
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CAPN1-TNKS1BP1 (FusionGDB2 ID:12869) |
Fusion Gene Summary for CAPN1-TNKS1BP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CAPN1-TNKS1BP1 | Fusion gene ID: 12869 | Hgene | Tgene | Gene symbol | CAPN1 | TNKS1BP1 | Gene ID | 823 | 85456 |
| Gene name | calpain 1 | tankyrase 1 binding protein 1 | |
| Synonyms | CANP|CANP1|CANPL1|SPG76|muCANP|muCL | TAB182 | |
| Cytomap | 11q13.1 | 11q12.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | calpain-1 catalytic subunitCANP 1calcium-activated neutral proteinase 1calpain 1, (mu/I) large subunitcalpain mu-typecalpain, large polypeptide L1calpain-1 large subunitcell proliferation-inducing gene 30 proteincell proliferation-inducing protein | 182 kDa tankyrase-1-binding proteintankyrase 1 binding protein 1, 182kDatankyrase 1-binding protein of 182 kDatestis secretory sperm-binding protein Li 206a | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | P07384 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000527469, ENST00000279247, ENST00000524773, ENST00000527323, ENST00000533129, ENST00000533820, | ENST00000358252, ENST00000532437, ENST00000530920, | |
| Fusion gene scores | * DoF score | 13 X 11 X 8=1144 | 8 X 8 X 3=192 |
| # samples | 13 | 8 | |
| ** MAII score | log2(13/1144*10)=-3.13750352374993 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/192*10)=-1.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CAPN1 [Title/Abstract] AND TNKS1BP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CAPN1(64951063)-TNKS1BP1(57068515), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CAPN1 | GO:0006508 | proteolysis | 2400579|2407243|16411745|21531719 |
| Hgene | CAPN1 | GO:0050790 | regulation of catalytic activity | 8954105|9271093 |
| Hgene | CAPN1 | GO:0097264 | self proteolysis | 8769305|8954105 |
| Fusion gene breakpoints across CAPN1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TNKS1BP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-DK-A6B5-01A | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
Top |
Fusion Gene ORF analysis for CAPN1-TNKS1BP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000527469 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| 3UTR-3CDS | ENST00000527469 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| 3UTR-intron | ENST00000527469 | ENST00000530920 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| 5CDS-intron | ENST00000279247 | ENST00000530920 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| 5CDS-intron | ENST00000524773 | ENST00000530920 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| 5CDS-intron | ENST00000527323 | ENST00000530920 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| 5CDS-intron | ENST00000533129 | ENST00000530920 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| 5CDS-intron | ENST00000533820 | ENST00000530920 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000279247 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000279247 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000524773 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000524773 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000527323 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000527323 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000533129 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000533129 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000533820 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| In-frame | ENST00000533820 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000533820 | CAPN1 | chr11 | 64951063 | + | ENST00000358252 | TNKS1BP1 | chr11 | 57068515 | - | 1345 | 674 | 78 | 869 | 263 |
| ENST00000533820 | CAPN1 | chr11 | 64951063 | + | ENST00000532437 | TNKS1BP1 | chr11 | 57068515 | - | 1343 | 674 | 78 | 869 | 263 |
| ENST00000533129 | CAPN1 | chr11 | 64951063 | + | ENST00000358252 | TNKS1BP1 | chr11 | 57068515 | - | 1202 | 531 | 75 | 749 | 224 |
| ENST00000533129 | CAPN1 | chr11 | 64951063 | + | ENST00000532437 | TNKS1BP1 | chr11 | 57068515 | - | 1200 | 531 | 75 | 749 | 224 |
| ENST00000524773 | CAPN1 | chr11 | 64951063 | + | ENST00000358252 | TNKS1BP1 | chr11 | 57068515 | - | 1227 | 556 | 100 | 774 | 224 |
| ENST00000524773 | CAPN1 | chr11 | 64951063 | + | ENST00000532437 | TNKS1BP1 | chr11 | 57068515 | - | 1225 | 556 | 100 | 774 | 224 |
| ENST00000279247 | CAPN1 | chr11 | 64951063 | + | ENST00000358252 | TNKS1BP1 | chr11 | 57068515 | - | 1270 | 599 | 63 | 794 | 243 |
| ENST00000279247 | CAPN1 | chr11 | 64951063 | + | ENST00000532437 | TNKS1BP1 | chr11 | 57068515 | - | 1268 | 599 | 63 | 794 | 243 |
| ENST00000527323 | CAPN1 | chr11 | 64951063 | + | ENST00000358252 | TNKS1BP1 | chr11 | 57068515 | - | 1367 | 696 | 207 | 914 | 235 |
| ENST00000527323 | CAPN1 | chr11 | 64951063 | + | ENST00000532437 | TNKS1BP1 | chr11 | 57068515 | - | 1365 | 696 | 207 | 914 | 235 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000533820 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.047193453 | 0.95280653 |
| ENST00000533820 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.047030475 | 0.95296955 |
| ENST00000533129 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.05602941 | 0.9439706 |
| ENST00000533129 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.056312878 | 0.9436872 |
| ENST00000524773 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.055603568 | 0.94439644 |
| ENST00000524773 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.055878345 | 0.94412166 |
| ENST00000279247 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.040529426 | 0.95947057 |
| ENST00000279247 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.04058767 | 0.9594123 |
| ENST00000527323 | ENST00000358252 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.04297983 | 0.95702016 |
| ENST00000527323 | ENST00000532437 | CAPN1 | chr11 | 64951063 | + | TNKS1BP1 | chr11 | 57068515 | - | 0.043221723 | 0.9567783 |
Top |
Fusion Genomic Features for CAPN1-TNKS1BP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
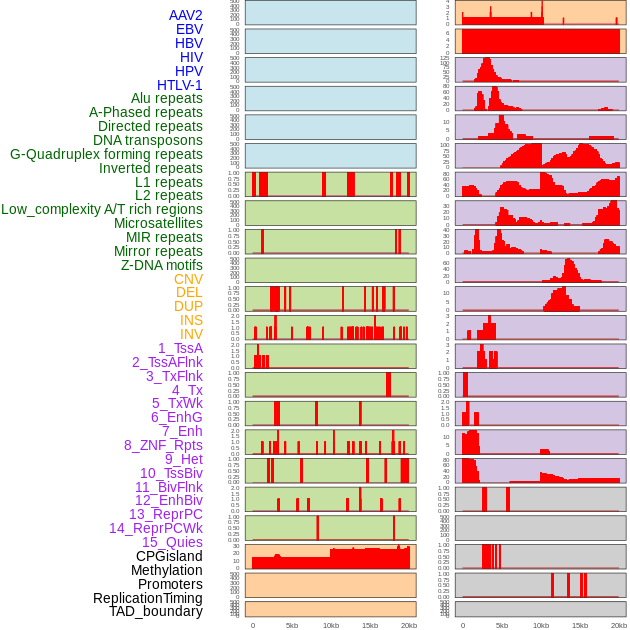 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CAPN1-TNKS1BP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:64951063/chr11:57068515) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CAPN1 | . |
| FUNCTION: Calcium-regulated non-lysosomal thiol-protease which catalyzes limited proteolysis of substrates involved in cytoskeletal remodeling and signal transduction (PubMed:21531719, PubMed:2400579). Proteolytically cleaves CTBP1 at 'Asn-375', 'Gly-387' and 'His-409' (PubMed:23707407). {ECO:0000269|PubMed:21531719, ECO:0000269|PubMed:23707407, ECO:0000269|PubMed:2400579}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 99_106 | 152 | 715.0 | Calcium binding | Note=1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 99_106 | 152 | 715.0 | Calcium binding | Note=1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 99_106 | 152 | 715.0 | Calcium binding | Note=1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 99_106 | 152 | 715.0 | Calcium binding | Note=1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 99_106 | 152 | 715.0 | Calcium binding | Note=1 |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000358252 | 8 | 12 | 1723_1729 | 1657 | 1818.6666666666667 | Motif | Nuclear localization signal | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000532437 | 7 | 11 | 1723_1729 | 1657 | 1553.6666666666667 | Motif | Nuclear localization signal |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 302_333 | 152 | 715.0 | Calcium binding | Note=2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 598_609 | 152 | 715.0 | Calcium binding | Note=3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 628_639 | 152 | 715.0 | Calcium binding | Note=4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 302_333 | 152 | 715.0 | Calcium binding | Note=2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 598_609 | 152 | 715.0 | Calcium binding | Note=3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 628_639 | 152 | 715.0 | Calcium binding | Note=4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 302_333 | 152 | 715.0 | Calcium binding | Note=2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 598_609 | 152 | 715.0 | Calcium binding | Note=3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 628_639 | 152 | 715.0 | Calcium binding | Note=4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 302_333 | 152 | 715.0 | Calcium binding | Note=2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 598_609 | 152 | 715.0 | Calcium binding | Note=3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 628_639 | 152 | 715.0 | Calcium binding | Note=4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 302_333 | 152 | 715.0 | Calcium binding | Note=2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 598_609 | 152 | 715.0 | Calcium binding | Note=3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 628_639 | 152 | 715.0 | Calcium binding | Note=4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 541_576 | 152 | 715.0 | Domain | EF-hand 1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 55_354 | 152 | 715.0 | Domain | Calpain catalytic |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 585_618 | 152 | 715.0 | Domain | EF-hand 2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 615_650 | 152 | 715.0 | Domain | EF-hand 3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 680_714 | 152 | 715.0 | Domain | EF-hand 4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 541_576 | 152 | 715.0 | Domain | EF-hand 1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 55_354 | 152 | 715.0 | Domain | Calpain catalytic |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 585_618 | 152 | 715.0 | Domain | EF-hand 2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 615_650 | 152 | 715.0 | Domain | EF-hand 3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 680_714 | 152 | 715.0 | Domain | EF-hand 4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 541_576 | 152 | 715.0 | Domain | EF-hand 1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 55_354 | 152 | 715.0 | Domain | Calpain catalytic |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 585_618 | 152 | 715.0 | Domain | EF-hand 2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 615_650 | 152 | 715.0 | Domain | EF-hand 3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 680_714 | 152 | 715.0 | Domain | EF-hand 4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 541_576 | 152 | 715.0 | Domain | EF-hand 1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 55_354 | 152 | 715.0 | Domain | Calpain catalytic |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 585_618 | 152 | 715.0 | Domain | EF-hand 2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 615_650 | 152 | 715.0 | Domain | EF-hand 3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 680_714 | 152 | 715.0 | Domain | EF-hand 4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 541_576 | 152 | 715.0 | Domain | EF-hand 1 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 55_354 | 152 | 715.0 | Domain | Calpain catalytic |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 585_618 | 152 | 715.0 | Domain | EF-hand 2 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 615_650 | 152 | 715.0 | Domain | EF-hand 3 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 680_714 | 152 | 715.0 | Domain | EF-hand 4 |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 355_526 | 152 | 715.0 | Region | Note=Domain III |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 527_542 | 152 | 715.0 | Region | Note=Linker |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000279247 | + | 4 | 22 | 543_713 | 152 | 715.0 | Region | Note=Domain IV |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 355_526 | 152 | 715.0 | Region | Note=Domain III |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 527_542 | 152 | 715.0 | Region | Note=Linker |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000524773 | + | 4 | 22 | 543_713 | 152 | 715.0 | Region | Note=Domain IV |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 355_526 | 152 | 715.0 | Region | Note=Domain III |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 527_542 | 152 | 715.0 | Region | Note=Linker |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000527323 | + | 3 | 21 | 543_713 | 152 | 715.0 | Region | Note=Domain IV |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 355_526 | 152 | 715.0 | Region | Note=Domain III |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 527_542 | 152 | 715.0 | Region | Note=Linker |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533129 | + | 4 | 22 | 543_713 | 152 | 715.0 | Region | Note=Domain IV |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 355_526 | 152 | 715.0 | Region | Note=Domain III |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 527_542 | 152 | 715.0 | Region | Note=Linker |
| Hgene | CAPN1 | chr11:64951063 | chr11:57068515 | ENST00000533820 | + | 4 | 22 | 543_713 | 152 | 715.0 | Region | Note=Domain IV |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000358252 | 8 | 12 | 1010_1340 | 1657 | 1818.6666666666667 | Compositional bias | Note=Gly-rich | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000358252 | 8 | 12 | 127_767 | 1657 | 1818.6666666666667 | Compositional bias | Note=Pro-rich | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000358252 | 8 | 12 | 1572_1729 | 1657 | 1818.6666666666667 | Compositional bias | Note=Arg/Glu/Lys-rich (charged) | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000358252 | 8 | 12 | 2_103 | 1657 | 1818.6666666666667 | Compositional bias | Note=Arg/Glu/Lys/Pro-rich (charged) | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000532437 | 7 | 11 | 1010_1340 | 1657 | 1553.6666666666667 | Compositional bias | Note=Gly-rich | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000532437 | 7 | 11 | 127_767 | 1657 | 1553.6666666666667 | Compositional bias | Note=Pro-rich | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000532437 | 7 | 11 | 1572_1729 | 1657 | 1553.6666666666667 | Compositional bias | Note=Arg/Glu/Lys-rich (charged) | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000532437 | 7 | 11 | 2_103 | 1657 | 1553.6666666666667 | Compositional bias | Note=Arg/Glu/Lys/Pro-rich (charged) | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000358252 | 8 | 12 | 1629_1635 | 1657 | 1818.6666666666667 | Motif | Nuclear localization signal | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000532437 | 7 | 11 | 1629_1635 | 1657 | 1553.6666666666667 | Motif | Nuclear localization signal | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000358252 | 8 | 12 | 1450_1542 | 1657 | 1818.6666666666667 | Region | Note=Tankyrase-binding | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000358252 | 8 | 12 | 210_1572 | 1657 | 1818.6666666666667 | Region | Note=Acidic | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000532437 | 7 | 11 | 1450_1542 | 1657 | 1553.6666666666667 | Region | Note=Tankyrase-binding | |
| Tgene | TNKS1BP1 | chr11:64951063 | chr11:57068515 | ENST00000532437 | 7 | 11 | 210_1572 | 1657 | 1553.6666666666667 | Region | Note=Acidic |
Top |
Fusion Gene Sequence for CAPN1-TNKS1BP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >12869_12869_1_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000279247_TNKS1BP1_chr11_57068515_ENST00000358252_length(transcript)=1270nt_BP=599nt AAGGAGAGAGGGAGGGCGGAGGGCGGAGGGGCGGCGGGAGGAGGGCGGGGAGGAGCGCTCTTCCTGGTTGGGCCCTGCCCTGAGCTGCCA CCGGGAAGCCAGCCTCAGGGACTGCAGCGACCCCCAAACACCCCTCCCCCAGGATGTCGGAGGAGATCATCACGCCGGTGTACTGCACTG GGGTGTCAGCCCAAGTGCAGAAGCAGCGGGCCAGGGAGCTGGGCCTGGGCCGCCATGAGAATGCCATCAAGTACCTGGGCCAGGATTATG AGCAGCTGCGGGTGCGATGCCTGCAGAGTGGGACCCTCTTCCGTGATGAGGCCTTCCCCCCGGTACCCCAGAGCCTGGGTTACAAGGACC TGGGTCCCAATTCCTCCAAGACCTATGGCATCAAGTGGAAGCGTCCCACGGAACTGCTGTCAAACCCCCAGTTCATTGTGGATGGAGCTA CCCGCACAGACATCTGCCAGGGAGCACTGGGGGACTGCTGGCTCTTGGCGGCCATCGCCTCCCTCACTCTCAACGACACCCTCCTGCACC GAGTGGTTCCGCACGGCCAGAGCTTCCAGAATGGCTATGCCGGCATCTTCCATTTCCAGGCCAAGCTGCGCCCCCGGAATCGCTCAGCTG AGGAGGGAGAGCTGGCTGAGAGCAAGTCGAGCCAGAAGGAGTCCGCGGTCCAGCGTTCGAAATCCTGCAAGGTCCCAGGACTGGGAAAGC CCCTCACGTTACCTCCCAAGCCAGAGAAATCCTCAGGGTCAGAAGGATCGTCGCCCAACTGGCTTCAAGCCCTGAAACTGAAGAAGAAGA AGGTCTGAGAAGTCACTGAGGTTCTTCCCACCTGGCAGTCTCAGGCAGTGCCCATTCCTGTGGGGTCCCTGGGTGAGGAGACGGCTGGAG CCCCACCATGCCCCAGGCTGCAGCCTCTGTCCCCTCCACCTCTGAGGAGCGTCTGGGGAGGCACATTTATGCACTTTGTATCACCCTCCG AACTCCCCCCACACCTTCCCTTCCCTGGATTTCATCACTAGTGGTTGAAGGTTTTGTCCCTTCCTCTCCTCCTTCCCTCTCCCTCTCTGC TTCCTCCTCCAGCCTCCCTTGGGTTTTCTTTTGATACCAATTTATAGCATTTTTTATAAAAGCCTTTGATTTTTATAATGGGTGGGACTG TATCCCTGCCTCACCCCAGGTCTCCGTCTGCCCCGCCAGGTACCCCACAGAGACCAATGACATTTTGCCACTTGAAACAATAAATAAAGT >12869_12869_1_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000279247_TNKS1BP1_chr11_57068515_ENST00000358252_length(amino acids)=243AA_BP=172 MVGPCPELPPGSQPQGLQRPPNTPPPGCRRRSSRRCTALGCQPKCRSSGPGSWAWAAMRMPSSTWARIMSSCGCDACRVGPSSVMRPSPR YPRAWVTRTWVPIPPRPMASSGSVPRNCCQTPSSLWMELPAQTSAREHWGTAGSWRPSPPSLSTTPSCTEWFRTARASRMAMPASSISRP -------------------------------------------------------------- >12869_12869_2_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000279247_TNKS1BP1_chr11_57068515_ENST00000532437_length(transcript)=1268nt_BP=599nt AAGGAGAGAGGGAGGGCGGAGGGCGGAGGGGCGGCGGGAGGAGGGCGGGGAGGAGCGCTCTTCCTGGTTGGGCCCTGCCCTGAGCTGCCA CCGGGAAGCCAGCCTCAGGGACTGCAGCGACCCCCAAACACCCCTCCCCCAGGATGTCGGAGGAGATCATCACGCCGGTGTACTGCACTG GGGTGTCAGCCCAAGTGCAGAAGCAGCGGGCCAGGGAGCTGGGCCTGGGCCGCCATGAGAATGCCATCAAGTACCTGGGCCAGGATTATG AGCAGCTGCGGGTGCGATGCCTGCAGAGTGGGACCCTCTTCCGTGATGAGGCCTTCCCCCCGGTACCCCAGAGCCTGGGTTACAAGGACC TGGGTCCCAATTCCTCCAAGACCTATGGCATCAAGTGGAAGCGTCCCACGGAACTGCTGTCAAACCCCCAGTTCATTGTGGATGGAGCTA CCCGCACAGACATCTGCCAGGGAGCACTGGGGGACTGCTGGCTCTTGGCGGCCATCGCCTCCCTCACTCTCAACGACACCCTCCTGCACC GAGTGGTTCCGCACGGCCAGAGCTTCCAGAATGGCTATGCCGGCATCTTCCATTTCCAGGCCAAGCTGCGCCCCCGGAATCGCTCAGCTG AGGAGGGAGAGCTGGCTGAGAGCAAGTCGAGCCAGAAGGAGTCCGCGGTCCAGCGTTCGAAATCCTGCAAGGTCCCAGGACTGGGAAAGC CCCTCACGTTACCTCCCAAGCCAGAGAAATCCTCAGGGTCAGAAGGATCGTCGCCCAACTGGCTTCAAGCCCTGAAACTGAAGAAGAAGA AGGTCTGAGAAGTCACTGAGGTTCTTCCCACCTGGCAGTCTCAGGCAGTGCCCATTCCTGTGGGGTCCCTGGGTGAGGAGACGGCTGGAG CCCCACCATGCCCCAGGCTGCAGCCTCTGTCCCCTCCACCTCTGAGGAGCGTCTGGGGAGGCACATTTATGCACTTTGTATCACCCTCCG AACTCCCCCCACACCTTCCCTTCCCTGGATTTCATCACTAGTGGTTGAAGGTTTTGTCCCTTCCTCTCCTCCTTCCCTCTCCCTCTCTGC TTCCTCCTCCAGCCTCCCTTGGGTTTTCTTTTGATACCAATTTATAGCATTTTTTATAAAAGCCTTTGATTTTTATAATGGGTGGGACTG TATCCCTGCCTCACCCCAGGTCTCCGTCTGCCCCGCCAGGTACCCCACAGAGACCAATGACATTTTGCCACTTGAAACAATAAATAAAGT >12869_12869_2_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000279247_TNKS1BP1_chr11_57068515_ENST00000532437_length(amino acids)=243AA_BP=172 MVGPCPELPPGSQPQGLQRPPNTPPPGCRRRSSRRCTALGCQPKCRSSGPGSWAWAAMRMPSSTWARIMSSCGCDACRVGPSSVMRPSPR YPRAWVTRTWVPIPPRPMASSGSVPRNCCQTPSSLWMELPAQTSAREHWGTAGSWRPSPPSLSTTPSCTEWFRTARASRMAMPASSISRP -------------------------------------------------------------- >12869_12869_3_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000524773_TNKS1BP1_chr11_57068515_ENST00000358252_length(transcript)=1227nt_BP=556nt TGGCCCCCGGCCTGCGGAGGGAGGGGCGGGGAGACACCGTGAGTAAGAGATAGTCAGAGACCGTGCCGGAGAGATAAGGGAGAGCCGAGA GGAAGCGGGGATGTCGGAGGAGATCATCACGCCGGTGTACTGCACTGGGGTGTCAGCCCAAGTGCAGAAGCAGCGGGCCAGGGAGCTGGG CCTGGGCCGCCATGAGAATGCCATCAAGTACCTGGGCCAGGATTATGAGCAGCTGCGGGTGCGATGCCTGCAGAGTGGGACCCTCTTCCG TGATGAGGCCTTCCCCCCGGTACCCCAGAGCCTGGGTTACAAGGACCTGGGTCCCAATTCCTCCAAGACCTATGGCATCAAGTGGAAGCG TCCCACGGAACTGCTGTCAAACCCCCAGTTCATTGTGGATGGAGCTACCCGCACAGACATCTGCCAGGGAGCACTGGGGGACTGCTGGCT CTTGGCGGCCATCGCCTCCCTCACTCTCAACGACACCCTCCTGCACCGAGTGGTTCCGCACGGCCAGAGCTTCCAGAATGGCTATGCCGG CATCTTCCATTTCCAGGCCAAGCTGCGCCCCCGGAATCGCTCAGCTGAGGAGGGAGAGCTGGCTGAGAGCAAGTCGAGCCAGAAGGAGTC CGCGGTCCAGCGTTCGAAATCCTGCAAGGTCCCAGGACTGGGAAAGCCCCTCACGTTACCTCCCAAGCCAGAGAAATCCTCAGGGTCAGA AGGATCGTCGCCCAACTGGCTTCAAGCCCTGAAACTGAAGAAGAAGAAGGTCTGAGAAGTCACTGAGGTTCTTCCCACCTGGCAGTCTCA GGCAGTGCCCATTCCTGTGGGGTCCCTGGGTGAGGAGACGGCTGGAGCCCCACCATGCCCCAGGCTGCAGCCTCTGTCCCCTCCACCTCT GAGGAGCGTCTGGGGAGGCACATTTATGCACTTTGTATCACCCTCCGAACTCCCCCCACACCTTCCCTTCCCTGGATTTCATCACTAGTG GTTGAAGGTTTTGTCCCTTCCTCTCCTCCTTCCCTCTCCCTCTCTGCTTCCTCCTCCAGCCTCCCTTGGGTTTTCTTTTGATACCAATTT ATAGCATTTTTTATAAAAGCCTTTGATTTTTATAATGGGTGGGACTGTATCCCTGCCTCACCCCAGGTCTCCGTCTGCCCCGCCAGGTAC >12869_12869_3_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000524773_TNKS1BP1_chr11_57068515_ENST00000358252_length(amino acids)=224AA_BP=151 MSEEIITPVYCTGVSAQVQKQRARELGLGRHENAIKYLGQDYEQLRVRCLQSGTLFRDEAFPPVPQSLGYKDLGPNSSKTYGIKWKRPTE LLSNPQFIVDGATRTDICQGALGDCWLLAAIASLTLNDTLLHRVVPHGQSFQNGYAGIFHFQAKLRPRNRSAEEGELAESKSSQKESAVQ -------------------------------------------------------------- >12869_12869_4_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000524773_TNKS1BP1_chr11_57068515_ENST00000532437_length(transcript)=1225nt_BP=556nt TGGCCCCCGGCCTGCGGAGGGAGGGGCGGGGAGACACCGTGAGTAAGAGATAGTCAGAGACCGTGCCGGAGAGATAAGGGAGAGCCGAGA GGAAGCGGGGATGTCGGAGGAGATCATCACGCCGGTGTACTGCACTGGGGTGTCAGCCCAAGTGCAGAAGCAGCGGGCCAGGGAGCTGGG CCTGGGCCGCCATGAGAATGCCATCAAGTACCTGGGCCAGGATTATGAGCAGCTGCGGGTGCGATGCCTGCAGAGTGGGACCCTCTTCCG TGATGAGGCCTTCCCCCCGGTACCCCAGAGCCTGGGTTACAAGGACCTGGGTCCCAATTCCTCCAAGACCTATGGCATCAAGTGGAAGCG TCCCACGGAACTGCTGTCAAACCCCCAGTTCATTGTGGATGGAGCTACCCGCACAGACATCTGCCAGGGAGCACTGGGGGACTGCTGGCT CTTGGCGGCCATCGCCTCCCTCACTCTCAACGACACCCTCCTGCACCGAGTGGTTCCGCACGGCCAGAGCTTCCAGAATGGCTATGCCGG CATCTTCCATTTCCAGGCCAAGCTGCGCCCCCGGAATCGCTCAGCTGAGGAGGGAGAGCTGGCTGAGAGCAAGTCGAGCCAGAAGGAGTC CGCGGTCCAGCGTTCGAAATCCTGCAAGGTCCCAGGACTGGGAAAGCCCCTCACGTTACCTCCCAAGCCAGAGAAATCCTCAGGGTCAGA AGGATCGTCGCCCAACTGGCTTCAAGCCCTGAAACTGAAGAAGAAGAAGGTCTGAGAAGTCACTGAGGTTCTTCCCACCTGGCAGTCTCA GGCAGTGCCCATTCCTGTGGGGTCCCTGGGTGAGGAGACGGCTGGAGCCCCACCATGCCCCAGGCTGCAGCCTCTGTCCCCTCCACCTCT GAGGAGCGTCTGGGGAGGCACATTTATGCACTTTGTATCACCCTCCGAACTCCCCCCACACCTTCCCTTCCCTGGATTTCATCACTAGTG GTTGAAGGTTTTGTCCCTTCCTCTCCTCCTTCCCTCTCCCTCTCTGCTTCCTCCTCCAGCCTCCCTTGGGTTTTCTTTTGATACCAATTT ATAGCATTTTTTATAAAAGCCTTTGATTTTTATAATGGGTGGGACTGTATCCCTGCCTCACCCCAGGTCTCCGTCTGCCCCGCCAGGTAC >12869_12869_4_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000524773_TNKS1BP1_chr11_57068515_ENST00000532437_length(amino acids)=224AA_BP=151 MSEEIITPVYCTGVSAQVQKQRARELGLGRHENAIKYLGQDYEQLRVRCLQSGTLFRDEAFPPVPQSLGYKDLGPNSSKTYGIKWKRPTE LLSNPQFIVDGATRTDICQGALGDCWLLAAIASLTLNDTLLHRVVPHGQSFQNGYAGIFHFQAKLRPRNRSAEEGELAESKSSQKESAVQ -------------------------------------------------------------- >12869_12869_5_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000527323_TNKS1BP1_chr11_57068515_ENST00000358252_length(transcript)=1367nt_BP=696nt GGGATCCGGGAAAGGAGAGGTGGCCGGCACGCCTGGGAACTGGGAAATCCCTTTCCTGGATTCACTGGGAGCACCGGGAGGTGGCTGAGA ACCCTACTTCTGTGAGGGGAGCAGTGAGGCAGGGAAACCCTAGGTTTGGGGATGGATAAGCAGGGGCAGGAGAGCAGAGCTTGCAGGCAG GAGCCCAGGTTCTAGTCTTGGGAAGGCCTGGGTTCTGAGCAGGCCCATCTGTCCGGCAGGATGTCGGAGGAGATCATCACGCCGGTGTAC TGCACTGGGGTGTCAGCCCAAGTGCAGAAGCAGCGGGCCAGGGAGCTGGGCCTGGGCCGCCATGAGAATGCCATCAAGTACCTGGGCCAG GATTATGAGCAGCTGCGGGTGCGATGCCTGCAGAGTGGGACCCTCTTCCGTGATGAGGCCTTCCCCCCGGTACCCCAGAGCCTGGGTTAC AAGGACCTGGGTCCCAATTCCTCCAAGACCTATGGCATCAAGTGGAAGCGTCCCACGGAACTGCTGTCAAACCCCCAGTTCATTGTGGAT GGAGCTACCCGCACAGACATCTGCCAGGGAGCACTGGGGGACTGCTGGCTCTTGGCGGCCATCGCCTCCCTCACTCTCAACGACACCCTC CTGCACCGAGTGGTTCCGCACGGCCAGAGCTTCCAGAATGGCTATGCCGGCATCTTCCATTTCCAGGCCAAGCTGCGCCCCCGGAATCGC TCAGCTGAGGAGGGAGAGCTGGCTGAGAGCAAGTCGAGCCAGAAGGAGTCCGCGGTCCAGCGTTCGAAATCCTGCAAGGTCCCAGGACTG GGAAAGCCCCTCACGTTACCTCCCAAGCCAGAGAAATCCTCAGGGTCAGAAGGATCGTCGCCCAACTGGCTTCAAGCCCTGAAACTGAAG AAGAAGAAGGTCTGAGAAGTCACTGAGGTTCTTCCCACCTGGCAGTCTCAGGCAGTGCCCATTCCTGTGGGGTCCCTGGGTGAGGAGACG GCTGGAGCCCCACCATGCCCCAGGCTGCAGCCTCTGTCCCCTCCACCTCTGAGGAGCGTCTGGGGAGGCACATTTATGCACTTTGTATCA CCCTCCGAACTCCCCCCACACCTTCCCTTCCCTGGATTTCATCACTAGTGGTTGAAGGTTTTGTCCCTTCCTCTCCTCCTTCCCTCTCCC TCTCTGCTTCCTCCTCCAGCCTCCCTTGGGTTTTCTTTTGATACCAATTTATAGCATTTTTTATAAAAGCCTTTGATTTTTATAATGGGT GGGACTGTATCCCTGCCTCACCCCAGGTCTCCGTCTGCCCCGCCAGGTACCCCACAGAGACCAATGACATTTTGCCACTTGAAACAATAA >12869_12869_5_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000527323_TNKS1BP1_chr11_57068515_ENST00000358252_length(amino acids)=235AA_BP=162 MGSEQAHLSGRMSEEIITPVYCTGVSAQVQKQRARELGLGRHENAIKYLGQDYEQLRVRCLQSGTLFRDEAFPPVPQSLGYKDLGPNSSK TYGIKWKRPTELLSNPQFIVDGATRTDICQGALGDCWLLAAIASLTLNDTLLHRVVPHGQSFQNGYAGIFHFQAKLRPRNRSAEEGELAE -------------------------------------------------------------- >12869_12869_6_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000527323_TNKS1BP1_chr11_57068515_ENST00000532437_length(transcript)=1365nt_BP=696nt GGGATCCGGGAAAGGAGAGGTGGCCGGCACGCCTGGGAACTGGGAAATCCCTTTCCTGGATTCACTGGGAGCACCGGGAGGTGGCTGAGA ACCCTACTTCTGTGAGGGGAGCAGTGAGGCAGGGAAACCCTAGGTTTGGGGATGGATAAGCAGGGGCAGGAGAGCAGAGCTTGCAGGCAG GAGCCCAGGTTCTAGTCTTGGGAAGGCCTGGGTTCTGAGCAGGCCCATCTGTCCGGCAGGATGTCGGAGGAGATCATCACGCCGGTGTAC TGCACTGGGGTGTCAGCCCAAGTGCAGAAGCAGCGGGCCAGGGAGCTGGGCCTGGGCCGCCATGAGAATGCCATCAAGTACCTGGGCCAG GATTATGAGCAGCTGCGGGTGCGATGCCTGCAGAGTGGGACCCTCTTCCGTGATGAGGCCTTCCCCCCGGTACCCCAGAGCCTGGGTTAC AAGGACCTGGGTCCCAATTCCTCCAAGACCTATGGCATCAAGTGGAAGCGTCCCACGGAACTGCTGTCAAACCCCCAGTTCATTGTGGAT GGAGCTACCCGCACAGACATCTGCCAGGGAGCACTGGGGGACTGCTGGCTCTTGGCGGCCATCGCCTCCCTCACTCTCAACGACACCCTC CTGCACCGAGTGGTTCCGCACGGCCAGAGCTTCCAGAATGGCTATGCCGGCATCTTCCATTTCCAGGCCAAGCTGCGCCCCCGGAATCGC TCAGCTGAGGAGGGAGAGCTGGCTGAGAGCAAGTCGAGCCAGAAGGAGTCCGCGGTCCAGCGTTCGAAATCCTGCAAGGTCCCAGGACTG GGAAAGCCCCTCACGTTACCTCCCAAGCCAGAGAAATCCTCAGGGTCAGAAGGATCGTCGCCCAACTGGCTTCAAGCCCTGAAACTGAAG AAGAAGAAGGTCTGAGAAGTCACTGAGGTTCTTCCCACCTGGCAGTCTCAGGCAGTGCCCATTCCTGTGGGGTCCCTGGGTGAGGAGACG GCTGGAGCCCCACCATGCCCCAGGCTGCAGCCTCTGTCCCCTCCACCTCTGAGGAGCGTCTGGGGAGGCACATTTATGCACTTTGTATCA CCCTCCGAACTCCCCCCACACCTTCCCTTCCCTGGATTTCATCACTAGTGGTTGAAGGTTTTGTCCCTTCCTCTCCTCCTTCCCTCTCCC TCTCTGCTTCCTCCTCCAGCCTCCCTTGGGTTTTCTTTTGATACCAATTTATAGCATTTTTTATAAAAGCCTTTGATTTTTATAATGGGT GGGACTGTATCCCTGCCTCACCCCAGGTCTCCGTCTGCCCCGCCAGGTACCCCACAGAGACCAATGACATTTTGCCACTTGAAACAATAA >12869_12869_6_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000527323_TNKS1BP1_chr11_57068515_ENST00000532437_length(amino acids)=235AA_BP=162 MGSEQAHLSGRMSEEIITPVYCTGVSAQVQKQRARELGLGRHENAIKYLGQDYEQLRVRCLQSGTLFRDEAFPPVPQSLGYKDLGPNSSK TYGIKWKRPTELLSNPQFIVDGATRTDICQGALGDCWLLAAIASLTLNDTLLHRVVPHGQSFQNGYAGIFHFQAKLRPRNRSAEEGELAE -------------------------------------------------------------- >12869_12869_7_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000533129_TNKS1BP1_chr11_57068515_ENST00000358252_length(transcript)=1202nt_BP=531nt CTCTCGCGGAATTGGCCCCCGGCCTGCGGAGGGAGGGGCGGGGAGACACCGTGAGTAAGAGATAGTCAGAGACCGATGTCGGAGGAGATC ATCACGCCGGTGTACTGCACTGGGGTGTCAGCCCAAGTGCAGAAGCAGCGGGCCAGGGAGCTGGGCCTGGGCCGCCATGAGAATGCCATC AAGTACCTGGGCCAGGATTATGAGCAGCTGCGGGTGCGATGCCTGCAGAGTGGGACCCTCTTCCGTGATGAGGCCTTCCCCCCGGTACCC CAGAGCCTGGGTTACAAGGACCTGGGTCCCAATTCCTCCAAGACCTATGGCATCAAGTGGAAGCGTCCCACGGAACTGCTGTCAAACCCC CAGTTCATTGTGGATGGAGCTACCCGCACAGACATCTGCCAGGGAGCACTGGGGGACTGCTGGCTCTTGGCGGCCATCGCCTCCCTCACT CTCAACGACACCCTCCTGCACCGAGTGGTTCCGCACGGCCAGAGCTTCCAGAATGGCTATGCCGGCATCTTCCATTTCCAGGCCAAGCTG CGCCCCCGGAATCGCTCAGCTGAGGAGGGAGAGCTGGCTGAGAGCAAGTCGAGCCAGAAGGAGTCCGCGGTCCAGCGTTCGAAATCCTGC AAGGTCCCAGGACTGGGAAAGCCCCTCACGTTACCTCCCAAGCCAGAGAAATCCTCAGGGTCAGAAGGATCGTCGCCCAACTGGCTTCAA GCCCTGAAACTGAAGAAGAAGAAGGTCTGAGAAGTCACTGAGGTTCTTCCCACCTGGCAGTCTCAGGCAGTGCCCATTCCTGTGGGGTCC CTGGGTGAGGAGACGGCTGGAGCCCCACCATGCCCCAGGCTGCAGCCTCTGTCCCCTCCACCTCTGAGGAGCGTCTGGGGAGGCACATTT ATGCACTTTGTATCACCCTCCGAACTCCCCCCACACCTTCCCTTCCCTGGATTTCATCACTAGTGGTTGAAGGTTTTGTCCCTTCCTCTC CTCCTTCCCTCTCCCTCTCTGCTTCCTCCTCCAGCCTCCCTTGGGTTTTCTTTTGATACCAATTTATAGCATTTTTTATAAAAGCCTTTG ATTTTTATAATGGGTGGGACTGTATCCCTGCCTCACCCCAGGTCTCCGTCTGCCCCGCCAGGTACCCCACAGAGACCAATGACATTTTGC >12869_12869_7_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000533129_TNKS1BP1_chr11_57068515_ENST00000358252_length(amino acids)=224AA_BP=151 MSEEIITPVYCTGVSAQVQKQRARELGLGRHENAIKYLGQDYEQLRVRCLQSGTLFRDEAFPPVPQSLGYKDLGPNSSKTYGIKWKRPTE LLSNPQFIVDGATRTDICQGALGDCWLLAAIASLTLNDTLLHRVVPHGQSFQNGYAGIFHFQAKLRPRNRSAEEGELAESKSSQKESAVQ -------------------------------------------------------------- >12869_12869_8_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000533129_TNKS1BP1_chr11_57068515_ENST00000532437_length(transcript)=1200nt_BP=531nt CTCTCGCGGAATTGGCCCCCGGCCTGCGGAGGGAGGGGCGGGGAGACACCGTGAGTAAGAGATAGTCAGAGACCGATGTCGGAGGAGATC ATCACGCCGGTGTACTGCACTGGGGTGTCAGCCCAAGTGCAGAAGCAGCGGGCCAGGGAGCTGGGCCTGGGCCGCCATGAGAATGCCATC AAGTACCTGGGCCAGGATTATGAGCAGCTGCGGGTGCGATGCCTGCAGAGTGGGACCCTCTTCCGTGATGAGGCCTTCCCCCCGGTACCC CAGAGCCTGGGTTACAAGGACCTGGGTCCCAATTCCTCCAAGACCTATGGCATCAAGTGGAAGCGTCCCACGGAACTGCTGTCAAACCCC CAGTTCATTGTGGATGGAGCTACCCGCACAGACATCTGCCAGGGAGCACTGGGGGACTGCTGGCTCTTGGCGGCCATCGCCTCCCTCACT CTCAACGACACCCTCCTGCACCGAGTGGTTCCGCACGGCCAGAGCTTCCAGAATGGCTATGCCGGCATCTTCCATTTCCAGGCCAAGCTG CGCCCCCGGAATCGCTCAGCTGAGGAGGGAGAGCTGGCTGAGAGCAAGTCGAGCCAGAAGGAGTCCGCGGTCCAGCGTTCGAAATCCTGC AAGGTCCCAGGACTGGGAAAGCCCCTCACGTTACCTCCCAAGCCAGAGAAATCCTCAGGGTCAGAAGGATCGTCGCCCAACTGGCTTCAA GCCCTGAAACTGAAGAAGAAGAAGGTCTGAGAAGTCACTGAGGTTCTTCCCACCTGGCAGTCTCAGGCAGTGCCCATTCCTGTGGGGTCC CTGGGTGAGGAGACGGCTGGAGCCCCACCATGCCCCAGGCTGCAGCCTCTGTCCCCTCCACCTCTGAGGAGCGTCTGGGGAGGCACATTT ATGCACTTTGTATCACCCTCCGAACTCCCCCCACACCTTCCCTTCCCTGGATTTCATCACTAGTGGTTGAAGGTTTTGTCCCTTCCTCTC CTCCTTCCCTCTCCCTCTCTGCTTCCTCCTCCAGCCTCCCTTGGGTTTTCTTTTGATACCAATTTATAGCATTTTTTATAAAAGCCTTTG ATTTTTATAATGGGTGGGACTGTATCCCTGCCTCACCCCAGGTCTCCGTCTGCCCCGCCAGGTACCCCACAGAGACCAATGACATTTTGC >12869_12869_8_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000533129_TNKS1BP1_chr11_57068515_ENST00000532437_length(amino acids)=224AA_BP=151 MSEEIITPVYCTGVSAQVQKQRARELGLGRHENAIKYLGQDYEQLRVRCLQSGTLFRDEAFPPVPQSLGYKDLGPNSSKTYGIKWKRPTE LLSNPQFIVDGATRTDICQGALGDCWLLAAIASLTLNDTLLHRVVPHGQSFQNGYAGIFHFQAKLRPRNRSAEEGELAESKSSQKESAVQ -------------------------------------------------------------- >12869_12869_9_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000533820_TNKS1BP1_chr11_57068515_ENST00000358252_length(transcript)=1345nt_BP=674nt GAAAGTCGGGCCGAACGGGGCAGGGACTTACCCAAGGTCACGCAGCGAGCCCGGTCCCCCTGCGTTCCCCGGGGAGCGCTGAGCCGGGAC GCGGCGGTGGGGTGGGGAAGGGGAGTGGCGCGGCCCTGCGGGGTGAGGCTGCCGTTTGCTGAGTGTCCGGCAGGGGTCTGCTCGCTGCCA GCCCGGCCCCTCCTCAGAGCAGCTGCCGCAGCCCGAGGATGTCGGAGGAGATCATCACGCCGGTGTACTGCACTGGGGTGTCAGCCCAAG TGCAGAAGCAGCGGGCCAGGGAGCTGGGCCTGGGCCGCCATGAGAATGCCATCAAGTACCTGGGCCAGGATTATGAGCAGCTGCGGGTGC GATGCCTGCAGAGTGGGACCCTCTTCCGTGATGAGGCCTTCCCCCCGGTACCCCAGAGCCTGGGTTACAAGGACCTGGGTCCCAATTCCT CCAAGACCTATGGCATCAAGTGGAAGCGTCCCACGGAACTGCTGTCAAACCCCCAGTTCATTGTGGATGGAGCTACCCGCACAGACATCT GCCAGGGAGCACTGGGGGACTGCTGGCTCTTGGCGGCCATCGCCTCCCTCACTCTCAACGACACCCTCCTGCACCGAGTGGTTCCGCACG GCCAGAGCTTCCAGAATGGCTATGCCGGCATCTTCCATTTCCAGGCCAAGCTGCGCCCCCGGAATCGCTCAGCTGAGGAGGGAGAGCTGG CTGAGAGCAAGTCGAGCCAGAAGGAGTCCGCGGTCCAGCGTTCGAAATCCTGCAAGGTCCCAGGACTGGGAAAGCCCCTCACGTTACCTC CCAAGCCAGAGAAATCCTCAGGGTCAGAAGGATCGTCGCCCAACTGGCTTCAAGCCCTGAAACTGAAGAAGAAGAAGGTCTGAGAAGTCA CTGAGGTTCTTCCCACCTGGCAGTCTCAGGCAGTGCCCATTCCTGTGGGGTCCCTGGGTGAGGAGACGGCTGGAGCCCCACCATGCCCCA GGCTGCAGCCTCTGTCCCCTCCACCTCTGAGGAGCGTCTGGGGAGGCACATTTATGCACTTTGTATCACCCTCCGAACTCCCCCCACACC TTCCCTTCCCTGGATTTCATCACTAGTGGTTGAAGGTTTTGTCCCTTCCTCTCCTCCTTCCCTCTCCCTCTCTGCTTCCTCCTCCAGCCT CCCTTGGGTTTTCTTTTGATACCAATTTATAGCATTTTTTATAAAAGCCTTTGATTTTTATAATGGGTGGGACTGTATCCCTGCCTCACC >12869_12869_9_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000533820_TNKS1BP1_chr11_57068515_ENST00000358252_length(amino acids)=263AA_BP=192 MSRDAAVGWGRGVARPCGVRLPFAECPAGVCSLPARPLLRAAAAARGCRRRSSRRCTALGCQPKCRSSGPGSWAWAAMRMPSSTWARIMS SCGCDACRVGPSSVMRPSPRYPRAWVTRTWVPIPPRPMASSGSVPRNCCQTPSSLWMELPAQTSAREHWGTAGSWRPSPPSLSTTPSCTE -------------------------------------------------------------- >12869_12869_10_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000533820_TNKS1BP1_chr11_57068515_ENST00000532437_length(transcript)=1343nt_BP=674nt GAAAGTCGGGCCGAACGGGGCAGGGACTTACCCAAGGTCACGCAGCGAGCCCGGTCCCCCTGCGTTCCCCGGGGAGCGCTGAGCCGGGAC GCGGCGGTGGGGTGGGGAAGGGGAGTGGCGCGGCCCTGCGGGGTGAGGCTGCCGTTTGCTGAGTGTCCGGCAGGGGTCTGCTCGCTGCCA GCCCGGCCCCTCCTCAGAGCAGCTGCCGCAGCCCGAGGATGTCGGAGGAGATCATCACGCCGGTGTACTGCACTGGGGTGTCAGCCCAAG TGCAGAAGCAGCGGGCCAGGGAGCTGGGCCTGGGCCGCCATGAGAATGCCATCAAGTACCTGGGCCAGGATTATGAGCAGCTGCGGGTGC GATGCCTGCAGAGTGGGACCCTCTTCCGTGATGAGGCCTTCCCCCCGGTACCCCAGAGCCTGGGTTACAAGGACCTGGGTCCCAATTCCT CCAAGACCTATGGCATCAAGTGGAAGCGTCCCACGGAACTGCTGTCAAACCCCCAGTTCATTGTGGATGGAGCTACCCGCACAGACATCT GCCAGGGAGCACTGGGGGACTGCTGGCTCTTGGCGGCCATCGCCTCCCTCACTCTCAACGACACCCTCCTGCACCGAGTGGTTCCGCACG GCCAGAGCTTCCAGAATGGCTATGCCGGCATCTTCCATTTCCAGGCCAAGCTGCGCCCCCGGAATCGCTCAGCTGAGGAGGGAGAGCTGG CTGAGAGCAAGTCGAGCCAGAAGGAGTCCGCGGTCCAGCGTTCGAAATCCTGCAAGGTCCCAGGACTGGGAAAGCCCCTCACGTTACCTC CCAAGCCAGAGAAATCCTCAGGGTCAGAAGGATCGTCGCCCAACTGGCTTCAAGCCCTGAAACTGAAGAAGAAGAAGGTCTGAGAAGTCA CTGAGGTTCTTCCCACCTGGCAGTCTCAGGCAGTGCCCATTCCTGTGGGGTCCCTGGGTGAGGAGACGGCTGGAGCCCCACCATGCCCCA GGCTGCAGCCTCTGTCCCCTCCACCTCTGAGGAGCGTCTGGGGAGGCACATTTATGCACTTTGTATCACCCTCCGAACTCCCCCCACACC TTCCCTTCCCTGGATTTCATCACTAGTGGTTGAAGGTTTTGTCCCTTCCTCTCCTCCTTCCCTCTCCCTCTCTGCTTCCTCCTCCAGCCT CCCTTGGGTTTTCTTTTGATACCAATTTATAGCATTTTTTATAAAAGCCTTTGATTTTTATAATGGGTGGGACTGTATCCCTGCCTCACC >12869_12869_10_CAPN1-TNKS1BP1_CAPN1_chr11_64951063_ENST00000533820_TNKS1BP1_chr11_57068515_ENST00000532437_length(amino acids)=263AA_BP=192 MSRDAAVGWGRGVARPCGVRLPFAECPAGVCSLPARPLLRAAAAARGCRRRSSRRCTALGCQPKCRSSGPGSWAWAAMRMPSSTWARIMS SCGCDACRVGPSSVMRPSPRYPRAWVTRTWVPIPPRPMASSGSVPRNCCQTPSSLWMELPAQTSAREHWGTAGSWRPSPPSLSTTPSCTE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CAPN1-TNKS1BP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CAPN1-TNKS1BP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CAPN1-TNKS1BP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies