
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CACUL1-EIF3A (FusionGDB2 ID:12426) |
Fusion Gene Summary for CACUL1-EIF3A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CACUL1-EIF3A | Fusion gene ID: 12426 | Hgene | Tgene | Gene symbol | CACUL1 | EIF3A | Gene ID | 143384 | 8661 |
| Gene name | CDK2 associated cullin domain 1 | eukaryotic translation initiation factor 3 subunit A | |
| Synonyms | C10orf46|CAC1 | EIF3|EIF3S10|P167|TIF32|eIF3-p170|eIF3-theta|p180|p185 | |
| Cytomap | 10q26.11 | 10q26.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | CDK2-associated and cullin domain-containing protein 1Cdk-Associated Cullin1cullin | eukaryotic translation initiation factor 3 subunit AEIF3, p180 subunitcentrosomin homologcytoplasmic protein p167eIF-3-thetaeIF3 p167eIF3 p180eIF3 p185eukaryotic translation initiation factor 3 subunit 10eukaryotic translation initiation factor 3 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q86Y37 | Q14152 | |
| Ensembl transtripts involved in fusion gene | ENST00000340214, ENST00000369151, ENST00000544392, | ENST00000369144, ENST00000541549, | |
| Fusion gene scores | * DoF score | 6 X 7 X 3=126 | 8 X 9 X 3=216 |
| # samples | 7 | 9 | |
| ** MAII score | log2(7/126*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/216*10)=-1.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CACUL1 [Title/Abstract] AND EIF3A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CACUL1(120488807)-EIF3A(120818909), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | EIF3A | GO:0001732 | formation of cytoplasmic translation initiation complex | 17581632 |
| Tgene | EIF3A | GO:0075522 | IRES-dependent viral translational initiation | 9573242|23766293|24357634 |
| Tgene | EIF3A | GO:0075525 | viral translational termination-reinitiation | 21347434 |
| Fusion gene breakpoints across CACUL1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across EIF3A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-D8-A1JK-01A | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - |
Top |
Fusion Gene ORF analysis for CACUL1-EIF3A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000340214 | ENST00000369144 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - |
| In-frame | ENST00000340214 | ENST00000541549 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - |
| In-frame | ENST00000369151 | ENST00000369144 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - |
| In-frame | ENST00000369151 | ENST00000541549 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - |
| intron-3CDS | ENST00000544392 | ENST00000369144 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - |
| intron-3CDS | ENST00000544392 | ENST00000541549 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000369151 | CACUL1 | chr10 | 120488807 | - | ENST00000369144 | EIF3A | chr10 | 120818909 | - | 4982 | 1081 | 484 | 3786 | 1100 |
| ENST00000369151 | CACUL1 | chr10 | 120488807 | - | ENST00000541549 | EIF3A | chr10 | 120818909 | - | 4033 | 1081 | 484 | 3786 | 1100 |
| ENST00000340214 | CACUL1 | chr10 | 120488807 | - | ENST00000369144 | EIF3A | chr10 | 120818909 | - | 4982 | 1081 | 484 | 3786 | 1100 |
| ENST00000340214 | CACUL1 | chr10 | 120488807 | - | ENST00000541549 | EIF3A | chr10 | 120818909 | - | 4033 | 1081 | 484 | 3786 | 1100 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000369151 | ENST00000369144 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - | 0.000487073 | 0.9995129 |
| ENST00000369151 | ENST00000541549 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - | 0.001701518 | 0.99829847 |
| ENST00000340214 | ENST00000369144 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - | 0.000487073 | 0.9995129 |
| ENST00000340214 | ENST00000541549 | CACUL1 | chr10 | 120488807 | - | EIF3A | chr10 | 120818909 | - | 0.001701518 | 0.99829847 |
Top |
Fusion Genomic Features for CACUL1-EIF3A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
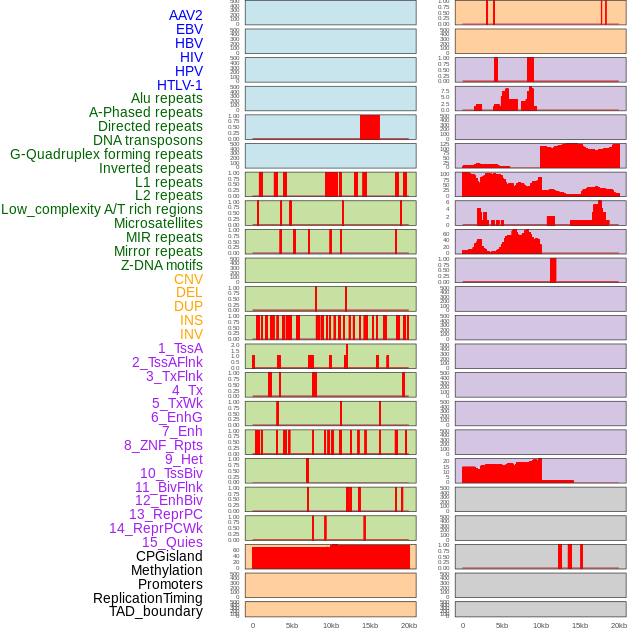 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CACUL1-EIF3A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:120488807/chr10:120818909) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CACUL1 | EIF3A |
| FUNCTION: Cell cycle associated protein capable of promoting cell proliferation through the activation of CDK2 at the G1/S phase transition. {ECO:0000269|PubMed:19829063}. | FUNCTION: RNA-binding component of the eukaryotic translation initiation factor 3 (eIF-3) complex, which is required for several steps in the initiation of protein synthesis (PubMed:17581632, PubMed:25849773). The eIF-3 complex associates with the 40S ribosome and facilitates the recruitment of eIF-1, eIF-1A, eIF-2:GTP:methionyl-tRNAi and eIF-5 to form the 43S pre-initiation complex (43S PIC). The eIF-3 complex stimulates mRNA recruitment to the 43S PIC and scanning of the mRNA for AUG recognition. The eIF-3 complex is also required for disassembly and recycling of post-termination ribosomal complexes and subsequently prevents premature joining of the 40S and 60S ribosomal subunits prior to initiation (PubMed:17581632, PubMed:11169732). The eIF-3 complex specifically targets and initiates translation of a subset of mRNAs involved in cell proliferation, including cell cycling, differentiation and apoptosis, and uses different modes of RNA stem-loop binding to exert either translational activation or repression (PubMed:25849773, PubMed:27462815). {ECO:0000255|HAMAP-Rule:MF_03000, ECO:0000269|PubMed:11169732, ECO:0000269|PubMed:17581632, ECO:0000269|PubMed:25849773, ECO:0000269|PubMed:27462815}.; FUNCTION: (Microbial infection) Essential for the initiation of translation on type-1 viral ribosomal entry sites (IRESs), like for HCV, PV, EV71 or BEV translation (PubMed:23766293, PubMed:24357634). {ECO:0000269|PubMed:23766293, ECO:0000269|PubMed:24357634}.; FUNCTION: (Microbial infection) In case of FCV infection, plays a role in the ribosomal termination-reinitiation event leading to the translation of VP2 (PubMed:18056426). {ECO:0000269|PubMed:18056426}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CACUL1 | chr10:120488807 | chr10:120818909 | ENST00000340214 | - | 3 | 7 | 35_82 | 199 | 304.0 | Compositional bias | Note=Pro-rich |
| Hgene | CACUL1 | chr10:120488807 | chr10:120818909 | ENST00000340214 | - | 3 | 7 | 96_106 | 199 | 304.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CACUL1 | chr10:120488807 | chr10:120818909 | ENST00000369151 | - | 3 | 9 | 35_82 | 199 | 370.0 | Compositional bias | Note=Pro-rich |
| Hgene | CACUL1 | chr10:120488807 | chr10:120818909 | ENST00000369151 | - | 3 | 9 | 96_106 | 199 | 370.0 | Compositional bias | Note=Poly-Ala |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 576_875 | 481 | 1383.0 | Compositional bias | Note=Glu-rich | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 925_1294 | 481 | 1383.0 | Compositional bias | Note=Asp-rich | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 925_1172 | 481 | 1383.0 | Region | Note=25 X 10 AA approximate tandem repeats of [DE]-[DE]-[DE]-R-[SEVGFPILV]-[HPSN]-[RSW]-[RL]-[DRGTIHN]-[EPMANLGDT] | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1003_1012 | 481 | 1383.0 | Repeat | Note=9 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1013_1022 | 481 | 1383.0 | Repeat | Note=10 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1023_1032 | 481 | 1383.0 | Repeat | Note=11 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1033_1042 | 481 | 1383.0 | Repeat | Note=12 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1043_1052 | 481 | 1383.0 | Repeat | Note=13 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1054_1063 | 481 | 1383.0 | Repeat | Note=14 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1064_1073 | 481 | 1383.0 | Repeat | Note=15 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1074_1083 | 481 | 1383.0 | Repeat | Note=16 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1084_1093 | 481 | 1383.0 | Repeat | Note=17 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1094_1103 | 481 | 1383.0 | Repeat | Note=18 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1104_1113 | 481 | 1383.0 | Repeat | Note=19 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1114_1123 | 481 | 1383.0 | Repeat | Note=20 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1124_1133 | 481 | 1383.0 | Repeat | Note=21 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1134_1143 | 481 | 1383.0 | Repeat | Note=22 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1144_1152 | 481 | 1383.0 | Repeat | Note=23%3B truncated | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1153_1162 | 481 | 1383.0 | Repeat | Note=24 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 1163_1172 | 481 | 1383.0 | Repeat | Note=25%3B approximate | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 925_934 | 481 | 1383.0 | Repeat | Note=1 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 935_942 | 481 | 1383.0 | Repeat | Note=2%3B truncated | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 943_952 | 481 | 1383.0 | Repeat | Note=3 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 953_962 | 481 | 1383.0 | Repeat | Note=4 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 963_972 | 481 | 1383.0 | Repeat | Note=5 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 973_982 | 481 | 1383.0 | Repeat | Note=6 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 983_992 | 481 | 1383.0 | Repeat | Note=7 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 993_1002 | 481 | 1383.0 | Repeat | Note=8 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 82_120 | 481 | 1383.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 315_498 | 481 | 1383.0 | Domain | PCI |
Top |
Fusion Gene Sequence for CACUL1-EIF3A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >12426_12426_1_CACUL1-EIF3A_CACUL1_chr10_120488807_ENST00000340214_EIF3A_chr10_120818909_ENST00000369144_length(transcript)=4982nt_BP=1081nt GAGGCCGGGCAGGGGGCGGGGCCGGCGAATGCCCGTCCCGACCCGTCGCGCCTCCCCTGTTAGCTCCCTGCCAGCCGAGGCGGGGCGAAC CTCTGCCCTGTTGCGTGGGAGTGACTCACAGCTCCCGCCCCTTTTGGCTCCGCTTTCTCGCGGCCAGTCCCTCGCACCACGTGCCCTCCT GGCCGCGCCCCCAGCTGCCCTTTCCAACTGCCTGTTGGAAGCCGCTGTAAAACGTCGTGAGGAGCGCCGCTGCTTTACGGCTGCCTCTCC CAGACTAGAGCCCCGGAGCGCCCACCGCCGTCAGCCGCGTCTTCAAGCTAGTCGGCCCCGCGGAGAGCGAGAGACCCTGCGCACCGCAGC CCTCTCCGCTGCGCCCATTCCTGCCGCCGGCGATGTAACTCGGGGAGGCAGCGGTGCCCGCTGGCCCGGGGTTGAGACAGGCGGCAGGTG CCTGTGAGGCGGGCGGGTGCCGGGGGCCAGCAGGATGGAGGAAAGCATGGAAGAGGAGGAGGGGGGCAGCTACGAGGCGATGATGGACGA CCAGAACCACAACAACTGGGAGGCTGCGGTGGACGGCTTCCGGCAGCCCCTGCCACCTCCGCCGCCCCCCTCGTCGATCCCGGCCCCTGC CCGAGAGCCTCCGGGGGGGCAGCTGCTGGCGGTGCCCGCGGTCTCCGTGGACAGGAAAGGCCCCAAGGAGGGGCTCCCGATGGGGCCGCA GCCACCGCCGGAGGCTAATGGGGTGATCATGATGTTGAAGAGCTGCGACGCGGCCGCCGCCGTGGCCAAGGCGGCCCCCGCCCCCACCGC CAGCTCCACCATCAACATCAACACCTCCACCTCCAAGTTCTTAATGAATGTTATAACTATTGAAGATTATAAGAGCACATACTGGCCAAA ATTGGATGGTGCCATAGATCAACTTTTAACTCAGAGTCCTGGTGACTATATCCCCATATCCTATGAACAGATATACAGTTGTGTGTATAA ATGTGTATGCCAGCAGCACTCGGAACAGATGTATAGTGATCTGATTAAAAAGATAACTAATCACTTAGAGAGAGTCTCAAAGGAGCTGCA GGTTCGTATTGATCACACTTCTCGGACCCTGAGTTTTGGATCTGATTTGAATTATGCTACTCGAGAAGATGCTCCGATTGGTCCTCATTT GCAAAGCATGCCTTCAGAGCAGATAAGAAACCAGCTGACAGCCATGTCCTCAGTACTTGCAAAAGCACTTGAAGTCATTAAACCAGCTCA TATACTGCAAGAGAAAGAAGAACAGCATCAGTTGGCTGTCACTGCATACCTTAAAAATTCACGAAAAGAGCACCAGCGGATCCTGGCTCG CCGCCAGACAATTGAGGAGAGAAAAGAGCGCCTTGAGAGTCTGAATATTCAGCGTGAGAAAGAAGAATTGGAACAGAGGGAAGCTGAACT CCAGAAAGTGCGGAAGGCTGAGGAAGAGAGGCTGCGCCAGGAAGCAAAGGAGAGAGAGAAGGAGCGTATCTTACAGGAACATGAACAAAT CAAAAAGAAAACTGTCCGAGAGCGTTTGGAGCAGATCAAGAAAACAGAACTGGGTGCCAAAGCATTCAAAGATATTGATATTGAAGACCT TGAGGAATTGGATCCAGATTTTATCATGGCTAAACAGGTTGAACAACTGGAGAAAGAAAAGAAAGAACTTCAAGAACGCCTAAAGAATCA AGAAAAGAAGATTGACTATTTTGAAAGAGCCAAACGTTTGGAAGAAATTCCTTTGATAAAGAGCGCTTACGAGGAACAGAGAATTAAAGA CATGGATCTGTGGGAGCAACAAGAGGAAGAAAGAATTACTACAATGCAGCTAGAACGTGAAAAGGCTCTTGAACATAAGAATCGAATGTC ACGAATGCTTGAAGACAGAGATTTATTCGTAATGCGACTCAAAGCTGCACGGCAGTCTGTTTATGAGGAAAAACTTAAACAGTTTGAAGA GCGATTAGCAGAAGAAAGGCATAATCGATTGGAAGAACGGAAAAGGCAGCGTAAAGAAGAACGCAGGATAACATACTATAGAGAAAAAGA AGAGGAGGAGCAGAGAAGGGCAGAAGAACAAATGCTAAAAGAGCGGGAAGAGAGAGAGCGCGCCGAACGAGCAAAACGCGAGGAAGAGCT ACGAGAGTATCAGGAGCGGGTGAAGAAATTAGAAGAAGTGGAAAGGAAAAAACGCCAAAGGGAGTTGGAAATTGAAGAACGAGAACGGCG TAGAGAGGAAGAGAGAAGACTTGGCGATAGTTCCCTTTCTAGAAAGGACTCTCGTTGGGGAGATAGAGATTCAGAAGGCACCTGGAGAAA AGGACCTGAAGCAGATTCTGAGTGGAGAAGAGGCCCGCCAGAGAAGGAGTGGAGACGTGGAGAAGGGCGAGATGAGGACAGGTCTCATAG AAGAGATGAAGAGCGGCCCCGGCGTCTGGGGGATGATGAAGATAGAGAGCCCTCTCTTAGACCAGACGATGATCGGGTTCCCCGGCGTGG CATGGATGATGACAGAGGCCCTAGACGTGGTCCTGAGGAAGATAGGTTCTCTCGTCGTGGGGCAGACGATGACCGGCCTTCCTGGCGTAA CACAGATGATGACAGGCCTCCCAGACGAATTGCCGATGAAGACAGGGGAAACTGGCGTCATGCGGATGATGACAGACCACCTAGACGAGG ACTGGATGAGGACAGAGGAAGCTGGCGAACAGCTGATGAGGACAGAGGACCAAGACGTGGGATGGATGATGACCGGGGGCCGAGGCGAGG AGGCGCTGATGATGAGCGATCATCCTGGCGTAATGCTGATGATGACCGGGGTCCCAGGCGAGGGTTGGATGATGATCGGGGTCCCAGGCG AGGCATGGATGATGACCGGGGTCCCAGGCGAGGCATGGATGATGACCGGGGTCCCAGGCGAGGCATGGATGATGACCGGGGTCCCAGGCG AGGGTTGGATGATGATCGAGGACCTTGGAGGAACGCCGATGATGACAGAATTCCCAGGCGTGGTGCAGAGGATGACAGGGGCCCTTGGAG AAACATGGATGATGATCGCCTTTCAAGACGTGCTGATGATGATCGGTTTCCCAGACGGGGTGATGACTCAAGACCTGGTCCTTGGAGACC ATTAGTCAAGCCAGGTGGATGGAGAGAGAAAGAAAAAGCCAGAGAGGAGAGCTGGGGTCCACCTCGAGAATCAAGGCCATCAGAAGAACG TGAATGGGACAGAGAAAAAGAAAGGGACAGAGATAATCAAGATCGGGAGGAGAATGACAAGGACCCTGAGAGAGAAAGGGACAGAGAGAG AGATGTGGATCGAGAGGATCGCTTCAGAAGACCTAGGGATGAAGGTGGCTGGAGAAGAGGACCAGCTGAGGAATCTTCAAGCTGGAGAGA CTCAAGTCGCCGGGACGATAGGGATAGGGATGACCGTCGCCGTGAGAGGGATGACCGGCGTGATCTAAGAGAAAGACGAGATCTAAGAGA CGACAGGGACCGAAGAGGACCTCCACTCAGATCAGAACGTGAAGAAGTAAGTTCTTGGAGACGTGCTGATGACAGGAAAGATGACCGGGT GGAAGAGCGGGACCCTCCTCGTCGAGTTCCTCCCCCAGCTCTTTCAAGAGACCGAGAAAGAGACCGAGACCGAGAAAGAGAAGGTGAAAA AGAGAAGGCCTCATGGAGAGCTGAGAAAGATAGGGAATCTCTCCGTCGTACTAAAAATGAGACTGATGAAGATGGATGGACCACAGTACG ACGTTAAGTCTCAAGATAATGGATTTAAACTGGTGTCTTAAATAGGTTTGATCACATTCAAGGATTATTATACTTGTGCTTCAACCAATC TAAATTGGATTCTTTAATGTTGTTTCACCATAACACAAAAAGCATGAACTTGTATTAATCCTATATAATAGATTGATCATGCACCATATC CACAGGAGGTTGGAAAAACCATGCCATTTTCTGGAATTTAAGGGTGTTGCATTATTTCATCAATCATTTGTTGACAAAAAAGAAAAACTA AAAAATAAATTTAAAATGTGACCCTTCAGGTATTGAGTAACACCTTTATCTTGGTATAGAACTGATACTTTTTTTTTGATTTTGAAATAT CTGATAATAATTTGGAATGAAGTAAGGTTCTGTTAAAATATATTTGAAGACCCTTTAAAGCAGTGAATCTGAAACAATTTTCACACCCTT AAGTGGTTGATACGTACCTATTTTAGGTATTTTGAGGTATTTACCATAAACTAAATTTAGAAATTTTTTAGATTCACTTGAAGTAAACAT TACAAACATTGGATACGGTGGGGTTTTCTTTAGATTTTACTTGAGAGAAGGTGAGTACAAAGCAATTTGCAGTTGTTGTAATGACAAGAT TACTGCGCAAGTGTGAATCCAAACAGTATAGCTTTTAAATTTTAAAGCATTTGGTAAATTATCGCTGAGTTTTTTTCTGTTGCCAATAGC AAACTGCTTTTCCATTAATGGAGAATTCATGCCTTTCAAGCATTTTAAATATGACAATATTTATAAATGTATGGTTTGGAGGAATCGTTT AAATTCTCTTTCCTAATTTTCTTTCTTTTGAAGATAGATTCTTTCAACAAGTAATTTGTAGTAATGACTGTGTTGACTTCAATTTTGGAG CGCAGTAGCTATGTTAAAGATGAACTATTTGGTCTCATTGAAGCCAACACAGAACTTGCTGCTGTGTTTTTTCTTCAGTGATAAATAAAA TACTTACAGAATTTGTTTTAGTGTTGATTTGTGGTTATAGTATTTTGTTTATAATGGTAAGTTTGCATATTCAGTTGAGTTTTTTTTACT TGAATTTTTATCAGTGCCATTAAATGTCTGTGTTTAGTATCAATGAAAATGAACCTAAATATAACAAAGAAAGCATATGTGGCTAGGATG >12426_12426_1_CACUL1-EIF3A_CACUL1_chr10_120488807_ENST00000340214_EIF3A_chr10_120818909_ENST00000369144_length(amino acids)=1100AA_BP=526 MEESMEEEEGGSYEAMMDDQNHNNWEAAVDGFRQPLPPPPPPSSIPAPAREPPGGQLLAVPAVSVDRKGPKEGLPMGPQPPPEANGVIMM LKSCDAAAAVAKAAPAPTASSTININTSTSKFLMNVITIEDYKSTYWPKLDGAIDQLLTQSPGDYIPISYEQIYSCVYKCVCQQHSEQMY SDLIKKITNHLERVSKELQVRIDHTSRTLSFGSDLNYATREDAPIGPHLQSMPSEQIRNQLTAMSSVLAKALEVIKPAHILQEKEEQHQL AVTAYLKNSRKEHQRILARRQTIEERKERLESLNIQREKEELEQREAELQKVRKAEEERLRQEAKEREKERILQEHEQIKKKTVRERLEQ IKKTELGAKAFKDIDIEDLEELDPDFIMAKQVEQLEKEKKELQERLKNQEKKIDYFERAKRLEEIPLIKSAYEEQRIKDMDLWEQQEEER ITTMQLEREKALEHKNRMSRMLEDRDLFVMRLKAARQSVYEEKLKQFEERLAEERHNRLEERKRQRKEERRITYYREKEEEEQRRAEEQM LKEREERERAERAKREEELREYQERVKKLEEVERKKRQRELEIEERERRREEERRLGDSSLSRKDSRWGDRDSEGTWRKGPEADSEWRRG PPEKEWRRGEGRDEDRSHRRDEERPRRLGDDEDREPSLRPDDDRVPRRGMDDDRGPRRGPEEDRFSRRGADDDRPSWRNTDDDRPPRRIA DEDRGNWRHADDDRPPRRGLDEDRGSWRTADEDRGPRRGMDDDRGPRRGGADDERSSWRNADDDRGPRRGLDDDRGPRRGMDDDRGPRRG MDDDRGPRRGMDDDRGPRRGLDDDRGPWRNADDDRIPRRGAEDDRGPWRNMDDDRLSRRADDDRFPRRGDDSRPGPWRPLVKPGGWREKE KAREESWGPPRESRPSEEREWDREKERDRDNQDREENDKDPERERDRERDVDREDRFRRPRDEGGWRRGPAEESSSWRDSSRRDDRDRDD RRRERDDRRDLRERRDLRDDRDRRGPPLRSEREEVSSWRRADDRKDDRVEERDPPRRVPPPALSRDRERDRDREREGEKEKASWRAEKDR -------------------------------------------------------------- >12426_12426_2_CACUL1-EIF3A_CACUL1_chr10_120488807_ENST00000340214_EIF3A_chr10_120818909_ENST00000541549_length(transcript)=4033nt_BP=1081nt GAGGCCGGGCAGGGGGCGGGGCCGGCGAATGCCCGTCCCGACCCGTCGCGCCTCCCCTGTTAGCTCCCTGCCAGCCGAGGCGGGGCGAAC CTCTGCCCTGTTGCGTGGGAGTGACTCACAGCTCCCGCCCCTTTTGGCTCCGCTTTCTCGCGGCCAGTCCCTCGCACCACGTGCCCTCCT GGCCGCGCCCCCAGCTGCCCTTTCCAACTGCCTGTTGGAAGCCGCTGTAAAACGTCGTGAGGAGCGCCGCTGCTTTACGGCTGCCTCTCC CAGACTAGAGCCCCGGAGCGCCCACCGCCGTCAGCCGCGTCTTCAAGCTAGTCGGCCCCGCGGAGAGCGAGAGACCCTGCGCACCGCAGC CCTCTCCGCTGCGCCCATTCCTGCCGCCGGCGATGTAACTCGGGGAGGCAGCGGTGCCCGCTGGCCCGGGGTTGAGACAGGCGGCAGGTG CCTGTGAGGCGGGCGGGTGCCGGGGGCCAGCAGGATGGAGGAAAGCATGGAAGAGGAGGAGGGGGGCAGCTACGAGGCGATGATGGACGA CCAGAACCACAACAACTGGGAGGCTGCGGTGGACGGCTTCCGGCAGCCCCTGCCACCTCCGCCGCCCCCCTCGTCGATCCCGGCCCCTGC CCGAGAGCCTCCGGGGGGGCAGCTGCTGGCGGTGCCCGCGGTCTCCGTGGACAGGAAAGGCCCCAAGGAGGGGCTCCCGATGGGGCCGCA GCCACCGCCGGAGGCTAATGGGGTGATCATGATGTTGAAGAGCTGCGACGCGGCCGCCGCCGTGGCCAAGGCGGCCCCCGCCCCCACCGC CAGCTCCACCATCAACATCAACACCTCCACCTCCAAGTTCTTAATGAATGTTATAACTATTGAAGATTATAAGAGCACATACTGGCCAAA ATTGGATGGTGCCATAGATCAACTTTTAACTCAGAGTCCTGGTGACTATATCCCCATATCCTATGAACAGATATACAGTTGTGTGTATAA ATGTGTATGCCAGCAGCACTCGGAACAGATGTATAGTGATCTGATTAAAAAGATAACTAATCACTTAGAGAGAGTCTCAAAGGAGCTGCA GGTTCGTATTGATCACACTTCTCGGACCCTGAGTTTTGGATCTGATTTGAATTATGCTACTCGAGAAGATGCTCCGATTGGTCCTCATTT GCAAAGCATGCCTTCAGAGCAGATAAGAAACCAGCTGACAGCCATGTCCTCAGTACTTGCAAAAGCACTTGAAGTCATTAAACCAGCTCA TATACTGCAAGAGAAAGAAGAACAGCATCAGTTGGCTGTCACTGCATACCTTAAAAATTCACGAAAAGAGCACCAGCGGATCCTGGCTCG CCGCCAGACAATTGAGGAGAGAAAAGAGCGCCTTGAGAGTCTGAATATTCAGCGTGAGAAAGAAGAATTGGAACAGAGGGAAGCTGAACT CCAGAAAGTGCGGAAGGCTGAGGAAGAGAGGCTGCGCCAGGAAGCAAAGGAGAGAGAGAAGGAGCGTATCTTACAGGAACATGAACAAAT CAAAAAGAAAACTGTCCGAGAGCGTTTGGAGCAGATCAAGAAAACAGAACTGGGTGCCAAAGCATTCAAAGATATTGATATTGAAGACCT TGAGGAATTGGATCCAGATTTTATCATGGCTAAACAGGTTGAACAACTGGAGAAAGAAAAGAAAGAACTTCAAGAACGCCTAAAGAATCA AGAAAAGAAGATTGACTATTTTGAAAGAGCCAAACGTTTGGAAGAAATTCCTTTGATAAAGAGCGCTTACGAGGAACAGAGAATTAAAGA CATGGATCTGTGGGAGCAACAAGAGGAAGAAAGAATTACTACAATGCAGCTAGAACGTGAAAAGGCTCTTGAACATAAGAATCGAATGTC ACGAATGCTTGAAGACAGAGATTTATTCGTAATGCGACTCAAAGCTGCACGGCAGTCTGTTTATGAGGAAAAACTTAAACAGTTTGAAGA GCGATTAGCAGAAGAAAGGCATAATCGATTGGAAGAACGGAAAAGGCAGCGTAAAGAAGAACGCAGGATAACATACTATAGAGAAAAAGA AGAGGAGGAGCAGAGAAGGGCAGAAGAACAAATGCTAAAAGAGCGGGAAGAGAGAGAGCGCGCCGAACGAGCAAAACGCGAGGAAGAGCT ACGAGAGTATCAGGAGCGGGTGAAGAAATTAGAAGAAGTGGAAAGGAAAAAACGCCAAAGGGAGTTGGAAATTGAAGAACGAGAACGGCG TAGAGAGGAAGAGAGAAGACTTGGCGATAGTTCCCTTTCTAGAAAGGACTCTCGTTGGGGAGATAGAGATTCAGAAGGCACCTGGAGAAA AGGACCTGAAGCAGATTCTGAGTGGAGAAGAGGCCCGCCAGAGAAGGAGTGGAGACGTGGAGAAGGGCGAGATGAGGACAGGTCTCATAG AAGAGATGAAGAGCGGCCCCGGCGTCTGGGGGATGATGAAGATAGAGAGCCCTCTCTTAGACCAGACGATGATCGGGTTCCCCGGCGTGG CATGGATGATGACAGAGGCCCTAGACGTGGTCCTGAGGAAGATAGGTTCTCTCGTCGTGGGGCAGACGATGACCGGCCTTCCTGGCGTAA CACAGATGATGACAGGCCTCCCAGACGAATTGCCGATGAAGACAGGGGAAACTGGCGTCATGCGGATGATGACAGACCACCTAGACGAGG ACTGGATGAGGACAGAGGAAGCTGGCGAACAGCTGATGAGGACAGAGGACCAAGACGTGGGATGGATGATGACCGGGGGCCGAGGCGAGG AGGCGCTGATGATGAGCGATCATCCTGGCGTAATGCTGATGATGACCGGGGTCCCAGGCGAGGGTTGGATGATGATCGGGGTCCCAGGCG AGGCATGGATGATGACCGGGGTCCCAGGCGAGGCATGGATGATGACCGGGGTCCCAGGCGAGGCATGGATGATGACCGGGGTCCCAGGCG AGGGTTGGATGATGATCGAGGACCTTGGAGGAACGCCGATGATGACAGAATTCCCAGGCGTGGTGCAGAGGATGACAGGGGCCCTTGGAG AAACATGGATGATGATCGCCTTTCAAGACGTGCTGATGATGATCGGTTTCCCAGACGGGGTGATGACTCAAGACCTGGTCCTTGGAGACC ATTAGTCAAGCCAGGTGGATGGAGAGAGAAAGAAAAAGCCAGAGAGGAGAGCTGGGGTCCACCTCGAGAATCAAGGCCATCAGAAGAACG TGAATGGGACAGAGAAAAAGAAAGGGACAGAGATAATCAAGATCGGGAGGAGAATGACAAGGACCCTGAGAGAGAAAGGGACAGAGAGAG AGATGTGGATCGAGAGGATCGCTTCAGAAGACCTAGGGATGAAGGTGGCTGGAGAAGAGGACCAGCTGAGGAATCTTCAAGCTGGAGAGA CTCAAGTCGCCGGGACGATAGGGATAGGGATGACCGTCGCCGTGAGAGGGATGACCGGCGTGATCTAAGAGAAAGACGAGATCTAAGAGA CGACAGGGACCGAAGAGGACCTCCACTCAGATCAGAACGTGAAGAAGTAAGTTCTTGGAGACGTGCTGATGACAGGAAAGATGACCGGGT GGAAGAGCGGGACCCTCCTCGTCGAGTTCCTCCCCCAGCTCTTTCAAGAGACCGAGAAAGAGACCGAGACCGAGAAAGAGAAGGTGAAAA AGAGAAGGCCTCATGGAGAGCTGAGAAAGATAGGGAATCTCTCCGTCGTACTAAAAATGAGACTGATGAAGATGGATGGACCACAGTACG ACGTTAAGTCTCAAGATAATGGATTTAAACTGGTGTCTTAAATAGGTTTGATCACATTCAAGGATTATTATACTTGTGCTTCAACCAATC TAAATTGGATTCTTTAATGTTGTTTCACCATAACACAAAAAGCATGAACTTGTATTAATCCTATATAATAGATTGATCATGCACCATATC >12426_12426_2_CACUL1-EIF3A_CACUL1_chr10_120488807_ENST00000340214_EIF3A_chr10_120818909_ENST00000541549_length(amino acids)=1100AA_BP=526 MEESMEEEEGGSYEAMMDDQNHNNWEAAVDGFRQPLPPPPPPSSIPAPAREPPGGQLLAVPAVSVDRKGPKEGLPMGPQPPPEANGVIMM LKSCDAAAAVAKAAPAPTASSTININTSTSKFLMNVITIEDYKSTYWPKLDGAIDQLLTQSPGDYIPISYEQIYSCVYKCVCQQHSEQMY SDLIKKITNHLERVSKELQVRIDHTSRTLSFGSDLNYATREDAPIGPHLQSMPSEQIRNQLTAMSSVLAKALEVIKPAHILQEKEEQHQL AVTAYLKNSRKEHQRILARRQTIEERKERLESLNIQREKEELEQREAELQKVRKAEEERLRQEAKEREKERILQEHEQIKKKTVRERLEQ IKKTELGAKAFKDIDIEDLEELDPDFIMAKQVEQLEKEKKELQERLKNQEKKIDYFERAKRLEEIPLIKSAYEEQRIKDMDLWEQQEEER ITTMQLEREKALEHKNRMSRMLEDRDLFVMRLKAARQSVYEEKLKQFEERLAEERHNRLEERKRQRKEERRITYYREKEEEEQRRAEEQM LKEREERERAERAKREEELREYQERVKKLEEVERKKRQRELEIEERERRREEERRLGDSSLSRKDSRWGDRDSEGTWRKGPEADSEWRRG PPEKEWRRGEGRDEDRSHRRDEERPRRLGDDEDREPSLRPDDDRVPRRGMDDDRGPRRGPEEDRFSRRGADDDRPSWRNTDDDRPPRRIA DEDRGNWRHADDDRPPRRGLDEDRGSWRTADEDRGPRRGMDDDRGPRRGGADDERSSWRNADDDRGPRRGLDDDRGPRRGMDDDRGPRRG MDDDRGPRRGMDDDRGPRRGLDDDRGPWRNADDDRIPRRGAEDDRGPWRNMDDDRLSRRADDDRFPRRGDDSRPGPWRPLVKPGGWREKE KAREESWGPPRESRPSEEREWDREKERDRDNQDREENDKDPERERDRERDVDREDRFRRPRDEGGWRRGPAEESSSWRDSSRRDDRDRDD RRRERDDRRDLRERRDLRDDRDRRGPPLRSEREEVSSWRRADDRKDDRVEERDPPRRVPPPALSRDRERDRDREREGEKEKASWRAEKDR -------------------------------------------------------------- >12426_12426_3_CACUL1-EIF3A_CACUL1_chr10_120488807_ENST00000369151_EIF3A_chr10_120818909_ENST00000369144_length(transcript)=4982nt_BP=1081nt GAGGCCGGGCAGGGGGCGGGGCCGGCGAATGCCCGTCCCGACCCGTCGCGCCTCCCCTGTTAGCTCCCTGCCAGCCGAGGCGGGGCGAAC CTCTGCCCTGTTGCGTGGGAGTGACTCACAGCTCCCGCCCCTTTTGGCTCCGCTTTCTCGCGGCCAGTCCCTCGCACCACGTGCCCTCCT GGCCGCGCCCCCAGCTGCCCTTTCCAACTGCCTGTTGGAAGCCGCTGTAAAACGTCGTGAGGAGCGCCGCTGCTTTACGGCTGCCTCTCC CAGACTAGAGCCCCGGAGCGCCCACCGCCGTCAGCCGCGTCTTCAAGCTAGTCGGCCCCGCGGAGAGCGAGAGACCCTGCGCACCGCAGC CCTCTCCGCTGCGCCCATTCCTGCCGCCGGCGATGTAACTCGGGGAGGCAGCGGTGCCCGCTGGCCCGGGGTTGAGACAGGCGGCAGGTG CCTGTGAGGCGGGCGGGTGCCGGGGGCCAGCAGGATGGAGGAAAGCATGGAAGAGGAGGAGGGGGGCAGCTACGAGGCGATGATGGACGA CCAGAACCACAACAACTGGGAGGCTGCGGTGGACGGCTTCCGGCAGCCCCTGCCACCTCCGCCGCCCCCCTCGTCGATCCCGGCCCCTGC CCGAGAGCCTCCGGGGGGGCAGCTGCTGGCGGTGCCCGCGGTCTCCGTGGACAGGAAAGGCCCCAAGGAGGGGCTCCCGATGGGGCCGCA GCCACCGCCGGAGGCTAATGGGGTGATCATGATGTTGAAGAGCTGCGACGCGGCCGCCGCCGTGGCCAAGGCGGCCCCCGCCCCCACCGC CAGCTCCACCATCAACATCAACACCTCCACCTCCAAGTTCTTAATGAATGTTATAACTATTGAAGATTATAAGAGCACATACTGGCCAAA ATTGGATGGTGCCATAGATCAACTTTTAACTCAGAGTCCTGGTGACTATATCCCCATATCCTATGAACAGATATACAGTTGTGTGTATAA ATGTGTATGCCAGCAGCACTCGGAACAGATGTATAGTGATCTGATTAAAAAGATAACTAATCACTTAGAGAGAGTCTCAAAGGAGCTGCA GGTTCGTATTGATCACACTTCTCGGACCCTGAGTTTTGGATCTGATTTGAATTATGCTACTCGAGAAGATGCTCCGATTGGTCCTCATTT GCAAAGCATGCCTTCAGAGCAGATAAGAAACCAGCTGACAGCCATGTCCTCAGTACTTGCAAAAGCACTTGAAGTCATTAAACCAGCTCA TATACTGCAAGAGAAAGAAGAACAGCATCAGTTGGCTGTCACTGCATACCTTAAAAATTCACGAAAAGAGCACCAGCGGATCCTGGCTCG CCGCCAGACAATTGAGGAGAGAAAAGAGCGCCTTGAGAGTCTGAATATTCAGCGTGAGAAAGAAGAATTGGAACAGAGGGAAGCTGAACT CCAGAAAGTGCGGAAGGCTGAGGAAGAGAGGCTGCGCCAGGAAGCAAAGGAGAGAGAGAAGGAGCGTATCTTACAGGAACATGAACAAAT CAAAAAGAAAACTGTCCGAGAGCGTTTGGAGCAGATCAAGAAAACAGAACTGGGTGCCAAAGCATTCAAAGATATTGATATTGAAGACCT TGAGGAATTGGATCCAGATTTTATCATGGCTAAACAGGTTGAACAACTGGAGAAAGAAAAGAAAGAACTTCAAGAACGCCTAAAGAATCA AGAAAAGAAGATTGACTATTTTGAAAGAGCCAAACGTTTGGAAGAAATTCCTTTGATAAAGAGCGCTTACGAGGAACAGAGAATTAAAGA CATGGATCTGTGGGAGCAACAAGAGGAAGAAAGAATTACTACAATGCAGCTAGAACGTGAAAAGGCTCTTGAACATAAGAATCGAATGTC ACGAATGCTTGAAGACAGAGATTTATTCGTAATGCGACTCAAAGCTGCACGGCAGTCTGTTTATGAGGAAAAACTTAAACAGTTTGAAGA GCGATTAGCAGAAGAAAGGCATAATCGATTGGAAGAACGGAAAAGGCAGCGTAAAGAAGAACGCAGGATAACATACTATAGAGAAAAAGA AGAGGAGGAGCAGAGAAGGGCAGAAGAACAAATGCTAAAAGAGCGGGAAGAGAGAGAGCGCGCCGAACGAGCAAAACGCGAGGAAGAGCT ACGAGAGTATCAGGAGCGGGTGAAGAAATTAGAAGAAGTGGAAAGGAAAAAACGCCAAAGGGAGTTGGAAATTGAAGAACGAGAACGGCG TAGAGAGGAAGAGAGAAGACTTGGCGATAGTTCCCTTTCTAGAAAGGACTCTCGTTGGGGAGATAGAGATTCAGAAGGCACCTGGAGAAA AGGACCTGAAGCAGATTCTGAGTGGAGAAGAGGCCCGCCAGAGAAGGAGTGGAGACGTGGAGAAGGGCGAGATGAGGACAGGTCTCATAG AAGAGATGAAGAGCGGCCCCGGCGTCTGGGGGATGATGAAGATAGAGAGCCCTCTCTTAGACCAGACGATGATCGGGTTCCCCGGCGTGG CATGGATGATGACAGAGGCCCTAGACGTGGTCCTGAGGAAGATAGGTTCTCTCGTCGTGGGGCAGACGATGACCGGCCTTCCTGGCGTAA CACAGATGATGACAGGCCTCCCAGACGAATTGCCGATGAAGACAGGGGAAACTGGCGTCATGCGGATGATGACAGACCACCTAGACGAGG ACTGGATGAGGACAGAGGAAGCTGGCGAACAGCTGATGAGGACAGAGGACCAAGACGTGGGATGGATGATGACCGGGGGCCGAGGCGAGG AGGCGCTGATGATGAGCGATCATCCTGGCGTAATGCTGATGATGACCGGGGTCCCAGGCGAGGGTTGGATGATGATCGGGGTCCCAGGCG AGGCATGGATGATGACCGGGGTCCCAGGCGAGGCATGGATGATGACCGGGGTCCCAGGCGAGGCATGGATGATGACCGGGGTCCCAGGCG AGGGTTGGATGATGATCGAGGACCTTGGAGGAACGCCGATGATGACAGAATTCCCAGGCGTGGTGCAGAGGATGACAGGGGCCCTTGGAG AAACATGGATGATGATCGCCTTTCAAGACGTGCTGATGATGATCGGTTTCCCAGACGGGGTGATGACTCAAGACCTGGTCCTTGGAGACC ATTAGTCAAGCCAGGTGGATGGAGAGAGAAAGAAAAAGCCAGAGAGGAGAGCTGGGGTCCACCTCGAGAATCAAGGCCATCAGAAGAACG TGAATGGGACAGAGAAAAAGAAAGGGACAGAGATAATCAAGATCGGGAGGAGAATGACAAGGACCCTGAGAGAGAAAGGGACAGAGAGAG AGATGTGGATCGAGAGGATCGCTTCAGAAGACCTAGGGATGAAGGTGGCTGGAGAAGAGGACCAGCTGAGGAATCTTCAAGCTGGAGAGA CTCAAGTCGCCGGGACGATAGGGATAGGGATGACCGTCGCCGTGAGAGGGATGACCGGCGTGATCTAAGAGAAAGACGAGATCTAAGAGA CGACAGGGACCGAAGAGGACCTCCACTCAGATCAGAACGTGAAGAAGTAAGTTCTTGGAGACGTGCTGATGACAGGAAAGATGACCGGGT GGAAGAGCGGGACCCTCCTCGTCGAGTTCCTCCCCCAGCTCTTTCAAGAGACCGAGAAAGAGACCGAGACCGAGAAAGAGAAGGTGAAAA AGAGAAGGCCTCATGGAGAGCTGAGAAAGATAGGGAATCTCTCCGTCGTACTAAAAATGAGACTGATGAAGATGGATGGACCACAGTACG ACGTTAAGTCTCAAGATAATGGATTTAAACTGGTGTCTTAAATAGGTTTGATCACATTCAAGGATTATTATACTTGTGCTTCAACCAATC TAAATTGGATTCTTTAATGTTGTTTCACCATAACACAAAAAGCATGAACTTGTATTAATCCTATATAATAGATTGATCATGCACCATATC CACAGGAGGTTGGAAAAACCATGCCATTTTCTGGAATTTAAGGGTGTTGCATTATTTCATCAATCATTTGTTGACAAAAAAGAAAAACTA AAAAATAAATTTAAAATGTGACCCTTCAGGTATTGAGTAACACCTTTATCTTGGTATAGAACTGATACTTTTTTTTTGATTTTGAAATAT CTGATAATAATTTGGAATGAAGTAAGGTTCTGTTAAAATATATTTGAAGACCCTTTAAAGCAGTGAATCTGAAACAATTTTCACACCCTT AAGTGGTTGATACGTACCTATTTTAGGTATTTTGAGGTATTTACCATAAACTAAATTTAGAAATTTTTTAGATTCACTTGAAGTAAACAT TACAAACATTGGATACGGTGGGGTTTTCTTTAGATTTTACTTGAGAGAAGGTGAGTACAAAGCAATTTGCAGTTGTTGTAATGACAAGAT TACTGCGCAAGTGTGAATCCAAACAGTATAGCTTTTAAATTTTAAAGCATTTGGTAAATTATCGCTGAGTTTTTTTCTGTTGCCAATAGC AAACTGCTTTTCCATTAATGGAGAATTCATGCCTTTCAAGCATTTTAAATATGACAATATTTATAAATGTATGGTTTGGAGGAATCGTTT AAATTCTCTTTCCTAATTTTCTTTCTTTTGAAGATAGATTCTTTCAACAAGTAATTTGTAGTAATGACTGTGTTGACTTCAATTTTGGAG CGCAGTAGCTATGTTAAAGATGAACTATTTGGTCTCATTGAAGCCAACACAGAACTTGCTGCTGTGTTTTTTCTTCAGTGATAAATAAAA TACTTACAGAATTTGTTTTAGTGTTGATTTGTGGTTATAGTATTTTGTTTATAATGGTAAGTTTGCATATTCAGTTGAGTTTTTTTTACT TGAATTTTTATCAGTGCCATTAAATGTCTGTGTTTAGTATCAATGAAAATGAACCTAAATATAACAAAGAAAGCATATGTGGCTAGGATG >12426_12426_3_CACUL1-EIF3A_CACUL1_chr10_120488807_ENST00000369151_EIF3A_chr10_120818909_ENST00000369144_length(amino acids)=1100AA_BP=526 MEESMEEEEGGSYEAMMDDQNHNNWEAAVDGFRQPLPPPPPPSSIPAPAREPPGGQLLAVPAVSVDRKGPKEGLPMGPQPPPEANGVIMM LKSCDAAAAVAKAAPAPTASSTININTSTSKFLMNVITIEDYKSTYWPKLDGAIDQLLTQSPGDYIPISYEQIYSCVYKCVCQQHSEQMY SDLIKKITNHLERVSKELQVRIDHTSRTLSFGSDLNYATREDAPIGPHLQSMPSEQIRNQLTAMSSVLAKALEVIKPAHILQEKEEQHQL AVTAYLKNSRKEHQRILARRQTIEERKERLESLNIQREKEELEQREAELQKVRKAEEERLRQEAKEREKERILQEHEQIKKKTVRERLEQ IKKTELGAKAFKDIDIEDLEELDPDFIMAKQVEQLEKEKKELQERLKNQEKKIDYFERAKRLEEIPLIKSAYEEQRIKDMDLWEQQEEER ITTMQLEREKALEHKNRMSRMLEDRDLFVMRLKAARQSVYEEKLKQFEERLAEERHNRLEERKRQRKEERRITYYREKEEEEQRRAEEQM LKEREERERAERAKREEELREYQERVKKLEEVERKKRQRELEIEERERRREEERRLGDSSLSRKDSRWGDRDSEGTWRKGPEADSEWRRG PPEKEWRRGEGRDEDRSHRRDEERPRRLGDDEDREPSLRPDDDRVPRRGMDDDRGPRRGPEEDRFSRRGADDDRPSWRNTDDDRPPRRIA DEDRGNWRHADDDRPPRRGLDEDRGSWRTADEDRGPRRGMDDDRGPRRGGADDERSSWRNADDDRGPRRGLDDDRGPRRGMDDDRGPRRG MDDDRGPRRGMDDDRGPRRGLDDDRGPWRNADDDRIPRRGAEDDRGPWRNMDDDRLSRRADDDRFPRRGDDSRPGPWRPLVKPGGWREKE KAREESWGPPRESRPSEEREWDREKERDRDNQDREENDKDPERERDRERDVDREDRFRRPRDEGGWRRGPAEESSSWRDSSRRDDRDRDD RRRERDDRRDLRERRDLRDDRDRRGPPLRSEREEVSSWRRADDRKDDRVEERDPPRRVPPPALSRDRERDRDREREGEKEKASWRAEKDR -------------------------------------------------------------- >12426_12426_4_CACUL1-EIF3A_CACUL1_chr10_120488807_ENST00000369151_EIF3A_chr10_120818909_ENST00000541549_length(transcript)=4033nt_BP=1081nt GAGGCCGGGCAGGGGGCGGGGCCGGCGAATGCCCGTCCCGACCCGTCGCGCCTCCCCTGTTAGCTCCCTGCCAGCCGAGGCGGGGCGAAC CTCTGCCCTGTTGCGTGGGAGTGACTCACAGCTCCCGCCCCTTTTGGCTCCGCTTTCTCGCGGCCAGTCCCTCGCACCACGTGCCCTCCT GGCCGCGCCCCCAGCTGCCCTTTCCAACTGCCTGTTGGAAGCCGCTGTAAAACGTCGTGAGGAGCGCCGCTGCTTTACGGCTGCCTCTCC CAGACTAGAGCCCCGGAGCGCCCACCGCCGTCAGCCGCGTCTTCAAGCTAGTCGGCCCCGCGGAGAGCGAGAGACCCTGCGCACCGCAGC CCTCTCCGCTGCGCCCATTCCTGCCGCCGGCGATGTAACTCGGGGAGGCAGCGGTGCCCGCTGGCCCGGGGTTGAGACAGGCGGCAGGTG CCTGTGAGGCGGGCGGGTGCCGGGGGCCAGCAGGATGGAGGAAAGCATGGAAGAGGAGGAGGGGGGCAGCTACGAGGCGATGATGGACGA CCAGAACCACAACAACTGGGAGGCTGCGGTGGACGGCTTCCGGCAGCCCCTGCCACCTCCGCCGCCCCCCTCGTCGATCCCGGCCCCTGC CCGAGAGCCTCCGGGGGGGCAGCTGCTGGCGGTGCCCGCGGTCTCCGTGGACAGGAAAGGCCCCAAGGAGGGGCTCCCGATGGGGCCGCA GCCACCGCCGGAGGCTAATGGGGTGATCATGATGTTGAAGAGCTGCGACGCGGCCGCCGCCGTGGCCAAGGCGGCCCCCGCCCCCACCGC CAGCTCCACCATCAACATCAACACCTCCACCTCCAAGTTCTTAATGAATGTTATAACTATTGAAGATTATAAGAGCACATACTGGCCAAA ATTGGATGGTGCCATAGATCAACTTTTAACTCAGAGTCCTGGTGACTATATCCCCATATCCTATGAACAGATATACAGTTGTGTGTATAA ATGTGTATGCCAGCAGCACTCGGAACAGATGTATAGTGATCTGATTAAAAAGATAACTAATCACTTAGAGAGAGTCTCAAAGGAGCTGCA GGTTCGTATTGATCACACTTCTCGGACCCTGAGTTTTGGATCTGATTTGAATTATGCTACTCGAGAAGATGCTCCGATTGGTCCTCATTT GCAAAGCATGCCTTCAGAGCAGATAAGAAACCAGCTGACAGCCATGTCCTCAGTACTTGCAAAAGCACTTGAAGTCATTAAACCAGCTCA TATACTGCAAGAGAAAGAAGAACAGCATCAGTTGGCTGTCACTGCATACCTTAAAAATTCACGAAAAGAGCACCAGCGGATCCTGGCTCG CCGCCAGACAATTGAGGAGAGAAAAGAGCGCCTTGAGAGTCTGAATATTCAGCGTGAGAAAGAAGAATTGGAACAGAGGGAAGCTGAACT CCAGAAAGTGCGGAAGGCTGAGGAAGAGAGGCTGCGCCAGGAAGCAAAGGAGAGAGAGAAGGAGCGTATCTTACAGGAACATGAACAAAT CAAAAAGAAAACTGTCCGAGAGCGTTTGGAGCAGATCAAGAAAACAGAACTGGGTGCCAAAGCATTCAAAGATATTGATATTGAAGACCT TGAGGAATTGGATCCAGATTTTATCATGGCTAAACAGGTTGAACAACTGGAGAAAGAAAAGAAAGAACTTCAAGAACGCCTAAAGAATCA AGAAAAGAAGATTGACTATTTTGAAAGAGCCAAACGTTTGGAAGAAATTCCTTTGATAAAGAGCGCTTACGAGGAACAGAGAATTAAAGA CATGGATCTGTGGGAGCAACAAGAGGAAGAAAGAATTACTACAATGCAGCTAGAACGTGAAAAGGCTCTTGAACATAAGAATCGAATGTC ACGAATGCTTGAAGACAGAGATTTATTCGTAATGCGACTCAAAGCTGCACGGCAGTCTGTTTATGAGGAAAAACTTAAACAGTTTGAAGA GCGATTAGCAGAAGAAAGGCATAATCGATTGGAAGAACGGAAAAGGCAGCGTAAAGAAGAACGCAGGATAACATACTATAGAGAAAAAGA AGAGGAGGAGCAGAGAAGGGCAGAAGAACAAATGCTAAAAGAGCGGGAAGAGAGAGAGCGCGCCGAACGAGCAAAACGCGAGGAAGAGCT ACGAGAGTATCAGGAGCGGGTGAAGAAATTAGAAGAAGTGGAAAGGAAAAAACGCCAAAGGGAGTTGGAAATTGAAGAACGAGAACGGCG TAGAGAGGAAGAGAGAAGACTTGGCGATAGTTCCCTTTCTAGAAAGGACTCTCGTTGGGGAGATAGAGATTCAGAAGGCACCTGGAGAAA AGGACCTGAAGCAGATTCTGAGTGGAGAAGAGGCCCGCCAGAGAAGGAGTGGAGACGTGGAGAAGGGCGAGATGAGGACAGGTCTCATAG AAGAGATGAAGAGCGGCCCCGGCGTCTGGGGGATGATGAAGATAGAGAGCCCTCTCTTAGACCAGACGATGATCGGGTTCCCCGGCGTGG CATGGATGATGACAGAGGCCCTAGACGTGGTCCTGAGGAAGATAGGTTCTCTCGTCGTGGGGCAGACGATGACCGGCCTTCCTGGCGTAA CACAGATGATGACAGGCCTCCCAGACGAATTGCCGATGAAGACAGGGGAAACTGGCGTCATGCGGATGATGACAGACCACCTAGACGAGG ACTGGATGAGGACAGAGGAAGCTGGCGAACAGCTGATGAGGACAGAGGACCAAGACGTGGGATGGATGATGACCGGGGGCCGAGGCGAGG AGGCGCTGATGATGAGCGATCATCCTGGCGTAATGCTGATGATGACCGGGGTCCCAGGCGAGGGTTGGATGATGATCGGGGTCCCAGGCG AGGCATGGATGATGACCGGGGTCCCAGGCGAGGCATGGATGATGACCGGGGTCCCAGGCGAGGCATGGATGATGACCGGGGTCCCAGGCG AGGGTTGGATGATGATCGAGGACCTTGGAGGAACGCCGATGATGACAGAATTCCCAGGCGTGGTGCAGAGGATGACAGGGGCCCTTGGAG AAACATGGATGATGATCGCCTTTCAAGACGTGCTGATGATGATCGGTTTCCCAGACGGGGTGATGACTCAAGACCTGGTCCTTGGAGACC ATTAGTCAAGCCAGGTGGATGGAGAGAGAAAGAAAAAGCCAGAGAGGAGAGCTGGGGTCCACCTCGAGAATCAAGGCCATCAGAAGAACG TGAATGGGACAGAGAAAAAGAAAGGGACAGAGATAATCAAGATCGGGAGGAGAATGACAAGGACCCTGAGAGAGAAAGGGACAGAGAGAG AGATGTGGATCGAGAGGATCGCTTCAGAAGACCTAGGGATGAAGGTGGCTGGAGAAGAGGACCAGCTGAGGAATCTTCAAGCTGGAGAGA CTCAAGTCGCCGGGACGATAGGGATAGGGATGACCGTCGCCGTGAGAGGGATGACCGGCGTGATCTAAGAGAAAGACGAGATCTAAGAGA CGACAGGGACCGAAGAGGACCTCCACTCAGATCAGAACGTGAAGAAGTAAGTTCTTGGAGACGTGCTGATGACAGGAAAGATGACCGGGT GGAAGAGCGGGACCCTCCTCGTCGAGTTCCTCCCCCAGCTCTTTCAAGAGACCGAGAAAGAGACCGAGACCGAGAAAGAGAAGGTGAAAA AGAGAAGGCCTCATGGAGAGCTGAGAAAGATAGGGAATCTCTCCGTCGTACTAAAAATGAGACTGATGAAGATGGATGGACCACAGTACG ACGTTAAGTCTCAAGATAATGGATTTAAACTGGTGTCTTAAATAGGTTTGATCACATTCAAGGATTATTATACTTGTGCTTCAACCAATC TAAATTGGATTCTTTAATGTTGTTTCACCATAACACAAAAAGCATGAACTTGTATTAATCCTATATAATAGATTGATCATGCACCATATC >12426_12426_4_CACUL1-EIF3A_CACUL1_chr10_120488807_ENST00000369151_EIF3A_chr10_120818909_ENST00000541549_length(amino acids)=1100AA_BP=526 MEESMEEEEGGSYEAMMDDQNHNNWEAAVDGFRQPLPPPPPPSSIPAPAREPPGGQLLAVPAVSVDRKGPKEGLPMGPQPPPEANGVIMM LKSCDAAAAVAKAAPAPTASSTININTSTSKFLMNVITIEDYKSTYWPKLDGAIDQLLTQSPGDYIPISYEQIYSCVYKCVCQQHSEQMY SDLIKKITNHLERVSKELQVRIDHTSRTLSFGSDLNYATREDAPIGPHLQSMPSEQIRNQLTAMSSVLAKALEVIKPAHILQEKEEQHQL AVTAYLKNSRKEHQRILARRQTIEERKERLESLNIQREKEELEQREAELQKVRKAEEERLRQEAKEREKERILQEHEQIKKKTVRERLEQ IKKTELGAKAFKDIDIEDLEELDPDFIMAKQVEQLEKEKKELQERLKNQEKKIDYFERAKRLEEIPLIKSAYEEQRIKDMDLWEQQEEER ITTMQLEREKALEHKNRMSRMLEDRDLFVMRLKAARQSVYEEKLKQFEERLAEERHNRLEERKRQRKEERRITYYREKEEEEQRRAEEQM LKEREERERAERAKREEELREYQERVKKLEEVERKKRQRELEIEERERRREEERRLGDSSLSRKDSRWGDRDSEGTWRKGPEADSEWRRG PPEKEWRRGEGRDEDRSHRRDEERPRRLGDDEDREPSLRPDDDRVPRRGMDDDRGPRRGPEEDRFSRRGADDDRPSWRNTDDDRPPRRIA DEDRGNWRHADDDRPPRRGLDEDRGSWRTADEDRGPRRGMDDDRGPRRGGADDERSSWRNADDDRGPRRGLDDDRGPRRGMDDDRGPRRG MDDDRGPRRGMDDDRGPRRGLDDDRGPWRNADDDRIPRRGAEDDRGPWRNMDDDRLSRRADDDRFPRRGDDSRPGPWRPLVKPGGWREKE KAREESWGPPRESRPSEEREWDREKERDRDNQDREENDKDPERERDRERDVDREDRFRRPRDEGGWRRGPAEESSSWRDSSRRDDRDRDD RRRERDDRRDLRERRDLRDDRDRRGPPLRSEREEVSSWRRADDRKDDRVEERDPPRRVPPPALSRDRERDRDREREGEKEKASWRAEKDR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CACUL1-EIF3A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | EIF3A | chr10:120488807 | chr10:120818909 | ENST00000369144 | 9 | 22 | 664_835 | 481.0 | 1383.0 | EIF3B |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CACUL1-EIF3A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CACUL1-EIF3A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies