
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ZNF277-CEACAM19 (FusionGDB2 ID:101765) |
Fusion Gene Summary for ZNF277-CEACAM19 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ZNF277-CEACAM19 | Fusion gene ID: 101765 | Hgene | Tgene | Gene symbol | ZNF277 | CEACAM19 | Gene ID | 11179 | 56971 |
| Gene name | zinc finger protein 277 | CEA cell adhesion molecule 19 | |
| Synonyms | NRIF4|ZNF277P | CEACM19|CEAL1 | |
| Cytomap | 7q31.1 | 19q13.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | zinc finger protein 277nuclear receptor-interacting factor 4zinc finger protein (C2H2 type) 277zinc finger protein 277 pseudogene | carcinoembryonic antigen-related cell adhesion molecule 19carcinoembryonic antigen related cell adhesion molecule 19carcinoembryonic antigen-like 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000361822, ENST00000421043, ENST00000450657, | ENST00000480278, ENST00000358777, ENST00000403660, | |
| Fusion gene scores | * DoF score | 8 X 4 X 7=224 | 4 X 3 X 3=36 |
| # samples | 8 | 5 | |
| ** MAII score | log2(8/224*10)=-1.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/36*10)=0.473931188332412 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: ZNF277 [Title/Abstract] AND CEACAM19 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ZNF277(111846862)-CEACAM19(45175868), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across ZNF277 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CEACAM19 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | KIRC | TCGA-B0-5081-01A | ZNF277 | chr7 | 111846862 | - | CEACAM19 | chr19 | 45175868 | + |
| ChimerDB4 | KIRC | TCGA-B0-5081-01A | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
Top |
Fusion Gene ORF analysis for ZNF277-CEACAM19 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000361822 | ENST00000480278 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| 5CDS-3UTR | ENST00000421043 | ENST00000480278 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| 5CDS-3UTR | ENST00000450657 | ENST00000480278 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| In-frame | ENST00000361822 | ENST00000358777 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| In-frame | ENST00000361822 | ENST00000403660 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| In-frame | ENST00000421043 | ENST00000358777 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| In-frame | ENST00000421043 | ENST00000403660 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| In-frame | ENST00000450657 | ENST00000358777 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| In-frame | ENST00000450657 | ENST00000403660 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000361822 | ZNF277 | chr7 | 111846862 | + | ENST00000358777 | CEACAM19 | chr19 | 45175868 | + | 1934 | 220 | 129 | 1064 | 311 |
| ENST00000361822 | ZNF277 | chr7 | 111846862 | + | ENST00000403660 | CEACAM19 | chr19 | 45175868 | + | 1937 | 220 | 129 | 1067 | 312 |
| ENST00000450657 | ZNF277 | chr7 | 111846862 | + | ENST00000358777 | CEACAM19 | chr19 | 45175868 | + | 1821 | 107 | 16 | 951 | 311 |
| ENST00000450657 | ZNF277 | chr7 | 111846862 | + | ENST00000403660 | CEACAM19 | chr19 | 45175868 | + | 1824 | 107 | 16 | 954 | 312 |
| ENST00000421043 | ZNF277 | chr7 | 111846862 | + | ENST00000358777 | CEACAM19 | chr19 | 45175868 | + | 1825 | 111 | 20 | 955 | 311 |
| ENST00000421043 | ZNF277 | chr7 | 111846862 | + | ENST00000403660 | CEACAM19 | chr19 | 45175868 | + | 1828 | 111 | 20 | 958 | 312 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000361822 | ENST00000358777 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + | 0.016414793 | 0.98358524 |
| ENST00000361822 | ENST00000403660 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + | 0.01641463 | 0.98358536 |
| ENST00000450657 | ENST00000358777 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + | 0.015317527 | 0.98468244 |
| ENST00000450657 | ENST00000403660 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + | 0.015905265 | 0.9840948 |
| ENST00000421043 | ENST00000358777 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + | 0.016262785 | 0.9837373 |
| ENST00000421043 | ENST00000403660 | ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175868 | + | 0.016440779 | 0.9835592 |
Top |
Fusion Genomic Features for ZNF277-CEACAM19 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175867 | + | 3.59E-07 | 0.99999964 |
| ZNF277 | chr7 | 111846862 | + | CEACAM19 | chr19 | 45175867 | + | 3.59E-07 | 0.99999964 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
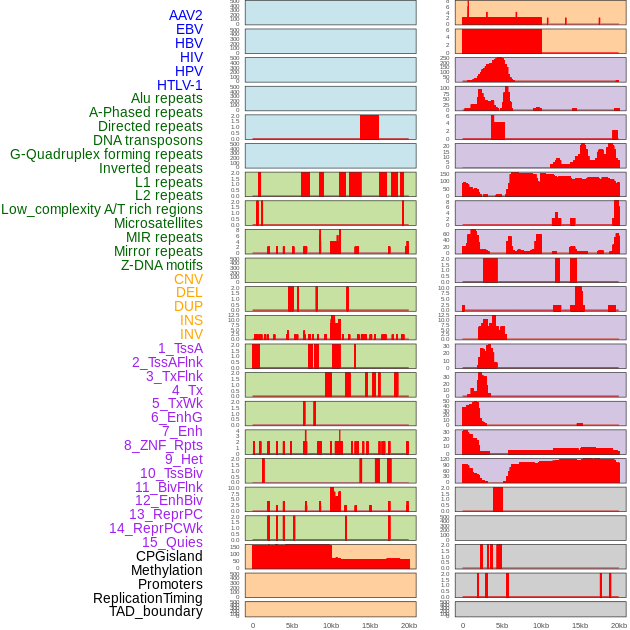 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
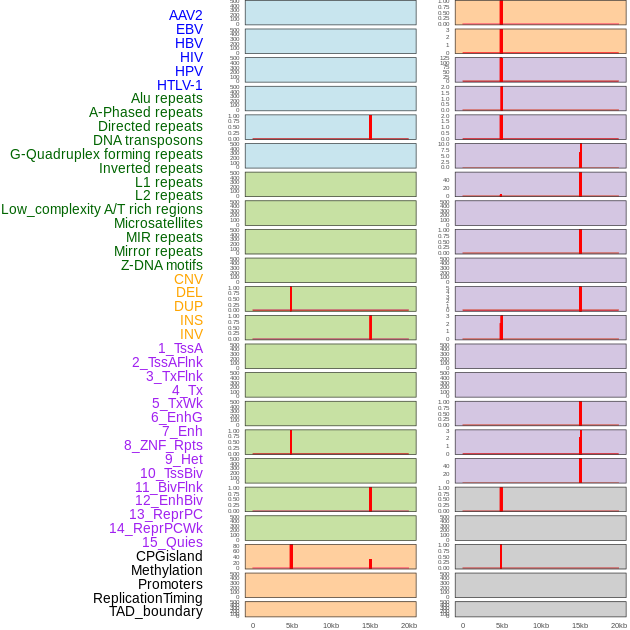 |
Top |
Fusion Protein Features for ZNF277-CEACAM19 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:111846862/chr19:45175868) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CEACAM19 | chr7:111846862 | chr19:45175868 | ENST00000358777 | 0 | 8 | 179_300 | 18 | 300.0 | Topological domain | Cytoplasmic | |
| Tgene | CEACAM19 | chr7:111846862 | chr19:45175868 | ENST00000358777 | 0 | 8 | 33_157 | 18 | 300.0 | Topological domain | Extracellular | |
| Tgene | CEACAM19 | chr7:111846862 | chr19:45175868 | ENST00000403660 | 0 | 8 | 179_300 | 18 | 301.0 | Topological domain | Cytoplasmic | |
| Tgene | CEACAM19 | chr7:111846862 | chr19:45175868 | ENST00000403660 | 0 | 8 | 33_157 | 18 | 301.0 | Topological domain | Extracellular | |
| Tgene | CEACAM19 | chr7:111846862 | chr19:45175868 | ENST00000358777 | 0 | 8 | 158_178 | 18 | 300.0 | Transmembrane | Helical | |
| Tgene | CEACAM19 | chr7:111846862 | chr19:45175868 | ENST00000403660 | 0 | 8 | 158_178 | 18 | 301.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ZNF277 | chr7:111846862 | chr19:45175868 | ENST00000361822 | + | 1 | 12 | 224_248 | 30 | 451.0 | Zinc finger | C2H2-type 1 |
| Hgene | ZNF277 | chr7:111846862 | chr19:45175868 | ENST00000361822 | + | 1 | 12 | 355_381 | 30 | 451.0 | Zinc finger | C2H2-type 2 |
Top |
Fusion Gene Sequence for ZNF277-CEACAM19 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >101765_101765_1_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000361822_CEACAM19_chr19_45175868_ENST00000358777_length(transcript)=1934nt_BP=220nt GTCCAGAGCGCGGCGTAGGTGTGGAGAAAACATTACGTCGACGGGGAGTTCGCCTCCAGTAGCGTTTCTACTGGTGCCACCCCGCCTCCG ACCCGCCCTGCGGCCCTCCCTTTTCTTTTCTGCCGGGTAATGGCTGCTTCCAAGACCCAGGGGGCTGTCGCCCGAATGCAGGAAGACCGT GATGGGAGCTGCAGCACAGTCGGGGGTGTAGGTTATGGGGCCTCAATCCTGGTCCTCTGGATGCTCCAAGGCTCCCAGGCAGCTCTCTAC ATCCAGAAGATTCCAGAGCAGCCTCAAAAGAACCAGGACCTTCTCCTGTCAGTCCAGGGTGTCCCAGACACCTTCCAGGACTTCAACTGG TACCTGGGGGAGGAGACGTACGGAGGCACGAGGCTATTTACCTACATCCCTGGGATACAACGGCCTCAGAGGGATGGCAGTGCCATGGGA CAGCGAGACATCGTGGGCTTCCCCAATGGTTCCATGCTGCTGCGCCGCGCCCAGCCTACAGACAGTGGCACCTACCAAGTAGCCATTACC ATCAACTCTGAATGGACTATGAAGGCCAAGACTGAGGTCCAGGTAGCTGAAAAGAATAAGGAGCTGCCCAGTACACACCTGCCCACCAAC GCTGGGATCCTGGCGGCCACCATCATTGGATCTCTTGCTGCCGGGGCCCTTCTCATCAGCTGCATTGCCTATCTCCTGGTGACAAGGAAC TGGAGGGGCCAGAGCCACAGACTGCCTGCTCCGAGGGGCCAGGGATCTCTGTCCATCTTGTGCTCGGCTGTATCCCCAGTGCCTTCAGTG ACGCCCAGCACATGGATGGCGACCACAGAGAAGCCAGAATTGGGCCCTGCTCATGATGCTGGTGACAACAACATCTATGAAGTGATGCCC TCTCCAGTCCTCCTGGTGTCCCCCATCAGTGACACAAGGTCCATAAACCCAGCCCGGCCCCTGCCCACACCCCCACACCTGCAGGCGGAG CCAGAGAACCACCAGTACCAGGACCTGCTAAACCCCGACCCTGCCCCCTACTGCCAGCTGGTGCCAACTTCCTGATGGGTCCTGGGCCAG GCCAGCCAGGGAGAAGACAAGGCCCCAGCCCTCCTCTGGGAGCCTCACACCTGAGACCAGCAGGACAAGGCCATTGGGGGCTGTGGGGCC GATGAGGTGGACTCAGCCAAAGACTCAGCAGCACATGGGGCAGGTGTCCTGGCAGGGGGACAGGAGACTGTAACAGGCCCAGGTCCTTGT GCAGCCCGTGAATGCACGCCCGCCTTCGGTCTGTTCCTTCAAGCAAGCTGGCCTGGGCCATGTGCCTGTGAAAGGCAGGCTCTGGCCCCT TTCCATGCCAAAGTCCCCCAAGATCTGGATATCTGGGGACAAGATGGTGGCCTCAGGCCTGCCTCCCAGGCAGTTGGCTGGGCTCCCAAC TGTCTGTCCTCAATGCCCTACCCCAACTCCACTAGTGACCCTCAGAGTCTTCTCCCCTTAGGACAAGGCAGACACCCCACCATGCGGGCC TCAGGTGGCAGAGAGGCCCAGCCTCACAGGCCTGTGGCCCCACACACCAGTCCCAGCAAGGTGACCACGGCTGCTGGACCCCTTCCCTGT TCAGGCAGGCCCAGCCCCTCTCAGAACCTGCTGCCAGCTGCTGGTCTTGGCCCCCACCCTGAATCTTACTGAGTCCCTCTGGGCAGCAGC TCCCTTCTCCACCCCACCCCAGCACCCGTCCCAAATGTGGCCTCAGCTTGTCCTCCCCTTCCCCAAACTATGCATTCATTCAGCAATAAA TGAGCCTTTGCTGTATGCCAGACCCAGTTCTAGGCTCTTGCAGCCCTGGTAGAAAGCAAAACAAAAACTCCCGCTTTCCCAGAGGGTCAC >101765_101765_1_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000361822_CEACAM19_chr19_45175868_ENST00000358777_length(amino acids)=311AA_BP=30 MAASKTQGAVARMQEDRDGSCSTVGGVGYGASILVLWMLQGSQAALYIQKIPEQPQKNQDLLLSVQGVPDTFQDFNWYLGEETYGGTRLF TYIPGIQRPQRDGSAMGQRDIVGFPNGSMLLRRAQPTDSGTYQVAITINSEWTMKAKTEVQVAEKNKELPSTHLPTNAGILAATIIGSLA AGALLISCIAYLLVTRNWRGQSHRLPAPRGQGSLSILCSAVSPVPSVTPSTWMATTEKPELGPAHDAGDNNIYEVMPSPVLLVSPISDTR -------------------------------------------------------------- >101765_101765_2_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000361822_CEACAM19_chr19_45175868_ENST00000403660_length(transcript)=1937nt_BP=220nt GTCCAGAGCGCGGCGTAGGTGTGGAGAAAACATTACGTCGACGGGGAGTTCGCCTCCAGTAGCGTTTCTACTGGTGCCACCCCGCCTCCG ACCCGCCCTGCGGCCCTCCCTTTTCTTTTCTGCCGGGTAATGGCTGCTTCCAAGACCCAGGGGGCTGTCGCCCGAATGCAGGAAGACCGT GATGGGAGCTGCAGCACAGTCGGGGGTGTAGGTTATGGGGCCTCAATCCTGGTCCTCTGGATGCTCCAAGGCTCCCAGGCAGCTCTCTAC ATCCAGAAGATTCCAGAGCAGCCTCAAAAGAACCAGGACCTTCTCCTGTCAGTCCAGGGTGTCCCAGACACCTTCCAGGACTTCAACTGG TACCTGGGGGAGGAGACGTACGGAGGCACGAGGCTATTTACCTACATCCCTGGGATACAACGGCCTCAGAGGGATGGCAGTGCCATGGGA CAGCGAGACATCGTGGGCTTCCCCAATGGTTCCATGCTGCTGCGCCGCGCCCAGCCTACAGACAGTGGCACCTACCAAGTAGCCATTACC ATCAACTCTGAATGGACTATGAAGGCCAAGACTGAGGTCCAGGTAGCTGAAAAGAATAAGGAGCTGCCCAGTACACACCTGCCCACCAAC GCTGGGATCCTGGCGGCCACCATCATTGGATCTCTTGCTGCCGGGGCCCTTCTCATCAGCTGCATTGCCTATCTCCTGGTGACAAGGAAC TGGAGGGGCCAGAGCCACAGACTGCCTGCTCCGAGGGGCCAGGGATCTCTGTCCATCTTGTGCTCGGCTGTATCCCCAGTGCCTTCAGTG ACGCCCAGCACATGGATGGCGACCACAGAGAAGCCAGAATTGGGCCCTGCTCATGATGCTGGTGACAACAACATCTATGAAGTGATGCCC TCTCCAGTCCTCCTGGTGTCCCCCATCAGTGACACAAGGTCCATAAACCCAGCCCGGCCCCTGCCCACACCCCCACACCTGCAGGCGGAG CCAGAGAACCACCAGTACCAGCAGGACCTGCTAAACCCCGACCCTGCCCCCTACTGCCAGCTGGTGCCAACTTCCTGATGGGTCCTGGGC CAGGCCAGCCAGGGAGAAGACAAGGCCCCAGCCCTCCTCTGGGAGCCTCACACCTGAGACCAGCAGGACAAGGCCATTGGGGGCTGTGGG GCCGATGAGGTGGACTCAGCCAAAGACTCAGCAGCACATGGGGCAGGTGTCCTGGCAGGGGGACAGGAGACTGTAACAGGCCCAGGTCCT TGTGCAGCCCGTGAATGCACGCCCGCCTTCGGTCTGTTCCTTCAAGCAAGCTGGCCTGGGCCATGTGCCTGTGAAAGGCAGGCTCTGGCC CCTTTCCATGCCAAAGTCCCCCAAGATCTGGATATCTGGGGACAAGATGGTGGCCTCAGGCCTGCCTCCCAGGCAGTTGGCTGGGCTCCC AACTGTCTGTCCTCAATGCCCTACCCCAACTCCACTAGTGACCCTCAGAGTCTTCTCCCCTTAGGACAAGGCAGACACCCCACCATGCGG GCCTCAGGTGGCAGAGAGGCCCAGCCTCACAGGCCTGTGGCCCCACACACCAGTCCCAGCAAGGTGACCACGGCTGCTGGACCCCTTCCC TGTTCAGGCAGGCCCAGCCCCTCTCAGAACCTGCTGCCAGCTGCTGGTCTTGGCCCCCACCCTGAATCTTACTGAGTCCCTCTGGGCAGC AGCTCCCTTCTCCACCCCACCCCAGCACCCGTCCCAAATGTGGCCTCAGCTTGTCCTCCCCTTCCCCAAACTATGCATTCATTCAGCAAT AAATGAGCCTTTGCTGTATGCCAGACCCAGTTCTAGGCTCTTGCAGCCCTGGTAGAAAGCAAAACAAAAACTCCCGCTTTCCCAGAGGGT >101765_101765_2_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000361822_CEACAM19_chr19_45175868_ENST00000403660_length(amino acids)=312AA_BP=30 MAASKTQGAVARMQEDRDGSCSTVGGVGYGASILVLWMLQGSQAALYIQKIPEQPQKNQDLLLSVQGVPDTFQDFNWYLGEETYGGTRLF TYIPGIQRPQRDGSAMGQRDIVGFPNGSMLLRRAQPTDSGTYQVAITINSEWTMKAKTEVQVAEKNKELPSTHLPTNAGILAATIIGSLA AGALLISCIAYLLVTRNWRGQSHRLPAPRGQGSLSILCSAVSPVPSVTPSTWMATTEKPELGPAHDAGDNNIYEVMPSPVLLVSPISDTR -------------------------------------------------------------- >101765_101765_3_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000421043_CEACAM19_chr19_45175868_ENST00000358777_length(transcript)=1825nt_BP=111nt CTTTTCTTTTCTGCCGGGTAATGGCTGCTTCCAAGACCCAGGGGGCTGTCGCCCGAATGCAGGAAGACCGTGATGGGAGCTGCAGCACAG TCGGGGGTGTAGGTTATGGGGCCTCAATCCTGGTCCTCTGGATGCTCCAAGGCTCCCAGGCAGCTCTCTACATCCAGAAGATTCCAGAGC AGCCTCAAAAGAACCAGGACCTTCTCCTGTCAGTCCAGGGTGTCCCAGACACCTTCCAGGACTTCAACTGGTACCTGGGGGAGGAGACGT ACGGAGGCACGAGGCTATTTACCTACATCCCTGGGATACAACGGCCTCAGAGGGATGGCAGTGCCATGGGACAGCGAGACATCGTGGGCT TCCCCAATGGTTCCATGCTGCTGCGCCGCGCCCAGCCTACAGACAGTGGCACCTACCAAGTAGCCATTACCATCAACTCTGAATGGACTA TGAAGGCCAAGACTGAGGTCCAGGTAGCTGAAAAGAATAAGGAGCTGCCCAGTACACACCTGCCCACCAACGCTGGGATCCTGGCGGCCA CCATCATTGGATCTCTTGCTGCCGGGGCCCTTCTCATCAGCTGCATTGCCTATCTCCTGGTGACAAGGAACTGGAGGGGCCAGAGCCACA GACTGCCTGCTCCGAGGGGCCAGGGATCTCTGTCCATCTTGTGCTCGGCTGTATCCCCAGTGCCTTCAGTGACGCCCAGCACATGGATGG CGACCACAGAGAAGCCAGAATTGGGCCCTGCTCATGATGCTGGTGACAACAACATCTATGAAGTGATGCCCTCTCCAGTCCTCCTGGTGT CCCCCATCAGTGACACAAGGTCCATAAACCCAGCCCGGCCCCTGCCCACACCCCCACACCTGCAGGCGGAGCCAGAGAACCACCAGTACC AGGACCTGCTAAACCCCGACCCTGCCCCCTACTGCCAGCTGGTGCCAACTTCCTGATGGGTCCTGGGCCAGGCCAGCCAGGGAGAAGACA AGGCCCCAGCCCTCCTCTGGGAGCCTCACACCTGAGACCAGCAGGACAAGGCCATTGGGGGCTGTGGGGCCGATGAGGTGGACTCAGCCA AAGACTCAGCAGCACATGGGGCAGGTGTCCTGGCAGGGGGACAGGAGACTGTAACAGGCCCAGGTCCTTGTGCAGCCCGTGAATGCACGC CCGCCTTCGGTCTGTTCCTTCAAGCAAGCTGGCCTGGGCCATGTGCCTGTGAAAGGCAGGCTCTGGCCCCTTTCCATGCCAAAGTCCCCC AAGATCTGGATATCTGGGGACAAGATGGTGGCCTCAGGCCTGCCTCCCAGGCAGTTGGCTGGGCTCCCAACTGTCTGTCCTCAATGCCCT ACCCCAACTCCACTAGTGACCCTCAGAGTCTTCTCCCCTTAGGACAAGGCAGACACCCCACCATGCGGGCCTCAGGTGGCAGAGAGGCCC AGCCTCACAGGCCTGTGGCCCCACACACCAGTCCCAGCAAGGTGACCACGGCTGCTGGACCCCTTCCCTGTTCAGGCAGGCCCAGCCCCT CTCAGAACCTGCTGCCAGCTGCTGGTCTTGGCCCCCACCCTGAATCTTACTGAGTCCCTCTGGGCAGCAGCTCCCTTCTCCACCCCACCC CAGCACCCGTCCCAAATGTGGCCTCAGCTTGTCCTCCCCTTCCCCAAACTATGCATTCATTCAGCAATAAATGAGCCTTTGCTGTATGCC AGACCCAGTTCTAGGCTCTTGCAGCCCTGGTAGAAAGCAAAACAAAAACTCCCGCTTTCCCAGAGGGTCACTTGGCAGGGGAAAGAATCA >101765_101765_3_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000421043_CEACAM19_chr19_45175868_ENST00000358777_length(amino acids)=311AA_BP=30 MAASKTQGAVARMQEDRDGSCSTVGGVGYGASILVLWMLQGSQAALYIQKIPEQPQKNQDLLLSVQGVPDTFQDFNWYLGEETYGGTRLF TYIPGIQRPQRDGSAMGQRDIVGFPNGSMLLRRAQPTDSGTYQVAITINSEWTMKAKTEVQVAEKNKELPSTHLPTNAGILAATIIGSLA AGALLISCIAYLLVTRNWRGQSHRLPAPRGQGSLSILCSAVSPVPSVTPSTWMATTEKPELGPAHDAGDNNIYEVMPSPVLLVSPISDTR -------------------------------------------------------------- >101765_101765_4_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000421043_CEACAM19_chr19_45175868_ENST00000403660_length(transcript)=1828nt_BP=111nt CTTTTCTTTTCTGCCGGGTAATGGCTGCTTCCAAGACCCAGGGGGCTGTCGCCCGAATGCAGGAAGACCGTGATGGGAGCTGCAGCACAG TCGGGGGTGTAGGTTATGGGGCCTCAATCCTGGTCCTCTGGATGCTCCAAGGCTCCCAGGCAGCTCTCTACATCCAGAAGATTCCAGAGC AGCCTCAAAAGAACCAGGACCTTCTCCTGTCAGTCCAGGGTGTCCCAGACACCTTCCAGGACTTCAACTGGTACCTGGGGGAGGAGACGT ACGGAGGCACGAGGCTATTTACCTACATCCCTGGGATACAACGGCCTCAGAGGGATGGCAGTGCCATGGGACAGCGAGACATCGTGGGCT TCCCCAATGGTTCCATGCTGCTGCGCCGCGCCCAGCCTACAGACAGTGGCACCTACCAAGTAGCCATTACCATCAACTCTGAATGGACTA TGAAGGCCAAGACTGAGGTCCAGGTAGCTGAAAAGAATAAGGAGCTGCCCAGTACACACCTGCCCACCAACGCTGGGATCCTGGCGGCCA CCATCATTGGATCTCTTGCTGCCGGGGCCCTTCTCATCAGCTGCATTGCCTATCTCCTGGTGACAAGGAACTGGAGGGGCCAGAGCCACA GACTGCCTGCTCCGAGGGGCCAGGGATCTCTGTCCATCTTGTGCTCGGCTGTATCCCCAGTGCCTTCAGTGACGCCCAGCACATGGATGG CGACCACAGAGAAGCCAGAATTGGGCCCTGCTCATGATGCTGGTGACAACAACATCTATGAAGTGATGCCCTCTCCAGTCCTCCTGGTGT CCCCCATCAGTGACACAAGGTCCATAAACCCAGCCCGGCCCCTGCCCACACCCCCACACCTGCAGGCGGAGCCAGAGAACCACCAGTACC AGCAGGACCTGCTAAACCCCGACCCTGCCCCCTACTGCCAGCTGGTGCCAACTTCCTGATGGGTCCTGGGCCAGGCCAGCCAGGGAGAAG ACAAGGCCCCAGCCCTCCTCTGGGAGCCTCACACCTGAGACCAGCAGGACAAGGCCATTGGGGGCTGTGGGGCCGATGAGGTGGACTCAG CCAAAGACTCAGCAGCACATGGGGCAGGTGTCCTGGCAGGGGGACAGGAGACTGTAACAGGCCCAGGTCCTTGTGCAGCCCGTGAATGCA CGCCCGCCTTCGGTCTGTTCCTTCAAGCAAGCTGGCCTGGGCCATGTGCCTGTGAAAGGCAGGCTCTGGCCCCTTTCCATGCCAAAGTCC CCCAAGATCTGGATATCTGGGGACAAGATGGTGGCCTCAGGCCTGCCTCCCAGGCAGTTGGCTGGGCTCCCAACTGTCTGTCCTCAATGC CCTACCCCAACTCCACTAGTGACCCTCAGAGTCTTCTCCCCTTAGGACAAGGCAGACACCCCACCATGCGGGCCTCAGGTGGCAGAGAGG CCCAGCCTCACAGGCCTGTGGCCCCACACACCAGTCCCAGCAAGGTGACCACGGCTGCTGGACCCCTTCCCTGTTCAGGCAGGCCCAGCC CCTCTCAGAACCTGCTGCCAGCTGCTGGTCTTGGCCCCCACCCTGAATCTTACTGAGTCCCTCTGGGCAGCAGCTCCCTTCTCCACCCCA CCCCAGCACCCGTCCCAAATGTGGCCTCAGCTTGTCCTCCCCTTCCCCAAACTATGCATTCATTCAGCAATAAATGAGCCTTTGCTGTAT GCCAGACCCAGTTCTAGGCTCTTGCAGCCCTGGTAGAAAGCAAAACAAAAACTCCCGCTTTCCCAGAGGGTCACTTGGCAGGGGAAAGAA >101765_101765_4_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000421043_CEACAM19_chr19_45175868_ENST00000403660_length(amino acids)=312AA_BP=30 MAASKTQGAVARMQEDRDGSCSTVGGVGYGASILVLWMLQGSQAALYIQKIPEQPQKNQDLLLSVQGVPDTFQDFNWYLGEETYGGTRLF TYIPGIQRPQRDGSAMGQRDIVGFPNGSMLLRRAQPTDSGTYQVAITINSEWTMKAKTEVQVAEKNKELPSTHLPTNAGILAATIIGSLA AGALLISCIAYLLVTRNWRGQSHRLPAPRGQGSLSILCSAVSPVPSVTPSTWMATTEKPELGPAHDAGDNNIYEVMPSPVLLVSPISDTR -------------------------------------------------------------- >101765_101765_5_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000450657_CEACAM19_chr19_45175868_ENST00000358777_length(transcript)=1821nt_BP=107nt TCTTTTCTGCCGGGTAATGGCTGCTTCCAAGACCCAGGGGGCTGTCGCCCGAATGCAGGAAGACCGTGATGGGAGCTGCAGCACAGTCGG GGGTGTAGGTTATGGGGCCTCAATCCTGGTCCTCTGGATGCTCCAAGGCTCCCAGGCAGCTCTCTACATCCAGAAGATTCCAGAGCAGCC TCAAAAGAACCAGGACCTTCTCCTGTCAGTCCAGGGTGTCCCAGACACCTTCCAGGACTTCAACTGGTACCTGGGGGAGGAGACGTACGG AGGCACGAGGCTATTTACCTACATCCCTGGGATACAACGGCCTCAGAGGGATGGCAGTGCCATGGGACAGCGAGACATCGTGGGCTTCCC CAATGGTTCCATGCTGCTGCGCCGCGCCCAGCCTACAGACAGTGGCACCTACCAAGTAGCCATTACCATCAACTCTGAATGGACTATGAA GGCCAAGACTGAGGTCCAGGTAGCTGAAAAGAATAAGGAGCTGCCCAGTACACACCTGCCCACCAACGCTGGGATCCTGGCGGCCACCAT CATTGGATCTCTTGCTGCCGGGGCCCTTCTCATCAGCTGCATTGCCTATCTCCTGGTGACAAGGAACTGGAGGGGCCAGAGCCACAGACT GCCTGCTCCGAGGGGCCAGGGATCTCTGTCCATCTTGTGCTCGGCTGTATCCCCAGTGCCTTCAGTGACGCCCAGCACATGGATGGCGAC CACAGAGAAGCCAGAATTGGGCCCTGCTCATGATGCTGGTGACAACAACATCTATGAAGTGATGCCCTCTCCAGTCCTCCTGGTGTCCCC CATCAGTGACACAAGGTCCATAAACCCAGCCCGGCCCCTGCCCACACCCCCACACCTGCAGGCGGAGCCAGAGAACCACCAGTACCAGGA CCTGCTAAACCCCGACCCTGCCCCCTACTGCCAGCTGGTGCCAACTTCCTGATGGGTCCTGGGCCAGGCCAGCCAGGGAGAAGACAAGGC CCCAGCCCTCCTCTGGGAGCCTCACACCTGAGACCAGCAGGACAAGGCCATTGGGGGCTGTGGGGCCGATGAGGTGGACTCAGCCAAAGA CTCAGCAGCACATGGGGCAGGTGTCCTGGCAGGGGGACAGGAGACTGTAACAGGCCCAGGTCCTTGTGCAGCCCGTGAATGCACGCCCGC CTTCGGTCTGTTCCTTCAAGCAAGCTGGCCTGGGCCATGTGCCTGTGAAAGGCAGGCTCTGGCCCCTTTCCATGCCAAAGTCCCCCAAGA TCTGGATATCTGGGGACAAGATGGTGGCCTCAGGCCTGCCTCCCAGGCAGTTGGCTGGGCTCCCAACTGTCTGTCCTCAATGCCCTACCC CAACTCCACTAGTGACCCTCAGAGTCTTCTCCCCTTAGGACAAGGCAGACACCCCACCATGCGGGCCTCAGGTGGCAGAGAGGCCCAGCC TCACAGGCCTGTGGCCCCACACACCAGTCCCAGCAAGGTGACCACGGCTGCTGGACCCCTTCCCTGTTCAGGCAGGCCCAGCCCCTCTCA GAACCTGCTGCCAGCTGCTGGTCTTGGCCCCCACCCTGAATCTTACTGAGTCCCTCTGGGCAGCAGCTCCCTTCTCCACCCCACCCCAGC ACCCGTCCCAAATGTGGCCTCAGCTTGTCCTCCCCTTCCCCAAACTATGCATTCATTCAGCAATAAATGAGCCTTTGCTGTATGCCAGAC CCAGTTCTAGGCTCTTGCAGCCCTGGTAGAAAGCAAAACAAAAACTCCCGCTTTCCCAGAGGGTCACTTGGCAGGGGAAAGAATCAGGAA >101765_101765_5_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000450657_CEACAM19_chr19_45175868_ENST00000358777_length(amino acids)=311AA_BP=30 MAASKTQGAVARMQEDRDGSCSTVGGVGYGASILVLWMLQGSQAALYIQKIPEQPQKNQDLLLSVQGVPDTFQDFNWYLGEETYGGTRLF TYIPGIQRPQRDGSAMGQRDIVGFPNGSMLLRRAQPTDSGTYQVAITINSEWTMKAKTEVQVAEKNKELPSTHLPTNAGILAATIIGSLA AGALLISCIAYLLVTRNWRGQSHRLPAPRGQGSLSILCSAVSPVPSVTPSTWMATTEKPELGPAHDAGDNNIYEVMPSPVLLVSPISDTR -------------------------------------------------------------- >101765_101765_6_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000450657_CEACAM19_chr19_45175868_ENST00000403660_length(transcript)=1824nt_BP=107nt TCTTTTCTGCCGGGTAATGGCTGCTTCCAAGACCCAGGGGGCTGTCGCCCGAATGCAGGAAGACCGTGATGGGAGCTGCAGCACAGTCGG GGGTGTAGGTTATGGGGCCTCAATCCTGGTCCTCTGGATGCTCCAAGGCTCCCAGGCAGCTCTCTACATCCAGAAGATTCCAGAGCAGCC TCAAAAGAACCAGGACCTTCTCCTGTCAGTCCAGGGTGTCCCAGACACCTTCCAGGACTTCAACTGGTACCTGGGGGAGGAGACGTACGG AGGCACGAGGCTATTTACCTACATCCCTGGGATACAACGGCCTCAGAGGGATGGCAGTGCCATGGGACAGCGAGACATCGTGGGCTTCCC CAATGGTTCCATGCTGCTGCGCCGCGCCCAGCCTACAGACAGTGGCACCTACCAAGTAGCCATTACCATCAACTCTGAATGGACTATGAA GGCCAAGACTGAGGTCCAGGTAGCTGAAAAGAATAAGGAGCTGCCCAGTACACACCTGCCCACCAACGCTGGGATCCTGGCGGCCACCAT CATTGGATCTCTTGCTGCCGGGGCCCTTCTCATCAGCTGCATTGCCTATCTCCTGGTGACAAGGAACTGGAGGGGCCAGAGCCACAGACT GCCTGCTCCGAGGGGCCAGGGATCTCTGTCCATCTTGTGCTCGGCTGTATCCCCAGTGCCTTCAGTGACGCCCAGCACATGGATGGCGAC CACAGAGAAGCCAGAATTGGGCCCTGCTCATGATGCTGGTGACAACAACATCTATGAAGTGATGCCCTCTCCAGTCCTCCTGGTGTCCCC CATCAGTGACACAAGGTCCATAAACCCAGCCCGGCCCCTGCCCACACCCCCACACCTGCAGGCGGAGCCAGAGAACCACCAGTACCAGCA GGACCTGCTAAACCCCGACCCTGCCCCCTACTGCCAGCTGGTGCCAACTTCCTGATGGGTCCTGGGCCAGGCCAGCCAGGGAGAAGACAA GGCCCCAGCCCTCCTCTGGGAGCCTCACACCTGAGACCAGCAGGACAAGGCCATTGGGGGCTGTGGGGCCGATGAGGTGGACTCAGCCAA AGACTCAGCAGCACATGGGGCAGGTGTCCTGGCAGGGGGACAGGAGACTGTAACAGGCCCAGGTCCTTGTGCAGCCCGTGAATGCACGCC CGCCTTCGGTCTGTTCCTTCAAGCAAGCTGGCCTGGGCCATGTGCCTGTGAAAGGCAGGCTCTGGCCCCTTTCCATGCCAAAGTCCCCCA AGATCTGGATATCTGGGGACAAGATGGTGGCCTCAGGCCTGCCTCCCAGGCAGTTGGCTGGGCTCCCAACTGTCTGTCCTCAATGCCCTA CCCCAACTCCACTAGTGACCCTCAGAGTCTTCTCCCCTTAGGACAAGGCAGACACCCCACCATGCGGGCCTCAGGTGGCAGAGAGGCCCA GCCTCACAGGCCTGTGGCCCCACACACCAGTCCCAGCAAGGTGACCACGGCTGCTGGACCCCTTCCCTGTTCAGGCAGGCCCAGCCCCTC TCAGAACCTGCTGCCAGCTGCTGGTCTTGGCCCCCACCCTGAATCTTACTGAGTCCCTCTGGGCAGCAGCTCCCTTCTCCACCCCACCCC AGCACCCGTCCCAAATGTGGCCTCAGCTTGTCCTCCCCTTCCCCAAACTATGCATTCATTCAGCAATAAATGAGCCTTTGCTGTATGCCA GACCCAGTTCTAGGCTCTTGCAGCCCTGGTAGAAAGCAAAACAAAAACTCCCGCTTTCCCAGAGGGTCACTTGGCAGGGGAAAGAATCAG >101765_101765_6_ZNF277-CEACAM19_ZNF277_chr7_111846862_ENST00000450657_CEACAM19_chr19_45175868_ENST00000403660_length(amino acids)=312AA_BP=30 MAASKTQGAVARMQEDRDGSCSTVGGVGYGASILVLWMLQGSQAALYIQKIPEQPQKNQDLLLSVQGVPDTFQDFNWYLGEETYGGTRLF TYIPGIQRPQRDGSAMGQRDIVGFPNGSMLLRRAQPTDSGTYQVAITINSEWTMKAKTEVQVAEKNKELPSTHLPTNAGILAATIIGSLA AGALLISCIAYLLVTRNWRGQSHRLPAPRGQGSLSILCSAVSPVPSVTPSTWMATTEKPELGPAHDAGDNNIYEVMPSPVLLVSPISDTR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ZNF277-CEACAM19 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ZNF277-CEACAM19 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ZNF277-CEACAM19 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies