
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CCNF-NOL4 (FusionGDB2 ID:14139) |
Fusion Gene Summary for CCNF-NOL4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CCNF-NOL4 | Fusion gene ID: 14139 | Hgene | Tgene | Gene symbol | CCNF | NOL4 | Gene ID | 899 | 8715 |
| Gene name | cyclin F | nucleolar protein 4 | |
| Synonyms | FBX1|FBXO1 | CT125|HRIHFB2255|NOLP | |
| Cytomap | 16p13.3 | 18q12.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cyclin-FF-box only protein 1G2/mitotic-specific cyclin-F | nucleolar protein 4cancer/testis antigen 125nucleolar localized protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P41002 | Q96MY1 | |
| Ensembl transtripts involved in fusion gene | ENST00000397066, | ENST00000535384, ENST00000535475, ENST00000538587, ENST00000589544, ENST00000590846, ENST00000261592, ENST00000269185, | |
| Fusion gene scores | * DoF score | 6 X 6 X 6=216 | 9 X 10 X 5=450 |
| # samples | 6 | 9 | |
| ** MAII score | log2(6/216*10)=-1.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/450*10)=-2.32192809488736 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CCNF [Title/Abstract] AND NOL4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CCNF(2489827)-NOL4(31673561), # samples:4 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CCNF | GO:0010826 | negative regulation of centrosome duplication | 20596027 |
| Hgene | CCNF | GO:0016567 | protein ubiquitination | 20596027 |
| Hgene | CCNF | GO:0031146 | SCF-dependent proteasomal ubiquitin-dependent protein catabolic process | 20596027 |
| Fusion gene breakpoints across CCNF (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NOL4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LGG | TCGA-TM-A84I-01A | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - |
| ChimerDB4 | LGG | TCGA-TM-A84I-01A | CCNF | chr16 | 2489827 | - | NOL4 | chr18 | 31673561 | - |
| ChimerDB4 | LGG | TCGA-TM-A84I-01A | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
| ChimerDB4 | LGG | TCGA-TM-A84I | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
Top |
Fusion Gene ORF analysis for CCNF-NOL4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000397066 | ENST00000535384 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - |
| 5CDS-intron | ENST00000397066 | ENST00000535384 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
| 5CDS-intron | ENST00000397066 | ENST00000535475 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - |
| 5CDS-intron | ENST00000397066 | ENST00000535475 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
| 5CDS-intron | ENST00000397066 | ENST00000538587 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - |
| 5CDS-intron | ENST00000397066 | ENST00000538587 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
| 5CDS-intron | ENST00000397066 | ENST00000589544 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - |
| 5CDS-intron | ENST00000397066 | ENST00000589544 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
| 5CDS-intron | ENST00000397066 | ENST00000590846 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - |
| 5CDS-intron | ENST00000397066 | ENST00000590846 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
| In-frame | ENST00000397066 | ENST00000261592 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - |
| In-frame | ENST00000397066 | ENST00000261592 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
| In-frame | ENST00000397066 | ENST00000269185 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - |
| In-frame | ENST00000397066 | ENST00000269185 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000397066 | CCNF | chr16 | 2489827 | + | ENST00000261592 | NOL4 | chr18 | 31673561 | - | 3885 | 865 | 88 | 2142 | 684 |
| ENST00000397066 | CCNF | chr16 | 2489827 | + | ENST00000269185 | NOL4 | chr18 | 31673561 | - | 3572 | 865 | 88 | 1836 | 582 |
| ENST00000397066 | CCNF | chr16 | 2489826 | + | ENST00000261592 | NOL4 | chr18 | 31673560 | - | 3885 | 865 | 88 | 2142 | 684 |
| ENST00000397066 | CCNF | chr16 | 2489826 | + | ENST00000269185 | NOL4 | chr18 | 31673560 | - | 3572 | 865 | 88 | 1836 | 582 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000397066 | ENST00000261592 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - | 0.002653625 | 0.9973464 |
| ENST00000397066 | ENST00000269185 | CCNF | chr16 | 2489827 | + | NOL4 | chr18 | 31673561 | - | 0.001676124 | 0.99832386 |
| ENST00000397066 | ENST00000261592 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - | 0.002653625 | 0.9973464 |
| ENST00000397066 | ENST00000269185 | CCNF | chr16 | 2489826 | + | NOL4 | chr18 | 31673560 | - | 0.001676124 | 0.99832386 |
Top |
Fusion Genomic Features for CCNF-NOL4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
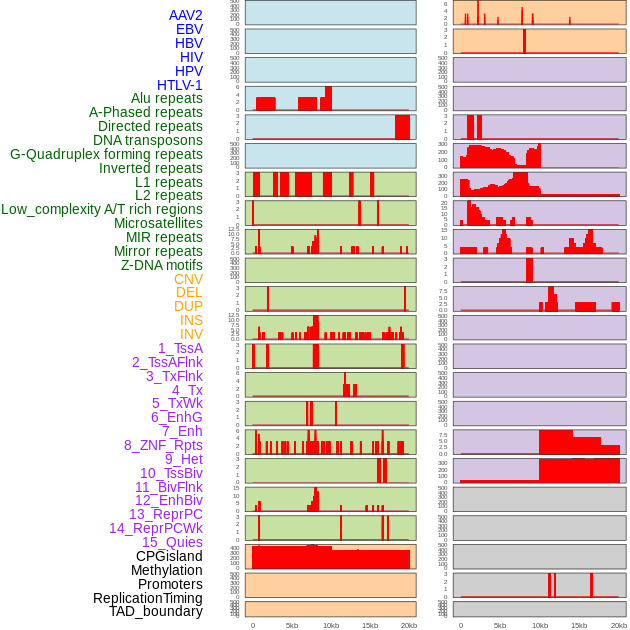 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CCNF-NOL4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr16:2489827/chr18:31673561) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CCNF | NOL4 |
| FUNCTION: Substrate recognition component of a SCF (SKP1-CUL1-F-box protein) E3 ubiquitin-protein ligase complex which mediates the ubiquitination and subsequent proteasomal degradation of CP110 during G2 phase, thereby acting as an inhibitor of centrosome reduplication. {ECO:0000269|PubMed:20596027}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CCNF | chr16:2489826 | chr18:31673560 | ENST00000397066 | + | 8 | 17 | 29_76 | 259 | 787.0 | Domain | F-box |
| Hgene | CCNF | chr16:2489827 | chr18:31673561 | ENST00000397066 | + | 8 | 17 | 29_76 | 259 | 787.0 | Domain | F-box |
| Hgene | CCNF | chr16:2489826 | chr18:31673560 | ENST00000397066 | + | 8 | 17 | 20_28 | 259 | 787.0 | Motif | Nuclear localization signal 1 |
| Hgene | CCNF | chr16:2489827 | chr18:31673561 | ENST00000397066 | + | 8 | 17 | 20_28 | 259 | 787.0 | Motif | Nuclear localization signal 1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CCNF | chr16:2489826 | chr18:31673560 | ENST00000397066 | + | 8 | 17 | 292_405 | 259 | 787.0 | Domain | Note=Cyclin N-terminal |
| Hgene | CCNF | chr16:2489827 | chr18:31673561 | ENST00000397066 | + | 8 | 17 | 292_405 | 259 | 787.0 | Domain | Note=Cyclin N-terminal |
| Hgene | CCNF | chr16:2489826 | chr18:31673560 | ENST00000397066 | + | 8 | 17 | 568_574 | 259 | 787.0 | Motif | Nuclear localization signal 2 |
| Hgene | CCNF | chr16:2489827 | chr18:31673561 | ENST00000397066 | + | 8 | 17 | 568_574 | 259 | 787.0 | Motif | Nuclear localization signal 2 |
| Hgene | CCNF | chr16:2489826 | chr18:31673560 | ENST00000397066 | + | 8 | 17 | 582_766 | 259 | 787.0 | Region | Note=PEST |
| Hgene | CCNF | chr16:2489827 | chr18:31673561 | ENST00000397066 | + | 8 | 17 | 582_766 | 259 | 787.0 | Region | Note=PEST |
Top |
Fusion Gene Sequence for CCNF-NOL4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >14139_14139_1_CCNF-NOL4_CCNF_chr16_2489826_ENST00000397066_NOL4_chr18_31673560_ENST00000261592_length(transcript)=3885nt_BP=865nt CTGCGCCTGCGCGAGGGCTACGCGCGCTCCGGCCGGGGCGCGGGCGCGCTCTCAGGCGGGCTCCGGCGGCAGCGACGCGAGCGCGGCGAT GGGGAGCGGCGGCGTGGTCCACTGTAGGTGTGCCAAGTGTTTCTGTTATCCTACAAAGCGAAGAATAAGGAGGAGGCCCCGAAACCTGAC CATCTTGAGTCTCCCCGAAGATGTGCTCTTTCACATCCTGAAATGGCTTTCTGTAGAGGACATCCTGGCCGTCCGAGCTGTACACTCCCA GCTGAAGGACCTGGTGGACAACCACGCCAGTGTGTGGGCATGTGCCAGCTTCCAGGAGCTGTGGCCGTCTCCAGGGAACCTGAAGCTCTT TGAAAGGGCTGCTGAAAAGGGGAATTTCGAAGCTGCTGTGAAGCTGGGCATAGCCTACCTCTACAATGAAGGCCTGTCTGTGTCTGATGA GGCCCGCGCAGAAGTGAATGGCCTGAAGGCCTCTCGCTTCTTCAGTCTCGCTGAGCGGCTGAATGTGGGTGCCGCACCTTTCATCTGGCT CTTCATCCGCCCTCCGTGGTCGGTGAGCGGAAGCTGCTGCAAGGCCGTGGTTCACGAGAGCCTCAGGGCAGAGTGCCAGCTGCAGAGGAC TCACAAAGCATCCATATTGCACTGCTTGGGCAGAGTGCTGAGTCTGTTCGAGGATGAGGAGAAGCAGCAGCAGGCCCATGACCTGTTTGA GGAGGCTGCTCATCAGGGATGTCTGACCAGCTCCTACCTCCTCTGGGAAAGCGACAGGAGGACAGATGTGTCAGATCCTGGGCGATGCCT CCACAGCTTCCGAAAACTCAGGGACTACGCTGCCAAAGGCTGCTGGGAAGCGCAGGATGAAAGTTCAATAGAAAGTGATGAATTTGACAT GAGTGATTCAACACGGATGTCAGCTGTGAACTCTGATCTTAGCTCCAATCTTGAAGAAAGAATGCAAAGTCCCCAGAATCTTCATGGCCA GCAAGATGATGATTCTGCTGCAGAGAGCTTTAATGGCAATGAGACTCTGGGGCACAGTTCAATTGCTTCAGGGGGAACACACAGCAGGGA GATGGGAGACTCCAACAGTGATGGCAAAACTGGGCTGGAGCAAGATGAACAGCCACTGAACCTGAGTGACAGTCCCCTCTCTGCGCAGCT AACTTCGGAATACAGAATAGATGATCACAACAGTAATGGGAAAAACAAGTATAAGAATCTTCTAATTTCTGACCTCAAGATGGAACGAGA GGCGAGAGAAAATGGAAGCAAGTCTCCTGCACATAGTTACTCCAGCTATGACTCTGGCAAAAATGAGAGTGTAGACCGAGGAGCTGAGGA CCTCTCACTAAACAGGGGAGATGAGGACGAAGATGACCACGAGGACCATGACGATTCGGAGAAAGTTAATGAGACAGACGGCGTTGAAGC CGAGCGGCTGAAAGCTTTTAATATGTTTGTCAGGCTGTTTGTAGATGAAAACTTGGACCGAATGGTCCCAATCTCTAAGCAGCCCAAAGA AAAGATCCAGGCTATCATTGACTCATGCAGGCGACAATTCCCTGAGTATCAAGAGCGTGCCAGAAAACGTATACGTACTTACCTCAAGTC CTGCAGGCGGATGAAAAGAAGTGGTTTTGAGATGTCTCGACCTATTCCTTCCCACCTTACTTCAGCAGTTGCAGAGAGTATCTTGGCTTC AGCTTGTGAGAGTGAGAGTAGAAATGCCGCCAAGAGGATGCGTCTGGAGAGACAGCAGGATGAGTCTGCTCCAGCTGACAAACAGTGTAA ACCAGAGGCGACCCAGGCCACTTACTCAACATCAGCTGTTCCAGGCTCACAGGACGTGCTGTACATCAATGGAAATGGGACCTATAGTTA CCATAGTTACAGAGGGCTAGGAGGGGGTCTGCTAAATCTGAATGATGCTTCCAGCAGTGGACCCACTGATCTCAGCATGAAGAGACAATT GGCGACTAGCTCAGGATCCTCCAGCAGCTCAAACTCCAGACCCCAGCTGAGTCCAACTGAAATCAATGCCGTGAGACAGCTTGTTGCAGG ATATCGAGAATCAGCTGCATTTTTATTGCGATCTGCAGATGAACTGGAAAATCTCATTTTACAACAGAACTGAGACAGACGACCACCATA TTCACTGAGGTCTAAATTTGCAGTTTCCACTAATGACATTTTGATTTCCCAACAGAGATACTTCTGGTCTTACTGCACAGTCTTTTAAGA GAAATACTTCCATTATGCCACATTGTCCTTGATCCGTAAGTGATGTGTTAAGGTGCTTCAAAGGAACTCTGACCTCTGAAGTACTTGAGC TACTTTAGTATGTCCAGCCTATTGCTTTTTGTTTTAGTGTGTCACCATAAATATCAGGGGCATAAAAGGCTATCTATTCTTAATTCAAGG ATAAAACAGAAGAAGCTTGTGGTATAAAACAATAGTTCAAGATCCAGCTGAAATATTAGTGGAATTTGCTACTGACTCATTGGACTGAAA GCTGAAGTACCTGGCAAAAAAAAAAAAAAGAAAAAAAAAAGCCAAATTTCTTGTTGCTACAGGATATAACAACAATGAAAAGGATCTCGT ATTTTAAAAAAATATGTAATTTTTATAAAAAGAAAACTTGTTTTTCATTCAAACTTGTCATTTTTACTTTGGTAACTTTTTCATAGGTCC TAAAAGAAAACTGTTTTGAGAAACTACTGTAAGTACCTTTTCCACATCCCTTTGCCTTCTCCTCTTTCCAAATTCTTTCTACAAAAATAA CACTTGATGCTGGAAAAACCCTTGCCTACGTTCTTTCAATCGTCACATCAGGAACTACTTCCAAGAGAAGCCTGCATTTCTGCTCTCATG CTGATCTCAAAAACCCCACTCAACACTGCAACTTTATCATAGCAGTTTTCATCCCAGAATTTTTTTTTTAATAATGACAAGACATGTTGT TGAAAAAAAATCACACCTTGGTTTCTTAGAGCTGCTCGTTCCTGATTGCCGCTGCTGTCTCCAGGCATCCCTCTAGCAGCACCTGGATGT AGATGACTGAATGTTAAGAGGTTGCAAGTGACAATCTGAAAATTTGCACTCTTGTGTGTAGTTTTCTTTTCATTTCTTTCAGAAATAGTT TCCAAAAAGACCATTACATCTCCTGATATGATTTGTATAATTTTCAGTTCTAGCTAAAAATAATGTAAGGAACTCTCAGCGGATGCAGCT GCAACTTACAATGAACTGTGCCCTCCTATCCCCCATACTTTACCCTTCTTTCTTATTTTATAGTGTGGGATACACATGAGTGATGTTTTC TTTGTGCACTGAGACAAGCCTATTTTTTAAATATTTAGGGAGAAGTACTTTAGTTCATGCTTCTTATACAACTTTTTTCTGTTGTTTAGC TTTGGTTGGATTACAAATTCTTTGTGCATTCCTGAATTTGCCTTATTTCATGTAAAATTTATGTCATTCAGTTTTTGACAATGAGTTTGA GGCATCAGTGATATTTCTTATCTACTTGTTACATATAGTTTTTCAAGTAATGACTGTGATTGTGACCGAGTAATGTGCACTTTTTCTTGT AACTGTGGACATTGCTATGCTTTTTTCTTCTAGTGTTTCTAGAATTACTGTTCCTTACAATTATGTAAACAAAAAACAAAAAAAAAACTT TTGTGATACTGTTGGTGAATATAATGTGAAAAATCTTATTGAAATATGAGTATTTTGGAAATACATAGCTGCACAAACATCTTTTAAGAT GTGGATTTAGAGTTTGCTTATTTAAATGAAAATTCAAAAATTGAGGGCTGGTATAATTTTCTCTGTTTTGTTTGGTTTAATAAACAGATT >14139_14139_1_CCNF-NOL4_CCNF_chr16_2489826_ENST00000397066_NOL4_chr18_31673560_ENST00000261592_length(amino acids)=684AA_BP=258 MGSGGVVHCRCAKCFCYPTKRRIRRRPRNLTILSLPEDVLFHILKWLSVEDILAVRAVHSQLKDLVDNHASVWACASFQELWPSPGNLKL FERAAEKGNFEAAVKLGIAYLYNEGLSVSDEARAEVNGLKASRFFSLAERLNVGAAPFIWLFIRPPWSVSGSCCKAVVHESLRAECQLQR THKASILHCLGRVLSLFEDEEKQQQAHDLFEEAAHQGCLTSSYLLWESDRRTDVSDPGRCLHSFRKLRDYAAKGCWEAQDESSIESDEFD MSDSTRMSAVNSDLSSNLEERMQSPQNLHGQQDDDSAAESFNGNETLGHSSIASGGTHSREMGDSNSDGKTGLEQDEQPLNLSDSPLSAQ LTSEYRIDDHNSNGKNKYKNLLISDLKMEREARENGSKSPAHSYSSYDSGKNESVDRGAEDLSLNRGDEDEDDHEDHDDSEKVNETDGVE AERLKAFNMFVRLFVDENLDRMVPISKQPKEKIQAIIDSCRRQFPEYQERARKRIRTYLKSCRRMKRSGFEMSRPIPSHLTSAVAESILA SACESESRNAAKRMRLERQQDESAPADKQCKPEATQATYSTSAVPGSQDVLYINGNGTYSYHSYRGLGGGLLNLNDASSSGPTDLSMKRQ -------------------------------------------------------------- >14139_14139_2_CCNF-NOL4_CCNF_chr16_2489826_ENST00000397066_NOL4_chr18_31673560_ENST00000269185_length(transcript)=3572nt_BP=865nt CTGCGCCTGCGCGAGGGCTACGCGCGCTCCGGCCGGGGCGCGGGCGCGCTCTCAGGCGGGCTCCGGCGGCAGCGACGCGAGCGCGGCGAT GGGGAGCGGCGGCGTGGTCCACTGTAGGTGTGCCAAGTGTTTCTGTTATCCTACAAAGCGAAGAATAAGGAGGAGGCCCCGAAACCTGAC CATCTTGAGTCTCCCCGAAGATGTGCTCTTTCACATCCTGAAATGGCTTTCTGTAGAGGACATCCTGGCCGTCCGAGCTGTACACTCCCA GCTGAAGGACCTGGTGGACAACCACGCCAGTGTGTGGGCATGTGCCAGCTTCCAGGAGCTGTGGCCGTCTCCAGGGAACCTGAAGCTCTT TGAAAGGGCTGCTGAAAAGGGGAATTTCGAAGCTGCTGTGAAGCTGGGCATAGCCTACCTCTACAATGAAGGCCTGTCTGTGTCTGATGA GGCCCGCGCAGAAGTGAATGGCCTGAAGGCCTCTCGCTTCTTCAGTCTCGCTGAGCGGCTGAATGTGGGTGCCGCACCTTTCATCTGGCT CTTCATCCGCCCTCCGTGGTCGGTGAGCGGAAGCTGCTGCAAGGCCGTGGTTCACGAGAGCCTCAGGGCAGAGTGCCAGCTGCAGAGGAC TCACAAAGCATCCATATTGCACTGCTTGGGCAGAGTGCTGAGTCTGTTCGAGGATGAGGAGAAGCAGCAGCAGGCCCATGACCTGTTTGA GGAGGCTGCTCATCAGGGATGTCTGACCAGCTCCTACCTCCTCTGGGAAAGCGACAGGAGGACAGATGTGTCAGATCCTGGGCGATGCCT CCACAGCTTCCGAAAACTCAGGGACTACGCTGCCAAAGGCTGCTGGGAAGCGCAGGATGAAAGTTCAATAGAAAGTGATGAATTTGACAT GAGTGATTCAACACGGATGTCAGCTGTGAACTCTGATCTTAGCTCCAATCTTGAAGAAAGAATGCAAAGTCCCCAGAATCTTCATGGCCA GCAAGATGATGATTCTGCTGCAGAGAGCTTTAATGGCAATGAGACTCTGGGGCACAGTTCAATTGCTTCAGGGGGAACACACAGCAGGGA GATGGGAGACTCCAACAGTGATGGCAAAACTGGGCTGGAGCAAGATGAACAGCCACTGAACCTGAGTGACAGTCCCCTCTCTGCGCAGCT AACTTCGGAATACAGAATAGATGATCACAACAGTAATGGGAAAAACAAGTATAAGAATCTTCTAATTTCTGACCTCAAGATGGAACGAGA GGCGAGAGAAAATGGAAGCAAGTCTCCTGCACATAGTTACTCCAGCTATGACTCTGGCAAAAATGAGAGTGTAGACCGAGGAGCTGAGGA CCTCTCACTAAACAGGGGAGATGAGGACGAAGATGACCACGAGGACCATGACGATTCGGAGAAAGTTAATGAGACAGACGGCGTTGAAGC CGAGCGGCTGAAAGCTTTTAATGATGAGTCTGCTCCAGCTGACAAACAGTGTAAACCAGAGGCGACCCAGGCCACTTACTCAACATCAGC TGTTCCAGGCTCACAGGACGTGCTGTACATCAATGGAAATGGGACCTATAGTTACCATAGTTACAGAGGGCTAGGAGGGGGTCTGCTAAA TCTGAATGATGCTTCCAGCAGTGGACCCACTGATCTCAGCATGAAGAGACAATTGGCGACTAGCTCAGGATCCTCCAGCAGCTCAAACTC CAGACCCCAGCTGAGTCCAACTGAAATCAATGCCGTGAGACAGCTTGTTGCAGGATATCGAGAATCAGCTGCATTTTTATTGCGATCTGC AGATGAACTGGAAAATCTCATTTTACAACAGAACTGAGACAGACGACCACCATATTCACTGAGGTCTAAATTTGCAGTTTCCACTAATGA CATTTTGATTTCCCAACAGAGATACTTCTGGTCTTACTGCACAGTCTTTTAAGAGAAATACTTCCATTATGCCACATTGTCCTTGATCCG TAAGTGATGTGTTAAGGTGCTTCAAAGGAACTCTGACCTCTGAAGTACTTGAGCTACTTTAGTATGTCCAGCCTATTGCTTTTTGTTTTA GTGTGTCACCATAAATATCAGGGGCATAAAAGGCTATCTATTCTTAATTCAAGGATAAAACAGAAGAAGCTTGTGGTATAAAACAATAGT TCAAGATCCAGCTGAAATATTAGTGGAATTTGCTACTGACTCATTGGACTGAAAGCTGAAGTACCTGGCAAAAAAAAAAAAAAGAAAAAA AAAAGCCAAATTTCTTGTTGCTACAGGATATAACAACAATGAAAAGGATCTCGTATTTTAAAAAAATATGTAATTTTTATAAAAAGAAAA CTTGTTTTTCATTCAAACTTGTCATTTTTACTTTGGTAACTTTTTCATAGGTCCTAAAAGAAAACTGTTTTGAGAAACTACTGTAAGTAC CTTTTCCACATCCCTTTGCCTTCTCCTCTTTCCAAATTCTTTCTACAAAAATAACACTTGATGCTGGAAAAACCCTTGCCTACGTTCTTT CAATCGTCACATCAGGAACTACTTCCAAGAGAAGCCTGCATTTCTGCTCTCATGCTGATCTCAAAAACCCCACTCAACACTGCAACTTTA TCATAGCAGTTTTCATCCCAGAATTTTTTTTTTAATAATGACAAGACATGTTGTTGAAAAAAAATCACACCTTGGTTTCTTAGAGCTGCT CGTTCCTGATTGCCGCTGCTGTCTCCAGGCATCCCTCTAGCAGCACCTGGATGTAGATGACTGAATGTTAAGAGGTTGCAAGTGACAATC TGAAAATTTGCACTCTTGTGTGTAGTTTTCTTTTCATTTCTTTCAGAAATAGTTTCCAAAAAGACCATTACATCTCCTGATATGATTTGT ATAATTTTCAGTTCTAGCTAAAAATAATGTAAGGAACTCTCAGCGGATGCAGCTGCAACTTACAATGAACTGTGCCCTCCTATCCCCCAT ACTTTACCCTTCTTTCTTATTTTATAGTGTGGGATACACATGAGTGATGTTTTCTTTGTGCACTGAGACAAGCCTATTTTTTAAATATTT AGGGAGAAGTACTTTAGTTCATGCTTCTTATACAACTTTTTTCTGTTGTTTAGCTTTGGTTGGATTACAAATTCTTTGTGCATTCCTGAA TTTGCCTTATTTCATGTAAAATTTATGTCATTCAGTTTTTGACAATGAGTTTGAGGCATCAGTGATATTTCTTATCTACTTGTTACATAT AGTTTTTCAAGTAATGACTGTGATTGTGACCGAGTAATGTGCACTTTTTCTTGTAACTGTGGACATTGCTATGCTTTTTTCTTCTAGTGT TTCTAGAATTACTGTTCCTTACAATTATGTAAACAAAAAACAAAAAAAAAACTTTTGTGATACTGTTGGTGAATATAATGTGAAAAATCT TATTGAAATATGAGTATTTTGGAAATACATAGCTGCACAAACATCTTTTAAGATGTGGATTTAGAGTTTGCTTATTTAAATGAAAATTCA >14139_14139_2_CCNF-NOL4_CCNF_chr16_2489826_ENST00000397066_NOL4_chr18_31673560_ENST00000269185_length(amino acids)=582AA_BP=258 MGSGGVVHCRCAKCFCYPTKRRIRRRPRNLTILSLPEDVLFHILKWLSVEDILAVRAVHSQLKDLVDNHASVWACASFQELWPSPGNLKL FERAAEKGNFEAAVKLGIAYLYNEGLSVSDEARAEVNGLKASRFFSLAERLNVGAAPFIWLFIRPPWSVSGSCCKAVVHESLRAECQLQR THKASILHCLGRVLSLFEDEEKQQQAHDLFEEAAHQGCLTSSYLLWESDRRTDVSDPGRCLHSFRKLRDYAAKGCWEAQDESSIESDEFD MSDSTRMSAVNSDLSSNLEERMQSPQNLHGQQDDDSAAESFNGNETLGHSSIASGGTHSREMGDSNSDGKTGLEQDEQPLNLSDSPLSAQ LTSEYRIDDHNSNGKNKYKNLLISDLKMEREARENGSKSPAHSYSSYDSGKNESVDRGAEDLSLNRGDEDEDDHEDHDDSEKVNETDGVE AERLKAFNDESAPADKQCKPEATQATYSTSAVPGSQDVLYINGNGTYSYHSYRGLGGGLLNLNDASSSGPTDLSMKRQLATSSGSSSSSN -------------------------------------------------------------- >14139_14139_3_CCNF-NOL4_CCNF_chr16_2489827_ENST00000397066_NOL4_chr18_31673561_ENST00000261592_length(transcript)=3885nt_BP=865nt CTGCGCCTGCGCGAGGGCTACGCGCGCTCCGGCCGGGGCGCGGGCGCGCTCTCAGGCGGGCTCCGGCGGCAGCGACGCGAGCGCGGCGAT GGGGAGCGGCGGCGTGGTCCACTGTAGGTGTGCCAAGTGTTTCTGTTATCCTACAAAGCGAAGAATAAGGAGGAGGCCCCGAAACCTGAC CATCTTGAGTCTCCCCGAAGATGTGCTCTTTCACATCCTGAAATGGCTTTCTGTAGAGGACATCCTGGCCGTCCGAGCTGTACACTCCCA GCTGAAGGACCTGGTGGACAACCACGCCAGTGTGTGGGCATGTGCCAGCTTCCAGGAGCTGTGGCCGTCTCCAGGGAACCTGAAGCTCTT TGAAAGGGCTGCTGAAAAGGGGAATTTCGAAGCTGCTGTGAAGCTGGGCATAGCCTACCTCTACAATGAAGGCCTGTCTGTGTCTGATGA GGCCCGCGCAGAAGTGAATGGCCTGAAGGCCTCTCGCTTCTTCAGTCTCGCTGAGCGGCTGAATGTGGGTGCCGCACCTTTCATCTGGCT CTTCATCCGCCCTCCGTGGTCGGTGAGCGGAAGCTGCTGCAAGGCCGTGGTTCACGAGAGCCTCAGGGCAGAGTGCCAGCTGCAGAGGAC TCACAAAGCATCCATATTGCACTGCTTGGGCAGAGTGCTGAGTCTGTTCGAGGATGAGGAGAAGCAGCAGCAGGCCCATGACCTGTTTGA GGAGGCTGCTCATCAGGGATGTCTGACCAGCTCCTACCTCCTCTGGGAAAGCGACAGGAGGACAGATGTGTCAGATCCTGGGCGATGCCT CCACAGCTTCCGAAAACTCAGGGACTACGCTGCCAAAGGCTGCTGGGAAGCGCAGGATGAAAGTTCAATAGAAAGTGATGAATTTGACAT GAGTGATTCAACACGGATGTCAGCTGTGAACTCTGATCTTAGCTCCAATCTTGAAGAAAGAATGCAAAGTCCCCAGAATCTTCATGGCCA GCAAGATGATGATTCTGCTGCAGAGAGCTTTAATGGCAATGAGACTCTGGGGCACAGTTCAATTGCTTCAGGGGGAACACACAGCAGGGA GATGGGAGACTCCAACAGTGATGGCAAAACTGGGCTGGAGCAAGATGAACAGCCACTGAACCTGAGTGACAGTCCCCTCTCTGCGCAGCT AACTTCGGAATACAGAATAGATGATCACAACAGTAATGGGAAAAACAAGTATAAGAATCTTCTAATTTCTGACCTCAAGATGGAACGAGA GGCGAGAGAAAATGGAAGCAAGTCTCCTGCACATAGTTACTCCAGCTATGACTCTGGCAAAAATGAGAGTGTAGACCGAGGAGCTGAGGA CCTCTCACTAAACAGGGGAGATGAGGACGAAGATGACCACGAGGACCATGACGATTCGGAGAAAGTTAATGAGACAGACGGCGTTGAAGC CGAGCGGCTGAAAGCTTTTAATATGTTTGTCAGGCTGTTTGTAGATGAAAACTTGGACCGAATGGTCCCAATCTCTAAGCAGCCCAAAGA AAAGATCCAGGCTATCATTGACTCATGCAGGCGACAATTCCCTGAGTATCAAGAGCGTGCCAGAAAACGTATACGTACTTACCTCAAGTC CTGCAGGCGGATGAAAAGAAGTGGTTTTGAGATGTCTCGACCTATTCCTTCCCACCTTACTTCAGCAGTTGCAGAGAGTATCTTGGCTTC AGCTTGTGAGAGTGAGAGTAGAAATGCCGCCAAGAGGATGCGTCTGGAGAGACAGCAGGATGAGTCTGCTCCAGCTGACAAACAGTGTAA ACCAGAGGCGACCCAGGCCACTTACTCAACATCAGCTGTTCCAGGCTCACAGGACGTGCTGTACATCAATGGAAATGGGACCTATAGTTA CCATAGTTACAGAGGGCTAGGAGGGGGTCTGCTAAATCTGAATGATGCTTCCAGCAGTGGACCCACTGATCTCAGCATGAAGAGACAATT GGCGACTAGCTCAGGATCCTCCAGCAGCTCAAACTCCAGACCCCAGCTGAGTCCAACTGAAATCAATGCCGTGAGACAGCTTGTTGCAGG ATATCGAGAATCAGCTGCATTTTTATTGCGATCTGCAGATGAACTGGAAAATCTCATTTTACAACAGAACTGAGACAGACGACCACCATA TTCACTGAGGTCTAAATTTGCAGTTTCCACTAATGACATTTTGATTTCCCAACAGAGATACTTCTGGTCTTACTGCACAGTCTTTTAAGA GAAATACTTCCATTATGCCACATTGTCCTTGATCCGTAAGTGATGTGTTAAGGTGCTTCAAAGGAACTCTGACCTCTGAAGTACTTGAGC TACTTTAGTATGTCCAGCCTATTGCTTTTTGTTTTAGTGTGTCACCATAAATATCAGGGGCATAAAAGGCTATCTATTCTTAATTCAAGG ATAAAACAGAAGAAGCTTGTGGTATAAAACAATAGTTCAAGATCCAGCTGAAATATTAGTGGAATTTGCTACTGACTCATTGGACTGAAA GCTGAAGTACCTGGCAAAAAAAAAAAAAAGAAAAAAAAAAGCCAAATTTCTTGTTGCTACAGGATATAACAACAATGAAAAGGATCTCGT ATTTTAAAAAAATATGTAATTTTTATAAAAAGAAAACTTGTTTTTCATTCAAACTTGTCATTTTTACTTTGGTAACTTTTTCATAGGTCC TAAAAGAAAACTGTTTTGAGAAACTACTGTAAGTACCTTTTCCACATCCCTTTGCCTTCTCCTCTTTCCAAATTCTTTCTACAAAAATAA CACTTGATGCTGGAAAAACCCTTGCCTACGTTCTTTCAATCGTCACATCAGGAACTACTTCCAAGAGAAGCCTGCATTTCTGCTCTCATG CTGATCTCAAAAACCCCACTCAACACTGCAACTTTATCATAGCAGTTTTCATCCCAGAATTTTTTTTTTAATAATGACAAGACATGTTGT TGAAAAAAAATCACACCTTGGTTTCTTAGAGCTGCTCGTTCCTGATTGCCGCTGCTGTCTCCAGGCATCCCTCTAGCAGCACCTGGATGT AGATGACTGAATGTTAAGAGGTTGCAAGTGACAATCTGAAAATTTGCACTCTTGTGTGTAGTTTTCTTTTCATTTCTTTCAGAAATAGTT TCCAAAAAGACCATTACATCTCCTGATATGATTTGTATAATTTTCAGTTCTAGCTAAAAATAATGTAAGGAACTCTCAGCGGATGCAGCT GCAACTTACAATGAACTGTGCCCTCCTATCCCCCATACTTTACCCTTCTTTCTTATTTTATAGTGTGGGATACACATGAGTGATGTTTTC TTTGTGCACTGAGACAAGCCTATTTTTTAAATATTTAGGGAGAAGTACTTTAGTTCATGCTTCTTATACAACTTTTTTCTGTTGTTTAGC TTTGGTTGGATTACAAATTCTTTGTGCATTCCTGAATTTGCCTTATTTCATGTAAAATTTATGTCATTCAGTTTTTGACAATGAGTTTGA GGCATCAGTGATATTTCTTATCTACTTGTTACATATAGTTTTTCAAGTAATGACTGTGATTGTGACCGAGTAATGTGCACTTTTTCTTGT AACTGTGGACATTGCTATGCTTTTTTCTTCTAGTGTTTCTAGAATTACTGTTCCTTACAATTATGTAAACAAAAAACAAAAAAAAAACTT TTGTGATACTGTTGGTGAATATAATGTGAAAAATCTTATTGAAATATGAGTATTTTGGAAATACATAGCTGCACAAACATCTTTTAAGAT GTGGATTTAGAGTTTGCTTATTTAAATGAAAATTCAAAAATTGAGGGCTGGTATAATTTTCTCTGTTTTGTTTGGTTTAATAAACAGATT >14139_14139_3_CCNF-NOL4_CCNF_chr16_2489827_ENST00000397066_NOL4_chr18_31673561_ENST00000261592_length(amino acids)=684AA_BP=258 MGSGGVVHCRCAKCFCYPTKRRIRRRPRNLTILSLPEDVLFHILKWLSVEDILAVRAVHSQLKDLVDNHASVWACASFQELWPSPGNLKL FERAAEKGNFEAAVKLGIAYLYNEGLSVSDEARAEVNGLKASRFFSLAERLNVGAAPFIWLFIRPPWSVSGSCCKAVVHESLRAECQLQR THKASILHCLGRVLSLFEDEEKQQQAHDLFEEAAHQGCLTSSYLLWESDRRTDVSDPGRCLHSFRKLRDYAAKGCWEAQDESSIESDEFD MSDSTRMSAVNSDLSSNLEERMQSPQNLHGQQDDDSAAESFNGNETLGHSSIASGGTHSREMGDSNSDGKTGLEQDEQPLNLSDSPLSAQ LTSEYRIDDHNSNGKNKYKNLLISDLKMEREARENGSKSPAHSYSSYDSGKNESVDRGAEDLSLNRGDEDEDDHEDHDDSEKVNETDGVE AERLKAFNMFVRLFVDENLDRMVPISKQPKEKIQAIIDSCRRQFPEYQERARKRIRTYLKSCRRMKRSGFEMSRPIPSHLTSAVAESILA SACESESRNAAKRMRLERQQDESAPADKQCKPEATQATYSTSAVPGSQDVLYINGNGTYSYHSYRGLGGGLLNLNDASSSGPTDLSMKRQ -------------------------------------------------------------- >14139_14139_4_CCNF-NOL4_CCNF_chr16_2489827_ENST00000397066_NOL4_chr18_31673561_ENST00000269185_length(transcript)=3572nt_BP=865nt CTGCGCCTGCGCGAGGGCTACGCGCGCTCCGGCCGGGGCGCGGGCGCGCTCTCAGGCGGGCTCCGGCGGCAGCGACGCGAGCGCGGCGAT GGGGAGCGGCGGCGTGGTCCACTGTAGGTGTGCCAAGTGTTTCTGTTATCCTACAAAGCGAAGAATAAGGAGGAGGCCCCGAAACCTGAC CATCTTGAGTCTCCCCGAAGATGTGCTCTTTCACATCCTGAAATGGCTTTCTGTAGAGGACATCCTGGCCGTCCGAGCTGTACACTCCCA GCTGAAGGACCTGGTGGACAACCACGCCAGTGTGTGGGCATGTGCCAGCTTCCAGGAGCTGTGGCCGTCTCCAGGGAACCTGAAGCTCTT TGAAAGGGCTGCTGAAAAGGGGAATTTCGAAGCTGCTGTGAAGCTGGGCATAGCCTACCTCTACAATGAAGGCCTGTCTGTGTCTGATGA GGCCCGCGCAGAAGTGAATGGCCTGAAGGCCTCTCGCTTCTTCAGTCTCGCTGAGCGGCTGAATGTGGGTGCCGCACCTTTCATCTGGCT CTTCATCCGCCCTCCGTGGTCGGTGAGCGGAAGCTGCTGCAAGGCCGTGGTTCACGAGAGCCTCAGGGCAGAGTGCCAGCTGCAGAGGAC TCACAAAGCATCCATATTGCACTGCTTGGGCAGAGTGCTGAGTCTGTTCGAGGATGAGGAGAAGCAGCAGCAGGCCCATGACCTGTTTGA GGAGGCTGCTCATCAGGGATGTCTGACCAGCTCCTACCTCCTCTGGGAAAGCGACAGGAGGACAGATGTGTCAGATCCTGGGCGATGCCT CCACAGCTTCCGAAAACTCAGGGACTACGCTGCCAAAGGCTGCTGGGAAGCGCAGGATGAAAGTTCAATAGAAAGTGATGAATTTGACAT GAGTGATTCAACACGGATGTCAGCTGTGAACTCTGATCTTAGCTCCAATCTTGAAGAAAGAATGCAAAGTCCCCAGAATCTTCATGGCCA GCAAGATGATGATTCTGCTGCAGAGAGCTTTAATGGCAATGAGACTCTGGGGCACAGTTCAATTGCTTCAGGGGGAACACACAGCAGGGA GATGGGAGACTCCAACAGTGATGGCAAAACTGGGCTGGAGCAAGATGAACAGCCACTGAACCTGAGTGACAGTCCCCTCTCTGCGCAGCT AACTTCGGAATACAGAATAGATGATCACAACAGTAATGGGAAAAACAAGTATAAGAATCTTCTAATTTCTGACCTCAAGATGGAACGAGA GGCGAGAGAAAATGGAAGCAAGTCTCCTGCACATAGTTACTCCAGCTATGACTCTGGCAAAAATGAGAGTGTAGACCGAGGAGCTGAGGA CCTCTCACTAAACAGGGGAGATGAGGACGAAGATGACCACGAGGACCATGACGATTCGGAGAAAGTTAATGAGACAGACGGCGTTGAAGC CGAGCGGCTGAAAGCTTTTAATGATGAGTCTGCTCCAGCTGACAAACAGTGTAAACCAGAGGCGACCCAGGCCACTTACTCAACATCAGC TGTTCCAGGCTCACAGGACGTGCTGTACATCAATGGAAATGGGACCTATAGTTACCATAGTTACAGAGGGCTAGGAGGGGGTCTGCTAAA TCTGAATGATGCTTCCAGCAGTGGACCCACTGATCTCAGCATGAAGAGACAATTGGCGACTAGCTCAGGATCCTCCAGCAGCTCAAACTC CAGACCCCAGCTGAGTCCAACTGAAATCAATGCCGTGAGACAGCTTGTTGCAGGATATCGAGAATCAGCTGCATTTTTATTGCGATCTGC AGATGAACTGGAAAATCTCATTTTACAACAGAACTGAGACAGACGACCACCATATTCACTGAGGTCTAAATTTGCAGTTTCCACTAATGA CATTTTGATTTCCCAACAGAGATACTTCTGGTCTTACTGCACAGTCTTTTAAGAGAAATACTTCCATTATGCCACATTGTCCTTGATCCG TAAGTGATGTGTTAAGGTGCTTCAAAGGAACTCTGACCTCTGAAGTACTTGAGCTACTTTAGTATGTCCAGCCTATTGCTTTTTGTTTTA GTGTGTCACCATAAATATCAGGGGCATAAAAGGCTATCTATTCTTAATTCAAGGATAAAACAGAAGAAGCTTGTGGTATAAAACAATAGT TCAAGATCCAGCTGAAATATTAGTGGAATTTGCTACTGACTCATTGGACTGAAAGCTGAAGTACCTGGCAAAAAAAAAAAAAAGAAAAAA AAAAGCCAAATTTCTTGTTGCTACAGGATATAACAACAATGAAAAGGATCTCGTATTTTAAAAAAATATGTAATTTTTATAAAAAGAAAA CTTGTTTTTCATTCAAACTTGTCATTTTTACTTTGGTAACTTTTTCATAGGTCCTAAAAGAAAACTGTTTTGAGAAACTACTGTAAGTAC CTTTTCCACATCCCTTTGCCTTCTCCTCTTTCCAAATTCTTTCTACAAAAATAACACTTGATGCTGGAAAAACCCTTGCCTACGTTCTTT CAATCGTCACATCAGGAACTACTTCCAAGAGAAGCCTGCATTTCTGCTCTCATGCTGATCTCAAAAACCCCACTCAACACTGCAACTTTA TCATAGCAGTTTTCATCCCAGAATTTTTTTTTTAATAATGACAAGACATGTTGTTGAAAAAAAATCACACCTTGGTTTCTTAGAGCTGCT CGTTCCTGATTGCCGCTGCTGTCTCCAGGCATCCCTCTAGCAGCACCTGGATGTAGATGACTGAATGTTAAGAGGTTGCAAGTGACAATC TGAAAATTTGCACTCTTGTGTGTAGTTTTCTTTTCATTTCTTTCAGAAATAGTTTCCAAAAAGACCATTACATCTCCTGATATGATTTGT ATAATTTTCAGTTCTAGCTAAAAATAATGTAAGGAACTCTCAGCGGATGCAGCTGCAACTTACAATGAACTGTGCCCTCCTATCCCCCAT ACTTTACCCTTCTTTCTTATTTTATAGTGTGGGATACACATGAGTGATGTTTTCTTTGTGCACTGAGACAAGCCTATTTTTTAAATATTT AGGGAGAAGTACTTTAGTTCATGCTTCTTATACAACTTTTTTCTGTTGTTTAGCTTTGGTTGGATTACAAATTCTTTGTGCATTCCTGAA TTTGCCTTATTTCATGTAAAATTTATGTCATTCAGTTTTTGACAATGAGTTTGAGGCATCAGTGATATTTCTTATCTACTTGTTACATAT AGTTTTTCAAGTAATGACTGTGATTGTGACCGAGTAATGTGCACTTTTTCTTGTAACTGTGGACATTGCTATGCTTTTTTCTTCTAGTGT TTCTAGAATTACTGTTCCTTACAATTATGTAAACAAAAAACAAAAAAAAAACTTTTGTGATACTGTTGGTGAATATAATGTGAAAAATCT TATTGAAATATGAGTATTTTGGAAATACATAGCTGCACAAACATCTTTTAAGATGTGGATTTAGAGTTTGCTTATTTAAATGAAAATTCA >14139_14139_4_CCNF-NOL4_CCNF_chr16_2489827_ENST00000397066_NOL4_chr18_31673561_ENST00000269185_length(amino acids)=582AA_BP=258 MGSGGVVHCRCAKCFCYPTKRRIRRRPRNLTILSLPEDVLFHILKWLSVEDILAVRAVHSQLKDLVDNHASVWACASFQELWPSPGNLKL FERAAEKGNFEAAVKLGIAYLYNEGLSVSDEARAEVNGLKASRFFSLAERLNVGAAPFIWLFIRPPWSVSGSCCKAVVHESLRAECQLQR THKASILHCLGRVLSLFEDEEKQQQAHDLFEEAAHQGCLTSSYLLWESDRRTDVSDPGRCLHSFRKLRDYAAKGCWEAQDESSIESDEFD MSDSTRMSAVNSDLSSNLEERMQSPQNLHGQQDDDSAAESFNGNETLGHSSIASGGTHSREMGDSNSDGKTGLEQDEQPLNLSDSPLSAQ LTSEYRIDDHNSNGKNKYKNLLISDLKMEREARENGSKSPAHSYSSYDSGKNESVDRGAEDLSLNRGDEDEDDHEDHDDSEKVNETDGVE AERLKAFNDESAPADKQCKPEATQATYSTSAVPGSQDVLYINGNGTYSYHSYRGLGGGLLNLNDASSSGPTDLSMKRQLATSSGSSSSSN -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CCNF-NOL4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CCNF-NOL4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CCNF-NOL4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies