
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CCDC142-M1AP (FusionGDB2 ID:13641) |
Fusion Gene Summary for CCDC142-M1AP |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CCDC142-M1AP | Fusion gene ID: 13641 | Hgene | Tgene | Gene symbol | CCDC142 | M1AP | Gene ID | 84865 | 130951 |
| Gene name | coiled-coil domain containing 142 | meiosis 1 associated protein | |
| Synonyms | - | C2orf65|D6Mm5e|SPATA37 | |
| Cytomap | 2p13.1 | 2p13.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | coiled-coil domain-containing protein 142 | meiosis 1 arrest proteinmeiosis 1 arresting proteinspermatogenesis associated 37 | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | Q17RM4 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000290418, ENST00000393965, ENST00000471713, | ENST00000358434, ENST00000464686, ENST00000290536, ENST00000409585, ENST00000536235, | |
| Fusion gene scores | * DoF score | 4 X 4 X 3=48 | 6 X 6 X 5=180 |
| # samples | 4 | 7 | |
| ** MAII score | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/180*10)=-1.36257007938471 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CCDC142 [Title/Abstract] AND M1AP [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CCDC142(74708350)-M1AP(74808974), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across CCDC142 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across M1AP (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-T3-A92M-01A | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| ChimerDB4 | HNSC | TCGA-T3-A92M | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
Top |
Fusion Gene ORF analysis for CCDC142-M1AP |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000290418 | ENST00000358434 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| 5CDS-5UTR | ENST00000393965 | ENST00000358434 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| 5CDS-intron | ENST00000290418 | ENST00000464686 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| 5CDS-intron | ENST00000393965 | ENST00000464686 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| 5UTR-3CDS | ENST00000471713 | ENST00000290536 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| 5UTR-3CDS | ENST00000471713 | ENST00000409585 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| 5UTR-3CDS | ENST00000471713 | ENST00000536235 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| 5UTR-5UTR | ENST00000471713 | ENST00000358434 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| 5UTR-intron | ENST00000471713 | ENST00000464686 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| In-frame | ENST00000290418 | ENST00000290536 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| In-frame | ENST00000290418 | ENST00000409585 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| In-frame | ENST00000290418 | ENST00000536235 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| In-frame | ENST00000393965 | ENST00000290536 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| In-frame | ENST00000393965 | ENST00000409585 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| In-frame | ENST00000393965 | ENST00000536235 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000393965 | CCDC142 | chr2 | 74708350 | - | ENST00000290536 | M1AP | chr2 | 74808974 | - | 3486 | 1655 | 331 | 2652 | 773 |
| ENST00000393965 | CCDC142 | chr2 | 74708350 | - | ENST00000409585 | M1AP | chr2 | 74808974 | - | 3465 | 1655 | 331 | 2640 | 769 |
| ENST00000393965 | CCDC142 | chr2 | 74708350 | - | ENST00000536235 | M1AP | chr2 | 74808974 | - | 3019 | 1655 | 331 | 2640 | 769 |
| ENST00000290418 | CCDC142 | chr2 | 74708350 | - | ENST00000290536 | M1AP | chr2 | 74808974 | - | 3248 | 1417 | 93 | 2414 | 773 |
| ENST00000290418 | CCDC142 | chr2 | 74708350 | - | ENST00000409585 | M1AP | chr2 | 74808974 | - | 3227 | 1417 | 93 | 2402 | 769 |
| ENST00000290418 | CCDC142 | chr2 | 74708350 | - | ENST00000536235 | M1AP | chr2 | 74808974 | - | 2781 | 1417 | 93 | 2402 | 769 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000393965 | ENST00000290536 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - | 0.029101495 | 0.9708985 |
| ENST00000393965 | ENST00000409585 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - | 0.028672682 | 0.9713273 |
| ENST00000393965 | ENST00000536235 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - | 0.03452184 | 0.9654781 |
| ENST00000290418 | ENST00000290536 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - | 0.033763643 | 0.96623635 |
| ENST00000290418 | ENST00000409585 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - | 0.033515304 | 0.9664847 |
| ENST00000290418 | ENST00000536235 | CCDC142 | chr2 | 74708350 | - | M1AP | chr2 | 74808974 | - | 0.04296813 | 0.95703185 |
Top |
Fusion Genomic Features for CCDC142-M1AP |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
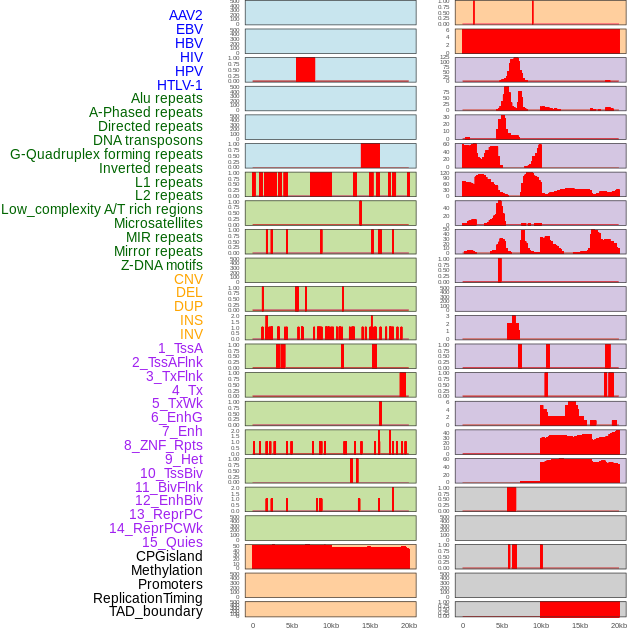 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CCDC142-M1AP |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:74708350/chr2:74808974) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CCDC142 | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CCDC142 | chr2:74708350 | chr2:74808974 | ENST00000290418 | - | 3 | 9 | 87_110 | 419 | 744.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CCDC142 | chr2:74708350 | chr2:74808974 | ENST00000393965 | - | 3 | 9 | 87_110 | 419 | 751.0 | Coiled coil | Ontology_term=ECO:0000255 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for CCDC142-M1AP |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >13641_13641_1_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000290418_M1AP_chr2_74808974_ENST00000290536_length(transcript)=3248nt_BP=1417nt AAGCCTCCCATTACGGAGCACGAGAGAGTCCATGAAGGTCCCCGCGACTCCCGGACTGGAGAAAACGGCTCTTGCGATGGGGCGAAGTCC GAGCTGCGGCGGGCGTTGGTCCGTGCAGGGAAGTGGGAATCGTTAGGTTCGTTCTGGACCCGCCGCCCCATGGCCCAGGCGTCTCGCTCA GGTAGCCTGCCTCCACTCGTTATCGTGCCCCCGCTGAGGGCGCAACCCGGGGGCACTGGGGAGGAGCAGTGGGAGAGAAGTCGAACGGGC GGTCTTCGCTGGGAGGTTCACTGCTGGCCGAGCGGAACTTCTGGAGGGACGCCGTGGTGGCCGACGCCGGCGGATGTGAGCGAGGACTAC GAGGCTGATGCTGCGGCCTGGAGGCGGGGGCCCGCAGGTGGCGGCCCGATCCCTCCCGCGCTGCAGCGTCTCCGGGCGGTGTTGCTGCGG CTGCATCGCGAGCGGGAGCAGCTCCTCCAGGCCCGAGACTGCGCCTACCACCTACAGTCGGCTGTGCGACTCATGAAGACCCTGAGTCCT GGCTCGCCATCCGGCGGCCCTAGCCCCTTGCCCCAGTGGTGCCGCGACCTGCAGCTGCACCCTTCCCAAGGGGCGGTTCTGCGAATCGGC CCTGGGGAGACTCTCGAGCCGCTGCTGCTAGCGCGCCCCATCGGACTAGCCGCCCAGTGCCTGGAGGCTGTCATCGAGATGCAGCTTCGC GCTCTCGGCCGGGAGCCCGCCAGCCCGGGCCTGTCGTCCCAACTCGCCGAGCTGCTCTTTGCACTTCCCGCCTACCACACACTACAGAGA AAAGCCTTGAGCCACGTCCCAGGGGCCGCACGTCCTTTCCCCACGTCCCGTGTGCTCCGCCTCTTGACGGGGGAGCGGGGTTGCCAGGTG GCAAGTCGGCTGGACGAGGCGCTCCAAGGATCGGCGTTGAGGGACCAGCTCCGCAGGCGGTGCCAAGAGGAGGGGGATCTGCTACCAGGG CTGCTGGGCCTGGTCGGGGGCGTGGCGGGTTCAGCCAGCTGTGGACTAGGGCTCGGAGGGGCTGGGGCCTTGTGGAGCCAATACTGGACC CTGCTGTGGGCAGCCTGTGCTCAGAGTCTGGACCTAAATCTGGGACCCTGGAGGGACCCCAGGGCAACAGCGCAACAGCTGAGTCAGGCA CTGGGTCAGGCATCCCTGCCTCAGGAGTGTGAGAAGGAGCTGGCATCTTTGTGTCACAGACTACTTCATCAGTCGCTTATCTGGAGCTGG GACCAAGGTTTCTGCCAGGCCTTGGGATCAGCTCTTGGGGGTCAGAGCAGCCTTCCCACATCCTCTGGCACTGCTGAACTTTTGCAGCAG CTCTTTCCTCCTCTCTTGGATGCCCTTCGAGAGCCCAGGTTACGACGGATTTTCTGCCAGCCTGCAGAGAGTTCTATTCTGGGAACTGAC ATTGACCTTCAGACTATAGACAATGATATCGTCAGCATGGAGATTTTCTTCAAAGCCTGGCTACATAACAGTGGAACAGACCAAGAACAA ATCCATCTTCTTCTTTCTTCACAGTGTTTCAGCAACATTTCCAGACCCAGAGATAATCCAATGTGTCTGAAATGTGATCTCCAAGAGCGA CTGCTCTGCCCATCCCTACTCGCTGGCACAGCTGACGGCTCCTTGAGAATGGATGACCCTAAAGGAGACTTCATCACACTCTACCAGATG GCTTCCCAGTCATCGGCCTCTCATTACAAGCTCCAAGTGATCAAGGCTTTAAAATCTAGCGGGCTCTGCGAGTCATTGACATATGGACTC CCGTTCATCCTCAGACCTACAAGCTGTTGGCAGCTGGACTGGGATGAGCTGGAGACAAATCAGCAACATTTCCATGCTTTGTGTCACAGC CTGCTGAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTTCTATGTG ATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCTACCTGAG GACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGC CACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGCATCCC TGCAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATG CCAGCAGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGA GCCCAGCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTG TGAGTGAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCT GTCCTTTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACC ATTGTTAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGACC TCAGGAACAAGGATGAGGTTTTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCACTA CACCACCAGGCTTCAGCCTCCAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAACA GGGGAGAGGATGGTGTAAAAAAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCACA GAATAATAGCTACCATTTATAAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGTGG GATGATCACTTGAGGCCAGGAGTTCGAGACCAGCCTGAGCAACACTGTGAGACCCCCCCGCCATCTCTACATAAATAATAAAAACTTTTA >13641_13641_1_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000290418_M1AP_chr2_74808974_ENST00000290536_length(amino acids)=773AA_BP=440 MRRALVRAGKWESLGSFWTRRPMAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYE ADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGP GETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVA SRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQAL GQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPAESSILGTDI DLQTIDNDIVSMEIFFKAWLHNSGTDQEQIHLLLSSQCFSNISRPRDNPMCLKCDLQERLLCPSLLAGTADGSLRMDDPKGDFITLYQMA SQSSASHYKLQVIKALKSSGLCESLTYGLPFILRPTSCWQLDWDELETNQQHFHALCHSLLKREWLLLAKGEPPGPGHSQRIPASTFYVI MPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKHPC -------------------------------------------------------------- >13641_13641_2_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000290418_M1AP_chr2_74808974_ENST00000409585_length(transcript)=3227nt_BP=1417nt AAGCCTCCCATTACGGAGCACGAGAGAGTCCATGAAGGTCCCCGCGACTCCCGGACTGGAGAAAACGGCTCTTGCGATGGGGCGAAGTCC GAGCTGCGGCGGGCGTTGGTCCGTGCAGGGAAGTGGGAATCGTTAGGTTCGTTCTGGACCCGCCGCCCCATGGCCCAGGCGTCTCGCTCA GGTAGCCTGCCTCCACTCGTTATCGTGCCCCCGCTGAGGGCGCAACCCGGGGGCACTGGGGAGGAGCAGTGGGAGAGAAGTCGAACGGGC GGTCTTCGCTGGGAGGTTCACTGCTGGCCGAGCGGAACTTCTGGAGGGACGCCGTGGTGGCCGACGCCGGCGGATGTGAGCGAGGACTAC GAGGCTGATGCTGCGGCCTGGAGGCGGGGGCCCGCAGGTGGCGGCCCGATCCCTCCCGCGCTGCAGCGTCTCCGGGCGGTGTTGCTGCGG CTGCATCGCGAGCGGGAGCAGCTCCTCCAGGCCCGAGACTGCGCCTACCACCTACAGTCGGCTGTGCGACTCATGAAGACCCTGAGTCCT GGCTCGCCATCCGGCGGCCCTAGCCCCTTGCCCCAGTGGTGCCGCGACCTGCAGCTGCACCCTTCCCAAGGGGCGGTTCTGCGAATCGGC CCTGGGGAGACTCTCGAGCCGCTGCTGCTAGCGCGCCCCATCGGACTAGCCGCCCAGTGCCTGGAGGCTGTCATCGAGATGCAGCTTCGC GCTCTCGGCCGGGAGCCCGCCAGCCCGGGCCTGTCGTCCCAACTCGCCGAGCTGCTCTTTGCACTTCCCGCCTACCACACACTACAGAGA AAAGCCTTGAGCCACGTCCCAGGGGCCGCACGTCCTTTCCCCACGTCCCGTGTGCTCCGCCTCTTGACGGGGGAGCGGGGTTGCCAGGTG GCAAGTCGGCTGGACGAGGCGCTCCAAGGATCGGCGTTGAGGGACCAGCTCCGCAGGCGGTGCCAAGAGGAGGGGGATCTGCTACCAGGG CTGCTGGGCCTGGTCGGGGGCGTGGCGGGTTCAGCCAGCTGTGGACTAGGGCTCGGAGGGGCTGGGGCCTTGTGGAGCCAATACTGGACC CTGCTGTGGGCAGCCTGTGCTCAGAGTCTGGACCTAAATCTGGGACCCTGGAGGGACCCCAGGGCAACAGCGCAACAGCTGAGTCAGGCA CTGGGTCAGGCATCCCTGCCTCAGGAGTGTGAGAAGGAGCTGGCATCTTTGTGTCACAGACTACTTCATCAGTCGCTTATCTGGAGCTGG GACCAAGGTTTCTGCCAGGCCTTGGGATCAGCTCTTGGGGGTCAGAGCAGCCTTCCCACATCCTCTGGCACTGCTGAACTTTTGCAGCAG CTCTTTCCTCCTCTCTTGGATGCCCTTCGAGAGCCCAGGTTACGACGGATTTTCTGCCAGCCTGCAGAGAGTTCTATTCTGGGAACTGAC ATTGACCTTCAGACTATAGACAATGATATCGTCAGCATGGAGATTTTCTTCAAAGCCTGGCTACATAACAGTGGAACAGACCAAGAACAA ATCCATCTTCTTCTTTCTTCACAGTGTTTCAGCAACATTTCCAGACCCAGAGATAATCCAATGTGTCTGAAATGTGATCTCCAAGAGCGA CTGCTCTGCCCATCCCTACTCGCTGGCACAGCTGACGGCTCCTTGAGAATGGATGACCCTAAAGGAGACTTCATCACACTCTACCAGATG GCTTCCCAGTCATCGGCCTCTCATTACAAGCTCCAAGTGATCAAGGCTTTAAAATCTAGCGGGCTCTGCGAGTCATTGACATATGGACTC CCGTTCATCCTCAGACCTACAAGCTGTTGGCAGCTGGACTGGGATGAGCTGGAGACAAATCAGCAACATTTCCATGCTTTGTGTCACAGC CTGCTGAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTTCTATGTG ATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCTACCTGAG GACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGC CACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGACTGGG CAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGC AAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCC AGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCT GACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCA GCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGC ATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGACCTCAGGAACAAGG ATGAGGTTTTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCACTACACCACCAGGCT TCAGCCTCCAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAACAGGGGAGAGGATG GTGTAAAAAAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCACAGAATAATAGCTA CCATTTATAAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGTGGGATGATCACTTG >13641_13641_2_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000290418_M1AP_chr2_74808974_ENST00000409585_length(amino acids)=769AA_BP=440 MRRALVRAGKWESLGSFWTRRPMAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYE ADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGP GETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVA SRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQAL GQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPAESSILGTDI DLQTIDNDIVSMEIFFKAWLHNSGTDQEQIHLLLSSQCFSNISRPRDNPMCLKCDLQERLLCPSLLAGTADGSLRMDDPKGDFITLYQMA SQSSASHYKLQVIKALKSSGLCESLTYGLPFILRPTSCWQLDWDELETNQQHFHALCHSLLKREWLLLAKGEPPGPGHSQRIPASTFYVI MPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKTGQ -------------------------------------------------------------- >13641_13641_3_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000290418_M1AP_chr2_74808974_ENST00000536235_length(transcript)=2781nt_BP=1417nt AAGCCTCCCATTACGGAGCACGAGAGAGTCCATGAAGGTCCCCGCGACTCCCGGACTGGAGAAAACGGCTCTTGCGATGGGGCGAAGTCC GAGCTGCGGCGGGCGTTGGTCCGTGCAGGGAAGTGGGAATCGTTAGGTTCGTTCTGGACCCGCCGCCCCATGGCCCAGGCGTCTCGCTCA GGTAGCCTGCCTCCACTCGTTATCGTGCCCCCGCTGAGGGCGCAACCCGGGGGCACTGGGGAGGAGCAGTGGGAGAGAAGTCGAACGGGC GGTCTTCGCTGGGAGGTTCACTGCTGGCCGAGCGGAACTTCTGGAGGGACGCCGTGGTGGCCGACGCCGGCGGATGTGAGCGAGGACTAC GAGGCTGATGCTGCGGCCTGGAGGCGGGGGCCCGCAGGTGGCGGCCCGATCCCTCCCGCGCTGCAGCGTCTCCGGGCGGTGTTGCTGCGG CTGCATCGCGAGCGGGAGCAGCTCCTCCAGGCCCGAGACTGCGCCTACCACCTACAGTCGGCTGTGCGACTCATGAAGACCCTGAGTCCT GGCTCGCCATCCGGCGGCCCTAGCCCCTTGCCCCAGTGGTGCCGCGACCTGCAGCTGCACCCTTCCCAAGGGGCGGTTCTGCGAATCGGC CCTGGGGAGACTCTCGAGCCGCTGCTGCTAGCGCGCCCCATCGGACTAGCCGCCCAGTGCCTGGAGGCTGTCATCGAGATGCAGCTTCGC GCTCTCGGCCGGGAGCCCGCCAGCCCGGGCCTGTCGTCCCAACTCGCCGAGCTGCTCTTTGCACTTCCCGCCTACCACACACTACAGAGA AAAGCCTTGAGCCACGTCCCAGGGGCCGCACGTCCTTTCCCCACGTCCCGTGTGCTCCGCCTCTTGACGGGGGAGCGGGGTTGCCAGGTG GCAAGTCGGCTGGACGAGGCGCTCCAAGGATCGGCGTTGAGGGACCAGCTCCGCAGGCGGTGCCAAGAGGAGGGGGATCTGCTACCAGGG CTGCTGGGCCTGGTCGGGGGCGTGGCGGGTTCAGCCAGCTGTGGACTAGGGCTCGGAGGGGCTGGGGCCTTGTGGAGCCAATACTGGACC CTGCTGTGGGCAGCCTGTGCTCAGAGTCTGGACCTAAATCTGGGACCCTGGAGGGACCCCAGGGCAACAGCGCAACAGCTGAGTCAGGCA CTGGGTCAGGCATCCCTGCCTCAGGAGTGTGAGAAGGAGCTGGCATCTTTGTGTCACAGACTACTTCATCAGTCGCTTATCTGGAGCTGG GACCAAGGTTTCTGCCAGGCCTTGGGATCAGCTCTTGGGGGTCAGAGCAGCCTTCCCACATCCTCTGGCACTGCTGAACTTTTGCAGCAG CTCTTTCCTCCTCTCTTGGATGCCCTTCGAGAGCCCAGGTTACGACGGATTTTCTGCCAGCCTGCAGAGAGTTCTATTCTGGGAACTGAC ATTGACCTTCAGACTATAGACAATGATATCGTCAGCATGGAGATTTTCTTCAAAGCCTGGCTACATAACAGTGGAACAGACCAAGAACAA ATCCATCTTCTTCTTTCTTCACAGTGTTTCAGCAACATTTCCAGACCCAGAGATAATCCAATGTGTCTGAAATGTGATCTCCAAGAGCGA CTGCTCTGCCCATCCCTACTCGCTGGCACAGCTGACGGCTCCTTGAGAATGGATGACCCTAAAGGAGACTTCATCACACTCTACCAGATG GCTTCCCAGTCATCGGCCTCTCATTACAAGCTCCAAGTGATCAAGGCTTTAAAATCTAGCGGGCTCTGCGAGTCATTGACATATGGACTC CCGTTCATCCTCAGACCTACAAGCTGTTGGCAGCTGGACTGGGATGAGCTGGAGACAAATCAGCAACATTTCCATGCTTTGTGTCACAGC CTGCTGAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTTCTATGTG ATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCTACCTGAG GACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGC CACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGACTGGG CAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGC AAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCC AGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCT GACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCA GCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGC >13641_13641_3_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000290418_M1AP_chr2_74808974_ENST00000536235_length(amino acids)=769AA_BP=440 MRRALVRAGKWESLGSFWTRRPMAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYE ADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGP GETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVA SRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQAL GQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPAESSILGTDI DLQTIDNDIVSMEIFFKAWLHNSGTDQEQIHLLLSSQCFSNISRPRDNPMCLKCDLQERLLCPSLLAGTADGSLRMDDPKGDFITLYQMA SQSSASHYKLQVIKALKSSGLCESLTYGLPFILRPTSCWQLDWDELETNQQHFHALCHSLLKREWLLLAKGEPPGPGHSQRIPASTFYVI MPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKTGQ -------------------------------------------------------------- >13641_13641_4_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000393965_M1AP_chr2_74808974_ENST00000290536_length(transcript)=3486nt_BP=1655nt CTGCATAAAATCCTACTCGAAACGTTCAGACCACAGGTGGACCCAAGAGGGGCTGCCTCTGCCCTCCTAGACCCCCACTGGTCTTGTCAT ACCGCTCACCTAGCTTGATCCGCCCCACAGTCTTTGGAATCGGCGCCATCGCATCTACAGTGACCCGGAAATGAAAGGTAGTCTAGTATT TGATACCAGCCAAAGGGCGGGGTGGGACAGAGTGGGCGGCCATGTTTGTTAGGGGCAGAAGCCTCCCATTACGGAGCACGAGAGAGTCCA TGAAGGTCCCCGCGACTCCCGGACTGGAGAAAACGGCTCTTGCGATGGGGCGAAGTCCGAGCTGCGGCGGGCGTTGGTCCGTGCAGGGAA GTGGGAATCGTTAGGTTCGTTCTGGACCCGCCGCCCCATGGCCCAGGCGTCTCGCTCAGGTAGCCTGCCTCCACTCGTTATCGTGCCCCC GCTGAGGGCGCAACCCGGGGGCACTGGGGAGGAGCAGTGGGAGAGAAGTCGAACGGGCGGTCTTCGCTGGGAGGTTCACTGCTGGCCGAG CGGAACTTCTGGAGGGACGCCGTGGTGGCCGACGCCGGCGGATGTGAGCGAGGACTACGAGGCTGATGCTGCGGCCTGGAGGCGGGGGCC CGCAGGTGGCGGCCCGATCCCTCCCGCGCTGCAGCGTCTCCGGGCGGTGTTGCTGCGGCTGCATCGCGAGCGGGAGCAGCTCCTCCAGGC CCGAGACTGCGCCTACCACCTACAGTCGGCTGTGCGACTCATGAAGACCCTGAGTCCTGGCTCGCCATCCGGCGGCCCTAGCCCCTTGCC CCAGTGGTGCCGCGACCTGCAGCTGCACCCTTCCCAAGGGGCGGTTCTGCGAATCGGCCCTGGGGAGACTCTCGAGCCGCTGCTGCTAGC GCGCCCCATCGGACTAGCCGCCCAGTGCCTGGAGGCTGTCATCGAGATGCAGCTTCGCGCTCTCGGCCGGGAGCCCGCCAGCCCGGGCCT GTCGTCCCAACTCGCCGAGCTGCTCTTTGCACTTCCCGCCTACCACACACTACAGAGAAAAGCCTTGAGCCACGTCCCAGGGGCCGCACG TCCTTTCCCCACGTCCCGTGTGCTCCGCCTCTTGACGGGGGAGCGGGGTTGCCAGGTGGCAAGTCGGCTGGACGAGGCGCTCCAAGGATC GGCGTTGAGGGACCAGCTCCGCAGGCGGTGCCAAGAGGAGGGGGATCTGCTACCAGGGCTGCTGGGCCTGGTCGGGGGCGTGGCGGGTTC AGCCAGCTGTGGACTAGGGCTCGGAGGGGCTGGGGCCTTGTGGAGCCAATACTGGACCCTGCTGTGGGCAGCCTGTGCTCAGAGTCTGGA CCTAAATCTGGGACCCTGGAGGGACCCCAGGGCAACAGCGCAACAGCTGAGTCAGGCACTGGGTCAGGCATCCCTGCCTCAGGAGTGTGA GAAGGAGCTGGCATCTTTGTGTCACAGACTACTTCATCAGTCGCTTATCTGGAGCTGGGACCAAGGTTTCTGCCAGGCCTTGGGATCAGC TCTTGGGGGTCAGAGCAGCCTTCCCACATCCTCTGGCACTGCTGAACTTTTGCAGCAGCTCTTTCCTCCTCTCTTGGATGCCCTTCGAGA GCCCAGGTTACGACGGATTTTCTGCCAGCCTGCAGAGAGTTCTATTCTGGGAACTGACATTGACCTTCAGACTATAGACAATGATATCGT CAGCATGGAGATTTTCTTCAAAGCCTGGCTACATAACAGTGGAACAGACCAAGAACAAATCCATCTTCTTCTTTCTTCACAGTGTTTCAG CAACATTTCCAGACCCAGAGATAATCCAATGTGTCTGAAATGTGATCTCCAAGAGCGACTGCTCTGCCCATCCCTACTCGCTGGCACAGC TGACGGCTCCTTGAGAATGGATGACCCTAAAGGAGACTTCATCACACTCTACCAGATGGCTTCCCAGTCATCGGCCTCTCATTACAAGCT CCAAGTGATCAAGGCTTTAAAATCTAGCGGGCTCTGCGAGTCATTGACATATGGACTCCCGTTCATCCTCAGACCTACAAGCTGTTGGCA GCTGGACTGGGATGAGCTGGAGACAAATCAGCAACATTTCCATGCTTTGTGTCACAGCCTGCTGAAAAGGGAATGGCTGCTGTTAGCCAA GGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTTCTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGT AAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCTACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGA GAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGC CAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGCATCCCTGCAAGACTGGGCAGTTGCAGACCAACCGAGC TCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTT CTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCT CAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTT CCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTT TAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCT TCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGACCTCAGGAACAAGGATGAGGTTTTGAAAGCTCAT AAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCACTACACCACCAGGCTTCAGCCTCCAAAGAGACAAG TGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAACAGGGGAGAGGATGGTGTAAAAAAAGACCTACTC CTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCACAGAATAATAGCTACCATTTATAAAATGTTTACT CTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGTGGGATGATCACTTGAGGCCAGGAGTTCGAGACCA >13641_13641_4_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000393965_M1AP_chr2_74808974_ENST00000290536_length(amino acids)=773AA_BP=440 MRRALVRAGKWESLGSFWTRRPMAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYE ADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGP GETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVA SRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQAL GQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPAESSILGTDI DLQTIDNDIVSMEIFFKAWLHNSGTDQEQIHLLLSSQCFSNISRPRDNPMCLKCDLQERLLCPSLLAGTADGSLRMDDPKGDFITLYQMA SQSSASHYKLQVIKALKSSGLCESLTYGLPFILRPTSCWQLDWDELETNQQHFHALCHSLLKREWLLLAKGEPPGPGHSQRIPASTFYVI MPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKHPC -------------------------------------------------------------- >13641_13641_5_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000393965_M1AP_chr2_74808974_ENST00000409585_length(transcript)=3465nt_BP=1655nt CTGCATAAAATCCTACTCGAAACGTTCAGACCACAGGTGGACCCAAGAGGGGCTGCCTCTGCCCTCCTAGACCCCCACTGGTCTTGTCAT ACCGCTCACCTAGCTTGATCCGCCCCACAGTCTTTGGAATCGGCGCCATCGCATCTACAGTGACCCGGAAATGAAAGGTAGTCTAGTATT TGATACCAGCCAAAGGGCGGGGTGGGACAGAGTGGGCGGCCATGTTTGTTAGGGGCAGAAGCCTCCCATTACGGAGCACGAGAGAGTCCA TGAAGGTCCCCGCGACTCCCGGACTGGAGAAAACGGCTCTTGCGATGGGGCGAAGTCCGAGCTGCGGCGGGCGTTGGTCCGTGCAGGGAA GTGGGAATCGTTAGGTTCGTTCTGGACCCGCCGCCCCATGGCCCAGGCGTCTCGCTCAGGTAGCCTGCCTCCACTCGTTATCGTGCCCCC GCTGAGGGCGCAACCCGGGGGCACTGGGGAGGAGCAGTGGGAGAGAAGTCGAACGGGCGGTCTTCGCTGGGAGGTTCACTGCTGGCCGAG CGGAACTTCTGGAGGGACGCCGTGGTGGCCGACGCCGGCGGATGTGAGCGAGGACTACGAGGCTGATGCTGCGGCCTGGAGGCGGGGGCC CGCAGGTGGCGGCCCGATCCCTCCCGCGCTGCAGCGTCTCCGGGCGGTGTTGCTGCGGCTGCATCGCGAGCGGGAGCAGCTCCTCCAGGC CCGAGACTGCGCCTACCACCTACAGTCGGCTGTGCGACTCATGAAGACCCTGAGTCCTGGCTCGCCATCCGGCGGCCCTAGCCCCTTGCC CCAGTGGTGCCGCGACCTGCAGCTGCACCCTTCCCAAGGGGCGGTTCTGCGAATCGGCCCTGGGGAGACTCTCGAGCCGCTGCTGCTAGC GCGCCCCATCGGACTAGCCGCCCAGTGCCTGGAGGCTGTCATCGAGATGCAGCTTCGCGCTCTCGGCCGGGAGCCCGCCAGCCCGGGCCT GTCGTCCCAACTCGCCGAGCTGCTCTTTGCACTTCCCGCCTACCACACACTACAGAGAAAAGCCTTGAGCCACGTCCCAGGGGCCGCACG TCCTTTCCCCACGTCCCGTGTGCTCCGCCTCTTGACGGGGGAGCGGGGTTGCCAGGTGGCAAGTCGGCTGGACGAGGCGCTCCAAGGATC GGCGTTGAGGGACCAGCTCCGCAGGCGGTGCCAAGAGGAGGGGGATCTGCTACCAGGGCTGCTGGGCCTGGTCGGGGGCGTGGCGGGTTC AGCCAGCTGTGGACTAGGGCTCGGAGGGGCTGGGGCCTTGTGGAGCCAATACTGGACCCTGCTGTGGGCAGCCTGTGCTCAGAGTCTGGA CCTAAATCTGGGACCCTGGAGGGACCCCAGGGCAACAGCGCAACAGCTGAGTCAGGCACTGGGTCAGGCATCCCTGCCTCAGGAGTGTGA GAAGGAGCTGGCATCTTTGTGTCACAGACTACTTCATCAGTCGCTTATCTGGAGCTGGGACCAAGGTTTCTGCCAGGCCTTGGGATCAGC TCTTGGGGGTCAGAGCAGCCTTCCCACATCCTCTGGCACTGCTGAACTTTTGCAGCAGCTCTTTCCTCCTCTCTTGGATGCCCTTCGAGA GCCCAGGTTACGACGGATTTTCTGCCAGCCTGCAGAGAGTTCTATTCTGGGAACTGACATTGACCTTCAGACTATAGACAATGATATCGT CAGCATGGAGATTTTCTTCAAAGCCTGGCTACATAACAGTGGAACAGACCAAGAACAAATCCATCTTCTTCTTTCTTCACAGTGTTTCAG CAACATTTCCAGACCCAGAGATAATCCAATGTGTCTGAAATGTGATCTCCAAGAGCGACTGCTCTGCCCATCCCTACTCGCTGGCACAGC TGACGGCTCCTTGAGAATGGATGACCCTAAAGGAGACTTCATCACACTCTACCAGATGGCTTCCCAGTCATCGGCCTCTCATTACAAGCT CCAAGTGATCAAGGCTTTAAAATCTAGCGGGCTCTGCGAGTCATTGACATATGGACTCCCGTTCATCCTCAGACCTACAAGCTGTTGGCA GCTGGACTGGGATGAGCTGGAGACAAATCAGCAACATTTCCATGCTTTGTGTCACAGCCTGCTGAAAAGGGAATGGCTGCTGTTAGCCAA GGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTTCTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGT AAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCTACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGA GAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGC CAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGT GGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTC AGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATA ATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTT CAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTG CTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCT GTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGACCTCAGGAACAAGGATGAGGTTTTGAAAGCTCATAAAAGACAAGTA AGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCACTACACCACCAGGCTTCAGCCTCCAAAGAGACAAGTGCTTGGTACCT ACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAACAGGGGAGAGGATGGTGTAAAAAAAGACCTACTCCTTTCCTGTTAC CCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCACAGAATAATAGCTACCATTTATAAAATGTTTACTCTGGGCTGGGAG CAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGTGGGATGATCACTTGAGGCCAGGAGTTCGAGACCAGCCTGAGCAACA >13641_13641_5_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000393965_M1AP_chr2_74808974_ENST00000409585_length(amino acids)=769AA_BP=440 MRRALVRAGKWESLGSFWTRRPMAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYE ADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGP GETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVA SRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQAL GQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPAESSILGTDI DLQTIDNDIVSMEIFFKAWLHNSGTDQEQIHLLLSSQCFSNISRPRDNPMCLKCDLQERLLCPSLLAGTADGSLRMDDPKGDFITLYQMA SQSSASHYKLQVIKALKSSGLCESLTYGLPFILRPTSCWQLDWDELETNQQHFHALCHSLLKREWLLLAKGEPPGPGHSQRIPASTFYVI MPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKTGQ -------------------------------------------------------------- >13641_13641_6_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000393965_M1AP_chr2_74808974_ENST00000536235_length(transcript)=3019nt_BP=1655nt CTGCATAAAATCCTACTCGAAACGTTCAGACCACAGGTGGACCCAAGAGGGGCTGCCTCTGCCCTCCTAGACCCCCACTGGTCTTGTCAT ACCGCTCACCTAGCTTGATCCGCCCCACAGTCTTTGGAATCGGCGCCATCGCATCTACAGTGACCCGGAAATGAAAGGTAGTCTAGTATT TGATACCAGCCAAAGGGCGGGGTGGGACAGAGTGGGCGGCCATGTTTGTTAGGGGCAGAAGCCTCCCATTACGGAGCACGAGAGAGTCCA TGAAGGTCCCCGCGACTCCCGGACTGGAGAAAACGGCTCTTGCGATGGGGCGAAGTCCGAGCTGCGGCGGGCGTTGGTCCGTGCAGGGAA GTGGGAATCGTTAGGTTCGTTCTGGACCCGCCGCCCCATGGCCCAGGCGTCTCGCTCAGGTAGCCTGCCTCCACTCGTTATCGTGCCCCC GCTGAGGGCGCAACCCGGGGGCACTGGGGAGGAGCAGTGGGAGAGAAGTCGAACGGGCGGTCTTCGCTGGGAGGTTCACTGCTGGCCGAG CGGAACTTCTGGAGGGACGCCGTGGTGGCCGACGCCGGCGGATGTGAGCGAGGACTACGAGGCTGATGCTGCGGCCTGGAGGCGGGGGCC CGCAGGTGGCGGCCCGATCCCTCCCGCGCTGCAGCGTCTCCGGGCGGTGTTGCTGCGGCTGCATCGCGAGCGGGAGCAGCTCCTCCAGGC CCGAGACTGCGCCTACCACCTACAGTCGGCTGTGCGACTCATGAAGACCCTGAGTCCTGGCTCGCCATCCGGCGGCCCTAGCCCCTTGCC CCAGTGGTGCCGCGACCTGCAGCTGCACCCTTCCCAAGGGGCGGTTCTGCGAATCGGCCCTGGGGAGACTCTCGAGCCGCTGCTGCTAGC GCGCCCCATCGGACTAGCCGCCCAGTGCCTGGAGGCTGTCATCGAGATGCAGCTTCGCGCTCTCGGCCGGGAGCCCGCCAGCCCGGGCCT GTCGTCCCAACTCGCCGAGCTGCTCTTTGCACTTCCCGCCTACCACACACTACAGAGAAAAGCCTTGAGCCACGTCCCAGGGGCCGCACG TCCTTTCCCCACGTCCCGTGTGCTCCGCCTCTTGACGGGGGAGCGGGGTTGCCAGGTGGCAAGTCGGCTGGACGAGGCGCTCCAAGGATC GGCGTTGAGGGACCAGCTCCGCAGGCGGTGCCAAGAGGAGGGGGATCTGCTACCAGGGCTGCTGGGCCTGGTCGGGGGCGTGGCGGGTTC AGCCAGCTGTGGACTAGGGCTCGGAGGGGCTGGGGCCTTGTGGAGCCAATACTGGACCCTGCTGTGGGCAGCCTGTGCTCAGAGTCTGGA CCTAAATCTGGGACCCTGGAGGGACCCCAGGGCAACAGCGCAACAGCTGAGTCAGGCACTGGGTCAGGCATCCCTGCCTCAGGAGTGTGA GAAGGAGCTGGCATCTTTGTGTCACAGACTACTTCATCAGTCGCTTATCTGGAGCTGGGACCAAGGTTTCTGCCAGGCCTTGGGATCAGC TCTTGGGGGTCAGAGCAGCCTTCCCACATCCTCTGGCACTGCTGAACTTTTGCAGCAGCTCTTTCCTCCTCTCTTGGATGCCCTTCGAGA GCCCAGGTTACGACGGATTTTCTGCCAGCCTGCAGAGAGTTCTATTCTGGGAACTGACATTGACCTTCAGACTATAGACAATGATATCGT CAGCATGGAGATTTTCTTCAAAGCCTGGCTACATAACAGTGGAACAGACCAAGAACAAATCCATCTTCTTCTTTCTTCACAGTGTTTCAG CAACATTTCCAGACCCAGAGATAATCCAATGTGTCTGAAATGTGATCTCCAAGAGCGACTGCTCTGCCCATCCCTACTCGCTGGCACAGC TGACGGCTCCTTGAGAATGGATGACCCTAAAGGAGACTTCATCACACTCTACCAGATGGCTTCCCAGTCATCGGCCTCTCATTACAAGCT CCAAGTGATCAAGGCTTTAAAATCTAGCGGGCTCTGCGAGTCATTGACATATGGACTCCCGTTCATCCTCAGACCTACAAGCTGTTGGCA GCTGGACTGGGATGAGCTGGAGACAAATCAGCAACATTTCCATGCTTTGTGTCACAGCCTGCTGAAAAGGGAATGGCTGCTGTTAGCCAA GGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTTCTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGT AAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCTACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGA GAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGC CAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGT GGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTC AGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATA ATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTT CAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTG CTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCT >13641_13641_6_CCDC142-M1AP_CCDC142_chr2_74708350_ENST00000393965_M1AP_chr2_74808974_ENST00000536235_length(amino acids)=769AA_BP=440 MRRALVRAGKWESLGSFWTRRPMAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYE ADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGP GETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVA SRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQAL GQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPAESSILGTDI DLQTIDNDIVSMEIFFKAWLHNSGTDQEQIHLLLSSQCFSNISRPRDNPMCLKCDLQERLLCPSLLAGTADGSLRMDDPKGDFITLYQMA SQSSASHYKLQVIKALKSSGLCESLTYGLPFILRPTSCWQLDWDELETNQQHFHALCHSLLKREWLLLAKGEPPGPGHSQRIPASTFYVI MPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKTGQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CCDC142-M1AP |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CCDC142-M1AP |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CCDC142-M1AP |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies