
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CAP1-KCNQ4 (FusionGDB2 ID:12813) |
Fusion Gene Summary for CAP1-KCNQ4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CAP1-KCNQ4 | Fusion gene ID: 12813 | Hgene | Tgene | Gene symbol | CAP1 | KCNQ4 | Gene ID | 10487 | 9132 |
| Gene name | cyclase associated actin cytoskeleton regulatory protein 1 | potassium voltage-gated channel subfamily Q member 4 | |
| Synonyms | CAP|CAP1-PEN | DFNA2|DFNA2A|KV7.4 | |
| Cytomap | 1p34.2 | 1p34.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | adenylyl cyclase-associated protein 1CAP, adenylate cyclase-associated protein 1adenylate cyclase associated protein 1testis secretory sperm-binding protein Li 218p | potassium voltage-gated channel subfamily KQT member 4potassium channel KQT-like 4potassium channel subunit alpha KvLQT4potassium channel, voltage gated KQT-like subfamily Q, member 4potassium voltage-gated channel, KQT-like subfamily, member 4 | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | Q01518 | P56696 | |
| Ensembl transtripts involved in fusion gene | ENST00000340450, ENST00000372792, ENST00000372797, ENST00000372798, ENST00000372802, ENST00000372805, ENST00000479759, | ENST00000506017, ENST00000347132, ENST00000509682, | |
| Fusion gene scores | * DoF score | 16 X 13 X 7=1456 | 3 X 3 X 3=27 |
| # samples | 19 | 3 | |
| ** MAII score | log2(19/1456*10)=-2.93793903186775 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: CAP1 [Title/Abstract] AND KCNQ4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CAP1(40527484)-KCNQ4(41285547), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across CAP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across KCNQ4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-CV-7235-01A | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
Top |
Fusion Gene ORF analysis for CAP1-KCNQ4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000340450 | ENST00000506017 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| 5CDS-3UTR | ENST00000372792 | ENST00000506017 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| 5CDS-3UTR | ENST00000372797 | ENST00000506017 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| 5CDS-3UTR | ENST00000372798 | ENST00000506017 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| 5CDS-3UTR | ENST00000372802 | ENST00000506017 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| 5CDS-3UTR | ENST00000372805 | ENST00000506017 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000340450 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000340450 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372792 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372792 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372797 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372797 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372798 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372798 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372802 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372802 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372805 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| In-frame | ENST00000372805 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| intron-3CDS | ENST00000479759 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| intron-3CDS | ENST00000479759 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| intron-3UTR | ENST00000479759 | ENST00000506017 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000372797 | CAP1 | chr1 | 40527484 | + | ENST00000347132 | KCNQ4 | chr1 | 41285547 | + | 4038 | 855 | 534 | 2108 | 524 |
| ENST00000372797 | CAP1 | chr1 | 40527484 | + | ENST00000509682 | KCNQ4 | chr1 | 41285547 | + | 1947 | 855 | 534 | 1946 | 470 |
| ENST00000372802 | CAP1 | chr1 | 40527484 | + | ENST00000347132 | KCNQ4 | chr1 | 41285547 | + | 4031 | 848 | 527 | 2101 | 524 |
| ENST00000372802 | CAP1 | chr1 | 40527484 | + | ENST00000509682 | KCNQ4 | chr1 | 41285547 | + | 1940 | 848 | 527 | 1939 | 471 |
| ENST00000372792 | CAP1 | chr1 | 40527484 | + | ENST00000347132 | KCNQ4 | chr1 | 41285547 | + | 3543 | 360 | 48 | 1613 | 521 |
| ENST00000372792 | CAP1 | chr1 | 40527484 | + | ENST00000509682 | KCNQ4 | chr1 | 41285547 | + | 1452 | 360 | 48 | 1451 | 467 |
| ENST00000372798 | CAP1 | chr1 | 40527484 | + | ENST00000347132 | KCNQ4 | chr1 | 41285547 | + | 3537 | 354 | 45 | 1607 | 520 |
| ENST00000372798 | CAP1 | chr1 | 40527484 | + | ENST00000509682 | KCNQ4 | chr1 | 41285547 | + | 1446 | 354 | 45 | 1445 | 466 |
| ENST00000340450 | CAP1 | chr1 | 40527484 | + | ENST00000347132 | KCNQ4 | chr1 | 41285547 | + | 3533 | 350 | 44 | 1603 | 519 |
| ENST00000340450 | CAP1 | chr1 | 40527484 | + | ENST00000509682 | KCNQ4 | chr1 | 41285547 | + | 1442 | 350 | 44 | 1441 | 466 |
| ENST00000372805 | CAP1 | chr1 | 40527484 | + | ENST00000347132 | KCNQ4 | chr1 | 41285547 | + | 3528 | 345 | 36 | 1598 | 520 |
| ENST00000372805 | CAP1 | chr1 | 40527484 | + | ENST00000509682 | KCNQ4 | chr1 | 41285547 | + | 1437 | 345 | 36 | 1436 | 466 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000372797 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.013852486 | 0.9861476 |
| ENST00000372797 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.014561886 | 0.9854381 |
| ENST00000372802 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.017676767 | 0.9823232 |
| ENST00000372802 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.022184635 | 0.9778154 |
| ENST00000372792 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.01754161 | 0.9824584 |
| ENST00000372792 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.007117428 | 0.9928826 |
| ENST00000372798 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.021762364 | 0.9782376 |
| ENST00000372798 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.010886589 | 0.98911345 |
| ENST00000340450 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.02124642 | 0.97875357 |
| ENST00000340450 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.011370545 | 0.98862946 |
| ENST00000372805 | ENST00000347132 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.017040554 | 0.9829594 |
| ENST00000372805 | ENST00000509682 | CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285547 | + | 0.007495433 | 0.9925046 |
Top |
Fusion Genomic Features for CAP1-KCNQ4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285546 | + | 0.012889804 | 0.98711026 |
| CAP1 | chr1 | 40527484 | + | KCNQ4 | chr1 | 41285546 | + | 0.012889804 | 0.98711026 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
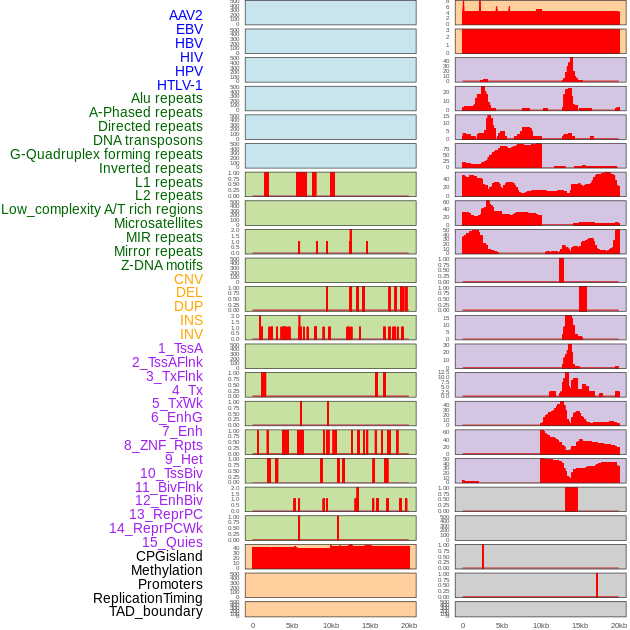 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
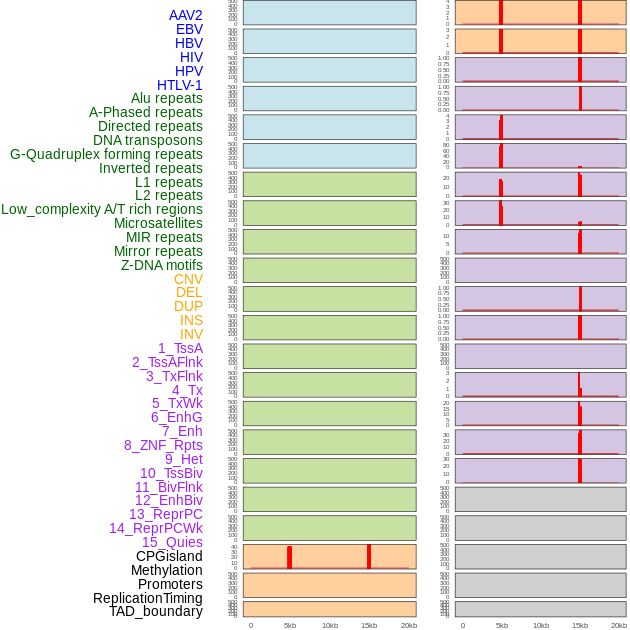 |
Top |
Fusion Protein Features for CAP1-KCNQ4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:40527484/chr1:41285547) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CAP1 | KCNQ4 |
| FUNCTION: Directly regulates filament dynamics and has been implicated in a number of complex developmental and morphological processes, including mRNA localization and the establishment of cell polarity. | FUNCTION: Probably important in the regulation of neuronal excitability. May underlie a potassium current involved in regulating the excitability of sensory cells of the cochlea. KCNQ4 channels are blocked by linopirdin, XE991 and bepridil, whereas clofilium is without significant effect. Muscarinic agonist oxotremorine-M strongly suppress KCNQ4 current in CHO cells in which cloned KCNQ4 channels were coexpressed with M1 muscarinic receptors. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 610_645 | 278 | 696.0 | Coiled coil | . | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 610_645 | 278 | 642.0 | Coiled coil | . | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 283_288 | 278 | 696.0 | Motif | Selectivity filter | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 283_288 | 278 | 642.0 | Motif | Selectivity filter | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 546_650 | 278 | 696.0 | Region | Note=A-domain (Tetramerization) | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 546_650 | 278 | 642.0 | Region | Note=A-domain (Tetramerization) | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 293_296 | 278 | 696.0 | Topological domain | Extracellular | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 318_695 | 278 | 696.0 | Topological domain | Cytoplasmic | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 293_296 | 278 | 642.0 | Topological domain | Extracellular | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 318_695 | 278 | 642.0 | Topological domain | Cytoplasmic | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 297_317 | 278 | 696.0 | Transmembrane | Helical%3B Name%3DSegment S6 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 297_317 | 278 | 642.0 | Transmembrane | Helical%3B Name%3DSegment S6 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000340450 | + | 4 | 13 | 218_256 | 97 | 475.0 | Compositional bias | Note=Ala/Pro/Ser-rich |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000340450 | + | 4 | 13 | 230_241 | 97 | 475.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372792 | + | 4 | 13 | 218_256 | 98 | 476.0 | Compositional bias | Note=Ala/Pro/Ser-rich |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372792 | + | 4 | 13 | 230_241 | 98 | 476.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372797 | + | 4 | 13 | 218_256 | 98 | 476.0 | Compositional bias | Note=Ala/Pro/Ser-rich |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372797 | + | 4 | 13 | 230_241 | 98 | 476.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372798 | + | 4 | 13 | 218_256 | 97 | 475.0 | Compositional bias | Note=Ala/Pro/Ser-rich |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372798 | + | 4 | 13 | 230_241 | 97 | 475.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372802 | + | 4 | 13 | 218_256 | 97 | 475.0 | Compositional bias | Note=Ala/Pro/Ser-rich |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372802 | + | 4 | 13 | 230_241 | 97 | 475.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372805 | + | 4 | 13 | 218_256 | 98 | 476.0 | Compositional bias | Note=Ala/Pro/Ser-rich |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372805 | + | 4 | 13 | 230_241 | 98 | 476.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000340450 | + | 4 | 13 | 319_453 | 97 | 475.0 | Domain | C-CAP/cofactor C-like |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372792 | + | 4 | 13 | 319_453 | 98 | 476.0 | Domain | C-CAP/cofactor C-like |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372797 | + | 4 | 13 | 319_453 | 98 | 476.0 | Domain | C-CAP/cofactor C-like |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372798 | + | 4 | 13 | 319_453 | 97 | 475.0 | Domain | C-CAP/cofactor C-like |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372802 | + | 4 | 13 | 319_453 | 97 | 475.0 | Domain | C-CAP/cofactor C-like |
| Hgene | CAP1 | chr1:40527484 | chr1:41285547 | ENST00000372805 | + | 4 | 13 | 319_453 | 98 | 476.0 | Domain | C-CAP/cofactor C-like |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 271_292 | 278 | 696.0 | Intramembrane | Pore-forming%3B Name%3DSegment H5 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 271_292 | 278 | 642.0 | Intramembrane | Pore-forming%3B Name%3DSegment H5 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 119_131 | 278 | 696.0 | Topological domain | Extracellular | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 153_172 | 278 | 696.0 | Topological domain | Cytoplasmic | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 194_201 | 278 | 696.0 | Topological domain | Extracellular | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 1_97 | 278 | 696.0 | Topological domain | Cytoplasmic | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 225_237 | 278 | 696.0 | Topological domain | Cytoplasmic | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 259_270 | 278 | 696.0 | Topological domain | Extracellular | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 119_131 | 278 | 642.0 | Topological domain | Extracellular | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 153_172 | 278 | 642.0 | Topological domain | Cytoplasmic | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 194_201 | 278 | 642.0 | Topological domain | Extracellular | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 1_97 | 278 | 642.0 | Topological domain | Cytoplasmic | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 225_237 | 278 | 642.0 | Topological domain | Cytoplasmic | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 259_270 | 278 | 642.0 | Topological domain | Extracellular | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 132_152 | 278 | 696.0 | Transmembrane | Helical%3B Name%3DSegment S2 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 173_193 | 278 | 696.0 | Transmembrane | Helical%3B Name%3DSegment S3 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 202_224 | 278 | 696.0 | Transmembrane | Helical%3B Voltage-sensor%3B Name%3DSegment S4 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 238_258 | 278 | 696.0 | Transmembrane | Helical%3B Name%3DSegment S5 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000347132 | 4 | 14 | 98_118 | 278 | 696.0 | Transmembrane | Helical%3B Name%3DSegment S1 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 132_152 | 278 | 642.0 | Transmembrane | Helical%3B Name%3DSegment S2 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 173_193 | 278 | 642.0 | Transmembrane | Helical%3B Name%3DSegment S3 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 202_224 | 278 | 642.0 | Transmembrane | Helical%3B Voltage-sensor%3B Name%3DSegment S4 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 238_258 | 278 | 642.0 | Transmembrane | Helical%3B Name%3DSegment S5 | |
| Tgene | KCNQ4 | chr1:40527484 | chr1:41285547 | ENST00000509682 | 4 | 13 | 98_118 | 278 | 642.0 | Transmembrane | Helical%3B Name%3DSegment S1 |
Top |
Fusion Gene Sequence for CAP1-KCNQ4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >12813_12813_1_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000340450_KCNQ4_chr1_41285547_ENST00000347132_length(transcript)=3533nt_BP=350nt GAAGCGGAGAGCGGCTGATCGCAGTCCGGAGGTGAGGCGGAACTCTGAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAAAGAT TGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCATACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGGAGCAGCTC CATATGTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAGAAAC ATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACATTGA CAACCATCGGCTATGGTGACAAGACACCGCACACATGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTCTTTG CCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATGCCGG CAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGACAGTA TCCTCCCATCCTTCAGAGAGCTGGCCCTCTTGTTTGAGCACGTGCAACGGGCCCGCAATGGGGGCCTACGGCCCCTGGAGGTGCGGCGGG CGCCGGTACCCGACGGAGCACCCTCCCGTTACCCGCCCGTTGCCACCTGCCACCGGCCGGGCAGCACCTCCTTCTGCCCTGGGGAAAGCA GCCGGATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCACCTCCAACAATGC CCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGACCGCACCCGCTTCC GGGCATCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTACCAGTGTGAGCTCA CGGTGGACGACATCATGCCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGGAAATTCAAGGAGA CACTGCGACCGTACGACGTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGATCAAGAGCCTGCAAACTC GGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCGGAGGTGGTGGATG AAATCAGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTGGGCTTCTATTCGC GCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCTCCGACTACCACAGCCCTG TGGACCACGAGGACATCTCCGTCTCCGCACAGACGCTCAGCATCTCCCGCTCGGTCAGCACCAACATGGACTGAGGGACTTCTCAGAGGC AGGGCAGCACACGGCCAGCCCCGCGGCCTGGCGCTCCGACTGCCCTCTGAGGCCTCCGGACTCCTCTCGTACTTGAACTCACTCCCTCAC GGGGAGAGAGACCACACGCAGTATTGAGCTGCCTGAGTGGGCGTGGTACCTGCTGTGGGTGCCAGCGCCCCTTCCCCACCTCAGGAGCGT GAGATGCCAGGTCGCACAGAGGGCAGCAGCAGCGGCCGTCCCGCGGCCTCTGGGCCCCCCAGTGCCCTGCCCACTCCATCAAGGCCCTAT GTGGCCCACCTGGCAGGGGCACAGCCCCGGGAGTGGGAGCGGGCGCTGGGGCCCTGGGCCCTGACCCAGCTTCCAGCTATGCAAGGTGAG GTCTCTGGCCCACCCTTCGGACACAGCAGGGAAGCCCTCCCGCCAAGTCCCCGCCCCACTTGGGGGTGGGCCAAGGTGCCCCCACAGGTA CCCACAAAGCACAGGACCCTGCCACAAGGCAGGTGGACACCATATATGCAAACCATGTTAAATATGCAACTTTGGGGACCCCCATGGGGT CTCTCTGTCCCTCCCCCATTGGGAGCTGGGCCCCCAGCAGTAGCTGGTCTCAGGCTGCTTGGCCACCACCCTGTCCCTATTCTTTGGCTT ATCACTCCTTCCCCTCCCAGCATGGGGCCTGTTTCTCCCCTGCCCTCTCCTAAGGGCAATGCCTGGGCCTTTCTTCCCATTTGCAAGTGT CAGCTCCCAGGGGCTCCCTCCTCCTGCTGGGTGGCCACTCCCCTCCTTGGCCCTCCAGACACCACTCATAGTCAGCACAGGTTTCTGTAT CCTCCCCAAAACTCCCAGACAGTGCTTCGTGGACGATCGCACAAACATAGCCTTTTAGTTTCTCCAGACAGGAAGAAAGCCTCTCACACT TAAACATGCAATGACGTGACACACTTGGAGACATGAGTGCAGAGCCACTCAGCCGCTCCTGGGCCTCTGCAGCAGATGCCAGTGGACTGG CCTTGCAGGGTGACGACCACTAAGAGGAAGACCCCCAACTCCATCTGAGCAGGAGAAGGAGCTTTGAAGTAACCCGAGAGCTCTCCAGGC CCCACCCAGACCTTTACCCGCTCCCCTTCTTCAAGAAGATCTCCTCCTCTCTGGTCCAGGAGCCCTAACCCACTGCCTCTGCCTGTCCCC AAGGGCCCGCCTCCGTGTCTCCACAGCACAACTCGGGCCCAGGCCTGACACCACTGGAGAGACCCCAGGCCCACTTCTAGCCAGGCCTGT GCCTTCCTAGTCACTCTAACTCCCAGAGAGAATAAGAATGCATGTAATAGCTATACCAACCGCGCATCCGGCTTTCACATGCACTGTCTC CCCTCCCTCCACACCCCACTTCTTCACTTCAATTGGCAGCGCCACATCCAGGCGTCAGCCCCCATTCACTCCAGGAACACTTTCTTATCC CCACCCCTTTGCTCCTCTTCTGCAAAGCCAATGCAGGTGGCAGGAAGGTGAGGGGTAGTGGACCAATGGCAACCCTCTGTGGGAACAAGG GGCCGAGGCCACGCTGCCTGCATCTCGTGCTGGGGACCTGCATGCGCCAGCACCAGGGCTTGGACTGGATCTTACTCAGTCCATGGTGCC CAGCCTCTGCCCCAACATGCCCTCTGCATGTGACCGTCATGCCCTGGATGGAGCCACTCCTGGCTCACCCCACCTGCACTGCACTGTCCC CAGAGAGCCACCCCTCCACCCACTCAGAGACAGCTGTGGAGAGGGCCAGGAGAATGGGATTACCCTATGACCAAGGAGACATGGGAAGAA GCCCTCCTTCCTTCCACGATCGAGGTTCCGCCATCAACTCGGTTCTCGGATATGCAAGTACCTCACTTTGTTAACTTATTAACTTATTGG >12813_12813_1_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000340450_KCNQ4_chr1_41285547_ENST00000347132_length(amino acids)=519AA_BP=1 MRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLKLERAL LVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWRLYSTD MSRAYLTATWYYYDSILPSFRELALLFEHVQRARNGGLRPLEVRRAPVPDGAPSRYPPVATCHRPGSTSFCPGESSRMGIKDRIRMGSSQ RRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKPRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIRS IRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGRGPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQV -------------------------------------------------------------- >12813_12813_2_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000340450_KCNQ4_chr1_41285547_ENST00000509682_length(transcript)=1442nt_BP=350nt GAAGCGGAGAGCGGCTGATCGCAGTCCGGAGGTGAGGCGGAACTCTGAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAAAGAT TGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCATACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGGAGCAGCTC CATATGTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAGAAAC ATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACATTGA CAACCATCGGCTATGGTGACAAGACACCGCACACATGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTCTTTG CCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATGCCGG CAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGACAGTA TCCTCCCATCCTTCAGCAGCCGGATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATC TGGCACCTCCAACAATGCCCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCA ATGACCGCACCCGCTTCCGGGCATCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGA GCTACCAGTGTGAGCTCACGGTGGACGACATCATGCCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCA AAAGGAAATTCAAGGAGACACTGCGACCGTACGACGTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGA TCAAGAGCCTGCAAACTCGGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCG ACGCGGAGGTGGTGGATGAAATCAGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGC TGTTGGGCTTCTATTCGCGCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCT CCGACTACCACAGCCCTGTGGACCACGAGGACATCTCCGTCTCCGCACAGACGCTCAGCATCTCCCGCTCGGTCAGCACCAACATGGACT >12813_12813_2_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000340450_KCNQ4_chr1_41285547_ENST00000509682_length(amino acids)=466AA_BP=1 MRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLKLERAL LVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWRLYSTD MSRAYLTATWYYYDSILPSFSSRMGIKDRIRMGSSQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKPR TSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIRSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGRG PGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQVQSIEHKLDLLLGFYSRCLRSGTSASLGAVQVPLFDPDITSDYHSPVDHEDISVS -------------------------------------------------------------- >12813_12813_3_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372792_KCNQ4_chr1_41285547_ENST00000347132_length(transcript)=3543nt_BP=360nt GCCGGAAGCGGAGAGCGGCTGATCGCAGTCCGGAGGTGAGGCGGAACTCTGAGCAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTA GAAAGATTGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCATACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGCA GGAGCAGCTCCATATGTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGAC GTGCAGAAACATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAA ATTACATTGACAACCATCGGCTATGGTGACAAGACACCGCACACATGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATC TCTTTCTTTGCCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGG AGGATGCCGGCAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTAC TATGACAGTATCCTCCCATCCTTCAGAGAGCTGGCCCTCTTGTTTGAGCACGTGCAACGGGCCCGCAATGGGGGCCTACGGCCCCTGGAG GTGCGGCGGGCGCCGGTACCCGACGGAGCACCCTCCCGTTACCCGCCCGTTGCCACCTGCCACCGGCCGGGCAGCACCTCCTTCTGCCCT GGGGAAAGCAGCCGGATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCACCT CCAACAATGCCCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGACCGC ACCCGCTTCCGGGCATCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTACCAG TGTGAGCTCACGGTGGACGACATCATGCCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGGAAA TTCAAGGAGACACTGCGACCGTACGACGTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGATCAAGAGC CTGCAAACTCGGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCGGAG GTGGTGGATGAAATCAGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTGGGC TTCTATTCGCGCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCTCCGACTAC CACAGCCCTGTGGACCACGAGGACATCTCCGTCTCCGCACAGACGCTCAGCATCTCCCGCTCGGTCAGCACCAACATGGACTGAGGGACT TCTCAGAGGCAGGGCAGCACACGGCCAGCCCCGCGGCCTGGCGCTCCGACTGCCCTCTGAGGCCTCCGGACTCCTCTCGTACTTGAACTC ACTCCCTCACGGGGAGAGAGACCACACGCAGTATTGAGCTGCCTGAGTGGGCGTGGTACCTGCTGTGGGTGCCAGCGCCCCTTCCCCACC TCAGGAGCGTGAGATGCCAGGTCGCACAGAGGGCAGCAGCAGCGGCCGTCCCGCGGCCTCTGGGCCCCCCAGTGCCCTGCCCACTCCATC AAGGCCCTATGTGGCCCACCTGGCAGGGGCACAGCCCCGGGAGTGGGAGCGGGCGCTGGGGCCCTGGGCCCTGACCCAGCTTCCAGCTAT GCAAGGTGAGGTCTCTGGCCCACCCTTCGGACACAGCAGGGAAGCCCTCCCGCCAAGTCCCCGCCCCACTTGGGGGTGGGCCAAGGTGCC CCCACAGGTACCCACAAAGCACAGGACCCTGCCACAAGGCAGGTGGACACCATATATGCAAACCATGTTAAATATGCAACTTTGGGGACC CCCATGGGGTCTCTCTGTCCCTCCCCCATTGGGAGCTGGGCCCCCAGCAGTAGCTGGTCTCAGGCTGCTTGGCCACCACCCTGTCCCTAT TCTTTGGCTTATCACTCCTTCCCCTCCCAGCATGGGGCCTGTTTCTCCCCTGCCCTCTCCTAAGGGCAATGCCTGGGCCTTTCTTCCCAT TTGCAAGTGTCAGCTCCCAGGGGCTCCCTCCTCCTGCTGGGTGGCCACTCCCCTCCTTGGCCCTCCAGACACCACTCATAGTCAGCACAG GTTTCTGTATCCTCCCCAAAACTCCCAGACAGTGCTTCGTGGACGATCGCACAAACATAGCCTTTTAGTTTCTCCAGACAGGAAGAAAGC CTCTCACACTTAAACATGCAATGACGTGACACACTTGGAGACATGAGTGCAGAGCCACTCAGCCGCTCCTGGGCCTCTGCAGCAGATGCC AGTGGACTGGCCTTGCAGGGTGACGACCACTAAGAGGAAGACCCCCAACTCCATCTGAGCAGGAGAAGGAGCTTTGAAGTAACCCGAGAG CTCTCCAGGCCCCACCCAGACCTTTACCCGCTCCCCTTCTTCAAGAAGATCTCCTCCTCTCTGGTCCAGGAGCCCTAACCCACTGCCTCT GCCTGTCCCCAAGGGCCCGCCTCCGTGTCTCCACAGCACAACTCGGGCCCAGGCCTGACACCACTGGAGAGACCCCAGGCCCACTTCTAG CCAGGCCTGTGCCTTCCTAGTCACTCTAACTCCCAGAGAGAATAAGAATGCATGTAATAGCTATACCAACCGCGCATCCGGCTTTCACAT GCACTGTCTCCCCTCCCTCCACACCCCACTTCTTCACTTCAATTGGCAGCGCCACATCCAGGCGTCAGCCCCCATTCACTCCAGGAACAC TTTCTTATCCCCACCCCTTTGCTCCTCTTCTGCAAAGCCAATGCAGGTGGCAGGAAGGTGAGGGGTAGTGGACCAATGGCAACCCTCTGT GGGAACAAGGGGCCGAGGCCACGCTGCCTGCATCTCGTGCTGGGGACCTGCATGCGCCAGCACCAGGGCTTGGACTGGATCTTACTCAGT CCATGGTGCCCAGCCTCTGCCCCAACATGCCCTCTGCATGTGACCGTCATGCCCTGGATGGAGCCACTCCTGGCTCACCCCACCTGCACT GCACTGTCCCCAGAGAGCCACCCCTCCACCCACTCAGAGACAGCTGTGGAGAGGGCCAGGAGAATGGGATTACCCTATGACCAAGGAGAC ATGGGAAGAAGCCCTCCTTCCTTCCACGATCGAGGTTCCGCCATCAACTCGGTTCTCGGATATGCAAGTACCTCACTTTGTTAACTTATT >12813_12813_3_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372792_KCNQ4_chr1_41285547_ENST00000347132_length(amino acids)=521AA_BP=1 MSRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKAGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLKLER ALLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWRLYS TDMSRAYLTATWYYYDSILPSFRELALLFEHVQRARNGGLRPLEVRRAPVPDGAPSRYPPVATCHRPGSTSFCPGESSRMGIKDRIRMGS SQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKPRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVI RSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGRGPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEK -------------------------------------------------------------- >12813_12813_4_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372792_KCNQ4_chr1_41285547_ENST00000509682_length(transcript)=1452nt_BP=360nt GCCGGAAGCGGAGAGCGGCTGATCGCAGTCCGGAGGTGAGGCGGAACTCTGAGCAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTA GAAAGATTGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCATACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGCA GGAGCAGCTCCATATGTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGAC GTGCAGAAACATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAA ATTACATTGACAACCATCGGCTATGGTGACAAGACACCGCACACATGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATC TCTTTCTTTGCCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGG AGGATGCCGGCAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTAC TATGACAGTATCCTCCCATCCTTCAGCAGCCGGATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCC AAGCAGCATCTGGCACCTCCAACAATGCCCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGC TGGAGCTTCAATGACCGCACCCGCTTCCGGGCATCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCA GAGGAGAAGAGCTACCAGTGTGAGCTCACGGTGGACGACATCATGCCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTC CTGGTGGCCAAAAGGAAATTCAAGGAGACACTGCGACCGTACGACGTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATG CTGGGCCGGATCAAGAGCCTGCAAACTCGGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAG GGGCCCTCCGACGCGGAGGTGGTGGATGAAATCAGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAG CTGGACCTGCTGTTGGGCTTCTATTCGCGCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCC GACATCACCTCCGACTACCACAGCCCTGTGGACCACGAGGACATCTCCGTCTCCGCACAGACGCTCAGCATCTCCCGCTCGGTCAGCACC >12813_12813_4_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372792_KCNQ4_chr1_41285547_ENST00000509682_length(amino acids)=467AA_BP=1 MSRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKAGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLKLER ALLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWRLYS TDMSRAYLTATWYYYDSILPSFSSRMGIKDRIRMGSSQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLK PRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIRSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVG RGPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQVQSIEHKLDLLLGFYSRCLRSGTSASLGAVQVPLFDPDITSDYHSPVDHEDIS -------------------------------------------------------------- >12813_12813_5_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372797_KCNQ4_chr1_41285547_ENST00000347132_length(transcript)=4038nt_BP=855nt GCGGAGCGTGGCCTCGATCACCACCGAGAGCTGACGGCCGCCCGGATTCCCGCCCTCAGAGAATCCTGGCCCCCAGTCGTTCCAAGACCC TTTACGGACTGCAGCTTAAAGGAACCGGCCTCTGCCATTGAGACCAAACTGACAGAGGAACTGGTCACTCTTCTGTTCTTTCCAGAGAGG AGCTTAGCCAGGGACTTCTGCCCTTCCTGGGCCCGGGCCTCGGGGGCGATTCCGGGTAGGTAAAGCGGAACGAGGGCGTGGCCTCTCTTG TGAGCCCGCCCTCCCCGTGTCGCTCCCGCCTTGAGGGCGGGGCTCTTTCCCAAGTGCCCTCTGTGAGAGCCGGGCCGCTCTCTCCGGGGC GTGGCGAAGAGGGGCGGAGTCACGAGCGGGGCGGTGAGACTTCCTGCCCAGTCGCGGGCCAGCCTAGCGCTTCAGCCGGCGGCTCATTTC CGGTGGGGGCGCCGCGCCCAGTGAGGGCCCGGAAGTGGGTCGCGCGGAGATTGCTGGGCGGTTCTTGCCGGAAGCGGAGAGCGGCTGATC GCAGTCCGGAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAAAGATTGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCAT ACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGCAGGAGCAGCTCCATATGTGCAGGCATTTGACTCGCTGCTTGCTGGT CCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAGAAACATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAG CGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACATTGACAACCATCGGCTATGGTGACAAGACACCGCACACA TGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTCTTTGCCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCC CTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATGCCGGCAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTAC TCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGACAGTATCCTCCCATCCTTCAGAGAGCTGGCCCTCTTGTTT GAGCACGTGCAACGGGCCCGCAATGGGGGCCTACGGCCCCTGGAGGTGCGGCGGGCGCCGGTACCCGACGGAGCACCCTCCCGTTACCCG CCCGTTGCCACCTGCCACCGGCCGGGCAGCACCTCCTTCTGCCCTGGGGAAAGCAGCCGGATGGGCATCAAAGACCGCATCCGCATGGGC AGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCACCTCCAACAATGCCCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCC ACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGACCGCACCCGCTTCCGGGCATCTCTGAGACTCAAACCCCGCACCTCTGCT GAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTACCAGTGTGAGCTCACGGTGGACGACATCATGCCTGCTGTGAAGACAGTC ATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGGAAATTCAAGGAGACACTGCGACCGTACGACGTGAAGGACGTCATTGAG CAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGATCAAGAGCCTGCAAACTCGGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGAC AGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCGGAGGTGGTGGATGAAATCAGCATGATGGGACGCGTGGTCAAGGTGGAG AAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTGGGCTTCTATTCGCGCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGC GCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCTCCGACTACCACAGCCCTGTGGACCACGAGGACATCTCCGTCTCCGCACAGACG CTCAGCATCTCCCGCTCGGTCAGCACCAACATGGACTGAGGGACTTCTCAGAGGCAGGGCAGCACACGGCCAGCCCCGCGGCCTGGCGCT CCGACTGCCCTCTGAGGCCTCCGGACTCCTCTCGTACTTGAACTCACTCCCTCACGGGGAGAGAGACCACACGCAGTATTGAGCTGCCTG AGTGGGCGTGGTACCTGCTGTGGGTGCCAGCGCCCCTTCCCCACCTCAGGAGCGTGAGATGCCAGGTCGCACAGAGGGCAGCAGCAGCGG CCGTCCCGCGGCCTCTGGGCCCCCCAGTGCCCTGCCCACTCCATCAAGGCCCTATGTGGCCCACCTGGCAGGGGCACAGCCCCGGGAGTG GGAGCGGGCGCTGGGGCCCTGGGCCCTGACCCAGCTTCCAGCTATGCAAGGTGAGGTCTCTGGCCCACCCTTCGGACACAGCAGGGAAGC CCTCCCGCCAAGTCCCCGCCCCACTTGGGGGTGGGCCAAGGTGCCCCCACAGGTACCCACAAAGCACAGGACCCTGCCACAAGGCAGGTG GACACCATATATGCAAACCATGTTAAATATGCAACTTTGGGGACCCCCATGGGGTCTCTCTGTCCCTCCCCCATTGGGAGCTGGGCCCCC AGCAGTAGCTGGTCTCAGGCTGCTTGGCCACCACCCTGTCCCTATTCTTTGGCTTATCACTCCTTCCCCTCCCAGCATGGGGCCTGTTTC TCCCCTGCCCTCTCCTAAGGGCAATGCCTGGGCCTTTCTTCCCATTTGCAAGTGTCAGCTCCCAGGGGCTCCCTCCTCCTGCTGGGTGGC CACTCCCCTCCTTGGCCCTCCAGACACCACTCATAGTCAGCACAGGTTTCTGTATCCTCCCCAAAACTCCCAGACAGTGCTTCGTGGACG ATCGCACAAACATAGCCTTTTAGTTTCTCCAGACAGGAAGAAAGCCTCTCACACTTAAACATGCAATGACGTGACACACTTGGAGACATG AGTGCAGAGCCACTCAGCCGCTCCTGGGCCTCTGCAGCAGATGCCAGTGGACTGGCCTTGCAGGGTGACGACCACTAAGAGGAAGACCCC CAACTCCATCTGAGCAGGAGAAGGAGCTTTGAAGTAACCCGAGAGCTCTCCAGGCCCCACCCAGACCTTTACCCGCTCCCCTTCTTCAAG AAGATCTCCTCCTCTCTGGTCCAGGAGCCCTAACCCACTGCCTCTGCCTGTCCCCAAGGGCCCGCCTCCGTGTCTCCACAGCACAACTCG GGCCCAGGCCTGACACCACTGGAGAGACCCCAGGCCCACTTCTAGCCAGGCCTGTGCCTTCCTAGTCACTCTAACTCCCAGAGAGAATAA GAATGCATGTAATAGCTATACCAACCGCGCATCCGGCTTTCACATGCACTGTCTCCCCTCCCTCCACACCCCACTTCTTCACTTCAATTG GCAGCGCCACATCCAGGCGTCAGCCCCCATTCACTCCAGGAACACTTTCTTATCCCCACCCCTTTGCTCCTCTTCTGCAAAGCCAATGCA GGTGGCAGGAAGGTGAGGGGTAGTGGACCAATGGCAACCCTCTGTGGGAACAAGGGGCCGAGGCCACGCTGCCTGCATCTCGTGCTGGGG ACCTGCATGCGCCAGCACCAGGGCTTGGACTGGATCTTACTCAGTCCATGGTGCCCAGCCTCTGCCCCAACATGCCCTCTGCATGTGACC GTCATGCCCTGGATGGAGCCACTCCTGGCTCACCCCACCTGCACTGCACTGTCCCCAGAGAGCCACCCCTCCACCCACTCAGAGACAGCT GTGGAGAGGGCCAGGAGAATGGGATTACCCTATGACCAAGGAGACATGGGAAGAAGCCCTCCTTCCTTCCACGATCGAGGTTCCGCCATC >12813_12813_5_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372797_KCNQ4_chr1_41285547_ENST00000347132_length(amino acids)=524AA_BP=5 MIAVRRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKAGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLK LERALLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWR LYSTDMSRAYLTATWYYYDSILPSFRELALLFEHVQRARNGGLRPLEVRRAPVPDGAPSRYPPVATCHRPGSTSFCPGESSRMGIKDRIR MGSSQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKPRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVK TVIRSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGRGPGDRKAREKGDKGPSDAEVVDEISMMGRVVK -------------------------------------------------------------- >12813_12813_6_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372797_KCNQ4_chr1_41285547_ENST00000509682_length(transcript)=1947nt_BP=855nt GCGGAGCGTGGCCTCGATCACCACCGAGAGCTGACGGCCGCCCGGATTCCCGCCCTCAGAGAATCCTGGCCCCCAGTCGTTCCAAGACCC TTTACGGACTGCAGCTTAAAGGAACCGGCCTCTGCCATTGAGACCAAACTGACAGAGGAACTGGTCACTCTTCTGTTCTTTCCAGAGAGG AGCTTAGCCAGGGACTTCTGCCCTTCCTGGGCCCGGGCCTCGGGGGCGATTCCGGGTAGGTAAAGCGGAACGAGGGCGTGGCCTCTCTTG TGAGCCCGCCCTCCCCGTGTCGCTCCCGCCTTGAGGGCGGGGCTCTTTCCCAAGTGCCCTCTGTGAGAGCCGGGCCGCTCTCTCCGGGGC GTGGCGAAGAGGGGCGGAGTCACGAGCGGGGCGGTGAGACTTCCTGCCCAGTCGCGGGCCAGCCTAGCGCTTCAGCCGGCGGCTCATTTC CGGTGGGGGCGCCGCGCCCAGTGAGGGCCCGGAAGTGGGTCGCGCGGAGATTGCTGGGCGGTTCTTGCCGGAAGCGGAGAGCGGCTGATC GCAGTCCGGAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAAAGATTGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCAT ACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGCAGGAGCAGCTCCATATGTGCAGGCATTTGACTCGCTGCTTGCTGGT CCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAGAAACATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAG CGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACATTGACAACCATCGGCTATGGTGACAAGACACCGCACACA TGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTCTTTGCCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCC CTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATGCCGGCAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTAC TCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGACAGTATCCTCCCATCCTTCAGCAGCCGGATGGGCATCAAA GACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCACCTCCAACAATGCCCACCTCCCCAAGCAGC GAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGACCGCACCCGCTTCCGGGCATCTCTGAGACTC AAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTACCAGTGTGAGCTCACGGTGGACGACATCATG CCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGGAAATTCAAGGAGACACTGCGACCGTACGAC GTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGATCAAGAGCCTGCAAACTCGGGTGGACCAAATTGTG GGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCGGAGGTGGTGGATGAAATCAGCATGATGGGA CGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTGGGCTTCTATTCGCGCTGCCTGCGCTCTGGC ACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCTCCGACTACCACAGCCCTGTGGACCACGAGGACATC >12813_12813_6_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372797_KCNQ4_chr1_41285547_ENST00000509682_length(amino acids)=470AA_BP=5 MIAVRRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKAGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLK LERALLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWR LYSTDMSRAYLTATWYYYDSILPSFSSRMGIKDRIRMGSSQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASL RLKPRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIRSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQ IVGRGPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQVQSIEHKLDLLLGFYSRCLRSGTSASLGAVQVPLFDPDITSDYHSPVDHE -------------------------------------------------------------- >12813_12813_7_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372798_KCNQ4_chr1_41285547_ENST00000347132_length(transcript)=3537nt_BP=354nt GGAAGCGGAGAGCGGCTGATCGCAGTCCGGAGGTGAGGCGGAACTCTGAGCAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAA AGATTGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCATACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGGAGCA GCTCCATATGTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAG AAACATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACA TTGACAACCATCGGCTATGGTGACAAGACACCGCACACATGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTC TTTGCCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATG CCGGCAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGAC AGTATCCTCCCATCCTTCAGAGAGCTGGCCCTCTTGTTTGAGCACGTGCAACGGGCCCGCAATGGGGGCCTACGGCCCCTGGAGGTGCGG CGGGCGCCGGTACCCGACGGAGCACCCTCCCGTTACCCGCCCGTTGCCACCTGCCACCGGCCGGGCAGCACCTCCTTCTGCCCTGGGGAA AGCAGCCGGATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCACCTCCAACA ATGCCCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGACCGCACCCGC TTCCGGGCATCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTACCAGTGTGAG CTCACGGTGGACGACATCATGCCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGGAAATTCAAG GAGACACTGCGACCGTACGACGTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGATCAAGAGCCTGCAA ACTCGGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCGGAGGTGGTG GATGAAATCAGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTGGGCTTCTAT TCGCGCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCTCCGACTACCACAGC CCTGTGGACCACGAGGACATCTCCGTCTCCGCACAGACGCTCAGCATCTCCCGCTCGGTCAGCACCAACATGGACTGAGGGACTTCTCAG AGGCAGGGCAGCACACGGCCAGCCCCGCGGCCTGGCGCTCCGACTGCCCTCTGAGGCCTCCGGACTCCTCTCGTACTTGAACTCACTCCC TCACGGGGAGAGAGACCACACGCAGTATTGAGCTGCCTGAGTGGGCGTGGTACCTGCTGTGGGTGCCAGCGCCCCTTCCCCACCTCAGGA GCGTGAGATGCCAGGTCGCACAGAGGGCAGCAGCAGCGGCCGTCCCGCGGCCTCTGGGCCCCCCAGTGCCCTGCCCACTCCATCAAGGCC CTATGTGGCCCACCTGGCAGGGGCACAGCCCCGGGAGTGGGAGCGGGCGCTGGGGCCCTGGGCCCTGACCCAGCTTCCAGCTATGCAAGG TGAGGTCTCTGGCCCACCCTTCGGACACAGCAGGGAAGCCCTCCCGCCAAGTCCCCGCCCCACTTGGGGGTGGGCCAAGGTGCCCCCACA GGTACCCACAAAGCACAGGACCCTGCCACAAGGCAGGTGGACACCATATATGCAAACCATGTTAAATATGCAACTTTGGGGACCCCCATG GGGTCTCTCTGTCCCTCCCCCATTGGGAGCTGGGCCCCCAGCAGTAGCTGGTCTCAGGCTGCTTGGCCACCACCCTGTCCCTATTCTTTG GCTTATCACTCCTTCCCCTCCCAGCATGGGGCCTGTTTCTCCCCTGCCCTCTCCTAAGGGCAATGCCTGGGCCTTTCTTCCCATTTGCAA GTGTCAGCTCCCAGGGGCTCCCTCCTCCTGCTGGGTGGCCACTCCCCTCCTTGGCCCTCCAGACACCACTCATAGTCAGCACAGGTTTCT GTATCCTCCCCAAAACTCCCAGACAGTGCTTCGTGGACGATCGCACAAACATAGCCTTTTAGTTTCTCCAGACAGGAAGAAAGCCTCTCA CACTTAAACATGCAATGACGTGACACACTTGGAGACATGAGTGCAGAGCCACTCAGCCGCTCCTGGGCCTCTGCAGCAGATGCCAGTGGA CTGGCCTTGCAGGGTGACGACCACTAAGAGGAAGACCCCCAACTCCATCTGAGCAGGAGAAGGAGCTTTGAAGTAACCCGAGAGCTCTCC AGGCCCCACCCAGACCTTTACCCGCTCCCCTTCTTCAAGAAGATCTCCTCCTCTCTGGTCCAGGAGCCCTAACCCACTGCCTCTGCCTGT CCCCAAGGGCCCGCCTCCGTGTCTCCACAGCACAACTCGGGCCCAGGCCTGACACCACTGGAGAGACCCCAGGCCCACTTCTAGCCAGGC CTGTGCCTTCCTAGTCACTCTAACTCCCAGAGAGAATAAGAATGCATGTAATAGCTATACCAACCGCGCATCCGGCTTTCACATGCACTG TCTCCCCTCCCTCCACACCCCACTTCTTCACTTCAATTGGCAGCGCCACATCCAGGCGTCAGCCCCCATTCACTCCAGGAACACTTTCTT ATCCCCACCCCTTTGCTCCTCTTCTGCAAAGCCAATGCAGGTGGCAGGAAGGTGAGGGGTAGTGGACCAATGGCAACCCTCTGTGGGAAC AAGGGGCCGAGGCCACGCTGCCTGCATCTCGTGCTGGGGACCTGCATGCGCCAGCACCAGGGCTTGGACTGGATCTTACTCAGTCCATGG TGCCCAGCCTCTGCCCCAACATGCCCTCTGCATGTGACCGTCATGCCCTGGATGGAGCCACTCCTGGCTCACCCCACCTGCACTGCACTG TCCCCAGAGAGCCACCCCTCCACCCACTCAGAGACAGCTGTGGAGAGGGCCAGGAGAATGGGATTACCCTATGACCAAGGAGACATGGGA AGAAGCCCTCCTTCCTTCCACGATCGAGGTTCCGCCATCAACTCGGTTCTCGGATATGCAAGTACCTCACTTTGTTAACTTATTAACTTA >12813_12813_7_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372798_KCNQ4_chr1_41285547_ENST00000347132_length(amino acids)=520AA_BP=1 MSRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLKLERA LLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWRLYST DMSRAYLTATWYYYDSILPSFRELALLFEHVQRARNGGLRPLEVRRAPVPDGAPSRYPPVATCHRPGSTSFCPGESSRMGIKDRIRMGSS QRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKPRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIR SIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGRGPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQ -------------------------------------------------------------- >12813_12813_8_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372798_KCNQ4_chr1_41285547_ENST00000509682_length(transcript)=1446nt_BP=354nt GGAAGCGGAGAGCGGCTGATCGCAGTCCGGAGGTGAGGCGGAACTCTGAGCAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAA AGATTGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCATACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGGAGCA GCTCCATATGTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAG AAACATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACA TTGACAACCATCGGCTATGGTGACAAGACACCGCACACATGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTC TTTGCCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATG CCGGCAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGAC AGTATCCTCCCATCCTTCAGCAGCCGGATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAG CATCTGGCACCTCCAACAATGCCCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGC TTCAATGACCGCACCCGCTTCCGGGCATCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAG AAGAGCTACCAGTGTGAGCTCACGGTGGACGACATCATGCCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTG GCCAAAAGGAAATTCAAGGAGACACTGCGACCGTACGACGTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGC CGGATCAAGAGCCTGCAAACTCGGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCC TCCGACGCGGAGGTGGTGGATGAAATCAGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGAC CTGCTGTTGGGCTTCTATTCGCGCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATC ACCTCCGACTACCACAGCCCTGTGGACCACGAGGACATCTCCGTCTCCGCACAGACGCTCAGCATCTCCCGCTCGGTCAGCACCAACATG >12813_12813_8_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372798_KCNQ4_chr1_41285547_ENST00000509682_length(amino acids)=466AA_BP=1 MSRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLKLERA LLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWRLYST DMSRAYLTATWYYYDSILPSFSSRMGIKDRIRMGSSQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKP RTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIRSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGR GPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQVQSIEHKLDLLLGFYSRCLRSGTSASLGAVQVPLFDPDITSDYHSPVDHEDISV -------------------------------------------------------------- >12813_12813_9_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372802_KCNQ4_chr1_41285547_ENST00000347132_length(transcript)=4031nt_BP=848nt GTGGCCTCGATCACCACCGAGAGCTGACGGCCGCCCGGATTCCCGCCCTCAGAGAATCCTGGCCCCCAGTCGTTCCAAGACCCTTTACGG ACTGCAGCTTAAAGGAACCGGCCTCTGCCATTGAGACCAAACTGACAGAGGAACTGGTCACTCTTCTGTTCTTTCCAGAGAGGAGCTTAG CCAGGGACTTCTGCCCTTCCTGGGCCCGGGCCTCGGGGGCGATTCCGGGTAGGTAAAGCGGAACGAGGGCGTGGCCTCTCTTGTGAGCCC GCCCTCCCCGTGTCGCTCCCGCCTTGAGGGCGGGGCTCTTTCCCAAGTGCCCTCTGTGAGAGCCGGGCCGCTCTCTCCGGGGCGTGGCGA AGAGGGGCGGAGTCACGAGCGGGGCGGTGAGACTTCCTGCCCAGTCGCGGGCCAGCCTAGCGCTTCAGCCGGCGGCTCATTTCCGGTGGG GGCGCCGCGCCCAGTGAGGGCCCGGAAGTGGGTCGCGCGGAGATTGCTGGGCGGTTCTTGCCGGAAGCGGAGAGCGGCTGATCGCAGTCC GGAGCAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAAAGATTGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCATACCT CTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGGAGCAGCTCCATATGTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGG CAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAGAAACATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTC TGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACATTGACAACCATCGGCTATGGTGACAAGACACCGCACACATGGCTGG GCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTCTTTGCCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGG TCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATGCCGGCAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCG ATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGACAGTATCCTCCCATCCTTCAGAGAGCTGGCCCTCTTGTTTGAGCACG TGCAACGGGCCCGCAATGGGGGCCTACGGCCCCTGGAGGTGCGGCGGGCGCCGGTACCCGACGGAGCACCCTCCCGTTACCCGCCCGTTG CCACCTGCCACCGGCCGGGCAGCACCTCCTTCTGCCCTGGGGAAAGCAGCCGGATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCC AGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCACCTCCAACAATGCCCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCC CCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGACCGCACCCGCTTCCGGGCATCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATG CCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTACCAGTGTGAGCTCACGGTGGACGACATCATGCCTGCTGTGAAGACAGTCATCCGCT CCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGGAAATTCAAGGAGACACTGCGACCGTACGACGTGAAGGACGTCATTGAGCAGTACT CAGCAGGCCACCTGGACATGCTGGGCCGGATCAAGAGCCTGCAAACTCGGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGG CCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCGGAGGTGGTGGATGAAATCAGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGG TGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTGGGCTTCTATTCGCGCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGC AAGTGCCGCTGTTCGACCCCGACATCACCTCCGACTACCACAGCCCTGTGGACCACGAGGACATCTCCGTCTCCGCACAGACGCTCAGCA TCTCCCGCTCGGTCAGCACCAACATGGACTGAGGGACTTCTCAGAGGCAGGGCAGCACACGGCCAGCCCCGCGGCCTGGCGCTCCGACTG CCCTCTGAGGCCTCCGGACTCCTCTCGTACTTGAACTCACTCCCTCACGGGGAGAGAGACCACACGCAGTATTGAGCTGCCTGAGTGGGC GTGGTACCTGCTGTGGGTGCCAGCGCCCCTTCCCCACCTCAGGAGCGTGAGATGCCAGGTCGCACAGAGGGCAGCAGCAGCGGCCGTCCC GCGGCCTCTGGGCCCCCCAGTGCCCTGCCCACTCCATCAAGGCCCTATGTGGCCCACCTGGCAGGGGCACAGCCCCGGGAGTGGGAGCGG GCGCTGGGGCCCTGGGCCCTGACCCAGCTTCCAGCTATGCAAGGTGAGGTCTCTGGCCCACCCTTCGGACACAGCAGGGAAGCCCTCCCG CCAAGTCCCCGCCCCACTTGGGGGTGGGCCAAGGTGCCCCCACAGGTACCCACAAAGCACAGGACCCTGCCACAAGGCAGGTGGACACCA TATATGCAAACCATGTTAAATATGCAACTTTGGGGACCCCCATGGGGTCTCTCTGTCCCTCCCCCATTGGGAGCTGGGCCCCCAGCAGTA GCTGGTCTCAGGCTGCTTGGCCACCACCCTGTCCCTATTCTTTGGCTTATCACTCCTTCCCCTCCCAGCATGGGGCCTGTTTCTCCCCTG CCCTCTCCTAAGGGCAATGCCTGGGCCTTTCTTCCCATTTGCAAGTGTCAGCTCCCAGGGGCTCCCTCCTCCTGCTGGGTGGCCACTCCC CTCCTTGGCCCTCCAGACACCACTCATAGTCAGCACAGGTTTCTGTATCCTCCCCAAAACTCCCAGACAGTGCTTCGTGGACGATCGCAC AAACATAGCCTTTTAGTTTCTCCAGACAGGAAGAAAGCCTCTCACACTTAAACATGCAATGACGTGACACACTTGGAGACATGAGTGCAG AGCCACTCAGCCGCTCCTGGGCCTCTGCAGCAGATGCCAGTGGACTGGCCTTGCAGGGTGACGACCACTAAGAGGAAGACCCCCAACTCC ATCTGAGCAGGAGAAGGAGCTTTGAAGTAACCCGAGAGCTCTCCAGGCCCCACCCAGACCTTTACCCGCTCCCCTTCTTCAAGAAGATCT CCTCCTCTCTGGTCCAGGAGCCCTAACCCACTGCCTCTGCCTGTCCCCAAGGGCCCGCCTCCGTGTCTCCACAGCACAACTCGGGCCCAG GCCTGACACCACTGGAGAGACCCCAGGCCCACTTCTAGCCAGGCCTGTGCCTTCCTAGTCACTCTAACTCCCAGAGAGAATAAGAATGCA TGTAATAGCTATACCAACCGCGCATCCGGCTTTCACATGCACTGTCTCCCCTCCCTCCACACCCCACTTCTTCACTTCAATTGGCAGCGC CACATCCAGGCGTCAGCCCCCATTCACTCCAGGAACACTTTCTTATCCCCACCCCTTTGCTCCTCTTCTGCAAAGCCAATGCAGGTGGCA GGAAGGTGAGGGGTAGTGGACCAATGGCAACCCTCTGTGGGAACAAGGGGCCGAGGCCACGCTGCCTGCATCTCGTGCTGGGGACCTGCA TGCGCCAGCACCAGGGCTTGGACTGGATCTTACTCAGTCCATGGTGCCCAGCCTCTGCCCCAACATGCCCTCTGCATGTGACCGTCATGC CCTGGATGGAGCCACTCCTGGCTCACCCCACCTGCACTGCACTGTCCCCAGAGAGCCACCCCTCCACCCACTCAGAGACAGCTGTGGAGA GGGCCAGGAGAATGGGATTACCCTATGACCAAGGAGACATGGGAAGAAGCCCTCCTTCCTTCCACGATCGAGGTTCCGCCATCAACTCGG >12813_12813_9_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372802_KCNQ4_chr1_41285547_ENST00000347132_length(amino acids)=524AA_BP=5 MIAVRSRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLK LERALLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWR LYSTDMSRAYLTATWYYYDSILPSFRELALLFEHVQRARNGGLRPLEVRRAPVPDGAPSRYPPVATCHRPGSTSFCPGESSRMGIKDRIR MGSSQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKPRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVK TVIRSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGRGPGDRKAREKGDKGPSDAEVVDEISMMGRVVK -------------------------------------------------------------- >12813_12813_10_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372802_KCNQ4_chr1_41285547_ENST00000509682_length(transcript)=1940nt_BP=848nt GTGGCCTCGATCACCACCGAGAGCTGACGGCCGCCCGGATTCCCGCCCTCAGAGAATCCTGGCCCCCAGTCGTTCCAAGACCCTTTACGG ACTGCAGCTTAAAGGAACCGGCCTCTGCCATTGAGACCAAACTGACAGAGGAACTGGTCACTCTTCTGTTCTTTCCAGAGAGGAGCTTAG CCAGGGACTTCTGCCCTTCCTGGGCCCGGGCCTCGGGGGCGATTCCGGGTAGGTAAAGCGGAACGAGGGCGTGGCCTCTCTTGTGAGCCC GCCCTCCCCGTGTCGCTCCCGCCTTGAGGGCGGGGCTCTTTCCCAAGTGCCCTCTGTGAGAGCCGGGCCGCTCTCTCCGGGGCGTGGCGA AGAGGGGCGGAGTCACGAGCGGGGCGGTGAGACTTCCTGCCCAGTCGCGGGCCAGCCTAGCGCTTCAGCCGGCGGCTCATTTCCGGTGGG GGCGCCGCGCCCAGTGAGGGCCCGGAAGTGGGTCGCGCGGAGATTGCTGGGCGGTTCTTGCCGGAAGCGGAGAGCGGCTGATCGCAGTCC GGAGCAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAAAGATTGGAGAGGGCAGTGGGCCGCCTGGAGGCAGTATCTCATACCT CTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGGAGCAGCTCCATATGTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGG CAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAGAAACATGCGGAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTC TGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACATTGACAACCATCGGCTATGGTGACAAGACACCGCACACATGGCTGG GCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTCTTTGCCCTGCCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGG TCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATGCCGGCAGCCAACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCG ATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGACAGTATCCTCCCATCCTTCAGCAGCCGGATGGGCATCAAAGACCGCA TCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCACCTCCAACAATGCCCACCTCCCCAAGCAGCGAGCAGG TGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGACCGCACCCGCTTCCGGGCATCTCTGAGACTCAAACCCC GCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTACCAGTGTGAGCTCACGGTGGACGACATCATGCCTGCTG TGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGGAAATTCAAGGAGACACTGCGACCGTACGACGTGAAGG ACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGATCAAGAGCCTGCAAACTCGGGTGGACCAAATTGTGGGTCGGG GGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCGGAGGTGGTGGATGAAATCAGCATGATGGGACGCGTGG TCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTGGGCTTCTATTCGCGCTGCCTGCGCTCTGGCACCTCGG CCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCTCCGACTACCACAGCCCTGTGGACCACGAGGACATCTCCGTCT >12813_12813_10_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372802_KCNQ4_chr1_41285547_ENST00000509682_length(amino acids)=471AA_BP=5 MIAVRSRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLK LERALLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWR LYSTDMSRAYLTATWYYYDSILPSFSSRMGIKDRIRMGSSQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASL RLKPRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIRSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQ IVGRGPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQVQSIEHKLDLLLGFYSRCLRSGTSASLGAVQVPLFDPDITSDYHSPVDHE -------------------------------------------------------------- >12813_12813_11_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372805_KCNQ4_chr1_41285547_ENST00000347132_length(transcript)=3528nt_BP=345nt GAGCGGCTGATCGCAGTCCGGAGGTGAGGCGGAACTCTGAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAAAGATTGGAGAGG GCAGTGGGCCGCCTGGAGGCAGTATCTCATACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGCAGGAGCAGCTCCATAT GTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAGAAACATGCG GAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACATTGACAACC ATCGGCTATGGTGACAAGACACCGCACACATGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTCTTTGCCCTG CCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATGCCGGCAGCC AACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGACAGTATCCTC CCATCCTTCAGAGAGCTGGCCCTCTTGTTTGAGCACGTGCAACGGGCCCGCAATGGGGGCCTACGGCCCCTGGAGGTGCGGCGGGCGCCG GTACCCGACGGAGCACCCTCCCGTTACCCGCCCGTTGCCACCTGCCACCGGCCGGGCAGCACCTCCTTCTGCCCTGGGGAAAGCAGCCGG ATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCACCTCCAACAATGCCCACC TCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGACCGCACCCGCTTCCGGGCA TCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTACCAGTGTGAGCTCACGGTG GACGACATCATGCCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGGAAATTCAAGGAGACACTG CGACCGTACGACGTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGATCAAGAGCCTGCAAACTCGGGTG GACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCGGAGGTGGTGGATGAAATC AGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTGGGCTTCTATTCGCGCTGC CTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCTCCGACTACCACAGCCCTGTGGAC CACGAGGACATCTCCGTCTCCGCACAGACGCTCAGCATCTCCCGCTCGGTCAGCACCAACATGGACTGAGGGACTTCTCAGAGGCAGGGC AGCACACGGCCAGCCCCGCGGCCTGGCGCTCCGACTGCCCTCTGAGGCCTCCGGACTCCTCTCGTACTTGAACTCACTCCCTCACGGGGA GAGAGACCACACGCAGTATTGAGCTGCCTGAGTGGGCGTGGTACCTGCTGTGGGTGCCAGCGCCCCTTCCCCACCTCAGGAGCGTGAGAT GCCAGGTCGCACAGAGGGCAGCAGCAGCGGCCGTCCCGCGGCCTCTGGGCCCCCCAGTGCCCTGCCCACTCCATCAAGGCCCTATGTGGC CCACCTGGCAGGGGCACAGCCCCGGGAGTGGGAGCGGGCGCTGGGGCCCTGGGCCCTGACCCAGCTTCCAGCTATGCAAGGTGAGGTCTC TGGCCCACCCTTCGGACACAGCAGGGAAGCCCTCCCGCCAAGTCCCCGCCCCACTTGGGGGTGGGCCAAGGTGCCCCCACAGGTACCCAC AAAGCACAGGACCCTGCCACAAGGCAGGTGGACACCATATATGCAAACCATGTTAAATATGCAACTTTGGGGACCCCCATGGGGTCTCTC TGTCCCTCCCCCATTGGGAGCTGGGCCCCCAGCAGTAGCTGGTCTCAGGCTGCTTGGCCACCACCCTGTCCCTATTCTTTGGCTTATCAC TCCTTCCCCTCCCAGCATGGGGCCTGTTTCTCCCCTGCCCTCTCCTAAGGGCAATGCCTGGGCCTTTCTTCCCATTTGCAAGTGTCAGCT CCCAGGGGCTCCCTCCTCCTGCTGGGTGGCCACTCCCCTCCTTGGCCCTCCAGACACCACTCATAGTCAGCACAGGTTTCTGTATCCTCC CCAAAACTCCCAGACAGTGCTTCGTGGACGATCGCACAAACATAGCCTTTTAGTTTCTCCAGACAGGAAGAAAGCCTCTCACACTTAAAC ATGCAATGACGTGACACACTTGGAGACATGAGTGCAGAGCCACTCAGCCGCTCCTGGGCCTCTGCAGCAGATGCCAGTGGACTGGCCTTG CAGGGTGACGACCACTAAGAGGAAGACCCCCAACTCCATCTGAGCAGGAGAAGGAGCTTTGAAGTAACCCGAGAGCTCTCCAGGCCCCAC CCAGACCTTTACCCGCTCCCCTTCTTCAAGAAGATCTCCTCCTCTCTGGTCCAGGAGCCCTAACCCACTGCCTCTGCCTGTCCCCAAGGG CCCGCCTCCGTGTCTCCACAGCACAACTCGGGCCCAGGCCTGACACCACTGGAGAGACCCCAGGCCCACTTCTAGCCAGGCCTGTGCCTT CCTAGTCACTCTAACTCCCAGAGAGAATAAGAATGCATGTAATAGCTATACCAACCGCGCATCCGGCTTTCACATGCACTGTCTCCCCTC CCTCCACACCCCACTTCTTCACTTCAATTGGCAGCGCCACATCCAGGCGTCAGCCCCCATTCACTCCAGGAACACTTTCTTATCCCCACC CCTTTGCTCCTCTTCTGCAAAGCCAATGCAGGTGGCAGGAAGGTGAGGGGTAGTGGACCAATGGCAACCCTCTGTGGGAACAAGGGGCCG AGGCCACGCTGCCTGCATCTCGTGCTGGGGACCTGCATGCGCCAGCACCAGGGCTTGGACTGGATCTTACTCAGTCCATGGTGCCCAGCC TCTGCCCCAACATGCCCTCTGCATGTGACCGTCATGCCCTGGATGGAGCCACTCCTGGCTCACCCCACCTGCACTGCACTGTCCCCAGAG AGCCACCCCTCCACCCACTCAGAGACAGCTGTGGAGAGGGCCAGGAGAATGGGATTACCCTATGACCAAGGAGACATGGGAAGAAGCCCT CCTTCCTTCCACGATCGAGGTTCCGCCATCAACTCGGTTCTCGGATATGCAAGTACCTCACTTTGTTAACTTATTAACTTATTGGTTTCA >12813_12813_11_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372805_KCNQ4_chr1_41285547_ENST00000347132_length(amino acids)=520AA_BP=1 MRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKAGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLKLERA LLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWRLYST DMSRAYLTATWYYYDSILPSFRELALLFEHVQRARNGGLRPLEVRRAPVPDGAPSRYPPVATCHRPGSTSFCPGESSRMGIKDRIRMGSS QRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKPRTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIR SIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGRGPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQ -------------------------------------------------------------- >12813_12813_12_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372805_KCNQ4_chr1_41285547_ENST00000509682_length(transcript)=1437nt_BP=345nt GAGCGGCTGATCGCAGTCCGGAGGTGAGGCGGAACTCTGAGGTGGTCCATTATGGCTGACATGCAAAATCTGGTAGAAAGATTGGAGAGG GCAGTGGGCCGCCTGGAGGCAGTATCTCATACCTCTGACATGCACCGTGGGTATGCAGACAGTCCTTCAAAAGCAGGAGCAGCTCCATAT GTGCAGGCATTTGACTCGCTGCTTGCTGGTCCTGTGGCAGAGTACTTGAAGATCAGTAAAGAGATTGGGGGAGACGTGCAGAAACATGCG GAGATGGTCCACACAGGTTTGAAGTTGGAGCGAGCTCTGTTGGTTACAGCTTCTCAGTGTCAACAGCCAGCAGAAATTACATTGACAACC ATCGGCTATGGTGACAAGACACCGCACACATGGCTGGGCAGGGTCCTGGCTGCTGGCTTCGCCTTACTGGGCATCTCTTTCTTTGCCCTG CCTGCCGGCATCCTAGGCTCCGGCTTTGCCCTGAAGGTCCAGGAGCAGCACCGGCAGAAGCACTTCGAGAAGCGGAGGATGCCGGCAGCC AACCTCATCCAGGCTGCCTGGCGCCTGTACTCCACCGATATGAGCCGGGCCTACCTGACAGCCACCTGGTACTACTATGACAGTATCCTC CCATCCTTCAGCAGCCGGATGGGCATCAAAGACCGCATCCGCATGGGCAGCTCCCAGCGGCGGACGGGTCCTTCCAAGCAGCATCTGGCA CCTCCAACAATGCCCACCTCCCCAAGCAGCGAGCAGGTGGGTGAGGCCACCAGCCCCACCAAGGTGCAAAAGAGCTGGAGCTTCAATGAC CGCACCCGCTTCCGGGCATCTCTGAGACTCAAACCCCGCACCTCTGCTGAGGATGCCCCCTCAGAGGAAGTAGCAGAGGAGAAGAGCTAC CAGTGTGAGCTCACGGTGGACGACATCATGCCTGCTGTGAAGACAGTCATCCGCTCCATCAGGATTCTCAAGTTCCTGGTGGCCAAAAGG AAATTCAAGGAGACACTGCGACCGTACGACGTGAAGGACGTCATTGAGCAGTACTCAGCAGGCCACCTGGACATGCTGGGCCGGATCAAG AGCCTGCAAACTCGGGTGGACCAAATTGTGGGTCGGGGGCCCGGGGACAGGAAGGCCCGGGAGAAGGGCGACAAGGGGCCCTCCGACGCG GAGGTGGTGGATGAAATCAGCATGATGGGACGCGTGGTCAAGGTGGAGAAGCAGGTGCAGTCCATCGAGCACAAGCTGGACCTGCTGTTG GGCTTCTATTCGCGCTGCCTGCGCTCTGGCACCTCGGCCAGCCTGGGCGCCGTGCAAGTGCCGCTGTTCGACCCCGACATCACCTCCGAC >12813_12813_12_CAP1-KCNQ4_CAP1_chr1_40527484_ENST00000372805_KCNQ4_chr1_41285547_ENST00000509682_length(amino acids)=466AA_BP=1 MRWSIMADMQNLVERLERAVGRLEAVSHTSDMHRGYADSPSKAGAAPYVQAFDSLLAGPVAEYLKISKEIGGDVQKHAEMVHTGLKLERA LLVTASQCQQPAEITLTTIGYGDKTPHTWLGRVLAAGFALLGISFFALPAGILGSGFALKVQEQHRQKHFEKRRMPAANLIQAAWRLYST DMSRAYLTATWYYYDSILPSFSSRMGIKDRIRMGSSQRRTGPSKQHLAPPTMPTSPSSEQVGEATSPTKVQKSWSFNDRTRFRASLRLKP RTSAEDAPSEEVAEEKSYQCELTVDDIMPAVKTVIRSIRILKFLVAKRKFKETLRPYDVKDVIEQYSAGHLDMLGRIKSLQTRVDQIVGR GPGDRKAREKGDKGPSDAEVVDEISMMGRVVKVEKQVQSIEHKLDLLLGFYSRCLRSGTSASLGAVQVPLFDPDITSDYHSPVDHEDISV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CAP1-KCNQ4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CAP1-KCNQ4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CAP1-KCNQ4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies