
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CHRDL1-GLUD1 (FusionGDB2 ID:16638) |
Fusion Gene Summary for CHRDL1-GLUD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CHRDL1-GLUD1 | Fusion gene ID: 16638 | Hgene | Tgene | Gene symbol | CHRDL1 | GLUD1 | Gene ID | 91851 | 2746 |
| Gene name | chordin like 1 | glutamate dehydrogenase 1 | |
| Synonyms | CHL|MGC1|MGCN|NRLN1|VOPT|dA141H5.1 | GDH|GDH1|GLUD | |
| Cytomap | Xq23 | 10q23.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | chordin-like protein 1neuralin-1neurogenesin-1ventroptin | glutamate dehydrogenase 1, mitochondrialepididymis secretory sperm binding proteinepididymis tissue sperm binding protein Li 18mPglutamate dehydrogenase (NAD(P)+) | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | Q9BU40 | P00367 | |
| Ensembl transtripts involved in fusion gene | ENST00000218054, ENST00000372042, ENST00000372045, ENST00000394797, ENST00000434224, ENST00000444321, ENST00000482160, | ENST00000465164, ENST00000277865, ENST00000537649, ENST00000544149, | |
| Fusion gene scores | * DoF score | 2 X 2 X 2=8 | 10 X 7 X 8=560 |
| # samples | 2 | 11 | |
| ** MAII score | log2(2/8*10)=1.32192809488736 | log2(11/560*10)=-2.34792330342031 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CHRDL1 [Title/Abstract] AND GLUD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CHRDL1(110002889)-GLUD1(88827914), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CHRDL1-GLUD1 seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | GLUD1 | GO:0006537 | glutamate biosynthetic process | 11032875 |
| Tgene | GLUD1 | GO:0006538 | glutamate catabolic process | 6121377|11032875 |
| Fusion gene breakpoints across CHRDL1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GLUD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | ERR315495 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
Top |
Fusion Gene ORF analysis for CHRDL1-GLUD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000218054 | ENST00000465164 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000372042 | ENST00000465164 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000372045 | ENST00000465164 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000394797 | ENST00000465164 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000434224 | ENST00000465164 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000444321 | ENST00000465164 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000482160 | ENST00000465164 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| Frame-shift | ENST00000218054 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| Frame-shift | ENST00000218054 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| Frame-shift | ENST00000218054 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| Frame-shift | ENST00000372045 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| Frame-shift | ENST00000372045 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| Frame-shift | ENST00000372045 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000372042 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000372042 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000372042 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000394797 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000394797 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000394797 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000434224 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000434224 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000434224 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000444321 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000444321 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000444321 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000482160 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000482160 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000482160 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000434224 | CHRDL1 | chrX | 110002889 | - | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2946 | 650 | 316 | 1680 | 454 |
| ENST00000434224 | CHRDL1 | chrX | 110002889 | - | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2942 | 650 | 316 | 1680 | 454 |
| ENST00000434224 | CHRDL1 | chrX | 110002889 | - | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1831 | 650 | 316 | 1680 | 454 |
| ENST00000394797 | CHRDL1 | chrX | 110002889 | - | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2653 | 357 | 23 | 1387 | 454 |
| ENST00000394797 | CHRDL1 | chrX | 110002889 | - | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2649 | 357 | 23 | 1387 | 454 |
| ENST00000394797 | CHRDL1 | chrX | 110002889 | - | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1538 | 357 | 23 | 1387 | 454 |
| ENST00000372042 | CHRDL1 | chrX | 110002889 | - | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2699 | 403 | 69 | 1433 | 454 |
| ENST00000372042 | CHRDL1 | chrX | 110002889 | - | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2695 | 403 | 69 | 1433 | 454 |
| ENST00000372042 | CHRDL1 | chrX | 110002889 | - | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1584 | 403 | 69 | 1433 | 454 |
| ENST00000482160 | CHRDL1 | chrX | 110002889 | - | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2707 | 411 | 77 | 1441 | 454 |
| ENST00000482160 | CHRDL1 | chrX | 110002889 | - | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2703 | 411 | 77 | 1441 | 454 |
| ENST00000482160 | CHRDL1 | chrX | 110002889 | - | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1592 | 411 | 77 | 1441 | 454 |
| ENST00000444321 | CHRDL1 | chrX | 110002889 | - | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2707 | 411 | 77 | 1441 | 454 |
| ENST00000444321 | CHRDL1 | chrX | 110002889 | - | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2703 | 411 | 77 | 1441 | 454 |
| ENST00000444321 | CHRDL1 | chrX | 110002889 | - | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1592 | 411 | 77 | 1441 | 454 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000434224 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000413927 | 0.99958605 |
| ENST00000434224 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000411039 | 0.999589 |
| ENST00000434224 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.001275888 | 0.99872404 |
| ENST00000394797 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000294373 | 0.9997056 |
| ENST00000394797 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000294526 | 0.9997055 |
| ENST00000394797 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000621387 | 0.99937856 |
| ENST00000372042 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000321498 | 0.9996785 |
| ENST00000372042 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000321765 | 0.99967825 |
| ENST00000372042 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000738675 | 0.9992613 |
| ENST00000482160 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000324864 | 0.99967515 |
| ENST00000482160 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000325134 | 0.9996749 |
| ENST00000482160 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000764511 | 0.9992355 |
| ENST00000444321 | ENST00000277865 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000324864 | 0.99967515 |
| ENST00000444321 | ENST00000537649 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000325134 | 0.9996749 |
| ENST00000444321 | ENST00000544149 | CHRDL1 | chrX | 110002889 | - | GLUD1 | chr10 | 88827914 | - | 0.000764511 | 0.9992355 |
Top |
Fusion Genomic Features for CHRDL1-GLUD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
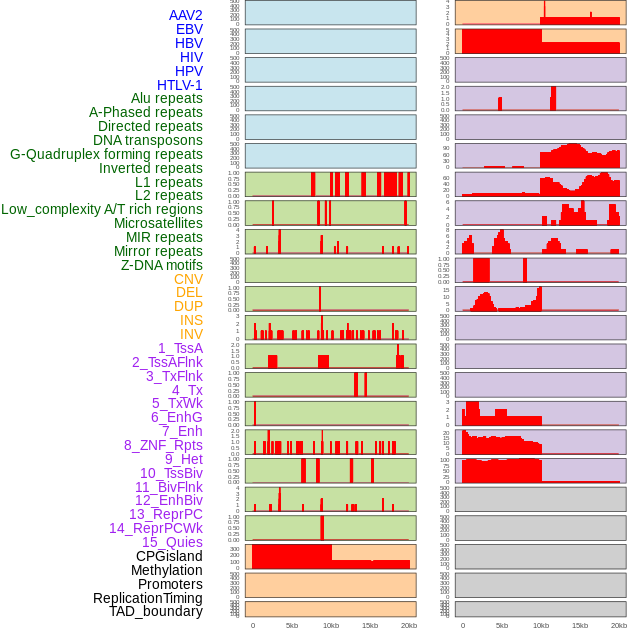 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CHRDL1-GLUD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chrX:110002889/chr10:88827914) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CHRDL1 | GLUD1 |
| FUNCTION: Antagonizes the function of BMP4 by binding to it and preventing its interaction with receptors. Alters the fate commitment of neural stem cells from gliogenesis to neurogenesis. Contributes to neuronal differentiation of neural stem cells in the brain by preventing the adoption of a glial fate. May play a crucial role in dorsoventral axis formation. May play a role in embryonic bone formation (By similarity). May also play an important role in regulating retinal angiogenesis through modulation of BMP4 actions in endothelial cells. Plays a role during anterior segment eye development. {ECO:0000250, ECO:0000269|PubMed:18587495, ECO:0000269|PubMed:22284829}. | FUNCTION: Mitochondrial glutamate dehydrogenase that catalyzes the conversion of L-glutamate into alpha-ketoglutarate. Plays a key role in glutamine anaplerosis by producing alpha-ketoglutarate, an important intermediate in the tricarboxylic acid cycle (PubMed:11032875, PubMed:16959573, PubMed:11254391, PubMed:16023112). Plays a role in insulin homeostasis (PubMed:9571255, PubMed:11297618). May be involved in learning and memory reactions by increasing the turnover of the excitatory neurotransmitter glutamate (By similarity). {ECO:0000250|UniProtKB:P10860, ECO:0000269|PubMed:11032875, ECO:0000269|PubMed:11254391, ECO:0000269|PubMed:11297618, ECO:0000269|PubMed:16023112, ECO:0000269|PubMed:16959573, ECO:0000269|PubMed:9571255}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000218054 | - | 4 | 12 | 35_100 | 100 | 457.0 | Domain | VWFC 1 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000372042 | - | 4 | 12 | 35_100 | 100 | 459.0 | Domain | VWFC 1 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000394797 | - | 4 | 12 | 35_100 | 100 | 457.0 | Domain | VWFC 1 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000444321 | - | 4 | 12 | 35_100 | 100 | 458.0 | Domain | VWFC 1 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000482160 | - | 4 | 10 | 35_100 | 100 | 379.0 | Domain | VWFC 1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000218054 | - | 4 | 12 | 113_179 | 100 | 457.0 | Domain | VWFC 2 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000218054 | - | 4 | 12 | 258_323 | 100 | 457.0 | Domain | VWFC 3 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000372042 | - | 4 | 12 | 113_179 | 100 | 459.0 | Domain | VWFC 2 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000372042 | - | 4 | 12 | 258_323 | 100 | 459.0 | Domain | VWFC 3 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000372045 | - | 4 | 12 | 113_179 | 94 | 451.0 | Domain | VWFC 2 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000372045 | - | 4 | 12 | 258_323 | 94 | 451.0 | Domain | VWFC 3 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000372045 | - | 4 | 12 | 35_100 | 94 | 451.0 | Domain | VWFC 1 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000394797 | - | 4 | 12 | 113_179 | 100 | 457.0 | Domain | VWFC 2 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000394797 | - | 4 | 12 | 258_323 | 100 | 457.0 | Domain | VWFC 3 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000444321 | - | 4 | 12 | 113_179 | 100 | 458.0 | Domain | VWFC 2 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000444321 | - | 4 | 12 | 258_323 | 100 | 458.0 | Domain | VWFC 3 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000482160 | - | 4 | 10 | 113_179 | 100 | 379.0 | Domain | VWFC 2 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000482160 | - | 4 | 10 | 258_323 | 100 | 379.0 | Domain | VWFC 3 |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000218054 | - | 4 | 12 | 179_181 | 100 | 457.0 | Motif | Cell attachment site |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000372042 | - | 4 | 12 | 179_181 | 100 | 459.0 | Motif | Cell attachment site |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000372045 | - | 4 | 12 | 179_181 | 94 | 451.0 | Motif | Cell attachment site |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000394797 | - | 4 | 12 | 179_181 | 100 | 457.0 | Motif | Cell attachment site |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000444321 | - | 4 | 12 | 179_181 | 100 | 458.0 | Motif | Cell attachment site |
| Hgene | CHRDL1 | chrX:110002889 | chr10:88827914 | ENST00000482160 | - | 4 | 10 | 179_181 | 100 | 379.0 | Motif | Cell attachment site |
| Tgene | GLUD1 | chrX:110002889 | chr10:88827914 | ENST00000277865 | 3 | 13 | 141_143 | 215 | 559.0 | Nucleotide binding | NAD |
Top |
Fusion Gene Sequence for CHRDL1-GLUD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >16638_16638_1_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000372042_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2699nt_BP=403nt CGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTT GCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAA ACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCT TATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTT TCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGG GAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGC CAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGC ATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACAT CGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTC AAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCA GCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCA GAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAG TGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAA GAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCT GAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGA TTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGAT CATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCC TGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACA AGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCA GCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGG ATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTT AGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAAT AGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAAT AAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTG TGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAG TCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGA GTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTAT CCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTT ATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCT >16638_16638_1_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000372042_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_2_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000372042_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2695nt_BP=403nt CGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTT GCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAA ACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCT TATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTT TCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGG GAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGC CAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGC ATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACAT CGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTC AAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCA GCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCA GAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAG TGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAA GAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCT GAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGA TTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGAT CATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCC TGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACA AGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCA GCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGG ATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTT AGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAAT AGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAAT AAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTG TGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAG TCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGA GTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTAT CCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTT ATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCT >16638_16638_2_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000372042_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_3_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000372042_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1584nt_BP=403nt CGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTT GCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAA ACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCT TATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTT TCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGG GAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGC CAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGC ATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACAT CGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTC AAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCA GCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCA GAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAG TGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAA GAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCT GAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGA TTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGAT CATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCC >16638_16638_3_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000372042_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_4_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000394797_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2653nt_BP=357nt GACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAAT ACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACA AGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGA ATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTC CTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACT ATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCT TCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTC AGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTA TATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCT ATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCA AAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAG ATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCA AATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCA TTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTT CTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCT TCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGA CCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTC AGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTG GTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGG GAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGT GTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACA AATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAA CAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTA TAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATT TTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCT TTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCT GGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACA GTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAG ATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAA >16638_16638_4_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000394797_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_5_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000394797_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2649nt_BP=357nt GACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAAT ACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACA AGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGA ATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTC CTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACT ATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCT TCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTC AGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTA TATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCT ATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCA AAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAG ATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCA AATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCA TTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTT CTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCT TCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGA CCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTC AGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTG GTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGG GAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGT GTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACA AATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAA CAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTA TAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATT TTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCT TTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCT GGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACA GTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAG ATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAA >16638_16638_5_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000394797_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_6_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000394797_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1538nt_BP=357nt GACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAAT ACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACA AGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGA ATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTC CTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACT ATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCT TCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTC AGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTA TATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCT ATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCA AAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAG ATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCA AATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCA TTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTT CTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCT TCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGA CCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTC >16638_16638_6_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000394797_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_7_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000434224_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2946nt_BP=650nt GTGCTTGCGGACTTCCCGCCAGCGCCGAGCGGCCGGCTTCTCGGGCCAAGTGGGGAGCGAGCGGGAGGGCGGGCAGGTGGCCCCGGGCCG CCGCGCCCGCGCCTTGGCTCTGCCCCCGGGAGCCGAGCAAGCCGCTGCTCCCTCGTGGTGTGAGGGCGGTGATGTTTTTCCTCCCACCCA CTTTTGAGTTCCCCCTCCCCCCTCGCGCGCACTCTAGCTCTCGCCACAACCTGCCAGCCCCAGACCTCGGACGAGAGCGCCCCGGGGAGC TCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTTGCAGTGGTCCAAATGAGAAAAAA GTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAAACAGAGCAAGTAAAACATTCAGA GACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCTTATGGGTTGGTTTACTGCGTGAA CTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTTTCTCCTGTGCATATTCCTCATCT GTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATAC CTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCAT CTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTT TGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGC TGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCT GGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGAC CAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGA GAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGT CAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGG AAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGG CTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTA TGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCC TCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCA TTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATC ACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCA ACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAAC TTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAA TTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAA TAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTT ATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATA CCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTT ATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTG GGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCA TTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACA GTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAAC >16638_16638_7_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000434224_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_8_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000434224_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2942nt_BP=650nt GTGCTTGCGGACTTCCCGCCAGCGCCGAGCGGCCGGCTTCTCGGGCCAAGTGGGGAGCGAGCGGGAGGGCGGGCAGGTGGCCCCGGGCCG CCGCGCCCGCGCCTTGGCTCTGCCCCCGGGAGCCGAGCAAGCCGCTGCTCCCTCGTGGTGTGAGGGCGGTGATGTTTTTCCTCCCACCCA CTTTTGAGTTCCCCCTCCCCCCTCGCGCGCACTCTAGCTCTCGCCACAACCTGCCAGCCCCAGACCTCGGACGAGAGCGCCCCGGGGAGC TCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTTGCAGTGGTCCAAATGAGAAAAAA GTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAAACAGAGCAAGTAAAACATTCAGA GACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCTTATGGGTTGGTTTACTGCGTGAA CTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTTTCTCCTGTGCATATTCCTCATCT GTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATAC CTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCAT CTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTT TGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGC TGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCT GGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGAC CAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGA GAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGT CAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGG AAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGG CTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTA TGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCC TCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCA TTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATC ACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCA ACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAAC TTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAA TTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAA TAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTT ATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATA CCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTT ATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTG GGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCA TTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACA GTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAAC >16638_16638_8_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000434224_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_9_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000434224_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1831nt_BP=650nt GTGCTTGCGGACTTCCCGCCAGCGCCGAGCGGCCGGCTTCTCGGGCCAAGTGGGGAGCGAGCGGGAGGGCGGGCAGGTGGCCCCGGGCCG CCGCGCCCGCGCCTTGGCTCTGCCCCCGGGAGCCGAGCAAGCCGCTGCTCCCTCGTGGTGTGAGGGCGGTGATGTTTTTCCTCCCACCCA CTTTTGAGTTCCCCCTCCCCCCTCGCGCGCACTCTAGCTCTCGCCACAACCTGCCAGCCCCAGACCTCGGACGAGAGCGCCCCGGGGAGC TCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGTCACCTTTTGCAGTGGTCCAAATGAGAAAAAA GTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAGGAGGCAAAACAGAGCAAGTAAAACATTCAGA GACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACCTGGAACCTTATGGGTTGGTTTACTGCGTGAA CTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTCATTGCCTTTCTCCTGTGCATATTCCTCATCT GTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATAC CTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCAT CTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTT TGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGC TGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCT GGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGAC CAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGA GAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGT CAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGG AAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGG CTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTA TGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCC TCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCA >16638_16638_9_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000434224_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_10_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000444321_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2707nt_BP=411nt CCAGACCTCGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGT CACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAG GAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACC TGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTC ATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAG GTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAAC CCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTT ACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGAT ATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGG AAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATAC TGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAA CAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTT ACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGT CTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGG GTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATA ACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACAT AGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCT TTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGAT CATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTG GCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATT TTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGT GAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCT TTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATA GAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAA AAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTA TGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATT CAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGA CTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATT TGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTT TTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAACCTGGTGATAAAAGCAGTTATTAAAAGTCTACGTTT >16638_16638_10_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000444321_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_11_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000444321_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2703nt_BP=411nt CCAGACCTCGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGT CACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAG GAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACC TGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTC ATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAG GTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAAC CCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTT ACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGAT ATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGG AAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATAC TGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAA CAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTT ACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGT CTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGG GTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATA ACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACAT AGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCT TTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGAT CATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTG GCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATT TTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGT GAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCT TTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATA GAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAA AAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTA TGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATT CAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGA CTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATT TGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTT TTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAACCTGGTGATAAAAGCAGTTATTAAAAGTCTACGTTT >16638_16638_11_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000444321_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_12_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000444321_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1592nt_BP=411nt CCAGACCTCGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGT CACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAG GAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACC TGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTC ATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAG GTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAAC CCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTT ACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGAT ATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGG AAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATAC TGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAA CAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTT ACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGT CTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGG GTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATA ACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACAT AGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCT >16638_16638_12_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000444321_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_13_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000482160_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2707nt_BP=411nt CCAGACCTCGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGT CACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAG GAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACC TGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTC ATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAG GTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAAC CCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTT ACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGAT ATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGG AAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATAC TGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAA CAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTT ACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGT CTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGG GTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATA ACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACAT AGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCT TTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGAT CATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTG GCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATT TTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGT GAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCT TTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATA GAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAA AAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTA TGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATT CAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGA CTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATT TGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTT TTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAACCTGGTGATAAAAGCAGTTATTAAAAGTCTACGTTT >16638_16638_13_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000482160_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_14_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000482160_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2703nt_BP=411nt CCAGACCTCGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGT CACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAG GAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACC TGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTC ATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAG GTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAAC CCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTT ACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGAT ATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGG AAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATAC TGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAA CAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTT ACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGT CTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGG GTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATA ACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACAT AGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCT TTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGAT CATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTG GCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATT TTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGT GAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCT TTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATA GAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAA AAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTA TGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATT CAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGA CTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATT TGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTT TTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAACCTGGTGATAAAAGCAGTTATTAAAAGTCTACGTTT >16638_16638_14_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000482160_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- >16638_16638_15_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000482160_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1592nt_BP=411nt CCAGACCTCGGACGAGAGCGCCCCGGGGAGCTCGGAGCGCGTGCACGCGTGGCAGACGGAGAAGGCCAGTGCCCAGCTTGAAGGTTCTGT CACCTTTTGCAGTGGTCCAAATGAGAAAAAAGTGGAAAATGGGAGGCATGAAATACATCTTTTCGTTGTTGTTCTTTCTTTTGCTAGAAG GAGGCAAAACAGAGCAAGTAAAACATTCAGAGACATATTGCATGTTTCAAGACAAGAAGTACAGAGTGGGTGAGAGATGGCATCCTTACC TGGAACCTTATGGGTTGGTTTACTGCGTGAACTGCATCTGCTCAGAGAATGGGAATGTGCTTTGCAGCCGAGTCAGATGTCCAAATGTTC ATTGCCTTTCTCCTGTGCATATTCCTCATCTGTGCTGCCCTCGCTGCCCAGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAG GTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAAC CCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTT ACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGAT ATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGG AAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATAC TGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAA CAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTT ACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGT CTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGG GTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATA ACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACAT AGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCT >16638_16638_15_CHRDL1-GLUD1_CHRDL1_chrX_110002889_ENST00000482160_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=454AA_BP=111 MKVLSPFAVVQMRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVR CPNVHCLSPVHIPHLCCPRCPGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFI NEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEA DCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNY HLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CHRDL1-GLUD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CHRDL1-GLUD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CHRDL1-GLUD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies