
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:COL26A1-GTF2IRD1 (FusionGDB2 ID:18258) |
Fusion Gene Summary for COL26A1-GTF2IRD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: COL26A1-GTF2IRD1 | Fusion gene ID: 18258 | Hgene | Tgene | Gene symbol | COL26A1 | GTF2IRD1 | Gene ID | 136227 | 9569 |
| Gene name | collagen type XXVI alpha 1 chain | GTF2I repeat domain containing 1 | |
| Synonyms | EMI6|EMID2|EMU2|SH2B | BEN|CREAM1|GTF3|MUSTRD1|RBAP2|WBS|WBSCR11|WBSCR12|hMusTRD1alpha1 | |
| Cytomap | 7q22.1 | 7q11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | collagen alpha-1(XXVI) chainEMI domain containing 2collagen, type XXVI, alpha 1emilin and multimerin domain-containing protein 2 | general transcription factor II-I repeat domain-containing protein 1USE B1-binding proteinWilliams-Beuren syndrome chromosome region 11binding factor for early enhancergeneral transcription factor 3general transcription factor IIImuscle TFII-I repea | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q96A83 | Q9UHL9 | |
| Ensembl transtripts involved in fusion gene | ENST00000313669, ENST00000397927, ENST00000528707, | ENST00000489094, ENST00000265755, ENST00000424337, ENST00000455841, ENST00000476977, | |
| Fusion gene scores | * DoF score | 5 X 5 X 4=100 | 12 X 10 X 9=1080 |
| # samples | 5 | 12 | |
| ** MAII score | log2(5/100*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/1080*10)=-3.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: COL26A1 [Title/Abstract] AND GTF2IRD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | COL26A1(101091068)-GTF2IRD1(73944064), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across COL26A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GTF2IRD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-L5-A8NE | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
Top |
Fusion Gene ORF analysis for COL26A1-GTF2IRD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000313669 | ENST00000489094 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| 5CDS-3UTR | ENST00000397927 | ENST00000489094 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| 5CDS-3UTR | ENST00000528707 | ENST00000489094 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000313669 | ENST00000265755 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000313669 | ENST00000424337 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000313669 | ENST00000455841 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000313669 | ENST00000476977 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000397927 | ENST00000265755 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000397927 | ENST00000424337 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000397927 | ENST00000455841 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000397927 | ENST00000476977 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000528707 | ENST00000265755 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000528707 | ENST00000424337 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000528707 | ENST00000455841 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| In-frame | ENST00000528707 | ENST00000476977 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000397927 | COL26A1 | chr7 | 101091068 | + | ENST00000265755 | GTF2IRD1 | chr7 | 73944064 | + | 2545 | 598 | 162 | 2387 | 741 |
| ENST00000397927 | COL26A1 | chr7 | 101091068 | + | ENST00000455841 | GTF2IRD1 | chr7 | 73944064 | + | 2514 | 598 | 162 | 2342 | 726 |
| ENST00000397927 | COL26A1 | chr7 | 101091068 | + | ENST00000424337 | GTF2IRD1 | chr7 | 73944064 | + | 2511 | 598 | 162 | 2342 | 726 |
| ENST00000397927 | COL26A1 | chr7 | 101091068 | + | ENST00000476977 | GTF2IRD1 | chr7 | 73944064 | + | 3685 | 598 | 162 | 2390 | 742 |
| ENST00000313669 | COL26A1 | chr7 | 101091068 | + | ENST00000265755 | GTF2IRD1 | chr7 | 73944064 | + | 2524 | 577 | 141 | 2366 | 741 |
| ENST00000313669 | COL26A1 | chr7 | 101091068 | + | ENST00000455841 | GTF2IRD1 | chr7 | 73944064 | + | 2493 | 577 | 141 | 2321 | 726 |
| ENST00000313669 | COL26A1 | chr7 | 101091068 | + | ENST00000424337 | GTF2IRD1 | chr7 | 73944064 | + | 2490 | 577 | 141 | 2321 | 726 |
| ENST00000313669 | COL26A1 | chr7 | 101091068 | + | ENST00000476977 | GTF2IRD1 | chr7 | 73944064 | + | 3664 | 577 | 141 | 2369 | 742 |
| ENST00000528707 | COL26A1 | chr7 | 101091068 | + | ENST00000265755 | GTF2IRD1 | chr7 | 73944064 | + | 2482 | 535 | 105 | 2324 | 739 |
| ENST00000528707 | COL26A1 | chr7 | 101091068 | + | ENST00000455841 | GTF2IRD1 | chr7 | 73944064 | + | 2451 | 535 | 105 | 2279 | 724 |
| ENST00000528707 | COL26A1 | chr7 | 101091068 | + | ENST00000424337 | GTF2IRD1 | chr7 | 73944064 | + | 2448 | 535 | 105 | 2279 | 724 |
| ENST00000528707 | COL26A1 | chr7 | 101091068 | + | ENST00000476977 | GTF2IRD1 | chr7 | 73944064 | + | 3622 | 535 | 105 | 2327 | 740 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000397927 | ENST00000265755 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.008361422 | 0.9916386 |
| ENST00000397927 | ENST00000455841 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.00801605 | 0.99198395 |
| ENST00000397927 | ENST00000424337 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.008278422 | 0.9917216 |
| ENST00000397927 | ENST00000476977 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.007702051 | 0.99229795 |
| ENST00000313669 | ENST00000265755 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.008443818 | 0.99155617 |
| ENST00000313669 | ENST00000455841 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.008053667 | 0.9919463 |
| ENST00000313669 | ENST00000424337 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.008302777 | 0.9916972 |
| ENST00000313669 | ENST00000476977 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.007709062 | 0.9922909 |
| ENST00000528707 | ENST00000265755 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.009206126 | 0.9907939 |
| ENST00000528707 | ENST00000455841 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.008139651 | 0.99186033 |
| ENST00000528707 | ENST00000424337 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.008376602 | 0.99162334 |
| ENST00000528707 | ENST00000476977 | COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944064 | + | 0.007418742 | 0.99258125 |
Top |
Fusion Genomic Features for COL26A1-GTF2IRD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944063 | + | 2.07E-12 | 1 |
| COL26A1 | chr7 | 101091068 | + | GTF2IRD1 | chr7 | 73944063 | + | 2.07E-12 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
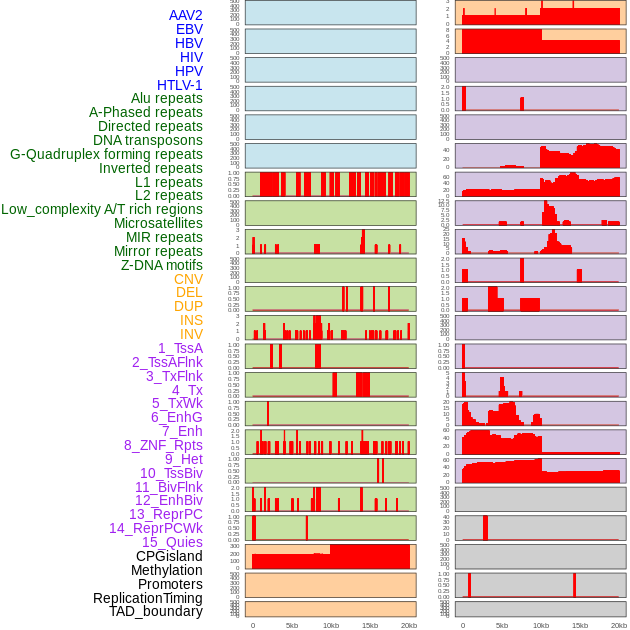 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
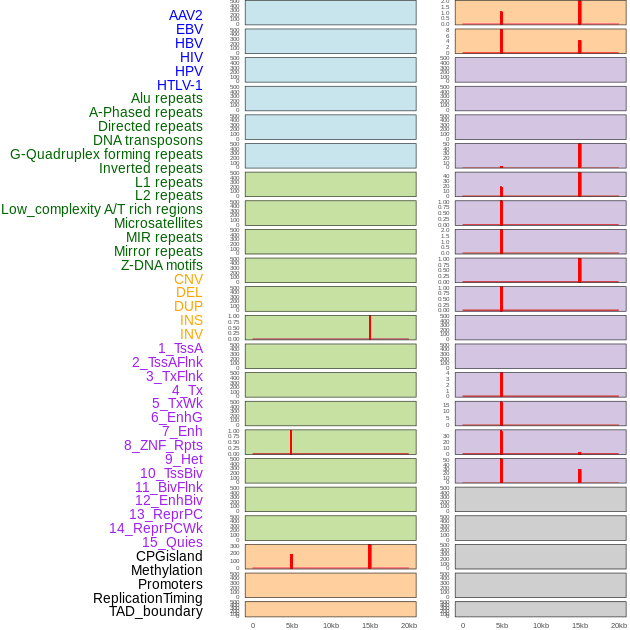 |
Top |
Fusion Protein Features for COL26A1-GTF2IRD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:101091068/chr7:73944064) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| COL26A1 | GTF2IRD1 |
| FUNCTION: May be a transcription regulator involved in cell-cycle progression and skeletal muscle differentiation. May repress GTF2I transcriptional functions, by preventing its nuclear residency, or by inhibiting its transcriptional activation. May contribute to slow-twitch fiber type specificity during myogenesis and in regenerating muscles. Binds troponin I slow-muscle fiber enhancer (USE B1). Binds specifically and with high affinity to the EFG sequences derived from the early enhancer of HOXC8 (By similarity). {ECO:0000250, ECO:0000269|PubMed:11438732}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COL26A1 | chr7:101091068 | chr7:73944064 | ENST00000397927 | + | 3 | 13 | 52_128 | 128 | 441.6666666666667 | Domain | EMI |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000265755 | 7 | 27 | 906_930 | 363 | 960.0 | Compositional bias | Note=Ser-rich | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000424337 | 7 | 27 | 906_930 | 363 | 945.0 | Compositional bias | Note=Ser-rich | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000455841 | 7 | 27 | 906_930 | 395 | 977.0 | Compositional bias | Note=Ser-rich | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000265755 | 7 | 27 | 898_905 | 363 | 960.0 | Motif | Nuclear localization signal | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000424337 | 7 | 27 | 898_905 | 363 | 945.0 | Motif | Nuclear localization signal | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000455841 | 7 | 27 | 898_905 | 395 | 977.0 | Motif | Nuclear localization signal | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000265755 | 7 | 27 | 556_650 | 363 | 960.0 | Repeat | Note=GTF2I-like 3 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000265755 | 7 | 27 | 696_790 | 363 | 960.0 | Repeat | Note=GTF2I-like 4 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000265755 | 7 | 27 | 793_887 | 363 | 960.0 | Repeat | Note=GTF2I-like 5 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000424337 | 7 | 27 | 556_650 | 363 | 945.0 | Repeat | Note=GTF2I-like 3 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000424337 | 7 | 27 | 696_790 | 363 | 945.0 | Repeat | Note=GTF2I-like 4 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000424337 | 7 | 27 | 793_887 | 363 | 945.0 | Repeat | Note=GTF2I-like 5 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000455841 | 7 | 27 | 556_650 | 395 | 977.0 | Repeat | Note=GTF2I-like 3 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000455841 | 7 | 27 | 696_790 | 395 | 977.0 | Repeat | Note=GTF2I-like 4 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000455841 | 7 | 27 | 793_887 | 395 | 977.0 | Repeat | Note=GTF2I-like 5 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COL26A1 | chr7:101091068 | chr7:73944064 | ENST00000397927 | + | 3 | 13 | 199_267 | 128 | 441.6666666666667 | Domain | Note=Collagen-like 1 |
| Hgene | COL26A1 | chr7:101091068 | chr7:73944064 | ENST00000397927 | + | 3 | 13 | 302_355 | 128 | 441.6666666666667 | Domain | Note=Collagen-like 2 |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000265755 | 7 | 27 | 119_213 | 363 | 960.0 | Repeat | Note=GTF2I-like 1 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000265755 | 7 | 27 | 342_436 | 363 | 960.0 | Repeat | Note=GTF2I-like 2 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000424337 | 7 | 27 | 119_213 | 363 | 945.0 | Repeat | Note=GTF2I-like 1 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000424337 | 7 | 27 | 342_436 | 363 | 945.0 | Repeat | Note=GTF2I-like 2 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000455841 | 7 | 27 | 119_213 | 395 | 977.0 | Repeat | Note=GTF2I-like 1 | |
| Tgene | GTF2IRD1 | chr7:101091068 | chr7:73944064 | ENST00000455841 | 7 | 27 | 342_436 | 395 | 977.0 | Repeat | Note=GTF2I-like 2 |
Top |
Fusion Gene Sequence for COL26A1-GTF2IRD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >18258_18258_1_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000313669_GTF2IRD1_chr7_73944064_ENST00000265755_length(transcript)=2524nt_BP=577nt GAATTTGAAAAGGCGGCCCCGGAGAGGCGTGGGCGCCCCCCACACATTTCCAGCTCGCACCCGGGCTCCGACCGCTCGCCCCGCTCCTCT CGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCGGGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCCGGGACTCCGGGTCCCCGCGGG CTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCCTGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTGGCCACCGGCTTCCTCTATCCC TTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCCGAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTACGCGAGCCGCCGGCACTGGTGC CATCACACAGTGACACGGACGGTGTCCTGCCAGGTGCAGAATGGCTCGGAGACGGTGGTCCAGCGCGTGTACCAGAGCTGCCGGTGGCCG GGGCCCTGCGCCAACCTCGTAAGTTACAGGACTCTGATCAGACCCACCTACAGAGTGTCCTACCGCACGGTGACGGTGCTGGAGTGGAGA TGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAAGCCCTGGGCCTGGACCACATGGTCCCCGTGCCCTACCGGAAGATTGCC TGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAGATCCCCTTCAAGCGCCCCTGCACTTATGGAGTCCCCAAGCTGAAGCGG ATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGGATGTTTGATGAGCGAATTTTCACAGGGAACAAGTTTACCAAAGACACC ACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCAGAGGTCTCTAGGGCCACCGTCCTTGACCTTGCTGGGAATGCTCGGTCA GACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCCGGGGAGCTGGGCGGGCTGAGGCCGATCAAAATTGAGCCAGAGGATCTG GACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCTGAGGAAATGACAGACTCGATGCCTGGGCACCTGCCATCGGAGGATTCT GGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAGGACGCGCGGCCCGAGGAGAGGCCCGTGGAGGACAGCCACGGTGACGTG ATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACACGATACGCCAAGGCCATTGGCATCTCGGAGCCCGTCAAGGTGCCGTAC TCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGACTGCCTGAAGGCATCTCCCTCCGCAGGCCCAACTGCTTCGGGATCGCC AAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTTGTCATCAAGAGGCCCGAGCTGCTCACTGAGGGAGTCAAAGAGCCCATC ATGGATAGTCAAGGAACTGCCTCCTCACTTGGCTTCTCTCCCCCTGCCCTGCCCCCAGAGAGGGATTCCGGGGACCCTCTGGTGGACGAG AGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGGCTCTCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAGGAC CTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTACCCGGTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCCGTG ATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCCTGTACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCTGAC AAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATCCCAAAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTGATC CTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGTGAGGCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTAATC CGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGATGACATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTGGAG AAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATTAACCAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTGCCA GCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTCTCGGAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCCTCG TCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCACTCGTGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAACGTG CAGCTCCCGGGACCTCTTAATTACTAGACCTCAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACAAAA TGTATATTCGGATATGTATCGATGCCTTTTAGTTTTTCCAATGATTTTTACACTATATTCCTGCCACCAAGGCCTTTTTAAATAAGTAAA >18258_18258_1_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000313669_GTF2IRD1_chr7_73944064_ENST00000265755_length(amino acids)=741AA_BP=145 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPF KRPCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGEL GGLRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYA KAIGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQGTASSLGFSPPAL PPERDSGDPLVDESLKRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTF GSQNLERILAVADKIKFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIP FRNPNTYDIHRLEKILKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQ -------------------------------------------------------------- >18258_18258_2_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000313669_GTF2IRD1_chr7_73944064_ENST00000424337_length(transcript)=2490nt_BP=577nt GAATTTGAAAAGGCGGCCCCGGAGAGGCGTGGGCGCCCCCCACACATTTCCAGCTCGCACCCGGGCTCCGACCGCTCGCCCCGCTCCTCT CGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCGGGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCCGGGACTCCGGGTCCCCGCGGG CTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCCTGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTGGCCACCGGCTTCCTCTATCCC TTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCCGAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTACGCGAGCCGCCGGCACTGGTGC CATCACACAGTGACACGGACGGTGTCCTGCCAGGTGCAGAATGGCTCGGAGACGGTGGTCCAGCGCGTGTACCAGAGCTGCCGGTGGCCG GGGCCCTGCGCCAACCTCGTAAGTTACAGGACTCTGATCAGACCCACCTACAGAGTGTCCTACCGCACGGTGACGGTGCTGGAGTGGAGA TGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAAGCCCTGGGCCTGGACCACATGGTCCCCGTGCCCTACCGGAAGATTGCC TGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAGATCCCCTTCAAGCGCCCCTGCACTTATGGAGTCCCCAAGCTGAAGCGG ATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGGATGTTTGATGAGCGAATTTTCACAGGGAACAAGTTTACCAAAGACACC ACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCAGAGGTCTCTAGGGCCACCGTCCTTGACCTTGCTGGGAATGCTCGGTCA GACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCCGGGGAGCTGGGCGGGCTGAGGCCGATCAAAATTGAGCCAGAGGATCTG GACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCTGAGGAAATGACAGACTCGATGCCTGGGCACCTGCCATCGGAGGATTCT GGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAGGACGCGCGGCCCGAGGAGAGGCCCGTGGAGGACAGCCACGGTGACGTG ATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACACGATACGCCAAGGCCATTGGCATCTCGGAGCCCGTCAAGGTGCCGTAC TCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGACTGCCTGAAGGCATCTCCCTCCGCAGGCCCAACTGCTTCGGGATCGCC AAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTTGTCATCAAGAGGCCCGAGCTGCTCACTGAGGGAGTCAAAGAGCCCATC ATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGACGAGAGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGGCTC TCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAGGACCTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTACCCG GTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCCGTGATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCCTGT ACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCTGACAAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATCCCA AAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTGATCCTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGTGAG GCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTAATCCGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGATGAC ATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTGGAGAAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATTAAC CAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTGCCAGCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTCTCG GAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCCTCGTCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCACTC GTGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAACGTGCAGCTCCCGGGACCTCTTAATTACTAGACCTCAGTACTGAATCAG GACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACAAAATGTATATTCGGATATGTATCGATGCCTTTTAGTTTTTCCAATGAT >18258_18258_2_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000313669_GTF2IRD1_chr7_73944064_ENST00000424337_length(amino acids)=726AA_BP=145 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPF KRPCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGEL GGLRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYA KAIGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESL KRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKI KFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKI LKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQWPMYMVDYAGLNVQL -------------------------------------------------------------- >18258_18258_3_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000313669_GTF2IRD1_chr7_73944064_ENST00000455841_length(transcript)=2493nt_BP=577nt GAATTTGAAAAGGCGGCCCCGGAGAGGCGTGGGCGCCCCCCACACATTTCCAGCTCGCACCCGGGCTCCGACCGCTCGCCCCGCTCCTCT CGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCGGGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCCGGGACTCCGGGTCCCCGCGGG CTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCCTGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTGGCCACCGGCTTCCTCTATCCC TTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCCGAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTACGCGAGCCGCCGGCACTGGTGC CATCACACAGTGACACGGACGGTGTCCTGCCAGGTGCAGAATGGCTCGGAGACGGTGGTCCAGCGCGTGTACCAGAGCTGCCGGTGGCCG GGGCCCTGCGCCAACCTCGTAAGTTACAGGACTCTGATCAGACCCACCTACAGAGTGTCCTACCGCACGGTGACGGTGCTGGAGTGGAGA TGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAAGCCCTGGGCCTGGACCACATGGTCCCCGTGCCCTACCGGAAGATTGCC TGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAGATCCCCTTCAAGCGCCCCTGCACTTATGGAGTCCCCAAGCTGAAGCGG ATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGGATGTTTGATGAGCGAATTTTCACAGGGAACAAGTTTACCAAAGACACC ACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCAGAGGTCTCTAGGGCCACCGTCCTTGACCTTGCTGGGAATGCTCGGTCA GACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCCGGGGAGCTGGGCGGGCTGAGGCCGATCAAAATTGAGCCAGAGGATCTG GACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCTGAGGAAATGACAGACTCGATGCCTGGGCACCTGCCATCGGAGGATTCT GGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAGGACGCGCGGCCCGAGGAGAGGCCCGTGGAGGACAGCCACGGTGACGTG ATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACACGATACGCCAAGGCCATTGGCATCTCGGAGCCCGTCAAGGTGCCGTAC TCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGACTGCCTGAAGGCATCTCCCTCCGCAGGCCCAACTGCTTCGGGATCGCC AAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTTGTCATCAAGAGGCCCGAGCTGCTCACTGAGGGAGTCAAAGAGCCCATC ATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGACGAGAGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGGCTC TCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAGGACCTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTACCCG GTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCCGTGATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCCTGT ACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCTGACAAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATCCCA AAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTGATCCTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGTGAG GCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTAATCCGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGATGAC ATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTGGAGAAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATTAAC CAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTGCCAGCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTCTCG GAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCCTCGTCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCACTC GTGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAACGTGCAGCTCCCGGGACCTCTTAATTACTAGACCTCAGTACTGAATCAG GACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACAAAATGTATATTCGGATATGTATCGATGCCTTTTAGTTTTTCCAATGAT >18258_18258_3_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000313669_GTF2IRD1_chr7_73944064_ENST00000455841_length(amino acids)=726AA_BP=145 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPF KRPCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGEL GGLRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYA KAIGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESL KRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKI KFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKI LKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQWPMYMVDYAGLNVQL -------------------------------------------------------------- >18258_18258_4_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000313669_GTF2IRD1_chr7_73944064_ENST00000476977_length(transcript)=3664nt_BP=577nt GAATTTGAAAAGGCGGCCCCGGAGAGGCGTGGGCGCCCCCCACACATTTCCAGCTCGCACCCGGGCTCCGACCGCTCGCCCCGCTCCTCT CGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCGGGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCCGGGACTCCGGGTCCCCGCGGG CTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCCTGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTGGCCACCGGCTTCCTCTATCCC TTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCCGAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTACGCGAGCCGCCGGCACTGGTGC CATCACACAGTGACACGGACGGTGTCCTGCCAGGTGCAGAATGGCTCGGAGACGGTGGTCCAGCGCGTGTACCAGAGCTGCCGGTGGCCG GGGCCCTGCGCCAACCTCGTAAGTTACAGGACTCTGATCAGACCCACCTACAGAGTGTCCTACCGCACGGTGACGGTGCTGGAGTGGAGA TGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAAGCCCTGGGCCTGGACCACATGGTCCCCGTGCCCTACCGGAAGATTGCC TGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAGATCCCCTTCAAGCGCCCCTGCACTTATGGAGTCCCCAAGCTGAAGCGG ATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGGATGTTTGATGAGCGAATTTTCACAGGGAACAAGTTTACCAAAGACACC ACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCAGAGGTCTCTAGGGCCACCGTCCTTGACCTTGCTGGGAATGCTCGGTCA GACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCCGGGGAGCTGGGCGGGCTGAGGCCGATCAAAATTGAGCCAGAGGATCTG GACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCTGAGGAAATGACAGACTCGATGCCTGGGCACCTGCCATCGGAGGATTCT GGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAGGACGCGCGGCCCGAGGAGAGGCCCGTGGAGGACAGCCACGGTGACGTG ATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACACGATACGCCAAGGCCATTGGCATCTCGGAGCCCGTCAAGGTGCCGTAC TCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGACTGCCTGAAGGCATCTCCCTCCGCAGGCCCAACTGCTTCGGGATCGCC AAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTTGTCATCAAGAGGCCCGAGCTGCTCACTGAGGGAGTCAAAGAGCCCATC ATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGACGAGAGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGGCTC TCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAGGACCTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTACCCG GTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCCGTGATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCCTGT ACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCTGACAAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATCCCA AAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTGATCCTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGTGAG GCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTAATCCGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGATGAC ATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTGGAGAAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATTAAC CAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTGCCAGCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTCTCG GAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCCTCGTCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCACTC GTGGTAAAGTTGCACCGATTTGGACTCCGGCACTCATCTCTGTGGCCCTCACCCCTCTGTCTGGCAGGGCCGTCTACTCTGGGATGTGGG CCCAGGGGACGGGGAGGCACTGGGCTTTGAGTGGGGACCTTCCGGCCTCGGGGGTTATAGATGCATCCACCTGTCTCACCCAAGAGGTAG CCCATCCTTCTCGTGGGGTACTCACAGGCACTCAGGCAGGAATTCACATCCTCGCTGGGCAGATGGGCCGGCTGAGGTCCACCTGCCCAC ACCCTTCAGCCGCACCAGAGCTGGAGACATGAAAAGACATGGCTGGCGGGTGCAGTGGCTCACGCCTGTAATCCCAGCACTTTGGCAGGT CAAGTCGGGTGGATCACCTGAGGTCAGGAGTTTGAGACCAGGCTGACCAACACGGGGAAACCCCATCTCTACTAAAAATACAAAATTAGC CGGGCAAAGTGGGGCATAGTGGCTCATGCCTGTAATCCCAGCTACTTGGAAGGCTGAGATAGGAGAATCGCTTGAACCTGGGAGGCAGAG GTTGCAATGAGCCGAGGTCGCGCCATTGCACTGCAGCCTGGGCAACAAGAGTGAAACACTGTCTCAGAAAAAAAAATTAGCCAGGCATGG TGGCACGTGCCTGTGGTCGCAGCTACTTGGGAGGCTGGGGCAGGAGGATCATTTGAGCCCAAGGGGATTGAGGCTGCAGTGAGCCAAGAT CGTCCCATTGCACTCCAGCCTGGGCAAGAGAACGAGACTCCATCTCAAAAATAAATAAATAGGCTGGGTGTGGTGGCTCACGCCTGTAAT CCTAGCACTTTGGGAGGCCGAGGCAGGCGGATCACTTGAGGCTCAGGAGTTCAAGACCAGCCTGGCCAACATGGCAAAACCCCGTCTCTA CTAAAAATAGAAAAATTAGCCGGGCATGGTGGCGGGCGCCTATAATCCCAGCTACTCGGGAGGCTGAGGCAGGAGACTCGCTTGAACCCG CGGGGCCAAGGTTGCAGTGAGCCGAGATTGCATCACTGCACTCCAGCCTGGGCAGAAGAGTGAAACTCCATCTCAAAAAAATAAAAAATA TAAATAAATAGCCTCTGAGAAAGCTCTTCCAAAAGCAGAACTAAGCATTTTGGGTTTGTTCCGCATCACCTGGAGTCCTAATCCAGTCCC TTTGTCCCTCTCTCTAGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAACGTGCAGCTCCCGGGACCTCTTAATTACTAGACCT CAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACAAAATGTATATTCGGATATGTATCGATGCCTTTTA >18258_18258_4_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000313669_GTF2IRD1_chr7_73944064_ENST00000476977_length(amino acids)=742AA_BP=145 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPF KRPCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGEL GGLRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYA KAIGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESL KRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKI KFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKI LKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVVKLHRFGLRHSSLWPS -------------------------------------------------------------- >18258_18258_5_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000397927_GTF2IRD1_chr7_73944064_ENST00000265755_length(transcript)=2545nt_BP=598nt CGGCTTAGAGCCCACCTCGCCGAATTTGAAAAGGCGGCCCCGGAGAGGCGTGGGCGCCCCCCACACATTTCCAGCTCGCACCCGGGCTCC GACCGCTCGCCCCGCTCCTCTCGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCGGGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCC GGGACTCCGGGTCCCCGCGGGCTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCCTGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTG GCCACCGGCTTCCTCTATCCCTTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCCGAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTAC GCGAGCCGCCGGCACTGGTGCCATCACACAGTGACACGGACGGTGTCCTGCCAGGTGCAGAATGGCTCGGAGACGGTGGTCCAGCGCGTG TACCAGAGCTGCCGGTGGCCGGGGCCCTGCGCCAACCTCGTAAGTTACAGGACTCTGATCAGACCCACCTACAGAGTGTCCTACCGCACG GTGACGGTGCTGGAGTGGAGATGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAAGCCCTGGGCCTGGACCACATGGTCCCC GTGCCCTACCGGAAGATTGCCTGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAGATCCCCTTCAAGCGCCCCTGCACTTAT GGAGTCCCCAAGCTGAAGCGGATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGGATGTTTGATGAGCGAATTTTCACAGGG AACAAGTTTACCAAAGACACCACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCAGAGGTCTCTAGGGCCACCGTCCTTGAC CTTGCTGGGAATGCTCGGTCAGACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCCGGGGAGCTGGGCGGGCTGAGGCCGATC AAAATTGAGCCAGAGGATCTGGACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCTGAGGAAATGACAGACTCGATGCCTGGG CACCTGCCATCGGAGGATTCTGGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAGGACGCGCGGCCCGAGGAGAGGCCCGTG GAGGACAGCCACGGTGACGTGATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACACGATACGCCAAGGCCATTGGCATCTCG GAGCCCGTCAAGGTGCCGTACTCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGACTGCCTGAAGGCATCTCCCTCCGCAGG CCCAACTGCTTCGGGATCGCCAAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTTGTCATCAAGAGGCCCGAGCTGCTCACT GAGGGAGTCAAAGAGCCCATCATGGATAGTCAAGGAACTGCCTCCTCACTTGGCTTCTCTCCCCCTGCCCTGCCCCCAGAGAGGGATTCC GGGGACCCTCTGGTGGACGAGAGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGGCTCTCACGGATCGACATCGCCAACACA CTAAGGGAGCAGGTCCAGGACCTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTACCCGGTCCAGGTCCCCTACAAGCGGATC AAGAGTAACCCCGGCTCCGTGATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCCTGTACCTTCGGCTCCCAGAACCTGGAG AGGATTCTTGCTGTGGCTGACAAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATCCCAAAGCCTGATGAAGATGACGCCAAC AGACTCGGGGAGAAGGTGATCCTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGTGAGGCCCTGGGCCTGAACCGGCCGGTG CTGGTCCCTTATAAACTAATCCGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGATGACATCCCCTTCCGGAACCCCAACACG TACGACATCCACCGGCTGGAGAAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATTAACCAGCTCCAACCCTTTGCAGAAATC TGCAATGATGCCAAGGTGCCAGCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTCTCGGAAGGAAATTCCGTCTCCTCTTCC TCCTCGTCTTCCTCTTCCTCGTCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCACTCGTGCAATGGCCAATGTACATGGTG GACTATGCCGGCCTGAACGTGCAGCTCCCGGGACCTCTTAATTACTAGACCTCAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGG AAATGTAATTTATGTACAAAATGTATATTCGGATATGTATCGATGCCTTTTAGTTTTTCCAATGATTTTTACACTATATTCCTGCCACCA >18258_18258_5_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000397927_GTF2IRD1_chr7_73944064_ENST00000265755_length(amino acids)=741AA_BP=145 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPF KRPCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGEL GGLRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYA KAIGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQGTASSLGFSPPAL PPERDSGDPLVDESLKRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTF GSQNLERILAVADKIKFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIP FRNPNTYDIHRLEKILKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQ -------------------------------------------------------------- >18258_18258_6_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000397927_GTF2IRD1_chr7_73944064_ENST00000424337_length(transcript)=2511nt_BP=598nt CGGCTTAGAGCCCACCTCGCCGAATTTGAAAAGGCGGCCCCGGAGAGGCGTGGGCGCCCCCCACACATTTCCAGCTCGCACCCGGGCTCC GACCGCTCGCCCCGCTCCTCTCGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCGGGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCC GGGACTCCGGGTCCCCGCGGGCTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCCTGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTG GCCACCGGCTTCCTCTATCCCTTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCCGAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTAC GCGAGCCGCCGGCACTGGTGCCATCACACAGTGACACGGACGGTGTCCTGCCAGGTGCAGAATGGCTCGGAGACGGTGGTCCAGCGCGTG TACCAGAGCTGCCGGTGGCCGGGGCCCTGCGCCAACCTCGTAAGTTACAGGACTCTGATCAGACCCACCTACAGAGTGTCCTACCGCACG GTGACGGTGCTGGAGTGGAGATGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAAGCCCTGGGCCTGGACCACATGGTCCCC GTGCCCTACCGGAAGATTGCCTGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAGATCCCCTTCAAGCGCCCCTGCACTTAT GGAGTCCCCAAGCTGAAGCGGATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGGATGTTTGATGAGCGAATTTTCACAGGG AACAAGTTTACCAAAGACACCACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCAGAGGTCTCTAGGGCCACCGTCCTTGAC CTTGCTGGGAATGCTCGGTCAGACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCCGGGGAGCTGGGCGGGCTGAGGCCGATC AAAATTGAGCCAGAGGATCTGGACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCTGAGGAAATGACAGACTCGATGCCTGGG CACCTGCCATCGGAGGATTCTGGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAGGACGCGCGGCCCGAGGAGAGGCCCGTG GAGGACAGCCACGGTGACGTGATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACACGATACGCCAAGGCCATTGGCATCTCG GAGCCCGTCAAGGTGCCGTACTCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGACTGCCTGAAGGCATCTCCCTCCGCAGG CCCAACTGCTTCGGGATCGCCAAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTTGTCATCAAGAGGCCCGAGCTGCTCACT GAGGGAGTCAAAGAGCCCATCATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGACGAGAGCCTGAAGAGACAGGGCTTTCAA GAAAATTATGACGCGAGGCTCTCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAGGACCTTTTCAATAAGAAATACGGGGAA GCCTTGGGCATCAAGTACCCGGTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCCGTGATCATCGAGGGGCTGCCCCCAGGA ATCCCGTTCCGAAAGCCCTGTACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCTGACAAGATCAAGTTCACAGTCACCAGG CCTTTCCAAGGACTCATCCCAAAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTGATCCTGCGGGAGCAGGTGAAGGAACTC TTCAACGAGAAATACGGTGAGGCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTAATCCGGGACAGCCCAGACGCCGTGGAG GTCACGGGTCTGCCTGATGACATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTGGAGAAGATCCTGAAGGCCCGAGAGCAT GTCCGCATGGTCATCATTAACCAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTGCCAGCCAAAGACAGCAGCATTCCCAAG CGCAAGAGAAAGCGGGTCTCGGAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCCTCGTCCTCTAACCCGGATTCAGTGGCA TCGGCCAACCAGATCTCACTCGTGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAACGTGCAGCTCCCGGGACCTCTTAATTAC TAGACCTCAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACAAAATGTATATTCGGATATGTATCGATG >18258_18258_6_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000397927_GTF2IRD1_chr7_73944064_ENST00000424337_length(amino acids)=726AA_BP=145 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPF KRPCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGEL GGLRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYA KAIGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESL KRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKI KFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKI LKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQWPMYMVDYAGLNVQL -------------------------------------------------------------- >18258_18258_7_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000397927_GTF2IRD1_chr7_73944064_ENST00000455841_length(transcript)=2514nt_BP=598nt CGGCTTAGAGCCCACCTCGCCGAATTTGAAAAGGCGGCCCCGGAGAGGCGTGGGCGCCCCCCACACATTTCCAGCTCGCACCCGGGCTCC GACCGCTCGCCCCGCTCCTCTCGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCGGGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCC GGGACTCCGGGTCCCCGCGGGCTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCCTGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTG GCCACCGGCTTCCTCTATCCCTTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCCGAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTAC GCGAGCCGCCGGCACTGGTGCCATCACACAGTGACACGGACGGTGTCCTGCCAGGTGCAGAATGGCTCGGAGACGGTGGTCCAGCGCGTG TACCAGAGCTGCCGGTGGCCGGGGCCCTGCGCCAACCTCGTAAGTTACAGGACTCTGATCAGACCCACCTACAGAGTGTCCTACCGCACG GTGACGGTGCTGGAGTGGAGATGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAAGCCCTGGGCCTGGACCACATGGTCCCC GTGCCCTACCGGAAGATTGCCTGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAGATCCCCTTCAAGCGCCCCTGCACTTAT GGAGTCCCCAAGCTGAAGCGGATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGGATGTTTGATGAGCGAATTTTCACAGGG AACAAGTTTACCAAAGACACCACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCAGAGGTCTCTAGGGCCACCGTCCTTGAC CTTGCTGGGAATGCTCGGTCAGACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCCGGGGAGCTGGGCGGGCTGAGGCCGATC AAAATTGAGCCAGAGGATCTGGACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCTGAGGAAATGACAGACTCGATGCCTGGG CACCTGCCATCGGAGGATTCTGGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAGGACGCGCGGCCCGAGGAGAGGCCCGTG GAGGACAGCCACGGTGACGTGATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACACGATACGCCAAGGCCATTGGCATCTCG GAGCCCGTCAAGGTGCCGTACTCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGACTGCCTGAAGGCATCTCCCTCCGCAGG CCCAACTGCTTCGGGATCGCCAAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTTGTCATCAAGAGGCCCGAGCTGCTCACT GAGGGAGTCAAAGAGCCCATCATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGACGAGAGCCTGAAGAGACAGGGCTTTCAA GAAAATTATGACGCGAGGCTCTCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAGGACCTTTTCAATAAGAAATACGGGGAA GCCTTGGGCATCAAGTACCCGGTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCCGTGATCATCGAGGGGCTGCCCCCAGGA ATCCCGTTCCGAAAGCCCTGTACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCTGACAAGATCAAGTTCACAGTCACCAGG CCTTTCCAAGGACTCATCCCAAAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTGATCCTGCGGGAGCAGGTGAAGGAACTC TTCAACGAGAAATACGGTGAGGCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTAATCCGGGACAGCCCAGACGCCGTGGAG GTCACGGGTCTGCCTGATGACATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTGGAGAAGATCCTGAAGGCCCGAGAGCAT GTCCGCATGGTCATCATTAACCAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTGCCAGCCAAAGACAGCAGCATTCCCAAG CGCAAGAGAAAGCGGGTCTCGGAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCCTCGTCCTCTAACCCGGATTCAGTGGCA TCGGCCAACCAGATCTCACTCGTGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAACGTGCAGCTCCCGGGACCTCTTAATTAC TAGACCTCAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACAAAATGTATATTCGGATATGTATCGATG >18258_18258_7_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000397927_GTF2IRD1_chr7_73944064_ENST00000455841_length(amino acids)=726AA_BP=145 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPF KRPCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGEL GGLRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYA KAIGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESL KRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKI KFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKI LKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQWPMYMVDYAGLNVQL -------------------------------------------------------------- >18258_18258_8_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000397927_GTF2IRD1_chr7_73944064_ENST00000476977_length(transcript)=3685nt_BP=598nt CGGCTTAGAGCCCACCTCGCCGAATTTGAAAAGGCGGCCCCGGAGAGGCGTGGGCGCCCCCCACACATTTCCAGCTCGCACCCGGGCTCC GACCGCTCGCCCCGCTCCTCTCGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCGGGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCC GGGACTCCGGGTCCCCGCGGGCTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCCTGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTG GCCACCGGCTTCCTCTATCCCTTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCCGAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTAC GCGAGCCGCCGGCACTGGTGCCATCACACAGTGACACGGACGGTGTCCTGCCAGGTGCAGAATGGCTCGGAGACGGTGGTCCAGCGCGTG TACCAGAGCTGCCGGTGGCCGGGGCCCTGCGCCAACCTCGTAAGTTACAGGACTCTGATCAGACCCACCTACAGAGTGTCCTACCGCACG GTGACGGTGCTGGAGTGGAGATGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAAGCCCTGGGCCTGGACCACATGGTCCCC GTGCCCTACCGGAAGATTGCCTGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAGATCCCCTTCAAGCGCCCCTGCACTTAT GGAGTCCCCAAGCTGAAGCGGATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGGATGTTTGATGAGCGAATTTTCACAGGG AACAAGTTTACCAAAGACACCACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCAGAGGTCTCTAGGGCCACCGTCCTTGAC CTTGCTGGGAATGCTCGGTCAGACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCCGGGGAGCTGGGCGGGCTGAGGCCGATC AAAATTGAGCCAGAGGATCTGGACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCTGAGGAAATGACAGACTCGATGCCTGGG CACCTGCCATCGGAGGATTCTGGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAGGACGCGCGGCCCGAGGAGAGGCCCGTG GAGGACAGCCACGGTGACGTGATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACACGATACGCCAAGGCCATTGGCATCTCG GAGCCCGTCAAGGTGCCGTACTCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGACTGCCTGAAGGCATCTCCCTCCGCAGG CCCAACTGCTTCGGGATCGCCAAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTTGTCATCAAGAGGCCCGAGCTGCTCACT GAGGGAGTCAAAGAGCCCATCATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGACGAGAGCCTGAAGAGACAGGGCTTTCAA GAAAATTATGACGCGAGGCTCTCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAGGACCTTTTCAATAAGAAATACGGGGAA GCCTTGGGCATCAAGTACCCGGTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCCGTGATCATCGAGGGGCTGCCCCCAGGA ATCCCGTTCCGAAAGCCCTGTACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCTGACAAGATCAAGTTCACAGTCACCAGG CCTTTCCAAGGACTCATCCCAAAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTGATCCTGCGGGAGCAGGTGAAGGAACTC TTCAACGAGAAATACGGTGAGGCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTAATCCGGGACAGCCCAGACGCCGTGGAG GTCACGGGTCTGCCTGATGACATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTGGAGAAGATCCTGAAGGCCCGAGAGCAT GTCCGCATGGTCATCATTAACCAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTGCCAGCCAAAGACAGCAGCATTCCCAAG CGCAAGAGAAAGCGGGTCTCGGAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCCTCGTCCTCTAACCCGGATTCAGTGGCA TCGGCCAACCAGATCTCACTCGTGGTAAAGTTGCACCGATTTGGACTCCGGCACTCATCTCTGTGGCCCTCACCCCTCTGTCTGGCAGGG CCGTCTACTCTGGGATGTGGGCCCAGGGGACGGGGAGGCACTGGGCTTTGAGTGGGGACCTTCCGGCCTCGGGGGTTATAGATGCATCCA CCTGTCTCACCCAAGAGGTAGCCCATCCTTCTCGTGGGGTACTCACAGGCACTCAGGCAGGAATTCACATCCTCGCTGGGCAGATGGGCC GGCTGAGGTCCACCTGCCCACACCCTTCAGCCGCACCAGAGCTGGAGACATGAAAAGACATGGCTGGCGGGTGCAGTGGCTCACGCCTGT AATCCCAGCACTTTGGCAGGTCAAGTCGGGTGGATCACCTGAGGTCAGGAGTTTGAGACCAGGCTGACCAACACGGGGAAACCCCATCTC TACTAAAAATACAAAATTAGCCGGGCAAAGTGGGGCATAGTGGCTCATGCCTGTAATCCCAGCTACTTGGAAGGCTGAGATAGGAGAATC GCTTGAACCTGGGAGGCAGAGGTTGCAATGAGCCGAGGTCGCGCCATTGCACTGCAGCCTGGGCAACAAGAGTGAAACACTGTCTCAGAA AAAAAAATTAGCCAGGCATGGTGGCACGTGCCTGTGGTCGCAGCTACTTGGGAGGCTGGGGCAGGAGGATCATTTGAGCCCAAGGGGATT GAGGCTGCAGTGAGCCAAGATCGTCCCATTGCACTCCAGCCTGGGCAAGAGAACGAGACTCCATCTCAAAAATAAATAAATAGGCTGGGT GTGGTGGCTCACGCCTGTAATCCTAGCACTTTGGGAGGCCGAGGCAGGCGGATCACTTGAGGCTCAGGAGTTCAAGACCAGCCTGGCCAA CATGGCAAAACCCCGTCTCTACTAAAAATAGAAAAATTAGCCGGGCATGGTGGCGGGCGCCTATAATCCCAGCTACTCGGGAGGCTGAGG CAGGAGACTCGCTTGAACCCGCGGGGCCAAGGTTGCAGTGAGCCGAGATTGCATCACTGCACTCCAGCCTGGGCAGAAGAGTGAAACTCC ATCTCAAAAAAATAAAAAATATAAATAAATAGCCTCTGAGAAAGCTCTTCCAAAAGCAGAACTAAGCATTTTGGGTTTGTTCCGCATCAC CTGGAGTCCTAATCCAGTCCCTTTGTCCCTCTCTCTAGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAACGTGCAGCTCCCGG GACCTCTTAATTACTAGACCTCAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACAAAATGTATATTCG >18258_18258_8_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000397927_GTF2IRD1_chr7_73944064_ENST00000476977_length(amino acids)=742AA_BP=145 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPF KRPCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGEL GGLRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYA KAIGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESL KRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKI KFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKI LKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVVKLHRFGLRHSSLWPS -------------------------------------------------------------- >18258_18258_9_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000528707_GTF2IRD1_chr7_73944064_ENST00000265755_length(transcript)=2482nt_BP=535nt CCCCCACACATTTCCAGCTCGCACCCGGGCTCCGACCGCTCGCCCCGCTCCTCTCGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCG GGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCCGGGACTCCGGGTCCCCGCGGGCTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCC TGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTGGCCACCGGCTTCCTCTATCCCTTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCC GAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTACGCGAGCCGCCGGCACTGGTGCCATCACACAGTGACACGGACGGTGTCCTGCCAGGTG CAGAATGGCTCGGAGACGGTGGTCCAGCGCGTGTACCAGAGCTGCCGGTGGCCGGGGCCCTGCGCCAACCTCGTAAGGACTCTGATCAGA CCCACCTACAGAGTGTCCTACCGCACGGTGACGGTGCTGGAGTGGAGATGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAA GCCCTGGGCCTGGACCACATGGTCCCCGTGCCCTACCGGAAGATTGCCTGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAG ATCCCCTTCAAGCGCCCCTGCACTTATGGAGTCCCCAAGCTGAAGCGGATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGG ATGTTTGATGAGCGAATTTTCACAGGGAACAAGTTTACCAAAGACACCACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCA GAGGTCTCTAGGGCCACCGTCCTTGACCTTGCTGGGAATGCTCGGTCAGACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCC GGGGAGCTGGGCGGGCTGAGGCCGATCAAAATTGAGCCAGAGGATCTGGACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCT GAGGAAATGACAGACTCGATGCCTGGGCACCTGCCATCGGAGGATTCTGGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAG GACGCGCGGCCCGAGGAGAGGCCCGTGGAGGACAGCCACGGTGACGTGATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACA CGATACGCCAAGGCCATTGGCATCTCGGAGCCCGTCAAGGTGCCGTACTCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGA CTGCCTGAAGGCATCTCCCTCCGCAGGCCCAACTGCTTCGGGATCGCCAAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTT GTCATCAAGAGGCCCGAGCTGCTCACTGAGGGAGTCAAAGAGCCCATCATGGATAGTCAAGGAACTGCCTCCTCACTTGGCTTCTCTCCC CCTGCCCTGCCCCCAGAGAGGGATTCCGGGGACCCTCTGGTGGACGAGAGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGG CTCTCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAGGACCTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTAC CCGGTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCCGTGATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCC TGTACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCTGACAAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATC CCAAAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTGATCCTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGT GAGGCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTAATCCGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGAT GACATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTGGAGAAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATT AACCAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTGCCAGCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTC TCGGAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCCTCGTCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCA CTCGTGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAACGTGCAGCTCCCGGGACCTCTTAATTACTAGACCTCAGTACTGAAT CAGGACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACAAAATGTATATTCGGATATGTATCGATGCCTTTTAGTTTTTCCAAT >18258_18258_9_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000528707_GTF2IRD1_chr7_73944064_ENST00000265755_length(amino acids)=739AA_BP=143 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPFKR PCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGELGG LRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYAKA IGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQGTASSLGFSPPALPP ERDSGDPLVDESLKRQGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGS QNLERILAVADKIKFTVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFR NPNTYDIHRLEKILKAREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQWP -------------------------------------------------------------- >18258_18258_10_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000528707_GTF2IRD1_chr7_73944064_ENST00000424337_length(transcript)=2448nt_BP=535nt CCCCCACACATTTCCAGCTCGCACCCGGGCTCCGACCGCTCGCCCCGCTCCTCTCGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCG GGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCCGGGACTCCGGGTCCCCGCGGGCTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCC TGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTGGCCACCGGCTTCCTCTATCCCTTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCC GAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTACGCGAGCCGCCGGCACTGGTGCCATCACACAGTGACACGGACGGTGTCCTGCCAGGTG CAGAATGGCTCGGAGACGGTGGTCCAGCGCGTGTACCAGAGCTGCCGGTGGCCGGGGCCCTGCGCCAACCTCGTAAGGACTCTGATCAGA CCCACCTACAGAGTGTCCTACCGCACGGTGACGGTGCTGGAGTGGAGATGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAA GCCCTGGGCCTGGACCACATGGTCCCCGTGCCCTACCGGAAGATTGCCTGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAG ATCCCCTTCAAGCGCCCCTGCACTTATGGAGTCCCCAAGCTGAAGCGGATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGG ATGTTTGATGAGCGAATTTTCACAGGGAACAAGTTTACCAAAGACACCACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCA GAGGTCTCTAGGGCCACCGTCCTTGACCTTGCTGGGAATGCTCGGTCAGACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCC GGGGAGCTGGGCGGGCTGAGGCCGATCAAAATTGAGCCAGAGGATCTGGACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCT GAGGAAATGACAGACTCGATGCCTGGGCACCTGCCATCGGAGGATTCTGGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAG GACGCGCGGCCCGAGGAGAGGCCCGTGGAGGACAGCCACGGTGACGTGATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACA CGATACGCCAAGGCCATTGGCATCTCGGAGCCCGTCAAGGTGCCGTACTCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGA CTGCCTGAAGGCATCTCCCTCCGCAGGCCCAACTGCTTCGGGATCGCCAAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTT GTCATCAAGAGGCCCGAGCTGCTCACTGAGGGAGTCAAAGAGCCCATCATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGAC GAGAGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGGCTCTCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAG GACCTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTACCCGGTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCC GTGATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCCTGTACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCT GACAAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATCCCAAAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTG ATCCTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGTGAGGCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTA ATCCGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGATGACATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTG GAGAAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATTAACCAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTG CCAGCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTCTCGGAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCC TCGTCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCACTCGTGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAAC GTGCAGCTCCCGGGACCTCTTAATTACTAGACCTCAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACA AAATGTATATTCGGATATGTATCGATGCCTTTTAGTTTTTCCAATGATTTTTACACTATATTCCTGCCACCAAGGCCTTTTTAAATAAGT >18258_18258_10_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000528707_GTF2IRD1_chr7_73944064_ENST00000424337_length(amino acids)=724AA_BP=143 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPFKR PCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGELGG LRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYAKA IGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESLKR QGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKIKF TVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKILK AREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQWPMYMVDYAGLNVQLPG -------------------------------------------------------------- >18258_18258_11_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000528707_GTF2IRD1_chr7_73944064_ENST00000455841_length(transcript)=2451nt_BP=535nt CCCCCACACATTTCCAGCTCGCACCCGGGCTCCGACCGCTCGCCCCGCTCCTCTCGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCG GGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCCGGGACTCCGGGTCCCCGCGGGCTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCC TGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTGGCCACCGGCTTCCTCTATCCCTTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCC GAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTACGCGAGCCGCCGGCACTGGTGCCATCACACAGTGACACGGACGGTGTCCTGCCAGGTG CAGAATGGCTCGGAGACGGTGGTCCAGCGCGTGTACCAGAGCTGCCGGTGGCCGGGGCCCTGCGCCAACCTCGTAAGGACTCTGATCAGA CCCACCTACAGAGTGTCCTACCGCACGGTGACGGTGCTGGAGTGGAGATGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAA GCCCTGGGCCTGGACCACATGGTCCCCGTGCCCTACCGGAAGATTGCCTGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAG ATCCCCTTCAAGCGCCCCTGCACTTATGGAGTCCCCAAGCTGAAGCGGATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGG ATGTTTGATGAGCGAATTTTCACAGGGAACAAGTTTACCAAAGACACCACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCA GAGGTCTCTAGGGCCACCGTCCTTGACCTTGCTGGGAATGCTCGGTCAGACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCC GGGGAGCTGGGCGGGCTGAGGCCGATCAAAATTGAGCCAGAGGATCTGGACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCT GAGGAAATGACAGACTCGATGCCTGGGCACCTGCCATCGGAGGATTCTGGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAG GACGCGCGGCCCGAGGAGAGGCCCGTGGAGGACAGCCACGGTGACGTGATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACA CGATACGCCAAGGCCATTGGCATCTCGGAGCCCGTCAAGGTGCCGTACTCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGA CTGCCTGAAGGCATCTCCCTCCGCAGGCCCAACTGCTTCGGGATCGCCAAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTT GTCATCAAGAGGCCCGAGCTGCTCACTGAGGGAGTCAAAGAGCCCATCATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGAC GAGAGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGGCTCTCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAG GACCTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTACCCGGTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCC GTGATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCCTGTACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCT GACAAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATCCCAAAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTG ATCCTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGTGAGGCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTA ATCCGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGATGACATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTG GAGAAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATTAACCAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTG CCAGCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTCTCGGAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCC TCGTCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCACTCGTGCAATGGCCAATGTACATGGTGGACTATGCCGGCCTGAAC GTGCAGCTCCCGGGACCTCTTAATTACTAGACCTCAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGGAAATGTAATTTATGTACA AAATGTATATTCGGATATGTATCGATGCCTTTTAGTTTTTCCAATGATTTTTACACTATATTCCTGCCACCAAGGCCTTTTTAAATAAGT >18258_18258_11_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000528707_GTF2IRD1_chr7_73944064_ENST00000455841_length(amino acids)=724AA_BP=143 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPFKR PCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGELGG LRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYAKA IGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESLKR QGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKIKF TVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKILK AREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVQWPMYMVDYAGLNVQLPG -------------------------------------------------------------- >18258_18258_12_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000528707_GTF2IRD1_chr7_73944064_ENST00000476977_length(transcript)=3622nt_BP=535nt CCCCCACACATTTCCAGCTCGCACCCGGGCTCCGACCGCTCGCCCCGCTCCTCTCGCTGTGCTCCCGGCCGGTGCCGCGGGTTCGGTCCG GGCGCCGGTGCGCTCCTGCCGGTCCTCGTGCCCGGGACTCCGGGTCCCCGCGGGCTGCTGCGCACGATGAAGCTGGCCCTGCTCCTGCCC TGGGCGTGTTGCTGCCTCTGCGGGTCGGCGCTGGCCACCGGCTTCCTCTATCCCTTCTCGGCCGCAGCTCTGCAGCAGCACGGCTACCCC GAGCCCGGCGCCGGCTCCCCTGGCAGCGGCTACGCGAGCCGCCGGCACTGGTGCCATCACACAGTGACACGGACGGTGTCCTGCCAGGTG CAGAATGGCTCGGAGACGGTGGTCCAGCGCGTGTACCAGAGCTGCCGGTGGCCGGGGCCCTGCGCCAACCTCGTAAGGACTCTGATCAGA CCCACCTACAGAGTGTCCTACCGCACGGTGACGGTGCTGGAGTGGAGATGCTGCCCTGGCTTCACCGGGAGCAACTGTGATGAGGCGGAA GCCCTGGGCCTGGACCACATGGTCCCCGTGCCCTACCGGAAGATTGCCTGTGACCCGGAGGCTGTGGAGATCGTGGGCATCCCGGACAAG ATCCCCTTCAAGCGCCCCTGCACTTATGGAGTCCCCAAGCTGAAGCGGATCCTGGAGGAGCGCCATAGTATCCACTTCATCATTAAGAGG ATGTTTGATGAGCGAATTTTCACAGGGAACAAGTTTACCAAAGACACCACGAAGCTGGAGCCAGCCAGCCCGCCAGAGGACACCTCTGCA GAGGTCTCTAGGGCCACCGTCCTTGACCTTGCTGGGAATGCTCGGTCAGACAAGGGCAGCATGTCTGAAGACTGTGGGCCAGGAACCTCC GGGGAGCTGGGCGGGCTGAGGCCGATCAAAATTGAGCCAGAGGATCTGGACATCATTCAGGTCACCGTCCCAGACCCCTCGCCAACCTCT GAGGAAATGACAGACTCGATGCCTGGGCACCTGCCATCGGAGGATTCTGGTTATGGGATGGAGATGCTGACAGACAAAGGTCTGAGTGAG GACGCGCGGCCCGAGGAGAGGCCCGTGGAGGACAGCCACGGTGACGTGATCCGGCCCCTGCGGAAGCAGGTGGAGCTGCTCTTCAACACA CGATACGCCAAGGCCATTGGCATCTCGGAGCCCGTCAAGGTGCCGTACTCCAAGTTTCTGATGCACCCGGAGGAGCTGTTTGTGGTGGGA CTGCCTGAAGGCATCTCCCTCCGCAGGCCCAACTGCTTCGGGATCGCCAAGCTCCGGAAGATTCTGGAGGCCAGCAACAGCATCCAGTTT GTCATCAAGAGGCCCGAGCTGCTCACTGAGGGAGTCAAAGAGCCCATCATGGATAGTCAAGAGAGGGATTCCGGGGACCCTCTGGTGGAC GAGAGCCTGAAGAGACAGGGCTTTCAAGAAAATTATGACGCGAGGCTCTCACGGATCGACATCGCCAACACACTAAGGGAGCAGGTCCAG GACCTTTTCAATAAGAAATACGGGGAAGCCTTGGGCATCAAGTACCCGGTCCAGGTCCCCTACAAGCGGATCAAGAGTAACCCCGGCTCC GTGATCATCGAGGGGCTGCCCCCAGGAATCCCGTTCCGAAAGCCCTGTACCTTCGGCTCCCAGAACCTGGAGAGGATTCTTGCTGTGGCT GACAAGATCAAGTTCACAGTCACCAGGCCTTTCCAAGGACTCATCCCAAAGCCTGATGAAGATGACGCCAACAGACTCGGGGAGAAGGTG ATCCTGCGGGAGCAGGTGAAGGAACTCTTCAACGAGAAATACGGTGAGGCCCTGGGCCTGAACCGGCCGGTGCTGGTCCCTTATAAACTA ATCCGGGACAGCCCAGACGCCGTGGAGGTCACGGGTCTGCCTGATGACATCCCCTTCCGGAACCCCAACACGTACGACATCCACCGGCTG GAGAAGATCCTGAAGGCCCGAGAGCATGTCCGCATGGTCATCATTAACCAGCTCCAACCCTTTGCAGAAATCTGCAATGATGCCAAGGTG CCAGCCAAAGACAGCAGCATTCCCAAGCGCAAGAGAAAGCGGGTCTCGGAAGGAAATTCCGTCTCCTCTTCCTCCTCGTCTTCCTCTTCC TCGTCCTCTAACCCGGATTCAGTGGCATCGGCCAACCAGATCTCACTCGTGGTAAAGTTGCACCGATTTGGACTCCGGCACTCATCTCTG TGGCCCTCACCCCTCTGTCTGGCAGGGCCGTCTACTCTGGGATGTGGGCCCAGGGGACGGGGAGGCACTGGGCTTTGAGTGGGGACCTTC CGGCCTCGGGGGTTATAGATGCATCCACCTGTCTCACCCAAGAGGTAGCCCATCCTTCTCGTGGGGTACTCACAGGCACTCAGGCAGGAA TTCACATCCTCGCTGGGCAGATGGGCCGGCTGAGGTCCACCTGCCCACACCCTTCAGCCGCACCAGAGCTGGAGACATGAAAAGACATGG CTGGCGGGTGCAGTGGCTCACGCCTGTAATCCCAGCACTTTGGCAGGTCAAGTCGGGTGGATCACCTGAGGTCAGGAGTTTGAGACCAGG CTGACCAACACGGGGAAACCCCATCTCTACTAAAAATACAAAATTAGCCGGGCAAAGTGGGGCATAGTGGCTCATGCCTGTAATCCCAGC TACTTGGAAGGCTGAGATAGGAGAATCGCTTGAACCTGGGAGGCAGAGGTTGCAATGAGCCGAGGTCGCGCCATTGCACTGCAGCCTGGG CAACAAGAGTGAAACACTGTCTCAGAAAAAAAAATTAGCCAGGCATGGTGGCACGTGCCTGTGGTCGCAGCTACTTGGGAGGCTGGGGCA GGAGGATCATTTGAGCCCAAGGGGATTGAGGCTGCAGTGAGCCAAGATCGTCCCATTGCACTCCAGCCTGGGCAAGAGAACGAGACTCCA TCTCAAAAATAAATAAATAGGCTGGGTGTGGTGGCTCACGCCTGTAATCCTAGCACTTTGGGAGGCCGAGGCAGGCGGATCACTTGAGGC TCAGGAGTTCAAGACCAGCCTGGCCAACATGGCAAAACCCCGTCTCTACTAAAAATAGAAAAATTAGCCGGGCATGGTGGCGGGCGCCTA TAATCCCAGCTACTCGGGAGGCTGAGGCAGGAGACTCGCTTGAACCCGCGGGGCCAAGGTTGCAGTGAGCCGAGATTGCATCACTGCACT CCAGCCTGGGCAGAAGAGTGAAACTCCATCTCAAAAAAATAAAAAATATAAATAAATAGCCTCTGAGAAAGCTCTTCCAAAAGCAGAACT AAGCATTTTGGGTTTGTTCCGCATCACCTGGAGTCCTAATCCAGTCCCTTTGTCCCTCTCTCTAGCAATGGCCAATGTACATGGTGGACT ATGCCGGCCTGAACGTGCAGCTCCCGGGACCTCTTAATTACTAGACCTCAGTACTGAATCAGGACCTCACTCAGAAAGACTAAAGGAAAT GTAATTTATGTACAAAATGTATATTCGGATATGTATCGATGCCTTTTAGTTTTTCCAATGATTTTTACACTATATTCCTGCCACCAAGGC >18258_18258_12_COL26A1-GTF2IRD1_COL26A1_chr7_101091068_ENST00000528707_GTF2IRD1_chr7_73944064_ENST00000476977_length(amino acids)=740AA_BP=143 MPVLVPGTPGPRGLLRTMKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSE TVVQRVYQSCRWPGPCANLVRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEAEALGLDHMVPVPYRKIACDPEAVEIVGIPDKIPFKR PCTYGVPKLKRILEERHSIHFIIKRMFDERIFTGNKFTKDTTKLEPASPPEDTSAEVSRATVLDLAGNARSDKGSMSEDCGPGTSGELGG LRPIKIEPEDLDIIQVTVPDPSPTSEEMTDSMPGHLPSEDSGYGMEMLTDKGLSEDARPEERPVEDSHGDVIRPLRKQVELLFNTRYAKA IGISEPVKVPYSKFLMHPEELFVVGLPEGISLRRPNCFGIAKLRKILEASNSIQFVIKRPELLTEGVKEPIMDSQERDSGDPLVDESLKR QGFQENYDARLSRIDIANTLREQVQDLFNKKYGEALGIKYPVQVPYKRIKSNPGSVIIEGLPPGIPFRKPCTFGSQNLERILAVADKIKF TVTRPFQGLIPKPDEDDANRLGEKVILREQVKELFNEKYGEALGLNRPVLVPYKLIRDSPDAVEVTGLPDDIPFRNPNTYDIHRLEKILK AREHVRMVIINQLQPFAEICNDAKVPAKDSSIPKRKRKRVSEGNSVSSSSSSSSSSSSNPDSVASANQISLVVKLHRFGLRHSSLWPSPL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for COL26A1-GTF2IRD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for COL26A1-GTF2IRD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for COL26A1-GTF2IRD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies