
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CCDC47-GH1 (FusionGDB2 ID:13814) |
Fusion Gene Summary for CCDC47-GH1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CCDC47-GH1 | Fusion gene ID: 13814 | Hgene | Tgene | Gene symbol | CCDC47 | GH1 | Gene ID | 57003 | 2688 |
| Gene name | coiled-coil domain containing 47 | growth hormone 1 | |
| Synonyms | GK001|MSTP041|THNS | GH|GH-N|GHB5|GHN|IGHD1A|IGHD1B|IGHD2|hGH-N | |
| Cytomap | 17q23.3 | 17q23.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | coiled-coil domain-containing protein 47Calumin | somatotropingrowth hormone B5pituitary growth hormone | |
| Modification date | 20200313 | 20200322 | |
| UniProtAcc | Q96A33 | P01241 | |
| Ensembl transtripts involved in fusion gene | ENST00000225726, ENST00000403162, ENST00000582252, | ENST00000323322, ENST00000342364, ENST00000351388, ENST00000458650, | |
| Fusion gene scores | * DoF score | 6 X 5 X 5=150 | 3 X 2 X 3=18 |
| # samples | 6 | 3 | |
| ** MAII score | log2(6/150*10)=-1.32192809488736 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: CCDC47 [Title/Abstract] AND GH1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CCDC47(61838274)-GH1(61995866), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | GH1 | GO:0002092 | positive regulation of receptor internalization | 9360546 |
| Tgene | GH1 | GO:0010536 | positive regulation of activation of Janus kinase activity | 8063815|12552091 |
| Tgene | GH1 | GO:0010828 | positive regulation of glucose transmembrane transport | 9144201 |
| Tgene | GH1 | GO:0014068 | positive regulation of phosphatidylinositol 3-kinase signaling | 7782332 |
| Tgene | GH1 | GO:0032355 | response to estradiol | 12552091 |
| Tgene | GH1 | GO:0040018 | positive regulation of multicellular organism growth | 7565946|20110402 |
| Tgene | GH1 | GO:0042531 | positive regulation of tyrosine phosphorylation of STAT protein | 8923468|12552091 |
| Tgene | GH1 | GO:0043568 | positive regulation of insulin-like growth factor receptor signaling pathway | 7565946 |
| Tgene | GH1 | GO:0046427 | positive regulation of JAK-STAT cascade | 8063815|8923468 |
| Tgene | GH1 | GO:0050731 | positive regulation of peptidyl-tyrosine phosphorylation | 7782332 |
| Tgene | GH1 | GO:0060396 | growth hormone receptor signaling pathway | 8063815 |
| Tgene | GH1 | GO:0070977 | bone maturation | 20110402 |
| Fusion gene breakpoints across CCDC47 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GH1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A1-A0SN-01A | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
Top |
Fusion Gene ORF analysis for CCDC47-GH1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000225726 | ENST00000323322 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000225726 | ENST00000342364 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000225726 | ENST00000351388 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000225726 | ENST00000458650 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000403162 | ENST00000323322 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000403162 | ENST00000342364 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000403162 | ENST00000351388 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000403162 | ENST00000458650 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000582252 | ENST00000323322 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000582252 | ENST00000342364 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000582252 | ENST00000351388 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| In-frame | ENST00000582252 | ENST00000458650 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000225726 | CCDC47 | chr17 | 61838274 | - | ENST00000351388 | GH1 | chr17 | 61995866 | - | 1751 | 1118 | 383 | 1285 | 300 |
| ENST00000225726 | CCDC47 | chr17 | 61838274 | - | ENST00000458650 | GH1 | chr17 | 61995866 | - | 1823 | 1118 | 383 | 1360 | 325 |
| ENST00000225726 | CCDC47 | chr17 | 61838274 | - | ENST00000323322 | GH1 | chr17 | 61995866 | - | 1868 | 1118 | 383 | 1405 | 340 |
| ENST00000225726 | CCDC47 | chr17 | 61838274 | - | ENST00000342364 | GH1 | chr17 | 61995866 | - | 1477 | 1118 | 383 | 1474 | 364 |
| ENST00000403162 | CCDC47 | chr17 | 61838274 | - | ENST00000351388 | GH1 | chr17 | 61995866 | - | 1633 | 1000 | 265 | 1167 | 300 |
| ENST00000403162 | CCDC47 | chr17 | 61838274 | - | ENST00000458650 | GH1 | chr17 | 61995866 | - | 1705 | 1000 | 265 | 1242 | 325 |
| ENST00000403162 | CCDC47 | chr17 | 61838274 | - | ENST00000323322 | GH1 | chr17 | 61995866 | - | 1750 | 1000 | 265 | 1287 | 340 |
| ENST00000403162 | CCDC47 | chr17 | 61838274 | - | ENST00000342364 | GH1 | chr17 | 61995866 | - | 1359 | 1000 | 265 | 1356 | 364 |
| ENST00000582252 | CCDC47 | chr17 | 61838274 | - | ENST00000351388 | GH1 | chr17 | 61995866 | - | 1546 | 913 | 178 | 1080 | 300 |
| ENST00000582252 | CCDC47 | chr17 | 61838274 | - | ENST00000458650 | GH1 | chr17 | 61995866 | - | 1618 | 913 | 178 | 1155 | 325 |
| ENST00000582252 | CCDC47 | chr17 | 61838274 | - | ENST00000323322 | GH1 | chr17 | 61995866 | - | 1663 | 913 | 178 | 1200 | 340 |
| ENST00000582252 | CCDC47 | chr17 | 61838274 | - | ENST00000342364 | GH1 | chr17 | 61995866 | - | 1272 | 913 | 178 | 1269 | 364 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000225726 | ENST00000351388 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.001528834 | 0.9984712 |
| ENST00000225726 | ENST00000458650 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.001420766 | 0.99857926 |
| ENST00000225726 | ENST00000323322 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.001363925 | 0.99863607 |
| ENST00000225726 | ENST00000342364 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.06539948 | 0.93460053 |
| ENST00000403162 | ENST00000351388 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.001329033 | 0.99867094 |
| ENST00000403162 | ENST00000458650 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.001370961 | 0.9986291 |
| ENST00000403162 | ENST00000323322 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.00133933 | 0.9986607 |
| ENST00000403162 | ENST00000342364 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.04053374 | 0.9594663 |
| ENST00000582252 | ENST00000351388 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.001258224 | 0.9987418 |
| ENST00000582252 | ENST00000458650 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.001175012 | 0.998825 |
| ENST00000582252 | ENST00000323322 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.001126187 | 0.9988738 |
| ENST00000582252 | ENST00000342364 | CCDC47 | chr17 | 61838274 | - | GH1 | chr17 | 61995866 | - | 0.05190437 | 0.9480956 |
Top |
Fusion Genomic Features for CCDC47-GH1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
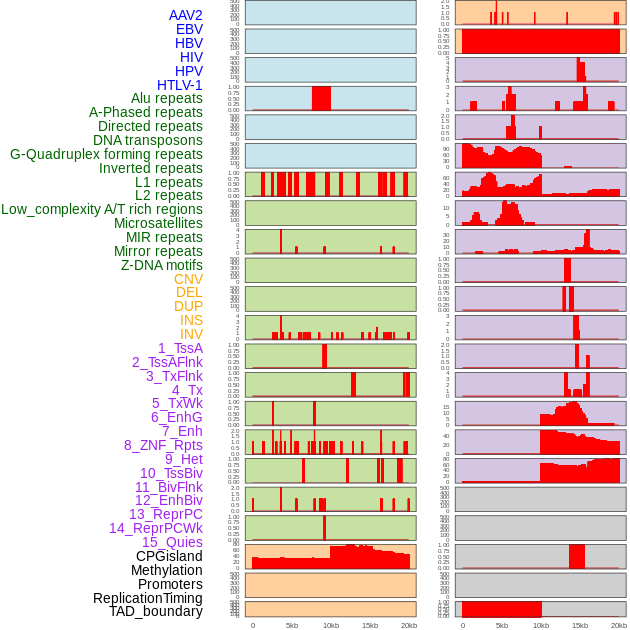 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CCDC47-GH1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:61838274/chr17:61995866) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CCDC47 | GH1 |
| FUNCTION: Component of the PAT complex, an endoplasmic reticulum (ER)-resident membrane multiprotein complex that facilitates multi-pass membrane proteins insertion into membranes (PubMed:32814900). The PAT complex acts as an intramembrane chaperone by directly interacting with nascent transmembrane domains (TMDs), releasing its substrates upon correct folding, and is needed for optimal biogenesis of multi-pass membrane proteins (PubMed:32814900). WDR83OS/Asterix is the substrate-interacting subunit of the PAT complex, whereas CCDC47 is required to maintain the stability of WDR83OS/Asterix (PubMed:32814900). The PAT complex favors the binding to TMDs with exposed hydrophilic amino acids within the lipid bilayer and provides a membrane-embedded partially hydrophilic environment in which the first transmembrane domain binds (PubMed:32814900). Component of a ribosome-associated ER translocon complex involved in multi-pass membrane protein transport into the ER membrane and biogenesis (PubMed:32820719). Involved in the regulation of calcium ion homeostasis in the ER (PubMed:30401460). Required for proper protein degradation via the ERAD (ER-associated degradation) pathway (PubMed:25009997). Has an essential role in the maintenance of ER organization during embryogenesis (By similarity). {ECO:0000250|UniProtKB:Q9D024, ECO:0000269|PubMed:25009997, ECO:0000269|PubMed:30401460, ECO:0000269|PubMed:32814900, ECO:0000269|PubMed:32820719}. | FUNCTION: Plays an important role in growth control. Its major role in stimulating body growth is to stimulate the liver and other tissues to secrete IGF-1. It stimulates both the differentiation and proliferation of myoblasts. It also stimulates amino acid uptake and protein synthesis in muscle and other tissues. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CCDC47 | chr17:61838274 | chr17:61995866 | ENST00000225726 | - | 6 | 13 | 136_155 | 245 | 484.0 | Transmembrane | Helical |
| Hgene | CCDC47 | chr17:61838274 | chr17:61995866 | ENST00000403162 | - | 7 | 14 | 136_155 | 245 | 484.0 | Transmembrane | Helical |
| Hgene | CCDC47 | chr17:61838274 | chr17:61995866 | ENST00000582252 | - | 6 | 12 | 136_155 | 245 | 481.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CCDC47 | chr17:61838274 | chr17:61995866 | ENST00000225726 | - | 6 | 13 | 450_483 | 245 | 484.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CCDC47 | chr17:61838274 | chr17:61995866 | ENST00000403162 | - | 7 | 14 | 450_483 | 245 | 484.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CCDC47 | chr17:61838274 | chr17:61995866 | ENST00000582252 | - | 6 | 12 | 450_483 | 245 | 481.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for CCDC47-GH1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >13814_13814_1_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000225726_GH1_chr17_61995866_ENST00000323322_length(transcript)=1868nt_BP=1118nt GTAGGAGGATTGGGATAGGCGAGGGCAGTTCCGGCCCAGGGGCGGGGATTATGTAATTTTCCCAAAAGCCCCACCTCGCCTCAGCCGGGC GGGAGAGAGGGAGGTCTCGCGCTTTCCCCGGGGTTGCGTCCCGCCCCGCAGGCTGCGCGCAGGCGCTGACGAGCCGCTCGCATTCTACGT AACGGACGGCGGAGGCTACGTGAAGAGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACC GCTGCGATCGCGGAGGCGGCGGCCAGGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCC ACAGCTTTTTTTCTCAAGGTGCAATGAAAGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTG ATGATTTTGAGGATGAGGAGGACATAGTAGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAAT CTCCTCAACGGGTCATAATCACTGAAGATGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTG AAGATGCAGATACCCAGGAGGGAGATACTGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTT CTAGCAAAAATAAAGACCCAATAACGATTGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGG TGACTGGTCTGCTTGCTTATATCATGAATTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGG AGCTTTTGGAGAGCAACTTTACTTTAGTGGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGC ACATCTATAACCTGTGGTGTTCTGGTCGAGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATG TCCTGGCCCGGATGATGAGGCCAGTGAGTGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCT TCAAGAGGGCAGTGCCTTCCCAACCATTCCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTT TGACACCTACCAGGAGTTTGAAGAAGCCTATATCCCAAAGGAACAGAAGTATTCATTCCTGCAGAACCCCCAGACCTCCCTCTGTTTCTC AGAGTCTATTCCGACACCCTCCAACAGGGAGGAAACACAACAGAAATCCAACCTAGAGCTGCTCCGCATCTCCCTGCTGCTCATCCAGTC GTGGCTGGAGCCCGTGCAGTTCCTCAGGAGTGTCTTCGCCAACAGCCTGGTGTACGGCGCCTCTGACAGCAACGTCTATGACCTCCTAAA GGACCTAGAGGAAGGCATCCAAACGCTGATGGGGAGGCTGGAAGATGGCAGCCCCCGGACTGGGCAGATCTTCAAGCAGACCTACAGCAA GTTCGACACAAACTCACACAACGATGACGCACTACTCAAGAACTACGGGCTGCTCTACTGCTTCAGGAAGGACATGGACAAGGTCGAGAC ATTCCTGCGCATCGTGCAGTGCCGCTCTGTGGAGGGCAGCTGTGGCTTCTAGCTGCCCGGGTGGCATCCCTGTGACCCCTCCCCAGTGCC >13814_13814_1_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000225726_GH1_chr17_61995866_ENST00000323322_length(amino acids)=340AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- >13814_13814_2_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000225726_GH1_chr17_61995866_ENST00000342364_length(transcript)=1477nt_BP=1118nt GTAGGAGGATTGGGATAGGCGAGGGCAGTTCCGGCCCAGGGGCGGGGATTATGTAATTTTCCCAAAAGCCCCACCTCGCCTCAGCCGGGC GGGAGAGAGGGAGGTCTCGCGCTTTCCCCGGGGTTGCGTCCCGCCCCGCAGGCTGCGCGCAGGCGCTGACGAGCCGCTCGCATTCTACGT AACGGACGGCGGAGGCTACGTGAAGAGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACC GCTGCGATCGCGGAGGCGGCGGCCAGGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCC ACAGCTTTTTTTCTCAAGGTGCAATGAAAGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTG ATGATTTTGAGGATGAGGAGGACATAGTAGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAAT CTCCTCAACGGGTCATAATCACTGAAGATGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTG AAGATGCAGATACCCAGGAGGGAGATACTGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTT CTAGCAAAAATAAAGACCCAATAACGATTGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGG TGACTGGTCTGCTTGCTTATATCATGAATTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGG AGCTTTTGGAGAGCAACTTTACTTTAGTGGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGC ACATCTATAACCTGTGGTGTTCTGGTCGAGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATG TCCTGGCCCGGATGATGAGGCCAGTGAGTGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCT TCAAGAGGGCAGTGCCTTCCCAACCATTCCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTT TGACACCTACCAGGAGTTTAGGCTGGAAGATGGCAGCCCCCGGACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTC ACACAACGATGACGCACTACTCAAGAACTACGGGCTGCTCTACTGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGT >13814_13814_2_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000225726_GH1_chr17_61995866_ENST00000342364_length(amino acids)=364AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ PFPYPGFLTTLCSAPIVCTSWPLTPTRSLGWKMAAPGLGRSSSRPTASSTQTHTTMTHYSRTTGCSTASGRTWTRSRHSCASCSAALWRA -------------------------------------------------------------- >13814_13814_3_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000225726_GH1_chr17_61995866_ENST00000351388_length(transcript)=1751nt_BP=1118nt GTAGGAGGATTGGGATAGGCGAGGGCAGTTCCGGCCCAGGGGCGGGGATTATGTAATTTTCCCAAAAGCCCCACCTCGCCTCAGCCGGGC GGGAGAGAGGGAGGTCTCGCGCTTTCCCCGGGGTTGCGTCCCGCCCCGCAGGCTGCGCGCAGGCGCTGACGAGCCGCTCGCATTCTACGT AACGGACGGCGGAGGCTACGTGAAGAGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACC GCTGCGATCGCGGAGGCGGCGGCCAGGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCC ACAGCTTTTTTTCTCAAGGTGCAATGAAAGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTG ATGATTTTGAGGATGAGGAGGACATAGTAGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAAT CTCCTCAACGGGTCATAATCACTGAAGATGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTG AAGATGCAGATACCCAGGAGGGAGATACTGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTT CTAGCAAAAATAAAGACCCAATAACGATTGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGG TGACTGGTCTGCTTGCTTATATCATGAATTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGG AGCTTTTGGAGAGCAACTTTACTTTAGTGGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGC ACATCTATAACCTGTGGTGTTCTGGTCGAGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATG TCCTGGCCCGGATGATGAGGCCAGTGAGTGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCT TCAAGAGGGCAGTGCCTTCCCAACCATTCCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTT TGACACCTACCAGGAGTTTAACCTAGAGCTGCTCCGCATCTCCCTGCTGCTCATCCAGTCGTGGCTGGAGCCCGTGCAGTTCCTCAGGAG TGTCTTCGCCAACAGCCTGGTGTACGGCGCCTCTGACAGCAACGTCTATGACCTCCTAAAGGACCTAGAGGAAGGCATCCAAACGCTGAT GGGGAGGCTGGAAGATGGCAGCCCCCGGACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGACGC ACTACTCAAGAACTACGGGCTGCTCTACTGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCTGT GGAGGGCAGCTGTGGCTTCTAGCTGCCCGGGTGGCATCCCTGTGACCCCTCCCCAGTGCCTCTCCTGGCCCTGGAAGTTGCCACTCCAGT >13814_13814_3_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000225726_GH1_chr17_61995866_ENST00000351388_length(amino acids)=300AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- >13814_13814_4_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000225726_GH1_chr17_61995866_ENST00000458650_length(transcript)=1823nt_BP=1118nt GTAGGAGGATTGGGATAGGCGAGGGCAGTTCCGGCCCAGGGGCGGGGATTATGTAATTTTCCCAAAAGCCCCACCTCGCCTCAGCCGGGC GGGAGAGAGGGAGGTCTCGCGCTTTCCCCGGGGTTGCGTCCCGCCCCGCAGGCTGCGCGCAGGCGCTGACGAGCCGCTCGCATTCTACGT AACGGACGGCGGAGGCTACGTGAAGAGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACC GCTGCGATCGCGGAGGCGGCGGCCAGGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCC ACAGCTTTTTTTCTCAAGGTGCAATGAAAGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTG ATGATTTTGAGGATGAGGAGGACATAGTAGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAAT CTCCTCAACGGGTCATAATCACTGAAGATGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTG AAGATGCAGATACCCAGGAGGGAGATACTGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTT CTAGCAAAAATAAAGACCCAATAACGATTGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGG TGACTGGTCTGCTTGCTTATATCATGAATTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGG AGCTTTTGGAGAGCAACTTTACTTTAGTGGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGC ACATCTATAACCTGTGGTGTTCTGGTCGAGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATG TCCTGGCCCGGATGATGAGGCCAGTGAGTGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCT TCAAGAGGGCAGTGCCTTCCCAACCATTCCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTT TGACACCTACCAGGAGTTTAACCCCCAGACCTCCCTCTGTTTCTCAGAGTCTATTCCGACACCCTCCAACAGGGAGGAAACACAACAGAA ATCCAACCTAGAGCTGCTCCGCATCTCCCTGCTGCTCATCCAGTCGTGGCTGGAGCCCGTGCAGTTCCTCAGGAGTGTCTTCGCCAACAG CCTGGTGTACGGCGCCTCTGACAGCAACGTCTATGACCTCCTAAAGGACCTAGAGGAAGGCATCCAAACGCTGATGGGGAGGCTGGAAGA TGGCAGCCCCCGGACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGACGCACTACTCAAGAACTA CGGGCTGCTCTACTGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCTGTGGAGGGCAGCTGTGG CTTCTAGCTGCCCGGGTGGCATCCCTGTGACCCCTCCCCAGTGCCTCTCCTGGCCCTGGAAGTTGCCACTCCAGTGCCCACCAGCCTTGT >13814_13814_4_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000225726_GH1_chr17_61995866_ENST00000458650_length(amino acids)=325AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- >13814_13814_5_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000403162_GH1_chr17_61995866_ENST00000323322_length(transcript)=1750nt_BP=1000nt AGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACCGCTGCGATCGCGGAGGCGGCGGCCA GGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCCACAGGAGTCATAGAGGCTGGGTGGT CTGGCAAGGACTTGTGCATTTGAGAACTGACAGGTGCAGCGGAGACTTCTAAGAGGGAAAACCAAGCTTTTTTTCTCAAGGTGCAATGAA AGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTGATGATTTTGAGGATGAGGAGGACATAGT AGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAATCTCCTCAACGGGTCATAATCACTGAAGA TGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTGAAGATGCAGATACCCAGGAGGGAGATAC TGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTTCTAGCAAAAATAAAGACCCAATAACGAT TGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGGTGACTGGTCTGCTTGCTTATATCATGAA TTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGGAGCTTTTGGAGAGCAACTTTACTTTAGT GGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGCACATCTATAACCTGTGGTGTTCTGGTCG AGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATGTCCTGGCCCGGATGATGAGGCCAGTGAG TGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCTTCAAGAGGGCAGTGCCTTCCCAACCATT CCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTTTGACACCTACCAGGAGTTTGAAGAAGCC TATATCCCAAAGGAACAGAAGTATTCATTCCTGCAGAACCCCCAGACCTCCCTCTGTTTCTCAGAGTCTATTCCGACACCCTCCAACAGG GAGGAAACACAACAGAAATCCAACCTAGAGCTGCTCCGCATCTCCCTGCTGCTCATCCAGTCGTGGCTGGAGCCCGTGCAGTTCCTCAGG AGTGTCTTCGCCAACAGCCTGGTGTACGGCGCCTCTGACAGCAACGTCTATGACCTCCTAAAGGACCTAGAGGAAGGCATCCAAACGCTG ATGGGGAGGCTGGAAGATGGCAGCCCCCGGACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGAC GCACTACTCAAGAACTACGGGCTGCTCTACTGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCT GTGGAGGGCAGCTGTGGCTTCTAGCTGCCCGGGTGGCATCCCTGTGACCCCTCCCCAGTGCCTCTCCTGGCCCTGGAAGTTGCCACTCCA >13814_13814_5_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000403162_GH1_chr17_61995866_ENST00000323322_length(amino acids)=340AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- >13814_13814_6_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000403162_GH1_chr17_61995866_ENST00000342364_length(transcript)=1359nt_BP=1000nt AGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACCGCTGCGATCGCGGAGGCGGCGGCCA GGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCCACAGGAGTCATAGAGGCTGGGTGGT CTGGCAAGGACTTGTGCATTTGAGAACTGACAGGTGCAGCGGAGACTTCTAAGAGGGAAAACCAAGCTTTTTTTCTCAAGGTGCAATGAA AGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTGATGATTTTGAGGATGAGGAGGACATAGT AGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAATCTCCTCAACGGGTCATAATCACTGAAGA TGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTGAAGATGCAGATACCCAGGAGGGAGATAC TGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTTCTAGCAAAAATAAAGACCCAATAACGAT TGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGGTGACTGGTCTGCTTGCTTATATCATGAA TTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGGAGCTTTTGGAGAGCAACTTTACTTTAGT GGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGCACATCTATAACCTGTGGTGTTCTGGTCG AGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATGTCCTGGCCCGGATGATGAGGCCAGTGAG TGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCTTCAAGAGGGCAGTGCCTTCCCAACCATT CCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTTTGACACCTACCAGGAGTTTAGGCTGGAA GATGGCAGCCCCCGGACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGACGCACTACTCAAGAAC TACGGGCTGCTCTACTGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCTGTGGAGGGCAGCTGT >13814_13814_6_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000403162_GH1_chr17_61995866_ENST00000342364_length(amino acids)=364AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ PFPYPGFLTTLCSAPIVCTSWPLTPTRSLGWKMAAPGLGRSSSRPTASSTQTHTTMTHYSRTTGCSTASGRTWTRSRHSCASCSAALWRA -------------------------------------------------------------- >13814_13814_7_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000403162_GH1_chr17_61995866_ENST00000351388_length(transcript)=1633nt_BP=1000nt AGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACCGCTGCGATCGCGGAGGCGGCGGCCA GGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCCACAGGAGTCATAGAGGCTGGGTGGT CTGGCAAGGACTTGTGCATTTGAGAACTGACAGGTGCAGCGGAGACTTCTAAGAGGGAAAACCAAGCTTTTTTTCTCAAGGTGCAATGAA AGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTGATGATTTTGAGGATGAGGAGGACATAGT AGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAATCTCCTCAACGGGTCATAATCACTGAAGA TGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTGAAGATGCAGATACCCAGGAGGGAGATAC TGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTTCTAGCAAAAATAAAGACCCAATAACGAT TGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGGTGACTGGTCTGCTTGCTTATATCATGAA TTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGGAGCTTTTGGAGAGCAACTTTACTTTAGT GGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGCACATCTATAACCTGTGGTGTTCTGGTCG AGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATGTCCTGGCCCGGATGATGAGGCCAGTGAG TGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCTTCAAGAGGGCAGTGCCTTCCCAACCATT CCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTTTGACACCTACCAGGAGTTTAACCTAGAG CTGCTCCGCATCTCCCTGCTGCTCATCCAGTCGTGGCTGGAGCCCGTGCAGTTCCTCAGGAGTGTCTTCGCCAACAGCCTGGTGTACGGC GCCTCTGACAGCAACGTCTATGACCTCCTAAAGGACCTAGAGGAAGGCATCCAAACGCTGATGGGGAGGCTGGAAGATGGCAGCCCCCGG ACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGACGCACTACTCAAGAACTACGGGCTGCTCTAC TGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCTGTGGAGGGCAGCTGTGGCTTCTAGCTGCCC GGGTGGCATCCCTGTGACCCCTCCCCAGTGCCTCTCCTGGCCCTGGAAGTTGCCACTCCAGTGCCCACCAGCCTTGTCCTAATAAAATTA >13814_13814_7_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000403162_GH1_chr17_61995866_ENST00000351388_length(amino acids)=300AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- >13814_13814_8_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000403162_GH1_chr17_61995866_ENST00000458650_length(transcript)=1705nt_BP=1000nt AGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACCGCTGCGATCGCGGAGGCGGCGGCCA GGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCCACAGGAGTCATAGAGGCTGGGTGGT CTGGCAAGGACTTGTGCATTTGAGAACTGACAGGTGCAGCGGAGACTTCTAAGAGGGAAAACCAAGCTTTTTTTCTCAAGGTGCAATGAA AGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTGATGATTTTGAGGATGAGGAGGACATAGT AGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAATCTCCTCAACGGGTCATAATCACTGAAGA TGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTGAAGATGCAGATACCCAGGAGGGAGATAC TGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTTCTAGCAAAAATAAAGACCCAATAACGAT TGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGGTGACTGGTCTGCTTGCTTATATCATGAA TTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGGAGCTTTTGGAGAGCAACTTTACTTTAGT GGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGCACATCTATAACCTGTGGTGTTCTGGTCG AGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATGTCCTGGCCCGGATGATGAGGCCAGTGAG TGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCTTCAAGAGGGCAGTGCCTTCCCAACCATT CCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTTTGACACCTACCAGGAGTTTAACCCCCAG ACCTCCCTCTGTTTCTCAGAGTCTATTCCGACACCCTCCAACAGGGAGGAAACACAACAGAAATCCAACCTAGAGCTGCTCCGCATCTCC CTGCTGCTCATCCAGTCGTGGCTGGAGCCCGTGCAGTTCCTCAGGAGTGTCTTCGCCAACAGCCTGGTGTACGGCGCCTCTGACAGCAAC GTCTATGACCTCCTAAAGGACCTAGAGGAAGGCATCCAAACGCTGATGGGGAGGCTGGAAGATGGCAGCCCCCGGACTGGGCAGATCTTC AAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGACGCACTACTCAAGAACTACGGGCTGCTCTACTGCTTCAGGAAGGAC ATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCTGTGGAGGGCAGCTGTGGCTTCTAGCTGCCCGGGTGGCATCCCTGT >13814_13814_8_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000403162_GH1_chr17_61995866_ENST00000458650_length(amino acids)=325AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- >13814_13814_9_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000582252_GH1_chr17_61995866_ENST00000323322_length(transcript)=1663nt_BP=913nt AGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACCGCTGCGATCGCGGAGGCGGCGGCCA GGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCCACAGCTTTTTTTCTCAAGGTGCAAT GAAAGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTGATGATTTTGAGGATGAGGAGGACAT AGTAGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAATCTCCTCAACGGGTCATAATCACTGA AGATGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTGAAGATGCAGATACCCAGGAGGGAGA TACTGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTTCTAGCAAAAATAAAGACCCAATAAC GATTGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGGTGACTGGTCTGCTTGCTTATATCAT GAATTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGGAGCTTTTGGAGAGCAACTTTACTTT AGTGGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGCACATCTATAACCTGTGGTGTTCTGG TCGAGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATGTCCTGGCCCGGATGATGAGGCCAGT GAGTGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCTTCAAGAGGGCAGTGCCTTCCCAACC ATTCCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTTTGACACCTACCAGGAGTTTGAAGAA GCCTATATCCCAAAGGAACAGAAGTATTCATTCCTGCAGAACCCCCAGACCTCCCTCTGTTTCTCAGAGTCTATTCCGACACCCTCCAAC AGGGAGGAAACACAACAGAAATCCAACCTAGAGCTGCTCCGCATCTCCCTGCTGCTCATCCAGTCGTGGCTGGAGCCCGTGCAGTTCCTC AGGAGTGTCTTCGCCAACAGCCTGGTGTACGGCGCCTCTGACAGCAACGTCTATGACCTCCTAAAGGACCTAGAGGAAGGCATCCAAACG CTGATGGGGAGGCTGGAAGATGGCAGCCCCCGGACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGAT GACGCACTACTCAAGAACTACGGGCTGCTCTACTGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGC TCTGTGGAGGGCAGCTGTGGCTTCTAGCTGCCCGGGTGGCATCCCTGTGACCCCTCCCCAGTGCCTCTCCTGGCCCTGGAAGTTGCCACT >13814_13814_9_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000582252_GH1_chr17_61995866_ENST00000323322_length(amino acids)=340AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- >13814_13814_10_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000582252_GH1_chr17_61995866_ENST00000342364_length(transcript)=1272nt_BP=913nt AGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACCGCTGCGATCGCGGAGGCGGCGGCCA GGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCCACAGCTTTTTTTCTCAAGGTGCAAT GAAAGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTGATGATTTTGAGGATGAGGAGGACAT AGTAGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAATCTCCTCAACGGGTCATAATCACTGA AGATGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTGAAGATGCAGATACCCAGGAGGGAGA TACTGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTTCTAGCAAAAATAAAGACCCAATAAC GATTGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGGTGACTGGTCTGCTTGCTTATATCAT GAATTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGGAGCTTTTGGAGAGCAACTTTACTTT AGTGGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGCACATCTATAACCTGTGGTGTTCTGG TCGAGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATGTCCTGGCCCGGATGATGAGGCCAGT GAGTGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCTTCAAGAGGGCAGTGCCTTCCCAACC ATTCCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTTTGACACCTACCAGGAGTTTAGGCTG GAAGATGGCAGCCCCCGGACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGACGCACTACTCAAG AACTACGGGCTGCTCTACTGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCTGTGGAGGGCAGC >13814_13814_10_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000582252_GH1_chr17_61995866_ENST00000342364_length(amino acids)=364AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ PFPYPGFLTTLCSAPIVCTSWPLTPTRSLGWKMAAPGLGRSSSRPTASSTQTHTTMTHYSRTTGCSTASGRTWTRSRHSCASCSAALWRA -------------------------------------------------------------- >13814_13814_11_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000582252_GH1_chr17_61995866_ENST00000351388_length(transcript)=1546nt_BP=913nt AGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACCGCTGCGATCGCGGAGGCGGCGGCCA GGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCCACAGCTTTTTTTCTCAAGGTGCAAT GAAAGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTGATGATTTTGAGGATGAGGAGGACAT AGTAGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAATCTCCTCAACGGGTCATAATCACTGA AGATGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTGAAGATGCAGATACCCAGGAGGGAGA TACTGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTTCTAGCAAAAATAAAGACCCAATAAC GATTGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGGTGACTGGTCTGCTTGCTTATATCAT GAATTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGGAGCTTTTGGAGAGCAACTTTACTTT AGTGGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGCACATCTATAACCTGTGGTGTTCTGG TCGAGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATGTCCTGGCCCGGATGATGAGGCCAGT GAGTGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCTTCAAGAGGGCAGTGCCTTCCCAACC ATTCCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTTTGACACCTACCAGGAGTTTAACCTA GAGCTGCTCCGCATCTCCCTGCTGCTCATCCAGTCGTGGCTGGAGCCCGTGCAGTTCCTCAGGAGTGTCTTCGCCAACAGCCTGGTGTAC GGCGCCTCTGACAGCAACGTCTATGACCTCCTAAAGGACCTAGAGGAAGGCATCCAAACGCTGATGGGGAGGCTGGAAGATGGCAGCCCC CGGACTGGGCAGATCTTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGACGCACTACTCAAGAACTACGGGCTGCTC TACTGCTTCAGGAAGGACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCTGTGGAGGGCAGCTGTGGCTTCTAGCTG CCCGGGTGGCATCCCTGTGACCCCTCCCCAGTGCCTCTCCTGGCCCTGGAAGTTGCCACTCCAGTGCCCACCAGCCTTGTCCTAATAAAA >13814_13814_11_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000582252_GH1_chr17_61995866_ENST00000351388_length(amino acids)=300AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- >13814_13814_12_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000582252_GH1_chr17_61995866_ENST00000458650_length(transcript)=1618nt_BP=913nt AGAGGCGCGGCGTGACTGAGCTACGGTTCTGGCTGCGTCCTAGAGGCATCCGGGGCAGTAAAACCGCTGCGATCGCGGAGGCGGCGGCCA GGCCGAGAGGCAGGCCGGGCAGGGGTGTCGGACGCAGGGCGCTGGGCCGGGTTTCGGCTTCGGCCACAGCTTTTTTTCTCAAGGTGCAAT GAAAGCCTTCCACACTTTCTGTGTTGTCCTTCTGGTGTTTGGGAGTGTCTCTGAAGCCAAGTTTGATGATTTTGAGGATGAGGAGGACAT AGTAGAGTATGATGATAATGACTTCGCTGAATTTGAGGATGTCATGGAAGACTCTGTTACTGAATCTCCTCAACGGGTCATAATCACTGA AGATGATGAAGATGAGACCACTGTGGAGTTGGAAGGGCAGGATGAAAACCAAGAAGGAGATTTTGAAGATGCAGATACCCAGGAGGGAGA TACTGAGAGTGAACCATATGATGATGAAGAATTTGAAGGTTATGAAGACAAACCAGATACTTCTTCTAGCAAAAATAAAGACCCAATAAC GATTGTTGATGTTCCTGCACACCTCCAGAACAGCTGGGAGAGTTATTATCTAGAAATTTTGATGGTGACTGGTCTGCTTGCTTATATCAT GAATTACATCATTGGGAAGAATAAAAACAGTCGCCTTGCACAGGCCTGGTTTAACACTCATAGGGAGCTTTTGGAGAGCAACTTTACTTT AGTGGGGGATGATGGAACTAACAAAGAAGCCACAAGCACAGGAAAGTTGAACCAGGAGAATGAGCACATCTATAACCTGTGGTGTTCTGG TCGAGTGTGCTGTGAGGGCATGCTTATCCAGCTGAGGTTCCTCAAGAGACAAGACTTACTGAATGTCCTGGCCCGGATGATGAGGCCAGT GAGTGATCAAGTGGCTCCCGGACGTCCCTGCTCCTGGCTTTTGGCCTGCTCTGCCTGCCCTGGCTTCAAGAGGGCAGTGCCTTCCCAACC ATTCCCTTATCCAGGCTTTTTGACAACGCTATGCTCCGCGCCCATCGTCTGCACCAGCTGGCCTTTGACACCTACCAGGAGTTTAACCCC CAGACCTCCCTCTGTTTCTCAGAGTCTATTCCGACACCCTCCAACAGGGAGGAAACACAACAGAAATCCAACCTAGAGCTGCTCCGCATC TCCCTGCTGCTCATCCAGTCGTGGCTGGAGCCCGTGCAGTTCCTCAGGAGTGTCTTCGCCAACAGCCTGGTGTACGGCGCCTCTGACAGC AACGTCTATGACCTCCTAAAGGACCTAGAGGAAGGCATCCAAACGCTGATGGGGAGGCTGGAAGATGGCAGCCCCCGGACTGGGCAGATC TTCAAGCAGACCTACAGCAAGTTCGACACAAACTCACACAACGATGACGCACTACTCAAGAACTACGGGCTGCTCTACTGCTTCAGGAAG GACATGGACAAGGTCGAGACATTCCTGCGCATCGTGCAGTGCCGCTCTGTGGAGGGCAGCTGTGGCTTCTAGCTGCCCGGGTGGCATCCC >13814_13814_12_CCDC47-GH1_CCDC47_chr17_61838274_ENST00000582252_GH1_chr17_61995866_ENST00000458650_length(amino acids)=325AA_BP=245 MKAFHTFCVVLLVFGSVSEAKFDDFEDEEDIVEYDDNDFAEFEDVMEDSVTESPQRVIITEDDEDETTVELEGQDENQEGDFEDADTQEG DTESEPYDDEEFEGYEDKPDTSSSKNKDPITIVDVPAHLQNSWESYYLEILMVTGLLAYIMNYIIGKNKNSRLAQAWFNTHRELLESNFT LVGDDGTNKEATSTGKLNQENEHIYNLWCSGRVCCEGMLIQLRFLKRQDLLNVLARMMRPVSDQVAPGRPCSWLLACSACPGFKRAVPSQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CCDC47-GH1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CCDC47-GH1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CCDC47-GH1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies