000404643 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000295566 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000295566 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000347088 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000347088 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000359205 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000359205 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000368339 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000368339 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000368340 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000368340 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000405763 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000405763 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000407221 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000407221 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000535662 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| In-frame | ENST00000535662 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| intron-3CDS | ENST00000438245 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| intron-3CDS | ENST00000438245 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| intron-3CDS | ENST00000476093 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| intron-3CDS | ENST00000476093 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| intron-intron | ENST00000438245 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| intron-intron | ENST00000476093 | ENST00000539515 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000368340 | YY1AP1 | chr1 | 155638417 | - | ENST00000240079 | CCDC53 | chr12 | 102406970 | - | 1596 | 1342 | 109 | 1365 | 418 |
| ENST00000368340 | YY1AP1 | chr1 | 155638417 | - | ENST00000545679 | CCDC53 | chr12 | 102406970 | - | 1593 | 1342 | 109 | 1365 | 418 |
| ENST00000347088 | YY1AP1 | chr1 | 155638417 | - | ENST00000240079 | CCDC53 | chr12 | 102406970 | - | 1193 | 939 | 57 | 962 | 301 |
| ENST00000347088 | YY1AP1 | chr1 | 155638417 | - | ENST00000545679 | CCDC53 | chr12 | 102406970 | - | 1190 | 939 | 57 | 962 | 301 |
| ENST00000407221 | YY1AP1 | chr1 | 155638417 | - | ENST00000240079 | CCDC53 | chr12 | 102406970 | - | 1374 | 1120 | 334 | 1143 | 269 |
| ENST00000407221 | YY1AP1 | chr1 | 155638417 | - | ENST00000545679 | CCDC53 | chr12 | 102406970 | - | 1371 | 1120 | 334 | 1143 | 269 |
| ENST00000359205 | YY1AP1 | chr1 | 155638417 | - | ENST00000240079 | CCDC53 | chr12 | 102406970 | - | 1359 | 1105 | 139 | 1128 | 329 |
| ENST00000359205 | YY1AP1 | chr1 | 155638417 | - | ENST00000545679 | CCDC53 | chr12 | 102406970 | - | 1356 | 1105 | 139 | 1128 | 329 |
| ENST00000295566 | YY1AP1 | chr1 | 155638417 | - | ENST00000240079 | CCDC53 | chr12 | 102406970 | - | 1295 | 1041 | 24 | 1064 | 346 |
| ENST00000295566 | YY1AP1 | chr1 | 155638417 | - | ENST00000545679 | CCDC53 | chr12 | 102406970 | - | 1292 | 1041 | 24 | 1064 | 346 |
| ENST00000368339 | YY1AP1 | chr1 | 155638417 | - | ENST00000240079 | CCDC53 | chr12 | 102406970 | - | 1552 | 1298 | 5 | 1321 | 438 |
| ENST00000368339 | YY1AP1 | chr1 | 155638417 | - | ENST00000545679 | CCDC53 | chr12 | 102406970 | - | 1549 | 1298 | 5 | 1321 | 438 |
| ENST00000535662 | YY1AP1 | chr1 | 155638417 | - | ENST00000240079 | CCDC53 | chr12 | 102406970 | - | 786 | 532 | 73 | 555 | 160 |
| ENST00000535662 | YY1AP1 | chr1 | 155638417 | - | ENST00000545679 | CCDC53 | chr12 | 102406970 | - | 783 | 532 | 73 | 555 | 160 |
| ENST00000405763 | YY1AP1 | chr1 | 155638417 | - | ENST00000240079 | CCDC53 | chr12 | 102406970 | - | 1558 | 1304 | 11 | 1327 | 438 |
| ENST00000405763 | YY1AP1 | chr1 | 155638417 | - | ENST00000545679 | CCDC53 | chr12 | 102406970 | - | 1555 | 1304 | 11 | 1327 | 438 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000368340 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.033346813 | 0.9666532 |
| ENST00000368340 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.033147078 | 0.9668529 |
| ENST00000347088 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.006344799 | 0.9936552 |
| ENST00000347088 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.006105422 | 0.9938945 |
| ENST00000407221 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.009502771 | 0.99049723 |
| ENST00000407221 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.009284864 | 0.99071515 |
| ENST00000359205 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.009753806 | 0.9902462 |
| ENST00000359205 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.009635855 | 0.99036413 |
| ENST00000295566 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.006758017 | 0.99324197 |
| ENST00000295566 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.006586136 | 0.99341387 |
| ENST00000368339 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.030033303 | 0.96996677 |
| ENST00000368339 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.029681578 | 0.9703184 |
| ENST00000535662 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.032001812 | 0.96799815 |
| ENST00000535662 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.030357737 | 0.9696423 |
| ENST00000405763 | ENST00000240079 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.031678624 | 0.9683214 |
| ENST00000405763 | ENST00000545679 | YY1AP1 | chr1 | 155638417 | - | CCDC53 | chr12 | 102406970 | - | 0.031146161 | 0.96885383 |
Top |
Fusion Genomic Features for YY1AP1-CCDC53 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
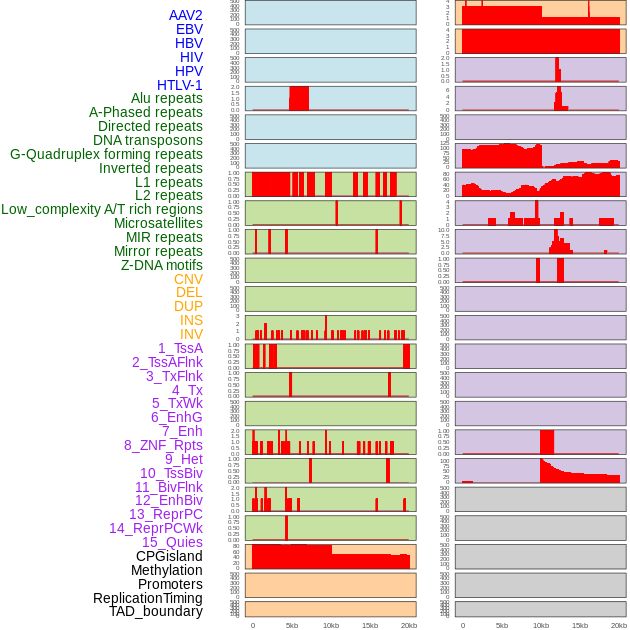 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for YY1AP1-CCDC53 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:155638417/chr12:102406970) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CCDC53 | chr1:155638417 | chr12:102406970 | ENST00000240079 | 5 | 7 | 46_74 | 166 | 195.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for YY1AP1-CCDC53 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >100238_100238_1_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000295566_CCDC53_chr12_102406970_ENST00000240079_length(transcript)=1295nt_BP=1041nt CCTCGATCCCCTCGCCGCGGTCCCATGGAGGAGGAGGCGAGCCGCAGCGCCGCGGCGACGAACCCAGGGAGTCGGCTTACCCGCTGGCCG CCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGGAGGAGCCTGGCGGCCACCCCCTCTTCCTCACTTCCCTGTACTCTC ATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGAAACTTTCCAAGATGAGATGGGATTCTCCAAC ATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCTCTACGGTTTGAGGAACTA CTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCTTCAGCCAAACAGCAGAAG GAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAGAGACTCCAGCAGCAGATG CAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCCAGTAGCACCAGGATATGT CTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCCTGTTCCAACCCTGTAAC TTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTGTCAAGAAGACTGCCAAT GAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTACTTCCAGTGTGTTCCCTG AAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAACAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACA GTGAGAATCAAGAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAA AACTGTAGAAGAAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACAT TTACATTCTGTAAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAA >100238_100238_1_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000295566_CCDC53_chr12_102406970_ENST00000240079_length(amino acids)=346AA_BP= MEEEASRSAAATNPGSRLTRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEE EERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLT QIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQ -------------------------------------------------------------- >100238_100238_2_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000295566_CCDC53_chr12_102406970_ENST00000545679_length(transcript)=1292nt_BP=1041nt CCTCGATCCCCTCGCCGCGGTCCCATGGAGGAGGAGGCGAGCCGCAGCGCCGCGGCGACGAACCCAGGGAGTCGGCTTACCCGCTGGCCG CCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGGAGGAGCCTGGCGGCCACCCCCTCTTCCTCACTTCCCTGTACTCTC ATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGAAACTTTCCAAGATGAGATGGGATTCTCCAAC ATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCTCTACGGTTTGAGGAACTA CTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCTTCAGCCAAACAGCAGAAG GAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAGAGACTCCAGCAGCAGATG CAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCCAGTAGCACCAGGATATGT CTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCCTGTTCCAACCCTGTAAC TTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTGTCAAGAAGACTGCCAAT GAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTACTTCCAGTGTGTTCCCTG AAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAACAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACA GTGAGAATCAAGAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAA AACTGTAGAAGAAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACAT TTACATTCTGTAAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAA >100238_100238_2_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000295566_CCDC53_chr12_102406970_ENST00000545679_length(amino acids)=346AA_BP= MEEEASRSAAATNPGSRLTRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEE EERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLT QIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQ -------------------------------------------------------------- >100238_100238_3_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000347088_CCDC53_chr12_102406970_ENST00000240079_length(transcript)=1193nt_BP=939nt GAAGAGGAGGTGGAGAAGGCTTGGGCTCGCGCCGCTGAAGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGAAACTTTCCAAGAT GAGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCT CTACGGTTTGAGGAACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCT TCAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAG AGACTCCAGCAGCAGATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCC AGTAGCACCAGGATATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACC CTGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACT GTCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTA CTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAATTTGTTAGCTTTAGGACTGAAG CATTTTGAAGGGACTGAGTTTCTTAACCCTCTAATCAGCAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAG AACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGA AAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTA AGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATAATAAT >100238_100238_3_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000347088_CCDC53_chr12_102406970_ENST00000240079_length(amino acids)=301AA_BP= MMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVH QTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFST HVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNLLALGLKHFEGTEFLNPLISKYLLTC -------------------------------------------------------------- >100238_100238_4_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000347088_CCDC53_chr12_102406970_ENST00000545679_length(transcript)=1190nt_BP=939nt GAAGAGGAGGTGGAGAAGGCTTGGGCTCGCGCCGCTGAAGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGAAACTTTCCAAGAT GAGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCT CTACGGTTTGAGGAACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCT TCAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAG AGACTCCAGCAGCAGATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCC AGTAGCACCAGGATATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACC CTGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACT GTCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTA CTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAATTTGTTAGCTTTAGGACTGAAG CATTTTGAAGGGACTGAGTTTCTTAACCCTCTAATCAGCAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAG AACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGA AAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTA AGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATAATAAT >100238_100238_4_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000347088_CCDC53_chr12_102406970_ENST00000545679_length(amino acids)=301AA_BP= MMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVH QTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFST HVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNLLALGLKHFEGTEFLNPLISKYLLTC -------------------------------------------------------------- >100238_100238_5_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000359205_CCDC53_chr12_102406970_ENST00000240079_length(transcript)=1359nt_BP=1105nt GTAGGGTGGGGGTGCTGGCGGCGGCTGCTTTGGCGGCGGTTGGTGGCCGTGCGGGCGGGGAGGGAGGGGGAGGAGAGAAGAGGAGGTGGA GAAGGCTTGGGCTCGCGCCGCTGAAGTCGGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGG AGGAGCCTGGCGGCCACCCCCTCTTCCTCACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGTTCCAAGATGAGATGGGATTCTC CAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCTCTACGGTTTGAGGA ACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCTTCAGCCAAACAGCA GAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAGAGACTCCAGCAGCA GATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCCAGTAGCACCAGGAT ATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCCTGTTCCAACCCTG TAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTGTCAAGAAGACTGC CAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTACTTCCAGTGTGTTC CCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAATTTGTTAGCTTTAGGACTGAAGCATTTTGAAGGGAC TGAGTTTCTTAACCCTCTAATCAGCAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAGAACCTCAACATGAA CAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGAAAGTTCAGATAGCG AATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTAAGAGATTGAGCCTG AACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATAATAATAAAGCAGTTTTAAC >100238_100238_5_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000359205_CCDC53_chr12_102406970_ENST00000240079_length(amino acids)=329AA_BP= MTSGRDPRWTQGSGGAWRPPPLPHFPVLSSLSASDTFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKEL FEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALH HQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAE -------------------------------------------------------------- >100238_100238_6_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000359205_CCDC53_chr12_102406970_ENST00000545679_length(transcript)=1356nt_BP=1105nt GTAGGGTGGGGGTGCTGGCGGCGGCTGCTTTGGCGGCGGTTGGTGGCCGTGCGGGCGGGGAGGGAGGGGGAGGAGAGAAGAGGAGGTGGA GAAGGCTTGGGCTCGCGCCGCTGAAGTCGGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGG AGGAGCCTGGCGGCCACCCCCTCTTCCTCACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGTTCCAAGATGAGATGGGATTCTC CAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCTCTACGGTTTGAGGA ACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCTTCAGCCAAACAGCA GAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAGAGACTCCAGCAGCA GATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCCAGTAGCACCAGGAT ATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCCTGTTCCAACCCTG TAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTGTCAAGAAGACTGC CAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTACTTCCAGTGTGTTC CCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAATTTGTTAGCTTTAGGACTGAAGCATTTTGAAGGGAC TGAGTTTCTTAACCCTCTAATCAGCAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAGAACCTCAACATGAA CAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGAAAGTTCAGATAGCG AATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTAAGAGATTGAGCCTG AACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATAATAATAAAGCAGTTTTAAC >100238_100238_6_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000359205_CCDC53_chr12_102406970_ENST00000545679_length(amino acids)=329AA_BP= MTSGRDPRWTQGSGGAWRPPPLPHFPVLSSLSASDTFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKEL FEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALH HQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAE -------------------------------------------------------------- >100238_100238_7_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000368339_CCDC53_chr12_102406970_ENST00000240079_length(transcript)=1552nt_BP=1298nt GCTACATGGCCGGAGTCGGGCGAAGCGGGGGACCGTGGGGAAGAACGCGAGGAGGGAGGAGTGGGAGGTTGGGGGTGTCGCTAGGCGCCC TTAGCTCCCTCCCTCTGGAGGAGCTGCCGCGGCCACTCTGCTGCCGCCGCTGCCGCCGCCATTTTGGGTTCGCTTTGCGAGGGGAAACGA TCCCAGTGTCGGTTGCGGGATCCGCCTCCTCTCAGTTTGCCCCTTTAGCCCTCCACCTTTCCCTTCTCCTCTCTCGCATTTCCGCCAGTC GGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGGAGGAGCCTGGCGGCCACCCCCTCTTCCT CACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGAAACTTTCCAAGATG AGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCTC TACGGTTTGAGGAACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCTT CAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAGA GACTCCAGCAGCAGATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCCA GTAGCACCAGGATATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCC TGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTG TCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTAC TTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAATTTGTTAGCTTTAGGACTGAAGC ATTTTGAAGGGACTGAGTTTCTTAACCCTCTAATCAGCAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAGA ACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGAA AGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTAA GAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATAATAATA >100238_100238_7_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000368339_CCDC53_chr12_102406970_ENST00000240079_length(amino acids)=438AA_BP= MAGVGRSGGPWGRTRGGRSGRLGVSLGALSSLPLEELPRPLCCRRCRRHFGFALRGETIPVSVAGSASSQFAPLALHLSLLLSRISASRL TRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALR FEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASS TRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLP -------------------------------------------------------------- >100238_100238_8_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000368339_CCDC53_chr12_102406970_ENST00000545679_length(transcript)=1549nt_BP=1298nt GCTACATGGCCGGAGTCGGGCGAAGCGGGGGACCGTGGGGAAGAACGCGAGGAGGGAGGAGTGGGAGGTTGGGGGTGTCGCTAGGCGCCC TTAGCTCCCTCCCTCTGGAGGAGCTGCCGCGGCCACTCTGCTGCCGCCGCTGCCGCCGCCATTTTGGGTTCGCTTTGCGAGGGGAAACGA TCCCAGTGTCGGTTGCGGGATCCGCCTCCTCTCAGTTTGCCCCTTTAGCCCTCCACCTTTCCCTTCTCCTCTCTCGCATTTCCGCCAGTC GGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGGAGGAGCCTGGCGGCCACCCCCTCTTCCT CACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGAAACTTTCCAAGATG AGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCTC TACGGTTTGAGGAACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCTT CAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAGA GACTCCAGCAGCAGATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCCA GTAGCACCAGGATATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCC TGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTG TCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTAC TTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAATTTGTTAGCTTTAGGACTGAAGC ATTTTGAAGGGACTGAGTTTCTTAACCCTCTAATCAGCAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAGA ACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGAA AGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTAA GAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATAATAATA >100238_100238_8_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000368339_CCDC53_chr12_102406970_ENST00000545679_length(amino acids)=438AA_BP= MAGVGRSGGPWGRTRGGRSGRLGVSLGALSSLPLEELPRPLCCRRCRRHFGFALRGETIPVSVAGSASSQFAPLALHLSLLLSRISASRL TRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALR FEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASS TRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLP -------------------------------------------------------------- >100238_100238_9_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000368340_CCDC53_chr12_102406970_ENST00000240079_length(transcript)=1596nt_BP=1342nt CGCGTACGGGATGGCTGGCTCGCAGGACGGCCGAAGGTGGTGGTTGGTGGGAGCAGCCAGCGACGAGCCCGTAGACACTCGTACGCGTGC GGGCTGACGTGCGCGCTACATGGCCGGAGTCGGGCGAAGCGGGGGACCGTGGGGAAGAACGCGAGGAGGGAGGAGTGGGAGGTTGGGGGT GTCGCTAGGCGCCCTTAGCTCCCTCCCTCTGGAGGAGCTGCCGCGGCCACTCTGCTGCCGCCGCTGCCGCCGCCATTTTGGGTTCGCTTT GCGAGGGGAAACGATCCCAGTGTCGGTTGCGGGATCCGCCTCCTCTCAGTTTGCCCCTTTAGCCCTCCACCTTTCCCTTCTCCTCTCTCG CATTTCCGCCAGTCGGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGGAGGAGCCTGGCGGC CACCCCCTCTTCCTCACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGA AACTTTCCAAGATGAGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAA CACCCCTCAAGCTCTACGGTTTGAGGAACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAA GATGAAGAAACCTTCAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCC AGCACAAAGGAAGAGACTCCAGCAGCAGATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCT CAATCCGGAGGCCAGTAGCACCAGGATATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCC CAAGTTTCAGACCCTGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAG CCCTCATAAAACTGTCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCAT GTATCCAGAGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAACAAGTACCT TCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAGAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAG ATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGAAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGAT AAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTAAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCA >100238_100238_9_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000368340_CCDC53_chr12_102406970_ENST00000240079_length(amino acids)=418AA_BP= MAGVGRSGGPWGRTRGGRSGRLGVSLGALSSLPLEELPRPLCCRRCRRHFGFALRGETIPVSVAGSASSQFAPLALHLSLLLSRISASRL TRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALR FEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASS TRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLP -------------------------------------------------------------- >100238_100238_10_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000368340_CCDC53_chr12_102406970_ENST00000545679_length(transcript)=1593nt_BP=1342nt CGCGTACGGGATGGCTGGCTCGCAGGACGGCCGAAGGTGGTGGTTGGTGGGAGCAGCCAGCGACGAGCCCGTAGACACTCGTACGCGTGC GGGCTGACGTGCGCGCTACATGGCCGGAGTCGGGCGAAGCGGGGGACCGTGGGGAAGAACGCGAGGAGGGAGGAGTGGGAGGTTGGGGGT GTCGCTAGGCGCCCTTAGCTCCCTCCCTCTGGAGGAGCTGCCGCGGCCACTCTGCTGCCGCCGCTGCCGCCGCCATTTTGGGTTCGCTTT GCGAGGGGAAACGATCCCAGTGTCGGTTGCGGGATCCGCCTCCTCTCAGTTTGCCCCTTTAGCCCTCCACCTTTCCCTTCTCCTCTCTCG CATTTCCGCCAGTCGGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGGAGGAGCCTGGCGGC CACCCCCTCTTCCTCACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGA AACTTTCCAAGATGAGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAA CACCCCTCAAGCTCTACGGTTTGAGGAACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAA GATGAAGAAACCTTCAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCC AGCACAAAGGAAGAGACTCCAGCAGCAGATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCT CAATCCGGAGGCCAGTAGCACCAGGATATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCC CAAGTTTCAGACCCTGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAG CCCTCATAAAACTGTCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCAT GTATCCAGAGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAACAAGTACCT TCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAGAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAG ATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGAAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGAT AAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTAAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCA >100238_100238_10_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000368340_CCDC53_chr12_102406970_ENST00000545679_length(amino acids)=418AA_BP= MAGVGRSGGPWGRTRGGRSGRLGVSLGALSSLPLEELPRPLCCRRCRRHFGFALRGETIPVSVAGSASSQFAPLALHLSLLLSRISASRL TRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALR FEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASS TRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLP -------------------------------------------------------------- >100238_100238_11_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000405763_CCDC53_chr12_102406970_ENST00000240079_length(transcript)=1558nt_BP=1304nt GTGCGCGCTACATGGCCGGAGTCGGGCGAAGCGGGGGACCGTGGGGAAGAACGCGAGGAGGGAGGAGTGGGAGGTTGGGGGTGTCGCTAG GCGCCCTTAGCTCCCTCCCTCTGGAGGAGCTGCCGCGGCCACTCTGCTGCCGCCGCTGCCGCCGCCATTTTGGGTTCGCTTTGCGAGGGG AAACGATCCCAGTGTCGGTTGCGGGATCCGCCTCCTCTCAGTTTGCCCCTTTAGCCCTCCACCTTTCCCTTCTCCTCTCTCGCATTTCCG CCAGTCGGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGGAGGAGCCTGGCGGCCACCCCCT CTTCCTCACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGAAACTTTCC AAGATGAGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTC AAGCTCTACGGTTTGAGGAACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGA AACCTTCAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAA GGAAGAGACTCCAGCAGCAGATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGG AGGCCAGTAGCACCAGGATATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTC AGACCCTGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATA AAACTGTCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAG AGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAATTTGTTAGCTTTAGGAC TGAAGCATTTTGAAGGGACTGAGTTTCTTAACCCTCTAATCAGCAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAA TCAAGAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTA GAAGAAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATT CTGTAAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATA >100238_100238_11_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000405763_CCDC53_chr12_102406970_ENST00000240079_length(amino acids)=438AA_BP= MAGVGRSGGPWGRTRGGRSGRLGVSLGALSSLPLEELPRPLCCRRCRRHFGFALRGETIPVSVAGSASSQFAPLALHLSLLLSRISASRL TRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALR FEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASS TRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLP -------------------------------------------------------------- >100238_100238_12_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000405763_CCDC53_chr12_102406970_ENST00000545679_length(transcript)=1555nt_BP=1304nt GTGCGCGCTACATGGCCGGAGTCGGGCGAAGCGGGGGACCGTGGGGAAGAACGCGAGGAGGGAGGAGTGGGAGGTTGGGGGTGTCGCTAG GCGCCCTTAGCTCCCTCCCTCTGGAGGAGCTGCCGCGGCCACTCTGCTGCCGCCGCTGCCGCCGCCATTTTGGGTTCGCTTTGCGAGGGG AAACGATCCCAGTGTCGGTTGCGGGATCCGCCTCCTCTCAGTTTGCCCCTTTAGCCCTCCACCTTTCCCTTCTCCTCTCTCGCATTTCCG CCAGTCGGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGGAGGAGCCTGGCGGCCACCCCCT CTTCCTCACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATGGAAGATCTGTTTGAAACTTTCC AAGATGAGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTC AAGCTCTACGGTTTGAGGAACTACTGGCCAACCTACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGA AACCTTCAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAA GGAAGAGACTCCAGCAGCAGATGCAGCAGCATGTTCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGG AGGCCAGTAGCACCAGGATATGTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTC AGACCCTGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATA AAACTGTCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAG AGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAATTTGTTAGCTTTAGGAC TGAAGCATTTTGAAGGGACTGAGTTTCTTAACCCTCTAATCAGCAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAA TCAAGAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTA GAAGAAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATT CTGTAAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATA >100238_100238_12_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000405763_CCDC53_chr12_102406970_ENST00000545679_length(amino acids)=438AA_BP= MAGVGRSGGPWGRTRGGRSGRLGVSLGALSSLPLEELPRPLCCRRCRRHFGFALRGETIPVSVAGSASSQFAPLALHLSLLLSRISASRL TRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALR FEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASS TRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLP -------------------------------------------------------------- >100238_100238_13_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000407221_CCDC53_chr12_102406970_ENST00000240079_length(transcript)=1374nt_BP=1120nt GTAGGGTGGGGGTGCTGGCGGCGGCTGCTTTGGCGGCGGTTGGTGGCCGTGCGGGCGGGGAGGGAGGGGGAGGAGAGAAGAGGAGGTGGA GAAGGCTTGGGCTCGCGCCGCTGAAGTCGGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGG AGGAGCCTGGCGGCCACCCCCTCTTCCTCACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATG GAAGATCTGTTTGAAACTGTGAGTAATGATCCTCAAGTGAGAACATGGGATTTTCCAAGATGAGATGGGATTCTCCAACATGGAAGATGA TGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCTCTACGGTTTGAGGAACTACTGGCCAACCT ACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCTTCAGCCAAACAGCAGAAGGAGGTAGAGAA GGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAGAGACTCCAGCAGCAGATGCAGCAGCATGT TCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCCAGTAGCACCAGGATATGTCTTAAAGAGCT GGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCCTGTTCCAACCCTGTAACTTGATGGGAGC TATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTGTCAAGAAGACTGCCAATGAATTTCCCTG TTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAA TCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAACAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAA GAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAG AAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGT AAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATAATAA >100238_100238_13_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000407221_CCDC53_chr12_102406970_ENST00000240079_length(amino acids)=269AA_BP= MGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKR LQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTV -------------------------------------------------------------- >100238_100238_14_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000407221_CCDC53_chr12_102406970_ENST00000545679_length(transcript)=1371nt_BP=1120nt GTAGGGTGGGGGTGCTGGCGGCGGCTGCTTTGGCGGCGGTTGGTGGCCGTGCGGGCGGGGAGGGAGGGGGAGGAGAGAAGAGGAGGTGGA GAAGGCTTGGGCTCGCGCCGCTGAAGTCGGCTTACCCGCTGGCCGCCTCCTGACAAGCGGGAGGGATCCGCGGTGGACCCAGGGAAGCGG AGGAGCCTGGCGGCCACCCCCTCTTCCTCACTTCCCTGTACTCTCATCGCTCTCGGCCTCCGACACGAAAAGGAAGCAAATGAGCTGATG GAAGATCTGTTTGAAACTGTGAGTAATGATCCTCAAGTGAGAACATGGGATTTTCCAAGATGAGATGGGATTCTCCAACATGGAAGATGA TGGCCCAGAAGAGGAGGAGCGTGTGGCTGAGCCTCAAGCTAACTTTAACACCCCTCAAGCTCTACGGTTTGAGGAACTACTGGCCAACCT ACTAAATGAACAACATCAGATAGCGAAGGAACTATTTGAACAGCTGAAGATGAAGAAACCTTCAGCCAAACAGCAGAAGGAGGTAGAGAA GGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGCACAAAGGAAGAGACTCCAGCAGCAGATGCAGCAGCATGT TCAGCTCTTGACACAAATCCACCTTCTTGCCACCTGCAACCCCAATCTCAATCCGGAGGCCAGTAGCACCAGGATATGTCTTAAAGAGCT GGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCCTGTTCCAACCCTGTAACTTGATGGGAGC TATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTGTCAAGAAGACTGCCAATGAATTTCCCTG TTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCATGTATCCAGAGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAA TCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAACAAGTACCTTCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAA GAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAGATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAG AAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGATAAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGT AAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCACATGTCCACTACCAAGCTTCTTCTATGTTAAAAAAATAATAA >100238_100238_14_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000407221_CCDC53_chr12_102406970_ENST00000545679_length(amino acids)=269AA_BP= MGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKR LQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTV -------------------------------------------------------------- >100238_100238_15_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000535662_CCDC53_chr12_102406970_ENST00000240079_length(transcript)=786nt_BP=532nt GAAGAAACCTTCAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGC ACAAAGGAAGAGACTCCAGCAGCAGATGCAGCAGAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCC CAAGTTTCAGACCCTGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAG CCCTCATAAAACTGTCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCAT GTATCCAGAGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAACAAGTACCT TCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAGAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAG ATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGAAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGAT AAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTAAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCA >100238_100238_15_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000535662_CCDC53_chr12_102406970_ENST00000240079_length(amino acids)=160AA_BP= MILDPAQRKRLQQQMQQKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILA -------------------------------------------------------------- >100238_100238_16_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000535662_CCDC53_chr12_102406970_ENST00000545679_length(transcript)=783nt_BP=532nt GAAGAAACCTTCAGCCAAACAGCAGAAGGAGGTAGAGAAGGTTAAACCCCAGTGTAAGGAAGTTCATCAGACCCTGATTCTGGACCCAGC ACAAAGGAAGAGACTCCAGCAGCAGATGCAGCAGAAAGAGCTGGGAACCTTTGCTCAAAGCTCCATCGCCCTTCACCATCAGTACAACCC CAAGTTTCAGACCCTGTTCCAACCCTGTAACTTGATGGGAGCTATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAG CCCTCATAAAACTGTCAAGAAGACTGCCAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATCCTGGCCACAAGCAAGGTTTTCAT GTATCCAGAGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCCTCTTCACCAAGGCTGAGGACAACAAGTACCT TCTAACCTGCAAGACTGCCCGCCAACTGACAGTGAGAATCAAGAACCTCAACATGAACAGAGCTCCTGACAACATCATTAAAGAGGCCAG ATGCTCCAGTGCCTGATGGCGAAAGTGAGAAAACTGTAGAAGAAAGTTCAGATAGCGAATCTTCTTTTAGTGATTAAGCTTAATTTTGAT AAGAATTACATATGCATGCATAGGGGTACATTTACATTCTGTAAGAGATTGAGCCTGAACTCTCTTAGTCATAAAAACATCAAATGGCCA >100238_100238_16_YY1AP1-CCDC53_YY1AP1_chr1_155638417_ENST00000535662_CCDC53_chr12_102406970_ENST00000545679_length(amino acids)=160AA_BP= MILDPAQRKRLQQQMQQKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for YY1AP1-CCDC53 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for YY1AP1-CCDC53 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for YY1AP1-CCDC53 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies