
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ZNF223-AP2A1 (FusionGDB2 ID:101644) |
Fusion Gene Summary for ZNF223-AP2A1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ZNF223-AP2A1 | Fusion gene ID: 101644 | Hgene | Tgene | Gene symbol | ZNF223 | AP2A1 | Gene ID | 7766 | 160 |
| Gene name | zinc finger protein 223 | adaptor related protein complex 2 subunit alpha 1 | |
| Synonyms | - | ADTAA|AP2-ALPHA|CLAPA1 | |
| Cytomap | 19q13.31 | 19q13.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | zinc finger protein 223Homo sapiens zinc finger protein 223KRAB A domain | AP-2 complex subunit alpha-1100 kDa coated vesicle protein Aadapter-related protein complex 2 alpha-1 subunitadapter-related protein complex 2 subunit alpha-1adaptin, alpha Aadaptor protein complex AP-2 subunit alpha-1adaptor related protein complex | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | O95782 | |
| Ensembl transtripts involved in fusion gene | ENST00000588518, ENST00000434772, ENST00000585552, ENST00000591793, | ENST00000354293, ENST00000359032, ENST00000600199, | |
| Fusion gene scores | * DoF score | 2 X 2 X 2=8 | 13 X 12 X 6=936 |
| # samples | 2 | 15 | |
| ** MAII score | log2(2/8*10)=1.32192809488736 | log2(15/936*10)=-2.64154602908752 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ZNF223 [Title/Abstract] AND AP2A1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ZNF223(44559344)-AP2A1(50298887), # samples:4 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | AP2A1 | GO:0072583 | clathrin-dependent endocytosis | 23676497 |
| Tgene | AP2A1 | GO:1900126 | negative regulation of hyaluronan biosynthetic process | 24251095 |
| Fusion gene breakpoints across ZNF223 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across AP2A1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SARC | TCGA-DX-AB2Q-01A | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| ChimerDB4 | SARC | TCGA-QQ-A8VF-01A | ZNF223 | chr19 | 44559344 | - | AP2A1 | chr19 | 50298887 | + |
| ChimerDB4 | SARC | TCGA-QQ-A8VF-01A | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
Top |
Fusion Gene ORF analysis for ZNF223-AP2A1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000588518 | ENST00000354293 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| 3UTR-3UTR | ENST00000588518 | ENST00000359032 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| 3UTR-3UTR | ENST00000588518 | ENST00000600199 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| 5CDS-3UTR | ENST00000434772 | ENST00000359032 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| 5CDS-3UTR | ENST00000434772 | ENST00000600199 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| 5CDS-3UTR | ENST00000585552 | ENST00000359032 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| 5CDS-3UTR | ENST00000585552 | ENST00000600199 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| 5CDS-3UTR | ENST00000591793 | ENST00000359032 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| 5CDS-3UTR | ENST00000591793 | ENST00000600199 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| In-frame | ENST00000434772 | ENST00000354293 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| In-frame | ENST00000585552 | ENST00000354293 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| In-frame | ENST00000591793 | ENST00000354293 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000591793 | ZNF223 | chr19 | 44559344 | + | ENST00000354293 | AP2A1 | chr19 | 50298887 | + | 2945 | 428 | 14 | 2590 | 858 |
| ENST00000434772 | ZNF223 | chr19 | 44559344 | + | ENST00000354293 | AP2A1 | chr19 | 50298887 | + | 2787 | 270 | 195 | 2432 | 745 |
| ENST00000585552 | ZNF223 | chr19 | 44559344 | + | ENST00000354293 | AP2A1 | chr19 | 50298887 | + | 2755 | 238 | 163 | 2400 | 745 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000591793 | ENST00000354293 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + | 0.005832758 | 0.9941672 |
| ENST00000434772 | ENST00000354293 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + | 0.012226836 | 0.9877731 |
| ENST00000585552 | ENST00000354293 | ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298887 | + | 0.012761513 | 0.9872385 |
Top |
Fusion Genomic Features for ZNF223-AP2A1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298886 | + | 5.16E-09 | 1 |
| ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298886 | + | 5.16E-09 | 1 |
| ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298886 | + | 5.16E-09 | 1 |
| ZNF223 | chr19 | 44559344 | + | AP2A1 | chr19 | 50298886 | + | 5.16E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
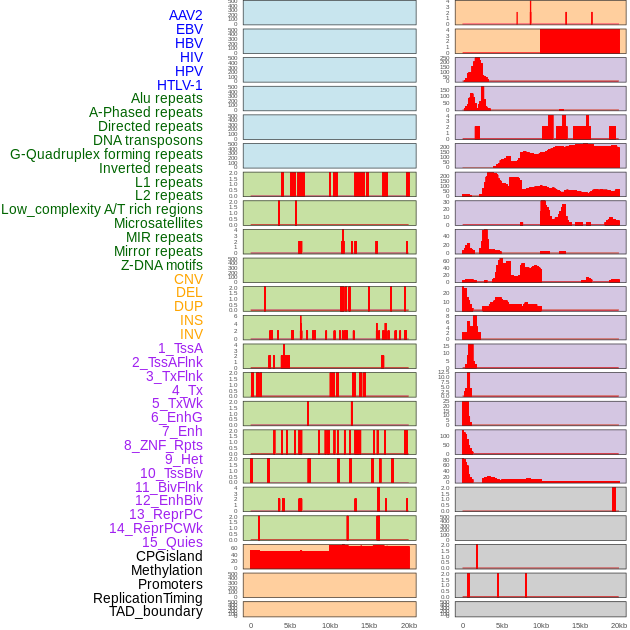 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
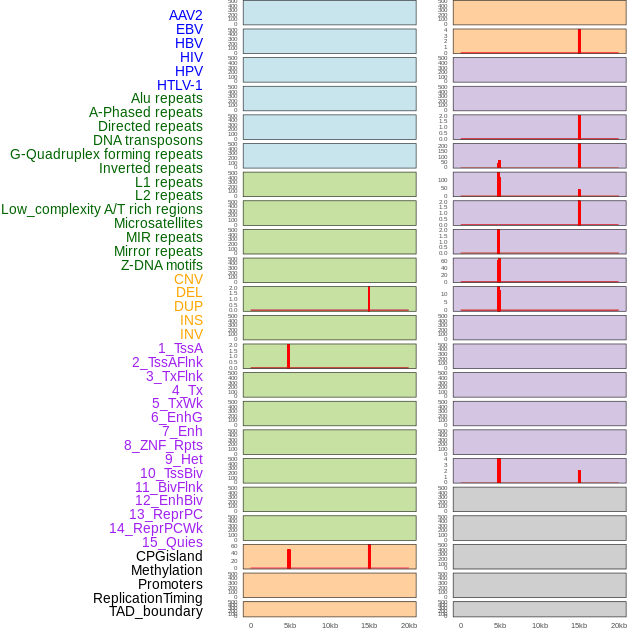 |
Top |
Fusion Protein Features for ZNF223-AP2A1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:44559344/chr19:50298887) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | AP2A1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Component of the adaptor protein complex 2 (AP-2). Adaptor protein complexes function in protein transport via transport vesicles in different membrane traffic pathways. Adaptor protein complexes are vesicle coat components and appear to be involved in cargo selection and vesicle formation. AP-2 is involved in clathrin-dependent endocytosis in which cargo proteins are incorporated into vesicles surrounded by clathrin (clathrin-coated vesicles, CCVs) which are destined for fusion with the early endosome. The clathrin lattice serves as a mechanical scaffold but is itself unable to bind directly to membrane components. Clathrin-associated adaptor protein (AP) complexes which can bind directly to both the clathrin lattice and to the lipid and protein components of membranes are considered to be the major clathrin adaptors contributing the CCV formation. AP-2 also serves as a cargo receptor to selectively sort the membrane proteins involved in receptor-mediated endocytosis. AP-2 seems to play a role in the recycling of synaptic vesicle membranes from the presynaptic surface. AP-2 recognizes Y-X-X-[FILMV] (Y-X-X-Phi) and [ED]-X-X-X-L-[LI] endocytosis signal motifs within the cytosolic tails of transmembrane cargo molecules. AP-2 may also play a role in maintaining normal post-endocytic trafficking through the ARF6-regulated, non-clathrin pathway. During long-term potentiation in hippocampal neurons, AP-2 is responsible for the endocytosis of ADAM10 (PubMed:23676497). The AP-2 alpha subunit binds polyphosphoinositide-containing lipids, positioning AP-2 on the membrane. The AP-2 alpha subunit acts via its C-terminal appendage domain as a scaffolding platform for endocytic accessory proteins. The AP-2 alpha and AP-2 sigma subunits are thought to contribute to the recognition of the [ED]-X-X-X-L-[LI] motif (By similarity). {ECO:0000250, ECO:0000269|PubMed:14745134, ECO:0000269|PubMed:15473838, ECO:0000269|PubMed:19033387, ECO:0000269|PubMed:23676497}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 8_78 | 5 | 483.0 | Domain | KRAB |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 176_198 | 5 | 483.0 | Zinc finger | C2H2-type 1 |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 204_226 | 5 | 483.0 | Zinc finger | C2H2-type 2 |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 232_254 | 5 | 483.0 | Zinc finger | C2H2-type 3 |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 260_282 | 5 | 483.0 | Zinc finger | C2H2-type 4 |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 288_310 | 5 | 483.0 | Zinc finger | C2H2-type 5 |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 316_338 | 5 | 483.0 | Zinc finger | C2H2-type 6%3B degenerate |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 344_366 | 5 | 483.0 | Zinc finger | C2H2-type 7 |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 372_394 | 5 | 483.0 | Zinc finger | C2H2-type 8 |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 400_422 | 5 | 483.0 | Zinc finger | C2H2-type 9 |
| Hgene | ZNF223 | chr19:44559344 | chr19:50298887 | ENST00000434772 | + | 2 | 5 | 428_450 | 5 | 483.0 | Zinc finger | C2H2-type 10%3B degenerate |
Top |
Fusion Gene Sequence for ZNF223-AP2A1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >101644_101644_1_ZNF223-AP2A1_ZNF223_chr19_44559344_ENST00000434772_AP2A1_chr19_50298887_ENST00000354293_length(transcript)=2787nt_BP=270nt GCGCAGAGAGGACACTTCCGGTCTCCTAGTCTGAGGTTCCTGCTTTAATGACCGGGGTAGTTTGAGCCATTTCTGCGTCTTGCAGGACAT TTTGAACGAACCCCCTTTGCTTGAGGCTCGCAACCACCCGATGATCGATGATCGTCTCAGGGGAAAAGAAGCCTTGGCGAAGAGCAGAGG TTTAGAGGCACAATTCTGCTTTCCCTGGAACTGTGTCATTCAGGACTCTGCAAATTCCCTAAAGTAGGAGGAAAAATGACCATGTCCAAG ATCGTCTCCTCTGCCTCCACCGACCTCCAGGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTG CAGTGCTACCCGCCTCCAGAGGATGCGGCTGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCC AAATCCAAGAAGGTGCAGCATTCCAACGCCAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAAC CTCCTGGTTCGGGCCTGCAACCAGCTGGGCCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACG CTGGCCAGCTCCGAGTTCTCCCATGAAGCCGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTG CGGCAGCGGGCGGCTGACCTCCTCTACGCCATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACG GCAGACTACGCCATCCGCGAGGAGATCGTCCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACC ATCCTCAACCTCATCCGCATTGCGGGCGACTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTC CAGGGCTATGCCGCCAAGACCGTCTTTGAGGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGG GAGTTTGGGAACCTGATTGCTGGGGACCCCCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTG GCCACGCGGGCGCTGCTGCTGTCCACCTACATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCC GGCTCCCAGCTGCGCAATGCTGACGTGGAGCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTG GCCACGGTGCTGGAGGAGATGCCGCCCTTCCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGC AGCGCCCTGGACGATGGCCGGAGGGACCCCAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCG CCCTCCGCCGACCTCCTGGGGCTGCGGGCAGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTC TTCGATGGCCCGGCCGCCCAGCCCAGCCTGGGGCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATT CCGGAAGCCGATGAGTTGCTGAATAAGTTTGTGTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCA GAGTTCCGACAGAACCTGGGCCGCATGTATCTCTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCAC CCGGGAGACCTCCAGACTCAGCTGGCTGTGCAGACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAAT ATCGAGTGCCTGCGGGACTTCCTGACGCCCCCGCTGCTGTCCGTGCGCTTCCGGTACGGTGGCGCCCCCCAGGCCCTCACCCTGAAGCTC CCAGTGACCATCAACAAGTTCTTCCAGCCCACCGAGATGGCGGCCCAGGATTTCTTCCAGCGCTGGAAGCAGCTGAGCCTCCCTCAACAG GAGGCGCAGAAAATCTTCAAAGCCAACCACCCCATGGACGCAGAAGTTACTAAGGCCAAGCTTCTGGGGTTTGGCTCTGCTCTCCTGGAC AATGTGGACCCCAACCCTGAGAACTTCGTGGGGGCGGGGATCATCCAGACTAAAGCCCTGCAGGTGGGCTGTCTGCTTCGGCTGGAGCCC AATGCCCAGGCCCAGATGTACCGGCTGACCCTGCGCACCAGCAAGGAGCCCGTCTCCCGTCACCTGTGTGAGCTGCTGGCACAGCAGTTC TGAGCCCTGGACTCTGCCCCGGGGGATGTGGCCGGCACTGGGCAGCCCCTTGGACTGAGGCAGTTTTGGTGGATGGGGGACCTCCACTGG TGACAGAGAAGACACCAGGGTTTGGGGGATGCCTGGGACTTTCCTCCGGCCTTTTGTATTTTTATTTTTGTTCATCTGCTGCTGTTTACA TTCTGGGGGGTTAGGGGGAGTCCCCCTCCCTCCCTTTCCCCCCCAAGCACAGAGGGGAGAGGGGCCAGGGAAGTGGATGTCTCCTCCCCT >101644_101644_1_ZNF223-AP2A1_ZNF223_chr19_44559344_ENST00000434772_AP2A1_chr19_50298887_ENST00000354293_length(amino acids)=745AA_BP=25 MLSLELCHSGLCKFPKVGGKMTMSKIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVKGRLVECLETVLNKAQEPPKSKKV QHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIDTVINALKTERDVSVRQRAA DLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYVSEEVWYRVLQIVTNRDDVQGYAA KTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIKFINLFPETKATIQGVLRAGSQLR NADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSSNDINGGMEPTPSTVSTPSPSADL LGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQN LGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTKRVAAQVDGGAQVQQVLNIECLRDFLTPPLLSVRFRYGGAPQALTLKLPVTIN KFFQPTEMAAQDFFQRWKQLSLPQQEAQKIFKANHPMDAEVTKAKLLGFGSALLDNVDPNPENFVGAGIIQTKALQVGCLLRLEPNAQAQ -------------------------------------------------------------- >101644_101644_2_ZNF223-AP2A1_ZNF223_chr19_44559344_ENST00000585552_AP2A1_chr19_50298887_ENST00000354293_length(transcript)=2755nt_BP=238nt GAGGTTCCTGCTTTAATGACCGGGGTAGTTTGAGCCATTTCTGCGTCTTGCAGGACATTTTGAACGAACCCCCTTTGCTTGAGGCTCGCA ACCACCCGATGATCGATGATCGTCTCAGGGGAAAAGAAGCCTTGGCGAAGAGCAGAGGTTTAGAGGCACAATTCTGCTTTCCCTGGAACT GTGTCATTCAGGACTCTGCAAATTCCCTAAAGTAGGAGGAAAAATGACCATGTCCAAGATCGTCTCCTCTGCCTCCACCGACCTCCAGGA CTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCTCCAGAGGATGCGGCTGT GAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTGCAGCATTCCAACGCCAA GAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCCTGCAACCAGCTGGGCCA GTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAGTTCTCCCATGAAGCCGT CAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCTGACCTCCTCTACGCCAT GTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATCCGCGAGGAGATCGTCCT GAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATCCGCATTGCGGGCGACTA CGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCCAAGACCGTCTTTGAGGC GCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTGATTGCTGGGGACCCCCG CTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTGCTGCTGTCCACCTACAT CAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGCAATGCTGACGTGGAGCT GCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAGGAGATGCCGCCCTTCCC CGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGATGGCCGGAGGGACCCCAG CAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTCCTGGGGCTGCGGGCAGC CCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCCGCCCAGCCCAGCCTGGG GCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTTTGT GTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTATCT CTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGTGCA GACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCCCCC GCTGCTGTCCGTGCGCTTCCGGTACGGTGGCGCCCCCCAGGCCCTCACCCTGAAGCTCCCAGTGACCATCAACAAGTTCTTCCAGCCCAC CGAGATGGCGGCCCAGGATTTCTTCCAGCGCTGGAAGCAGCTGAGCCTCCCTCAACAGGAGGCGCAGAAAATCTTCAAAGCCAACCACCC CATGGACGCAGAAGTTACTAAGGCCAAGCTTCTGGGGTTTGGCTCTGCTCTCCTGGACAATGTGGACCCCAACCCTGAGAACTTCGTGGG GGCGGGGATCATCCAGACTAAAGCCCTGCAGGTGGGCTGTCTGCTTCGGCTGGAGCCCAATGCCCAGGCCCAGATGTACCGGCTGACCCT GCGCACCAGCAAGGAGCCCGTCTCCCGTCACCTGTGTGAGCTGCTGGCACAGCAGTTCTGAGCCCTGGACTCTGCCCCGGGGGATGTGGC CGGCACTGGGCAGCCCCTTGGACTGAGGCAGTTTTGGTGGATGGGGGACCTCCACTGGTGACAGAGAAGACACCAGGGTTTGGGGGATGC CTGGGACTTTCCTCCGGCCTTTTGTATTTTTATTTTTGTTCATCTGCTGCTGTTTACATTCTGGGGGGTTAGGGGGAGTCCCCCTCCCTC CCTTTCCCCCCCAAGCACAGAGGGGAGAGGGGCCAGGGAAGTGGATGTCTCCTCCCCTCCCACCCCACCCTGTTGTAGCCCCTCCTACCC >101644_101644_2_ZNF223-AP2A1_ZNF223_chr19_44559344_ENST00000585552_AP2A1_chr19_50298887_ENST00000354293_length(amino acids)=745AA_BP=25 MLSLELCHSGLCKFPKVGGKMTMSKIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVKGRLVECLETVLNKAQEPPKSKKV QHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIDTVINALKTERDVSVRQRAA DLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYVSEEVWYRVLQIVTNRDDVQGYAA KTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIKFINLFPETKATIQGVLRAGSQLR NADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSSNDINGGMEPTPSTVSTPSPSADL LGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQN LGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTKRVAAQVDGGAQVQQVLNIECLRDFLTPPLLSVRFRYGGAPQALTLKLPVTIN KFFQPTEMAAQDFFQRWKQLSLPQQEAQKIFKANHPMDAEVTKAKLLGFGSALLDNVDPNPENFVGAGIIQTKALQVGCLLRLEPNAQAQ -------------------------------------------------------------- >101644_101644_3_ZNF223-AP2A1_ZNF223_chr19_44559344_ENST00000591793_AP2A1_chr19_50298887_ENST00000354293_length(transcript)=2945nt_BP=428nt TTTACCACAGTAGTTTGAGTCATTTCCACATCTTGCGAGTCCTTCCGAACGAGTCTCCTTTCCTTGGGGCTCGCAACCACCCAATGATCG ATTCAGGAGAAAAGAAGCCTGGGCGGAGAGCAGAGGAGGCAGTGACCTTCAAGGATGTGGCTGTGATCTTCACTGAGGAGGAGCTGGGGC TGCTGGACCCTGCCCAGAGGAAGCTGTACCGAGATGTGATGCTTGAGAACTTCAGGAACCTGCTCTCAGTGGGGCATCAACCATTCCATG GAGATACTTTCCACTTCCTAAGGGAAGAAAAGTTTTGGGTGATGGGGACAACAAGCCAAAGAGAAGGGAATTTGGGCACAATTCTGCTTT CCCTGGAACTGTGTCATTCAGGACTCTGCAAATTCCCTAAAGTAGGAGGAAAAATGACCATGTCCAAGATCGTCTCCTCTGCCTCCACCG ACCTCCAGGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCTCCAGAGG ATGCGGCTGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTGCAGCATT CCAACGCCAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCCTGCAACC AGCTGGGCCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAGTTCTCCC ATGAAGCCGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCTGACCTCC TCTACGCCATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATCCGCGAGG AGATCGTCCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATCCGCATTG CGGGCGACTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCCAAGACCG TCTTTGAGGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTGATTGCTG GGGACCCCCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTGCTGCTGT CCACCTACATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGCAATGCTG ACGTGGAGCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAGGAGATGC CGCCCTTCCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGATGGCCGGA GGGACCCCAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTCCTGGGGC TGCGGGCAGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCCGCCCAGC CCAGCCTGGGGCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGA ATAAGTTTGTGTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCC GCATGTATCTCTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGC TGGCTGTGCAGACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCC TGACGCCCCCGCTGCTGTCCGTGCGCTTCCGGTACGGTGGCGCCCCCCAGGCCCTCACCCTGAAGCTCCCAGTGACCATCAACAAGTTCT TCCAGCCCACCGAGATGGCGGCCCAGGATTTCTTCCAGCGCTGGAAGCAGCTGAGCCTCCCTCAACAGGAGGCGCAGAAAATCTTCAAAG CCAACCACCCCATGGACGCAGAAGTTACTAAGGCCAAGCTTCTGGGGTTTGGCTCTGCTCTCCTGGACAATGTGGACCCCAACCCTGAGA ACTTCGTGGGGGCGGGGATCATCCAGACTAAAGCCCTGCAGGTGGGCTGTCTGCTTCGGCTGGAGCCCAATGCCCAGGCCCAGATGTACC GGCTGACCCTGCGCACCAGCAAGGAGCCCGTCTCCCGTCACCTGTGTGAGCTGCTGGCACAGCAGTTCTGAGCCCTGGACTCTGCCCCGG GGGATGTGGCCGGCACTGGGCAGCCCCTTGGACTGAGGCAGTTTTGGTGGATGGGGGACCTCCACTGGTGACAGAGAAGACACCAGGGTT TGGGGGATGCCTGGGACTTTCCTCCGGCCTTTTGTATTTTTATTTTTGTTCATCTGCTGCTGTTTACATTCTGGGGGGTTAGGGGGAGTC CCCCTCCCTCCCTTTCCCCCCCAAGCACAGAGGGGAGAGGGGCCAGGGAAGTGGATGTCTCCTCCCCTCCCACCCCACCCTGTTGTAGCC >101644_101644_3_ZNF223-AP2A1_ZNF223_chr19_44559344_ENST00000591793_AP2A1_chr19_50298887_ENST00000354293_length(amino acids)=858AA_BP=138 MSHFHILRVLPNESPFLGARNHPMIDSGEKKPGRRAEEAVTFKDVAVIFTEEELGLLDPAQRKLYRDVMLENFRNLLSVGHQPFHGDTFH FLREEKFWVMGTTSQREGNLGTILLSLELCHSGLCKFPKVGGKMTMSKIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVK GRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVK THIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYV SEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIK FINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSS NDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVC KNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTKRVAAQVDGGAQVQQVLNIECLRDFLTPPL LSVRFRYGGAPQALTLKLPVTINKFFQPTEMAAQDFFQRWKQLSLPQQEAQKIFKANHPMDAEVTKAKLLGFGSALLDNVDPNPENFVGA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ZNF223-AP2A1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ZNF223-AP2A1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ZNF223-AP2A1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies