
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:C22orf34-HDAC10 (FusionGDB2 ID:11568) |
Fusion Gene Summary for C22orf34-HDAC10 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: C22orf34-HDAC10 | Fusion gene ID: 11568 | Hgene | Tgene | Gene symbol | C22orf34 | HDAC10 | Gene ID | 348645 | 83933 |
| Gene name | chromosome 22 open reading frame 34 | histone deacetylase 10 | |
| Synonyms | - | HD10 | |
| Cytomap | 22q13.33 | 22q13.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | putative uncharacterized protein C22orf34uncharacterized protein C22orf34 | polyamine deacetylase HDAC10 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q969S8 | |
| Ensembl transtripts involved in fusion gene | ENST00000405854, ENST00000444628, ENST00000400023, ENST00000498829, | ENST00000349505, ENST00000498366, ENST00000216271, ENST00000448072, | |
| Fusion gene scores | * DoF score | 6 X 3 X 4=72 | 3 X 3 X 2=18 |
| # samples | 6 | 3 | |
| ** MAII score | log2(6/72*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: C22orf34 [Title/Abstract] AND HDAC10 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | C22orf34(50020491)-HDAC10(50689334), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | HDAC10 | GO:0000122 | negative regulation of transcription by RNA polymerase II | 11726666 |
| Tgene | HDAC10 | GO:0006355 | regulation of transcription, DNA-templated | 11861901 |
| Tgene | HDAC10 | GO:0006476 | protein deacetylation | 17172643 |
| Tgene | HDAC10 | GO:0006476 | protein deacetylation | 28516954 |
| Tgene | HDAC10 | GO:0016575 | histone deacetylation | 11861901 |
| Tgene | HDAC10 | GO:0032425 | positive regulation of mismatch repair | 26221039 |
| Tgene | HDAC10 | GO:0034983 | peptidyl-lysine deacetylation | 26221039 |
| Tgene | HDAC10 | GO:0045892 | negative regulation of transcription, DNA-templated | 11726666|11861901 |
| Tgene | HDAC10 | GO:0106047 | polyamine deacetylation | 28516954 |
| Tgene | HDAC10 | GO:0106048 | spermidine deacetylation | 28516954 |
| Fusion gene breakpoints across C22orf34 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
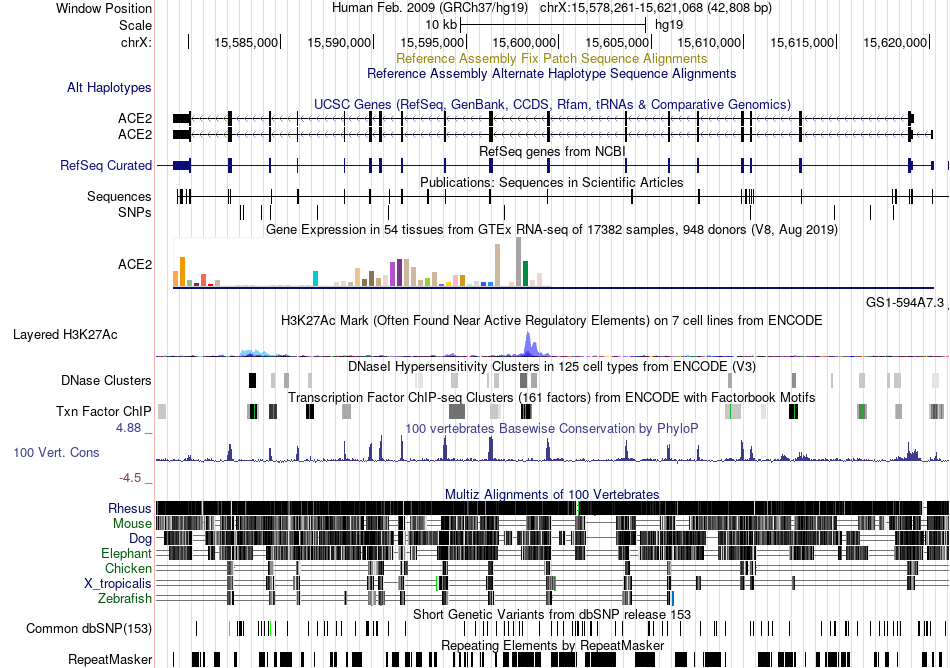 |
| Fusion gene breakpoints across HDAC10 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
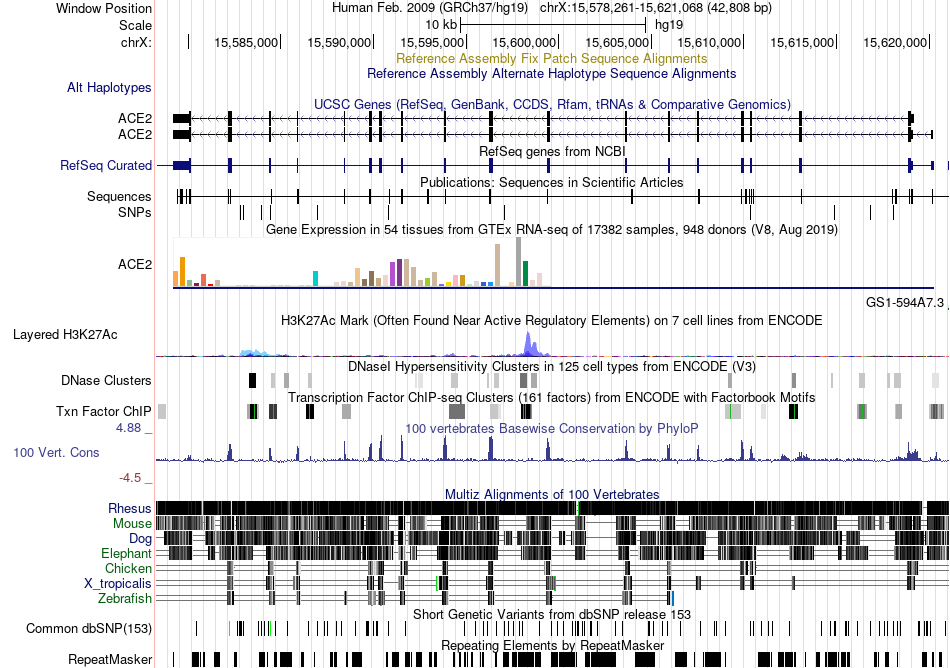 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-BR-4357-01A | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
Top |
Fusion Gene ORF analysis for C22orf34-HDAC10 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000405854 | ENST00000349505 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| 5CDS-5UTR | ENST00000405854 | ENST00000498366 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| 5CDS-5UTR | ENST00000444628 | ENST00000349505 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| 5CDS-5UTR | ENST00000444628 | ENST00000498366 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| In-frame | ENST00000405854 | ENST00000216271 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| In-frame | ENST00000405854 | ENST00000448072 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| In-frame | ENST00000444628 | ENST00000216271 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| In-frame | ENST00000444628 | ENST00000448072 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| intron-3CDS | ENST00000400023 | ENST00000216271 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| intron-3CDS | ENST00000400023 | ENST00000448072 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| intron-3CDS | ENST00000498829 | ENST00000216271 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| intron-3CDS | ENST00000498829 | ENST00000448072 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| intron-5UTR | ENST00000400023 | ENST00000349505 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| intron-5UTR | ENST00000400023 | ENST00000498366 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| intron-5UTR | ENST00000498829 | ENST00000349505 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| intron-5UTR | ENST00000498829 | ENST00000498366 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000405854 | C22orf34 | chr22 | 50020491 | - | ENST00000216271 | HDAC10 | chr22 | 50689334 | - | 3287 | 1012 | 1043 | 2962 | 639 |
| ENST00000405854 | C22orf34 | chr22 | 50020491 | - | ENST00000448072 | HDAC10 | chr22 | 50689334 | - | 2878 | 1012 | 1043 | 2812 | 589 |
| ENST00000444628 | C22orf34 | chr22 | 50020491 | - | ENST00000216271 | HDAC10 | chr22 | 50689334 | - | 3399 | 1124 | 1155 | 3074 | 639 |
| ENST00000444628 | C22orf34 | chr22 | 50020491 | - | ENST00000448072 | HDAC10 | chr22 | 50689334 | - | 2990 | 1124 | 1155 | 2924 | 589 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000405854 | ENST00000216271 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - | 0.09987097 | 0.90012896 |
| ENST00000405854 | ENST00000448072 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - | 0.06890005 | 0.93109995 |
| ENST00000444628 | ENST00000216271 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - | 0.09583505 | 0.9041649 |
| ENST00000444628 | ENST00000448072 | C22orf34 | chr22 | 50020491 | - | HDAC10 | chr22 | 50689334 | - | 0.06610829 | 0.9338918 |
Top |
Fusion Genomic Features for C22orf34-HDAC10 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
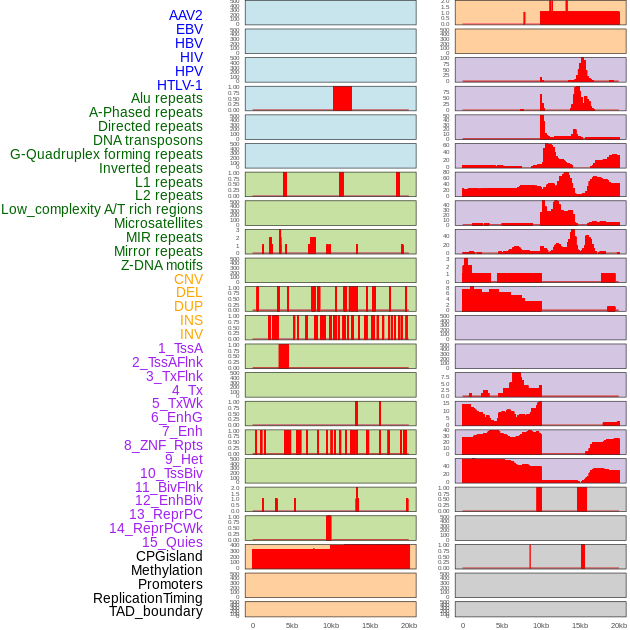 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for C22orf34-HDAC10 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:50020491/chr22:50689334) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | HDAC10 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Polyamine deacetylase (PDAC), which acts preferentially on N(8)-acetylspermidine, and also on acetylcadaverine and acetylputrescine (PubMed:28516954). Exhibits attenuated catalytic activity toward N(1),N(8)-diacetylspermidine and very low activity, if any, toward N(1)-acetylspermidine (PubMed:28516954). Histone deacetylase activity has been observed in vitro (PubMed:11861901, PubMed:11726666, PubMed:11677242, PubMed:11739383). Has also been shown to be involved in MSH2 deacetylation (PubMed:26221039). The physiological relevance of protein/histone deacetylase activity is unclear and could be very weak (PubMed:28516954). May play a role in the promotion of late stages of autophagy, possibly autophagosome-lysosome fusion and/or lysosomal exocytosis in neuroblastoma cells (PubMed:23801752, PubMed:29968769). May play a role in homologous recombination (PubMed:21247901). May promote DNA mismatch repair (PubMed:26221039). {ECO:0000269|PubMed:11677242, ECO:0000269|PubMed:11726666, ECO:0000269|PubMed:11739383, ECO:0000269|PubMed:11861901, ECO:0000269|PubMed:21247901, ECO:0000269|PubMed:23801752, ECO:0000269|PubMed:26221039, ECO:0000269|PubMed:28516954, ECO:0000269|PubMed:29968769}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | HDAC10 | chr22:50020491 | chr22:50689334 | ENST00000216271 | 0 | 20 | 21_24 | 19 | 670.0 | Motif | Substrate specificity | |
| Tgene | HDAC10 | chr22:50020491 | chr22:50689334 | ENST00000349505 | 0 | 19 | 21_24 | 19 | 650.0 | Motif | Substrate specificity |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | C22orf34 | chr22:50020491 | chr22:50689334 | ENST00000400023 | - | 1 | 4 | 79_98 | 0 | 184.0 | Compositional bias | Note=Cys-rich |
| Tgene | HDAC10 | chr22:50020491 | chr22:50689334 | ENST00000216271 | 0 | 20 | 1_323 | 19 | 670.0 | Region | Note=Histone deacetylase | |
| Tgene | HDAC10 | chr22:50020491 | chr22:50689334 | ENST00000349505 | 0 | 19 | 1_323 | 19 | 650.0 | Region | Note=Histone deacetylase |
Top |
Fusion Gene Sequence for C22orf34-HDAC10 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >11568_11568_1_C22orf34-HDAC10_C22orf34_chr22_50020491_ENST00000405854_HDAC10_chr22_50689334_ENST00000216271_length(transcript)=3287nt_BP=1012nt ACGCTTCCTGTACAGCCTGCAGAACTGTGAGTCAACCAAACTTCCTTTTAAAATAAATTACCCAGTCTCAGTTAGGTCTTTCTAGCAGTG TGAGAACGGACACGTAGAGGGTGTGAGAGCCAGAAGACTTTAAGGAGAGGGACGAGCTGGGGCCTGGATGCCCGGGGAGGTGGACCTGGA CCAGGACAGGTGTCAGCGGGCAGAGATGGGGCAGAGGTGCGGCTGTCTACCCGCGACCGGGGCCATGCCCTCTCGGGCTCGGTTGAGGAG CTGCTCTTCCTCCAGAATGCGCTCGGACGGAACGTTAGGAAGGCCCTGGTGAGTGGCCCCGACCTCCTCCCCCAGGACTGGCTTCTCCGG CCCTCTGCCCTTTCGGGCAGAACAGCTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCAGAACAGCTCGTGGCTCTTCCAGGACCTG GGGCTCCATCTTGCAGAACAGCTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCTGAGGGGTGCTTTCTTGAGACTCCTTAGGGACG ATTCTGATTTTCCCTGGAGCTGTACAATGGCGGTTTATCTTTCAAGGTCCCCTGGGCCTGGGCTCCGAGGCAGCCACTTTCCCTGGAGCC CGTGAAGGAGGTTTGGACGCCAGCTGGGCTGCCTGCCTGTGGCGGGGCAGGAATGAGAGCTGGTGCGGCTGGGGCCCCTGGGTGCCTGGT CCTGCTCTCATGACGCCCACCCCTTGAACCCTGACATGGGCGCCCAAGGATTCTCCCCGCAGGCTCGCAGACTCACCTGATCACCGGGAG ATGTTTGAGAAGGAGCCTGTGTCAAAGTGTAGGCATCAGATGAAAATTTACCTTCTTGTTACCTATGTAAATGGGCCGGGCTCCACGAAG TCCTTGGCTGAGAACGGTGCCACTGACCGACTGAGCTCCCGATCGTTCTGAGAGAGGCTTATGTGCACAGTGGACGTGGAAGGCTTTGAT GATGTTGGTGAAACTCTCTCTGCCCCGAGTGCGAGATCGAGCGTCCTGAGCGCCTGACCGCAGCCCTGGATCGCCTGCGGCAGCGCGGCC TGGAACAGAGGTGTCTGCGGTTGTCAGCCCGCGAGGCCTCGGAAGAGGAGCTGGGCCTGGTGCACAGCCCAGAGTATGTATCCCTGGTCA GGGAGACCCAGGTCCTAGGCAAGGAGGAGCTGCAGGCGCTGTCCGGACAGTTCGACGCCATCTACTTCCACCCGAGTACCTTTCACTGCG CGCGGCTGGCCGCAGGGGCTGGACTGCAGCTGGTGGACGCTGTGCTCACTGGAGCTGTGCAAAATGGGCTTGCCCTGGTGAGGCCTCCCG GGCACCATGGCCAGAGGGCGGCTGCCAACGGGTTCTGTGTGTTCAACAACGTGGCCATAGCAGCTGCACATGCCAAGCAGAAACACGGGC TACACAGGATCCTCGTCGTGGACTGGGATGTGCACCATGGCCAGGGGATCCAGTATCTCTTTGAGGATGACCCCAGCGTCCTTTACTTCT CCTGGCACCGCTATGAGCATGGGCGCTTCTGGCCTTTCCTGCGAGAGTCAGATGCAGACGCAGTGGGGCGGGGACAGGGCCTCGGCTTCA CTGTCAACCTGCCCTGGAACCAGGTTGGGATGGGAAACGCTGACTACGTGGCTGCCTTCCTGCACCTGCTGCTCCCACTGGCCTTTGAGT TTGACCCTGAGCTGGTGCTGGTCTCGGCAGGATTTGACTCAGCCATCGGGGACCCTGAGGGGCAAATGCAGGCCACGCCAGAGTGCTTCG CCCACCTCACACAGCTGCTGCAGGTGCTGGCCGGCGGCCGGGTCTGTGCCGTGCTGGAGGGCGGCTACCACCTGGAGTCACTGGCGGAGT CAGTGTGCATGACAGTACAGACGCTGCTGGGTGACCCGGCCCCACCCCTGTCAGGGCCAATGGCGCCATGTCAGAGTGCCCTAGAGTCCA TCCAGAGTGCCCGTGCTGCCCAGGCCCCGCACTGGAAGAGCCTCCAGCAGCAAGATGTGACCGCTGTGCCGATGAGCCCCAGCAGCCACT CCCCAGAGGGGAGGCCTCCACCTCTGCTGCCTGGGGGTCCAGTGTGTAAGGCAGCTGCATCTGCACCGAGCTCCCTCCTGGACCAGCCGT GCCTCTGCCCCGCACCCTCTGTCCGCACCGCTGTTGCCCTGACAACGCCGGATATCACATTGGTTCTGCCCCCTGACGTCATCCAACAGG AAGCGTCAGCCCTGAGGGAGGAGACAGAAGCCTGGGCCAGGCCACACGAGTCCCTGGCCCGGGAGGAGGCCCTCACTGCACTTGGGAAGC TCCTGTACCTCTTAGATGGGATGCTGGATGGGCAGGTGAACAGTGGTATAGCAGCCACTCCAGCCTCTGCTGCAGCAGCCACCCTGGATG TGGCTGTTCGGAGAGGCCTGTCCCACGGAGCCCAGAGGCTGCTGTGCGTGGCCCTGGGACAGCTGGACCGGCCTCCAGACCTCGCCCATG ACGGGAGGAGTCTGTGGCTGAACATCAGGGGCAAGGAGGCGGCTGCCCTATCCATGTTCCATGTCTCCACGCCACTGCCAGTGATGACCG GTGGTTTCCTGAGCTGCATCTTGGGCTTGGTGCTGCCCCTGGCCTATGGCTTCCAGCCTGACCTGGTGCTGGTGGCGCTGGGGCCTGGCC ATGGCCTGCAGGGCCCCCACGCTGCACTCCTGGCTGCAATGCTTCGGGGGCTGGCAGGGGGCCGAGTCCTGGCCCTCCTGGAGGAGAACT CCACACCCCAGCTAGCAGGGATCCTGGCCCGGGTGCTGAATGGAGAGGCACCTCCTAGCCTAGGCCCTTCCTCTGTGGCCTCCCCAGAGG ACGTCCAGGCCCTGATGTACCTGAGAGGGCAGCTGGAGCCTCAGTGGAAGATGTTGCAGTGCCATCCTCACCTGGTGGCTTGAAATCGGC CAAGGTGGGAGCATTTACACCGCAGAAATGACACCGCACGCCAGCGCCCCGCGGCCGCGATCCGGACCCCAAGCCCACGGCTCCCTCGAC TCTGGGGCACGGAACCCCGCCCACTCCCAATCCCCGCGCCCCGCCCTCTCCCACCCGTGCTTCCCCCGCTCCACCCCTCACCTCACCTCG CCCCCGCCCCACCCATCGCGCCCCGGCCCGTCCCATCGAGGCCCATGCAACCCACGCTCGGTCCCGTTCCGGCCCCTGCGCCCCGCTGCG >11568_11568_1_C22orf34-HDAC10_C22orf34_chr22_50020491_ENST00000405854_HDAC10_chr22_50689334_ENST00000216271_length(amino acids)=639AA_BP= MTAALDRLRQRGLEQRCLRLSAREASEEELGLVHSPEYVSLVRETQVLGKEELQALSGQFDAIYFHPSTFHCARLAAGAGLQLVDAVLTG AVQNGLALVRPPGHHGQRAAANGFCVFNNVAIAAAHAKQKHGLHRILVVDWDVHHGQGIQYLFEDDPSVLYFSWHRYEHGRFWPFLRESD ADAVGRGQGLGFTVNLPWNQVGMGNADYVAAFLHLLLPLAFEFDPELVLVSAGFDSAIGDPEGQMQATPECFAHLTQLLQVLAGGRVCAV LEGGYHLESLAESVCMTVQTLLGDPAPPLSGPMAPCQSALESIQSARAAQAPHWKSLQQQDVTAVPMSPSSHSPEGRPPPLLPGGPVCKA AASAPSSLLDQPCLCPAPSVRTAVALTTPDITLVLPPDVIQQEASALREETEAWARPHESLAREEALTALGKLLYLLDGMLDGQVNSGIA ATPASAAAATLDVAVRRGLSHGAQRLLCVALGQLDRPPDLAHDGRSLWLNIRGKEAAALSMFHVSTPLPVMTGGFLSCILGLVLPLAYGF QPDLVLVALGPGHGLQGPHAALLAAMLRGLAGGRVLALLEENSTPQLAGILARVLNGEAPPSLGPSSVASPEDVQALMYLRGQLEPQWKM -------------------------------------------------------------- >11568_11568_2_C22orf34-HDAC10_C22orf34_chr22_50020491_ENST00000405854_HDAC10_chr22_50689334_ENST00000448072_length(transcript)=2878nt_BP=1012nt ACGCTTCCTGTACAGCCTGCAGAACTGTGAGTCAACCAAACTTCCTTTTAAAATAAATTACCCAGTCTCAGTTAGGTCTTTCTAGCAGTG TGAGAACGGACACGTAGAGGGTGTGAGAGCCAGAAGACTTTAAGGAGAGGGACGAGCTGGGGCCTGGATGCCCGGGGAGGTGGACCTGGA CCAGGACAGGTGTCAGCGGGCAGAGATGGGGCAGAGGTGCGGCTGTCTACCCGCGACCGGGGCCATGCCCTCTCGGGCTCGGTTGAGGAG CTGCTCTTCCTCCAGAATGCGCTCGGACGGAACGTTAGGAAGGCCCTGGTGAGTGGCCCCGACCTCCTCCCCCAGGACTGGCTTCTCCGG CCCTCTGCCCTTTCGGGCAGAACAGCTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCAGAACAGCTCGTGGCTCTTCCAGGACCTG GGGCTCCATCTTGCAGAACAGCTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCTGAGGGGTGCTTTCTTGAGACTCCTTAGGGACG ATTCTGATTTTCCCTGGAGCTGTACAATGGCGGTTTATCTTTCAAGGTCCCCTGGGCCTGGGCTCCGAGGCAGCCACTTTCCCTGGAGCC CGTGAAGGAGGTTTGGACGCCAGCTGGGCTGCCTGCCTGTGGCGGGGCAGGAATGAGAGCTGGTGCGGCTGGGGCCCCTGGGTGCCTGGT CCTGCTCTCATGACGCCCACCCCTTGAACCCTGACATGGGCGCCCAAGGATTCTCCCCGCAGGCTCGCAGACTCACCTGATCACCGGGAG ATGTTTGAGAAGGAGCCTGTGTCAAAGTGTAGGCATCAGATGAAAATTTACCTTCTTGTTACCTATGTAAATGGGCCGGGCTCCACGAAG TCCTTGGCTGAGAACGGTGCCACTGACCGACTGAGCTCCCGATCGTTCTGAGAGAGGCTTATGTGCACAGTGGACGTGGAAGGCTTTGAT GATGTTGGTGAAACTCTCTCTGCCCCGAGTGCGAGATCGAGCGTCCTGAGCGCCTGACCGCAGCCCTGGATCGCCTGCGGCAGCGCGGCC TGGAACAGAGGTGTCTGCGGTTGTCAGCCCGCGAGGCCTCGGAAGAGGAGCTGGGCCTGGTGCACAGCCCAGAGTATGTATCCCTGGTCA GGGAGACCCAGGTCCTAGGCAAGGAGGAGCTGCAGGCGCTGTCCGGACAGTTCGACGCCATCTACTTCCACCCGAGTACCTTTCACTGCG CGCGGCTGGCCGCAGGGGCTGGACTGCAGCTGGTGGACGCTGTGCTCACTGGAGCTGTGCAAAATGGGCTTGCCCTGGTGAGGCCTCCCG GGCACCATGGCCAGAGGGCGGCTGCCAACGGGTTCTGTGTGTTCAACAACGTGGCCATAGCAGCTGCACATGCCAAGCAGAAACACGGGC TACACAGGATCCTCGTCGTGGACTGGGATGTGCACCATGGCCAGGGGATCCAGTATCTCTTTGAGGATGACCCCAGCGTCCTTTACTTCT CCTGGCACCGCTATGAGCATGGGCGCTTCTGGCCTTTCCTGCGAGAGTCAGATGCAGACGCAGTGGGGCGGGGACAGGGCCTCGGCTTCA CTGTCAACCTGCCCTGGAACCAGGTTGGGATGGGAAACGCTGACTACGTGGCTGCCTTCCTGCACCTGCTGCTCCCACTGGCCTTTGAGG GCGGCTACCACCTGGAGTCACTGGCGGAGTCAGTGTGCATGACAGTACAGACGCTGCTGGGTGACCCGGCCCCACCCCTGTCAGGGCCAA TGGCGCCATGTCAGAGTGCCCTAGAGTCCATCCAGAGTGCCCGTGCTGCCCAGGCCCCGCACTGGAAGAGCCTCCAGCAGCAAGATGTGA CCGCTGTGCCGATGAGCCCCAGCAGCCACTCCCCAGAGGGGAGGCCTCCACCTCTGCTGCCTGGGGGTCCAGTGTGTAAGGCAGCTGCAT CTGCACCGAGCTCCCTCCTGGACCAGCCGTGCCTCTGCCCCGCACCCTCTGTCCGCACCGCTGTTGCCCTGACAACGCCGGATATCACAT TGGTTCTGCCCCCTGACGTCATCCAACAGGAAGCGTCAGCCCTGAGGGAGGAGACAGAAGCCTGGGCCAGGCCACACGAGTCCCTGGCCC GGGAGGAGGCCCTCACTGCACTTGGGAAGCTCCTGTACCTCTTAGATGGGATGCTGGATGGGCAGGTGAACAGTGGTATAGCAGCCACTC CAGCCTCTGCTGCAGCAGCCACCCTGGATGTGGCTGTTCGGAGAGGCCTGTCCCACGGAGCCCAGAGGCTGCTGTGCGTGGCCCTGGGAC AGCTGGACCGGCCTCCAGACCTCGCCCATGACGGGAGGAGTCTGTGGCTGAACATCAGGGGCAAGGAGGCGGCTGCCCTATCCATGTTCC ATGTCTCCACGCCACTGCCAGTGATGACCGGTGGTTTCCTGAGCTGCATCTTGGGCTTGGTGCTGCCCCTGGCCTATGGCTTCCAGCCTG ACCTGGTGCTGGTGGCGCTGGGGCCTGGCCATGGCCTGCAGGGCCCCCACGCTGCACTCCTGGCTGCAATGCTTCGGGGGCTGGCAGGGG GCCGAGTCCTGGCCCTCCTGGAGGAGAACTCCACACCCCAGCTAGCAGGGATCCTGGCCCGGGTGCTGAATGGAGAGGCACCTCCTAGCC TAGGCCCTTCCTCTGTGGCCTCCCCAGAGGACGTCCAGGCCCTGATGTACCTGAGAGGGCAGCTGGAGCCTCAGTGGAAGATGTTGCAGT >11568_11568_2_C22orf34-HDAC10_C22orf34_chr22_50020491_ENST00000405854_HDAC10_chr22_50689334_ENST00000448072_length(amino acids)=589AA_BP= MTAALDRLRQRGLEQRCLRLSAREASEEELGLVHSPEYVSLVRETQVLGKEELQALSGQFDAIYFHPSTFHCARLAAGAGLQLVDAVLTG AVQNGLALVRPPGHHGQRAAANGFCVFNNVAIAAAHAKQKHGLHRILVVDWDVHHGQGIQYLFEDDPSVLYFSWHRYEHGRFWPFLRESD ADAVGRGQGLGFTVNLPWNQVGMGNADYVAAFLHLLLPLAFEGGYHLESLAESVCMTVQTLLGDPAPPLSGPMAPCQSALESIQSARAAQ APHWKSLQQQDVTAVPMSPSSHSPEGRPPPLLPGGPVCKAAASAPSSLLDQPCLCPAPSVRTAVALTTPDITLVLPPDVIQQEASALREE TEAWARPHESLAREEALTALGKLLYLLDGMLDGQVNSGIAATPASAAAATLDVAVRRGLSHGAQRLLCVALGQLDRPPDLAHDGRSLWLN IRGKEAAALSMFHVSTPLPVMTGGFLSCILGLVLPLAYGFQPDLVLVALGPGHGLQGPHAALLAAMLRGLAGGRVLALLEENSTPQLAGI -------------------------------------------------------------- >11568_11568_3_C22orf34-HDAC10_C22orf34_chr22_50020491_ENST00000444628_HDAC10_chr22_50689334_ENST00000216271_length(transcript)=3399nt_BP=1124nt CGTGTGCGGTCCCTCCCCCTCACGTTCTCTCTTCCTCTGCTCCGCCATGATGAGAAGCGCCTGCTTCCCCTTCCCCTTCCGCCATGATTG TGTTTCCTGAGACCTCCCAGCCACGCTTCCTGTACAGCCTGCAGAACTGTGAGTCAACCAAACTTCCTTTTAAAATAAATTACCCAGTCT CAGTTAGGTCTTTCTAGCAGTGTGAGAACGGACACGTAGAGGGTGTGAGAGCCAGAAGACTTTAAGGAGAGGGACGAGCTGGGGCCTGGA TGCCCGGGGAGGTGGACCTGGACCAGGACAGGTGTCAGCGGGCAGAGATGGGGCAGAGGTGCGGCTGTCTACCCGCGACCGGGGCCATGC CCTCTCGGGCTCGGTTGAGGAGCTGCTCTTCCTCCAGAATGCGCTCGGACGGAACGTTAGGAAGGCCCTGGTGAGTGGCCCCGACCTCCT CCCCCAGGACTGGCTTCTCCGGCCCTCTGCCCTTTCGGGCAGAACAGCTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCAGAACAG CTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCAGAACAGCTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCTGAGGGGTGCT TTCTTGAGACTCCTTAGGGACGATTCTGATTTTCCCTGGAGCTGTACAATGGCGGTTTATCTTTCAAGGTCCCCTGGGCCTGGGCTCCGA GGCAGCCACTTTCCCTGGAGCCCGTGAAGGAGGTTTGGACGCCAGCTGGGCTGCCTGCCTGTGGCGGGGCAGGAATGAGAGCTGGTGCGG CTGGGGCCCCTGGGTGCCTGGTCCTGCTCTCATGACGCCCACCCCTTGAACCCTGACATGGGCGCCCAAGGATTCTCCCCGCAGGCTCGC AGACTCACCTGATCACCGGGAGATGTTTGAGAAGGAGCCTGTGTCAAAGTGTAGGCATCAGATGAAAATTTACCTTCTTGTTACCTATGT AAATGGGCCGGGCTCCACGAAGTCCTTGGCTGAGAACGGTGCCACTGACCGACTGAGCTCCCGATCGTTCTGAGAGAGGCTTATGTGCAC AGTGGACGTGGAAGGCTTTGATGATGTTGGTGAAACTCTCTCTGCCCCGAGTGCGAGATCGAGCGTCCTGAGCGCCTGACCGCAGCCCTG GATCGCCTGCGGCAGCGCGGCCTGGAACAGAGGTGTCTGCGGTTGTCAGCCCGCGAGGCCTCGGAAGAGGAGCTGGGCCTGGTGCACAGC CCAGAGTATGTATCCCTGGTCAGGGAGACCCAGGTCCTAGGCAAGGAGGAGCTGCAGGCGCTGTCCGGACAGTTCGACGCCATCTACTTC CACCCGAGTACCTTTCACTGCGCGCGGCTGGCCGCAGGGGCTGGACTGCAGCTGGTGGACGCTGTGCTCACTGGAGCTGTGCAAAATGGG CTTGCCCTGGTGAGGCCTCCCGGGCACCATGGCCAGAGGGCGGCTGCCAACGGGTTCTGTGTGTTCAACAACGTGGCCATAGCAGCTGCA CATGCCAAGCAGAAACACGGGCTACACAGGATCCTCGTCGTGGACTGGGATGTGCACCATGGCCAGGGGATCCAGTATCTCTTTGAGGAT GACCCCAGCGTCCTTTACTTCTCCTGGCACCGCTATGAGCATGGGCGCTTCTGGCCTTTCCTGCGAGAGTCAGATGCAGACGCAGTGGGG CGGGGACAGGGCCTCGGCTTCACTGTCAACCTGCCCTGGAACCAGGTTGGGATGGGAAACGCTGACTACGTGGCTGCCTTCCTGCACCTG CTGCTCCCACTGGCCTTTGAGTTTGACCCTGAGCTGGTGCTGGTCTCGGCAGGATTTGACTCAGCCATCGGGGACCCTGAGGGGCAAATG CAGGCCACGCCAGAGTGCTTCGCCCACCTCACACAGCTGCTGCAGGTGCTGGCCGGCGGCCGGGTCTGTGCCGTGCTGGAGGGCGGCTAC CACCTGGAGTCACTGGCGGAGTCAGTGTGCATGACAGTACAGACGCTGCTGGGTGACCCGGCCCCACCCCTGTCAGGGCCAATGGCGCCA TGTCAGAGTGCCCTAGAGTCCATCCAGAGTGCCCGTGCTGCCCAGGCCCCGCACTGGAAGAGCCTCCAGCAGCAAGATGTGACCGCTGTG CCGATGAGCCCCAGCAGCCACTCCCCAGAGGGGAGGCCTCCACCTCTGCTGCCTGGGGGTCCAGTGTGTAAGGCAGCTGCATCTGCACCG AGCTCCCTCCTGGACCAGCCGTGCCTCTGCCCCGCACCCTCTGTCCGCACCGCTGTTGCCCTGACAACGCCGGATATCACATTGGTTCTG CCCCCTGACGTCATCCAACAGGAAGCGTCAGCCCTGAGGGAGGAGACAGAAGCCTGGGCCAGGCCACACGAGTCCCTGGCCCGGGAGGAG GCCCTCACTGCACTTGGGAAGCTCCTGTACCTCTTAGATGGGATGCTGGATGGGCAGGTGAACAGTGGTATAGCAGCCACTCCAGCCTCT GCTGCAGCAGCCACCCTGGATGTGGCTGTTCGGAGAGGCCTGTCCCACGGAGCCCAGAGGCTGCTGTGCGTGGCCCTGGGACAGCTGGAC CGGCCTCCAGACCTCGCCCATGACGGGAGGAGTCTGTGGCTGAACATCAGGGGCAAGGAGGCGGCTGCCCTATCCATGTTCCATGTCTCC ACGCCACTGCCAGTGATGACCGGTGGTTTCCTGAGCTGCATCTTGGGCTTGGTGCTGCCCCTGGCCTATGGCTTCCAGCCTGACCTGGTG CTGGTGGCGCTGGGGCCTGGCCATGGCCTGCAGGGCCCCCACGCTGCACTCCTGGCTGCAATGCTTCGGGGGCTGGCAGGGGGCCGAGTC CTGGCCCTCCTGGAGGAGAACTCCACACCCCAGCTAGCAGGGATCCTGGCCCGGGTGCTGAATGGAGAGGCACCTCCTAGCCTAGGCCCT TCCTCTGTGGCCTCCCCAGAGGACGTCCAGGCCCTGATGTACCTGAGAGGGCAGCTGGAGCCTCAGTGGAAGATGTTGCAGTGCCATCCT CACCTGGTGGCTTGAAATCGGCCAAGGTGGGAGCATTTACACCGCAGAAATGACACCGCACGCCAGCGCCCCGCGGCCGCGATCCGGACC CCAAGCCCACGGCTCCCTCGACTCTGGGGCACGGAACCCCGCCCACTCCCAATCCCCGCGCCCCGCCCTCTCCCACCCGTGCTTCCCCCG CTCCACCCCTCACCTCACCTCGCCCCCGCCCCACCCATCGCGCCCCGGCCCGTCCCATCGAGGCCCATGCAACCCACGCTCGGTCCCGTT >11568_11568_3_C22orf34-HDAC10_C22orf34_chr22_50020491_ENST00000444628_HDAC10_chr22_50689334_ENST00000216271_length(amino acids)=639AA_BP= MTAALDRLRQRGLEQRCLRLSAREASEEELGLVHSPEYVSLVRETQVLGKEELQALSGQFDAIYFHPSTFHCARLAAGAGLQLVDAVLTG AVQNGLALVRPPGHHGQRAAANGFCVFNNVAIAAAHAKQKHGLHRILVVDWDVHHGQGIQYLFEDDPSVLYFSWHRYEHGRFWPFLRESD ADAVGRGQGLGFTVNLPWNQVGMGNADYVAAFLHLLLPLAFEFDPELVLVSAGFDSAIGDPEGQMQATPECFAHLTQLLQVLAGGRVCAV LEGGYHLESLAESVCMTVQTLLGDPAPPLSGPMAPCQSALESIQSARAAQAPHWKSLQQQDVTAVPMSPSSHSPEGRPPPLLPGGPVCKA AASAPSSLLDQPCLCPAPSVRTAVALTTPDITLVLPPDVIQQEASALREETEAWARPHESLAREEALTALGKLLYLLDGMLDGQVNSGIA ATPASAAAATLDVAVRRGLSHGAQRLLCVALGQLDRPPDLAHDGRSLWLNIRGKEAAALSMFHVSTPLPVMTGGFLSCILGLVLPLAYGF QPDLVLVALGPGHGLQGPHAALLAAMLRGLAGGRVLALLEENSTPQLAGILARVLNGEAPPSLGPSSVASPEDVQALMYLRGQLEPQWKM -------------------------------------------------------------- >11568_11568_4_C22orf34-HDAC10_C22orf34_chr22_50020491_ENST00000444628_HDAC10_chr22_50689334_ENST00000448072_length(transcript)=2990nt_BP=1124nt CGTGTGCGGTCCCTCCCCCTCACGTTCTCTCTTCCTCTGCTCCGCCATGATGAGAAGCGCCTGCTTCCCCTTCCCCTTCCGCCATGATTG TGTTTCCTGAGACCTCCCAGCCACGCTTCCTGTACAGCCTGCAGAACTGTGAGTCAACCAAACTTCCTTTTAAAATAAATTACCCAGTCT CAGTTAGGTCTTTCTAGCAGTGTGAGAACGGACACGTAGAGGGTGTGAGAGCCAGAAGACTTTAAGGAGAGGGACGAGCTGGGGCCTGGA TGCCCGGGGAGGTGGACCTGGACCAGGACAGGTGTCAGCGGGCAGAGATGGGGCAGAGGTGCGGCTGTCTACCCGCGACCGGGGCCATGC CCTCTCGGGCTCGGTTGAGGAGCTGCTCTTCCTCCAGAATGCGCTCGGACGGAACGTTAGGAAGGCCCTGGTGAGTGGCCCCGACCTCCT CCCCCAGGACTGGCTTCTCCGGCCCTCTGCCCTTTCGGGCAGAACAGCTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCAGAACAG CTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCAGAACAGCTCGTGGCTCTTCCAGGACCTGGGGCTCCATCTTGCTGAGGGGTGCT TTCTTGAGACTCCTTAGGGACGATTCTGATTTTCCCTGGAGCTGTACAATGGCGGTTTATCTTTCAAGGTCCCCTGGGCCTGGGCTCCGA GGCAGCCACTTTCCCTGGAGCCCGTGAAGGAGGTTTGGACGCCAGCTGGGCTGCCTGCCTGTGGCGGGGCAGGAATGAGAGCTGGTGCGG CTGGGGCCCCTGGGTGCCTGGTCCTGCTCTCATGACGCCCACCCCTTGAACCCTGACATGGGCGCCCAAGGATTCTCCCCGCAGGCTCGC AGACTCACCTGATCACCGGGAGATGTTTGAGAAGGAGCCTGTGTCAAAGTGTAGGCATCAGATGAAAATTTACCTTCTTGTTACCTATGT AAATGGGCCGGGCTCCACGAAGTCCTTGGCTGAGAACGGTGCCACTGACCGACTGAGCTCCCGATCGTTCTGAGAGAGGCTTATGTGCAC AGTGGACGTGGAAGGCTTTGATGATGTTGGTGAAACTCTCTCTGCCCCGAGTGCGAGATCGAGCGTCCTGAGCGCCTGACCGCAGCCCTG GATCGCCTGCGGCAGCGCGGCCTGGAACAGAGGTGTCTGCGGTTGTCAGCCCGCGAGGCCTCGGAAGAGGAGCTGGGCCTGGTGCACAGC CCAGAGTATGTATCCCTGGTCAGGGAGACCCAGGTCCTAGGCAAGGAGGAGCTGCAGGCGCTGTCCGGACAGTTCGACGCCATCTACTTC CACCCGAGTACCTTTCACTGCGCGCGGCTGGCCGCAGGGGCTGGACTGCAGCTGGTGGACGCTGTGCTCACTGGAGCTGTGCAAAATGGG CTTGCCCTGGTGAGGCCTCCCGGGCACCATGGCCAGAGGGCGGCTGCCAACGGGTTCTGTGTGTTCAACAACGTGGCCATAGCAGCTGCA CATGCCAAGCAGAAACACGGGCTACACAGGATCCTCGTCGTGGACTGGGATGTGCACCATGGCCAGGGGATCCAGTATCTCTTTGAGGAT GACCCCAGCGTCCTTTACTTCTCCTGGCACCGCTATGAGCATGGGCGCTTCTGGCCTTTCCTGCGAGAGTCAGATGCAGACGCAGTGGGG CGGGGACAGGGCCTCGGCTTCACTGTCAACCTGCCCTGGAACCAGGTTGGGATGGGAAACGCTGACTACGTGGCTGCCTTCCTGCACCTG CTGCTCCCACTGGCCTTTGAGGGCGGCTACCACCTGGAGTCACTGGCGGAGTCAGTGTGCATGACAGTACAGACGCTGCTGGGTGACCCG GCCCCACCCCTGTCAGGGCCAATGGCGCCATGTCAGAGTGCCCTAGAGTCCATCCAGAGTGCCCGTGCTGCCCAGGCCCCGCACTGGAAG AGCCTCCAGCAGCAAGATGTGACCGCTGTGCCGATGAGCCCCAGCAGCCACTCCCCAGAGGGGAGGCCTCCACCTCTGCTGCCTGGGGGT CCAGTGTGTAAGGCAGCTGCATCTGCACCGAGCTCCCTCCTGGACCAGCCGTGCCTCTGCCCCGCACCCTCTGTCCGCACCGCTGTTGCC CTGACAACGCCGGATATCACATTGGTTCTGCCCCCTGACGTCATCCAACAGGAAGCGTCAGCCCTGAGGGAGGAGACAGAAGCCTGGGCC AGGCCACACGAGTCCCTGGCCCGGGAGGAGGCCCTCACTGCACTTGGGAAGCTCCTGTACCTCTTAGATGGGATGCTGGATGGGCAGGTG AACAGTGGTATAGCAGCCACTCCAGCCTCTGCTGCAGCAGCCACCCTGGATGTGGCTGTTCGGAGAGGCCTGTCCCACGGAGCCCAGAGG CTGCTGTGCGTGGCCCTGGGACAGCTGGACCGGCCTCCAGACCTCGCCCATGACGGGAGGAGTCTGTGGCTGAACATCAGGGGCAAGGAG GCGGCTGCCCTATCCATGTTCCATGTCTCCACGCCACTGCCAGTGATGACCGGTGGTTTCCTGAGCTGCATCTTGGGCTTGGTGCTGCCC CTGGCCTATGGCTTCCAGCCTGACCTGGTGCTGGTGGCGCTGGGGCCTGGCCATGGCCTGCAGGGCCCCCACGCTGCACTCCTGGCTGCA ATGCTTCGGGGGCTGGCAGGGGGCCGAGTCCTGGCCCTCCTGGAGGAGAACTCCACACCCCAGCTAGCAGGGATCCTGGCCCGGGTGCTG AATGGAGAGGCACCTCCTAGCCTAGGCCCTTCCTCTGTGGCCTCCCCAGAGGACGTCCAGGCCCTGATGTACCTGAGAGGGCAGCTGGAG CCTCAGTGGAAGATGTTGCAGTGCCATCCTCACCTGGTGGCTTGAAATCGGCCAAGGTGGGAGCATTTACACCGCAGAAATGACACCGCA >11568_11568_4_C22orf34-HDAC10_C22orf34_chr22_50020491_ENST00000444628_HDAC10_chr22_50689334_ENST00000448072_length(amino acids)=589AA_BP= MTAALDRLRQRGLEQRCLRLSAREASEEELGLVHSPEYVSLVRETQVLGKEELQALSGQFDAIYFHPSTFHCARLAAGAGLQLVDAVLTG AVQNGLALVRPPGHHGQRAAANGFCVFNNVAIAAAHAKQKHGLHRILVVDWDVHHGQGIQYLFEDDPSVLYFSWHRYEHGRFWPFLRESD ADAVGRGQGLGFTVNLPWNQVGMGNADYVAAFLHLLLPLAFEGGYHLESLAESVCMTVQTLLGDPAPPLSGPMAPCQSALESIQSARAAQ APHWKSLQQQDVTAVPMSPSSHSPEGRPPPLLPGGPVCKAAASAPSSLLDQPCLCPAPSVRTAVALTTPDITLVLPPDVIQQEASALREE TEAWARPHESLAREEALTALGKLLYLLDGMLDGQVNSGIAATPASAAAATLDVAVRRGLSHGAQRLLCVALGQLDRPPDLAHDGRSLWLN IRGKEAAALSMFHVSTPLPVMTGGFLSCILGLVLPLAYGFQPDLVLVALGPGHGLQGPHAALLAAMLRGLAGGRVLALLEENSTPQLAGI -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for C22orf34-HDAC10 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for C22orf34-HDAC10 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for C22orf34-HDAC10 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies