
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CDC42-CAPZB (FusionGDB2 ID:14867) |
Fusion Gene Summary for CDC42-CAPZB |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CDC42-CAPZB | Fusion gene ID: 14867 | Hgene | Tgene | Gene symbol | CDC42 | CAPZB | Gene ID | 998 | 832 |
| Gene name | cell division cycle 42 | capping actin protein of muscle Z-line subunit beta | |
| Synonyms | CDC42Hs|G25K|TKS | CAPB|CAPPB|CAPZ | |
| Cytomap | 1p36.12 | 1p36.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cell division control protein 42 homologG25K GTP-binding proteinGTP binding protein, 25kDadJ224A6.1.1 (cell division cycle 42 (GTP-binding protein, 25kD))dJ224A6.1.2 (cell division cycle 42 (GTP-binding protein, 25kD))growth-regulating proteinsmall | F-actin-capping protein subunit betacapZ betacapping actin protein of muscle Z-line beta subunitcapping protein (actin filament) muscle Z-line, betaepididymis secretory sperm binding protein | |
| Modification date | 20200327 | 20200320 | |
| UniProtAcc | . | P47756 | |
| Ensembl transtripts involved in fusion gene | ENST00000498236, ENST00000315554, ENST00000344548, ENST00000400259, ENST00000421089, | ENST00000264202, ENST00000264203, ENST00000375142, ENST00000401084, ENST00000433834, ENST00000375144, ENST00000482808, | |
| Fusion gene scores | * DoF score | 12 X 9 X 6=648 | 23 X 15 X 8=2760 |
| # samples | 13 | 27 | |
| ** MAII score | log2(13/648*10)=-2.31748218985617 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(27/2760*10)=-3.3536369546147 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CDC42 [Title/Abstract] AND CAPZB [Title/Abstract] AND fusion [Title/Abstract] | ||
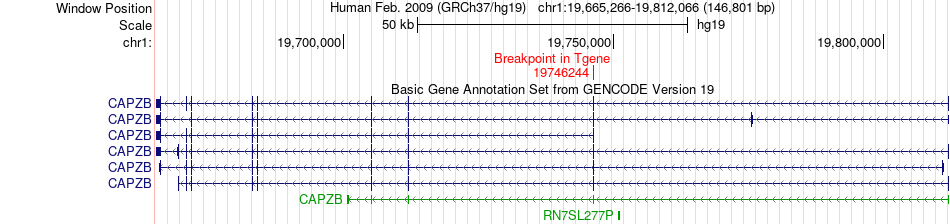
| Most frequent breakpoint | CDC42(22413359)-CAPZB(19746244), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CDC42 | GO:0030036 | actin cytoskeleton organization | 11035016 |
| Hgene | CDC42 | GO:0031274 | positive regulation of pseudopodium assembly | 11035016 |
| Hgene | CDC42 | GO:0051489 | regulation of filopodium assembly | 14978216 |
| Hgene | CDC42 | GO:1900026 | positive regulation of substrate adhesion-dependent cell spreading | 11807099 |
| Fusion gene breakpoints across CDC42 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CAPZB (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-RD-A7BT | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
Top |
Fusion Gene ORF analysis for CDC42-CAPZB |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000498236 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 3UTR-3CDS | ENST00000498236 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 3UTR-3CDS | ENST00000498236 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 3UTR-3CDS | ENST00000498236 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 3UTR-3CDS | ENST00000498236 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 3UTR-5UTR | ENST00000498236 | ENST00000375144 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 3UTR-5UTR | ENST00000498236 | ENST00000482808 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000315554 | ENST00000375144 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000315554 | ENST00000482808 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000344548 | ENST00000375144 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000344548 | ENST00000482808 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000400259 | ENST00000375144 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000400259 | ENST00000482808 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000421089 | ENST00000375144 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000421089 | ENST00000482808 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000315554 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000315554 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000315554 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000315554 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000315554 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000344548 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000344548 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000344548 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000344548 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000344548 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000400259 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000400259 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000400259 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000400259 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000400259 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000421089 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000421089 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000421089 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000421089 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000421089 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000400259 | CDC42 | chr1 | 22413359 | + | ENST00000401084 | CAPZB | chr1 | 19746244 | - | 2225 | 652 | 166 | 1467 | 433 |
| ENST00000400259 | CDC42 | chr1 | 22413359 | + | ENST00000264203 | CAPZB | chr1 | 19746244 | - | 2145 | 652 | 166 | 1353 | 395 |
| ENST00000400259 | CDC42 | chr1 | 22413359 | + | ENST00000375142 | CAPZB | chr1 | 19746244 | - | 2288 | 652 | 166 | 1482 | 438 |
| ENST00000400259 | CDC42 | chr1 | 22413359 | + | ENST00000433834 | CAPZB | chr1 | 19746244 | - | 1639 | 652 | 166 | 1467 | 433 |
| ENST00000400259 | CDC42 | chr1 | 22413359 | + | ENST00000264202 | CAPZB | chr1 | 19746244 | - | 1483 | 652 | 166 | 1482 | 439 |
| ENST00000344548 | CDC42 | chr1 | 22413359 | + | ENST00000401084 | CAPZB | chr1 | 19746244 | - | 2310 | 737 | 251 | 1552 | 433 |
| ENST00000344548 | CDC42 | chr1 | 22413359 | + | ENST00000264203 | CAPZB | chr1 | 19746244 | - | 2230 | 737 | 251 | 1438 | 395 |
| ENST00000344548 | CDC42 | chr1 | 22413359 | + | ENST00000375142 | CAPZB | chr1 | 19746244 | - | 2373 | 737 | 251 | 1567 | 438 |
| ENST00000344548 | CDC42 | chr1 | 22413359 | + | ENST00000433834 | CAPZB | chr1 | 19746244 | - | 1724 | 737 | 251 | 1552 | 433 |
| ENST00000344548 | CDC42 | chr1 | 22413359 | + | ENST00000264202 | CAPZB | chr1 | 19746244 | - | 1568 | 737 | 251 | 1567 | 439 |
| ENST00000315554 | CDC42 | chr1 | 22413359 | + | ENST00000401084 | CAPZB | chr1 | 19746244 | - | 2163 | 590 | 104 | 1405 | 433 |
| ENST00000315554 | CDC42 | chr1 | 22413359 | + | ENST00000264203 | CAPZB | chr1 | 19746244 | - | 2083 | 590 | 104 | 1291 | 395 |
| ENST00000315554 | CDC42 | chr1 | 22413359 | + | ENST00000375142 | CAPZB | chr1 | 19746244 | - | 2226 | 590 | 104 | 1420 | 438 |
| ENST00000315554 | CDC42 | chr1 | 22413359 | + | ENST00000433834 | CAPZB | chr1 | 19746244 | - | 1577 | 590 | 104 | 1405 | 433 |
| ENST00000315554 | CDC42 | chr1 | 22413359 | + | ENST00000264202 | CAPZB | chr1 | 19746244 | - | 1421 | 590 | 104 | 1420 | 439 |
| ENST00000421089 | CDC42 | chr1 | 22413359 | + | ENST00000401084 | CAPZB | chr1 | 19746244 | - | 2317 | 744 | 132 | 1559 | 475 |
| ENST00000421089 | CDC42 | chr1 | 22413359 | + | ENST00000264203 | CAPZB | chr1 | 19746244 | - | 2237 | 744 | 132 | 1445 | 437 |
| ENST00000421089 | CDC42 | chr1 | 22413359 | + | ENST00000375142 | CAPZB | chr1 | 19746244 | - | 2380 | 744 | 132 | 1574 | 480 |
| ENST00000421089 | CDC42 | chr1 | 22413359 | + | ENST00000433834 | CAPZB | chr1 | 19746244 | - | 1731 | 744 | 132 | 1559 | 475 |
| ENST00000421089 | CDC42 | chr1 | 22413359 | + | ENST00000264202 | CAPZB | chr1 | 19746244 | - | 1575 | 744 | 132 | 1574 | 480 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000400259 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000794048 | 0.999206 |
| ENST00000400259 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000904785 | 0.9990952 |
| ENST00000400259 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000776588 | 0.99922335 |
| ENST00000400259 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.001640278 | 0.99835974 |
| ENST00000400259 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.001261066 | 0.99873894 |
| ENST00000344548 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000983305 | 0.99901664 |
| ENST00000344548 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.001126353 | 0.99887365 |
| ENST00000344548 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.001040049 | 0.9989599 |
| ENST00000344548 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.002284661 | 0.99771535 |
| ENST00000344548 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.001864741 | 0.9981352 |
| ENST00000315554 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000785051 | 0.9992149 |
| ENST00000315554 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.00089451 | 0.9991055 |
| ENST00000315554 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000761847 | 0.99923813 |
| ENST00000315554 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.001617927 | 0.9983821 |
| ENST00000315554 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.001283996 | 0.998716 |
| ENST00000421089 | ENST00000401084 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000614082 | 0.99938595 |
| ENST00000421089 | ENST00000264203 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000645384 | 0.99935466 |
| ENST00000421089 | ENST00000375142 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.000685962 | 0.99931407 |
| ENST00000421089 | ENST00000433834 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.0011881 | 0.99881196 |
| ENST00000421089 | ENST00000264202 | CDC42 | chr1 | 22413359 | + | CAPZB | chr1 | 19746244 | - | 0.00111016 | 0.99888986 |
Top |
Fusion Genomic Features for CDC42-CAPZB |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
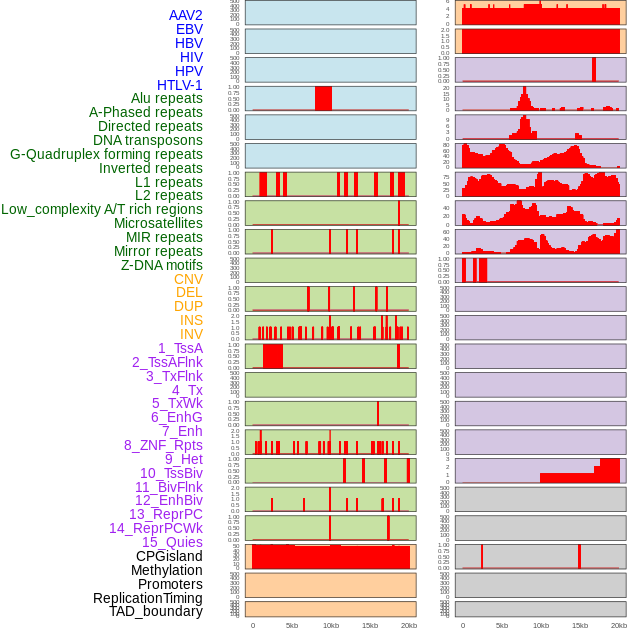 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CDC42-CAPZB |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:22413359/chr1:19746244) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CAPZB |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: F-actin-capping proteins bind in a Ca(2+)-independent manner to the fast growing ends of actin filaments (barbed end) thereby blocking the exchange of subunits at these ends. Unlike other capping proteins (such as gelsolin and severin), these proteins do not sever actin filaments. Plays a role in the regulation of cell morphology and cytoskeletal organization. {ECO:0000269|PubMed:21834987}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000315554 | + | 5 | 6 | 32_40 | 162 | 192.0 | Motif | Effector region |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000344548 | + | 6 | 7 | 32_40 | 162 | 192.0 | Motif | Effector region |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000400259 | + | 5 | 6 | 32_40 | 162 | 192.0 | Motif | Effector region |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000315554 | + | 5 | 6 | 10_17 | 162 | 192.0 | Nucleotide binding | Note=GTP |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000315554 | + | 5 | 6 | 115_118 | 162 | 192.0 | Nucleotide binding | Note=GTP |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000315554 | + | 5 | 6 | 57_61 | 162 | 192.0 | Nucleotide binding | GTP |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000344548 | + | 6 | 7 | 10_17 | 162 | 192.0 | Nucleotide binding | Note=GTP |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000344548 | + | 6 | 7 | 115_118 | 162 | 192.0 | Nucleotide binding | Note=GTP |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000344548 | + | 6 | 7 | 57_61 | 162 | 192.0 | Nucleotide binding | GTP |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000400259 | + | 5 | 6 | 10_17 | 162 | 192.0 | Nucleotide binding | Note=GTP |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000400259 | + | 5 | 6 | 115_118 | 162 | 192.0 | Nucleotide binding | Note=GTP |
| Hgene | CDC42 | chr1:22413359 | chr1:19746244 | ENST00000400259 | + | 5 | 6 | 57_61 | 162 | 192.0 | Nucleotide binding | GTP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for CDC42-CAPZB |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >14867_14867_1_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000264202_length(transcript)=1421nt_BP=590nt GGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACA AAACTATTTCAGCAATGCAGACAATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAA ACAAATTTCCATCGGAATATGTACCGACTGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTT TTGATACTGCAGGGCAAGAGGATTATGACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCT CTCCATCTTCATTTGAAAACGTGAAAGAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTC AAATTGATCTCAGAGATGACCCCTCTACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGG CCCGTGACCTGAAGGCTGTCAAGTATGTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGC GCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCA GAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGT >14867_14867_1_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000264202_length(amino acids)=439AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_2_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000264203_length(transcript)=2083nt_BP=590nt GGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACA AAACTATTTCAGCAATGCAGACAATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAA ACAAATTTCCATCGGAATATGTACCGACTGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTT TTGATACTGCAGGGCAAGAGGATTATGACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCT CTCCATCTTCATTTGAAAACGTGAAAGAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTC AAATTGATCTCAGAGATGACCCCTCTACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGG CCCGTGACCTGAAGGCTGTCAAGTATGTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGC GCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGTCTGTGCAGACTTTTGCA GACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCA GACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAA CAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACA CCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTA TAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATG AACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGG ACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGG GGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGT TTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAAGAAA >14867_14867_2_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000264203_length(amino acids)=395AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_3_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000375142_length(transcript)=2226nt_BP=590nt GGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACA AAACTATTTCAGCAATGCAGACAATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAA ACAAATTTCCATCGGAATATGTACCGACTGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTT TTGATACTGCAGGGCAAGAGGATTATGACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCT CTCCATCTTCATTTGAAAACGTGAAAGAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTC AAATTGATCTCAGAGATGACCCCTCTACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGG CCCGTGACCTGAAGGCTGTCAAGTATGTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGC GCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCA GAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGT TTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAAGCCGATCCAGGTCTGTGCA GACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTC ATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACA GGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGC TTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTC CCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAA AAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGG GGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGT GGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGT >14867_14867_3_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000375142_length(amino acids)=438AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_4_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000401084_length(transcript)=2163nt_BP=590nt GGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACA AAACTATTTCAGCAATGCAGACAATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAA ACAAATTTCCATCGGAATATGTACCGACTGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTT TTGATACTGCAGGGCAAGAGGATTATGACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCT CTCCATCTTCATTTGAAAACGTGAAAGAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTC AAATTGATCTCAGAGATGACCCCTCTACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGG CCCGTGACCTGAAGGCTGTCAAGTATGTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGC GCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCA GAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAAC AAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCA CTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATT GACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGT TCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATC CACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGT GTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCT CTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCG ACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGC TTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAAGAAACTGGGGCGCAGTT >14867_14867_4_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000401084_length(amino acids)=433AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_5_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000433834_length(transcript)=1577nt_BP=590nt GGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACA AAACTATTTCAGCAATGCAGACAATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAA ACAAATTTCCATCGGAATATGTACCGACTGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTT TTGATACTGCAGGGCAAGAGGATTATGACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCT CTCCATCTTCATTTGAAAACGTGAAAGAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTC AAATTGATCTCAGAGATGACCCCTCTACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGG CCCGTGACCTGAAGGCTGTCAAGTATGTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGC GCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCA GAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAAC AAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCA CTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATT >14867_14867_5_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000315554_CAPZB_chr1_19746244_ENST00000433834_length(amino acids)=433AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_6_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000264202_length(transcript)=1568nt_BP=737nt GTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGACGGAGTCTCACTGT GTTGCCCAGGCTGGAGTGCAGTGGCGCCATCTTGGCTCACTGCAGTGCGCCTCTGCCCCCCGAGTTCAAGCGATTCTCCTGCCTCAGGCT CCTGAGTAGCTGGGACTACAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAAGTGTG TTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGACTGTTT TTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGACAGAT TACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGAAAAGT GGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTACTATTG AGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGTGGAGT GTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCA GCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGG GAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATG GGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCG TCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAG GCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGT GGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACT GCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAA CAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGC >14867_14867_6_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000264202_length(amino acids)=439AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_7_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000264203_length(transcript)=2230nt_BP=737nt GTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGACGGAGTCTCACTGT GTTGCCCAGGCTGGAGTGCAGTGGCGCCATCTTGGCTCACTGCAGTGCGCCTCTGCCCCCCGAGTTCAAGCGATTCTCCTGCCTCAGGCT CCTGAGTAGCTGGGACTACAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAAGTGTG TTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGACTGTTT TTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGACAGAT TACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGAAAAGT GGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTACTATTG AGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGTGGAGT GTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCA GCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGG GAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATG GGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCG TCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAG GCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGT GGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACT GCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGAC CTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTA GAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCT CCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGA GACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCT TCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAA ACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCT CGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCC AGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATC >14867_14867_7_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000264203_length(amino acids)=395AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_8_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000375142_length(transcript)=2373nt_BP=737nt GTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGACGGAGTCTCACTGT GTTGCCCAGGCTGGAGTGCAGTGGCGCCATCTTGGCTCACTGCAGTGCGCCTCTGCCCCCCGAGTTCAAGCGATTCTCCTGCCTCAGGCT CCTGAGTAGCTGGGACTACAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAAGTGTG TTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGACTGTTT TTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGACAGAT TACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGAAAAGT GGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTACTATTG AGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGTGGAGT GTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCA GCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGG GAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATG GGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCG TCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAG GCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGT GGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACT GCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAA CAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGC TGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAAGCCGATCCAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCT GAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGAT TCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAG CGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACA TTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGC CAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGA GAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAG AGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGC TCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAA >14867_14867_8_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000375142_length(amino acids)=438AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_9_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000401084_length(transcript)=2310nt_BP=737nt GTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGACGGAGTCTCACTGT GTTGCCCAGGCTGGAGTGCAGTGGCGCCATCTTGGCTCACTGCAGTGCGCCTCTGCCCCCCGAGTTCAAGCGATTCTCCTGCCTCAGGCT CCTGAGTAGCTGGGACTACAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAAGTGTG TTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGACTGTTT TTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGACAGAT TACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGAAAAGT GGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTACTATTG AGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGTGGAGT GTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCA GCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGG GAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATG GGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCG TCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAG GCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGT GGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACT GCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAA CAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTT TGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTT CTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAA GCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTT TTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTT TTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTA TTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTG CGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTG TCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCC >14867_14867_9_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000401084_length(amino acids)=433AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_10_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000433834_length(transcript)=1724nt_BP=737nt GTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGACGGAGTCTCACTGT GTTGCCCAGGCTGGAGTGCAGTGGCGCCATCTTGGCTCACTGCAGTGCGCCTCTGCCCCCCGAGTTCAAGCGATTCTCCTGCCTCAGGCT CCTGAGTAGCTGGGACTACAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAAGTGTG TTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGACTGTTT TTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGACAGAT TACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGAAAAGT GGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTACTATTG AGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGTGGAGT GTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCA GCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGG GAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATG GGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCG TCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAG GCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGT GGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACT GCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAA CAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTT TGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTT CTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAA >14867_14867_10_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000344548_CAPZB_chr1_19746244_ENST00000433834_length(amino acids)=433AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_11_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000264202_length(transcript)=1483nt_BP=652nt ACTTCCGCGGGCACCCAACTGTGCGTCTCCTGCGCGCTGACGTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCT GCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAA GTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGAC TGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGA CAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGA AAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTAC TATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGT GGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAA CCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGT GGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGA GGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGG TGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGAT CAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGAT GCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAG TGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGG AAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCA >14867_14867_11_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000264202_length(amino acids)=439AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_12_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000264203_length(transcript)=2145nt_BP=652nt ACTTCCGCGGGCACCCAACTGTGCGTCTCCTGCGCGCTGACGTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCT GCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAA GTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGAC TGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGA CAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGA AAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTAC TATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGT GGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAA CCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGT GGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGA GGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGG TGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGAT CAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGAT GCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAG TGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGA ATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTT TCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCA TCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCC ATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCC TCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAA GAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTG GCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTC CGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCT >14867_14867_12_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000264203_length(amino acids)=395AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_13_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000375142_length(transcript)=2288nt_BP=652nt ACTTCCGCGGGCACCCAACTGTGCGTCTCCTGCGCGCTGACGTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCT GCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAA GTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGAC TGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGA CAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGA AAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTAC TATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGT GGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAA CCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGT GGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGA GGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGG TGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGAT CAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGAT GCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAG TGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGG AAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCA AGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAAGCCGATCCAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAA GCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGT TAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCG CACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCT CCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTG TCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTG AAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGG AGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGT TCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAG >14867_14867_13_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000375142_length(amino acids)=438AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_14_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000401084_length(transcript)=2225nt_BP=652nt ACTTCCGCGGGCACCCAACTGTGCGTCTCCTGCGCGCTGACGTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCT GCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAA GTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGAC TGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGA CAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGA AAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTAC TATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGT GGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAA CCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGT GGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGA GGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGG TGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGAT CAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGAT GCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAG TGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGG AAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGA GGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTC GTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGA ATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGT GGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCC ACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAA TCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCG TCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTT TTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTT >14867_14867_14_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000401084_length(amino acids)=433AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_15_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000433834_length(transcript)=1639nt_BP=652nt ACTTCCGCGGGCACCCAACTGTGCGTCTCCTGCGCGCTGACGTCAGGTGCGTGCCCCTGTCCGGCAGCCGAGGAGACCCCGCGCAGTGCT GCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGACAATTAA GTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGTACCGAC TGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTATGA CAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAAGA AAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCTAC TATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTATGT GGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAA CCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGT GGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGA GGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGG TGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGAT CAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGAT GCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAG TGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGG AAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGA GGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTC GTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGA >14867_14867_15_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000400259_CAPZB_chr1_19746244_ENST00000433834_length(amino acids)=433AA_BP=161 MQTIKCVVVGDGAVGKTCLLISYTTNKFPSEYVPTVFDNYAVTVMIGGEPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSF ENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPITPETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQ QIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRD LYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEK -------------------------------------------------------------- >14867_14867_16_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000264202_length(transcript)=1575nt_BP=744nt AGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGAC AATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGT ACCGACTATCTTGACTTCTCATGGGTAAATTATATACACTTTAAACAGCTGAAAAATCAGTGGAAAGTCAGAAGGGGTGACACAGGGTTT GCAAGAAGTGCTGGGAGGCAAAACTCCAGTAGACAAGATTCTAACGAGTGGTGGTCTCAATTTGGTGAAGTATGCCCTACATCTTGGAAT GAGGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTAT GACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAA GAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCT ACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTAT GTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAA AACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAG GTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTG GAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAA GGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAG ATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTG ATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTG AGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTT GGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCT >14867_14867_16_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000264202_length(amino acids)=480AA_BP=203 MSPDILHNKQISIGICTDYLDFSWVNYIHFKQLKNQWKVRRGDTGFARSAGRQNSSRQDSNEWWSQFGEVCPTSWNEVFDNYAVTVMIGG EPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSFENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPIT PETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRD GDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQ EKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSID -------------------------------------------------------------- >14867_14867_17_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000264203_length(transcript)=2237nt_BP=744nt AGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGAC AATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGT ACCGACTATCTTGACTTCTCATGGGTAAATTATATACACTTTAAACAGCTGAAAAATCAGTGGAAAGTCAGAAGGGGTGACACAGGGTTT GCAAGAAGTGCTGGGAGGCAAAACTCCAGTAGACAAGATTCTAACGAGTGGTGGTCTCAATTTGGTGAAGTATGCCCTACATCTTGGAAT GAGGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTAT GACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAA GAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCT ACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTAT GTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAA AACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAG GTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTG GAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAA GGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAG ATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTG ATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTG AGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAA GAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCC TTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGC CATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTT CCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAG CCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAG AAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGG TGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCT TCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAAT >14867_14867_17_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000264203_length(amino acids)=437AA_BP=203 MSPDILHNKQISIGICTDYLDFSWVNYIHFKQLKNQWKVRRGDTGFARSAGRQNSSRQDSNEWWSQFGEVCPTSWNEVFDNYAVTVMIGG EPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSFENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPIT PETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRD GDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQ -------------------------------------------------------------- >14867_14867_18_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000375142_length(transcript)=2380nt_BP=744nt AGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGAC AATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGT ACCGACTATCTTGACTTCTCATGGGTAAATTATATACACTTTAAACAGCTGAAAAATCAGTGGAAAGTCAGAAGGGGTGACACAGGGTTT GCAAGAAGTGCTGGGAGGCAAAACTCCAGTAGACAAGATTCTAACGAGTGGTGGTCTCAATTTGGTGAAGTATGCCCTACATCTTGGAAT GAGGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTAT GACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAA GAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCT ACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTAT GTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAA AACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAG GTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTG GAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAA GGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAG ATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTG ATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTG AGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTT GGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCT CAAGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAAGCCGATCCAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAG AAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTC GTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGAC CGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCT CTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCAC TGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTG TGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTG GGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACC GTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTA >14867_14867_18_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000375142_length(amino acids)=480AA_BP=203 MSPDILHNKQISIGICTDYLDFSWVNYIHFKQLKNQWKVRRGDTGFARSAGRQNSSRQDSNEWWSQFGEVCPTSWNEVFDNYAVTVMIGG EPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSFENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPIT PETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRD GDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQ EKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSID -------------------------------------------------------------- >14867_14867_19_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000401084_length(transcript)=2317nt_BP=744nt AGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGAC AATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGT ACCGACTATCTTGACTTCTCATGGGTAAATTATATACACTTTAAACAGCTGAAAAATCAGTGGAAAGTCAGAAGGGGTGACACAGGGTTT GCAAGAAGTGCTGGGAGGCAAAACTCCAGTAGACAAGATTCTAACGAGTGGTGGTCTCAATTTGGTGAAGTATGCCCTACATCTTGGAAT GAGGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTAT GACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAA GAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCT ACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTAT GTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAA AACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAG GTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTG GAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAA GGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAG ATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTG ATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTG AGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTT GGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTG GAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAAC TCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGA GAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGT GTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTC CCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGA AATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGC CGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGC TTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATAC >14867_14867_19_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000401084_length(amino acids)=475AA_BP=203 MSPDILHNKQISIGICTDYLDFSWVNYIHFKQLKNQWKVRRGDTGFARSAGRQNSSRQDSNEWWSQFGEVCPTSWNEVFDNYAVTVMIGG EPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSFENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPIT PETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRD GDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQ EKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQ -------------------------------------------------------------- >14867_14867_20_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000433834_length(transcript)=1731nt_BP=744nt AGTGCTGCCAACGCCCCGGTGGAGAAGCTGAGGTCATCATCAGATTTGAAATATTTAAAGTGGATACAAAACTATTTCAGCAATGCAGAC AATTAAGTGTGTTGTTGTGGGCGATGGTGCTGTTGGTAAAACATGTCTCCTGATATCCTACACAACAAACAAATTTCCATCGGAATATGT ACCGACTATCTTGACTTCTCATGGGTAAATTATATACACTTTAAACAGCTGAAAAATCAGTGGAAAGTCAGAAGGGGTGACACAGGGTTT GCAAGAAGTGCTGGGAGGCAAAACTCCAGTAGACAAGATTCTAACGAGTGGTGGTCTCAATTTGGTGAAGTATGCCCTACATCTTGGAAT GAGGTTTTTGACAACTATGCAGTCACAGTTATGATTGGTGGAGAACCATATACTCTTGGACTTTTTGATACTGCAGGGCAAGAGGATTAT GACAGATTACGACCGCTGAGTTATCCACAAACAGATGTATTTCTAGTCTGTTTTTCAGTGGTCTCTCCATCTTCATTTGAAAACGTGAAA GAAAAGTGGGTGCCTGAGATAACTCACCACTGTCCAAAGACTCCTTTCTTGCTTGTTGGGACTCAAATTGATCTCAGAGATGACCCCTCT ACTATTGAGAAACTTGCCAAGAACAAACAGAAGCCTATCACTCCAGAGACTGCTGAAAAGCTGGCCCGTGACCTGAAGGCTGTCAAGTAT GTGGAGTGTTCTGCACTTACACAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAA AACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAG GTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTG GAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAA GGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAG ATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTG ATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTG AGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTT GGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTG GAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAAC TCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGA >14867_14867_20_CDC42-CAPZB_CDC42_chr1_22413359_ENST00000421089_CAPZB_chr1_19746244_ENST00000433834_length(amino acids)=475AA_BP=203 MSPDILHNKQISIGICTDYLDFSWVNYIHFKQLKNQWKVRRGDTGFARSAGRQNSSRQDSNEWWSQFGEVCPTSWNEVFDNYAVTVMIGG EPYTLGLFDTAGQEDYDRLRPLSYPQTDVFLVCFSVVSPSSFENVKEKWVPEITHHCPKTPFLLVGTQIDLRDDPSTIEKLAKNKQKPIT PETAEKLARDLKAVKYVECSALTQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRD GDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQ EKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CDC42-CAPZB |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CDC42-CAPZB |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CDC42-CAPZB |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies