
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CLIP1-TMED2 (FusionGDB2 ID:17171) |
Fusion Gene Summary for CLIP1-TMED2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CLIP1-TMED2 | Fusion gene ID: 17171 | Hgene | Tgene | Gene symbol | CLIP1 | TMED2 | Gene ID | 6249 | 10959 |
| Gene name | CAP-Gly domain containing linker protein 1 | transmembrane p24 trafficking protein 2 | |
| Synonyms | CLIP|CLIP-170|CLIP170|CYLN1|RSN | P24A|RNP24|p24|p24b1|p24beta1 | |
| Cytomap | 12q24.31 | 12q24.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | CAP-Gly domain-containing linker protein 1cytoplasmic linker protein 1cytoplasmic linker protein 170 alpha-2cytoplasmic linker protein CLIP-170restin (Reed-Steinberg cell-expressed intermediate filament-associated protein) | transmembrane emp24 domain-containing protein 2coated vesicle membrane proteinmembrane protein p24Ap24 family protein beta-1transmembrane emp24 domain trafficking protein 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P30622 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000302528, ENST00000540338, ENST00000358808, ENST00000361654, ENST00000537178, ENST00000536634, ENST00000540539, ENST00000545889, | ENST00000262225, ENST00000509052, | |
| Fusion gene scores | * DoF score | 22 X 22 X 13=6292 | 6 X 8 X 3=144 |
| # samples | 31 | 8 | |
| ** MAII score | log2(31/6292*10)=-4.34317855014145 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/144*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CLIP1 [Title/Abstract] AND TMED2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CLIP1(122861936)-TMED2(124081152), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CLIP1-TMED2 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. CLIP1-TMED2 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. CLIP1-TMED2 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | TMED2 | GO:0006886 | intracellular protein transport | 20427317 |
| Tgene | TMED2 | GO:0034260 | negative regulation of GTPase activity | 10761932 |
| Tgene | TMED2 | GO:0072659 | protein localization to plasma membrane | 20361938 |
| Fusion gene breakpoints across CLIP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
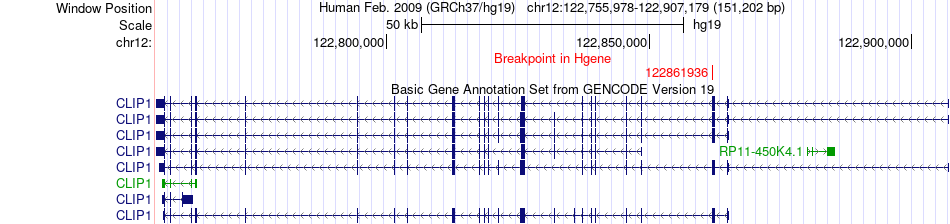 |
| Fusion gene breakpoints across TMED2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-BR-8364-01A | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
Top |
Fusion Gene ORF analysis for CLIP1-TMED2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000302528 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| Frame-shift | ENST00000302528 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| Frame-shift | ENST00000540338 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| Frame-shift | ENST00000540338 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| In-frame | ENST00000358808 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| In-frame | ENST00000358808 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| In-frame | ENST00000361654 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| In-frame | ENST00000361654 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| In-frame | ENST00000537178 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| In-frame | ENST00000537178 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| intron-3CDS | ENST00000536634 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| intron-3CDS | ENST00000536634 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| intron-3CDS | ENST00000540539 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| intron-3CDS | ENST00000540539 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| intron-3CDS | ENST00000545889 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| intron-3CDS | ENST00000545889 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000361654 | CLIP1 | chr12 | 122861936 | - | ENST00000262225 | TMED2 | chr12 | 124081152 | + | 2796 | 831 | 174 | 890 | 238 |
| ENST00000361654 | CLIP1 | chr12 | 122861936 | - | ENST00000509052 | TMED2 | chr12 | 124081152 | + | 1320 | 831 | 174 | 890 | 238 |
| ENST00000358808 | CLIP1 | chr12 | 122861936 | - | ENST00000262225 | TMED2 | chr12 | 124081152 | + | 2777 | 812 | 155 | 871 | 238 |
| ENST00000358808 | CLIP1 | chr12 | 122861936 | - | ENST00000509052 | TMED2 | chr12 | 124081152 | + | 1301 | 812 | 155 | 871 | 238 |
| ENST00000537178 | CLIP1 | chr12 | 122861936 | - | ENST00000262225 | TMED2 | chr12 | 124081152 | + | 2840 | 875 | 218 | 934 | 238 |
| ENST00000537178 | CLIP1 | chr12 | 122861936 | - | ENST00000509052 | TMED2 | chr12 | 124081152 | + | 1364 | 875 | 218 | 934 | 238 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000361654 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + | 0.001600176 | 0.9983998 |
| ENST00000361654 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + | 0.00783265 | 0.9921673 |
| ENST00000358808 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + | 0.001443552 | 0.99855644 |
| ENST00000358808 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + | 0.008069847 | 0.99193007 |
| ENST00000537178 | ENST00000262225 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + | 0.001370917 | 0.9986291 |
| ENST00000537178 | ENST00000509052 | CLIP1 | chr12 | 122861936 | - | TMED2 | chr12 | 124081152 | + | 0.008302568 | 0.99169743 |
Top |
Fusion Genomic Features for CLIP1-TMED2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CLIP1 | chr12 | 122861935 | - | TMED2 | chr12 | 124081151 | + | 1.15E-11 | 1 |
| CLIP1 | chr12 | 122861935 | - | TMED2 | chr12 | 124081151 | + | 1.15E-11 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
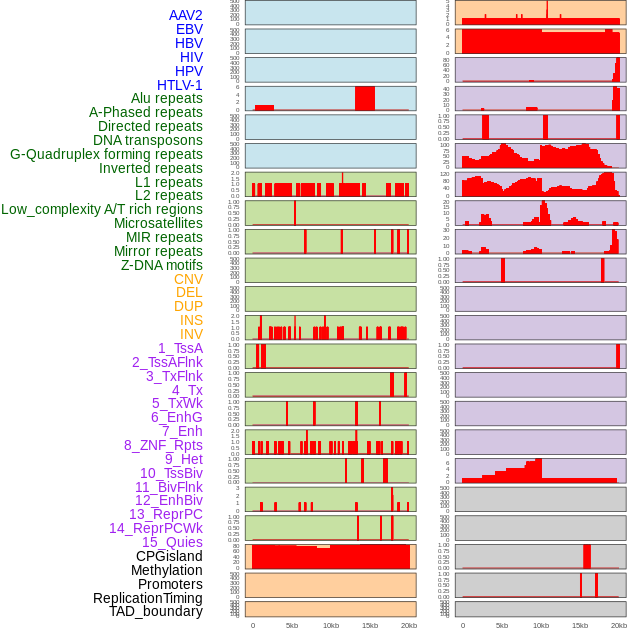 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
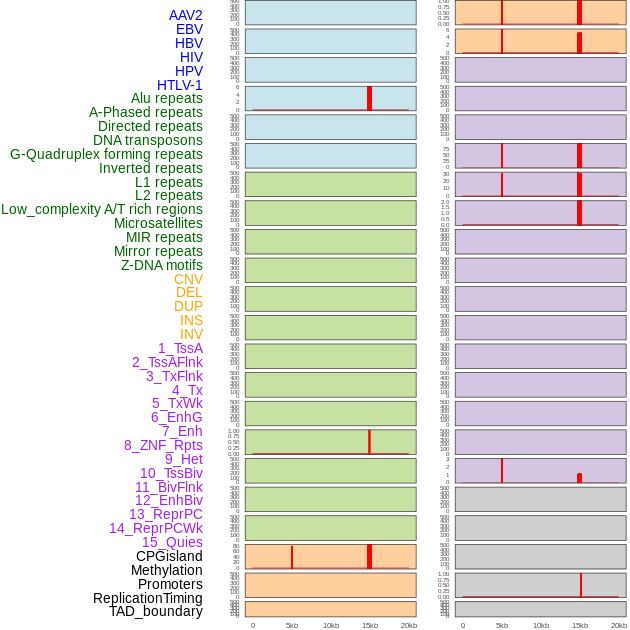 |
Top |
Fusion Protein Features for CLIP1-TMED2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:122861936/chr12:124081152) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CLIP1 | . |
| FUNCTION: Binds to the plus end of microtubules and regulates the dynamics of the microtubule cytoskeleton. Promotes microtubule growth and microtubule bundling. Links cytoplasmic vesicles to microtubules and thereby plays an important role in intracellular vesicle trafficking. Plays a role macropinocytosis and endosome trafficking. {ECO:0000269|PubMed:12433698, ECO:0000269|PubMed:17563362, ECO:0000269|PubMed:17889670}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000302528 | - | 2 | 24 | 143_204 | 219 | 1428.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000358808 | - | 3 | 25 | 143_204 | 219 | 1428.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000537178 | - | 3 | 24 | 143_204 | 219 | 1393.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000540338 | - | 2 | 25 | 143_204 | 219 | 1439.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000302528 | - | 2 | 24 | 78_120 | 219 | 1428.0 | Domain | CAP-Gly 1 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000358808 | - | 3 | 25 | 78_120 | 219 | 1428.0 | Domain | CAP-Gly 1 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000537178 | - | 3 | 24 | 78_120 | 219 | 1393.0 | Domain | CAP-Gly 1 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000540338 | - | 2 | 25 | 78_120 | 219 | 1439.0 | Domain | CAP-Gly 1 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000302528 | - | 2 | 24 | 97_101 | 219 | 1428.0 | Region | Important for tubulin binding |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000358808 | - | 3 | 25 | 97_101 | 219 | 1428.0 | Region | Important for tubulin binding |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000537178 | - | 3 | 24 | 97_101 | 219 | 1393.0 | Region | Important for tubulin binding |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000540338 | - | 2 | 25 | 97_101 | 219 | 1439.0 | Region | Important for tubulin binding |
| Tgene | TMED2 | chr12:122861936 | chr12:124081152 | ENST00000262225 | 2 | 4 | 194_201 | 160 | 202.0 | Motif | COPI vesicle coat-binding | |
| Tgene | TMED2 | chr12:122861936 | chr12:124081152 | ENST00000262225 | 2 | 4 | 190_201 | 160 | 202.0 | Topological domain | Cytoplasmic | |
| Tgene | TMED2 | chr12:122861936 | chr12:124081152 | ENST00000262225 | 2 | 4 | 169_189 | 160 | 202.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000302528 | - | 2 | 24 | 350_1353 | 219 | 1428.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000358808 | - | 3 | 25 | 350_1353 | 219 | 1428.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000537178 | - | 3 | 24 | 350_1353 | 219 | 1393.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000540338 | - | 2 | 25 | 350_1353 | 219 | 1439.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000302528 | - | 2 | 24 | 304_331 | 219 | 1428.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000358808 | - | 3 | 25 | 304_331 | 219 | 1428.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000537178 | - | 3 | 24 | 304_331 | 219 | 1393.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000540338 | - | 2 | 25 | 304_331 | 219 | 1439.0 | Compositional bias | Note=Ser-rich |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000302528 | - | 2 | 24 | 232_274 | 219 | 1428.0 | Domain | CAP-Gly 2 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000358808 | - | 3 | 25 | 232_274 | 219 | 1428.0 | Domain | CAP-Gly 2 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000537178 | - | 3 | 24 | 232_274 | 219 | 1393.0 | Domain | CAP-Gly 2 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000540338 | - | 2 | 25 | 232_274 | 219 | 1439.0 | Domain | CAP-Gly 2 |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000302528 | - | 2 | 24 | 1417_1434 | 219 | 1428.0 | Zinc finger | CCHC-type |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000358808 | - | 3 | 25 | 1417_1434 | 219 | 1428.0 | Zinc finger | CCHC-type |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000537178 | - | 3 | 24 | 1417_1434 | 219 | 1393.0 | Zinc finger | CCHC-type |
| Hgene | CLIP1 | chr12:122861936 | chr12:124081152 | ENST00000540338 | - | 2 | 25 | 1417_1434 | 219 | 1439.0 | Zinc finger | CCHC-type |
| Tgene | TMED2 | chr12:122861936 | chr12:124081152 | ENST00000262225 | 2 | 4 | 117_167 | 160 | 202.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TMED2 | chr12:122861936 | chr12:124081152 | ENST00000262225 | 2 | 4 | 30_112 | 160 | 202.0 | Domain | GOLD | |
| Tgene | TMED2 | chr12:122861936 | chr12:124081152 | ENST00000262225 | 2 | 4 | 118_157 | 160 | 202.0 | Region | Note=Required for TMED10 and TMED2 cis-Golgi network localization | |
| Tgene | TMED2 | chr12:122861936 | chr12:124081152 | ENST00000262225 | 2 | 4 | 21_168 | 160 | 202.0 | Topological domain | Lumenal |
Top |
Fusion Gene Sequence for CLIP1-TMED2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >17171_17171_1_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000358808_TMED2_chr12_124081152_ENST00000262225_length(transcript)=2777nt_BP=812nt GCTGCTGCTGCAGTGGGACAGGTGGCGGCGACCGGCGGCGTCCGAGGAGATTTAATCCAGAGACTGACTTCACTATAGAACCCACAGTTG TATCAATGGTTGGGGAAAGATAGTGGCAACAGGCAAAGGAGAAACAGCTCTGACATACAAAGAAAATGAGTATGCTAAAGCCAAGTGGGC TTAAGGCCCCCACCAAGATCCTGAAGCCTGGAAGCACAGCTCTGAAGACACCTACGGCTGTTGTAGCTCCAGTAGAAAAAACCATATCCA GTGAAAAAGCATCAAGCACTCCATCATCTGAGACTCAGGAGGAATTTGTGGATGACTTTCGAGTTGGGGAGCGAGTTTGGGTGAATGGAA ATAAGCCTGGATTTATCCAGTTTCTTGGAGAAACCCAGTTTGCACCAGGCCAGTGGGCTGGAATTGTTTTAGATGAACCCATAGGCAAGA ACGATGGTTCGGTGGCAGGAGTTCGGTATTTCCAGTGTGAACCTTTAAAGGGCATATTTACCCGACCTTCAAAGTTAACAAGGAAGGTGC AAGCAGAAGATGAAGCTAATGGCCTGCAGACAACGCCCGCCTCCCGAGCTACTTCACCGCTGTGCACTTCTACGGCCAGCATGGTGTCTT CCTCCCCCTCCACCCCTTCAAACATCCCTCAGAAACCATCACAGCCAGCAGCAAAGGAACCTTCAGCTACGCCTCCGATCAGCAACCTTA CAAAAACTGCCAGTGAATCTATCTCCAACCTTTCAGAGGCTGGCTCAATCAAGAAAGGAGAAAGAGAGCTCAAAATCGGAGACAGAGTAT TGTCAACGACAACACAAACAGCAGAGTGGTCCTTTGGTCCTTCTTTGAAGCTCTTGTTCTAGTTGCCATGACATTGGGACAGATCTACTA CCTGAAGAGATTTTTTGAAGTCCGGAGAGTTGTTTAAAAAGCCTCTTCCTGATGATCCCAACTCAGAATTCACTGTTTACCAAACACCTT GGTCATAATAATGTCATTAGTTTCTCCATTTTTATTTTCTGAACTGTACATTCACAACTTATGTTTCTTTGAGATTAATAGATATTGGGG GAAAAACGCCTTTTTAGGAAAATTATAGTGAAAATTTGACAGTTGATTGGCATAATTTCTTGTTTGAATGCTGCCTCCATTATATAGGTC CTTCCAGGAACTCAAACACTGTAAGTGAAATATGGGAGTATAGTTTTTATTATTTCTTCTTTTCCTTTTGTTTTCATAATATAATGCAGT TTGTTCAGGAAATCAGCACAAAGCCTGATAGTACTTTACTAAAATGACTGCATTCTTTGGATTCCTTCAGTCTATGGTTCAAGTCACTAA AGATTCATTTTTGTTGAGTCCTTATGAGAAACAGCAGTATGAATCTTGACGGTTTCTGCCCGTCCTAATGGCAGAGCTCTCTGACTTGGG TGTATGCTGCCAGGCTGGGTACTTTCATACTTTGTTTTCTTGTTTTGCTTTAAAACTACGACTCAGCATACATTTTCCCACATACATTTT TACATTGTACCTTAGGACTCAGTCATCTCCACTTAAATTGATGACACAAGCAGCTAATAACCATTTCTGGGTTTCTGCCTAACCCCCTAA TTGTCTGTTAAAGCCAATTCTCTGGGTGTCCCAGTGAGTGGTGGCTTTTTTTCTTTCCACATTGGCACATTCACTTCTCCCACTCTTGGC ATGTAAGAAATAAGCATTTACATAATTGGAAAAATCTGGATTTCTGATGCCAAAGGGTTAAAGCTTCTTGGATTTCATTTCATTGATATA CAGCCACTATTTTATTTTTGATCAGTGGCCTTTGGGCCACTGTTCAGGGTACTGACCATCAGTGTCAGCATTAGGGTTTTGGTTTTTGTT TCTTTTGGGTCTTTCTTTTTTGGCACATGTGAATCTTGTTTTGTGTAAAATGAAATTACTTTCTCTTGTTCTCTGATGATGGGTTTAAAA TTAAAAGAGCATCCGGTTTTGGTATGGGGATGATCCAGGATTATGTTGTGACTGATACATATTAGTTACTTGTGCTTTTTTTTTTTTTTT TGGATCTTTGCAAGGGCAAAACTACAAGTAACGAGTTTTATATAATTAATTTAAATTTGTTACAGGTTTTCATGTTCAGGATAAACCATA CTTCCACCTTGGGTGAGAACACTTGCAACAGTTTATTAATGAGGTGACTTTCACCTTAGGACAACTGTTGCATGCCAAGTTTTTTGTGTG TGTGAAACACTTCAAAACTGATTTAAAAGATGTAAATTTAAAATTGGTTGTATCTAATATGCCCCAGGTTCGGTAAATAAACAATTCTTT TTAAAAACAGTATTCTGTGTTTTATATATTGACAGCTAATCCACATTTTTTACACACCAACTTTCTGTTCTTATTTGACATGAGACATGT TCATGTTTTCTGAGTATTTATACCTATTACGTCTGTTACTTTTTAATTCTATAAACTTGAGGATAGTGAATGGTACCAAGTTTTAGTTTC TGCGTAGGTTTTCCAGTGTGGCTTCTCTGATGGATCAGTGCTAAAATCTTAAGTATTTTTCTATTTGGGAAAAAAGGGTTGAATTATTTT CACTTGCCCACGTAGTTTATGAATGTGGGAAATAGCTTCAAAGACAGATTAAATGATTTGCCCAAGGCCACAGAAAAGAGTGAAAGGTGG >17171_17171_1_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000358808_TMED2_chr12_124081152_ENST00000262225_length(amino acids)=238AA_BP=219 MSMLKPSGLKAPTKILKPGSTALKTPTAVVAPVEKTISSEKASSTPSSETQEEFVDDFRVGERVWVNGNKPGFIQFLGETQFAPGQWAGI VLDEPIGKNDGSVAGVRYFQCEPLKGIFTRPSKLTRKVQAEDEANGLQTTPASRATSPLCTSTASMVSSSPSTPSNIPQKPSQPAAKEPS -------------------------------------------------------------- >17171_17171_2_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000358808_TMED2_chr12_124081152_ENST00000509052_length(transcript)=1301nt_BP=812nt GCTGCTGCTGCAGTGGGACAGGTGGCGGCGACCGGCGGCGTCCGAGGAGATTTAATCCAGAGACTGACTTCACTATAGAACCCACAGTTG TATCAATGGTTGGGGAAAGATAGTGGCAACAGGCAAAGGAGAAACAGCTCTGACATACAAAGAAAATGAGTATGCTAAAGCCAAGTGGGC TTAAGGCCCCCACCAAGATCCTGAAGCCTGGAAGCACAGCTCTGAAGACACCTACGGCTGTTGTAGCTCCAGTAGAAAAAACCATATCCA GTGAAAAAGCATCAAGCACTCCATCATCTGAGACTCAGGAGGAATTTGTGGATGACTTTCGAGTTGGGGAGCGAGTTTGGGTGAATGGAA ATAAGCCTGGATTTATCCAGTTTCTTGGAGAAACCCAGTTTGCACCAGGCCAGTGGGCTGGAATTGTTTTAGATGAACCCATAGGCAAGA ACGATGGTTCGGTGGCAGGAGTTCGGTATTTCCAGTGTGAACCTTTAAAGGGCATATTTACCCGACCTTCAAAGTTAACAAGGAAGGTGC AAGCAGAAGATGAAGCTAATGGCCTGCAGACAACGCCCGCCTCCCGAGCTACTTCACCGCTGTGCACTTCTACGGCCAGCATGGTGTCTT CCTCCCCCTCCACCCCTTCAAACATCCCTCAGAAACCATCACAGCCAGCAGCAAAGGAACCTTCAGCTACGCCTCCGATCAGCAACCTTA CAAAAACTGCCAGTGAATCTATCTCCAACCTTTCAGAGGCTGGCTCAATCAAGAAAGGAGAAAGAGAGCTCAAAATCGGAGACAGAGTAT TGTCAACGACAACACAAACAGCAGAGTGGTCCTTTGGTCCTTCTTTGAAGCTCTTGTTCTAGTTGCCATGACATTGGGACAGATCTACTA CCTGAAGAGATTTTTTGAAGTCCGGAGAGTTGTTTAAAAAGCCTCTTCCTGATGATCCCAACTCAGAATTCACTGTTTACCAAACACCTT GGTCATAATAATGTCATTAGTTTCTCCATTTTTATTTTCTGAACTGTACATTCACAACTTATGTTTCTTTGAGATTAATAGATATTGGGG GAAAAACGCCTTTTTAGGAAAATTATAGTGAAAATTTGACAGTTGATTGGCATAATTTCTTGTTTGAATGCTGCCTCCATTATATAGGTC CTTCCAGGAACTCAAACACTGTAAGTGAAATATGGGAGTATAGTTTTTATTATTTCTTCTTTTCCTTTTGTTTTCATAATATAATGCAGT >17171_17171_2_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000358808_TMED2_chr12_124081152_ENST00000509052_length(amino acids)=238AA_BP=219 MSMLKPSGLKAPTKILKPGSTALKTPTAVVAPVEKTISSEKASSTPSSETQEEFVDDFRVGERVWVNGNKPGFIQFLGETQFAPGQWAGI VLDEPIGKNDGSVAGVRYFQCEPLKGIFTRPSKLTRKVQAEDEANGLQTTPASRATSPLCTSTASMVSSSPSTPSNIPQKPSQPAAKEPS -------------------------------------------------------------- >17171_17171_3_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000361654_TMED2_chr12_124081152_ENST00000262225_length(transcript)=2796nt_BP=831nt GGCGGCGGCCGCGGCGGCTGCTGCTGCTGCAGTGGGACAGGTGGCGGCGACCGGCGGCGTCCGAGGAGATTTAATCCAGAGACTGACTTC ACTATAGAACCCACAGTTGTATCAATGGTTGGGGAAAGATAGTGGCAACAGGCAAAGGAGAAACAGCTCTGACATACAAAGAAAATGAGT ATGCTAAAGCCAAGTGGGCTTAAGGCCCCCACCAAGATCCTGAAGCCTGGAAGCACAGCTCTGAAGACACCTACGGCTGTTGTAGCTCCA GTAGAAAAAACCATATCCAGTGAAAAAGCATCAAGCACTCCATCATCTGAGACTCAGGAGGAATTTGTGGATGACTTTCGAGTTGGGGAG CGAGTTTGGGTGAATGGAAATAAGCCTGGATTTATCCAGTTTCTTGGAGAAACCCAGTTTGCACCAGGCCAGTGGGCTGGAATTGTTTTA GATGAACCCATAGGCAAGAACGATGGTTCGGTGGCAGGAGTTCGGTATTTCCAGTGTGAACCTTTAAAGGGCATATTTACCCGACCTTCA AAGTTAACAAGGAAGGTGCAAGCAGAAGATGAAGCTAATGGCCTGCAGACAACGCCCGCCTCCCGAGCTACTTCACCGCTGTGCACTTCT ACGGCCAGCATGGTGTCTTCCTCCCCCTCCACCCCTTCAAACATCCCTCAGAAACCATCACAGCCAGCAGCAAAGGAACCTTCAGCTACG CCTCCGATCAGCAACCTTACAAAAACTGCCAGTGAATCTATCTCCAACCTTTCAGAGGCTGGCTCAATCAAGAAAGGAGAAAGAGAGCTC AAAATCGGAGACAGAGTATTGTCAACGACAACACAAACAGCAGAGTGGTCCTTTGGTCCTTCTTTGAAGCTCTTGTTCTAGTTGCCATGA CATTGGGACAGATCTACTACCTGAAGAGATTTTTTGAAGTCCGGAGAGTTGTTTAAAAAGCCTCTTCCTGATGATCCCAACTCAGAATTC ACTGTTTACCAAACACCTTGGTCATAATAATGTCATTAGTTTCTCCATTTTTATTTTCTGAACTGTACATTCACAACTTATGTTTCTTTG AGATTAATAGATATTGGGGGAAAAACGCCTTTTTAGGAAAATTATAGTGAAAATTTGACAGTTGATTGGCATAATTTCTTGTTTGAATGC TGCCTCCATTATATAGGTCCTTCCAGGAACTCAAACACTGTAAGTGAAATATGGGAGTATAGTTTTTATTATTTCTTCTTTTCCTTTTGT TTTCATAATATAATGCAGTTTGTTCAGGAAATCAGCACAAAGCCTGATAGTACTTTACTAAAATGACTGCATTCTTTGGATTCCTTCAGT CTATGGTTCAAGTCACTAAAGATTCATTTTTGTTGAGTCCTTATGAGAAACAGCAGTATGAATCTTGACGGTTTCTGCCCGTCCTAATGG CAGAGCTCTCTGACTTGGGTGTATGCTGCCAGGCTGGGTACTTTCATACTTTGTTTTCTTGTTTTGCTTTAAAACTACGACTCAGCATAC ATTTTCCCACATACATTTTTACATTGTACCTTAGGACTCAGTCATCTCCACTTAAATTGATGACACAAGCAGCTAATAACCATTTCTGGG TTTCTGCCTAACCCCCTAATTGTCTGTTAAAGCCAATTCTCTGGGTGTCCCAGTGAGTGGTGGCTTTTTTTCTTTCCACATTGGCACATT CACTTCTCCCACTCTTGGCATGTAAGAAATAAGCATTTACATAATTGGAAAAATCTGGATTTCTGATGCCAAAGGGTTAAAGCTTCTTGG ATTTCATTTCATTGATATACAGCCACTATTTTATTTTTGATCAGTGGCCTTTGGGCCACTGTTCAGGGTACTGACCATCAGTGTCAGCAT TAGGGTTTTGGTTTTTGTTTCTTTTGGGTCTTTCTTTTTTGGCACATGTGAATCTTGTTTTGTGTAAAATGAAATTACTTTCTCTTGTTC TCTGATGATGGGTTTAAAATTAAAAGAGCATCCGGTTTTGGTATGGGGATGATCCAGGATTATGTTGTGACTGATACATATTAGTTACTT GTGCTTTTTTTTTTTTTTTTGGATCTTTGCAAGGGCAAAACTACAAGTAACGAGTTTTATATAATTAATTTAAATTTGTTACAGGTTTTC ATGTTCAGGATAAACCATACTTCCACCTTGGGTGAGAACACTTGCAACAGTTTATTAATGAGGTGACTTTCACCTTAGGACAACTGTTGC ATGCCAAGTTTTTTGTGTGTGTGAAACACTTCAAAACTGATTTAAAAGATGTAAATTTAAAATTGGTTGTATCTAATATGCCCCAGGTTC GGTAAATAAACAATTCTTTTTAAAAACAGTATTCTGTGTTTTATATATTGACAGCTAATCCACATTTTTTACACACCAACTTTCTGTTCT TATTTGACATGAGACATGTTCATGTTTTCTGAGTATTTATACCTATTACGTCTGTTACTTTTTAATTCTATAAACTTGAGGATAGTGAAT GGTACCAAGTTTTAGTTTCTGCGTAGGTTTTCCAGTGTGGCTTCTCTGATGGATCAGTGCTAAAATCTTAAGTATTTTTCTATTTGGGAA AAAAGGGTTGAATTATTTTCACTTGCCCACGTAGTTTATGAATGTGGGAAATAGCTTCAAAGACAGATTAAATGATTTGCCCAAGGCCAC AGAAAAGAGTGAAAGGTGGAACCGGAGACTAGATCACCACCTGTAGAAACTGTTCTTCCTCTGTGAAACTAACGGCCTGCTGGTAATAAA >17171_17171_3_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000361654_TMED2_chr12_124081152_ENST00000262225_length(amino acids)=238AA_BP=219 MSMLKPSGLKAPTKILKPGSTALKTPTAVVAPVEKTISSEKASSTPSSETQEEFVDDFRVGERVWVNGNKPGFIQFLGETQFAPGQWAGI VLDEPIGKNDGSVAGVRYFQCEPLKGIFTRPSKLTRKVQAEDEANGLQTTPASRATSPLCTSTASMVSSSPSTPSNIPQKPSQPAAKEPS -------------------------------------------------------------- >17171_17171_4_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000361654_TMED2_chr12_124081152_ENST00000509052_length(transcript)=1320nt_BP=831nt GGCGGCGGCCGCGGCGGCTGCTGCTGCTGCAGTGGGACAGGTGGCGGCGACCGGCGGCGTCCGAGGAGATTTAATCCAGAGACTGACTTC ACTATAGAACCCACAGTTGTATCAATGGTTGGGGAAAGATAGTGGCAACAGGCAAAGGAGAAACAGCTCTGACATACAAAGAAAATGAGT ATGCTAAAGCCAAGTGGGCTTAAGGCCCCCACCAAGATCCTGAAGCCTGGAAGCACAGCTCTGAAGACACCTACGGCTGTTGTAGCTCCA GTAGAAAAAACCATATCCAGTGAAAAAGCATCAAGCACTCCATCATCTGAGACTCAGGAGGAATTTGTGGATGACTTTCGAGTTGGGGAG CGAGTTTGGGTGAATGGAAATAAGCCTGGATTTATCCAGTTTCTTGGAGAAACCCAGTTTGCACCAGGCCAGTGGGCTGGAATTGTTTTA GATGAACCCATAGGCAAGAACGATGGTTCGGTGGCAGGAGTTCGGTATTTCCAGTGTGAACCTTTAAAGGGCATATTTACCCGACCTTCA AAGTTAACAAGGAAGGTGCAAGCAGAAGATGAAGCTAATGGCCTGCAGACAACGCCCGCCTCCCGAGCTACTTCACCGCTGTGCACTTCT ACGGCCAGCATGGTGTCTTCCTCCCCCTCCACCCCTTCAAACATCCCTCAGAAACCATCACAGCCAGCAGCAAAGGAACCTTCAGCTACG CCTCCGATCAGCAACCTTACAAAAACTGCCAGTGAATCTATCTCCAACCTTTCAGAGGCTGGCTCAATCAAGAAAGGAGAAAGAGAGCTC AAAATCGGAGACAGAGTATTGTCAACGACAACACAAACAGCAGAGTGGTCCTTTGGTCCTTCTTTGAAGCTCTTGTTCTAGTTGCCATGA CATTGGGACAGATCTACTACCTGAAGAGATTTTTTGAAGTCCGGAGAGTTGTTTAAAAAGCCTCTTCCTGATGATCCCAACTCAGAATTC ACTGTTTACCAAACACCTTGGTCATAATAATGTCATTAGTTTCTCCATTTTTATTTTCTGAACTGTACATTCACAACTTATGTTTCTTTG AGATTAATAGATATTGGGGGAAAAACGCCTTTTTAGGAAAATTATAGTGAAAATTTGACAGTTGATTGGCATAATTTCTTGTTTGAATGC TGCCTCCATTATATAGGTCCTTCCAGGAACTCAAACACTGTAAGTGAAATATGGGAGTATAGTTTTTATTATTTCTTCTTTTCCTTTTGT >17171_17171_4_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000361654_TMED2_chr12_124081152_ENST00000509052_length(amino acids)=238AA_BP=219 MSMLKPSGLKAPTKILKPGSTALKTPTAVVAPVEKTISSEKASSTPSSETQEEFVDDFRVGERVWVNGNKPGFIQFLGETQFAPGQWAGI VLDEPIGKNDGSVAGVRYFQCEPLKGIFTRPSKLTRKVQAEDEANGLQTTPASRATSPLCTSTASMVSSSPSTPSNIPQKPSQPAAKEPS -------------------------------------------------------------- >17171_17171_5_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000537178_TMED2_chr12_124081152_ENST00000262225_length(transcript)=2840nt_BP=875nt GTCACGCTCTCCCCCGCCCCGAGCCGACGAGCCGGGAGGCGGGAGGCGGCGGCCGCGGCGGCTGCTGCTGCTGCAGTGGGACAGGTGGCG GCGACCGGCGGCGTCCGAGGAGATTTAATCCAGAGACTGACTTCACTATAGAACCCACAGTTGTATCAATGGTTGGGGAAAGATAGTGGC AACAGGCAAAGGAGAAACAGCTCTGACATACAAAGAAAATGAGTATGCTAAAGCCAAGTGGGCTTAAGGCCCCCACCAAGATCCTGAAGC CTGGAAGCACAGCTCTGAAGACACCTACGGCTGTTGTAGCTCCAGTAGAAAAAACCATATCCAGTGAAAAAGCATCAAGCACTCCATCAT CTGAGACTCAGGAGGAATTTGTGGATGACTTTCGAGTTGGGGAGCGAGTTTGGGTGAATGGAAATAAGCCTGGATTTATCCAGTTTCTTG GAGAAACCCAGTTTGCACCAGGCCAGTGGGCTGGAATTGTTTTAGATGAACCCATAGGCAAGAACGATGGTTCGGTGGCAGGAGTTCGGT ATTTCCAGTGTGAACCTTTAAAGGGCATATTTACCCGACCTTCAAAGTTAACAAGGAAGGTGCAAGCAGAAGATGAAGCTAATGGCCTGC AGACAACGCCCGCCTCCCGAGCTACTTCACCGCTGTGCACTTCTACGGCCAGCATGGTGTCTTCCTCCCCCTCCACCCCTTCAAACATCC CTCAGAAACCATCACAGCCAGCAGCAAAGGAACCTTCAGCTACGCCTCCGATCAGCAACCTTACAAAAACTGCCAGTGAATCTATCTCCA ACCTTTCAGAGGCTGGCTCAATCAAGAAAGGAGAAAGAGAGCTCAAAATCGGAGACAGAGTATTGTCAACGACAACACAAACAGCAGAGT GGTCCTTTGGTCCTTCTTTGAAGCTCTTGTTCTAGTTGCCATGACATTGGGACAGATCTACTACCTGAAGAGATTTTTTGAAGTCCGGAG AGTTGTTTAAAAAGCCTCTTCCTGATGATCCCAACTCAGAATTCACTGTTTACCAAACACCTTGGTCATAATAATGTCATTAGTTTCTCC ATTTTTATTTTCTGAACTGTACATTCACAACTTATGTTTCTTTGAGATTAATAGATATTGGGGGAAAAACGCCTTTTTAGGAAAATTATA GTGAAAATTTGACAGTTGATTGGCATAATTTCTTGTTTGAATGCTGCCTCCATTATATAGGTCCTTCCAGGAACTCAAACACTGTAAGTG AAATATGGGAGTATAGTTTTTATTATTTCTTCTTTTCCTTTTGTTTTCATAATATAATGCAGTTTGTTCAGGAAATCAGCACAAAGCCTG ATAGTACTTTACTAAAATGACTGCATTCTTTGGATTCCTTCAGTCTATGGTTCAAGTCACTAAAGATTCATTTTTGTTGAGTCCTTATGA GAAACAGCAGTATGAATCTTGACGGTTTCTGCCCGTCCTAATGGCAGAGCTCTCTGACTTGGGTGTATGCTGCCAGGCTGGGTACTTTCA TACTTTGTTTTCTTGTTTTGCTTTAAAACTACGACTCAGCATACATTTTCCCACATACATTTTTACATTGTACCTTAGGACTCAGTCATC TCCACTTAAATTGATGACACAAGCAGCTAATAACCATTTCTGGGTTTCTGCCTAACCCCCTAATTGTCTGTTAAAGCCAATTCTCTGGGT GTCCCAGTGAGTGGTGGCTTTTTTTCTTTCCACATTGGCACATTCACTTCTCCCACTCTTGGCATGTAAGAAATAAGCATTTACATAATT GGAAAAATCTGGATTTCTGATGCCAAAGGGTTAAAGCTTCTTGGATTTCATTTCATTGATATACAGCCACTATTTTATTTTTGATCAGTG GCCTTTGGGCCACTGTTCAGGGTACTGACCATCAGTGTCAGCATTAGGGTTTTGGTTTTTGTTTCTTTTGGGTCTTTCTTTTTTGGCACA TGTGAATCTTGTTTTGTGTAAAATGAAATTACTTTCTCTTGTTCTCTGATGATGGGTTTAAAATTAAAAGAGCATCCGGTTTTGGTATGG GGATGATCCAGGATTATGTTGTGACTGATACATATTAGTTACTTGTGCTTTTTTTTTTTTTTTTGGATCTTTGCAAGGGCAAAACTACAA GTAACGAGTTTTATATAATTAATTTAAATTTGTTACAGGTTTTCATGTTCAGGATAAACCATACTTCCACCTTGGGTGAGAACACTTGCA ACAGTTTATTAATGAGGTGACTTTCACCTTAGGACAACTGTTGCATGCCAAGTTTTTTGTGTGTGTGAAACACTTCAAAACTGATTTAAA AGATGTAAATTTAAAATTGGTTGTATCTAATATGCCCCAGGTTCGGTAAATAAACAATTCTTTTTAAAAACAGTATTCTGTGTTTTATAT ATTGACAGCTAATCCACATTTTTTACACACCAACTTTCTGTTCTTATTTGACATGAGACATGTTCATGTTTTCTGAGTATTTATACCTAT TACGTCTGTTACTTTTTAATTCTATAAACTTGAGGATAGTGAATGGTACCAAGTTTTAGTTTCTGCGTAGGTTTTCCAGTGTGGCTTCTC TGATGGATCAGTGCTAAAATCTTAAGTATTTTTCTATTTGGGAAAAAAGGGTTGAATTATTTTCACTTGCCCACGTAGTTTATGAATGTG GGAAATAGCTTCAAAGACAGATTAAATGATTTGCCCAAGGCCACAGAAAAGAGTGAAAGGTGGAACCGGAGACTAGATCACCACCTGTAG >17171_17171_5_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000537178_TMED2_chr12_124081152_ENST00000262225_length(amino acids)=238AA_BP=219 MSMLKPSGLKAPTKILKPGSTALKTPTAVVAPVEKTISSEKASSTPSSETQEEFVDDFRVGERVWVNGNKPGFIQFLGETQFAPGQWAGI VLDEPIGKNDGSVAGVRYFQCEPLKGIFTRPSKLTRKVQAEDEANGLQTTPASRATSPLCTSTASMVSSSPSTPSNIPQKPSQPAAKEPS -------------------------------------------------------------- >17171_17171_6_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000537178_TMED2_chr12_124081152_ENST00000509052_length(transcript)=1364nt_BP=875nt GTCACGCTCTCCCCCGCCCCGAGCCGACGAGCCGGGAGGCGGGAGGCGGCGGCCGCGGCGGCTGCTGCTGCTGCAGTGGGACAGGTGGCG GCGACCGGCGGCGTCCGAGGAGATTTAATCCAGAGACTGACTTCACTATAGAACCCACAGTTGTATCAATGGTTGGGGAAAGATAGTGGC AACAGGCAAAGGAGAAACAGCTCTGACATACAAAGAAAATGAGTATGCTAAAGCCAAGTGGGCTTAAGGCCCCCACCAAGATCCTGAAGC CTGGAAGCACAGCTCTGAAGACACCTACGGCTGTTGTAGCTCCAGTAGAAAAAACCATATCCAGTGAAAAAGCATCAAGCACTCCATCAT CTGAGACTCAGGAGGAATTTGTGGATGACTTTCGAGTTGGGGAGCGAGTTTGGGTGAATGGAAATAAGCCTGGATTTATCCAGTTTCTTG GAGAAACCCAGTTTGCACCAGGCCAGTGGGCTGGAATTGTTTTAGATGAACCCATAGGCAAGAACGATGGTTCGGTGGCAGGAGTTCGGT ATTTCCAGTGTGAACCTTTAAAGGGCATATTTACCCGACCTTCAAAGTTAACAAGGAAGGTGCAAGCAGAAGATGAAGCTAATGGCCTGC AGACAACGCCCGCCTCCCGAGCTACTTCACCGCTGTGCACTTCTACGGCCAGCATGGTGTCTTCCTCCCCCTCCACCCCTTCAAACATCC CTCAGAAACCATCACAGCCAGCAGCAAAGGAACCTTCAGCTACGCCTCCGATCAGCAACCTTACAAAAACTGCCAGTGAATCTATCTCCA ACCTTTCAGAGGCTGGCTCAATCAAGAAAGGAGAAAGAGAGCTCAAAATCGGAGACAGAGTATTGTCAACGACAACACAAACAGCAGAGT GGTCCTTTGGTCCTTCTTTGAAGCTCTTGTTCTAGTTGCCATGACATTGGGACAGATCTACTACCTGAAGAGATTTTTTGAAGTCCGGAG AGTTGTTTAAAAAGCCTCTTCCTGATGATCCCAACTCAGAATTCACTGTTTACCAAACACCTTGGTCATAATAATGTCATTAGTTTCTCC ATTTTTATTTTCTGAACTGTACATTCACAACTTATGTTTCTTTGAGATTAATAGATATTGGGGGAAAAACGCCTTTTTAGGAAAATTATA GTGAAAATTTGACAGTTGATTGGCATAATTTCTTGTTTGAATGCTGCCTCCATTATATAGGTCCTTCCAGGAACTCAAACACTGTAAGTG AAATATGGGAGTATAGTTTTTATTATTTCTTCTTTTCCTTTTGTTTTCATAATATAATGCAGTTTGTTCAGGAAATCAGCACAAAGCCTG >17171_17171_6_CLIP1-TMED2_CLIP1_chr12_122861936_ENST00000537178_TMED2_chr12_124081152_ENST00000509052_length(amino acids)=238AA_BP=219 MSMLKPSGLKAPTKILKPGSTALKTPTAVVAPVEKTISSEKASSTPSSETQEEFVDDFRVGERVWVNGNKPGFIQFLGETQFAPGQWAGI VLDEPIGKNDGSVAGVRYFQCEPLKGIFTRPSKLTRKVQAEDEANGLQTTPASRATSPLCTSTASMVSSSPSTPSNIPQKPSQPAAKEPS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CLIP1-TMED2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | TMED2 | chr12:122861936 | chr12:124081152 | ENST00000262225 | 2 | 4 | 1_181 | 160.33333333333334 | 202.0 | F2RL1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CLIP1-TMED2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CLIP1-TMED2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies