
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CSNK1D-CCDC57 (FusionGDB2 ID:19815) |
Fusion Gene Summary for CSNK1D-CCDC57 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CSNK1D-CCDC57 | Fusion gene ID: 19815 | Hgene | Tgene | Gene symbol | CSNK1D | CCDC57 | Gene ID | 1453 | 284001 |
| Gene name | casein kinase 1 delta | coiled-coil domain containing 57 | |
| Synonyms | ASPS|CKI-delta|CKId|CKIdelta|FASPS2|HCKID | - | |
| Cytomap | 17q25.3 | 17q25.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | casein kinase I isoform deltacasein kinase Itau-protein kinase CSNK1D | coiled-coil domain-containing protein 57 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P48730 | Q2TAC2 | |
| Ensembl transtripts involved in fusion gene | ENST00000314028, ENST00000392334, ENST00000398519, ENST00000578904, | ENST00000327026, ENST00000392343, ENST00000392346, ENST00000389641, ENST00000392347, | |
| Fusion gene scores | * DoF score | 17 X 16 X 13=3536 | 19 X 12 X 13=2964 |
| # samples | 24 | 22 | |
| ** MAII score | log2(24/3536*10)=-3.88101196378291 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(22/2964*10)=-3.75197001878117 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CSNK1D [Title/Abstract] AND CCDC57 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CCDC57(80109436)-CSNK1D(80209403), # samples:2 CSNK1D(80209254)-CCDC57(80059742), # samples:1 CSNK1D(80209255)-CCDC57(80059742), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CCDC57-CSNK1D seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. CCDC57-CSNK1D seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. CCDC57-CSNK1D seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. CSNK1D-CCDC57 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. CSNK1D-CCDC57 seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. CSNK1D-CCDC57 seems lost the major protein functional domain in Hgene partner, which is a kinase due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CSNK1D | GO:0006468 | protein phosphorylation | 16618118 |
| Hgene | CSNK1D | GO:0018105 | peptidyl-serine phosphorylation | 25500533 |
| Hgene | CSNK1D | GO:0051225 | spindle assembly | 10826492 |
| Fusion gene breakpoints across CSNK1D (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CCDC57 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
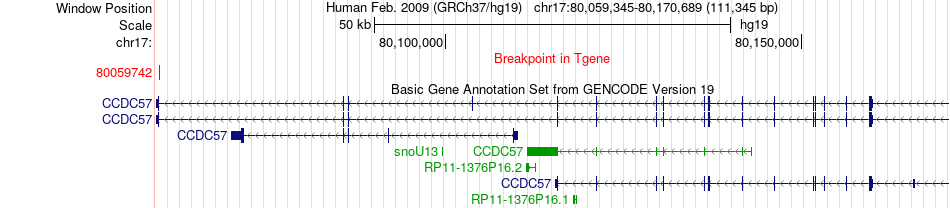 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-95-7944-01A | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| ChimerDB4 | LUAD | TCGA-95-7944 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
Top |
Fusion Gene ORF analysis for CSNK1D-CCDC57 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000314028 | ENST00000327026 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000314028 | ENST00000327026 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000314028 | ENST00000392343 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000314028 | ENST00000392343 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000314028 | ENST00000392346 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000314028 | ENST00000392346 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000392334 | ENST00000327026 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000392334 | ENST00000327026 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000392334 | ENST00000392343 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000392334 | ENST00000392343 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000392334 | ENST00000392346 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000392334 | ENST00000392346 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000398519 | ENST00000327026 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000398519 | ENST00000327026 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000398519 | ENST00000392343 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000398519 | ENST00000392343 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000398519 | ENST00000392346 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5CDS-intron | ENST00000398519 | ENST00000392346 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-3CDS | ENST00000578904 | ENST00000389641 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-3CDS | ENST00000578904 | ENST00000389641 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-3CDS | ENST00000578904 | ENST00000392347 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-3CDS | ENST00000578904 | ENST00000392347 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-intron | ENST00000578904 | ENST00000327026 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-intron | ENST00000578904 | ENST00000327026 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-intron | ENST00000578904 | ENST00000392343 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-intron | ENST00000578904 | ENST00000392343 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-intron | ENST00000578904 | ENST00000392346 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| 5UTR-intron | ENST00000578904 | ENST00000392346 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| Frame-shift | ENST00000392334 | ENST00000389641 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| Frame-shift | ENST00000392334 | ENST00000389641 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| Frame-shift | ENST00000392334 | ENST00000392347 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| Frame-shift | ENST00000392334 | ENST00000392347 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| In-frame | ENST00000314028 | ENST00000389641 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| In-frame | ENST00000314028 | ENST00000389641 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| In-frame | ENST00000314028 | ENST00000392347 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| In-frame | ENST00000314028 | ENST00000392347 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| In-frame | ENST00000398519 | ENST00000389641 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| In-frame | ENST00000398519 | ENST00000389641 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| In-frame | ENST00000398519 | ENST00000392347 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - |
| In-frame | ENST00000398519 | ENST00000392347 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000398519 | CSNK1D | chr17 | 80209254 | - | ENST00000392347 | CCDC57 | chr17 | 80059742 | - | 1329 | 932 | 47 | 1003 | 318 |
| ENST00000398519 | CSNK1D | chr17 | 80209254 | - | ENST00000389641 | CCDC57 | chr17 | 80059742 | - | 1329 | 932 | 47 | 1003 | 318 |
| ENST00000314028 | CSNK1D | chr17 | 80209254 | - | ENST00000392347 | CCDC57 | chr17 | 80059742 | - | 1632 | 1235 | 11 | 1306 | 431 |
| ENST00000314028 | CSNK1D | chr17 | 80209254 | - | ENST00000389641 | CCDC57 | chr17 | 80059742 | - | 1632 | 1235 | 11 | 1306 | 431 |
| ENST00000398519 | CSNK1D | chr17 | 80209255 | - | ENST00000392347 | CCDC57 | chr17 | 80059742 | - | 1329 | 932 | 47 | 1003 | 318 |
| ENST00000398519 | CSNK1D | chr17 | 80209255 | - | ENST00000389641 | CCDC57 | chr17 | 80059742 | - | 1329 | 932 | 47 | 1003 | 318 |
| ENST00000314028 | CSNK1D | chr17 | 80209255 | - | ENST00000392347 | CCDC57 | chr17 | 80059742 | - | 1632 | 1235 | 11 | 1306 | 431 |
| ENST00000314028 | CSNK1D | chr17 | 80209255 | - | ENST00000389641 | CCDC57 | chr17 | 80059742 | - | 1632 | 1235 | 11 | 1306 | 431 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000398519 | ENST00000392347 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - | 0.006793924 | 0.99320614 |
| ENST00000398519 | ENST00000389641 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - | 0.006793924 | 0.99320614 |
| ENST00000314028 | ENST00000392347 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - | 0.009239291 | 0.9907607 |
| ENST00000314028 | ENST00000389641 | CSNK1D | chr17 | 80209254 | - | CCDC57 | chr17 | 80059742 | - | 0.009239291 | 0.9907607 |
| ENST00000398519 | ENST00000392347 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - | 0.006793924 | 0.99320614 |
| ENST00000398519 | ENST00000389641 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - | 0.006793924 | 0.99320614 |
| ENST00000314028 | ENST00000392347 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - | 0.009239291 | 0.9907607 |
| ENST00000314028 | ENST00000389641 | CSNK1D | chr17 | 80209255 | - | CCDC57 | chr17 | 80059742 | - | 0.009239291 | 0.9907607 |
Top |
Fusion Genomic Features for CSNK1D-CCDC57 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
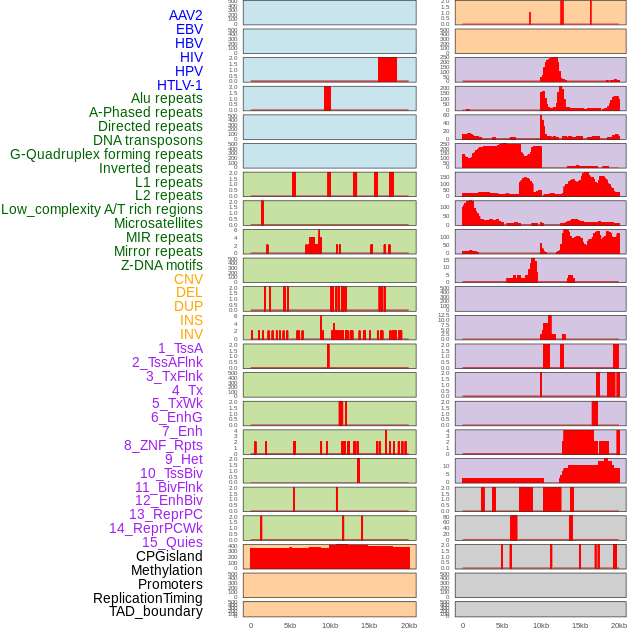 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for CSNK1D-CCDC57 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:80109436/chr17:80209403) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CSNK1D | CCDC57 |
| FUNCTION: Essential serine/threonine-protein kinase that regulates diverse cellular growth and survival processes including Wnt signaling, DNA repair and circadian rhythms. It can phosphorylate a large number of proteins. Casein kinases are operationally defined by their preferential utilization of acidic proteins such as caseins as substrates. Phosphorylates connexin-43/GJA1, MAP1A, SNAPIN, MAPT/TAU, TOP2A, DCK, HIF1A, EIF6, p53/TP53, DVL2, DVL3, ESR1, AIB1/NCOA3, DNMT1, PKD2, YAP1, PER1 and PER2. Central component of the circadian clock. In balance with PP1, determines the circadian period length through the regulation of the speed and rhythmicity of PER1 and PER2 phosphorylation. Controls PER1 and PER2 nuclear transport and degradation. YAP1 phosphorylation promotes its SCF(beta-TRCP) E3 ubiquitin ligase-mediated ubiquitination and subsequent degradation. DNMT1 phosphorylation reduces its DNA-binding activity. Phosphorylation of ESR1 and AIB1/NCOA3 stimulates their activity and coactivation. Phosphorylation of DVL2 and DVL3 regulates WNT3A signaling pathway that controls neurite outgrowth. EIF6 phosphorylation promotes its nuclear export. Triggers down-regulation of dopamine receptors in the forebrain. Activates DCK in vitro by phosphorylation. TOP2A phosphorylation favors DNA cleavable complex formation. May regulate the formation of the mitotic spindle apparatus in extravillous trophoblast. Modulates connexin-43/GJA1 gap junction assembly by phosphorylation. Probably involved in lymphocyte physiology. Regulates fast synaptic transmission mediated by glutamate. {ECO:0000269|PubMed:10606744, ECO:0000269|PubMed:12270943, ECO:0000269|PubMed:14761950, ECO:0000269|PubMed:16027726, ECO:0000269|PubMed:17562708, ECO:0000269|PubMed:17962809, ECO:0000269|PubMed:19043076, ECO:0000269|PubMed:19339517, ECO:0000269|PubMed:20041275, ECO:0000269|PubMed:20048001, ECO:0000269|PubMed:20407760, ECO:0000269|PubMed:20637175, ECO:0000269|PubMed:20696890, ECO:0000269|PubMed:20699359, ECO:0000269|PubMed:21084295, ECO:0000269|PubMed:21422228, ECO:0000269|PubMed:23636092}. | FUNCTION: Pleiotropic regulator of centriole duplication, mitosis, and ciliogenesis. Critical interface between centrosome and microtubule-mediated cellular processes. Centriole duplication protein required for recruitment of CEP63, CEP152, and PLK4 to the centrosome. Independent of its centrosomal targeting, localizes to and interacts with microtubules and regulates microtubule nucleation, stability, and mitotic progression. {ECO:0000269|PubMed:32402286}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CSNK1D | chr17:80209254 | chr17:80059742 | ENST00000314028 | - | 6 | 9 | 9_277 | 295 | 416.0 | Domain | Protein kinase |
| Hgene | CSNK1D | chr17:80209254 | chr17:80059742 | ENST00000392334 | - | 6 | 10 | 9_277 | 295 | 420.3333333333333 | Domain | Protein kinase |
| Hgene | CSNK1D | chr17:80209255 | chr17:80059742 | ENST00000314028 | - | 6 | 9 | 9_277 | 295 | 416.0 | Domain | Protein kinase |
| Hgene | CSNK1D | chr17:80209255 | chr17:80059742 | ENST00000392334 | - | 6 | 10 | 9_277 | 295 | 420.3333333333333 | Domain | Protein kinase |
| Hgene | CSNK1D | chr17:80209254 | chr17:80059742 | ENST00000314028 | - | 6 | 9 | 15_23 | 295 | 416.0 | Nucleotide binding | ATP |
| Hgene | CSNK1D | chr17:80209254 | chr17:80059742 | ENST00000392334 | - | 6 | 10 | 15_23 | 295 | 420.3333333333333 | Nucleotide binding | ATP |
| Hgene | CSNK1D | chr17:80209255 | chr17:80059742 | ENST00000314028 | - | 6 | 9 | 15_23 | 295 | 416.0 | Nucleotide binding | ATP |
| Hgene | CSNK1D | chr17:80209255 | chr17:80059742 | ENST00000392334 | - | 6 | 10 | 15_23 | 295 | 420.3333333333333 | Nucleotide binding | ATP |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392343 | 0 | 15 | 214_422 | 0 | 752.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392343 | 0 | 15 | 456_483 | 0 | 752.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392343 | 0 | 15 | 521_548 | 0 | 752.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392343 | 0 | 15 | 92_173 | 0 | 752.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392343 | 0 | 15 | 214_422 | 0 | 752.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392343 | 0 | 15 | 456_483 | 0 | 752.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392343 | 0 | 15 | 521_548 | 0 | 752.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392343 | 0 | 15 | 92_173 | 0 | 752.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392343 | 0 | 15 | 1_502 | 0 | 752.0 | Region | Centrosomal targeting domain | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392343 | 0 | 15 | 606_915 | 0 | 752.0 | Region | Microtubule binding domain | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392343 | 0 | 15 | 1_502 | 0 | 752.0 | Region | Centrosomal targeting domain | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392343 | 0 | 15 | 606_915 | 0 | 752.0 | Region | Microtubule binding domain |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CSNK1D | chr17:80209254 | chr17:80059742 | ENST00000314028 | - | 6 | 9 | 278_364 | 295 | 416.0 | Region | Note=Centrosomal localization signal (CLS) |
| Hgene | CSNK1D | chr17:80209254 | chr17:80059742 | ENST00000314028 | - | 6 | 9 | 317_342 | 295 | 416.0 | Region | Autoinhibitory |
| Hgene | CSNK1D | chr17:80209254 | chr17:80059742 | ENST00000392334 | - | 6 | 10 | 278_364 | 295 | 420.3333333333333 | Region | Note=Centrosomal localization signal (CLS) |
| Hgene | CSNK1D | chr17:80209254 | chr17:80059742 | ENST00000392334 | - | 6 | 10 | 317_342 | 295 | 420.3333333333333 | Region | Autoinhibitory |
| Hgene | CSNK1D | chr17:80209255 | chr17:80059742 | ENST00000314028 | - | 6 | 9 | 278_364 | 295 | 416.0 | Region | Note=Centrosomal localization signal (CLS) |
| Hgene | CSNK1D | chr17:80209255 | chr17:80059742 | ENST00000314028 | - | 6 | 9 | 317_342 | 295 | 416.0 | Region | Autoinhibitory |
| Hgene | CSNK1D | chr17:80209255 | chr17:80059742 | ENST00000392334 | - | 6 | 10 | 278_364 | 295 | 420.3333333333333 | Region | Note=Centrosomal localization signal (CLS) |
| Hgene | CSNK1D | chr17:80209255 | chr17:80059742 | ENST00000392334 | - | 6 | 10 | 317_342 | 295 | 420.3333333333333 | Region | Autoinhibitory |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000389641 | 16 | 18 | 214_422 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000389641 | 16 | 18 | 456_483 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000389641 | 16 | 18 | 521_548 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000389641 | 16 | 18 | 92_173 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392347 | 15 | 17 | 214_422 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392347 | 15 | 17 | 456_483 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392347 | 15 | 17 | 521_548 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392347 | 15 | 17 | 92_173 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000389641 | 16 | 18 | 214_422 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000389641 | 16 | 18 | 456_483 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000389641 | 16 | 18 | 521_548 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000389641 | 16 | 18 | 92_173 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392347 | 15 | 17 | 214_422 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392347 | 15 | 17 | 456_483 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392347 | 15 | 17 | 521_548 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392347 | 15 | 17 | 92_173 | 855 | 917.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000389641 | 16 | 18 | 1_502 | 855 | 917.0 | Region | Centrosomal targeting domain | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000389641 | 16 | 18 | 606_915 | 855 | 917.0 | Region | Microtubule binding domain | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392347 | 15 | 17 | 1_502 | 855 | 917.0 | Region | Centrosomal targeting domain | |
| Tgene | CCDC57 | chr17:80209254 | chr17:80059742 | ENST00000392347 | 15 | 17 | 606_915 | 855 | 917.0 | Region | Microtubule binding domain | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000389641 | 16 | 18 | 1_502 | 855 | 917.0 | Region | Centrosomal targeting domain | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000389641 | 16 | 18 | 606_915 | 855 | 917.0 | Region | Microtubule binding domain | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392347 | 15 | 17 | 1_502 | 855 | 917.0 | Region | Centrosomal targeting domain | |
| Tgene | CCDC57 | chr17:80209255 | chr17:80059742 | ENST00000392347 | 15 | 17 | 606_915 | 855 | 917.0 | Region | Microtubule binding domain |
Top |
Fusion Gene Sequence for CSNK1D-CCDC57 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >19815_19815_1_CSNK1D-CCDC57_CSNK1D_chr17_80209254_ENST00000314028_CCDC57_chr17_80059742_ENST00000389641_length(transcript)=1632nt_BP=1235nt GCCCCGCCGGGTTGCTAGGGGAAGTGACGTCACAGCGCGATGGCGGCGGCTCCTTTAGGCAGCTGAAAGGGGATTTAGGCCCGGAAGATC CGAGTCCATCCGCGGCGGGGAGAGGGCAAGCGGGACCGGTAGGGGCCGGAGCAGCGGCGGCGGCGCTCGGACTGTCCCATCCGCCCCGTA TTGAGGCGCTGGGAGCGGCGGGGCGACAGGAAAGCGATGGTGAAAGCGGGGCCGTGAGGGGGGCGGAGCCGGGAGCCGGACCCGCAGTAG CGGCAGCAGCGGCGCCGCCTCCCAGAGTTCAGACCCAGGAAGCGGCCGGGAGGGCAGGAGCGAATCGGGCCGCCGCCGCCATGGAGCTGA GAGTCGGGAACAGGTACCGGCTGGGCCGGAAGATCGGCAGCGGCTCCTTCGGAGACATCTATCTCGGTACGGACATTGCTGCAGGAGAAG AGGTTGCCATCAAGCTTGAATGTGTCAAAACCAAACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGG GCATCCCCACCATCAGATGGTGCGGGGCAGAGGGGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCA ACTTCTGCTCCAGGAAATTCAGCCTCAAAACCGTCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACT TCATCCACCGGGATGTGAAGCCAGACAACTTCCTCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCA AGAAGTACCGGGATGCACGCACCCACCAGCACATCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACA CGCACCTTGGAATTGAACAATCCCGAAGAGATGACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGC AGGGGCTGAAGGCTGCCACCAAGAGACAGAAATACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCT ACCCTTCCGAATTTGCCACATACCTGAATTTCTGCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCC GGAATCTGTTCCATCGCCAGGGCTTCTCCTATGACTACGTGTTCGACTGGAACATGCTCAAATTTAGCTCCCAGCTCCTCCAGCAGCCGA CAGGAGGCCCGTCAAGATGCAGGCAGGCATTGCCACCCCAGGGATGAAGACAGCAGCCCAGGCAAAGGCCAAGACCACAGGAGCCTCCCG GTCTCATCCTGCAAAAGCTAAAGGCTGCCAGAGGCCCCCCAAGATCCGTAACTACAACATTATGGACTGACTTCCTCCCCCCACCCCGCC CCACTAAGGGGTGCTCGGGGCCTCCGCATGGTGCCTGTGCTTTCACCTACGTGTTGTGGGGGGGTGTGGGCACAGCGTGCAGGGTGGAGG CAGGGAGCTGCAGGGCAGGCTCCCAAATGCTGCTGAGGCGACCCTGCTGACTGAAGGCCTCCCTGAGCACAGGGCCCATTAAAACCAGGT >19815_19815_1_CSNK1D-CCDC57_CSNK1D_chr17_80209254_ENST00000314028_CCDC57_chr17_80059742_ENST00000389641_length(amino acids)=431AA_BP=28 MLGEVTSQRDGGGSFRQLKGDLGPEDPSPSAAGRGQAGPVGAGAAAAALGLSHPPRIEALGAAGRQESDGESGAVRGAEPGAGPAVAAAA APPPRVQTQEAAGRAGANRAAAAMELRVGNRYRLGRKIGSGSFGDIYLGTDIAAGEEVAIKLECVKTKHPQLHIESKIYKMMQGGVGIPT IRWCGAEGDYNVMVMELLGPSLEDLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNLVYIIDFGLAKKYR DARTHQHIPYRENKNLTGTARYASINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMSTPIEVLCKGYPSE -------------------------------------------------------------- >19815_19815_2_CSNK1D-CCDC57_CSNK1D_chr17_80209254_ENST00000314028_CCDC57_chr17_80059742_ENST00000392347_length(transcript)=1632nt_BP=1235nt GCCCCGCCGGGTTGCTAGGGGAAGTGACGTCACAGCGCGATGGCGGCGGCTCCTTTAGGCAGCTGAAAGGGGATTTAGGCCCGGAAGATC CGAGTCCATCCGCGGCGGGGAGAGGGCAAGCGGGACCGGTAGGGGCCGGAGCAGCGGCGGCGGCGCTCGGACTGTCCCATCCGCCCCGTA TTGAGGCGCTGGGAGCGGCGGGGCGACAGGAAAGCGATGGTGAAAGCGGGGCCGTGAGGGGGGCGGAGCCGGGAGCCGGACCCGCAGTAG CGGCAGCAGCGGCGCCGCCTCCCAGAGTTCAGACCCAGGAAGCGGCCGGGAGGGCAGGAGCGAATCGGGCCGCCGCCGCCATGGAGCTGA GAGTCGGGAACAGGTACCGGCTGGGCCGGAAGATCGGCAGCGGCTCCTTCGGAGACATCTATCTCGGTACGGACATTGCTGCAGGAGAAG AGGTTGCCATCAAGCTTGAATGTGTCAAAACCAAACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGG GCATCCCCACCATCAGATGGTGCGGGGCAGAGGGGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCA ACTTCTGCTCCAGGAAATTCAGCCTCAAAACCGTCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACT TCATCCACCGGGATGTGAAGCCAGACAACTTCCTCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCA AGAAGTACCGGGATGCACGCACCCACCAGCACATCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACA CGCACCTTGGAATTGAACAATCCCGAAGAGATGACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGC AGGGGCTGAAGGCTGCCACCAAGAGACAGAAATACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCT ACCCTTCCGAATTTGCCACATACCTGAATTTCTGCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCC GGAATCTGTTCCATCGCCAGGGCTTCTCCTATGACTACGTGTTCGACTGGAACATGCTCAAATTTAGCTCCCAGCTCCTCCAGCAGCCGA CAGGAGGCCCGTCAAGATGCAGGCAGGCATTGCCACCCCAGGGATGAAGACAGCAGCCCAGGCAAAGGCCAAGACCACAGGAGCCTCCCG GTCTCATCCTGCAAAAGCTAAAGGCTGCCAGAGGCCCCCCAAGATCCGTAACTACAACATTATGGACTGACTTCCTCCCCCCACCCCGCC CCACTAAGGGGTGCTCGGGGCCTCCGCATGGTGCCTGTGCTTTCACCTACGTGTTGTGGGGGGGTGTGGGCACAGCGTGCAGGGTGGAGG CAGGGAGCTGCAGGGCAGGCTCCCAAATGCTGCTGAGGCGACCCTGCTGACTGAAGGCCTCCCTGAGCACAGGGCCCATTAAAACCAGGT >19815_19815_2_CSNK1D-CCDC57_CSNK1D_chr17_80209254_ENST00000314028_CCDC57_chr17_80059742_ENST00000392347_length(amino acids)=431AA_BP=28 MLGEVTSQRDGGGSFRQLKGDLGPEDPSPSAAGRGQAGPVGAGAAAAALGLSHPPRIEALGAAGRQESDGESGAVRGAEPGAGPAVAAAA APPPRVQTQEAAGRAGANRAAAAMELRVGNRYRLGRKIGSGSFGDIYLGTDIAAGEEVAIKLECVKTKHPQLHIESKIYKMMQGGVGIPT IRWCGAEGDYNVMVMELLGPSLEDLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNLVYIIDFGLAKKYR DARTHQHIPYRENKNLTGTARYASINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMSTPIEVLCKGYPSE -------------------------------------------------------------- >19815_19815_3_CSNK1D-CCDC57_CSNK1D_chr17_80209254_ENST00000398519_CCDC57_chr17_80059742_ENST00000389641_length(transcript)=1329nt_BP=932nt CCCAGGAAGCGGCCGGGAGGGCAGGAGCGAATCGGGCCGCCGCCGCCATGGAGCTGAGAGTCGGGAACAGGTACCGGCTGGGCCGGAAGA TCGGCAGCGGCTCCTTCGGAGACATCTATCTCGGTACGGACATTGCTGCAGGAGAAGAGGTTGCCATCAAGCTTGAATGTGTCAAAACCA AACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGGGCATCCCCACCATCAGATGGTGCGGGGCAGAGG GGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCAACTTCTGCTCCAGGAAATTCAGCCTCAAAACCG TCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACTTCATCCACCGGGATGTGAAGCCAGACAACTTCC TCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCAAGAAGTACCGGGATGCACGCACCCACCAGCACA TCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACACGCACCTTGGAATTGAACAATCCCGAAGAGATG ACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGCAGGGGCTGAAGGCTGCCACCAAGAGACAGAAAT ACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCTACCCTTCCGAATTTGCCACATACCTGAATTTCT GCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCCGGAATCTGTTCCATCGCCAGGGCTTCTCCTATG ACTACGTGTTCGACTGGAACATGCTCAAATTTAGCTCCCAGCTCCTCCAGCAGCCGACAGGAGGCCCGTCAAGATGCAGGCAGGCATTGC CACCCCAGGGATGAAGACAGCAGCCCAGGCAAAGGCCAAGACCACAGGAGCCTCCCGGTCTCATCCTGCAAAAGCTAAAGGCTGCCAGAG GCCCCCCAAGATCCGTAACTACAACATTATGGACTGACTTCCTCCCCCCACCCCGCCCCACTAAGGGGTGCTCGGGGCCTCCGCATGGTG CCTGTGCTTTCACCTACGTGTTGTGGGGGGGTGTGGGCACAGCGTGCAGGGTGGAGGCAGGGAGCTGCAGGGCAGGCTCCCAAATGCTGC >19815_19815_3_CSNK1D-CCDC57_CSNK1D_chr17_80209254_ENST00000398519_CCDC57_chr17_80059742_ENST00000389641_length(amino acids)=318AA_BP=0 MELRVGNRYRLGRKIGSGSFGDIYLGTDIAAGEEVAIKLECVKTKHPQLHIESKIYKMMQGGVGIPTIRWCGAEGDYNVMVMELLGPSLE DLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNLVYIIDFGLAKKYRDARTHQHIPYRENKNLTGTARYA SINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMSTPIEVLCKGYPSEFATYLNFCRSLRFDDKPDYSYLR -------------------------------------------------------------- >19815_19815_4_CSNK1D-CCDC57_CSNK1D_chr17_80209254_ENST00000398519_CCDC57_chr17_80059742_ENST00000392347_length(transcript)=1329nt_BP=932nt CCCAGGAAGCGGCCGGGAGGGCAGGAGCGAATCGGGCCGCCGCCGCCATGGAGCTGAGAGTCGGGAACAGGTACCGGCTGGGCCGGAAGA TCGGCAGCGGCTCCTTCGGAGACATCTATCTCGGTACGGACATTGCTGCAGGAGAAGAGGTTGCCATCAAGCTTGAATGTGTCAAAACCA AACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGGGCATCCCCACCATCAGATGGTGCGGGGCAGAGG GGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCAACTTCTGCTCCAGGAAATTCAGCCTCAAAACCG TCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACTTCATCCACCGGGATGTGAAGCCAGACAACTTCC TCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCAAGAAGTACCGGGATGCACGCACCCACCAGCACA TCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACACGCACCTTGGAATTGAACAATCCCGAAGAGATG ACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGCAGGGGCTGAAGGCTGCCACCAAGAGACAGAAAT ACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCTACCCTTCCGAATTTGCCACATACCTGAATTTCT GCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCCGGAATCTGTTCCATCGCCAGGGCTTCTCCTATG ACTACGTGTTCGACTGGAACATGCTCAAATTTAGCTCCCAGCTCCTCCAGCAGCCGACAGGAGGCCCGTCAAGATGCAGGCAGGCATTGC CACCCCAGGGATGAAGACAGCAGCCCAGGCAAAGGCCAAGACCACAGGAGCCTCCCGGTCTCATCCTGCAAAAGCTAAAGGCTGCCAGAG GCCCCCCAAGATCCGTAACTACAACATTATGGACTGACTTCCTCCCCCCACCCCGCCCCACTAAGGGGTGCTCGGGGCCTCCGCATGGTG CCTGTGCTTTCACCTACGTGTTGTGGGGGGGTGTGGGCACAGCGTGCAGGGTGGAGGCAGGGAGCTGCAGGGCAGGCTCCCAAATGCTGC >19815_19815_4_CSNK1D-CCDC57_CSNK1D_chr17_80209254_ENST00000398519_CCDC57_chr17_80059742_ENST00000392347_length(amino acids)=318AA_BP=0 MELRVGNRYRLGRKIGSGSFGDIYLGTDIAAGEEVAIKLECVKTKHPQLHIESKIYKMMQGGVGIPTIRWCGAEGDYNVMVMELLGPSLE DLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNLVYIIDFGLAKKYRDARTHQHIPYRENKNLTGTARYA SINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMSTPIEVLCKGYPSEFATYLNFCRSLRFDDKPDYSYLR -------------------------------------------------------------- >19815_19815_5_CSNK1D-CCDC57_CSNK1D_chr17_80209255_ENST00000314028_CCDC57_chr17_80059742_ENST00000389641_length(transcript)=1632nt_BP=1235nt GCCCCGCCGGGTTGCTAGGGGAAGTGACGTCACAGCGCGATGGCGGCGGCTCCTTTAGGCAGCTGAAAGGGGATTTAGGCCCGGAAGATC CGAGTCCATCCGCGGCGGGGAGAGGGCAAGCGGGACCGGTAGGGGCCGGAGCAGCGGCGGCGGCGCTCGGACTGTCCCATCCGCCCCGTA TTGAGGCGCTGGGAGCGGCGGGGCGACAGGAAAGCGATGGTGAAAGCGGGGCCGTGAGGGGGGCGGAGCCGGGAGCCGGACCCGCAGTAG CGGCAGCAGCGGCGCCGCCTCCCAGAGTTCAGACCCAGGAAGCGGCCGGGAGGGCAGGAGCGAATCGGGCCGCCGCCGCCATGGAGCTGA GAGTCGGGAACAGGTACCGGCTGGGCCGGAAGATCGGCAGCGGCTCCTTCGGAGACATCTATCTCGGTACGGACATTGCTGCAGGAGAAG AGGTTGCCATCAAGCTTGAATGTGTCAAAACCAAACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGG GCATCCCCACCATCAGATGGTGCGGGGCAGAGGGGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCA ACTTCTGCTCCAGGAAATTCAGCCTCAAAACCGTCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACT TCATCCACCGGGATGTGAAGCCAGACAACTTCCTCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCA AGAAGTACCGGGATGCACGCACCCACCAGCACATCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACA CGCACCTTGGAATTGAACAATCCCGAAGAGATGACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGC AGGGGCTGAAGGCTGCCACCAAGAGACAGAAATACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCT ACCCTTCCGAATTTGCCACATACCTGAATTTCTGCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCC GGAATCTGTTCCATCGCCAGGGCTTCTCCTATGACTACGTGTTCGACTGGAACATGCTCAAATTTAGCTCCCAGCTCCTCCAGCAGCCGA CAGGAGGCCCGTCAAGATGCAGGCAGGCATTGCCACCCCAGGGATGAAGACAGCAGCCCAGGCAAAGGCCAAGACCACAGGAGCCTCCCG GTCTCATCCTGCAAAAGCTAAAGGCTGCCAGAGGCCCCCCAAGATCCGTAACTACAACATTATGGACTGACTTCCTCCCCCCACCCCGCC CCACTAAGGGGTGCTCGGGGCCTCCGCATGGTGCCTGTGCTTTCACCTACGTGTTGTGGGGGGGTGTGGGCACAGCGTGCAGGGTGGAGG CAGGGAGCTGCAGGGCAGGCTCCCAAATGCTGCTGAGGCGACCCTGCTGACTGAAGGCCTCCCTGAGCACAGGGCCCATTAAAACCAGGT >19815_19815_5_CSNK1D-CCDC57_CSNK1D_chr17_80209255_ENST00000314028_CCDC57_chr17_80059742_ENST00000389641_length(amino acids)=431AA_BP=28 MLGEVTSQRDGGGSFRQLKGDLGPEDPSPSAAGRGQAGPVGAGAAAAALGLSHPPRIEALGAAGRQESDGESGAVRGAEPGAGPAVAAAA APPPRVQTQEAAGRAGANRAAAAMELRVGNRYRLGRKIGSGSFGDIYLGTDIAAGEEVAIKLECVKTKHPQLHIESKIYKMMQGGVGIPT IRWCGAEGDYNVMVMELLGPSLEDLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNLVYIIDFGLAKKYR DARTHQHIPYRENKNLTGTARYASINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMSTPIEVLCKGYPSE -------------------------------------------------------------- >19815_19815_6_CSNK1D-CCDC57_CSNK1D_chr17_80209255_ENST00000314028_CCDC57_chr17_80059742_ENST00000392347_length(transcript)=1632nt_BP=1235nt GCCCCGCCGGGTTGCTAGGGGAAGTGACGTCACAGCGCGATGGCGGCGGCTCCTTTAGGCAGCTGAAAGGGGATTTAGGCCCGGAAGATC CGAGTCCATCCGCGGCGGGGAGAGGGCAAGCGGGACCGGTAGGGGCCGGAGCAGCGGCGGCGGCGCTCGGACTGTCCCATCCGCCCCGTA TTGAGGCGCTGGGAGCGGCGGGGCGACAGGAAAGCGATGGTGAAAGCGGGGCCGTGAGGGGGGCGGAGCCGGGAGCCGGACCCGCAGTAG CGGCAGCAGCGGCGCCGCCTCCCAGAGTTCAGACCCAGGAAGCGGCCGGGAGGGCAGGAGCGAATCGGGCCGCCGCCGCCATGGAGCTGA GAGTCGGGAACAGGTACCGGCTGGGCCGGAAGATCGGCAGCGGCTCCTTCGGAGACATCTATCTCGGTACGGACATTGCTGCAGGAGAAG AGGTTGCCATCAAGCTTGAATGTGTCAAAACCAAACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGG GCATCCCCACCATCAGATGGTGCGGGGCAGAGGGGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCA ACTTCTGCTCCAGGAAATTCAGCCTCAAAACCGTCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACT TCATCCACCGGGATGTGAAGCCAGACAACTTCCTCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCA AGAAGTACCGGGATGCACGCACCCACCAGCACATCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACA CGCACCTTGGAATTGAACAATCCCGAAGAGATGACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGC AGGGGCTGAAGGCTGCCACCAAGAGACAGAAATACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCT ACCCTTCCGAATTTGCCACATACCTGAATTTCTGCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCC GGAATCTGTTCCATCGCCAGGGCTTCTCCTATGACTACGTGTTCGACTGGAACATGCTCAAATTTAGCTCCCAGCTCCTCCAGCAGCCGA CAGGAGGCCCGTCAAGATGCAGGCAGGCATTGCCACCCCAGGGATGAAGACAGCAGCCCAGGCAAAGGCCAAGACCACAGGAGCCTCCCG GTCTCATCCTGCAAAAGCTAAAGGCTGCCAGAGGCCCCCCAAGATCCGTAACTACAACATTATGGACTGACTTCCTCCCCCCACCCCGCC CCACTAAGGGGTGCTCGGGGCCTCCGCATGGTGCCTGTGCTTTCACCTACGTGTTGTGGGGGGGTGTGGGCACAGCGTGCAGGGTGGAGG CAGGGAGCTGCAGGGCAGGCTCCCAAATGCTGCTGAGGCGACCCTGCTGACTGAAGGCCTCCCTGAGCACAGGGCCCATTAAAACCAGGT >19815_19815_6_CSNK1D-CCDC57_CSNK1D_chr17_80209255_ENST00000314028_CCDC57_chr17_80059742_ENST00000392347_length(amino acids)=431AA_BP=28 MLGEVTSQRDGGGSFRQLKGDLGPEDPSPSAAGRGQAGPVGAGAAAAALGLSHPPRIEALGAAGRQESDGESGAVRGAEPGAGPAVAAAA APPPRVQTQEAAGRAGANRAAAAMELRVGNRYRLGRKIGSGSFGDIYLGTDIAAGEEVAIKLECVKTKHPQLHIESKIYKMMQGGVGIPT IRWCGAEGDYNVMVMELLGPSLEDLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNLVYIIDFGLAKKYR DARTHQHIPYRENKNLTGTARYASINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMSTPIEVLCKGYPSE -------------------------------------------------------------- >19815_19815_7_CSNK1D-CCDC57_CSNK1D_chr17_80209255_ENST00000398519_CCDC57_chr17_80059742_ENST00000389641_length(transcript)=1329nt_BP=932nt CCCAGGAAGCGGCCGGGAGGGCAGGAGCGAATCGGGCCGCCGCCGCCATGGAGCTGAGAGTCGGGAACAGGTACCGGCTGGGCCGGAAGA TCGGCAGCGGCTCCTTCGGAGACATCTATCTCGGTACGGACATTGCTGCAGGAGAAGAGGTTGCCATCAAGCTTGAATGTGTCAAAACCA AACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGGGCATCCCCACCATCAGATGGTGCGGGGCAGAGG GGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCAACTTCTGCTCCAGGAAATTCAGCCTCAAAACCG TCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACTTCATCCACCGGGATGTGAAGCCAGACAACTTCC TCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCAAGAAGTACCGGGATGCACGCACCCACCAGCACA TCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACACGCACCTTGGAATTGAACAATCCCGAAGAGATG ACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGCAGGGGCTGAAGGCTGCCACCAAGAGACAGAAAT ACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCTACCCTTCCGAATTTGCCACATACCTGAATTTCT GCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCCGGAATCTGTTCCATCGCCAGGGCTTCTCCTATG ACTACGTGTTCGACTGGAACATGCTCAAATTTAGCTCCCAGCTCCTCCAGCAGCCGACAGGAGGCCCGTCAAGATGCAGGCAGGCATTGC CACCCCAGGGATGAAGACAGCAGCCCAGGCAAAGGCCAAGACCACAGGAGCCTCCCGGTCTCATCCTGCAAAAGCTAAAGGCTGCCAGAG GCCCCCCAAGATCCGTAACTACAACATTATGGACTGACTTCCTCCCCCCACCCCGCCCCACTAAGGGGTGCTCGGGGCCTCCGCATGGTG CCTGTGCTTTCACCTACGTGTTGTGGGGGGGTGTGGGCACAGCGTGCAGGGTGGAGGCAGGGAGCTGCAGGGCAGGCTCCCAAATGCTGC >19815_19815_7_CSNK1D-CCDC57_CSNK1D_chr17_80209255_ENST00000398519_CCDC57_chr17_80059742_ENST00000389641_length(amino acids)=318AA_BP=0 MELRVGNRYRLGRKIGSGSFGDIYLGTDIAAGEEVAIKLECVKTKHPQLHIESKIYKMMQGGVGIPTIRWCGAEGDYNVMVMELLGPSLE DLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNLVYIIDFGLAKKYRDARTHQHIPYRENKNLTGTARYA SINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMSTPIEVLCKGYPSEFATYLNFCRSLRFDDKPDYSYLR -------------------------------------------------------------- >19815_19815_8_CSNK1D-CCDC57_CSNK1D_chr17_80209255_ENST00000398519_CCDC57_chr17_80059742_ENST00000392347_length(transcript)=1329nt_BP=932nt CCCAGGAAGCGGCCGGGAGGGCAGGAGCGAATCGGGCCGCCGCCGCCATGGAGCTGAGAGTCGGGAACAGGTACCGGCTGGGCCGGAAGA TCGGCAGCGGCTCCTTCGGAGACATCTATCTCGGTACGGACATTGCTGCAGGAGAAGAGGTTGCCATCAAGCTTGAATGTGTCAAAACCA AACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGGGCATCCCCACCATCAGATGGTGCGGGGCAGAGG GGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCAACTTCTGCTCCAGGAAATTCAGCCTCAAAACCG TCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACTTCATCCACCGGGATGTGAAGCCAGACAACTTCC TCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCAAGAAGTACCGGGATGCACGCACCCACCAGCACA TCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACACGCACCTTGGAATTGAACAATCCCGAAGAGATG ACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGCAGGGGCTGAAGGCTGCCACCAAGAGACAGAAAT ACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCTACCCTTCCGAATTTGCCACATACCTGAATTTCT GCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCCGGAATCTGTTCCATCGCCAGGGCTTCTCCTATG ACTACGTGTTCGACTGGAACATGCTCAAATTTAGCTCCCAGCTCCTCCAGCAGCCGACAGGAGGCCCGTCAAGATGCAGGCAGGCATTGC CACCCCAGGGATGAAGACAGCAGCCCAGGCAAAGGCCAAGACCACAGGAGCCTCCCGGTCTCATCCTGCAAAAGCTAAAGGCTGCCAGAG GCCCCCCAAGATCCGTAACTACAACATTATGGACTGACTTCCTCCCCCCACCCCGCCCCACTAAGGGGTGCTCGGGGCCTCCGCATGGTG CCTGTGCTTTCACCTACGTGTTGTGGGGGGGTGTGGGCACAGCGTGCAGGGTGGAGGCAGGGAGCTGCAGGGCAGGCTCCCAAATGCTGC >19815_19815_8_CSNK1D-CCDC57_CSNK1D_chr17_80209255_ENST00000398519_CCDC57_chr17_80059742_ENST00000392347_length(amino acids)=318AA_BP=0 MELRVGNRYRLGRKIGSGSFGDIYLGTDIAAGEEVAIKLECVKTKHPQLHIESKIYKMMQGGVGIPTIRWCGAEGDYNVMVMELLGPSLE DLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNLVYIIDFGLAKKYRDARTHQHIPYRENKNLTGTARYA SINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMSTPIEVLCKGYPSEFATYLNFCRSLRFDDKPDYSYLR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CSNK1D-CCDC57 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CSNK1D-CCDC57 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CSNK1D-CCDC57 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies