
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CTNND2-NRBP1 (FusionGDB2 ID:20396) |
Fusion Gene Summary for CTNND2-NRBP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CTNND2-NRBP1 | Fusion gene ID: 20396 | Hgene | Tgene | Gene symbol | CTNND2 | NRBP1 | Gene ID | 1501 | 29959 |
| Gene name | catenin delta 2 | nuclear receptor binding protein 1 | |
| Synonyms | GT24|NPRAP | BCON3|MADM|MUDPNP|NRBP | |
| Cytomap | 5p15.2 | 2p23.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | catenin delta-2T-cell delta-catenincatenin (cadherin-associated protein), delta 2 (neural plakophilin-related arm-repeat protein)neurojungin | nuclear receptor-binding proteinmultiple domain putative nuclear proteinmyeloid leukemia factor 1 adaptor molecule | |
| Modification date | 20200320 | 20200329 | |
| UniProtAcc | Q9UQB3 | Q9UHY1 | |
| Ensembl transtripts involved in fusion gene | ENST00000458100, ENST00000304623, ENST00000359640, ENST00000495388, ENST00000503622, ENST00000511377, | ENST00000233557, ENST00000379852, ENST00000379863, | |
| Fusion gene scores | * DoF score | 14 X 13 X 7=1274 | 6 X 8 X 4=192 |
| # samples | 15 | 8 | |
| ** MAII score | log2(15/1274*10)=-3.08633087176042 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/192*10)=-1.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CTNND2 [Title/Abstract] AND NRBP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CTNND2(11732248)-NRBP1(27656540), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | NRBP1 | GO:0006888 | ER to Golgi vesicle-mediated transport | 11956649 |
| Fusion gene breakpoints across CTNND2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
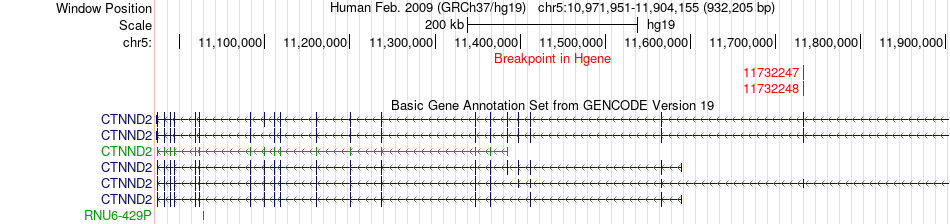 |
| Fusion gene breakpoints across NRBP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LGG | TCGA-QH-A6XC-01A | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| ChimerDB4 | LGG | TCGA-QH-A6XC | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| ChimerDB4 | LGG | TCGA-QH-A6XC | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
Top |
Fusion Gene ORF analysis for CTNND2-NRBP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5UTR-3CDS | ENST00000458100 | ENST00000233557 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| 5UTR-3CDS | ENST00000458100 | ENST00000233557 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| 5UTR-3CDS | ENST00000458100 | ENST00000379852 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| 5UTR-3CDS | ENST00000458100 | ENST00000379852 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| 5UTR-3CDS | ENST00000458100 | ENST00000379863 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| 5UTR-3CDS | ENST00000458100 | ENST00000379863 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| In-frame | ENST00000304623 | ENST00000233557 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| In-frame | ENST00000304623 | ENST00000233557 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| In-frame | ENST00000304623 | ENST00000379852 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| In-frame | ENST00000304623 | ENST00000379852 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| In-frame | ENST00000304623 | ENST00000379863 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| In-frame | ENST00000304623 | ENST00000379863 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| In-frame | ENST00000359640 | ENST00000233557 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| In-frame | ENST00000359640 | ENST00000233557 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| In-frame | ENST00000359640 | ENST00000379852 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| In-frame | ENST00000359640 | ENST00000379852 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| In-frame | ENST00000359640 | ENST00000379863 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| In-frame | ENST00000359640 | ENST00000379863 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000495388 | ENST00000233557 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000495388 | ENST00000233557 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000495388 | ENST00000379852 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000495388 | ENST00000379852 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000495388 | ENST00000379863 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000495388 | ENST00000379863 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000503622 | ENST00000233557 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000503622 | ENST00000233557 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000503622 | ENST00000379852 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000503622 | ENST00000379852 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000503622 | ENST00000379863 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000503622 | ENST00000379863 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000511377 | ENST00000233557 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000511377 | ENST00000233557 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000511377 | ENST00000379852 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000511377 | ENST00000379852 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| intron-3CDS | ENST00000511377 | ENST00000379863 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + |
| intron-3CDS | ENST00000511377 | ENST00000379863 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000304623 | CTNND2 | chr5 | 11732248 | - | ENST00000233557 | NRBP1 | chr2 | 27656540 | + | 2209 | 364 | 190 | 1761 | 523 |
| ENST00000304623 | CTNND2 | chr5 | 11732248 | - | ENST00000379852 | NRBP1 | chr2 | 27656540 | + | 2205 | 364 | 190 | 1761 | 523 |
| ENST00000304623 | CTNND2 | chr5 | 11732248 | - | ENST00000379863 | NRBP1 | chr2 | 27656540 | + | 2229 | 364 | 190 | 1785 | 531 |
| ENST00000359640 | CTNND2 | chr5 | 11732248 | - | ENST00000233557 | NRBP1 | chr2 | 27656540 | + | 2164 | 319 | 145 | 1716 | 523 |
| ENST00000359640 | CTNND2 | chr5 | 11732248 | - | ENST00000379852 | NRBP1 | chr2 | 27656540 | + | 2160 | 319 | 145 | 1716 | 523 |
| ENST00000359640 | CTNND2 | chr5 | 11732248 | - | ENST00000379863 | NRBP1 | chr2 | 27656540 | + | 2184 | 319 | 145 | 1740 | 531 |
| ENST00000304623 | CTNND2 | chr5 | 11732247 | - | ENST00000233557 | NRBP1 | chr2 | 27656539 | + | 2209 | 364 | 190 | 1761 | 523 |
| ENST00000304623 | CTNND2 | chr5 | 11732247 | - | ENST00000379852 | NRBP1 | chr2 | 27656539 | + | 2205 | 364 | 190 | 1761 | 523 |
| ENST00000304623 | CTNND2 | chr5 | 11732247 | - | ENST00000379863 | NRBP1 | chr2 | 27656539 | + | 2229 | 364 | 190 | 1785 | 531 |
| ENST00000359640 | CTNND2 | chr5 | 11732247 | - | ENST00000233557 | NRBP1 | chr2 | 27656539 | + | 2164 | 319 | 145 | 1716 | 523 |
| ENST00000359640 | CTNND2 | chr5 | 11732247 | - | ENST00000379852 | NRBP1 | chr2 | 27656539 | + | 2160 | 319 | 145 | 1716 | 523 |
| ENST00000359640 | CTNND2 | chr5 | 11732247 | - | ENST00000379863 | NRBP1 | chr2 | 27656539 | + | 2184 | 319 | 145 | 1740 | 531 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000304623 | ENST00000233557 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + | 0.007816052 | 0.992184 |
| ENST00000304623 | ENST00000379852 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + | 0.007894124 | 0.99210584 |
| ENST00000304623 | ENST00000379863 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + | 0.007337264 | 0.9926628 |
| ENST00000359640 | ENST00000233557 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + | 0.006910818 | 0.99308914 |
| ENST00000359640 | ENST00000379852 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + | 0.006970047 | 0.99303 |
| ENST00000359640 | ENST00000379863 | CTNND2 | chr5 | 11732248 | - | NRBP1 | chr2 | 27656540 | + | 0.006465006 | 0.99353504 |
| ENST00000304623 | ENST00000233557 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 0.007816052 | 0.992184 |
| ENST00000304623 | ENST00000379852 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 0.007894124 | 0.99210584 |
| ENST00000304623 | ENST00000379863 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 0.007337264 | 0.9926628 |
| ENST00000359640 | ENST00000233557 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 0.006910818 | 0.99308914 |
| ENST00000359640 | ENST00000379852 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 0.006970047 | 0.99303 |
| ENST00000359640 | ENST00000379863 | CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 0.006465006 | 0.99353504 |
Top |
Fusion Genomic Features for CTNND2-NRBP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 8.84E-09 | 1 |
| CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 8.84E-09 | 1 |
| CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 8.84E-09 | 1 |
| CTNND2 | chr5 | 11732247 | - | NRBP1 | chr2 | 27656539 | + | 8.84E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for CTNND2-NRBP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:11732248/chr2:27656540) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CTNND2 | NRBP1 |
| FUNCTION: Has a critical role in neuronal development, particularly in the formation and/or maintenance of dendritic spines and synapses (PubMed:25807484). Involved in the regulation of Wnt signaling (PubMed:25807484). It probably acts on beta-catenin turnover, facilitating beta-catenin interaction with GSK3B, phosphorylation, ubiquitination and degradation (By similarity). Functions as a transcriptional activator when bound to ZBTB33 (By similarity). May be involved in neuronal cell adhesion and tissue morphogenesis and integrity by regulating adhesion molecules. {ECO:0000250|UniProtKB:O35927, ECO:0000269|PubMed:25807484, ECO:0000269|PubMed:9971746}. | FUNCTION: May play a role in subcellular trafficking between the endoplasmic reticulum and Golgi apparatus through interactions with the Rho-type GTPases. Binding to the NS3 protein of dengue virus type 2 appears to subvert this activity into the alteration of the intracellular membrane structure associated with flaviviral replication. {ECO:0000269|PubMed:11956649, ECO:0000269|PubMed:15084397, ECO:0000303|PubMed:11956649}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NRBP1 | chr5:11732247 | chr2:27656539 | ENST00000233557 | 2 | 19 | 68_327 | 70 | 536.0 | Domain | Protein kinase | |
| Tgene | NRBP1 | chr5:11732247 | chr2:27656539 | ENST00000379852 | 1 | 18 | 68_327 | 70 | 536.0 | Domain | Protein kinase | |
| Tgene | NRBP1 | chr5:11732248 | chr2:27656540 | ENST00000233557 | 2 | 19 | 68_327 | 70 | 536.0 | Domain | Protein kinase | |
| Tgene | NRBP1 | chr5:11732248 | chr2:27656540 | ENST00000379852 | 1 | 18 | 68_327 | 70 | 536.0 | Domain | Protein kinase |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 49_84 | 58 | 1226.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 49_84 | 58 | 1168.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 49_84 | 58 | 1226.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 49_84 | 58 | 1168.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 216_226 | 58 | 1226.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 811_817 | 58 | 1226.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 216_226 | 58 | 1168.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 811_817 | 58 | 1168.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 216_226 | 58 | 1226.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 811_817 | 58 | 1226.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 216_226 | 58 | 1168.0 | Compositional bias | Note=Poly-Pro |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 811_817 | 58 | 1168.0 | Compositional bias | Note=Poly-Lys |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 394_438 | 58 | 1226.0 | Repeat | Note=ARM 1 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 540_579 | 58 | 1226.0 | Repeat | Note=ARM 2 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 582_621 | 58 | 1226.0 | Repeat | Note=ARM 3 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 626_666 | 58 | 1226.0 | Repeat | Note=ARM 4 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 682_724 | 58 | 1226.0 | Repeat | Note=ARM 5 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 728_773 | 58 | 1226.0 | Repeat | Note=ARM 6 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 835_875 | 58 | 1226.0 | Repeat | Note=ARM 7 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 882_921 | 58 | 1226.0 | Repeat | Note=ARM 8 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000304623 | - | 2 | 22 | 975_1018 | 58 | 1226.0 | Repeat | Note=ARM 9 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 394_438 | 58 | 1168.0 | Repeat | Note=ARM 1 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 540_579 | 58 | 1168.0 | Repeat | Note=ARM 2 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 582_621 | 58 | 1168.0 | Repeat | Note=ARM 3 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 626_666 | 58 | 1168.0 | Repeat | Note=ARM 4 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 682_724 | 58 | 1168.0 | Repeat | Note=ARM 5 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 728_773 | 58 | 1168.0 | Repeat | Note=ARM 6 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 835_875 | 58 | 1168.0 | Repeat | Note=ARM 7 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 882_921 | 58 | 1168.0 | Repeat | Note=ARM 8 |
| Hgene | CTNND2 | chr5:11732247 | chr2:27656539 | ENST00000359640 | - | 2 | 21 | 975_1018 | 58 | 1168.0 | Repeat | Note=ARM 9 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 394_438 | 58 | 1226.0 | Repeat | Note=ARM 1 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 540_579 | 58 | 1226.0 | Repeat | Note=ARM 2 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 582_621 | 58 | 1226.0 | Repeat | Note=ARM 3 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 626_666 | 58 | 1226.0 | Repeat | Note=ARM 4 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 682_724 | 58 | 1226.0 | Repeat | Note=ARM 5 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 728_773 | 58 | 1226.0 | Repeat | Note=ARM 6 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 835_875 | 58 | 1226.0 | Repeat | Note=ARM 7 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 882_921 | 58 | 1226.0 | Repeat | Note=ARM 8 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000304623 | - | 2 | 22 | 975_1018 | 58 | 1226.0 | Repeat | Note=ARM 9 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 394_438 | 58 | 1168.0 | Repeat | Note=ARM 1 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 540_579 | 58 | 1168.0 | Repeat | Note=ARM 2 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 582_621 | 58 | 1168.0 | Repeat | Note=ARM 3 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 626_666 | 58 | 1168.0 | Repeat | Note=ARM 4 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 682_724 | 58 | 1168.0 | Repeat | Note=ARM 5 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 728_773 | 58 | 1168.0 | Repeat | Note=ARM 6 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 835_875 | 58 | 1168.0 | Repeat | Note=ARM 7 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 882_921 | 58 | 1168.0 | Repeat | Note=ARM 8 |
| Hgene | CTNND2 | chr5:11732248 | chr2:27656540 | ENST00000359640 | - | 2 | 21 | 975_1018 | 58 | 1168.0 | Repeat | Note=ARM 9 |
Top |
Fusion Gene Sequence for CTNND2-NRBP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >20396_20396_1_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000304623_NRBP1_chr2_27656539_ENST00000233557_length(transcript)=2209nt_BP=364nt GCGTCGGGAGCCGCCTCTCGCCCGCGGCGCTCGCCCCTGCCGCCCGCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGG AAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGGGCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGG CGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTTGGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAA GACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGGCTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGA ACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCTGGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGT ACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGTTCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACAT TGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGCCAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAA GCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGAAAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAG CTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGACCTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGG CTCTGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCGAGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGA AGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCATGTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGA GTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCTTCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCA GTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCACCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCA CTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGAGGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAAT CCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCAGTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAA TGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCAGCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGT CAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGTGGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAA ACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCGGCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTT GGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCAGAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAA TTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTCCTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTG TCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGTATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCT GGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCTCTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGG GCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGCTGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACG GGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGGGCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCAT >20396_20396_1_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000304623_NRBP1_chr2_27656539_ENST00000233557_length(amino acids)=523AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEIQGNGESSY VPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSAVLAEIPAG PGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESVEEGVKHHL -------------------------------------------------------------- >20396_20396_2_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000304623_NRBP1_chr2_27656539_ENST00000379852_length(transcript)=2205nt_BP=364nt GCGTCGGGAGCCGCCTCTCGCCCGCGGCGCTCGCCCCTGCCGCCCGCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGG AAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGGGCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGG CGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTTGGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAA GACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGGCTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGA ACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCTGGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGT ACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGTTCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACAT TGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGCCAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAA GCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGAAAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAG CTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGACCTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGG CTCTGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCGAGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGA AGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCATGTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGA GTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCTTCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCA GTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCACCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCA CTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGAGGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAAT CCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCAGTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAA TGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCAGCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGT CAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGTGGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAA ACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCGGCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTT GGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCAGAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAA TTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTCCTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTG TCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGTATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCT GGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCTCTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGG GCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGCTGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACG GGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGGGCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCAT >20396_20396_2_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000304623_NRBP1_chr2_27656539_ENST00000379852_length(amino acids)=523AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEIQGNGESSY VPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSAVLAEIPAG PGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESVEEGVKHHL -------------------------------------------------------------- >20396_20396_3_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000304623_NRBP1_chr2_27656539_ENST00000379863_length(transcript)=2229nt_BP=364nt GCGTCGGGAGCCGCCTCTCGCCCGCGGCGCTCGCCCCTGCCGCCCGCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGG AAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGGGCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGG CGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTTGGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAA GACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGGCTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGA ACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCTGGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGT ACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGTTCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACAT TGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGCCAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAA GCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGAAAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAG CTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGACCTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGG CTCTGTCTTTCATAGGATTTTTGCTAATGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCGAGAAGAGCAGAAGAATCTACA CTTCTTTGCACCAGAGTATGGAGAAGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCATGTGTGCACTGGAGATGGCAGT GCTGGAGATTCAGGGCAATGGAGAGTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCTTCTAGAAGACCCATTACAGAG GGAGTTCATTCAAAAGTGCCTGCAGTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCACCCAGCATTGTTTGAAGTGCC CTCGCTCAAACTCCTTGCGGCCCACTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGAGGAGATCACCAAAAACATGGA TACTAGTGCCGTACTGGCTGAAATCCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCAGTCACCAGCTCTGGAATTAGA TAAATTCCTTGAAGATGTCAGGAATGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCAGCCACAGCAGGAGGAGGTGAC ATCACCTGTCGTGCCCCCCTCTGTCAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGTGGTGCTGATGCAGTGCAACAT TGAGTCGGTGGAGGAGGGAGTCAAACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCGGCACCTGAGCTGTGACCTGAT GCCAAATGAGAATATCCCCGAGTTGGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCAGAGCCGGTTGACTTCTCTGCT AGAAGAGACCTTGAACAAGTTCAATTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTCCTCTTAGAGCTCACTCGGGCC AGGCCCTGATCTGCGCTGTGGCTGTCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGTATTACCCTGTGAAGCCCCTTC CCTCCTTTATTATTCAGGAGGGCTGGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCTCTTCCTCCCCTCTGCACTTTG TTTACTTGTTTTGCACAGACGTGGGCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGCTGATCTGCCGGCTCCCGCCCA GCCTGTGTGGAAAGGAGGCCCACGGGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGGGCGGGAGAGAAAGGTGGTGCT >20396_20396_3_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000304623_NRBP1_chr2_27656539_ENST00000379863_length(amino acids)=531AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVFHRIFANVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEI QGNGESSYVPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSA VLAEIPAGPGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESV -------------------------------------------------------------- >20396_20396_4_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000359640_NRBP1_chr2_27656539_ENST00000233557_length(transcript)=2164nt_BP=319nt GCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGGAAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGG GCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGGCGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTT GGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAAGACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGG CTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGAACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCT GGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGTACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGT TCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACATTGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGC CAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAAGCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGA AAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAGCTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGAC CTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGGCTCTGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCG AGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGAAGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCAT GTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGAGTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCT TCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCAGTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCA CCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCACTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGA GGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAATCCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCA GTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAATGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCA GCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGTCAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGT GGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAAACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCG GCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTTGGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCA GAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAATTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTC CTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTGTCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGT ATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCTGGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCT CTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGGGCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGC TGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACGGGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGG GCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCATTCGATTCGCCTCAGTTGCTGCTGTAATAAAAGTCTACTTTTTGCT >20396_20396_4_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000359640_NRBP1_chr2_27656539_ENST00000233557_length(amino acids)=523AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEIQGNGESSY VPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSAVLAEIPAG PGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESVEEGVKHHL -------------------------------------------------------------- >20396_20396_5_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000359640_NRBP1_chr2_27656539_ENST00000379852_length(transcript)=2160nt_BP=319nt GCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGGAAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGG GCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGGCGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTT GGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAAGACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGG CTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGAACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCT GGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGTACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGT TCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACATTGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGC CAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAAGCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGA AAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAGCTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGAC CTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGGCTCTGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCG AGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGAAGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCAT GTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGAGTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCT TCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCAGTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCA CCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCACTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGA GGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAATCCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCA GTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAATGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCA GCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGTCAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGT GGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAAACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCG GCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTTGGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCA GAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAATTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTC CTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTGTCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGT ATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCTGGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCT CTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGGGCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGC TGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACGGGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGG GCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCATTCGATTCGCCTCAGTTGCTGCTGTAATAAAAGTCTACTTTTTGCT >20396_20396_5_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000359640_NRBP1_chr2_27656539_ENST00000379852_length(amino acids)=523AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEIQGNGESSY VPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSAVLAEIPAG PGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESVEEGVKHHL -------------------------------------------------------------- >20396_20396_6_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000359640_NRBP1_chr2_27656539_ENST00000379863_length(transcript)=2184nt_BP=319nt GCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGGAAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGG GCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGGCGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTT GGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAAGACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGG CTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGAACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCT GGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGTACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGT TCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACATTGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGC CAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAAGCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGA AAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAGCTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGAC CTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGGCTCTGTCTTTCATAGGATTTTTGCTAATGTGGCTCCTGACACTAT CAACAATCATGTGAAGACTTGTCGAGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGAAGTCACTAATGTGACAACAGC AGTGGACATCTACTCCTTTGGCATGTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGAGTCCTCATATGTGCCACAGGA AGCCATCAGCAGTGCCATCCAGCTTCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCAGTCTGAGCCTGCTCGCAGACC AACAGCCAGAGAACTTCTGTTCCACCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCACTGCATTGTGGGACACCAACA CATGATCCCAGAGAACGCTCTAGAGGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAATCCCTGCAGGACCAGGAAGAGA ACCAGTTCAGACTTTGTACTCTCAGTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAATGGGATCTATCCTCTGACAGC CTTTGGGCTGCCTCGGCCCCAGCAGCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGTCAAGACTCCGACACCTGAACC AGCTGAGGTGGAGACTCGCAAGGTGGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAAACACCACCTGACACTTCTGCT GAAGTTGGAGGACAAACTGAACCGGCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTTGGCGGCTGAGCTGGTGCAGCT GGGCTTCATTAGTGAGGCTGACCAGAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAATTTTGCCAGGAACAGTACCCT CAACTCAGCCGCTGTCACCGTCTCCTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTGTCCCTGGACGTGCTGCAGCCC TCCTGTCCCTTCCCCCCAGTCAGTATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCTGGGGGGGCTCCCTGGTTCTGA GCATCATCCTTTCCCCTCCCCTCTCTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGGGCCTGGGCCTTCTCAGCAGCC GCCTTCTAGTTGGGGGCTAGTCGCTGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACGGGCACTAGGGGAGCCGAATTC TACAATCCCGCTGGGGCGGCCGGGGCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCATTCGATTCGCCTCAGTTGCTGC >20396_20396_6_CTNND2-NRBP1_CTNND2_chr5_11732247_ENST00000359640_NRBP1_chr2_27656539_ENST00000379863_length(amino acids)=531AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVFHRIFANVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEI QGNGESSYVPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSA VLAEIPAGPGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESV -------------------------------------------------------------- >20396_20396_7_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000304623_NRBP1_chr2_27656540_ENST00000233557_length(transcript)=2209nt_BP=364nt GCGTCGGGAGCCGCCTCTCGCCCGCGGCGCTCGCCCCTGCCGCCCGCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGG AAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGGGCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGG CGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTTGGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAA GACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGGCTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGA ACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCTGGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGT ACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGTTCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACAT TGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGCCAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAA GCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGAAAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAG CTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGACCTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGG CTCTGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCGAGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGA AGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCATGTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGA GTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCTTCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCA GTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCACCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCA CTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGAGGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAAT CCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCAGTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAA TGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCAGCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGT CAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGTGGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAA ACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCGGCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTT GGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCAGAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAA TTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTCCTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTG TCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGTATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCT GGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCTCTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGG GCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGCTGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACG GGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGGGCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCAT >20396_20396_7_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000304623_NRBP1_chr2_27656540_ENST00000233557_length(amino acids)=523AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEIQGNGESSY VPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSAVLAEIPAG PGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESVEEGVKHHL -------------------------------------------------------------- >20396_20396_8_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000304623_NRBP1_chr2_27656540_ENST00000379852_length(transcript)=2205nt_BP=364nt GCGTCGGGAGCCGCCTCTCGCCCGCGGCGCTCGCCCCTGCCGCCCGCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGG AAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGGGCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGG CGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTTGGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAA GACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGGCTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGA ACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCTGGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGT ACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGTTCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACAT TGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGCCAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAA GCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGAAAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAG CTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGACCTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGG CTCTGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCGAGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGA AGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCATGTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGA GTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCTTCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCA GTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCACCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCA CTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGAGGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAAT CCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCAGTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAA TGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCAGCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGT CAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGTGGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAA ACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCGGCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTT GGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCAGAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAA TTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTCCTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTG TCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGTATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCT GGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCTCTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGG GCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGCTGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACG GGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGGGCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCAT >20396_20396_8_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000304623_NRBP1_chr2_27656540_ENST00000379852_length(amino acids)=523AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEIQGNGESSY VPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSAVLAEIPAG PGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESVEEGVKHHL -------------------------------------------------------------- >20396_20396_9_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000304623_NRBP1_chr2_27656540_ENST00000379863_length(transcript)=2229nt_BP=364nt GCGTCGGGAGCCGCCTCTCGCCCGCGGCGCTCGCCCCTGCCGCCCGCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGG AAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGGGCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGG CGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTTGGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAA GACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGGCTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGA ACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCTGGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGT ACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGTTCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACAT TGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGCCAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAA GCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGAAAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAG CTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGACCTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGG CTCTGTCTTTCATAGGATTTTTGCTAATGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCGAGAAGAGCAGAAGAATCTACA CTTCTTTGCACCAGAGTATGGAGAAGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCATGTGTGCACTGGAGATGGCAGT GCTGGAGATTCAGGGCAATGGAGAGTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCTTCTAGAAGACCCATTACAGAG GGAGTTCATTCAAAAGTGCCTGCAGTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCACCCAGCATTGTTTGAAGTGCC CTCGCTCAAACTCCTTGCGGCCCACTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGAGGAGATCACCAAAAACATGGA TACTAGTGCCGTACTGGCTGAAATCCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCAGTCACCAGCTCTGGAATTAGA TAAATTCCTTGAAGATGTCAGGAATGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCAGCCACAGCAGGAGGAGGTGAC ATCACCTGTCGTGCCCCCCTCTGTCAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGTGGTGCTGATGCAGTGCAACAT TGAGTCGGTGGAGGAGGGAGTCAAACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCGGCACCTGAGCTGTGACCTGAT GCCAAATGAGAATATCCCCGAGTTGGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCAGAGCCGGTTGACTTCTCTGCT AGAAGAGACCTTGAACAAGTTCAATTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTCCTCTTAGAGCTCACTCGGGCC AGGCCCTGATCTGCGCTGTGGCTGTCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGTATTACCCTGTGAAGCCCCTTC CCTCCTTTATTATTCAGGAGGGCTGGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCTCTTCCTCCCCTCTGCACTTTG TTTACTTGTTTTGCACAGACGTGGGCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGCTGATCTGCCGGCTCCCGCCCA GCCTGTGTGGAAAGGAGGCCCACGGGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGGGCGGGAGAGAAAGGTGGTGCT >20396_20396_9_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000304623_NRBP1_chr2_27656540_ENST00000379863_length(amino acids)=531AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVFHRIFANVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEI QGNGESSYVPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSA VLAEIPAGPGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESV -------------------------------------------------------------- >20396_20396_10_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000359640_NRBP1_chr2_27656540_ENST00000233557_length(transcript)=2164nt_BP=319nt GCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGGAAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGG GCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGGCGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTT GGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAAGACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGG CTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGAACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCT GGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGTACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGT TCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACATTGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGC CAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAAGCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGA AAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAGCTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGAC CTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGGCTCTGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCG AGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGAAGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCAT GTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGAGTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCT TCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCAGTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCA CCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCACTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGA GGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAATCCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCA GTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAATGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCA GCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGTCAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGT GGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAAACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCG GCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTTGGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCA GAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAATTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTC CTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTGTCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGT ATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCTGGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCT CTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGGGCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGC TGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACGGGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGG GCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCATTCGATTCGCCTCAGTTGCTGCTGTAATAAAAGTCTACTTTTTGCT >20396_20396_10_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000359640_NRBP1_chr2_27656540_ENST00000233557_length(amino acids)=523AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEIQGNGESSY VPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSAVLAEIPAG PGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESVEEGVKHHL -------------------------------------------------------------- >20396_20396_11_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000359640_NRBP1_chr2_27656540_ENST00000379852_length(transcript)=2160nt_BP=319nt GCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGGAAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGG GCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGGCGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTT GGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAAGACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGG CTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGAACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCT GGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGTACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGT TCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACATTGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGC CAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAAGCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGA AAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAGCTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGAC CTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGGCTCTGTGGCTCCTGACACTATCAACAATCATGTGAAGACTTGTCG AGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGAAGTCACTAATGTGACAACAGCAGTGGACATCTACTCCTTTGGCAT GTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGAGTCCTCATATGTGCCACAGGAAGCCATCAGCAGTGCCATCCAGCT TCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCAGTCTGAGCCTGCTCGCAGACCAACAGCCAGAGAACTTCTGTTCCA CCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCACTGCATTGTGGGACACCAACACATGATCCCAGAGAACGCTCTAGA GGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAATCCCTGCAGGACCAGGAAGAGAACCAGTTCAGACTTTGTACTCTCA GTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAATGGGATCTATCCTCTGACAGCCTTTGGGCTGCCTCGGCCCCAGCA GCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGTCAAGACTCCGACACCTGAACCAGCTGAGGTGGAGACTCGCAAGGT GGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAAACACCACCTGACACTTCTGCTGAAGTTGGAGGACAAACTGAACCG GCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTTGGCGGCTGAGCTGGTGCAGCTGGGCTTCATTAGTGAGGCTGACCA GAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAATTTTGCCAGGAACAGTACCCTCAACTCAGCCGCTGTCACCGTCTC CTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTGTCCCTGGACGTGCTGCAGCCCTCCTGTCCCTTCCCCCCAGTCAGT ATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCTGGGGGGGCTCCCTGGTTCTGAGCATCATCCTTTCCCCTCCCCTCT CTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGGGCCTGGGCCTTCTCAGCAGCCGCCTTCTAGTTGGGGGCTAGTCGC TGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACGGGCACTAGGGGAGCCGAATTCTACAATCCCGCTGGGGCGGCCGGG GCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCATTCGATTCGCCTCAGTTGCTGCTGTAATAAAAGTCTACTTTTTGCT >20396_20396_11_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000359640_NRBP1_chr2_27656540_ENST00000379852_length(amino acids)=523AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEIQGNGESSY VPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSAVLAEIPAG PGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESVEEGVKHHL -------------------------------------------------------------- >20396_20396_12_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000359640_NRBP1_chr2_27656540_ENST00000379863_length(transcript)=2184nt_BP=319nt GCCAGCATCCCTTGTCCCGCGGCCGCGCTCAGACAACAAAAGCGGAAGATGCTGCAGTTGGGCAAGGTCAGGACCTTGCCCTGAAGCCGG GCGGCGCCGCGCACGCCTCTTCCCGGACTGAGGAGCTGTCGCCGGCGGAGGGTGCATGTTTGCGAGGAAGCCGCCGGGCGCCGCGCCTTT GGGAGCTATGCCTGTTCCAGACCAGCCTTCATCAGCCTCAGAGAAGACGAGTTCCCTGAGCCCCGGCTTAAACACCTCCAACGGGGATGG CTCTGAAACAGAAACCACCTCTGCCATCCTCGCCTCAGTCAAAGAACAGGTGAATCAACGGAATGTACCAGGTATTGACAGTGCATACCT GGCCATGGATACAGAGGAAGGTGTAGAGGTTGTGTGGAATGAGGTACAGTTCTCTGAACGCAAGAACTACAAGCTGCAGGAGGAAAAGGT TCGTGCTGTGTTTGATAATCTGATTCAATTGGAGCATCTTAACATTGTTAAGTTTCACAAATATTGGGCTGACATTAAAGAGAACAAGGC CAGGGTCATTTTTATCACAGAATACATGTCATCTGGGAGTCTGAAGCAATTTCTGAAGAAGACCAAAAAGAACCACAAGACGATGAATGA AAAGGCATGGAAGCGTTGGTGCACACAAATCCTCTCTGCCCTAAGCTACCTGCACTCCTGTGACCCCCCCATCATCCATGGGAACCTGAC CTGTGACACCATCTTCATCCAGCACAACGGACTCATCAAGATTGGCTCTGTCTTTCATAGGATTTTTGCTAATGTGGCTCCTGACACTAT CAACAATCATGTGAAGACTTGTCGAGAAGAGCAGAAGAATCTACACTTCTTTGCACCAGAGTATGGAGAAGTCACTAATGTGACAACAGC AGTGGACATCTACTCCTTTGGCATGTGTGCACTGGAGATGGCAGTGCTGGAGATTCAGGGCAATGGAGAGTCCTCATATGTGCCACAGGA AGCCATCAGCAGTGCCATCCAGCTTCTAGAAGACCCATTACAGAGGGAGTTCATTCAAAAGTGCCTGCAGTCTGAGCCTGCTCGCAGACC AACAGCCAGAGAACTTCTGTTCCACCCAGCATTGTTTGAAGTGCCCTCGCTCAAACTCCTTGCGGCCCACTGCATTGTGGGACACCAACA CATGATCCCAGAGAACGCTCTAGAGGAGATCACCAAAAACATGGATACTAGTGCCGTACTGGCTGAAATCCCTGCAGGACCAGGAAGAGA ACCAGTTCAGACTTTGTACTCTCAGTCACCAGCTCTGGAATTAGATAAATTCCTTGAAGATGTCAGGAATGGGATCTATCCTCTGACAGC CTTTGGGCTGCCTCGGCCCCAGCAGCCACAGCAGGAGGAGGTGACATCACCTGTCGTGCCCCCCTCTGTCAAGACTCCGACACCTGAACC AGCTGAGGTGGAGACTCGCAAGGTGGTGCTGATGCAGTGCAACATTGAGTCGGTGGAGGAGGGAGTCAAACACCACCTGACACTTCTGCT GAAGTTGGAGGACAAACTGAACCGGCACCTGAGCTGTGACCTGATGCCAAATGAGAATATCCCCGAGTTGGCGGCTGAGCTGGTGCAGCT GGGCTTCATTAGTGAGGCTGACCAGAGCCGGTTGACTTCTCTGCTAGAAGAGACCTTGAACAAGTTCAATTTTGCCAGGAACAGTACCCT CAACTCAGCCGCTGTCACCGTCTCCTCTTAGAGCTCACTCGGGCCAGGCCCTGATCTGCGCTGTGGCTGTCCCTGGACGTGCTGCAGCCC TCCTGTCCCTTCCCCCCAGTCAGTATTACCCTGTGAAGCCCCTTCCCTCCTTTATTATTCAGGAGGGCTGGGGGGGCTCCCTGGTTCTGA GCATCATCCTTTCCCCTCCCCTCTCTTCCTCCCCTCTGCACTTTGTTTACTTGTTTTGCACAGACGTGGGCCTGGGCCTTCTCAGCAGCC GCCTTCTAGTTGGGGGCTAGTCGCTGATCTGCCGGCTCCCGCCCAGCCTGTGTGGAAAGGAGGCCCACGGGCACTAGGGGAGCCGAATTC TACAATCCCGCTGGGGCGGCCGGGGCGGGAGAGAAAGGTGGTGCTGCAGTGGTGGCCCTGGGGGGCCATTCGATTCGCCTCAGTTGCTGC >20396_20396_12_CTNND2-NRBP1_CTNND2_chr5_11732248_ENST00000359640_NRBP1_chr2_27656540_ENST00000379863_length(amino acids)=531AA_BP=57 MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQVNQRNVPGIDSAYLAMDTEEGVEVVWNEVQFS ERKNYKLQEEKVRAVFDNLIQLEHLNIVKFHKYWADIKENKARVIFITEYMSSGSLKQFLKKTKKNHKTMNEKAWKRWCTQILSALSYLH SCDPPIIHGNLTCDTIFIQHNGLIKIGSVFHRIFANVAPDTINNHVKTCREEQKNLHFFAPEYGEVTNVTTAVDIYSFGMCALEMAVLEI QGNGESSYVPQEAISSAIQLLEDPLQREFIQKCLQSEPARRPTARELLFHPALFEVPSLKLLAAHCIVGHQHMIPENALEEITKNMDTSA VLAEIPAGPGREPVQTLYSQSPALELDKFLEDVRNGIYPLTAFGLPRPQQPQQEEVTSPVVPPSVKTPTPEPAEVETRKVVLMQCNIESV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CTNND2-NRBP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CTNND2-NRBP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CTNND2-NRBP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies