
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CTSB-UBAP2L (FusionGDB2 ID:20480) |
Fusion Gene Summary for CTSB-UBAP2L |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CTSB-UBAP2L | Fusion gene ID: 20480 | Hgene | Tgene | Gene symbol | CTSB | UBAP2L | Gene ID | 1508 | 9898 |
| Gene name | cathepsin B | ubiquitin associated protein 2 like | |
| Synonyms | APPS|CPSB|RECEUP | NICE-4|NICE4 | |
| Cytomap | 8p23.1 | 1q21.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cathepsin BAPP secretaseamyloid precursor protein secretasecathepsin B1cysteine proteaseepididymis secretory sperm binding protein | ubiquitin-associated protein 2-likeprotein NICE-4 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P07858 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000345125, ENST00000353047, ENST00000415599, ENST00000434271, ENST00000453527, ENST00000530640, ENST00000531089, ENST00000533455, ENST00000534510, ENST00000525076, | ENST00000484819, ENST00000271877, ENST00000343815, ENST00000361546, ENST00000428931, | |
| Fusion gene scores | * DoF score | 24 X 19 X 10=4560 | 17 X 15 X 7=1785 |
| # samples | 25 | 18 | |
| ** MAII score | log2(25/4560*10)=-4.18903382439002 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(18/1785*10)=-3.30985526258679 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CTSB [Title/Abstract] AND UBAP2L [Title/Abstract] AND fusion [Title/Abstract] | ||
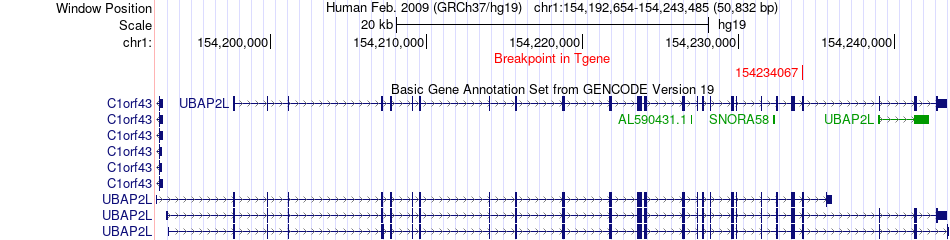
| Most frequent breakpoint | CTSB(11710837)-UBAP2L(154234067), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CTSB-UBAP2L seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. CTSB-UBAP2L seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CTSB | GO:0006508 | proteolysis | 7890620|8811434 |
| Hgene | CTSB | GO:0030574 | collagen catabolic process | 22952693 |
| Hgene | CTSB | GO:0051603 | proteolysis involved in cellular protein catabolic process | 22952693 |
| Fusion gene breakpoints across CTSB (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across UBAP2L (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-61-2008 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
Top |
Fusion Gene ORF analysis for CTSB-UBAP2L |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000345125 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5CDS-intron | ENST00000353047 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5CDS-intron | ENST00000415599 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5CDS-intron | ENST00000434271 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5CDS-intron | ENST00000453527 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5CDS-intron | ENST00000530640 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5CDS-intron | ENST00000531089 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5CDS-intron | ENST00000533455 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5CDS-intron | ENST00000534510 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5UTR-3CDS | ENST00000525076 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5UTR-3CDS | ENST00000525076 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5UTR-3CDS | ENST00000525076 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5UTR-3CDS | ENST00000525076 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| 5UTR-intron | ENST00000525076 | ENST00000484819 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000345125 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000345125 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000345125 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000345125 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000353047 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000353047 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000353047 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000353047 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000453527 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000453527 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000453527 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000453527 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000531089 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000531089 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000531089 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000531089 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000534510 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000534510 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000534510 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| Frame-shift | ENST00000534510 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000415599 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000415599 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000415599 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000415599 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000434271 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000434271 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000434271 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000434271 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000530640 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000530640 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000530640 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000530640 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000533455 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000533455 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000533455 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| In-frame | ENST00000533455 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000434271 | CTSB | chr8 | 11710837 | - | ENST00000343815 | UBAP2L | chr1 | 154234067 | + | 873 | 364 | 817 | 401 | 138 |
| ENST00000434271 | CTSB | chr8 | 11710837 | - | ENST00000428931 | UBAP2L | chr1 | 154234067 | + | 1389 | 364 | 238 | 831 | 197 |
| ENST00000434271 | CTSB | chr8 | 11710837 | - | ENST00000271877 | UBAP2L | chr1 | 154234067 | + | 862 | 364 | 238 | 771 | 177 |
| ENST00000434271 | CTSB | chr8 | 11710837 | - | ENST00000361546 | UBAP2L | chr1 | 154234067 | + | 1390 | 364 | 238 | 831 | 197 |
| ENST00000530640 | CTSB | chr8 | 11710837 | - | ENST00000343815 | UBAP2L | chr1 | 154234067 | + | 772 | 263 | 716 | 300 | 138 |
| ENST00000530640 | CTSB | chr8 | 11710837 | - | ENST00000428931 | UBAP2L | chr1 | 154234067 | + | 1288 | 263 | 137 | 730 | 197 |
| ENST00000530640 | CTSB | chr8 | 11710837 | - | ENST00000271877 | UBAP2L | chr1 | 154234067 | + | 761 | 263 | 137 | 670 | 177 |
| ENST00000530640 | CTSB | chr8 | 11710837 | - | ENST00000361546 | UBAP2L | chr1 | 154234067 | + | 1289 | 263 | 137 | 730 | 197 |
| ENST00000415599 | CTSB | chr8 | 11710837 | - | ENST00000343815 | UBAP2L | chr1 | 154234067 | + | 707 | 198 | 651 | 235 | 138 |
| ENST00000415599 | CTSB | chr8 | 11710837 | - | ENST00000428931 | UBAP2L | chr1 | 154234067 | + | 1223 | 198 | 72 | 665 | 197 |
| ENST00000415599 | CTSB | chr8 | 11710837 | - | ENST00000271877 | UBAP2L | chr1 | 154234067 | + | 696 | 198 | 72 | 605 | 177 |
| ENST00000415599 | CTSB | chr8 | 11710837 | - | ENST00000361546 | UBAP2L | chr1 | 154234067 | + | 1224 | 198 | 72 | 665 | 197 |
| ENST00000533455 | CTSB | chr8 | 11710837 | - | ENST00000343815 | UBAP2L | chr1 | 154234067 | + | 854 | 345 | 798 | 382 | 138 |
| ENST00000533455 | CTSB | chr8 | 11710837 | - | ENST00000428931 | UBAP2L | chr1 | 154234067 | + | 1370 | 345 | 219 | 812 | 197 |
| ENST00000533455 | CTSB | chr8 | 11710837 | - | ENST00000271877 | UBAP2L | chr1 | 154234067 | + | 843 | 345 | 219 | 752 | 177 |
| ENST00000533455 | CTSB | chr8 | 11710837 | - | ENST00000361546 | UBAP2L | chr1 | 154234067 | + | 1371 | 345 | 219 | 812 | 197 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000434271 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.52296996 | 0.47703004 |
| ENST00000434271 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.015650302 | 0.98434967 |
| ENST00000434271 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.008325049 | 0.99167496 |
| ENST00000434271 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.015490466 | 0.9845095 |
| ENST00000530640 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.39361292 | 0.606387 |
| ENST00000530640 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.010002761 | 0.98999727 |
| ENST00000530640 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.002836654 | 0.99716336 |
| ENST00000530640 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.009885254 | 0.9901148 |
| ENST00000415599 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.57264173 | 0.4273583 |
| ENST00000415599 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.010309302 | 0.98969066 |
| ENST00000415599 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.003078716 | 0.9969213 |
| ENST00000415599 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.010242282 | 0.98975766 |
| ENST00000533455 | ENST00000343815 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.4436393 | 0.5563607 |
| ENST00000533455 | ENST00000428931 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.013185445 | 0.9868146 |
| ENST00000533455 | ENST00000271877 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.004706887 | 0.9952931 |
| ENST00000533455 | ENST00000361546 | CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.013055465 | 0.9869445 |
Top |
Fusion Genomic Features for CTSB-UBAP2L |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.013857483 | 0.9861426 |
| CTSB | chr8 | 11710837 | - | UBAP2L | chr1 | 154234067 | + | 0.013857483 | 0.9861426 |
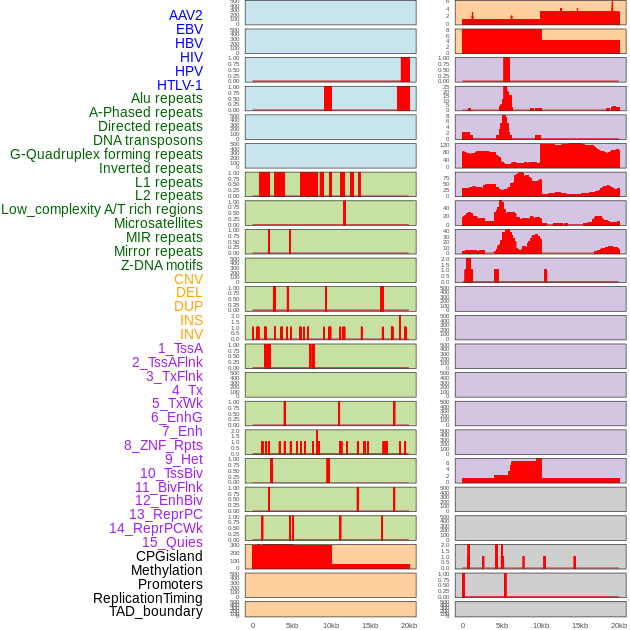
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
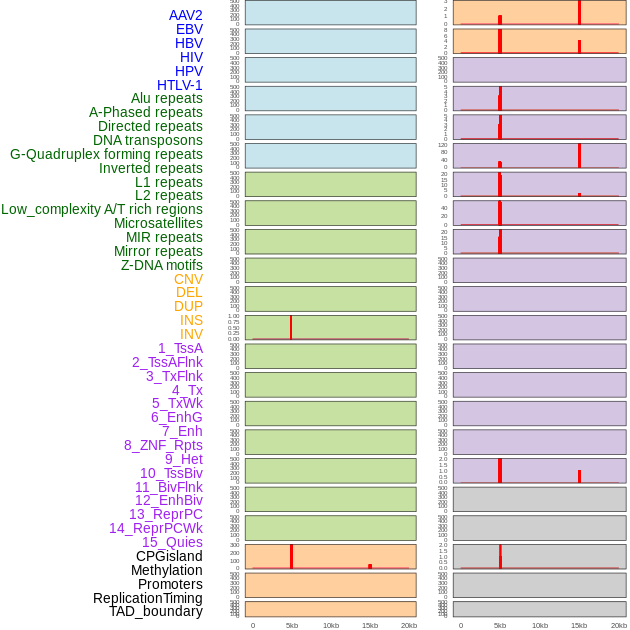
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for CTSB-UBAP2L |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:11710837/chr1:154234067) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CTSB | . |
| FUNCTION: Thiol protease which is believed to participate in intracellular degradation and turnover of proteins (PubMed:12220505). Cleaves matrix extracellular phosphoglycoprotein MEPE (PubMed:12220505). Involved in the solubilization of cross-linked TG/thyroglobulin in the thyroid follicle lumen (By similarity). Has also been implicated in tumor invasion and metastasis (PubMed:3972105). {ECO:0000250|UniProtKB:P10605, ECO:0000269|PubMed:12220505, ECO:0000269|PubMed:3972105}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | UBAP2L | chr8:11710837 | chr1:154234067 | ENST00000343815 | 22 | 25 | 49_89 | 932 | 984.0 | Domain | UBA | |
| Tgene | UBAP2L | chr8:11710837 | chr1:154234067 | ENST00000361546 | 21 | 26 | 49_89 | 932 | 1088.0 | Domain | UBA | |
| Tgene | UBAP2L | chr8:11710837 | chr1:154234067 | ENST00000428931 | 22 | 27 | 49_89 | 932 | 1088.0 | Domain | UBA |
Top |
Fusion Gene Sequence for CTSB-UBAP2L |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >20480_20480_1_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000415599_UBAP2L_chr1_154234067_ENST00000271877_length(transcript)=696nt_BP=198nt CGACCCACATAACAGAGAGGTGTCCTGATGCCCTCTGTCCTCTCCAGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCC TCCCTCTGCTGCCTGCTGGTGTTGGCCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAA CGGAATACCACGTGGCAGGTGGCTCCTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAG CCGAGTGGATATGGGTCTCATGGATACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTAC TCCAAAACCCAGTCCTTTGAGAAACAAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGC CCCATCAATCCGGCCACAGCTGCTGCCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTT CACCATCACCTGCAGCAGGATGGCCAGGACATCCTCAATTTCGTCGATGACCAGCTTGGTGAATAAGTATTACTGTACCAACTGGGCCTC >20480_20480_1_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000415599_UBAP2L_chr1_154234067_ENST00000271877_length(amino acids)=177AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD -------------------------------------------------------------- >20480_20480_2_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000415599_UBAP2L_chr1_154234067_ENST00000343815_length(transcript)=707nt_BP=198nt CGACCCACATAACAGAGAGGTGTCCTGATGCCCTCTGTCCTCTCCAGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCC TCCCTCTGCTGCCTGCTGGTGTTGGCCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAA CGGAATACCACGTGGCAGGTGGCTCCTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAG CCGAGTGGATATGGGTCTCATGGATACAACACTGGAAGAAAATATCCACCCCCTTACAAGCATTTCTGGACGGCTGAGAGCTAATTTGGC CCAAGGCTGGGGGCTGTGTTTTGTGTGTGTGTATAAATTTGCACTGAAGTCTTGTTTCAGAAACCAGACCACTGAGGAGAGCCTGCTGAG CTGAGGCCATGGCCTGCGTGGCTTGGGGAAATGAGTTGGTGGATACCTTCTGGGCTTTTGAACTTGCCCCTCCCCCATTTCCCTCTCCCC CATGTGTCTGACCCTGTCTTACCCATTTCAAGTTCAAGCGGTGCAGCACCTTCGAAGCATCAATGCACACACCTGCTGTTGCTTTTGATT >20480_20480_2_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000415599_UBAP2L_chr1_154234067_ENST00000343815_length(amino acids)=138AA_BP= MKLHAFQKSKATAGVCIDASKVLHRLNLKWVRQGQTHGGEGNGGGASSKAQKVSTNSFPQATQAMASAQQALLSGLVSETRLQCKFIHTH -------------------------------------------------------------- >20480_20480_3_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000415599_UBAP2L_chr1_154234067_ENST00000361546_length(transcript)=1224nt_BP=198nt CGACCCACATAACAGAGAGGTGTCCTGATGCCCTCTGTCCTCTCCAGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCC TCCCTCTGCTGCCTGCTGGTGTTGGCCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAA CGGAATACCACGTGGCAGGTGGCTCCTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAG CCGAGTGGATATGGGTCTCATGGATACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTAC TCCAAAACCCAGCAGTCCTTTGAGAAACAAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGG GGCCCCATCAATCCGGCCACAGCTGCTGCCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATC CTTCACCATCACCTGCAGCAGGATGGCCAGACGGGCAGCGGGCAACGTAGCCAGACCAGCTCCATCCCGCAGAAGCCCCAGACCAACAAG TCTGCCTACAACAGCTACAGCTGGGGGGCCAACTGAGGCCCTGACCCTCTTCTCCCGGTCCCATCTTCTGAGAGGGCTTCTCAGCCTGGA AACTATGGAAACAGCATCAAAGAGAAAGGAATGTGGGGGGTTTCCGCTGCCCCCCACCCCCAGCGGCCCACCCCATGCCTCAGCTTCATG TCTGTCCCATTCCTATACCATCCCCACCCTGTTGTATGTATTATAGGATTTGTATTTTCTCCTTTTTTTTCCCCCTTCCATTCCTTCTCC CCTCTTGCATTCAAGATTATGAAACTTTGCTATGGGCCCTGCACTTCCTTTGCTTCCTCCTGTTCACCCTGGTGGTGTACGGATGAGGCG GGGAGGTGGGACCCCCAAACATATATCAGCCCAACAGCCCTAAGTCTCCTTCTTTATTATTAGGAAAACAACAACAACAACAAACAAAAA AATGGCGTCATGAATATGAACAGCATTGTCAGATGAATTAGTTGAAGTGGTTTTTTTTTTGTTTTTTTTTTTTTTTTGTACTGTGTCCTC >20480_20480_3_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000415599_UBAP2L_chr1_154234067_ENST00000361546_length(amino acids)=197AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD ISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQ -------------------------------------------------------------- >20480_20480_4_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000415599_UBAP2L_chr1_154234067_ENST00000428931_length(transcript)=1223nt_BP=198nt CGACCCACATAACAGAGAGGTGTCCTGATGCCCTCTGTCCTCTCCAGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCC TCCCTCTGCTGCCTGCTGGTGTTGGCCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAA CGGAATACCACGTGGCAGGTGGCTCCTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAG CCGAGTGGATATGGGTCTCATGGATACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTAC TCCAAAACCCAGCAGTCCTTTGAGAAACAAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGG GGCCCCATCAATCCGGCCACAGCTGCTGCCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATC CTTCACCATCACCTGCAGCAGGATGGCCAGACGGGCAGCGGGCAACGTAGCCAGACCAGCTCCATCCCGCAGAAGCCCCAGACCAACAAG TCTGCCTACAACAGCTACAGCTGGGGGGCCAACTGAGGCCCTGACCCTCTTCTCCCGGTCCCATCTTCTGAGAGGGCTTCTCAGCCTGGA AACTATGGAAACAGCATCAAAGAGAAAGGAATGTGGGGGGTTTCCGCTGCCCCCCACCCCCAGCGGCCCACCCCATGCCTCAGCTTCATG TCTGTCCCATTCCTATACCATCCCCACCCTGTTGTATGTATTATAGGATTTGTATTTTCTCCTTTTTTTTCCCCCTTCCATTCCTTCTCC CCTCTTGCATTCAAGATTATGAAACTTTGCTATGGGCCCTGCACTTCCTTTGCTTCCTCCTGTTCACCCTGGTGGTGTACGGATGAGGCG GGGAGGTGGGACCCCCAAACATATATCAGCCCAACAGCCCTAAGTCTCCTTCTTTATTATTAGGAAAACAACAACAACAACAAACAAAAA AATGGCGTCATGAATATGAACAGCATTGTCAGATGAATTAGTTGAAGTGGTTTTTTTTTTGTTTTTTTTTTTTTTTTGTACTGTGTCCTC >20480_20480_4_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000415599_UBAP2L_chr1_154234067_ENST00000428931_length(amino acids)=197AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD ISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQ -------------------------------------------------------------- >20480_20480_5_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000434271_UBAP2L_chr1_154234067_ENST00000271877_length(transcript)=862nt_BP=364nt GGGGCGGGGCCGGGAGGGTACTTAGGGCCGGGGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCG CTCCGCTGCGCGCAGGCTGGGCTGCAGGCTCTCGGCTGCAGCGCTGGGTGAGTGCTGGGGACCCGGGGCCACCGCAGCGTAAGTGACCCA GAGAGGTGTCCTGATGCCCTCTGTCCTCTCCAGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCT GCTGGTGTTGGCCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTG GCAGGTGGCTCCTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGG GTCTCATGGATACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGTC CTTTGAGAAACAAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCCGGC CACAGCTGCTGCCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCTGCA GCAGGATGGCCAGGACATCCTCAATTTCGTCGATGACCAGCTTGGTGAATAAGTATTACTGTACCAACTGGGCCTCCTCTAGCAGGCCCC >20480_20480_5_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000434271_UBAP2L_chr1_154234067_ENST00000271877_length(amino acids)=177AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD -------------------------------------------------------------- >20480_20480_6_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000434271_UBAP2L_chr1_154234067_ENST00000343815_length(transcript)=873nt_BP=364nt GGGGCGGGGCCGGGAGGGTACTTAGGGCCGGGGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCG CTCCGCTGCGCGCAGGCTGGGCTGCAGGCTCTCGGCTGCAGCGCTGGGTGAGTGCTGGGGACCCGGGGCCACCGCAGCGTAAGTGACCCA GAGAGGTGTCCTGATGCCCTCTGTCCTCTCCAGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCT GCTGGTGTTGGCCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTG GCAGGTGGCTCCTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGG GTCTCATGGATACAACACTGGAAGAAAATATCCACCCCCTTACAAGCATTTCTGGACGGCTGAGAGCTAATTTGGCCCAAGGCTGGGGGC TGTGTTTTGTGTGTGTGTATAAATTTGCACTGAAGTCTTGTTTCAGAAACCAGACCACTGAGGAGAGCCTGCTGAGCTGAGGCCATGGCC TGCGTGGCTTGGGGAAATGAGTTGGTGGATACCTTCTGGGCTTTTGAACTTGCCCCTCCCCCATTTCCCTCTCCCCCATGTGTCTGACCC TGTCTTACCCATTTCAAGTTCAAGCGGTGCAGCACCTTCGAAGCATCAATGCACACACCTGCTGTTGCTTTTGATTTCTGGAAGGCATGT >20480_20480_6_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000434271_UBAP2L_chr1_154234067_ENST00000343815_length(amino acids)=138AA_BP= MKLHAFQKSKATAGVCIDASKVLHRLNLKWVRQGQTHGGEGNGGGASSKAQKVSTNSFPQATQAMASAQQALLSGLVSETRLQCKFIHTH -------------------------------------------------------------- >20480_20480_7_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000434271_UBAP2L_chr1_154234067_ENST00000361546_length(transcript)=1390nt_BP=364nt GGGGCGGGGCCGGGAGGGTACTTAGGGCCGGGGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCG CTCCGCTGCGCGCAGGCTGGGCTGCAGGCTCTCGGCTGCAGCGCTGGGTGAGTGCTGGGGACCCGGGGCCACCGCAGCGTAAGTGACCCA GAGAGGTGTCCTGATGCCCTCTGTCCTCTCCAGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCT GCTGGTGTTGGCCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTG GCAGGTGGCTCCTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGG GTCTCATGGATACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGCA GTCCTTTGAGAAACAAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCC GGCCACAGCTGCTGCCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCT GCAGCAGGATGGCCAGACGGGCAGCGGGCAACGTAGCCAGACCAGCTCCATCCCGCAGAAGCCCCAGACCAACAAGTCTGCCTACAACAG CTACAGCTGGGGGGCCAACTGAGGCCCTGACCCTCTTCTCCCGGTCCCATCTTCTGAGAGGGCTTCTCAGCCTGGAAACTATGGAAACAG CATCAAAGAGAAAGGAATGTGGGGGGTTTCCGCTGCCCCCCACCCCCAGCGGCCCACCCCATGCCTCAGCTTCATGTCTGTCCCATTCCT ATACCATCCCCACCCTGTTGTATGTATTATAGGATTTGTATTTTCTCCTTTTTTTTCCCCCTTCCATTCCTTCTCCCCTCTTGCATTCAA GATTATGAAACTTTGCTATGGGCCCTGCACTTCCTTTGCTTCCTCCTGTTCACCCTGGTGGTGTACGGATGAGGCGGGGAGGTGGGACCC CCAAACATATATCAGCCCAACAGCCCTAAGTCTCCTTCTTTATTATTAGGAAAACAACAACAACAACAAACAAAAAAATGGCGTCATGAA TATGAACAGCATTGTCAGATGAATTAGTTGAAGTGGTTTTTTTTTTGTTTTTTTTTTTTTTTTGTACTGTGTCCTCAAATTTAATGGATT >20480_20480_7_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000434271_UBAP2L_chr1_154234067_ENST00000361546_length(amino acids)=197AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD ISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQ -------------------------------------------------------------- >20480_20480_8_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000434271_UBAP2L_chr1_154234067_ENST00000428931_length(transcript)=1389nt_BP=364nt GGGGCGGGGCCGGGAGGGTACTTAGGGCCGGGGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCG CTCCGCTGCGCGCAGGCTGGGCTGCAGGCTCTCGGCTGCAGCGCTGGGTGAGTGCTGGGGACCCGGGGCCACCGCAGCGTAAGTGACCCA GAGAGGTGTCCTGATGCCCTCTGTCCTCTCCAGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCT GCTGGTGTTGGCCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTG GCAGGTGGCTCCTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGG GTCTCATGGATACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGCA GTCCTTTGAGAAACAAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCC GGCCACAGCTGCTGCCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCT GCAGCAGGATGGCCAGACGGGCAGCGGGCAACGTAGCCAGACCAGCTCCATCCCGCAGAAGCCCCAGACCAACAAGTCTGCCTACAACAG CTACAGCTGGGGGGCCAACTGAGGCCCTGACCCTCTTCTCCCGGTCCCATCTTCTGAGAGGGCTTCTCAGCCTGGAAACTATGGAAACAG CATCAAAGAGAAAGGAATGTGGGGGGTTTCCGCTGCCCCCCACCCCCAGCGGCCCACCCCATGCCTCAGCTTCATGTCTGTCCCATTCCT ATACCATCCCCACCCTGTTGTATGTATTATAGGATTTGTATTTTCTCCTTTTTTTTCCCCCTTCCATTCCTTCTCCCCTCTTGCATTCAA GATTATGAAACTTTGCTATGGGCCCTGCACTTCCTTTGCTTCCTCCTGTTCACCCTGGTGGTGTACGGATGAGGCGGGGAGGTGGGACCC CCAAACATATATCAGCCCAACAGCCCTAAGTCTCCTTCTTTATTATTAGGAAAACAACAACAACAACAAACAAAAAAATGGCGTCATGAA TATGAACAGCATTGTCAGATGAATTAGTTGAAGTGGTTTTTTTTTTGTTTTTTTTTTTTTTTTGTACTGTGTCCTCAAATTTAATGGATT >20480_20480_8_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000434271_UBAP2L_chr1_154234067_ENST00000428931_length(amino acids)=197AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD ISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQ -------------------------------------------------------------- >20480_20480_9_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000530640_UBAP2L_chr1_154234067_ENST00000271877_length(transcript)=761nt_BP=263nt GGCCGGGGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCGCTCCGCTGCGCGCAGGCTGGGCTGC AGGCTCTCGGCTGCAGCGCTGGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCTGCTGGTGTTGG CCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTGGCAGGTGGCTC CTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGGGTCTCATGGAT ACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGTCCTTTGAGAAAC AAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCCGGCCACAGCTGCTG CCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCTGCAGCAGGATGGCC AGGACATCCTCAATTTCGTCGATGACCAGCTTGGTGAATAAGTATTACTGTACCAACTGGGCCTCCTCTAGCAGGCCCCTGAAGGCAGTG >20480_20480_9_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000530640_UBAP2L_chr1_154234067_ENST00000271877_length(amino acids)=177AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD -------------------------------------------------------------- >20480_20480_10_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000530640_UBAP2L_chr1_154234067_ENST00000343815_length(transcript)=772nt_BP=263nt GGCCGGGGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCGCTCCGCTGCGCGCAGGCTGGGCTGC AGGCTCTCGGCTGCAGCGCTGGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCTGCTGGTGTTGG CCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTGGCAGGTGGCTC CTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGGGTCTCATGGAT ACAACACTGGAAGAAAATATCCACCCCCTTACAAGCATTTCTGGACGGCTGAGAGCTAATTTGGCCCAAGGCTGGGGGCTGTGTTTTGTG TGTGTGTATAAATTTGCACTGAAGTCTTGTTTCAGAAACCAGACCACTGAGGAGAGCCTGCTGAGCTGAGGCCATGGCCTGCGTGGCTTG GGGAAATGAGTTGGTGGATACCTTCTGGGCTTTTGAACTTGCCCCTCCCCCATTTCCCTCTCCCCCATGTGTCTGACCCTGTCTTACCCA TTTCAAGTTCAAGCGGTGCAGCACCTTCGAAGCATCAATGCACACACCTGCTGTTGCTTTTGATTTCTGGAAGGCATGTAGTTTCAACTT >20480_20480_10_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000530640_UBAP2L_chr1_154234067_ENST00000343815_length(amino acids)=138AA_BP= MKLHAFQKSKATAGVCIDASKVLHRLNLKWVRQGQTHGGEGNGGGASSKAQKVSTNSFPQATQAMASAQQALLSGLVSETRLQCKFIHTH -------------------------------------------------------------- >20480_20480_11_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000530640_UBAP2L_chr1_154234067_ENST00000361546_length(transcript)=1289nt_BP=263nt GGCCGGGGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCGCTCCGCTGCGCGCAGGCTGGGCTGC AGGCTCTCGGCTGCAGCGCTGGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCTGCTGGTGTTGG CCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTGGCAGGTGGCTC CTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGGGTCTCATGGAT ACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGCAGTCCTTTGAGA AACAAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCCGGCCACAGCTG CTGCCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCTGCAGCAGGATG GCCAGACGGGCAGCGGGCAACGTAGCCAGACCAGCTCCATCCCGCAGAAGCCCCAGACCAACAAGTCTGCCTACAACAGCTACAGCTGGG GGGCCAACTGAGGCCCTGACCCTCTTCTCCCGGTCCCATCTTCTGAGAGGGCTTCTCAGCCTGGAAACTATGGAAACAGCATCAAAGAGA AAGGAATGTGGGGGGTTTCCGCTGCCCCCCACCCCCAGCGGCCCACCCCATGCCTCAGCTTCATGTCTGTCCCATTCCTATACCATCCCC ACCCTGTTGTATGTATTATAGGATTTGTATTTTCTCCTTTTTTTTCCCCCTTCCATTCCTTCTCCCCTCTTGCATTCAAGATTATGAAAC TTTGCTATGGGCCCTGCACTTCCTTTGCTTCCTCCTGTTCACCCTGGTGGTGTACGGATGAGGCGGGGAGGTGGGACCCCCAAACATATA TCAGCCCAACAGCCCTAAGTCTCCTTCTTTATTATTAGGAAAACAACAACAACAACAAACAAAAAAATGGCGTCATGAATATGAACAGCA TTGTCAGATGAATTAGTTGAAGTGGTTTTTTTTTTGTTTTTTTTTTTTTTTTGTACTGTGTCCTCAAATTTAATGGATTAATGTGTCTTG >20480_20480_11_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000530640_UBAP2L_chr1_154234067_ENST00000361546_length(amino acids)=197AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD ISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQ -------------------------------------------------------------- >20480_20480_12_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000530640_UBAP2L_chr1_154234067_ENST00000428931_length(transcript)=1288nt_BP=263nt GGCCGGGGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCGCTCCGCTGCGCGCAGGCTGGGCTGC AGGCTCTCGGCTGCAGCGCTGGGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCTGCTGGTGTTGG CCAATGCCCGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTGGCAGGTGGCTC CTACCTCTTCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGGGTCTCATGGAT ACAACACTGGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGCAGTCCTTTGAGA AACAAGGTTTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCCGGCCACAGCTG CTGCCTACCCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCTGCAGCAGGATG GCCAGACGGGCAGCGGGCAACGTAGCCAGACCAGCTCCATCCCGCAGAAGCCCCAGACCAACAAGTCTGCCTACAACAGCTACAGCTGGG GGGCCAACTGAGGCCCTGACCCTCTTCTCCCGGTCCCATCTTCTGAGAGGGCTTCTCAGCCTGGAAACTATGGAAACAGCATCAAAGAGA AAGGAATGTGGGGGGTTTCCGCTGCCCCCCACCCCCAGCGGCCCACCCCATGCCTCAGCTTCATGTCTGTCCCATTCCTATACCATCCCC ACCCTGTTGTATGTATTATAGGATTTGTATTTTCTCCTTTTTTTTCCCCCTTCCATTCCTTCTCCCCTCTTGCATTCAAGATTATGAAAC TTTGCTATGGGCCCTGCACTTCCTTTGCTTCCTCCTGTTCACCCTGGTGGTGTACGGATGAGGCGGGGAGGTGGGACCCCCAAACATATA TCAGCCCAACAGCCCTAAGTCTCCTTCTTTATTATTAGGAAAACAACAACAACAACAAACAAAAAAATGGCGTCATGAATATGAACAGCA TTGTCAGATGAATTAGTTGAAGTGGTTTTTTTTTTGTTTTTTTTTTTTTTTTGTACTGTGTCCTCAAATTTAATGGATTAATGTGTCTTG >20480_20480_12_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000530640_UBAP2L_chr1_154234067_ENST00000428931_length(amino acids)=197AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD ISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQ -------------------------------------------------------------- >20480_20480_13_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000533455_UBAP2L_chr1_154234067_ENST00000271877_length(transcript)=843nt_BP=345nt GGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCGCTCCGCTGCGCGCAGGCTGGGCTGCAGGCTC TCGGCTGCAGCGCTGGGCTGGTGTGCAGTGGTGCGACCACGGCTCACGGCAGCCTCAGCCACCCAGATGTAAGCGATCTGGTTCCCACCT CAGCCTCCCGAGTAGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCTGCTGGTGTTGGCCAATGCC CGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTGGCAGGTGGCTCCTACCTCT TCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGGGTCTCATGGATACAACACT GGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGTCCTTTGAGAAACAAGGTTTT CATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCCGGCCACAGCTGCTGCCTACCCA CCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCTGCAGCAGGATGGCCAGGACATC CTCAATTTCGTCGATGACCAGCTTGGTGAATAAGTATTACTGTACCAACTGGGCCTCCTCTAGCAGGCCCCTGAAGGCAGTGGAATAAAA >20480_20480_13_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000533455_UBAP2L_chr1_154234067_ENST00000271877_length(amino acids)=177AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD -------------------------------------------------------------- >20480_20480_14_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000533455_UBAP2L_chr1_154234067_ENST00000343815_length(transcript)=854nt_BP=345nt GGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCGCTCCGCTGCGCGCAGGCTGGGCTGCAGGCTC TCGGCTGCAGCGCTGGGCTGGTGTGCAGTGGTGCGACCACGGCTCACGGCAGCCTCAGCCACCCAGATGTAAGCGATCTGGTTCCCACCT CAGCCTCCCGAGTAGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCTGCTGGTGTTGGCCAATGCC CGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTGGCAGGTGGCTCCTACCTCT TCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGGGTCTCATGGATACAACACT GGAAGAAAATATCCACCCCCTTACAAGCATTTCTGGACGGCTGAGAGCTAATTTGGCCCAAGGCTGGGGGCTGTGTTTTGTGTGTGTGTA TAAATTTGCACTGAAGTCTTGTTTCAGAAACCAGACCACTGAGGAGAGCCTGCTGAGCTGAGGCCATGGCCTGCGTGGCTTGGGGAAATG AGTTGGTGGATACCTTCTGGGCTTTTGAACTTGCCCCTCCCCCATTTCCCTCTCCCCCATGTGTCTGACCCTGTCTTACCCATTTCAAGT TCAAGCGGTGCAGCACCTTCGAAGCATCAATGCACACACCTGCTGTTGCTTTTGATTTCTGGAAGGCATGTAGTTTCAACTTGTAACAAA >20480_20480_14_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000533455_UBAP2L_chr1_154234067_ENST00000343815_length(amino acids)=138AA_BP= MKLHAFQKSKATAGVCIDASKVLHRLNLKWVRQGQTHGGEGNGGGASSKAQKVSTNSFPQATQAMASAQQALLSGLVSETRLQCKFIHTH -------------------------------------------------------------- >20480_20480_15_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000533455_UBAP2L_chr1_154234067_ENST00000361546_length(transcript)=1371nt_BP=345nt GGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCGCTCCGCTGCGCGCAGGCTGGGCTGCAGGCTC TCGGCTGCAGCGCTGGGCTGGTGTGCAGTGGTGCGACCACGGCTCACGGCAGCCTCAGCCACCCAGATGTAAGCGATCTGGTTCCCACCT CAGCCTCCCGAGTAGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCTGCTGGTGTTGGCCAATGCC CGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTGGCAGGTGGCTCCTACCTCT TCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGGGTCTCATGGATACAACACT GGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGCAGTCCTTTGAGAAACAAGGT TTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCCGGCCACAGCTGCTGCCTAC CCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCTGCAGCAGGATGGCCAGACG GGCAGCGGGCAACGTAGCCAGACCAGCTCCATCCCGCAGAAGCCCCAGACCAACAAGTCTGCCTACAACAGCTACAGCTGGGGGGCCAAC TGAGGCCCTGACCCTCTTCTCCCGGTCCCATCTTCTGAGAGGGCTTCTCAGCCTGGAAACTATGGAAACAGCATCAAAGAGAAAGGAATG TGGGGGGTTTCCGCTGCCCCCCACCCCCAGCGGCCCACCCCATGCCTCAGCTTCATGTCTGTCCCATTCCTATACCATCCCCACCCTGTT GTATGTATTATAGGATTTGTATTTTCTCCTTTTTTTTCCCCCTTCCATTCCTTCTCCCCTCTTGCATTCAAGATTATGAAACTTTGCTAT GGGCCCTGCACTTCCTTTGCTTCCTCCTGTTCACCCTGGTGGTGTACGGATGAGGCGGGGAGGTGGGACCCCCAAACATATATCAGCCCA ACAGCCCTAAGTCTCCTTCTTTATTATTAGGAAAACAACAACAACAACAAACAAAAAAATGGCGTCATGAATATGAACAGCATTGTCAGA TGAATTAGTTGAAGTGGTTTTTTTTTTGTTTTTTTTTTTTTTTTGTACTGTGTCCTCAAATTTAATGGATTAATGTGTCTTGTATATATA >20480_20480_15_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000533455_UBAP2L_chr1_154234067_ENST00000361546_length(amino acids)=197AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD ISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQ -------------------------------------------------------------- >20480_20480_16_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000533455_UBAP2L_chr1_154234067_ENST00000428931_length(transcript)=1370nt_BP=345nt GGCTGGCCCAGGCTACGGCGGCTGCAGGGCTCCGGCAACCGCTCCGGCAACGCCAACCGCTCCGCTGCGCGCAGGCTGGGCTGCAGGCTC TCGGCTGCAGCGCTGGGCTGGTGTGCAGTGGTGCGACCACGGCTCACGGCAGCCTCAGCCACCCAGATGTAAGCGATCTGGTTCCCACCT CAGCCTCCCGAGTAGTGGATCTAGGATCCGGCTTCCAACATGTGGCAGCTCTGGGCCTCCCTCTGCTGCCTGCTGGTGTTGGCCAATGCC CGGAGCAGGCCCTCTTTCCATCCCCTGTCGGATGAGCTGGTCAACTATGTCAACAAACGGAATACCACGTGGCAGGTGGCTCCTACCTCT TCCAAGCAGCATGGTGTGAATGTCAGTGTGAATGCATCGGCCACCCCTTTCCAACAGCCGAGTGGATATGGGTCTCATGGATACAACACT GGTGTTTCAGTCACCTCCAGTAACACGGGCGTGCCAGATATCTCGGGTTCTGTGTACTCCAAAACCCAGCAGTCCTTTGAGAAACAAGGT TTTCATTCCGGTACTCCTGCTGCTTCCTTCAACTTGCCTTCAGCCCTAGGAAGTGGGGGCCCCATCAATCCGGCCACAGCTGCTGCCTAC CCACCTGCCCCCTTTATGCACATTCTGACCCCCCATCAGCAGCCGCATTCTCAGATCCTTCACCATCACCTGCAGCAGGATGGCCAGACG GGCAGCGGGCAACGTAGCCAGACCAGCTCCATCCCGCAGAAGCCCCAGACCAACAAGTCTGCCTACAACAGCTACAGCTGGGGGGCCAAC TGAGGCCCTGACCCTCTTCTCCCGGTCCCATCTTCTGAGAGGGCTTCTCAGCCTGGAAACTATGGAAACAGCATCAAAGAGAAAGGAATG TGGGGGGTTTCCGCTGCCCCCCACCCCCAGCGGCCCACCCCATGCCTCAGCTTCATGTCTGTCCCATTCCTATACCATCCCCACCCTGTT GTATGTATTATAGGATTTGTATTTTCTCCTTTTTTTTCCCCCTTCCATTCCTTCTCCCCTCTTGCATTCAAGATTATGAAACTTTGCTAT GGGCCCTGCACTTCCTTTGCTTCCTCCTGTTCACCCTGGTGGTGTACGGATGAGGCGGGGAGGTGGGACCCCCAAACATATATCAGCCCA ACAGCCCTAAGTCTCCTTCTTTATTATTAGGAAAACAACAACAACAACAAACAAAAAAATGGCGTCATGAATATGAACAGCATTGTCAGA TGAATTAGTTGAAGTGGTTTTTTTTTTGTTTTTTTTTTTTTTTTGTACTGTGTCCTCAAATTTAATGGATTAATGTGTCTTGTATATATA >20480_20480_16_CTSB-UBAP2L_CTSB_chr8_11710837_ENST00000533455_UBAP2L_chr1_154234067_ENST00000428931_length(amino acids)=197AA_BP=42 MWQLWASLCCLLVLANARSRPSFHPLSDELVNYVNKRNTTWQVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPD ISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CTSB-UBAP2L |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CTSB-UBAP2L |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CTSB-UBAP2L |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies