
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CDK1-NRG1 (FusionGDB2 ID:15227) |
Fusion Gene Summary for CDK1-NRG1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CDK1-NRG1 | Fusion gene ID: 15227 | Hgene | Tgene | Gene symbol | CDK1 | NRG1 | Gene ID | 983 | 3084 |
| Gene name | cyclin dependent kinase 1 | neuregulin 1 | |
| Synonyms | CDC2|CDC28A|P34CDC2 | ARIA|GGF|GGF2|HGL|HRG|HRG1|HRGA|MST131|MSTP131|NDF|NRG1-IT2|SMDF | |
| Cytomap | 10q21.2 | 8p12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cyclin-dependent kinase 1cell cycle controller CDC2cell division control protein 2 homologcell division cycle 2, G1 to S and G2 to Mcell division protein kinase 1p34 protein kinase | pro-neuregulin-1, membrane-bound isoformacetylcholine receptor-inducing activityglial growth factor 2heregulin, alpha (45kD, ERBB2 p185-activator)neu differentiation factorpro-NRG1sensory and motor neuron derived factor | |
| Modification date | 20200327 | 20200320 | |
| UniProtAcc | P06493 | Q02297 | |
| Ensembl transtripts involved in fusion gene | ENST00000519760, ENST00000316629, ENST00000373809, ENST00000395284, ENST00000448257, | ENST00000287842, ENST00000287845, ENST00000338921, ENST00000341377, ENST00000356819, ENST00000405005, ENST00000519301, ENST00000520407, ENST00000520502, ENST00000521670, ENST00000523079, ENST00000539990, ENST00000523681, | |
| Fusion gene scores | * DoF score | 5 X 5 X 3=75 | 25 X 17 X 14=5950 |
| # samples | 5 | 27 | |
| ** MAII score | log2(5/75*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(27/5950*10)=-4.46185835603184 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CDK1 [Title/Abstract] AND NRG1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CDK1(62539960)-NRG1(32585467), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CDK1 | GO:0006468 | protein phosphorylation | 23509069|23574715 |
| Hgene | CDK1 | GO:0018105 | peptidyl-serine phosphorylation | 11298763|19879842 |
| Hgene | CDK1 | GO:0018107 | peptidyl-threonine phosphorylation | 11298763 |
| Hgene | CDK1 | GO:0034501 | protein localization to kinetochore | 18195732 |
| Hgene | CDK1 | GO:0043066 | negative regulation of apoptotic process | 11069302 |
| Tgene | NRG1 | GO:0003222 | ventricular trabecula myocardium morphogenesis | 17336907 |
| Tgene | NRG1 | GO:0031334 | positive regulation of protein complex assembly | 10559227 |
| Tgene | NRG1 | GO:0038127 | ERBB signaling pathway | 11389077 |
| Tgene | NRG1 | GO:0038129 | ERBB3 signaling pathway | 27353365 |
| Tgene | NRG1 | GO:0045892 | negative regulation of transcription, DNA-templated | 15073182 |
| Tgene | NRG1 | GO:0051048 | negative regulation of secretion | 10559227 |
| Tgene | NRG1 | GO:0060379 | cardiac muscle cell myoblast differentiation | 17336907 |
| Tgene | NRG1 | GO:0060956 | endocardial cell differentiation | 17336907 |
| Fusion gene breakpoints across CDK1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NRG1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
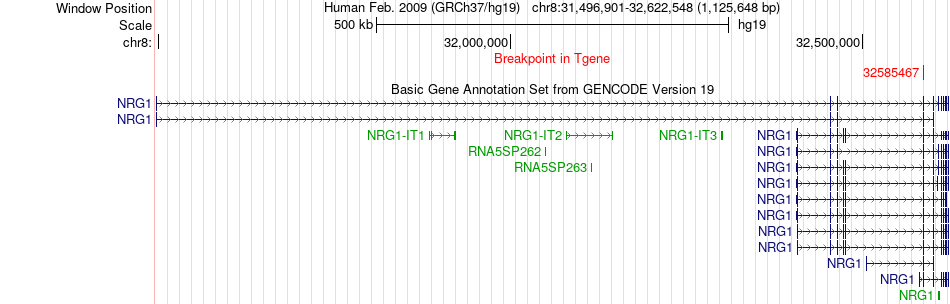 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-FD-A5BR-01A | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
Top |
Fusion Gene ORF analysis for CDK1-NRG1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000519760 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-3CDS | ENST00000519760 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 3UTR-intron | ENST00000519760 | ENST00000523681 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 5CDS-intron | ENST00000316629 | ENST00000523681 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 5CDS-intron | ENST00000373809 | ENST00000523681 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 5CDS-intron | ENST00000395284 | ENST00000523681 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| 5CDS-intron | ENST00000448257 | ENST00000523681 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000316629 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000373809 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000395284 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000448257 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000519301 | NRG1 | chr8 | 32585467 | + | 1618 | 179 | 142 | 1614 | 490 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000520407 | NRG1 | chr8 | 32585467 | + | 859 | 179 | 12 | 320 | 102 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000523079 | NRG1 | chr8 | 32585467 | + | 1519 | 179 | 142 | 939 | 265 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000338921 | NRG1 | chr8 | 32585467 | + | 2252 | 179 | 142 | 1623 | 493 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000356819 | NRG1 | chr8 | 32585467 | + | 2243 | 179 | 142 | 1614 | 490 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000287845 | NRG1 | chr8 | 32585467 | + | 2243 | 179 | 142 | 1614 | 490 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000341377 | NRG1 | chr8 | 32585467 | + | 2287 | 179 | 420 | 1658 | 412 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000287842 | NRG1 | chr8 | 32585467 | + | 1700 | 179 | 142 | 1590 | 482 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000521670 | NRG1 | chr8 | 32585467 | + | 1338 | 179 | 142 | 1065 | 307 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000405005 | NRG1 | chr8 | 32585467 | + | 1669 | 179 | 142 | 1599 | 485 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000520502 | NRG1 | chr8 | 32585467 | + | 842 | 179 | 12 | 320 | 102 |
| ENST00000316629 | CDK1 | chr10 | 62539960 | - | ENST00000539990 | NRG1 | chr8 | 32585467 | + | 1697 | 179 | 142 | 1590 | 482 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000519301 | NRG1 | chr8 | 32585467 | + | 1618 | 179 | 142 | 1614 | 490 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000520407 | NRG1 | chr8 | 32585467 | + | 859 | 179 | 12 | 320 | 102 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000523079 | NRG1 | chr8 | 32585467 | + | 1519 | 179 | 142 | 939 | 265 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000338921 | NRG1 | chr8 | 32585467 | + | 2252 | 179 | 142 | 1623 | 493 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000356819 | NRG1 | chr8 | 32585467 | + | 2243 | 179 | 142 | 1614 | 490 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000287845 | NRG1 | chr8 | 32585467 | + | 2243 | 179 | 142 | 1614 | 490 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000341377 | NRG1 | chr8 | 32585467 | + | 2287 | 179 | 420 | 1658 | 412 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000287842 | NRG1 | chr8 | 32585467 | + | 1700 | 179 | 142 | 1590 | 482 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000521670 | NRG1 | chr8 | 32585467 | + | 1338 | 179 | 142 | 1065 | 307 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000405005 | NRG1 | chr8 | 32585467 | + | 1669 | 179 | 142 | 1599 | 485 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000520502 | NRG1 | chr8 | 32585467 | + | 842 | 179 | 12 | 320 | 102 |
| ENST00000395284 | CDK1 | chr10 | 62539960 | - | ENST00000539990 | NRG1 | chr8 | 32585467 | + | 1697 | 179 | 142 | 1590 | 482 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000519301 | NRG1 | chr8 | 32585467 | + | 1677 | 238 | 201 | 1673 | 490 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000520407 | NRG1 | chr8 | 32585467 | + | 918 | 238 | 201 | 461 | 86 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000523079 | NRG1 | chr8 | 32585467 | + | 1578 | 238 | 201 | 998 | 265 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000338921 | NRG1 | chr8 | 32585467 | + | 2311 | 238 | 201 | 1682 | 493 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000356819 | NRG1 | chr8 | 32585467 | + | 2302 | 238 | 201 | 1673 | 490 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000287845 | NRG1 | chr8 | 32585467 | + | 2302 | 238 | 201 | 1673 | 490 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000341377 | NRG1 | chr8 | 32585467 | + | 2346 | 238 | 479 | 1717 | 412 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000287842 | NRG1 | chr8 | 32585467 | + | 1759 | 238 | 201 | 1649 | 482 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000521670 | NRG1 | chr8 | 32585467 | + | 1397 | 238 | 201 | 1124 | 307 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000405005 | NRG1 | chr8 | 32585467 | + | 1728 | 238 | 201 | 1658 | 485 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000520502 | NRG1 | chr8 | 32585467 | + | 901 | 238 | 201 | 461 | 86 |
| ENST00000448257 | CDK1 | chr10 | 62539960 | - | ENST00000539990 | NRG1 | chr8 | 32585467 | + | 1756 | 238 | 201 | 1649 | 482 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000519301 | NRG1 | chr8 | 32585467 | + | 1489 | 50 | 13 | 1485 | 490 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000520407 | NRG1 | chr8 | 32585467 | + | 730 | 50 | 13 | 273 | 86 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000523079 | NRG1 | chr8 | 32585467 | + | 1390 | 50 | 13 | 810 | 265 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000338921 | NRG1 | chr8 | 32585467 | + | 2123 | 50 | 13 | 1494 | 493 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000356819 | NRG1 | chr8 | 32585467 | + | 2114 | 50 | 13 | 1485 | 490 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000287845 | NRG1 | chr8 | 32585467 | + | 2114 | 50 | 13 | 1485 | 490 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000341377 | NRG1 | chr8 | 32585467 | + | 2158 | 50 | 291 | 1529 | 412 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000287842 | NRG1 | chr8 | 32585467 | + | 1571 | 50 | 13 | 1461 | 482 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000521670 | NRG1 | chr8 | 32585467 | + | 1209 | 50 | 13 | 936 | 307 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000405005 | NRG1 | chr8 | 32585467 | + | 1540 | 50 | 13 | 1470 | 485 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000520502 | NRG1 | chr8 | 32585467 | + | 713 | 50 | 13 | 273 | 86 |
| ENST00000373809 | CDK1 | chr10 | 62539960 | - | ENST00000539990 | NRG1 | chr8 | 32585467 | + | 1568 | 50 | 13 | 1461 | 482 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000316629 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.00731029 | 0.99268967 |
| ENST00000316629 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.5029475 | 0.4970525 |
| ENST00000316629 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.03506162 | 0.9649384 |
| ENST00000316629 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.002767893 | 0.99723214 |
| ENST00000316629 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.001999782 | 0.9980002 |
| ENST00000316629 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.001999782 | 0.9980002 |
| ENST00000316629 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.003109179 | 0.99689084 |
| ENST00000316629 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.005697317 | 0.99430275 |
| ENST00000316629 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.042134006 | 0.95786595 |
| ENST00000316629 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.004230952 | 0.995769 |
| ENST00000316629 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.4872516 | 0.5127484 |
| ENST00000316629 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.005812686 | 0.99418736 |
| ENST00000395284 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.00731029 | 0.99268967 |
| ENST00000395284 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.5029475 | 0.4970525 |
| ENST00000395284 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.03506162 | 0.9649384 |
| ENST00000395284 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.002767893 | 0.99723214 |
| ENST00000395284 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.001999782 | 0.9980002 |
| ENST00000395284 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.001999782 | 0.9980002 |
| ENST00000395284 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.003109179 | 0.99689084 |
| ENST00000395284 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.005697317 | 0.99430275 |
| ENST00000395284 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.042134006 | 0.95786595 |
| ENST00000395284 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.004230952 | 0.995769 |
| ENST00000395284 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.4872516 | 0.5127484 |
| ENST00000395284 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.005812686 | 0.99418736 |
| ENST00000448257 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.005777123 | 0.9942228 |
| ENST00000448257 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.2983041 | 0.70169586 |
| ENST00000448257 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.023292782 | 0.9767072 |
| ENST00000448257 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.002205076 | 0.997795 |
| ENST00000448257 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.001514745 | 0.99848527 |
| ENST00000448257 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.001514745 | 0.99848527 |
| ENST00000448257 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.002355217 | 0.9976447 |
| ENST00000448257 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.004935317 | 0.9950647 |
| ENST00000448257 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.02976176 | 0.9702382 |
| ENST00000448257 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.003492407 | 0.9965076 |
| ENST00000448257 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.24362448 | 0.75637555 |
| ENST00000448257 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.004980462 | 0.99501956 |
| ENST00000373809 | ENST00000519301 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.008702557 | 0.9912975 |
| ENST00000373809 | ENST00000520407 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.47772795 | 0.52227205 |
| ENST00000373809 | ENST00000523079 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.030514734 | 0.9694853 |
| ENST00000373809 | ENST00000338921 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.002848679 | 0.9971513 |
| ENST00000373809 | ENST00000356819 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.002055594 | 0.9979444 |
| ENST00000373809 | ENST00000287845 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.002055594 | 0.9979444 |
| ENST00000373809 | ENST00000341377 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.00319545 | 0.9968046 |
| ENST00000373809 | ENST00000287842 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.006709037 | 0.9932909 |
| ENST00000373809 | ENST00000521670 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.04782211 | 0.9521779 |
| ENST00000373809 | ENST00000405005 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.004884794 | 0.99511516 |
| ENST00000373809 | ENST00000520502 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.44064942 | 0.55935055 |
| ENST00000373809 | ENST00000539990 | CDK1 | chr10 | 62539960 | - | NRG1 | chr8 | 32585467 | + | 0.006773506 | 0.99322647 |
Top |
Fusion Genomic Features for CDK1-NRG1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
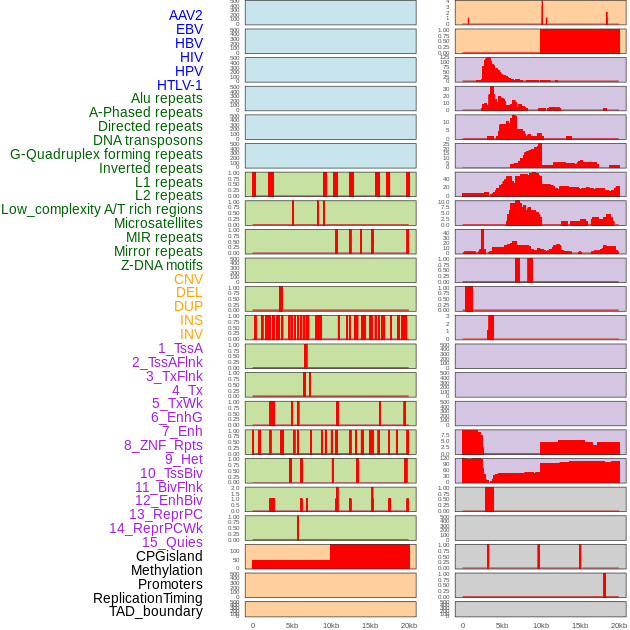 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CDK1-NRG1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:62539960/chr8:32585467) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CDK1 | NRG1 |
| FUNCTION: Plays a key role in the control of the eukaryotic cell cycle by modulating the centrosome cycle as well as mitotic onset; promotes G2-M transition, and regulates G1 progress and G1-S transition via association with multiple interphase cyclins. Required in higher cells for entry into S-phase and mitosis. Phosphorylates PARVA/actopaxin, APC, AMPH, APC, BARD1, Bcl-xL/BCL2L1, BRCA2, CALD1, CASP8, CDC7, CDC20, CDC25A, CDC25C, CC2D1A, CENPA, CSNK2 proteins/CKII, FZR1/CDH1, CDK7, CEBPB, CHAMP1, DMD/dystrophin, EEF1 proteins/EF-1, EZH2, KIF11/EG5, EGFR, FANCG, FOS, GFAP, GOLGA2/GM130, GRASP1, UBE2A/hHR6A, HIST1H1 proteins/histone H1, HMGA1, HIVEP3/KRC, LMNA, LMNB, LMNC, LBR, LATS1, MAP1B, MAP4, MARCKS, MCM2, MCM4, MKLP1, MYB, NEFH, NFIC, NPC/nuclear pore complex, PITPNM1/NIR2, NPM1, NCL, NUCKS1, NPM1/numatrin, ORC1, PRKAR2A, EEF1E1/p18, EIF3F/p47, p53/TP53, NONO/p54NRB, PAPOLA, PLEC/plectin, RB1, TPPP, UL40/R2, RAB4A, RAP1GAP, RCC1, RPS6KB1/S6K1, KHDRBS1/SAM68, ESPL1, SKI, BIRC5/survivin, STIP1, TEX14, beta-tubulins, MAPT/TAU, NEDD1, VIM/vimentin, TK1, FOXO1, RUNX1/AML1, SAMHD1, SIRT2 and RUNX2. CDK1/CDC2-cyclin-B controls pronuclear union in interphase fertilized eggs. Essential for early stages of embryonic development. During G2 and early mitosis, CDC25A/B/C-mediated dephosphorylation activates CDK1/cyclin complexes which phosphorylate several substrates that trigger at least centrosome separation, Golgi dynamics, nuclear envelope breakdown and chromosome condensation. Once chromosomes are condensed and aligned at the metaphase plate, CDK1 activity is switched off by WEE1- and PKMYT1-mediated phosphorylation to allow sister chromatid separation, chromosome decondensation, reformation of the nuclear envelope and cytokinesis. Inactivated by PKR/EIF2AK2- and WEE1-mediated phosphorylation upon DNA damage to stop cell cycle and genome replication at the G2 checkpoint thus facilitating DNA repair. Reactivated after successful DNA repair through WIP1-dependent signaling leading to CDC25A/B/C-mediated dephosphorylation and restoring cell cycle progression. In proliferating cells, CDK1-mediated FOXO1 phosphorylation at the G2-M phase represses FOXO1 interaction with 14-3-3 proteins and thereby promotes FOXO1 nuclear accumulation and transcription factor activity, leading to cell death of postmitotic neurons. The phosphorylation of beta-tubulins regulates microtubule dynamics during mitosis. NEDD1 phosphorylation promotes PLK1-mediated NEDD1 phosphorylation and subsequent targeting of the gamma-tubulin ring complex (gTuRC) to the centrosome, an important step for spindle formation. In addition, CC2D1A phosphorylation regulates CC2D1A spindle pole localization and association with SCC1/RAD21 and centriole cohesion during mitosis. The phosphorylation of Bcl-xL/BCL2L1 after prolongated G2 arrest upon DNA damage triggers apoptosis. In contrast, CASP8 phosphorylation during mitosis prevents its activation by proteolysis and subsequent apoptosis. This phosphorylation occurs in cancer cell lines, as well as in primary breast tissues and lymphocytes. EZH2 phosphorylation promotes H3K27me3 maintenance and epigenetic gene silencing. CALD1 phosphorylation promotes Schwann cell migration during peripheral nerve regeneration. CDK1-cyclin-B complex phosphorylates NCKAP5L and mediates its dissociation from centrosomes during mitosis (PubMed:26549230). Regulates the amplitude of the cyclic expression of the core clock gene ARNTL/BMAL1 by phosphorylating its transcriptional repressor NR1D1, and this phosphorylation is necessary for SCF(FBXW7)-mediated ubiquitination and proteasomal degradation of NR1D1 (PubMed:27238018). Phosphorylates EML3 at 'Thr-881' which is essential for its interaction with HAUS augmin-like complex and TUBG1 (PubMed:30723163). {ECO:0000269|PubMed:16371510, ECO:0000269|PubMed:16407259, ECO:0000269|PubMed:16933150, ECO:0000269|PubMed:17459720, ECO:0000269|PubMed:18356527, ECO:0000269|PubMed:18480403, ECO:0000269|PubMed:19509060, ECO:0000269|PubMed:19917720, ECO:0000269|PubMed:20171170, ECO:0000269|PubMed:20360007, ECO:0000269|PubMed:20395957, ECO:0000269|PubMed:20935635, ECO:0000269|PubMed:20937773, ECO:0000269|PubMed:21063390, ECO:0000269|PubMed:23355470, ECO:0000269|PubMed:23601106, ECO:0000269|PubMed:23602554, ECO:0000269|PubMed:25556658, ECO:0000269|PubMed:26549230, ECO:0000269|PubMed:27238018, ECO:0000269|PubMed:30723163}.; FUNCTION: (Microbial infection) Acts as a receptor for hepatitis C virus (HCV) in hepatocytes and facilitates its cell entry. {ECO:0000269|PubMed:21516087}. | FUNCTION: Direct ligand for ERBB3 and ERBB4 tyrosine kinase receptors. Concomitantly recruits ERBB1 and ERBB2 coreceptors, resulting in ligand-stimulated tyrosine phosphorylation and activation of the ERBB receptors. The multiple isoforms perform diverse functions such as inducing growth and differentiation of epithelial, glial, neuronal, and skeletal muscle cells; inducing expression of acetylcholine receptor in synaptic vesicles during the formation of the neuromuscular junction; stimulating lobuloalveolar budding and milk production in the mammary gland and inducing differentiation of mammary tumor cells; stimulating Schwann cell proliferation; implication in the development of the myocardium such as trabeculation of the developing heart. Isoform 10 may play a role in motor and sensory neuron development. Binds to ERBB4 (PubMed:10867024, PubMed:7902537). Binds to ERBB3 (PubMed:20682778). Acts as a ligand for integrins and binds (via EGF domain) to integrins ITGAV:ITGB3 or ITGA6:ITGB4. Its binding to integrins and subsequent ternary complex formation with integrins and ERRB3 are essential for NRG1-ERBB signaling. Induces the phosphorylation and activation of MAPK3/ERK1, MAPK1/ERK2 and AKT1 (PubMed:20682778). Ligand-dependent ERBB4 endocytosis is essential for the NRG1-mediated activation of these kinases in neurons (By similarity). {ECO:0000250|UniProtKB:P43322, ECO:0000269|PubMed:10867024, ECO:0000269|PubMed:1348215, ECO:0000269|PubMed:20682778, ECO:0000269|PubMed:7902537}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000287842 | 4 | 12 | 165_177 | 167 | 638.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000341377 | 4 | 13 | 165_177 | 167 | 525.3333333333334 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000356819 | 4 | 13 | 165_177 | 167 | 646.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000405005 | 4 | 12 | 165_177 | 167 | 641.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000519301 | 2 | 11 | 165_177 | 112 | 591.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000521670 | 4 | 13 | 165_177 | 167 | 477.3333333333333 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000523079 | 4 | 11 | 165_177 | 167 | 421.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000287842 | 4 | 12 | 178_222 | 167 | 638.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000341377 | 4 | 13 | 178_222 | 167 | 525.3333333333334 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000356819 | 4 | 13 | 178_222 | 167 | 646.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000405005 | 4 | 12 | 178_222 | 167 | 641.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000519301 | 2 | 11 | 178_222 | 112 | 591.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000521670 | 4 | 13 | 178_222 | 167 | 477.3333333333333 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000523079 | 4 | 11 | 178_222 | 167 | 421.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000287842 | 4 | 12 | 266_640 | 167 | 638.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000341377 | 4 | 13 | 266_640 | 167 | 525.3333333333334 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000356819 | 4 | 13 | 266_640 | 167 | 646.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000405005 | 4 | 12 | 266_640 | 167 | 641.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000519301 | 2 | 11 | 266_640 | 112 | 591.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520502 | 0 | 3 | 266_640 | 222 | 297.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000521670 | 4 | 13 | 266_640 | 167 | 477.3333333333333 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000523079 | 4 | 11 | 266_640 | 167 | 421.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000287842 | 4 | 12 | 243_265 | 167 | 638.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000341377 | 4 | 13 | 243_265 | 167 | 525.3333333333334 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000356819 | 4 | 13 | 243_265 | 167 | 646.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000405005 | 4 | 12 | 243_265 | 167 | 641.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000519301 | 2 | 11 | 243_265 | 112 | 591.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520502 | 0 | 3 | 243_265 | 222 | 297.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000521670 | 4 | 13 | 243_265 | 167 | 477.3333333333333 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000523079 | 4 | 11 | 243_265 | 167 | 421.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CDK1 | chr10:62539960 | chr8:32585467 | ENST00000316629 | - | 2 | 7 | 4_287 | 12 | 241.0 | Domain | Protein kinase |
| Hgene | CDK1 | chr10:62539960 | chr8:32585467 | ENST00000373809 | - | 1 | 6 | 4_287 | 12 | 241.0 | Domain | Protein kinase |
| Hgene | CDK1 | chr10:62539960 | chr8:32585467 | ENST00000395284 | - | 2 | 8 | 4_287 | 12 | 298.0 | Domain | Protein kinase |
| Hgene | CDK1 | chr10:62539960 | chr8:32585467 | ENST00000448257 | - | 2 | 8 | 4_287 | 12 | 298.0 | Domain | Protein kinase |
| Hgene | CDK1 | chr10:62539960 | chr8:32585467 | ENST00000316629 | - | 2 | 7 | 10_18 | 12 | 241.0 | Nucleotide binding | ATP |
| Hgene | CDK1 | chr10:62539960 | chr8:32585467 | ENST00000373809 | - | 1 | 6 | 10_18 | 12 | 241.0 | Nucleotide binding | ATP |
| Hgene | CDK1 | chr10:62539960 | chr8:32585467 | ENST00000395284 | - | 2 | 8 | 10_18 | 12 | 298.0 | Nucleotide binding | ATP |
| Hgene | CDK1 | chr10:62539960 | chr8:32585467 | ENST00000448257 | - | 2 | 8 | 10_18 | 12 | 298.0 | Nucleotide binding | ATP |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520407 | 2 | 5 | 165_177 | 348 | 423.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520502 | 0 | 3 | 165_177 | 222 | 297.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000287842 | 4 | 12 | 37_128 | 167 | 638.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000341377 | 4 | 13 | 37_128 | 167 | 525.3333333333334 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000356819 | 4 | 13 | 37_128 | 167 | 646.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000405005 | 4 | 12 | 37_128 | 167 | 641.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000519301 | 2 | 11 | 37_128 | 112 | 591.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520407 | 2 | 5 | 178_222 | 348 | 423.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520407 | 2 | 5 | 37_128 | 348 | 423.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520502 | 0 | 3 | 178_222 | 222 | 297.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520502 | 0 | 3 | 37_128 | 222 | 297.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000521670 | 4 | 13 | 37_128 | 167 | 477.3333333333333 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000523079 | 4 | 11 | 37_128 | 167 | 421.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000287842 | 4 | 12 | 20_242 | 167 | 638.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000341377 | 4 | 13 | 20_242 | 167 | 525.3333333333334 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000356819 | 4 | 13 | 20_242 | 167 | 646.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000405005 | 4 | 12 | 20_242 | 167 | 641.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000519301 | 2 | 11 | 20_242 | 112 | 591.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520407 | 2 | 5 | 20_242 | 348 | 423.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520407 | 2 | 5 | 266_640 | 348 | 423.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520502 | 0 | 3 | 20_242 | 222 | 297.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000521670 | 4 | 13 | 20_242 | 167 | 477.3333333333333 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000523079 | 4 | 11 | 20_242 | 167 | 421.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr10:62539960 | chr8:32585467 | ENST00000520407 | 2 | 5 | 243_265 | 348 | 423.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
Top |
Fusion Gene Sequence for CDK1-NRG1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >15227_15227_1_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000287842_length(transcript)=1700nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGT GGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAA CATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGA GCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCC TAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCA CAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAAC CCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACAC GCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTT CATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTT CCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTA CGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGA AGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCAT ACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACA GGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGT >15227_15227_1_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000287842_length(amino acids)=482AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT STAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAM TTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLR IVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAFRLA -------------------------------------------------------------- >15227_15227_2_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000287845_length(transcript)=2243nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCT CCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCG GTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGT ATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCA CTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGAT GTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAG CTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCG TATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCAT GCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCA TCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGA GGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAA TGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGG TGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAA CCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCT AAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTT CTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAG TATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCAC AGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGA CTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTAT GAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGA >15227_15227_2_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000287845_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_3_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000338921_length(transcript)=2252nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAA AGTCCAAAACCAAGAAAAGCATTCTGGAGAACCCTTTCCAGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTG CATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCA GAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAA TCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCAC AGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGT AATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGA ATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCAC CCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGAC GGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAA GTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGT GGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAAC CAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGA AAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAG CAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGT ATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATT TTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAAT TTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTG CTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGA TTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCT CTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGAT AATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAAATATTAGGAAGAAAGTAATACTGTGAT >15227_15227_3_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000338921_length(amino acids)=493AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKHSGEPFPEAEE LYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVERE AETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRD SPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAH DSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAA -------------------------------------------------------------- >15227_15227_4_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000341377_length(transcript)=2287nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAA AGTCCAAAACCAAGAAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTG TACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAG AAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCAT CCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCA GAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGA CACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCA AGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCT CCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCC CCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTA CTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGAC AGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTT AAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCC CAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGT CTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTG TCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAA AGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATG TATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTA TGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCT TGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTAT GTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCT GCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGT >15227_15227_4_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000341377_length(amino acids)=412AA_BP= MASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >15227_15227_5_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000356819_length(transcript)=2243nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCT CCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCG GTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGT ATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCA CTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGAT GTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAG CTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCG TATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCAT GCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCA TCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGA GGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAA TGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGG TGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAA CCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCT AAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTT CTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAG TATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCAC AGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGA CTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTAT GAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGA >15227_15227_5_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000356819_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_6_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000405005_length(transcript)=1669nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAA AGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCAT CATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAA TATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCAT CTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCAC CCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAA CAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGC CAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGA TTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGT CAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTT CAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGAC CCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAA CAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTT CCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTT CTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGA >15227_15227_6_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000405005_length(amino acids)=485AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLT ITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTS HYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYV SAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPAS PLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAF -------------------------------------------------------------- >15227_15227_7_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000519301_length(transcript)=1618nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCT CCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCG GTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGT ATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCA CTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGAT GTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAG CTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCG TATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCAT GCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCA TCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGA GGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAA TGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGG TGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAA >15227_15227_7_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000519301_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_8_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000520407_length(transcript)=859nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCA GATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATT ACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGAT ACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTAC TGAACAGTCCATCTTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTT >15227_15227_8_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000520407_length(amino acids)=102AA_BP=55 MKLLALGFKAGSWKLSGERRGCCSCRCGRRGIISRDLPYPLTNYGRLYQNRENWRSYIYIHHWDKPSCKMCGEGENFLCEWRGVLHGERP -------------------------------------------------------------- >15227_15227_9_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000520502_length(transcript)=842nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCA GATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATT ACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGAT ACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTAC TGAACAGTCCATCTTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTT >15227_15227_9_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000520502_length(amino acids)=102AA_BP=55 MKLLALGFKAGSWKLSGERRGCCSCRCGRRGIISRDLPYPLTNYGRLYQNRENWRSYIYIHHWDKPSCKMCGEGENFLCEWRGVLHGERP -------------------------------------------------------------- >15227_15227_10_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000521670_length(transcript)=1338nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAA AGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCAT CATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAA TATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCAT CTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCAC CCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAA CAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGC CAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGACATAACCTTATAGCTGAGCTAAGGAGAAACAAGGCACACAGATC CAAATGCATGCAGATCCAGCTATCAGCAACTCATCTTAGATCTTCTTCCATTCCCCATTTGGGCTTCATTCTCTAAGACCCCTTGGCCTT TAGGAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGG AAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCG >15227_15227_10_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000521670_length(amino acids)=307AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLT ITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTS HYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERHN -------------------------------------------------------------- >15227_15227_11_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000523079_length(transcript)=1519nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGT GGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAA CATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGA GCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCC TAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCA CAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAAC CCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTAAAACCGAAGGGCAAAGCTACTGCAGAGGAGAAACTCAGTCAGAGAATCCCT GTGAGCACCTGCGGTCTCACCTCAGGAAATCTACTCTAATCAGAATAAGGGGCGGCAGTTACCTGTTCTAGGAGTGCTCCTAGTTGATGA AGTCATCTCTTTGTTTGACGGAACTTATTTCTTCTGAGCTTCTCTCGTCGTCCCAGTGACTGACAGGCAACAGACTCTTAAAGAGCTGGG ATGCTTTGATGCGGAAGGTGCAGCACATGGAGTTTCCAGCTCTGGCCATGGGCTCAGACCCACTCGGGGTCTCAGTGTCCTCAGTTGTAA CATTAGAGAGATGGCATCAATGCTTGATAAGGACCCTTCTATAATTCCAATTGCCAGTTATCCAAACTCTGATTCGGTGGTCGAGCTGGC CTCGTGTTCTTATCTGCTAACCCTGTCTTACCTTCCAGCCTCAGTTAAGTCAAATCAAGGGCTATGTCATTGCTGAATGTCATGGGGGGC >15227_15227_11_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000523079_length(amino acids)=265AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT -------------------------------------------------------------- >15227_15227_12_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000539990_length(transcript)=1697nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGT GGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAA CATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGA GCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCC TAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCA CAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAAC CCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACAC GCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTT CATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTT CCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTA CGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGA AGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCAT ACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACA GGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGT >15227_15227_12_CDK1-NRG1_CDK1_chr10_62539960_ENST00000316629_NRG1_chr8_32585467_ENST00000539990_length(amino acids)=482AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT STAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAM TTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLR IVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAFRLA -------------------------------------------------------------- >15227_15227_13_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000287842_length(transcript)=1571nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCT GACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCT GCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGA GAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCAC CAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCT TTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGG CACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTA TGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCC ACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACC AAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGC TAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAG CCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGA GAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGC CTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAA CCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAAT >15227_15227_13_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000287842_length(amino acids)=482AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT STAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAM TTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLR IVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAFRLA -------------------------------------------------------------- >15227_15227_14_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000287845_length(transcript)=2114nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGA GGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAA AACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCC TCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAG AGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAG CAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGG GGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCG AGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAA ATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAG ACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGC GCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGA GCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACAC AAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGC AGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGC CAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTAT ATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAA ATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGT TATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCT GGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGA TCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGT CTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGC >15227_15227_14_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000287845_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_15_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000338921_length(transcript)=2123nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGCATTCTGGAGAACCCTTTCC AGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGC CTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGC CAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATAT TGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCA CAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAG CCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGA TTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAG CTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGA AGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCA CAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCC AGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGA CAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAA CCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGA AATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACT TTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTT ATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTG CCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCA GTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGT AGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAAT GAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCA >15227_15227_15_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000338921_length(amino acids)=493AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKHSGEPFPEAEE LYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVERE AETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRD SPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAH DSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAA -------------------------------------------------------------- >15227_15227_16_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000341377_length(transcript)=2158nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAGTGCCCAAATGAGTTTACTGGT GATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATC GCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGC CTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAA TACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCC CATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATC GTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGT AACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCG GCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTG TCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTT GACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAG GATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAG CCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGA GTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGG ACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAA AACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAG CAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTT TACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTT TCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTG CAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTG TGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATA >15227_15227_16_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000341377_length(amino acids)=412AA_BP= MASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >15227_15227_17_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000356819_length(transcript)=2114nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGA GGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAA AACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCC TCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAG AGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAG CAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGG GGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCG AGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAA ATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAG ACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGC GCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGA GCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACAC AAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGC AGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGC CAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTAT ATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAA ATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGT TATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCT GGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGA TCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGT CTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGC >15227_15227_17_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000356819_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_18_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000405005_length(transcript)=1540nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAA GAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCG GAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCC ACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATC CTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGA AAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACG TCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAG TGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGA AATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGT GACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAG CCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACT CGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAG TAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGC AACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGT AATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCC >15227_15227_18_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000405005_length(amino acids)=485AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLT ITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTS HYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYV SAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPAS PLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAF -------------------------------------------------------------- >15227_15227_19_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000519301_length(transcript)=1489nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGA GGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAA AACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCC TCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAG AGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAG CAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGG GGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCG AGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAA ATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAG ACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGC GCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGA GCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACAC AAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGC AGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGC >15227_15227_19_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000519301_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_20_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000520407_length(transcript)=730nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGA ATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAAT ATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAA TAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAA TAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATCTTCTTTATACAATGACCACATCCTGA AAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTTAATTTTGATTCAGAATGTGTTATTTGTCACAAATAAACA >15227_15227_20_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000520407_length(amino acids)=86AA_BP=12 -------------------------------------------------------------- >15227_15227_21_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000520502_length(transcript)=713nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGA ATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAAT ATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAA TAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAA TAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATCTTCTTTATACAATGACCACATCCTGA >15227_15227_21_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000520502_length(amino acids)=86AA_BP=12 -------------------------------------------------------------- >15227_15227_22_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000521670_length(transcript)=1209nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAA GAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCG GAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCC ACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATC CTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGA AAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACG TCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAG TGAAAGACATAACCTTATAGCTGAGCTAAGGAGAAACAAGGCACACAGATCCAAATGCATGCAGATCCAGCTATCAGCAACTCATCTTAG ATCTTCTTCCATTCCCCATTTGGGCTTCATTCTCTAAGACCCCTTGGCCTTTAGGAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTA TGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGC CTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATC >15227_15227_22_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000521670_length(amino acids)=307AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLT ITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTS HYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERHN -------------------------------------------------------------- >15227_15227_23_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000523079_length(transcript)=1390nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCT GACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCT GCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGA GAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCAC CAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCT TTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGG CACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTA AAACCGAAGGGCAAAGCTACTGCAGAGGAGAAACTCAGTCAGAGAATCCCTGTGAGCACCTGCGGTCTCACCTCAGGAAATCTACTCTAA TCAGAATAAGGGGCGGCAGTTACCTGTTCTAGGAGTGCTCCTAGTTGATGAAGTCATCTCTTTGTTTGACGGAACTTATTTCTTCTGAGC TTCTCTCGTCGTCCCAGTGACTGACAGGCAACAGACTCTTAAAGAGCTGGGATGCTTTGATGCGGAAGGTGCAGCACATGGAGTTTCCAG CTCTGGCCATGGGCTCAGACCCACTCGGGGTCTCAGTGTCCTCAGTTGTAACATTAGAGAGATGGCATCAATGCTTGATAAGGACCCTTC TATAATTCCAATTGCCAGTTATCCAAACTCTGATTCGGTGGTCGAGCTGGCCTCGTGTTCTTATCTGCTAACCCTGTCTTACCTTCCAGC CTCAGTTAAGTCAAATCAAGGGCTATGTCATTGCTGAATGTCATGGGGGGCAACTGCTTGCCCTCCACCCTATAGTATCTATTTTATGAA >15227_15227_23_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000523079_length(amino acids)=265AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT -------------------------------------------------------------- >15227_15227_24_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000539990_length(transcript)=1568nt_BP=50nt CCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAA ATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAA GTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCT GACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCT GCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGA GAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCAC CAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCT TTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGG CACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTA TGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCC ACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACC AAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGC TAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAG CCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGA GAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGC CTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAA CCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAAT >15227_15227_24_CDK1-NRG1_CDK1_chr10_62539960_ENST00000373809_NRG1_chr8_32585467_ENST00000539990_length(amino acids)=482AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT STAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAM TTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLR IVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAFRLA -------------------------------------------------------------- >15227_15227_25_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000287842_length(transcript)=1700nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGT GGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAA CATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGA GCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCC TAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCA CAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAAC CCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACAC GCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTT CATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTT CCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTA CGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGA AGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCAT ACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACA GGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGT >15227_15227_25_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000287842_length(amino acids)=482AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT STAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAM TTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLR IVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAFRLA -------------------------------------------------------------- >15227_15227_26_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000287845_length(transcript)=2243nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCT CCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCG GTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGT ATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCA CTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGAT GTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAG CTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCG TATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCAT GCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCA TCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGA GGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAA TGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGG TGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAA CCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCT AAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTT CTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAG TATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCAC AGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGA CTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTAT GAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGA >15227_15227_26_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000287845_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_27_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000338921_length(transcript)=2252nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAA AGTCCAAAACCAAGAAAAGCATTCTGGAGAACCCTTTCCAGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTG CATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCA GAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAA TCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCAC AGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGT AATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGA ATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCAC CCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGAC GGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAA GTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGT GGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAAC CAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGA AAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAG CAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGT ATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATT TTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAAT TTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTG CTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGA TTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCT CTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGAT AATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAAATATTAGGAAGAAAGTAATACTGTGAT >15227_15227_27_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000338921_length(amino acids)=493AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKHSGEPFPEAEE LYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVERE AETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRD SPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAH DSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAA -------------------------------------------------------------- >15227_15227_28_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000341377_length(transcript)=2287nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAA AGTCCAAAACCAAGAAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTG TACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAG AAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCAT CCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCA GAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGA CACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCA AGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCT CCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCC CCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTA CTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGAC AGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTT AAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCC CAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGT CTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTG TCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAA AGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATG TATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTA TGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCT TGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTAT GTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCT GCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGT >15227_15227_28_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000341377_length(amino acids)=412AA_BP= MASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >15227_15227_29_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000356819_length(transcript)=2243nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCT CCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCG GTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGT ATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCA CTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGAT GTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAG CTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCG TATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCAT GCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCA TCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGA GGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAA TGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGG TGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAA CCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCT AAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTT CTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAG TATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCAC AGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGA CTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTAT GAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGA >15227_15227_29_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000356819_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_30_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000405005_length(transcript)=1669nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAA AGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCAT CATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAA TATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCAT CTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCAC CCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAA CAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGC CAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGA TTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGT CAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTT CAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGAC CCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAA CAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTT CCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTT CTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGA >15227_15227_30_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000405005_length(amino acids)=485AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLT ITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTS HYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYV SAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPAS PLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAF -------------------------------------------------------------- >15227_15227_31_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000519301_length(transcript)=1618nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCT CCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCG GTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGT ATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCA CTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGAT GTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAG CTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCG TATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCAT GCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCA TCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGA GGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAA TGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGG TGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAA >15227_15227_31_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000519301_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_32_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000520407_length(transcript)=859nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCA GATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATT ACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGAT ACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTAC TGAACAGTCCATCTTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTT >15227_15227_32_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000520407_length(amino acids)=102AA_BP=55 MKLLALGFKAGSWKLSGERRGCCSCRCGRRGIISRDLPYPLTNYGRLYQNRENWRSYIYIHHWDKPSCKMCGEGENFLCEWRGVLHGERP -------------------------------------------------------------- >15227_15227_33_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000520502_length(transcript)=842nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCA GATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATT ACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGAT ACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTAC TGAACAGTCCATCTTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTT >15227_15227_33_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000520502_length(amino acids)=102AA_BP=55 MKLLALGFKAGSWKLSGERRGCCSCRCGRRGIISRDLPYPLTNYGRLYQNRENWRSYIYIHHWDKPSCKMCGEGENFLCEWRGVLHGERP -------------------------------------------------------------- >15227_15227_34_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000521670_length(transcript)=1338nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAA AGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCAT CATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAA TATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCAT CTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCAC CCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAA CAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGC CAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGACATAACCTTATAGCTGAGCTAAGGAGAAACAAGGCACACAGATC CAAATGCATGCAGATCCAGCTATCAGCAACTCATCTTAGATCTTCTTCCATTCCCCATTTGGGCTTCATTCTCTAAGACCCCTTGGCCTT TAGGAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGG AAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCG >15227_15227_34_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000521670_length(amino acids)=307AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLT ITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTS HYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERHN -------------------------------------------------------------- >15227_15227_35_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000523079_length(transcript)=1519nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGT GGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAA CATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGA GCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCC TAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCA CAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAAC CCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTAAAACCGAAGGGCAAAGCTACTGCAGAGGAGAAACTCAGTCAGAGAATCCCT GTGAGCACCTGCGGTCTCACCTCAGGAAATCTACTCTAATCAGAATAAGGGGCGGCAGTTACCTGTTCTAGGAGTGCTCCTAGTTGATGA AGTCATCTCTTTGTTTGACGGAACTTATTTCTTCTGAGCTTCTCTCGTCGTCCCAGTGACTGACAGGCAACAGACTCTTAAAGAGCTGGG ATGCTTTGATGCGGAAGGTGCAGCACATGGAGTTTCCAGCTCTGGCCATGGGCTCAGACCCACTCGGGGTCTCAGTGTCCTCAGTTGTAA CATTAGAGAGATGGCATCAATGCTTGATAAGGACCCTTCTATAATTCCAATTGCCAGTTATCCAAACTCTGATTCGGTGGTCGAGCTGGC CTCGTGTTCTTATCTGCTAACCCTGTCTTACCTTCCAGCCTCAGTTAAGTCAAATCAAGGGCTATGTCATTGCTGAATGTCATGGGGGGC >15227_15227_35_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000523079_length(amino acids)=265AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT -------------------------------------------------------------- >15227_15227_36_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000539990_length(transcript)=1697nt_BP=179nt AGCGCGGTGAGTTTGAAACTGCTCGCACTTGGCTTCAAAGCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGC TGCGGCCGCCGCGGAATAATAAGCCGGGATCTACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGC TACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCAT GGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAG CTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGT GGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAA CATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGA GCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCC TAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCA CAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAAC CCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACAC GCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTT CATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTT CCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTA CGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGA AGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCAT ACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACA GGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGT >15227_15227_36_CDK1-NRG1_CDK1_chr10_62539960_ENST00000395284_NRG1_chr8_32585467_ENST00000539990_length(amino acids)=482AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT STAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAM TTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLR IVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAFRLA -------------------------------------------------------------- >15227_15227_37_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000287842_length(transcript)=1759nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAG AGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGG AAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCA CCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCC TTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAA AGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGT CTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGT GAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAA ATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTG ACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGC CTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTC GCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGT AACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCA ACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTA ATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCA >15227_15227_37_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000287842_length(amino acids)=482AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT STAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAM TTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLR IVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAFRLA -------------------------------------------------------------- >15227_15227_38_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000287845_length(transcript)=2302nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATG GAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCC TACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCC AATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATT GTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCAC AGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGC CCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGAT TCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGC TCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAA GAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCAC AACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCA GCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGAC AGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAAC CCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAA ATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTT TATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTA TAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGC CTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAG TTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTA GCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATG AGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAA >15227_15227_38_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000287845_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_39_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000338921_length(transcript)=2311nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGCATTCTGGAGAA CCCTTTCCAGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGT GTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATG AACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGT GAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACT CCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGG CACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAA ACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCAC ACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCC TTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCC TTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAG TACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTG GAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGC ATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACA CAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCT GTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAA AAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATAT CAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCA TAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTG CTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAA TATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAA >15227_15227_39_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000338921_length(amino acids)=493AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKHSGEPFPEAEE LYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVERE AETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRD SPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAH DSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAA -------------------------------------------------------------- >15227_15227_40_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000341377_length(transcript)=2346nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAGTGCCCAAATGAGT TTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCA TCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTC GGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGG TGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTT CCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACT CTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTC GTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGA CCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCA TGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGA AGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGA TAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAA GAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAG ATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTG ACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTG CTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTT TATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAG CAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTG ATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGT ATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGC CTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTG AGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAAATATTAGGAAGAAAGTAATACTG >15227_15227_40_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000341377_length(amino acids)=412AA_BP= MASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >15227_15227_41_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000356819_length(transcript)=2302nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATG GAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCC TACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCC AATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATT GTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCAC AGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGC CCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGAT TCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGC TCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAA GAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCAC AACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCA GCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGAC AGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAAC CCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAA ATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTT TATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTA TAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGC CTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAG TTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTA GCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATG AGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAA >15227_15227_41_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000356819_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_42_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000405005_length(transcript)=1728nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGGCGGAGGAGCTG TACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAG AAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCAT CCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCA GAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGA CACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCA AGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCT CCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCC CCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTA CTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGAC AGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTT AAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCC CAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGT CTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTG TCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAA >15227_15227_42_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000405005_length(amino acids)=485AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLT ITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTS HYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYV SAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPAS PLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAF -------------------------------------------------------------- >15227_15227_43_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000519301_length(transcript)=1677nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATG GAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCC TACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCC AATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATT GTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCAC AGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGC CCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGAT TCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGC TCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAA GAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCAC AACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCA GCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGAC AGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAAC CCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAA >15227_15227_43_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000519301_length(amino acids)=490AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQ KRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAET SFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPH SERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSN SLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLE -------------------------------------------------------------- >15227_15227_44_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000520407_length(transcript)=918nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACGTCCACTCCCTTTCTGTCT CTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGAGCTAGATGTGTCTTACCA GATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTCGCGACTAGTTGGCTCTGA GATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGTCAATATCAAGCAGTGAAA TATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATCTTCTTTATACAATGACCA CATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTTAATTTTGATTCAGAATGTGTTATTTGTCACA >15227_15227_44_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000520407_length(amino acids)=86AA_BP=12 -------------------------------------------------------------- >15227_15227_45_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000520502_length(transcript)=901nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACGTCCACTCCCTTTCTGTCT CTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGAGCTAGATGTGTCTTACCA GATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTCGCGACTAGTTGGCTCTGA GATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGTCAATATCAAGCAGTGAAA TATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATCTTCTTTATACAATGACCA CATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTTAATTTTGATTCAGAATGTGTTATTTGTCACA >15227_15227_45_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000520502_length(amino acids)=86AA_BP=12 -------------------------------------------------------------- >15227_15227_46_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000521670_length(transcript)=1397nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGGCGGAGGAGCTG TACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAG AAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCAT CCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCA GAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGA CACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCA AGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCT CCTCATAGTGAAAGACATAACCTTATAGCTGAGCTAAGGAGAAACAAGGCACACAGATCCAAATGCATGCAGATCCAGCTATCAGCAACT CATCTTAGATCTTCTTCCATTCCCCATTTGGGCTTCATTCTCTAAGACCCCTTGGCCTTTAGGAAGGTATGTGTCAGCCATGACCACCCC GGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGT GTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTT >15227_15227_46_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000521670_length(amino acids)=307AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLT ITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTS HYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERHN -------------------------------------------------------------- >15227_15227_47_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000523079_length(transcript)=1578nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAG AGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGG AAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCA CCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCC TTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAA AGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGT CTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGT GAAAGGTAAAACCGAAGGGCAAAGCTACTGCAGAGGAGAAACTCAGTCAGAGAATCCCTGTGAGCACCTGCGGTCTCACCTCAGGAAATC TACTCTAATCAGAATAAGGGGCGGCAGTTACCTGTTCTAGGAGTGCTCCTAGTTGATGAAGTCATCTCTTTGTTTGACGGAACTTATTTC TTCTGAGCTTCTCTCGTCGTCCCAGTGACTGACAGGCAACAGACTCTTAAAGAGCTGGGATGCTTTGATGCGGAAGGTGCAGCACATGGA GTTTCCAGCTCTGGCCATGGGCTCAGACCCACTCGGGGTCTCAGTGTCCTCAGTTGTAACATTAGAGAGATGGCATCAATGCTTGATAAG GACCCTTCTATAATTCCAATTGCCAGTTATCCAAACTCTGATTCGGTGGTCGAGCTGGCCTCGTGTTCTTATCTGCTAACCCTGTCTTAC CTTCCAGCCTCAGTTAAGTCAAATCAAGGGCTATGTCATTGCTGAATGTCATGGGGGGCAACTGCTTGCCCTCCACCCTATAGTATCTAT >15227_15227_47_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000523079_length(amino acids)=265AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT -------------------------------------------------------------- >15227_15227_48_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000539990_length(transcript)=1756nt_BP=238nt GCTGGCTCTTGGAAATTGAGCGGAGAGCGACGCGGTTGTTGTAGCTGCCGCTGCGGCCGCCGCGGAATAATAAGCCGGGTACAGTGGCTG GGGTCAGGGTCGTGTCTAGGGGACGGCCGAGGGCCTCGGAGGGCGAGTATTGAGGAACGGGGTCCTCTAAGAAGGCCGGACTGGAGGATC TACCATACCCATTGACTAACTATGGAAGATTATACCAAAATAGAGAAAATTGGAGAAGCTACATCTACATCCACCACTGGGACAAGCCAT CTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATAC TTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAG AGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGG AAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCA CCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCC TTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAA AGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGT CTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGT GAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAA ATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTG ACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGC CTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTC GCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGT AACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCA ACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTA ATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCA >15227_15227_48_CDK1-NRG1_CDK1_chr10_62539960_ENST00000448257_NRG1_chr8_32585467_ENST00000539990_length(amino acids)=482AA_BP=12 MEDYTKIEKIGEATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITG ICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYT STAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAM TTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLR IVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASLEATPAFRLA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CDK1-NRG1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CDK1-NRG1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CDK1-NRG1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies