
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CNN2-PPP1R12C (FusionGDB2 ID:17676) |
Fusion Gene Summary for CNN2-PPP1R12C |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CNN2-PPP1R12C | Fusion gene ID: 17676 | Hgene | Tgene | Gene symbol | CNN2 | PPP1R12C | Gene ID | 1265 | 54776 |
| Gene name | calponin 2 | protein phosphatase 1 regulatory subunit 12C | |
| Synonyms | - | AAVS1|LENG3|MBS85|p84|p85 | |
| Cytomap | 19p13.3 | 19q13.42 | |
| Type of gene | protein-coding | protein-coding | |
| Description | calponin-2calponin H2, smooth muscleneutral calponin | protein phosphatase 1 regulatory subunit 12Cleukocyte receptor cluster (LRC) encoded novel gene 3leukocyte receptor cluster (LRC) member 3myosin-binding subunit 85protein phosphatase 1 myosin-binding subunit of 85 kDaprotein phosphatase 1 myosin-bind | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000606983, ENST00000263097, ENST00000348419, ENST00000562958, ENST00000565096, | ENST00000263433, ENST00000376393, ENST00000435544, | |
| Fusion gene scores | * DoF score | 9 X 8 X 6=432 | 16 X 6 X 9=864 |
| # samples | 9 | 16 | |
| ** MAII score | log2(9/432*10)=-2.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(16/864*10)=-2.43295940727611 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CNN2 [Title/Abstract] AND PPP1R12C [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PPP1R12C(55610151)-CNN2(1036128), # samples:3 PPP1R12C(55610152)-CNN2(1036129), # samples:3 CNN2(1032695)-PPP1R12C(55607703), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CNN2 | GO:0032970 | regulation of actin filament-based process | 16236705 |
| Hgene | CNN2 | GO:0071260 | cellular response to mechanical stimulus | 16236705 |
| Fusion gene breakpoints across CNN2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
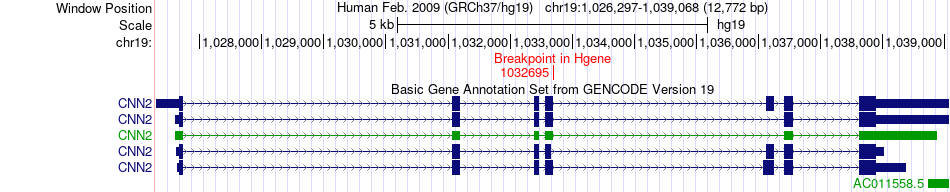 |
| Fusion gene breakpoints across PPP1R12C (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | TCGA-IP-7968-11A | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
Top |
Fusion Gene ORF analysis for CNN2-PPP1R12C |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000606983 | ENST00000263433 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| 3UTR-3CDS | ENST00000606983 | ENST00000376393 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| 3UTR-3CDS | ENST00000606983 | ENST00000435544 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000263097 | ENST00000263433 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000263097 | ENST00000376393 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000263097 | ENST00000435544 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000348419 | ENST00000263433 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000348419 | ENST00000376393 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000348419 | ENST00000435544 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000562958 | ENST00000263433 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000562958 | ENST00000376393 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000562958 | ENST00000435544 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| intron-3CDS | ENST00000565096 | ENST00000263433 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| intron-3CDS | ENST00000565096 | ENST00000376393 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| intron-3CDS | ENST00000565096 | ENST00000435544 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000263097 | CNN2 | chr19 | 1032695 | + | ENST00000263433 | PPP1R12C | chr19 | 55607703 | - | 2710 | 753 | 234 | 2150 | 638 |
| ENST00000263097 | CNN2 | chr19 | 1032695 | + | ENST00000376393 | PPP1R12C | chr19 | 55607703 | - | 2519 | 753 | 234 | 1961 | 575 |
| ENST00000263097 | CNN2 | chr19 | 1032695 | + | ENST00000435544 | PPP1R12C | chr19 | 55607703 | - | 2259 | 753 | 234 | 2147 | 637 |
| ENST00000348419 | CNN2 | chr19 | 1032695 | + | ENST00000263433 | PPP1R12C | chr19 | 55607703 | - | 2398 | 441 | 51 | 1838 | 595 |
| ENST00000348419 | CNN2 | chr19 | 1032695 | + | ENST00000376393 | PPP1R12C | chr19 | 55607703 | - | 2207 | 441 | 51 | 1649 | 532 |
| ENST00000348419 | CNN2 | chr19 | 1032695 | + | ENST00000435544 | PPP1R12C | chr19 | 55607703 | - | 1947 | 441 | 51 | 1835 | 594 |
| ENST00000562958 | CNN2 | chr19 | 1032695 | + | ENST00000263433 | PPP1R12C | chr19 | 55607703 | - | 2380 | 423 | 33 | 1820 | 595 |
| ENST00000562958 | CNN2 | chr19 | 1032695 | + | ENST00000376393 | PPP1R12C | chr19 | 55607703 | - | 2189 | 423 | 33 | 1631 | 532 |
| ENST00000562958 | CNN2 | chr19 | 1032695 | + | ENST00000435544 | PPP1R12C | chr19 | 55607703 | - | 1929 | 423 | 33 | 1817 | 594 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000263097 | ENST00000263433 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.031467836 | 0.96853215 |
| ENST00000263097 | ENST00000376393 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.030095687 | 0.9699043 |
| ENST00000263097 | ENST00000435544 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.036585387 | 0.9634146 |
| ENST00000348419 | ENST00000263433 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.034183558 | 0.9658164 |
| ENST00000348419 | ENST00000376393 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.031887606 | 0.9681124 |
| ENST00000348419 | ENST00000435544 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.04189028 | 0.95810974 |
| ENST00000562958 | ENST00000263433 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.035630547 | 0.9643694 |
| ENST00000562958 | ENST00000376393 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.03284212 | 0.96715784 |
| ENST00000562958 | ENST00000435544 | CNN2 | chr19 | 1032695 | + | PPP1R12C | chr19 | 55607703 | - | 0.04335595 | 0.95664406 |
Top |
Fusion Genomic Features for CNN2-PPP1R12C |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
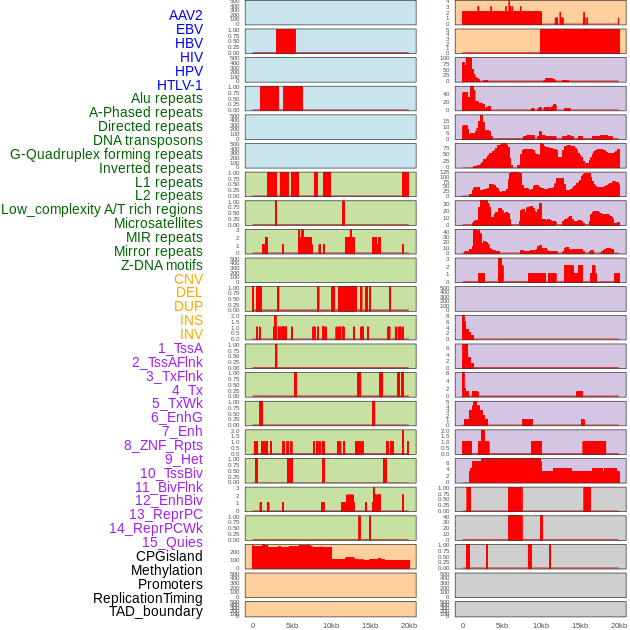 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CNN2-PPP1R12C |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:55610151/chr19:1036128) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CNN2 | chr19:1032695 | chr19:55607703 | ENST00000263097 | + | 4 | 7 | 28_132 | 130 | 310.0 | Domain | Calponin-homology (CH) |
| Hgene | CNN2 | chr19:1032695 | chr19:55607703 | ENST00000348419 | + | 4 | 6 | 28_132 | 130 | 271.0 | Domain | Calponin-homology (CH) |
| Tgene | PPP1R12C | chr19:1032695 | chr19:55607703 | ENST00000263433 | 5 | 22 | 681_782 | 317 | 783.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PPP1R12C | chr19:1032695 | chr19:55607703 | ENST00000263433 | 5 | 22 | 473_523 | 317 | 783.0 | Compositional bias | Pro-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CNN2 | chr19:1032695 | chr19:55607703 | ENST00000263097 | + | 4 | 7 | 166_191 | 130 | 310.0 | Repeat | Note=Calponin-like 1 |
| Hgene | CNN2 | chr19:1032695 | chr19:55607703 | ENST00000263097 | + | 4 | 7 | 206_231 | 130 | 310.0 | Repeat | Note=Calponin-like 2 |
| Hgene | CNN2 | chr19:1032695 | chr19:55607703 | ENST00000263097 | + | 4 | 7 | 245_269 | 130 | 310.0 | Repeat | Note=Calponin-like 3 |
| Hgene | CNN2 | chr19:1032695 | chr19:55607703 | ENST00000348419 | + | 4 | 6 | 166_191 | 130 | 271.0 | Repeat | Note=Calponin-like 1 |
| Hgene | CNN2 | chr19:1032695 | chr19:55607703 | ENST00000348419 | + | 4 | 6 | 206_231 | 130 | 271.0 | Repeat | Note=Calponin-like 2 |
| Hgene | CNN2 | chr19:1032695 | chr19:55607703 | ENST00000348419 | + | 4 | 6 | 245_269 | 130 | 271.0 | Repeat | Note=Calponin-like 3 |
| Tgene | PPP1R12C | chr19:1032695 | chr19:55607703 | ENST00000263433 | 5 | 22 | 297_329 | 317 | 783.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PPP1R12C | chr19:1032695 | chr19:55607703 | ENST00000263433 | 5 | 22 | 100_129 | 317 | 783.0 | Repeat | ANK 1 | |
| Tgene | PPP1R12C | chr19:1032695 | chr19:55607703 | ENST00000263433 | 5 | 22 | 133_162 | 317 | 783.0 | Repeat | ANK 2 | |
| Tgene | PPP1R12C | chr19:1032695 | chr19:55607703 | ENST00000263433 | 5 | 22 | 226_255 | 317 | 783.0 | Repeat | ANK 3 | |
| Tgene | PPP1R12C | chr19:1032695 | chr19:55607703 | ENST00000263433 | 5 | 22 | 259_288 | 317 | 783.0 | Repeat | ANK 4 |
Top |
Fusion Gene Sequence for CNN2-PPP1R12C |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >17676_17676_1_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000263097_PPP1R12C_chr19_55607703_ENST00000263433_length(transcript)=2710nt_BP=753nt GAAAGAGTGAGAGCCGCCCACGAGCTCTGAGCAGAGAGCCCGCAGGAGTGCCACGTCCCGGCGGCCTCGGCCCCTCCCTGCCTCAGTTTC CCGTGGCATCAAAGGGGGCGAGGGGCCCCTCCAGGCCTCTGGTGACGGGGGTGCTGTGCCCAGGCGGGGGTCCGGGGGCGACCGAGGGGG CTCAGGAAGTCCGCGGCCGCAGGAATTCGGCGCCTCCAGGCCTTATAAGGACATTTGCGCTCCGGGCCAATCAGCGGCGGGGGCGTGGCG CGCGGAGCCCGGCGCGTCCCAACCCCGCGCCAGCCCGGCGGTCCCGTCCCGTCCCGTCCTGTGCGGCCCCGTCCCGCCGCCCGCCCGCCA GCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGGCTGTCGGCCGAGGTCAAGAACCGGCTCCTGTCCAAATATGACCCCCAG AAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGCCTCTCCATCGGCCCCGACTTCCAGAAGGGCCTGAAGGATGGAACTATC TTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCCAAGATCAACCGCTCCATGCAGAACTGGCACCAGCTAGAAAACCTGTCC AACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTGGACCTGTTCGAGGCCAACGACCTGTTTGAGAGTGGGAACATGACGCAG GTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCT AGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGT GGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGC GTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGG AGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTG GAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCT GAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCC ACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGA AAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGG AAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCC CAGAGAGCAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCG GAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGG GACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGG CTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCT GAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTG TCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGG ACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTC TCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGA GGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCA AGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGA TCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTT TTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATAAAAGTCGTGAAGT >17676_17676_1_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000263097_PPP1R12C_chr19_55607703_ENST00000263433_length(amino acids)=638AA_BP=173 MRSGPISGGGVARGARRVPTPRQPGGPVPSRPVRPRPAARPPAMSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIG PDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSNFIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEA SQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEA PFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRI PEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSRRP RVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFR TLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLRADNQRLKDENAALI -------------------------------------------------------------- >17676_17676_2_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000263097_PPP1R12C_chr19_55607703_ENST00000376393_length(transcript)=2519nt_BP=753nt GAAAGAGTGAGAGCCGCCCACGAGCTCTGAGCAGAGAGCCCGCAGGAGTGCCACGTCCCGGCGGCCTCGGCCCCTCCCTGCCTCAGTTTC CCGTGGCATCAAAGGGGGCGAGGGGCCCCTCCAGGCCTCTGGTGACGGGGGTGCTGTGCCCAGGCGGGGGTCCGGGGGCGACCGAGGGGG CTCAGGAAGTCCGCGGCCGCAGGAATTCGGCGCCTCCAGGCCTTATAAGGACATTTGCGCTCCGGGCCAATCAGCGGCGGGGGCGTGGCG CGCGGAGCCCGGCGCGTCCCAACCCCGCGCCAGCCCGGCGGTCCCGTCCCGTCCCGTCCTGTGCGGCCCCGTCCCGCCGCCCGCCCGCCA GCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGGCTGTCGGCCGAGGTCAAGAACCGGCTCCTGTCCAAATATGACCCCCAG AAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGCCTCTCCATCGGCCCCGACTTCCAGAAGGGCCTGAAGGATGGAACTATC TTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCCAAGATCAACCGCTCCATGCAGAACTGGCACCAGCTAGAAAACCTGTCC AACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTGGACCTGTTCGAGGCCAACGACCTGTTTGAGAGTGGGAACATGACGCAG GTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCT AGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGT GGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGC GTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGG AGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTG GAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCT GAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCC ACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGA AAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGGGGAG GAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAAC CCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAG GCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCA GCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTC CGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCG CACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAAG CCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGGGAGG CCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGATCAGT AGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAAGAAT GTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCTGCCC >17676_17676_2_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000263097_PPP1R12C_chr19_55607703_ENST00000376393_length(amino acids)=575AA_BP=173 MRSGPISGGGVARGARRVPTPRQPGGPVPSRPVRPRPAARPPAMSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIG PDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSNFIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEA SQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEA PFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRI PEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAEPADRSQESSTLEGGP SARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAA -------------------------------------------------------------- >17676_17676_3_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000263097_PPP1R12C_chr19_55607703_ENST00000435544_length(transcript)=2259nt_BP=753nt GAAAGAGTGAGAGCCGCCCACGAGCTCTGAGCAGAGAGCCCGCAGGAGTGCCACGTCCCGGCGGCCTCGGCCCCTCCCTGCCTCAGTTTC CCGTGGCATCAAAGGGGGCGAGGGGCCCCTCCAGGCCTCTGGTGACGGGGGTGCTGTGCCCAGGCGGGGGTCCGGGGGCGACCGAGGGGG CTCAGGAAGTCCGCGGCCGCAGGAATTCGGCGCCTCCAGGCCTTATAAGGACATTTGCGCTCCGGGCCAATCAGCGGCGGGGGCGTGGCG CGCGGAGCCCGGCGCGTCCCAACCCCGCGCCAGCCCGGCGGTCCCGTCCCGTCCCGTCCTGTGCGGCCCCGTCCCGCCGCCCGCCCGCCA GCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGGCTGTCGGCCGAGGTCAAGAACCGGCTCCTGTCCAAATATGACCCCCAG AAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGCCTCTCCATCGGCCCCGACTTCCAGAAGGGCCTGAAGGATGGAACTATC TTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCCAAGATCAACCGCTCCATGCAGAACTGGCACCAGCTAGAAAACCTGTCC AACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTGGACCTGTTCGAGGCCAACGACCTGTTTGAGAGTGGGAACATGACGCAG GTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCT AGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGT GGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGC GTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGG AGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTG GAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCT GAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCC ACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGA AAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGG AAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCC CAGAGAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAG GGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGAC CTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTT CGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAG AGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCT GACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACT TTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCA >17676_17676_3_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000263097_PPP1R12C_chr19_55607703_ENST00000435544_length(amino acids)=637AA_BP=173 MRSGPISGGGVARGARRVPTPRQPGGPVPSRPVRPRPAARPPAMSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIG PDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSNFIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEA SQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEA PFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRI PEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSRRP RVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRT LYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLRADNQRLKDENAALIR -------------------------------------------------------------- >17676_17676_4_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000348419_PPP1R12C_chr19_55607703_ENST00000263433_length(transcript)=2398nt_BP=441nt CCCGTCCCGTCCCGTCCTGTGCGGCCCCGTCCCGCCGCCCGCCCGCCAGCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGG CTGTCGGCCGAGGTCAAGAACCGGCTCCTGTCCAAATATGACCCCCAGAAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGC CTCTCCATCGGCCCCGACTTCCAGAAGGGCCTGAAGGATGGAACTATCTTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCC AAGATCAACCGCTCCATGCAGAACTGGCACCAGCTAGAAAACCTGTCCAACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTG GACCTGTTCGAGGCCAACGACCTGTTTGAGAGTGGGAACATGACGCAGGTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAAC CAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGT CGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAA GAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAG CTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAG GGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGA ATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCT CCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGG AGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACA CAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCT TCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGAGAGCAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAG GCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCC AGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGAC GGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAG CTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGG GCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAAT GCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACG CACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGG GGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGA CCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCC ATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGG GCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAA >17676_17676_4_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000348419_PPP1R12C_chr19_55607703_ENST00000263433_length(amino acids)=595AA_BP=130 MSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIGPDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSN FIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGG AGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLE GTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRK ARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSRRPRVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAE GEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAE -------------------------------------------------------------- >17676_17676_5_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000348419_PPP1R12C_chr19_55607703_ENST00000376393_length(transcript)=2207nt_BP=441nt CCCGTCCCGTCCCGTCCTGTGCGGCCCCGTCCCGCCGCCCGCCCGCCAGCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGG CTGTCGGCCGAGGTCAAGAACCGGCTCCTGTCCAAATATGACCCCCAGAAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGC CTCTCCATCGGCCCCGACTTCCAGAAGGGCCTGAAGGATGGAACTATCTTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCC AAGATCAACCGCTCCATGCAGAACTGGCACCAGCTAGAAAACCTGTCCAACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTG GACCTGTTCGAGGCCAACGACCTGTTTGAGAGTGGGAACATGACGCAGGTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAAC CAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGT CGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAA GAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAG CTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAG GGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGA ATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCT CCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGG AGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACA CAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTG GAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTT AGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTG GAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAA CGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTG ATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTC CCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAG TCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCA GAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGT GTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATA TAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTC >17676_17676_5_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000348419_PPP1R12C_chr19_55607703_ENST00000376393_length(amino acids)=532AA_BP=130 MSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIGPDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSN FIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGG AGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLE GTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRK ARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREA -------------------------------------------------------------- >17676_17676_6_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000348419_PPP1R12C_chr19_55607703_ENST00000435544_length(transcript)=1947nt_BP=441nt CCCGTCCCGTCCCGTCCTGTGCGGCCCCGTCCCGCCGCCCGCCCGCCAGCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGG CTGTCGGCCGAGGTCAAGAACCGGCTCCTGTCCAAATATGACCCCCAGAAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGC CTCTCCATCGGCCCCGACTTCCAGAAGGGCCTGAAGGATGGAACTATCTTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCC AAGATCAACCGCTCCATGCAGAACTGGCACCAGCTAGAAAACCTGTCCAACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTG GACCTGTTCGAGGCCAACGACCTGTTTGAGAGTGGGAACATGACGCAGGTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAAC CAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGT CGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAA GAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAG CTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAG GGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGA ATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCT CCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGG AGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACA CAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCT TCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGAGAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCG GCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGC ACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGA GGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTC AAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCC CTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCA GCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCAC >17676_17676_6_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000348419_PPP1R12C_chr19_55607703_ENST00000435544_length(amino acids)=594AA_BP=130 MSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIGPDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSN FIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGG AGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLE GTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRK ARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSRRPRVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEG EEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAER -------------------------------------------------------------- >17676_17676_7_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000562958_PPP1R12C_chr19_55607703_ENST00000263433_length(transcript)=2380nt_BP=423nt GTGCGGCCCCGTCCCGCCGCCCGCCCGCCAGCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGGCTGTCGGCCGAGGTCAAG AACCGGCTCCTGTCCAAATATGACCCCCAGAAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGCCTCTCCATCGGCCCCGAC TTCCAGAAGGGCCTGAAGGATGGAACTATCTTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCCAAGATCAACCGCTCCATG CAGAACTGGCACCAGCTAGAAAACCTGTCCAACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTGGACCTGTTCGAGGCCAAC GACCTGTTTGAGAGTGGGAACATGACGCAGGTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAACCAAAAAGAAGCTTCCCAG AGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTC CAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCA CCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTC TCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGG CTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCC CCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAG CCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCT GTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACA GACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTC CCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGAGAGCAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGC AAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGC CCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTG TATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAG CGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCC GCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTC ATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTG AACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGA GCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGA CCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCA CCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCA TGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAG >17676_17676_7_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000562958_PPP1R12C_chr19_55607703_ENST00000263433_length(amino acids)=595AA_BP=130 MSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIGPDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSN FIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGG AGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLE GTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRK ARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSRRPRVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAE GEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAE -------------------------------------------------------------- >17676_17676_8_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000562958_PPP1R12C_chr19_55607703_ENST00000376393_length(transcript)=2189nt_BP=423nt GTGCGGCCCCGTCCCGCCGCCCGCCCGCCAGCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGGCTGTCGGCCGAGGTCAAG AACCGGCTCCTGTCCAAATATGACCCCCAGAAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGCCTCTCCATCGGCCCCGAC TTCCAGAAGGGCCTGAAGGATGGAACTATCTTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCCAAGATCAACCGCTCCATG CAGAACTGGCACCAGCTAGAAAACCTGTCCAACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTGGACCTGTTCGAGGCCAAC GACCTGTTTGAGAGTGGGAACATGACGCAGGTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAACCAAAAAGAAGCTTCCCAG AGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTC CAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCA CCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTC TCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGG CTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCC CCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAG CCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCT GTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACA GACCTGAAGGAGGCAGAGAAGGCTGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCC CGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAG CTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACG CAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTG GAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAA CTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGT GACAGGGCTCCGGGGGAAGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGG GCCACCCGAGGCCAGGATGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGG AACTGAGGACCAAGAAGTGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCAC CCCTCCCCTCCTGAGCAGGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATA GGGAGGGACGTCTTCTATTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCAC >17676_17676_8_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000562958_PPP1R12C_chr19_55607703_ENST00000376393_length(amino acids)=532AA_BP=130 MSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIGPDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSN FIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGG AGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLE GTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRK ARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREA -------------------------------------------------------------- >17676_17676_9_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000562958_PPP1R12C_chr19_55607703_ENST00000435544_length(transcript)=1929nt_BP=423nt GTGCGGCCCCGTCCCGCCGCCCGCCCGCCAGCCATGAGCTCCACGCAGTTCAACAAGGGCCCCTCGTACGGGCTGTCGGCCGAGGTCAAG AACCGGCTCCTGTCCAAATATGACCCCCAGAAGGAGGCAGAGCTCCGCACCTGGATCGAGGGACTCACCGGCCTCTCCATCGGCCCCGAC TTCCAGAAGGGCCTGAAGGATGGAACTATCTTATGCACACTCATGAACAAGCTACAGCCGGGCTCCGTCCCCAAGATCAACCGCTCCATG CAGAACTGGCACCAGCTAGAAAACCTGTCCAACTTCATCAAGGCCATGGTCAGCTACGGCATGAACCCTGTGGACCTGTTCGAGGCCAAC GACCTGTTTGAGAGTGGGAACATGACGCAGGTGCAGGTGTCTCTTCTCGCCCTGGCGGGGAAGCTTCGGAACCAAAAAGAAGCTTCCCAG AGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTC CAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCA CCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTC TCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGG CTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCC CCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAG CCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCT GTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACA GACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTC CCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGAGAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAG GTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCC TCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTAT GCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGG GCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCA GAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATC AGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAAC >17676_17676_9_CNN2-PPP1R12C_CNN2_chr19_1032695_ENST00000562958_PPP1R12C_chr19_55607703_ENST00000435544_length(amino acids)=594AA_BP=130 MSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIGPDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSN FIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGG AGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLE GTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRK ARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSRRPRVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEG EEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAER -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CNN2-PPP1R12C |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CNN2-PPP1R12C |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CNN2-PPP1R12C |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies