
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:COX6B1-LIG1 (FusionGDB2 ID:18816) |
Fusion Gene Summary for COX6B1-LIG1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: COX6B1-LIG1 | Fusion gene ID: 18816 | Hgene | Tgene | Gene symbol | COX6B1 | LIG1 | Gene ID | 1340 | 26018 |
| Gene name | cytochrome c oxidase subunit 6B1 | leucine rich repeats and immunoglobulin like domains 1 | |
| Synonyms | COX6B|COXG|COXVIb1 | LIG-1|LIG1 | |
| Cytomap | 19q13.12 | 3p14.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cytochrome c oxidase subunit 6B1COX VIb-1cytochrome c oxidase subunit VIb polypeptide 1 (ubiquitous) | leucine-rich repeats and immunoglobulin-like domains protein 1leucine-rich repeat protein LRIG1ortholog of mouse integral membrane glycoprotein LIG-1 | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | P14854 | P18858 | |
| Ensembl transtripts involved in fusion gene | ENST00000246554, ENST00000392201, ENST00000592141, | ENST00000599165, ENST00000263274, ENST00000427526, ENST00000536218, | |
| Fusion gene scores | * DoF score | 11 X 9 X 6=594 | 6 X 6 X 5=180 |
| # samples | 12 | 6 | |
| ** MAII score | log2(12/594*10)=-2.30742852519225 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/180*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: COX6B1 [Title/Abstract] AND LIG1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | COX6B1(36145573)-LIG1(48626575), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across COX6B1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across LIG1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCS | TCGA-NG-A4VW | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
Top |
Fusion Gene ORF analysis for COX6B1-LIG1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000246554 | ENST00000599165 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| 5CDS-intron | ENST00000392201 | ENST00000599165 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| 5CDS-intron | ENST00000592141 | ENST00000599165 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000246554 | ENST00000263274 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000246554 | ENST00000427526 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000246554 | ENST00000536218 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000392201 | ENST00000263274 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000392201 | ENST00000427526 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000392201 | ENST00000536218 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000592141 | ENST00000263274 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000592141 | ENST00000427526 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| In-frame | ENST00000592141 | ENST00000536218 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000246554 | COX6B1 | chr19 | 36145573 | + | ENST00000263274 | LIG1 | chr19 | 48626575 | - | 1359 | 399 | 114 | 1154 | 346 |
| ENST00000246554 | COX6B1 | chr19 | 36145573 | + | ENST00000536218 | LIG1 | chr19 | 48626575 | - | 1354 | 399 | 114 | 1154 | 346 |
| ENST00000246554 | COX6B1 | chr19 | 36145573 | + | ENST00000427526 | LIG1 | chr19 | 48626575 | - | 1354 | 399 | 114 | 1154 | 346 |
| ENST00000592141 | COX6B1 | chr19 | 36145573 | + | ENST00000263274 | LIG1 | chr19 | 48626575 | - | 1432 | 472 | 148 | 1227 | 359 |
| ENST00000592141 | COX6B1 | chr19 | 36145573 | + | ENST00000536218 | LIG1 | chr19 | 48626575 | - | 1427 | 472 | 148 | 1227 | 359 |
| ENST00000592141 | COX6B1 | chr19 | 36145573 | + | ENST00000427526 | LIG1 | chr19 | 48626575 | - | 1427 | 472 | 148 | 1227 | 359 |
| ENST00000392201 | COX6B1 | chr19 | 36145573 | + | ENST00000263274 | LIG1 | chr19 | 48626575 | - | 1262 | 302 | 11 | 1057 | 348 |
| ENST00000392201 | COX6B1 | chr19 | 36145573 | + | ENST00000536218 | LIG1 | chr19 | 48626575 | - | 1257 | 302 | 11 | 1057 | 348 |
| ENST00000392201 | COX6B1 | chr19 | 36145573 | + | ENST00000427526 | LIG1 | chr19 | 48626575 | - | 1257 | 302 | 11 | 1057 | 348 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000246554 | ENST00000263274 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.006642434 | 0.9933576 |
| ENST00000246554 | ENST00000536218 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.006423384 | 0.9935766 |
| ENST00000246554 | ENST00000427526 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.006423384 | 0.9935766 |
| ENST00000592141 | ENST00000263274 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.008681991 | 0.991318 |
| ENST00000592141 | ENST00000536218 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.008533706 | 0.9914663 |
| ENST00000592141 | ENST00000427526 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.008533706 | 0.9914663 |
| ENST00000392201 | ENST00000263274 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.013381606 | 0.98661834 |
| ENST00000392201 | ENST00000536218 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.012963039 | 0.98703694 |
| ENST00000392201 | ENST00000427526 | COX6B1 | chr19 | 36145573 | + | LIG1 | chr19 | 48626575 | - | 0.012963039 | 0.98703694 |
Top |
Fusion Genomic Features for COX6B1-LIG1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
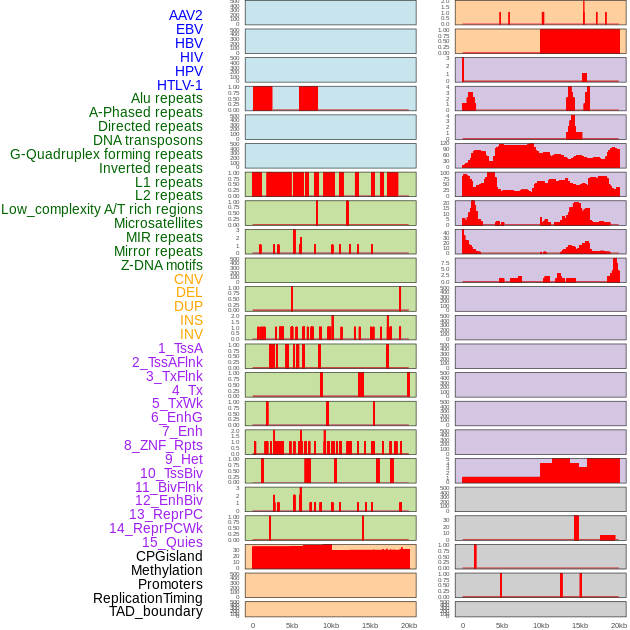 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for COX6B1-LIG1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:36145573/chr19:48626575) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| COX6B1 | LIG1 |
| FUNCTION: Component of the cytochrome c oxidase, the last enzyme in the mitochondrial electron transport chain which drives oxidative phosphorylation. The respiratory chain contains 3 multisubunit complexes succinate dehydrogenase (complex II, CII), ubiquinol-cytochrome c oxidoreductase (cytochrome b-c1 complex, complex III, CIII) and cytochrome c oxidase (complex IV, CIV), that cooperate to transfer electrons derived from NADH and succinate to molecular oxygen, creating an electrochemical gradient over the inner membrane that drives transmembrane transport and the ATP synthase. Cytochrome c oxidase is the component of the respiratory chain that catalyzes the reduction of oxygen to water. Electrons originating from reduced cytochrome c in the intermembrane space (IMS) are transferred via the dinuclear copper A center (CU(A)) of subunit 2 and heme A of subunit 1 to the active site in subunit 1, a binuclear center (BNC) formed by heme A3 and copper B (CU(B)). The BNC reduces molecular oxygen to 2 water molecules using 4 electrons from cytochrome c in the IMS and 4 protons from the mitochondrial matrix. {ECO:0000250|UniProtKB:Q01519}. | FUNCTION: DNA ligase that seals nicks in double-stranded DNA during DNA replication, DNA recombination and DNA repair. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000246554 | + | 3 | 4 | 30_40 | 69 | 87.0 | Motif | Cx9C motif |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000246554 | + | 3 | 4 | 54_65 | 69 | 87.0 | Motif | Cx10C motif |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000392201 | + | 3 | 4 | 30_40 | 69 | 87.0 | Motif | Cx9C motif |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000392201 | + | 3 | 4 | 54_65 | 69 | 87.0 | Motif | Cx10C motif |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000592141 | + | 3 | 4 | 30_40 | 69 | 87.0 | Motif | Cx9C motif |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000592141 | + | 3 | 4 | 54_65 | 69 | 87.0 | Motif | Cx10C motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000246554 | + | 3 | 4 | 27_73 | 69 | 87.0 | Domain | CHCH |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000392201 | + | 3 | 4 | 27_73 | 69 | 87.0 | Domain | CHCH |
| Hgene | COX6B1 | chr19:36145573 | chr19:48626575 | ENST00000592141 | + | 3 | 4 | 27_73 | 69 | 87.0 | Domain | CHCH |
Top |
Fusion Gene Sequence for COX6B1-LIG1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >18816_18816_1_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000246554_LIG1_chr19_48626575_ENST00000263274_length(transcript)=1359nt_BP=399nt TGGGCGTGGCTTGAATGACTTCAGTGGCCTCCTCCTGGGAGGGAGCTGAAGCCGCTCGCAAGACTCCCGTAGTCCCCACCTCTCTCAGCT TCCGGCTGGTAGTAGTTCCGCTTCCTGTCCGACTGTGGTGTCTTTGCTGAGGGTCACATTGAGCTGCAGGTTGAATCCGGGGTGCCTTTA GGATTCAGCACCATGGCGGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAG ACTAGAAACTGCTGGCAGAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGG TACCAGCGTGTGTACCAGTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAAC TTTGTGGAGACAGAGGGCGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTG AAAGACTCCTGCGAGGGGCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTG AAGAAGGACTACCTTGATGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTAC GGGGGCTTCCTGCTGGCCTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTG GAGGAGCATCACCAGAGCCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGG CTGGACCCCAGCGCTGTGTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGAC AAGGGCATCTCCCTTCGCTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGT TTGTACCGGAAGCAAAGTCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTA GGGCCTGGGTACAGGGCATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTT TGAGAGTCAGGGGAGGGGTGTGTGTGTGAGGGGGTGGCTTACTCCGGAGTCTGGGATTCATCCCGTCATTTCTTTCAATAAATAATTATT >18816_18816_1_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000246554_LIG1_chr19_48626575_ENST00000263274_length(amino acids)=346AA_BP=95 MSDCGVFAEGHIELQVESGVPLGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDISVCEWYQRVYQSL CPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSHNWLKLKKDYLDGV GDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAVIPDHWLDPSAVWE -------------------------------------------------------------- >18816_18816_2_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000246554_LIG1_chr19_48626575_ENST00000427526_length(transcript)=1354nt_BP=399nt TGGGCGTGGCTTGAATGACTTCAGTGGCCTCCTCCTGGGAGGGAGCTGAAGCCGCTCGCAAGACTCCCGTAGTCCCCACCTCTCTCAGCT TCCGGCTGGTAGTAGTTCCGCTTCCTGTCCGACTGTGGTGTCTTTGCTGAGGGTCACATTGAGCTGCAGGTTGAATCCGGGGTGCCTTTA GGATTCAGCACCATGGCGGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAG ACTAGAAACTGCTGGCAGAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGG TACCAGCGTGTGTACCAGTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAAC TTTGTGGAGACAGAGGGCGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTG AAAGACTCCTGCGAGGGGCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTG AAGAAGGACTACCTTGATGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTAC GGGGGCTTCCTGCTGGCCTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTG GAGGAGCATCACCAGAGCCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGG CTGGACCCCAGCGCTGTGTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGAC AAGGGCATCTCCCTTCGCTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGT TTGTACCGGAAGCAAAGTCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTA GGGCCTGGGTACAGGGCATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTT TGAGAGTCAGGGGAGGGGTGTGTGTGTGAGGGGGTGGCTTACTCCGGAGTCTGGGATTCATCCCGTCATTTCTTTCAATAAATAATTATT >18816_18816_2_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000246554_LIG1_chr19_48626575_ENST00000427526_length(amino acids)=346AA_BP=95 MSDCGVFAEGHIELQVESGVPLGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDISVCEWYQRVYQSL CPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSHNWLKLKKDYLDGV GDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAVIPDHWLDPSAVWE -------------------------------------------------------------- >18816_18816_3_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000246554_LIG1_chr19_48626575_ENST00000536218_length(transcript)=1354nt_BP=399nt TGGGCGTGGCTTGAATGACTTCAGTGGCCTCCTCCTGGGAGGGAGCTGAAGCCGCTCGCAAGACTCCCGTAGTCCCCACCTCTCTCAGCT TCCGGCTGGTAGTAGTTCCGCTTCCTGTCCGACTGTGGTGTCTTTGCTGAGGGTCACATTGAGCTGCAGGTTGAATCCGGGGTGCCTTTA GGATTCAGCACCATGGCGGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAG ACTAGAAACTGCTGGCAGAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGG TACCAGCGTGTGTACCAGTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAAC TTTGTGGAGACAGAGGGCGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTG AAAGACTCCTGCGAGGGGCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTG AAGAAGGACTACCTTGATGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTAC GGGGGCTTCCTGCTGGCCTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTG GAGGAGCATCACCAGAGCCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGG CTGGACCCCAGCGCTGTGTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGAC AAGGGCATCTCCCTTCGCTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGT TTGTACCGGAAGCAAAGTCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTA GGGCCTGGGTACAGGGCATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTT TGAGAGTCAGGGGAGGGGTGTGTGTGTGAGGGGGTGGCTTACTCCGGAGTCTGGGATTCATCCCGTCATTTCTTTCAATAAATAATTATT >18816_18816_3_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000246554_LIG1_chr19_48626575_ENST00000536218_length(amino acids)=346AA_BP=95 MSDCGVFAEGHIELQVESGVPLGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDISVCEWYQRVYQSL CPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSHNWLKLKKDYLDGV GDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAVIPDHWLDPSAVWE -------------------------------------------------------------- >18816_18816_4_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000392201_LIG1_chr19_48626575_ENST00000263274_length(transcript)=1262nt_BP=302nt CATCCTCCCTTTTGGACGTTGGAGGGGCCGCAGCGTCATCTCCGATGCACCCTCATCCTCAGATACCGGGTAGAGATCTCGCCGGATTCA GCACCATGGCGGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAGACTAGAA ACTGCTGGCAGAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGGTACCAGC GTGTGTACCAGTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAACTTTGTGG AGACAGAGGGCGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTGAAAGACT CCTGCGAGGGGCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTGAAGAAGG ACTACCTTGATGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTACGGGGGCT TCCTGCTGGCCTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTGGAGGAGC ATCACCAGAGCCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGGCTGGACC CCAGCGCTGTGTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGACAAGGGCA TCTCCCTTCGCTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGTTTGTACC GGAAGCAAAGTCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTAGGGCCTG GGTACAGGGCATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTTTGAGAGT CAGGGGAGGGGTGTGTGTGTGAGGGGGTGGCTTACTCCGGAGTCTGGGATTCATCCCGTCATTTCTTTCAATAAATAATTATTGGATAGC >18816_18816_4_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000392201_LIG1_chr19_48626575_ENST00000263274_length(amino acids)=348AA_BP=97 MDVGGAAASSPMHPHPQIPGRDLAGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDISVCEWYQRVYQ SLCPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSHNWLKLKKDYLD GVGDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAVIPDHWLDPSAV -------------------------------------------------------------- >18816_18816_5_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000392201_LIG1_chr19_48626575_ENST00000427526_length(transcript)=1257nt_BP=302nt CATCCTCCCTTTTGGACGTTGGAGGGGCCGCAGCGTCATCTCCGATGCACCCTCATCCTCAGATACCGGGTAGAGATCTCGCCGGATTCA GCACCATGGCGGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAGACTAGAA ACTGCTGGCAGAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGGTACCAGC GTGTGTACCAGTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAACTTTGTGG AGACAGAGGGCGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTGAAAGACT CCTGCGAGGGGCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTGAAGAAGG ACTACCTTGATGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTACGGGGGCT TCCTGCTGGCCTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTGGAGGAGC ATCACCAGAGCCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGGCTGGACC CCAGCGCTGTGTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGACAAGGGCA TCTCCCTTCGCTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGTTTGTACC GGAAGCAAAGTCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTAGGGCCTG GGTACAGGGCATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTTTGAGAGT >18816_18816_5_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000392201_LIG1_chr19_48626575_ENST00000427526_length(amino acids)=348AA_BP=97 MDVGGAAASSPMHPHPQIPGRDLAGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDISVCEWYQRVYQ SLCPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSHNWLKLKKDYLD GVGDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAVIPDHWLDPSAV -------------------------------------------------------------- >18816_18816_6_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000392201_LIG1_chr19_48626575_ENST00000536218_length(transcript)=1257nt_BP=302nt CATCCTCCCTTTTGGACGTTGGAGGGGCCGCAGCGTCATCTCCGATGCACCCTCATCCTCAGATACCGGGTAGAGATCTCGCCGGATTCA GCACCATGGCGGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAGACTAGAA ACTGCTGGCAGAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGGTACCAGC GTGTGTACCAGTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAACTTTGTGG AGACAGAGGGCGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTGAAAGACT CCTGCGAGGGGCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTGAAGAAGG ACTACCTTGATGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTACGGGGGCT TCCTGCTGGCCTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTGGAGGAGC ATCACCAGAGCCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGGCTGGACC CCAGCGCTGTGTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGACAAGGGCA TCTCCCTTCGCTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGTTTGTACC GGAAGCAAAGTCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTAGGGCCTG GGTACAGGGCATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTTTGAGAGT >18816_18816_6_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000392201_LIG1_chr19_48626575_ENST00000536218_length(amino acids)=348AA_BP=97 MDVGGAAASSPMHPHPQIPGRDLAGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDISVCEWYQRVYQ SLCPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSHNWLKLKKDYLD GVGDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAVIPDHWLDPSAV -------------------------------------------------------------- >18816_18816_7_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000592141_LIG1_chr19_48626575_ENST00000263274_length(transcript)=1432nt_BP=472nt TAGGGCCTGCGATTATCCCCTTTTGTCAGTAAACAGGCTCAGAGATACCAAGCGACCTAGCTGAACCTACACAGCGACCAGGATTTGGCC CAGGAGTTTGTCCTCCAGGGCTCTTCATGGCTAATTCACAGGCGTGGCCTCTCGCGGCTTGCCTGGGCCGCAGCCTGGCTCCCGGGTGTC CAGTCCATCCTCCCTTTTGGACGTTGGAGGGGCCGCAGCGTCATCTCCGATGCACCCTCATCCTCAGATACCGGGATTCAGCACCATGGC GGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAGACTAGAAACTGCTGGCA GAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGGTACCAGCGTGTGTACCA GTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAACTTTGTGGAGACAGAGGG CGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTGAAAGACTCCTGCGAGGG GCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTGAAGAAGGACTACCTTGA TGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTACGGGGGCTTCCTGCTGGC CTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTGGAGGAGCATCACCAGAG CCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGGCTGGACCCCAGCGCTGT GTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGACAAGGGCATCTCCCTTCG CTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGTTTGTACCGGAAGCAAAG TCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTAGGGCCTGGGTACAGGGC ATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTTTGAGAGTCAGGGGAGGG >18816_18816_7_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000592141_LIG1_chr19_48626575_ENST00000263274_length(amino acids)=359AA_BP=108 MPGPQPGSRVSSPSSLLDVGGAAASSPMHPHPQIPGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDI SVCEWYQRVYQSLCPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSH NWLKLKKDYLDGVGDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAV -------------------------------------------------------------- >18816_18816_8_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000592141_LIG1_chr19_48626575_ENST00000427526_length(transcript)=1427nt_BP=472nt TAGGGCCTGCGATTATCCCCTTTTGTCAGTAAACAGGCTCAGAGATACCAAGCGACCTAGCTGAACCTACACAGCGACCAGGATTTGGCC CAGGAGTTTGTCCTCCAGGGCTCTTCATGGCTAATTCACAGGCGTGGCCTCTCGCGGCTTGCCTGGGCCGCAGCCTGGCTCCCGGGTGTC CAGTCCATCCTCCCTTTTGGACGTTGGAGGGGCCGCAGCGTCATCTCCGATGCACCCTCATCCTCAGATACCGGGATTCAGCACCATGGC GGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAGACTAGAAACTGCTGGCA GAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGGTACCAGCGTGTGTACCA GTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAACTTTGTGGAGACAGAGGG CGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTGAAAGACTCCTGCGAGGG GCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTGAAGAAGGACTACCTTGA TGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTACGGGGGCTTCCTGCTGGC CTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTGGAGGAGCATCACCAGAG CCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGGCTGGACCCCAGCGCTGT GTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGACAAGGGCATCTCCCTTCG CTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGTTTGTACCGGAAGCAAAG TCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTAGGGCCTGGGTACAGGGC ATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTTTGAGAGTCAGGGGAGGG >18816_18816_8_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000592141_LIG1_chr19_48626575_ENST00000427526_length(amino acids)=359AA_BP=108 MPGPQPGSRVSSPSSLLDVGGAAASSPMHPHPQIPGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDI SVCEWYQRVYQSLCPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSH NWLKLKKDYLDGVGDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAV -------------------------------------------------------------- >18816_18816_9_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000592141_LIG1_chr19_48626575_ENST00000536218_length(transcript)=1427nt_BP=472nt TAGGGCCTGCGATTATCCCCTTTTGTCAGTAAACAGGCTCAGAGATACCAAGCGACCTAGCTGAACCTACACAGCGACCAGGATTTGGCC CAGGAGTTTGTCCTCCAGGGCTCTTCATGGCTAATTCACAGGCGTGGCCTCTCGCGGCTTGCCTGGGCCGCAGCCTGGCTCCCGGGTGTC CAGTCCATCCTCCCTTTTGGACGTTGGAGGGGCCGCAGCGTCATCTCCGATGCACCCTCATCCTCAGATACCGGGATTCAGCACCATGGC GGAAGACATGGAGACCAAAATCAAGAACTACAAGACCGCCCCTTTTGACAGCCGCTTCCCCAACCAGAACCAGACTAGAAACTGCTGGCA GAACTACCTGGACTTCCACCGCTGTCAGAAGGCAATGACCGCTAAAGGAGGCGATATCTCTGTGTGCGAATGGTACCAGCGTGTGTACCA GTCCCTCTGCCCCACATCCTGGTCCCTGGTACGTGAGCCCCTTTCCCGGCGCCGGCAGCTGCTCCGGGAGAACTTTGTGGAGACAGAGGG CGAGTTTGTCTTCGCCACCTCCCTGGACACCAAGGACATCGAGCAGATCGCCGAGTTCCTGGAGCAGTCAGTGAAAGACTCCTGCGAGGG GCTGATGGTGAAGACCCTGGATGTTGATGCCACCTACGAGATCGCCAAGAGATCGCACAACTGGCTCAAGCTGAAGAAGGACTACCTTGA TGGCGTGGGTGACACCCTGGACCTGGTGGTGATCGGCGCCTACCTGGGCCGGGGGAAGCGGGCCGGCCGGTACGGGGGCTTCCTGCTGGC CTCCTACGACGAGGACAGTGAGGAGCTGCAGGCCATATGCAAGCTTGGAACTGGCTTCAGTGATGAGGAGCTGGAGGAGCATCACCAGAG CCTCAAGGCGCTGGTGCTGCCCAGCCCACGCCCTTACGTGCGGATAGATGGCGCTGTGATTCCCGACCACTGGCTGGACCCCAGCGCTGT GTGGGAGGTGAAGTGCGCTGACCTCTCCCTCTCTCCCATCTACCCTGCTGCGCGGGGCCTGGTGGATAGTGACAAGGGCATCTCCCTTCG CTTCCCTCGGTTTATTCGAGTCCGTGAAGACAAGCAGCCGGAGCAGGCCACCACCAGTGCTCAGGTGGCCTGTTTGTACCGGAAGCAAAG TCAGATTCAGAACCAACAAGGCGAGGACTCAGGCTCTGACCCTGAAGATACCTACTAAGCCCTCGCCCTCCTAGGGCCTGGGTACAGGGC ATGAGTTGGACGGACCCCAGGGTTATTATTGCCTTTGCTTTTTAGCAAATCTGCTGTGGCAGGCTGTGGATTTTGAGAGTCAGGGGAGGG >18816_18816_9_COX6B1-LIG1_COX6B1_chr19_36145573_ENST00000592141_LIG1_chr19_48626575_ENST00000536218_length(amino acids)=359AA_BP=108 MPGPQPGSRVSSPSSLLDVGGAAASSPMHPHPQIPGFSTMAEDMETKIKNYKTAPFDSRFPNQNQTRNCWQNYLDFHRCQKAMTAKGGDI SVCEWYQRVYQSLCPTSWSLVREPLSRRRQLLRENFVETEGEFVFATSLDTKDIEQIAEFLEQSVKDSCEGLMVKTLDVDATYEIAKRSH NWLKLKKDYLDGVGDTLDLVVIGAYLGRGKRAGRYGGFLLASYDEDSEELQAICKLGTGFSDEELEEHHQSLKALVLPSPRPYVRIDGAV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for COX6B1-LIG1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | LIG1 | chr19:36145573 | chr19:48626575 | ENST00000263274 | 20 | 28 | 449_458 | 668.0 | 920.0 | target DNA | |
| Tgene | LIG1 | chr19:36145573 | chr19:48626575 | ENST00000263274 | 20 | 28 | 642_644 | 668.0 | 920.0 | target DNA |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for COX6B1-LIG1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for COX6B1-LIG1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies