
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CLASP1-SEPT10 (FusionGDB2 ID:16937) |
Fusion Gene Summary for CLASP1-SEPT10 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CLASP1-SEPT10 | Fusion gene ID: 16937 | Hgene | Tgene | Gene symbol | CLASP1 | SEPT10 | Gene ID | 23332 | 151011 |
| Gene name | cytoplasmic linker associated protein 1 | septin 10 | |
| Synonyms | MAST1 | SEPT10 | |
| Cytomap | 2q14.2-q14.3 | 2q13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | CLIP-associating protein 1multiple asters 1multiple asters homolog 1protein Orbit homolog 1 | septin-10 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q7Z460 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000263710, ENST00000397587, ENST00000409078, ENST00000455322, ENST00000541377, ENST00000430234, ENST00000541859, ENST00000545861, | ENST00000334001, ENST00000415095, ENST00000437928, ENST00000545389, ENST00000397714, ENST00000468616, ENST00000356688, ENST00000397712, | |
| Fusion gene scores | * DoF score | 8 X 6 X 5=240 | 3 X 2 X 3=18 |
| # samples | 8 | 4 | |
| ** MAII score | log2(8/240*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/18*10)=1.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: CLASP1 [Title/Abstract] AND SEPT10 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CLASP1(122363277)-SEPT10(110350696), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CLASP1 | GO:0051294 | establishment of spindle orientation | 21822276 |
| Hgene | CLASP1 | GO:0051301 | cell division | 21822276 |
| Fusion gene breakpoints across CLASP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SEPT10 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
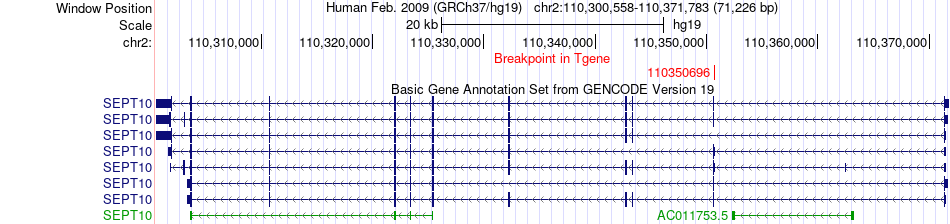 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-HU-A4GN-01A | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
Top |
Fusion Gene ORF analysis for CLASP1-SEPT10 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000263710 | ENST00000334001 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000263710 | ENST00000415095 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000263710 | ENST00000437928 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000263710 | ENST00000545389 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000397587 | ENST00000334001 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000397587 | ENST00000415095 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000397587 | ENST00000437928 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000397587 | ENST00000545389 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000409078 | ENST00000334001 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000409078 | ENST00000415095 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000409078 | ENST00000437928 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000409078 | ENST00000545389 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000455322 | ENST00000334001 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000455322 | ENST00000415095 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000455322 | ENST00000437928 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000455322 | ENST00000545389 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000541377 | ENST00000334001 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000541377 | ENST00000415095 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000541377 | ENST00000437928 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-5UTR | ENST00000541377 | ENST00000545389 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000263710 | ENST00000397714 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000263710 | ENST00000468616 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000397587 | ENST00000397714 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000397587 | ENST00000468616 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000409078 | ENST00000397714 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000409078 | ENST00000468616 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000455322 | ENST00000397714 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000455322 | ENST00000468616 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000541377 | ENST00000397714 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| 5CDS-intron | ENST00000541377 | ENST00000468616 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000263710 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000263710 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000397587 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000397587 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000409078 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000409078 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000455322 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000455322 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000541377 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| In-frame | ENST00000541377 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-3CDS | ENST00000430234 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-3CDS | ENST00000430234 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-3CDS | ENST00000541859 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-3CDS | ENST00000541859 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-3CDS | ENST00000545861 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-3CDS | ENST00000545861 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000430234 | ENST00000334001 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000430234 | ENST00000415095 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000430234 | ENST00000437928 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000430234 | ENST00000545389 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000541859 | ENST00000334001 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000541859 | ENST00000415095 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000541859 | ENST00000437928 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000541859 | ENST00000545389 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000545861 | ENST00000334001 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000545861 | ENST00000415095 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000545861 | ENST00000437928 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-5UTR | ENST00000545861 | ENST00000545389 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-intron | ENST00000430234 | ENST00000397714 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-intron | ENST00000430234 | ENST00000468616 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-intron | ENST00000541859 | ENST00000397714 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-intron | ENST00000541859 | ENST00000468616 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-intron | ENST00000545861 | ENST00000397714 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| intron-intron | ENST00000545861 | ENST00000468616 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000409078 | CLASP1 | chr2 | 122363277 | - | ENST00000356688 | SEPT10 | chr2 | 110350696 | - | 3441 | 696 | 474 | 2300 | 608 |
| ENST00000409078 | CLASP1 | chr2 | 122363277 | - | ENST00000397712 | SEPT10 | chr2 | 110350696 | - | 3358 | 696 | 474 | 2030 | 518 |
| ENST00000541377 | CLASP1 | chr2 | 122363277 | - | ENST00000356688 | SEPT10 | chr2 | 110350696 | - | 3330 | 585 | 363 | 2189 | 608 |
| ENST00000541377 | CLASP1 | chr2 | 122363277 | - | ENST00000397712 | SEPT10 | chr2 | 110350696 | - | 3247 | 585 | 363 | 1919 | 518 |
| ENST00000455322 | CLASP1 | chr2 | 122363277 | - | ENST00000356688 | SEPT10 | chr2 | 110350696 | - | 3330 | 585 | 363 | 2189 | 608 |
| ENST00000455322 | CLASP1 | chr2 | 122363277 | - | ENST00000397712 | SEPT10 | chr2 | 110350696 | - | 3247 | 585 | 363 | 1919 | 518 |
| ENST00000397587 | CLASP1 | chr2 | 122363277 | - | ENST00000356688 | SEPT10 | chr2 | 110350696 | - | 3330 | 585 | 363 | 2189 | 608 |
| ENST00000397587 | CLASP1 | chr2 | 122363277 | - | ENST00000397712 | SEPT10 | chr2 | 110350696 | - | 3247 | 585 | 363 | 1919 | 518 |
| ENST00000263710 | CLASP1 | chr2 | 122363277 | - | ENST00000356688 | SEPT10 | chr2 | 110350696 | - | 3330 | 585 | 363 | 2189 | 608 |
| ENST00000263710 | CLASP1 | chr2 | 122363277 | - | ENST00000397712 | SEPT10 | chr2 | 110350696 | - | 3247 | 585 | 363 | 1919 | 518 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000409078 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000206193 | 0.9997938 |
| ENST00000409078 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000172123 | 0.99982786 |
| ENST00000541377 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000224899 | 0.9997751 |
| ENST00000541377 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000187756 | 0.9998123 |
| ENST00000455322 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000224899 | 0.9997751 |
| ENST00000455322 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000187756 | 0.9998123 |
| ENST00000397587 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000224899 | 0.9997751 |
| ENST00000397587 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000187756 | 0.9998123 |
| ENST00000263710 | ENST00000356688 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000224899 | 0.9997751 |
| ENST00000263710 | ENST00000397712 | CLASP1 | chr2 | 122363277 | - | SEPT10 | chr2 | 110350696 | - | 0.000187756 | 0.9998123 |
Top |
Fusion Genomic Features for CLASP1-SEPT10 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
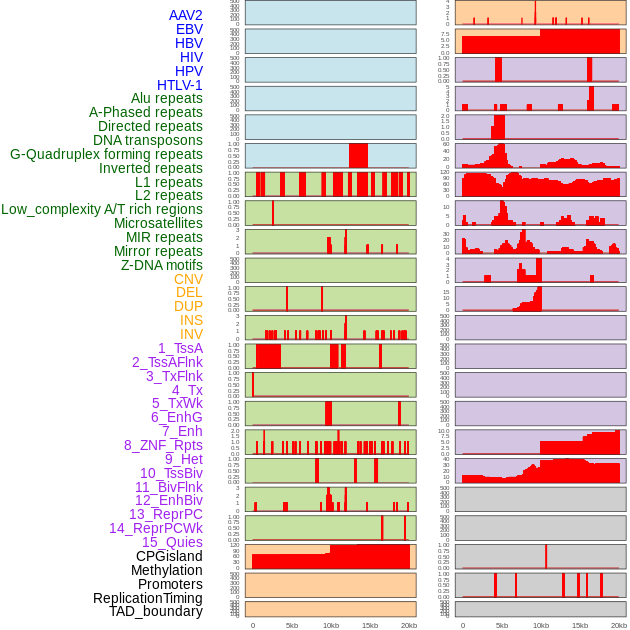 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CLASP1-SEPT10 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:122363277/chr2:110350696) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CLASP1 | . |
| FUNCTION: Microtubule plus-end tracking protein that promotes the stabilization of dynamic microtubules. Involved in the nucleation of noncentrosomal microtubules originating from the trans-Golgi network (TGN). Required for the polarization of the cytoplasmic microtubule arrays in migrating cells towards the leading edge of the cell. May act at the cell cortex to enhance the frequency of rescue of depolymerizing microtubules by attaching their plus-ends to cortical platforms composed of ERC1 and PHLDB2. This cortical microtubule stabilizing activity is regulated at least in part by phosphatidylinositol 3-kinase signaling. Also performs a similar stabilizing function at the kinetochore which is essential for the bipolar alignment of chromosomes on the mitotic spindle. {ECO:0000269|PubMed:11290329, ECO:0000269|PubMed:12837247, ECO:0000269|PubMed:15631994, ECO:0000269|PubMed:16866869, ECO:0000269|PubMed:16914514, ECO:0000269|PubMed:17543864}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397712 | 0 | 11 | 63_329 | 10 | 455.0 | Domain | Septin-type G | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397714 | 0 | 10 | 63_329 | 0 | 432.0 | Domain | Septin-type G | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397712 | 0 | 11 | 209_217 | 10 | 455.0 | Nucleotide binding | GTP | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397714 | 0 | 10 | 209_217 | 0 | 432.0 | Nucleotide binding | GTP | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397712 | 0 | 11 | 125_128 | 10 | 455.0 | Region | G3 motif | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397712 | 0 | 11 | 208_211 | 10 | 455.0 | Region | G4 motif | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397712 | 0 | 11 | 73_80 | 10 | 455.0 | Region | G1 motif | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397714 | 0 | 10 | 125_128 | 0 | 432.0 | Region | G3 motif | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397714 | 0 | 10 | 208_211 | 0 | 432.0 | Region | G4 motif | |
| Tgene | SEPT10 | chr2:122363277 | chr2:110350696 | ENST00000397714 | 0 | 10 | 73_80 | 0 | 432.0 | Region | G1 motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 1299_1330 | 65 | 1539.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 1299_1330 | 65 | 1472.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 1526_1532 | 65 | 1539.0 | Compositional bias | Note=Poly-Ser |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 530_765 | 65 | 1539.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 1526_1532 | 65 | 1472.0 | Compositional bias | Note=Poly-Ser |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 530_765 | 65 | 1472.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 1256_1538 | 65 | 1539.0 | Region | Note=Localization to kinetochores |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 1256_1538 | 65 | 1472.0 | Region | Note=Localization to kinetochores |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 1342_1379 | 65 | 1539.0 | Repeat | Note=HEAT 6 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 1460_1497 | 65 | 1539.0 | Repeat | Note=HEAT 7 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 163_200 | 65 | 1539.0 | Repeat | Note=HEAT 2 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 405_440 | 65 | 1539.0 | Repeat | Note=HEAT 3 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 441_477 | 65 | 1539.0 | Repeat | Note=HEAT 4 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 87_124 | 65 | 1539.0 | Repeat | Note=HEAT 1 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 974_1011 | 65 | 1539.0 | Repeat | Note=HEAT 5 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 1342_1379 | 65 | 1472.0 | Repeat | Note=HEAT 6 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 1460_1497 | 65 | 1472.0 | Repeat | Note=HEAT 7 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 163_200 | 65 | 1472.0 | Repeat | Note=HEAT 2 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 405_440 | 65 | 1472.0 | Repeat | Note=HEAT 3 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 441_477 | 65 | 1472.0 | Repeat | Note=HEAT 4 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 87_124 | 65 | 1472.0 | Repeat | Note=HEAT 1 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 974_1011 | 65 | 1472.0 | Repeat | Note=HEAT 5 |
Top |
Fusion Gene Sequence for CLASP1-SEPT10 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >16937_16937_1_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000263710_SEPT10_chr2_110350696_ENST00000356688_length(transcript)=3330nt_BP=585nt TTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTCTGGTCCGCAGCGGCAACAGTA ACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTGCCACTCACTCCTTTATCTCCT ACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGCCATTCCCCAGATTGCATCTTT GAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGAGTCATCGTGACTGCCCTCTAG CTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTGCAGAAGGATGTGGGGAAACGA TTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGACCAGACCATGTTAGATAAACTT GTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACGAAAACAACTTGTATGTCTTCA CAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGTTTTGAGAGTTTGCCTGATCAG CTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGAAAATCAACACTGATTGACACA TTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAGACATATGAACTCCAGGAAAGT AATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGCTACCAACCAATAGTTGACTAC ATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCATGATTCTCGCATCCATGTGTGT CTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGACAGCAAGGTAAACATTATACCA GTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAATTGGTCAGCAATGGCGTCCAG ATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCGTTTGCTGTTGTGGGAAGTATG GATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAAAATGAAAACCACTGTGACTTT GTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCACTATGAGCTTTACAGGCGCTGC AAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTATGAAGCCAAAAGACATGAGTTC CATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAAGCCATATTGAAAGAAGCTGAG AGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAAAAGAGAAGACTTTTGGAAGAA GAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACAGGCAGCAACCTGAGGAAGGAC AAGGACCGTAAGAAGGAACCAGGCTGTCGATTCGAACTCCTGTGCATTGATGTCAGAGCTTGTGAAACCAATGGTGGACGTAAAGACGCA GAGAAAGCTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTTATTAAAAAAAAACTAGAAGTG TGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTTATGGAAAAGTACTTTCAAGTA CAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAATCCAGAAGCTTCAAAATCTGAA TCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGTTCAGTTTAAACAGATTTTGTT TCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTATGTAATTAGAGTCGGGTCCCG TTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGGATACTCAGCTTGTACCTATAT ATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTCTTGCTACCAAGCTATTGTCAC TGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTATCTGATTACATTTATATTCCA AGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAACTCTAACCTCTTAATAGTTTT ATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTATTTAATATGATGACTTCATGC TTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATCCAGATATATAAGCTATTTTTT CCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATACTTGTTTAAACTCTGTCTTCCA GGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGAATATTAAAGATATAAAAATGC ACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGATTTCTAACATTTCTTAACAGTC ATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAATAAAACATATATTTACTAAAA >16937_16937_1_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000263710_SEPT10_chr2_110350696_ENST00000356688_length(amino acids)=608AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER ELQAKFEHLKRLHQEERMKLEEKRRLLEEEIIAFSKKKATSEIFHSQSFLATGSNLRKDKDRKKEPGCRFELLCIDVRACETNGGRKDAE -------------------------------------------------------------- >16937_16937_2_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000263710_SEPT10_chr2_110350696_ENST00000397712_length(transcript)=3247nt_BP=585nt TTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTCTGGTCCGCAGCGGCAACAGTA ACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTGCCACTCACTCCTTTATCTCCT ACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGCCATTCCCCAGATTGCATCTTT GAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGAGTCATCGTGACTGCCCTCTAG CTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTGCAGAAGGATGTGGGGAAACGA TTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGACCAGACCATGTTAGATAAACTT GTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACGAAAACAACTTGTATGTCTTCA CAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGTTTTGAGAGTTTGCCTGATCAG CTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGAAAATCAACACTGATTGACACA TTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAGACATATGAACTCCAGGAAAGT AATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGCTACCAACCAATAGTTGACTAC ATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCATGATTCTCGCATCCATGTGTGT CTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGACAGCAAGGTAAACATTATACCA GTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAATTGGTCAGCAATGGCGTCCAG ATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCGTTTGCTGTTGTGGGAAGTATG GATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAAAATGAAAACCACTGTGACTTT GTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCACTATGAGCTTTACAGGCGCTGC AAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTATGAAGCCAAAAGACATGAGTTC CATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAAGCCATATTGAAAGAAGCTGAG AGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAAAAGAGAAGACTTTTGGAAGAA GAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACAGGCAGCAACCTGAGGAAGGAC AAGGACCGTAAGAACTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTTATTAAAAAAAAACT AGAAGTGTGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTTATGGAAAAGTACTT TCAAGTACAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAATCCAGAAGCTTCAAA ATCTGAATCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGTTCAGTTTAAACAGA TTTTGTTTCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTATGTAATTAGAGTCG GGTCCCGTTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGGATACTCAGCTTGTA CCTATATATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTCTTGCTACCAAGCTA TTGTCACTGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTATCTGATTACATTTA TATTCCAAGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAACTCTAACCTCTTAA TAGTTTTATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTATTTAATATGATGAC TTCATGCTTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATCCAGATATATAAGCT ATTTTTTCCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATACTTGTTTAAACTCTG TCTTCCAGGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGAATATTAAAGATATA AAAATGCACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGATTTCTAACATTTCTT AACAGTCATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAATAAAACATATATTT >16937_16937_2_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000263710_SEPT10_chr2_110350696_ENST00000397712_length(amino acids)=518AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER -------------------------------------------------------------- >16937_16937_3_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000397587_SEPT10_chr2_110350696_ENST00000356688_length(transcript)=3330nt_BP=585nt TTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTCTGGTCCGCAGCGGCAACAGTA ACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTGCCACTCACTCCTTTATCTCCT ACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGCCATTCCCCAGATTGCATCTTT GAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGAGTCATCGTGACTGCCCTCTAG CTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTGCAGAAGGATGTGGGGAAACGA TTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGACCAGACCATGTTAGATAAACTT GTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACGAAAACAACTTGTATGTCTTCA CAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGTTTTGAGAGTTTGCCTGATCAG CTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGAAAATCAACACTGATTGACACA TTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAGACATATGAACTCCAGGAAAGT AATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGCTACCAACCAATAGTTGACTAC ATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCATGATTCTCGCATCCATGTGTGT CTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGACAGCAAGGTAAACATTATACCA GTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAATTGGTCAGCAATGGCGTCCAG ATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCGTTTGCTGTTGTGGGAAGTATG GATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAAAATGAAAACCACTGTGACTTT GTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCACTATGAGCTTTACAGGCGCTGC AAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTATGAAGCCAAAAGACATGAGTTC CATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAAGCCATATTGAAAGAAGCTGAG AGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAAAAGAGAAGACTTTTGGAAGAA GAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACAGGCAGCAACCTGAGGAAGGAC AAGGACCGTAAGAAGGAACCAGGCTGTCGATTCGAACTCCTGTGCATTGATGTCAGAGCTTGTGAAACCAATGGTGGACGTAAAGACGCA GAGAAAGCTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTTATTAAAAAAAAACTAGAAGTG TGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTTATGGAAAAGTACTTTCAAGTA CAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAATCCAGAAGCTTCAAAATCTGAA TCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGTTCAGTTTAAACAGATTTTGTT TCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTATGTAATTAGAGTCGGGTCCCG TTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGGATACTCAGCTTGTACCTATAT ATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTCTTGCTACCAAGCTATTGTCAC TGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTATCTGATTACATTTATATTCCA AGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAACTCTAACCTCTTAATAGTTTT ATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTATTTAATATGATGACTTCATGC TTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATCCAGATATATAAGCTATTTTTT CCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATACTTGTTTAAACTCTGTCTTCCA GGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGAATATTAAAGATATAAAAATGC ACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGATTTCTAACATTTCTTAACAGTC ATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAATAAAACATATATTTACTAAAA >16937_16937_3_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000397587_SEPT10_chr2_110350696_ENST00000356688_length(amino acids)=608AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER ELQAKFEHLKRLHQEERMKLEEKRRLLEEEIIAFSKKKATSEIFHSQSFLATGSNLRKDKDRKKEPGCRFELLCIDVRACETNGGRKDAE -------------------------------------------------------------- >16937_16937_4_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000397587_SEPT10_chr2_110350696_ENST00000397712_length(transcript)=3247nt_BP=585nt TTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTCTGGTCCGCAGCGGCAACAGTA ACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTGCCACTCACTCCTTTATCTCCT ACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGCCATTCCCCAGATTGCATCTTT GAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGAGTCATCGTGACTGCCCTCTAG CTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTGCAGAAGGATGTGGGGAAACGA TTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGACCAGACCATGTTAGATAAACTT GTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACGAAAACAACTTGTATGTCTTCA CAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGTTTTGAGAGTTTGCCTGATCAG CTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGAAAATCAACACTGATTGACACA TTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAGACATATGAACTCCAGGAAAGT AATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGCTACCAACCAATAGTTGACTAC ATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCATGATTCTCGCATCCATGTGTGT CTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGACAGCAAGGTAAACATTATACCA GTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAATTGGTCAGCAATGGCGTCCAG ATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCGTTTGCTGTTGTGGGAAGTATG GATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAAAATGAAAACCACTGTGACTTT GTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCACTATGAGCTTTACAGGCGCTGC AAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTATGAAGCCAAAAGACATGAGTTC CATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAAGCCATATTGAAAGAAGCTGAG AGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAAAAGAGAAGACTTTTGGAAGAA GAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACAGGCAGCAACCTGAGGAAGGAC AAGGACCGTAAGAACTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTTATTAAAAAAAAACT AGAAGTGTGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTTATGGAAAAGTACTT TCAAGTACAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAATCCAGAAGCTTCAAA ATCTGAATCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGTTCAGTTTAAACAGA TTTTGTTTCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTATGTAATTAGAGTCG GGTCCCGTTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGGATACTCAGCTTGTA CCTATATATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTCTTGCTACCAAGCTA TTGTCACTGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTATCTGATTACATTTA TATTCCAAGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAACTCTAACCTCTTAA TAGTTTTATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTATTTAATATGATGAC TTCATGCTTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATCCAGATATATAAGCT ATTTTTTCCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATACTTGTTTAAACTCTG TCTTCCAGGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGAATATTAAAGATATA AAAATGCACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGATTTCTAACATTTCTT AACAGTCATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAATAAAACATATATTT >16937_16937_4_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000397587_SEPT10_chr2_110350696_ENST00000397712_length(amino acids)=518AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER -------------------------------------------------------------- >16937_16937_5_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000409078_SEPT10_chr2_110350696_ENST00000356688_length(transcript)=3441nt_BP=696nt GCTCTCTATGGTGTACCCGGGTTGGTGGCGGTAAGAAGAAAAAGGGTGACCGCACTGCGCAGGCGCCCTCGGCGTCTCTCTCGCTCTCTC GGTCTTTTTTTTTTTTTTCTTTTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTC TGGTCCGCAGCGGCAACAGTAACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTG CCACTCACTCCTTTATCTCCTACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGC CATTCCCCAGATTGCATCTTTGAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGA GTCATCGTGACTGCCCTCTAGCTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTG CAGAAGGATGTGGGGAAACGATTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGAC CAGACCATGTTAGATAAACTTGTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACG AAAACAACTTGTATGTCTTCACAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGT TTTGAGAGTTTGCCTGATCAGCTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGA AAATCAACACTGATTGACACATTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAG ACATATGAACTCCAGGAAAGTAATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGC TACCAACCAATAGTTGACTACATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCAT GATTCTCGCATCCATGTGTGTCTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGAC AGCAAGGTAAACATTATACCAGTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAA TTGGTCAGCAATGGCGTCCAGATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCG TTTGCTGTTGTGGGAAGTATGGATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAA AATGAAAACCACTGTGACTTTGTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCAC TATGAGCTTTACAGGCGCTGCAAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTAT GAAGCCAAAAGACATGAGTTCCATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAA GCCATATTGAAAGAAGCTGAGAGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAA AAGAGAAGACTTTTGGAAGAAGAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACA GGCAGCAACCTGAGGAAGGACAAGGACCGTAAGAAGGAACCAGGCTGTCGATTCGAACTCCTGTGCATTGATGTCAGAGCTTGTGAAACC AATGGTGGACGTAAAGACGCAGAGAAAGCTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTT ATTAAAAAAAAACTAGAAGTGTGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTT ATGGAAAAGTACTTTCAAGTACAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAAT CCAGAAGCTTCAAAATCTGAATCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGT TCAGTTTAAACAGATTTTGTTTCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTA TGTAATTAGAGTCGGGTCCCGTTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGG ATACTCAGCTTGTACCTATATATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTC TTGCTACCAAGCTATTGTCACTGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTA TCTGATTACATTTATATTCCAAGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAA CTCTAACCTCTTAATAGTTTTATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTA TTTAATATGATGACTTCATGCTTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATC CAGATATATAAGCTATTTTTTCCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATAC TTGTTTAAACTCTGTCTTCCAGGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGA ATATTAAAGATATAAAAATGCACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGAT TTCTAACATTTCTTAACAGTCATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAA >16937_16937_5_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000409078_SEPT10_chr2_110350696_ENST00000356688_length(amino acids)=608AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER ELQAKFEHLKRLHQEERMKLEEKRRLLEEEIIAFSKKKATSEIFHSQSFLATGSNLRKDKDRKKEPGCRFELLCIDVRACETNGGRKDAE -------------------------------------------------------------- >16937_16937_6_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000409078_SEPT10_chr2_110350696_ENST00000397712_length(transcript)=3358nt_BP=696nt GCTCTCTATGGTGTACCCGGGTTGGTGGCGGTAAGAAGAAAAAGGGTGACCGCACTGCGCAGGCGCCCTCGGCGTCTCTCTCGCTCTCTC GGTCTTTTTTTTTTTTTTCTTTTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTC TGGTCCGCAGCGGCAACAGTAACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTG CCACTCACTCCTTTATCTCCTACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGC CATTCCCCAGATTGCATCTTTGAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGA GTCATCGTGACTGCCCTCTAGCTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTG CAGAAGGATGTGGGGAAACGATTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGAC CAGACCATGTTAGATAAACTTGTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACG AAAACAACTTGTATGTCTTCACAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGT TTTGAGAGTTTGCCTGATCAGCTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGA AAATCAACACTGATTGACACATTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAG ACATATGAACTCCAGGAAAGTAATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGC TACCAACCAATAGTTGACTACATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCAT GATTCTCGCATCCATGTGTGTCTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGAC AGCAAGGTAAACATTATACCAGTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAA TTGGTCAGCAATGGCGTCCAGATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCG TTTGCTGTTGTGGGAAGTATGGATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAA AATGAAAACCACTGTGACTTTGTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCAC TATGAGCTTTACAGGCGCTGCAAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTAT GAAGCCAAAAGACATGAGTTCCATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAA GCCATATTGAAAGAAGCTGAGAGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAA AAGAGAAGACTTTTGGAAGAAGAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACA GGCAGCAACCTGAGGAAGGACAAGGACCGTAAGAACTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGC AAACTTTATTAAAAAAAAACTAGAAGTGTGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACT GATATTTATGGAAAAGTACTTTCAAGTACAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAAT CTGAAATCCAGAAGCTTCAAAATCTGAATCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTC TGATGGTTCAGTTTAAACAGATTTTGTTTCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACA TGAATTATGTAATTAGAGTCGGGTCCCGTTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGG ATAAGGGATACTCAGCTTGTACCTATATATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATC TTTTCTCTTGCTACCAAGCTATTGTCACTGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATC GTGGCTATCTGATTACATTTATATTCCAAGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGA GCTAAAACTCTAACCTCTTAATAGTTTTATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGT CAGATTATTTAATATGATGACTTCATGCTTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTA AAACATCCAGATATATAAGCTATTTTTTCCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCAT TACATACTTGTTTAAACTCTGTCTTCCAGGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAA CATCTGAATATTAAAGATATAAAAATGCACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTT TAATGATTTCTAACATTTCTTAACAGTCATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCT >16937_16937_6_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000409078_SEPT10_chr2_110350696_ENST00000397712_length(amino acids)=518AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER -------------------------------------------------------------- >16937_16937_7_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000455322_SEPT10_chr2_110350696_ENST00000356688_length(transcript)=3330nt_BP=585nt TTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTCTGGTCCGCAGCGGCAACAGTA ACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTGCCACTCACTCCTTTATCTCCT ACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGCCATTCCCCAGATTGCATCTTT GAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGAGTCATCGTGACTGCCCTCTAG CTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTGCAGAAGGATGTGGGGAAACGA TTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGACCAGACCATGTTAGATAAACTT GTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACGAAAACAACTTGTATGTCTTCA CAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGTTTTGAGAGTTTGCCTGATCAG CTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGAAAATCAACACTGATTGACACA TTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAGACATATGAACTCCAGGAAAGT AATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGCTACCAACCAATAGTTGACTAC ATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCATGATTCTCGCATCCATGTGTGT CTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGACAGCAAGGTAAACATTATACCA GTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAATTGGTCAGCAATGGCGTCCAG ATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCGTTTGCTGTTGTGGGAAGTATG GATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAAAATGAAAACCACTGTGACTTT GTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCACTATGAGCTTTACAGGCGCTGC AAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTATGAAGCCAAAAGACATGAGTTC CATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAAGCCATATTGAAAGAAGCTGAG AGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAAAAGAGAAGACTTTTGGAAGAA GAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACAGGCAGCAACCTGAGGAAGGAC AAGGACCGTAAGAAGGAACCAGGCTGTCGATTCGAACTCCTGTGCATTGATGTCAGAGCTTGTGAAACCAATGGTGGACGTAAAGACGCA GAGAAAGCTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTTATTAAAAAAAAACTAGAAGTG TGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTTATGGAAAAGTACTTTCAAGTA CAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAATCCAGAAGCTTCAAAATCTGAA TCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGTTCAGTTTAAACAGATTTTGTT TCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTATGTAATTAGAGTCGGGTCCCG TTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGGATACTCAGCTTGTACCTATAT ATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTCTTGCTACCAAGCTATTGTCAC TGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTATCTGATTACATTTATATTCCA AGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAACTCTAACCTCTTAATAGTTTT ATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTATTTAATATGATGACTTCATGC TTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATCCAGATATATAAGCTATTTTTT CCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATACTTGTTTAAACTCTGTCTTCCA GGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGAATATTAAAGATATAAAAATGC ACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGATTTCTAACATTTCTTAACAGTC ATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAATAAAACATATATTTACTAAAA >16937_16937_7_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000455322_SEPT10_chr2_110350696_ENST00000356688_length(amino acids)=608AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER ELQAKFEHLKRLHQEERMKLEEKRRLLEEEIIAFSKKKATSEIFHSQSFLATGSNLRKDKDRKKEPGCRFELLCIDVRACETNGGRKDAE -------------------------------------------------------------- >16937_16937_8_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000455322_SEPT10_chr2_110350696_ENST00000397712_length(transcript)=3247nt_BP=585nt TTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTCTGGTCCGCAGCGGCAACAGTA ACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTGCCACTCACTCCTTTATCTCCT ACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGCCATTCCCCAGATTGCATCTTT GAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGAGTCATCGTGACTGCCCTCTAG CTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTGCAGAAGGATGTGGGGAAACGA TTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGACCAGACCATGTTAGATAAACTT GTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACGAAAACAACTTGTATGTCTTCA CAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGTTTTGAGAGTTTGCCTGATCAG CTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGAAAATCAACACTGATTGACACA TTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAGACATATGAACTCCAGGAAAGT AATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGCTACCAACCAATAGTTGACTAC ATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCATGATTCTCGCATCCATGTGTGT CTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGACAGCAAGGTAAACATTATACCA GTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAATTGGTCAGCAATGGCGTCCAG ATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCGTTTGCTGTTGTGGGAAGTATG GATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAAAATGAAAACCACTGTGACTTT GTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCACTATGAGCTTTACAGGCGCTGC AAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTATGAAGCCAAAAGACATGAGTTC CATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAAGCCATATTGAAAGAAGCTGAG AGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAAAAGAGAAGACTTTTGGAAGAA GAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACAGGCAGCAACCTGAGGAAGGAC AAGGACCGTAAGAACTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTTATTAAAAAAAAACT AGAAGTGTGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTTATGGAAAAGTACTT TCAAGTACAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAATCCAGAAGCTTCAAA ATCTGAATCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGTTCAGTTTAAACAGA TTTTGTTTCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTATGTAATTAGAGTCG GGTCCCGTTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGGATACTCAGCTTGTA CCTATATATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTCTTGCTACCAAGCTA TTGTCACTGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTATCTGATTACATTTA TATTCCAAGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAACTCTAACCTCTTAA TAGTTTTATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTATTTAATATGATGAC TTCATGCTTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATCCAGATATATAAGCT ATTTTTTCCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATACTTGTTTAAACTCTG TCTTCCAGGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGAATATTAAAGATATA AAAATGCACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGATTTCTAACATTTCTT AACAGTCATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAATAAAACATATATTT >16937_16937_8_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000455322_SEPT10_chr2_110350696_ENST00000397712_length(amino acids)=518AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER -------------------------------------------------------------- >16937_16937_9_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000541377_SEPT10_chr2_110350696_ENST00000356688_length(transcript)=3330nt_BP=585nt TTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTCTGGTCCGCAGCGGCAACAGTA ACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTGCCACTCACTCCTTTATCTCCT ACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGCCATTCCCCAGATTGCATCTTT GAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGAGTCATCGTGACTGCCCTCTAG CTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTGCAGAAGGATGTGGGGAAACGA TTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGACCAGACCATGTTAGATAAACTT GTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACGAAAACAACTTGTATGTCTTCA CAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGTTTTGAGAGTTTGCCTGATCAG CTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGAAAATCAACACTGATTGACACA TTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAGACATATGAACTCCAGGAAAGT AATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGCTACCAACCAATAGTTGACTAC ATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCATGATTCTCGCATCCATGTGTGT CTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGACAGCAAGGTAAACATTATACCA GTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAATTGGTCAGCAATGGCGTCCAG ATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCGTTTGCTGTTGTGGGAAGTATG GATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAAAATGAAAACCACTGTGACTTT GTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCACTATGAGCTTTACAGGCGCTGC AAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTATGAAGCCAAAAGACATGAGTTC CATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAAGCCATATTGAAAGAAGCTGAG AGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAAAAGAGAAGACTTTTGGAAGAA GAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACAGGCAGCAACCTGAGGAAGGAC AAGGACCGTAAGAAGGAACCAGGCTGTCGATTCGAACTCCTGTGCATTGATGTCAGAGCTTGTGAAACCAATGGTGGACGTAAAGACGCA GAGAAAGCTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTTATTAAAAAAAAACTAGAAGTG TGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTTATGGAAAAGTACTTTCAAGTA CAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAATCCAGAAGCTTCAAAATCTGAA TCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGTTCAGTTTAAACAGATTTTGTT TCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTATGTAATTAGAGTCGGGTCCCG TTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGGATACTCAGCTTGTACCTATAT ATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTCTTGCTACCAAGCTATTGTCAC TGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTATCTGATTACATTTATATTCCA AGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAACTCTAACCTCTTAATAGTTTT ATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTATTTAATATGATGACTTCATGC TTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATCCAGATATATAAGCTATTTTTT CCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATACTTGTTTAAACTCTGTCTTCCA GGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGAATATTAAAGATATAAAAATGC ACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGATTTCTAACATTTCTTAACAGTC ATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAATAAAACATATATTTACTAAAA >16937_16937_9_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000541377_SEPT10_chr2_110350696_ENST00000356688_length(amino acids)=608AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER ELQAKFEHLKRLHQEERMKLEEKRRLLEEEIIAFSKKKATSEIFHSQSFLATGSNLRKDKDRKKEPGCRFELLCIDVRACETNGGRKDAE -------------------------------------------------------------- >16937_16937_10_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000541377_SEPT10_chr2_110350696_ENST00000397712_length(transcript)=3247nt_BP=585nt TTTTTTTTTTTTTAATCCCCGCACCAAGCGCTTAACCTCATTGGGGTGGAGGAGAAGGCGGCGGCTCTCTGGTCCGCAGCGGCAACAGTA ACGAAAAACAGGGCTAATGGACTGCTGAATTATGAAGTATTTCAGACCCAGTAGTAGAACATCACTCTGCCACTCACTCCTTTATCTCCT ACTAGTTATTTAAATTGGACTTTTAATATCCTACCAGCTGCTCTTCAGACACACATGGTGCATTGTTGCCATTCCCCAGATTGCATCTTT GAAACACAGGCTCTTAGTAACCTTCAGCGAACAAAGAGGCAACCTCCCAGATACGTCTGCTGGGAGGGAGTCATCGTGACTGCCCTCTAG CTTTTGCTGGATCTGGATTTGAATTCCACTATGGAGCCTCGCATGGAGTCCTGCCTGGCGCAGGTGTTGCAGAAGGATGTGGGGAAACGA TTGCAGGTTGGCCAAGAACTGATAGACTATTTCTCAGACAAACAGAAGTCTGCTGACCTTGAGCATGACCAGACCATGTTAGATAAACTT GTGGATGGACTTGCTACCTCTTGGGTGAACTCTAGCAATTACAAGCTCTTTCAGTCTCACATGGCAACGAAAACAACTTGTATGTCTTCA CAAGGATCAGATGATGAACAGATAAAAAGAGAAAACATTCGTTCGTTGACTATGTCTGGCCATGTTGGTTTTGAGAGTTTGCCTGATCAG CTGGTGAACAGATCCATTCAGCAAGGTTTCTGCTTTAATATTCTCTGTGTGGGGGAAACTGGAATTGGAAAATCAACACTGATTGACACA TTGTTTAATACTAATTTTGAAGACTATGAATCCTCACATTTTTGCCCAAATGTTAAACTTAAAGCTCAGACATATGAACTCCAGGAAAGT AATGTTCAATTGAAATTGACCATTGTGAATACAGTGGGATTTGGTGACCAAATAAATAAAGAAGAGAGCTACCAACCAATAGTTGACTAC ATAGATGCTCAGTTTGAGGCCTATCTCCAAGAAGAACTGAAGATTAAGCGTTCTCTCTTTACCTACCATGATTCTCGCATCCATGTGTGT CTCTACTTCATTTCACCGACAGGCCACTCTCTGAAGACACTTGATCTCTTAACCATGAAGAACCTTGACAGCAAGGTAAACATTATACCA GTGATTGCCAAAGCAGATACGGTTTCTAAAACTGAATTACAGAAGTTTAAGATCAAGCTCATGAGTGAATTGGTCAGCAATGGCGTCCAG ATATACCAGTTCCCAACGGATGATGACACTATTGCTAAGGTCAACGCTGCAATGAATGGACAGTTGCCGTTTGCTGTTGTGGGAAGTATG GATGAGGTAAAAGTCGGAAACAAGATGGTCAAAGCTCGCCAGTACCCTTGGGGTGTTGTACAAGTGGAAAATGAAAACCACTGTGACTTT GTAAAGCTGCGGGAAATGCTCATTTGTACAAATATGGAGGACCTGCGAGAGCAGACCCATACCAGGCACTATGAGCTTTACAGGCGCTGC AAACTGGAGGAAATGGGCTTTACAGATGTGGGCCCAGAAAACAAGCCAGTCAGTGTTCAAGAGACCTATGAAGCCAAAAGACATGAGTTC CATGGTGAACGTCAGAGGAAGGAAGAAGAAATGAAACAGATGTTTGTGCAGCGAGTAAAGGAGAAAGAAGCCATATTGAAAGAAGCTGAG AGAGAGCTACAGGCCAAATTTGAGCACCTTAAGAGACTTCACCAAGAAGAGAGAATGAAGCTTGAAGAAAAGAGAAGACTTTTGGAAGAA GAAATAATTGCTTTCTCTAAAAAGAAAGCTACCTCCGAGATATTTCACAGCCAGTCCTTTCTGGCAACAGGCAGCAACCTGAGGAAGGAC AAGGACCGTAAGAACTCCAATTTTTTGTAAAACAGAAGTTCCAGAGCACAGAAGGTCATCATCACAAGCAAACTTTATTAAAAAAAAACT AGAAGTGTGCTTTGATTTTGCTGTTATTTGTTTTATCACTTCTATATTTGGTGAACAGCCACAGTTACTGATATTTATGGAAAAGTACTT TCAAGTACAAGGTCAATACATAAGCCAGAGTGAATGATACTACAAGTTGAGCATCTCTAATTCAAAAATCTGAAATCCAGAAGCTTCAAA ATCTGAATCTTTTTGAGCACTGACTTGACCCCACAAGTGGAAAATTCCCCACCCGACACCTTTGCTTTCTGATGGTTCAGTTTAAACAGA TTTTGTTTCTTGCACAAAATTTTTGTATAAATTACTTTCAGGCTATATGTATAAGGTGGATGTGAAACATGAATTATGTAATTAGAGTCG GGTCCCGTTGTGTATATGCAGATATTCCAAACCTGAAATCCAAAACACTTCTGGTCCCTAGCATTTTGGATAAGGGATACTCAGCTTGTA CCTATATATTCATATATATTCACTGTTGTTAGAAATGTTTAAGTTGCTGTTCTGTGATGAATCTAAATCTTTTCTCTTGCTACCAAGCTA TTGTCACTGCAGTGCATTATACCAAAGAGCGAAGTCAGTGCCACTGAAAATACAGAACCCATTAATATCGTGGCTATCTGATTACATTTA TATTCCAAGATGAACCTTTTTTATATATGCTAAAAATTTTGGGGAATATGTTTTGGGATGTATTATGGAGCTAAAACTCTAACCTCTTAA TAGTTTTATAGAACTTAAAAATTTTTTATACAATTACCCAATTGGTGATATGATCTTAAGCTTTTGTGTCAGATTATTTAATATGATGAC TTCATGCTTTATTATGCCTTATTATGGCTGACGTATTACTGTGGTGAAACAAAATATCTTTAAAAGTTAAAACATCCAGATATATAAGCT ATTTTTTCCTAAGGATAAAGTACCTTTGAGCATGAGTGTATCACAGCTTTCATTAGGAAAACTTTTCATTACATACTTGTTTAAACTCTG TCTTCCAGGGTAAAAATAATAAGGTTGAATCATTTTATTAAAAATACTTTTTAAGAAAATAACTATGAACATCTGAATATTAAAGATATA AAAATGCACATAATTCATATTTCAGGTGGTATTTGCATTCAGTGCCTTACTGGTATTCTCAGAACATTTTAATGATTTCTAACATTTCTT AACAGTCATAGATATATACATTTTCATTTTTTGTACTTGAATATTCTAAATAAAACTGACATTTACTCTTGACAAATAAAACATATATTT >16937_16937_10_CLASP1-SEPT10_CLASP1_chr2_122363277_ENST00000541377_SEPT10_chr2_110350696_ENST00000397712_length(amino acids)=518AA_BP=74 MLDLDLNSTMEPRMESCLAQVLQKDVGKRLQVGQELIDYFSDKQKSADLEHDQTMLDKLVDGLATSWVNSSNYKLFQSHMATKTTCMSSQ GSDDEQIKRENIRSLTMSGHVGFESLPDQLVNRSIQQGFCFNILCVGETGIGKSTLIDTLFNTNFEDYESSHFCPNVKLKAQTYELQESN VQLKLTIVNTVGFGDQINKEESYQPIVDYIDAQFEAYLQEELKIKRSLFTYHDSRIHVCLYFISPTGHSLKTLDLLTMKNLDSKVNIIPV IAKADTVSKTELQKFKIKLMSELVSNGVQIYQFPTDDDTIAKVNAAMNGQLPFAVVGSMDEVKVGNKMVKARQYPWGVVQVENENHCDFV KLREMLICTNMEDLREQTHTRHYELYRRCKLEEMGFTDVGPENKPVSVQETYEAKRHEFHGERQRKEEEMKQMFVQRVKEKEAILKEAER -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CLASP1-SEPT10 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 662_785 | 65.0 | 1539.0 | microtubules%2C MAPRE1 and MAPRE3 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 662_785 | 65.0 | 1472.0 | microtubules%2C MAPRE1 and MAPRE3 |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000263710 | - | 2 | 40 | 1254_1538 | 65.0 | 1539.0 | PHLDB2 and RSN |
| Hgene | CLASP1 | chr2:122363277 | chr2:110350696 | ENST00000409078 | - | 2 | 39 | 1254_1538 | 65.0 | 1472.0 | PHLDB2 and RSN |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CLASP1-SEPT10 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CLASP1-SEPT10 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies