
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CTNNA1-WNT8A (FusionGDB2 ID:20276) |
Fusion Gene Summary for CTNNA1-WNT8A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CTNNA1-WNT8A | Fusion gene ID: 20276 | Hgene | Tgene | Gene symbol | CTNNA1 | WNT8A | Gene ID | 1495 | 7478 |
| Gene name | catenin alpha 1 | Wnt family member 8A | |
| Synonyms | CAP102|MDPT2 | WNT8D | |
| Cytomap | 5q31.2 | 5q31.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | catenin alpha-1alpha-E-catenincatenin (cadherin-associated protein), alpha 1, 102kDaepididymis secretory sperm binding proteinrenal carcinoma antigen NY-REN-13 | protein Wnt-8aWNT8dprotein Wnt-8dwingless-type MMTV integration site family, member 8A | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000520400, ENST00000302763, ENST00000355078, ENST00000518825, ENST00000540387, | ENST00000398754, ENST00000506684, | |
| Fusion gene scores | * DoF score | 25 X 19 X 12=5700 | 1 X 1 X 1=1 |
| # samples | 34 | 1 | |
| ** MAII score | log2(34/5700*10)=-4.06735526780176 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: CTNNA1 [Title/Abstract] AND WNT8A [Title/Abstract] AND fusion [Title/Abstract] | ||
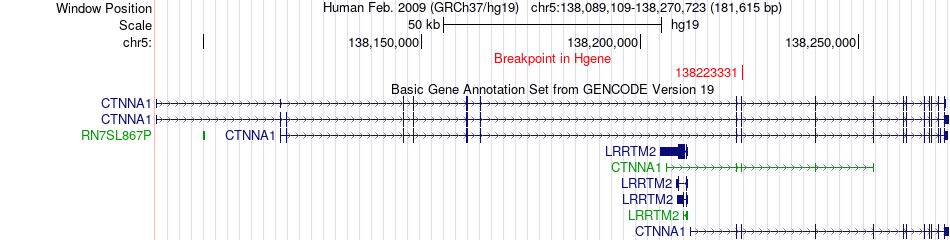
| Most frequent breakpoint | CTNNA1(138223331)-WNT8A(137420187), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CTNNA1 | GO:0071681 | cellular response to indole-3-methanol | 10868478 |
| Tgene | WNT8A | GO:0060070 | canonical Wnt signaling pathway | 28733458 |
| Fusion gene breakpoints across CTNNA1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across WNT8A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCEC | TCGA-PG-A914-01A | CTNNA1 | chr5 | 138223331 | - | WNT8A | chr5 | 137420187 | + |
| ChimerDB4 | UCEC | TCGA-PG-A914-01A | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| ChimerDB4 | UCEC | TCGA-PG-A914 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
Top |
Fusion Gene ORF analysis for CTNNA1-WNT8A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000520400 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| 3UTR-3CDS | ENST00000520400 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| In-frame | ENST00000302763 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| In-frame | ENST00000302763 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| In-frame | ENST00000355078 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| In-frame | ENST00000355078 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| In-frame | ENST00000518825 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| In-frame | ENST00000518825 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| In-frame | ENST00000540387 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| In-frame | ENST00000540387 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000355078 | CTNNA1 | chr5 | 138223331 | + | ENST00000506684 | WNT8A | chr5 | 137420187 | + | 2343 | 1192 | 202 | 2145 | 647 |
| ENST00000355078 | CTNNA1 | chr5 | 138223331 | + | ENST00000398754 | WNT8A | chr5 | 137420187 | + | 2583 | 1192 | 202 | 2145 | 647 |
| ENST00000302763 | CTNNA1 | chr5 | 138223331 | + | ENST00000506684 | WNT8A | chr5 | 137420187 | + | 2537 | 1386 | 90 | 2339 | 749 |
| ENST00000302763 | CTNNA1 | chr5 | 138223331 | + | ENST00000398754 | WNT8A | chr5 | 137420187 | + | 2777 | 1386 | 90 | 2339 | 749 |
| ENST00000518825 | CTNNA1 | chr5 | 138223331 | + | ENST00000506684 | WNT8A | chr5 | 137420187 | + | 2449 | 1298 | 2 | 2251 | 749 |
| ENST00000518825 | CTNNA1 | chr5 | 138223331 | + | ENST00000398754 | WNT8A | chr5 | 137420187 | + | 2689 | 1298 | 2 | 2251 | 749 |
| ENST00000540387 | CTNNA1 | chr5 | 138223331 | + | ENST00000506684 | WNT8A | chr5 | 137420187 | + | 1471 | 320 | 134 | 1273 | 379 |
| ENST00000540387 | CTNNA1 | chr5 | 138223331 | + | ENST00000398754 | WNT8A | chr5 | 137420187 | + | 1711 | 320 | 134 | 1273 | 379 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000355078 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + | 0.008795735 | 0.9912042 |
| ENST00000355078 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + | 0.007080681 | 0.99291927 |
| ENST00000302763 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + | 0.004407742 | 0.9955922 |
| ENST00000302763 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + | 0.003299107 | 0.9967008 |
| ENST00000518825 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + | 0.003903931 | 0.9960961 |
| ENST00000518825 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + | 0.002979816 | 0.9970202 |
| ENST00000540387 | ENST00000506684 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + | 0.011630209 | 0.9883698 |
| ENST00000540387 | ENST00000398754 | CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420187 | + | 0.010211103 | 0.98978883 |
Top |
Fusion Genomic Features for CTNNA1-WNT8A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420186 | + | 7.24E-07 | 0.9999993 |
| CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420186 | + | 7.24E-07 | 0.9999993 |
| CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420186 | + | 7.24E-07 | 0.9999993 |
| CTNNA1 | chr5 | 138223331 | + | WNT8A | chr5 | 137420186 | + | 7.24E-07 | 0.9999993 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for CTNNA1-WNT8A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:138223331/chr5:137420187) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CTNNA1 | chr5:138223331 | chr5:137420187 | ENST00000302763 | + | 9 | 18 | 2_228 | 432 | 907.0 | Region | Note=Involved in homodimerization |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CTNNA1 | chr5:138223331 | chr5:137420187 | ENST00000540387 | + | 3 | 12 | 2_228 | 62 | 537.0 | Region | Note=Involved in homodimerization |
Top |
Fusion Gene Sequence for CTNNA1-WNT8A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >20276_20276_1_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000302763_WNT8A_chr5_137420187_ENST00000398754_length(transcript)=2777nt_BP=1386nt TCCTCCTCCTAGCCGGACTGGAGGGAGACAAAGCAGCGCCCGTCTGCTTCGGGCCTCTGGAATTTAGCGCTCGCCCAGCTAGCCGCAGAA ATGACTGCTGTCCATGCAGGCAACATAAACTTCAAGTGGGATCCTAAAAGTCTAGAGATCAGGACTCTGGCAGTTGAGAGACTGTTGGAG CCTCTTGTTACACAGGTTACAACCCTTGTAAACACCAATAGTAAAGGGCCCTCTAATAAGAAGAGAGGTCGTTCTAAGAAGGCCCATGTT TTGGCTGCATCTGTTGAACAAGCAACTGAGAATTTCTTGGAGAAGGGGGATAAAATTGCGAAGGAGAGCCAGTTTCTCAAGGAGGAGCTT GTGGCTGCTGTAGAAGATGTTCGAAAACAAGGTGATTTGATGAAGGCTGCTGCAGGAGAGTTCGCAGATGATCCCTGCTCTTCTGTGAAG CGAGGCAACATGGTTCGGGCAGCTCGAGCTTTGCTCTCTGCTGTTACCCGGTTGCTGATTTTGGCTGACATGGCAGATGTCTACAAATTA CTTGTTCAGCTGAAAGTTGTGGAAGATGGTATCTTGAAGTTGAGGAATGCTGGCAATGAACAAGACTTAGGAATCCAGTATAAAGCCCTA AAACCTGAAGTGGATAAGCTGAACATTATGGCAGCCAAAAGACAACAGGAATTGAAAGATGTTGGCCATCGTGATCAGATGGCTGCAGCT AGAGGAATCCTGCAGAAGAACGTTCCGATCCTCTATACTGCATCCCAGGCATGCCTACAGCACCCTGATGTCGCAGCCTATAAGGCCAAC AGGGACCTGATATACAAGCAGCTGCAGCAGGCGGTCACAGGCATTTCCAATGCAGCCCAGGCCACTGCCTCAGACGATGCCTCACAGCAC CAGGGTGGAGGAGGAGGAGAACTGGCATATGCACTCAATAACTTTGACAAACAAATCATTGTGGACCCCTTGAGCTTCAGCGAGGAGCGC TTTAGGCCTTCCCTGGAGGAGCGTCTGGAAAGCATCATTAGTGGGGCTGCCTTGATGGCCGACTCGTCCTGCACGCGTGATGACCGTCGT GAGCGAATTGTGGCAGAGTGTAATGCTGTCCGCCAGGCCCTGCAGGACCTGCTTTCGGAGTACATGGGCAATGCTGGACGTAAAGAAAGA AGTGATGCACTCAATTCTGCAATAGATAAAATGACCAAGAAGACCAGGGACTTGCGTAGACAGCTCCGCAAAGCTGTCATGGACCACGTT TCAGATTCTTTCCTGGAAACCAATGTTCCACTTTTGGTATTGATTGAAGCTGCAAAGAATGGAAATGAGAAAGAAGTTAAGGAGTATGCC CAAGTTTTCCGTGAACATGCCAACAAATTGATTGAGGCCTATCTGACCTACACGACTAGTGTGGCCTTGGGTGCCCAGAGTGGCATCGAG GAGTGCAAGTTCCAGTTTGCTTGGGAACGCTGGAACTGCCCTGAAAATGCTCTTCAGCTCTCCACCCACAACAGGCTGAGAAGTGCTACC AGAGAGACTTCCTTCATACATGCTATCAGCTCTGCTGGAGTCATGTACATCATCACCAAGAACTGTAGCATGGGTGACTTCGAAAACTGT GGCTGTGATGGGTCAAACAATGGAAAAACAGGAGGCCATGGCTGGATCTGGGGAGGCTGCAGCGACAATGTGGAATTTGGGGAAAGGATC TCCAAACTCTTTGTGGACAGTTTGGAGAAGGGGAAGGATGCCAGAGCCCTGATGAATCTTCACAACAACAGGGCCGGCAGACTGGCAGTG AGAGCCACCATGAAAAGGACATGCAAATGTCATGGCATCTCTGGGAGCTGCAGCATACAGACATGCTGGCTGCAGCTGGCTGAATTCCGG GAGATGGGAGACTACCTAAAGGCCAAGTATGACCAGGCGCTGAAAATTGAAATGGATAAGCGGCAGCTGAGAGCTGGGAACAGCGCCGAG GGCCACTGGGTGCCCGCTGAGGCCTTCCTTCCTAGCGCAGAGGCGGAACTGATCTTTTTAGAGGAATCACCAGATTACTGTACCTGCAAT TCCAGCCTGGGCATCTATGGCACAGAGGGTCGTGAGTGCCTACAGAACAGCCACAACACATCCAGGTGGGAGCGACGTAGCTGTGGGCGC CTGTGCACTGAGTGTGGGCTGCAGGTGGAAGAGAGGAAAACTGAGGTCATAAGCAGCTGTAACTGCAAATTCCAGTGGTGCTGTACGGTC AAGTGTGACCAGTGTAGGCATGTGGTGAGCAAGTATTACTGCGCACGCTCCCCAGGCAGTGCCCAGTCCCTGGGTAAGGGCAGTGCCTGA TAATACCCCACACAAGTTCACTTGATTAATTGCATCAGTGGAAGGGGACATAGCTTCTCTCTTAGAGAGAACAGATTGGAAAGCAATCGG AAAATTGCAGTTTTGGTCTGTAGTCCTCATGATATCTGCTATCAGTGGGGAAAATGGAGGCCCAAGATTCTACAGCATATTCCTGGCGGG GCTGAAATTGGAACCTGGGCCTCCTGACTTTGGCAGACCCCCATTTCATCTTTCCTGCAAACTACTTTCCCATCTTTGTGCCTGTACTTA TGCAGCTTTCTACAGGGAGAGTTTGGTTTGGGGTCTATATCTAGAGGGACCTTCAAAGTATTTGTTCCTTTAAATTTCAGACCATGTCCA >20276_20276_1_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000302763_WNT8A_chr5_137420187_ENST00000398754_length(amino acids)=749AA_BP=432 MTAVHAGNINFKWDPKSLEIRTLAVERLLEPLVTQVTTLVNTNSKGPSNKKRGRSKKAHVLAASVEQATENFLEKGDKIAKESQFLKEEL VAAVEDVRKQGDLMKAAAGEFADDPCSSVKRGNMVRAARALLSAVTRLLILADMADVYKLLVQLKVVEDGILKLRNAGNEQDLGIQYKAL KPEVDKLNIMAAKRQQELKDVGHRDQMAAARGILQKNVPILYTASQACLQHPDVAAYKANRDLIYKQLQQAVTGISNAAQATASDDASQH QGGGGGELAYALNNFDKQIIVDPLSFSEERFRPSLEERLESIISGAALMADSSCTRDDRRERIVAECNAVRQALQDLLSEYMGNAGRKER SDALNSAIDKMTKKTRDLRRQLRKAVMDHVSDSFLETNVPLLVLIEAAKNGNEKEVKEYAQVFREHANKLIEAYLTYTTSVALGAQSGIE ECKFQFAWERWNCPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERI SKLFVDSLEKGKDARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAE GHWVPAEAFLPSAEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTV -------------------------------------------------------------- >20276_20276_2_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000302763_WNT8A_chr5_137420187_ENST00000506684_length(transcript)=2537nt_BP=1386nt TCCTCCTCCTAGCCGGACTGGAGGGAGACAAAGCAGCGCCCGTCTGCTTCGGGCCTCTGGAATTTAGCGCTCGCCCAGCTAGCCGCAGAA ATGACTGCTGTCCATGCAGGCAACATAAACTTCAAGTGGGATCCTAAAAGTCTAGAGATCAGGACTCTGGCAGTTGAGAGACTGTTGGAG CCTCTTGTTACACAGGTTACAACCCTTGTAAACACCAATAGTAAAGGGCCCTCTAATAAGAAGAGAGGTCGTTCTAAGAAGGCCCATGTT TTGGCTGCATCTGTTGAACAAGCAACTGAGAATTTCTTGGAGAAGGGGGATAAAATTGCGAAGGAGAGCCAGTTTCTCAAGGAGGAGCTT GTGGCTGCTGTAGAAGATGTTCGAAAACAAGGTGATTTGATGAAGGCTGCTGCAGGAGAGTTCGCAGATGATCCCTGCTCTTCTGTGAAG CGAGGCAACATGGTTCGGGCAGCTCGAGCTTTGCTCTCTGCTGTTACCCGGTTGCTGATTTTGGCTGACATGGCAGATGTCTACAAATTA CTTGTTCAGCTGAAAGTTGTGGAAGATGGTATCTTGAAGTTGAGGAATGCTGGCAATGAACAAGACTTAGGAATCCAGTATAAAGCCCTA AAACCTGAAGTGGATAAGCTGAACATTATGGCAGCCAAAAGACAACAGGAATTGAAAGATGTTGGCCATCGTGATCAGATGGCTGCAGCT AGAGGAATCCTGCAGAAGAACGTTCCGATCCTCTATACTGCATCCCAGGCATGCCTACAGCACCCTGATGTCGCAGCCTATAAGGCCAAC AGGGACCTGATATACAAGCAGCTGCAGCAGGCGGTCACAGGCATTTCCAATGCAGCCCAGGCCACTGCCTCAGACGATGCCTCACAGCAC CAGGGTGGAGGAGGAGGAGAACTGGCATATGCACTCAATAACTTTGACAAACAAATCATTGTGGACCCCTTGAGCTTCAGCGAGGAGCGC TTTAGGCCTTCCCTGGAGGAGCGTCTGGAAAGCATCATTAGTGGGGCTGCCTTGATGGCCGACTCGTCCTGCACGCGTGATGACCGTCGT GAGCGAATTGTGGCAGAGTGTAATGCTGTCCGCCAGGCCCTGCAGGACCTGCTTTCGGAGTACATGGGCAATGCTGGACGTAAAGAAAGA AGTGATGCACTCAATTCTGCAATAGATAAAATGACCAAGAAGACCAGGGACTTGCGTAGACAGCTCCGCAAAGCTGTCATGGACCACGTT TCAGATTCTTTCCTGGAAACCAATGTTCCACTTTTGGTATTGATTGAAGCTGCAAAGAATGGAAATGAGAAAGAAGTTAAGGAGTATGCC CAAGTTTTCCGTGAACATGCCAACAAATTGATTGAGGCCTATCTGACCTACACGACTAGTGTGGCCTTGGGTGCCCAGAGTGGCATCGAG GAGTGCAAGTTCCAGTTTGCTTGGGAACGCTGGAACTGCCCTGAAAATGCTCTTCAGCTCTCCACCCACAACAGGCTGAGAAGTGCTACC AGAGAGACTTCCTTCATACATGCTATCAGCTCTGCTGGAGTCATGTACATCATCACCAAGAACTGTAGCATGGGTGACTTCGAAAACTGT GGCTGTGATGGGTCAAACAATGGAAAAACAGGAGGCCATGGCTGGATCTGGGGAGGCTGCAGCGACAATGTGGAATTTGGGGAAAGGATC TCCAAACTCTTTGTGGACAGTTTGGAGAAGGGGAAGGATGCCAGAGCCCTGATGAATCTTCACAACAACAGGGCCGGCAGACTGGCAGTG AGAGCCACCATGAAAAGGACATGCAAATGTCATGGCATCTCTGGGAGCTGCAGCATACAGACATGCTGGCTGCAGCTGGCTGAATTCCGG GAGATGGGAGACTACCTAAAGGCCAAGTATGACCAGGCGCTGAAAATTGAAATGGATAAGCGGCAGCTGAGAGCTGGGAACAGCGCCGAG GGCCACTGGGTGCCCGCTGAGGCCTTCCTTCCTAGCGCAGAGGCGGAACTGATCTTTTTAGAGGAATCACCAGATTACTGTACCTGCAAT TCCAGCCTGGGCATCTATGGCACAGAGGGTCGTGAGTGCCTACAGAACAGCCACAACACATCCAGGTGGGAGCGACGTAGCTGTGGGCGC CTGTGCACTGAGTGTGGGCTGCAGGTGGAAGAGAGGAAAACTGAGGTCATAAGCAGCTGTAACTGCAAATTCCAGTGGTGCTGTACGGTC AAGTGTGACCAGTGTAGGCATGTGGTGAGCAAGTATTACTGCGCACGCTCCCCAGGCAGTGCCCAGTCCCTGGGTAAGGGCAGTGCCTGA TAATACCCCACACAAGTTCACTTGATTAATTGCATCAGTGGAAGGGGACATAGCTTCTCTCTTAGAGAGAACAGATTGGAAAGCAATCGG AAAATTGCAGTTTTGGTCTGTAGTCCTCATGATATCTGCTATCAGTGGGGAAAATGGAGGCCCAAGATTCTACAGCATATTCCTGGCGGG >20276_20276_2_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000302763_WNT8A_chr5_137420187_ENST00000506684_length(amino acids)=749AA_BP=432 MTAVHAGNINFKWDPKSLEIRTLAVERLLEPLVTQVTTLVNTNSKGPSNKKRGRSKKAHVLAASVEQATENFLEKGDKIAKESQFLKEEL VAAVEDVRKQGDLMKAAAGEFADDPCSSVKRGNMVRAARALLSAVTRLLILADMADVYKLLVQLKVVEDGILKLRNAGNEQDLGIQYKAL KPEVDKLNIMAAKRQQELKDVGHRDQMAAARGILQKNVPILYTASQACLQHPDVAAYKANRDLIYKQLQQAVTGISNAAQATASDDASQH QGGGGGELAYALNNFDKQIIVDPLSFSEERFRPSLEERLESIISGAALMADSSCTRDDRRERIVAECNAVRQALQDLLSEYMGNAGRKER SDALNSAIDKMTKKTRDLRRQLRKAVMDHVSDSFLETNVPLLVLIEAAKNGNEKEVKEYAQVFREHANKLIEAYLTYTTSVALGAQSGIE ECKFQFAWERWNCPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERI SKLFVDSLEKGKDARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAE GHWVPAEAFLPSAEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTV -------------------------------------------------------------- >20276_20276_3_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000355078_WNT8A_chr5_137420187_ENST00000398754_length(transcript)=2583nt_BP=1192nt TTTCCTCCTCCTAGCCGGACTGGAGGGAGACAAAGCAGCGCCCGTCTGCTTCGGGCCTCTGGAATTTAGCGCTCGCCCAGCTAGCCGCAG AAATGACTGCTGTCCATGCAGGCAACATAAACTTCAAGTGGGATCCTAAAAGTCTAGAGATCAGGACTCTGGCAGTTGAGAGACTGTTGG AGCCTCTTGTTACACAGGTGATTTGATGAAGGCTGCTGCAGGAGAGTTCGCAGATGATCCCTGCTCTTCTGTGAAGCGAGGCAACATGGT TCGGGCAGCTCGAGCTTTGCTCTCTGCTGTTACCCGGTTGCTGATTTTGGCTGACATGGCAGATGTCTACAAATTACTTGTTCAGCTGAA AGTTGTGGAAGATGGTATCTTGAAGTTGAGGAATGCTGGCAATGAACAAGACTTAGGAATCCAGTATAAAGCCCTAAAACCTGAAGTGGA TAAGCTGAACATTATGGCAGCCAAAAGACAACAGGAATTGAAAGATGTTGGCCATCGTGATCAGATGGCTGCAGCTAGAGGAATCCTGCA GAAGAACGTTCCGATCCTCTATACTGCATCCCAGGCATGCCTACAGCACCCTGATGTCGCAGCCTATAAGGCCAACAGGGACCTGATATA CAAGCAGCTGCAGCAGGCGGTCACAGGCATTTCCAATGCAGCCCAGGCCACTGCCTCAGACGATGCCTCACAGCACCAGGGTGGAGGAGG AGGAGAACTGGCATATGCACTCAATAACTTTGACAAACAAATCATTGTGGACCCCTTGAGCTTCAGCGAGGAGCGCTTTAGGCCTTCCCT GGAGGAGCGTCTGGAAAGCATCATTAGTGGGGCTGCCTTGATGGCCGACTCGTCCTGCACGCGTGATGACCGTCGTGAGCGAATTGTGGC AGAGTGTAATGCTGTCCGCCAGGCCCTGCAGGACCTGCTTTCGGAGTACATGGGCAATGCTGGACGTAAAGAAAGAAGTGATGCACTCAA TTCTGCAATAGATAAAATGACCAAGAAGACCAGGGACTTGCGTAGACAGCTCCGCAAAGCTGTCATGGACCACGTTTCAGATTCTTTCCT GGAAACCAATGTTCCACTTTTGGTATTGATTGAAGCTGCAAAGAATGGAAATGAGAAAGAAGTTAAGGAGTATGCCCAAGTTTTCCGTGA ACATGCCAACAAATTGATTGAGGCCTATCTGACCTACACGACTAGTGTGGCCTTGGGTGCCCAGAGTGGCATCGAGGAGTGCAAGTTCCA GTTTGCTTGGGAACGCTGGAACTGCCCTGAAAATGCTCTTCAGCTCTCCACCCACAACAGGCTGAGAAGTGCTACCAGAGAGACTTCCTT CATACATGCTATCAGCTCTGCTGGAGTCATGTACATCATCACCAAGAACTGTAGCATGGGTGACTTCGAAAACTGTGGCTGTGATGGGTC AAACAATGGAAAAACAGGAGGCCATGGCTGGATCTGGGGAGGCTGCAGCGACAATGTGGAATTTGGGGAAAGGATCTCCAAACTCTTTGT GGACAGTTTGGAGAAGGGGAAGGATGCCAGAGCCCTGATGAATCTTCACAACAACAGGGCCGGCAGACTGGCAGTGAGAGCCACCATGAA AAGGACATGCAAATGTCATGGCATCTCTGGGAGCTGCAGCATACAGACATGCTGGCTGCAGCTGGCTGAATTCCGGGAGATGGGAGACTA CCTAAAGGCCAAGTATGACCAGGCGCTGAAAATTGAAATGGATAAGCGGCAGCTGAGAGCTGGGAACAGCGCCGAGGGCCACTGGGTGCC CGCTGAGGCCTTCCTTCCTAGCGCAGAGGCGGAACTGATCTTTTTAGAGGAATCACCAGATTACTGTACCTGCAATTCCAGCCTGGGCAT CTATGGCACAGAGGGTCGTGAGTGCCTACAGAACAGCCACAACACATCCAGGTGGGAGCGACGTAGCTGTGGGCGCCTGTGCACTGAGTG TGGGCTGCAGGTGGAAGAGAGGAAAACTGAGGTCATAAGCAGCTGTAACTGCAAATTCCAGTGGTGCTGTACGGTCAAGTGTGACCAGTG TAGGCATGTGGTGAGCAAGTATTACTGCGCACGCTCCCCAGGCAGTGCCCAGTCCCTGGGTAAGGGCAGTGCCTGATAATACCCCACACA AGTTCACTTGATTAATTGCATCAGTGGAAGGGGACATAGCTTCTCTCTTAGAGAGAACAGATTGGAAAGCAATCGGAAAATTGCAGTTTT GGTCTGTAGTCCTCATGATATCTGCTATCAGTGGGGAAAATGGAGGCCCAAGATTCTACAGCATATTCCTGGCGGGGCTGAAATTGGAAC CTGGGCCTCCTGACTTTGGCAGACCCCCATTTCATCTTTCCTGCAAACTACTTTCCCATCTTTGTGCCTGTACTTATGCAGCTTTCTACA GGGAGAGTTTGGTTTGGGGTCTATATCTAGAGGGACCTTCAAAGTATTTGTTCCTTTAAATTTCAGACCATGTCCAACCCAGCTGTGCTG >20276_20276_3_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000355078_WNT8A_chr5_137420187_ENST00000398754_length(amino acids)=647AA_BP=330 MMKAAAGEFADDPCSSVKRGNMVRAARALLSAVTRLLILADMADVYKLLVQLKVVEDGILKLRNAGNEQDLGIQYKALKPEVDKLNIMAA KRQQELKDVGHRDQMAAARGILQKNVPILYTASQACLQHPDVAAYKANRDLIYKQLQQAVTGISNAAQATASDDASQHQGGGGGELAYAL NNFDKQIIVDPLSFSEERFRPSLEERLESIISGAALMADSSCTRDDRRERIVAECNAVRQALQDLLSEYMGNAGRKERSDALNSAIDKMT KKTRDLRRQLRKAVMDHVSDSFLETNVPLLVLIEAAKNGNEKEVKEYAQVFREHANKLIEAYLTYTTSVALGAQSGIEECKFQFAWERWN CPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERISKLFVDSLEKGK DARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAEGHWVPAEAFLPS AEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTVKCDQCRHVVSKY -------------------------------------------------------------- >20276_20276_4_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000355078_WNT8A_chr5_137420187_ENST00000506684_length(transcript)=2343nt_BP=1192nt TTTCCTCCTCCTAGCCGGACTGGAGGGAGACAAAGCAGCGCCCGTCTGCTTCGGGCCTCTGGAATTTAGCGCTCGCCCAGCTAGCCGCAG AAATGACTGCTGTCCATGCAGGCAACATAAACTTCAAGTGGGATCCTAAAAGTCTAGAGATCAGGACTCTGGCAGTTGAGAGACTGTTGG AGCCTCTTGTTACACAGGTGATTTGATGAAGGCTGCTGCAGGAGAGTTCGCAGATGATCCCTGCTCTTCTGTGAAGCGAGGCAACATGGT TCGGGCAGCTCGAGCTTTGCTCTCTGCTGTTACCCGGTTGCTGATTTTGGCTGACATGGCAGATGTCTACAAATTACTTGTTCAGCTGAA AGTTGTGGAAGATGGTATCTTGAAGTTGAGGAATGCTGGCAATGAACAAGACTTAGGAATCCAGTATAAAGCCCTAAAACCTGAAGTGGA TAAGCTGAACATTATGGCAGCCAAAAGACAACAGGAATTGAAAGATGTTGGCCATCGTGATCAGATGGCTGCAGCTAGAGGAATCCTGCA GAAGAACGTTCCGATCCTCTATACTGCATCCCAGGCATGCCTACAGCACCCTGATGTCGCAGCCTATAAGGCCAACAGGGACCTGATATA CAAGCAGCTGCAGCAGGCGGTCACAGGCATTTCCAATGCAGCCCAGGCCACTGCCTCAGACGATGCCTCACAGCACCAGGGTGGAGGAGG AGGAGAACTGGCATATGCACTCAATAACTTTGACAAACAAATCATTGTGGACCCCTTGAGCTTCAGCGAGGAGCGCTTTAGGCCTTCCCT GGAGGAGCGTCTGGAAAGCATCATTAGTGGGGCTGCCTTGATGGCCGACTCGTCCTGCACGCGTGATGACCGTCGTGAGCGAATTGTGGC AGAGTGTAATGCTGTCCGCCAGGCCCTGCAGGACCTGCTTTCGGAGTACATGGGCAATGCTGGACGTAAAGAAAGAAGTGATGCACTCAA TTCTGCAATAGATAAAATGACCAAGAAGACCAGGGACTTGCGTAGACAGCTCCGCAAAGCTGTCATGGACCACGTTTCAGATTCTTTCCT GGAAACCAATGTTCCACTTTTGGTATTGATTGAAGCTGCAAAGAATGGAAATGAGAAAGAAGTTAAGGAGTATGCCCAAGTTTTCCGTGA ACATGCCAACAAATTGATTGAGGCCTATCTGACCTACACGACTAGTGTGGCCTTGGGTGCCCAGAGTGGCATCGAGGAGTGCAAGTTCCA GTTTGCTTGGGAACGCTGGAACTGCCCTGAAAATGCTCTTCAGCTCTCCACCCACAACAGGCTGAGAAGTGCTACCAGAGAGACTTCCTT CATACATGCTATCAGCTCTGCTGGAGTCATGTACATCATCACCAAGAACTGTAGCATGGGTGACTTCGAAAACTGTGGCTGTGATGGGTC AAACAATGGAAAAACAGGAGGCCATGGCTGGATCTGGGGAGGCTGCAGCGACAATGTGGAATTTGGGGAAAGGATCTCCAAACTCTTTGT GGACAGTTTGGAGAAGGGGAAGGATGCCAGAGCCCTGATGAATCTTCACAACAACAGGGCCGGCAGACTGGCAGTGAGAGCCACCATGAA AAGGACATGCAAATGTCATGGCATCTCTGGGAGCTGCAGCATACAGACATGCTGGCTGCAGCTGGCTGAATTCCGGGAGATGGGAGACTA CCTAAAGGCCAAGTATGACCAGGCGCTGAAAATTGAAATGGATAAGCGGCAGCTGAGAGCTGGGAACAGCGCCGAGGGCCACTGGGTGCC CGCTGAGGCCTTCCTTCCTAGCGCAGAGGCGGAACTGATCTTTTTAGAGGAATCACCAGATTACTGTACCTGCAATTCCAGCCTGGGCAT CTATGGCACAGAGGGTCGTGAGTGCCTACAGAACAGCCACAACACATCCAGGTGGGAGCGACGTAGCTGTGGGCGCCTGTGCACTGAGTG TGGGCTGCAGGTGGAAGAGAGGAAAACTGAGGTCATAAGCAGCTGTAACTGCAAATTCCAGTGGTGCTGTACGGTCAAGTGTGACCAGTG TAGGCATGTGGTGAGCAAGTATTACTGCGCACGCTCCCCAGGCAGTGCCCAGTCCCTGGGTAAGGGCAGTGCCTGATAATACCCCACACA AGTTCACTTGATTAATTGCATCAGTGGAAGGGGACATAGCTTCTCTCTTAGAGAGAACAGATTGGAAAGCAATCGGAAAATTGCAGTTTT GGTCTGTAGTCCTCATGATATCTGCTATCAGTGGGGAAAATGGAGGCCCAAGATTCTACAGCATATTCCTGGCGGGGCTGAAATTGGAAC >20276_20276_4_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000355078_WNT8A_chr5_137420187_ENST00000506684_length(amino acids)=647AA_BP=330 MMKAAAGEFADDPCSSVKRGNMVRAARALLSAVTRLLILADMADVYKLLVQLKVVEDGILKLRNAGNEQDLGIQYKALKPEVDKLNIMAA KRQQELKDVGHRDQMAAARGILQKNVPILYTASQACLQHPDVAAYKANRDLIYKQLQQAVTGISNAAQATASDDASQHQGGGGGELAYAL NNFDKQIIVDPLSFSEERFRPSLEERLESIISGAALMADSSCTRDDRRERIVAECNAVRQALQDLLSEYMGNAGRKERSDALNSAIDKMT KKTRDLRRQLRKAVMDHVSDSFLETNVPLLVLIEAAKNGNEKEVKEYAQVFREHANKLIEAYLTYTTSVALGAQSGIEECKFQFAWERWN CPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERISKLFVDSLEKGK DARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAEGHWVPAEAFLPS AEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTVKCDQCRHVVSKY -------------------------------------------------------------- >20276_20276_5_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000518825_WNT8A_chr5_137420187_ENST00000398754_length(transcript)=2689nt_BP=1298nt AAATGACTGCTGTCCATGCAGGCAACATAAACTTCAAGTGGGATCCTAAAAGTCTAGAGATCAGGACTCTGGCAGTTGAGAGACTGTTGG AGCCTCTTGTTACACAGGTTACAACCCTTGTAAACACCAATAGTAAAGGGCCCTCTAATAAGAAGAGAGGTCGTTCTAAGAAGGCCCATG TTTTGGCTGCATCTGTTGAACAAGCAACTGAGAATTTCTTGGAGAAGGGGGATAAAATTGCGAAGGAGAGCCAGTTTCTCAAGGAGGAGC TTGTGGCTGCTGTAGAAGATGTTCGAAAACAAGGTGATTTGATGAAGGCTGCTGCAGGAGAGTTCGCAGATGATCCCTGCTCTTCTGTGA AGCGAGGCAACATGGTTCGGGCAGCTCGAGCTTTGCTCTCTGCTGTTACCCGGTTGCTGATTTTGGCTGACATGGCAGATGTCTACAAAT TACTTGTTCAGCTGAAAGTTGTGGAAGATGGTATCTTGAAGTTGAGGAATGCTGGCAATGAACAAGACTTAGGAATCCAGTATAAAGCCC TAAAACCTGAAGTGGATAAGCTGAACATTATGGCAGCCAAAAGACAACAGGAATTGAAAGATGTTGGCCATCGTGATCAGATGGCTGCAG CTAGAGGAATCCTGCAGAAGAACGTTCCGATCCTCTATACTGCATCCCAGGCATGCCTACAGCACCCTGATGTCGCAGCCTATAAGGCCA ACAGGGACCTGATATACAAGCAGCTGCAGCAGGCGGTCACAGGCATTTCCAATGCAGCCCAGGCCACTGCCTCAGACGATGCCTCACAGC ACCAGGGTGGAGGAGGAGGAGAACTGGCATATGCACTCAATAACTTTGACAAACAAATCATTGTGGACCCCTTGAGCTTCAGCGAGGAGC GCTTTAGGCCTTCCCTGGAGGAGCGTCTGGAAAGCATCATTAGTGGGGCTGCCTTGATGGCCGACTCGTCCTGCACGCGTGATGACCGTC GTGAGCGAATTGTGGCAGAGTGTAATGCTGTCCGCCAGGCCCTGCAGGACCTGCTTTCGGAGTACATGGGCAATGCTGGACGTAAAGAAA GAAGTGATGCACTCAATTCTGCAATAGATAAAATGACCAAGAAGACCAGGGACTTGCGTAGACAGCTCCGCAAAGCTGTCATGGACCACG TTTCAGATTCTTTCCTGGAAACCAATGTTCCACTTTTGGTATTGATTGAAGCTGCAAAGAATGGAAATGAGAAAGAAGTTAAGGAGTATG CCCAAGTTTTCCGTGAACATGCCAACAAATTGATTGAGGCCTATCTGACCTACACGACTAGTGTGGCCTTGGGTGCCCAGAGTGGCATCG AGGAGTGCAAGTTCCAGTTTGCTTGGGAACGCTGGAACTGCCCTGAAAATGCTCTTCAGCTCTCCACCCACAACAGGCTGAGAAGTGCTA CCAGAGAGACTTCCTTCATACATGCTATCAGCTCTGCTGGAGTCATGTACATCATCACCAAGAACTGTAGCATGGGTGACTTCGAAAACT GTGGCTGTGATGGGTCAAACAATGGAAAAACAGGAGGCCATGGCTGGATCTGGGGAGGCTGCAGCGACAATGTGGAATTTGGGGAAAGGA TCTCCAAACTCTTTGTGGACAGTTTGGAGAAGGGGAAGGATGCCAGAGCCCTGATGAATCTTCACAACAACAGGGCCGGCAGACTGGCAG TGAGAGCCACCATGAAAAGGACATGCAAATGTCATGGCATCTCTGGGAGCTGCAGCATACAGACATGCTGGCTGCAGCTGGCTGAATTCC GGGAGATGGGAGACTACCTAAAGGCCAAGTATGACCAGGCGCTGAAAATTGAAATGGATAAGCGGCAGCTGAGAGCTGGGAACAGCGCCG AGGGCCACTGGGTGCCCGCTGAGGCCTTCCTTCCTAGCGCAGAGGCGGAACTGATCTTTTTAGAGGAATCACCAGATTACTGTACCTGCA ATTCCAGCCTGGGCATCTATGGCACAGAGGGTCGTGAGTGCCTACAGAACAGCCACAACACATCCAGGTGGGAGCGACGTAGCTGTGGGC GCCTGTGCACTGAGTGTGGGCTGCAGGTGGAAGAGAGGAAAACTGAGGTCATAAGCAGCTGTAACTGCAAATTCCAGTGGTGCTGTACGG TCAAGTGTGACCAGTGTAGGCATGTGGTGAGCAAGTATTACTGCGCACGCTCCCCAGGCAGTGCCCAGTCCCTGGGTAAGGGCAGTGCCT GATAATACCCCACACAAGTTCACTTGATTAATTGCATCAGTGGAAGGGGACATAGCTTCTCTCTTAGAGAGAACAGATTGGAAAGCAATC GGAAAATTGCAGTTTTGGTCTGTAGTCCTCATGATATCTGCTATCAGTGGGGAAAATGGAGGCCCAAGATTCTACAGCATATTCCTGGCG GGGCTGAAATTGGAACCTGGGCCTCCTGACTTTGGCAGACCCCCATTTCATCTTTCCTGCAAACTACTTTCCCATCTTTGTGCCTGTACT TATGCAGCTTTCTACAGGGAGAGTTTGGTTTGGGGTCTATATCTAGAGGGACCTTCAAAGTATTTGTTCCTTTAAATTTCAGACCATGTC >20276_20276_5_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000518825_WNT8A_chr5_137420187_ENST00000398754_length(amino acids)=749AA_BP=432 MTAVHAGNINFKWDPKSLEIRTLAVERLLEPLVTQVTTLVNTNSKGPSNKKRGRSKKAHVLAASVEQATENFLEKGDKIAKESQFLKEEL VAAVEDVRKQGDLMKAAAGEFADDPCSSVKRGNMVRAARALLSAVTRLLILADMADVYKLLVQLKVVEDGILKLRNAGNEQDLGIQYKAL KPEVDKLNIMAAKRQQELKDVGHRDQMAAARGILQKNVPILYTASQACLQHPDVAAYKANRDLIYKQLQQAVTGISNAAQATASDDASQH QGGGGGELAYALNNFDKQIIVDPLSFSEERFRPSLEERLESIISGAALMADSSCTRDDRRERIVAECNAVRQALQDLLSEYMGNAGRKER SDALNSAIDKMTKKTRDLRRQLRKAVMDHVSDSFLETNVPLLVLIEAAKNGNEKEVKEYAQVFREHANKLIEAYLTYTTSVALGAQSGIE ECKFQFAWERWNCPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERI SKLFVDSLEKGKDARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAE GHWVPAEAFLPSAEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTV -------------------------------------------------------------- >20276_20276_6_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000518825_WNT8A_chr5_137420187_ENST00000506684_length(transcript)=2449nt_BP=1298nt AAATGACTGCTGTCCATGCAGGCAACATAAACTTCAAGTGGGATCCTAAAAGTCTAGAGATCAGGACTCTGGCAGTTGAGAGACTGTTGG AGCCTCTTGTTACACAGGTTACAACCCTTGTAAACACCAATAGTAAAGGGCCCTCTAATAAGAAGAGAGGTCGTTCTAAGAAGGCCCATG TTTTGGCTGCATCTGTTGAACAAGCAACTGAGAATTTCTTGGAGAAGGGGGATAAAATTGCGAAGGAGAGCCAGTTTCTCAAGGAGGAGC TTGTGGCTGCTGTAGAAGATGTTCGAAAACAAGGTGATTTGATGAAGGCTGCTGCAGGAGAGTTCGCAGATGATCCCTGCTCTTCTGTGA AGCGAGGCAACATGGTTCGGGCAGCTCGAGCTTTGCTCTCTGCTGTTACCCGGTTGCTGATTTTGGCTGACATGGCAGATGTCTACAAAT TACTTGTTCAGCTGAAAGTTGTGGAAGATGGTATCTTGAAGTTGAGGAATGCTGGCAATGAACAAGACTTAGGAATCCAGTATAAAGCCC TAAAACCTGAAGTGGATAAGCTGAACATTATGGCAGCCAAAAGACAACAGGAATTGAAAGATGTTGGCCATCGTGATCAGATGGCTGCAG CTAGAGGAATCCTGCAGAAGAACGTTCCGATCCTCTATACTGCATCCCAGGCATGCCTACAGCACCCTGATGTCGCAGCCTATAAGGCCA ACAGGGACCTGATATACAAGCAGCTGCAGCAGGCGGTCACAGGCATTTCCAATGCAGCCCAGGCCACTGCCTCAGACGATGCCTCACAGC ACCAGGGTGGAGGAGGAGGAGAACTGGCATATGCACTCAATAACTTTGACAAACAAATCATTGTGGACCCCTTGAGCTTCAGCGAGGAGC GCTTTAGGCCTTCCCTGGAGGAGCGTCTGGAAAGCATCATTAGTGGGGCTGCCTTGATGGCCGACTCGTCCTGCACGCGTGATGACCGTC GTGAGCGAATTGTGGCAGAGTGTAATGCTGTCCGCCAGGCCCTGCAGGACCTGCTTTCGGAGTACATGGGCAATGCTGGACGTAAAGAAA GAAGTGATGCACTCAATTCTGCAATAGATAAAATGACCAAGAAGACCAGGGACTTGCGTAGACAGCTCCGCAAAGCTGTCATGGACCACG TTTCAGATTCTTTCCTGGAAACCAATGTTCCACTTTTGGTATTGATTGAAGCTGCAAAGAATGGAAATGAGAAAGAAGTTAAGGAGTATG CCCAAGTTTTCCGTGAACATGCCAACAAATTGATTGAGGCCTATCTGACCTACACGACTAGTGTGGCCTTGGGTGCCCAGAGTGGCATCG AGGAGTGCAAGTTCCAGTTTGCTTGGGAACGCTGGAACTGCCCTGAAAATGCTCTTCAGCTCTCCACCCACAACAGGCTGAGAAGTGCTA CCAGAGAGACTTCCTTCATACATGCTATCAGCTCTGCTGGAGTCATGTACATCATCACCAAGAACTGTAGCATGGGTGACTTCGAAAACT GTGGCTGTGATGGGTCAAACAATGGAAAAACAGGAGGCCATGGCTGGATCTGGGGAGGCTGCAGCGACAATGTGGAATTTGGGGAAAGGA TCTCCAAACTCTTTGTGGACAGTTTGGAGAAGGGGAAGGATGCCAGAGCCCTGATGAATCTTCACAACAACAGGGCCGGCAGACTGGCAG TGAGAGCCACCATGAAAAGGACATGCAAATGTCATGGCATCTCTGGGAGCTGCAGCATACAGACATGCTGGCTGCAGCTGGCTGAATTCC GGGAGATGGGAGACTACCTAAAGGCCAAGTATGACCAGGCGCTGAAAATTGAAATGGATAAGCGGCAGCTGAGAGCTGGGAACAGCGCCG AGGGCCACTGGGTGCCCGCTGAGGCCTTCCTTCCTAGCGCAGAGGCGGAACTGATCTTTTTAGAGGAATCACCAGATTACTGTACCTGCA ATTCCAGCCTGGGCATCTATGGCACAGAGGGTCGTGAGTGCCTACAGAACAGCCACAACACATCCAGGTGGGAGCGACGTAGCTGTGGGC GCCTGTGCACTGAGTGTGGGCTGCAGGTGGAAGAGAGGAAAACTGAGGTCATAAGCAGCTGTAACTGCAAATTCCAGTGGTGCTGTACGG TCAAGTGTGACCAGTGTAGGCATGTGGTGAGCAAGTATTACTGCGCACGCTCCCCAGGCAGTGCCCAGTCCCTGGGTAAGGGCAGTGCCT GATAATACCCCACACAAGTTCACTTGATTAATTGCATCAGTGGAAGGGGACATAGCTTCTCTCTTAGAGAGAACAGATTGGAAAGCAATC GGAAAATTGCAGTTTTGGTCTGTAGTCCTCATGATATCTGCTATCAGTGGGGAAAATGGAGGCCCAAGATTCTACAGCATATTCCTGGCG >20276_20276_6_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000518825_WNT8A_chr5_137420187_ENST00000506684_length(amino acids)=749AA_BP=432 MTAVHAGNINFKWDPKSLEIRTLAVERLLEPLVTQVTTLVNTNSKGPSNKKRGRSKKAHVLAASVEQATENFLEKGDKIAKESQFLKEEL VAAVEDVRKQGDLMKAAAGEFADDPCSSVKRGNMVRAARALLSAVTRLLILADMADVYKLLVQLKVVEDGILKLRNAGNEQDLGIQYKAL KPEVDKLNIMAAKRQQELKDVGHRDQMAAARGILQKNVPILYTASQACLQHPDVAAYKANRDLIYKQLQQAVTGISNAAQATASDDASQH QGGGGGELAYALNNFDKQIIVDPLSFSEERFRPSLEERLESIISGAALMADSSCTRDDRRERIVAECNAVRQALQDLLSEYMGNAGRKER SDALNSAIDKMTKKTRDLRRQLRKAVMDHVSDSFLETNVPLLVLIEAAKNGNEKEVKEYAQVFREHANKLIEAYLTYTTSVALGAQSGIE ECKFQFAWERWNCPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERI SKLFVDSLEKGKDARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAE GHWVPAEAFLPSAEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTV -------------------------------------------------------------- >20276_20276_7_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000540387_WNT8A_chr5_137420187_ENST00000398754_length(transcript)=1711nt_BP=320nt CTGCCGATTCTGCATAGAGAGATCATCTAAATGGGCAGAAGCCTGCACAATTTATGAAGTGCTGATTTAACACCAGCCTATGCAAGGCTG GACGTAAAGAAAGAAGTGATGCACTCAATTCTGCAATAGATAAAATGACCAAGAAGACCAGGGACTTGCGTAGACAGCTCCGCAAAGCTG TCATGGACCACGTTTCAGATTCTTTCCTGGAAACCAATGTTCCACTTTTGGTATTGATTGAAGCTGCAAAGAATGGAAATGAGAAAGAAG TTAAGGAGTATGCCCAAGTTTTCCGTGAACATGCCAACAAATTGATTGAGGCCTATCTGACCTACACGACTAGTGTGGCCTTGGGTGCCC AGAGTGGCATCGAGGAGTGCAAGTTCCAGTTTGCTTGGGAACGCTGGAACTGCCCTGAAAATGCTCTTCAGCTCTCCACCCACAACAGGC TGAGAAGTGCTACCAGAGAGACTTCCTTCATACATGCTATCAGCTCTGCTGGAGTCATGTACATCATCACCAAGAACTGTAGCATGGGTG ACTTCGAAAACTGTGGCTGTGATGGGTCAAACAATGGAAAAACAGGAGGCCATGGCTGGATCTGGGGAGGCTGCAGCGACAATGTGGAAT TTGGGGAAAGGATCTCCAAACTCTTTGTGGACAGTTTGGAGAAGGGGAAGGATGCCAGAGCCCTGATGAATCTTCACAACAACAGGGCCG GCAGACTGGCAGTGAGAGCCACCATGAAAAGGACATGCAAATGTCATGGCATCTCTGGGAGCTGCAGCATACAGACATGCTGGCTGCAGC TGGCTGAATTCCGGGAGATGGGAGACTACCTAAAGGCCAAGTATGACCAGGCGCTGAAAATTGAAATGGATAAGCGGCAGCTGAGAGCTG GGAACAGCGCCGAGGGCCACTGGGTGCCCGCTGAGGCCTTCCTTCCTAGCGCAGAGGCGGAACTGATCTTTTTAGAGGAATCACCAGATT ACTGTACCTGCAATTCCAGCCTGGGCATCTATGGCACAGAGGGTCGTGAGTGCCTACAGAACAGCCACAACACATCCAGGTGGGAGCGAC GTAGCTGTGGGCGCCTGTGCACTGAGTGTGGGCTGCAGGTGGAAGAGAGGAAAACTGAGGTCATAAGCAGCTGTAACTGCAAATTCCAGT GGTGCTGTACGGTCAAGTGTGACCAGTGTAGGCATGTGGTGAGCAAGTATTACTGCGCACGCTCCCCAGGCAGTGCCCAGTCCCTGGGTA AGGGCAGTGCCTGATAATACCCCACACAAGTTCACTTGATTAATTGCATCAGTGGAAGGGGACATAGCTTCTCTCTTAGAGAGAACAGAT TGGAAAGCAATCGGAAAATTGCAGTTTTGGTCTGTAGTCCTCATGATATCTGCTATCAGTGGGGAAAATGGAGGCCCAAGATTCTACAGC ATATTCCTGGCGGGGCTGAAATTGGAACCTGGGCCTCCTGACTTTGGCAGACCCCCATTTCATCTTTCCTGCAAACTACTTTCCCATCTT TGTGCCTGTACTTATGCAGCTTTCTACAGGGAGAGTTTGGTTTGGGGTCTATATCTAGAGGGACCTTCAAAGTATTTGTTCCTTTAAATT TCAGACCATGTCCAACCCAGCTGTGCTGCTGGGAATCAGGAGAATAGAAGCAAAAAACGAAAGAGTTCTGTTCAGACTTCTGAAGAGCAG >20276_20276_7_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000540387_WNT8A_chr5_137420187_ENST00000398754_length(amino acids)=379AA_BP=62 MTKKTRDLRRQLRKAVMDHVSDSFLETNVPLLVLIEAAKNGNEKEVKEYAQVFREHANKLIEAYLTYTTSVALGAQSGIEECKFQFAWER WNCPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERISKLFVDSLEK GKDARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAEGHWVPAEAFL PSAEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTVKCDQCRHVVS -------------------------------------------------------------- >20276_20276_8_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000540387_WNT8A_chr5_137420187_ENST00000506684_length(transcript)=1471nt_BP=320nt CTGCCGATTCTGCATAGAGAGATCATCTAAATGGGCAGAAGCCTGCACAATTTATGAAGTGCTGATTTAACACCAGCCTATGCAAGGCTG GACGTAAAGAAAGAAGTGATGCACTCAATTCTGCAATAGATAAAATGACCAAGAAGACCAGGGACTTGCGTAGACAGCTCCGCAAAGCTG TCATGGACCACGTTTCAGATTCTTTCCTGGAAACCAATGTTCCACTTTTGGTATTGATTGAAGCTGCAAAGAATGGAAATGAGAAAGAAG TTAAGGAGTATGCCCAAGTTTTCCGTGAACATGCCAACAAATTGATTGAGGCCTATCTGACCTACACGACTAGTGTGGCCTTGGGTGCCC AGAGTGGCATCGAGGAGTGCAAGTTCCAGTTTGCTTGGGAACGCTGGAACTGCCCTGAAAATGCTCTTCAGCTCTCCACCCACAACAGGC TGAGAAGTGCTACCAGAGAGACTTCCTTCATACATGCTATCAGCTCTGCTGGAGTCATGTACATCATCACCAAGAACTGTAGCATGGGTG ACTTCGAAAACTGTGGCTGTGATGGGTCAAACAATGGAAAAACAGGAGGCCATGGCTGGATCTGGGGAGGCTGCAGCGACAATGTGGAAT TTGGGGAAAGGATCTCCAAACTCTTTGTGGACAGTTTGGAGAAGGGGAAGGATGCCAGAGCCCTGATGAATCTTCACAACAACAGGGCCG GCAGACTGGCAGTGAGAGCCACCATGAAAAGGACATGCAAATGTCATGGCATCTCTGGGAGCTGCAGCATACAGACATGCTGGCTGCAGC TGGCTGAATTCCGGGAGATGGGAGACTACCTAAAGGCCAAGTATGACCAGGCGCTGAAAATTGAAATGGATAAGCGGCAGCTGAGAGCTG GGAACAGCGCCGAGGGCCACTGGGTGCCCGCTGAGGCCTTCCTTCCTAGCGCAGAGGCGGAACTGATCTTTTTAGAGGAATCACCAGATT ACTGTACCTGCAATTCCAGCCTGGGCATCTATGGCACAGAGGGTCGTGAGTGCCTACAGAACAGCCACAACACATCCAGGTGGGAGCGAC GTAGCTGTGGGCGCCTGTGCACTGAGTGTGGGCTGCAGGTGGAAGAGAGGAAAACTGAGGTCATAAGCAGCTGTAACTGCAAATTCCAGT GGTGCTGTACGGTCAAGTGTGACCAGTGTAGGCATGTGGTGAGCAAGTATTACTGCGCACGCTCCCCAGGCAGTGCCCAGTCCCTGGGTA AGGGCAGTGCCTGATAATACCCCACACAAGTTCACTTGATTAATTGCATCAGTGGAAGGGGACATAGCTTCTCTCTTAGAGAGAACAGAT TGGAAAGCAATCGGAAAATTGCAGTTTTGGTCTGTAGTCCTCATGATATCTGCTATCAGTGGGGAAAATGGAGGCCCAAGATTCTACAGC >20276_20276_8_CTNNA1-WNT8A_CTNNA1_chr5_138223331_ENST00000540387_WNT8A_chr5_137420187_ENST00000506684_length(amino acids)=379AA_BP=62 MTKKTRDLRRQLRKAVMDHVSDSFLETNVPLLVLIEAAKNGNEKEVKEYAQVFREHANKLIEAYLTYTTSVALGAQSGIEECKFQFAWER WNCPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERISKLFVDSLEK GKDARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAEGHWVPAEAFL PSAEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTVKCDQCRHVVS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CTNNA1-WNT8A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Hgene | CTNNA1 | chr5:138223331 | chr5:137420187 | ENST00000302763 | + | 9 | 18 | 325_394 | 432.0 | 907.0 | alpha-actinin |
| Hgene | CTNNA1 | chr5:138223331 | chr5:137420187 | ENST00000302763 | + | 9 | 18 | 97_148 | 432.0 | 907.0 | JUP and CTNNB1 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | CTNNA1 | chr5:138223331 | chr5:137420187 | ENST00000540387 | + | 3 | 12 | 325_394 | 62.0 | 537.0 | alpha-actinin |
| Hgene | CTNNA1 | chr5:138223331 | chr5:137420187 | ENST00000540387 | + | 3 | 12 | 97_148 | 62.0 | 537.0 | JUP and CTNNB1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CTNNA1-WNT8A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CTNNA1-WNT8A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies