
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CACNB1-IGSF8 (FusionGDB2 ID:12387) |
Fusion Gene Summary for CACNB1-IGSF8 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CACNB1-IGSF8 | Fusion gene ID: 12387 | Hgene | Tgene | Gene symbol | CACNB1 | IGSF8 | Gene ID | 782 | 93185 |
| Gene name | calcium voltage-gated channel auxiliary subunit beta 1 | immunoglobulin superfamily member 8 | |
| Synonyms | CAB1|CACNLB1|CCHLB1 | CD316|CD81P3|EWI-2|EWI2|KCT-4|LIR-D1|PGRL | |
| Cytomap | 17q12 | 1q23.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | voltage-dependent L-type calcium channel subunit beta-1calcium channel voltage-dependent subunit beta 1calcium channel, L type, beta 1 polypeptidecalcium channel, voltage-dependent, beta 1 subunitdihydropyridine-sensitive L-type, calcium channel beta- | immunoglobulin superfamily member 8CD81 partner 3glu-Trp-Ile EWI motif-containing protein 2keratinocytes-associated transmembrane protein 4prostaglandin regulatory-like protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q02641 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000344140, ENST00000394303, ENST00000394310, ENST00000582877, | ENST00000460351, ENST00000314485, ENST00000368086, | |
| Fusion gene scores | * DoF score | 16 X 13 X 5=1040 | 7 X 4 X 7=196 |
| # samples | 17 | 8 | |
| ** MAII score | log2(17/1040*10)=-2.61297687689075 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/196*10)=-1.29278174922785 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CACNB1 [Title/Abstract] AND IGSF8 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CACNB1(37339966)-IGSF8(160065036), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across CACNB1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across IGSF8 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-93-7348-01A | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
Top |
Fusion Gene ORF analysis for CACNB1-IGSF8 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000344140 | ENST00000460351 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| 5CDS-5UTR | ENST00000394303 | ENST00000460351 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| 5CDS-5UTR | ENST00000394310 | ENST00000460351 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| In-frame | ENST00000344140 | ENST00000314485 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| In-frame | ENST00000344140 | ENST00000368086 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| In-frame | ENST00000394303 | ENST00000314485 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| In-frame | ENST00000394303 | ENST00000368086 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| In-frame | ENST00000394310 | ENST00000314485 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| In-frame | ENST00000394310 | ENST00000368086 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| intron-3CDS | ENST00000582877 | ENST00000314485 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| intron-3CDS | ENST00000582877 | ENST00000368086 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| intron-5UTR | ENST00000582877 | ENST00000460351 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000394303 | CACNB1 | chr17 | 37339966 | - | ENST00000314485 | IGSF8 | chr1 | 160065036 | - | 3320 | 1258 | 1260 | 3035 | 591 |
| ENST00000394303 | CACNB1 | chr17 | 37339966 | - | ENST00000368086 | IGSF8 | chr1 | 160065036 | - | 3343 | 1258 | 1260 | 3035 | 591 |
| ENST00000394310 | CACNB1 | chr17 | 37339966 | - | ENST00000314485 | IGSF8 | chr1 | 160065036 | - | 3319 | 1257 | 1259 | 3034 | 591 |
| ENST00000394310 | CACNB1 | chr17 | 37339966 | - | ENST00000368086 | IGSF8 | chr1 | 160065036 | - | 3342 | 1257 | 1259 | 3034 | 591 |
| ENST00000344140 | CACNB1 | chr17 | 37339966 | - | ENST00000314485 | IGSF8 | chr1 | 160065036 | - | 3455 | 1393 | 1395 | 3170 | 591 |
| ENST00000344140 | CACNB1 | chr17 | 37339966 | - | ENST00000368086 | IGSF8 | chr1 | 160065036 | - | 3478 | 1393 | 1395 | 3170 | 591 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000394303 | ENST00000314485 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - | 0.009814126 | 0.99018586 |
| ENST00000394303 | ENST00000368086 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - | 0.009681415 | 0.99031854 |
| ENST00000394310 | ENST00000314485 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - | 0.009782352 | 0.9902176 |
| ENST00000394310 | ENST00000368086 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - | 0.009649142 | 0.9903508 |
| ENST00000344140 | ENST00000314485 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - | 0.010126802 | 0.9898732 |
| ENST00000344140 | ENST00000368086 | CACNB1 | chr17 | 37339966 | - | IGSF8 | chr1 | 160065036 | - | 0.009948857 | 0.9900511 |
Top |
Fusion Genomic Features for CACNB1-IGSF8 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
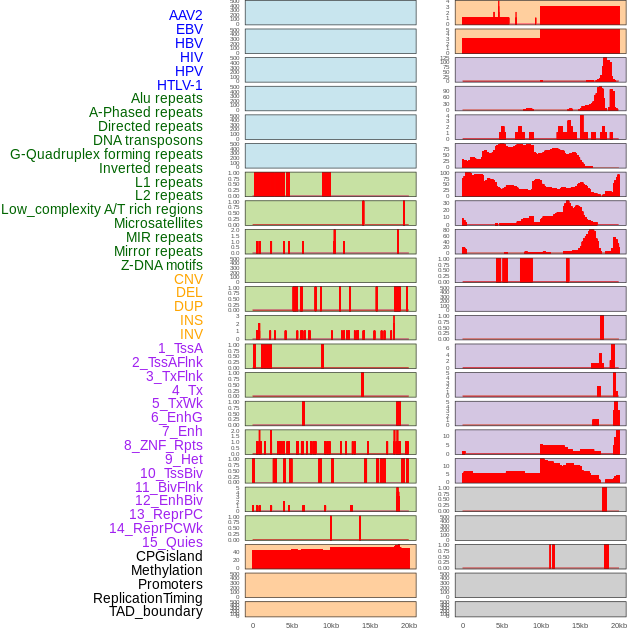 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CACNB1-IGSF8 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:37339966/chr1:160065036) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CACNB1 | . |
| FUNCTION: Regulatory subunit of L-type calcium channels (PubMed:1309651, PubMed:8107964, PubMed:15615847). Regulates the activity of L-type calcium channels that contain CACNA1A as pore-forming subunit (By similarity). Regulates the activity of L-type calcium channels that contain CACNA1C as pore-forming subunit and increases the presence of the channel complex at the cell membrane (PubMed:15615847). Required for functional expression L-type calcium channels that contain CACNA1D as pore-forming subunit (PubMed:1309651). Regulates the activity of L-type calcium channels that contain CACNA1B as pore-forming subunit (PubMed:8107964). {ECO:0000250|UniProtKB:P19517, ECO:0000269|PubMed:1309651, ECO:0000269|PubMed:15615847, ECO:0000269|PubMed:8107964}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CACNB1 | chr17:37339966 | chr1:160065036 | ENST00000344140 | - | 11 | 13 | 100_169 | 395 | 524.0 | Domain | SH3 |
| Hgene | CACNB1 | chr17:37339966 | chr1:160065036 | ENST00000394303 | - | 11 | 14 | 100_169 | 350 | 599.0 | Domain | SH3 |
| Hgene | CACNB1 | chr17:37339966 | chr1:160065036 | ENST00000394310 | - | 11 | 13 | 100_169 | 350 | 479.0 | Domain | SH3 |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000314485 | 0 | 7 | 162_286 | 21 | 527.6666666666666 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000314485 | 0 | 7 | 28_149 | 21 | 527.6666666666666 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000314485 | 0 | 7 | 303_424 | 21 | 527.6666666666666 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000314485 | 0 | 7 | 431_560 | 21 | 527.6666666666666 | Domain | Note=Ig-like C2-type 4 | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000368086 | 0 | 7 | 162_286 | 21 | 535.3333333333334 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000368086 | 0 | 7 | 28_149 | 21 | 535.3333333333334 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000368086 | 0 | 7 | 303_424 | 21 | 535.3333333333334 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000368086 | 0 | 7 | 431_560 | 21 | 535.3333333333334 | Domain | Note=Ig-like C2-type 4 | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000314485 | 0 | 7 | 274_276 | 21 | 527.6666666666666 | Motif | Note=EWI motif | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000368086 | 0 | 7 | 274_276 | 21 | 535.3333333333334 | Motif | Note=EWI motif | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000314485 | 0 | 7 | 28_579 | 21 | 527.6666666666666 | Topological domain | Extracellular | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000314485 | 0 | 7 | 601_613 | 21 | 527.6666666666666 | Topological domain | Cytoplasmic | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000368086 | 0 | 7 | 28_579 | 21 | 535.3333333333334 | Topological domain | Extracellular | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000368086 | 0 | 7 | 601_613 | 21 | 535.3333333333334 | Topological domain | Cytoplasmic | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000314485 | 0 | 7 | 580_600 | 21 | 527.6666666666666 | Transmembrane | Helical | |
| Tgene | IGSF8 | chr17:37339966 | chr1:160065036 | ENST00000368086 | 0 | 7 | 580_600 | 21 | 535.3333333333334 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for CACNB1-IGSF8 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >12387_12387_1_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000344140_IGSF8_chr1_160065036_ENST00000314485_length(transcript)=3455nt_BP=1393nt GAGATGCTGAGCCTACGGGGGAGGCGGCGGCGGCAGTGGAGAGAGCGGGAGGAGCGAGGGAAGGCAGGAAGGAGGCAGCCGAAGGCCGAG CTGGGTGGCTGGACCGGGTGCTGGCTGCGCCGCGCTGCTTTCGGCTCCCACGGCCTCTCCCATGCGCTGAGGGAGCCCGGCTGGGCCGGG CCGGCGGCGGGAGGGGAGGCTCCTCTCCATGGTCCAGAAGACCAGCATGTCCCGGGGCCCTTACCCACCCTCCCAGGAGATCCCCATGGA GGTCTTCGACCCCAGCCCGCAGGGCAAATACAGCAAGAGGAAAGGGCGATTCAAACGGTCAGATGGGAGCACGTCCTCGGATACCACATC CAACAGCTTTGTCCGCCAGGGCTCAGCGGAGTCCTACACCAGCCGTCCATCAGACTCTGATGTATCTCTGGAGGAGGACCGGGAAGCCTT AAGGAAGGAAGCAGAGCGCCAGGCATTAGCGCAGCTCGAGAAGGCCAAGACCAAGCCAGTGGCATTTGCTGTGCGGACAAATGTTGGCTA CAATCCGTCTCCAGGGGATGAGGTGCCTGTGCAGGGAGTGGCCATCACCTTCGAGCCCAAAGACTTCCTGCACATCAAGGAGAAATACAA TAATGACTGGTGGATCGGGCGGCTGGTGAAGGAGGGCTGTGAGGTTGGCTTCATTCCCAGCCCCGTCAAACTGGACAGCCTTCGCCTGCT GCAGGAACAGAAGCTGCGCCAGAACCGCCTCGGCTCCAGCAAATCAGGCGATAACTCCAGTTCCAGTCTGGGAGATGTGGTGACTGGCAC CCGCCGCCCCACACCCCCTGCCAGTGGTAATGAAATGACTAACTTAGCCTTTGAACTAGACCCCCTAGAGTTAGAGGAGGAAGAGGCTGA GCTTGGTGAGCAGAGTGGCTCTGCCAAGACTAGTGTTAGCAGTGTCACCACCCCGCCACCCCATGGCAAACGCATCCCCTTCTTTAAGAA GACAGAGCATGTGCCCCCCTATGACGTGGTGCCTTCCATGAGGCCCATCATCCTGGTGGGACCGTCGCTCAAGGGCTACGAGGTTACAGA CATGATGCAGAAAGCTTTATTTGACTTCTTGAAGCATCGGTTTGATGGCAGGATCTCCATCACTCGTGTGACGGCAGATATTTCCCTGGC TAAGCGCTCAGTTCTCAACAACCCCAGCAAACACATCATCATTGAGCGCTCCAACACACGCTCCAGCCTGGCTGAGGTGCAGAGTGAAAT CGAGCGAATCTTCGAGCTGGCCCGGACCCTTCAGTTGGTCGCTCTGGATGCTGACACCATCAATCACCCAGCCCAGCTGTCCAAGACCTC GCTGGCCCCCATCATTGTTTACATCAAGATCACCTCTCCCAAGGAATGGGATGCTGGGCCCGGGAGGTGCTGGTCCCCGAGGGGCCCTTG TACCGCGTGGCTGGCACAGCTGTCTCCATCTCCTGCAATGTGACCGGCTATGAGGGCCCTGCCCAGCAGAACTTCGAGTGGTTCCTGTAT AGGCCCGAGGCCCCAGATACTGCACTGGGCATTGTCAGTACCAAGGATACCCAGTTCTCCTATGCTGTCTTCAAGTCCCGAGTGGTGGCG GGTGAGGTGCAGGTGCAGCGCCTACAAGGTGATGCCGTGGTGCTCAAGATTGCCCGCCTGCAGGCCCAGGATGCCGGCATTTATGAGTGC CACACCCCCTCCACTGATACCCGCTACCTGGGCAGCTACAGCGGCAAGGTGGAGCTGAGAGTTCTTCCAGATGTCCTCCAGGTGTCTGCT GCCCCCCCAGGGCCCCGAGGCCGCCAGGCCCCAACCTCACCCCCACGCATGACGGTGCATGAGGGGCAGGAGCTGGCACTGGGCTGCCTG GCGAGGACAAGCACACAGAAGCACACACACCTGGCAGTGTCCTTTGGGCGATCTGTGCCCGAGGCACCAGTTGGGCGGTCAACTCTGCAG GAAGTGGTGGGAATCCGGTCAGACTTGGCCGTGGAGGCTGGAGCTCCCTATGCTGAGCGATTGGCTGCAGGGGAGCTTCGTCTGGGCAAG GAAGGGACCGATCGGTACCGCATGGTAGTAGGGGGTGCCCAGGCAGGGGACGCAGGCACCTACCACTGCACTGCCGCTGAGTGGATTCAG GATCCTGATGGCAGCTGGGCCCAGATTGCAGAGAAAAGGGCCGTCCTGGCCCACGTGGATGTGCAGACGCTGTCCAGCCAGCTGGCAGTG ACAGTGGGGCCTGGTGAACGTCGGATCGGCCCAGGGGAGCCCTTGGAACTGCTGTGCAATGTGTCAGGGGCACTTCCCCCAGCAGGCCGT CATGCTGCATACTCTGTAGGTTGGGAGATGGCACCTGCGGGGGCACCTGGGCCCGGCCGCCTGGTAGCCCAGCTGGACACAGAGGGTGTG GGCAGCCTGGGCCCTGGCTATGAGGGCCGACACATTGCCATGGAGAAGGTGGCATCCAGAACATACCGGCTACGGCTAGAGGCTGCCAGG CCTGGTGATGCGGGCACCTACCGCTGCCTCGCCAAAGCCTATGTTCGAGGGTCTGGGACCCGGCTTCGTGAAGCAGCCAGTGCCCGTTCC CGGCCTCTCCCTGTACATGTGCGGGAGGAAGGTGTGGTGCTGGAGGCTGTGGCATGGCTAGCAGGAGGCACAGTGTACCGCGGGGAGACT GCCTCCCTGCTGTGCAACATCTCTGTGCGGGGTGGCCCCCCAGGACTGCGGCTGGCCGCCAGCTGGTGGGTGGAGCGACCAGAGGACGGA GAGCTCAGCTCTGTCCCTGCCCAGCTGGTGGGTGGCGTAGGCCAGGATGGTGTGGCAGAGCTGGGAGTCCGGCCTGGAGGAGGCCCTGTC AGCGTAGAGCTGGTGGGGCCCCGAAGCCATCGGCTGAGACTACACAGCTTGGGGCCCGAGGATGAAGGCGTGTACCACTGTGCCCCCAGC GCCTGGGTGCAGCATGCCGACTACAGCTGGTACCAGGCGGGCAGTGCCCGCTCAGGGCCTGTTACAGTCTACCCCTACATGCATGCCCTG GACACCCTATTTGTGCCTCTGCTGGTGGGTACAGGGGTGGCCCTAGTCACTGGTGCCACTGTCCTTGGTACCATCACTTGCTGCTTCATG AAGAGGCTTCGAAAACGGTGATCCCTTACTCCCCAGGTCTTGCAGGTGTCGACTGTCTTCCGGCCCAGCTCCAAGCCCTCCTCTGGTTGC CTGGACACCCTCTCCCTCTGTCCACTCTTCCTTTAATTTATTTGACCTCCCACTACCCAGAATGGGAGACGTGCCTCCCCTTCCCCACTC CTTCCCTCCCAAGCCCCTCCCTCTGGCCTTCTGTTCTTGATCTCTTAGGGATCCTATAGGGAGGCCATTTCCTGTCCTGGAATTAGTTTT >12387_12387_1_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000344140_IGSF8_chr1_160065036_ENST00000314485_length(amino acids)=591AA_BP=0 MGCWAREVLVPEGPLYRVAGTAVSISCNVTGYEGPAQQNFEWFLYRPEAPDTALGIVSTKDTQFSYAVFKSRVVAGEVQVQRLQGDAVVL KIARLQAQDAGIYECHTPSTDTRYLGSYSGKVELRVLPDVLQVSAAPPGPRGRQAPTSPPRMTVHEGQELALGCLARTSTQKHTHLAVSF GRSVPEAPVGRSTLQEVVGIRSDLAVEAGAPYAERLAAGELRLGKEGTDRYRMVVGGAQAGDAGTYHCTAAEWIQDPDGSWAQIAEKRAV LAHVDVQTLSSQLAVTVGPGERRIGPGEPLELLCNVSGALPPAGRHAAYSVGWEMAPAGAPGPGRLVAQLDTEGVGSLGPGYEGRHIAME KVASRTYRLRLEAARPGDAGTYRCLAKAYVRGSGTRLREAASARSRPLPVHVREEGVVLEAVAWLAGGTVYRGETASLLCNISVRGGPPG LRLAASWWVERPEDGELSSVPAQLVGGVGQDGVAELGVRPGGGPVSVELVGPRSHRLRLHSLGPEDEGVYHCAPSAWVQHADYSWYQAGS -------------------------------------------------------------- >12387_12387_2_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000344140_IGSF8_chr1_160065036_ENST00000368086_length(transcript)=3478nt_BP=1393nt GAGATGCTGAGCCTACGGGGGAGGCGGCGGCGGCAGTGGAGAGAGCGGGAGGAGCGAGGGAAGGCAGGAAGGAGGCAGCCGAAGGCCGAG CTGGGTGGCTGGACCGGGTGCTGGCTGCGCCGCGCTGCTTTCGGCTCCCACGGCCTCTCCCATGCGCTGAGGGAGCCCGGCTGGGCCGGG CCGGCGGCGGGAGGGGAGGCTCCTCTCCATGGTCCAGAAGACCAGCATGTCCCGGGGCCCTTACCCACCCTCCCAGGAGATCCCCATGGA GGTCTTCGACCCCAGCCCGCAGGGCAAATACAGCAAGAGGAAAGGGCGATTCAAACGGTCAGATGGGAGCACGTCCTCGGATACCACATC CAACAGCTTTGTCCGCCAGGGCTCAGCGGAGTCCTACACCAGCCGTCCATCAGACTCTGATGTATCTCTGGAGGAGGACCGGGAAGCCTT AAGGAAGGAAGCAGAGCGCCAGGCATTAGCGCAGCTCGAGAAGGCCAAGACCAAGCCAGTGGCATTTGCTGTGCGGACAAATGTTGGCTA CAATCCGTCTCCAGGGGATGAGGTGCCTGTGCAGGGAGTGGCCATCACCTTCGAGCCCAAAGACTTCCTGCACATCAAGGAGAAATACAA TAATGACTGGTGGATCGGGCGGCTGGTGAAGGAGGGCTGTGAGGTTGGCTTCATTCCCAGCCCCGTCAAACTGGACAGCCTTCGCCTGCT GCAGGAACAGAAGCTGCGCCAGAACCGCCTCGGCTCCAGCAAATCAGGCGATAACTCCAGTTCCAGTCTGGGAGATGTGGTGACTGGCAC CCGCCGCCCCACACCCCCTGCCAGTGGTAATGAAATGACTAACTTAGCCTTTGAACTAGACCCCCTAGAGTTAGAGGAGGAAGAGGCTGA GCTTGGTGAGCAGAGTGGCTCTGCCAAGACTAGTGTTAGCAGTGTCACCACCCCGCCACCCCATGGCAAACGCATCCCCTTCTTTAAGAA GACAGAGCATGTGCCCCCCTATGACGTGGTGCCTTCCATGAGGCCCATCATCCTGGTGGGACCGTCGCTCAAGGGCTACGAGGTTACAGA CATGATGCAGAAAGCTTTATTTGACTTCTTGAAGCATCGGTTTGATGGCAGGATCTCCATCACTCGTGTGACGGCAGATATTTCCCTGGC TAAGCGCTCAGTTCTCAACAACCCCAGCAAACACATCATCATTGAGCGCTCCAACACACGCTCCAGCCTGGCTGAGGTGCAGAGTGAAAT CGAGCGAATCTTCGAGCTGGCCCGGACCCTTCAGTTGGTCGCTCTGGATGCTGACACCATCAATCACCCAGCCCAGCTGTCCAAGACCTC GCTGGCCCCCATCATTGTTTACATCAAGATCACCTCTCCCAAGGAATGGGATGCTGGGCCCGGGAGGTGCTGGTCCCCGAGGGGCCCTTG TACCGCGTGGCTGGCACAGCTGTCTCCATCTCCTGCAATGTGACCGGCTATGAGGGCCCTGCCCAGCAGAACTTCGAGTGGTTCCTGTAT AGGCCCGAGGCCCCAGATACTGCACTGGGCATTGTCAGTACCAAGGATACCCAGTTCTCCTATGCTGTCTTCAAGTCCCGAGTGGTGGCG GGTGAGGTGCAGGTGCAGCGCCTACAAGGTGATGCCGTGGTGCTCAAGATTGCCCGCCTGCAGGCCCAGGATGCCGGCATTTATGAGTGC CACACCCCCTCCACTGATACCCGCTACCTGGGCAGCTACAGCGGCAAGGTGGAGCTGAGAGTTCTTCCAGATGTCCTCCAGGTGTCTGCT GCCCCCCCAGGGCCCCGAGGCCGCCAGGCCCCAACCTCACCCCCACGCATGACGGTGCATGAGGGGCAGGAGCTGGCACTGGGCTGCCTG GCGAGGACAAGCACACAGAAGCACACACACCTGGCAGTGTCCTTTGGGCGATCTGTGCCCGAGGCACCAGTTGGGCGGTCAACTCTGCAG GAAGTGGTGGGAATCCGGTCAGACTTGGCCGTGGAGGCTGGAGCTCCCTATGCTGAGCGATTGGCTGCAGGGGAGCTTCGTCTGGGCAAG GAAGGGACCGATCGGTACCGCATGGTAGTAGGGGGTGCCCAGGCAGGGGACGCAGGCACCTACCACTGCACTGCCGCTGAGTGGATTCAG GATCCTGATGGCAGCTGGGCCCAGATTGCAGAGAAAAGGGCCGTCCTGGCCCACGTGGATGTGCAGACGCTGTCCAGCCAGCTGGCAGTG ACAGTGGGGCCTGGTGAACGTCGGATCGGCCCAGGGGAGCCCTTGGAACTGCTGTGCAATGTGTCAGGGGCACTTCCCCCAGCAGGCCGT CATGCTGCATACTCTGTAGGTTGGGAGATGGCACCTGCGGGGGCACCTGGGCCCGGCCGCCTGGTAGCCCAGCTGGACACAGAGGGTGTG GGCAGCCTGGGCCCTGGCTATGAGGGCCGACACATTGCCATGGAGAAGGTGGCATCCAGAACATACCGGCTACGGCTAGAGGCTGCCAGG CCTGGTGATGCGGGCACCTACCGCTGCCTCGCCAAAGCCTATGTTCGAGGGTCTGGGACCCGGCTTCGTGAAGCAGCCAGTGCCCGTTCC CGGCCTCTCCCTGTACATGTGCGGGAGGAAGGTGTGGTGCTGGAGGCTGTGGCATGGCTAGCAGGAGGCACAGTGTACCGCGGGGAGACT GCCTCCCTGCTGTGCAACATCTCTGTGCGGGGTGGCCCCCCAGGACTGCGGCTGGCCGCCAGCTGGTGGGTGGAGCGACCAGAGGACGGA GAGCTCAGCTCTGTCCCTGCCCAGCTGGTGGGTGGCGTAGGCCAGGATGGTGTGGCAGAGCTGGGAGTCCGGCCTGGAGGAGGCCCTGTC AGCGTAGAGCTGGTGGGGCCCCGAAGCCATCGGCTGAGACTACACAGCTTGGGGCCCGAGGATGAAGGCGTGTACCACTGTGCCCCCAGC GCCTGGGTGCAGCATGCCGACTACAGCTGGTACCAGGCGGGCAGTGCCCGCTCAGGGCCTGTTACAGTCTACCCCTACATGCATGCCCTG GACACCCTATTTGTGCCTCTGCTGGTGGGTACAGGGGTGGCCCTAGTCACTGGTGCCACTGTCCTTGGTACCATCACTTGCTGCTTCATG AAGAGGCTTCGAAAACGGTGATCCCTTACTCCCCAGCCCACACCGGGCACCCTTTTCAGGTCTTGCAGGTGTCGACTGTCTTCCGGCCCA GCTCCAAGCCCTCCTCTGGTTGCCTGGACACCCTCTCCCTCTGTCCACTCTTCCTTTAATTTATTTGACCTCCCACTACCCAGAATGGGA GACGTGCCTCCCCTTCCCCACTCCTTCCCTCCCAAGCCCCTCCCTCTGGCCTTCTGTTCTTGATCTCTTAGGGATCCTATAGGGAGGCCA >12387_12387_2_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000344140_IGSF8_chr1_160065036_ENST00000368086_length(amino acids)=591AA_BP=0 MGCWAREVLVPEGPLYRVAGTAVSISCNVTGYEGPAQQNFEWFLYRPEAPDTALGIVSTKDTQFSYAVFKSRVVAGEVQVQRLQGDAVVL KIARLQAQDAGIYECHTPSTDTRYLGSYSGKVELRVLPDVLQVSAAPPGPRGRQAPTSPPRMTVHEGQELALGCLARTSTQKHTHLAVSF GRSVPEAPVGRSTLQEVVGIRSDLAVEAGAPYAERLAAGELRLGKEGTDRYRMVVGGAQAGDAGTYHCTAAEWIQDPDGSWAQIAEKRAV LAHVDVQTLSSQLAVTVGPGERRIGPGEPLELLCNVSGALPPAGRHAAYSVGWEMAPAGAPGPGRLVAQLDTEGVGSLGPGYEGRHIAME KVASRTYRLRLEAARPGDAGTYRCLAKAYVRGSGTRLREAASARSRPLPVHVREEGVVLEAVAWLAGGTVYRGETASLLCNISVRGGPPG LRLAASWWVERPEDGELSSVPAQLVGGVGQDGVAELGVRPGGGPVSVELVGPRSHRLRLHSLGPEDEGVYHCAPSAWVQHADYSWYQAGS -------------------------------------------------------------- >12387_12387_3_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000394303_IGSF8_chr1_160065036_ENST00000314485_length(transcript)=3320nt_BP=1258nt GAGATGCTGAGCCTACGGGGGAGGCGGCGGCGGCAGTGGAGAGAGCGGGAGGAGCGAGGGAAGGCAGGAAGGAGGCAGCCGAAGGCCGAG CTGGGTGGCTGGACCGGGTGCTGGCTGCGCCGCGCTGCTTTCGGCTCCCACGGCCTCTCCCATGCGCTGAGGGAGCCCGGCTGGGCCGGG CCGGCGGCGGGAGGGGAGGCTCCTCTCCATGGTCCAGAAGACCAGCATGTCCCGGGGCCCTTACCCACCCTCCCAGGAGATCCCCATGGA GGTCTTCGACCCCAGCCCGCAGGGCAAATACAGCAAGAGGAAAGGGCGATTCAAACGGTCAGATGGGAGCACGTCCTCGGATACCACATC CAACAGCTTTGTCCGCCAGGGCTCAGCGGAGTCCTACACCAGCCGTCCATCAGACTCTGATGTATCTCTGGAGGAGGACCGGGAAGCCTT AAGGAAGGAAGCAGAGCGCCAGGCATTAGCGCAGCTCGAGAAGGCCAAGACCAAGCCAGTGGCATTTGCTGTGCGGACAAATGTTGGCTA CAATCCGTCTCCAGGGGATGAGGTGCCTGTGCAGGGAGTGGCCATCACCTTCGAGCCCAAAGACTTCCTGCACATCAAGGAGAAATACAA TAATGACTGGTGGATCGGGCGGCTGGTGAAGGAGGGCTGTGAGGTTGGCTTCATTCCCAGCCCCGTCAAACTGGACAGCCTTCGCCTGCT GCAGGAACAGAAGCTGCGCCAGAACCGCCTCGGCTCCAGCAAATCAGGCGATAACTCCAGTTCCAGTCTGGGAGATGTGGTGACTGGCAC CCGCCGCCCCACACCCCCTGCCAGTGCCAAACAGAAGCAGAAGTCGACAGAGCATGTGCCCCCCTATGACGTGGTGCCTTCCATGAGGCC CATCATCCTGGTGGGACCGTCGCTCAAGGGCTACGAGGTTACAGACATGATGCAGAAAGCTTTATTTGACTTCTTGAAGCATCGGTTTGA TGGCAGGATCTCCATCACTCGTGTGACGGCAGATATTTCCCTGGCTAAGCGCTCAGTTCTCAACAACCCCAGCAAACACATCATCATTGA GCGCTCCAACACACGCTCCAGCCTGGCTGAGGTGCAGAGTGAAATCGAGCGAATCTTCGAGCTGGCCCGGACCCTTCAGTTGGTCGCTCT GGATGCTGACACCATCAATCACCCAGCCCAGCTGTCCAAGACCTCGCTGGCCCCCATCATTGTTTACATCAAGATCACCTCTCCCAAGGA ATGGGATGCTGGGCCCGGGAGGTGCTGGTCCCCGAGGGGCCCTTGTACCGCGTGGCTGGCACAGCTGTCTCCATCTCCTGCAATGTGACC GGCTATGAGGGCCCTGCCCAGCAGAACTTCGAGTGGTTCCTGTATAGGCCCGAGGCCCCAGATACTGCACTGGGCATTGTCAGTACCAAG GATACCCAGTTCTCCTATGCTGTCTTCAAGTCCCGAGTGGTGGCGGGTGAGGTGCAGGTGCAGCGCCTACAAGGTGATGCCGTGGTGCTC AAGATTGCCCGCCTGCAGGCCCAGGATGCCGGCATTTATGAGTGCCACACCCCCTCCACTGATACCCGCTACCTGGGCAGCTACAGCGGC AAGGTGGAGCTGAGAGTTCTTCCAGATGTCCTCCAGGTGTCTGCTGCCCCCCCAGGGCCCCGAGGCCGCCAGGCCCCAACCTCACCCCCA CGCATGACGGTGCATGAGGGGCAGGAGCTGGCACTGGGCTGCCTGGCGAGGACAAGCACACAGAAGCACACACACCTGGCAGTGTCCTTT GGGCGATCTGTGCCCGAGGCACCAGTTGGGCGGTCAACTCTGCAGGAAGTGGTGGGAATCCGGTCAGACTTGGCCGTGGAGGCTGGAGCT CCCTATGCTGAGCGATTGGCTGCAGGGGAGCTTCGTCTGGGCAAGGAAGGGACCGATCGGTACCGCATGGTAGTAGGGGGTGCCCAGGCA GGGGACGCAGGCACCTACCACTGCACTGCCGCTGAGTGGATTCAGGATCCTGATGGCAGCTGGGCCCAGATTGCAGAGAAAAGGGCCGTC CTGGCCCACGTGGATGTGCAGACGCTGTCCAGCCAGCTGGCAGTGACAGTGGGGCCTGGTGAACGTCGGATCGGCCCAGGGGAGCCCTTG GAACTGCTGTGCAATGTGTCAGGGGCACTTCCCCCAGCAGGCCGTCATGCTGCATACTCTGTAGGTTGGGAGATGGCACCTGCGGGGGCA CCTGGGCCCGGCCGCCTGGTAGCCCAGCTGGACACAGAGGGTGTGGGCAGCCTGGGCCCTGGCTATGAGGGCCGACACATTGCCATGGAG AAGGTGGCATCCAGAACATACCGGCTACGGCTAGAGGCTGCCAGGCCTGGTGATGCGGGCACCTACCGCTGCCTCGCCAAAGCCTATGTT CGAGGGTCTGGGACCCGGCTTCGTGAAGCAGCCAGTGCCCGTTCCCGGCCTCTCCCTGTACATGTGCGGGAGGAAGGTGTGGTGCTGGAG GCTGTGGCATGGCTAGCAGGAGGCACAGTGTACCGCGGGGAGACTGCCTCCCTGCTGTGCAACATCTCTGTGCGGGGTGGCCCCCCAGGA CTGCGGCTGGCCGCCAGCTGGTGGGTGGAGCGACCAGAGGACGGAGAGCTCAGCTCTGTCCCTGCCCAGCTGGTGGGTGGCGTAGGCCAG GATGGTGTGGCAGAGCTGGGAGTCCGGCCTGGAGGAGGCCCTGTCAGCGTAGAGCTGGTGGGGCCCCGAAGCCATCGGCTGAGACTACAC AGCTTGGGGCCCGAGGATGAAGGCGTGTACCACTGTGCCCCCAGCGCCTGGGTGCAGCATGCCGACTACAGCTGGTACCAGGCGGGCAGT GCCCGCTCAGGGCCTGTTACAGTCTACCCCTACATGCATGCCCTGGACACCCTATTTGTGCCTCTGCTGGTGGGTACAGGGGTGGCCCTA GTCACTGGTGCCACTGTCCTTGGTACCATCACTTGCTGCTTCATGAAGAGGCTTCGAAAACGGTGATCCCTTACTCCCCAGGTCTTGCAG GTGTCGACTGTCTTCCGGCCCAGCTCCAAGCCCTCCTCTGGTTGCCTGGACACCCTCTCCCTCTGTCCACTCTTCCTTTAATTTATTTGA CCTCCCACTACCCAGAATGGGAGACGTGCCTCCCCTTCCCCACTCCTTCCCTCCCAAGCCCCTCCCTCTGGCCTTCTGTTCTTGATCTCT >12387_12387_3_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000394303_IGSF8_chr1_160065036_ENST00000314485_length(amino acids)=591AA_BP=0 MGCWAREVLVPEGPLYRVAGTAVSISCNVTGYEGPAQQNFEWFLYRPEAPDTALGIVSTKDTQFSYAVFKSRVVAGEVQVQRLQGDAVVL KIARLQAQDAGIYECHTPSTDTRYLGSYSGKVELRVLPDVLQVSAAPPGPRGRQAPTSPPRMTVHEGQELALGCLARTSTQKHTHLAVSF GRSVPEAPVGRSTLQEVVGIRSDLAVEAGAPYAERLAAGELRLGKEGTDRYRMVVGGAQAGDAGTYHCTAAEWIQDPDGSWAQIAEKRAV LAHVDVQTLSSQLAVTVGPGERRIGPGEPLELLCNVSGALPPAGRHAAYSVGWEMAPAGAPGPGRLVAQLDTEGVGSLGPGYEGRHIAME KVASRTYRLRLEAARPGDAGTYRCLAKAYVRGSGTRLREAASARSRPLPVHVREEGVVLEAVAWLAGGTVYRGETASLLCNISVRGGPPG LRLAASWWVERPEDGELSSVPAQLVGGVGQDGVAELGVRPGGGPVSVELVGPRSHRLRLHSLGPEDEGVYHCAPSAWVQHADYSWYQAGS -------------------------------------------------------------- >12387_12387_4_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000394303_IGSF8_chr1_160065036_ENST00000368086_length(transcript)=3343nt_BP=1258nt GAGATGCTGAGCCTACGGGGGAGGCGGCGGCGGCAGTGGAGAGAGCGGGAGGAGCGAGGGAAGGCAGGAAGGAGGCAGCCGAAGGCCGAG CTGGGTGGCTGGACCGGGTGCTGGCTGCGCCGCGCTGCTTTCGGCTCCCACGGCCTCTCCCATGCGCTGAGGGAGCCCGGCTGGGCCGGG CCGGCGGCGGGAGGGGAGGCTCCTCTCCATGGTCCAGAAGACCAGCATGTCCCGGGGCCCTTACCCACCCTCCCAGGAGATCCCCATGGA GGTCTTCGACCCCAGCCCGCAGGGCAAATACAGCAAGAGGAAAGGGCGATTCAAACGGTCAGATGGGAGCACGTCCTCGGATACCACATC CAACAGCTTTGTCCGCCAGGGCTCAGCGGAGTCCTACACCAGCCGTCCATCAGACTCTGATGTATCTCTGGAGGAGGACCGGGAAGCCTT AAGGAAGGAAGCAGAGCGCCAGGCATTAGCGCAGCTCGAGAAGGCCAAGACCAAGCCAGTGGCATTTGCTGTGCGGACAAATGTTGGCTA CAATCCGTCTCCAGGGGATGAGGTGCCTGTGCAGGGAGTGGCCATCACCTTCGAGCCCAAAGACTTCCTGCACATCAAGGAGAAATACAA TAATGACTGGTGGATCGGGCGGCTGGTGAAGGAGGGCTGTGAGGTTGGCTTCATTCCCAGCCCCGTCAAACTGGACAGCCTTCGCCTGCT GCAGGAACAGAAGCTGCGCCAGAACCGCCTCGGCTCCAGCAAATCAGGCGATAACTCCAGTTCCAGTCTGGGAGATGTGGTGACTGGCAC CCGCCGCCCCACACCCCCTGCCAGTGCCAAACAGAAGCAGAAGTCGACAGAGCATGTGCCCCCCTATGACGTGGTGCCTTCCATGAGGCC CATCATCCTGGTGGGACCGTCGCTCAAGGGCTACGAGGTTACAGACATGATGCAGAAAGCTTTATTTGACTTCTTGAAGCATCGGTTTGA TGGCAGGATCTCCATCACTCGTGTGACGGCAGATATTTCCCTGGCTAAGCGCTCAGTTCTCAACAACCCCAGCAAACACATCATCATTGA GCGCTCCAACACACGCTCCAGCCTGGCTGAGGTGCAGAGTGAAATCGAGCGAATCTTCGAGCTGGCCCGGACCCTTCAGTTGGTCGCTCT GGATGCTGACACCATCAATCACCCAGCCCAGCTGTCCAAGACCTCGCTGGCCCCCATCATTGTTTACATCAAGATCACCTCTCCCAAGGA ATGGGATGCTGGGCCCGGGAGGTGCTGGTCCCCGAGGGGCCCTTGTACCGCGTGGCTGGCACAGCTGTCTCCATCTCCTGCAATGTGACC GGCTATGAGGGCCCTGCCCAGCAGAACTTCGAGTGGTTCCTGTATAGGCCCGAGGCCCCAGATACTGCACTGGGCATTGTCAGTACCAAG GATACCCAGTTCTCCTATGCTGTCTTCAAGTCCCGAGTGGTGGCGGGTGAGGTGCAGGTGCAGCGCCTACAAGGTGATGCCGTGGTGCTC AAGATTGCCCGCCTGCAGGCCCAGGATGCCGGCATTTATGAGTGCCACACCCCCTCCACTGATACCCGCTACCTGGGCAGCTACAGCGGC AAGGTGGAGCTGAGAGTTCTTCCAGATGTCCTCCAGGTGTCTGCTGCCCCCCCAGGGCCCCGAGGCCGCCAGGCCCCAACCTCACCCCCA CGCATGACGGTGCATGAGGGGCAGGAGCTGGCACTGGGCTGCCTGGCGAGGACAAGCACACAGAAGCACACACACCTGGCAGTGTCCTTT GGGCGATCTGTGCCCGAGGCACCAGTTGGGCGGTCAACTCTGCAGGAAGTGGTGGGAATCCGGTCAGACTTGGCCGTGGAGGCTGGAGCT CCCTATGCTGAGCGATTGGCTGCAGGGGAGCTTCGTCTGGGCAAGGAAGGGACCGATCGGTACCGCATGGTAGTAGGGGGTGCCCAGGCA GGGGACGCAGGCACCTACCACTGCACTGCCGCTGAGTGGATTCAGGATCCTGATGGCAGCTGGGCCCAGATTGCAGAGAAAAGGGCCGTC CTGGCCCACGTGGATGTGCAGACGCTGTCCAGCCAGCTGGCAGTGACAGTGGGGCCTGGTGAACGTCGGATCGGCCCAGGGGAGCCCTTG GAACTGCTGTGCAATGTGTCAGGGGCACTTCCCCCAGCAGGCCGTCATGCTGCATACTCTGTAGGTTGGGAGATGGCACCTGCGGGGGCA CCTGGGCCCGGCCGCCTGGTAGCCCAGCTGGACACAGAGGGTGTGGGCAGCCTGGGCCCTGGCTATGAGGGCCGACACATTGCCATGGAG AAGGTGGCATCCAGAACATACCGGCTACGGCTAGAGGCTGCCAGGCCTGGTGATGCGGGCACCTACCGCTGCCTCGCCAAAGCCTATGTT CGAGGGTCTGGGACCCGGCTTCGTGAAGCAGCCAGTGCCCGTTCCCGGCCTCTCCCTGTACATGTGCGGGAGGAAGGTGTGGTGCTGGAG GCTGTGGCATGGCTAGCAGGAGGCACAGTGTACCGCGGGGAGACTGCCTCCCTGCTGTGCAACATCTCTGTGCGGGGTGGCCCCCCAGGA CTGCGGCTGGCCGCCAGCTGGTGGGTGGAGCGACCAGAGGACGGAGAGCTCAGCTCTGTCCCTGCCCAGCTGGTGGGTGGCGTAGGCCAG GATGGTGTGGCAGAGCTGGGAGTCCGGCCTGGAGGAGGCCCTGTCAGCGTAGAGCTGGTGGGGCCCCGAAGCCATCGGCTGAGACTACAC AGCTTGGGGCCCGAGGATGAAGGCGTGTACCACTGTGCCCCCAGCGCCTGGGTGCAGCATGCCGACTACAGCTGGTACCAGGCGGGCAGT GCCCGCTCAGGGCCTGTTACAGTCTACCCCTACATGCATGCCCTGGACACCCTATTTGTGCCTCTGCTGGTGGGTACAGGGGTGGCCCTA GTCACTGGTGCCACTGTCCTTGGTACCATCACTTGCTGCTTCATGAAGAGGCTTCGAAAACGGTGATCCCTTACTCCCCAGCCCACACCG GGCACCCTTTTCAGGTCTTGCAGGTGTCGACTGTCTTCCGGCCCAGCTCCAAGCCCTCCTCTGGTTGCCTGGACACCCTCTCCCTCTGTC CACTCTTCCTTTAATTTATTTGACCTCCCACTACCCAGAATGGGAGACGTGCCTCCCCTTCCCCACTCCTTCCCTCCCAAGCCCCTCCCT CTGGCCTTCTGTTCTTGATCTCTTAGGGATCCTATAGGGAGGCCATTTCCTGTCCTGGAATTAGTTTTTCTAAAATGTGAATAAACTTGT >12387_12387_4_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000394303_IGSF8_chr1_160065036_ENST00000368086_length(amino acids)=591AA_BP=0 MGCWAREVLVPEGPLYRVAGTAVSISCNVTGYEGPAQQNFEWFLYRPEAPDTALGIVSTKDTQFSYAVFKSRVVAGEVQVQRLQGDAVVL KIARLQAQDAGIYECHTPSTDTRYLGSYSGKVELRVLPDVLQVSAAPPGPRGRQAPTSPPRMTVHEGQELALGCLARTSTQKHTHLAVSF GRSVPEAPVGRSTLQEVVGIRSDLAVEAGAPYAERLAAGELRLGKEGTDRYRMVVGGAQAGDAGTYHCTAAEWIQDPDGSWAQIAEKRAV LAHVDVQTLSSQLAVTVGPGERRIGPGEPLELLCNVSGALPPAGRHAAYSVGWEMAPAGAPGPGRLVAQLDTEGVGSLGPGYEGRHIAME KVASRTYRLRLEAARPGDAGTYRCLAKAYVRGSGTRLREAASARSRPLPVHVREEGVVLEAVAWLAGGTVYRGETASLLCNISVRGGPPG LRLAASWWVERPEDGELSSVPAQLVGGVGQDGVAELGVRPGGGPVSVELVGPRSHRLRLHSLGPEDEGVYHCAPSAWVQHADYSWYQAGS -------------------------------------------------------------- >12387_12387_5_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000394310_IGSF8_chr1_160065036_ENST00000314485_length(transcript)=3319nt_BP=1257nt AGATGCTGAGCCTACGGGGGAGGCGGCGGCGGCAGTGGAGAGAGCGGGAGGAGCGAGGGAAGGCAGGAAGGAGGCAGCCGAAGGCCGAGC TGGGTGGCTGGACCGGGTGCTGGCTGCGCCGCGCTGCTTTCGGCTCCCACGGCCTCTCCCATGCGCTGAGGGAGCCCGGCTGGGCCGGGC CGGCGGCGGGAGGGGAGGCTCCTCTCCATGGTCCAGAAGACCAGCATGTCCCGGGGCCCTTACCCACCCTCCCAGGAGATCCCCATGGAG GTCTTCGACCCCAGCCCGCAGGGCAAATACAGCAAGAGGAAAGGGCGATTCAAACGGTCAGATGGGAGCACGTCCTCGGATACCACATCC AACAGCTTTGTCCGCCAGGGCTCAGCGGAGTCCTACACCAGCCGTCCATCAGACTCTGATGTATCTCTGGAGGAGGACCGGGAAGCCTTA AGGAAGGAAGCAGAGCGCCAGGCATTAGCGCAGCTCGAGAAGGCCAAGACCAAGCCAGTGGCATTTGCTGTGCGGACAAATGTTGGCTAC AATCCGTCTCCAGGGGATGAGGTGCCTGTGCAGGGAGTGGCCATCACCTTCGAGCCCAAAGACTTCCTGCACATCAAGGAGAAATACAAT AATGACTGGTGGATCGGGCGGCTGGTGAAGGAGGGCTGTGAGGTTGGCTTCATTCCCAGCCCCGTCAAACTGGACAGCCTTCGCCTGCTG CAGGAACAGAAGCTGCGCCAGAACCGCCTCGGCTCCAGCAAATCAGGCGATAACTCCAGTTCCAGTCTGGGAGATGTGGTGACTGGCACC CGCCGCCCCACACCCCCTGCCAGTGCCAAACAGAAGCAGAAGTCGACAGAGCATGTGCCCCCCTATGACGTGGTGCCTTCCATGAGGCCC ATCATCCTGGTGGGACCGTCGCTCAAGGGCTACGAGGTTACAGACATGATGCAGAAAGCTTTATTTGACTTCTTGAAGCATCGGTTTGAT GGCAGGATCTCCATCACTCGTGTGACGGCAGATATTTCCCTGGCTAAGCGCTCAGTTCTCAACAACCCCAGCAAACACATCATCATTGAG CGCTCCAACACACGCTCCAGCCTGGCTGAGGTGCAGAGTGAAATCGAGCGAATCTTCGAGCTGGCCCGGACCCTTCAGTTGGTCGCTCTG GATGCTGACACCATCAATCACCCAGCCCAGCTGTCCAAGACCTCGCTGGCCCCCATCATTGTTTACATCAAGATCACCTCTCCCAAGGAA TGGGATGCTGGGCCCGGGAGGTGCTGGTCCCCGAGGGGCCCTTGTACCGCGTGGCTGGCACAGCTGTCTCCATCTCCTGCAATGTGACCG GCTATGAGGGCCCTGCCCAGCAGAACTTCGAGTGGTTCCTGTATAGGCCCGAGGCCCCAGATACTGCACTGGGCATTGTCAGTACCAAGG ATACCCAGTTCTCCTATGCTGTCTTCAAGTCCCGAGTGGTGGCGGGTGAGGTGCAGGTGCAGCGCCTACAAGGTGATGCCGTGGTGCTCA AGATTGCCCGCCTGCAGGCCCAGGATGCCGGCATTTATGAGTGCCACACCCCCTCCACTGATACCCGCTACCTGGGCAGCTACAGCGGCA AGGTGGAGCTGAGAGTTCTTCCAGATGTCCTCCAGGTGTCTGCTGCCCCCCCAGGGCCCCGAGGCCGCCAGGCCCCAACCTCACCCCCAC GCATGACGGTGCATGAGGGGCAGGAGCTGGCACTGGGCTGCCTGGCGAGGACAAGCACACAGAAGCACACACACCTGGCAGTGTCCTTTG GGCGATCTGTGCCCGAGGCACCAGTTGGGCGGTCAACTCTGCAGGAAGTGGTGGGAATCCGGTCAGACTTGGCCGTGGAGGCTGGAGCTC CCTATGCTGAGCGATTGGCTGCAGGGGAGCTTCGTCTGGGCAAGGAAGGGACCGATCGGTACCGCATGGTAGTAGGGGGTGCCCAGGCAG GGGACGCAGGCACCTACCACTGCACTGCCGCTGAGTGGATTCAGGATCCTGATGGCAGCTGGGCCCAGATTGCAGAGAAAAGGGCCGTCC TGGCCCACGTGGATGTGCAGACGCTGTCCAGCCAGCTGGCAGTGACAGTGGGGCCTGGTGAACGTCGGATCGGCCCAGGGGAGCCCTTGG AACTGCTGTGCAATGTGTCAGGGGCACTTCCCCCAGCAGGCCGTCATGCTGCATACTCTGTAGGTTGGGAGATGGCACCTGCGGGGGCAC CTGGGCCCGGCCGCCTGGTAGCCCAGCTGGACACAGAGGGTGTGGGCAGCCTGGGCCCTGGCTATGAGGGCCGACACATTGCCATGGAGA AGGTGGCATCCAGAACATACCGGCTACGGCTAGAGGCTGCCAGGCCTGGTGATGCGGGCACCTACCGCTGCCTCGCCAAAGCCTATGTTC GAGGGTCTGGGACCCGGCTTCGTGAAGCAGCCAGTGCCCGTTCCCGGCCTCTCCCTGTACATGTGCGGGAGGAAGGTGTGGTGCTGGAGG CTGTGGCATGGCTAGCAGGAGGCACAGTGTACCGCGGGGAGACTGCCTCCCTGCTGTGCAACATCTCTGTGCGGGGTGGCCCCCCAGGAC TGCGGCTGGCCGCCAGCTGGTGGGTGGAGCGACCAGAGGACGGAGAGCTCAGCTCTGTCCCTGCCCAGCTGGTGGGTGGCGTAGGCCAGG ATGGTGTGGCAGAGCTGGGAGTCCGGCCTGGAGGAGGCCCTGTCAGCGTAGAGCTGGTGGGGCCCCGAAGCCATCGGCTGAGACTACACA GCTTGGGGCCCGAGGATGAAGGCGTGTACCACTGTGCCCCCAGCGCCTGGGTGCAGCATGCCGACTACAGCTGGTACCAGGCGGGCAGTG CCCGCTCAGGGCCTGTTACAGTCTACCCCTACATGCATGCCCTGGACACCCTATTTGTGCCTCTGCTGGTGGGTACAGGGGTGGCCCTAG TCACTGGTGCCACTGTCCTTGGTACCATCACTTGCTGCTTCATGAAGAGGCTTCGAAAACGGTGATCCCTTACTCCCCAGGTCTTGCAGG TGTCGACTGTCTTCCGGCCCAGCTCCAAGCCCTCCTCTGGTTGCCTGGACACCCTCTCCCTCTGTCCACTCTTCCTTTAATTTATTTGAC CTCCCACTACCCAGAATGGGAGACGTGCCTCCCCTTCCCCACTCCTTCCCTCCCAAGCCCCTCCCTCTGGCCTTCTGTTCTTGATCTCTT >12387_12387_5_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000394310_IGSF8_chr1_160065036_ENST00000314485_length(amino acids)=591AA_BP=0 MGCWAREVLVPEGPLYRVAGTAVSISCNVTGYEGPAQQNFEWFLYRPEAPDTALGIVSTKDTQFSYAVFKSRVVAGEVQVQRLQGDAVVL KIARLQAQDAGIYECHTPSTDTRYLGSYSGKVELRVLPDVLQVSAAPPGPRGRQAPTSPPRMTVHEGQELALGCLARTSTQKHTHLAVSF GRSVPEAPVGRSTLQEVVGIRSDLAVEAGAPYAERLAAGELRLGKEGTDRYRMVVGGAQAGDAGTYHCTAAEWIQDPDGSWAQIAEKRAV LAHVDVQTLSSQLAVTVGPGERRIGPGEPLELLCNVSGALPPAGRHAAYSVGWEMAPAGAPGPGRLVAQLDTEGVGSLGPGYEGRHIAME KVASRTYRLRLEAARPGDAGTYRCLAKAYVRGSGTRLREAASARSRPLPVHVREEGVVLEAVAWLAGGTVYRGETASLLCNISVRGGPPG LRLAASWWVERPEDGELSSVPAQLVGGVGQDGVAELGVRPGGGPVSVELVGPRSHRLRLHSLGPEDEGVYHCAPSAWVQHADYSWYQAGS -------------------------------------------------------------- >12387_12387_6_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000394310_IGSF8_chr1_160065036_ENST00000368086_length(transcript)=3342nt_BP=1257nt AGATGCTGAGCCTACGGGGGAGGCGGCGGCGGCAGTGGAGAGAGCGGGAGGAGCGAGGGAAGGCAGGAAGGAGGCAGCCGAAGGCCGAGC TGGGTGGCTGGACCGGGTGCTGGCTGCGCCGCGCTGCTTTCGGCTCCCACGGCCTCTCCCATGCGCTGAGGGAGCCCGGCTGGGCCGGGC CGGCGGCGGGAGGGGAGGCTCCTCTCCATGGTCCAGAAGACCAGCATGTCCCGGGGCCCTTACCCACCCTCCCAGGAGATCCCCATGGAG GTCTTCGACCCCAGCCCGCAGGGCAAATACAGCAAGAGGAAAGGGCGATTCAAACGGTCAGATGGGAGCACGTCCTCGGATACCACATCC AACAGCTTTGTCCGCCAGGGCTCAGCGGAGTCCTACACCAGCCGTCCATCAGACTCTGATGTATCTCTGGAGGAGGACCGGGAAGCCTTA AGGAAGGAAGCAGAGCGCCAGGCATTAGCGCAGCTCGAGAAGGCCAAGACCAAGCCAGTGGCATTTGCTGTGCGGACAAATGTTGGCTAC AATCCGTCTCCAGGGGATGAGGTGCCTGTGCAGGGAGTGGCCATCACCTTCGAGCCCAAAGACTTCCTGCACATCAAGGAGAAATACAAT AATGACTGGTGGATCGGGCGGCTGGTGAAGGAGGGCTGTGAGGTTGGCTTCATTCCCAGCCCCGTCAAACTGGACAGCCTTCGCCTGCTG CAGGAACAGAAGCTGCGCCAGAACCGCCTCGGCTCCAGCAAATCAGGCGATAACTCCAGTTCCAGTCTGGGAGATGTGGTGACTGGCACC CGCCGCCCCACACCCCCTGCCAGTGCCAAACAGAAGCAGAAGTCGACAGAGCATGTGCCCCCCTATGACGTGGTGCCTTCCATGAGGCCC ATCATCCTGGTGGGACCGTCGCTCAAGGGCTACGAGGTTACAGACATGATGCAGAAAGCTTTATTTGACTTCTTGAAGCATCGGTTTGAT GGCAGGATCTCCATCACTCGTGTGACGGCAGATATTTCCCTGGCTAAGCGCTCAGTTCTCAACAACCCCAGCAAACACATCATCATTGAG CGCTCCAACACACGCTCCAGCCTGGCTGAGGTGCAGAGTGAAATCGAGCGAATCTTCGAGCTGGCCCGGACCCTTCAGTTGGTCGCTCTG GATGCTGACACCATCAATCACCCAGCCCAGCTGTCCAAGACCTCGCTGGCCCCCATCATTGTTTACATCAAGATCACCTCTCCCAAGGAA TGGGATGCTGGGCCCGGGAGGTGCTGGTCCCCGAGGGGCCCTTGTACCGCGTGGCTGGCACAGCTGTCTCCATCTCCTGCAATGTGACCG GCTATGAGGGCCCTGCCCAGCAGAACTTCGAGTGGTTCCTGTATAGGCCCGAGGCCCCAGATACTGCACTGGGCATTGTCAGTACCAAGG ATACCCAGTTCTCCTATGCTGTCTTCAAGTCCCGAGTGGTGGCGGGTGAGGTGCAGGTGCAGCGCCTACAAGGTGATGCCGTGGTGCTCA AGATTGCCCGCCTGCAGGCCCAGGATGCCGGCATTTATGAGTGCCACACCCCCTCCACTGATACCCGCTACCTGGGCAGCTACAGCGGCA AGGTGGAGCTGAGAGTTCTTCCAGATGTCCTCCAGGTGTCTGCTGCCCCCCCAGGGCCCCGAGGCCGCCAGGCCCCAACCTCACCCCCAC GCATGACGGTGCATGAGGGGCAGGAGCTGGCACTGGGCTGCCTGGCGAGGACAAGCACACAGAAGCACACACACCTGGCAGTGTCCTTTG GGCGATCTGTGCCCGAGGCACCAGTTGGGCGGTCAACTCTGCAGGAAGTGGTGGGAATCCGGTCAGACTTGGCCGTGGAGGCTGGAGCTC CCTATGCTGAGCGATTGGCTGCAGGGGAGCTTCGTCTGGGCAAGGAAGGGACCGATCGGTACCGCATGGTAGTAGGGGGTGCCCAGGCAG GGGACGCAGGCACCTACCACTGCACTGCCGCTGAGTGGATTCAGGATCCTGATGGCAGCTGGGCCCAGATTGCAGAGAAAAGGGCCGTCC TGGCCCACGTGGATGTGCAGACGCTGTCCAGCCAGCTGGCAGTGACAGTGGGGCCTGGTGAACGTCGGATCGGCCCAGGGGAGCCCTTGG AACTGCTGTGCAATGTGTCAGGGGCACTTCCCCCAGCAGGCCGTCATGCTGCATACTCTGTAGGTTGGGAGATGGCACCTGCGGGGGCAC CTGGGCCCGGCCGCCTGGTAGCCCAGCTGGACACAGAGGGTGTGGGCAGCCTGGGCCCTGGCTATGAGGGCCGACACATTGCCATGGAGA AGGTGGCATCCAGAACATACCGGCTACGGCTAGAGGCTGCCAGGCCTGGTGATGCGGGCACCTACCGCTGCCTCGCCAAAGCCTATGTTC GAGGGTCTGGGACCCGGCTTCGTGAAGCAGCCAGTGCCCGTTCCCGGCCTCTCCCTGTACATGTGCGGGAGGAAGGTGTGGTGCTGGAGG CTGTGGCATGGCTAGCAGGAGGCACAGTGTACCGCGGGGAGACTGCCTCCCTGCTGTGCAACATCTCTGTGCGGGGTGGCCCCCCAGGAC TGCGGCTGGCCGCCAGCTGGTGGGTGGAGCGACCAGAGGACGGAGAGCTCAGCTCTGTCCCTGCCCAGCTGGTGGGTGGCGTAGGCCAGG ATGGTGTGGCAGAGCTGGGAGTCCGGCCTGGAGGAGGCCCTGTCAGCGTAGAGCTGGTGGGGCCCCGAAGCCATCGGCTGAGACTACACA GCTTGGGGCCCGAGGATGAAGGCGTGTACCACTGTGCCCCCAGCGCCTGGGTGCAGCATGCCGACTACAGCTGGTACCAGGCGGGCAGTG CCCGCTCAGGGCCTGTTACAGTCTACCCCTACATGCATGCCCTGGACACCCTATTTGTGCCTCTGCTGGTGGGTACAGGGGTGGCCCTAG TCACTGGTGCCACTGTCCTTGGTACCATCACTTGCTGCTTCATGAAGAGGCTTCGAAAACGGTGATCCCTTACTCCCCAGCCCACACCGG GCACCCTTTTCAGGTCTTGCAGGTGTCGACTGTCTTCCGGCCCAGCTCCAAGCCCTCCTCTGGTTGCCTGGACACCCTCTCCCTCTGTCC ACTCTTCCTTTAATTTATTTGACCTCCCACTACCCAGAATGGGAGACGTGCCTCCCCTTCCCCACTCCTTCCCTCCCAAGCCCCTCCCTC TGGCCTTCTGTTCTTGATCTCTTAGGGATCCTATAGGGAGGCCATTTCCTGTCCTGGAATTAGTTTTTCTAAAATGTGAATAAACTTGTT >12387_12387_6_CACNB1-IGSF8_CACNB1_chr17_37339966_ENST00000394310_IGSF8_chr1_160065036_ENST00000368086_length(amino acids)=591AA_BP=0 MGCWAREVLVPEGPLYRVAGTAVSISCNVTGYEGPAQQNFEWFLYRPEAPDTALGIVSTKDTQFSYAVFKSRVVAGEVQVQRLQGDAVVL KIARLQAQDAGIYECHTPSTDTRYLGSYSGKVELRVLPDVLQVSAAPPGPRGRQAPTSPPRMTVHEGQELALGCLARTSTQKHTHLAVSF GRSVPEAPVGRSTLQEVVGIRSDLAVEAGAPYAERLAAGELRLGKEGTDRYRMVVGGAQAGDAGTYHCTAAEWIQDPDGSWAQIAEKRAV LAHVDVQTLSSQLAVTVGPGERRIGPGEPLELLCNVSGALPPAGRHAAYSVGWEMAPAGAPGPGRLVAQLDTEGVGSLGPGYEGRHIAME KVASRTYRLRLEAARPGDAGTYRCLAKAYVRGSGTRLREAASARSRPLPVHVREEGVVLEAVAWLAGGTVYRGETASLLCNISVRGGPPG LRLAASWWVERPEDGELSSVPAQLVGGVGQDGVAELGVRPGGGPVSVELVGPRSHRLRLHSLGPEDEGVYHCAPSAWVQHADYSWYQAGS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CACNB1-IGSF8 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CACNB1-IGSF8 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CACNB1-IGSF8 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies