
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:COLEC11-PINX1 (FusionGDB2 ID:18481) |
Fusion Gene Summary for COLEC11-PINX1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: COLEC11-PINX1 | Fusion gene ID: 18481 | Hgene | Tgene | Gene symbol | COLEC11 | PINX1 | Gene ID | 78989 | 54984 |
| Gene name | collectin subfamily member 11 | PIN2 (TERF1) interacting telomerase inhibitor 1 | |
| Synonyms | 3MC2|CL-K1-I|CL-K1-II|CL-K1-IIa|CL-K1-IIb|CLK1 | Gno1|LPTL|LPTS|Pxr1 | |
| Cytomap | 2p25.3 | 8p23.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | collectin-11Collectin K1collectin kidney protein 1collectin sub-family member 11 | PIN2/TERF1-interacting telomerase inhibitor 167-11-3 proteinPIN2-interacting protein 1TRF1-interacting protein 1hepatocellular carcinoma-related putative tumor suppressorliver-related putative tumor suppressorpin2-interacting protein X1protein 67-1 | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | Q9BWP8 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000487365, ENST00000236693, ENST00000349077, ENST00000382062, ENST00000418971, ENST00000402794, ENST00000402922, ENST00000403096, ENST00000404205, | ENST00000314787, ENST00000426190, ENST00000519088, ENST00000520018, | |
| Fusion gene scores | * DoF score | 3 X 2 X 2=12 | 6 X 4 X 5=120 |
| # samples | 2 | 6 | |
| ** MAII score | log2(2/12*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(6/120*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: COLEC11 [Title/Abstract] AND PINX1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | COLEC11(3652060)-PINX1(10692285), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | COLEC11-PINX1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. COLEC11-PINX1 seems lost the major protein functional domain in Tgene partner, which is a tumor suppressor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | COLEC11 | GO:0006956 | complement activation | 23954398 |
| Hgene | COLEC11 | GO:0019730 | antimicrobial humoral response | 20956340 |
| Tgene | PINX1 | GO:0007004 | telomere maintenance via telomerase | 11701125 |
| Tgene | PINX1 | GO:0010972 | negative regulation of G2/M transition of mitotic cell cycle | 11701125 |
| Tgene | PINX1 | GO:0032211 | negative regulation of telomere maintenance via telomerase | 11701125 |
| Tgene | PINX1 | GO:0051974 | negative regulation of telomerase activity | 11701125 |
| Tgene | PINX1 | GO:1902570 | protein localization to nucleolus | 24415760 |
| Tgene | PINX1 | GO:1904744 | positive regulation of telomeric DNA binding | 19265708|24415760 |
| Tgene | PINX1 | GO:1904751 | positive regulation of protein localization to nucleolus | 19265708 |
| Fusion gene breakpoints across COLEC11 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
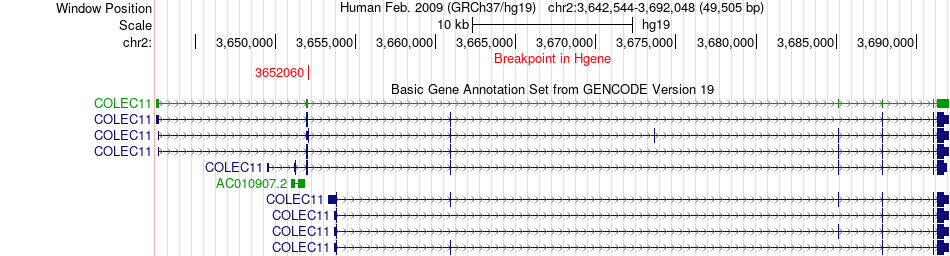 |
| Fusion gene breakpoints across PINX1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SARC | TCGA-X6-A8C6-01A | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
Top |
Fusion Gene ORF analysis for COLEC11-PINX1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000487365 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| 3UTR-3CDS | ENST00000487365 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| 3UTR-3CDS | ENST00000487365 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| 3UTR-5UTR | ENST00000487365 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| 5CDS-5UTR | ENST00000236693 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| 5CDS-5UTR | ENST00000349077 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| 5CDS-5UTR | ENST00000382062 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| 5CDS-5UTR | ENST00000418971 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| Frame-shift | ENST00000236693 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| Frame-shift | ENST00000236693 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| Frame-shift | ENST00000236693 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000349077 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000349077 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000349077 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000382062 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000382062 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000382062 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000418971 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000418971 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| In-frame | ENST00000418971 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000402794 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000402794 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000402794 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000402922 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000402922 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000402922 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000403096 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000403096 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000403096 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000404205 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000404205 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-3CDS | ENST00000404205 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-5UTR | ENST00000402794 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-5UTR | ENST00000402922 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-5UTR | ENST00000403096 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| intron-5UTR | ENST00000404205 | ENST00000520018 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000382062 | COLEC11 | chr2 | 3652060 | + | ENST00000314787 | PINX1 | chr8 | 10692285 | - | 1776 | 370 | 225 | 1337 | 370 |
| ENST00000382062 | COLEC11 | chr2 | 3652060 | + | ENST00000426190 | PINX1 | chr8 | 10692285 | - | 1697 | 370 | 225 | 875 | 216 |
| ENST00000382062 | COLEC11 | chr2 | 3652060 | + | ENST00000519088 | PINX1 | chr8 | 10692285 | - | 1503 | 370 | 225 | 875 | 216 |
| ENST00000349077 | COLEC11 | chr2 | 3652060 | + | ENST00000314787 | PINX1 | chr8 | 10692285 | - | 1639 | 233 | 88 | 1200 | 370 |
| ENST00000349077 | COLEC11 | chr2 | 3652060 | + | ENST00000426190 | PINX1 | chr8 | 10692285 | - | 1560 | 233 | 88 | 738 | 216 |
| ENST00000349077 | COLEC11 | chr2 | 3652060 | + | ENST00000519088 | PINX1 | chr8 | 10692285 | - | 1366 | 233 | 88 | 738 | 216 |
| ENST00000418971 | COLEC11 | chr2 | 3652060 | + | ENST00000314787 | PINX1 | chr8 | 10692285 | - | 1789 | 383 | 211 | 1350 | 379 |
| ENST00000418971 | COLEC11 | chr2 | 3652060 | + | ENST00000426190 | PINX1 | chr8 | 10692285 | - | 1710 | 383 | 211 | 888 | 225 |
| ENST00000418971 | COLEC11 | chr2 | 3652060 | + | ENST00000519088 | PINX1 | chr8 | 10692285 | - | 1516 | 383 | 211 | 888 | 225 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000382062 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.001734494 | 0.99826556 |
| ENST00000382062 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.012711735 | 0.98728824 |
| ENST00000382062 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.015293216 | 0.9847068 |
| ENST00000349077 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.001590466 | 0.99840957 |
| ENST00000349077 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.009711576 | 0.9902884 |
| ENST00000349077 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.015500511 | 0.98449945 |
| ENST00000418971 | ENST00000314787 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.000885666 | 0.99911433 |
| ENST00000418971 | ENST00000426190 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.008503214 | 0.99149674 |
| ENST00000418971 | ENST00000519088 | COLEC11 | chr2 | 3652060 | + | PINX1 | chr8 | 10692285 | - | 0.012496789 | 0.98750323 |
Top |
Fusion Genomic Features for COLEC11-PINX1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
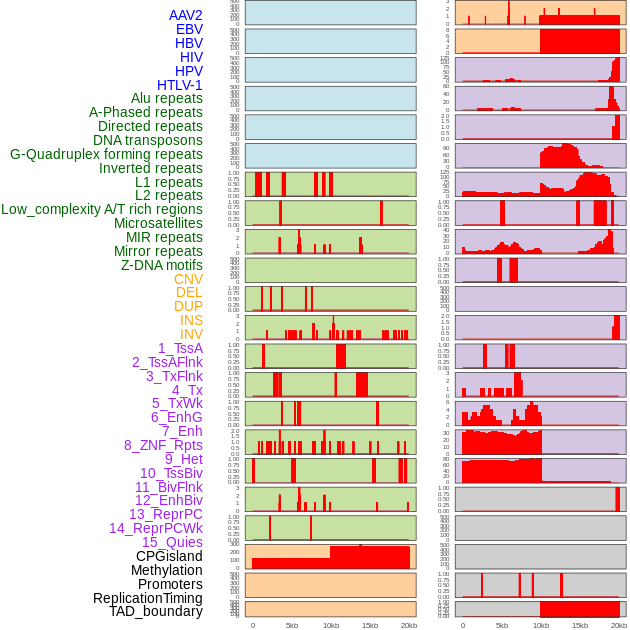 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for COLEC11-PINX1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:3652060/chr8:10692285) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| COLEC11 | . |
| FUNCTION: Lectin that plays a role in innate immunity, apoptosis and embryogenesis (PubMed:23954398, PubMed:25912189, PubMed:21258343). Calcium-dependent lectin that binds self and non-self glycoproteins presenting high mannose oligosaccharides with at least one terminal alpha-1,2-linked mannose epitope (PubMed:25912189). Primarily recognizes the terminal disaccharide of the glycan (PubMed:25912189). Also recognizes a subset of fucosylated glycans and lipopolysaccharides (PubMed:17179669, PubMed:25912189). Plays a role in innate immunity through its ability to bind non-self sugars presented by microorganisms and to activate the complement through the recruitment of MAPS1 (PubMed:20956340, PubMed:25912189). Also plays a role in apoptosis through its ability to bind in a calcium-independent manner the DNA present at the surface of apoptotic cells and to activate the complement in response to this binding (Probable). Finally, plays a role in development, probably serving as a guidance cue during the migration of neural crest cells and other cell types during embryogenesis (PubMed:21258343, PubMed:28301481). {ECO:0000269|PubMed:17179669, ECO:0000269|PubMed:20956340, ECO:0000269|PubMed:21258343, ECO:0000269|PubMed:23954398, ECO:0000269|PubMed:25912189, ECO:0000269|PubMed:28301481, ECO:0000305|PubMed:20956340, ECO:0000305|PubMed:23954398}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PINX1 | chr2:3652060 | chr8:10692285 | ENST00000314787 | 0 | 7 | 26_72 | 6 | 329.0 | Domain | G-patch | |
| Tgene | PINX1 | chr2:3652060 | chr8:10692285 | ENST00000519088 | 0 | 6 | 26_72 | 6 | 175.0 | Domain | G-patch | |
| Tgene | PINX1 | chr2:3652060 | chr8:10692285 | ENST00000314787 | 0 | 7 | 287_297 | 6 | 329.0 | Motif | Note=TBM | |
| Tgene | PINX1 | chr2:3652060 | chr8:10692285 | ENST00000519088 | 0 | 6 | 287_297 | 6 | 175.0 | Motif | Note=TBM | |
| Tgene | PINX1 | chr2:3652060 | chr8:10692285 | ENST00000314787 | 0 | 7 | 254_328 | 6 | 329.0 | Region | Note=Telomerase inhibitory domain (TID) | |
| Tgene | PINX1 | chr2:3652060 | chr8:10692285 | ENST00000519088 | 0 | 6 | 254_328 | 6 | 175.0 | Region | Note=Telomerase inhibitory domain (TID) |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000236693 | + | 2 | 8 | 114_148 | 14 | 269.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000349077 | + | 2 | 7 | 114_148 | 43 | 272.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000382062 | + | 2 | 6 | 114_148 | 43 | 248.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000402794 | + | 1 | 5 | 114_148 | 0 | 222.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000402922 | + | 1 | 5 | 114_148 | 0 | 222.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000403096 | + | 1 | 6 | 114_148 | 0 | 246.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000404205 | + | 1 | 4 | 114_148 | 0 | 198.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000418971 | + | 3 | 8 | 114_148 | 57 | 286.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000236693 | + | 2 | 8 | 149_265 | 14 | 269.0 | Domain | C-type lectin |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000236693 | + | 2 | 8 | 65_112 | 14 | 269.0 | Domain | Note=Collagen-like |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000349077 | + | 2 | 7 | 149_265 | 43 | 272.0 | Domain | C-type lectin |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000349077 | + | 2 | 7 | 65_112 | 43 | 272.0 | Domain | Note=Collagen-like |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000382062 | + | 2 | 6 | 149_265 | 43 | 248.0 | Domain | C-type lectin |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000382062 | + | 2 | 6 | 65_112 | 43 | 248.0 | Domain | Note=Collagen-like |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000402794 | + | 1 | 5 | 149_265 | 0 | 222.0 | Domain | C-type lectin |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000402794 | + | 1 | 5 | 65_112 | 0 | 222.0 | Domain | Note=Collagen-like |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000402922 | + | 1 | 5 | 149_265 | 0 | 222.0 | Domain | C-type lectin |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000402922 | + | 1 | 5 | 65_112 | 0 | 222.0 | Domain | Note=Collagen-like |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000403096 | + | 1 | 6 | 149_265 | 0 | 246.0 | Domain | C-type lectin |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000403096 | + | 1 | 6 | 65_112 | 0 | 246.0 | Domain | Note=Collagen-like |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000404205 | + | 1 | 4 | 149_265 | 0 | 198.0 | Domain | C-type lectin |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000404205 | + | 1 | 4 | 65_112 | 0 | 198.0 | Domain | Note=Collagen-like |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000418971 | + | 3 | 8 | 149_265 | 57 | 286.0 | Domain | C-type lectin |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000418971 | + | 3 | 8 | 65_112 | 57 | 286.0 | Domain | Note=Collagen-like |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000236693 | + | 2 | 8 | 252_254 | 14 | 269.0 | Region | Carbohydrate binding |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000349077 | + | 2 | 7 | 252_254 | 43 | 272.0 | Region | Carbohydrate binding |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000382062 | + | 2 | 6 | 252_254 | 43 | 248.0 | Region | Carbohydrate binding |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000402794 | + | 1 | 5 | 252_254 | 0 | 222.0 | Region | Carbohydrate binding |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000402922 | + | 1 | 5 | 252_254 | 0 | 222.0 | Region | Carbohydrate binding |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000403096 | + | 1 | 6 | 252_254 | 0 | 246.0 | Region | Carbohydrate binding |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000404205 | + | 1 | 4 | 252_254 | 0 | 198.0 | Region | Carbohydrate binding |
| Hgene | COLEC11 | chr2:3652060 | chr8:10692285 | ENST00000418971 | + | 3 | 8 | 252_254 | 57 | 286.0 | Region | Carbohydrate binding |
Top |
Fusion Gene Sequence for COLEC11-PINX1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >18481_18481_1_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000349077_PINX1_chr8_10692285_ENST00000314787_length(transcript)=1639nt_BP=233nt GCCATGAGGCGCCTGGGGGCAGTGTCCTCGCGGGCCAGCGACGGGCAGGACGCCCCGTTCGCCTAGCGCGTGCTCAGGAGTTGGTGTCCT GCCTGCGCTCAGGATGAGGGGGAATCTGGCCCTGGTGGGCGTTCTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCA GCCGGCTGGCGATGACGCCTGCTCTGTGCAGATCCTCGTCCCTGGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAA CACTGCCTGGAGTAATGACGATTCCAAGTTTGGCCAGCGGATGCTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGA GCAAGGAGCCACAGATCATATTAAAGTTCAAGTGAAAAATAACCACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGC CCATCAGGATGATTTTAACCAGCTTCTGGCCGAACTGAACACTTGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAA ATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGAAGGATCTGTCATCTCGGAG CAAAACAGATCTTGACTGCATTTTTGGGAAAAGACAGAGTAAGAAGACTCCCGAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGA AACCACGACAACCAGCGCCTTCACCATCCAGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGG GTCTGACATTTCTGAGACGCAGGTGGAACGTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCA GCCTAAGGCCAAGAGGCACACGGAGGGAAAGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGA GCAGCTCAGAGGCCCCTGCTGGGACCAGAGTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTT CACCCTGAAGCCCAAAAAGAGGAGAGGGAAGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGT GAAAAAGAAGAAGAAGAAAGATTCCAAATGAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACA CCTCTGGCCTGAAGTCACAGCAGAGTTCACCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCG CCACATTTCCCCCAAGTTACATTCCCAGGAGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTC TGAGCCCTTCAGCAAGAGAGTTTAATTATAATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCT GTGTGTGTGTGTGTGTGTCACTATCTCCGTTTGCTCTCGGTTCCCTTCAATAACAATGAATGGTGCTTTCTTCTGAAAGACTCAGCCTAA >18481_18481_1_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000349077_PINX1_chr8_10692285_ENST00000314787_length(amino acids)=370AA_BP=48 MPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQ EQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGKDLSSR SKTDLDCIFGKRQSKKTPEGDASPSTPEENETTTTSAFTIQEYFAKRMAALKNKPQVPVPGSDISETQVERKRGKKRNKEATGKDVESYL QPKAKRHTEGKPERAEAQERVAKKKSAPAEEQLRGPCWDQSSKASAQDAGDHVQPPEGRDFTLKPKKRRGKKKLQKPVEIAEDATLEETL -------------------------------------------------------------- >18481_18481_2_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000349077_PINX1_chr8_10692285_ENST00000426190_length(transcript)=1560nt_BP=233nt GCCATGAGGCGCCTGGGGGCAGTGTCCTCGCGGGCCAGCGACGGGCAGGACGCCCCGTTCGCCTAGCGCGTGCTCAGGAGTTGGTGTCCT GCCTGCGCTCAGGATGAGGGGGAATCTGGCCCTGGTGGGCGTTCTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCA GCCGGCTGGCGATGACGCCTGCTCTGTGCAGATCCTCGTCCCTGGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAA CACTGCCTGGAGTAATGACGATTCCAAGTTTGGCCAGCGGATGCTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGA GCAAGGAGCCACAGATCATATTAAAGTTCAAGTGAAAAATAACCACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGC CCATCAGGATGATTTTAACCAGCTTCTGGCCGAACTGAACACTTGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAA ATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTC CAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCCAGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGG TTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAACGTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGG AAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAAAGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCG CGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGAGTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTG AGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGAAGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAG AAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAATGAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACT GCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCACCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAG TCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGGAGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATT TTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTAATTATAATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTG CATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTATCTCCGTTTGCTCTCGGTTCCCTTCAATAACAATGAATGGTGCTTTCTTCTGAA >18481_18481_2_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000349077_PINX1_chr8_10692285_ENST00000426190_length(amino acids)=216AA_BP=48 MPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQ EQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGRCQSLH -------------------------------------------------------------- >18481_18481_3_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000349077_PINX1_chr8_10692285_ENST00000519088_length(transcript)=1366nt_BP=233nt GCCATGAGGCGCCTGGGGGCAGTGTCCTCGCGGGCCAGCGACGGGCAGGACGCCCCGTTCGCCTAGCGCGTGCTCAGGAGTTGGTGTCCT GCCTGCGCTCAGGATGAGGGGGAATCTGGCCCTGGTGGGCGTTCTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCA GCCGGCTGGCGATGACGCCTGCTCTGTGCAGATCCTCGTCCCTGGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAA CACTGCCTGGAGTAATGACGATTCCAAGTTTGGCCAGCGGATGCTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGA GCAAGGAGCCACAGATCATATTAAAGTTCAAGTGAAAAATAACCACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGC CCATCAGGATGATTTTAACCAGCTTCTGGCCGAACTGAACACTTGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAA ATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTC CAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCCAGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGG TTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAACGTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGG AAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAAAGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCG CGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGAGTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTG AGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGAAGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAG AAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAATGAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACT GCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCACCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAG TCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGGAGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATT >18481_18481_3_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000349077_PINX1_chr8_10692285_ENST00000519088_length(amino acids)=216AA_BP=48 MPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQ EQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGRCQSLH -------------------------------------------------------------- >18481_18481_4_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000382062_PINX1_chr8_10692285_ENST00000314787_length(transcript)=1776nt_BP=370nt GGACGGTGGACGCAGCGCAGACAGGAAGCTCCCCGAGATAACGCTGCGGCCGGGCGGCCTGATTTGCTGGGCTGTCTGATGGCCCGGGCC GAGGCTTCTCCCTGCGCCTGGGACTGCGGCCGCCTCTCTAAATAGCAGCCATGAGGCGCCTGGGGGCAGTGTCCTCGCGGGCCAGCGACG GGCAGGACGCCCCGTTCGCCTAGCGCGTGCTCAGGAGTTGGTGTCCTGCCTGCGCTCAGGATGAGGGGGAATCTGGCCCTGGTGGGCGTT CTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCAGCCGGCTGGCGATGACGCCTGCTCTGTGCAGATCCTCGTCCCT GGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAACACTGCCTGGAGTAATGACGATTCCAAGTTTGGCCAGCGGATG CTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGAGCAAGGAGCCACAGATCATATTAAAGTTCAAGTGAAAAATAAC CACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGCCCATCAGGATGATTTTAACCAGCTTCTGGCCGAACTGAACACT TGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCGT GTTCACTATATGAAATTCACAAAAGGGAAGGATCTGTCATCTCGGAGCAAAACAGATCTTGACTGCATTTTTGGGAAAAGACAGAGTAAG AAGACTCCCGAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCCAGGAGTACTTTGCC AAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAACGTAAAAGGGGGAAG AAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAAAGCCCGAGAGGGCC GAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGAGTTCCAAGGCCTCT GCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGAAGAAAAAGCTGCAA AAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAATGAATCCTTCCCAGC CGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCACCCCAGAGCGCCTG GGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGGAGGACCTTTTTAAT GTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTAATTATAATCATTACAAATA CATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTATCTCCGTTTGCTCTCGGTTC >18481_18481_4_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000382062_PINX1_chr8_10692285_ENST00000314787_length(amino acids)=370AA_BP=48 MPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQ EQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGKDLSSR SKTDLDCIFGKRQSKKTPEGDASPSTPEENETTTTSAFTIQEYFAKRMAALKNKPQVPVPGSDISETQVERKRGKKRNKEATGKDVESYL QPKAKRHTEGKPERAEAQERVAKKKSAPAEEQLRGPCWDQSSKASAQDAGDHVQPPEGRDFTLKPKKRRGKKKLQKPVEIAEDATLEETL -------------------------------------------------------------- >18481_18481_5_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000382062_PINX1_chr8_10692285_ENST00000426190_length(transcript)=1697nt_BP=370nt GGACGGTGGACGCAGCGCAGACAGGAAGCTCCCCGAGATAACGCTGCGGCCGGGCGGCCTGATTTGCTGGGCTGTCTGATGGCCCGGGCC GAGGCTTCTCCCTGCGCCTGGGACTGCGGCCGCCTCTCTAAATAGCAGCCATGAGGCGCCTGGGGGCAGTGTCCTCGCGGGCCAGCGACG GGCAGGACGCCCCGTTCGCCTAGCGCGTGCTCAGGAGTTGGTGTCCTGCCTGCGCTCAGGATGAGGGGGAATCTGGCCCTGGTGGGCGTT CTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCAGCCGGCTGGCGATGACGCCTGCTCTGTGCAGATCCTCGTCCCT GGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAACACTGCCTGGAGTAATGACGATTCCAAGTTTGGCCAGCGGATG CTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGAGCAAGGAGCCACAGATCATATTAAAGTTCAAGTGAAAAATAAC CACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGCCCATCAGGATGATTTTAACCAGCTTCTGGCCGAACTGAACACT TGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCGT GTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCCA GGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAACG TAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAAA GCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGAG TTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGAA GAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAATG AATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCAC CCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGGA GGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTAATTATA ATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTATCTCCGT >18481_18481_5_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000382062_PINX1_chr8_10692285_ENST00000426190_length(amino acids)=216AA_BP=48 MPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQ EQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGRCQSLH -------------------------------------------------------------- >18481_18481_6_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000382062_PINX1_chr8_10692285_ENST00000519088_length(transcript)=1503nt_BP=370nt GGACGGTGGACGCAGCGCAGACAGGAAGCTCCCCGAGATAACGCTGCGGCCGGGCGGCCTGATTTGCTGGGCTGTCTGATGGCCCGGGCC GAGGCTTCTCCCTGCGCCTGGGACTGCGGCCGCCTCTCTAAATAGCAGCCATGAGGCGCCTGGGGGCAGTGTCCTCGCGGGCCAGCGACG GGCAGGACGCCCCGTTCGCCTAGCGCGTGCTCAGGAGTTGGTGTCCTGCCTGCGCTCAGGATGAGGGGGAATCTGGCCCTGGTGGGCGTT CTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCAGCCGGCTGGCGATGACGCCTGCTCTGTGCAGATCCTCGTCCCT GGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAACACTGCCTGGAGTAATGACGATTCCAAGTTTGGCCAGCGGATG CTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGAGCAAGGAGCCACAGATCATATTAAAGTTCAAGTGAAAAATAAC CACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGCCCATCAGGATGATTTTAACCAGCTTCTGGCCGAACTGAACACT TGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCGT GTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCCA GGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAACG TAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAAA GCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGAG TTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGAA GAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAATG AATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCAC CCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGGA >18481_18481_6_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000382062_PINX1_chr8_10692285_ENST00000519088_length(amino acids)=216AA_BP=48 MPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQ EQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGRCQSLH -------------------------------------------------------------- >18481_18481_7_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000418971_PINX1_chr8_10692285_ENST00000314787_length(transcript)=1789nt_BP=383nt AGATTTGGGAGAAGGATTTCAAATGACTTCCCTTCGAGCTGCAGGGCTATCTTGGGCATCTTGACCTCCACACATTTCTGGGAGAACTCC TCGTGCAGCAGGACATCAGGTGGCAAAGGTGATCTGCCCACCTCAGCCTCCCAAAGTGCTGGAATTACAGGTGTGAGCCACTGCGCCTGG TCTTGTTTTCCAAGTTGTAACGCCCTTCACGATGAAGAAACAAAGAGGAGTTGGTGTCCTGCCTGCGCTCAGGATGAGGGGGAATCTGGC CCTGGTGGGCGTTCTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCAGCCGGCTGGCGATGACGCCTGCTCTGTGCA GATCCTCGTCCCTGGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAACACTGCCTGGAGTAATGACGATTCCAAGTT TGGCCAGCGGATGCTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGAGCAAGGAGCCACAGATCATATTAAAGTTCA AGTGAAAAATAACCACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGCCCATCAGGATGATTTTAACCAGCTTCTGGC CGAACTGAACACTTGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAAT CTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGAAGGATCTGTCATCTCGGAGCAAAACAGATCTTGACTGCATTTTTGGGAA AAGACAGAGTAAGAAGACTCCCGAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCCA GGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAACG TAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAAA GCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGAG TTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGAA GAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAATG AATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCAC CCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGGA GGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTAATTATA ATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTATCTCCGT >18481_18481_7_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000418971_PINX1_chr8_10692285_ENST00000314787_length(amino acids)=379AA_BP=57 MKKQRGVGVLPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGW SKGKGLGAQEQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKF TKGKDLSSRSKTDLDCIFGKRQSKKTPEGDASPSTPEENETTTTSAFTIQEYFAKRMAALKNKPQVPVPGSDISETQVERKRGKKRNKEA TGKDVESYLQPKAKRHTEGKPERAEAQERVAKKKSAPAEEQLRGPCWDQSSKASAQDAGDHVQPPEGRDFTLKPKKRRGKKKLQKPVEIA -------------------------------------------------------------- >18481_18481_8_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000418971_PINX1_chr8_10692285_ENST00000426190_length(transcript)=1710nt_BP=383nt AGATTTGGGAGAAGGATTTCAAATGACTTCCCTTCGAGCTGCAGGGCTATCTTGGGCATCTTGACCTCCACACATTTCTGGGAGAACTCC TCGTGCAGCAGGACATCAGGTGGCAAAGGTGATCTGCCCACCTCAGCCTCCCAAAGTGCTGGAATTACAGGTGTGAGCCACTGCGCCTGG TCTTGTTTTCCAAGTTGTAACGCCCTTCACGATGAAGAAACAAAGAGGAGTTGGTGTCCTGCCTGCGCTCAGGATGAGGGGGAATCTGGC CCTGGTGGGCGTTCTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCAGCCGGCTGGCGATGACGCCTGCTCTGTGCA GATCCTCGTCCCTGGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAACACTGCCTGGAGTAATGACGATTCCAAGTT TGGCCAGCGGATGCTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGAGCAAGGAGCCACAGATCATATTAAAGTTCA AGTGAAAAATAACCACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGCCCATCAGGATGATTTTAACCAGCTTCTGGC CGAACTGAACACTTGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAAT CTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCG CCTTCACCATCCAGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGA CGCAGGTGGAACGTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGC ACACGGAGGGAAAGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCT GCTGGGACCAGAGTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAA AGAGGAGAGGGAAGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGA AAGATTCCAAATGAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCA CAGCAGAGTTCACCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGT TACATTCCCAGGAGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGA GAGTTTAATTATAATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTG TCACTATCTCCGTTTGCTCTCGGTTCCCTTCAATAACAATGAATGGTGCTTTCTTCTGAAAGACTCAGCCTAATTAAAGGATTAAGAGGC >18481_18481_8_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000418971_PINX1_chr8_10692285_ENST00000426190_length(amino acids)=225AA_BP=57 MKKQRGVGVLPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGW SKGKGLGAQEQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKF -------------------------------------------------------------- >18481_18481_9_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000418971_PINX1_chr8_10692285_ENST00000519088_length(transcript)=1516nt_BP=383nt AGATTTGGGAGAAGGATTTCAAATGACTTCCCTTCGAGCTGCAGGGCTATCTTGGGCATCTTGACCTCCACACATTTCTGGGAGAACTCC TCGTGCAGCAGGACATCAGGTGGCAAAGGTGATCTGCCCACCTCAGCCTCCCAAAGTGCTGGAATTACAGGTGTGAGCCACTGCGCCTGG TCTTGTTTTCCAAGTTGTAACGCCCTTCACGATGAAGAAACAAAGAGGAGTTGGTGTCCTGCCTGCGCTCAGGATGAGGGGGAATCTGGC CCTGGTGGGCGTTCTAATCAGCCTGGCCTTCCTGTCACTGCTGCCATCTGGACATCCTCAGCCGGCTGGCGATGACGCCTGCTCTGTGCA GATCCTCGTCCCTGGCCTCAAAGGTCGGCGGAAGCAGAAGTGGGCTGTGGATCCTCAGAACACTGCCTGGAGTAATGACGATTCCAAGTT TGGCCAGCGGATGCTAGAGAAGATGGGGTGGTCTAAAGGAAAGGGTTTAGGGGCTCAGGAGCAAGGAGCCACAGATCATATTAAAGTTCA AGTGAAAAATAACCACCTGGGACTCGGAGCTACCATCAATAATGAAGACAACTGGATTGCCCATCAGGATGATTTTAACCAGCTTCTGGC CGAACTGAACACTTGCCATGGGCAGGAAACCACAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAAT CTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCG CCTTCACCATCCAGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGA CGCAGGTGGAACGTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGC ACACGGAGGGAAAGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCT GCTGGGACCAGAGTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAA AGAGGAGAGGGAAGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGA AAGATTCCAAATGAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCA CAGCAGAGTTCACCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGT >18481_18481_9_COLEC11-PINX1_COLEC11_chr2_3652060_ENST00000418971_PINX1_chr8_10692285_ENST00000519088_length(amino acids)=225AA_BP=57 MKKQRGVGVLPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGW SKGKGLGAQEQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKF -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for COLEC11-PINX1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for COLEC11-PINX1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for COLEC11-PINX1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies