
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CAB39L-CPQ (FusionGDB2 ID:12213) |
Fusion Gene Summary for CAB39L-CPQ |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CAB39L-CPQ | Fusion gene ID: 12213 | Hgene | Tgene | Gene symbol | CAB39L | CPQ | Gene ID | 81617 | 10404 |
| Gene name | calcium binding protein 39 like | carboxypeptidase Q | |
| Synonyms | MO25-BETA|MO2L|bA103J18.3 | LDP|PGCP | |
| Cytomap | 13q14.2 | 8q22.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | calcium-binding protein 39-likeMO25betaU937-associated antigenantigen MLAA-34mo25-like proteinsarcoma antigen NY-SAR-79 | carboxypeptidase QSer-Met dipeptidaseaminopeptidaseblood plasma glutamate carboxypeptidaselysosomal dipeptidase | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q9Y646 | |
| Ensembl transtripts involved in fusion gene | ENST00000347776, ENST00000355854, ENST00000409130, ENST00000409308, ENST00000410043, ENST00000476943, | ENST00000529551, ENST00000220763, | |
| Fusion gene scores | * DoF score | 9 X 10 X 6=540 | 16 X 14 X 11=2464 |
| # samples | 10 | 19 | |
| ** MAII score | log2(10/540*10)=-2.43295940727611 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(19/2464*10)=-3.69693093236395 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CAB39L [Title/Abstract] AND CPQ [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CAB39L(49924880)-CPQ(97847201), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | CAB39L-CPQ seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CPQ | GO:0006508 | proteolysis | 10206990 |
| Tgene | CPQ | GO:0043171 | peptide catabolic process | 10206990 |
| Fusion gene breakpoints across CAB39L (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
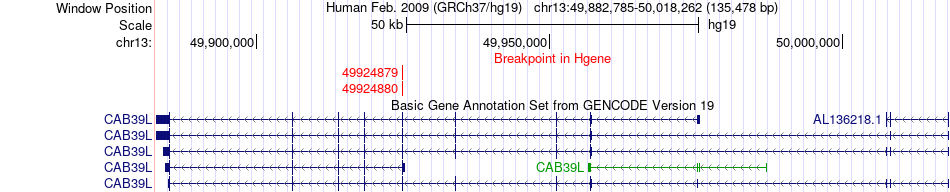 |
| Fusion gene breakpoints across CPQ (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-DK-A2I6-01A | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| ChimerDB4 | BLCA | TCGA-DK-A2I6 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
Top |
Fusion Gene ORF analysis for CAB39L-CPQ |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000347776 | ENST00000529551 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| 5CDS-intron | ENST00000347776 | ENST00000529551 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| 5CDS-intron | ENST00000355854 | ENST00000529551 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| 5CDS-intron | ENST00000355854 | ENST00000529551 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| 5CDS-intron | ENST00000409130 | ENST00000529551 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| 5CDS-intron | ENST00000409130 | ENST00000529551 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| 5CDS-intron | ENST00000409308 | ENST00000529551 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| 5CDS-intron | ENST00000409308 | ENST00000529551 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| 5CDS-intron | ENST00000410043 | ENST00000529551 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| 5CDS-intron | ENST00000410043 | ENST00000529551 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| Frame-shift | ENST00000409130 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| Frame-shift | ENST00000409130 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| In-frame | ENST00000347776 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| In-frame | ENST00000347776 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| In-frame | ENST00000355854 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| In-frame | ENST00000355854 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| In-frame | ENST00000409308 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| In-frame | ENST00000409308 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| In-frame | ENST00000410043 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| In-frame | ENST00000410043 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| intron-3CDS | ENST00000476943 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| intron-3CDS | ENST00000476943 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| intron-intron | ENST00000476943 | ENST00000529551 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + |
| intron-intron | ENST00000476943 | ENST00000529551 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000355854 | CAB39L | chr13 | 49924880 | - | ENST00000220763 | CPQ | chr8 | 97847201 | + | 2366 | 1062 | 1079 | 2047 | 322 |
| ENST00000347776 | CAB39L | chr13 | 49924880 | - | ENST00000220763 | CPQ | chr8 | 97847201 | + | 2213 | 909 | 926 | 1894 | 322 |
| ENST00000409308 | CAB39L | chr13 | 49924880 | - | ENST00000220763 | CPQ | chr8 | 97847201 | + | 2254 | 950 | 967 | 1935 | 322 |
| ENST00000410043 | CAB39L | chr13 | 49924880 | - | ENST00000220763 | CPQ | chr8 | 97847201 | + | 2319 | 1015 | 1032 | 2000 | 322 |
| ENST00000355854 | CAB39L | chr13 | 49924879 | - | ENST00000220763 | CPQ | chr8 | 97847200 | + | 2366 | 1062 | 1079 | 2047 | 322 |
| ENST00000347776 | CAB39L | chr13 | 49924879 | - | ENST00000220763 | CPQ | chr8 | 97847200 | + | 2213 | 909 | 926 | 1894 | 322 |
| ENST00000409308 | CAB39L | chr13 | 49924879 | - | ENST00000220763 | CPQ | chr8 | 97847200 | + | 2254 | 950 | 967 | 1935 | 322 |
| ENST00000410043 | CAB39L | chr13 | 49924879 | - | ENST00000220763 | CPQ | chr8 | 97847200 | + | 2319 | 1015 | 1032 | 2000 | 322 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000355854 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + | 0.003168237 | 0.9968317 |
| ENST00000347776 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + | 0.007157985 | 0.9928421 |
| ENST00000409308 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + | 0.002303175 | 0.9976968 |
| ENST00000410043 | ENST00000220763 | CAB39L | chr13 | 49924880 | - | CPQ | chr8 | 97847201 | + | 0.002278158 | 0.99772185 |
| ENST00000355854 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + | 0.003168237 | 0.9968317 |
| ENST00000347776 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + | 0.007157985 | 0.9928421 |
| ENST00000409308 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + | 0.002303175 | 0.9976968 |
| ENST00000410043 | ENST00000220763 | CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + | 0.002278158 | 0.99772185 |
Top |
Fusion Genomic Features for CAB39L-CPQ |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + | 2.52E-05 | 0.99997485 |
| CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + | 2.52E-05 | 0.99997485 |
| CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + | 2.52E-05 | 0.99997485 |
| CAB39L | chr13 | 49924879 | - | CPQ | chr8 | 97847200 | + | 2.52E-05 | 0.99997485 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
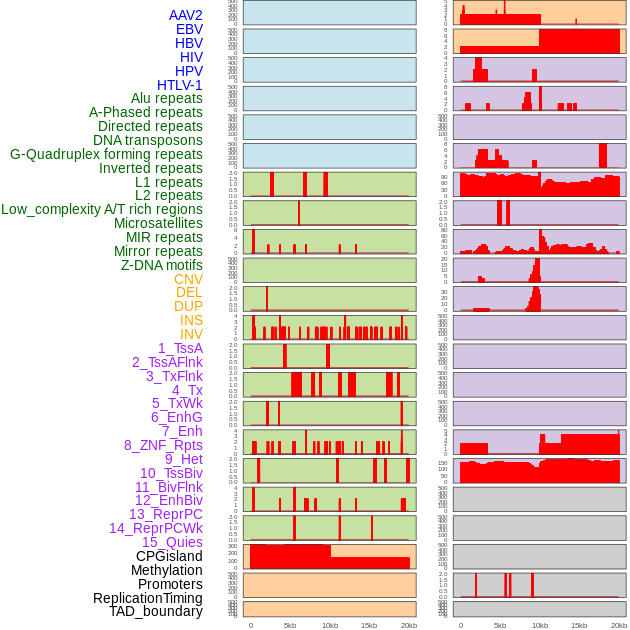 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
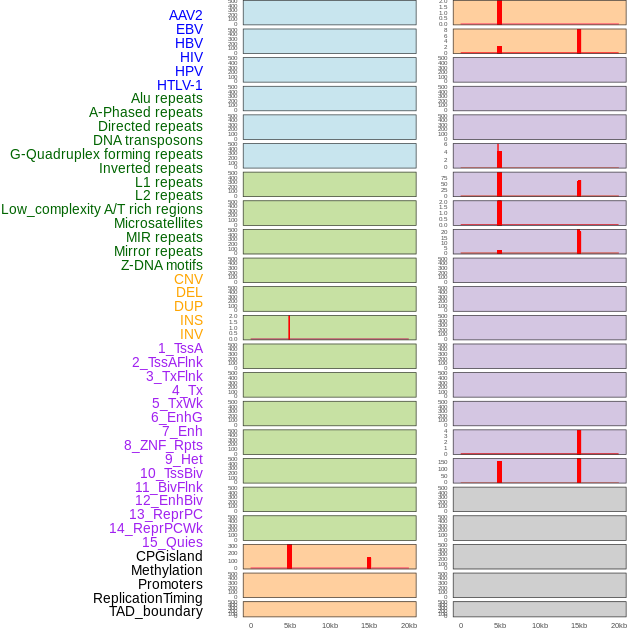 |
Top |
Fusion Protein Features for CAB39L-CPQ |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr13:49924880/chr8:97847201) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CPQ |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Carboxypeptidase that may play an important role in the hydrolysis of circulating peptides. Catalyzes the hydrolysis of dipeptides with unsubstituted terminals into amino acids. May play a role in the liberation of thyroxine hormone from its thyroglobulin (Tg) precursor. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for CAB39L-CPQ |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >12213_12213_1_CAB39L-CPQ_CAB39L_chr13_49924879_ENST00000347776_CPQ_chr8_97847200_ENST00000220763_length(transcript)=2213nt_BP=909nt AGCGCTCTCGGCTTGTCTCGCGCACTGTAGCTGAGCCAATGGAGTTACTCGTAGTCGAGAGGCCGGCATCACTGGAGTGGTGGCGCAGCT GTTTCCTCCGGATATCCATCAAATATTGAGAAGAAAGAATATCAGGAGCAAAGTGTTCTAAGTTGCTGTTCAGAACGTAAAGATGCGAAC CCCAAATCAGTGGTTTGTTCATTCTTCATGCAAGAGCAATGCACTAAAGGAGAGAAGCGTAAGTTTTCTCTTATTTCTGATGGGGAAACA AGCACACGCATACACACTCTTGTGATGGAGATAGATTTTACAAGCATTCCATATTGGAAGAAGAGATTTCTACACATGAAAAAAATGCCT TTGTTTAGTAAATCACACAAAAATCCAGCAGAAATTGTGAAAATCCTGAAAGACAATTTGGCCATTTTGGAAAAGCAAGACAAAAAGACA GACAAGGCTTCAGAAGAAGTGTCTAAATCACTGCAAGCAATGAAAGAAATTCTGTGTGGTACAAACGAGAAAGAACCCCCAACAGAAGCA GTGGCTCAGCTAGCACAAGAACTCTACAGCAGTGGCCTGCTAGTGACACTGATAGCTGACCTGCAGCTGATAGACTTTGAGGGAAAAAAA GATGTGACCCAGATATTTAACAACATCTTGAGAAGACAGATAGGCACTCGGAGTCCTACTGTGGAGTATATTAGTGCTCATCCTCATATC CTGTTTATGCTCCTCAAAGGATATGAAGCCCCACAGATTGCCTTACGTTGTGGGATTATGCTGAGAGAATGTATTCGACATGAACCACTT GCCAAAATCATCCTCTTTTCTAATCAATTCAGAGATTTCTTTAAGTACGTGGAGTTGTCAACATTTGATATTGCTTCAGATGCCTTTGCT ACTTTCAAGGCATTACAGCAGAAGTTCTGGTGGTGACCTCTTTCGATGAACTGCAGAGAAGGGCCTCAGAAGCAAGAGGGAAGATTGTTG TTTATAACCAACCTTACATCAACTACTCAAGGACGGTGCAATACCGAACGCAGGGGGCGGTGGAAGCTGCCAAGGTGGGGGCTTTGGCAT CTCTCATTCGATCCGTGGCCTCCTTCTCCATCTACAGTCCTCACACAGGTATTCAGGAATACCAGGATGGCGTGCCCAAGATTCCAACAG CCTGTATTACGGTGGAAGATGCAGAAATGATGTCAAGAATGGCTTCTCATGGGATCAAAATTGTCATTCAGCTAAAGATGGGGGCAAAGA CCTACCCAGATACTGATTCCTTCAACACTGTAGCAGAGATCACTGGGAGCAAATATCCAGAACAGGTTGTACTGGTCAGTGGACATCTGG ACAGCTGGGATGTTGGGCAGGGTGCCATGGATGATGGCGGTGGAGCCTTTATATCATGGGAAGCACTCTCACTTATTAAAGATCTTGGGC TGCGTCCAAAGAGGACTCTGCGGCTGGTGCTCTGGACTGCAGAAGAACAAGGTGGAGTTGGTGCCTTCCAGTATTATCAGTTACACAAGG TAAATATTTCCAACTACAGTCTGGTGATGGAGTCTGACGCAGGAACCTTCTTACCCACTGGGCTGCAATTCACTGGCAGTGAAAAGGCCA GGGCCATCATGGAGGAGGTTATGAGCCTGCTGCAGCCCCTCAATATCACTCAGGTCCTGAGCCATGGAGAAGGGACAGACATCAACTTTT GGATCCAAGCTGGAGTGCCTGGAGCCAGTCTACTTGATGACTTATACAAGTATTTCTTCTTCCATCACTCCCACGGAGACACCATGACTG TCATGGATCCAAAGCAGATGAATGTTGCTGCTGCTGTTTGGGCTGTTGTTTCTTATGTTGTTGCAGACATGGAAGAAATGCTGCCTAGGT CCTAGAAACAGTAAGAAAGAAACGTTTTCATGCTTCTGGCCAGGAATCCTGGGTCTGCAACTTTGGAAAACTCCTCTTCACATAACAATT TCATCCAATTCATCTTCAAAGCACAACTCTATTTCATGCTTTCTGTTATTATCTTTCTTGATACTTTCCAAATTCTCTGATTCTAGAAAA AGGAATCATTCTCCCCTCCCTCCCACCACATAGAATCAACATATGGTAGGGATTACAGTGGGGGCATTTCTTTATATCACCTCTTAAAAA >12213_12213_1_CAB39L-CPQ_CAB39L_chr13_49924879_ENST00000347776_CPQ_chr8_97847200_ENST00000220763_length(amino acids)=322AA_BP= MVVTSFDELQRRASEARGKIVVYNQPYINYSRTVQYRTQGAVEAAKVGALASLIRSVASFSIYSPHTGIQEYQDGVPKIPTACITVEDAE MMSRMASHGIKIVIQLKMGAKTYPDTDSFNTVAEITGSKYPEQVVLVSGHLDSWDVGQGAMDDGGGAFISWEALSLIKDLGLRPKRTLRL VLWTAEEQGGVGAFQYYQLHKVNISNYSLVMESDAGTFLPTGLQFTGSEKARAIMEEVMSLLQPLNITQVLSHGEGTDINFWIQAGVPGA -------------------------------------------------------------- >12213_12213_2_CAB39L-CPQ_CAB39L_chr13_49924879_ENST00000355854_CPQ_chr8_97847200_ENST00000220763_length(transcript)=2366nt_BP=1062nt GTGACGTTACAGGACTGAGGAGGGAGGAAGTAAAAGGGAGCTGTGACTGTGGTACGTATCTGAAAGCAAGTGTTAGAGAGGGAGTGGAGA ACGCATAAGCAAGCTGGTTTGACCAGAAACAGAACTGCCTGTGACAGATTAAGAGACAAGCAAGGCTTGGAATCTGAGAGCAAGCAAAGA GAGTGGAAATTTACAGCTGCCCTATGTGAGTGTTCAAGTGATCATTTTCTGGTAACGTTTTCCAGTGGTAACTGTTACTCTTCAAAAAGA GGGACAGAAAGTCAAGACCTAATTGTGGAAACTCTTTTCTCTGCCACGCTTGGTAATAGGAGGCAACCTCTATTAAATGGACGATAAAGG CTACTTCATCTAAAGTGCTTTGAGCTCAAGAAAGAGCTGTCTTCAGCACCTCACCATGTGTCTACATTTTGTTGCTTAGAAAAGCCTAGG CATTTCTGTAACATTTGCATTCCATATTGGAAGAAGAGATTTCTACACATGAAAAAAATGCCTTTGTTTAGTAAATCACACAAAAATCCA GCAGAAATTGTGAAAATCCTGAAAGACAATTTGGCCATTTTGGAAAAGCAAGACAAAAAGACAGACAAGGCTTCAGAAGAAGTGTCTAAA TCACTGCAAGCAATGAAAGAAATTCTGTGTGGTACAAACGAGAAAGAACCCCCAACAGAAGCAGTGGCTCAGCTAGCACAAGAACTCTAC AGCAGTGGCCTGCTAGTGACACTGATAGCTGACCTGCAGCTGATAGACTTTGAGGGAAAAAAAGATGTGACCCAGATATTTAACAACATC TTGAGAAGACAGATAGGCACTCGGAGTCCTACTGTGGAGTATATTAGTGCTCATCCTCATATCCTGTTTATGCTCCTCAAAGGATATGAA GCCCCACAGATTGCCTTACGTTGTGGGATTATGCTGAGAGAATGTATTCGACATGAACCACTTGCCAAAATCATCCTCTTTTCTAATCAA TTCAGAGATTTCTTTAAGTACGTGGAGTTGTCAACATTTGATATTGCTTCAGATGCCTTTGCTACTTTCAAGGCATTACAGCAGAAGTTC TGGTGGTGACCTCTTTCGATGAACTGCAGAGAAGGGCCTCAGAAGCAAGAGGGAAGATTGTTGTTTATAACCAACCTTACATCAACTACT CAAGGACGGTGCAATACCGAACGCAGGGGGCGGTGGAAGCTGCCAAGGTGGGGGCTTTGGCATCTCTCATTCGATCCGTGGCCTCCTTCT CCATCTACAGTCCTCACACAGGTATTCAGGAATACCAGGATGGCGTGCCCAAGATTCCAACAGCCTGTATTACGGTGGAAGATGCAGAAA TGATGTCAAGAATGGCTTCTCATGGGATCAAAATTGTCATTCAGCTAAAGATGGGGGCAAAGACCTACCCAGATACTGATTCCTTCAACA CTGTAGCAGAGATCACTGGGAGCAAATATCCAGAACAGGTTGTACTGGTCAGTGGACATCTGGACAGCTGGGATGTTGGGCAGGGTGCCA TGGATGATGGCGGTGGAGCCTTTATATCATGGGAAGCACTCTCACTTATTAAAGATCTTGGGCTGCGTCCAAAGAGGACTCTGCGGCTGG TGCTCTGGACTGCAGAAGAACAAGGTGGAGTTGGTGCCTTCCAGTATTATCAGTTACACAAGGTAAATATTTCCAACTACAGTCTGGTGA TGGAGTCTGACGCAGGAACCTTCTTACCCACTGGGCTGCAATTCACTGGCAGTGAAAAGGCCAGGGCCATCATGGAGGAGGTTATGAGCC TGCTGCAGCCCCTCAATATCACTCAGGTCCTGAGCCATGGAGAAGGGACAGACATCAACTTTTGGATCCAAGCTGGAGTGCCTGGAGCCA GTCTACTTGATGACTTATACAAGTATTTCTTCTTCCATCACTCCCACGGAGACACCATGACTGTCATGGATCCAAAGCAGATGAATGTTG CTGCTGCTGTTTGGGCTGTTGTTTCTTATGTTGTTGCAGACATGGAAGAAATGCTGCCTAGGTCCTAGAAACAGTAAGAAAGAAACGTTT TCATGCTTCTGGCCAGGAATCCTGGGTCTGCAACTTTGGAAAACTCCTCTTCACATAACAATTTCATCCAATTCATCTTCAAAGCACAAC TCTATTTCATGCTTTCTGTTATTATCTTTCTTGATACTTTCCAAATTCTCTGATTCTAGAAAAAGGAATCATTCTCCCCTCCCTCCCACC ACATAGAATCAACATATGGTAGGGATTACAGTGGGGGCATTTCTTTATATCACCTCTTAAAAACATTGTTTCCACTTTAAAAGTAAACAC >12213_12213_2_CAB39L-CPQ_CAB39L_chr13_49924879_ENST00000355854_CPQ_chr8_97847200_ENST00000220763_length(amino acids)=322AA_BP= MVVTSFDELQRRASEARGKIVVYNQPYINYSRTVQYRTQGAVEAAKVGALASLIRSVASFSIYSPHTGIQEYQDGVPKIPTACITVEDAE MMSRMASHGIKIVIQLKMGAKTYPDTDSFNTVAEITGSKYPEQVVLVSGHLDSWDVGQGAMDDGGGAFISWEALSLIKDLGLRPKRTLRL VLWTAEEQGGVGAFQYYQLHKVNISNYSLVMESDAGTFLPTGLQFTGSEKARAIMEEVMSLLQPLNITQVLSHGEGTDINFWIQAGVPGA -------------------------------------------------------------- >12213_12213_3_CAB39L-CPQ_CAB39L_chr13_49924879_ENST00000409308_CPQ_chr8_97847200_ENST00000220763_length(transcript)=2254nt_BP=950nt CCGCAGTGGCGCCCGAGCGCGCCGCCTCCCGATTGACTGCTAGCGCTCTCGGCTTGTCTCGCGCACTGTAGCTGAGCCAATGGAGTTACT CGTAGTCGAGAGGCCGGCATCACTGGAGTGGTGGCGCAGCTGTTTCCTCCGGATATCCATCAAATATTGAGAAGAAAGAATATCAGGAGC AAAGTGTTCTAAGTTGCTGTTCAGAACGTAAAGATGCGAACCCCAAATCAGTGGTTTGTTCATTCTTCATGCAAGAGCAATGCACTAAAG GAGAGAAGCAAGCTGTGGTGATCAGTGACTTTGGTGAAAGCTAAGAAGGTTCAAACAAATTTGCAAATGATATACAACTTCTAAGCATTC CATATTGGAAGAAGAGATTTCTACACATGAAAAAAATGCCTTTGTTTAGTAAATCACACAAAAATCCAGCAGAAATTGTGAAAATCCTGA AAGACAATTTGGCCATTTTGGAAAAGCAAGACAAAAAGACAGACAAGGCTTCAGAAGAAGTGTCTAAATCACTGCAAGCAATGAAAGAAA TTCTGTGTGGTACAAACGAGAAAGAACCCCCAACAGAAGCAGTGGCTCAGCTAGCACAAGAACTCTACAGCAGTGGCCTGCTAGTGACAC TGATAGCTGACCTGCAGCTGATAGACTTTGAGGGAAAAAAAGATGTGACCCAGATATTTAACAACATCTTGAGAAGACAGATAGGCACTC GGAGTCCTACTGTGGAGTATATTAGTGCTCATCCTCATATCCTGTTTATGCTCCTCAAAGGATATGAAGCCCCACAGATTGCCTTACGTT GTGGGATTATGCTGAGAGAATGTATTCGACATGAACCACTTGCCAAAATCATCCTCTTTTCTAATCAATTCAGAGATTTCTTTAAGTACG TGGAGTTGTCAACATTTGATATTGCTTCAGATGCCTTTGCTACTTTCAAGGCATTACAGCAGAAGTTCTGGTGGTGACCTCTTTCGATGA ACTGCAGAGAAGGGCCTCAGAAGCAAGAGGGAAGATTGTTGTTTATAACCAACCTTACATCAACTACTCAAGGACGGTGCAATACCGAAC GCAGGGGGCGGTGGAAGCTGCCAAGGTGGGGGCTTTGGCATCTCTCATTCGATCCGTGGCCTCCTTCTCCATCTACAGTCCTCACACAGG TATTCAGGAATACCAGGATGGCGTGCCCAAGATTCCAACAGCCTGTATTACGGTGGAAGATGCAGAAATGATGTCAAGAATGGCTTCTCA TGGGATCAAAATTGTCATTCAGCTAAAGATGGGGGCAAAGACCTACCCAGATACTGATTCCTTCAACACTGTAGCAGAGATCACTGGGAG CAAATATCCAGAACAGGTTGTACTGGTCAGTGGACATCTGGACAGCTGGGATGTTGGGCAGGGTGCCATGGATGATGGCGGTGGAGCCTT TATATCATGGGAAGCACTCTCACTTATTAAAGATCTTGGGCTGCGTCCAAAGAGGACTCTGCGGCTGGTGCTCTGGACTGCAGAAGAACA AGGTGGAGTTGGTGCCTTCCAGTATTATCAGTTACACAAGGTAAATATTTCCAACTACAGTCTGGTGATGGAGTCTGACGCAGGAACCTT CTTACCCACTGGGCTGCAATTCACTGGCAGTGAAAAGGCCAGGGCCATCATGGAGGAGGTTATGAGCCTGCTGCAGCCCCTCAATATCAC TCAGGTCCTGAGCCATGGAGAAGGGACAGACATCAACTTTTGGATCCAAGCTGGAGTGCCTGGAGCCAGTCTACTTGATGACTTATACAA GTATTTCTTCTTCCATCACTCCCACGGAGACACCATGACTGTCATGGATCCAAAGCAGATGAATGTTGCTGCTGCTGTTTGGGCTGTTGT TTCTTATGTTGTTGCAGACATGGAAGAAATGCTGCCTAGGTCCTAGAAACAGTAAGAAAGAAACGTTTTCATGCTTCTGGCCAGGAATCC TGGGTCTGCAACTTTGGAAAACTCCTCTTCACATAACAATTTCATCCAATTCATCTTCAAAGCACAACTCTATTTCATGCTTTCTGTTAT TATCTTTCTTGATACTTTCCAAATTCTCTGATTCTAGAAAAAGGAATCATTCTCCCCTCCCTCCCACCACATAGAATCAACATATGGTAG GGATTACAGTGGGGGCATTTCTTTATATCACCTCTTAAAAACATTGTTTCCACTTTAAAAGTAAACACTTAATAAATTTTTGGAAGATCT >12213_12213_3_CAB39L-CPQ_CAB39L_chr13_49924879_ENST00000409308_CPQ_chr8_97847200_ENST00000220763_length(amino acids)=322AA_BP= MVVTSFDELQRRASEARGKIVVYNQPYINYSRTVQYRTQGAVEAAKVGALASLIRSVASFSIYSPHTGIQEYQDGVPKIPTACITVEDAE MMSRMASHGIKIVIQLKMGAKTYPDTDSFNTVAEITGSKYPEQVVLVSGHLDSWDVGQGAMDDGGGAFISWEALSLIKDLGLRPKRTLRL VLWTAEEQGGVGAFQYYQLHKVNISNYSLVMESDAGTFLPTGLQFTGSEKARAIMEEVMSLLQPLNITQVLSHGEGTDINFWIQAGVPGA -------------------------------------------------------------- >12213_12213_4_CAB39L-CPQ_CAB39L_chr13_49924879_ENST00000410043_CPQ_chr8_97847200_ENST00000220763_length(transcript)=2319nt_BP=1015nt GAGCCAATGGAGTTACTCGTAGTCGAGAGGCCGGCATCACTGGAGTGGTGGCGCAGCTGTTTCCTCCGGATATCCATCAAATATTGAGAA GAAAGAATATCAGGAGCAAAGTGTTCTAAGTTGCTGTTCAGAACGTAAAGATGCGAACCCCAAATCAGTGGTTTGTTCATTCTTCATGCA AGAGCAATGCACTAAAGGAGAGAAGCAAGCTGTGGTGATCAGTGACTTTGGTGAAAGCTAAGAAGGTTCAAACAAATTTGCAAATGATAT ACAACTTCTAAGGAGGCAACCTCTATTAAATGGACGATAAAGGCTACTTCATCTAAAGTGCTTTGAGCTCAAGAAAGAGCTGTCTTCAGC ACCTCACCATGTGTCTACATTTTGTTGCTTAGAAAAGCCTAGGCATTTCTGTAACATTTGCATTCCATATTGGAAGAAGAGATTTCTACA CATGAAAAAAATGCCTTTGTTTAGTAAATCACACAAAAATCCAGCAGAAATTGTGAAAATCCTGAAAGACAATTTGGCCATTTTGGAAAA GCAAGACAAAAAGACAGACAAGGCTTCAGAAGAAGTGTCTAAATCACTGCAAGCAATGAAAGAAATTCTGTGTGGTACAAACGAGAAAGA ACCCCCAACAGAAGCAGTGGCTCAGCTAGCACAAGAACTCTACAGCAGTGGCCTGCTAGTGACACTGATAGCTGACCTGCAGCTGATAGA CTTTGAGGGAAAAAAAGATGTGACCCAGATATTTAACAACATCTTGAGAAGACAGATAGGCACTCGGAGTCCTACTGTGGAGTATATTAG TGCTCATCCTCATATCCTGTTTATGCTCCTCAAAGGATATGAAGCCCCACAGATTGCCTTACGTTGTGGGATTATGCTGAGAGAATGTAT TCGACATGAACCACTTGCCAAAATCATCCTCTTTTCTAATCAATTCAGAGATTTCTTTAAGTACGTGGAGTTGTCAACATTTGATATTGC TTCAGATGCCTTTGCTACTTTCAAGGCATTACAGCAGAAGTTCTGGTGGTGACCTCTTTCGATGAACTGCAGAGAAGGGCCTCAGAAGCA AGAGGGAAGATTGTTGTTTATAACCAACCTTACATCAACTACTCAAGGACGGTGCAATACCGAACGCAGGGGGCGGTGGAAGCTGCCAAG GTGGGGGCTTTGGCATCTCTCATTCGATCCGTGGCCTCCTTCTCCATCTACAGTCCTCACACAGGTATTCAGGAATACCAGGATGGCGTG CCCAAGATTCCAACAGCCTGTATTACGGTGGAAGATGCAGAAATGATGTCAAGAATGGCTTCTCATGGGATCAAAATTGTCATTCAGCTA AAGATGGGGGCAAAGACCTACCCAGATACTGATTCCTTCAACACTGTAGCAGAGATCACTGGGAGCAAATATCCAGAACAGGTTGTACTG GTCAGTGGACATCTGGACAGCTGGGATGTTGGGCAGGGTGCCATGGATGATGGCGGTGGAGCCTTTATATCATGGGAAGCACTCTCACTT ATTAAAGATCTTGGGCTGCGTCCAAAGAGGACTCTGCGGCTGGTGCTCTGGACTGCAGAAGAACAAGGTGGAGTTGGTGCCTTCCAGTAT TATCAGTTACACAAGGTAAATATTTCCAACTACAGTCTGGTGATGGAGTCTGACGCAGGAACCTTCTTACCCACTGGGCTGCAATTCACT GGCAGTGAAAAGGCCAGGGCCATCATGGAGGAGGTTATGAGCCTGCTGCAGCCCCTCAATATCACTCAGGTCCTGAGCCATGGAGAAGGG ACAGACATCAACTTTTGGATCCAAGCTGGAGTGCCTGGAGCCAGTCTACTTGATGACTTATACAAGTATTTCTTCTTCCATCACTCCCAC GGAGACACCATGACTGTCATGGATCCAAAGCAGATGAATGTTGCTGCTGCTGTTTGGGCTGTTGTTTCTTATGTTGTTGCAGACATGGAA GAAATGCTGCCTAGGTCCTAGAAACAGTAAGAAAGAAACGTTTTCATGCTTCTGGCCAGGAATCCTGGGTCTGCAACTTTGGAAAACTCC TCTTCACATAACAATTTCATCCAATTCATCTTCAAAGCACAACTCTATTTCATGCTTTCTGTTATTATCTTTCTTGATACTTTCCAAATT CTCTGATTCTAGAAAAAGGAATCATTCTCCCCTCCCTCCCACCACATAGAATCAACATATGGTAGGGATTACAGTGGGGGCATTTCTTTA >12213_12213_4_CAB39L-CPQ_CAB39L_chr13_49924879_ENST00000410043_CPQ_chr8_97847200_ENST00000220763_length(amino acids)=322AA_BP= MVVTSFDELQRRASEARGKIVVYNQPYINYSRTVQYRTQGAVEAAKVGALASLIRSVASFSIYSPHTGIQEYQDGVPKIPTACITVEDAE MMSRMASHGIKIVIQLKMGAKTYPDTDSFNTVAEITGSKYPEQVVLVSGHLDSWDVGQGAMDDGGGAFISWEALSLIKDLGLRPKRTLRL VLWTAEEQGGVGAFQYYQLHKVNISNYSLVMESDAGTFLPTGLQFTGSEKARAIMEEVMSLLQPLNITQVLSHGEGTDINFWIQAGVPGA -------------------------------------------------------------- >12213_12213_5_CAB39L-CPQ_CAB39L_chr13_49924880_ENST00000347776_CPQ_chr8_97847201_ENST00000220763_length(transcript)=2213nt_BP=909nt AGCGCTCTCGGCTTGTCTCGCGCACTGTAGCTGAGCCAATGGAGTTACTCGTAGTCGAGAGGCCGGCATCACTGGAGTGGTGGCGCAGCT GTTTCCTCCGGATATCCATCAAATATTGAGAAGAAAGAATATCAGGAGCAAAGTGTTCTAAGTTGCTGTTCAGAACGTAAAGATGCGAAC CCCAAATCAGTGGTTTGTTCATTCTTCATGCAAGAGCAATGCACTAAAGGAGAGAAGCGTAAGTTTTCTCTTATTTCTGATGGGGAAACA AGCACACGCATACACACTCTTGTGATGGAGATAGATTTTACAAGCATTCCATATTGGAAGAAGAGATTTCTACACATGAAAAAAATGCCT TTGTTTAGTAAATCACACAAAAATCCAGCAGAAATTGTGAAAATCCTGAAAGACAATTTGGCCATTTTGGAAAAGCAAGACAAAAAGACA GACAAGGCTTCAGAAGAAGTGTCTAAATCACTGCAAGCAATGAAAGAAATTCTGTGTGGTACAAACGAGAAAGAACCCCCAACAGAAGCA GTGGCTCAGCTAGCACAAGAACTCTACAGCAGTGGCCTGCTAGTGACACTGATAGCTGACCTGCAGCTGATAGACTTTGAGGGAAAAAAA GATGTGACCCAGATATTTAACAACATCTTGAGAAGACAGATAGGCACTCGGAGTCCTACTGTGGAGTATATTAGTGCTCATCCTCATATC CTGTTTATGCTCCTCAAAGGATATGAAGCCCCACAGATTGCCTTACGTTGTGGGATTATGCTGAGAGAATGTATTCGACATGAACCACTT GCCAAAATCATCCTCTTTTCTAATCAATTCAGAGATTTCTTTAAGTACGTGGAGTTGTCAACATTTGATATTGCTTCAGATGCCTTTGCT ACTTTCAAGGCATTACAGCAGAAGTTCTGGTGGTGACCTCTTTCGATGAACTGCAGAGAAGGGCCTCAGAAGCAAGAGGGAAGATTGTTG TTTATAACCAACCTTACATCAACTACTCAAGGACGGTGCAATACCGAACGCAGGGGGCGGTGGAAGCTGCCAAGGTGGGGGCTTTGGCAT CTCTCATTCGATCCGTGGCCTCCTTCTCCATCTACAGTCCTCACACAGGTATTCAGGAATACCAGGATGGCGTGCCCAAGATTCCAACAG CCTGTATTACGGTGGAAGATGCAGAAATGATGTCAAGAATGGCTTCTCATGGGATCAAAATTGTCATTCAGCTAAAGATGGGGGCAAAGA CCTACCCAGATACTGATTCCTTCAACACTGTAGCAGAGATCACTGGGAGCAAATATCCAGAACAGGTTGTACTGGTCAGTGGACATCTGG ACAGCTGGGATGTTGGGCAGGGTGCCATGGATGATGGCGGTGGAGCCTTTATATCATGGGAAGCACTCTCACTTATTAAAGATCTTGGGC TGCGTCCAAAGAGGACTCTGCGGCTGGTGCTCTGGACTGCAGAAGAACAAGGTGGAGTTGGTGCCTTCCAGTATTATCAGTTACACAAGG TAAATATTTCCAACTACAGTCTGGTGATGGAGTCTGACGCAGGAACCTTCTTACCCACTGGGCTGCAATTCACTGGCAGTGAAAAGGCCA GGGCCATCATGGAGGAGGTTATGAGCCTGCTGCAGCCCCTCAATATCACTCAGGTCCTGAGCCATGGAGAAGGGACAGACATCAACTTTT GGATCCAAGCTGGAGTGCCTGGAGCCAGTCTACTTGATGACTTATACAAGTATTTCTTCTTCCATCACTCCCACGGAGACACCATGACTG TCATGGATCCAAAGCAGATGAATGTTGCTGCTGCTGTTTGGGCTGTTGTTTCTTATGTTGTTGCAGACATGGAAGAAATGCTGCCTAGGT CCTAGAAACAGTAAGAAAGAAACGTTTTCATGCTTCTGGCCAGGAATCCTGGGTCTGCAACTTTGGAAAACTCCTCTTCACATAACAATT TCATCCAATTCATCTTCAAAGCACAACTCTATTTCATGCTTTCTGTTATTATCTTTCTTGATACTTTCCAAATTCTCTGATTCTAGAAAA AGGAATCATTCTCCCCTCCCTCCCACCACATAGAATCAACATATGGTAGGGATTACAGTGGGGGCATTTCTTTATATCACCTCTTAAAAA >12213_12213_5_CAB39L-CPQ_CAB39L_chr13_49924880_ENST00000347776_CPQ_chr8_97847201_ENST00000220763_length(amino acids)=322AA_BP= MVVTSFDELQRRASEARGKIVVYNQPYINYSRTVQYRTQGAVEAAKVGALASLIRSVASFSIYSPHTGIQEYQDGVPKIPTACITVEDAE MMSRMASHGIKIVIQLKMGAKTYPDTDSFNTVAEITGSKYPEQVVLVSGHLDSWDVGQGAMDDGGGAFISWEALSLIKDLGLRPKRTLRL VLWTAEEQGGVGAFQYYQLHKVNISNYSLVMESDAGTFLPTGLQFTGSEKARAIMEEVMSLLQPLNITQVLSHGEGTDINFWIQAGVPGA -------------------------------------------------------------- >12213_12213_6_CAB39L-CPQ_CAB39L_chr13_49924880_ENST00000355854_CPQ_chr8_97847201_ENST00000220763_length(transcript)=2366nt_BP=1062nt GTGACGTTACAGGACTGAGGAGGGAGGAAGTAAAAGGGAGCTGTGACTGTGGTACGTATCTGAAAGCAAGTGTTAGAGAGGGAGTGGAGA ACGCATAAGCAAGCTGGTTTGACCAGAAACAGAACTGCCTGTGACAGATTAAGAGACAAGCAAGGCTTGGAATCTGAGAGCAAGCAAAGA GAGTGGAAATTTACAGCTGCCCTATGTGAGTGTTCAAGTGATCATTTTCTGGTAACGTTTTCCAGTGGTAACTGTTACTCTTCAAAAAGA GGGACAGAAAGTCAAGACCTAATTGTGGAAACTCTTTTCTCTGCCACGCTTGGTAATAGGAGGCAACCTCTATTAAATGGACGATAAAGG CTACTTCATCTAAAGTGCTTTGAGCTCAAGAAAGAGCTGTCTTCAGCACCTCACCATGTGTCTACATTTTGTTGCTTAGAAAAGCCTAGG CATTTCTGTAACATTTGCATTCCATATTGGAAGAAGAGATTTCTACACATGAAAAAAATGCCTTTGTTTAGTAAATCACACAAAAATCCA GCAGAAATTGTGAAAATCCTGAAAGACAATTTGGCCATTTTGGAAAAGCAAGACAAAAAGACAGACAAGGCTTCAGAAGAAGTGTCTAAA TCACTGCAAGCAATGAAAGAAATTCTGTGTGGTACAAACGAGAAAGAACCCCCAACAGAAGCAGTGGCTCAGCTAGCACAAGAACTCTAC AGCAGTGGCCTGCTAGTGACACTGATAGCTGACCTGCAGCTGATAGACTTTGAGGGAAAAAAAGATGTGACCCAGATATTTAACAACATC TTGAGAAGACAGATAGGCACTCGGAGTCCTACTGTGGAGTATATTAGTGCTCATCCTCATATCCTGTTTATGCTCCTCAAAGGATATGAA GCCCCACAGATTGCCTTACGTTGTGGGATTATGCTGAGAGAATGTATTCGACATGAACCACTTGCCAAAATCATCCTCTTTTCTAATCAA TTCAGAGATTTCTTTAAGTACGTGGAGTTGTCAACATTTGATATTGCTTCAGATGCCTTTGCTACTTTCAAGGCATTACAGCAGAAGTTC TGGTGGTGACCTCTTTCGATGAACTGCAGAGAAGGGCCTCAGAAGCAAGAGGGAAGATTGTTGTTTATAACCAACCTTACATCAACTACT CAAGGACGGTGCAATACCGAACGCAGGGGGCGGTGGAAGCTGCCAAGGTGGGGGCTTTGGCATCTCTCATTCGATCCGTGGCCTCCTTCT CCATCTACAGTCCTCACACAGGTATTCAGGAATACCAGGATGGCGTGCCCAAGATTCCAACAGCCTGTATTACGGTGGAAGATGCAGAAA TGATGTCAAGAATGGCTTCTCATGGGATCAAAATTGTCATTCAGCTAAAGATGGGGGCAAAGACCTACCCAGATACTGATTCCTTCAACA CTGTAGCAGAGATCACTGGGAGCAAATATCCAGAACAGGTTGTACTGGTCAGTGGACATCTGGACAGCTGGGATGTTGGGCAGGGTGCCA TGGATGATGGCGGTGGAGCCTTTATATCATGGGAAGCACTCTCACTTATTAAAGATCTTGGGCTGCGTCCAAAGAGGACTCTGCGGCTGG TGCTCTGGACTGCAGAAGAACAAGGTGGAGTTGGTGCCTTCCAGTATTATCAGTTACACAAGGTAAATATTTCCAACTACAGTCTGGTGA TGGAGTCTGACGCAGGAACCTTCTTACCCACTGGGCTGCAATTCACTGGCAGTGAAAAGGCCAGGGCCATCATGGAGGAGGTTATGAGCC TGCTGCAGCCCCTCAATATCACTCAGGTCCTGAGCCATGGAGAAGGGACAGACATCAACTTTTGGATCCAAGCTGGAGTGCCTGGAGCCA GTCTACTTGATGACTTATACAAGTATTTCTTCTTCCATCACTCCCACGGAGACACCATGACTGTCATGGATCCAAAGCAGATGAATGTTG CTGCTGCTGTTTGGGCTGTTGTTTCTTATGTTGTTGCAGACATGGAAGAAATGCTGCCTAGGTCCTAGAAACAGTAAGAAAGAAACGTTT TCATGCTTCTGGCCAGGAATCCTGGGTCTGCAACTTTGGAAAACTCCTCTTCACATAACAATTTCATCCAATTCATCTTCAAAGCACAAC TCTATTTCATGCTTTCTGTTATTATCTTTCTTGATACTTTCCAAATTCTCTGATTCTAGAAAAAGGAATCATTCTCCCCTCCCTCCCACC ACATAGAATCAACATATGGTAGGGATTACAGTGGGGGCATTTCTTTATATCACCTCTTAAAAACATTGTTTCCACTTTAAAAGTAAACAC >12213_12213_6_CAB39L-CPQ_CAB39L_chr13_49924880_ENST00000355854_CPQ_chr8_97847201_ENST00000220763_length(amino acids)=322AA_BP= MVVTSFDELQRRASEARGKIVVYNQPYINYSRTVQYRTQGAVEAAKVGALASLIRSVASFSIYSPHTGIQEYQDGVPKIPTACITVEDAE MMSRMASHGIKIVIQLKMGAKTYPDTDSFNTVAEITGSKYPEQVVLVSGHLDSWDVGQGAMDDGGGAFISWEALSLIKDLGLRPKRTLRL VLWTAEEQGGVGAFQYYQLHKVNISNYSLVMESDAGTFLPTGLQFTGSEKARAIMEEVMSLLQPLNITQVLSHGEGTDINFWIQAGVPGA -------------------------------------------------------------- >12213_12213_7_CAB39L-CPQ_CAB39L_chr13_49924880_ENST00000409308_CPQ_chr8_97847201_ENST00000220763_length(transcript)=2254nt_BP=950nt CCGCAGTGGCGCCCGAGCGCGCCGCCTCCCGATTGACTGCTAGCGCTCTCGGCTTGTCTCGCGCACTGTAGCTGAGCCAATGGAGTTACT CGTAGTCGAGAGGCCGGCATCACTGGAGTGGTGGCGCAGCTGTTTCCTCCGGATATCCATCAAATATTGAGAAGAAAGAATATCAGGAGC AAAGTGTTCTAAGTTGCTGTTCAGAACGTAAAGATGCGAACCCCAAATCAGTGGTTTGTTCATTCTTCATGCAAGAGCAATGCACTAAAG GAGAGAAGCAAGCTGTGGTGATCAGTGACTTTGGTGAAAGCTAAGAAGGTTCAAACAAATTTGCAAATGATATACAACTTCTAAGCATTC CATATTGGAAGAAGAGATTTCTACACATGAAAAAAATGCCTTTGTTTAGTAAATCACACAAAAATCCAGCAGAAATTGTGAAAATCCTGA AAGACAATTTGGCCATTTTGGAAAAGCAAGACAAAAAGACAGACAAGGCTTCAGAAGAAGTGTCTAAATCACTGCAAGCAATGAAAGAAA TTCTGTGTGGTACAAACGAGAAAGAACCCCCAACAGAAGCAGTGGCTCAGCTAGCACAAGAACTCTACAGCAGTGGCCTGCTAGTGACAC TGATAGCTGACCTGCAGCTGATAGACTTTGAGGGAAAAAAAGATGTGACCCAGATATTTAACAACATCTTGAGAAGACAGATAGGCACTC GGAGTCCTACTGTGGAGTATATTAGTGCTCATCCTCATATCCTGTTTATGCTCCTCAAAGGATATGAAGCCCCACAGATTGCCTTACGTT GTGGGATTATGCTGAGAGAATGTATTCGACATGAACCACTTGCCAAAATCATCCTCTTTTCTAATCAATTCAGAGATTTCTTTAAGTACG TGGAGTTGTCAACATTTGATATTGCTTCAGATGCCTTTGCTACTTTCAAGGCATTACAGCAGAAGTTCTGGTGGTGACCTCTTTCGATGA ACTGCAGAGAAGGGCCTCAGAAGCAAGAGGGAAGATTGTTGTTTATAACCAACCTTACATCAACTACTCAAGGACGGTGCAATACCGAAC GCAGGGGGCGGTGGAAGCTGCCAAGGTGGGGGCTTTGGCATCTCTCATTCGATCCGTGGCCTCCTTCTCCATCTACAGTCCTCACACAGG TATTCAGGAATACCAGGATGGCGTGCCCAAGATTCCAACAGCCTGTATTACGGTGGAAGATGCAGAAATGATGTCAAGAATGGCTTCTCA TGGGATCAAAATTGTCATTCAGCTAAAGATGGGGGCAAAGACCTACCCAGATACTGATTCCTTCAACACTGTAGCAGAGATCACTGGGAG CAAATATCCAGAACAGGTTGTACTGGTCAGTGGACATCTGGACAGCTGGGATGTTGGGCAGGGTGCCATGGATGATGGCGGTGGAGCCTT TATATCATGGGAAGCACTCTCACTTATTAAAGATCTTGGGCTGCGTCCAAAGAGGACTCTGCGGCTGGTGCTCTGGACTGCAGAAGAACA AGGTGGAGTTGGTGCCTTCCAGTATTATCAGTTACACAAGGTAAATATTTCCAACTACAGTCTGGTGATGGAGTCTGACGCAGGAACCTT CTTACCCACTGGGCTGCAATTCACTGGCAGTGAAAAGGCCAGGGCCATCATGGAGGAGGTTATGAGCCTGCTGCAGCCCCTCAATATCAC TCAGGTCCTGAGCCATGGAGAAGGGACAGACATCAACTTTTGGATCCAAGCTGGAGTGCCTGGAGCCAGTCTACTTGATGACTTATACAA GTATTTCTTCTTCCATCACTCCCACGGAGACACCATGACTGTCATGGATCCAAAGCAGATGAATGTTGCTGCTGCTGTTTGGGCTGTTGT TTCTTATGTTGTTGCAGACATGGAAGAAATGCTGCCTAGGTCCTAGAAACAGTAAGAAAGAAACGTTTTCATGCTTCTGGCCAGGAATCC TGGGTCTGCAACTTTGGAAAACTCCTCTTCACATAACAATTTCATCCAATTCATCTTCAAAGCACAACTCTATTTCATGCTTTCTGTTAT TATCTTTCTTGATACTTTCCAAATTCTCTGATTCTAGAAAAAGGAATCATTCTCCCCTCCCTCCCACCACATAGAATCAACATATGGTAG GGATTACAGTGGGGGCATTTCTTTATATCACCTCTTAAAAACATTGTTTCCACTTTAAAAGTAAACACTTAATAAATTTTTGGAAGATCT >12213_12213_7_CAB39L-CPQ_CAB39L_chr13_49924880_ENST00000409308_CPQ_chr8_97847201_ENST00000220763_length(amino acids)=322AA_BP= MVVTSFDELQRRASEARGKIVVYNQPYINYSRTVQYRTQGAVEAAKVGALASLIRSVASFSIYSPHTGIQEYQDGVPKIPTACITVEDAE MMSRMASHGIKIVIQLKMGAKTYPDTDSFNTVAEITGSKYPEQVVLVSGHLDSWDVGQGAMDDGGGAFISWEALSLIKDLGLRPKRTLRL VLWTAEEQGGVGAFQYYQLHKVNISNYSLVMESDAGTFLPTGLQFTGSEKARAIMEEVMSLLQPLNITQVLSHGEGTDINFWIQAGVPGA -------------------------------------------------------------- >12213_12213_8_CAB39L-CPQ_CAB39L_chr13_49924880_ENST00000410043_CPQ_chr8_97847201_ENST00000220763_length(transcript)=2319nt_BP=1015nt GAGCCAATGGAGTTACTCGTAGTCGAGAGGCCGGCATCACTGGAGTGGTGGCGCAGCTGTTTCCTCCGGATATCCATCAAATATTGAGAA GAAAGAATATCAGGAGCAAAGTGTTCTAAGTTGCTGTTCAGAACGTAAAGATGCGAACCCCAAATCAGTGGTTTGTTCATTCTTCATGCA AGAGCAATGCACTAAAGGAGAGAAGCAAGCTGTGGTGATCAGTGACTTTGGTGAAAGCTAAGAAGGTTCAAACAAATTTGCAAATGATAT ACAACTTCTAAGGAGGCAACCTCTATTAAATGGACGATAAAGGCTACTTCATCTAAAGTGCTTTGAGCTCAAGAAAGAGCTGTCTTCAGC ACCTCACCATGTGTCTACATTTTGTTGCTTAGAAAAGCCTAGGCATTTCTGTAACATTTGCATTCCATATTGGAAGAAGAGATTTCTACA CATGAAAAAAATGCCTTTGTTTAGTAAATCACACAAAAATCCAGCAGAAATTGTGAAAATCCTGAAAGACAATTTGGCCATTTTGGAAAA GCAAGACAAAAAGACAGACAAGGCTTCAGAAGAAGTGTCTAAATCACTGCAAGCAATGAAAGAAATTCTGTGTGGTACAAACGAGAAAGA ACCCCCAACAGAAGCAGTGGCTCAGCTAGCACAAGAACTCTACAGCAGTGGCCTGCTAGTGACACTGATAGCTGACCTGCAGCTGATAGA CTTTGAGGGAAAAAAAGATGTGACCCAGATATTTAACAACATCTTGAGAAGACAGATAGGCACTCGGAGTCCTACTGTGGAGTATATTAG TGCTCATCCTCATATCCTGTTTATGCTCCTCAAAGGATATGAAGCCCCACAGATTGCCTTACGTTGTGGGATTATGCTGAGAGAATGTAT TCGACATGAACCACTTGCCAAAATCATCCTCTTTTCTAATCAATTCAGAGATTTCTTTAAGTACGTGGAGTTGTCAACATTTGATATTGC TTCAGATGCCTTTGCTACTTTCAAGGCATTACAGCAGAAGTTCTGGTGGTGACCTCTTTCGATGAACTGCAGAGAAGGGCCTCAGAAGCA AGAGGGAAGATTGTTGTTTATAACCAACCTTACATCAACTACTCAAGGACGGTGCAATACCGAACGCAGGGGGCGGTGGAAGCTGCCAAG GTGGGGGCTTTGGCATCTCTCATTCGATCCGTGGCCTCCTTCTCCATCTACAGTCCTCACACAGGTATTCAGGAATACCAGGATGGCGTG CCCAAGATTCCAACAGCCTGTATTACGGTGGAAGATGCAGAAATGATGTCAAGAATGGCTTCTCATGGGATCAAAATTGTCATTCAGCTA AAGATGGGGGCAAAGACCTACCCAGATACTGATTCCTTCAACACTGTAGCAGAGATCACTGGGAGCAAATATCCAGAACAGGTTGTACTG GTCAGTGGACATCTGGACAGCTGGGATGTTGGGCAGGGTGCCATGGATGATGGCGGTGGAGCCTTTATATCATGGGAAGCACTCTCACTT ATTAAAGATCTTGGGCTGCGTCCAAAGAGGACTCTGCGGCTGGTGCTCTGGACTGCAGAAGAACAAGGTGGAGTTGGTGCCTTCCAGTAT TATCAGTTACACAAGGTAAATATTTCCAACTACAGTCTGGTGATGGAGTCTGACGCAGGAACCTTCTTACCCACTGGGCTGCAATTCACT GGCAGTGAAAAGGCCAGGGCCATCATGGAGGAGGTTATGAGCCTGCTGCAGCCCCTCAATATCACTCAGGTCCTGAGCCATGGAGAAGGG ACAGACATCAACTTTTGGATCCAAGCTGGAGTGCCTGGAGCCAGTCTACTTGATGACTTATACAAGTATTTCTTCTTCCATCACTCCCAC GGAGACACCATGACTGTCATGGATCCAAAGCAGATGAATGTTGCTGCTGCTGTTTGGGCTGTTGTTTCTTATGTTGTTGCAGACATGGAA GAAATGCTGCCTAGGTCCTAGAAACAGTAAGAAAGAAACGTTTTCATGCTTCTGGCCAGGAATCCTGGGTCTGCAACTTTGGAAAACTCC TCTTCACATAACAATTTCATCCAATTCATCTTCAAAGCACAACTCTATTTCATGCTTTCTGTTATTATCTTTCTTGATACTTTCCAAATT CTCTGATTCTAGAAAAAGGAATCATTCTCCCCTCCCTCCCACCACATAGAATCAACATATGGTAGGGATTACAGTGGGGGCATTTCTTTA >12213_12213_8_CAB39L-CPQ_CAB39L_chr13_49924880_ENST00000410043_CPQ_chr8_97847201_ENST00000220763_length(amino acids)=322AA_BP= MVVTSFDELQRRASEARGKIVVYNQPYINYSRTVQYRTQGAVEAAKVGALASLIRSVASFSIYSPHTGIQEYQDGVPKIPTACITVEDAE MMSRMASHGIKIVIQLKMGAKTYPDTDSFNTVAEITGSKYPEQVVLVSGHLDSWDVGQGAMDDGGGAFISWEALSLIKDLGLRPKRTLRL VLWTAEEQGGVGAFQYYQLHKVNISNYSLVMESDAGTFLPTGLQFTGSEKARAIMEEVMSLLQPLNITQVLSHGEGTDINFWIQAGVPGA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CAB39L-CPQ |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CAB39L-CPQ |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CAB39L-CPQ |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies