
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:C1orf52-PPP3CB (FusionGDB2 ID:11367) |
Fusion Gene Summary for C1orf52-PPP3CB |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: C1orf52-PPP3CB | Fusion gene ID: 11367 | Hgene | Tgene | Gene symbol | C1orf52 | PPP3CB | Gene ID | 148423 | 5532 |
| Gene name | chromosome 1 open reading frame 52 | protein phosphatase 3 catalytic subunit beta | |
| Synonyms | gm117 | CALNA2|CALNB|CNA2|PP2Bbeta | |
| Cytomap | 1p22.3 | 10q22.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | UPF0690 protein C1orf52BCL10-associated gene protein | serine/threonine-protein phosphatase 2B catalytic subunit beta isoformCAM-PRP catalytic subunitCNA betacalcineurin A betacalcineurin A2calmodulin-dependent calcineurin A subunit beta isoformprotein phosphatase 2B, catalytic subunit, beta isoformpro | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q8N6N3 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000344356, ENST00000471115, ENST00000294661, | ENST00000495897, ENST00000544628, ENST00000342558, ENST00000360663, ENST00000394822, ENST00000394828, ENST00000394829, ENST00000545874, | |
| Fusion gene scores | * DoF score | 1 X 1 X 1=1 | 4 X 5 X 3=60 |
| # samples | 1 | 5 | |
| ** MAII score | log2(1/1*10)=3.32192809488736 | log2(5/60*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: C1orf52 [Title/Abstract] AND PPP3CB [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | C1orf52(85724206)-PPP3CB(75231371), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PPP3CB | GO:0006470 | protein dephosphorylation | 19154138|26794871 |
| Tgene | PPP3CB | GO:0033173 | calcineurin-NFAT signaling cascade | 19154138|22688515 |
| Tgene | PPP3CB | GO:0035690 | cellular response to drug | 11005320 |
| Tgene | PPP3CB | GO:0045944 | positive regulation of transcription by RNA polymerase II | 22688515 |
| Fusion gene breakpoints across C1orf52 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
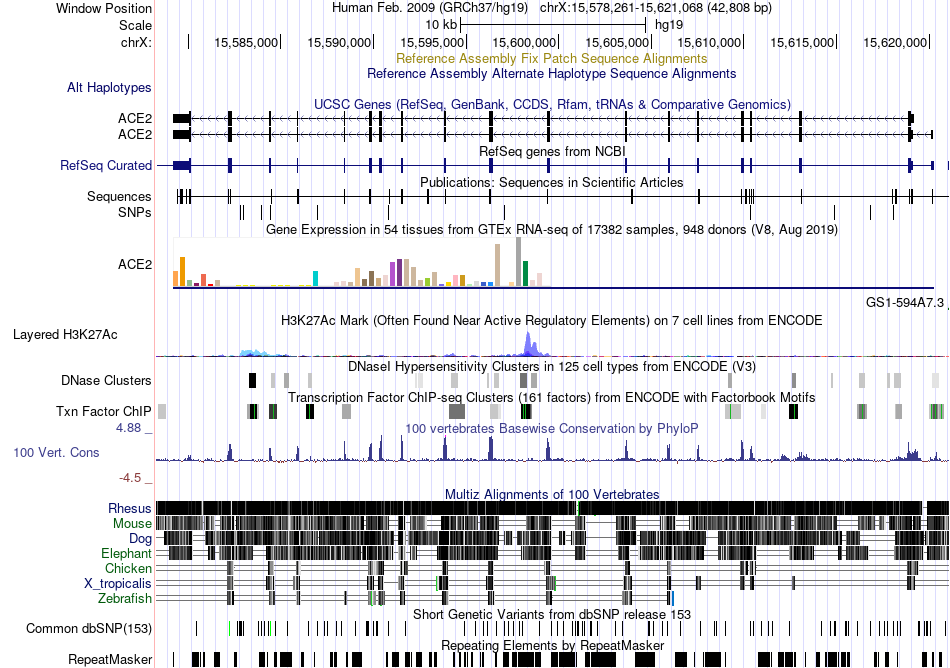 |
| Fusion gene breakpoints across PPP3CB (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
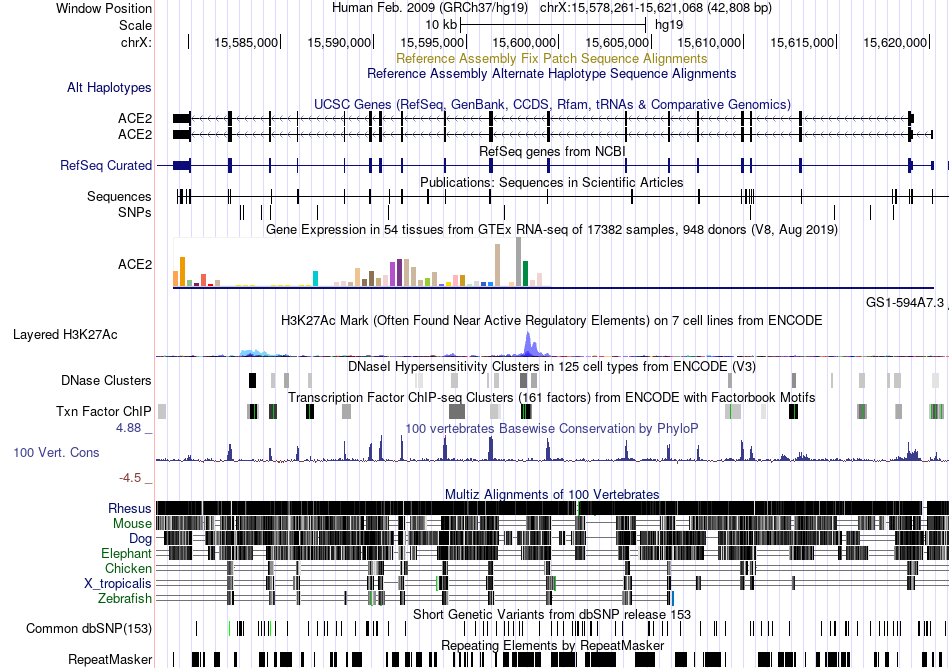 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 149N | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
Top |
Fusion Gene ORF analysis for C1orf52-PPP3CB |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000344356 | ENST00000495897 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5CDS-intron | ENST00000344356 | ENST00000544628 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5CDS-intron | ENST00000471115 | ENST00000495897 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5CDS-intron | ENST00000471115 | ENST00000544628 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5UTR-3CDS | ENST00000294661 | ENST00000342558 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5UTR-3CDS | ENST00000294661 | ENST00000360663 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5UTR-3CDS | ENST00000294661 | ENST00000394822 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5UTR-3CDS | ENST00000294661 | ENST00000394828 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5UTR-3CDS | ENST00000294661 | ENST00000394829 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5UTR-3CDS | ENST00000294661 | ENST00000545874 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5UTR-intron | ENST00000294661 | ENST00000495897 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| 5UTR-intron | ENST00000294661 | ENST00000544628 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000344356 | ENST00000342558 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000344356 | ENST00000360663 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000344356 | ENST00000394822 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000344356 | ENST00000394828 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000344356 | ENST00000394829 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000344356 | ENST00000545874 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000471115 | ENST00000342558 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000471115 | ENST00000360663 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000471115 | ENST00000394822 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000471115 | ENST00000394828 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000471115 | ENST00000394829 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| In-frame | ENST00000471115 | ENST00000545874 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000471115 | C1orf52 | chr1 | 85724206 | - | ENST00000360663 | PPP3CB | chr10 | 75231371 | - | 3350 | 484 | 9 | 1535 | 508 |
| ENST00000471115 | C1orf52 | chr1 | 85724206 | - | ENST00000394828 | PPP3CB | chr10 | 75231371 | - | 2945 | 484 | 9 | 1508 | 499 |
| ENST00000471115 | C1orf52 | chr1 | 85724206 | - | ENST00000394829 | PPP3CB | chr10 | 75231371 | - | 2975 | 484 | 9 | 1538 | 509 |
| ENST00000471115 | C1orf52 | chr1 | 85724206 | - | ENST00000342558 | PPP3CB | chr10 | 75231371 | - | 2272 | 484 | 9 | 1451 | 480 |
| ENST00000471115 | C1orf52 | chr1 | 85724206 | - | ENST00000545874 | PPP3CB | chr10 | 75231371 | - | 1918 | 484 | 9 | 1454 | 481 |
| ENST00000471115 | C1orf52 | chr1 | 85724206 | - | ENST00000394822 | PPP3CB | chr10 | 75231371 | - | 1452 | 484 | 9 | 1451 | 480 |
| ENST00000344356 | C1orf52 | chr1 | 85724206 | - | ENST00000360663 | PPP3CB | chr10 | 75231371 | - | 3341 | 475 | 0 | 1526 | 508 |
| ENST00000344356 | C1orf52 | chr1 | 85724206 | - | ENST00000394828 | PPP3CB | chr10 | 75231371 | - | 2936 | 475 | 0 | 1499 | 499 |
| ENST00000344356 | C1orf52 | chr1 | 85724206 | - | ENST00000394829 | PPP3CB | chr10 | 75231371 | - | 2966 | 475 | 0 | 1529 | 509 |
| ENST00000344356 | C1orf52 | chr1 | 85724206 | - | ENST00000342558 | PPP3CB | chr10 | 75231371 | - | 2263 | 475 | 0 | 1442 | 480 |
| ENST00000344356 | C1orf52 | chr1 | 85724206 | - | ENST00000545874 | PPP3CB | chr10 | 75231371 | - | 1909 | 475 | 0 | 1445 | 481 |
| ENST00000344356 | C1orf52 | chr1 | 85724206 | - | ENST00000394822 | PPP3CB | chr10 | 75231371 | - | 1443 | 475 | 0 | 1442 | 480 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000471115 | ENST00000360663 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000204619 | 0.9997954 |
| ENST00000471115 | ENST00000394828 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000256387 | 0.99974364 |
| ENST00000471115 | ENST00000394829 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000276813 | 0.99972314 |
| ENST00000471115 | ENST00000342558 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.00019577 | 0.9998042 |
| ENST00000471115 | ENST00000545874 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000263766 | 0.99973625 |
| ENST00000471115 | ENST00000394822 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000647117 | 0.9993529 |
| ENST00000344356 | ENST00000360663 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000198618 | 0.99980146 |
| ENST00000344356 | ENST00000394828 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000248601 | 0.9997514 |
| ENST00000344356 | ENST00000394829 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000268726 | 0.99973124 |
| ENST00000344356 | ENST00000342558 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000191227 | 0.99980885 |
| ENST00000344356 | ENST00000545874 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000253683 | 0.99974626 |
| ENST00000344356 | ENST00000394822 | C1orf52 | chr1 | 85724206 | - | PPP3CB | chr10 | 75231371 | - | 0.000608185 | 0.9993918 |
Top |
Fusion Genomic Features for C1orf52-PPP3CB |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
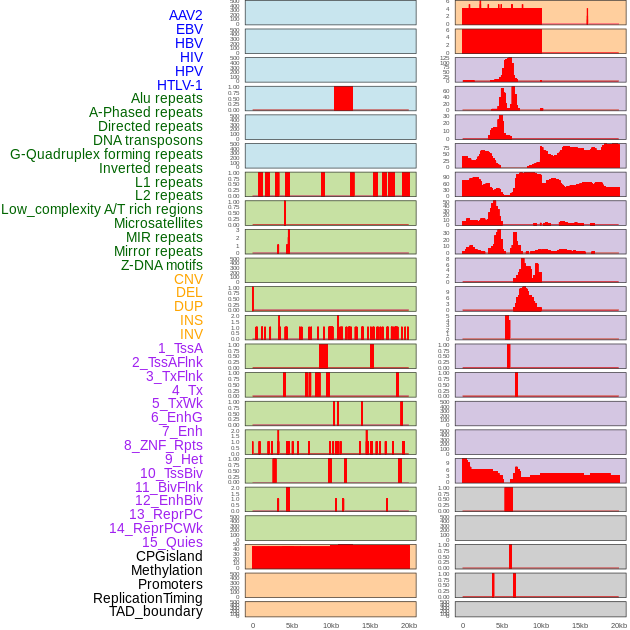 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for C1orf52-PPP3CB |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:85724206/chr10:75231371) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| C1orf52 | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000360663 | 3 | 14 | 316_320 | 174 | 525.0 | Motif | SAPNY motif | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394822 | 4 | 13 | 316_320 | 192 | 515.0 | Motif | SAPNY motif | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394828 | 3 | 13 | 316_320 | 174 | 516.0 | Motif | SAPNY motif | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394829 | 3 | 14 | 316_320 | 174 | 526.0 | Motif | SAPNY motif | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000360663 | 3 | 14 | 357_379 | 174 | 525.0 | Region | Calcineurin B binding | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000360663 | 3 | 14 | 401_415 | 174 | 525.0 | Region | Calmodulin-binding | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000360663 | 3 | 14 | 416_423 | 174 | 525.0 | Region | Autoinhibitory segment | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000360663 | 3 | 14 | 474_496 | 174 | 525.0 | Region | Autoinhibitory domain | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394822 | 4 | 13 | 357_379 | 192 | 515.0 | Region | Calcineurin B binding | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394822 | 4 | 13 | 401_415 | 192 | 515.0 | Region | Calmodulin-binding | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394822 | 4 | 13 | 416_423 | 192 | 515.0 | Region | Autoinhibitory segment | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394822 | 4 | 13 | 474_496 | 192 | 515.0 | Region | Autoinhibitory domain | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394828 | 3 | 13 | 357_379 | 174 | 516.0 | Region | Calcineurin B binding | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394828 | 3 | 13 | 401_415 | 174 | 516.0 | Region | Calmodulin-binding | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394828 | 3 | 13 | 416_423 | 174 | 516.0 | Region | Autoinhibitory segment | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394828 | 3 | 13 | 474_496 | 174 | 516.0 | Region | Autoinhibitory domain | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394829 | 3 | 14 | 357_379 | 174 | 526.0 | Region | Calcineurin B binding | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394829 | 3 | 14 | 401_415 | 174 | 526.0 | Region | Calmodulin-binding | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394829 | 3 | 14 | 416_423 | 174 | 526.0 | Region | Autoinhibitory segment | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394829 | 3 | 14 | 474_496 | 174 | 526.0 | Region | Autoinhibitory domain |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000360663 | 3 | 14 | 11_21 | 174 | 525.0 | Compositional bias | Poly-Pro | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394822 | 4 | 13 | 11_21 | 192 | 515.0 | Compositional bias | Poly-Pro | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394828 | 3 | 13 | 11_21 | 174 | 516.0 | Compositional bias | Poly-Pro | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394829 | 3 | 14 | 11_21 | 174 | 526.0 | Compositional bias | Poly-Pro | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000360663 | 3 | 14 | 65_356 | 174 | 525.0 | Region | Catalytic | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394822 | 4 | 13 | 65_356 | 192 | 515.0 | Region | Catalytic | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394828 | 3 | 13 | 65_356 | 174 | 516.0 | Region | Catalytic | |
| Tgene | PPP3CB | chr1:85724206 | chr10:75231371 | ENST00000394829 | 3 | 14 | 65_356 | 174 | 526.0 | Region | Catalytic |
Top |
Fusion Gene Sequence for C1orf52-PPP3CB |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >11367_11367_1_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000342558_length(transcript)=2263nt_BP=475nt ATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGATAACATCGAG CCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCGGGACCTGAC GAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTCAAGGCGCCT GAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCTCCGCCTCCA GAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGGCTTCTACCA GAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGTTTGCCTCTT GCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGATTAGATAGA TTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCACAGGAACAT TTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTGTTATCGATT ATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACAATTTTTTCG GCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTTAACTGTTCT CCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATGTTGGTAAAT GTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGGTTCAGCTGCAGCCCGGAAAGAAATCATAAGA AACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAGGGCCTGACT CCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGGTAATGATGTTATGCAACTTGCTGTGCCTCAG ATGGACTGGGGCACACCTCACTCTTTTGCTAACAATTCACATAATGCATGCAGGGAATTCCTTCTGTTTTTTAGTTCCTGTCTCAGCAGC TGACCTAGACAGGGTACTGTATTAGCTAGTGTCTCATTAATACCTGATCAGGGCAGAAAACTGATAGAATGGGTATTCCTTTCAATTGAA AATAATGGTCAGTTCCTCAGCTTTTCATGAAATGATATGGGAGCAGCTCATATCATAATGTCTGAAATATTTATTTATTCATCTGTCTAA TTCACCCTTTTCTTTTAAAAGCCCCAGTTTCAGAATGTGAATCAGGGATATTCCTGTTACTAAAATGGAAATGTAATTCCAAGTTTCTTT TTTAATTTTTTAAATTTATGTCATTGTATTGGACTATGCTTATATTTAAAACTACTTAATTTAGAGTTAACTACCTGCTTAGGCCCCAGA ACATTACTTATGCCCTTCAGTTACCAAAAGATTTGTGCAAGGTTTTGTACCCTGGTAAATGATGCCAAAGTTTGTTTTCTGTGGTGTTTG TCAAATGTTCTATGTATAATTAACTGTCTGTAACATGCTGTTTCCTTCCTCTGCAGATGTAGCTGCTTTCCTAAATCTGTCTGTCTTTCT TTAGGTTAGCTGTATGTCTGTAAAAGTATGTTCAATTAAATTACTCCATCAGACACTTGTCTGTCTTGCAATGTAGAAGCAGCTTTGTAG CACCTTGTTTTGAGGTTTGCTGCATTTGTTGCTGCACTTTGTGCATTCTGAACATGAATGTAACATTAGATATTAAGTCATTGTTATAAG GGGTTGAATTTAAATCCTGTAAGTCAAAATTGAAAGGGTGTTATTAAGTGTGCCTTTATTTTGCATGAAAATAAAAAGAATTATACGTAA >11367_11367_1_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000342558_length(amino acids)=480AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSGNDVMQLAVPQ -------------------------------------------------------------- >11367_11367_2_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000360663_length(transcript)=3341nt_BP=475nt ATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGATAACATCGAG CCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCGGGACCTGAC GAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTCAAGGCGCCT GAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCTCCGCCTCCA GAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGGCTTCTACCA GAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGTTTGCCTCTT GCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGATTAGATAGA TTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCACAGGAACAT TTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTGTTATCGATT ATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACAATTTTTTCG GCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTTAACTGTTCT CCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATGTTGGTAAAT GTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGGTTCAGCTGCAGCCCGGAAAGAAATCATAAGA AACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAGGGCCTGACT CCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGCCACAGTTGAGGCTATTGAGGCTGAAAAAGCA ATACGAGGATTCTCTCCACCACATAGAATCTGCAGTTTTGAAGAGGCAAAGGGTTTGGATAGGATCAATGAGAGAATGCCACCTCGGAAA GATGCTGTACAGCAAGATGGTTTCAATTCTCTGAACACCGCACATGCCACTGAGAACCACGGGACGGGCAACCATACTGCCCAGTGACCC ACTACTTCCCAGGGACTCTCACATCTCGGGCCCCAAATGGACAGATCACCCGAGGAGCTGGAGGGGTCGGCCAAGCTGACTGTAAATTTC ACAGTCTCTCTGAAGAAACCATTGTGCTTCTGAGACCCTAGCCCCCTTCCTGGATGGAGGCTTGAGGGCCCTGGGACATGTGCTATCTGA TAAGATTGGGTCATCGCTGCCAAGGTGGAGAGCAGTGAGCAAGGGGCTTGGGGCAATTTCCAGTGGAGGGCATCCACACCTCCATTTTAT GCTTGTGGTTCACACATTTAAGTTTACAAATCAGATTTCTTTTCCCCTTCAGTAGAATTAGATTTTGTTTTTCAATCATGATTTCAAATG CAATCCTAAGAGCTAATGTGGACTTTTCTTTTTCCATGAAATGTCTTTAAAGGATGAATTAGCATGGTCTTAAAATACATTTCTGAGGTT ACTAGCTGTATTTTGAATTGTGAGCAAAATGCCGAGAAACCCAGTTGGCATTTATACAAAATGTTGACCTCAGGTCTATAGTTCTTAAAT GTGGCTAATTCTGTAACATAGTCTTGGTATTTTTTAATTATGAATGCATATCCTATTTCCAGGCAGGCTCTCTTACTTGAACACAAATCC AAAAACTAATTTAGAGTCTTTTTTGCCCAGATCTTTTAAGACTTACACCCCAGAGATTTAAGAAGAAAACCTCTAAATTTCAAAATTATG AAGAATTACAGAATTACTCATTTAAGGTACTTTAAAAGAAGTTTGTACATTGTCAAAGTAAATTTTAATTCAAATCATGTCTGTAAAACT TGACGTATTTTGTGTATGCATGTTTTCATTTTGCAAATATTTAATATATAGACCTATGATGTACAGGTACGACATGTATAGGTTACCTAG ATGTTATGAGAAATTTTAGTTTATTGTGAGTACTCAAGTTGCTTAGAGAGCCACCAGGGTGATTTGCTGCTGGCTTTCTATCATTTTTAT GTTTTAATGCAAAGGAAATTTTAAAATGTTCTGGAAGTGTTTTTGATTAAGCAATGCAGCCTAGAAGCAATGGTTCTGTTCAATCATTCA GATGTTAGTGGAAGCATAAAAGTCAAGACTGCATGTTGAAACCTTTCTTTTGATAGTTACTGAACTGCTTGGTTAAACTAAATGGAACCA TGTGCTAATTTTTCACAATTATTGACCTGTATTGATTGCCACTGTAGTTTGGTATTTCCCTTTACTTTGGTGGCCTGCTTCCCTCATGCC CTGGAATACAACTCAGAGCTCCAGGCAGCGGAACCATCTATTGTTTTGTTTGCCAGAAAGTGCACCCTGTATGGTCTCCTGTCTAAGTTG GAAATATTATGCATGTGCAGGACTATTCGAGTATTTTATAAACAGTAGCACACAATAAATTCCATGCATGGGCCGCTGCTCCTATCTCTG TGTTGGGTTTTATTTGGAAGATGCAATCTGATTTGTCCTTTTGATGCAAATCAGAAAATCCTGTTACTAGAGCTGGGATGTCCTCCGGAG ATTATCTCGTGGATAGTTCATGGTAATTTGATTAATTAAATTCTTTATAAATTTTGCCTTAAAAAAAACTTTTGTTATATACTTGTTTTA CATGAGCATTAGTAACTGAGCACTAGAGGACTTTGAATGCCTACTGTAGGCCTCCTAAGTCTAATATTTAAGATCACTGTTTATTGTCTT TTAATTGAAAGAAAATATGTTATTGTCTAGAATTTTGTTATAGTGGTATTGGGAATTTACTGGGTGTTCTAACAATAAGAAAAATATTAG >11367_11367_2_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000360663_length(amino acids)=508AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSATVEAIEAEKA -------------------------------------------------------------- >11367_11367_3_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000394822_length(transcript)=1443nt_BP=475nt ATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGATAACATCGAG CCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCGGGACCTGAC GAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTCAAGGCGCCT GAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCTCCGCCTCCA GAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGGCTTCTACCA GAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGTTTGCCTCTT GCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGATTAGATAGA TTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCACAGGAACAT TTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTGTTATCGATT ATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACAATTTTTTCG GCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTTAACTGTTCT CCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATGTTGGTAAAT GTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGGTTCAGCTGCAGCCCGGAAAGAAATCATAAGA AACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAGGGCCTGACT CCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGGTAATGATGTTATGCAACTTGCTGTGCCTCAG ATGGACTGGGGCACACCTCACTCTTTTGCTAACAATTCACATAATGCATGCAGGGAATTCCTTCTGTTTTTTAGTTCCTGTCTCAGCAGC >11367_11367_3_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000394822_length(amino acids)=480AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSGNDVMQLAVPQ -------------------------------------------------------------- >11367_11367_4_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000394828_length(transcript)=2936nt_BP=475nt ATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGATAACATCGAG CCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCGGGACCTGAC GAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTCAAGGCGCCT GAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCTCCGCCTCCA GAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGGCTTCTACCA GAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGTTTGCCTCTT GCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGATTAGATAGA TTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCACAGGAACAT TTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTGTTATCGATT ATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACAATTTTTTCG GCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTTAACTGTTCT CCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATGTTGGTAAAT GTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGTAGGTTCAGCTGCAGCCCGGAAAGAAATCATA AGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAGGGCCTG ACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGCAATACGAGGATTCTCTCCACCACATAGA ATCTGCAGTTTTGAAGAGGCAAAGGGTTTGGATAGGATCAATGAGAGAATGCCACCTCGGAAAGATGCTGTACAGCAAGATGGTTTCAAT TCTCTGAACACCGCACATGCCACTGAGAACCACGGGACGGGCAACCATACTGCCCAGTGACCCACTACTTCCCAGGGACTCTCACATCTC GGGCCCCAAATGGACAGATCACCCGAGGAGCTGGAGGGGTCGGCCAAGCTGACTGTAAATTTCACAGTCTCTCTGAAGAAACCATTGTGC TTCTGAGACCCTAGCCCCCTTCCTGGATGGAGGCTTGAGGGCCCTGGGACATGTGCTATCTGATAAGATTGGGTCATCGCTGCCAAGGTG GAGAGCAGTGAGCAAGGGGCTTGGGGCAATTTCCAGTGGAGGGCATCCACACCTCCATTTTATGCTTGTGGTTCACACATTTAAGTTTAC AAATCAGATTTCTTTTCCCCTTCAGTAGAATTAGATTTTGTTTTTCAATCATGATTTCAAATGCAATCCTAAGAGCTAATGTGGACTTTT CTTTTTCCATGAAATGTCTTTAAAGGATGAATTAGCATGGTCTTAAAATACATTTCTGAGGTTACTAGCTGTATTTTGAATTGTGAGCAA AATGCCGAGAAACCCAGTTGGCATTTATACAAAATGTTGACCTCAGGTCTATAGTTCTTAAATGTGGCTAATTCTGTAACATAGTCTTGG TATTTTTTAATTATGAATGCATATCCTATTTCCAGGCAGGCTCTCTTACTTGAACACAAATCCAAAAACTAATTTAGAGTCTTTTTTGCC CAGATCTTTTAAGACTTACACCCCAGAGATTTAAGAAGAAAACCTCTAAATTTCAAAATTATGAAGAATTACAGAATTACTCATTTAAGG TACTTTAAAAGAAGTTTGTACATTGTCAAAGTAAATTTTAATTCAAATCATGTCTGTAAAACTTGACGTATTTTGTGTATGCATGTTTTC ATTTTGCAAATATTTAATATATAGACCTATGATGTACAGGTACGACATGTATAGGTTACCTAGATGTTATGAGAAATTTTAGTTTATTGT GAGTACTCAAGTTGCTTAGAGAGCCACCAGGGTGATTTGCTGCTGGCTTTCTATCATTTTTATGTTTTAATGCAAAGGAAATTTTAAAAT GTTCTGGAAGTGTTTTTGATTAAGCAATGCAGCCTAGAAGCAATGGTTCTGTTCAATCATTCAGATGTTAGTGGAAGCATAAAAGTCAAG ACTGCATGTTGAAACCTTTCTTTTGATAGTTACTGAACTGCTTGGTTAAACTAAATGGAACCATGTGCTAATTTTTCACAATTATTGACC TGTATTGATTGCCACTGTAGTTTGGTATTTCCCTTTACTTTGGTGGCCTGCTTCCCTCATGCCCTGGAATACAACTCAGAGCTCCAGGCA GCGGAACCATCTATTGTTTTGTTTGCCAGAAAGTGCACCCTGTATGGTCTCCTGTCTAAGTTGGAAATATTATGCATGTGCAGGACTATT >11367_11367_4_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000394828_length(amino acids)=499AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDVGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSAIRGFSPPHR -------------------------------------------------------------- >11367_11367_5_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000394829_length(transcript)=2966nt_BP=475nt ATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGATAACATCGAG CCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCGGGACCTGAC GAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTCAAGGCGCCT GAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCTCCGCCTCCA GAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGGCTTCTACCA GAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGTTTGCCTCTT GCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGATTAGATAGA TTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCACAGGAACAT TTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTGTTATCGATT ATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACAATTTTTTCG GCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTTAACTGTTCT CCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATGTTGGTAAAT GTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGTAGGTTCAGCTGCAGCCCGGAAAGAAATCATA AGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAGGGCCTG ACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGCCACAGTTGAGGCTATTGAGGCTGAAAAA GCAATACGAGGATTCTCTCCACCACATAGAATCTGCAGTTTTGAAGAGGCAAAGGGTTTGGATAGGATCAATGAGAGAATGCCACCTCGG AAAGATGCTGTACAGCAAGATGGTTTCAATTCTCTGAACACCGCACATGCCACTGAGAACCACGGGACGGGCAACCATACTGCCCAGTGA CCCACTACTTCCCAGGGACTCTCACATCTCGGGCCCCAAATGGACAGATCACCCGAGGAGCTGGAGGGGTCGGCCAAGCTGACTGTAAAT TTCACAGTCTCTCTGAAGAAACCATTGTGCTTCTGAGACCCTAGCCCCCTTCCTGGATGGAGGCTTGAGGGCCCTGGGACATGTGCTATC TGATAAGATTGGGTCATCGCTGCCAAGGTGGAGAGCAGTGAGCAAGGGGCTTGGGGCAATTTCCAGTGGAGGGCATCCACACCTCCATTT TATGCTTGTGGTTCACACATTTAAGTTTACAAATCAGATTTCTTTTCCCCTTCAGTAGAATTAGATTTTGTTTTTCAATCATGATTTCAA ATGCAATCCTAAGAGCTAATGTGGACTTTTCTTTTTCCATGAAATGTCTTTAAAGGATGAATTAGCATGGTCTTAAAATACATTTCTGAG GTTACTAGCTGTATTTTGAATTGTGAGCAAAATGCCGAGAAACCCAGTTGGCATTTATACAAAATGTTGACCTCAGGTCTATAGTTCTTA AATGTGGCTAATTCTGTAACATAGTCTTGGTATTTTTTAATTATGAATGCATATCCTATTTCCAGGCAGGCTCTCTTACTTGAACACAAA TCCAAAAACTAATTTAGAGTCTTTTTTGCCCAGATCTTTTAAGACTTACACCCCAGAGATTTAAGAAGAAAACCTCTAAATTTCAAAATT ATGAAGAATTACAGAATTACTCATTTAAGGTACTTTAAAAGAAGTTTGTACATTGTCAAAGTAAATTTTAATTCAAATCATGTCTGTAAA ACTTGACGTATTTTGTGTATGCATGTTTTCATTTTGCAAATATTTAATATATAGACCTATGATGTACAGGTACGACATGTATAGGTTACC TAGATGTTATGAGAAATTTTAGTTTATTGTGAGTACTCAAGTTGCTTAGAGAGCCACCAGGGTGATTTGCTGCTGGCTTTCTATCATTTT TATGTTTTAATGCAAAGGAAATTTTAAAATGTTCTGGAAGTGTTTTTGATTAAGCAATGCAGCCTAGAAGCAATGGTTCTGTTCAATCAT TCAGATGTTAGTGGAAGCATAAAAGTCAAGACTGCATGTTGAAACCTTTCTTTTGATAGTTACTGAACTGCTTGGTTAAACTAAATGGAA CCATGTGCTAATTTTTCACAATTATTGACCTGTATTGATTGCCACTGTAGTTTGGTATTTCCCTTTACTTTGGTGGCCTGCTTCCCTCAT GCCCTGGAATACAACTCAGAGCTCCAGGCAGCGGAACCATCTATTGTTTTGTTTGCCAGAAAGTGCACCCTGTATGGTCTCCTGTCTAAG >11367_11367_5_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000394829_length(amino acids)=509AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDVGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSATVEAIEAEK -------------------------------------------------------------- >11367_11367_6_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000545874_length(transcript)=1909nt_BP=475nt ATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGATAACATCGAG CCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCGGGACCTGAC GAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTCAAGGCGCCT GAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCTCCGCCTCCA GAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGGCTTCTACCA GAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGTTTGCCTCTT GCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGATTAGATAGA TTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCACAGGAACAT TTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTGTTATCGATT ATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACAATTTTTTCG GCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTTAACTGTTCT CCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATGTTGGTAAAT GTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGTAGGTTCAGCTGCAGCCCGGAAAGAAATCATA AGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAGGGCCTG ACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGGTAATGATGTTATGCAACTTGCTGTGCCT CAGATGGACTGGGGCACACCTCACTCTTTTGCTAACAATTCACATAATGCATGCAGGGAATTCCTTCTGTTTTTTAGTTCCTGTCTCAGC AGCTGACCTAGACAGGGTACTGTATTAGCTAGTGTCTCATTAATACCTGATCAGGGCAGAAAACTGATAGAATGGGTATTCCTTTCAATT GAAAATAATGGTCAGTTCCTCAGCTTTTCATGAAATGATATGGGAGCAGCTCATATCATAATGTCTGAAATATTTATTTATTCATCTGTC TAATTCACCCTTTTCTTTTAAAAGCCCCAGTTTCAGAATGTGAATCAGGGATATTCCTGTTACTAAAATGGAAATGTAATTCCAAGTTTC TTTTTTAATTTTTTAAATTTATGTCATTGTATTGGACTATGCTTATATTTAAAACTACTTAATTTAGAGTTAACTACCTGCTTAGGCCCC AGAACATTACTTATGCCCTTCAGTTACCAAAAGATTTGTGCAAGGTTTTGTACCCTGGTAAATGATGCCAAAGTTTGTTTTCTGTGGTGT >11367_11367_6_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000344356_PPP3CB_chr10_75231371_ENST00000545874_length(amino acids)=481AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDVGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSGNDVMQLAVP -------------------------------------------------------------- >11367_11367_7_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000342558_length(transcript)=2272nt_BP=484nt GCAGCCGTCATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGAT AACATCGAGCCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCG GGACCTGACGAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTC AAGGCGCCTGAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCT CCGCCTCCAGAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGG CTTCTACCAGAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGT TTGCCTCTTGCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGA TTAGATAGATTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCA CAGGAACATTTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTG TTATCGATTATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACA ATTTTTTCGGCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTT AACTGTTCTCCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATG TTGGTAAATGTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGGTTCAGCTGCAGCCCGGAAAGAA ATCATAAGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAG GGCCTGACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGGTAATGATGTTATGCAACTTGCT GTGCCTCAGATGGACTGGGGCACACCTCACTCTTTTGCTAACAATTCACATAATGCATGCAGGGAATTCCTTCTGTTTTTTAGTTCCTGT CTCAGCAGCTGACCTAGACAGGGTACTGTATTAGCTAGTGTCTCATTAATACCTGATCAGGGCAGAAAACTGATAGAATGGGTATTCCTT TCAATTGAAAATAATGGTCAGTTCCTCAGCTTTTCATGAAATGATATGGGAGCAGCTCATATCATAATGTCTGAAATATTTATTTATTCA TCTGTCTAATTCACCCTTTTCTTTTAAAAGCCCCAGTTTCAGAATGTGAATCAGGGATATTCCTGTTACTAAAATGGAAATGTAATTCCA AGTTTCTTTTTTAATTTTTTAAATTTATGTCATTGTATTGGACTATGCTTATATTTAAAACTACTTAATTTAGAGTTAACTACCTGCTTA GGCCCCAGAACATTACTTATGCCCTTCAGTTACCAAAAGATTTGTGCAAGGTTTTGTACCCTGGTAAATGATGCCAAAGTTTGTTTTCTG TGGTGTTTGTCAAATGTTCTATGTATAATTAACTGTCTGTAACATGCTGTTTCCTTCCTCTGCAGATGTAGCTGCTTTCCTAAATCTGTC TGTCTTTCTTTAGGTTAGCTGTATGTCTGTAAAAGTATGTTCAATTAAATTACTCCATCAGACACTTGTCTGTCTTGCAATGTAGAAGCA GCTTTGTAGCACCTTGTTTTGAGGTTTGCTGCATTTGTTGCTGCACTTTGTGCATTCTGAACATGAATGTAACATTAGATATTAAGTCAT TGTTATAAGGGGTTGAATTTAAATCCTGTAAGTCAAAATTGAAAGGGTGTTATTAAGTGTGCCTTTATTTTGCATGAAAATAAAAAGAAT >11367_11367_7_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000342558_length(amino acids)=480AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSGNDVMQLAVPQ -------------------------------------------------------------- >11367_11367_8_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000360663_length(transcript)=3350nt_BP=484nt GCAGCCGTCATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGAT AACATCGAGCCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCG GGACCTGACGAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTC AAGGCGCCTGAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCT CCGCCTCCAGAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGG CTTCTACCAGAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGT TTGCCTCTTGCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGA TTAGATAGATTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCA CAGGAACATTTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTG TTATCGATTATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACA ATTTTTTCGGCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTT AACTGTTCTCCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATG TTGGTAAATGTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGGTTCAGCTGCAGCCCGGAAAGAA ATCATAAGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAG GGCCTGACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGCCACAGTTGAGGCTATTGAGGCT GAAAAAGCAATACGAGGATTCTCTCCACCACATAGAATCTGCAGTTTTGAAGAGGCAAAGGGTTTGGATAGGATCAATGAGAGAATGCCA CCTCGGAAAGATGCTGTACAGCAAGATGGTTTCAATTCTCTGAACACCGCACATGCCACTGAGAACCACGGGACGGGCAACCATACTGCC CAGTGACCCACTACTTCCCAGGGACTCTCACATCTCGGGCCCCAAATGGACAGATCACCCGAGGAGCTGGAGGGGTCGGCCAAGCTGACT GTAAATTTCACAGTCTCTCTGAAGAAACCATTGTGCTTCTGAGACCCTAGCCCCCTTCCTGGATGGAGGCTTGAGGGCCCTGGGACATGT GCTATCTGATAAGATTGGGTCATCGCTGCCAAGGTGGAGAGCAGTGAGCAAGGGGCTTGGGGCAATTTCCAGTGGAGGGCATCCACACCT CCATTTTATGCTTGTGGTTCACACATTTAAGTTTACAAATCAGATTTCTTTTCCCCTTCAGTAGAATTAGATTTTGTTTTTCAATCATGA TTTCAAATGCAATCCTAAGAGCTAATGTGGACTTTTCTTTTTCCATGAAATGTCTTTAAAGGATGAATTAGCATGGTCTTAAAATACATT TCTGAGGTTACTAGCTGTATTTTGAATTGTGAGCAAAATGCCGAGAAACCCAGTTGGCATTTATACAAAATGTTGACCTCAGGTCTATAG TTCTTAAATGTGGCTAATTCTGTAACATAGTCTTGGTATTTTTTAATTATGAATGCATATCCTATTTCCAGGCAGGCTCTCTTACTTGAA CACAAATCCAAAAACTAATTTAGAGTCTTTTTTGCCCAGATCTTTTAAGACTTACACCCCAGAGATTTAAGAAGAAAACCTCTAAATTTC AAAATTATGAAGAATTACAGAATTACTCATTTAAGGTACTTTAAAAGAAGTTTGTACATTGTCAAAGTAAATTTTAATTCAAATCATGTC TGTAAAACTTGACGTATTTTGTGTATGCATGTTTTCATTTTGCAAATATTTAATATATAGACCTATGATGTACAGGTACGACATGTATAG GTTACCTAGATGTTATGAGAAATTTTAGTTTATTGTGAGTACTCAAGTTGCTTAGAGAGCCACCAGGGTGATTTGCTGCTGGCTTTCTAT CATTTTTATGTTTTAATGCAAAGGAAATTTTAAAATGTTCTGGAAGTGTTTTTGATTAAGCAATGCAGCCTAGAAGCAATGGTTCTGTTC AATCATTCAGATGTTAGTGGAAGCATAAAAGTCAAGACTGCATGTTGAAACCTTTCTTTTGATAGTTACTGAACTGCTTGGTTAAACTAA ATGGAACCATGTGCTAATTTTTCACAATTATTGACCTGTATTGATTGCCACTGTAGTTTGGTATTTCCCTTTACTTTGGTGGCCTGCTTC CCTCATGCCCTGGAATACAACTCAGAGCTCCAGGCAGCGGAACCATCTATTGTTTTGTTTGCCAGAAAGTGCACCCTGTATGGTCTCCTG TCTAAGTTGGAAATATTATGCATGTGCAGGACTATTCGAGTATTTTATAAACAGTAGCACACAATAAATTCCATGCATGGGCCGCTGCTC CTATCTCTGTGTTGGGTTTTATTTGGAAGATGCAATCTGATTTGTCCTTTTGATGCAAATCAGAAAATCCTGTTACTAGAGCTGGGATGT CCTCCGGAGATTATCTCGTGGATAGTTCATGGTAATTTGATTAATTAAATTCTTTATAAATTTTGCCTTAAAAAAAACTTTTGTTATATA CTTGTTTTACATGAGCATTAGTAACTGAGCACTAGAGGACTTTGAATGCCTACTGTAGGCCTCCTAAGTCTAATATTTAAGATCACTGTT TATTGTCTTTTAATTGAAAGAAAATATGTTATTGTCTAGAATTTTGTTATAGTGGTATTGGGAATTTACTGGGTGTTCTAACAATAAGAA >11367_11367_8_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000360663_length(amino acids)=508AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSATVEAIEAEKA -------------------------------------------------------------- >11367_11367_9_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000394822_length(transcript)=1452nt_BP=484nt GCAGCCGTCATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGAT AACATCGAGCCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCG GGACCTGACGAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTC AAGGCGCCTGAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCT CCGCCTCCAGAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGG CTTCTACCAGAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGT TTGCCTCTTGCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGA TTAGATAGATTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCA CAGGAACATTTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTG TTATCGATTATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACA ATTTTTTCGGCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTT AACTGTTCTCCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATG TTGGTAAATGTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGGTTCAGCTGCAGCCCGGAAAGAA ATCATAAGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTCAAG GGCCTGACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGGTAATGATGTTATGCAACTTGCT GTGCCTCAGATGGACTGGGGCACACCTCACTCTTTTGCTAACAATTCACATAATGCATGCAGGGAATTCCTTCTGTTTTTTAGTTCCTGT >11367_11367_9_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000394822_length(amino acids)=480AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSGNDVMQLAVPQ -------------------------------------------------------------- >11367_11367_10_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000394828_length(transcript)=2945nt_BP=484nt GCAGCCGTCATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGAT AACATCGAGCCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCG GGACCTGACGAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTC AAGGCGCCTGAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCT CCGCCTCCAGAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGG CTTCTACCAGAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGT TTGCCTCTTGCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGA TTAGATAGATTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCA CAGGAACATTTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTG TTATCGATTATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACA ATTTTTTCGGCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTT AACTGTTCTCCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATG TTGGTAAATGTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGTAGGTTCAGCTGCAGCCCGGAAA GAAATCATAAGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTC AAGGGCCTGACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGCAATACGAGGATTCTCTCCA CCACATAGAATCTGCAGTTTTGAAGAGGCAAAGGGTTTGGATAGGATCAATGAGAGAATGCCACCTCGGAAAGATGCTGTACAGCAAGAT GGTTTCAATTCTCTGAACACCGCACATGCCACTGAGAACCACGGGACGGGCAACCATACTGCCCAGTGACCCACTACTTCCCAGGGACTC TCACATCTCGGGCCCCAAATGGACAGATCACCCGAGGAGCTGGAGGGGTCGGCCAAGCTGACTGTAAATTTCACAGTCTCTCTGAAGAAA CCATTGTGCTTCTGAGACCCTAGCCCCCTTCCTGGATGGAGGCTTGAGGGCCCTGGGACATGTGCTATCTGATAAGATTGGGTCATCGCT GCCAAGGTGGAGAGCAGTGAGCAAGGGGCTTGGGGCAATTTCCAGTGGAGGGCATCCACACCTCCATTTTATGCTTGTGGTTCACACATT TAAGTTTACAAATCAGATTTCTTTTCCCCTTCAGTAGAATTAGATTTTGTTTTTCAATCATGATTTCAAATGCAATCCTAAGAGCTAATG TGGACTTTTCTTTTTCCATGAAATGTCTTTAAAGGATGAATTAGCATGGTCTTAAAATACATTTCTGAGGTTACTAGCTGTATTTTGAAT TGTGAGCAAAATGCCGAGAAACCCAGTTGGCATTTATACAAAATGTTGACCTCAGGTCTATAGTTCTTAAATGTGGCTAATTCTGTAACA TAGTCTTGGTATTTTTTAATTATGAATGCATATCCTATTTCCAGGCAGGCTCTCTTACTTGAACACAAATCCAAAAACTAATTTAGAGTC TTTTTTGCCCAGATCTTTTAAGACTTACACCCCAGAGATTTAAGAAGAAAACCTCTAAATTTCAAAATTATGAAGAATTACAGAATTACT CATTTAAGGTACTTTAAAAGAAGTTTGTACATTGTCAAAGTAAATTTTAATTCAAATCATGTCTGTAAAACTTGACGTATTTTGTGTATG CATGTTTTCATTTTGCAAATATTTAATATATAGACCTATGATGTACAGGTACGACATGTATAGGTTACCTAGATGTTATGAGAAATTTTA GTTTATTGTGAGTACTCAAGTTGCTTAGAGAGCCACCAGGGTGATTTGCTGCTGGCTTTCTATCATTTTTATGTTTTAATGCAAAGGAAA TTTTAAAATGTTCTGGAAGTGTTTTTGATTAAGCAATGCAGCCTAGAAGCAATGGTTCTGTTCAATCATTCAGATGTTAGTGGAAGCATA AAAGTCAAGACTGCATGTTGAAACCTTTCTTTTGATAGTTACTGAACTGCTTGGTTAAACTAAATGGAACCATGTGCTAATTTTTCACAA TTATTGACCTGTATTGATTGCCACTGTAGTTTGGTATTTCCCTTTACTTTGGTGGCCTGCTTCCCTCATGCCCTGGAATACAACTCAGAG CTCCAGGCAGCGGAACCATCTATTGTTTTGTTTGCCAGAAAGTGCACCCTGTATGGTCTCCTGTCTAAGTTGGAAATATTATGCATGTGC >11367_11367_10_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000394828_length(amino acids)=499AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDVGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSAIRGFSPPHR -------------------------------------------------------------- >11367_11367_11_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000394829_length(transcript)=2975nt_BP=484nt GCAGCCGTCATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGAT AACATCGAGCCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCG GGACCTGACGAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTC AAGGCGCCTGAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCT CCGCCTCCAGAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGG CTTCTACCAGAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGT TTGCCTCTTGCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGA TTAGATAGATTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCA CAGGAACATTTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTG TTATCGATTATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACA ATTTTTTCGGCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTT AACTGTTCTCCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATG TTGGTAAATGTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGTAGGTTCAGCTGCAGCCCGGAAA GAAATCATAAGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTC AAGGGCCTGACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGCCACAGTTGAGGCTATTGAG GCTGAAAAAGCAATACGAGGATTCTCTCCACCACATAGAATCTGCAGTTTTGAAGAGGCAAAGGGTTTGGATAGGATCAATGAGAGAATG CCACCTCGGAAAGATGCTGTACAGCAAGATGGTTTCAATTCTCTGAACACCGCACATGCCACTGAGAACCACGGGACGGGCAACCATACT GCCCAGTGACCCACTACTTCCCAGGGACTCTCACATCTCGGGCCCCAAATGGACAGATCACCCGAGGAGCTGGAGGGGTCGGCCAAGCTG ACTGTAAATTTCACAGTCTCTCTGAAGAAACCATTGTGCTTCTGAGACCCTAGCCCCCTTCCTGGATGGAGGCTTGAGGGCCCTGGGACA TGTGCTATCTGATAAGATTGGGTCATCGCTGCCAAGGTGGAGAGCAGTGAGCAAGGGGCTTGGGGCAATTTCCAGTGGAGGGCATCCACA CCTCCATTTTATGCTTGTGGTTCACACATTTAAGTTTACAAATCAGATTTCTTTTCCCCTTCAGTAGAATTAGATTTTGTTTTTCAATCA TGATTTCAAATGCAATCCTAAGAGCTAATGTGGACTTTTCTTTTTCCATGAAATGTCTTTAAAGGATGAATTAGCATGGTCTTAAAATAC ATTTCTGAGGTTACTAGCTGTATTTTGAATTGTGAGCAAAATGCCGAGAAACCCAGTTGGCATTTATACAAAATGTTGACCTCAGGTCTA TAGTTCTTAAATGTGGCTAATTCTGTAACATAGTCTTGGTATTTTTTAATTATGAATGCATATCCTATTTCCAGGCAGGCTCTCTTACTT GAACACAAATCCAAAAACTAATTTAGAGTCTTTTTTGCCCAGATCTTTTAAGACTTACACCCCAGAGATTTAAGAAGAAAACCTCTAAAT TTCAAAATTATGAAGAATTACAGAATTACTCATTTAAGGTACTTTAAAAGAAGTTTGTACATTGTCAAAGTAAATTTTAATTCAAATCAT GTCTGTAAAACTTGACGTATTTTGTGTATGCATGTTTTCATTTTGCAAATATTTAATATATAGACCTATGATGTACAGGTACGACATGTA TAGGTTACCTAGATGTTATGAGAAATTTTAGTTTATTGTGAGTACTCAAGTTGCTTAGAGAGCCACCAGGGTGATTTGCTGCTGGCTTTC TATCATTTTTATGTTTTAATGCAAAGGAAATTTTAAAATGTTCTGGAAGTGTTTTTGATTAAGCAATGCAGCCTAGAAGCAATGGTTCTG TTCAATCATTCAGATGTTAGTGGAAGCATAAAAGTCAAGACTGCATGTTGAAACCTTTCTTTTGATAGTTACTGAACTGCTTGGTTAAAC TAAATGGAACCATGTGCTAATTTTTCACAATTATTGACCTGTATTGATTGCCACTGTAGTTTGGTATTTCCCTTTACTTTGGTGGCCTGC TTCCCTCATGCCCTGGAATACAACTCAGAGCTCCAGGCAGCGGAACCATCTATTGTTTTGTTTGCCAGAAAGTGCACCCTGTATGGTCTC CTGTCTAAGTTGGAAATATTATGCATGTGCAGGACTATTCGAGTATTTTATAAACAGTAGCACACAATAAATTCCATGCATGGGCCGCTG >11367_11367_11_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000394829_length(amino acids)=509AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDVGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSATVEAIEAEK -------------------------------------------------------------- >11367_11367_12_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000545874_length(transcript)=1918nt_BP=484nt GCAGCCGTCATGGCAGCGGAGGAGAAGGACCCTCTGAGCTATTTTGCGGCATACGGGAGCAGCAGCTCAGGCTCCTCGGACGAGGAGGAT AACATCGAGCCGGAGGAGACGAGTCGCAGAACCCCGGATCCGGCGAAGTCGGCGGGCGGCTGTAGGAACAAGGCGGAGAAGCGGCTCCCG GGACCTGACGAGCTGTTTAGGAGCGTGACTCGCCCGGCCTTTCTCTACAATCCGCTCAACAAACAGATAGACTGGGAGAGGCACGTCGTC AAGGCGCCTGAGGAGCCTCCAAAGGAATTCAAAATATGGAAGTCAAATTATGTACCACCTCCTGAGACCTACACCACTGAGAAGAAGCCT CCGCCTCCAGAGCTTGACATGGCAATAAAATGGTCTAACATATATGAGGACAATGGTGATGATGCTCCACAGAATGCTAAGAAAGCTAGG CTTCTACCAGAAGGGGAGGAGACGTTGGAATCAGGTAAAATTAAGTATTCGGAAAGAGTCTATGAAGCTTGTATGGAAGCTTTTGATAGT TTGCCTCTTGCTGCACTTTTAAACCAACAGTTTCTTTGTGTTCATGGTGGACTTTCACCAGAAATACACACACTGGATGATATTAGGAGA TTAGATAGATTCAAAGAGCCACCTGCATTTGGACCAATGTGTGACTTGTTATGGTCCGATCCTTCTGAAGATTTTGGAAATGAAAAATCA CAGGAACATTTTAGTCACAATACAGTTCGAGGATGTTCTTATTTTTATAACTATCCAGCAGTGTGTGAATTTTTGCAAAACAATAATTTG TTATCGATTATTAGAGCTCATGAAGCTCAAGATGCAGGCTATAGAATGTACAGAAAAAGTCAAACTACAGGGTTCCCTTCATTAATAACA ATTTTTTCGGCACCTAATTACTTAGATGTCTACAATAATAAAGCTGCTGTATTAAAGTATGAAAATAATGTGATGAATATTCGACAGTTT AACTGTTCTCCACATCCTTACTGGTTGCCTAATTTTATGGATGTCTTCACGTGGTCTTTACCGTTTGTTGGAGAAAAAGTGACAGAAATG TTGGTAAATGTTCTGAGTATTTGCTCTGATGATGAACTAATGACTGAAGGTGAAGACCAGTTTGATGTAGGTTCAGCTGCAGCCCGGAAA GAAATCATAAGAAACAAAATTCGAGCAATTGGCAAGATGGCAAGAGTCTTCTCTGTTCTCAGGGAGGAGAGTGAAAGTGTGCTGACACTC AAGGGCCTGACTCCCACAGGGATGTTGCCTAGTGGAGTGTTAGCTGGAGGACGGCAGACCCTGCAAAGTGGTAATGATGTTATGCAACTT GCTGTGCCTCAGATGGACTGGGGCACACCTCACTCTTTTGCTAACAATTCACATAATGCATGCAGGGAATTCCTTCTGTTTTTTAGTTCC TGTCTCAGCAGCTGACCTAGACAGGGTACTGTATTAGCTAGTGTCTCATTAATACCTGATCAGGGCAGAAAACTGATAGAATGGGTATTC CTTTCAATTGAAAATAATGGTCAGTTCCTCAGCTTTTCATGAAATGATATGGGAGCAGCTCATATCATAATGTCTGAAATATTTATTTAT TCATCTGTCTAATTCACCCTTTTCTTTTAAAAGCCCCAGTTTCAGAATGTGAATCAGGGATATTCCTGTTACTAAAATGGAAATGTAATT CCAAGTTTCTTTTTTAATTTTTTAAATTTATGTCATTGTATTGGACTATGCTTATATTTAAAACTACTTAATTTAGAGTTAACTACCTGC TTAGGCCCCAGAACATTACTTATGCCCTTCAGTTACCAAAAGATTTGTGCAAGGTTTTGTACCCTGGTAAATGATGCCAAAGTTTGTTTT >11367_11367_12_C1orf52-PPP3CB_C1orf52_chr1_85724206_ENST00000471115_PPP3CB_chr10_75231371_ENST00000545874_length(amino acids)=481AA_BP=158 MAAEEKDPLSYFAAYGSSSSGSSDEEDNIEPEETSRRTPDPAKSAGGCRNKAEKRLPGPDELFRSVTRPAFLYNPLNKQIDWERHVVKAP EEPPKEFKIWKSNYVPPPETYTTEKKPPPPELDMAIKWSNIYEDNGDDAPQNAKKARLLPEGEETLESGKIKYSERVYEACMEAFDSLPL AALLNQQFLCVHGGLSPEIHTLDDIRRLDRFKEPPAFGPMCDLLWSDPSEDFGNEKSQEHFSHNTVRGCSYFYNYPAVCEFLQNNNLLSI IRAHEAQDAGYRMYRKSQTTGFPSLITIFSAPNYLDVYNNKAAVLKYENNVMNIRQFNCSPHPYWLPNFMDVFTWSLPFVGEKVTEMLVN VLSICSDDELMTEGEDQFDVGSAAARKEIIRNKIRAIGKMARVFSVLREESESVLTLKGLTPTGMLPSGVLAGGRQTLQSGNDVMQLAVP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for C1orf52-PPP3CB |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for C1orf52-PPP3CB |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for C1orf52-PPP3CB |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies