
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CC2D2A-BST1 (FusionGDB2 ID:13508) |
Fusion Gene Summary for CC2D2A-BST1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CC2D2A-BST1 | Fusion gene ID: 13508 | Hgene | Tgene | Gene symbol | CC2D2A | BST1 | Gene ID | 57545 | 683 |
| Gene name | coiled-coil and C2 domain containing 2A | bone marrow stromal cell antigen 1 | |
| Synonyms | JBTS9|MKS6 | CD157 | |
| Cytomap | 4p15.32 | 4p15.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | coiled-coil and C2 domain-containing protein 2A | ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 2ADP-ribosyl cyclase 2NAD(+) nucleosidasebone marrow stromal antigen 1bone marrow stromal cell antigen 1 variant 2cADPr hydrolase 2cyclic ADP-ribose hydrolase 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9P2K1 | Q10588 | |
| Ensembl transtripts involved in fusion gene | ENST00000513811, ENST00000438599, ENST00000503658, ENST00000511544, ENST00000389652, ENST00000413206, ENST00000424120, ENST00000503292, ENST00000507954, ENST00000515124, | ENST00000265016, ENST00000382346, | |
| Fusion gene scores | * DoF score | 5 X 5 X 3=75 | 1 X 1 X 1=1 |
| # samples | 6 | 1 | |
| ** MAII score | log2(6/75*10)=-0.321928094887362 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: CC2D2A [Title/Abstract] AND BST1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CC2D2A(15482451)-BST1(15713430), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | CC2D2A-BST1 seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | BST1 | GO:0001952 | regulation of cell-matrix adhesion | 15328157 |
| Tgene | BST1 | GO:0008284 | positive regulation of cell proliferation | 8202488 |
| Tgene | BST1 | GO:0032956 | regulation of actin cytoskeleton organization | 15328157 |
| Tgene | BST1 | GO:0050727 | regulation of inflammatory response | 15328157 |
| Tgene | BST1 | GO:0050730 | regulation of peptidyl-tyrosine phosphorylation | 8941363 |
| Tgene | BST1 | GO:0090022 | regulation of neutrophil chemotaxis | 15328157 |
| Fusion gene breakpoints across CC2D2A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
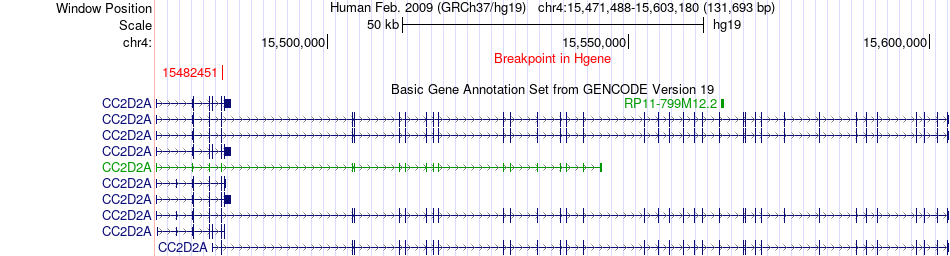 |
| Fusion gene breakpoints across BST1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ACC | TCGA-OU-A5PI-01A | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
Top |
Fusion Gene ORF analysis for CC2D2A-BST1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000513811 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| 3UTR-3CDS | ENST00000513811 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| Frame-shift | ENST00000438599 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| Frame-shift | ENST00000438599 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| Frame-shift | ENST00000503658 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| Frame-shift | ENST00000503658 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| Frame-shift | ENST00000511544 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| Frame-shift | ENST00000511544 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000389652 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000389652 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000413206 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000413206 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000424120 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000424120 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000503292 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000503292 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000507954 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000507954 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000515124 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| In-frame | ENST00000515124 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000424120 | CC2D2A | chr4 | 15482451 | + | ENST00000265016 | BST1 | chr4 | 15713430 | + | 1335 | 501 | 221 | 1006 | 261 |
| ENST00000424120 | CC2D2A | chr4 | 15482451 | + | ENST00000382346 | BST1 | chr4 | 15713430 | + | 1949 | 501 | 221 | 1006 | 261 |
| ENST00000413206 | CC2D2A | chr4 | 15482451 | + | ENST00000265016 | BST1 | chr4 | 15713430 | + | 1320 | 486 | 239 | 991 | 250 |
| ENST00000413206 | CC2D2A | chr4 | 15482451 | + | ENST00000382346 | BST1 | chr4 | 15713430 | + | 1934 | 486 | 239 | 991 | 250 |
| ENST00000503292 | CC2D2A | chr4 | 15482451 | + | ENST00000265016 | BST1 | chr4 | 15713430 | + | 1261 | 427 | 180 | 932 | 250 |
| ENST00000503292 | CC2D2A | chr4 | 15482451 | + | ENST00000382346 | BST1 | chr4 | 15713430 | + | 1875 | 427 | 180 | 932 | 250 |
| ENST00000389652 | CC2D2A | chr4 | 15482451 | + | ENST00000265016 | BST1 | chr4 | 15713430 | + | 1064 | 230 | 130 | 735 | 201 |
| ENST00000389652 | CC2D2A | chr4 | 15482451 | + | ENST00000382346 | BST1 | chr4 | 15713430 | + | 1678 | 230 | 130 | 735 | 201 |
| ENST00000507954 | CC2D2A | chr4 | 15482451 | + | ENST00000265016 | BST1 | chr4 | 15713430 | + | 1288 | 454 | 207 | 959 | 250 |
| ENST00000507954 | CC2D2A | chr4 | 15482451 | + | ENST00000382346 | BST1 | chr4 | 15713430 | + | 1902 | 454 | 207 | 959 | 250 |
| ENST00000515124 | CC2D2A | chr4 | 15482451 | + | ENST00000265016 | BST1 | chr4 | 15713430 | + | 1245 | 411 | 164 | 916 | 250 |
| ENST00000515124 | CC2D2A | chr4 | 15482451 | + | ENST00000382346 | BST1 | chr4 | 15713430 | + | 1859 | 411 | 164 | 916 | 250 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000424120 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.002286875 | 0.9977131 |
| ENST00000424120 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.001316875 | 0.99868315 |
| ENST00000413206 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.002286212 | 0.9977138 |
| ENST00000413206 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.001402156 | 0.9985978 |
| ENST00000503292 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.002633196 | 0.99736685 |
| ENST00000503292 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.001329019 | 0.99867105 |
| ENST00000389652 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.002512589 | 0.9974874 |
| ENST00000389652 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.001107886 | 0.9988921 |
| ENST00000507954 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.002754215 | 0.9972458 |
| ENST00000507954 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.001314766 | 0.9986852 |
| ENST00000515124 | ENST00000265016 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.002862838 | 0.9971372 |
| ENST00000515124 | ENST00000382346 | CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713430 | + | 0.001452675 | 0.99854726 |
Top |
Fusion Genomic Features for CC2D2A-BST1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713429 | + | 8.50E-05 | 0.9999149 |
| CC2D2A | chr4 | 15482451 | + | BST1 | chr4 | 15713429 | + | 8.50E-05 | 0.9999149 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
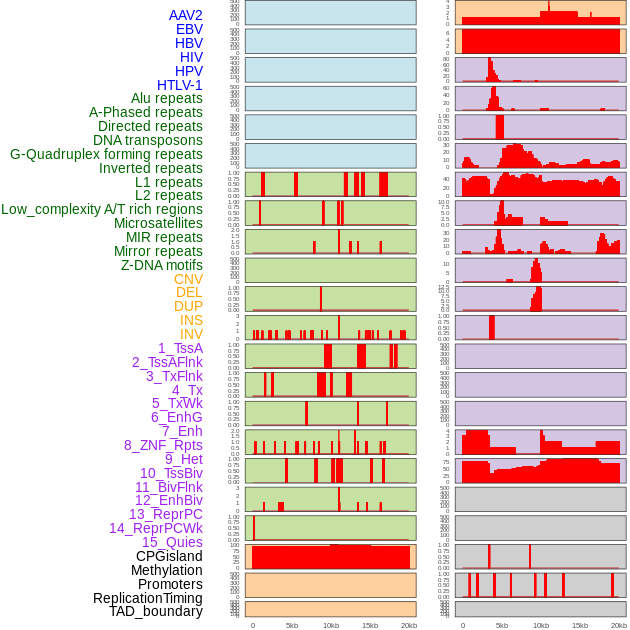 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
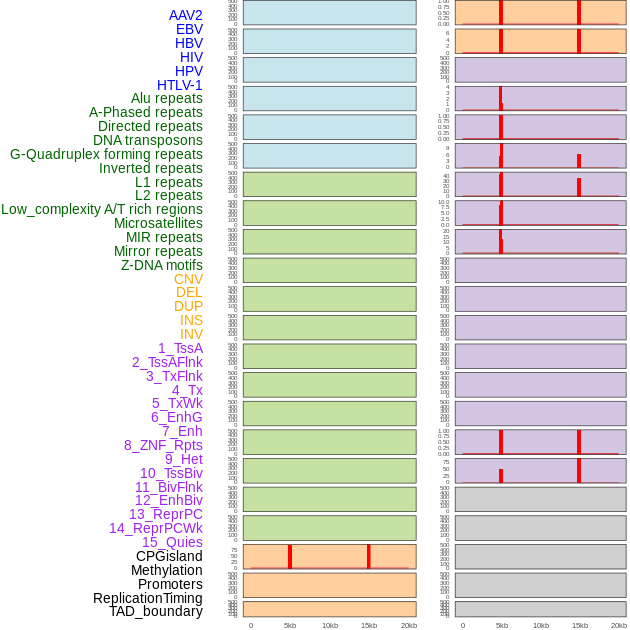 |
Top |
Fusion Protein Features for CC2D2A-BST1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr4:15482451/chr4:15713430) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CC2D2A | BST1 |
| FUNCTION: Component of the tectonic-like complex, a complex localized at the transition zone of primary cilia and acting as a barrier that prevents diffusion of transmembrane proteins between the cilia and plasma membranes. Required for ciliogenesis and sonic hedgehog/SHH signaling (By similarity). {ECO:0000250, ECO:0000269|PubMed:18513680}. | FUNCTION: Synthesizes the second messengers cyclic ADP-ribose and nicotinate-adenine dinucleotide phosphate, the former a second messenger that elicits calcium release from intracellular stores. May be involved in pre-B-cell growth. {ECO:0000269|PubMed:11866528}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000389652 | + | 2 | 34 | 439_493 | 33 | 1513.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000389652 | + | 2 | 34 | 532_582 | 33 | 1513.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000413206 | + | 4 | 37 | 439_493 | 82 | 1621.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000413206 | + | 4 | 37 | 532_582 | 82 | 1621.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000424120 | + | 4 | 37 | 439_493 | 82 | 1621.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000424120 | + | 4 | 37 | 532_582 | 82 | 1621.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000438599 | + | 5 | 6 | 439_493 | 117 | 123.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000438599 | + | 5 | 6 | 532_582 | 117 | 123.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503292 | + | 5 | 38 | 439_493 | 82 | 1621.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503292 | + | 5 | 38 | 532_582 | 82 | 1621.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503658 | + | 6 | 7 | 439_493 | 117 | 123.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503658 | + | 6 | 7 | 532_582 | 117 | 123.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000507954 | + | 5 | 6 | 439_493 | 82 | 112.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000507954 | + | 5 | 6 | 532_582 | 82 | 112.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000511544 | + | 5 | 6 | 439_493 | 117 | 123.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000511544 | + | 5 | 6 | 532_582 | 117 | 123.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000515124 | + | 4 | 5 | 439_493 | 82 | 112.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000515124 | + | 4 | 5 | 532_582 | 82 | 112.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000389652 | + | 2 | 34 | 1491_1494 | 33 | 1513.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000389652 | + | 2 | 34 | 221_229 | 33 | 1513.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000389652 | + | 2 | 34 | 591_596 | 33 | 1513.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000413206 | + | 4 | 37 | 1491_1494 | 82 | 1621.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000413206 | + | 4 | 37 | 221_229 | 82 | 1621.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000413206 | + | 4 | 37 | 591_596 | 82 | 1621.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000424120 | + | 4 | 37 | 1491_1494 | 82 | 1621.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000424120 | + | 4 | 37 | 221_229 | 82 | 1621.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000424120 | + | 4 | 37 | 591_596 | 82 | 1621.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000438599 | + | 5 | 6 | 1491_1494 | 117 | 123.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000438599 | + | 5 | 6 | 221_229 | 117 | 123.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000438599 | + | 5 | 6 | 591_596 | 117 | 123.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503292 | + | 5 | 38 | 1491_1494 | 82 | 1621.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503292 | + | 5 | 38 | 221_229 | 82 | 1621.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503292 | + | 5 | 38 | 591_596 | 82 | 1621.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503658 | + | 6 | 7 | 1491_1494 | 117 | 123.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503658 | + | 6 | 7 | 221_229 | 117 | 123.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503658 | + | 6 | 7 | 591_596 | 117 | 123.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000507954 | + | 5 | 6 | 1491_1494 | 82 | 112.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000507954 | + | 5 | 6 | 221_229 | 82 | 112.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000507954 | + | 5 | 6 | 591_596 | 82 | 112.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000511544 | + | 5 | 6 | 1491_1494 | 117 | 123.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000511544 | + | 5 | 6 | 221_229 | 117 | 123.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000511544 | + | 5 | 6 | 591_596 | 117 | 123.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000515124 | + | 4 | 5 | 1491_1494 | 82 | 112.0 | Compositional bias | Note=Poly-Ala |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000515124 | + | 4 | 5 | 221_229 | 82 | 112.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000515124 | + | 4 | 5 | 591_596 | 82 | 112.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000389652 | + | 2 | 34 | 1025_1203 | 33 | 1513.0 | Domain | C2 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000413206 | + | 4 | 37 | 1025_1203 | 82 | 1621.0 | Domain | C2 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000424120 | + | 4 | 37 | 1025_1203 | 82 | 1621.0 | Domain | C2 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000438599 | + | 5 | 6 | 1025_1203 | 117 | 123.0 | Domain | C2 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503292 | + | 5 | 38 | 1025_1203 | 82 | 1621.0 | Domain | C2 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000503658 | + | 6 | 7 | 1025_1203 | 117 | 123.0 | Domain | C2 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000507954 | + | 5 | 6 | 1025_1203 | 82 | 112.0 | Domain | C2 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000511544 | + | 5 | 6 | 1025_1203 | 117 | 123.0 | Domain | C2 |
| Hgene | CC2D2A | chr4:15482451 | chr4:15713430 | ENST00000515124 | + | 4 | 5 | 1025_1203 | 82 | 112.0 | Domain | C2 |
Top |
Fusion Gene Sequence for CC2D2A-BST1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >13508_13508_1_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000389652_BST1_chr4_15713430_ENST00000265016_length(transcript)=1064nt_BP=230nt AAGCCAACTCCTTTCTCCCGAGCCTGCTGGCAGATCCTCCCCCACCTCTCCGCAGGAGTTCCCCTCCTAGGCTGGGAGCATCCCGTGCAG GGTAAATCTTTTCAAGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGGA GGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTGA AAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTTC AGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGAT CTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGGG GTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGTC GGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTTC CAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGTA TACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATTT CAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACAA >13508_13508_1_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000389652_BST1_chr4_15713430_ENST00000265016_length(amino acids)=201AA_BP=0 MVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCPTSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFA DYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEKRLKDMGFQYSCINDYRPVKLLQCVDHSTHPDCALKSAAAATQRKAPSLY -------------------------------------------------------------- >13508_13508_2_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000389652_BST1_chr4_15713430_ENST00000382346_length(transcript)=1678nt_BP=230nt AAGCCAACTCCTTTCTCCCGAGCCTGCTGGCAGATCCTCCCCCACCTCTCCGCAGGAGTTCCCCTCCTAGGCTGGGAGCATCCCGTGCAG GGTAAATCTTTTCAAGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGGA GGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTGA AAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTTC AGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGAT CTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGGG GTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGTC GGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTTC CAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGTA TACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATTT CAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACAA AGCATTGGGAGTCAGACTGCTTGTATATTATCAAACATTTTAAGAGAATTCTAATAAAGCTGTATTTTACATCATCTATATTTTCCTATA TCTCCAGCAGCACGGACACTGCATGCTTGTTGATTGCTTAAGACATATGTATACTATATAAATGTATGCATATATGGTCTGCAAAGTTTT CATTTTTCATTTATTTGGTATAAAGATGTTCAGTTAATGGTTCCTTTTTGTTTTGAGAGACAGAGTTTCGCTCCTTTGCCCAGGCTGGAG TGAGGTGGGGAGATCTCAGCTCACTGCAACCTCTGCTTCCAGGATTCAAGCGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGGGATTGCA GGTGCCTGCCACCATGTCCAGCTAATTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTGGCCAGGCTAGTCTCGAATTCCTGACC TCAGGTGATCCACCCACCTCAGCCTCCCAAAGTGCTAGGATTACAGGCGTGAGCCACCACATCCAGCCATAATAGTTACTTATAATGAGG GAAAAACCCAAAATATCCAGTAATATTTACATATTTACTGAAACTGTTTGGAACTTGTATTAGTTTGTTCTTGCATTGCTATAAAGAACT >13508_13508_2_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000389652_BST1_chr4_15713430_ENST00000382346_length(amino acids)=201AA_BP=0 MVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCPTSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFA DYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEKRLKDMGFQYSCINDYRPVKLLQCVDHSTHPDCALKSAAAATQRKAPSLY -------------------------------------------------------------- >13508_13508_3_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000413206_BST1_chr4_15713430_ENST00000265016_length(transcript)=1320nt_BP=486nt CTTAGGAACGGGTTGCTAAGCTGGTGTTTTTGCTCCAAGACATGGCTGCAGCTTCCCAGGGAGGAGCCCAGGGGCATCTCCAACACTCAG CCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCACCGTCTCTCTCCACTTCCATCCTAGAATGCAGAATCTGCAAAGTGCCTTTTGT AAAGTTTCTTAAGGTAAATCAGTCCCTATGTTCTTTGTCAGGGACCCATCCCAGCCAAAATGAATCCCAGGGAAGAAAAAGTAAAAATAA TTACAGAGGAGTTCATTGAAAATGATGAGGATGCAGACATGGGAAGACAGAATAAGAACTCAAAGGTTCGAAGACAGCCAAGAAAGAAAC AGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGGAGGAGCCCAAGACCC GCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTGAAAATAATCCTGTGG ATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTTCAGAGCCAACAGGAG CCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGATCTGGGTTATGCATG AAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGGGGTTCCAGTACAGCT GTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGTCGGCAGCAGCCGCTA CTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTTCCAGGACTCAACTGT AACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGTATACCAAATGATTCT GTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATTTCAGAAACAAGAAGT TAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACAAAGCATTGGGAGTCA >13508_13508_3_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000413206_BST1_chr4_15713430_ENST00000265016_length(amino acids)=250AA_BP=0 MNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCP TSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEK -------------------------------------------------------------- >13508_13508_4_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000413206_BST1_chr4_15713430_ENST00000382346_length(transcript)=1934nt_BP=486nt CTTAGGAACGGGTTGCTAAGCTGGTGTTTTTGCTCCAAGACATGGCTGCAGCTTCCCAGGGAGGAGCCCAGGGGCATCTCCAACACTCAG CCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCACCGTCTCTCTCCACTTCCATCCTAGAATGCAGAATCTGCAAAGTGCCTTTTGT AAAGTTTCTTAAGGTAAATCAGTCCCTATGTTCTTTGTCAGGGACCCATCCCAGCCAAAATGAATCCCAGGGAAGAAAAAGTAAAAATAA TTACAGAGGAGTTCATTGAAAATGATGAGGATGCAGACATGGGAAGACAGAATAAGAACTCAAAGGTTCGAAGACAGCCAAGAAAGAAAC AGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGGAGGAGCCCAAGACCC GCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTGAAAATAATCCTGTGG ATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTTCAGAGCCAACAGGAG CCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGATCTGGGTTATGCATG AAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGGGGTTCCAGTACAGCT GTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGTCGGCAGCAGCCGCTA CTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTTCCAGGACTCAACTGT AACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGTATACCAAATGATTCT GTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATTTCAGAAACAAGAAGT TAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACAAAGCATTGGGAGTCA GACTGCTTGTATATTATCAAACATTTTAAGAGAATTCTAATAAAGCTGTATTTTACATCATCTATATTTTCCTATATCTCCAGCAGCACG GACACTGCATGCTTGTTGATTGCTTAAGACATATGTATACTATATAAATGTATGCATATATGGTCTGCAAAGTTTTCATTTTTCATTTAT TTGGTATAAAGATGTTCAGTTAATGGTTCCTTTTTGTTTTGAGAGACAGAGTTTCGCTCCTTTGCCCAGGCTGGAGTGAGGTGGGGAGAT CTCAGCTCACTGCAACCTCTGCTTCCAGGATTCAAGCGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGGGATTGCAGGTGCCTGCCACCA TGTCCAGCTAATTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTGGCCAGGCTAGTCTCGAATTCCTGACCTCAGGTGATCCACC CACCTCAGCCTCCCAAAGTGCTAGGATTACAGGCGTGAGCCACCACATCCAGCCATAATAGTTACTTATAATGAGGGAAAAACCCAAAAT ATCCAGTAATATTTACATATTTACTGAAACTGTTTGGAACTTGTATTAGTTTGTTCTTGCATTGCTATAAAGAACTGCCCGAGACTGGGT >13508_13508_4_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000413206_BST1_chr4_15713430_ENST00000382346_length(amino acids)=250AA_BP=0 MNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCP TSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEK -------------------------------------------------------------- >13508_13508_5_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000424120_BST1_chr4_15713430_ENST00000265016_length(transcript)=1335nt_BP=501nt CTTAGGAACGGGTTGCTAAGCTGGTGTTTTTGCTCCAAGACATGGCTGCAGCTTCCCAGGGAGGAGCCCAGGGGCATCTCCAACACTCAG CCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCACCGTCTCTCTCCACTTCCATCCTAGAATGCAGAATCTGCAAAGTGCCTTTTGT AAAGTTTCTTAAGGTAAATCAGTCCCTAACCGGACTTTAGGCTGCAACATTGTCAGGGACCCATCCCAGCCAAAATGAATCCCAGGGAAG AAAAAGTAAAAATAATTACAGAGGAGTTCATTGAAAATGATGAGGATGCAGACATGGGAAGACAGAATAAGAACTCAAAGGTTCGAAGAC AGCCAAGAAAGAAACAGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGG AGGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTG AAAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTT CAGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGA TCTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGG GGTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGT CGGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTT CCAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGT ATACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATT TCAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACA >13508_13508_5_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000424120_BST1_chr4_15713430_ENST00000265016_length(amino acids)=261AA_BP=3 MQHCQGPIPAKMNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRR GPRRLDYQSCPTSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVES -------------------------------------------------------------- >13508_13508_6_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000424120_BST1_chr4_15713430_ENST00000382346_length(transcript)=1949nt_BP=501nt CTTAGGAACGGGTTGCTAAGCTGGTGTTTTTGCTCCAAGACATGGCTGCAGCTTCCCAGGGAGGAGCCCAGGGGCATCTCCAACACTCAG CCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCACCGTCTCTCTCCACTTCCATCCTAGAATGCAGAATCTGCAAAGTGCCTTTTGT AAAGTTTCTTAAGGTAAATCAGTCCCTAACCGGACTTTAGGCTGCAACATTGTCAGGGACCCATCCCAGCCAAAATGAATCCCAGGGAAG AAAAAGTAAAAATAATTACAGAGGAGTTCATTGAAAATGATGAGGATGCAGACATGGGAAGACAGAATAAGAACTCAAAGGTTCGAAGAC AGCCAAGAAAGAAACAGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGG AGGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTG AAAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTT CAGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGA TCTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGG GGTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGT CGGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTT CCAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGT ATACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATT TCAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACA AAGCATTGGGAGTCAGACTGCTTGTATATTATCAAACATTTTAAGAGAATTCTAATAAAGCTGTATTTTACATCATCTATATTTTCCTAT ATCTCCAGCAGCACGGACACTGCATGCTTGTTGATTGCTTAAGACATATGTATACTATATAAATGTATGCATATATGGTCTGCAAAGTTT TCATTTTTCATTTATTTGGTATAAAGATGTTCAGTTAATGGTTCCTTTTTGTTTTGAGAGACAGAGTTTCGCTCCTTTGCCCAGGCTGGA GTGAGGTGGGGAGATCTCAGCTCACTGCAACCTCTGCTTCCAGGATTCAAGCGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGGGATTGC AGGTGCCTGCCACCATGTCCAGCTAATTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTGGCCAGGCTAGTCTCGAATTCCTGAC CTCAGGTGATCCACCCACCTCAGCCTCCCAAAGTGCTAGGATTACAGGCGTGAGCCACCACATCCAGCCATAATAGTTACTTATAATGAG GGAAAAACCCAAAATATCCAGTAATATTTACATATTTACTGAAACTGTTTGGAACTTGTATTAGTTTGTTCTTGCATTGCTATAAAGAAC >13508_13508_6_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000424120_BST1_chr4_15713430_ENST00000382346_length(amino acids)=261AA_BP=3 MQHCQGPIPAKMNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRR GPRRLDYQSCPTSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVES -------------------------------------------------------------- >13508_13508_7_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000503292_BST1_chr4_15713430_ENST00000265016_length(transcript)=1261nt_BP=427nt GCCCAGGGGCATCTCCAACACTCAGCCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCACCGTCTCTCTCCACTTCCATCCTAGAAT GCAGAATCTGCAAAGTGCCTTTTGTAAAGTTTCTTAAGCTATATTCTAATGGATATGGGCTGACATTAACAAGGACCCATCCCAGCCAAA ATGAATCCCAGGGAAGAAAAAGTAAAAATAATTACAGAGGAGTTCATTGAAAATGATGAGGATGCAGACATGGGAAGACAGAATAAGAAC TCAAAGGTTCGAAGACAGCCAAGAAAGAAACAGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCC CAGGAGCCTGTGCAGGAGGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCT ACATCAGAAGACTGTGAAAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCAC GTCATGCTGAATGGTTCAGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAA ATTACACGAATCGAGATCTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAG AGGCTGAAGGACATGGGGTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCT GACTGTGCCTTAAAGTCGGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTC TTTCTGGTGCTGGCTTCCAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCAT CATTCGTGTTCTGTGTATACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAG GCATATGTTCAGGATTTCAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTA TTTGTATAATGACACAAAGCATTGGGAGTCAGACTGCTTGTATATTATCAAACATTTTAAGAGAATTCTAATAAAGCTGTATTTTACATC >13508_13508_7_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000503292_BST1_chr4_15713430_ENST00000265016_length(amino acids)=250AA_BP=0 MNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCP TSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEK -------------------------------------------------------------- >13508_13508_8_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000503292_BST1_chr4_15713430_ENST00000382346_length(transcript)=1875nt_BP=427nt GCCCAGGGGCATCTCCAACACTCAGCCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCACCGTCTCTCTCCACTTCCATCCTAGAAT GCAGAATCTGCAAAGTGCCTTTTGTAAAGTTTCTTAAGCTATATTCTAATGGATATGGGCTGACATTAACAAGGACCCATCCCAGCCAAA ATGAATCCCAGGGAAGAAAAAGTAAAAATAATTACAGAGGAGTTCATTGAAAATGATGAGGATGCAGACATGGGAAGACAGAATAAGAAC TCAAAGGTTCGAAGACAGCCAAGAAAGAAACAGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCC CAGGAGCCTGTGCAGGAGGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCT ACATCAGAAGACTGTGAAAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCAC GTCATGCTGAATGGTTCAGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAA ATTACACGAATCGAGATCTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAG AGGCTGAAGGACATGGGGTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCT GACTGTGCCTTAAAGTCGGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTC TTTCTGGTGCTGGCTTCCAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCAT CATTCGTGTTCTGTGTATACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAG GCATATGTTCAGGATTTCAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTA TTTGTATAATGACACAAAGCATTGGGAGTCAGACTGCTTGTATATTATCAAACATTTTAAGAGAATTCTAATAAAGCTGTATTTTACATC ATCTATATTTTCCTATATCTCCAGCAGCACGGACACTGCATGCTTGTTGATTGCTTAAGACATATGTATACTATATAAATGTATGCATAT ATGGTCTGCAAAGTTTTCATTTTTCATTTATTTGGTATAAAGATGTTCAGTTAATGGTTCCTTTTTGTTTTGAGAGACAGAGTTTCGCTC CTTTGCCCAGGCTGGAGTGAGGTGGGGAGATCTCAGCTCACTGCAACCTCTGCTTCCAGGATTCAAGCGATTCTCCTGCCTCAGCCTCCC AAGTAGCTGGGATTGCAGGTGCCTGCCACCATGTCCAGCTAATTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTGGCCAGGCTA GTCTCGAATTCCTGACCTCAGGTGATCCACCCACCTCAGCCTCCCAAAGTGCTAGGATTACAGGCGTGAGCCACCACATCCAGCCATAAT AGTTACTTATAATGAGGGAAAAACCCAAAATATCCAGTAATATTTACATATTTACTGAAACTGTTTGGAACTTGTATTAGTTTGTTCTTG >13508_13508_8_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000503292_BST1_chr4_15713430_ENST00000382346_length(amino acids)=250AA_BP=0 MNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCP TSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEK -------------------------------------------------------------- >13508_13508_9_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000507954_BST1_chr4_15713430_ENST00000265016_length(transcript)=1288nt_BP=454nt GACATGGCTGCAGCTTCCCAGGGAGGAGCCCAGGGGCATCTCCAACACTCAGCCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCAC CGTCTCTCTCCACTTCCATCCTAGAATGCAGAATCTGCAAAGTGCCTTTTGTAAAGTTTCTTAAGCTATATTCTAATGGATATGGGCTGA CATTAACAAGGACCCATCCCAGCCAAAATGAATCCCAGGGAAGAAAAAGTAAAAATAATTACAGAGGAGTTCATTGAAAATGATGAGGAT GCAGACATGGGAAGACAGAATAAGAACTCAAAGGTTCGAAGACAGCCAAGAAAGAAACAGCCACCAACTGCTGTCCCCAAGGAAATGGTG TCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGGAGGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCA CGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTGAAAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTAT TCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTTCAGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTAT GAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGATCTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGG GAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGGGGTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTA CAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGTCGGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAA CAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTTCCAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCC AGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGTATACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACG ATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATTTCAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCA TTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACAAAGCATTGGGAGTCAGACTGCTTGTATATTATCAAACATTTTAAGAG >13508_13508_9_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000507954_BST1_chr4_15713430_ENST00000265016_length(amino acids)=250AA_BP=0 MNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCP TSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEK -------------------------------------------------------------- >13508_13508_10_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000507954_BST1_chr4_15713430_ENST00000382346_length(transcript)=1902nt_BP=454nt GACATGGCTGCAGCTTCCCAGGGAGGAGCCCAGGGGCATCTCCAACACTCAGCCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCAC CGTCTCTCTCCACTTCCATCCTAGAATGCAGAATCTGCAAAGTGCCTTTTGTAAAGTTTCTTAAGCTATATTCTAATGGATATGGGCTGA CATTAACAAGGACCCATCCCAGCCAAAATGAATCCCAGGGAAGAAAAAGTAAAAATAATTACAGAGGAGTTCATTGAAAATGATGAGGAT GCAGACATGGGAAGACAGAATAAGAACTCAAAGGTTCGAAGACAGCCAAGAAAGAAACAGCCACCAACTGCTGTCCCCAAGGAAATGGTG TCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGGAGGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCA CGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTGAAAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTAT TCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTTCAGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTAT GAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGATCTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGG GAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGGGGTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTA CAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGTCGGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAA CAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTTCCAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCC AGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGTATACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACG ATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATTTCAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCA TTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACAAAGCATTGGGAGTCAGACTGCTTGTATATTATCAAACATTTTAAGAG AATTCTAATAAAGCTGTATTTTACATCATCTATATTTTCCTATATCTCCAGCAGCACGGACACTGCATGCTTGTTGATTGCTTAAGACAT ATGTATACTATATAAATGTATGCATATATGGTCTGCAAAGTTTTCATTTTTCATTTATTTGGTATAAAGATGTTCAGTTAATGGTTCCTT TTTGTTTTGAGAGACAGAGTTTCGCTCCTTTGCCCAGGCTGGAGTGAGGTGGGGAGATCTCAGCTCACTGCAACCTCTGCTTCCAGGATT CAAGCGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGGGATTGCAGGTGCCTGCCACCATGTCCAGCTAATTTTTGTATTTTTAGTAGAGA TGGGGTTTCACCATGTTGGCCAGGCTAGTCTCGAATTCCTGACCTCAGGTGATCCACCCACCTCAGCCTCCCAAAGTGCTAGGATTACAG GCGTGAGCCACCACATCCAGCCATAATAGTTACTTATAATGAGGGAAAAACCCAAAATATCCAGTAATATTTACATATTTACTGAAACTG TTTGGAACTTGTATTAGTTTGTTCTTGCATTGCTATAAAGAACTGCCCGAGACTGGGTAATTTACAAAAATAAAAATAAAAAAGAGGTTT >13508_13508_10_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000507954_BST1_chr4_15713430_ENST00000382346_length(amino acids)=250AA_BP=0 MNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCP TSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEK -------------------------------------------------------------- >13508_13508_11_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000515124_BST1_chr4_15713430_ENST00000265016_length(transcript)=1245nt_BP=411nt GCAGCTTCCCAGGGAGGAGCCCAGGGGCATCTCCAACACTCAGCCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCACCGTCTCTCT CCACTTCCATCCTAGAATGCAGAATCTGCAAAGTGCCTTTTGTAAAGTTTCTTAAGGGACCCATCCCAGCCAAAATGAATCCCAGGGAAG AAAAAGTAAAAATAATTACAGAGGAGTTCATTGAAAATGATGAGGATGCAGACATGGGAAGACAGAATAAGAACTCAAAGGTTCGAAGAC AGCCAAGAAAGAAACAGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGG AGGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTG AAAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTT CAGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGA TCTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGG GGTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGT CGGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTT CCAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGT ATACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATT TCAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACA >13508_13508_11_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000515124_BST1_chr4_15713430_ENST00000265016_length(amino acids)=250AA_BP=0 MNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCP TSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEK -------------------------------------------------------------- >13508_13508_12_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000515124_BST1_chr4_15713430_ENST00000382346_length(transcript)=1859nt_BP=411nt GCAGCTTCCCAGGGAGGAGCCCAGGGGCATCTCCAACACTCAGCCTTTCCCTCCGGACCCTTTTAAAAGATTCAACAGCACCGTCTCTCT CCACTTCCATCCTAGAATGCAGAATCTGCAAAGTGCCTTTTGTAAAGTTTCTTAAGGGACCCATCCCAGCCAAAATGAATCCCAGGGAAG AAAAAGTAAAAATAATTACAGAGGAGTTCATTGAAAATGATGAGGATGCAGACATGGGAAGACAGAATAAGAACTCAAAGGTTCGAAGAC AGCCAAGAAAGAAACAGCCACCAACTGCTGTCCCCAAGGAAATGGTGTCCGAAAAATCCCACCTTGGCAACCCCCAGGAGCCTGTGCAGG AGGAGCCCAAGACCCGCCTCCTGAGTATGACAGTCCGGAGAGGCCCACGGAGACTCGATTACCAATCCTGCCCTACATCAGAAGACTGTG AAAATAATCCTGTGGATTCCTTTTGGAAAAGGGCATCCATCCAGTATTCCAAGGATAGTTCTGGGGTGATCCACGTCATGCTGAATGGTT CAGAGCCAACAGGAGCCTATCCCATCAAAGGTTTTTTTGCAGATTATGAAATTCCAAACCTCCAGAAGGAAAAAATTACACGAATCGAGA TCTGGGTTATGCATGAAATTGGGGGACCCAATGTGGAATCCTGCGGGGAAGGCAGCATGAAAGTCCTGGAAAAGAGGCTGAAGGACATGG GGTTCCAGTACAGCTGTATTAATGATTACCGACCAGTGAAGCTCTTACAGTGCGTGGACCACAGCACCCATCCTGACTGTGCCTTAAAGT CGGCAGCAGCCGCTACTCAAAGAAAAGCCCCAAGTCTTTATACAGAACAAAGGGCGGGTCTTATCATTCCCCTCTTTCTGGTGCTGGCTT CCAGGACTCAACTGTAACTGGAAACTGTGTTGCTCTAACCCTCCTCCAGCCCTGCAGCCTCCCCTTGCAGTCATCATTCGTGTTCTGTGT ATACCAAATGATTCTGTTATCTAAAGAAGCTTTTTGCTGGGAAAACGATGTCCTGAAAATGGTATTTCAATGAGGCATATGTTCAGGATT TCAGAAACAAGAAGTTAGTTCTATTTAGCAGGTTAAAAAATGCTGCATTAGAATTAAAGCAAGTTATTTTCTTATTTGTATAATGACACA AAGCATTGGGAGTCAGACTGCTTGTATATTATCAAACATTTTAAGAGAATTCTAATAAAGCTGTATTTTACATCATCTATATTTTCCTAT ATCTCCAGCAGCACGGACACTGCATGCTTGTTGATTGCTTAAGACATATGTATACTATATAAATGTATGCATATATGGTCTGCAAAGTTT TCATTTTTCATTTATTTGGTATAAAGATGTTCAGTTAATGGTTCCTTTTTGTTTTGAGAGACAGAGTTTCGCTCCTTTGCCCAGGCTGGA GTGAGGTGGGGAGATCTCAGCTCACTGCAACCTCTGCTTCCAGGATTCAAGCGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGGGATTGC AGGTGCCTGCCACCATGTCCAGCTAATTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTGGCCAGGCTAGTCTCGAATTCCTGAC CTCAGGTGATCCACCCACCTCAGCCTCCCAAAGTGCTAGGATTACAGGCGTGAGCCACCACATCCAGCCATAATAGTTACTTATAATGAG GGAAAAACCCAAAATATCCAGTAATATTTACATATTTACTGAAACTGTTTGGAACTTGTATTAGTTTGTTCTTGCATTGCTATAAAGAAC >13508_13508_12_CC2D2A-BST1_CC2D2A_chr4_15482451_ENST00000515124_BST1_chr4_15713430_ENST00000382346_length(amino acids)=250AA_BP=0 MNPREEKVKIITEEFIENDEDADMGRQNKNSKVRRQPRKKQPPTAVPKEMVSEKSHLGNPQEPVQEEPKTRLLSMTVRRGPRRLDYQSCP TSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CC2D2A-BST1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CC2D2A-BST1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CC2D2A-BST1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies