
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:C22orf39-GNB1L (FusionGDB2 ID:11575) |
Fusion Gene Summary for C22orf39-GNB1L |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: C22orf39-GNB1L | Fusion gene ID: 11575 | Hgene | Tgene | Gene symbol | C22orf39 | GNB1L | Gene ID | 128977 | 54584 |
| Gene name | chromosome 22 open reading frame 39 | G protein subunit beta 1 like | |
| Synonyms | - | DGCRK3|FKSG1|GY2|WDR14|WDVCF | |
| Cytomap | 22q11.21 | 22q11.21 | |
| Type of gene | protein-coding | protein-coding | |
| Description | UPF0545 protein C22orf39 | guanine nucleotide-binding protein subunit beta-like protein 1G-protein beta subunit-like proteinWD repeat-containing protein 14WD40 repeat-containing protein deleted in VCFSg protein subunit beta-like protein 1guanine nucleotide binding protein (G p | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q9BYB4 | |
| Ensembl transtripts involved in fusion gene | ENST00000333059, ENST00000399562, ENST00000399568, ENST00000542103, | ENST00000460402, ENST00000329517, ENST00000403325, ENST00000405009, | |
| Fusion gene scores | * DoF score | 15 X 10 X 10=1500 | 8 X 8 X 6=384 |
| # samples | 16 | 9 | |
| ** MAII score | log2(16/1500*10)=-3.22881869049588 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/384*10)=-2.09310940439148 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: C22orf39 [Title/Abstract] AND GNB1L [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | C22orf39(19434901)-GNB1L(19789739), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across C22orf39 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
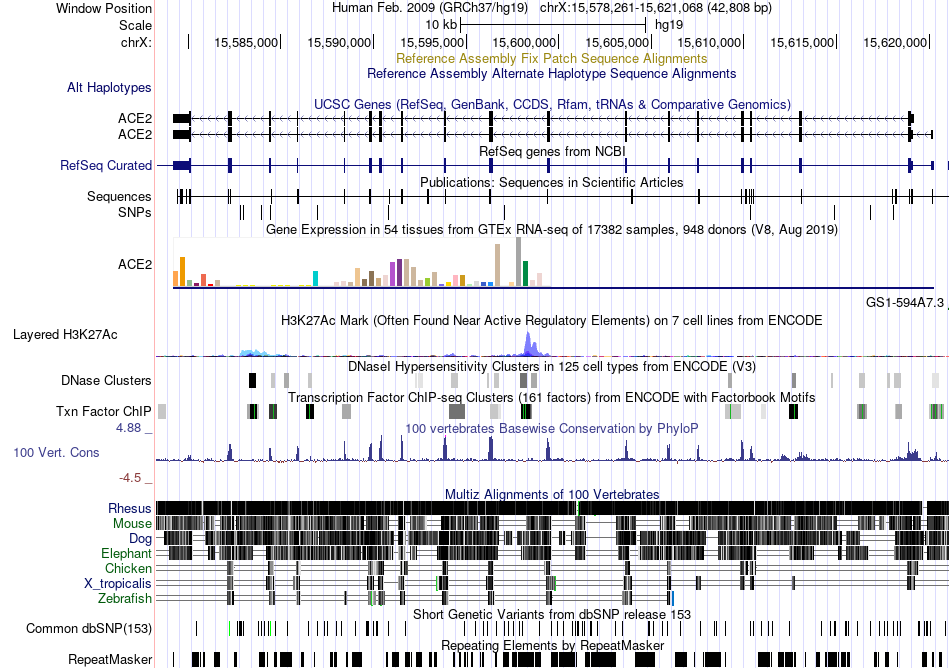 |
| Fusion gene breakpoints across GNB1L (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
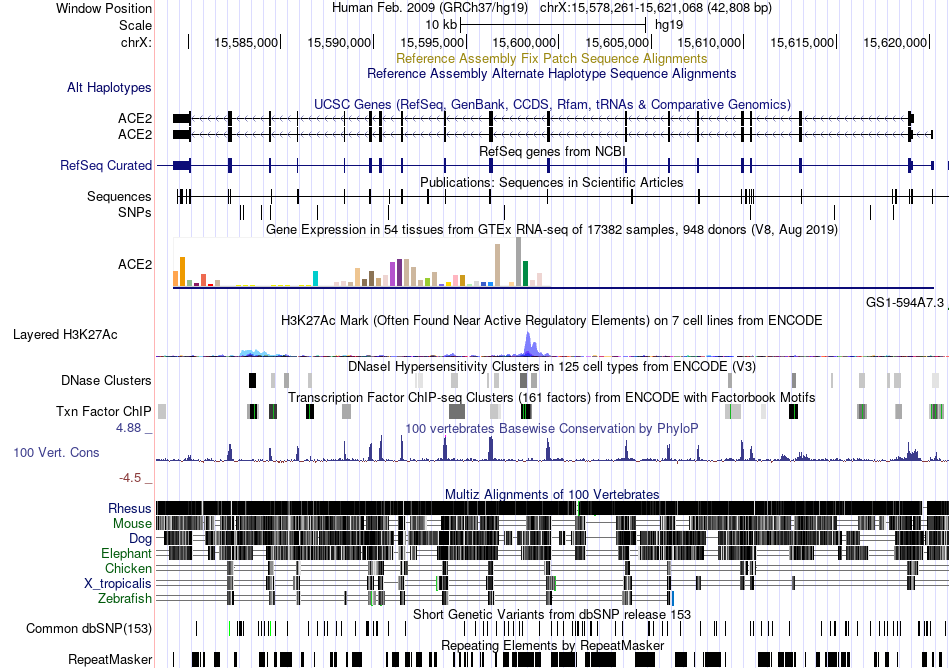 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LIHC | TCGA-FV-A4ZP-01A | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
Top |
Fusion Gene ORF analysis for C22orf39-GNB1L |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000333059 | ENST00000460402 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| 5CDS-5UTR | ENST00000399562 | ENST00000460402 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| 5CDS-5UTR | ENST00000399568 | ENST00000460402 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| 5CDS-5UTR | ENST00000542103 | ENST00000460402 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000333059 | ENST00000329517 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000333059 | ENST00000403325 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000333059 | ENST00000405009 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000399562 | ENST00000329517 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000399562 | ENST00000403325 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000399562 | ENST00000405009 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000399568 | ENST00000329517 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000399568 | ENST00000403325 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000399568 | ENST00000405009 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000542103 | ENST00000329517 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000542103 | ENST00000403325 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| In-frame | ENST00000542103 | ENST00000405009 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000399568 | C22orf39 | chr22 | 19434901 | - | ENST00000329517 | GNB1L | chr22 | 19789739 | - | 6149 | 196 | 4 | 663 | 219 |
| ENST00000399568 | C22orf39 | chr22 | 19434901 | - | ENST00000403325 | GNB1L | chr22 | 19789739 | - | 958 | 196 | 4 | 663 | 219 |
| ENST00000399568 | C22orf39 | chr22 | 19434901 | - | ENST00000405009 | GNB1L | chr22 | 19789739 | - | 519 | 196 | 487 | 2 | 162 |
| ENST00000542103 | C22orf39 | chr22 | 19434901 | - | ENST00000329517 | GNB1L | chr22 | 19789739 | - | 6689 | 736 | 497 | 1276 | 259 |
| ENST00000542103 | C22orf39 | chr22 | 19434901 | - | ENST00000403325 | GNB1L | chr22 | 19789739 | - | 1498 | 736 | 497 | 1276 | 259 |
| ENST00000542103 | C22orf39 | chr22 | 19434901 | - | ENST00000405009 | GNB1L | chr22 | 19789739 | - | 1059 | 736 | 497 | 1057 | 187 |
| ENST00000399562 | C22orf39 | chr22 | 19434901 | - | ENST00000329517 | GNB1L | chr22 | 19789739 | - | 6689 | 736 | 497 | 1276 | 259 |
| ENST00000399562 | C22orf39 | chr22 | 19434901 | - | ENST00000403325 | GNB1L | chr22 | 19789739 | - | 1498 | 736 | 497 | 1276 | 259 |
| ENST00000399562 | C22orf39 | chr22 | 19434901 | - | ENST00000405009 | GNB1L | chr22 | 19789739 | - | 1059 | 736 | 497 | 1057 | 187 |
| ENST00000333059 | C22orf39 | chr22 | 19434901 | - | ENST00000329517 | GNB1L | chr22 | 19789739 | - | 6154 | 201 | 9 | 668 | 219 |
| ENST00000333059 | C22orf39 | chr22 | 19434901 | - | ENST00000403325 | GNB1L | chr22 | 19789739 | - | 963 | 201 | 9 | 668 | 219 |
| ENST00000333059 | C22orf39 | chr22 | 19434901 | - | ENST00000405009 | GNB1L | chr22 | 19789739 | - | 524 | 201 | 492 | 1 | 164 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000399568 | ENST00000329517 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.10153628 | 0.8984637 |
| ENST00000399568 | ENST00000403325 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.058270227 | 0.9417298 |
| ENST00000399568 | ENST00000405009 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.06774906 | 0.9322509 |
| ENST00000542103 | ENST00000329517 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.13952392 | 0.860476 |
| ENST00000542103 | ENST00000403325 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.16159752 | 0.8384025 |
| ENST00000542103 | ENST00000405009 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.1946154 | 0.8053846 |
| ENST00000399562 | ENST00000329517 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.13952392 | 0.860476 |
| ENST00000399562 | ENST00000403325 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.16159752 | 0.8384025 |
| ENST00000399562 | ENST00000405009 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.1946154 | 0.8053846 |
| ENST00000333059 | ENST00000329517 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.10167643 | 0.89832354 |
| ENST00000333059 | ENST00000403325 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.06197834 | 0.9380217 |
| ENST00000333059 | ENST00000405009 | C22orf39 | chr22 | 19434901 | - | GNB1L | chr22 | 19789739 | - | 0.07222392 | 0.9277761 |
Top |
Fusion Genomic Features for C22orf39-GNB1L |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for C22orf39-GNB1L |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:19434901/chr22:19789739) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | GNB1L |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000329517 | 5 | 8 | 200_237 | 172 | 328.0 | Repeat | Note=WD 5 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000329517 | 5 | 8 | 242_282 | 172 | 328.0 | Repeat | Note=WD 6 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000329517 | 5 | 8 | 286_323 | 172 | 328.0 | Repeat | Note=WD 7 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000403325 | 4 | 7 | 200_237 | 172 | 328.0 | Repeat | Note=WD 5 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000403325 | 4 | 7 | 242_282 | 172 | 328.0 | Repeat | Note=WD 6 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000403325 | 4 | 7 | 286_323 | 172 | 328.0 | Repeat | Note=WD 7 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000405009 | 5 | 8 | 200_237 | 172 | 213.0 | Repeat | Note=WD 5 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000405009 | 5 | 8 | 242_282 | 172 | 213.0 | Repeat | Note=WD 6 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000405009 | 5 | 8 | 286_323 | 172 | 213.0 | Repeat | Note=WD 7 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000329517 | 5 | 8 | 4_12 | 172 | 328.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000403325 | 4 | 7 | 4_12 | 172 | 328.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000405009 | 5 | 8 | 4_12 | 172 | 213.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000329517 | 5 | 8 | 103_145 | 172 | 328.0 | Repeat | Note=WD 3 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000329517 | 5 | 8 | 153_195 | 172 | 328.0 | Repeat | Note=WD 4 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000329517 | 5 | 8 | 16_54 | 172 | 328.0 | Repeat | Note=WD 1 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000329517 | 5 | 8 | 58_97 | 172 | 328.0 | Repeat | Note=WD 2 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000403325 | 4 | 7 | 103_145 | 172 | 328.0 | Repeat | Note=WD 3 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000403325 | 4 | 7 | 153_195 | 172 | 328.0 | Repeat | Note=WD 4 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000403325 | 4 | 7 | 16_54 | 172 | 328.0 | Repeat | Note=WD 1 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000403325 | 4 | 7 | 58_97 | 172 | 328.0 | Repeat | Note=WD 2 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000405009 | 5 | 8 | 103_145 | 172 | 213.0 | Repeat | Note=WD 3 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000405009 | 5 | 8 | 153_195 | 172 | 213.0 | Repeat | Note=WD 4 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000405009 | 5 | 8 | 16_54 | 172 | 213.0 | Repeat | Note=WD 1 | |
| Tgene | GNB1L | chr22:19434901 | chr22:19789739 | ENST00000405009 | 5 | 8 | 58_97 | 172 | 213.0 | Repeat | Note=WD 2 |
Top |
Fusion Gene Sequence for C22orf39-GNB1L |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >11575_11575_1_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000333059_GNB1L_chr22_19789739_ENST00000329517_length(transcript)=6154nt_BP=201nt CGCCCAGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGG CACTTCCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAG CGCCGGAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTC TCTGAGCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGTCATGGACCTTGACTTTGACTCCCAGAAGGCCAGGGGCATCTCA GGCTCCGCGGGGAAGGCGCTGGCTGTCTGGAGCCTGGACTGGCAGCAGGCCCTGCAGGTGCGTGGGACTCATGAACTCACCAATCCCGGG ATCGCCGAGGTCACGATCCGGCCAGATCGCAAGATCCTGGCCACCGCAGGCTGGGACCACCGCATCCGCGTGTTCCACTGGCGGACGATG CAGCCACTGGCCGTGCTGGCCTTCCACAGCGCCGCTGTCCAGTGCGTGGCCTTCACCGCCGATGGCTTGCTGGCCGCGGGCTCCAAGGAT CAGCGGATCAGCCTCTGGTCACTCTACCCACGCGCATGACTCACCCACTCCCTTCCCGGGAGACGAGGAGGGCGGGCAGGGAGGTGGGCA TCAGGCCCCAGCCTTGGCCTGAAACCTCAAGGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCTGTCTTCATG AGGTTGGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGCCTGCAGGAG ACGTTGGCTTGGGCCTGCTGTGTTGCCAGCTGAGGGTATTTTATAATAAATTTCCATTGCCAAGTTGCAGGCTTGAGGTGGGAGCTCCCT GAGGAGGCCCTGGTCCCCCACTTAGCATCAGTGCCCTCAGACCCCCACCAGGCAGGATGCTCAGCCCCACCCTCACACCTGCTGTTGAAT GGGCCACCCCGAGTGTGGGTTTCCTGGGCCAGGCCTCAGGAGATGATAGGCCCCAACCATAGCTGCGTCGATGTCCACATGACCCCTCAC CCCGAGGAGGCCAGGAGCTCCCAACACACAGGTTGAGGCCAGGATCAGGATCAGGAAGTAACTGAACTCCCTAAAGAGTGAAGCAGAGAA AGGTGCCTGTGAGGGACGGCAAGGGGGGCTTGCAGCGCACAGGGCCAGGCCAGATGTGGGATCCGGGAGGGCACGCCTGCCCGCAGAGGG TGCAGTGGGGAAGGCGCACAGGGTGCACCTCCAGGTGAGTGCTGGGCAGAAGGCACGAGAGCAGCAAGGGAGTGTGACAAGCACCGCCTC ACAGTGGCCAAGGCCACAGTCACAGCTGCGGCTGCACACAGGGTGGCCCCCAGGGCACAACACAGCAAGAGCAGGACTTAGCAGCCAGAG CCTCACACTGCATGCAGCCGGGCCCAGCCTGGCCGGTCGTCTCCTCCTAAAAGCGGGTGTTGATTGGGAAAGAACCATGACCCTGAATAT TGGAGTGGGGCCCATGGGCAGATCCAGAGAAGCTGGGACCACACACGCCTGTGTCTGCCCGGATTGCCGGAAGAGCCCCTCTAGCTGAAG GCCCGGGGTGGCCTCCCTTGAGGCAGTTGCCCTGCAAGGCCCTGCCGATGCTCCTTGGGACCCCCACCTGGGCTTCTAGTCCTAGAACTA GACTCGAGTCCAGCAGACCCCCAGGATGAGATACAGAGGGTGACCCTGAGAGTGGCACCAGCCTCCTGCAGGACCACATGGCATTTCCAG GTTTCCAGGCAGAAATCTGAACATGTGTGGGACGGATCGGAAGGGTGTGGGATCCAGGTGGCCGGAGCAGGGGTGGATCAGGGGAGTTCC CGGAACAGACCTGCCAAACGGAGGGCTGGACTGGGCGCTGCAGCTTGGGGCCAGGAAGGCTCCAGTGCCGGGCTGGGGGTGGGGGCTGGA TTACAGCCTGAGGGTGGCTGCACTGAGTGAAGTGGACATGGCCAGCCGCCGTGGGGTACAGCCGAGGAGGGCTTCCAAGGCCTGGGGATG GGGGTGTTGGATTTGTCAGTGAGACCTGTGCACCCACTGCAGGGGGTCCCAAGGCCGTGCCTCCCCAACCCCACTGTGAGGAACATGGTT GCTGGGGGGCCCGGAGTCCTTGAGGAGTCCTGTGACCACACTTCTCTGTTGGTCAGAGGTACCATGGGGACCGTTCCATCAAACGGGAAT GTCAGTGCTGGCCGGGAAAGCGGCCCCTGGCCCAAGCTTGGAGACCACCTGGCTCGGGTACTGGCCTGGCTCCGTTGGACAAGGGTGGCC ACCAGGTGCCCAGGACCTTTGGAGAGGGGGGCCCTGCTGCTTTTCCTCGAGTGTCCTATAGCCGCCAGGATGCGTAGGGCACTCCGGGAG GTATTTTCATATCACTGAGGTGTCAGGGAGGGGAAGGGTCCTGGGTTTAGGCTGCAGTGACTGCAGGTGCTGAGGGAGCTGTGCCCTGGG TGCTCATCACAGGCTGTCACAGTGAGGGAAGGTGTCAGGTTCTGACATCCCCATGACAGCGGCAGGGTAGGTGGAGTGGGAATTGGCTTT GCAGTTTCCCTGCATGCCCTTGACAGCCTTGCCAAAGGCACATCTGCCCCGCCTCAGCTCCCACCCTGAGGGTTCTGGGCCTCTACCCCT TCCCCTGTTTATGTCCCTGTCATCTTTGGCATCATCACTGTAGTTACAAAACTCCCTACGTCCCACAGCCACGAGGTGGGTATCCCACAT GAGGGCCCAGGTGTGCATGCCAGCATGAGGTTGGCGAGTGGCACTGCCTGCTGATGTCTTACATAGAGGCCATGAAGAGCTGTGGGCAGG GTGTACAGACCCTGAGTTGGCCCCTGGCCCTCGTGCTTTCAGTCAAAGGCACAAGCAGGGTGGATGGCAGGCGGCTGCCCCCTAGCCTGG CCTTGAGCTCCCTGCCCCAGGCCATGTGGCGTTGAGCAGTGTCCAGGCACATCTTGTTCTGAATCTCAGTGTGCAGGGATGGAGTCGGGA CAGCGTGAGTCCTGCATGCCTAACACAGCCCTCACCCCTCCAGTGCACAACGGGGCCACGTGCCCGCATCTGGGTGGCTAGGCAGATAGG GCCCCCCTTGCCAGGCAGATCCAGCTTCTGAGGCCTTATAGACGTCCTGTGGAGGGCAGGCCCAGGACTTTCATTCACCTGGCTGAGCTG CCTGGGAGAGCAGCAGAACCGGTGCTGGGGTCCAAGCCGGCCAAGAGCAGTGCAGCCCTCCTGGTCCTGTTCCTCTCTTGAGCTGCTCCG TGGTGTCCACAGCAGAGCCATGTGGCTCTGGACAGGTCGGCCTTTGTGTCAACAGAACCTGGGTCGTGATGAATCACCATGCGTCTGACC AGCCTTGAAACCCCCACAACAGAAGAAGAAACGGTCTCAGCTCCAGACATCCAGCTTGGAAAAGATGCACCTGAACATTGGCATTCTCTT CCTAGCAAACAGCCACTTCCTGTAGGCTGGCAGGAACGCCAACAGAGCCAGCAGTGAAGGCATTAAGTGGGGAGGAGGGGTGGCCCGGAG GCAGCACGCGAAGGTCAGCATGCAGCTCCTGGGATGAACCTGAGAGGCGACTCCTGGCAGCATGGCTGGTCGCTGCCATCACGCCCCTGG CCAACCCACCAACTGGGAGAGGCAGCCCTTCCACATCTTCCTCCATAATGCTCTTGGGTAGCAGTGAGGCCTCTCAAGCCAGAGAGAACT TGGTGTTTGGAAACAACGGCGGACATTTCTTGCCATTTTCAGTGCCAACTCAGGTAGGTGTGTTCTACCATCCTGTGTTTTTGGGGTGTT TTTTTTTTTGAGTCAGAGTCTCACTCTGTCCCCCAGGCTGGAGTGCAATGGAGCAGTCTCGGCTCACTGCAACCTCTGATTCCCAGGTTC AAGCGATTCTCCTGCCTCAGCCTCCCGAGAAGCTCAGGACCACCCACATAGGTGCAGGCCATCATGCCCAGCTAATTTTTTATTTTTTTT TATAGAGAAGGAGTCTCGCTATGTTGCCCAGGCTGGTTTCGAACTCCTGGGCTCAAGCGATCGATCCTCCCGCCTCTAGCCTCCCAAAGC ACTAGAATTATAGGCCTGAGCCACTGCGCCCGGCCCACCATCCTGTTCTTATTGGAAGAATTTCCATGTGTCGAGGCACGGGCACAACGT AGCTGGTCCTCTGCTCAGGGCCCCACAAGGCTGCGTCAGGGTGGCAGCGCGGCTGGGGGCTTTTTCTGTTCAAATCCAGATTCTCGTGGC TGTGAGCCCCAGCCCTGGGCACTGTCCGCCTGGTGGTGTCTTCACAGCCAGCAGGGGTGGCCTTGGGGTGTTCTGTGGAGTAACTTTCAC GGCCCAGAGTGGGATCCTGAGTGGCTGGAGCCGTATGCTCCAGCATCCCCAGCCGCTGCCTCCGGTGCAGGTGGAGTGGGCCCCTCTGAT TACCAGGAGCTGTCAGAGGGGCAGCAGGTCCCACTCCACTGGCCGGTGGGCAGCTGTGTGCAGGGACGCGGGTCCTGGCACGTCTGCCTG GTGAGGCCCTGCCTCCAGTGCCAAGGGGCCTCCCCTCTCGACGGTGGGCGCCACCATGTGCTGACCTCTGTGCAGCCCCACTTTACAAGG TAGGTTCGGCCAGCACCCCATCCGCGGGCGGGCAGCACTCACCCAGCGTTGCGCCGCCAACAGGGTCCCTCTTAGACAAGCAGCTGTGCC TAGAGCCTTTTCCTTCCTCCCTGCGTGTTACCTGCAGGCCAACAGACGGCCCTGGGTCTGGGACCAGGAGAACCTGCCTCCGCCTCTGGC AGTGGGTGTCCCTGCAGGCAGATTGGGCTTGGCACGTAGACACCGAGGGGTCAGCCGATGCCGGGAGATGATCCCGGGAAGGGCTCCGGA GCACAGCCCAGGACCCGCCGCCGCTGCTGGGCGCTCCATGTTGACGTGCTGTGCGTGTCTCCACTCCCCAGGCAATGATGTTCAATCAGG TGTTTCCCACCTGTGTCTCTGCCAAGAAGCCACAGAACACCCTCTGCACAAAAGGAGTGTTTGCACAAAGAAAAACAACCCTCCGGGGGT TCTTTAGAAATGCTTATACTCAATTAGCTAGAACTTCATGTGAAATCCCAGCGTGGAAGACAACAAGCCGGCACCGGTGAAAACTTTGCT GTGCACCTGCCCTCTACCAAGCTGCCAGCCCCACCAGCCCTGTGGTCCTAGGTGGGCACAGCTGCTGCACGGTCCCCCAGGCCTGCCTCT CCTCGGGGTCTCAACCTTCATACCAGATTTGCCAGCATCCCCATTCCCGCCTTGTGGGTGGAGAGTCCTTGAGACCCTCTGTCACTCTGT CAGCTTCCCCAGGTCAGCGAGCTGTGGCTTGGCTCCCACGCATCAGCTTTTATGGGAGGCCCATTAGGAGCTGGGCAGGAGGGACAGAGG GGAGGCCAGGCAGCCACTGCTGAGTGGGACGGGTAGCCCAGCCCATGAGGCTGGCCAGCCCTACAGGGGAGGTCCCACAGCACTGGCCGG GAAGTCCACATAGGAAAGCATCAGTTGAGGGATGAAGCCACGGACGATGGGGACAACGGCCACAGGGTGTGCTAAGCTGAGGAAATTAGT AGGAGGTGCTCATAAGCTGTTTTGTTTTTTGGTTTGTTTGTTTGTTTTTTCTTTTAAGAGACCAGGGACAGTGGGGGTCTCACTCTGTCA CCCAGGCTGGAGTGCAGTGGCATGATCATAGCTTACTGCAGCCTCCAACTAATAGGCTCAAGTGATCCTCCTGCCTCAGCCTCCCGAGTA ACTCATGGCCTTTAAGTGAACTGCTTCCACCATCCAGCTGTGCAGGTGGCCTGGGAACAGCAGCACATCTGTCCCCTGCCACCTCTTGCA TGCACACTTGACCTCCTGACTTGGGCTCTGAAACCTGTAAAATGTGGGGTGTAGAGAAATCGAGTCATTTGGCCTCATCCTGGTGCCATT >11575_11575_1_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000333059_GNB1L_chr22_19789739_ENST00000329517_length(amino acids)=219AA_BP=63 MADGSGWQPPRPCEAYRAEWKLCRSARHFLHHYYVHGERPACEQWQRDLASCRDWEERRNAEAQADCSSRPLLLAGYEDGSVVLWDVSEQ KVCSRIACHEEPVMDLDFDSQKARGISGSAGKALAVWSLDWQQALQVRGTHELTNPGIAEVTIRPDRKILATAGWDHRIRVFHWRTMQPL -------------------------------------------------------------- >11575_11575_2_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000333059_GNB1L_chr22_19789739_ENST00000403325_length(transcript)=963nt_BP=201nt CGCCCAGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGG CACTTCCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAG CGCCGGAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTC TCTGAGCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGTCATGGACCTTGACTTTGACTCCCAGAAGGCCAGGGGCATCTCA GGCTCCGCGGGGAAGGCGCTGGCTGTCTGGAGCCTGGACTGGCAGCAGGCCCTGCAGGTGCGTGGGACTCATGAACTCACCAATCCCGGG ATCGCCGAGGTCACGATCCGGCCAGATCGCAAGATCCTGGCCACCGCAGGCTGGGACCACCGCATCCGCGTGTTCCACTGGCGGACGATG CAGCCACTGGCCGTGCTGGCCTTCCACAGCGCCGCTGTCCAGTGCGTGGCCTTCACCGCCGATGGCTTGCTGGCCGCGGGCTCCAAGGAT CAGCGGATCAGCCTCTGGTCACTCTACCCACGCGCATGACTCACCCACTCCCTTCCCGGGAGACGAGGAGGGCGGGCAGGGAGGTGGGCA TCAGGCCCCAGCCTTGGCCTGAAACCTCAAGGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCTGTCTTCATG AGGTTGGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGCCTGCAGGAG >11575_11575_2_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000333059_GNB1L_chr22_19789739_ENST00000403325_length(amino acids)=219AA_BP=63 MADGSGWQPPRPCEAYRAEWKLCRSARHFLHHYYVHGERPACEQWQRDLASCRDWEERRNAEAQADCSSRPLLLAGYEDGSVVLWDVSEQ KVCSRIACHEEPVMDLDFDSQKARGISGSAGKALAVWSLDWQQALQVRGTHELTNPGIAEVTIRPDRKILATAGWDHRIRVFHWRTMQPL -------------------------------------------------------------- >11575_11575_3_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000333059_GNB1L_chr22_19789739_ENST00000405009_length(transcript)=524nt_BP=201nt CGCCCAGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGG CACTTCCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAG CGCCGGAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTC TCTGAGCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCC CCGCTGTCTTCATGAGGTTGGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCC >11575_11575_3_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000333059_GNB1L_chr22_19789739_ENST00000405009_length(amino acids)=164AA_BP=1 MATQQAQANVSCRPRTARALAGPQSHRPVMRHSTKGNTNLMKTAGTPWSLGHDLLVLRGRAPHGRRCGCTPSAQRRPTGPPIHPHSRPEG -------------------------------------------------------------- >11575_11575_4_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399562_GNB1L_chr22_19789739_ENST00000329517_length(transcript)=6689nt_BP=736nt ATATGTCATGCCCAACCAATCTCAGTTACTTTGCGAGTTCACCTCCATCCTGAGTGGACGCTCAAGCAAGACTGCTGGAGCTGCAGATCT GGGAGGTTCGCTGCACCACCTTGATGCTCAGTATGTACTTTTGAAAATATACCGGATTGTTGAGATTTGAGAAAATCTCATAAAGCTGCT GAAAAGAACTGGCCAGAGCCGTGTGATTTGAGAGGCGGCTGACGTAAGGTAGCTGCGCGGCCCAGGATGCCCGCCTGGCCCGGGGTGAAT GGCGCTGTCGTCGCGGTGGTCGCGTAGGCTTCGCGCCAGGTCTCGCCCCGGATTTACCCTGCGACCCCGGCCCTCCGCGCGCGCCGCAGC CGCCCTCGGTTGCTATTGGTTGCTCGTCCTGTTTGTCGGCGCTTCTCGAAGAAGGGGGCGAAGACGTGATTGAATGTGTCGGTGCTCATT AGTTCTTCTGTCAGTCGATCACGAGGTGCCGTTTTCTTCATTTTTCATTGGCTGGCGGACTGAGGGGCGGGCTTGGCGCGCCGGTCGCCC AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGTCATGGACCTTGACTTTGACTCCCAGAAGGCCAGGGGCATCTCAGGCTC CGCGGGGAAGGCGCTGGCTGTCTGGAGCCTGGACTGGCAGCAGGCCCTGCAGGTGCGTGGGACTCATGAACTCACCAATCCCGGGATCGC CGAGGTCACGATCCGGCCAGATCGCAAGATCCTGGCCACCGCAGGCTGGGACCACCGCATCCGCGTGTTCCACTGGCGGACGATGCAGCC ACTGGCCGTGCTGGCCTTCCACAGCGCCGCTGTCCAGTGCGTGGCCTTCACCGCCGATGGCTTGCTGGCCGCGGGCTCCAAGGATCAGCG GATCAGCCTCTGGTCACTCTACCCACGCGCATGACTCACCCACTCCCTTCCCGGGAGACGAGGAGGGCGGGCAGGGAGGTGGGCATCAGG CCCCAGCCTTGGCCTGAAACCTCAAGGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCTGTCTTCATGAGGTT GGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGCCTGCAGGAGACGTT GGCTTGGGCCTGCTGTGTTGCCAGCTGAGGGTATTTTATAATAAATTTCCATTGCCAAGTTGCAGGCTTGAGGTGGGAGCTCCCTGAGGA GGCCCTGGTCCCCCACTTAGCATCAGTGCCCTCAGACCCCCACCAGGCAGGATGCTCAGCCCCACCCTCACACCTGCTGTTGAATGGGCC ACCCCGAGTGTGGGTTTCCTGGGCCAGGCCTCAGGAGATGATAGGCCCCAACCATAGCTGCGTCGATGTCCACATGACCCCTCACCCCGA GGAGGCCAGGAGCTCCCAACACACAGGTTGAGGCCAGGATCAGGATCAGGAAGTAACTGAACTCCCTAAAGAGTGAAGCAGAGAAAGGTG CCTGTGAGGGACGGCAAGGGGGGCTTGCAGCGCACAGGGCCAGGCCAGATGTGGGATCCGGGAGGGCACGCCTGCCCGCAGAGGGTGCAG TGGGGAAGGCGCACAGGGTGCACCTCCAGGTGAGTGCTGGGCAGAAGGCACGAGAGCAGCAAGGGAGTGTGACAAGCACCGCCTCACAGT GGCCAAGGCCACAGTCACAGCTGCGGCTGCACACAGGGTGGCCCCCAGGGCACAACACAGCAAGAGCAGGACTTAGCAGCCAGAGCCTCA CACTGCATGCAGCCGGGCCCAGCCTGGCCGGTCGTCTCCTCCTAAAAGCGGGTGTTGATTGGGAAAGAACCATGACCCTGAATATTGGAG TGGGGCCCATGGGCAGATCCAGAGAAGCTGGGACCACACACGCCTGTGTCTGCCCGGATTGCCGGAAGAGCCCCTCTAGCTGAAGGCCCG GGGTGGCCTCCCTTGAGGCAGTTGCCCTGCAAGGCCCTGCCGATGCTCCTTGGGACCCCCACCTGGGCTTCTAGTCCTAGAACTAGACTC GAGTCCAGCAGACCCCCAGGATGAGATACAGAGGGTGACCCTGAGAGTGGCACCAGCCTCCTGCAGGACCACATGGCATTTCCAGGTTTC CAGGCAGAAATCTGAACATGTGTGGGACGGATCGGAAGGGTGTGGGATCCAGGTGGCCGGAGCAGGGGTGGATCAGGGGAGTTCCCGGAA CAGACCTGCCAAACGGAGGGCTGGACTGGGCGCTGCAGCTTGGGGCCAGGAAGGCTCCAGTGCCGGGCTGGGGGTGGGGGCTGGATTACA GCCTGAGGGTGGCTGCACTGAGTGAAGTGGACATGGCCAGCCGCCGTGGGGTACAGCCGAGGAGGGCTTCCAAGGCCTGGGGATGGGGGT GTTGGATTTGTCAGTGAGACCTGTGCACCCACTGCAGGGGGTCCCAAGGCCGTGCCTCCCCAACCCCACTGTGAGGAACATGGTTGCTGG GGGGCCCGGAGTCCTTGAGGAGTCCTGTGACCACACTTCTCTGTTGGTCAGAGGTACCATGGGGACCGTTCCATCAAACGGGAATGTCAG TGCTGGCCGGGAAAGCGGCCCCTGGCCCAAGCTTGGAGACCACCTGGCTCGGGTACTGGCCTGGCTCCGTTGGACAAGGGTGGCCACCAG GTGCCCAGGACCTTTGGAGAGGGGGGCCCTGCTGCTTTTCCTCGAGTGTCCTATAGCCGCCAGGATGCGTAGGGCACTCCGGGAGGTATT TTCATATCACTGAGGTGTCAGGGAGGGGAAGGGTCCTGGGTTTAGGCTGCAGTGACTGCAGGTGCTGAGGGAGCTGTGCCCTGGGTGCTC ATCACAGGCTGTCACAGTGAGGGAAGGTGTCAGGTTCTGACATCCCCATGACAGCGGCAGGGTAGGTGGAGTGGGAATTGGCTTTGCAGT TTCCCTGCATGCCCTTGACAGCCTTGCCAAAGGCACATCTGCCCCGCCTCAGCTCCCACCCTGAGGGTTCTGGGCCTCTACCCCTTCCCC TGTTTATGTCCCTGTCATCTTTGGCATCATCACTGTAGTTACAAAACTCCCTACGTCCCACAGCCACGAGGTGGGTATCCCACATGAGGG CCCAGGTGTGCATGCCAGCATGAGGTTGGCGAGTGGCACTGCCTGCTGATGTCTTACATAGAGGCCATGAAGAGCTGTGGGCAGGGTGTA CAGACCCTGAGTTGGCCCCTGGCCCTCGTGCTTTCAGTCAAAGGCACAAGCAGGGTGGATGGCAGGCGGCTGCCCCCTAGCCTGGCCTTG AGCTCCCTGCCCCAGGCCATGTGGCGTTGAGCAGTGTCCAGGCACATCTTGTTCTGAATCTCAGTGTGCAGGGATGGAGTCGGGACAGCG TGAGTCCTGCATGCCTAACACAGCCCTCACCCCTCCAGTGCACAACGGGGCCACGTGCCCGCATCTGGGTGGCTAGGCAGATAGGGCCCC CCTTGCCAGGCAGATCCAGCTTCTGAGGCCTTATAGACGTCCTGTGGAGGGCAGGCCCAGGACTTTCATTCACCTGGCTGAGCTGCCTGG GAGAGCAGCAGAACCGGTGCTGGGGTCCAAGCCGGCCAAGAGCAGTGCAGCCCTCCTGGTCCTGTTCCTCTCTTGAGCTGCTCCGTGGTG TCCACAGCAGAGCCATGTGGCTCTGGACAGGTCGGCCTTTGTGTCAACAGAACCTGGGTCGTGATGAATCACCATGCGTCTGACCAGCCT TGAAACCCCCACAACAGAAGAAGAAACGGTCTCAGCTCCAGACATCCAGCTTGGAAAAGATGCACCTGAACATTGGCATTCTCTTCCTAG CAAACAGCCACTTCCTGTAGGCTGGCAGGAACGCCAACAGAGCCAGCAGTGAAGGCATTAAGTGGGGAGGAGGGGTGGCCCGGAGGCAGC ACGCGAAGGTCAGCATGCAGCTCCTGGGATGAACCTGAGAGGCGACTCCTGGCAGCATGGCTGGTCGCTGCCATCACGCCCCTGGCCAAC CCACCAACTGGGAGAGGCAGCCCTTCCACATCTTCCTCCATAATGCTCTTGGGTAGCAGTGAGGCCTCTCAAGCCAGAGAGAACTTGGTG TTTGGAAACAACGGCGGACATTTCTTGCCATTTTCAGTGCCAACTCAGGTAGGTGTGTTCTACCATCCTGTGTTTTTGGGGTGTTTTTTT TTTTGAGTCAGAGTCTCACTCTGTCCCCCAGGCTGGAGTGCAATGGAGCAGTCTCGGCTCACTGCAACCTCTGATTCCCAGGTTCAAGCG ATTCTCCTGCCTCAGCCTCCCGAGAAGCTCAGGACCACCCACATAGGTGCAGGCCATCATGCCCAGCTAATTTTTTATTTTTTTTTATAG AGAAGGAGTCTCGCTATGTTGCCCAGGCTGGTTTCGAACTCCTGGGCTCAAGCGATCGATCCTCCCGCCTCTAGCCTCCCAAAGCACTAG AATTATAGGCCTGAGCCACTGCGCCCGGCCCACCATCCTGTTCTTATTGGAAGAATTTCCATGTGTCGAGGCACGGGCACAACGTAGCTG GTCCTCTGCTCAGGGCCCCACAAGGCTGCGTCAGGGTGGCAGCGCGGCTGGGGGCTTTTTCTGTTCAAATCCAGATTCTCGTGGCTGTGA GCCCCAGCCCTGGGCACTGTCCGCCTGGTGGTGTCTTCACAGCCAGCAGGGGTGGCCTTGGGGTGTTCTGTGGAGTAACTTTCACGGCCC AGAGTGGGATCCTGAGTGGCTGGAGCCGTATGCTCCAGCATCCCCAGCCGCTGCCTCCGGTGCAGGTGGAGTGGGCCCCTCTGATTACCA GGAGCTGTCAGAGGGGCAGCAGGTCCCACTCCACTGGCCGGTGGGCAGCTGTGTGCAGGGACGCGGGTCCTGGCACGTCTGCCTGGTGAG GCCCTGCCTCCAGTGCCAAGGGGCCTCCCCTCTCGACGGTGGGCGCCACCATGTGCTGACCTCTGTGCAGCCCCACTTTACAAGGTAGGT TCGGCCAGCACCCCATCCGCGGGCGGGCAGCACTCACCCAGCGTTGCGCCGCCAACAGGGTCCCTCTTAGACAAGCAGCTGTGCCTAGAG CCTTTTCCTTCCTCCCTGCGTGTTACCTGCAGGCCAACAGACGGCCCTGGGTCTGGGACCAGGAGAACCTGCCTCCGCCTCTGGCAGTGG GTGTCCCTGCAGGCAGATTGGGCTTGGCACGTAGACACCGAGGGGTCAGCCGATGCCGGGAGATGATCCCGGGAAGGGCTCCGGAGCACA GCCCAGGACCCGCCGCCGCTGCTGGGCGCTCCATGTTGACGTGCTGTGCGTGTCTCCACTCCCCAGGCAATGATGTTCAATCAGGTGTTT CCCACCTGTGTCTCTGCCAAGAAGCCACAGAACACCCTCTGCACAAAAGGAGTGTTTGCACAAAGAAAAACAACCCTCCGGGGGTTCTTT AGAAATGCTTATACTCAATTAGCTAGAACTTCATGTGAAATCCCAGCGTGGAAGACAACAAGCCGGCACCGGTGAAAACTTTGCTGTGCA CCTGCCCTCTACCAAGCTGCCAGCCCCACCAGCCCTGTGGTCCTAGGTGGGCACAGCTGCTGCACGGTCCCCCAGGCCTGCCTCTCCTCG GGGTCTCAACCTTCATACCAGATTTGCCAGCATCCCCATTCCCGCCTTGTGGGTGGAGAGTCCTTGAGACCCTCTGTCACTCTGTCAGCT TCCCCAGGTCAGCGAGCTGTGGCTTGGCTCCCACGCATCAGCTTTTATGGGAGGCCCATTAGGAGCTGGGCAGGAGGGACAGAGGGGAGG CCAGGCAGCCACTGCTGAGTGGGACGGGTAGCCCAGCCCATGAGGCTGGCCAGCCCTACAGGGGAGGTCCCACAGCACTGGCCGGGAAGT CCACATAGGAAAGCATCAGTTGAGGGATGAAGCCACGGACGATGGGGACAACGGCCACAGGGTGTGCTAAGCTGAGGAAATTAGTAGGAG GTGCTCATAAGCTGTTTTGTTTTTTGGTTTGTTTGTTTGTTTTTTCTTTTAAGAGACCAGGGACAGTGGGGGTCTCACTCTGTCACCCAG GCTGGAGTGCAGTGGCATGATCATAGCTTACTGCAGCCTCCAACTAATAGGCTCAAGTGATCCTCCTGCCTCAGCCTCCCGAGTAACTCA TGGCCTTTAAGTGAACTGCTTCCACCATCCAGCTGTGCAGGTGGCCTGGGAACAGCAGCACATCTGTCCCCTGCCACCTCTTGCATGCAC ACTTGACCTCCTGACTTGGGCTCTGAAACCTGTAAAATGTGGGGTGTAGAGAAATCGAGTCATTTGGCCTCATCCTGGTGCCATTATCTC >11575_11575_4_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399562_GNB1L_chr22_19789739_ENST00000329517_length(amino acids)=259AA_BP=79 MAGGLRGGLGAPVAQTWRTAAAGSRRAPARPTAPSGSSAAAPGTSYTTTTSTASGRPANSGSATWPAAATGRSAGTPRPRPTAAPAHSFW PAMRMDRWSCGTSLSRRCAAASPAMRSPSWTLTLTPRRPGASQAPRGRRWLSGAWTGSRPCRCVGLMNSPIPGSPRSRSGQIARSWPPQA -------------------------------------------------------------- >11575_11575_5_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399562_GNB1L_chr22_19789739_ENST00000403325_length(transcript)=1498nt_BP=736nt ATATGTCATGCCCAACCAATCTCAGTTACTTTGCGAGTTCACCTCCATCCTGAGTGGACGCTCAAGCAAGACTGCTGGAGCTGCAGATCT GGGAGGTTCGCTGCACCACCTTGATGCTCAGTATGTACTTTTGAAAATATACCGGATTGTTGAGATTTGAGAAAATCTCATAAAGCTGCT GAAAAGAACTGGCCAGAGCCGTGTGATTTGAGAGGCGGCTGACGTAAGGTAGCTGCGCGGCCCAGGATGCCCGCCTGGCCCGGGGTGAAT GGCGCTGTCGTCGCGGTGGTCGCGTAGGCTTCGCGCCAGGTCTCGCCCCGGATTTACCCTGCGACCCCGGCCCTCCGCGCGCGCCGCAGC CGCCCTCGGTTGCTATTGGTTGCTCGTCCTGTTTGTCGGCGCTTCTCGAAGAAGGGGGCGAAGACGTGATTGAATGTGTCGGTGCTCATT AGTTCTTCTGTCAGTCGATCACGAGGTGCCGTTTTCTTCATTTTTCATTGGCTGGCGGACTGAGGGGCGGGCTTGGCGCGCCGGTCGCCC AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGTCATGGACCTTGACTTTGACTCCCAGAAGGCCAGGGGCATCTCAGGCTC CGCGGGGAAGGCGCTGGCTGTCTGGAGCCTGGACTGGCAGCAGGCCCTGCAGGTGCGTGGGACTCATGAACTCACCAATCCCGGGATCGC CGAGGTCACGATCCGGCCAGATCGCAAGATCCTGGCCACCGCAGGCTGGGACCACCGCATCCGCGTGTTCCACTGGCGGACGATGCAGCC ACTGGCCGTGCTGGCCTTCCACAGCGCCGCTGTCCAGTGCGTGGCCTTCACCGCCGATGGCTTGCTGGCCGCGGGCTCCAAGGATCAGCG GATCAGCCTCTGGTCACTCTACCCACGCGCATGACTCACCCACTCCCTTCCCGGGAGACGAGGAGGGCGGGCAGGGAGGTGGGCATCAGG CCCCAGCCTTGGCCTGAAACCTCAAGGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCTGTCTTCATGAGGTT GGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGCCTGCAGGAGACGTT >11575_11575_5_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399562_GNB1L_chr22_19789739_ENST00000403325_length(amino acids)=259AA_BP=79 MAGGLRGGLGAPVAQTWRTAAAGSRRAPARPTAPSGSSAAAPGTSYTTTTSTASGRPANSGSATWPAAATGRSAGTPRPRPTAAPAHSFW PAMRMDRWSCGTSLSRRCAAASPAMRSPSWTLTLTPRRPGASQAPRGRRWLSGAWTGSRPCRCVGLMNSPIPGSPRSRSGQIARSWPPQA -------------------------------------------------------------- >11575_11575_6_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399562_GNB1L_chr22_19789739_ENST00000405009_length(transcript)=1059nt_BP=736nt ATATGTCATGCCCAACCAATCTCAGTTACTTTGCGAGTTCACCTCCATCCTGAGTGGACGCTCAAGCAAGACTGCTGGAGCTGCAGATCT GGGAGGTTCGCTGCACCACCTTGATGCTCAGTATGTACTTTTGAAAATATACCGGATTGTTGAGATTTGAGAAAATCTCATAAAGCTGCT GAAAAGAACTGGCCAGAGCCGTGTGATTTGAGAGGCGGCTGACGTAAGGTAGCTGCGCGGCCCAGGATGCCCGCCTGGCCCGGGGTGAAT GGCGCTGTCGTCGCGGTGGTCGCGTAGGCTTCGCGCCAGGTCTCGCCCCGGATTTACCCTGCGACCCCGGCCCTCCGCGCGCGCCGCAGC CGCCCTCGGTTGCTATTGGTTGCTCGTCCTGTTTGTCGGCGCTTCTCGAAGAAGGGGGCGAAGACGTGATTGAATGTGTCGGTGCTCATT AGTTCTTCTGTCAGTCGATCACGAGGTGCCGTTTTCTTCATTTTTCATTGGCTGGCGGACTGAGGGGCGGGCTTGGCGCGCCGGTCGCCC AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCT GTCTTCATGAGGTTGGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGC >11575_11575_6_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399562_GNB1L_chr22_19789739_ENST00000405009_length(amino acids)=187AA_BP=79 MAGGLRGGLGAPVAQTWRTAAAGSRRAPARPTAPSGSSAAAPGTSYTTTTSTASGRPANSGSATWPAAATGRSAGTPRPRPTAAPAHSFW PAMRMDRWSCGTSLSRRCAAASPAMRSPASEDQQVMAQGPWSPRCLHEVGISFCGVPHHRTVTLGASQSPGRPRPAGDVGLGLLCCQLRV -------------------------------------------------------------- >11575_11575_7_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399568_GNB1L_chr22_19789739_ENST00000329517_length(transcript)=6149nt_BP=196nt AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGTCATGGACCTTGACTTTGACTCCCAGAAGGCCAGGGGCATCTCAGGCTC CGCGGGGAAGGCGCTGGCTGTCTGGAGCCTGGACTGGCAGCAGGCCCTGCAGGTGCGTGGGACTCATGAACTCACCAATCCCGGGATCGC CGAGGTCACGATCCGGCCAGATCGCAAGATCCTGGCCACCGCAGGCTGGGACCACCGCATCCGCGTGTTCCACTGGCGGACGATGCAGCC ACTGGCCGTGCTGGCCTTCCACAGCGCCGCTGTCCAGTGCGTGGCCTTCACCGCCGATGGCTTGCTGGCCGCGGGCTCCAAGGATCAGCG GATCAGCCTCTGGTCACTCTACCCACGCGCATGACTCACCCACTCCCTTCCCGGGAGACGAGGAGGGCGGGCAGGGAGGTGGGCATCAGG CCCCAGCCTTGGCCTGAAACCTCAAGGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCTGTCTTCATGAGGTT GGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGCCTGCAGGAGACGTT GGCTTGGGCCTGCTGTGTTGCCAGCTGAGGGTATTTTATAATAAATTTCCATTGCCAAGTTGCAGGCTTGAGGTGGGAGCTCCCTGAGGA GGCCCTGGTCCCCCACTTAGCATCAGTGCCCTCAGACCCCCACCAGGCAGGATGCTCAGCCCCACCCTCACACCTGCTGTTGAATGGGCC ACCCCGAGTGTGGGTTTCCTGGGCCAGGCCTCAGGAGATGATAGGCCCCAACCATAGCTGCGTCGATGTCCACATGACCCCTCACCCCGA GGAGGCCAGGAGCTCCCAACACACAGGTTGAGGCCAGGATCAGGATCAGGAAGTAACTGAACTCCCTAAAGAGTGAAGCAGAGAAAGGTG CCTGTGAGGGACGGCAAGGGGGGCTTGCAGCGCACAGGGCCAGGCCAGATGTGGGATCCGGGAGGGCACGCCTGCCCGCAGAGGGTGCAG TGGGGAAGGCGCACAGGGTGCACCTCCAGGTGAGTGCTGGGCAGAAGGCACGAGAGCAGCAAGGGAGTGTGACAAGCACCGCCTCACAGT GGCCAAGGCCACAGTCACAGCTGCGGCTGCACACAGGGTGGCCCCCAGGGCACAACACAGCAAGAGCAGGACTTAGCAGCCAGAGCCTCA CACTGCATGCAGCCGGGCCCAGCCTGGCCGGTCGTCTCCTCCTAAAAGCGGGTGTTGATTGGGAAAGAACCATGACCCTGAATATTGGAG TGGGGCCCATGGGCAGATCCAGAGAAGCTGGGACCACACACGCCTGTGTCTGCCCGGATTGCCGGAAGAGCCCCTCTAGCTGAAGGCCCG GGGTGGCCTCCCTTGAGGCAGTTGCCCTGCAAGGCCCTGCCGATGCTCCTTGGGACCCCCACCTGGGCTTCTAGTCCTAGAACTAGACTC GAGTCCAGCAGACCCCCAGGATGAGATACAGAGGGTGACCCTGAGAGTGGCACCAGCCTCCTGCAGGACCACATGGCATTTCCAGGTTTC CAGGCAGAAATCTGAACATGTGTGGGACGGATCGGAAGGGTGTGGGATCCAGGTGGCCGGAGCAGGGGTGGATCAGGGGAGTTCCCGGAA CAGACCTGCCAAACGGAGGGCTGGACTGGGCGCTGCAGCTTGGGGCCAGGAAGGCTCCAGTGCCGGGCTGGGGGTGGGGGCTGGATTACA GCCTGAGGGTGGCTGCACTGAGTGAAGTGGACATGGCCAGCCGCCGTGGGGTACAGCCGAGGAGGGCTTCCAAGGCCTGGGGATGGGGGT GTTGGATTTGTCAGTGAGACCTGTGCACCCACTGCAGGGGGTCCCAAGGCCGTGCCTCCCCAACCCCACTGTGAGGAACATGGTTGCTGG GGGGCCCGGAGTCCTTGAGGAGTCCTGTGACCACACTTCTCTGTTGGTCAGAGGTACCATGGGGACCGTTCCATCAAACGGGAATGTCAG TGCTGGCCGGGAAAGCGGCCCCTGGCCCAAGCTTGGAGACCACCTGGCTCGGGTACTGGCCTGGCTCCGTTGGACAAGGGTGGCCACCAG GTGCCCAGGACCTTTGGAGAGGGGGGCCCTGCTGCTTTTCCTCGAGTGTCCTATAGCCGCCAGGATGCGTAGGGCACTCCGGGAGGTATT TTCATATCACTGAGGTGTCAGGGAGGGGAAGGGTCCTGGGTTTAGGCTGCAGTGACTGCAGGTGCTGAGGGAGCTGTGCCCTGGGTGCTC ATCACAGGCTGTCACAGTGAGGGAAGGTGTCAGGTTCTGACATCCCCATGACAGCGGCAGGGTAGGTGGAGTGGGAATTGGCTTTGCAGT TTCCCTGCATGCCCTTGACAGCCTTGCCAAAGGCACATCTGCCCCGCCTCAGCTCCCACCCTGAGGGTTCTGGGCCTCTACCCCTTCCCC TGTTTATGTCCCTGTCATCTTTGGCATCATCACTGTAGTTACAAAACTCCCTACGTCCCACAGCCACGAGGTGGGTATCCCACATGAGGG CCCAGGTGTGCATGCCAGCATGAGGTTGGCGAGTGGCACTGCCTGCTGATGTCTTACATAGAGGCCATGAAGAGCTGTGGGCAGGGTGTA CAGACCCTGAGTTGGCCCCTGGCCCTCGTGCTTTCAGTCAAAGGCACAAGCAGGGTGGATGGCAGGCGGCTGCCCCCTAGCCTGGCCTTG AGCTCCCTGCCCCAGGCCATGTGGCGTTGAGCAGTGTCCAGGCACATCTTGTTCTGAATCTCAGTGTGCAGGGATGGAGTCGGGACAGCG TGAGTCCTGCATGCCTAACACAGCCCTCACCCCTCCAGTGCACAACGGGGCCACGTGCCCGCATCTGGGTGGCTAGGCAGATAGGGCCCC CCTTGCCAGGCAGATCCAGCTTCTGAGGCCTTATAGACGTCCTGTGGAGGGCAGGCCCAGGACTTTCATTCACCTGGCTGAGCTGCCTGG GAGAGCAGCAGAACCGGTGCTGGGGTCCAAGCCGGCCAAGAGCAGTGCAGCCCTCCTGGTCCTGTTCCTCTCTTGAGCTGCTCCGTGGTG TCCACAGCAGAGCCATGTGGCTCTGGACAGGTCGGCCTTTGTGTCAACAGAACCTGGGTCGTGATGAATCACCATGCGTCTGACCAGCCT TGAAACCCCCACAACAGAAGAAGAAACGGTCTCAGCTCCAGACATCCAGCTTGGAAAAGATGCACCTGAACATTGGCATTCTCTTCCTAG CAAACAGCCACTTCCTGTAGGCTGGCAGGAACGCCAACAGAGCCAGCAGTGAAGGCATTAAGTGGGGAGGAGGGGTGGCCCGGAGGCAGC ACGCGAAGGTCAGCATGCAGCTCCTGGGATGAACCTGAGAGGCGACTCCTGGCAGCATGGCTGGTCGCTGCCATCACGCCCCTGGCCAAC CCACCAACTGGGAGAGGCAGCCCTTCCACATCTTCCTCCATAATGCTCTTGGGTAGCAGTGAGGCCTCTCAAGCCAGAGAGAACTTGGTG TTTGGAAACAACGGCGGACATTTCTTGCCATTTTCAGTGCCAACTCAGGTAGGTGTGTTCTACCATCCTGTGTTTTTGGGGTGTTTTTTT TTTTGAGTCAGAGTCTCACTCTGTCCCCCAGGCTGGAGTGCAATGGAGCAGTCTCGGCTCACTGCAACCTCTGATTCCCAGGTTCAAGCG ATTCTCCTGCCTCAGCCTCCCGAGAAGCTCAGGACCACCCACATAGGTGCAGGCCATCATGCCCAGCTAATTTTTTATTTTTTTTTATAG AGAAGGAGTCTCGCTATGTTGCCCAGGCTGGTTTCGAACTCCTGGGCTCAAGCGATCGATCCTCCCGCCTCTAGCCTCCCAAAGCACTAG AATTATAGGCCTGAGCCACTGCGCCCGGCCCACCATCCTGTTCTTATTGGAAGAATTTCCATGTGTCGAGGCACGGGCACAACGTAGCTG GTCCTCTGCTCAGGGCCCCACAAGGCTGCGTCAGGGTGGCAGCGCGGCTGGGGGCTTTTTCTGTTCAAATCCAGATTCTCGTGGCTGTGA GCCCCAGCCCTGGGCACTGTCCGCCTGGTGGTGTCTTCACAGCCAGCAGGGGTGGCCTTGGGGTGTTCTGTGGAGTAACTTTCACGGCCC AGAGTGGGATCCTGAGTGGCTGGAGCCGTATGCTCCAGCATCCCCAGCCGCTGCCTCCGGTGCAGGTGGAGTGGGCCCCTCTGATTACCA GGAGCTGTCAGAGGGGCAGCAGGTCCCACTCCACTGGCCGGTGGGCAGCTGTGTGCAGGGACGCGGGTCCTGGCACGTCTGCCTGGTGAG GCCCTGCCTCCAGTGCCAAGGGGCCTCCCCTCTCGACGGTGGGCGCCACCATGTGCTGACCTCTGTGCAGCCCCACTTTACAAGGTAGGT TCGGCCAGCACCCCATCCGCGGGCGGGCAGCACTCACCCAGCGTTGCGCCGCCAACAGGGTCCCTCTTAGACAAGCAGCTGTGCCTAGAG CCTTTTCCTTCCTCCCTGCGTGTTACCTGCAGGCCAACAGACGGCCCTGGGTCTGGGACCAGGAGAACCTGCCTCCGCCTCTGGCAGTGG GTGTCCCTGCAGGCAGATTGGGCTTGGCACGTAGACACCGAGGGGTCAGCCGATGCCGGGAGATGATCCCGGGAAGGGCTCCGGAGCACA GCCCAGGACCCGCCGCCGCTGCTGGGCGCTCCATGTTGACGTGCTGTGCGTGTCTCCACTCCCCAGGCAATGATGTTCAATCAGGTGTTT CCCACCTGTGTCTCTGCCAAGAAGCCACAGAACACCCTCTGCACAAAAGGAGTGTTTGCACAAAGAAAAACAACCCTCCGGGGGTTCTTT AGAAATGCTTATACTCAATTAGCTAGAACTTCATGTGAAATCCCAGCGTGGAAGACAACAAGCCGGCACCGGTGAAAACTTTGCTGTGCA CCTGCCCTCTACCAAGCTGCCAGCCCCACCAGCCCTGTGGTCCTAGGTGGGCACAGCTGCTGCACGGTCCCCCAGGCCTGCCTCTCCTCG GGGTCTCAACCTTCATACCAGATTTGCCAGCATCCCCATTCCCGCCTTGTGGGTGGAGAGTCCTTGAGACCCTCTGTCACTCTGTCAGCT TCCCCAGGTCAGCGAGCTGTGGCTTGGCTCCCACGCATCAGCTTTTATGGGAGGCCCATTAGGAGCTGGGCAGGAGGGACAGAGGGGAGG CCAGGCAGCCACTGCTGAGTGGGACGGGTAGCCCAGCCCATGAGGCTGGCCAGCCCTACAGGGGAGGTCCCACAGCACTGGCCGGGAAGT CCACATAGGAAAGCATCAGTTGAGGGATGAAGCCACGGACGATGGGGACAACGGCCACAGGGTGTGCTAAGCTGAGGAAATTAGTAGGAG GTGCTCATAAGCTGTTTTGTTTTTTGGTTTGTTTGTTTGTTTTTTCTTTTAAGAGACCAGGGACAGTGGGGGTCTCACTCTGTCACCCAG GCTGGAGTGCAGTGGCATGATCATAGCTTACTGCAGCCTCCAACTAATAGGCTCAAGTGATCCTCCTGCCTCAGCCTCCCGAGTAACTCA TGGCCTTTAAGTGAACTGCTTCCACCATCCAGCTGTGCAGGTGGCCTGGGAACAGCAGCACATCTGTCCCCTGCCACCTCTTGCATGCAC ACTTGACCTCCTGACTTGGGCTCTGAAACCTGTAAAATGTGGGGTGTAGAGAAATCGAGTCATTTGGCCTCATCCTGGTGCCATTATCTC >11575_11575_7_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399568_GNB1L_chr22_19789739_ENST00000329517_length(amino acids)=219AA_BP=63 MADGSGWQPPRPCEAYRAEWKLCRSARHFLHHYYVHGERPACEQWQRDLASCRDWEERRNAEAQADCSSRPLLLAGYEDGSVVLWDVSEQ KVCSRIACHEEPVMDLDFDSQKARGISGSAGKALAVWSLDWQQALQVRGTHELTNPGIAEVTIRPDRKILATAGWDHRIRVFHWRTMQPL -------------------------------------------------------------- >11575_11575_8_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399568_GNB1L_chr22_19789739_ENST00000403325_length(transcript)=958nt_BP=196nt AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGTCATGGACCTTGACTTTGACTCCCAGAAGGCCAGGGGCATCTCAGGCTC CGCGGGGAAGGCGCTGGCTGTCTGGAGCCTGGACTGGCAGCAGGCCCTGCAGGTGCGTGGGACTCATGAACTCACCAATCCCGGGATCGC CGAGGTCACGATCCGGCCAGATCGCAAGATCCTGGCCACCGCAGGCTGGGACCACCGCATCCGCGTGTTCCACTGGCGGACGATGCAGCC ACTGGCCGTGCTGGCCTTCCACAGCGCCGCTGTCCAGTGCGTGGCCTTCACCGCCGATGGCTTGCTGGCCGCGGGCTCCAAGGATCAGCG GATCAGCCTCTGGTCACTCTACCCACGCGCATGACTCACCCACTCCCTTCCCGGGAGACGAGGAGGGCGGGCAGGGAGGTGGGCATCAGG CCCCAGCCTTGGCCTGAAACCTCAAGGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCTGTCTTCATGAGGTT GGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGCCTGCAGGAGACGTT >11575_11575_8_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399568_GNB1L_chr22_19789739_ENST00000403325_length(amino acids)=219AA_BP=63 MADGSGWQPPRPCEAYRAEWKLCRSARHFLHHYYVHGERPACEQWQRDLASCRDWEERRNAEAQADCSSRPLLLAGYEDGSVVLWDVSEQ KVCSRIACHEEPVMDLDFDSQKARGISGSAGKALAVWSLDWQQALQVRGTHELTNPGIAEVTIRPDRKILATAGWDHRIRVFHWRTMQPL -------------------------------------------------------------- >11575_11575_9_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399568_GNB1L_chr22_19789739_ENST00000405009_length(transcript)=519nt_BP=196nt AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCT GTCTTCATGAGGTTGGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGC >11575_11575_9_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000399568_GNB1L_chr22_19789739_ENST00000405009_length(amino acids)=162AA_BP=1 MATQQAQANVSCRPRTARALAGPQSHRPVMRHSTKGNTNLMKTAGTPWSLGHDLLVLRGRAPHGRRCGCTPSAQRRPTGPPIHPHSRPEG -------------------------------------------------------------- >11575_11575_10_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000542103_GNB1L_chr22_19789739_ENST00000329517_length(transcript)=6689nt_BP=736nt ATATGTCATGCCCAACCAATCTCAGTTACTTTGCGAGTTCACCTCCATCCTGAGTGGACGCTCAAGCAAGACTGCTGGAGCTGCAGATCT GGGAGGTTCGCTGCACCACCTTGATGCTCAGTATGTACTTTTGAAAATATACCGGATTGTTGAGATTTGAGAAAATCTCATAAAGCTGCT GAAAAGAACTGGCCAGAGCCGTGTGATTTGAGAGGCGGCTGACGTAAGGTAGCTGCGCGGCCCAGGATGCCCGCCTGGCCCGGGGTGAAT GGCGCTGTCGTCGCGGTGGTCGCGTAGGCTTCGCGCCAGGTCTCGCCCCGGATTTACCCTGCGACCCCGGCCCTCCGCGCGCGCCGCAGC CGCCCTCGGTTGCTATTGGTTGCTCGTCCTGTTTGTCGGCGCTTCTCGAAGAAGGGGGCGAAGACGTGATTGAATGTGTCGGTGCTCATT AGTTCTTCTGTCAGTCGATCACGAGGTGCCGTTTTCTTCATTTTTCATTGGCTGGCGGACTGAGGGGCGGGCTTGGCGCGCCGGTCGCCC AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGTCATGGACCTTGACTTTGACTCCCAGAAGGCCAGGGGCATCTCAGGCTC CGCGGGGAAGGCGCTGGCTGTCTGGAGCCTGGACTGGCAGCAGGCCCTGCAGGTGCGTGGGACTCATGAACTCACCAATCCCGGGATCGC CGAGGTCACGATCCGGCCAGATCGCAAGATCCTGGCCACCGCAGGCTGGGACCACCGCATCCGCGTGTTCCACTGGCGGACGATGCAGCC ACTGGCCGTGCTGGCCTTCCACAGCGCCGCTGTCCAGTGCGTGGCCTTCACCGCCGATGGCTTGCTGGCCGCGGGCTCCAAGGATCAGCG GATCAGCCTCTGGTCACTCTACCCACGCGCATGACTCACCCACTCCCTTCCCGGGAGACGAGGAGGGCGGGCAGGGAGGTGGGCATCAGG CCCCAGCCTTGGCCTGAAACCTCAAGGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCTGTCTTCATGAGGTT GGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGCCTGCAGGAGACGTT GGCTTGGGCCTGCTGTGTTGCCAGCTGAGGGTATTTTATAATAAATTTCCATTGCCAAGTTGCAGGCTTGAGGTGGGAGCTCCCTGAGGA GGCCCTGGTCCCCCACTTAGCATCAGTGCCCTCAGACCCCCACCAGGCAGGATGCTCAGCCCCACCCTCACACCTGCTGTTGAATGGGCC ACCCCGAGTGTGGGTTTCCTGGGCCAGGCCTCAGGAGATGATAGGCCCCAACCATAGCTGCGTCGATGTCCACATGACCCCTCACCCCGA GGAGGCCAGGAGCTCCCAACACACAGGTTGAGGCCAGGATCAGGATCAGGAAGTAACTGAACTCCCTAAAGAGTGAAGCAGAGAAAGGTG CCTGTGAGGGACGGCAAGGGGGGCTTGCAGCGCACAGGGCCAGGCCAGATGTGGGATCCGGGAGGGCACGCCTGCCCGCAGAGGGTGCAG TGGGGAAGGCGCACAGGGTGCACCTCCAGGTGAGTGCTGGGCAGAAGGCACGAGAGCAGCAAGGGAGTGTGACAAGCACCGCCTCACAGT GGCCAAGGCCACAGTCACAGCTGCGGCTGCACACAGGGTGGCCCCCAGGGCACAACACAGCAAGAGCAGGACTTAGCAGCCAGAGCCTCA CACTGCATGCAGCCGGGCCCAGCCTGGCCGGTCGTCTCCTCCTAAAAGCGGGTGTTGATTGGGAAAGAACCATGACCCTGAATATTGGAG TGGGGCCCATGGGCAGATCCAGAGAAGCTGGGACCACACACGCCTGTGTCTGCCCGGATTGCCGGAAGAGCCCCTCTAGCTGAAGGCCCG GGGTGGCCTCCCTTGAGGCAGTTGCCCTGCAAGGCCCTGCCGATGCTCCTTGGGACCCCCACCTGGGCTTCTAGTCCTAGAACTAGACTC GAGTCCAGCAGACCCCCAGGATGAGATACAGAGGGTGACCCTGAGAGTGGCACCAGCCTCCTGCAGGACCACATGGCATTTCCAGGTTTC CAGGCAGAAATCTGAACATGTGTGGGACGGATCGGAAGGGTGTGGGATCCAGGTGGCCGGAGCAGGGGTGGATCAGGGGAGTTCCCGGAA CAGACCTGCCAAACGGAGGGCTGGACTGGGCGCTGCAGCTTGGGGCCAGGAAGGCTCCAGTGCCGGGCTGGGGGTGGGGGCTGGATTACA GCCTGAGGGTGGCTGCACTGAGTGAAGTGGACATGGCCAGCCGCCGTGGGGTACAGCCGAGGAGGGCTTCCAAGGCCTGGGGATGGGGGT GTTGGATTTGTCAGTGAGACCTGTGCACCCACTGCAGGGGGTCCCAAGGCCGTGCCTCCCCAACCCCACTGTGAGGAACATGGTTGCTGG GGGGCCCGGAGTCCTTGAGGAGTCCTGTGACCACACTTCTCTGTTGGTCAGAGGTACCATGGGGACCGTTCCATCAAACGGGAATGTCAG TGCTGGCCGGGAAAGCGGCCCCTGGCCCAAGCTTGGAGACCACCTGGCTCGGGTACTGGCCTGGCTCCGTTGGACAAGGGTGGCCACCAG GTGCCCAGGACCTTTGGAGAGGGGGGCCCTGCTGCTTTTCCTCGAGTGTCCTATAGCCGCCAGGATGCGTAGGGCACTCCGGGAGGTATT TTCATATCACTGAGGTGTCAGGGAGGGGAAGGGTCCTGGGTTTAGGCTGCAGTGACTGCAGGTGCTGAGGGAGCTGTGCCCTGGGTGCTC ATCACAGGCTGTCACAGTGAGGGAAGGTGTCAGGTTCTGACATCCCCATGACAGCGGCAGGGTAGGTGGAGTGGGAATTGGCTTTGCAGT TTCCCTGCATGCCCTTGACAGCCTTGCCAAAGGCACATCTGCCCCGCCTCAGCTCCCACCCTGAGGGTTCTGGGCCTCTACCCCTTCCCC TGTTTATGTCCCTGTCATCTTTGGCATCATCACTGTAGTTACAAAACTCCCTACGTCCCACAGCCACGAGGTGGGTATCCCACATGAGGG CCCAGGTGTGCATGCCAGCATGAGGTTGGCGAGTGGCACTGCCTGCTGATGTCTTACATAGAGGCCATGAAGAGCTGTGGGCAGGGTGTA CAGACCCTGAGTTGGCCCCTGGCCCTCGTGCTTTCAGTCAAAGGCACAAGCAGGGTGGATGGCAGGCGGCTGCCCCCTAGCCTGGCCTTG AGCTCCCTGCCCCAGGCCATGTGGCGTTGAGCAGTGTCCAGGCACATCTTGTTCTGAATCTCAGTGTGCAGGGATGGAGTCGGGACAGCG TGAGTCCTGCATGCCTAACACAGCCCTCACCCCTCCAGTGCACAACGGGGCCACGTGCCCGCATCTGGGTGGCTAGGCAGATAGGGCCCC CCTTGCCAGGCAGATCCAGCTTCTGAGGCCTTATAGACGTCCTGTGGAGGGCAGGCCCAGGACTTTCATTCACCTGGCTGAGCTGCCTGG GAGAGCAGCAGAACCGGTGCTGGGGTCCAAGCCGGCCAAGAGCAGTGCAGCCCTCCTGGTCCTGTTCCTCTCTTGAGCTGCTCCGTGGTG TCCACAGCAGAGCCATGTGGCTCTGGACAGGTCGGCCTTTGTGTCAACAGAACCTGGGTCGTGATGAATCACCATGCGTCTGACCAGCCT TGAAACCCCCACAACAGAAGAAGAAACGGTCTCAGCTCCAGACATCCAGCTTGGAAAAGATGCACCTGAACATTGGCATTCTCTTCCTAG CAAACAGCCACTTCCTGTAGGCTGGCAGGAACGCCAACAGAGCCAGCAGTGAAGGCATTAAGTGGGGAGGAGGGGTGGCCCGGAGGCAGC ACGCGAAGGTCAGCATGCAGCTCCTGGGATGAACCTGAGAGGCGACTCCTGGCAGCATGGCTGGTCGCTGCCATCACGCCCCTGGCCAAC CCACCAACTGGGAGAGGCAGCCCTTCCACATCTTCCTCCATAATGCTCTTGGGTAGCAGTGAGGCCTCTCAAGCCAGAGAGAACTTGGTG TTTGGAAACAACGGCGGACATTTCTTGCCATTTTCAGTGCCAACTCAGGTAGGTGTGTTCTACCATCCTGTGTTTTTGGGGTGTTTTTTT TTTTGAGTCAGAGTCTCACTCTGTCCCCCAGGCTGGAGTGCAATGGAGCAGTCTCGGCTCACTGCAACCTCTGATTCCCAGGTTCAAGCG ATTCTCCTGCCTCAGCCTCCCGAGAAGCTCAGGACCACCCACATAGGTGCAGGCCATCATGCCCAGCTAATTTTTTATTTTTTTTTATAG AGAAGGAGTCTCGCTATGTTGCCCAGGCTGGTTTCGAACTCCTGGGCTCAAGCGATCGATCCTCCCGCCTCTAGCCTCCCAAAGCACTAG AATTATAGGCCTGAGCCACTGCGCCCGGCCCACCATCCTGTTCTTATTGGAAGAATTTCCATGTGTCGAGGCACGGGCACAACGTAGCTG GTCCTCTGCTCAGGGCCCCACAAGGCTGCGTCAGGGTGGCAGCGCGGCTGGGGGCTTTTTCTGTTCAAATCCAGATTCTCGTGGCTGTGA GCCCCAGCCCTGGGCACTGTCCGCCTGGTGGTGTCTTCACAGCCAGCAGGGGTGGCCTTGGGGTGTTCTGTGGAGTAACTTTCACGGCCC AGAGTGGGATCCTGAGTGGCTGGAGCCGTATGCTCCAGCATCCCCAGCCGCTGCCTCCGGTGCAGGTGGAGTGGGCCCCTCTGATTACCA GGAGCTGTCAGAGGGGCAGCAGGTCCCACTCCACTGGCCGGTGGGCAGCTGTGTGCAGGGACGCGGGTCCTGGCACGTCTGCCTGGTGAG GCCCTGCCTCCAGTGCCAAGGGGCCTCCCCTCTCGACGGTGGGCGCCACCATGTGCTGACCTCTGTGCAGCCCCACTTTACAAGGTAGGT TCGGCCAGCACCCCATCCGCGGGCGGGCAGCACTCACCCAGCGTTGCGCCGCCAACAGGGTCCCTCTTAGACAAGCAGCTGTGCCTAGAG CCTTTTCCTTCCTCCCTGCGTGTTACCTGCAGGCCAACAGACGGCCCTGGGTCTGGGACCAGGAGAACCTGCCTCCGCCTCTGGCAGTGG GTGTCCCTGCAGGCAGATTGGGCTTGGCACGTAGACACCGAGGGGTCAGCCGATGCCGGGAGATGATCCCGGGAAGGGCTCCGGAGCACA GCCCAGGACCCGCCGCCGCTGCTGGGCGCTCCATGTTGACGTGCTGTGCGTGTCTCCACTCCCCAGGCAATGATGTTCAATCAGGTGTTT CCCACCTGTGTCTCTGCCAAGAAGCCACAGAACACCCTCTGCACAAAAGGAGTGTTTGCACAAAGAAAAACAACCCTCCGGGGGTTCTTT AGAAATGCTTATACTCAATTAGCTAGAACTTCATGTGAAATCCCAGCGTGGAAGACAACAAGCCGGCACCGGTGAAAACTTTGCTGTGCA CCTGCCCTCTACCAAGCTGCCAGCCCCACCAGCCCTGTGGTCCTAGGTGGGCACAGCTGCTGCACGGTCCCCCAGGCCTGCCTCTCCTCG GGGTCTCAACCTTCATACCAGATTTGCCAGCATCCCCATTCCCGCCTTGTGGGTGGAGAGTCCTTGAGACCCTCTGTCACTCTGTCAGCT TCCCCAGGTCAGCGAGCTGTGGCTTGGCTCCCACGCATCAGCTTTTATGGGAGGCCCATTAGGAGCTGGGCAGGAGGGACAGAGGGGAGG CCAGGCAGCCACTGCTGAGTGGGACGGGTAGCCCAGCCCATGAGGCTGGCCAGCCCTACAGGGGAGGTCCCACAGCACTGGCCGGGAAGT CCACATAGGAAAGCATCAGTTGAGGGATGAAGCCACGGACGATGGGGACAACGGCCACAGGGTGTGCTAAGCTGAGGAAATTAGTAGGAG GTGCTCATAAGCTGTTTTGTTTTTTGGTTTGTTTGTTTGTTTTTTCTTTTAAGAGACCAGGGACAGTGGGGGTCTCACTCTGTCACCCAG GCTGGAGTGCAGTGGCATGATCATAGCTTACTGCAGCCTCCAACTAATAGGCTCAAGTGATCCTCCTGCCTCAGCCTCCCGAGTAACTCA TGGCCTTTAAGTGAACTGCTTCCACCATCCAGCTGTGCAGGTGGCCTGGGAACAGCAGCACATCTGTCCCCTGCCACCTCTTGCATGCAC ACTTGACCTCCTGACTTGGGCTCTGAAACCTGTAAAATGTGGGGTGTAGAGAAATCGAGTCATTTGGCCTCATCCTGGTGCCATTATCTC >11575_11575_10_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000542103_GNB1L_chr22_19789739_ENST00000329517_length(amino acids)=259AA_BP=79 MAGGLRGGLGAPVAQTWRTAAAGSRRAPARPTAPSGSSAAAPGTSYTTTTSTASGRPANSGSATWPAAATGRSAGTPRPRPTAAPAHSFW PAMRMDRWSCGTSLSRRCAAASPAMRSPSWTLTLTPRRPGASQAPRGRRWLSGAWTGSRPCRCVGLMNSPIPGSPRSRSGQIARSWPPQA -------------------------------------------------------------- >11575_11575_11_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000542103_GNB1L_chr22_19789739_ENST00000403325_length(transcript)=1498nt_BP=736nt ATATGTCATGCCCAACCAATCTCAGTTACTTTGCGAGTTCACCTCCATCCTGAGTGGACGCTCAAGCAAGACTGCTGGAGCTGCAGATCT GGGAGGTTCGCTGCACCACCTTGATGCTCAGTATGTACTTTTGAAAATATACCGGATTGTTGAGATTTGAGAAAATCTCATAAAGCTGCT GAAAAGAACTGGCCAGAGCCGTGTGATTTGAGAGGCGGCTGACGTAAGGTAGCTGCGCGGCCCAGGATGCCCGCCTGGCCCGGGGTGAAT GGCGCTGTCGTCGCGGTGGTCGCGTAGGCTTCGCGCCAGGTCTCGCCCCGGATTTACCCTGCGACCCCGGCCCTCCGCGCGCGCCGCAGC CGCCCTCGGTTGCTATTGGTTGCTCGTCCTGTTTGTCGGCGCTTCTCGAAGAAGGGGGCGAAGACGTGATTGAATGTGTCGGTGCTCATT AGTTCTTCTGTCAGTCGATCACGAGGTGCCGTTTTCTTCATTTTTCATTGGCTGGCGGACTGAGGGGCGGGCTTGGCGCGCCGGTCGCCC AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGTCATGGACCTTGACTTTGACTCCCAGAAGGCCAGGGGCATCTCAGGCTC CGCGGGGAAGGCGCTGGCTGTCTGGAGCCTGGACTGGCAGCAGGCCCTGCAGGTGCGTGGGACTCATGAACTCACCAATCCCGGGATCGC CGAGGTCACGATCCGGCCAGATCGCAAGATCCTGGCCACCGCAGGCTGGGACCACCGCATCCGCGTGTTCCACTGGCGGACGATGCAGCC ACTGGCCGTGCTGGCCTTCCACAGCGCCGCTGTCCAGTGCGTGGCCTTCACCGCCGATGGCTTGCTGGCCGCGGGCTCCAAGGATCAGCG GATCAGCCTCTGGTCACTCTACCCACGCGCATGACTCACCCACTCCCTTCCCGGGAGACGAGGAGGGCGGGCAGGGAGGTGGGCATCAGG CCCCAGCCTTGGCCTGAAACCTCAAGGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCTGTCTTCATGAGGTT GGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGCCTGCAGGAGACGTT >11575_11575_11_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000542103_GNB1L_chr22_19789739_ENST00000403325_length(amino acids)=259AA_BP=79 MAGGLRGGLGAPVAQTWRTAAAGSRRAPARPTAPSGSSAAAPGTSYTTTTSTASGRPANSGSATWPAAATGRSAGTPRPRPTAAPAHSFW PAMRMDRWSCGTSLSRRCAAASPAMRSPSWTLTLTPRRPGASQAPRGRRWLSGAWTGSRPCRCVGLMNSPIPGSPRSRSGQIARSWPPQA -------------------------------------------------------------- >11575_11575_12_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000542103_GNB1L_chr22_19789739_ENST00000405009_length(transcript)=1059nt_BP=736nt ATATGTCATGCCCAACCAATCTCAGTTACTTTGCGAGTTCACCTCCATCCTGAGTGGACGCTCAAGCAAGACTGCTGGAGCTGCAGATCT GGGAGGTTCGCTGCACCACCTTGATGCTCAGTATGTACTTTTGAAAATATACCGGATTGTTGAGATTTGAGAAAATCTCATAAAGCTGCT GAAAAGAACTGGCCAGAGCCGTGTGATTTGAGAGGCGGCTGACGTAAGGTAGCTGCGCGGCCCAGGATGCCCGCCTGGCCCGGGGTGAAT GGCGCTGTCGTCGCGGTGGTCGCGTAGGCTTCGCGCCAGGTCTCGCCCCGGATTTACCCTGCGACCCCGGCCCTCCGCGCGCGCCGCAGC CGCCCTCGGTTGCTATTGGTTGCTCGTCCTGTTTGTCGGCGCTTCTCGAAGAAGGGGGCGAAGACGTGATTGAATGTGTCGGTGCTCATT AGTTCTTCTGTCAGTCGATCACGAGGTGCCGTTTTCTTCATTTTTCATTGGCTGGCGGACTGAGGGGCGGGCTTGGCGCGCCGGTCGCCC AGACATGGCGGACGGCAGCGGCTGGCAGCCGCCGCGCCCCTGCGAGGCCTACCGCGCCGAGTGGAAGCTCTGCCGCAGCGCCAGGCACTT CCTACACCACTACTACGTCCACGGCGAGCGGCCGGCCTGCGAACAGTGGCAGCGCGACCTGGCCAGCTGCCGCGACTGGGAGGAGCGCCG GAACGCCGAGGCCCAGGCCGACTGCAGCTCCCGCCCACTCCTTCTGGCCGGCTATGAGGATGGATCGGTGGTCCTGTGGGACGTCTCTGA GCAGAAGGTGTGCAGCCGCATCGCCTGCCATGAGGAGCCCGGCCTCTGAGGACCAGCAAGTCATGGCCCAAGGACCATGGAGTCCCCGCT GTCTTCATGAGGTTGGTATTTCCTTTTGTGGAGTGCCTCATCACAGGACGGTGACTCTGGGGGCCAGCCAGAGCCCTGGCCGTCCGAGGC >11575_11575_12_C22orf39-GNB1L_C22orf39_chr22_19434901_ENST00000542103_GNB1L_chr22_19789739_ENST00000405009_length(amino acids)=187AA_BP=79 MAGGLRGGLGAPVAQTWRTAAAGSRRAPARPTAPSGSSAAAPGTSYTTTTSTASGRPANSGSATWPAAATGRSAGTPRPRPTAAPAHSFW PAMRMDRWSCGTSLSRRCAAASPAMRSPASEDQQVMAQGPWSPRCLHEVGISFCGVPHHRTVTLGASQSPGRPRPAGDVGLGLLCCQLRV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for C22orf39-GNB1L |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for C22orf39-GNB1L |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for C22orf39-GNB1L |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies