
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CHP1-ANXA2 (FusionGDB2 ID:16602) |
Fusion Gene Summary for CHP1-ANXA2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CHP1-ANXA2 | Fusion gene ID: 16602 | Hgene | Tgene | Gene symbol | CHP1 | ANXA2 | Gene ID | 26973 | 302 |
| Gene name | cysteine and histidine rich domain containing 1 | annexin A2 | |
| Synonyms | CHP1 | ANX2|ANX2L4|CAL1H|HEL-S-270|LIP2|LPC2|LPC2D|P36|PAP-IV | |
| Cytomap | 11q14.3 | 15q22.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cysteine and histidine-rich domain-containing protein 1CHORD-containing protein 1CHP-1chord domain-containing protein 1cysteine and histidine-rich domain (CHORD) containing 1cysteine and histidine-rich domain (CHORD)-containing, zinc-binding protein | annexin A2annexin IIannexin-2calpactin I heavy chaincalpactin I heavy polypeptidecalpactin-1 heavy chainchromobindin 8epididymis secretory protein Li 270epididymis secretory sperm binding proteinlipocortin IIplacental anticoagulant protein IVpr | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q99653 | A6NMY6 | |
| Ensembl transtripts involved in fusion gene | ENST00000334660, ENST00000560397, ENST00000558351, | ENST00000557937, ENST00000332680, ENST00000396024, ENST00000421017, ENST00000451270, | |
| Fusion gene scores | * DoF score | 11 X 13 X 7=1001 | 33 X 12 X 13=5148 |
| # samples | 15 | 39 | |
| ** MAII score | log2(15/1001*10)=-2.73840756834011 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(39/5148*10)=-3.72246602447109 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CHP1 [Title/Abstract] AND ANXA2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CHP1(41523647)-ANXA2(60656722), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | ANXA2 | GO:0001921 | positive regulation of receptor recycling | 22848640 |
| Tgene | ANXA2 | GO:0031340 | positive regulation of vesicle fusion | 2138016 |
| Tgene | ANXA2 | GO:0032804 | negative regulation of low-density lipoprotein particle receptor catabolic process | 22848640 |
| Tgene | ANXA2 | GO:0036035 | osteoclast development | 7961821 |
| Tgene | ANXA2 | GO:1905581 | positive regulation of low-density lipoprotein particle clearance | 22848640 |
| Tgene | ANXA2 | GO:1905597 | positive regulation of low-density lipoprotein particle receptor binding | 22848640 |
| Tgene | ANXA2 | GO:1905602 | positive regulation of receptor-mediated endocytosis involved in cholesterol transport | 22848640 |
| Fusion gene breakpoints across CHP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ANXA2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-8530-01A | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
Top |
Fusion Gene ORF analysis for CHP1-ANXA2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000334660 | ENST00000557937 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| 5CDS-5UTR | ENST00000560397 | ENST00000557937 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000334660 | ENST00000332680 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000334660 | ENST00000396024 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000334660 | ENST00000421017 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000334660 | ENST00000451270 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000560397 | ENST00000332680 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000560397 | ENST00000396024 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000560397 | ENST00000421017 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000560397 | ENST00000451270 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000558351 | ENST00000332680 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000558351 | ENST00000396024 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000558351 | ENST00000421017 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000558351 | ENST00000451270 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| intron-5UTR | ENST00000558351 | ENST00000557937 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000334660 | CHP1 | chr15 | 41523647 | + | ENST00000396024 | ANXA2 | chr15 | 60656722 | - | 1675 | 307 | 63 | 1178 | 371 |
| ENST00000334660 | CHP1 | chr15 | 41523647 | + | ENST00000451270 | ANXA2 | chr15 | 60656722 | - | 1482 | 307 | 63 | 1178 | 371 |
| ENST00000334660 | CHP1 | chr15 | 41523647 | + | ENST00000332680 | ANXA2 | chr15 | 60656722 | - | 1477 | 307 | 63 | 1178 | 371 |
| ENST00000334660 | CHP1 | chr15 | 41523647 | + | ENST00000421017 | ANXA2 | chr15 | 60656722 | - | 1467 | 307 | 63 | 1178 | 371 |
| ENST00000560397 | CHP1 | chr15 | 41523647 | + | ENST00000396024 | ANXA2 | chr15 | 60656722 | - | 1525 | 157 | 0 | 1028 | 342 |
| ENST00000560397 | CHP1 | chr15 | 41523647 | + | ENST00000451270 | ANXA2 | chr15 | 60656722 | - | 1332 | 157 | 0 | 1028 | 342 |
| ENST00000560397 | CHP1 | chr15 | 41523647 | + | ENST00000332680 | ANXA2 | chr15 | 60656722 | - | 1327 | 157 | 0 | 1028 | 342 |
| ENST00000560397 | CHP1 | chr15 | 41523647 | + | ENST00000421017 | ANXA2 | chr15 | 60656722 | - | 1317 | 157 | 0 | 1028 | 342 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000334660 | ENST00000396024 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - | 0.0020771 | 0.99792296 |
| ENST00000334660 | ENST00000451270 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - | 0.002253481 | 0.9977465 |
| ENST00000334660 | ENST00000332680 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - | 0.002328635 | 0.9976713 |
| ENST00000334660 | ENST00000421017 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - | 0.002366967 | 0.997633 |
| ENST00000560397 | ENST00000396024 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - | 0.001774857 | 0.99822515 |
| ENST00000560397 | ENST00000451270 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - | 0.00170474 | 0.99829525 |
| ENST00000560397 | ENST00000332680 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - | 0.001785217 | 0.99821484 |
| ENST00000560397 | ENST00000421017 | CHP1 | chr15 | 41523647 | + | ANXA2 | chr15 | 60656722 | - | 0.00181363 | 0.9981864 |
Top |
Fusion Genomic Features for CHP1-ANXA2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
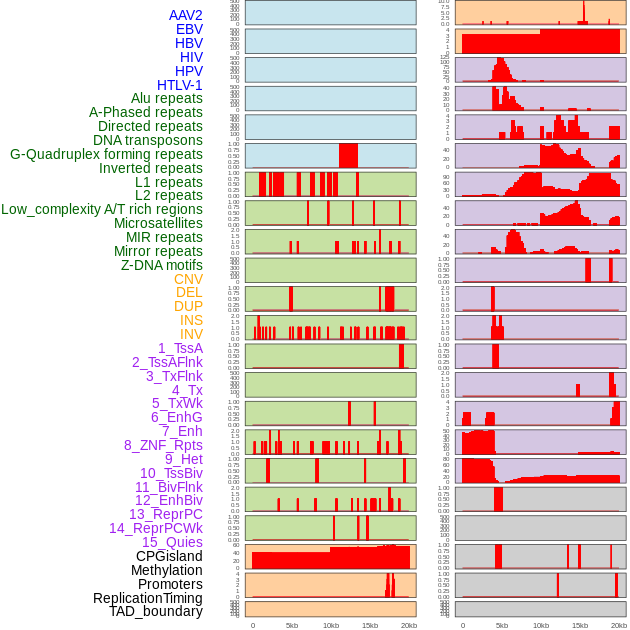 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CHP1-ANXA2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr15:41523647/chr15:60656722) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CHP1 | ANXA2 |
| FUNCTION: Calcium-binding protein involved in different processes such as regulation of vesicular trafficking, plasma membrane Na(+)/H(+) exchanger and gene transcription. Involved in the constitutive exocytic membrane traffic. Mediates the association between microtubules and membrane-bound organelles of the endoplasmic reticulum and Golgi apparatus and is also required for the targeting and fusion of transcytotic vesicles (TCV) with the plasma membrane. Functions as an integral cofactor in cell pH regulation by controlling plasma membrane-type Na(+)/H(+) exchange activity. Affects the pH sensitivity of SLC9A1/NHE1 by increasing its sensitivity at acidic pH. Required for the stabilization and localization of SLC9A1/NHE1 at the plasma membrane. Inhibits serum- and GTPase-stimulated Na(+)/H(+) exchange. Plays a role as an inhibitor of ribosomal RNA transcription by repressing the nucleolar UBF1 transcriptional activity. May sequester UBF1 in the nucleoplasm and limit its translocation to the nucleolus. Associates to the ribosomal gene promoter. Acts as a negative regulator of the calcineurin/NFAT signaling pathway. Inhibits NFAT nuclear translocation and transcriptional activity by suppressing the calcium-dependent calcineurin phosphatase activity. Also negatively regulates the kinase activity of the apoptosis-induced kinase STK17B. Inhibits both STK17B auto- and substrate-phosphorylations in a calcium-dependent manner. {ECO:0000269|PubMed:10593895, ECO:0000269|PubMed:11350981, ECO:0000269|PubMed:15035633, ECO:0000269|PubMed:8901634}. | FUNCTION: Calcium-regulated membrane-binding protein whose affinity for calcium is greatly enhanced by anionic phospholipids. It binds two calcium ions with high affinity. May be involved in heat-stress response. {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000332680 | 2 | 13 | 105_176 | 67 | 358.0 | Repeat | Annexin 2 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000332680 | 2 | 13 | 189_261 | 67 | 358.0 | Repeat | Annexin 3 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000332680 | 2 | 13 | 265_336 | 67 | 358.0 | Repeat | Annexin 4 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000396024 | 3 | 14 | 105_176 | 49 | 340.0 | Repeat | Annexin 2 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000396024 | 3 | 14 | 189_261 | 49 | 340.0 | Repeat | Annexin 3 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000396024 | 3 | 14 | 265_336 | 49 | 340.0 | Repeat | Annexin 4 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000421017 | 3 | 14 | 105_176 | 49 | 340.0 | Repeat | Annexin 2 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000421017 | 3 | 14 | 189_261 | 49 | 340.0 | Repeat | Annexin 3 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000421017 | 3 | 14 | 265_336 | 49 | 340.0 | Repeat | Annexin 4 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000451270 | 2 | 13 | 105_176 | 49 | 340.0 | Repeat | Annexin 2 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000451270 | 2 | 13 | 189_261 | 49 | 340.0 | Repeat | Annexin 3 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000451270 | 2 | 13 | 265_336 | 49 | 340.0 | Repeat | Annexin 4 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 123_134 | 22 | 196.0 | Calcium binding | Note=1 |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 164_175 | 22 | 196.0 | Calcium binding | Note=2 |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 110_145 | 22 | 196.0 | Domain | EF-hand 3 |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 151_186 | 22 | 196.0 | Domain | EF-hand 4 |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 26_61 | 22 | 196.0 | Domain | EF-hand 1 |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 66_101 | 22 | 196.0 | Domain | EF-hand 2 |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 138_147 | 22 | 196.0 | Motif | Nuclear export signal 1 |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 176_185 | 22 | 196.0 | Motif | Nuclear export signal 2 |
| Hgene | CHP1 | chr15:41523647 | chr15:60656722 | ENST00000334660 | + | 1 | 7 | 143_185 | 22 | 196.0 | Region | Note=Necessary for nuclear export signal |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000332680 | 2 | 13 | 2_24 | 67 | 358.0 | Region | S100A10-binding site | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000396024 | 3 | 14 | 2_24 | 49 | 340.0 | Region | S100A10-binding site | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000421017 | 3 | 14 | 2_24 | 49 | 340.0 | Region | S100A10-binding site | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000451270 | 2 | 13 | 2_24 | 49 | 340.0 | Region | S100A10-binding site | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000332680 | 2 | 13 | 33_104 | 67 | 358.0 | Repeat | Annexin 1 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000396024 | 3 | 14 | 33_104 | 49 | 340.0 | Repeat | Annexin 1 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000421017 | 3 | 14 | 33_104 | 49 | 340.0 | Repeat | Annexin 1 | |
| Tgene | ANXA2 | chr15:41523647 | chr15:60656722 | ENST00000451270 | 2 | 13 | 33_104 | 49 | 340.0 | Repeat | Annexin 1 |
Top |
Fusion Gene Sequence for CHP1-ANXA2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >16602_16602_1_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000334660_ANXA2_chr15_60656722_ENST00000332680_length(transcript)=1477nt_BP=307nt CATTCGGGGCTGGAACTCGAACGCTGACGTTGGCTCCTGAGCCGGGCGCTGCCTCGCGCCTGATTGGCGGGTCCTCGGGGCCGCCCTCCC CAGCGCACCACCCCTGGGTTCCCTCCCGGGTCCGCAGTGGAAACACTGCCCTCTCCCTTCTTGACCCCTAGCCCTTCCTTCCCTCCCTCC TTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCGATGGGTTCTCGGGCCTCCACGTTACTGCGG GACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAG AGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACG GTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCT CTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAG GACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGAT TATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATG ACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAG GTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCC ATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAAGTGGACATGTTGAAAATTAGGTCTGAATTC AAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTACCAGAAAGCGCTGCTGTACCTGTGTGGTGGA GATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCTAACAGGTCTAGAAAACCAGCTTGCGAATAA CAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGTTGCCTAAGCATTGCCTGGCCTTCCTGTCTA GTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATGTGAAACACTTTGCCTCCTGTGTACTGTGTC >16602_16602_1_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000334660_ANXA2_chr15_60656722_ENST00000332680_length(amino acids)=371AA_BP=82 MAGPRGRPPQRTTPGFPPGSAVETLPSPFLTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGCVDEVTIVN ILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYK EMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPY DMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGTRDKVLIRIMVSRSEVDMLKIRSEFKRKYGKSLYYYIQQDTKGDYQ -------------------------------------------------------------- >16602_16602_2_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000334660_ANXA2_chr15_60656722_ENST00000396024_length(transcript)=1675nt_BP=307nt CATTCGGGGCTGGAACTCGAACGCTGACGTTGGCTCCTGAGCCGGGCGCTGCCTCGCGCCTGATTGGCGGGTCCTCGGGGCCGCCCTCCC CAGCGCACCACCCCTGGGTTCCCTCCCGGGTCCGCAGTGGAAACACTGCCCTCTCCCTTCTTGACCCCTAGCCCTTCCTTCCCTCCCTCC TTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCGATGGGTTCTCGGGCCTCCACGTTACTGCGG GACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAG AGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACG GTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCT CTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAG GACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGAT TATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATG ACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAG GTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCC ATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAAGTGGACATGTTGAAAATTAGGTCTGAATTC AAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTACCAGAAAGCGCTGCTGTACCTGTGTGGTGGA GATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCTAACAGGTCTAGAAAACCAGCTTGCGAATAA CAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGTTGCCTAAGCATTGCCTGGCCTTCCTGTCTA GTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATGTGAAACACTTTGCCTCCTGTGTACTGTGTC ATAAACAGATGAATAAACTGAATTTGTACTTTAGAAACACGTACTTTGTGGCCCTGCTTTCAACTGAATTGTTTGAAAATTAAACGTGCT TGGGGTTCAGCTGGTGAGGCTGTCCCTGTAGGAAGAAAGCTCTGGGACTGAGCTGTACAGTATGGTTGCCCCTATCCAAGTGTCGCTATT >16602_16602_2_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000334660_ANXA2_chr15_60656722_ENST00000396024_length(amino acids)=371AA_BP=82 MAGPRGRPPQRTTPGFPPGSAVETLPSPFLTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGCVDEVTIVN ILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYK EMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPY DMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGTRDKVLIRIMVSRSEVDMLKIRSEFKRKYGKSLYYYIQQDTKGDYQ -------------------------------------------------------------- >16602_16602_3_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000334660_ANXA2_chr15_60656722_ENST00000421017_length(transcript)=1467nt_BP=307nt CATTCGGGGCTGGAACTCGAACGCTGACGTTGGCTCCTGAGCCGGGCGCTGCCTCGCGCCTGATTGGCGGGTCCTCGGGGCCGCCCTCCC CAGCGCACCACCCCTGGGTTCCCTCCCGGGTCCGCAGTGGAAACACTGCCCTCTCCCTTCTTGACCCCTAGCCCTTCCTTCCCTCCCTCC TTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCGATGGGTTCTCGGGCCTCCACGTTACTGCGG GACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAG AGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACG GTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCT CTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAG GACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGAT TATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATG ACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAG GTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCC ATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAAGTGGACATGTTGAAAATTAGGTCTGAATTC AAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTACCAGAAAGCGCTGCTGTACCTGTGTGGTGGA GATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCTAACAGGTCTAGAAAACCAGCTTGCGAATAA CAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGTTGCCTAAGCATTGCCTGGCCTTCCTGTCTA GTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATGTGAAACACTTTGCCTCCTGTGTACTGTGTC >16602_16602_3_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000334660_ANXA2_chr15_60656722_ENST00000421017_length(amino acids)=371AA_BP=82 MAGPRGRPPQRTTPGFPPGSAVETLPSPFLTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGCVDEVTIVN ILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYK EMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPY DMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGTRDKVLIRIMVSRSEVDMLKIRSEFKRKYGKSLYYYIQQDTKGDYQ -------------------------------------------------------------- >16602_16602_4_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000334660_ANXA2_chr15_60656722_ENST00000451270_length(transcript)=1482nt_BP=307nt CATTCGGGGCTGGAACTCGAACGCTGACGTTGGCTCCTGAGCCGGGCGCTGCCTCGCGCCTGATTGGCGGGTCCTCGGGGCCGCCCTCCC CAGCGCACCACCCCTGGGTTCCCTCCCGGGTCCGCAGTGGAAACACTGCCCTCTCCCTTCTTGACCCCTAGCCCTTCCTTCCCTCCCTCC TTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCGATGGGTTCTCGGGCCTCCACGTTACTGCGG GACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAG AGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACG GTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCT CTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAG GACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGAT TATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATG ACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAG GTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCC ATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAAGTGGACATGTTGAAAATTAGGTCTGAATTC AAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTACCAGAAAGCGCTGCTGTACCTGTGTGGTGGA GATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCTAACAGGTCTAGAAAACCAGCTTGCGAATAA CAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGTTGCCTAAGCATTGCCTGGCCTTCCTGTCTA GTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATGTGAAACACTTTGCCTCCTGTGTACTGTGTC >16602_16602_4_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000334660_ANXA2_chr15_60656722_ENST00000451270_length(amino acids)=371AA_BP=82 MAGPRGRPPQRTTPGFPPGSAVETLPSPFLTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGCVDEVTIVN ILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYK EMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPY DMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGTRDKVLIRIMVSRSEVDMLKIRSEFKRKYGKSLYYYIQQDTKGDYQ -------------------------------------------------------------- >16602_16602_5_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000560397_ANXA2_chr15_60656722_ENST00000332680_length(transcript)=1327nt_BP=157nt TTGACCCCTAGCCCTTCCTTCCCTCCCTCCTTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCG ATGGGTTCTCGGGCCTCCACGTTACTGCGGGACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTGTGTGGATGAGGTCACCATTGTC AACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTG AAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCC ATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTAC AAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGT AGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGA ACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCT TATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCC CTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAA GTGGACATGTTGAAAATTAGGTCTGAATTCAAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTAC CAGAAAGCGCTGCTGTACCTGTGTGGTGGAGATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCT AACAGGTCTAGAAAACCAGCTTGCGAATAACAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGT TGCCTAAGCATTGCCTGGCCTTCCTGTCTAGTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATG >16602_16602_5_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000560397_ANXA2_chr15_60656722_ENST00000332680_length(amino acids)=342AA_BP=53 LTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGCVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASAL KSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKG RRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKP -------------------------------------------------------------- >16602_16602_6_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000560397_ANXA2_chr15_60656722_ENST00000396024_length(transcript)=1525nt_BP=157nt TTGACCCCTAGCCCTTCCTTCCCTCCCTCCTTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCG ATGGGTTCTCGGGCCTCCACGTTACTGCGGGACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTGTGTGGATGAGGTCACCATTGTC AACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTG AAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCC ATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTAC AAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGT AGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGA ACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCT TATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCC CTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAA GTGGACATGTTGAAAATTAGGTCTGAATTCAAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTAC CAGAAAGCGCTGCTGTACCTGTGTGGTGGAGATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCT AACAGGTCTAGAAAACCAGCTTGCGAATAACAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGT TGCCTAAGCATTGCCTGGCCTTCCTGTCTAGTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATG TGAAACACTTTGCCTCCTGTGTACTGTGTCATAAACAGATGAATAAACTGAATTTGTACTTTAGAAACACGTACTTTGTGGCCCTGCTTT CAACTGAATTGTTTGAAAATTAAACGTGCTTGGGGTTCAGCTGGTGAGGCTGTCCCTGTAGGAAGAAAGCTCTGGGACTGAGCTGTACAG >16602_16602_6_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000560397_ANXA2_chr15_60656722_ENST00000396024_length(amino acids)=342AA_BP=53 LTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGCVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASAL KSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKG RRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKP -------------------------------------------------------------- >16602_16602_7_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000560397_ANXA2_chr15_60656722_ENST00000421017_length(transcript)=1317nt_BP=157nt TTGACCCCTAGCCCTTCCTTCCCTCCCTCCTTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCG ATGGGTTCTCGGGCCTCCACGTTACTGCGGGACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTGTGTGGATGAGGTCACCATTGTC AACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTG AAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCC ATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTAC AAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGT AGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGA ACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCT TATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCC CTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAA GTGGACATGTTGAAAATTAGGTCTGAATTCAAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTAC CAGAAAGCGCTGCTGTACCTGTGTGGTGGAGATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCT AACAGGTCTAGAAAACCAGCTTGCGAATAACAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGT TGCCTAAGCATTGCCTGGCCTTCCTGTCTAGTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATG >16602_16602_7_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000560397_ANXA2_chr15_60656722_ENST00000421017_length(amino acids)=342AA_BP=53 LTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGCVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASAL KSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKG RRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKP -------------------------------------------------------------- >16602_16602_8_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000560397_ANXA2_chr15_60656722_ENST00000451270_length(transcript)=1332nt_BP=157nt TTGACCCCTAGCCCTTCCTTCCCTCCCTCCTTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCG ATGGGTTCTCGGGCCTCCACGTTACTGCGGGACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTGTGTGGATGAGGTCACCATTGTC AACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTG AAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCC ATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTAC AAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGT AGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGA ACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCT TATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCC CTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAA GTGGACATGTTGAAAATTAGGTCTGAATTCAAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTAC CAGAAAGCGCTGCTGTACCTGTGTGGTGGAGATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCT AACAGGTCTAGAAAACCAGCTTGCGAATAACAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGT TGCCTAAGCATTGCCTGGCCTTCCTGTCTAGTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATG >16602_16602_8_CHP1-ANXA2_CHP1_chr15_41523647_ENST00000560397_ANXA2_chr15_60656722_ENST00000451270_length(amino acids)=342AA_BP=53 LTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGCVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASAL KSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKG RRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CHP1-ANXA2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CHP1-ANXA2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CHP1-ANXA2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies