
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CSMD1-EIF3E (FusionGDB2 ID:19739) |
Fusion Gene Summary for CSMD1-EIF3E |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CSMD1-EIF3E | Fusion gene ID: 19739 | Hgene | Tgene | Gene symbol | CSMD1 | EIF3E | Gene ID | 64478 | 3646 |
| Gene name | CUB and Sushi multiple domains 1 | eukaryotic translation initiation factor 3 subunit E | |
| Synonyms | PPP1R24 | EIF3-P48|EIF3S6|INT6|eIF3-p46 | |
| Cytomap | 8p23.2 | 8q23.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | CUB and sushi domain-containing protein 1protein phosphatase 1, regulatory subunit 24 | eukaryotic translation initiation factor 3 subunit EeIF-3 p48eukaryotic translation initiation factor 3 subunit 6eukaryotic translation initiation factor 3 subunit E isoform 2 transcripteukaryotic translation initiation factor 3, subunit 6 (48kD)euka | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q96PZ7 | P60228 | |
| Ensembl transtripts involved in fusion gene | ENST00000400186, ENST00000520002, ENST00000537824, ENST00000539096, ENST00000542608, ENST00000602557, ENST00000602723, ENST00000523387, | ENST00000519517, ENST00000220849, ENST00000519030, | |
| Fusion gene scores | * DoF score | 31 X 30 X 4=3720 | 21 X 12 X 10=2520 |
| # samples | 32 | 21 | |
| ** MAII score | log2(32/3720*10)=-3.53915881110803 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(21/2520*10)=-3.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CSMD1 [Title/Abstract] AND EIF3E [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CSMD1(4494863)-EIF3E(109215732), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | EIF3E | GO:0006413 | translational initiation | 17581632 |
| Fusion gene breakpoints across CSMD1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
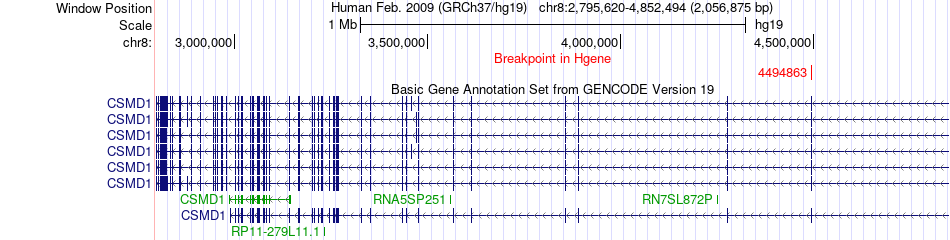 |
| Fusion gene breakpoints across EIF3E (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-IG-A3YA | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
Top |
Fusion Gene ORF analysis for CSMD1-EIF3E |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000400186 | ENST00000519517 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| 5CDS-5UTR | ENST00000520002 | ENST00000519517 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| 5CDS-5UTR | ENST00000537824 | ENST00000519517 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| 5CDS-5UTR | ENST00000539096 | ENST00000519517 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| 5CDS-5UTR | ENST00000542608 | ENST00000519517 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| 5CDS-5UTR | ENST00000602557 | ENST00000519517 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| 5CDS-5UTR | ENST00000602723 | ENST00000519517 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000400186 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000400186 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000520002 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000520002 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000537824 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000537824 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000539096 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000539096 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000542608 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000542608 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000602557 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000602557 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000602723 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| In-frame | ENST00000602723 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| intron-3CDS | ENST00000523387 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| intron-3CDS | ENST00000523387 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| intron-5UTR | ENST00000523387 | ENST00000519517 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000602723 | CSMD1 | chr8 | 4494863 | - | ENST00000220849 | EIF3E | chr8 | 109215732 | - | 1006 | 587 | 81 | 863 | 260 |
| ENST00000602723 | CSMD1 | chr8 | 4494863 | - | ENST00000519030 | EIF3E | chr8 | 109215732 | - | 969 | 587 | 81 | 863 | 260 |
| ENST00000400186 | CSMD1 | chr8 | 4494863 | - | ENST00000220849 | EIF3E | chr8 | 109215732 | - | 1006 | 587 | 81 | 863 | 260 |
| ENST00000400186 | CSMD1 | chr8 | 4494863 | - | ENST00000519030 | EIF3E | chr8 | 109215732 | - | 969 | 587 | 81 | 863 | 260 |
| ENST00000520002 | CSMD1 | chr8 | 4494863 | - | ENST00000220849 | EIF3E | chr8 | 109215732 | - | 1277 | 858 | 190 | 1134 | 314 |
| ENST00000520002 | CSMD1 | chr8 | 4494863 | - | ENST00000519030 | EIF3E | chr8 | 109215732 | - | 1240 | 858 | 190 | 1134 | 314 |
| ENST00000602557 | CSMD1 | chr8 | 4494863 | - | ENST00000220849 | EIF3E | chr8 | 109215732 | - | 1277 | 858 | 190 | 1134 | 314 |
| ENST00000602557 | CSMD1 | chr8 | 4494863 | - | ENST00000519030 | EIF3E | chr8 | 109215732 | - | 1240 | 858 | 190 | 1134 | 314 |
| ENST00000537824 | CSMD1 | chr8 | 4494863 | - | ENST00000220849 | EIF3E | chr8 | 109215732 | - | 721 | 302 | 0 | 578 | 192 |
| ENST00000537824 | CSMD1 | chr8 | 4494863 | - | ENST00000519030 | EIF3E | chr8 | 109215732 | - | 684 | 302 | 0 | 578 | 192 |
| ENST00000542608 | CSMD1 | chr8 | 4494863 | - | ENST00000220849 | EIF3E | chr8 | 109215732 | - | 721 | 302 | 0 | 578 | 192 |
| ENST00000542608 | CSMD1 | chr8 | 4494863 | - | ENST00000519030 | EIF3E | chr8 | 109215732 | - | 684 | 302 | 0 | 578 | 192 |
| ENST00000539096 | CSMD1 | chr8 | 4494863 | - | ENST00000220849 | EIF3E | chr8 | 109215732 | - | 721 | 302 | 0 | 578 | 192 |
| ENST00000539096 | CSMD1 | chr8 | 4494863 | - | ENST00000519030 | EIF3E | chr8 | 109215732 | - | 684 | 302 | 0 | 578 | 192 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000602723 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.001799409 | 0.99820054 |
| ENST00000602723 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.00161464 | 0.9983854 |
| ENST00000400186 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.001799409 | 0.99820054 |
| ENST00000400186 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.00161464 | 0.9983854 |
| ENST00000520002 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.002146469 | 0.99785346 |
| ENST00000520002 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.00163902 | 0.99836093 |
| ENST00000602557 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.002146469 | 0.99785346 |
| ENST00000602557 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.00163902 | 0.99836093 |
| ENST00000537824 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.001434966 | 0.998565 |
| ENST00000537824 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.001694668 | 0.9983053 |
| ENST00000542608 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.001434966 | 0.998565 |
| ENST00000542608 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.001694668 | 0.9983053 |
| ENST00000539096 | ENST00000220849 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.001434966 | 0.998565 |
| ENST00000539096 | ENST00000519030 | CSMD1 | chr8 | 4494863 | - | EIF3E | chr8 | 109215732 | - | 0.001694668 | 0.9983053 |
Top |
Fusion Genomic Features for CSMD1-EIF3E |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
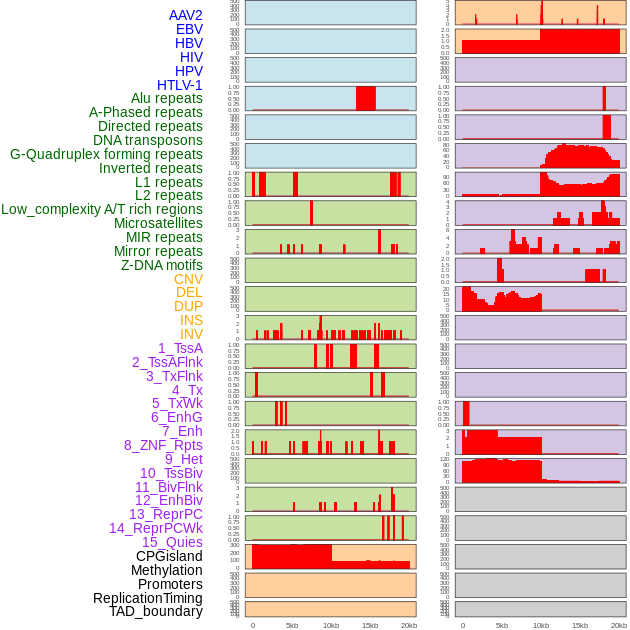 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CSMD1-EIF3E |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:4494863/chr8:109215732) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CSMD1 | EIF3E |
| FUNCTION: Potential suppressor of squamous cell carcinomas. | FUNCTION: Component of the eukaryotic translation initiation factor 3 (eIF-3) complex, which is required for several steps in the initiation of protein synthesis (PubMed:17581632, PubMed:25849773, PubMed:27462815). The eIF-3 complex associates with the 40S ribosome and facilitates the recruitment of eIF-1, eIF-1A, eIF-2:GTP:methionyl-tRNAi and eIF-5 to form the 43S pre-initiation complex (43S PIC). The eIF-3 complex stimulates mRNA recruitment to the 43S PIC and scanning of the mRNA for AUG recognition. The eIF-3 complex is also required for disassembly and recycling of post-termination ribosomal complexes and subsequently prevents premature joining of the 40S and 60S ribosomal subunits prior to initiation (PubMed:17581632). The eIF-3 complex specifically targets and initiates translation of a subset of mRNAs involved in cell proliferation, including cell cycling, differentiation and apoptosis, and uses different modes of RNA stem-loop binding to exert either translational activation or repression (PubMed:25849773). Required for nonsense-mediated mRNA decay (NMD); may act in conjunction with UPF2 to divert mRNAs from translation to the NMD pathway (PubMed:17468741). May interact with MCM7 and EPAS1 and regulate the proteasome-mediated degradation of these proteins (PubMed:17310990, PubMed:17324924). {ECO:0000255|HAMAP-Rule:MF_03004, ECO:0000269|PubMed:17310990, ECO:0000269|PubMed:17324924, ECO:0000269|PubMed:17468741, ECO:0000269|PubMed:17581632, ECO:0000269|PubMed:25849773, ECO:0000269|PubMed:27462815}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | EIF3E | chr8:4494863 | chr8:109215732 | ENST00000220849 | 9 | 13 | 221_398 | 353 | 446.0 | Domain | PCI |
Top |
Fusion Gene Sequence for CSMD1-EIF3E |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >19739_19739_1_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000400186_EIF3E_chr8_109215732_ENST00000220849_length(transcript)=1006nt_BP=587nt CCTTCCTGCCCGGCTCGGCCGGCGCTCGTCCCCGGCCCCGGCCCCGCCAGCCCGGGTCTCCGCGCTCGGAGCAGCTCAGCCCTGCAGTGG CTCGGGACCCGATGCTATGAGAGGGAAGCGAGCCGGGCGCCCAGACCTTCAGGAGGCGTCGGATGCGCGGCGGGTCTTGGGACCGGGCTC TCTCTCCGGCTCGCCTTGCCCTCGGGTGATTATTTGGCTCCGCTCATAGCCCTGCCTTCCTCGGAGGAGCCATCGGTGTCGCGTGCGTGT GGAGTATCTGCAGACATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACT GCAGCGAAGGGTCAGAACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTAT GCCAACTGCACCTGGATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATT TTATCAGTTTACGATGGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAA AGGTGGATTGTAAATTTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTC TCACCCTATCAGCAAGTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAG AATAGCAGGTCAGAGGCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCA AAGAAAGATGAAATAATAAAACTATTATATAAAGGGTGACTTACATTTTGGAAACAACATATTACGTATAAATTTTGAAGAATTGGAATA >19739_19739_1_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000400186_EIF3E_chr8_109215732_ENST00000220849_length(amino acids)=260AA_BP=168 MQWLGTRCYEREASRAPRPSGGVGCAAGLGTGLSLRLALPSGDYLAPLIALPSSEEPSVSRACGVSADMTAWRRFQSLLLLLGLLVLCAR LLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYDGQPQQGNLKVSMLADKLNMTPE -------------------------------------------------------------- >19739_19739_2_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000400186_EIF3E_chr8_109215732_ENST00000519030_length(transcript)=969nt_BP=587nt CCTTCCTGCCCGGCTCGGCCGGCGCTCGTCCCCGGCCCCGGCCCCGCCAGCCCGGGTCTCCGCGCTCGGAGCAGCTCAGCCCTGCAGTGG CTCGGGACCCGATGCTATGAGAGGGAAGCGAGCCGGGCGCCCAGACCTTCAGGAGGCGTCGGATGCGCGGCGGGTCTTGGGACCGGGCTC TCTCTCCGGCTCGCCTTGCCCTCGGGTGATTATTTGGCTCCGCTCATAGCCCTGCCTTCCTCGGAGGAGCCATCGGTGTCGCGTGCGTGT GGAGTATCTGCAGACATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACT GCAGCGAAGGGTCAGAACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTAT GCCAACTGCACCTGGATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATT TTATCAGTTTACGATGGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAA AGGTGGATTGTAAATTTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTC TCACCCTATCAGCAAGTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAG AATAGCAGGTCAGAGGCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCA >19739_19739_2_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000400186_EIF3E_chr8_109215732_ENST00000519030_length(amino acids)=260AA_BP=168 MQWLGTRCYEREASRAPRPSGGVGCAAGLGTGLSLRLALPSGDYLAPLIALPSSEEPSVSRACGVSADMTAWRRFQSLLLLLGLLVLCAR LLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYDGQPQQGNLKVSMLADKLNMTPE -------------------------------------------------------------- >19739_19739_3_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000520002_EIF3E_chr8_109215732_ENST00000220849_length(transcript)=1277nt_BP=858nt GACTGCGCCGTGCCCAGCCTCGGTCCCCTCTCTGTGGGTAAGGATGGTTGAGTCCAGCCTCCACGGCAGCGGCTCCTTGTGCCACTAGCA GCCCTTCTTCTGCGCTCTCCGCCTTTTCTCTCTAGACTGGATCTCTCCTCCCCCCCGCGCCCCCCTCCCCGCATCTCCCACTCGCTGGCT CTCTCTCCAGCTGCCTCCTCTCCAGGTCTCTCCTGGCTGCGCGCGCTCCTCTCCCCGCTTCTCCCCCTCCCGCAGCCTCGCCGCCTTGGT GCCTTCCTGCCCGGCTCGGCCGGCGCTCGTCCCCGGCCCCGGCCCCGCCAGCCCGGGTCTCCGCGCTCGGAGCAGCTCAGCCCTGCAGTG GCTCGGGACCCGATGCTATGAGAGGGAAGCGAGCCGGGCGCCCAGACCTTCAGGAGGCGTCGGATGCGCGGCGGGTCTTGGGACCGGGCT CTCTCTCCGGCTCGCCTTGCCCTCGGGTGATTATTTGGCTCCGCTCATAGCCCTGCCTTCCTCGGAGGAGCCATCGGTGTCGCGTGCGTG TGGAGTATCTGCAGACATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCAC TGCAGCGAAGGGTCAGAACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTA TGCCAACTGCACCTGGATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATAT TTTATCAGTTTACGATGGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGA AAGGTGGATTGTAAATTTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGT CTCACCCTATCAGCAAGTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCA GAATAGCAGGTCAGAGGCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATC AAAGAAAGATGAAATAATAAAACTATTATATAAAGGGTGACTTACATTTTGGAAACAACATATTACGTATAAATTTTGAAGAATTGGAAT >19739_19739_3_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000520002_EIF3E_chr8_109215732_ENST00000220849_length(amino acids)=314AA_BP=222 MPPLQVSPGCARSSPRFSPSRSLAALVPSCPARPALVPGPGPASPGLRARSSSALQWLGTRCYEREASRAPRPSGGVGCAAGLGTGLSLR LALPSGDYLAPLIALPSSEEPSVSRACGVSADMTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANC TWIIITGERNRIQLSFHTFALEEDFDILSVYDGQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPY -------------------------------------------------------------- >19739_19739_4_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000520002_EIF3E_chr8_109215732_ENST00000519030_length(transcript)=1240nt_BP=858nt GACTGCGCCGTGCCCAGCCTCGGTCCCCTCTCTGTGGGTAAGGATGGTTGAGTCCAGCCTCCACGGCAGCGGCTCCTTGTGCCACTAGCA GCCCTTCTTCTGCGCTCTCCGCCTTTTCTCTCTAGACTGGATCTCTCCTCCCCCCCGCGCCCCCCTCCCCGCATCTCCCACTCGCTGGCT CTCTCTCCAGCTGCCTCCTCTCCAGGTCTCTCCTGGCTGCGCGCGCTCCTCTCCCCGCTTCTCCCCCTCCCGCAGCCTCGCCGCCTTGGT GCCTTCCTGCCCGGCTCGGCCGGCGCTCGTCCCCGGCCCCGGCCCCGCCAGCCCGGGTCTCCGCGCTCGGAGCAGCTCAGCCCTGCAGTG GCTCGGGACCCGATGCTATGAGAGGGAAGCGAGCCGGGCGCCCAGACCTTCAGGAGGCGTCGGATGCGCGGCGGGTCTTGGGACCGGGCT CTCTCTCCGGCTCGCCTTGCCCTCGGGTGATTATTTGGCTCCGCTCATAGCCCTGCCTTCCTCGGAGGAGCCATCGGTGTCGCGTGCGTG TGGAGTATCTGCAGACATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCAC TGCAGCGAAGGGTCAGAACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTA TGCCAACTGCACCTGGATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATAT TTTATCAGTTTACGATGGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGA AAGGTGGATTGTAAATTTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGT CTCACCCTATCAGCAAGTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCA GAATAGCAGGTCAGAGGCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATC >19739_19739_4_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000520002_EIF3E_chr8_109215732_ENST00000519030_length(amino acids)=314AA_BP=222 MPPLQVSPGCARSSPRFSPSRSLAALVPSCPARPALVPGPGPASPGLRARSSSALQWLGTRCYEREASRAPRPSGGVGCAAGLGTGLSLR LALPSGDYLAPLIALPSSEEPSVSRACGVSADMTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANC TWIIITGERNRIQLSFHTFALEEDFDILSVYDGQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPY -------------------------------------------------------------- >19739_19739_5_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000537824_EIF3E_chr8_109215732_ENST00000220849_length(transcript)=721nt_BP=302nt ATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACTGCAGCGAAGGGTCAG AACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTATGCCAACTGCACCTGG ATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATTTTATCAGTTTACGAT GGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAAAGGTGGATTGTAAAT TTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTCTCACCCTATCAGCAA GTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAGAATAGCAGGTCAGAG GCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCAAAGAAAGATGAAATA ATAAAACTATTATATAAAGGGTGACTTACATTTTGGAAACAACATATTACGTATAAATTTTGAAGAATTGGAATAAAATTGATTCATTTT >19739_19739_5_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000537824_EIF3E_chr8_109215732_ENST00000220849_length(amino acids)=192AA_BP=100 MTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYD GQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPYQQVIEKTKSLSFRSQMLAMNIEKKLNQNSRSE -------------------------------------------------------------- >19739_19739_6_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000537824_EIF3E_chr8_109215732_ENST00000519030_length(transcript)=684nt_BP=302nt ATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACTGCAGCGAAGGGTCAG AACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTATGCCAACTGCACCTGG ATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATTTTATCAGTTTACGAT GGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAAAGGTGGATTGTAAAT TTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTCTCACCCTATCAGCAA GTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAGAATAGCAGGTCAGAG GCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCAAAGAAAGATGAAATA >19739_19739_6_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000537824_EIF3E_chr8_109215732_ENST00000519030_length(amino acids)=192AA_BP=100 MTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYD GQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPYQQVIEKTKSLSFRSQMLAMNIEKKLNQNSRSE -------------------------------------------------------------- >19739_19739_7_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000539096_EIF3E_chr8_109215732_ENST00000220849_length(transcript)=721nt_BP=302nt ATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACTGCAGCGAAGGGTCAG AACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTATGCCAACTGCACCTGG ATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATTTTATCAGTTTACGAT GGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAAAGGTGGATTGTAAAT TTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTCTCACCCTATCAGCAA GTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAGAATAGCAGGTCAGAG GCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCAAAGAAAGATGAAATA ATAAAACTATTATATAAAGGGTGACTTACATTTTGGAAACAACATATTACGTATAAATTTTGAAGAATTGGAATAAAATTGATTCATTTT >19739_19739_7_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000539096_EIF3E_chr8_109215732_ENST00000220849_length(amino acids)=192AA_BP=100 MTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYD GQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPYQQVIEKTKSLSFRSQMLAMNIEKKLNQNSRSE -------------------------------------------------------------- >19739_19739_8_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000539096_EIF3E_chr8_109215732_ENST00000519030_length(transcript)=684nt_BP=302nt ATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACTGCAGCGAAGGGTCAG AACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTATGCCAACTGCACCTGG ATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATTTTATCAGTTTACGAT GGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAAAGGTGGATTGTAAAT TTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTCTCACCCTATCAGCAA GTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAGAATAGCAGGTCAGAG GCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCAAAGAAAGATGAAATA >19739_19739_8_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000539096_EIF3E_chr8_109215732_ENST00000519030_length(amino acids)=192AA_BP=100 MTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYD GQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPYQQVIEKTKSLSFRSQMLAMNIEKKLNQNSRSE -------------------------------------------------------------- >19739_19739_9_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000542608_EIF3E_chr8_109215732_ENST00000220849_length(transcript)=721nt_BP=302nt ATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACTGCAGCGAAGGGTCAG AACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTATGCCAACTGCACCTGG ATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATTTTATCAGTTTACGAT GGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAAAGGTGGATTGTAAAT TTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTCTCACCCTATCAGCAA GTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAGAATAGCAGGTCAGAG GCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCAAAGAAAGATGAAATA ATAAAACTATTATATAAAGGGTGACTTACATTTTGGAAACAACATATTACGTATAAATTTTGAAGAATTGGAATAAAATTGATTCATTTT >19739_19739_9_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000542608_EIF3E_chr8_109215732_ENST00000220849_length(amino acids)=192AA_BP=100 MTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYD GQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPYQQVIEKTKSLSFRSQMLAMNIEKKLNQNSRSE -------------------------------------------------------------- >19739_19739_10_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000542608_EIF3E_chr8_109215732_ENST00000519030_length(transcript)=684nt_BP=302nt ATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACTGCAGCGAAGGGTCAG AACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTATGCCAACTGCACCTGG ATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATTTTATCAGTTTACGAT GGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAAAGGTGGATTGTAAAT TTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTCTCACCCTATCAGCAA GTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAGAATAGCAGGTCAGAG GCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCAAAGAAAGATGAAATA >19739_19739_10_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000542608_EIF3E_chr8_109215732_ENST00000519030_length(amino acids)=192AA_BP=100 MTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYD GQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPYQQVIEKTKSLSFRSQMLAMNIEKKLNQNSRSE -------------------------------------------------------------- >19739_19739_11_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000602557_EIF3E_chr8_109215732_ENST00000220849_length(transcript)=1277nt_BP=858nt GACTGCGCCGTGCCCAGCCTCGGTCCCCTCTCTGTGGGTAAGGATGGTTGAGTCCAGCCTCCACGGCAGCGGCTCCTTGTGCCACTAGCA GCCCTTCTTCTGCGCTCTCCGCCTTTTCTCTCTAGACTGGATCTCTCCTCCCCCCCGCGCCCCCCTCCCCGCATCTCCCACTCGCTGGCT CTCTCTCCAGCTGCCTCCTCTCCAGGTCTCTCCTGGCTGCGCGCGCTCCTCTCCCCGCTTCTCCCCCTCCCGCAGCCTCGCCGCCTTGGT GCCTTCCTGCCCGGCTCGGCCGGCGCTCGTCCCCGGCCCCGGCCCCGCCAGCCCGGGTCTCCGCGCTCGGAGCAGCTCAGCCCTGCAGTG GCTCGGGACCCGATGCTATGAGAGGGAAGCGAGCCGGGCGCCCAGACCTTCAGGAGGCGTCGGATGCGCGGCGGGTCTTGGGACCGGGCT CTCTCTCCGGCTCGCCTTGCCCTCGGGTGATTATTTGGCTCCGCTCATAGCCCTGCCTTCCTCGGAGGAGCCATCGGTGTCGCGTGCGTG TGGAGTATCTGCAGACATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCAC TGCAGCGAAGGGTCAGAACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTA TGCCAACTGCACCTGGATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATAT TTTATCAGTTTACGATGGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGA AAGGTGGATTGTAAATTTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGT CTCACCCTATCAGCAAGTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCA GAATAGCAGGTCAGAGGCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATC AAAGAAAGATGAAATAATAAAACTATTATATAAAGGGTGACTTACATTTTGGAAACAACATATTACGTATAAATTTTGAAGAATTGGAAT >19739_19739_11_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000602557_EIF3E_chr8_109215732_ENST00000220849_length(amino acids)=314AA_BP=222 MPPLQVSPGCARSSPRFSPSRSLAALVPSCPARPALVPGPGPASPGLRARSSSALQWLGTRCYEREASRAPRPSGGVGCAAGLGTGLSLR LALPSGDYLAPLIALPSSEEPSVSRACGVSADMTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANC TWIIITGERNRIQLSFHTFALEEDFDILSVYDGQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPY -------------------------------------------------------------- >19739_19739_12_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000602557_EIF3E_chr8_109215732_ENST00000519030_length(transcript)=1240nt_BP=858nt GACTGCGCCGTGCCCAGCCTCGGTCCCCTCTCTGTGGGTAAGGATGGTTGAGTCCAGCCTCCACGGCAGCGGCTCCTTGTGCCACTAGCA GCCCTTCTTCTGCGCTCTCCGCCTTTTCTCTCTAGACTGGATCTCTCCTCCCCCCCGCGCCCCCCTCCCCGCATCTCCCACTCGCTGGCT CTCTCTCCAGCTGCCTCCTCTCCAGGTCTCTCCTGGCTGCGCGCGCTCCTCTCCCCGCTTCTCCCCCTCCCGCAGCCTCGCCGCCTTGGT GCCTTCCTGCCCGGCTCGGCCGGCGCTCGTCCCCGGCCCCGGCCCCGCCAGCCCGGGTCTCCGCGCTCGGAGCAGCTCAGCCCTGCAGTG GCTCGGGACCCGATGCTATGAGAGGGAAGCGAGCCGGGCGCCCAGACCTTCAGGAGGCGTCGGATGCGCGGCGGGTCTTGGGACCGGGCT CTCTCTCCGGCTCGCCTTGCCCTCGGGTGATTATTTGGCTCCGCTCATAGCCCTGCCTTCCTCGGAGGAGCCATCGGTGTCGCGTGCGTG TGGAGTATCTGCAGACATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCAC TGCAGCGAAGGGTCAGAACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTA TGCCAACTGCACCTGGATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATAT TTTATCAGTTTACGATGGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGA AAGGTGGATTGTAAATTTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGT CTCACCCTATCAGCAAGTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCA GAATAGCAGGTCAGAGGCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATC >19739_19739_12_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000602557_EIF3E_chr8_109215732_ENST00000519030_length(amino acids)=314AA_BP=222 MPPLQVSPGCARSSPRFSPSRSLAALVPSCPARPALVPGPGPASPGLRARSSSALQWLGTRCYEREASRAPRPSGGVGCAAGLGTGLSLR LALPSGDYLAPLIALPSSEEPSVSRACGVSADMTAWRRFQSLLLLLGLLVLCARLLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANC TWIIITGERNRIQLSFHTFALEEDFDILSVYDGQPQQGNLKVSMLADKLNMTPEEAERWIVNLIRNARLDAKIDSKLGHVVMGNNAVSPY -------------------------------------------------------------- >19739_19739_13_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000602723_EIF3E_chr8_109215732_ENST00000220849_length(transcript)=1006nt_BP=587nt CCTTCCTGCCCGGCTCGGCCGGCGCTCGTCCCCGGCCCCGGCCCCGCCAGCCCGGGTCTCCGCGCTCGGAGCAGCTCAGCCCTGCAGTGG CTCGGGACCCGATGCTATGAGAGGGAAGCGAGCCGGGCGCCCAGACCTTCAGGAGGCGTCGGATGCGCGGCGGGTCTTGGGACCGGGCTC TCTCTCCGGCTCGCCTTGCCCTCGGGTGATTATTTGGCTCCGCTCATAGCCCTGCCTTCCTCGGAGGAGCCATCGGTGTCGCGTGCGTGT GGAGTATCTGCAGACATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACT GCAGCGAAGGGTCAGAACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTAT GCCAACTGCACCTGGATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATT TTATCAGTTTACGATGGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAA AGGTGGATTGTAAATTTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTC TCACCCTATCAGCAAGTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAG AATAGCAGGTCAGAGGCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCA AAGAAAGATGAAATAATAAAACTATTATATAAAGGGTGACTTACATTTTGGAAACAACATATTACGTATAAATTTTGAAGAATTGGAATA >19739_19739_13_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000602723_EIF3E_chr8_109215732_ENST00000220849_length(amino acids)=260AA_BP=168 MQWLGTRCYEREASRAPRPSGGVGCAAGLGTGLSLRLALPSGDYLAPLIALPSSEEPSVSRACGVSADMTAWRRFQSLLLLLGLLVLCAR LLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYDGQPQQGNLKVSMLADKLNMTPE -------------------------------------------------------------- >19739_19739_14_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000602723_EIF3E_chr8_109215732_ENST00000519030_length(transcript)=969nt_BP=587nt CCTTCCTGCCCGGCTCGGCCGGCGCTCGTCCCCGGCCCCGGCCCCGCCAGCCCGGGTCTCCGCGCTCGGAGCAGCTCAGCCCTGCAGTGG CTCGGGACCCGATGCTATGAGAGGGAAGCGAGCCGGGCGCCCAGACCTTCAGGAGGCGTCGGATGCGCGGCGGGTCTTGGGACCGGGCTC TCTCTCCGGCTCGCCTTGCCCTCGGGTGATTATTTGGCTCCGCTCATAGCCCTGCCTTCCTCGGAGGAGCCATCGGTGTCGCGTGCGTGT GGAGTATCTGCAGACATGACTGCGTGGAGGAGATTCCAGTCGCTGCTCCTGCTTCTCGGGCTGCTGGTGCTGTGCGCGAGGCTCCTCACT GCAGCGAAGGGTCAGAACTGTGGAGGCTTAGTCCAGGGTCCCAATGGCACTATTGAGAGCCCAGGGTTTCCTCACGGGTATCCGAACTAT GCCAACTGCACCTGGATCATCATCACGGGCGAGCGCAATAGGATACAGTTGTCCTTCCATACCTTTGCTCTTGAAGAAGATTTTGATATT TTATCAGTTTACGATGGACAGCCTCAACAAGGGAATTTAAAAGTGAGCATGTTGGCAGATAAATTGAACATGACTCCAGAAGAAGCTGAA AGGTGGATTGTAAATTTGATTAGAAATGCAAGACTGGATGCCAAGATTGATTCTAAATTAGGTCATGTGGTTATGGGTAACAATGCAGTC TCACCCTATCAGCAAGTGATTGAAAAGACCAAAAGCCTTTCCTTTAGAAGCCAGATGTTGGCCATGAATATTGAGAAGAAACTTAATCAG AATAGCAGGTCAGAGGCTCCTAACTGGGCAACTCAAGATTCTGGCTTCTACTGAAGAACCATAAAGAAAAGATGAAAAAAAAAACTATCA >19739_19739_14_CSMD1-EIF3E_CSMD1_chr8_4494863_ENST00000602723_EIF3E_chr8_109215732_ENST00000519030_length(amino acids)=260AA_BP=168 MQWLGTRCYEREASRAPRPSGGVGCAAGLGTGLSLRLALPSGDYLAPLIALPSSEEPSVSRACGVSADMTAWRRFQSLLLLLGLLVLCAR LLTAAKGQNCGGLVQGPNGTIESPGFPHGYPNYANCTWIIITGERNRIQLSFHTFALEEDFDILSVYDGQPQQGNLKVSMLADKLNMTPE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CSMD1-EIF3E |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CSMD1-EIF3E |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CSMD1-EIF3E |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies