
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CDC123-HK1 (FusionGDB2 ID:14764) |
Fusion Gene Summary for CDC123-HK1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CDC123-HK1 | Fusion gene ID: 14764 | Hgene | Tgene | Gene symbol | CDC123 | HK1 | Gene ID | 8872 | 255061 |
| Gene name | cell division cycle 123 | tachykinin precursor 4 | |
| Synonyms | C10orf7|D123 | EK|HK-1|HK1|PPT-C | |
| Cytomap | 10p14-p13 | 17q21.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cell division cycle protein 123 homologHT-1080PZ32cell division cycle 123 homolog | tachykinin-4endokininpreprotachykinin-Ctachykinin 4 (hemokinin) | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O75794 | P19367 | |
| Ensembl transtripts involved in fusion gene | ENST00000455773, ENST00000281141, ENST00000378900, | ENST00000298649, ENST00000359426, ENST00000360289, ENST00000404387, ENST00000448642, ENST00000494253, | |
| Fusion gene scores | * DoF score | 3 X 3 X 3=27 | 11 X 13 X 7=1001 |
| # samples | 4 | 15 | |
| ** MAII score | log2(4/27*10)=0.567040592723894 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(15/1001*10)=-2.73840756834011 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CDC123 [Title/Abstract] AND HK1 [Title/Abstract] AND fusion [Title/Abstract] | ||
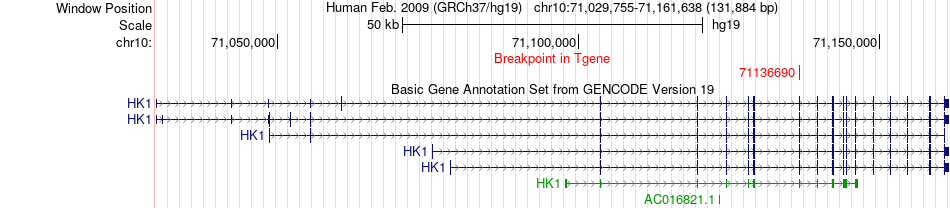
| Most frequent breakpoint | CDC123(12240775)-HK1(71136690), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | HK1 | GO:1902093 | positive regulation of flagellated sperm motility | 17437961 |
| Fusion gene breakpoints across CDC123 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across HK1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | MESO | TCGA-SH-A7BD-01A | CDC123 | chr10 | 12240775 | - | HK1 | chr10 | 71136690 | + |
| ChimerDB4 | MESO | TCGA-SH-A7BD-01A | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
Top |
Fusion Gene ORF analysis for CDC123-HK1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000455773 | ENST00000298649 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| 3UTR-3CDS | ENST00000455773 | ENST00000359426 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| 3UTR-3CDS | ENST00000455773 | ENST00000360289 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| 3UTR-3CDS | ENST00000455773 | ENST00000404387 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| 3UTR-3CDS | ENST00000455773 | ENST00000448642 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| 3UTR-3UTR | ENST00000455773 | ENST00000494253 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| 5CDS-3UTR | ENST00000281141 | ENST00000494253 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| 5CDS-3UTR | ENST00000378900 | ENST00000494253 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000281141 | ENST00000298649 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000281141 | ENST00000359426 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000281141 | ENST00000360289 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000281141 | ENST00000404387 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000281141 | ENST00000448642 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000378900 | ENST00000298649 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000378900 | ENST00000359426 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000378900 | ENST00000360289 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000378900 | ENST00000404387 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| In-frame | ENST00000378900 | ENST00000448642 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000281141 | CDC123 | chr10 | 12240775 | + | ENST00000360289 | HK1 | chr10 | 71136690 | + | 3049 | 426 | 280 | 2304 | 674 |
| ENST00000281141 | CDC123 | chr10 | 12240775 | + | ENST00000448642 | HK1 | chr10 | 71136690 | + | 3049 | 426 | 280 | 2304 | 674 |
| ENST00000281141 | CDC123 | chr10 | 12240775 | + | ENST00000404387 | HK1 | chr10 | 71136690 | + | 2305 | 426 | 280 | 2304 | 675 |
| ENST00000281141 | CDC123 | chr10 | 12240775 | + | ENST00000298649 | HK1 | chr10 | 71136690 | + | 3049 | 426 | 280 | 2304 | 674 |
| ENST00000281141 | CDC123 | chr10 | 12240775 | + | ENST00000359426 | HK1 | chr10 | 71136690 | + | 3052 | 426 | 280 | 2304 | 674 |
| ENST00000378900 | CDC123 | chr10 | 12240775 | + | ENST00000360289 | HK1 | chr10 | 71136690 | + | 2792 | 169 | 23 | 2047 | 674 |
| ENST00000378900 | CDC123 | chr10 | 12240775 | + | ENST00000448642 | HK1 | chr10 | 71136690 | + | 2792 | 169 | 23 | 2047 | 674 |
| ENST00000378900 | CDC123 | chr10 | 12240775 | + | ENST00000404387 | HK1 | chr10 | 71136690 | + | 2048 | 169 | 23 | 2047 | 675 |
| ENST00000378900 | CDC123 | chr10 | 12240775 | + | ENST00000298649 | HK1 | chr10 | 71136690 | + | 2792 | 169 | 23 | 2047 | 674 |
| ENST00000378900 | CDC123 | chr10 | 12240775 | + | ENST00000359426 | HK1 | chr10 | 71136690 | + | 2795 | 169 | 23 | 2047 | 674 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000281141 | ENST00000360289 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.001853522 | 0.99814653 |
| ENST00000281141 | ENST00000448642 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.001853522 | 0.99814653 |
| ENST00000281141 | ENST00000404387 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.002996657 | 0.9970034 |
| ENST00000281141 | ENST00000298649 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.001853522 | 0.99814653 |
| ENST00000281141 | ENST00000359426 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.001846289 | 0.99815375 |
| ENST00000378900 | ENST00000360289 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.002231282 | 0.99776876 |
| ENST00000378900 | ENST00000448642 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.002231282 | 0.99776876 |
| ENST00000378900 | ENST00000404387 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.003917738 | 0.99608225 |
| ENST00000378900 | ENST00000298649 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.002231282 | 0.99776876 |
| ENST00000378900 | ENST00000359426 | CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136690 | + | 0.002220615 | 0.9977794 |
Top |
Fusion Genomic Features for CDC123-HK1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136689 | + | 2.05E-05 | 0.9999795 |
| CDC123 | chr10 | 12240775 | + | HK1 | chr10 | 71136689 | + | 2.05E-05 | 0.9999795 |
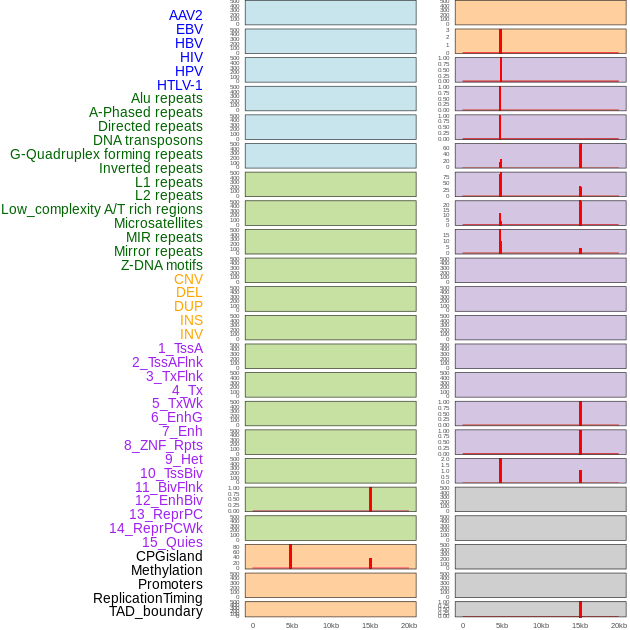
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for CDC123-HK1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:12240775/chr10:71136690) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CDC123 | HK1 |
| FUNCTION: Required for S phase entry of the cell cycle. {ECO:0000250}. | FUNCTION: Catalyzes the phosphorylation of various hexoses, such as D-glucose, D-glucosamine, D-fructose, D-mannose and 2-deoxy-D-glucose, to hexose 6-phosphate (D-glucose 6-phosphate, D-glucosamine 6-phosphate, D-fructose 6-phosphate, D-mannose 6-phosphate and 2-deoxy-D-glucose 6-phosphate, respectively) (PubMed:1637300, PubMed:25316723, PubMed:27374331). Does not phosphorylate N-acetyl-D-glucosamine (PubMed:27374331). Mediates the initial step of glycolysis by catalyzing phosphorylation of D-glucose to D-glucose 6-phosphate (By similarity). Involved in innate immunity and inflammation by acting as a pattern recognition receptor for bacterial peptidoglycan (PubMed:27374331). When released in the cytosol, N-acetyl-D-glucosamine component of bacterial peptidoglycan inhibits the hexokinase activity of HK1 and causes its dissociation from mitochondrial outer membrane, thereby activating the NLRP3 inflammasome (PubMed:27374331). {ECO:0000250|UniProtKB:P05708, ECO:0000269|PubMed:1637300, ECO:0000269|PubMed:25316723, ECO:0000269|PubMed:27374331}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 464_906 | 290 | 917.0 | Domain | Hexokinase 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 464_906 | 291 | 918.0 | Domain | Hexokinase 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 464_906 | 279 | 906.0 | Domain | Hexokinase 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 464_906 | 295 | 922.0 | Domain | Hexokinase 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 425_426 | 290 | 917.0 | Nucleotide binding | ATP 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 532_537 | 290 | 917.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 747_748 | 290 | 917.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 784_788 | 290 | 917.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 425_426 | 291 | 918.0 | Nucleotide binding | ATP 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 532_537 | 291 | 918.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 747_748 | 291 | 918.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 784_788 | 291 | 918.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 425_426 | 279 | 906.0 | Nucleotide binding | ATP 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 532_537 | 279 | 906.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 747_748 | 279 | 906.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 784_788 | 279 | 906.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 425_426 | 295 | 922.0 | Nucleotide binding | ATP 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 532_537 | 295 | 922.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 747_748 | 295 | 922.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 784_788 | 295 | 922.0 | Nucleotide binding | ATP 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 291_294 | 290 | 917.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 413_415 | 290 | 917.0 | Region | Glucose-6-phosphate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 521_655 | 290 | 917.0 | Region | Hexokinase small subdomain 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 532_536 | 290 | 917.0 | Region | Glucose-6-phosphate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 603_604 | 290 | 917.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 620_621 | 290 | 917.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 656_657 | 290 | 917.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 656_895 | 290 | 917.0 | Region | Hexokinase large subdomain 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 682_683 | 290 | 917.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 861_863 | 290 | 917.0 | Region | Glucose-6-phosphate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 291_294 | 291 | 918.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 413_415 | 291 | 918.0 | Region | Glucose-6-phosphate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 521_655 | 291 | 918.0 | Region | Hexokinase small subdomain 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 532_536 | 291 | 918.0 | Region | Glucose-6-phosphate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 603_604 | 291 | 918.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 620_621 | 291 | 918.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 656_657 | 291 | 918.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 656_895 | 291 | 918.0 | Region | Hexokinase large subdomain 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 682_683 | 291 | 918.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 861_863 | 291 | 918.0 | Region | Glucose-6-phosphate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 291_294 | 279 | 906.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 413_415 | 279 | 906.0 | Region | Glucose-6-phosphate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 521_655 | 279 | 906.0 | Region | Hexokinase small subdomain 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 532_536 | 279 | 906.0 | Region | Glucose-6-phosphate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 603_604 | 279 | 906.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 620_621 | 279 | 906.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 656_657 | 279 | 906.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 656_895 | 279 | 906.0 | Region | Hexokinase large subdomain 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 682_683 | 279 | 906.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 861_863 | 279 | 906.0 | Region | Glucose-6-phosphate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 413_415 | 295 | 922.0 | Region | Glucose-6-phosphate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 521_655 | 295 | 922.0 | Region | Hexokinase small subdomain 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 532_536 | 295 | 922.0 | Region | Glucose-6-phosphate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 603_604 | 295 | 922.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 620_621 | 295 | 922.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 656_657 | 295 | 922.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 656_895 | 295 | 922.0 | Region | Hexokinase large subdomain 2 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 682_683 | 295 | 922.0 | Region | Substrate 2 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 861_863 | 295 | 922.0 | Region | Glucose-6-phosphate 2 binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 16_458 | 290 | 917.0 | Domain | Hexokinase 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 16_458 | 291 | 918.0 | Domain | Hexokinase 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 16_458 | 279 | 906.0 | Domain | Hexokinase 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 16_458 | 295 | 922.0 | Domain | Hexokinase 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 84_89 | 290 | 917.0 | Nucleotide binding | ATP 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 84_89 | 291 | 918.0 | Nucleotide binding | ATP 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 84_89 | 279 | 906.0 | Nucleotide binding | ATP 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 84_89 | 295 | 922.0 | Nucleotide binding | ATP 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 172_173 | 290 | 917.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 1_10 | 290 | 917.0 | Region | Mitochondrial-binding peptide (MBP) | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 208_209 | 290 | 917.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 208_447 | 290 | 917.0 | Region | Hexokinase large subdomain 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 73_207 | 290 | 917.0 | Region | Hexokinase small subdomain 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000298649 | 6 | 18 | 84_91 | 290 | 917.0 | Region | Glucose-6-phosphate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 172_173 | 291 | 918.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 1_10 | 291 | 918.0 | Region | Mitochondrial-binding peptide (MBP) | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 208_209 | 291 | 918.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 208_447 | 291 | 918.0 | Region | Hexokinase large subdomain 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 73_207 | 291 | 918.0 | Region | Hexokinase small subdomain 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000359426 | 6 | 18 | 84_91 | 291 | 918.0 | Region | Glucose-6-phosphate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 172_173 | 279 | 906.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 1_10 | 279 | 906.0 | Region | Mitochondrial-binding peptide (MBP) | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 208_209 | 279 | 906.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 208_447 | 279 | 906.0 | Region | Hexokinase large subdomain 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 73_207 | 279 | 906.0 | Region | Hexokinase small subdomain 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000360289 | 10 | 22 | 84_91 | 279 | 906.0 | Region | Glucose-6-phosphate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 172_173 | 295 | 922.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 1_10 | 295 | 922.0 | Region | Mitochondrial-binding peptide (MBP) | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 208_209 | 295 | 922.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 208_447 | 295 | 922.0 | Region | Hexokinase large subdomain 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 291_294 | 295 | 922.0 | Region | Substrate 1 binding | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 73_207 | 295 | 922.0 | Region | Hexokinase small subdomain 1 | |
| Tgene | HK1 | chr10:12240775 | chr10:71136690 | ENST00000404387 | 7 | 19 | 84_91 | 295 | 922.0 | Region | Glucose-6-phosphate 1 binding |
Top |
Fusion Gene Sequence for CDC123-HK1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >14764_14764_1_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000298649_length(transcript)=3049nt_BP=426nt TGCGTTTAGGGCGAAGACGGAGTTGTAAACTTCTTAAAATTCCTCTCTCGACACTTCGGTAATTCCTCTTTCGAGACTAAAGCTCTTTTT GTATGCGTGTGTGTCAAGCGTATGCCCCGGGATTCTCCTCCGCTTCCTTTTCTCGGTCTTCCTTCTTGCTTTAGGGACCGGAAGAGTCCT TGAACCAAAATAGCTCGGCGGGCACTTCCGGGGCCGGCGCCCAGAGTTCCGGGAGGGTGCAGGCAGGAGAGGGAAAGGCAGCAGCGGCGG CAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCATCAAGAGTGTCAT TCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGATGGTCAGTGGCAT GTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCCCGGAGCTGCTCAC CCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCCTGACCCGCCTGGG AGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGGTGGCTGCCACACT GGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTCTTTACAAGACGCA CCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGGAGAGTGGCAGCGG CAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTCATTTCCACCTCAC CAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACAATGCCGTGGTTAA GATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAACCAATTTCCGTGT GCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAATCATGCAGGGCAC TGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGATGCCTCTGGGCTT CACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAACAGACTGCGTGGG CCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCAACGACACAGTGGG CACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCTACATGGAGGAGAT GAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACGGGTGTCTGGATGA TATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCAGTGGTATGTACCT GGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGCTGAAGACCCGGGG CATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGCAGCTAGGTCTGAA TAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCGCAGGCATGGCTGC GGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACAAGCTTCATCCACA CTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATGGCAGCGGCAAGGG GGCCGCCCTCATCACGGCCGTGGGCGTGCGGTTACGCACAGAGGCAAGCAGCTAAGAGTCCGGGATCCCCAGCCTACTGCCTCTCCAGCA CTTCTCTCTTCAAGCGGCGACCCCCTACCCTCCCAGCGAGTTGCGCTGGGAGACGCTGGCGCCAGGGCCTGCCGGCGCGGGGAGGAAAGC AAAATCCAACTAATGGTATATATTGTAGGGTACAGAATAGAGCGTGTGCTGTTGATAATATCTCTCACCCGGATCCCTCCTCACTTGCCC TGCCACTTTGCATGGTTTGATTTTGACCTGGTCCCCCACGTGTGAAGTGTAGTGGCATCCATTTCTAATGTATGCATTCATCCAACAGAG TTATTTATTGGCTGGAGATGGAAAATCACACCACCTGACAGGCCTTCTGGGCCTCCAAAGCCCATCCTTGGGGTTCCCCCTCCCTGTGTG AAATGTATTATCACCAGCAGACACTGCCGGGCCTCCCTCCCGGGGGCACTGCCTGAAGGCGAGTGTGGGCATAGCATTAGCTGCTTCCTC CCCTCCTGGCACCCACTGTGGCCTGGCATCGCATCGTGGTGTGTCAATGCCACAAAATCGTGTGTCCGTGGAACCAGTCCTAGCCGCGTG TGACAGTCTTGCATTCTGTTTGTCTCGTGGGGGGAGGTGGACAGTCCTGCGGAAATGTGTCTTGTCTCCATTTGGATAAAAGGAACCAAC >14764_14764_1_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000298649_length(amino acids)=674AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_2_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000359426_length(transcript)=3052nt_BP=426nt TGCGTTTAGGGCGAAGACGGAGTTGTAAACTTCTTAAAATTCCTCTCTCGACACTTCGGTAATTCCTCTTTCGAGACTAAAGCTCTTTTT GTATGCGTGTGTGTCAAGCGTATGCCCCGGGATTCTCCTCCGCTTCCTTTTCTCGGTCTTCCTTCTTGCTTTAGGGACCGGAAGAGTCCT TGAACCAAAATAGCTCGGCGGGCACTTCCGGGGCCGGCGCCCAGAGTTCCGGGAGGGTGCAGGCAGGAGAGGGAAAGGCAGCAGCGGCGG CAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCATCAAGAGTGTCAT TCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGATGGTCAGTGGCAT GTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCCCGGAGCTGCTCAC CCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCCTGACCCGCCTGGG AGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGGTGGCTGCCACACT GGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTCTTTACAAGACGCA CCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGGAGAGTGGCAGCGG CAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTCATTTCCACCTCAC CAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACAATGCCGTGGTTAA GATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAACCAATTTCCGTGT GCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAATCATGCAGGGCAC TGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGATGCCTCTGGGCTT CACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAACAGACTGCGTGGG CCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCAACGACACAGTGGG CACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCTACATGGAGGAGAT GAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACGGGTGTCTGGATGA TATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCAGTGGTATGTACCT GGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGCTGAAGACCCGGGG CATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGCAGCTAGGTCTGAA TAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCGCAGGCATGGCTGC GGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACAAGCTTCATCCACA CTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATGGCAGCGGCAAGGG GGCCGCCCTCATCACGGCCGTGGGCGTGCGGTTACGCACAGAGGCAAGCAGCTAAGAGTCCGGGATCCCCAGCCTACTGCCTCTCCAGCA CTTCTCTCTTCAAGCGGCGACCCCCTACCCTCCCAGCGAGTTGCGCTGGGAGACGCTGGCGCCAGGGCCTGCCGGCGCGGGGAGGAAAGC AAAATCCAACTAATGGTATATATTGTAGGGTACAGAATAGAGCGTGTGCTGTTGATAATATCTCTCACCCGGATCCCTCCTCACTTGCCC TGCCACTTTGCATGGTTTGATTTTGACCTGGTCCCCCACGTGTGAAGTGTAGTGGCATCCATTTCTAATGTATGCATTCATCCAACAGAG TTATTTATTGGCTGGAGATGGAAAATCACACCACCTGACAGGCCTTCTGGGCCTCCAAAGCCCATCCTTGGGGTTCCCCCTCCCTGTGTG AAATGTATTATCACCAGCAGACACTGCCGGGCCTCCCTCCCGGGGGCACTGCCTGAAGGCGAGTGTGGGCATAGCATTAGCTGCTTCCTC CCCTCCTGGCACCCACTGTGGCCTGGCATCGCATCGTGGTGTGTCAATGCCACAAAATCGTGTGTCCGTGGAACCAGTCCTAGCCGCGTG TGACAGTCTTGCATTCTGTTTGTCTCGTGGGGGGAGGTGGACAGTCCTGCGGAAATGTGTCTTGTCTCCATTTGGATAAAAGGAACCAAC >14764_14764_2_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000359426_length(amino acids)=674AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_3_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000360289_length(transcript)=3049nt_BP=426nt TGCGTTTAGGGCGAAGACGGAGTTGTAAACTTCTTAAAATTCCTCTCTCGACACTTCGGTAATTCCTCTTTCGAGACTAAAGCTCTTTTT GTATGCGTGTGTGTCAAGCGTATGCCCCGGGATTCTCCTCCGCTTCCTTTTCTCGGTCTTCCTTCTTGCTTTAGGGACCGGAAGAGTCCT TGAACCAAAATAGCTCGGCGGGCACTTCCGGGGCCGGCGCCCAGAGTTCCGGGAGGGTGCAGGCAGGAGAGGGAAAGGCAGCAGCGGCGG CAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCATCAAGAGTGTCAT TCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGATGGTCAGTGGCAT GTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCCCGGAGCTGCTCAC CCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCCTGACCCGCCTGGG AGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGGTGGCTGCCACACT GGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTCTTTACAAGACGCA CCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGGAGAGTGGCAGCGG CAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTCATTTCCACCTCAC CAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACAATGCCGTGGTTAA GATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAACCAATTTCCGTGT GCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAATCATGCAGGGCAC TGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGATGCCTCTGGGCTT CACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAACAGACTGCGTGGG CCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCAACGACACAGTGGG CACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCTACATGGAGGAGAT GAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACGGGTGTCTGGATGA TATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCAGTGGTATGTACCT GGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGCTGAAGACCCGGGG CATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGCAGCTAGGTCTGAA TAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCGCAGGCATGGCTGC GGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACAAGCTTCATCCACA CTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATGGCAGCGGCAAGGG GGCCGCCCTCATCACGGCCGTGGGCGTGCGGTTACGCACAGAGGCAAGCAGCTAAGAGTCCGGGATCCCCAGCCTACTGCCTCTCCAGCA CTTCTCTCTTCAAGCGGCGACCCCCTACCCTCCCAGCGAGTTGCGCTGGGAGACGCTGGCGCCAGGGCCTGCCGGCGCGGGGAGGAAAGC AAAATCCAACTAATGGTATATATTGTAGGGTACAGAATAGAGCGTGTGCTGTTGATAATATCTCTCACCCGGATCCCTCCTCACTTGCCC TGCCACTTTGCATGGTTTGATTTTGACCTGGTCCCCCACGTGTGAAGTGTAGTGGCATCCATTTCTAATGTATGCATTCATCCAACAGAG TTATTTATTGGCTGGAGATGGAAAATCACACCACCTGACAGGCCTTCTGGGCCTCCAAAGCCCATCCTTGGGGTTCCCCCTCCCTGTGTG AAATGTATTATCACCAGCAGACACTGCCGGGCCTCCCTCCCGGGGGCACTGCCTGAAGGCGAGTGTGGGCATAGCATTAGCTGCTTCCTC CCCTCCTGGCACCCACTGTGGCCTGGCATCGCATCGTGGTGTGTCAATGCCACAAAATCGTGTGTCCGTGGAACCAGTCCTAGCCGCGTG TGACAGTCTTGCATTCTGTTTGTCTCGTGGGGGGAGGTGGACAGTCCTGCGGAAATGTGTCTTGTCTCCATTTGGATAAAAGGAACCAAC >14764_14764_3_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000360289_length(amino acids)=674AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_4_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000404387_length(transcript)=2305nt_BP=426nt TGCGTTTAGGGCGAAGACGGAGTTGTAAACTTCTTAAAATTCCTCTCTCGACACTTCGGTAATTCCTCTTTCGAGACTAAAGCTCTTTTT GTATGCGTGTGTGTCAAGCGTATGCCCCGGGATTCTCCTCCGCTTCCTTTTCTCGGTCTTCCTTCTTGCTTTAGGGACCGGAAGAGTCCT TGAACCAAAATAGCTCGGCGGGCACTTCCGGGGCCGGCGCCCAGAGTTCCGGGAGGGTGCAGGCAGGAGAGGGAAAGGCAGCAGCGGCGG CAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCATCAAGAGTGTCAT TCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGATGGTCAGTGGCAT GTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCCCGGAGCTGCTCAC CCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCCTGACCCGCCTGGG AGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGGTGGCTGCCACACT GGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTCTTTACAAGACGCA CCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGGAGAGTGGCAGCGG CAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTCATTTCCACCTCAC CAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACAATGCCGTGGTTAA GATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAACCAATTTCCGTGT GCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAATCATGCAGGGCAC TGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGATGCCTCTGGGCTT CACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAACAGACTGCGTGGG CCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCAACGACACAGTGGG CACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCTACATGGAGGAGAT GAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACGGGTGTCTGGATGA TATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCAGTGGTATGTACCT GGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGCTGAAGACCCGGGG CATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGCAGCTAGGTCTGAA TAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCGCAGGCATGGCTGC GGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACAAGCTTCATCCACA CTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATGGCAGCGGCAAGGG >14764_14764_4_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000404387_length(amino acids)=675AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_5_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000448642_length(transcript)=3049nt_BP=426nt TGCGTTTAGGGCGAAGACGGAGTTGTAAACTTCTTAAAATTCCTCTCTCGACACTTCGGTAATTCCTCTTTCGAGACTAAAGCTCTTTTT GTATGCGTGTGTGTCAAGCGTATGCCCCGGGATTCTCCTCCGCTTCCTTTTCTCGGTCTTCCTTCTTGCTTTAGGGACCGGAAGAGTCCT TGAACCAAAATAGCTCGGCGGGCACTTCCGGGGCCGGCGCCCAGAGTTCCGGGAGGGTGCAGGCAGGAGAGGGAAAGGCAGCAGCGGCGG CAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCATCAAGAGTGTCAT TCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGATGGTCAGTGGCAT GTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCCCGGAGCTGCTCAC CCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCCTGACCCGCCTGGG AGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGGTGGCTGCCACACT GGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTCTTTACAAGACGCA CCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGGAGAGTGGCAGCGG CAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTCATTTCCACCTCAC CAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACAATGCCGTGGTTAA GATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAACCAATTTCCGTGT GCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAATCATGCAGGGCAC TGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGATGCCTCTGGGCTT CACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAACAGACTGCGTGGG CCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCAACGACACAGTGGG CACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCTACATGGAGGAGAT GAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACGGGTGTCTGGATGA TATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCAGTGGTATGTACCT GGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGCTGAAGACCCGGGG CATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGCAGCTAGGTCTGAA TAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCGCAGGCATGGCTGC GGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACAAGCTTCATCCACA CTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATGGCAGCGGCAAGGG GGCCGCCCTCATCACGGCCGTGGGCGTGCGGTTACGCACAGAGGCAAGCAGCTAAGAGTCCGGGATCCCCAGCCTACTGCCTCTCCAGCA CTTCTCTCTTCAAGCGGCGACCCCCTACCCTCCCAGCGAGTTGCGCTGGGAGACGCTGGCGCCAGGGCCTGCCGGCGCGGGGAGGAAAGC AAAATCCAACTAATGGTATATATTGTAGGGTACAGAATAGAGCGTGTGCTGTTGATAATATCTCTCACCCGGATCCCTCCTCACTTGCCC TGCCACTTTGCATGGTTTGATTTTGACCTGGTCCCCCACGTGTGAAGTGTAGTGGCATCCATTTCTAATGTATGCATTCATCCAACAGAG TTATTTATTGGCTGGAGATGGAAAATCACACCACCTGACAGGCCTTCTGGGCCTCCAAAGCCCATCCTTGGGGTTCCCCCTCCCTGTGTG AAATGTATTATCACCAGCAGACACTGCCGGGCCTCCCTCCCGGGGGCACTGCCTGAAGGCGAGTGTGGGCATAGCATTAGCTGCTTCCTC CCCTCCTGGCACCCACTGTGGCCTGGCATCGCATCGTGGTGTGTCAATGCCACAAAATCGTGTGTCCGTGGAACCAGTCCTAGCCGCGTG TGACAGTCTTGCATTCTGTTTGTCTCGTGGGGGGAGGTGGACAGTCCTGCGGAAATGTGTCTTGTCTCCATTTGGATAAAAGGAACCAAC >14764_14764_5_CDC123-HK1_CDC123_chr10_12240775_ENST00000281141_HK1_chr10_71136690_ENST00000448642_length(amino acids)=674AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_6_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000298649_length(transcript)=2792nt_BP=169nt GCAGCAGCGGCGGCAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCA TCAAGAGTGTCATTCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGA TGGTCAGTGGCATGTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCC CGGAGCTGCTCACCCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCC TGACCCGCCTGGGAGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGG TGGCTGCCACACTGGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTC TTTACAAGACGCACCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGG AGAGTGGCAGCGGCAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTC ATTTCCACCTCACCAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACA ATGCCGTGGTTAAGATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAA CCAATTTCCGTGTGCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAA TCATGCAGGGCACTGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGA TGCCTCTGGGCTTCACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAA CAGACTGCGTGGGCCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCA ACGACACAGTGGGCACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCT ACATGGAGGAGATGAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACG GGTGTCTGGATGATATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCA GTGGTATGTACCTGGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGC TGAAGACCCGGGGCATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGC AGCTAGGTCTGAATAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCG CAGGCATGGCTGCGGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACA AGCTTCATCCACACTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATG GCAGCGGCAAGGGGGCCGCCCTCATCACGGCCGTGGGCGTGCGGTTACGCACAGAGGCAAGCAGCTAAGAGTCCGGGATCCCCAGCCTAC TGCCTCTCCAGCACTTCTCTCTTCAAGCGGCGACCCCCTACCCTCCCAGCGAGTTGCGCTGGGAGACGCTGGCGCCAGGGCCTGCCGGCG CGGGGAGGAAAGCAAAATCCAACTAATGGTATATATTGTAGGGTACAGAATAGAGCGTGTGCTGTTGATAATATCTCTCACCCGGATCCC TCCTCACTTGCCCTGCCACTTTGCATGGTTTGATTTTGACCTGGTCCCCCACGTGTGAAGTGTAGTGGCATCCATTTCTAATGTATGCAT TCATCCAACAGAGTTATTTATTGGCTGGAGATGGAAAATCACACCACCTGACAGGCCTTCTGGGCCTCCAAAGCCCATCCTTGGGGTTCC CCCTCCCTGTGTGAAATGTATTATCACCAGCAGACACTGCCGGGCCTCCCTCCCGGGGGCACTGCCTGAAGGCGAGTGTGGGCATAGCAT TAGCTGCTTCCTCCCCTCCTGGCACCCACTGTGGCCTGGCATCGCATCGTGGTGTGTCAATGCCACAAAATCGTGTGTCCGTGGAACCAG TCCTAGCCGCGTGTGACAGTCTTGCATTCTGTTTGTCTCGTGGGGGGAGGTGGACAGTCCTGCGGAAATGTGTCTTGTCTCCATTTGGAT AAAAGGAACCAACCAACAAACAATGCCATCACTGGAATTTCCCACCGCTTTGTGAGCCGTGTCGTATGACCTAGTAAACTTTGTACCAAT >14764_14764_6_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000298649_length(amino acids)=674AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_7_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000359426_length(transcript)=2795nt_BP=169nt GCAGCAGCGGCGGCAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCA TCAAGAGTGTCATTCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGA TGGTCAGTGGCATGTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCC CGGAGCTGCTCACCCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCC TGACCCGCCTGGGAGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGG TGGCTGCCACACTGGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTC TTTACAAGACGCACCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGG AGAGTGGCAGCGGCAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTC ATTTCCACCTCACCAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACA ATGCCGTGGTTAAGATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAA CCAATTTCCGTGTGCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAA TCATGCAGGGCACTGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGA TGCCTCTGGGCTTCACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAA CAGACTGCGTGGGCCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCA ACGACACAGTGGGCACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCT ACATGGAGGAGATGAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACG GGTGTCTGGATGATATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCA GTGGTATGTACCTGGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGC TGAAGACCCGGGGCATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGC AGCTAGGTCTGAATAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCG CAGGCATGGCTGCGGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACA AGCTTCATCCACACTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATG GCAGCGGCAAGGGGGCCGCCCTCATCACGGCCGTGGGCGTGCGGTTACGCACAGAGGCAAGCAGCTAAGAGTCCGGGATCCCCAGCCTAC TGCCTCTCCAGCACTTCTCTCTTCAAGCGGCGACCCCCTACCCTCCCAGCGAGTTGCGCTGGGAGACGCTGGCGCCAGGGCCTGCCGGCG CGGGGAGGAAAGCAAAATCCAACTAATGGTATATATTGTAGGGTACAGAATAGAGCGTGTGCTGTTGATAATATCTCTCACCCGGATCCC TCCTCACTTGCCCTGCCACTTTGCATGGTTTGATTTTGACCTGGTCCCCCACGTGTGAAGTGTAGTGGCATCCATTTCTAATGTATGCAT TCATCCAACAGAGTTATTTATTGGCTGGAGATGGAAAATCACACCACCTGACAGGCCTTCTGGGCCTCCAAAGCCCATCCTTGGGGTTCC CCCTCCCTGTGTGAAATGTATTATCACCAGCAGACACTGCCGGGCCTCCCTCCCGGGGGCACTGCCTGAAGGCGAGTGTGGGCATAGCAT TAGCTGCTTCCTCCCCTCCTGGCACCCACTGTGGCCTGGCATCGCATCGTGGTGTGTCAATGCCACAAAATCGTGTGTCCGTGGAACCAG TCCTAGCCGCGTGTGACAGTCTTGCATTCTGTTTGTCTCGTGGGGGGAGGTGGACAGTCCTGCGGAAATGTGTCTTGTCTCCATTTGGAT AAAAGGAACCAACCAACAAACAATGCCATCACTGGAATTTCCCACCGCTTTGTGAGCCGTGTCGTATGACCTAGTAAACTTTGTACCAAT >14764_14764_7_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000359426_length(amino acids)=674AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_8_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000360289_length(transcript)=2792nt_BP=169nt GCAGCAGCGGCGGCAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCA TCAAGAGTGTCATTCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGA TGGTCAGTGGCATGTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCC CGGAGCTGCTCACCCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCC TGACCCGCCTGGGAGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGG TGGCTGCCACACTGGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTC TTTACAAGACGCACCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGG AGAGTGGCAGCGGCAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTC ATTTCCACCTCACCAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACA ATGCCGTGGTTAAGATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAA CCAATTTCCGTGTGCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAA TCATGCAGGGCACTGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGA TGCCTCTGGGCTTCACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAA CAGACTGCGTGGGCCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCA ACGACACAGTGGGCACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCT ACATGGAGGAGATGAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACG GGTGTCTGGATGATATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCA GTGGTATGTACCTGGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGC TGAAGACCCGGGGCATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGC AGCTAGGTCTGAATAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCG CAGGCATGGCTGCGGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACA AGCTTCATCCACACTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATG GCAGCGGCAAGGGGGCCGCCCTCATCACGGCCGTGGGCGTGCGGTTACGCACAGAGGCAAGCAGCTAAGAGTCCGGGATCCCCAGCCTAC TGCCTCTCCAGCACTTCTCTCTTCAAGCGGCGACCCCCTACCCTCCCAGCGAGTTGCGCTGGGAGACGCTGGCGCCAGGGCCTGCCGGCG CGGGGAGGAAAGCAAAATCCAACTAATGGTATATATTGTAGGGTACAGAATAGAGCGTGTGCTGTTGATAATATCTCTCACCCGGATCCC TCCTCACTTGCCCTGCCACTTTGCATGGTTTGATTTTGACCTGGTCCCCCACGTGTGAAGTGTAGTGGCATCCATTTCTAATGTATGCAT TCATCCAACAGAGTTATTTATTGGCTGGAGATGGAAAATCACACCACCTGACAGGCCTTCTGGGCCTCCAAAGCCCATCCTTGGGGTTCC CCCTCCCTGTGTGAAATGTATTATCACCAGCAGACACTGCCGGGCCTCCCTCCCGGGGGCACTGCCTGAAGGCGAGTGTGGGCATAGCAT TAGCTGCTTCCTCCCCTCCTGGCACCCACTGTGGCCTGGCATCGCATCGTGGTGTGTCAATGCCACAAAATCGTGTGTCCGTGGAACCAG TCCTAGCCGCGTGTGACAGTCTTGCATTCTGTTTGTCTCGTGGGGGGAGGTGGACAGTCCTGCGGAAATGTGTCTTGTCTCCATTTGGAT AAAAGGAACCAACCAACAAACAATGCCATCACTGGAATTTCCCACCGCTTTGTGAGCCGTGTCGTATGACCTAGTAAACTTTGTACCAAT >14764_14764_8_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000360289_length(amino acids)=674AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_9_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000404387_length(transcript)=2048nt_BP=169nt GCAGCAGCGGCGGCAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCA TCAAGAGTGTCATTCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGA TGGTCAGTGGCATGTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCC CGGAGCTGCTCACCCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCC TGACCCGCCTGGGAGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGG TGGCTGCCACACTGGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTC TTTACAAGACGCACCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGG AGAGTGGCAGCGGCAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTC ATTTCCACCTCACCAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACA ATGCCGTGGTTAAGATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAA CCAATTTCCGTGTGCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAA TCATGCAGGGCACTGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGA TGCCTCTGGGCTTCACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAA CAGACTGCGTGGGCCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCA ACGACACAGTGGGCACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCT ACATGGAGGAGATGAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACG GGTGTCTGGATGATATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCA GTGGTATGTACCTGGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGC TGAAGACCCGGGGCATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGC AGCTAGGTCTGAATAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCG CAGGCATGGCTGCGGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACA AGCTTCATCCACACTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATG >14764_14764_9_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000404387_length(amino acids)=675AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- >14764_14764_10_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000448642_length(transcript)=2792nt_BP=169nt GCAGCAGCGGCGGCAGCTGGAGGATGAAGAAGGAGCATGTGCTTCACTGCCAGTTCTCCGCGTGGTACCCGTTCTTCCGAGGCGTTACCA TCAAGAGTGTCATTCTTCCACTTCCTCAGAATGTGAAGGATTATTTACTCGATGATGGAACTCTGGTGGTTTCAGGAAGGTTTGAGAAGA TGGTCAGTGGCATGTACTTGGGAGAGCTGGTTCGACTGATCCTAGTCAAGATGGCCAAGGAGGGCCTCTTATTTGAAGGGCGGATCACCC CGGAGCTGCTCACCCGAGGGAAGTTTAACACCAGTGATGTGTCAGCCATCGAAAAGAATAAGGAAGGCCTCCACAATGCCAAAGAAATCC TGACCCGCCTGGGAGTGGAGCCGTCCGATGATGACTGTGTCTCAGTCCAGCACGTTTGCACCATTGTCTCATTTCGCTCAGCCAACTTGG TGGCTGCCACACTGGGCGCCATCTTGAACCGCCTGCGTGATAACAAGGGCACACCCAGGCTGCGGACCACGGTTGGTGTCGACGGATCTC TTTACAAGACGCACCCACAGTATTCCCGGCGTTTCCACAAGACTCTAAGGCGCTTGGTGCCAGACTCCGATGTGCGCTTCCTCCTCTCGG AGAGTGGCAGCGGCAAGGGGGCTGCCATGGTGACGGCGGTGGCCTACCGCTTGGCCGAGCAGCACCGGCAGATAGAGGAGACCCTGGCTC ATTTCCACCTCACCAAGGACATGCTGCTGGAGGTGAAGAAGAGGATGCGGGCCGAGATGGAGCTGGGGCTGAGGAAGCAGACGCACAACA ATGCCGTGGTTAAGATGCTGCCCTCCTTCGTCCGGAGAACTCCCGACGGGACCGAGAATGGTGACTTCTTGGCCCTGGATCTTGGAGGAA CCAATTTCCGTGTGCTGCTGGTGAAAATCCGTAGTGGGAAAAAGAGAACGGTGGAAATGCACAACAAGATCTACGCCATTCCTATTGAAA TCATGCAGGGCACTGGGGAAGAGCTGTTTGATCACATTGTCTCCTGCATCTCTGACTTCTTGGACTACATGGGGATCAAAGGCCCCAGGA TGCCTCTGGGCTTCACGTTCTCATTTCCCTGCCAGCAGACGAGTCTGGACGCGGGAATCTTGATCACGTGGACAAAGGGTTTTAAGGCAA CAGACTGCGTGGGCCACGATGTAGTCACCTTACTAAGGGATGCGATAAAAAGGAGAGAGGAATTTGACCTGGACGTGGTGGCTGTGGTCA ACGACACAGTGGGCACCATGATGACCTGTGCTTATGAGGAGCCCACCTGTGAGGTTGGACTCATTGTTGGGACCGGCAGCAATGCCTGCT ACATGGAGGAGATGAAGAACGTGGAGATGGTGGAGGGGGACCAGGGGCAGATGTGCATCAACATGGAGTGGGGGGCCTTTGGGGACAACG GGTGTCTGGATGATATCAGGACACACTACGACAGACTGGTGGACGAATATTCCCTAAATGCTGGGAAACAAAGGTATGAGAAGATGATCA GTGGTATGTACCTGGGTGAAATCGTCCGCAACATCTTAATCGACTTCACCAAGAAGGGATTCCTCTTCCGAGGGCAGATCTCTGAGACGC TGAAGACCCGGGGCATCTTTGAGACCAAGTTTCTCTCTCAGATCGAGAGTGACCGATTAGCACTGCTCCAGGTCCGGGCTATCCTCCAGC AGCTAGGTCTGAATAGCACCTGCGATGACAGTATCCTCGTCAAGACAGTGTGCGGGGTGGTGTCCAGGAGGGCCGCACAGCTGTGTGGCG CAGGCATGGCTGCGGTTGTGGATAAGATCCGCGAGAACAGAGGACTGGACCGTCTGAATGTGACTGTGGGAGTGGACGGGACACTCTACA AGCTTCATCCACACTTCTCCAGAATCATGCACCAGACGGTGAAGGAACTGTCACCAAAATGTAACGTGTCCTTCCTCCTGTCTGAGGATG GCAGCGGCAAGGGGGCCGCCCTCATCACGGCCGTGGGCGTGCGGTTACGCACAGAGGCAAGCAGCTAAGAGTCCGGGATCCCCAGCCTAC TGCCTCTCCAGCACTTCTCTCTTCAAGCGGCGACCCCCTACCCTCCCAGCGAGTTGCGCTGGGAGACGCTGGCGCCAGGGCCTGCCGGCG CGGGGAGGAAAGCAAAATCCAACTAATGGTATATATTGTAGGGTACAGAATAGAGCGTGTGCTGTTGATAATATCTCTCACCCGGATCCC TCCTCACTTGCCCTGCCACTTTGCATGGTTTGATTTTGACCTGGTCCCCCACGTGTGAAGTGTAGTGGCATCCATTTCTAATGTATGCAT TCATCCAACAGAGTTATTTATTGGCTGGAGATGGAAAATCACACCACCTGACAGGCCTTCTGGGCCTCCAAAGCCCATCCTTGGGGTTCC CCCTCCCTGTGTGAAATGTATTATCACCAGCAGACACTGCCGGGCCTCCCTCCCGGGGGCACTGCCTGAAGGCGAGTGTGGGCATAGCAT TAGCTGCTTCCTCCCCTCCTGGCACCCACTGTGGCCTGGCATCGCATCGTGGTGTGTCAATGCCACAAAATCGTGTGTCCGTGGAACCAG TCCTAGCCGCGTGTGACAGTCTTGCATTCTGTTTGTCTCGTGGGGGGAGGTGGACAGTCCTGCGGAAATGTGTCTTGTCTCCATTTGGAT AAAAGGAACCAACCAACAAACAATGCCATCACTGGAATTTCCCACCGCTTTGTGAGCCGTGTCGTATGACCTAGTAAACTTTGTACCAAT >14764_14764_10_CDC123-HK1_CDC123_chr10_12240775_ENST00000378900_HK1_chr10_71136690_ENST00000448642_length(amino acids)=674AA_BP=190 MKKEHVLHCQFSAWYPFFRGVTIKSVILPLPQNVKDYLLDDGTLVVSGRFEKMVSGMYLGELVRLILVKMAKEGLLFEGRITPELLTRGK FNTSDVSAIEKNKEGLHNAKEILTRLGVEPSDDDCVSVQHVCTIVSFRSANLVAATLGAILNRLRDNKGTPRLRTTVGVDGSLYKTHPQY SRRFHKTLRRLVPDSDVRFLLSESGSGKGAAMVTAVAYRLAEQHRQIEETLAHFHLTKDMLLEVKKRMRAEMELGLRKQTHNNAVVKMLP SFVRRTPDGTENGDFLALDLGGTNFRVLLVKIRSGKKRTVEMHNKIYAIPIEIMQGTGEELFDHIVSCISDFLDYMGIKGPRMPLGFTFS FPCQQTSLDAGILITWTKGFKATDCVGHDVVTLLRDAIKRREEFDLDVVAVVNDTVGTMMTCAYEEPTCEVGLIVGTGSNACYMEEMKNV EMVEGDQGQMCINMEWGAFGDNGCLDDIRTHYDRLVDEYSLNAGKQRYEKMISGMYLGEIVRNILIDFTKKGFLFRGQISETLKTRGIFE TKFLSQIESDRLALLQVRAILQQLGLNSTCDDSILVKTVCGVVSRRAAQLCGAGMAAVVDKIRENRGLDRLNVTVGVDGTLYKLHPHFSR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CDC123-HK1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CDC123-HK1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CDC123-HK1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies