
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:C4B-DLK1 (FusionGDB2 ID:11766) |
Fusion Gene Summary for C4B-DLK1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: C4B-DLK1 | Fusion gene ID: 11766 | Hgene | Tgene | Gene symbol | C4B | DLK1 | Gene ID | 721 | 8788 |
| Gene name | complement C4B (Chido blood group) | delta like non-canonical Notch ligand 1 | |
| Synonyms | C4B1|C4B12|C4B2|C4B3|C4B5|C4BD|C4B_2|C4F|CH|CO4|CPAMD3 | DLK|DLK-1|Delta1|FA1|PREF1|Pref-1|ZOG|pG2 | |
| Cytomap | 6p21.33 | 14q32.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | complement C4-BC3 and PZP-like alpha-2-macroglobulin domain-containing protein 3Chido form of C4basic complement C4complement C4B1acomplement component 4B (Chido blood group) | protein delta homolog 1delta-like 1 homologfetal antigen 1preadipocyte factor 1secredeltin | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | P0C0L5 | P80370 | |
| Ensembl transtripts involved in fusion gene | ENST00000435363, ENST00000375177, ENST00000411583, ENST00000425700, ENST00000445788, ENST00000449788, ENST00000485543, ENST00000487226, ENST00000488817, ENST00000494210, ENST00000546399, ENST00000548301, ENST00000548530, ENST00000550398, | ENST00000556051, ENST00000331224, ENST00000341267, | |
| Fusion gene scores | * DoF score | 9 X 7 X 6=378 | 11 X 12 X 3=396 |
| # samples | 8 | 10 | |
| ** MAII score | log2(8/378*10)=-2.24031432933371 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/396*10)=-1.98550043030488 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: C4B [Title/Abstract] AND DLK1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | C4B(31999910)-DLK1(101200985), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | C4B | GO:0032490 | detection of molecule of bacterial origin | 22333221 |
| Tgene | DLK1 | GO:0045746 | negative regulation of Notch signaling pathway | 25093684 |
| Fusion gene breakpoints across C4B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across DLK1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ACC | TCGA-OR-A5JT-01A | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
Top |
Fusion Gene ORF analysis for C4B-DLK1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000435363 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| In-frame | ENST00000435363 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| In-frame | ENST00000435363 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000375177 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000375177 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000411583 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000411583 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000425700 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000425700 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000445788 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000445788 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000449788 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000449788 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000485543 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000485543 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000487226 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000487226 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000488817 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000488817 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000494210 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000494210 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000546399 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000546399 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000548301 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000548301 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000548530 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000548530 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000550398 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-3CDS | ENST00000550398 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000375177 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000411583 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000425700 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000445788 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000449788 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000485543 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000487226 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000488817 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000494210 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000546399 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000548301 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000548530 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| intron-intron | ENST00000550398 | ENST00000556051 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000435363 | C4B | chr6 | 31999910 | + | ENST00000341267 | DLK1 | chr14 | 101200985 | + | 5147 | 4593 | 69 | 4802 | 1577 |
| ENST00000435363 | C4B | chr6 | 31999910 | + | ENST00000331224 | DLK1 | chr14 | 101200985 | + | 5073 | 4593 | 69 | 4841 | 1590 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000435363 | ENST00000341267 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + | 0.002240185 | 0.9977598 |
| ENST00000435363 | ENST00000331224 | C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200985 | + | 0.001989123 | 0.99801093 |
Top |
Fusion Genomic Features for C4B-DLK1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200984 | + | 0.037115768 | 0.96288425 |
| C4B | chr6 | 31999910 | + | DLK1 | chr14 | 101200984 | + | 0.037115768 | 0.96288425 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
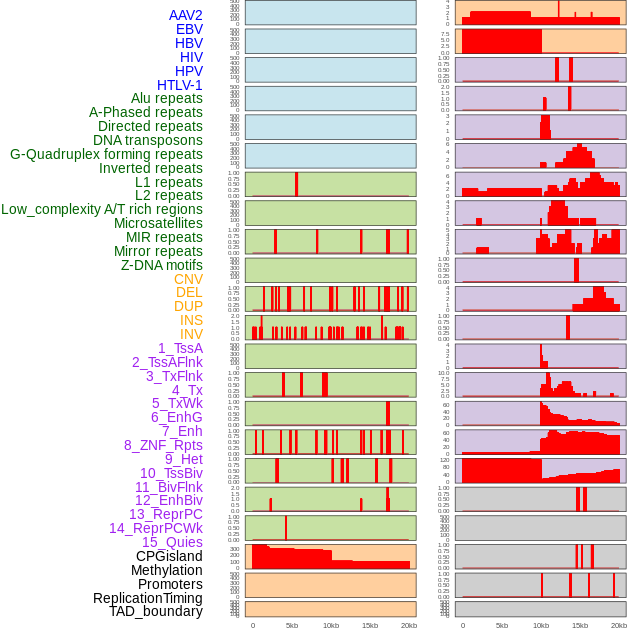 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
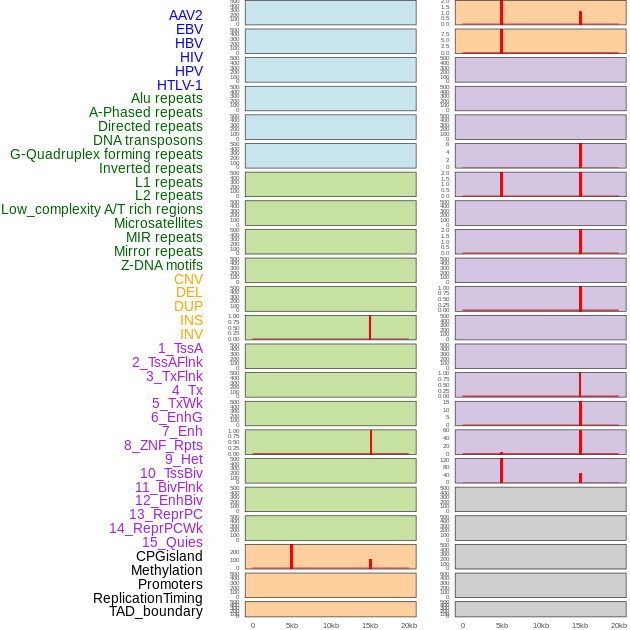 |
Top |
Fusion Protein Features for C4B-DLK1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr6:31999910/chr14:101200985) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| C4B | DLK1 |
| FUNCTION: Non-enzymatic component of the C3 and C5 convertases and thus essential for the propagation of the classical complement pathway. Covalently binds to immunoglobulins and immune complexes and enhances the solubilization of immune aggregates and the clearance of IC through CR1 on erythrocytes. C4A isotype is responsible for effective binding to form amide bonds with immune aggregates or protein antigens, while C4B isotype catalyzes the transacylation of the thioester carbonyl group to form ester bonds with carbohydrate antigens.; FUNCTION: Derived from proteolytic degradation of complement C4, C4a anaphylatoxin is a mediator of local inflammatory process. It induces the contraction of smooth muscle, increases vascular permeability and causes histamine release from mast cells and basophilic leukocytes. | FUNCTION: May have a role in neuroendocrine differentiation. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | C4B | chr6:31999910 | chr14:101200985 | ENST00000435363 | + | 34 | 41 | 702_736 | 1503 | 1745.0 | Domain | Anaphylatoxin-like |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 127_168 | 0 | 384.0 | Domain | EGF-like 4 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 170_206 | 0 | 384.0 | Domain | EGF-like 5 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 208_245 | 0 | 384.0 | Domain | EGF-like 6 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 24_55 | 0 | 384.0 | Domain | EGF-like 1 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 53_86 | 0 | 384.0 | Domain | EGF-like 2 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 88_125 | 0 | 384.0 | Domain | EGF-like 3 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 328_383 | 228 | 311.0 | Topological domain | Cytoplasmic | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 24_303 | 0 | 384.0 | Topological domain | Extracellular | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 328_383 | 0 | 384.0 | Topological domain | Cytoplasmic | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 304_327 | 228 | 311.0 | Transmembrane | Helical | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000341267 | 0 | 5 | 304_327 | 0 | 384.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | C4B | chr6:31999910 | chr14:101200985 | ENST00000375177 | + | 1 | 41 | 1595_1742 | 0 | 1745.0 | Domain | NTR |
| Hgene | C4B | chr6:31999910 | chr14:101200985 | ENST00000375177 | + | 1 | 41 | 702_736 | 0 | 1745.0 | Domain | Anaphylatoxin-like |
| Hgene | C4B | chr6:31999910 | chr14:101200985 | ENST00000411583 | + | 1 | 41 | 1595_1742 | 0 | 1745.0 | Domain | NTR |
| Hgene | C4B | chr6:31999910 | chr14:101200985 | ENST00000411583 | + | 1 | 41 | 702_736 | 0 | 1745.0 | Domain | Anaphylatoxin-like |
| Hgene | C4B | chr6:31999910 | chr14:101200985 | ENST00000435363 | + | 34 | 41 | 1595_1742 | 1503 | 1745.0 | Domain | NTR |
| Hgene | C4B | chr6:31999910 | chr14:101200985 | ENST00000449788 | + | 1 | 41 | 1595_1742 | 0 | 1745.0 | Domain | NTR |
| Hgene | C4B | chr6:31999910 | chr14:101200985 | ENST00000449788 | + | 1 | 41 | 702_736 | 0 | 1745.0 | Domain | Anaphylatoxin-like |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 127_168 | 228 | 311.0 | Domain | EGF-like 4 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 170_206 | 228 | 311.0 | Domain | EGF-like 5 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 208_245 | 228 | 311.0 | Domain | EGF-like 6 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 24_55 | 228 | 311.0 | Domain | EGF-like 1 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 53_86 | 228 | 311.0 | Domain | EGF-like 2 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 88_125 | 228 | 311.0 | Domain | EGF-like 3 | |
| Tgene | DLK1 | chr6:31999910 | chr14:101200985 | ENST00000331224 | 4 | 6 | 24_303 | 228 | 311.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for C4B-DLK1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >11766_11766_1_C4B-DLK1_C4B_chr6_31999910_ENST00000435363_DLK1_chr14_101200985_ENST00000331224_length(transcript)=5073nt_BP=4593nt AGAGTCAACTCTGCCCCGAGGCCTAGCTTGGCCAGAAGGTAGCAGACAGACAGACGGATCTAACCTCTCTTGGATCCTCCAGCCATGAGG CTGCTCTGGGGGCTGATCTGGGCATCCAGCTTCTTCACCTTATCTCTGCAGAAGCCCAGGTTGCTCTTGTTCTCTCCTTCTGTGGTTCAT CTGGGGGTCCCCCTATCGGTGGGGGTGCAGCTCCAGGATGTGCCCCGAGGACAGGTAGTGAAAGGATCAGTGTTCCTGAGAAACCCATCT CGTAATAATGTCCCCTGCTCCCCAAAGGTGGACTTCACCCTTAGCTCAGAAAGAGACTTCGCACTCCTCAGTCTCCAGGTGCCCTTGAAA GATGCGAAGAGCTGTGGCCTCCATCAACTCCTCAGAGGCCCTGAGGTCCAGCTGGTGGCCCATTCGCCATGGCTAAAGGACTCTCTGTCC AGAACGACAAACATCCAGGGTATCAACCTGCTCTTCTCCTCTCGCCGGGGGCACCTCTTTTTGCAGACGGACCAGCCCATTTACAACCCT GGCCAGCGGGTTCGGTACCGGGTCTTTGCTCTGGATCAGAAGATGCGCCCGAGCACTGACACCATCACAGTCATGGTGGAGAACTCTCAC GGCCTCCGCGTGCGGAAGAAGGAGGTGTACATGCCCTCGTCCATCTTCCAGGATGACTTTGTGATCCCAGACATCTCAGAGCCAGGGACC TGGAAGATCTCAGCCCGATTCTCAGATGGCCTGGAATCCAACAGCAGCACCCAGTTTGAGGTGAAGAAATATGTCCTTCCCAACTTTGAG GTGAAGATCACCCCTGGAAAGCCCTACATCCTGACGGTGCCAGGCCATCTTGATGAAATGCAGTTAGACATCCAGGCCAGGTACATCTAT GGGAAGCCAGTGCAGGGGGTGGCATATGTGCGCTTTGGGCTCCTAGATGAGGATGGTAAGAAGACTTTCTTTCGGGGGCTGGAGAGTCAG ACCAAGCTGGTGAATGGACAGAGCCACATTTCCCTCTCAAAGGCAGAGTTCCAGGACGCCCTGGAGAAGCTGAATATGGGCATTACTGAC CTCCAGGGGCTGCGCCTCTACGTTGCTGCAGCCATCATTGAGTCTCCAGGTGGGGAGATGGAGGAGGCAGAGCTCACATCCTGGTATTTT GTGTCATCTCCCTTCTCCTTGGATCTTAGCAAGACCAAGCGACACCTTGTGCCTGGGGCCCCCTTCCTGCTGCAGGCCTTGGTCCGTGAG ATGTCAGGCTCCCCAGCTTCTGGCATTCCTGTCAAAGTTTCTGCCACGGTGTCTTCTCCTGGGTCTGTTCCTGAAGTCCAGGACATTCAG CAAAACACAGACGGGAGCGGCCAAGTCAGCATTCCAATAATTATCCCTCAGACCATCTCAGAGCTGCAGCTCTCAGTATCTGCAGGCTCC CCACATCCAGCGATAGCCAGGCTCACTGTGGCAGCCCCACCTTCAGGAGGCCCCGGGTTTCTGTCTATTGAGCGGCCGGATTCTCGACCT CCTCGTGTTGGGGACACTCTGAACCTGAACTTGCGAGCCGTGGGCAGTGGGGCCACCTTTTCTCATTACTACTACATGATCCTATCCCGA GGGCAGATCGTGTTCATGAATCGAGAGCCCAAGAGGACCCTGACCTCGGTCTCGGTGTTTGTGGACCATCACCTGGCACCCTCCTTCTAC TTTGTGGCCTTCTACTACCATGGAGACCACCCAGTGGCCAACTCCCTGCGAGTGGATGTCCAGGCTGGGGCCTGCGAGGGCAAGCTGGAG CTCAGCGTGGACGGTGCCAAGCAGTACCGGAACGGGGAGTCCGTGAAGCTCCACTTAGAAACCGACTCCCTAGCCCTGGTGGCGCTGGGA GCCTTGGACACAGCTCTGTATGCTGCAGGCAGCAAGTCCCACAAGCCCCTCAACATGGGCAAGGTCTTTGAAGCTATGAACAGCTATGAC CTCGGCTGTGGTCCTGGGGGTGGGGACAGTGCCCTTCAGGTGTTCCAGGCAGCGGGCCTGGCCTTTTCTGATGGAGACCAGTGGACCTTA TCCAGAAAGAGACTAAGCTGTCCCAAGGAGAAGACAACCCGGAAAAAGAGAAACGTGAACTTCCAAAAGGCGATTAATGAGAAATTGGGT CAGTATGCTTCCCCGACAGCCAAGCGCTGCTGCCAGGATGGGGTGACACGTCTGCCCATGATGCGTTCCTGCGAGCAGCGGGCAGCCCGC GTGCAGCAGCCGGACTGCCGGGAGCCCTTCCTGTCCTGCTGCCAATTTGCTGAGAGTCTGCGCAAGAAGAGCAGGGACAAGGGCCAGGCG GGCCTCCAACGAGCCCTGGAGATCCTGCAGGAGGAGGACCTGATTGATGAGGATGACATTCCCGTGCGCAGCTTCTTCCCAGAGAACTGG CTCTGGAGAGTGGAAACAGTGGACCGCTTTCAAATATTGACACTGTGGCTCCCCGACTCTCTGACCACGTGGGAGATCCATGGCCTGAGC CTGTCCAAAACCAAAGGCCTATGTGTGGCCACCCCAGTCCAGCTCCGGGTGTTCCGCGAGTTCCACCTGCACCTCCGCCTGCCCATGTCT GTCCGCCGCTTTGAGCAGCTGGAGCTGCGGCCTGTCCTCTATAACTACCTGGATAAAAACCTGACTGTGAGCGTCCACGTGTCCCCAGTG GAGGGGCTGTGCCTGGCTGGGGGCGGAGGGCTGGCCCAGCAGGTGCTGGTGCCTGCGGGCTCTGCCCGGCCTGTTGCCTTCTCTGTGGTG CCCACGGCAGCCACCGCTGTGTCTCTGAAGGTGGTGGCTCGAGGGTCCTTCGAATTCCCTGTGGGAGATGCGGTGTCCAAGGTTCTGCAG ATTGAGAAGGAAGGGGCCATCCATAGAGAGGAGCTGGTCTATGAACTCAACCCCTTGGACCACCGAGGCCGGACCTTGGAAATACCTGGC AACTCTGATCCCAATATGATCCCTGATGGGGACTTTAACAGCTACGTCAGGGTTACAGCCTCAGATCCATTGGACACTTTAGGCTCTGAG GGGGCCTTGTCACCAGGAGGCGTGGCCTCCCTCTTGAGGCTTCCTCGAGGCTGTGGGGAGCAAACCATGATCTACTTGGCTCCGACACTG GCTGCTTCCCGCTACCTGGACAAGACAGAGCAGTGGAGCACACTGCCTCCCGAGACCAAGGACCACGCCGTGGATCTGATCCAGAAAGGC TACATGCGGATCCAGCAGTTTCGGAAGGCGGATGGTTCCTATGCGGCTTGGTTGTCACGGGGCAGCAGCACCTGGCTCACAGCCTTTGTG TTGAAGGTCCTGAGTTTGGCCCAGGAGCAGGTAGGAGGCTCGCCTGAGAAACTGCAGGAGACATCTAACTGGCTTCTGTCCCAGCAGCAG GCTGACGGCTCGTTCCAGGACCTCTCTCCAGTGATACATAGGAGCATGCAGGGGGGTTTGGTGGGCAATGATGAGACTGTGGCACTCACA GCCTTTGTGACCATCGCCCTTCATCATGGGCTGGCCGTCTTCCAGGATGAGGGTGCAGAGCCATTGAAGCAGAGAGTGGAAGCCTCCATC TCAAAGGCAAGCTCATTTTTGGGGGAGAAAGCAAGTGCTGGGCTCCTGGGTGCCCACGCAGCTGCCATCACGGCCTATGCCCTGACACTG ACCAAGGCCCCTGCGGACCTGCGGGGTGTTGCCCACAACAACCTCATGGCAATGGCCCAGGAGACTGGAGATAACCTGTACTGGGGCTCA GTCACTGGTTCTCAGAGCAATGCCGTGTCGCCCACCCCGGCTCCTCGCAACCCATCCGACCCCATGCCCCAGGCCCCAGCCCTGTGGATT GAAACCACAGCCTACGCCCTGCTGCACCTCCTGCTTCACGAGGGCAAAGCAGAGATGGCAGACCAGGCTGCGGCCTGGCTCACCCGTCAG GGCAGCTTCCAAGGGGGATTCCGCAGTACCCAAGACACGGTGATTGCCCTGGATGCCCTGTCTGCCTACTGGATTGCCTCCCACACCACT GAGGAGAGGGGTCTCAATGTGACTCTCAGCTCCACAGGCCGGAATGGGTTCAAGTCCCACGCGCTGCAGCTGAACAACCGCCAGATTCGC GGCCTGGAGGAGGAGCTGCAGTTTTCCTTGGGCAGCAAGATCAATGTGAAGGTGGGAGGAAACAGCAAAGGAACCCTGAAGGTCCTTCGT ACCTACAATGTCCTGGACATGAAGAACACGACCTGCCAGGACCTACAGATAGAAGTGACAGTCAAAGGCCACGTCGAGTACACGATGGAA GCAAACGAGGACTATGAGGACTATGAGTACGATGAGCTTCCAGCCAAGGATGACCCAGATGCCCCTCTGCAGCCCGTGACACCCCTGCAG CTGTTTGAGGGTCGGAGGAACCGCCGCAGGAGGGAGGCGCCCAAGGTGGTGGAGGAGCAGGAGTCCAGGGTGCACTACACCGTGTGCATC TGGCGGAACGGCAAGGTGGGGCTGTCTGGCATGGCCATCGCGGACGTCACCCTCCTGAGTGGATTCCACGCCCTGCGTGCTGACCTGGAG AAGGGCCAGGCCATCTGCTTCACCATCCTGGGCGTGCTCACCAGCCTGGTGGTGCTGGGCACTGTGGGTATCGTCTTCCTCAACAAGTGC GAGACCTGGGTGTCCAACCTGCGCTACAACCACATGCTGCGGAAGAAGAAGAACCTGCTGCTTCAGTACAACAGCGGGGAGGACCTGGCC GTCAACATCATCTTCCCCGAGAAGATCGACATGACCACCTTCAGCAAGGAGGCCGGCGACGAGGAGATCTAAGCAGCGTTCCCACAGCCC CCTCTAGATTCTTGGAGTTCCGCAGAGCTTACTATACGCGGTCTGTCCTAATCTTTGTGGTGTTCGCTATCTCTTGTGTCAAATCTGGTG AACGCTACGCTTACATATATTGTCTTTGTGCTGCTGTGTGACAAACGCAATGCAAAAACAATCCTCTTTCTCTCTCTTAATGCATGATAC >11766_11766_1_C4B-DLK1_C4B_chr6_31999910_ENST00000435363_DLK1_chr14_101200985_ENST00000331224_length(amino acids)=1590AA_BP=1508 MDPPAMRLLWGLIWASSFFTLSLQKPRLLLFSPSVVHLGVPLSVGVQLQDVPRGQVVKGSVFLRNPSRNNVPCSPKVDFTLSSERDFALL SLQVPLKDAKSCGLHQLLRGPEVQLVAHSPWLKDSLSRTTNIQGINLLFSSRRGHLFLQTDQPIYNPGQRVRYRVFALDQKMRPSTDTIT VMVENSHGLRVRKKEVYMPSSIFQDDFVIPDISEPGTWKISARFSDGLESNSSTQFEVKKYVLPNFEVKITPGKPYILTVPGHLDEMQLD IQARYIYGKPVQGVAYVRFGLLDEDGKKTFFRGLESQTKLVNGQSHISLSKAEFQDALEKLNMGITDLQGLRLYVAAAIIESPGGEMEEA ELTSWYFVSSPFSLDLSKTKRHLVPGAPFLLQALVREMSGSPASGIPVKVSATVSSPGSVPEVQDIQQNTDGSGQVSIPIIIPQTISELQ LSVSAGSPHPAIARLTVAAPPSGGPGFLSIERPDSRPPRVGDTLNLNLRAVGSGATFSHYYYMILSRGQIVFMNREPKRTLTSVSVFVDH HLAPSFYFVAFYYHGDHPVANSLRVDVQAGACEGKLELSVDGAKQYRNGESVKLHLETDSLALVALGALDTALYAAGSKSHKPLNMGKVF EAMNSYDLGCGPGGGDSALQVFQAAGLAFSDGDQWTLSRKRLSCPKEKTTRKKRNVNFQKAINEKLGQYASPTAKRCCQDGVTRLPMMRS CEQRAARVQQPDCREPFLSCCQFAESLRKKSRDKGQAGLQRALEILQEEDLIDEDDIPVRSFFPENWLWRVETVDRFQILTLWLPDSLTT WEIHGLSLSKTKGLCVATPVQLRVFREFHLHLRLPMSVRRFEQLELRPVLYNYLDKNLTVSVHVSPVEGLCLAGGGGLAQQVLVPAGSAR PVAFSVVPTAATAVSLKVVARGSFEFPVGDAVSKVLQIEKEGAIHREELVYELNPLDHRGRTLEIPGNSDPNMIPDGDFNSYVRVTASDP LDTLGSEGALSPGGVASLLRLPRGCGEQTMIYLAPTLAASRYLDKTEQWSTLPPETKDHAVDLIQKGYMRIQQFRKADGSYAAWLSRGSS TWLTAFVLKVLSLAQEQVGGSPEKLQETSNWLLSQQQADGSFQDLSPVIHRSMQGGLVGNDETVALTAFVTIALHHGLAVFQDEGAEPLK QRVEASISKASSFLGEKASAGLLGAHAAAITAYALTLTKAPADLRGVAHNNLMAMAQETGDNLYWGSVTGSQSNAVSPTPAPRNPSDPMP QAPALWIETTAYALLHLLLHEGKAEMADQAAAWLTRQGSFQGGFRSTQDTVIALDALSAYWIASHTTEERGLNVTLSSTGRNGFKSHALQ LNNRQIRGLEEELQFSLGSKINVKVGGNSKGTLKVLRTYNVLDMKNTTCQDLQIEVTVKGHVEYTMEANEDYEDYEYDELPAKDDPDAPL QPVTPLQLFEGRRNRRRREAPKVVEEQESRVHYTVCIWRNGKVGLSGMAIADVTLLSGFHALRADLEKGQAICFTILGVLTSLVVLGTVG -------------------------------------------------------------- >11766_11766_2_C4B-DLK1_C4B_chr6_31999910_ENST00000435363_DLK1_chr14_101200985_ENST00000341267_length(transcript)=5147nt_BP=4593nt AGAGTCAACTCTGCCCCGAGGCCTAGCTTGGCCAGAAGGTAGCAGACAGACAGACGGATCTAACCTCTCTTGGATCCTCCAGCCATGAGG CTGCTCTGGGGGCTGATCTGGGCATCCAGCTTCTTCACCTTATCTCTGCAGAAGCCCAGGTTGCTCTTGTTCTCTCCTTCTGTGGTTCAT CTGGGGGTCCCCCTATCGGTGGGGGTGCAGCTCCAGGATGTGCCCCGAGGACAGGTAGTGAAAGGATCAGTGTTCCTGAGAAACCCATCT CGTAATAATGTCCCCTGCTCCCCAAAGGTGGACTTCACCCTTAGCTCAGAAAGAGACTTCGCACTCCTCAGTCTCCAGGTGCCCTTGAAA GATGCGAAGAGCTGTGGCCTCCATCAACTCCTCAGAGGCCCTGAGGTCCAGCTGGTGGCCCATTCGCCATGGCTAAAGGACTCTCTGTCC AGAACGACAAACATCCAGGGTATCAACCTGCTCTTCTCCTCTCGCCGGGGGCACCTCTTTTTGCAGACGGACCAGCCCATTTACAACCCT GGCCAGCGGGTTCGGTACCGGGTCTTTGCTCTGGATCAGAAGATGCGCCCGAGCACTGACACCATCACAGTCATGGTGGAGAACTCTCAC GGCCTCCGCGTGCGGAAGAAGGAGGTGTACATGCCCTCGTCCATCTTCCAGGATGACTTTGTGATCCCAGACATCTCAGAGCCAGGGACC TGGAAGATCTCAGCCCGATTCTCAGATGGCCTGGAATCCAACAGCAGCACCCAGTTTGAGGTGAAGAAATATGTCCTTCCCAACTTTGAG GTGAAGATCACCCCTGGAAAGCCCTACATCCTGACGGTGCCAGGCCATCTTGATGAAATGCAGTTAGACATCCAGGCCAGGTACATCTAT GGGAAGCCAGTGCAGGGGGTGGCATATGTGCGCTTTGGGCTCCTAGATGAGGATGGTAAGAAGACTTTCTTTCGGGGGCTGGAGAGTCAG ACCAAGCTGGTGAATGGACAGAGCCACATTTCCCTCTCAAAGGCAGAGTTCCAGGACGCCCTGGAGAAGCTGAATATGGGCATTACTGAC CTCCAGGGGCTGCGCCTCTACGTTGCTGCAGCCATCATTGAGTCTCCAGGTGGGGAGATGGAGGAGGCAGAGCTCACATCCTGGTATTTT GTGTCATCTCCCTTCTCCTTGGATCTTAGCAAGACCAAGCGACACCTTGTGCCTGGGGCCCCCTTCCTGCTGCAGGCCTTGGTCCGTGAG ATGTCAGGCTCCCCAGCTTCTGGCATTCCTGTCAAAGTTTCTGCCACGGTGTCTTCTCCTGGGTCTGTTCCTGAAGTCCAGGACATTCAG CAAAACACAGACGGGAGCGGCCAAGTCAGCATTCCAATAATTATCCCTCAGACCATCTCAGAGCTGCAGCTCTCAGTATCTGCAGGCTCC CCACATCCAGCGATAGCCAGGCTCACTGTGGCAGCCCCACCTTCAGGAGGCCCCGGGTTTCTGTCTATTGAGCGGCCGGATTCTCGACCT CCTCGTGTTGGGGACACTCTGAACCTGAACTTGCGAGCCGTGGGCAGTGGGGCCACCTTTTCTCATTACTACTACATGATCCTATCCCGA GGGCAGATCGTGTTCATGAATCGAGAGCCCAAGAGGACCCTGACCTCGGTCTCGGTGTTTGTGGACCATCACCTGGCACCCTCCTTCTAC TTTGTGGCCTTCTACTACCATGGAGACCACCCAGTGGCCAACTCCCTGCGAGTGGATGTCCAGGCTGGGGCCTGCGAGGGCAAGCTGGAG CTCAGCGTGGACGGTGCCAAGCAGTACCGGAACGGGGAGTCCGTGAAGCTCCACTTAGAAACCGACTCCCTAGCCCTGGTGGCGCTGGGA GCCTTGGACACAGCTCTGTATGCTGCAGGCAGCAAGTCCCACAAGCCCCTCAACATGGGCAAGGTCTTTGAAGCTATGAACAGCTATGAC CTCGGCTGTGGTCCTGGGGGTGGGGACAGTGCCCTTCAGGTGTTCCAGGCAGCGGGCCTGGCCTTTTCTGATGGAGACCAGTGGACCTTA TCCAGAAAGAGACTAAGCTGTCCCAAGGAGAAGACAACCCGGAAAAAGAGAAACGTGAACTTCCAAAAGGCGATTAATGAGAAATTGGGT CAGTATGCTTCCCCGACAGCCAAGCGCTGCTGCCAGGATGGGGTGACACGTCTGCCCATGATGCGTTCCTGCGAGCAGCGGGCAGCCCGC GTGCAGCAGCCGGACTGCCGGGAGCCCTTCCTGTCCTGCTGCCAATTTGCTGAGAGTCTGCGCAAGAAGAGCAGGGACAAGGGCCAGGCG GGCCTCCAACGAGCCCTGGAGATCCTGCAGGAGGAGGACCTGATTGATGAGGATGACATTCCCGTGCGCAGCTTCTTCCCAGAGAACTGG CTCTGGAGAGTGGAAACAGTGGACCGCTTTCAAATATTGACACTGTGGCTCCCCGACTCTCTGACCACGTGGGAGATCCATGGCCTGAGC CTGTCCAAAACCAAAGGCCTATGTGTGGCCACCCCAGTCCAGCTCCGGGTGTTCCGCGAGTTCCACCTGCACCTCCGCCTGCCCATGTCT GTCCGCCGCTTTGAGCAGCTGGAGCTGCGGCCTGTCCTCTATAACTACCTGGATAAAAACCTGACTGTGAGCGTCCACGTGTCCCCAGTG GAGGGGCTGTGCCTGGCTGGGGGCGGAGGGCTGGCCCAGCAGGTGCTGGTGCCTGCGGGCTCTGCCCGGCCTGTTGCCTTCTCTGTGGTG CCCACGGCAGCCACCGCTGTGTCTCTGAAGGTGGTGGCTCGAGGGTCCTTCGAATTCCCTGTGGGAGATGCGGTGTCCAAGGTTCTGCAG ATTGAGAAGGAAGGGGCCATCCATAGAGAGGAGCTGGTCTATGAACTCAACCCCTTGGACCACCGAGGCCGGACCTTGGAAATACCTGGC AACTCTGATCCCAATATGATCCCTGATGGGGACTTTAACAGCTACGTCAGGGTTACAGCCTCAGATCCATTGGACACTTTAGGCTCTGAG GGGGCCTTGTCACCAGGAGGCGTGGCCTCCCTCTTGAGGCTTCCTCGAGGCTGTGGGGAGCAAACCATGATCTACTTGGCTCCGACACTG GCTGCTTCCCGCTACCTGGACAAGACAGAGCAGTGGAGCACACTGCCTCCCGAGACCAAGGACCACGCCGTGGATCTGATCCAGAAAGGC TACATGCGGATCCAGCAGTTTCGGAAGGCGGATGGTTCCTATGCGGCTTGGTTGTCACGGGGCAGCAGCACCTGGCTCACAGCCTTTGTG TTGAAGGTCCTGAGTTTGGCCCAGGAGCAGGTAGGAGGCTCGCCTGAGAAACTGCAGGAGACATCTAACTGGCTTCTGTCCCAGCAGCAG GCTGACGGCTCGTTCCAGGACCTCTCTCCAGTGATACATAGGAGCATGCAGGGGGGTTTGGTGGGCAATGATGAGACTGTGGCACTCACA GCCTTTGTGACCATCGCCCTTCATCATGGGCTGGCCGTCTTCCAGGATGAGGGTGCAGAGCCATTGAAGCAGAGAGTGGAAGCCTCCATC TCAAAGGCAAGCTCATTTTTGGGGGAGAAAGCAAGTGCTGGGCTCCTGGGTGCCCACGCAGCTGCCATCACGGCCTATGCCCTGACACTG ACCAAGGCCCCTGCGGACCTGCGGGGTGTTGCCCACAACAACCTCATGGCAATGGCCCAGGAGACTGGAGATAACCTGTACTGGGGCTCA GTCACTGGTTCTCAGAGCAATGCCGTGTCGCCCACCCCGGCTCCTCGCAACCCATCCGACCCCATGCCCCAGGCCCCAGCCCTGTGGATT GAAACCACAGCCTACGCCCTGCTGCACCTCCTGCTTCACGAGGGCAAAGCAGAGATGGCAGACCAGGCTGCGGCCTGGCTCACCCGTCAG GGCAGCTTCCAAGGGGGATTCCGCAGTACCCAAGACACGGTGATTGCCCTGGATGCCCTGTCTGCCTACTGGATTGCCTCCCACACCACT GAGGAGAGGGGTCTCAATGTGACTCTCAGCTCCACAGGCCGGAATGGGTTCAAGTCCCACGCGCTGCAGCTGAACAACCGCCAGATTCGC GGCCTGGAGGAGGAGCTGCAGTTTTCCTTGGGCAGCAAGATCAATGTGAAGGTGGGAGGAAACAGCAAAGGAACCCTGAAGGTCCTTCGT ACCTACAATGTCCTGGACATGAAGAACACGACCTGCCAGGACCTACAGATAGAAGTGACAGTCAAAGGCCACGTCGAGTACACGATGGAA GCAAACGAGGACTATGAGGACTATGAGTACGATGAGCTTCCAGCCAAGGATGACCCAGATGCCCCTCTGCAGCCCGTGACACCCCTGCAG CTGTTTGAGGGTCGGAGGAACCGCCGCAGGAGGGAGGCGCCCAAGGTGGTGGAGGAGCAGGAGTCCAGGGTGCACTACACCGTGTGCATC TGGCGGAACGGCAAGGTGGGGCTGTCTGGCATGGCCATCGCGGACGTCACCCTCCTGAGTGGATTCCACGCCCTGCGTGCTGACCTGGAG AAGGCCAGGCCATCTGCTTCACCATCCTGGGCGTGCTCACCAGCCTGGTGGTGCTGGGCACTGTGGGTATCGTCTTCCTCAACAAGTGCG AGACCTGGGTGTCCAACCTGCGCTACAACCACATGCTGCGGAAGAAGAAGAACCTGCTGCTTCAGTACAACAGCGGGGAGGACCTGGCCG TCAACATCATCTTCCCCGAGAAGATCGACATGACCACCTTCAGCAAGGAGGCCGGCGACGAGGAGATCTAAGCAGCGTTCCCACAGCCCC CTCTAGATTCTTGGAGTTCCGCAGAGCTTACTATACGCGGTCTGTCCTAATCTTTGTGGTGTTCGCTATCTCTTGTGTCAAATCTGGTGA ACGCTACGCTTACATATATTGTCTTTGTGCTGCTGTGTGACAAACGCAATGCAAAAACAATCCTCTTTCTCTCTCTTAATGCATGATACA GAATAATAATAAGAATTTCATCTTTAAATGAGTAAGAGAAATAAGTATGTTATTCTAAAATCTAAACTCAAATGAAATTTCAAAAAAGAC >11766_11766_2_C4B-DLK1_C4B_chr6_31999910_ENST00000435363_DLK1_chr14_101200985_ENST00000341267_length(amino acids)=1577AA_BP=1508 MDPPAMRLLWGLIWASSFFTLSLQKPRLLLFSPSVVHLGVPLSVGVQLQDVPRGQVVKGSVFLRNPSRNNVPCSPKVDFTLSSERDFALL SLQVPLKDAKSCGLHQLLRGPEVQLVAHSPWLKDSLSRTTNIQGINLLFSSRRGHLFLQTDQPIYNPGQRVRYRVFALDQKMRPSTDTIT VMVENSHGLRVRKKEVYMPSSIFQDDFVIPDISEPGTWKISARFSDGLESNSSTQFEVKKYVLPNFEVKITPGKPYILTVPGHLDEMQLD IQARYIYGKPVQGVAYVRFGLLDEDGKKTFFRGLESQTKLVNGQSHISLSKAEFQDALEKLNMGITDLQGLRLYVAAAIIESPGGEMEEA ELTSWYFVSSPFSLDLSKTKRHLVPGAPFLLQALVREMSGSPASGIPVKVSATVSSPGSVPEVQDIQQNTDGSGQVSIPIIIPQTISELQ LSVSAGSPHPAIARLTVAAPPSGGPGFLSIERPDSRPPRVGDTLNLNLRAVGSGATFSHYYYMILSRGQIVFMNREPKRTLTSVSVFVDH HLAPSFYFVAFYYHGDHPVANSLRVDVQAGACEGKLELSVDGAKQYRNGESVKLHLETDSLALVALGALDTALYAAGSKSHKPLNMGKVF EAMNSYDLGCGPGGGDSALQVFQAAGLAFSDGDQWTLSRKRLSCPKEKTTRKKRNVNFQKAINEKLGQYASPTAKRCCQDGVTRLPMMRS CEQRAARVQQPDCREPFLSCCQFAESLRKKSRDKGQAGLQRALEILQEEDLIDEDDIPVRSFFPENWLWRVETVDRFQILTLWLPDSLTT WEIHGLSLSKTKGLCVATPVQLRVFREFHLHLRLPMSVRRFEQLELRPVLYNYLDKNLTVSVHVSPVEGLCLAGGGGLAQQVLVPAGSAR PVAFSVVPTAATAVSLKVVARGSFEFPVGDAVSKVLQIEKEGAIHREELVYELNPLDHRGRTLEIPGNSDPNMIPDGDFNSYVRVTASDP LDTLGSEGALSPGGVASLLRLPRGCGEQTMIYLAPTLAASRYLDKTEQWSTLPPETKDHAVDLIQKGYMRIQQFRKADGSYAAWLSRGSS TWLTAFVLKVLSLAQEQVGGSPEKLQETSNWLLSQQQADGSFQDLSPVIHRSMQGGLVGNDETVALTAFVTIALHHGLAVFQDEGAEPLK QRVEASISKASSFLGEKASAGLLGAHAAAITAYALTLTKAPADLRGVAHNNLMAMAQETGDNLYWGSVTGSQSNAVSPTPAPRNPSDPMP QAPALWIETTAYALLHLLLHEGKAEMADQAAAWLTRQGSFQGGFRSTQDTVIALDALSAYWIASHTTEERGLNVTLSSTGRNGFKSHALQ LNNRQIRGLEEELQFSLGSKINVKVGGNSKGTLKVLRTYNVLDMKNTTCQDLQIEVTVKGHVEYTMEANEDYEDYEYDELPAKDDPDAPL QPVTPLQLFEGRRNRRRREAPKVVEEQESRVHYTVCIWRNGKVGLSGMAIADVTLLSGFHALRADLEKARPSASPSWACSPAWWCWALWV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for C4B-DLK1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for C4B-DLK1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for C4B-DLK1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies