
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CPQ-MATN2 (FusionGDB2 ID:19081) |
Fusion Gene Summary for CPQ-MATN2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CPQ-MATN2 | Fusion gene ID: 19081 | Hgene | Tgene | Gene symbol | CPQ | MATN2 | Gene ID | 10404 | 4147 |
| Gene name | carboxypeptidase Q | matrilin 2 | |
| Synonyms | LDP|PGCP | - | |
| Cytomap | 8q22.1 | 8q22.1-q22.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | carboxypeptidase QSer-Met dipeptidaseaminopeptidaseblood plasma glutamate carboxypeptidaselysosomal dipeptidase | matrilin-2testis tissue sperm-binding protein Li 94mP | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9Y646 | O00339 | |
| Ensembl transtripts involved in fusion gene | ENST00000220763, ENST00000529551, | ENST00000518238, ENST00000520016, ENST00000522025, ENST00000254898, ENST00000521689, ENST00000524308, | |
| Fusion gene scores | * DoF score | 12 X 7 X 9=756 | 13 X 15 X 10=1950 |
| # samples | 13 | 19 | |
| ** MAII score | log2(13/756*10)=-2.53987461119262 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(19/1950*10)=-3.35940280030603 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CPQ [Title/Abstract] AND MATN2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CPQ(97797558)-MATN2(98943181), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CPQ | GO:0006508 | proteolysis | 10206990 |
| Hgene | CPQ | GO:0043171 | peptide catabolic process | 10206990 |
| Fusion gene breakpoints across CPQ (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MATN2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SARC | TCGA-DX-A3M1-01A | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
Top |
Fusion Gene ORF analysis for CPQ-MATN2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000220763 | ENST00000518238 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| 5CDS-intron | ENST00000220763 | ENST00000520016 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| 5CDS-intron | ENST00000220763 | ENST00000522025 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| In-frame | ENST00000220763 | ENST00000254898 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| In-frame | ENST00000220763 | ENST00000521689 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| In-frame | ENST00000220763 | ENST00000524308 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| intron-3CDS | ENST00000529551 | ENST00000254898 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| intron-3CDS | ENST00000529551 | ENST00000521689 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| intron-3CDS | ENST00000529551 | ENST00000524308 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| intron-intron | ENST00000529551 | ENST00000518238 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| intron-intron | ENST00000529551 | ENST00000520016 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| intron-intron | ENST00000529551 | ENST00000522025 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000220763 | CPQ | chr8 | 97797558 | + | ENST00000521689 | MATN2 | chr8 | 98943181 | + | 3581 | 643 | 198 | 3314 | 1038 |
| ENST00000220763 | CPQ | chr8 | 97797558 | + | ENST00000254898 | MATN2 | chr8 | 98943181 | + | 4379 | 643 | 198 | 3374 | 1058 |
| ENST00000220763 | CPQ | chr8 | 97797558 | + | ENST00000524308 | MATN2 | chr8 | 98943181 | + | 3747 | 643 | 198 | 3248 | 1016 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000220763 | ENST00000521689 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + | 0.001007762 | 0.99899226 |
| ENST00000220763 | ENST00000254898 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + | 0.000560989 | 0.99943894 |
| ENST00000220763 | ENST00000524308 | CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943181 | + | 0.000433427 | 0.9995666 |
Top |
Fusion Genomic Features for CPQ-MATN2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943180 | + | 9.24E-07 | 0.99999905 |
| CPQ | chr8 | 97797558 | + | MATN2 | chr8 | 98943180 | + | 9.24E-07 | 0.99999905 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
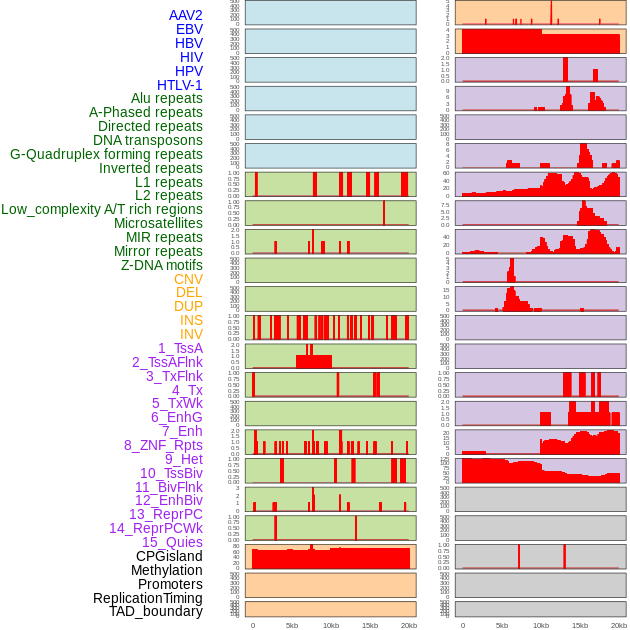 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
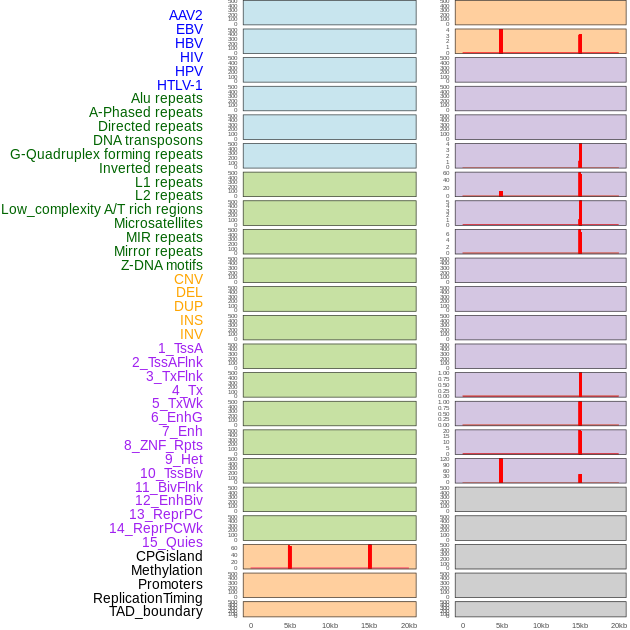 |
Top |
Fusion Protein Features for CPQ-MATN2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:97797558/chr8:98943181) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CPQ | MATN2 |
| FUNCTION: Carboxypeptidase that may play an important role in the hydrolysis of circulating peptides. Catalyzes the hydrolysis of dipeptides with unsubstituted terminals into amino acids. May play a role in the liberation of thyroxine hormone from its thyroglobulin (Tg) precursor. | FUNCTION: Involved in matrix assembly. {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 917_955 | 47 | 957.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 917_955 | 47 | 938.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 917_955 | 0 | 673.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 917_955 | 47 | 916.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 238_278 | 47 | 957.0 | Domain | EGF-like 1 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 279_319 | 47 | 957.0 | Domain | EGF-like 2 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 320_360 | 47 | 957.0 | Domain | EGF-like 3 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 402_442 | 47 | 957.0 | Domain | EGF-like 5 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 443_483 | 47 | 957.0 | Domain | EGF-like 6 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 484_524 | 47 | 957.0 | Domain | EGF-like 7 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 525_565 | 47 | 957.0 | Domain | EGF-like 8 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 566_606 | 47 | 957.0 | Domain | EGF-like 9 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 57_232 | 47 | 957.0 | Domain | VWFA 1 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 607_647 | 47 | 957.0 | Domain | EGF-like 10 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000520016 | 0 | 18 | 655_830 | 47 | 957.0 | Domain | VWFA 2 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 238_278 | 47 | 938.0 | Domain | EGF-like 1 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 279_319 | 47 | 938.0 | Domain | EGF-like 2 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 320_360 | 47 | 938.0 | Domain | EGF-like 3 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 402_442 | 47 | 938.0 | Domain | EGF-like 5 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 443_483 | 47 | 938.0 | Domain | EGF-like 6 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 484_524 | 47 | 938.0 | Domain | EGF-like 7 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 525_565 | 47 | 938.0 | Domain | EGF-like 8 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 566_606 | 47 | 938.0 | Domain | EGF-like 9 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 57_232 | 47 | 938.0 | Domain | VWFA 1 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 607_647 | 47 | 938.0 | Domain | EGF-like 10 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000521689 | 1 | 19 | 655_830 | 47 | 938.0 | Domain | VWFA 2 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 238_278 | 0 | 673.0 | Domain | EGF-like 1 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 279_319 | 0 | 673.0 | Domain | EGF-like 2 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 320_360 | 0 | 673.0 | Domain | EGF-like 3 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 402_442 | 0 | 673.0 | Domain | EGF-like 5 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 443_483 | 0 | 673.0 | Domain | EGF-like 6 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 484_524 | 0 | 673.0 | Domain | EGF-like 7 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 525_565 | 0 | 673.0 | Domain | EGF-like 8 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 566_606 | 0 | 673.0 | Domain | EGF-like 9 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 57_232 | 0 | 673.0 | Domain | VWFA 1 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 607_647 | 0 | 673.0 | Domain | EGF-like 10 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000522025 | 0 | 18 | 655_830 | 0 | 673.0 | Domain | VWFA 2 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 238_278 | 47 | 916.0 | Domain | EGF-like 1 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 279_319 | 47 | 916.0 | Domain | EGF-like 2 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 320_360 | 47 | 916.0 | Domain | EGF-like 3 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 402_442 | 47 | 916.0 | Domain | EGF-like 5 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 443_483 | 47 | 916.0 | Domain | EGF-like 6 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 484_524 | 47 | 916.0 | Domain | EGF-like 7 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 525_565 | 47 | 916.0 | Domain | EGF-like 8 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 566_606 | 47 | 916.0 | Domain | EGF-like 9 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 57_232 | 47 | 916.0 | Domain | VWFA 1 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 607_647 | 47 | 916.0 | Domain | EGF-like 10 | |
| Tgene | MATN2 | chr8:97797558 | chr8:98943181 | ENST00000524308 | 1 | 18 | 655_830 | 47 | 916.0 | Domain | VWFA 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for CPQ-MATN2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >19081_19081_1_CPQ-MATN2_CPQ_chr8_97797558_ENST00000220763_MATN2_chr8_98943181_ENST00000254898_length(transcript)=4379nt_BP=643nt AGGTCTTTGCCCCGCCTCTCGGCCCCGCGGCCTGGCCGGCAAGCAGGGCTGCAGTCACGGGGCGGCGCGGAGGGCCCCAGCCCAGTCAGG GGTGTGGCCGCCGCCACCGTAAGGCTAGGCCGCGAGCTTAGTCCTGGGAGCCGCCTCCGTCGCCGCCGTCAGAGCCGCCCTATCAGATTA TCTTAACAAGAAAACCAACTGGAAAAAAAAATGAAATTCCTTATCTTCGCATTTTTCGGTGGTGTTCACCTTTTATCCCTGTGCTCTGGG AAAGCTATATGCAAGAATGGCATCTCTAAGAGGACTTTTGAAGAAATAAAAGAAGAAATAGCCAGCTGTGGAGATGTTGCTAAAGCAATC ATCAACCTAGCTGTTTATGGTAAAGCCCAGAACAGATCCTATGAGCGATTGGCACTTCTGGTTGATACTGTTGGACCCAGACTGAGTGGC TCCAAGAACCTAGAAAAAGCCATCCAAATTATGTACCAAAACCTGCAGCAAGATGGGCTGGAGAAAGTTCACCTGGAGCCAGTGAGAATA CCCCACTGGGAGAGGGGAGAAGAATCAGCTGTGATGCTGGAGCCAAGAATTCATAAGATAGCCATCCTGGGTCTTGGCAGCAGCATTGGG ACTCCTCCAGAAGAGAGTTCCTGTGAGAACAAGCGGGCAGACCTGGTTTTCATCATTGACAGCTCTCGCAGTGTCAACACCCATGACTAT GCAAAGGTCAAGGAGTTCATCGTGGACATCTTGCAATTCTTGGACATTGGTCCTGATGTCACCCGAGTGGGCCTGCTCCAATATGGCAGC ACTGTCAAGAATGAGTTCTCCCTCAAGACCTTCAAGAGGAAGTCCGAGGTGGAGCGTGCTGTCAAGAGGATGCGGCATCTGTCCACGGGC ACCATGACTGGGCTGGCCATCCAGTATGCCCTGAACATCGCATTCTCAGAAGCAGAGGGGGCCCGGCCCCTGAGGGAGAATGTGCCACGG GTCATAATGATCGTGACAGATGGGAGACCTCAGGACTCCGTGGCCGAGGTGGCTGCTAAGGCACGGGACACGGGCATCCTAATCTTTGCC ATTGGTGTGGGCCAGGTAGACTTCAACACCTTGAAGTCCATTGGGAGTGAGCCCCATGAGGACCATGTCTTCCTTGTGGCCAATTTCAGC CAGATTGAGACGCTGACCTCCGTGTTCCAGAAGAAGTTGTGCACGGCCCATATGTGCAGCACCCTGGAGCATAACTGTGCCCACTTCTGC ATCAACATCCCTGGCTCATACGTCTGCAGGTGCAAACAAGGCTACATTCTCAACTCGGATCAGACGACTTGCAGAATCCAGGATCTGTGT GCCATGGAGGACCACAACTGTGAGCAGCTCTGTGTGAATGTGCCGGGCTCCTTCGTCTGCCAGTGCTACAGTGGCTACGCCCTGGCTGAG GATGGGAAGAGGTGTGTGGCTGTGGACTACTGTGCCTCAGAAAACCACGGATGTGAACATGAGTGTGTAAATGCTGATGGCTCCTACCTT TGCCAGTGCCATGAAGGATTTGCTCTTAACCCAGATAAAAAAACGTGCACAAAGATAGACTACTGTGCCTCATCTAATCACGGATGTCAG CACGAGTGTGTTAACACAGATGATTCCTATTCCTGCCACTGCCTGAAAGGCTTTACCCTGAATCCAGATAAGAAAACCTGCAGAAGGATC AACTACTGTGCACTGAACAAACCGGGCTGTGAGCATGAGTGCGTCAACATGGAGGAGAGCTACTACTGCCGCTGCCACCGTGGCTACACT CTGGACCCCAATGGCAAAACCTGCAGCCGAGTGGACCACTGTGCACAGCAGGACCATGGCTGTGAGCAGCTGTGTCTGAACACGGAGGAT TCCTTCGTCTGCCAGTGCTCAGAAGGCTTCCTCATCAACGAGGACCTCAAGACCTGCTCCCGGGTGGATTACTGCCTGCTGAGTGACCAT GGTTGTGAATACTCCTGTGTCAACATGGACAGATCCTTTGCCTGTCAGTGTCCTGAGGGACACGTGCTCCGCAGCGATGGGAAGACGTGT GCAAAATTGGACTCTTGTGCTCTGGGGGACCACGGTTGTGAACATTCGTGTGTAAGCAGTGAAGATTCGTTTGTGTGCCAGTGCTTTGAA GGTTATATACTCCGTGAAGATGGAAAAACCTGCAGAAGGAAAGATGTCTGCCAAGCTATAGACCATGGCTGTGAACACATTTGTGTGAAC AGTGATGACTCATACACGTGCGAGTGCTTGGAGGGATTCCGGCTCGCTGAGGATGGGAAACGCTGCCGAAGGAAGGATGTCTGCAAATCA ACCCACCATGGCTGCGAACACATTTGTGTTAATAATGGGAATTCCTACATCTGCAAATGCTCAGAGGGATTTGTTCTAGCTGAGGACGGA AGACGGTGCAAGAAATGCACTGAAGGCCCAATTGACCTGGTCTTTGTGATCGATGGATCCAAGAGTCTTGGAGAAGAGAATTTTGAGGTC GTGAAGCAGTTTGTCACTGGAATTATAGATTCCTTGACAATTTCCCCCAAAGCCGCTCGAGTGGGGCTGCTCCAGTATTCCACACAGGTC CACACAGAGTTCACTCTGAGAAACTTCAACTCAGCCAAAGACATGAAAAAAGCCGTGGCCCACATGAAATACATGGGAAAGGGCTCTATG ACTGGGCTGGCCCTGAAACACATGTTTGAGAGAAGTTTTACCCAAGGAGAAGGGGCCAGGCCCCTTTCCACAAGGGTGCCCAGAGCAGCC ATTGTGTTCACCGACGGACGGGCTCAGGATGACGTCTCCGAGTGGGCCAGTAAAGCCAAGGCCAATGGTATCACTATGTATGCTGTTGGG GTAGGAAAAGCCATTGAGGAGGAACTACAAGAGATTGCCTCTGAGCCCACAAACAAGCATCTCTTCTATGCCGAAGACTTCAGCACAATG GATGAGATAAGTGAAAAACTCAAGAAAGGCATCTGTGAAGCTCTAGAAGACTCCGATGGAAGACAGGACTCTCCAGCAGGGGAACTGCCA AAAACGGTCCAACAGCCAACAGAATCTGAGCCAGTCACCATAAATATCCAAGACCTACTTTCCTGTTCTAATTTTGCAGTGCAACACAGA TATCTGTTTGAAGAAGACAATCTTTTACGGTCTACACAAAAGCTTTCCCATTCAACAAAACCTTCAGGAAGCCCTTTGGAAGAAAAACAC GATCAATGCAAATGTGAAAACCTTATAATGTTCCAGAACCTTGCAAACGAAGAAGTAAGAAAATTAACACAGCGTTTACTAGAAGAAATG ACACAGAGAATGGAAGCCCTGGAAAATCGCCTGAGATACAGATGAAGATTAGAAATCGCGACACATTTGTAGTCATTGTATCACGGATTA CAATGAACGCAGTGCAGAGCCCCAAAGCTCAGGCTATTGTTAAATCAATAATGTTGTGAAGTAAAACAATCAGTACTGAGAAACCTGGTT TGCCACAGAACAAAGACAAGAAGTATACACTAACTTGTATAAATTTATCTAGGAAAAAAATCCTTCAGAATTCTAAGATGAATTTACCAG GTGAGAATGAATAAGCTATGCAAGGTATTTTGTAATATACTGTGGACACAACTTGCTTCTGCCTCATCCTGCCTTAGTGTGCAATCTCAT TTGACTATACGATAAAGTTTGCACAGTCTTACTTCTGTAGAACACTGGCCATAGGAAATGCTGTTTTTTTGTACTGGACTTTACCTTGAT ATATGTATATGGATGTATGCATAAAATCATAGGACATATGTACTTGTGGAACAAGTTGGATTTTTTATACAATATTAAAATTCACCACTT CAGAGAATGGTATTCAGTGCAAAAATTCTTAGTTTAACTTTAAATGGAAGATATGTATGTATGAGAAATGGCCAACATGCCTATGAAAAA AATGCTGAATCTCATCAGTAATCAGGAAAATGCAGGTTAAAACAATACCATTTTTCACCCATCAGCTTAGCAAAAATGAGTATATTTTTT AACAAGTGTTGGTAAGGATGTGGAAATGTGAGGTTCTTGTAGTAAGAATGCAAATGGCACTCTTTGTAGAGTAAGTCTGTTGACATCTCA TAAAACTGAAAATGCACACAACCCTGTAAATCTAGCAACTGCACTCAGTTGATTTCAGCCCATACATACAAAGAGACCTGCATAAGAATG TTACTAGGCTTTGTAAAAGCAAAAAATAAGGAACAACTTAAACATCATCAGAAGGGGAACTGATAAACTCTGGTGTAATCCATACCACAG >19081_19081_1_CPQ-MATN2_CPQ_chr8_97797558_ENST00000220763_MATN2_chr8_98943181_ENST00000254898_length(amino acids)=1058AA_BP=1 MEKKMKFLIFAFFGGVHLLSLCSGKAICKNGISKRTFEEIKEEIASCGDVAKAIINLAVYGKAQNRSYERLALLVDTVGPRLSGSKNLEK AIQIMYQNLQQDGLEKVHLEPVRIPHWERGEESAVMLEPRIHKIAILGLGSSIGTPPEESSCENKRADLVFIIDSSRSVNTHDYAKVKEF IVDILQFLDIGPDVTRVGLLQYGSTVKNEFSLKTFKRKSEVERAVKRMRHLSTGTMTGLAIQYALNIAFSEAEGARPLRENVPRVIMIVT DGRPQDSVAEVAAKARDTGILIFAIGVGQVDFNTLKSIGSEPHEDHVFLVANFSQIETLTSVFQKKLCTAHMCSTLEHNCAHFCINIPGS YVCRCKQGYILNSDQTTCRIQDLCAMEDHNCEQLCVNVPGSFVCQCYSGYALAEDGKRCVAVDYCASENHGCEHECVNADGSYLCQCHEG FALNPDKKTCTKIDYCASSNHGCQHECVNTDDSYSCHCLKGFTLNPDKKTCRRINYCALNKPGCEHECVNMEESYYCRCHRGYTLDPNGK TCSRVDHCAQQDHGCEQLCLNTEDSFVCQCSEGFLINEDLKTCSRVDYCLLSDHGCEYSCVNMDRSFACQCPEGHVLRSDGKTCAKLDSC ALGDHGCEHSCVSSEDSFVCQCFEGYILREDGKTCRRKDVCQAIDHGCEHICVNSDDSYTCECLEGFRLAEDGKRCRRKDVCKSTHHGCE HICVNNGNSYICKCSEGFVLAEDGRRCKKCTEGPIDLVFVIDGSKSLGEENFEVVKQFVTGIIDSLTISPKAARVGLLQYSTQVHTEFTL RNFNSAKDMKKAVAHMKYMGKGSMTGLALKHMFERSFTQGEGARPLSTRVPRAAIVFTDGRAQDDVSEWASKAKANGITMYAVGVGKAIE EELQEIASEPTNKHLFYAEDFSTMDEISEKLKKGICEALEDSDGRQDSPAGELPKTVQQPTESEPVTINIQDLLSCSNFAVQHRYLFEED -------------------------------------------------------------- >19081_19081_2_CPQ-MATN2_CPQ_chr8_97797558_ENST00000220763_MATN2_chr8_98943181_ENST00000521689_length(transcript)=3581nt_BP=643nt AGGTCTTTGCCCCGCCTCTCGGCCCCGCGGCCTGGCCGGCAAGCAGGGCTGCAGTCACGGGGCGGCGCGGAGGGCCCCAGCCCAGTCAGG GGTGTGGCCGCCGCCACCGTAAGGCTAGGCCGCGAGCTTAGTCCTGGGAGCCGCCTCCGTCGCCGCCGTCAGAGCCGCCCTATCAGATTA TCTTAACAAGAAAACCAACTGGAAAAAAAAATGAAATTCCTTATCTTCGCATTTTTCGGTGGTGTTCACCTTTTATCCCTGTGCTCTGGG AAAGCTATATGCAAGAATGGCATCTCTAAGAGGACTTTTGAAGAAATAAAAGAAGAAATAGCCAGCTGTGGAGATGTTGCTAAAGCAATC ATCAACCTAGCTGTTTATGGTAAAGCCCAGAACAGATCCTATGAGCGATTGGCACTTCTGGTTGATACTGTTGGACCCAGACTGAGTGGC TCCAAGAACCTAGAAAAAGCCATCCAAATTATGTACCAAAACCTGCAGCAAGATGGGCTGGAGAAAGTTCACCTGGAGCCAGTGAGAATA CCCCACTGGGAGAGGGGAGAAGAATCAGCTGTGATGCTGGAGCCAAGAATTCATAAGATAGCCATCCTGGGTCTTGGCAGCAGCATTGGG ACTCCTCCAGAAGAGAGTTCCTGTGAGAACAAGCGGGCAGACCTGGTTTTCATCATTGACAGCTCTCGCAGTGTCAACACCCATGACTAT GCAAAGGTCAAGGAGTTCATCGTGGACATCTTGCAATTCTTGGACATTGGTCCTGATGTCACCCGAGTGGGCCTGCTCCAATATGGCAGC ACTGTCAAGAATGAGTTCTCCCTCAAGACCTTCAAGAGGAAGTCCGAGGTGGAGCGTGCTGTCAAGAGGATGCGGCATCTGTCCACGGGC ACCATGACTGGGCTGGCCATCCAGTATGCCCTGAACATCGCATTCTCAGAAGCAGAGGGGGCCCGGCCCCTGAGGGAGAATGTGCCACGG GTCATAATGATCGTGACAGATGGGAGACCTCAGGACTCCGTGGCCGAGGTGGCTGCTAAGGCACGGGACACGGGCATCCTAATCTTTGCC ATTGGTGTGGGCCAGGTAGACTTCAACACCTTGAAGTCCATTGGGAGTGAGCCCCATGAGGACCATGTCTTCCTTGTGGCCAATTTCAGC CAGATTGAGACGCTGACCTCCGTGTTCCAGAAGAAGTTGTGCACGGCCCATATGTGCAGCACCCTGGAGCATAACTGTGCCCACTTCTGC ATCAACATCCCTGGCTCATACGTCTGCAGGTGCAAACAAGGCTACATTCTCAACTCGGATCAGACGACTTGCAGAATCCAGGATCTGTGT GCCATGGAGGACCACAACTGTGAGCAGCTCTGTGTGAATGTGCCGGGCTCCTTCGTCTGCCAGTGCTACAGTGGCTACGCCCTGGCTGAG GATGGGAAGAGGTGTGTGGCTGTGGACTACTGTGCCTCAGAAAACCACGGATGTGAACATGAGTGTGTAAATGCTGATGGCTCCTACCTT TGCCAGTGCCATGAAGGATTTGCTCTTAACCCAGATAAAAAAACGTGCACAAAGATAGACTACTGTGCCTCATCTAATCACGGATGTCAG CACGAGTGTGTTAACACAGATGATTCCTATTCCTGCCACTGCCTGAAAGGCTTTACCCTGAATCCAGATAAGAAAACCTGCAGAAGGATC AACTACTGTGCACTGAACAAACCGGGCTGTGAGCATGAGTGCGTCAACATGGAGGAGAGCTACTACTGCCGCTGCCACCGTGGCTACACT CTGGACCCCAATGGCAAAACCTGCAGCCGAGTGGACCACTGTGCACAGCAGGACCATGGCTGTGAGCAGCTGTGTCTGAACACGGAGGAT TCCTTCGTCTGCCAGTGCTCAGAAGGCTTCCTCATCAACGAGGACCTCAAGACCTGCTCCCGGGTGGATTACTGCCTGCTGAGTGACCAT GGTTGTGAATACTCCTGTGTCAACATGGACAGATCCTTTGCCTGTCAGTGTCCTGAGGGACACGTGCTCCGCAGCGATGGGAAGACGTGT GCAAAATTGGACTCTTGTGCTCTGGGGGACCACGGTTGTGAACATTCGTGTGTAAGCAGTGAAGATTCGTTTGTGTGCCAGTGCTTTGAA GGTTATATACTCCGTGAAGATGGAAAAACCTGCAGAAGGAAAGATGTCTGCCAAGCTATAGACCATGGCTGTGAACACATTTGTGTGAAC AGTGATGACTCATACACGTGCGAGTGCTTGGAGGGATTCCGGCTCGCTGAGGATGGGAAACGCTGCCGAAGGAAGGATGTCTGCAAATCA ACCCACCATGGCTGCGAACACATTTGTGTTAATAATGGGAATTCCTACATCTGCAAATGCTCAGAGGGATTTGTTCTAGCTGAGGACGGA AGACGGTGCAAGAAATGCACTGAAGGCCCAATTGACCTGGTCTTTGTGATCGATGGATCCAAGAGTCTTGGAGAAGAGAATTTTGAGGTC GTGAAGCAGTTTGTCACTGGAATTATAGATTCCTTGACAATTTCCCCCAAAGCCGCTCGAGTGGGGCTGCTCCAGTATTCCACACAGGTC CACACAGAGTTCACTCTGAGAAACTTCAACTCAGCCAAAGACATGAAAAAAGCCGTGGCCCACATGAAATACATGGGAAAGGGCTCTATG ACTGGGCTGGCCCTGAAACACATGTTTGAGAGAAGTTTTACCCAAGGAGAAGGGGCCAGGCCCCTTTCCACAAGGGTGCCCAGAGCAGCC ATTGTGTTCACCGACGGACGGGCTCAGGATGACGTCTCCGAGTGGGCCAGTAAAGCCAAGGCCAATGGTATCACTATGTATGCTGTTGGG GTAGGAAAAGCCATTGAGGAGGAACTACAAGAGATTGCCTCTGAGCCCACAAACAAGCATCTCTTCTATGCCGAAGACTTCAGCACAATG GATGAGATAAGTGAAAAACTCAAGAAAGGCATCTGTGAAGCTCTAGAAGACTCCGATGGAAGACAGGACTCTCCAGCAGGGGAACTGCCA AAAACGGTCCAACAGCCAACAGTGCAACACAGATATCTGTTTGAAGAAGACAATCTTTTACGGTCTACACAAAAGCTTTCCCATTCAACA AAACCTTCAGGAAGCCCTTTGGAAGAAAAACACGATCAATGCAAATGTGAAAACCTTATAATGTTCCAGAACCTTGCAAACGAAGAAGTA AGAAAATTAACACAGCGCTTAGAAGAAATGACACAGAGAATGGAAGCCCTGGAAAATCGCCTGAGATACAGATGAAGATTAGAAATCGCG ACACATTTGTAGTCATTGTATCACGGATTACAATGAACGCAGTGCAGAGCCCCAAAGCTCAGGCTATTGTTAAATCAATAATGTTGTGAA GTAAAACAATCAGTACTGAGAAACCTGGTTTGCCACAGAACAAAGACAAGAAGTATACACTAACTTGTATAAATTTATCTAGGAAAAAAA >19081_19081_2_CPQ-MATN2_CPQ_chr8_97797558_ENST00000220763_MATN2_chr8_98943181_ENST00000521689_length(amino acids)=1038AA_BP=1 MEKKMKFLIFAFFGGVHLLSLCSGKAICKNGISKRTFEEIKEEIASCGDVAKAIINLAVYGKAQNRSYERLALLVDTVGPRLSGSKNLEK AIQIMYQNLQQDGLEKVHLEPVRIPHWERGEESAVMLEPRIHKIAILGLGSSIGTPPEESSCENKRADLVFIIDSSRSVNTHDYAKVKEF IVDILQFLDIGPDVTRVGLLQYGSTVKNEFSLKTFKRKSEVERAVKRMRHLSTGTMTGLAIQYALNIAFSEAEGARPLRENVPRVIMIVT DGRPQDSVAEVAAKARDTGILIFAIGVGQVDFNTLKSIGSEPHEDHVFLVANFSQIETLTSVFQKKLCTAHMCSTLEHNCAHFCINIPGS YVCRCKQGYILNSDQTTCRIQDLCAMEDHNCEQLCVNVPGSFVCQCYSGYALAEDGKRCVAVDYCASENHGCEHECVNADGSYLCQCHEG FALNPDKKTCTKIDYCASSNHGCQHECVNTDDSYSCHCLKGFTLNPDKKTCRRINYCALNKPGCEHECVNMEESYYCRCHRGYTLDPNGK TCSRVDHCAQQDHGCEQLCLNTEDSFVCQCSEGFLINEDLKTCSRVDYCLLSDHGCEYSCVNMDRSFACQCPEGHVLRSDGKTCAKLDSC ALGDHGCEHSCVSSEDSFVCQCFEGYILREDGKTCRRKDVCQAIDHGCEHICVNSDDSYTCECLEGFRLAEDGKRCRRKDVCKSTHHGCE HICVNNGNSYICKCSEGFVLAEDGRRCKKCTEGPIDLVFVIDGSKSLGEENFEVVKQFVTGIIDSLTISPKAARVGLLQYSTQVHTEFTL RNFNSAKDMKKAVAHMKYMGKGSMTGLALKHMFERSFTQGEGARPLSTRVPRAAIVFTDGRAQDDVSEWASKAKANGITMYAVGVGKAIE EELQEIASEPTNKHLFYAEDFSTMDEISEKLKKGICEALEDSDGRQDSPAGELPKTVQQPTVQHRYLFEEDNLLRSTQKLSHSTKPSGSP -------------------------------------------------------------- >19081_19081_3_CPQ-MATN2_CPQ_chr8_97797558_ENST00000220763_MATN2_chr8_98943181_ENST00000524308_length(transcript)=3747nt_BP=643nt AGGTCTTTGCCCCGCCTCTCGGCCCCGCGGCCTGGCCGGCAAGCAGGGCTGCAGTCACGGGGCGGCGCGGAGGGCCCCAGCCCAGTCAGG GGTGTGGCCGCCGCCACCGTAAGGCTAGGCCGCGAGCTTAGTCCTGGGAGCCGCCTCCGTCGCCGCCGTCAGAGCCGCCCTATCAGATTA TCTTAACAAGAAAACCAACTGGAAAAAAAAATGAAATTCCTTATCTTCGCATTTTTCGGTGGTGTTCACCTTTTATCCCTGTGCTCTGGG AAAGCTATATGCAAGAATGGCATCTCTAAGAGGACTTTTGAAGAAATAAAAGAAGAAATAGCCAGCTGTGGAGATGTTGCTAAAGCAATC ATCAACCTAGCTGTTTATGGTAAAGCCCAGAACAGATCCTATGAGCGATTGGCACTTCTGGTTGATACTGTTGGACCCAGACTGAGTGGC TCCAAGAACCTAGAAAAAGCCATCCAAATTATGTACCAAAACCTGCAGCAAGATGGGCTGGAGAAAGTTCACCTGGAGCCAGTGAGAATA CCCCACTGGGAGAGGGGAGAAGAATCAGCTGTGATGCTGGAGCCAAGAATTCATAAGATAGCCATCCTGGGTCTTGGCAGCAGCATTGGG ACTCCTCCAGAAGAGAGTTCCTGTGAGAACAAGCGGGCAGACCTGGTTTTCATCATTGACAGCTCTCGCAGTGTCAACACCCATGACTAT GCAAAGGTCAAGGAGTTCATCGTGGACATCTTGCAATTCTTGGACATTGGTCCTGATGTCACCCGAGTGGGCCTGCTCCAATATGGCAGC ACTGTCAAGAATGAGTTCTCCCTCAAGACCTTCAAGAGGAAGTCCGAGGTGGAGCGTGCTGTCAAGAGGATGCGGCATCTGTCCACGGGC ACCATGACTGGGCTGGCCATCCAGTATGCCCTGAACATCGCATTCTCAGAAGCAGAGGGGGCCCGGCCCCTGAGGGAGAATGTGCCACGG GTCATAATGATCGTGACAGATGGGAGACCTCAGGACTCCGTGGCCGAGGTGGCTGCTAAGGCACGGGACACGGGCATCCTAATCTTTGCC ATTGGTGTGGGCCAGGTAGACTTCAACACCTTGAAGTCCATTGGGAGTGAGCCCCATGAGGACCATGTCTTCCTTGTGGCCAATTTCAGC CAGATTGAGACGCTGACCTCCGTGTTCCAGAAGAAGTTGTGCACGGCCCATATGTGCAGCACCCTGGAGCATAACTGTGCCCACTTCTGC ATCAACATCCCTGGCTCATACGTCTGCAGGTGCAAACAAGGCTACATTCTCAACTCGGATCAGACGACTTGCAGAATCCAGGATCTGTGT GCCATGGAGGACCACAACTGTGAGCAGCTCTGTGTGAATGTGCCGGGCTCCTTCGTCTGCCAGTGCTACAGTGGCTACGCCCTGGCTGAG GATGGGAAGAGGTGTGTGGCTGTGGACTACTGTGCCTCAGAAAACCACGGATGTGAACATGAGTGTGTAAATGCTGATGGCTCCTACCTT TGCCAGTGCCATGAAGGATTTGCTCTTAACCCAGATAAAAAAACGTGCACAAGGATCAACTACTGTGCACTGAACAAACCGGGCTGTGAG CATGAGTGCGTCAACATGGAGGAGAGCTACTACTGCCGCTGCCACCGTGGCTACACTCTGGACCCCAATGGCAAAACCTGCAGCCGAGTG GACCACTGTGCACAGCAGGACCATGGCTGTGAGCAGCTGTGTCTGAACACGGAGGATTCCTTCGTCTGCCAGTGCTCAGAAGGCTTCCTC ATCAACGAGGACCTCAAGACCTGCTCCCGGGTGGATTACTGCCTGCTGAGTGACCATGGTTGTGAATACTCCTGTGTCAACATGGACAGA TCCTTTGCCTGTCAGTGTCCTGAGGGACACGTGCTCCGCAGCGATGGGAAGACGTGTGCAAAATTGGACTCTTGTGCTCTGGGGGACCAC GGTTGTGAACATTCGTGTGTAAGCAGTGAAGATTCGTTTGTGTGCCAGTGCTTTGAAGGTTATATACTCCGTGAAGATGGAAAAACCTGC AGAAGGAAAGATGTCTGCCAAGCTATAGACCATGGCTGTGAACACATTTGTGTGAACAGTGATGACTCATACACGTGCGAGTGCTTGGAG GGATTCCGGCTCGCTGAGGATGGGAAACGCTGCCGAAGGAAGGATGTCTGCAAATCAACCCACCATGGCTGCGAACACATTTGTGTTAAT AATGGGAATTCCTACATCTGCAAATGCTCAGAGGGATTTGTTCTAGCTGAGGACGGAAGACGGTGCAAGAAATGCACTGAAGGCCCAATT GACCTGGTCTTTGTGATCGATGGATCCAAGAGTCTTGGAGAAGAGAATTTTGAGGTCGTGAAGCAGTTTGTCACTGGAATTATAGATTCC TTGACAATTTCCCCCAAAGCCGCTCGAGTGGGGCTGCTCCAGTATTCCACACAGGTCCACACAGAGTTCACTCTGAGAAACTTCAACTCA GCCAAAGACATGAAAAAAGCCGTGGCCCACATGAAATACATGGGAAAGGGCTCTATGACTGGGCTGGCCCTGAAACACATGTTTGAGAGA AGTTTTACCCAAGGAGAAGGGGCCAGGCCCCTTTCCACAAGGGTGCCCAGAGCAGCCATTGTGTTCACCGACGGACGGGCTCAGGATGAC GTCTCCGAGTGGGCCAGTAAAGCCAAGGCCAATGGTATCACTATGTATGCTGTTGGGGTAGGAAAAGCCATTGAGGAGGAACTACAAGAG ATTGCCTCTGAGCCCACAAACAAGCATCTCTTCTATGCCGAAGACTTCAGCACAATGGATGAGATAAGTGAAAAACTCAAGAAAGGCATC TGTGAAGCTCTAGAAGACTCCGATGGAAGACAGGACTCTCCAGCAGGGGAACTGCCAAAAACGGTCCAACAGCCAACAGAATCTGAGCCA GTCACCATAAATATCCAAGACCTACTTTCCTGTTCTAATTTTGCAGTGCAACACAGATATCTGTTTGAAGAAGACAATCTTTTACGGTCT ACACAAAAGCTTTCCCATTCAACAAAACCTTCAGGAAGCCCTTTGGAAGAAAAACACGATCAATGCAAATGTGAAAACCTTATAATGTTC CAGAACCTTGCAAACGAAGAAGTAAGAAAATTAACACAGCGCTTAGAAGAAATGACACAGAGAATGGAAGCCCTGGAAAATCGCCTGAGA TACAGATGAAGATTAGAAATCGCGACACATTTGTAGTCATTGTATCACGGATTACAATGAACGCAGTGCAGAGCCCCAAAGCTCAGGCTA TTGTTAAATCAATAATGTTGTGAAGTAAAACAATCAGTACTGAGAAACCTGGTTTGCCACAGAACAAAGACAAGAAGTATACACTAACTT GTATAAATTTATCTAGGAAAAAAATCCTTCAGAATTCTAAGATGAATTTACCAGGTGAGAATGAATAAGCTATGCAAGGTATTTTGTAAT ATACTGTGGACACAACTTGCTTCTGCCTCATCCTGCCTTAGTGTGCAATCTCATTTGACTATACGATAAAGTTTGCACAGTCTTACTTCT GTAGAACACTGGCCATAGGAAATGCTGTTTTTTTGTACTGGACTTTACCTTGATATATGTATATGGATGTATGCATAAAATCATAGGACA >19081_19081_3_CPQ-MATN2_CPQ_chr8_97797558_ENST00000220763_MATN2_chr8_98943181_ENST00000524308_length(amino acids)=1016AA_BP=1 MEKKMKFLIFAFFGGVHLLSLCSGKAICKNGISKRTFEEIKEEIASCGDVAKAIINLAVYGKAQNRSYERLALLVDTVGPRLSGSKNLEK AIQIMYQNLQQDGLEKVHLEPVRIPHWERGEESAVMLEPRIHKIAILGLGSSIGTPPEESSCENKRADLVFIIDSSRSVNTHDYAKVKEF IVDILQFLDIGPDVTRVGLLQYGSTVKNEFSLKTFKRKSEVERAVKRMRHLSTGTMTGLAIQYALNIAFSEAEGARPLRENVPRVIMIVT DGRPQDSVAEVAAKARDTGILIFAIGVGQVDFNTLKSIGSEPHEDHVFLVANFSQIETLTSVFQKKLCTAHMCSTLEHNCAHFCINIPGS YVCRCKQGYILNSDQTTCRIQDLCAMEDHNCEQLCVNVPGSFVCQCYSGYALAEDGKRCVAVDYCASENHGCEHECVNADGSYLCQCHEG FALNPDKKTCTRINYCALNKPGCEHECVNMEESYYCRCHRGYTLDPNGKTCSRVDHCAQQDHGCEQLCLNTEDSFVCQCSEGFLINEDLK TCSRVDYCLLSDHGCEYSCVNMDRSFACQCPEGHVLRSDGKTCAKLDSCALGDHGCEHSCVSSEDSFVCQCFEGYILREDGKTCRRKDVC QAIDHGCEHICVNSDDSYTCECLEGFRLAEDGKRCRRKDVCKSTHHGCEHICVNNGNSYICKCSEGFVLAEDGRRCKKCTEGPIDLVFVI DGSKSLGEENFEVVKQFVTGIIDSLTISPKAARVGLLQYSTQVHTEFTLRNFNSAKDMKKAVAHMKYMGKGSMTGLALKHMFERSFTQGE GARPLSTRVPRAAIVFTDGRAQDDVSEWASKAKANGITMYAVGVGKAIEEELQEIASEPTNKHLFYAEDFSTMDEISEKLKKGICEALED SDGRQDSPAGELPKTVQQPTESEPVTINIQDLLSCSNFAVQHRYLFEEDNLLRSTQKLSHSTKPSGSPLEEKHDQCKCENLIMFQNLANE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CPQ-MATN2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CPQ-MATN2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CPQ-MATN2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies