
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ACVR1C-ACVR1B (FusionGDB2 ID:1894) |
Fusion Gene Summary for ACVR1C-ACVR1B |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ACVR1C-ACVR1B | Fusion gene ID: 1894 | Hgene | Tgene | Gene symbol | ACVR1C | ACVR1B | Gene ID | 130399 | 91 |
| Gene name | activin A receptor type 1C | activin A receptor type 1B | |
| Synonyms | ACVRLK7|ALK7 | ACTRIB|ACVRLK4|ALK4|SKR2 | |
| Cytomap | 2q24.1 | 12q13.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | activin receptor type-1CACTR-ICALK-7activin A receptor, type ICactivin receptor type ICactivin receptor-like kinase 7 | activin receptor type-1Bactivin A receptor, type IBactivin A receptor, type II-like kinase 4activin receptor-like kinase 4serine/threonine-protein kinase receptor R2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q8NER5 | P36896 | |
| Ensembl transtripts involved in fusion gene | ENST00000243349, ENST00000335450, ENST00000409680, ENST00000348328, | ENST00000563121, ENST00000257963, ENST00000415850, ENST00000426655, ENST00000541224, ENST00000542485, | |
| Fusion gene scores | * DoF score | 4 X 4 X 3=48 | 6 X 5 X 6=180 |
| # samples | 4 | 6 | |
| ** MAII score | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/180*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ACVR1C [Title/Abstract] AND ACVR1B [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ACVR1C(158406673)-ACVR1B(52377782), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ACVR1C | GO:0001834 | trophectodermal cell proliferation | 15150278 |
| Hgene | ACVR1C | GO:0030154 | cell differentiation | 15531507 |
| Hgene | ACVR1C | GO:0030262 | apoptotic nuclear changes | 15531507 |
| Hgene | ACVR1C | GO:0043065 | positive regulation of apoptotic process | 15150278 |
| Hgene | ACVR1C | GO:1901164 | negative regulation of trophoblast cell migration | 21356369 |
| Tgene | ACVR1B | GO:0000082 | G1/S transition of mitotic cell cycle | 11117535 |
| Tgene | ACVR1B | GO:0006355 | regulation of transcription, DNA-templated | 8622651|12665502 |
| Tgene | ACVR1B | GO:0006468 | protein phosphorylation | 12065756 |
| Tgene | ACVR1B | GO:0007165 | signal transduction | 8622651|12665502 |
| Tgene | ACVR1B | GO:0018107 | peptidyl-threonine phosphorylation | 18039968 |
| Tgene | ACVR1B | GO:0030308 | negative regulation of cell growth | 11117535 |
| Tgene | ACVR1B | GO:0032924 | activin receptor signaling pathway | 9892009 |
| Tgene | ACVR1B | GO:0032927 | positive regulation of activin receptor signaling pathway | 16720724 |
| Tgene | ACVR1B | GO:0045648 | positive regulation of erythrocyte differentiation | 9032295 |
| Tgene | ACVR1B | GO:0046777 | protein autophosphorylation | 18039968 |
| Tgene | ACVR1B | GO:1901165 | positive regulation of trophoblast cell migration | 21356369 |
| Fusion gene breakpoints across ACVR1C (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ACVR1B (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 203N | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
Top |
Fusion Gene ORF analysis for ACVR1C-ACVR1B |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000243349 | ENST00000563121 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| 5CDS-intron | ENST00000335450 | ENST00000563121 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| 5CDS-intron | ENST00000409680 | ENST00000563121 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000243349 | ENST00000257963 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000243349 | ENST00000415850 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000243349 | ENST00000426655 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000243349 | ENST00000541224 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000243349 | ENST00000542485 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000335450 | ENST00000257963 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000335450 | ENST00000415850 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000335450 | ENST00000426655 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000335450 | ENST00000541224 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000335450 | ENST00000542485 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000409680 | ENST00000257963 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000409680 | ENST00000415850 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000409680 | ENST00000426655 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000409680 | ENST00000541224 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| In-frame | ENST00000409680 | ENST00000542485 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| intron-3CDS | ENST00000348328 | ENST00000257963 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| intron-3CDS | ENST00000348328 | ENST00000415850 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| intron-3CDS | ENST00000348328 | ENST00000426655 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| intron-3CDS | ENST00000348328 | ENST00000541224 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| intron-3CDS | ENST00000348328 | ENST00000542485 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| intron-intron | ENST00000348328 | ENST00000563121 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000243349 | ACVR1C | chr2 | 158406673 | - | ENST00000257963 | ACVR1B | chr12 | 52377782 | + | 4811 | 1136 | 352 | 1842 | 496 |
| ENST00000243349 | ACVR1C | chr2 | 158406673 | - | ENST00000541224 | ACVR1B | chr12 | 52377782 | + | 1950 | 1136 | 352 | 1842 | 496 |
| ENST00000243349 | ACVR1C | chr2 | 158406673 | - | ENST00000426655 | ACVR1B | chr12 | 52377782 | + | 2065 | 1136 | 352 | 1755 | 467 |
| ENST00000243349 | ACVR1C | chr2 | 158406673 | - | ENST00000415850 | ACVR1B | chr12 | 52377782 | + | 1990 | 1136 | 352 | 1788 | 478 |
| ENST00000243349 | ACVR1C | chr2 | 158406673 | - | ENST00000542485 | ACVR1B | chr12 | 52377782 | + | 2658 | 1136 | 352 | 1842 | 496 |
| ENST00000335450 | ACVR1C | chr2 | 158406673 | - | ENST00000257963 | ACVR1B | chr12 | 52377782 | + | 4293 | 618 | 74 | 1324 | 416 |
| ENST00000335450 | ACVR1C | chr2 | 158406673 | - | ENST00000541224 | ACVR1B | chr12 | 52377782 | + | 1432 | 618 | 74 | 1324 | 416 |
| ENST00000335450 | ACVR1C | chr2 | 158406673 | - | ENST00000426655 | ACVR1B | chr12 | 52377782 | + | 1547 | 618 | 74 | 1237 | 387 |
| ENST00000335450 | ACVR1C | chr2 | 158406673 | - | ENST00000415850 | ACVR1B | chr12 | 52377782 | + | 1472 | 618 | 74 | 1270 | 398 |
| ENST00000335450 | ACVR1C | chr2 | 158406673 | - | ENST00000542485 | ACVR1B | chr12 | 52377782 | + | 2140 | 618 | 74 | 1324 | 416 |
| ENST00000409680 | ACVR1C | chr2 | 158406673 | - | ENST00000257963 | ACVR1B | chr12 | 52377782 | + | 4578 | 903 | 152 | 1609 | 485 |
| ENST00000409680 | ACVR1C | chr2 | 158406673 | - | ENST00000541224 | ACVR1B | chr12 | 52377782 | + | 1717 | 903 | 152 | 1609 | 485 |
| ENST00000409680 | ACVR1C | chr2 | 158406673 | - | ENST00000426655 | ACVR1B | chr12 | 52377782 | + | 1832 | 903 | 152 | 1522 | 456 |
| ENST00000409680 | ACVR1C | chr2 | 158406673 | - | ENST00000415850 | ACVR1B | chr12 | 52377782 | + | 1757 | 903 | 152 | 1555 | 467 |
| ENST00000409680 | ACVR1C | chr2 | 158406673 | - | ENST00000542485 | ACVR1B | chr12 | 52377782 | + | 2425 | 903 | 152 | 1609 | 485 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000243349 | ENST00000257963 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.001266378 | 0.9987336 |
| ENST00000243349 | ENST00000541224 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.004636993 | 0.995363 |
| ENST00000243349 | ENST00000426655 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.003171724 | 0.99682826 |
| ENST00000243349 | ENST00000415850 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.002763582 | 0.9972364 |
| ENST00000243349 | ENST00000542485 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.004107871 | 0.99589217 |
| ENST00000335450 | ENST00000257963 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.000618014 | 0.999382 |
| ENST00000335450 | ENST00000541224 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.001609206 | 0.9983908 |
| ENST00000335450 | ENST00000426655 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.001213752 | 0.9987863 |
| ENST00000335450 | ENST00000415850 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.000580732 | 0.99941933 |
| ENST00000335450 | ENST00000542485 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.002091441 | 0.9979086 |
| ENST00000409680 | ENST00000257963 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.003903664 | 0.9960963 |
| ENST00000409680 | ENST00000541224 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.00593436 | 0.99406564 |
| ENST00000409680 | ENST00000426655 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.003827069 | 0.99617296 |
| ENST00000409680 | ENST00000415850 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.003198025 | 0.996802 |
| ENST00000409680 | ENST00000542485 | ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.006850655 | 0.99314934 |
Top |
Fusion Genomic Features for ACVR1C-ACVR1B |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.5166849 | 0.4833151 |
| ACVR1C | chr2 | 158406673 | - | ACVR1B | chr12 | 52377782 | + | 0.5166849 | 0.4833151 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
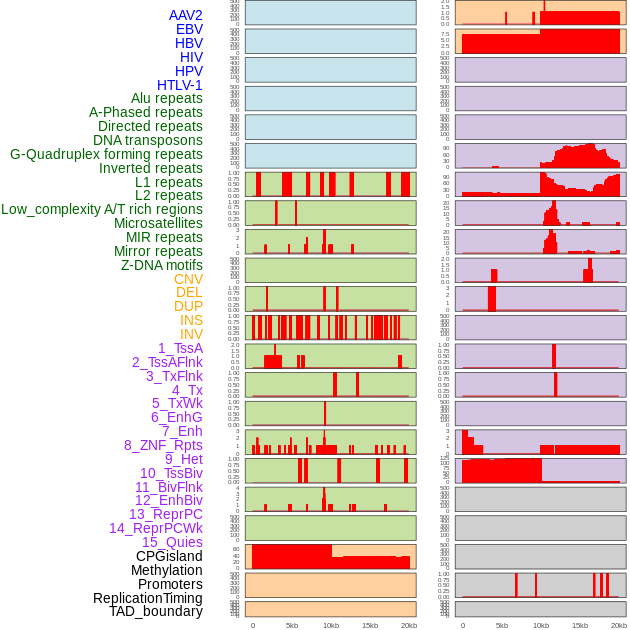 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
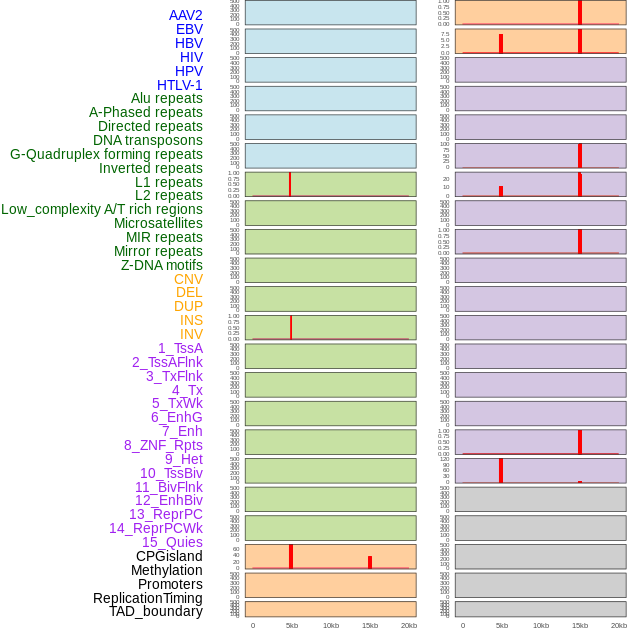 |
Top |
Fusion Protein Features for ACVR1C-ACVR1B |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:158406673/chr12:52377782) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ACVR1C | ACVR1B |
| FUNCTION: Serine/threonine protein kinase which forms a receptor complex on ligand binding. The receptor complex consisting of 2 type II and 2 type I transmembrane serine/threonine kinases. Type II receptors phosphorylate and activate type I receptors which autophosphorylate, then bind and activate SMAD transcriptional regulators, SMAD2 and SMAD3. Receptor for activin AB, activin B and NODAL. Plays a role in cell differentiation, growth arrest and apoptosis. {ECO:0000269|PubMed:12063393, ECO:0000269|PubMed:15531507}. | FUNCTION: Transmembrane serine/threonine kinase activin type-1 receptor forming an activin receptor complex with activin receptor type-2 (ACVR2A or ACVR2B). Transduces the activin signal from the cell surface to the cytoplasm and is thus regulating a many physiological and pathological processes including neuronal differentiation and neuronal survival, hair follicle development and cycling, FSH production by the pituitary gland, wound healing, extracellular matrix production, immunosuppression and carcinogenesis. Activin is also thought to have a paracrine or autocrine role in follicular development in the ovary. Within the receptor complex, type-2 receptors (ACVR2A and/or ACVR2B) act as a primary activin receptors whereas the type-1 receptors like ACVR1B act as downstream transducers of activin signals. Activin binds to type-2 receptor at the plasma membrane and activates its serine-threonine kinase. The activated receptor type-2 then phosphorylates and activates the type-1 receptor such as ACVR1B. Once activated, the type-1 receptor binds and phosphorylates the SMAD proteins SMAD2 and SMAD3, on serine residues of the C-terminal tail. Soon after their association with the activin receptor and subsequent phosphorylation, SMAD2 and SMAD3 are released into the cytoplasm where they interact with the common partner SMAD4. This SMAD complex translocates into the nucleus where it mediates activin-induced transcription. Inhibitory SMAD7, which is recruited to ACVR1B through FKBP1A, can prevent the association of SMAD2 and SMAD3 with the activin receptor complex, thereby blocking the activin signal. Activin signal transduction is also antagonized by the binding to the receptor of inhibin-B via the IGSF1 inhibin coreceptor. ACVR1B also phosphorylates TDP2. {ECO:0000269|PubMed:12364468, ECO:0000269|PubMed:12639945, ECO:0000269|PubMed:18039968, ECO:0000269|PubMed:20226172, ECO:0000269|PubMed:8196624, ECO:0000269|PubMed:9032295, ECO:0000269|PubMed:9892009}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000243349 | - | 4 | 9 | 165_194 | 258 | 494.0 | Domain | GS |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000409680 | - | 4 | 9 | 165_194 | 208 | 444.0 | Domain | GS |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000243349 | - | 4 | 9 | 201_209 | 258 | 494.0 | Nucleotide binding | ATP |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000409680 | - | 4 | 9 | 201_209 | 208 | 444.0 | Nucleotide binding | ATP |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000243349 | - | 4 | 9 | 22_113 | 258 | 494.0 | Topological domain | Extracellular |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000335450 | - | 3 | 8 | 22_113 | 178 | 414.0 | Topological domain | Extracellular |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000409680 | - | 4 | 9 | 22_113 | 208 | 444.0 | Topological domain | Extracellular |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000243349 | - | 4 | 9 | 114_134 | 258 | 494.0 | Transmembrane | Helical |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000335450 | - | 3 | 8 | 114_134 | 178 | 414.0 | Transmembrane | Helical |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000409680 | - | 4 | 9 | 114_134 | 208 | 444.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000243349 | - | 4 | 9 | 195_485 | 258 | 494.0 | Domain | Protein kinase |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000335450 | - | 3 | 8 | 165_194 | 178 | 414.0 | Domain | GS |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000335450 | - | 3 | 8 | 195_485 | 178 | 414.0 | Domain | Protein kinase |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000348328 | - | 1 | 7 | 165_194 | 0 | 337.0 | Domain | GS |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000348328 | - | 1 | 7 | 195_485 | 0 | 337.0 | Domain | Protein kinase |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000409680 | - | 4 | 9 | 195_485 | 208 | 444.0 | Domain | Protein kinase |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000335450 | - | 3 | 8 | 201_209 | 178 | 414.0 | Nucleotide binding | ATP |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000348328 | - | 1 | 7 | 201_209 | 0 | 337.0 | Nucleotide binding | ATP |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000243349 | - | 4 | 9 | 135_493 | 258 | 494.0 | Topological domain | Cytoplasmic |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000335450 | - | 3 | 8 | 135_493 | 178 | 414.0 | Topological domain | Cytoplasmic |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000348328 | - | 1 | 7 | 135_493 | 0 | 337.0 | Topological domain | Cytoplasmic |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000348328 | - | 1 | 7 | 22_113 | 0 | 337.0 | Topological domain | Extracellular |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000409680 | - | 4 | 9 | 135_493 | 208 | 444.0 | Topological domain | Cytoplasmic |
| Hgene | ACVR1C | chr2:158406673 | chr12:52377782 | ENST00000348328 | - | 1 | 7 | 114_134 | 0 | 337.0 | Transmembrane | Helical |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000257963 | 3 | 9 | 177_206 | 270 | 506.0 | Domain | GS | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000257963 | 3 | 9 | 207_497 | 270 | 506.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000415850 | 3 | 7 | 177_206 | 270 | 488.0 | Domain | GS | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000415850 | 3 | 7 | 207_497 | 270 | 488.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000426655 | 3 | 8 | 177_206 | 270 | 477.0 | Domain | GS | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000426655 | 3 | 8 | 207_497 | 270 | 477.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000541224 | 4 | 10 | 177_206 | 311 | 547.0 | Domain | GS | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000541224 | 4 | 10 | 207_497 | 311 | 547.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000542485 | 3 | 9 | 177_206 | 218 | 454.0 | Domain | GS | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000542485 | 3 | 9 | 207_497 | 218 | 454.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000257963 | 3 | 9 | 213_221 | 270 | 506.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000415850 | 3 | 7 | 213_221 | 270 | 488.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000426655 | 3 | 8 | 213_221 | 270 | 477.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000541224 | 4 | 10 | 213_221 | 311 | 547.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000542485 | 3 | 9 | 213_221 | 218 | 454.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000257963 | 3 | 9 | 150_505 | 270 | 506.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000257963 | 3 | 9 | 24_126 | 270 | 506.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000415850 | 3 | 7 | 150_505 | 270 | 488.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000415850 | 3 | 7 | 24_126 | 270 | 488.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000426655 | 3 | 8 | 150_505 | 270 | 477.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000426655 | 3 | 8 | 24_126 | 270 | 477.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000541224 | 4 | 10 | 150_505 | 311 | 547.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000541224 | 4 | 10 | 24_126 | 311 | 547.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000542485 | 3 | 9 | 150_505 | 218 | 454.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000542485 | 3 | 9 | 24_126 | 218 | 454.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000257963 | 3 | 9 | 127_149 | 270 | 506.0 | Transmembrane | Helical | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000415850 | 3 | 7 | 127_149 | 270 | 488.0 | Transmembrane | Helical | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000426655 | 3 | 8 | 127_149 | 270 | 477.0 | Transmembrane | Helical | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000541224 | 4 | 10 | 127_149 | 311 | 547.0 | Transmembrane | Helical | |
| Tgene | ACVR1B | chr2:158406673 | chr12:52377782 | ENST00000542485 | 3 | 9 | 127_149 | 218 | 454.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for ACVR1C-ACVR1B |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >1894_1894_1_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000257963_length(transcript)=4811nt_BP=1136nt GCCGGGCACAGGGCCGCCTTTGCCTGCCTGCCCTGCAGCAGCAGGCCCGGGCGGCTGCGAGAGGGCGCAGGGGGCGGAGGCGCGGCAGGG GCGGGCTCTGCCGCCCGCCCCACCACCCGCTCCCCGCCCGGCTGCGGGGCCAGTGGCAGGAGCGCCGCGCACCGCCAGCCGCAGGGGGCG TGGGATGGGGGCGGCCGGGGAGGGGGGCGCCCACACTGACTAGAGCCAACCGCGCACTTCAAAAGGGTGTCGGTGCCGCGCTCCCCTCCC GCGGCCCGGGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGC GATGACCCGGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATG TCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGAT CAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGA TTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAAAACTTGGACCCATGGAGCTGGCCATCATTATTACTGT GCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGGGTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAA TGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGAAAGATCTGATTTATGATGTGACCGCCTCTGGATCTGG CTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTG GCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCA GACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTC TGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGC TAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCT GGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAA TCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGA TATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGA CTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAG TTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAA GACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCAC AGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGA GCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGA ATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCA TGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGC ACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCT GCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGG TTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGG TCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGA GGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTACTCTGTGTCTGGCAGGCTACTCTGCCCACCCCAGCATCAGCACAGCTCTC CTCCTCCATCTCAGACTGTGGAACCAAAGCTGGCCCAGTTGTCCATGACAAAAGAGGCTTTTGGGCCAAAATGTGAGGGTGGTGGGTGGG ATGGGCAGGGAAGGAATCCTGGTGGAAGTCTTGGGTGTTAGTGTCAGCCATGGGAAATGAGCCAGCCCAAGGGCATCATCCTCAGCAGCA TCGAGGAAGGGCCGAGGAATGTGAAGCCAGATCTCGGGACTCAGATTGGAATGTTACATCTGTCTTTCATCTCCCAGATCCTGGAAACAG CAGTGTATATTTTTGGTGGTGGTGGGTTTGGGGTGGGGAAGGGAAGGGCGGGCAAGGAGTGGGGAGGGAGTCTGGGGTGGGAGGGAGGCA TCTGCATGGGTCTTCTTTTACTGGACTGTCTGATCAGGGTGGAGGGAAGGTGAGAGGTTTGCATCCACTTCAGGAGCCCTACTGAAGGGA ACAGCCTGAGCCGAACATGTTATTTAACCTGAGTATAGTATTTAACGAAGCCTAGAAGCACGGCTGTGGGTGGTGATTTGGTCAGCATAT CTTAGGTATATAATAACTTTGAAGCCATAACTTTTAACTGGAGTGGTTTGATTTCTTTTTTTAATTTTATTGGGAGGGTTTGGATTTTAA CTTTTTTTAATGTTGTTAAATATTAAGTTTTTGTAAAAGGAAAACCATCTCTGTGATTACCTCTCAATCTATTTGTTTTTAAAGAAATCC CTAAAAAAAAAAATTATCCAATTGAACGCACATAGCTCAATCACACTGGAAATGTTTGTCCTTGCACCTGAGCCTGTTCCCACTCAGCAG TGAGAGTTCCTCTTTGCCCTGAGGCTCAGTCTCTCTCGTATTTTGTCCCCACCCCCAATTCCTTGAGTGGTTTTTGCTCTAGGGCCCTTT CTTGCACTGTCCAGCTGGTTGTACCCTCTCCAGGCATTTATTCAACAAATGTGGGTGAAGTGCCTGCTGGGTGCCAGGTGCTGGGAATAC ATCTGTGGACAAGACATGCTTGGGTCCTACTCCTGGAGCACTGTAAAAAGAGCTGATTCAAGTAAGTAGATGCCTGTTTTGAGACCAGAA GGTTTCATAATTGGTTCTACGACCCTTTTGAGCCTAGAATTATTGTTCTTATATAAGATCACTGAAGAAAGAGGAACCCCCACAACCCCC TCCACAAAGAGACCAGGGGCGGGTGATGAGACCTGGGGTTTAGAACCCCAGGTGAGACCTCAAATCACTGCATTCATTCTGAGCCCCCTT CCTGTCCCCAGGGGAGGTGTATTGTGTATGTAGCCTTAGAGCATCTCTGCCTCCAACCCAGCAGTTCTCTGCCAAAGCTTGTGGAGGAGG GAGAGCCCTGTCCCTGCCCTCAGGCTCCCCAGTGCTCCTGGCCCTTCTATTTATTTGACTGATTATTGCTTCTTTCCTTGCATTAAAGGA GATCTTCCCCTAACCTTTGGGCCAATTTACTGGCCACTAATTTCGTTTAAATACCATTGTGTCATTGGGGGGACCGTCTTTACCCCTGCT GACCTCCCACCTATCCGCCCTGCAGCAGAACCTTGGCGGTTTATAGGTAATGATGGAACTTAGACTCCTCTTCCCAGAGTCACAAGTAGC CTCTGGGATCTGCCAACACACGTCCACTCCCAAGCCACTAGCCCACTCCCCAGTTGGCCCTTCTGCCCTTACCCCACACACAGTCCAACT CTTCCACCTCTGGGGAAGATGGAGCAGGTCTTTGGGAAGCTCCCACACCCACCTCTGCCACTCTTAACACTAAGTGAGAGTTGGGGAGAA ACTGAAGCCGTGTTTTTGGCCCCCCGAGGCTAACCCTGATCCATAGTGCTACCTGCACCTCTGGATTCTGGATTCACAGACCAAGTCCAA GCCCGTTCTTACGTCGCCATAAAGGCCCCCGAACGGCATTCTCGGTACTTCTGTTTGTTTTTGTACATTTTATTAGAAAGGACTGTAAAA TAGCCACTTAGACACTTTACCTCTTCAGTATGCAAATGTAAATAAATTGTAATATAGGAAATCTTTTGTTTTAATATAAGAATGAGCCTG >1894_1894_1_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000257963_length(amino acids)=496AA_BP=184 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTAS GSGSGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLW LVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDI APNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNIPNW -------------------------------------------------------------- >1894_1894_2_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000415850_length(transcript)=1990nt_BP=1136nt GCCGGGCACAGGGCCGCCTTTGCCTGCCTGCCCTGCAGCAGCAGGCCCGGGCGGCTGCGAGAGGGCGCAGGGGGCGGAGGCGCGGCAGGG GCGGGCTCTGCCGCCCGCCCCACCACCCGCTCCCCGCCCGGCTGCGGGGCCAGTGGCAGGAGCGCCGCGCACCGCCAGCCGCAGGGGGCG TGGGATGGGGGCGGCCGGGGAGGGGGGCGCCCACACTGACTAGAGCCAACCGCGCACTTCAAAAGGGTGTCGGTGCCGCGCTCCCCTCCC GCGGCCCGGGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGC GATGACCCGGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATG TCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGAT CAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGA TTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAAAACTTGGACCCATGGAGCTGGCCATCATTATTACTGT GCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGGGTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAA TGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGAAAGATCTGATTTATGATGTGACCGCCTCTGGATCTGG CTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTG GCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCA GACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTC TGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGC TAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCT GGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAA TCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGA TATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGTACCTTTCTTTTTTGCCTTTGCTCCTACCTCCC ATTCCAGGATGCTGGATCACCCAAAGCTGTTTTACTGCCCCCTTTCTTTTTACAACCTGTTGGATGCCTGTTGCCAGAGCCTGAATCATC GTTTAAGGTTGCCATCAAAGGTGTGGAGGTAGCTGTGCTTAGGGTGCGTTTATTCTTCAGGGATCAGTTTGTTGAATAGCGTTGTGTGTT ATGGTAACCATTCTGAAGGCTCGTTTGGCTTTATAAACAAACAAACATTGTTTTATTAGTCCGTGGCGGGGAGTGCCCCGGTGCGCATAG CACGGGATTCATGCAGTGGTCTCCTTCACATCAGAAGCAGTATATTCTAACGCGGTGGCTCCCAAGCCACATTCATGGGAAACCCTGCTG >1894_1894_2_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000415850_length(amino acids)=478AA_BP=184 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTAS GSGSGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLW LVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDI APNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGTFLFCLCSYLPFQDAGSPKAVLLPPFFLQPVGCLLPEP -------------------------------------------------------------- >1894_1894_3_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000426655_length(transcript)=2065nt_BP=1136nt GCCGGGCACAGGGCCGCCTTTGCCTGCCTGCCCTGCAGCAGCAGGCCCGGGCGGCTGCGAGAGGGCGCAGGGGGCGGAGGCGCGGCAGGG GCGGGCTCTGCCGCCCGCCCCACCACCCGCTCCCCGCCCGGCTGCGGGGCCAGTGGCAGGAGCGCCGCGCACCGCCAGCCGCAGGGGGCG TGGGATGGGGGCGGCCGGGGAGGGGGGCGCCCACACTGACTAGAGCCAACCGCGCACTTCAAAAGGGTGTCGGTGCCGCGCTCCCCTCCC GCGGCCCGGGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGC GATGACCCGGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATG TCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGAT CAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGA TTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAAAACTTGGACCCATGGAGCTGGCCATCATTATTACTGT GCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGGGTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAA TGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGAAAGATCTGATTTATGATGTGACCGCCTCTGGATCTGG CTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTG GCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCA GACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTC TGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGC TAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCT GGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAA TCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGA TATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGA CTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAG TTATGAGGTAAGAAGCTGGCCTCCTGCGGCTTTCCCATCAGCCTGATTTCTCCACCTTAGAAAAGGGTTTCTTGACAATGGGGTCAGGCC CCAGAGGAGCCCCCTGAGAGTGTCAGTTATTATTTACTATTACGTGCTATTTTACATATCCCAAGCCCTTTAGGGCTACAGTCTCTTGTC CTGGACCCTGTAGGGTGCCATTTGGAGTTCACAGCCTAGAAGAAGAAAAGGCTTTGGGCCTGGTGTGGTGGCATAGGCCTGTAATCGTAG >1894_1894_3_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000426655_length(amino acids)=467AA_BP=184 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTAS GSGSGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLW LVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDI APNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNIPNW -------------------------------------------------------------- >1894_1894_4_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000541224_length(transcript)=1950nt_BP=1136nt GCCGGGCACAGGGCCGCCTTTGCCTGCCTGCCCTGCAGCAGCAGGCCCGGGCGGCTGCGAGAGGGCGCAGGGGGCGGAGGCGCGGCAGGG GCGGGCTCTGCCGCCCGCCCCACCACCCGCTCCCCGCCCGGCTGCGGGGCCAGTGGCAGGAGCGCCGCGCACCGCCAGCCGCAGGGGGCG TGGGATGGGGGCGGCCGGGGAGGGGGGCGCCCACACTGACTAGAGCCAACCGCGCACTTCAAAAGGGTGTCGGTGCCGCGCTCCCCTCCC GCGGCCCGGGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGC GATGACCCGGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATG TCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGAT CAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGA TTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAAAACTTGGACCCATGGAGCTGGCCATCATTATTACTGT GCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGGGTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAA TGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGAAAGATCTGATTTATGATGTGACCGCCTCTGGATCTGG CTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTG GCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCA GACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTC TGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGC TAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCT GGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAA TCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGA TATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGA CTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAG TTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAA GACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCAC >1894_1894_4_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000541224_length(amino acids)=496AA_BP=184 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTAS GSGSGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLW LVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDI APNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNIPNW -------------------------------------------------------------- >1894_1894_5_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000542485_length(transcript)=2658nt_BP=1136nt GCCGGGCACAGGGCCGCCTTTGCCTGCCTGCCCTGCAGCAGCAGGCCCGGGCGGCTGCGAGAGGGCGCAGGGGGCGGAGGCGCGGCAGGG GCGGGCTCTGCCGCCCGCCCCACCACCCGCTCCCCGCCCGGCTGCGGGGCCAGTGGCAGGAGCGCCGCGCACCGCCAGCCGCAGGGGGCG TGGGATGGGGGCGGCCGGGGAGGGGGGCGCCCACACTGACTAGAGCCAACCGCGCACTTCAAAAGGGTGTCGGTGCCGCGCTCCCCTCCC GCGGCCCGGGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGC GATGACCCGGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATG TCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGAT CAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGA TTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAAAACTTGGACCCATGGAGCTGGCCATCATTATTACTGT GCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGGGTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAA TGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGAAAGATCTGATTTATGATGTGACCGCCTCTGGATCTGG CTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTG GCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCA GACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTC TGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGC TAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCT GGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAA TCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGA TATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGA CTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAG TTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAA GACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCAC AGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGA GCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGA ATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCA TGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGC ACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCT GCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGG TTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGG TCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGA >1894_1894_5_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000243349_ACVR1B_chr12_52377782_ENST00000542485_length(amino acids)=496AA_BP=184 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTAS GSGSGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLW LVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDI APNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNIPNW -------------------------------------------------------------- >1894_1894_6_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000257963_length(transcript)=4293nt_BP=618nt GGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGCGATGACCC GGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATGTCTTTTGT GTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCT GTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCA ACAACATAACACTGCACCTTCCAACAGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAA AAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGT TTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCT GGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGA TTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAG ACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTG ACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACT TTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAG AATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCA ACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCC TGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCT CCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGC CCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAAT GGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCA TCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTT CCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCC CCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAG GTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTT GAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGT TTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTACTCTGTGTCTGGCAGGCTACTCTGCCCA CCCCAGCATCAGCACAGCTCTCCTCCTCCATCTCAGACTGTGGAACCAAAGCTGGCCCAGTTGTCCATGACAAAAGAGGCTTTTGGGCCA AAATGTGAGGGTGGTGGGTGGGATGGGCAGGGAAGGAATCCTGGTGGAAGTCTTGGGTGTTAGTGTCAGCCATGGGAAATGAGCCAGCCC AAGGGCATCATCCTCAGCAGCATCGAGGAAGGGCCGAGGAATGTGAAGCCAGATCTCGGGACTCAGATTGGAATGTTACATCTGTCTTTC ATCTCCCAGATCCTGGAAACAGCAGTGTATATTTTTGGTGGTGGTGGGTTTGGGGTGGGGAAGGGAAGGGCGGGCAAGGAGTGGGGAGGG AGTCTGGGGTGGGAGGGAGGCATCTGCATGGGTCTTCTTTTACTGGACTGTCTGATCAGGGTGGAGGGAAGGTGAGAGGTTTGCATCCAC TTCAGGAGCCCTACTGAAGGGAACAGCCTGAGCCGAACATGTTATTTAACCTGAGTATAGTATTTAACGAAGCCTAGAAGCACGGCTGTG GGTGGTGATTTGGTCAGCATATCTTAGGTATATAATAACTTTGAAGCCATAACTTTTAACTGGAGTGGTTTGATTTCTTTTTTTAATTTT ATTGGGAGGGTTTGGATTTTAACTTTTTTTAATGTTGTTAAATATTAAGTTTTTGTAAAAGGAAAACCATCTCTGTGATTACCTCTCAAT CTATTTGTTTTTAAAGAAATCCCTAAAAAAAAAAATTATCCAATTGAACGCACATAGCTCAATCACACTGGAAATGTTTGTCCTTGCACC TGAGCCTGTTCCCACTCAGCAGTGAGAGTTCCTCTTTGCCCTGAGGCTCAGTCTCTCTCGTATTTTGTCCCCACCCCCAATTCCTTGAGT GGTTTTTGCTCTAGGGCCCTTTCTTGCACTGTCCAGCTGGTTGTACCCTCTCCAGGCATTTATTCAACAAATGTGGGTGAAGTGCCTGCT GGGTGCCAGGTGCTGGGAATACATCTGTGGACAAGACATGCTTGGGTCCTACTCCTGGAGCACTGTAAAAAGAGCTGATTCAAGTAAGTA GATGCCTGTTTTGAGACCAGAAGGTTTCATAATTGGTTCTACGACCCTTTTGAGCCTAGAATTATTGTTCTTATATAAGATCACTGAAGA AAGAGGAACCCCCACAACCCCCTCCACAAAGAGACCAGGGGCGGGTGATGAGACCTGGGGTTTAGAACCCCAGGTGAGACCTCAAATCAC TGCATTCATTCTGAGCCCCCTTCCTGTCCCCAGGGGAGGTGTATTGTGTATGTAGCCTTAGAGCATCTCTGCCTCCAACCCAGCAGTTCT CTGCCAAAGCTTGTGGAGGAGGGAGAGCCCTGTCCCTGCCCTCAGGCTCCCCAGTGCTCCTGGCCCTTCTATTTATTTGACTGATTATTG CTTCTTTCCTTGCATTAAAGGAGATCTTCCCCTAACCTTTGGGCCAATTTACTGGCCACTAATTTCGTTTAAATACCATTGTGTCATTGG GGGGACCGTCTTTACCCCTGCTGACCTCCCACCTATCCGCCCTGCAGCAGAACCTTGGCGGTTTATAGGTAATGATGGAACTTAGACTCC TCTTCCCAGAGTCACAAGTAGCCTCTGGGATCTGCCAACACACGTCCACTCCCAAGCCACTAGCCCACTCCCCAGTTGGCCCTTCTGCCC TTACCCCACACACAGTCCAACTCTTCCACCTCTGGGGAAGATGGAGCAGGTCTTTGGGAAGCTCCCACACCCACCTCTGCCACTCTTAAC ACTAAGTGAGAGTTGGGGAGAAACTGAAGCCGTGTTTTTGGCCCCCCGAGGCTAACCCTGATCCATAGTGCTACCTGCACCTCTGGATTC TGGATTCACAGACCAAGTCCAAGCCCGTTCTTACGTCGCCATAAAGGCCCCCGAACGGCATTCTCGGTACTTCTGTTTGTTTTTGTACAT TTTATTAGAAAGGACTGTAAAATAGCCACTTAGACACTTTACCTCTTCAGTATGCAAATGTAAATAAATTGTAATATAGGAAATCTTTTG >1894_1894_6_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000257963_length(amino acids)=416AA_BP=103 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADN KDNGTWTQLWLVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVR HDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCD -------------------------------------------------------------- >1894_1894_7_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000415850_length(transcript)=1472nt_BP=618nt GGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGCGATGACCC GGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATGTCTTTTGT GTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCT GTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCA ACAACATAACACTGCACCTTCCAACAGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAA AAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGT TTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCT GGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGA TTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAG ACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTG ACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACT TTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGTACCTTTCTTT TTTGCCTTTGCTCCTACCTCCCATTCCAGGATGCTGGATCACCCAAAGCTGTTTTACTGCCCCCTTTCTTTTTACAACCTGTTGGATGCC TGTTGCCAGAGCCTGAATCATCGTTTAAGGTTGCCATCAAAGGTGTGGAGGTAGCTGTGCTTAGGGTGCGTTTATTCTTCAGGGATCAGT TTGTTGAATAGCGTTGTGTGTTATGGTAACCATTCTGAAGGCTCGTTTGGCTTTATAAACAAACAAACATTGTTTTATTAGTCCGTGGCG GGGAGTGCCCCGGTGCGCATAGCACGGGATTCATGCAGTGGTCTCCTTCACATCAGAAGCAGTATATTCTAACGCGGTGGCTCCCAAGCC >1894_1894_7_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000415850_length(amino acids)=398AA_BP=103 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADN KDNGTWTQLWLVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVR HDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGTFLFCLCSYLPFQDAGSPKAVLLPPFFL -------------------------------------------------------------- >1894_1894_8_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000426655_length(transcript)=1547nt_BP=618nt GGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGCGATGACCC GGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATGTCTTTTGT GTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCT GTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCA ACAACATAACACTGCACCTTCCAACAGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAA AAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGT TTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCT GGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGA TTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAG ACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTG ACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACT TTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAG AATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCA ACATCCCCAACTGGTGGCAGAGTTATGAGGTAAGAAGCTGGCCTCCTGCGGCTTTCCCATCAGCCTGATTTCTCCACCTTAGAAAAGGGT TTCTTGACAATGGGGTCAGGCCCCAGAGGAGCCCCCTGAGAGTGTCAGTTATTATTTACTATTACGTGCTATTTTACATATCCCAAGCCC TTTAGGGCTACAGTCTCTTGTCCTGGACCCTGTAGGGTGCCATTTGGAGTTCACAGCCTAGAAGAAGAAAAGGCTTTGGGCCTGGTGTGG TGGCATAGGCCTGTAATCGTAGCGCTTTGAGAGGCTGAGGCAGGAAGATAGCTTGAGCTCAGAAGTTCGAGACAAACCTGGGCAATGTGG >1894_1894_8_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000426655_length(amino acids)=387AA_BP=103 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADN KDNGTWTQLWLVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVR HDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCD -------------------------------------------------------------- >1894_1894_9_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000541224_length(transcript)=1432nt_BP=618nt GGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGCGATGACCC GGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATGTCTTTTGT GTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCT GTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCA ACAACATAACACTGCACCTTCCAACAGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAA AAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGT TTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCT GGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGA TTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAG ACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTG ACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACT TTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAG AATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCA ACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCC TGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCT >1894_1894_9_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000541224_length(amino acids)=416AA_BP=103 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADN KDNGTWTQLWLVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVR HDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCD -------------------------------------------------------------- >1894_1894_10_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000542485_length(transcript)=2140nt_BP=618nt GGAACTTCAAAGCGGGCCGTGCTGCCCCGGCTGCCTCGCTCTGCTCTGGGGCCTCGCAGCCCCGGCGCGGCCGCCTGGTGGCGATGACCC GGGCGCTCTGCTCAGCGCTCCGCCAGGCTCTCCTGCTGCTCGCAGCGGCCGCCGAGCTCTCGCCAGGACTGAAGTGTGTATGTCTTTTGT GTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGGCATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCT GTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTTCCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCA ACAACATAACACTGCACCTTCCAACAGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTCAGGAAATAGTAGGAA AAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAGATGAAAGATCTTGGT TTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACAAAGATAATGGCACCT GGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGACAATTGAGGGGATGA TTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTGGAATTGCTCATCGAG ACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTG ACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACT TTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAG AATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCA ACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCC TGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCT CCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGC CCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAAT GGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCA TCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTT CCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCC CCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAG GTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTT GAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGT >1894_1894_10_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000335450_ACVR1B_chr12_52377782_ENST00000542485_length(amino acids)=416AA_BP=103 MVAMTRALCSALRQALLLLAAAAELSPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECC FTDFCNNITLHLPTGLPLLVQRTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADN KDNGTWTQLWLVSDYHEHGSLFDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVR HDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCD -------------------------------------------------------------- >1894_1894_11_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000257963_length(transcript)=4578nt_BP=903nt GTTGCGCTGCCGTCGGGCAGGTGGCCGAGCCCCGCGGGAGCTGTCGTCGGGGCCGAATTCACTGCGCCAAGGTCCAGCGGAAAGCTGGGG CATCCCGGCGACCGCAGGGTGTCCCTTCGCAAATTCATCAGGCGAAGGGGAGGCGGAAGCTCCTGGCCGCTGCTCTGGGGGAGGGCTCCG AGCTCCAACCTGCAAGTCCAGGACTGAAGTGTGTATGTCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGG CATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTT CCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAA AACTTGGACCCATGGAGCTGGCCATCATTATTACTGTGCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGG GTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAATGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGA AAGATCTGATTTATGATGTGACCGCCTCTGGATCTGGCTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTC AGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAG ATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACA AAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGA CAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTG GAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTC ATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCA TTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTG GAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATC AGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCA ACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTC TCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCC TCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGACAGACACCTTTTC TATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGTAGTGGGAAGTCCC GCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAG CTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTCTCACAGGCAGCTC TGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGTCTGTCCAGCCGTG TGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTG CGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAG TGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTACTCTGTGTCTGGC AGGCTACTCTGCCCACCCCAGCATCAGCACAGCTCTCCTCCTCCATCTCAGACTGTGGAACCAAAGCTGGCCCAGTTGTCCATGACAAAA GAGGCTTTTGGGCCAAAATGTGAGGGTGGTGGGTGGGATGGGCAGGGAAGGAATCCTGGTGGAAGTCTTGGGTGTTAGTGTCAGCCATGG GAAATGAGCCAGCCCAAGGGCATCATCCTCAGCAGCATCGAGGAAGGGCCGAGGAATGTGAAGCCAGATCTCGGGACTCAGATTGGAATG TTACATCTGTCTTTCATCTCCCAGATCCTGGAAACAGCAGTGTATATTTTTGGTGGTGGTGGGTTTGGGGTGGGGAAGGGAAGGGCGGGC AAGGAGTGGGGAGGGAGTCTGGGGTGGGAGGGAGGCATCTGCATGGGTCTTCTTTTACTGGACTGTCTGATCAGGGTGGAGGGAAGGTGA GAGGTTTGCATCCACTTCAGGAGCCCTACTGAAGGGAACAGCCTGAGCCGAACATGTTATTTAACCTGAGTATAGTATTTAACGAAGCCT AGAAGCACGGCTGTGGGTGGTGATTTGGTCAGCATATCTTAGGTATATAATAACTTTGAAGCCATAACTTTTAACTGGAGTGGTTTGATT TCTTTTTTTAATTTTATTGGGAGGGTTTGGATTTTAACTTTTTTTAATGTTGTTAAATATTAAGTTTTTGTAAAAGGAAAACCATCTCTG TGATTACCTCTCAATCTATTTGTTTTTAAAGAAATCCCTAAAAAAAAAAATTATCCAATTGAACGCACATAGCTCAATCACACTGGAAAT GTTTGTCCTTGCACCTGAGCCTGTTCCCACTCAGCAGTGAGAGTTCCTCTTTGCCCTGAGGCTCAGTCTCTCTCGTATTTTGTCCCCACC CCCAATTCCTTGAGTGGTTTTTGCTCTAGGGCCCTTTCTTGCACTGTCCAGCTGGTTGTACCCTCTCCAGGCATTTATTCAACAAATGTG GGTGAAGTGCCTGCTGGGTGCCAGGTGCTGGGAATACATCTGTGGACAAGACATGCTTGGGTCCTACTCCTGGAGCACTGTAAAAAGAGC TGATTCAAGTAAGTAGATGCCTGTTTTGAGACCAGAAGGTTTCATAATTGGTTCTACGACCCTTTTGAGCCTAGAATTATTGTTCTTATA TAAGATCACTGAAGAAAGAGGAACCCCCACAACCCCCTCCACAAAGAGACCAGGGGCGGGTGATGAGACCTGGGGTTTAGAACCCCAGGT GAGACCTCAAATCACTGCATTCATTCTGAGCCCCCTTCCTGTCCCCAGGGGAGGTGTATTGTGTATGTAGCCTTAGAGCATCTCTGCCTC CAACCCAGCAGTTCTCTGCCAAAGCTTGTGGAGGAGGGAGAGCCCTGTCCCTGCCCTCAGGCTCCCCAGTGCTCCTGGCCCTTCTATTTA TTTGACTGATTATTGCTTCTTTCCTTGCATTAAAGGAGATCTTCCCCTAACCTTTGGGCCAATTTACTGGCCACTAATTTCGTTTAAATA CCATTGTGTCATTGGGGGGACCGTCTTTACCCCTGCTGACCTCCCACCTATCCGCCCTGCAGCAGAACCTTGGCGGTTTATAGGTAATGA TGGAACTTAGACTCCTCTTCCCAGAGTCACAAGTAGCCTCTGGGATCTGCCAACACACGTCCACTCCCAAGCCACTAGCCCACTCCCCAG TTGGCCCTTCTGCCCTTACCCCACACACAGTCCAACTCTTCCACCTCTGGGGAAGATGGAGCAGGTCTTTGGGAAGCTCCCACACCCACC TCTGCCACTCTTAACACTAAGTGAGAGTTGGGGAGAAACTGAAGCCGTGTTTTTGGCCCCCCGAGGCTAACCCTGATCCATAGTGCTACC TGCACCTCTGGATTCTGGATTCACAGACCAAGTCCAAGCCCGTTCTTACGTCGCCATAAAGGCCCCCGAACGGCATTCTCGGTACTTCTG TTTGTTTTTGTACATTTTATTAGAAAGGACTGTAAAATAGCCACTTAGACACTTTACCTCTTCAGTATGCAAATGTAAATAAATTGTAAT >1894_1894_11_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000257963_length(amino acids)=485AA_BP=173 MAAALGEGSELQPASPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECCFTDFCNNITLH LPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTASGSGSGLPLLVQ RTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLWLVSDYHEHGSL FDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRY MAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNIPNWWQSYEALRVMG -------------------------------------------------------------- >1894_1894_12_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000415850_length(transcript)=1757nt_BP=903nt GTTGCGCTGCCGTCGGGCAGGTGGCCGAGCCCCGCGGGAGCTGTCGTCGGGGCCGAATTCACTGCGCCAAGGTCCAGCGGAAAGCTGGGG CATCCCGGCGACCGCAGGGTGTCCCTTCGCAAATTCATCAGGCGAAGGGGAGGCGGAAGCTCCTGGCCGCTGCTCTGGGGGAGGGCTCCG AGCTCCAACCTGCAAGTCCAGGACTGAAGTGTGTATGTCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGG CATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTT CCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAA AACTTGGACCCATGGAGCTGGCCATCATTATTACTGTGCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGG GTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAATGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGA AAGATCTGATTTATGATGTGACCGCCTCTGGATCTGGCTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTC AGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAG ATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACA AAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGA CAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTG GAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTC ATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCA TTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTG GAGGTACCTTTCTTTTTTGCCTTTGCTCCTACCTCCCATTCCAGGATGCTGGATCACCCAAAGCTGTTTTACTGCCCCCTTTCTTTTTAC AACCTGTTGGATGCCTGTTGCCAGAGCCTGAATCATCGTTTAAGGTTGCCATCAAAGGTGTGGAGGTAGCTGTGCTTAGGGTGCGTTTAT TCTTCAGGGATCAGTTTGTTGAATAGCGTTGTGTGTTATGGTAACCATTCTGAAGGCTCGTTTGGCTTTATAAACAAACAAACATTGTTT TATTAGTCCGTGGCGGGGAGTGCCCCGGTGCGCATAGCACGGGATTCATGCAGTGGTCTCCTTCACATCAGAAGCAGTATATTCTAACGC >1894_1894_12_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000415850_length(amino acids)=467AA_BP=173 MAAALGEGSELQPASPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECCFTDFCNNITLH LPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTASGSGSGLPLLVQ RTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLWLVSDYHEHGSL FDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRY MAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGTFLFCLCSYLPFQDAGSPKAVLLPPFFLQPVGCLLPEPESSFKVAIKGV -------------------------------------------------------------- >1894_1894_13_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000426655_length(transcript)=1832nt_BP=903nt GTTGCGCTGCCGTCGGGCAGGTGGCCGAGCCCCGCGGGAGCTGTCGTCGGGGCCGAATTCACTGCGCCAAGGTCCAGCGGAAAGCTGGGG CATCCCGGCGACCGCAGGGTGTCCCTTCGCAAATTCATCAGGCGAAGGGGAGGCGGAAGCTCCTGGCCGCTGCTCTGGGGGAGGGCTCCG AGCTCCAACCTGCAAGTCCAGGACTGAAGTGTGTATGTCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGG CATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTT CCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAA AACTTGGACCCATGGAGCTGGCCATCATTATTACTGTGCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGG GTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAATGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGA AAGATCTGATTTATGATGTGACCGCCTCTGGATCTGGCTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTC AGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAG ATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACA AAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGA CAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTG GAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTC ATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCA TTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTG GAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATC AGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGTAAGAAGCTGGCCTCCTGCGGCTTTCCCATCAGCCTGATTTCTCC ACCTTAGAAAAGGGTTTCTTGACAATGGGGTCAGGCCCCAGAGGAGCCCCCTGAGAGTGTCAGTTATTATTTACTATTACGTGCTATTTT ACATATCCCAAGCCCTTTAGGGCTACAGTCTCTTGTCCTGGACCCTGTAGGGTGCCATTTGGAGTTCACAGCCTAGAAGAAGAAAAGGCT TTGGGCCTGGTGTGGTGGCATAGGCCTGTAATCGTAGCGCTTTGAGAGGCTGAGGCAGGAAGATAGCTTGAGCTCAGAAGTTCGAGACAA >1894_1894_13_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000426655_length(amino acids)=456AA_BP=173 MAAALGEGSELQPASPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECCFTDFCNNITLH LPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTASGSGSGLPLLVQ RTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLWLVSDYHEHGSL FDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRY MAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNIPNWWQSYEVRSWPP -------------------------------------------------------------- >1894_1894_14_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000541224_length(transcript)=1717nt_BP=903nt GTTGCGCTGCCGTCGGGCAGGTGGCCGAGCCCCGCGGGAGCTGTCGTCGGGGCCGAATTCACTGCGCCAAGGTCCAGCGGAAAGCTGGGG CATCCCGGCGACCGCAGGGTGTCCCTTCGCAAATTCATCAGGCGAAGGGGAGGCGGAAGCTCCTGGCCGCTGCTCTGGGGGAGGGCTCCG AGCTCCAACCTGCAAGTCCAGGACTGAAGTGTGTATGTCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGG CATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTT CCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAA AACTTGGACCCATGGAGCTGGCCATCATTATTACTGTGCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGG GTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAATGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGA AAGATCTGATTTATGATGTGACCGCCTCTGGATCTGGCTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTC AGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAG ATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACA AAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGA CAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTG GAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTC ATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCA TTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTG GAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATC AGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCA ACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTC TCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCC >1894_1894_14_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000541224_length(amino acids)=485AA_BP=173 MAAALGEGSELQPASPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECCFTDFCNNITLH LPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTASGSGSGLPLLVQ RTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLWLVSDYHEHGSL FDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRY MAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNIPNWWQSYEALRVMG -------------------------------------------------------------- >1894_1894_15_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000542485_length(transcript)=2425nt_BP=903nt GTTGCGCTGCCGTCGGGCAGGTGGCCGAGCCCCGCGGGAGCTGTCGTCGGGGCCGAATTCACTGCGCCAAGGTCCAGCGGAAAGCTGGGG CATCCCGGCGACCGCAGGGTGTCCCTTCGCAAATTCATCAGGCGAAGGGGAGGCGGAAGCTCCTGGCCGCTGCTCTGGGGGAGGGCTCCG AGCTCCAACCTGCAAGTCCAGGACTGAAGTGTGTATGTCTTTTGTGTGATTCTTCAAACTTCACCTGCCAAACAGAAGGAGCATGTTGGG CATCAGTCATGCTAACCAATGGAAAAGAGCAGGTGATCAAATCCTGTGTCTCCCTTCCAGAACTGAATGCTCAAGTCTTCTGTCATAGTT CCAACAATGTTACCAAAACCGAATGCTGCTTCACAGATTTTTGCAACAACATAACACTGCACCTTCCAACAGCATCACCAAATGCCCCAA AACTTGGACCCATGGAGCTGGCCATCATTATTACTGTGCCTGTTTGCCTCCTGTCCATAGCTGCGATGCTGACAGTATGGGCATGCCAGG GTCGACAGTGCTCCTACAGGAAGAAAAAGAGACCAAATGTGGAGGAACCACTCTCTGAGTGCAATCTGGTAAATGCTGGAAAAACTCTGA AAGATCTGATTTATGATGTGACCGCCTCTGGATCTGGCTCTGGTCTACCTCTGTTGGTTCAAAGGACAATTGCAAGGACGATTGTGCTTC AGGAAATAGTAGGAAAAGGTAGATTTGGTGAGGTGTGGCATGGAAGATGGTGTGGGGAAGATGTGGCTGTGAAAATATTCTCCTCCAGAG ATGAAAGATCTTGGTTTCGTGAGGCAGAAATTTACCAGACGGTCATGCTGCGACATGAAAACATCCTTGGTTTCATTGCTGCTGACAACA AAGATAATGGCACCTGGACACAGCTGTGGCTTGTTTCTGACTATCATGAGCACGGGTCCCTGTTTGATTATCTGAACCGGTACACAGTGA CAATTGAGGGGATGATTAAGCTGGCCTTGTCTGCTGCTAGTGGGCTGGCACACCTGCACATGGAGATCGTGGGCACCCAAGGGAAGCCTG GAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTC ATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCA TTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTG GAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATC AGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCA ACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTC TCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCC TCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGACAGACACCTTTTC TATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGTAGTGGGAAGTCCC GCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAG CTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTCTCACAGGCAGCTC TGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGTCTGTCCAGCCGTG TGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTG CGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAG >1894_1894_15_ACVR1C-ACVR1B_ACVR1C_chr2_158406673_ENST00000409680_ACVR1B_chr12_52377782_ENST00000542485_length(amino acids)=485AA_BP=173 MAAALGEGSELQPASPGLKCVCLLCDSSNFTCQTEGACWASVMLTNGKEQVIKSCVSLPELNAQVFCHSSNNVTKTECCFTDFCNNITLH LPTASPNAPKLGPMELAIIITVPVCLLSIAAMLTVWACQGRQCSYRKKKRPNVEEPLSECNLVNAGKTLKDLIYDVTASGSGSGLPLLVQ RTIARTIVLQEIVGKGRFGEVWHGRWCGEDVAVKIFSSRDERSWFREAEIYQTVMLRHENILGFIAADNKDNGTWTQLWLVSDYHEHGSL FDYLNRYTVTIEGMIKLALSAASGLAHLHMEIVGTQGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRY MAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNIPNWWQSYEALRVMG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ACVR1C-ACVR1B |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ACVR1C-ACVR1B |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ACVR1C-ACVR1B |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies