
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CMC1-ANXA2 (FusionGDB2 ID:17498) |
Fusion Gene Summary for CMC1-ANXA2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CMC1-ANXA2 | Fusion gene ID: 17498 | Hgene | Tgene | Gene symbol | CMC1 | ANXA2 | Gene ID | 152100 | 302 |
| Gene name | C-X9-C motif containing 1 | annexin A2 | |
| Synonyms | C3orf68 | ANX2|ANX2L4|CAL1H|HEL-S-270|LIP2|LPC2|LPC2D|P36|PAP-IV | |
| Cytomap | 3p24.1 | 15q22.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | COX assembly mitochondrial protein homologC-x(9)-C motif containing 1COX assembly mitochondrial protein 1 homologCX9C mitochondrial protein required for full expression of COX 1cmc1pmitochondrial metallochaperone-like protein | annexin A2annexin IIannexin-2calpactin I heavy chaincalpactin I heavy polypeptidecalpactin-1 heavy chainchromobindin 8epididymis secretory protein Li 270epididymis secretory sperm binding proteinlipocortin IIplacental anticoagulant protein IVpr | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | Q7Z7K0 | A6NMY6 | |
| Ensembl transtripts involved in fusion gene | ENST00000466830, ENST00000423894, ENST00000469102, | ENST00000557937, ENST00000332680, ENST00000396024, ENST00000421017, ENST00000451270, | |
| Fusion gene scores | * DoF score | 9 X 5 X 8=360 | 33 X 12 X 13=5148 |
| # samples | 11 | 39 | |
| ** MAII score | log2(11/360*10)=-1.71049338280502 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(39/5148*10)=-3.72246602447109 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CMC1 [Title/Abstract] AND ANXA2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CMC1(28304871)-ANXA2(60656722), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | ANXA2 | GO:0001921 | positive regulation of receptor recycling | 22848640 |
| Tgene | ANXA2 | GO:0031340 | positive regulation of vesicle fusion | 2138016 |
| Tgene | ANXA2 | GO:0032804 | negative regulation of low-density lipoprotein particle receptor catabolic process | 22848640 |
| Tgene | ANXA2 | GO:0036035 | osteoclast development | 7961821 |
| Tgene | ANXA2 | GO:1905581 | positive regulation of low-density lipoprotein particle clearance | 22848640 |
| Tgene | ANXA2 | GO:1905597 | positive regulation of low-density lipoprotein particle receptor binding | 22848640 |
| Tgene | ANXA2 | GO:1905602 | positive regulation of receptor-mediated endocytosis involved in cholesterol transport | 22848640 |
| Fusion gene breakpoints across CMC1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ANXA2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | ERR315353 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
Top |
Fusion Gene ORF analysis for CMC1-ANXA2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000466830 | ENST00000557937 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000466830 | ENST00000332680 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000466830 | ENST00000396024 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000466830 | ENST00000421017 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| In-frame | ENST00000466830 | ENST00000451270 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000423894 | ENST00000332680 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000423894 | ENST00000396024 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000423894 | ENST00000421017 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000423894 | ENST00000451270 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000469102 | ENST00000332680 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000469102 | ENST00000396024 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000469102 | ENST00000421017 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-3CDS | ENST00000469102 | ENST00000451270 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-5UTR | ENST00000423894 | ENST00000557937 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| intron-5UTR | ENST00000469102 | ENST00000557937 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000466830 | CMC1 | chr3 | 28304871 | + | ENST00000396024 | ANXA2 | chr15 | 60656722 | - | 1676 | 308 | 199 | 1179 | 326 |
| ENST00000466830 | CMC1 | chr3 | 28304871 | + | ENST00000451270 | ANXA2 | chr15 | 60656722 | - | 1483 | 308 | 199 | 1179 | 326 |
| ENST00000466830 | CMC1 | chr3 | 28304871 | + | ENST00000332680 | ANXA2 | chr15 | 60656722 | - | 1478 | 308 | 199 | 1179 | 326 |
| ENST00000466830 | CMC1 | chr3 | 28304871 | + | ENST00000421017 | ANXA2 | chr15 | 60656722 | - | 1468 | 308 | 199 | 1179 | 326 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000466830 | ENST00000396024 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - | 0.001399318 | 0.99860066 |
| ENST00000466830 | ENST00000451270 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - | 0.001615053 | 0.99838495 |
| ENST00000466830 | ENST00000332680 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - | 0.001646745 | 0.99835324 |
| ENST00000466830 | ENST00000421017 | CMC1 | chr3 | 28304871 | + | ANXA2 | chr15 | 60656722 | - | 0.001708125 | 0.9982919 |
Top |
Fusion Genomic Features for CMC1-ANXA2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
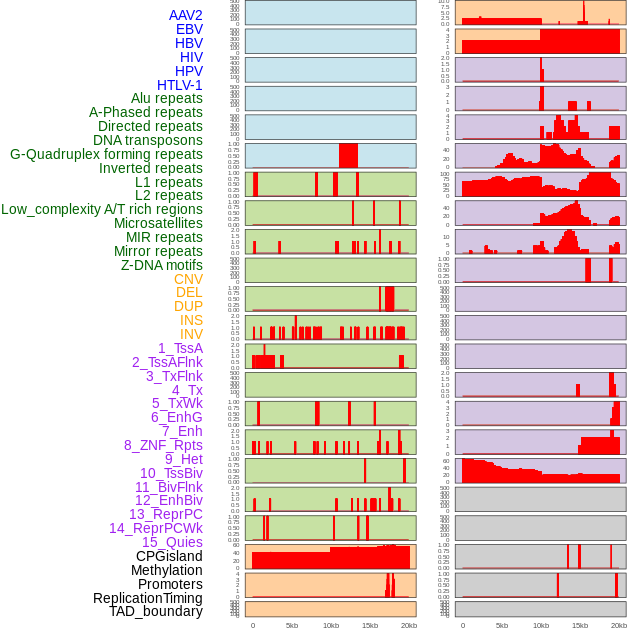 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CMC1-ANXA2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:28304871/chr15:60656722) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CMC1 | ANXA2 |
| FUNCTION: Component of the MITRAC (mitochondrial translation regulation assembly intermediate of cytochrome c oxidase complex) complex, that regulates cytochrome c oxidase assembly. {ECO:0000250}. | FUNCTION: Calcium-regulated membrane-binding protein whose affinity for calcium is greatly enhanced by anionic phospholipids. It binds two calcium ions with high affinity. May be involved in heat-stress response. {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000332680 | 2 | 13 | 105_176 | 67 | 358.0 | Repeat | Annexin 2 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000332680 | 2 | 13 | 189_261 | 67 | 358.0 | Repeat | Annexin 3 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000332680 | 2 | 13 | 265_336 | 67 | 358.0 | Repeat | Annexin 4 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000396024 | 3 | 14 | 105_176 | 49 | 340.0 | Repeat | Annexin 2 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000396024 | 3 | 14 | 189_261 | 49 | 340.0 | Repeat | Annexin 3 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000396024 | 3 | 14 | 265_336 | 49 | 340.0 | Repeat | Annexin 4 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000421017 | 3 | 14 | 105_176 | 49 | 340.0 | Repeat | Annexin 2 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000421017 | 3 | 14 | 189_261 | 49 | 340.0 | Repeat | Annexin 3 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000421017 | 3 | 14 | 265_336 | 49 | 340.0 | Repeat | Annexin 4 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000451270 | 2 | 13 | 105_176 | 49 | 340.0 | Repeat | Annexin 2 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000451270 | 2 | 13 | 189_261 | 49 | 340.0 | Repeat | Annexin 3 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000451270 | 2 | 13 | 265_336 | 49 | 340.0 | Repeat | Annexin 4 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CMC1 | chr3:28304871 | chr15:60656722 | ENST00000466830 | + | 2 | 4 | 28_71 | 36 | 107.0 | Domain | CHCH |
| Hgene | CMC1 | chr3:28304871 | chr15:60656722 | ENST00000466830 | + | 2 | 4 | 31_41 | 36 | 107.0 | Motif | Cx9C motif 1 |
| Hgene | CMC1 | chr3:28304871 | chr15:60656722 | ENST00000466830 | + | 2 | 4 | 53_63 | 36 | 107.0 | Motif | Cx9C motif 2 |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000332680 | 2 | 13 | 2_24 | 67 | 358.0 | Region | S100A10-binding site | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000396024 | 3 | 14 | 2_24 | 49 | 340.0 | Region | S100A10-binding site | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000421017 | 3 | 14 | 2_24 | 49 | 340.0 | Region | S100A10-binding site | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000451270 | 2 | 13 | 2_24 | 49 | 340.0 | Region | S100A10-binding site | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000332680 | 2 | 13 | 33_104 | 67 | 358.0 | Repeat | Annexin 1 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000396024 | 3 | 14 | 33_104 | 49 | 340.0 | Repeat | Annexin 1 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000421017 | 3 | 14 | 33_104 | 49 | 340.0 | Repeat | Annexin 1 | |
| Tgene | ANXA2 | chr3:28304871 | chr15:60656722 | ENST00000451270 | 2 | 13 | 33_104 | 49 | 340.0 | Repeat | Annexin 1 |
Top |
Fusion Gene Sequence for CMC1-ANXA2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >17498_17498_1_CMC1-ANXA2_CMC1_chr3_28304871_ENST00000466830_ANXA2_chr15_60656722_ENST00000332680_length(transcript)=1478nt_BP=308nt GGCGCAACGGGCGGCGGAAGTAGGAGCCTGGGAAGGAAGAGGGAACGGGTCCTGGCGGTGCTTTGCAAAGGGCCCGTGTTTCTGTTGCGG GAAGCTCCCGGGGGTCGCACGTGCGTCCGAGCCCAAGCCCCTCCCCTCCACTCCCCTTCCTGCGTGCCCCGGAGCCGCCAAGCGGCTACG TTCTTCTCGGCCCGCCGAGATGGCGCTCGACCCCGCAGACCAGCATCTCAGACATGTCGAAAAAGATGTTTTGATCCCTAAAATAATGAG AGAAAAGGCCAAAGAGAGGTGTTCTGAACAAGTTCAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACA GAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGAC GGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTC TCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAA GGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGA TTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCAT GACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGA GGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTC CATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAAGTGGACATGTTGAAAATTAGGTCTGAATT CAAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTACCAGAAAGCGCTGCTGTACCTGTGTGGTGG AGATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCTAACAGGTCTAGAAAACCAGCTTGCGAATA ACAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGTTGCCTAAGCATTGCCTGGCCTTCCTGTCT AGTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATGTGAAACACTTTGCCTCCTGTGTACTGTGT >17498_17498_1_CMC1-ANXA2_CMC1_chr3_28304871_ENST00000466830_ANXA2_chr15_60656722_ENST00000332680_length(amino acids)=326AA_BP=36 MALDPADQHLRHVEKDVLIPKIMREKAKERCSEQVQGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLL KTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQ DARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGT -------------------------------------------------------------- >17498_17498_2_CMC1-ANXA2_CMC1_chr3_28304871_ENST00000466830_ANXA2_chr15_60656722_ENST00000396024_length(transcript)=1676nt_BP=308nt GGCGCAACGGGCGGCGGAAGTAGGAGCCTGGGAAGGAAGAGGGAACGGGTCCTGGCGGTGCTTTGCAAAGGGCCCGTGTTTCTGTTGCGG GAAGCTCCCGGGGGTCGCACGTGCGTCCGAGCCCAAGCCCCTCCCCTCCACTCCCCTTCCTGCGTGCCCCGGAGCCGCCAAGCGGCTACG TTCTTCTCGGCCCGCCGAGATGGCGCTCGACCCCGCAGACCAGCATCTCAGACATGTCGAAAAAGATGTTTTGATCCCTAAAATAATGAG AGAAAAGGCCAAAGAGAGGTGTTCTGAACAAGTTCAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACA GAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGAC GGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTC TCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAA GGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGA TTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCAT GACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGA GGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTC CATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAAGTGGACATGTTGAAAATTAGGTCTGAATT CAAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTACCAGAAAGCGCTGCTGTACCTGTGTGGTGG AGATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCTAACAGGTCTAGAAAACCAGCTTGCGAATA ACAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGTTGCCTAAGCATTGCCTGGCCTTCCTGTCT AGTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATGTGAAACACTTTGCCTCCTGTGTACTGTGT CATAAACAGATGAATAAACTGAATTTGTACTTTAGAAACACGTACTTTGTGGCCCTGCTTTCAACTGAATTGTTTGAAAATTAAACGTGC TTGGGGTTCAGCTGGTGAGGCTGTCCCTGTAGGAAGAAAGCTCTGGGACTGAGCTGTACAGTATGGTTGCCCCTATCCAAGTGTCGCTAT >17498_17498_2_CMC1-ANXA2_CMC1_chr3_28304871_ENST00000466830_ANXA2_chr15_60656722_ENST00000396024_length(amino acids)=326AA_BP=36 MALDPADQHLRHVEKDVLIPKIMREKAKERCSEQVQGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLL KTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQ DARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGT -------------------------------------------------------------- >17498_17498_3_CMC1-ANXA2_CMC1_chr3_28304871_ENST00000466830_ANXA2_chr15_60656722_ENST00000421017_length(transcript)=1468nt_BP=308nt GGCGCAACGGGCGGCGGAAGTAGGAGCCTGGGAAGGAAGAGGGAACGGGTCCTGGCGGTGCTTTGCAAAGGGCCCGTGTTTCTGTTGCGG GAAGCTCCCGGGGGTCGCACGTGCGTCCGAGCCCAAGCCCCTCCCCTCCACTCCCCTTCCTGCGTGCCCCGGAGCCGCCAAGCGGCTACG TTCTTCTCGGCCCGCCGAGATGGCGCTCGACCCCGCAGACCAGCATCTCAGACATGTCGAAAAAGATGTTTTGATCCCTAAAATAATGAG AGAAAAGGCCAAAGAGAGGTGTTCTGAACAAGTTCAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACA GAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGAC GGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTC TCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAA GGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGA TTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCAT GACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGA GGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTC CATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAAGTGGACATGTTGAAAATTAGGTCTGAATT CAAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTACCAGAAAGCGCTGCTGTACCTGTGTGGTGG AGATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCTAACAGGTCTAGAAAACCAGCTTGCGAATA ACAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGTTGCCTAAGCATTGCCTGGCCTTCCTGTCT AGTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATGTGAAACACTTTGCCTCCTGTGTACTGTGT >17498_17498_3_CMC1-ANXA2_CMC1_chr3_28304871_ENST00000466830_ANXA2_chr15_60656722_ENST00000421017_length(amino acids)=326AA_BP=36 MALDPADQHLRHVEKDVLIPKIMREKAKERCSEQVQGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLL KTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQ DARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGT -------------------------------------------------------------- >17498_17498_4_CMC1-ANXA2_CMC1_chr3_28304871_ENST00000466830_ANXA2_chr15_60656722_ENST00000451270_length(transcript)=1483nt_BP=308nt GGCGCAACGGGCGGCGGAAGTAGGAGCCTGGGAAGGAAGAGGGAACGGGTCCTGGCGGTGCTTTGCAAAGGGCCCGTGTTTCTGTTGCGG GAAGCTCCCGGGGGTCGCACGTGCGTCCGAGCCCAAGCCCCTCCCCTCCACTCCCCTTCCTGCGTGCCCCGGAGCCGCCAAGCGGCTACG TTCTTCTCGGCCCGCCGAGATGGCGCTCGACCCCGCAGACCAGCATCTCAGACATGTCGAAAAAGATGTTTTGATCCCTAAAATAATGAG AGAAAAGGCCAAAGAGAGGTGTTCTGAACAAGTTCAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACA GAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGAC GGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTC TCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAA GGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGA TTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCAT GACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGA GGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTC CATGAAGGGCAAGGGGACGCGAGATAAGGTCCTGATCAGAATCATGGTCTCCCGCAGTGAAGTGGACATGTTGAAAATTAGGTCTGAATT CAAGAGAAAGTACGGCAAGTCCCTGTACTATTATATCCAGCAAGACACTAAGGGCGACTACCAGAAAGCGCTGCTGTACCTGTGTGGTGG AGATGACTGAAGCCCGACACGGCCTGAGCGTCCAGAAATGGTGCTCACCATGCTTCCAGCTAACAGGTCTAGAAAACCAGCTTGCGAATA ACAGTCCCCGTGGCCATCCCTGTGAGGGTGACGTTAGCATTACCCCCAACCTCATTTTAGTTGCCTAAGCATTGCCTGGCCTTCCTGTCT AGTCTCTCCTGTAAGCCAAAGAAATGAACATTCCAAGGAGTTGGAAGTGAAGTCTATGATGTGAAACACTTTGCCTCCTGTGTACTGTGT >17498_17498_4_CMC1-ANXA2_CMC1_chr3_28304871_ENST00000466830_ANXA2_chr15_60656722_ENST00000451270_length(amino acids)=326AA_BP=36 MALDPADQHLRHVEKDVLIPKIMREKAKERCSEQVQGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLL KTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQ DARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CMC1-ANXA2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CMC1-ANXA2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CMC1-ANXA2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies