
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CYP2E1-ASPSCR1 (FusionGDB2 ID:21056) |
Fusion Gene Summary for CYP2E1-ASPSCR1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CYP2E1-ASPSCR1 | Fusion gene ID: 21056 | Hgene | Tgene | Gene symbol | CYP2E1 | ASPSCR1 | Gene ID | 1571 | 79058 |
| Gene name | cytochrome P450 family 2 subfamily E member 1 | ASPSCR1 tether for SLC2A4, UBX domain containing | |
| Synonyms | CPE1|CYP2E|P450-J|P450C2E | ASPCR1|ASPL|ASPS|RCC17|TUG|UBXD9|UBXN9 | |
| Cytomap | 10q26.3 | 17q25.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cytochrome P450 2E14-nitrophenol 2-hydroxylaseCYPIIE1cytochrome P450, family 2, subfamily E, polypeptide 1cytochrome P450, subfamily IIE (ethanol-inducible), polypeptide 1cytochrome P450-Jflavoprotein-linked monooxygenasemicrosomal monooxygenasexe | tether containing UBX domain for GLUT4ASPSCR1, UBX domain containing tether for SLC2A4UBX domain protein 9UBX domain-containing protein 9alveolar soft part sarcoma chromosomal region candidate gene 1 proteinalveolar soft part sarcoma chromosome regio | |
| Modification date | 20200315 | 20200313 | |
| UniProtAcc | P05181 | Q9BZE9 | |
| Ensembl transtripts involved in fusion gene | ENST00000252945, ENST00000463117, ENST00000480558, | ENST00000581647, ENST00000582404, ENST00000306729, ENST00000306739, ENST00000580534, | |
| Fusion gene scores | * DoF score | 8 X 5 X 3=120 | 16 X 16 X 12=3072 |
| # samples | 8 | 19 | |
| ** MAII score | log2(8/120*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(19/3072*10)=-4.01510689239021 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CYP2E1 [Title/Abstract] AND ASPSCR1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CYP2E1(135341076)-ASPSCR1(79966913), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CYP2E1 | GO:0002933 | lipid hydroxylation | 10553002 |
| Hgene | CYP2E1 | GO:0016098 | monoterpenoid metabolic process | 16401082 |
| Hgene | CYP2E1 | GO:0017144 | drug metabolic process | 19219744 |
| Hgene | CYP2E1 | GO:0018960 | 4-nitrophenol metabolic process | 9348445 |
| Hgene | CYP2E1 | GO:0046483 | heterocycle metabolic process | 19651758 |
| Hgene | CYP2E1 | GO:0055114 | oxidation-reduction process | 16401082|19219744 |
| Fusion gene breakpoints across CYP2E1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ASPSCR1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LIHC | TCGA-BC-A69I-01A | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
Top |
Fusion Gene ORF analysis for CYP2E1-ASPSCR1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000252945 | ENST00000581647 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| 5CDS-intron | ENST00000252945 | ENST00000582404 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| 5CDS-intron | ENST00000463117 | ENST00000581647 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| 5CDS-intron | ENST00000463117 | ENST00000582404 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000252945 | ENST00000306729 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000252945 | ENST00000306739 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000252945 | ENST00000580534 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000463117 | ENST00000306729 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000463117 | ENST00000306739 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000463117 | ENST00000580534 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| intron-3CDS | ENST00000480558 | ENST00000306729 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| intron-3CDS | ENST00000480558 | ENST00000306739 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| intron-3CDS | ENST00000480558 | ENST00000580534 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| intron-intron | ENST00000480558 | ENST00000581647 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| intron-intron | ENST00000480558 | ENST00000582404 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000463117 | CYP2E1 | chr10 | 135341076 | + | ENST00000306729 | ASPSCR1 | chr17 | 79966913 | + | 1542 | 449 | 200 | 1459 | 419 |
| ENST00000463117 | CYP2E1 | chr10 | 135341076 | + | ENST00000306739 | ASPSCR1 | chr17 | 79966913 | + | 1262 | 449 | 200 | 1177 | 325 |
| ENST00000463117 | CYP2E1 | chr10 | 135341076 | + | ENST00000580534 | ASPSCR1 | chr17 | 79966913 | + | 1335 | 449 | 200 | 1252 | 350 |
| ENST00000252945 | CYP2E1 | chr10 | 135341076 | + | ENST00000306729 | ASPSCR1 | chr17 | 79966913 | + | 1303 | 210 | 33 | 1220 | 395 |
| ENST00000252945 | CYP2E1 | chr10 | 135341076 | + | ENST00000306739 | ASPSCR1 | chr17 | 79966913 | + | 1023 | 210 | 33 | 938 | 301 |
| ENST00000252945 | CYP2E1 | chr10 | 135341076 | + | ENST00000580534 | ASPSCR1 | chr17 | 79966913 | + | 1096 | 210 | 33 | 1013 | 326 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000463117 | ENST00000306729 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + | 0.20636049 | 0.79363954 |
| ENST00000463117 | ENST00000306739 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + | 0.058319725 | 0.94168025 |
| ENST00000463117 | ENST00000580534 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + | 0.09298829 | 0.90701175 |
| ENST00000252945 | ENST00000306729 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + | 0.06269884 | 0.93730116 |
| ENST00000252945 | ENST00000306739 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + | 0.016113311 | 0.98388666 |
| ENST00000252945 | ENST00000580534 | CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966913 | + | 0.027266713 | 0.9727333 |
Top |
Fusion Genomic Features for CYP2E1-ASPSCR1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966912 | + | 0.01278693 | 0.9872131 |
| CYP2E1 | chr10 | 135341076 | + | ASPSCR1 | chr17 | 79966912 | + | 0.01278693 | 0.9872131 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
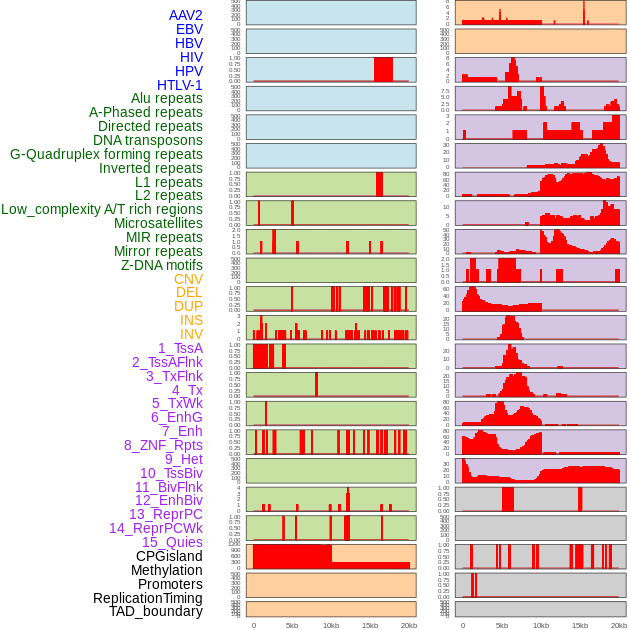 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
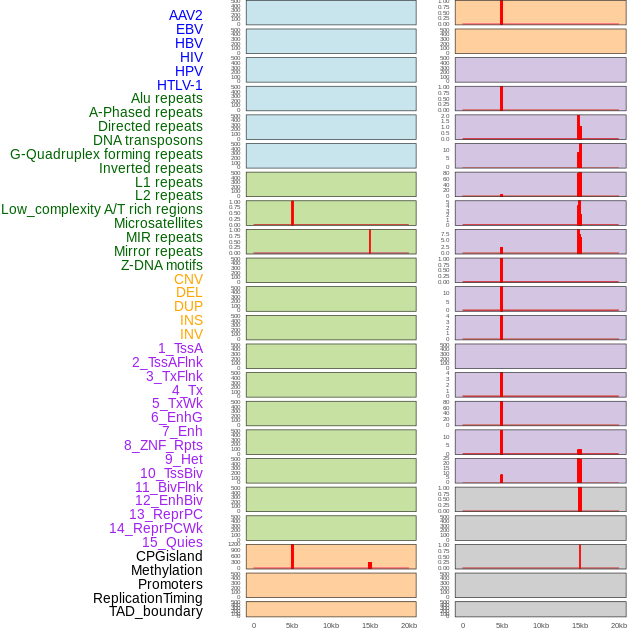 |
Top |
Fusion Protein Features for CYP2E1-ASPSCR1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:135341076/chr17:79966913) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CYP2E1 | ASPSCR1 |
| FUNCTION: A cytochrome P450 monooxygenase involved in the metabolism of fatty acids (PubMed:10553002, PubMed:18577768). Mechanistically, uses molecular oxygen inserting one oxygen atom into a substrate, and reducing the second into a water molecule, with two electrons provided by NADPH via cytochrome P450 reductase (NADPH--hemoprotein reductase) (PubMed:10553002, PubMed:18577768). Catalyzes the hydroxylation of carbon-hydrogen bonds. Hydroxylates fatty acids specifically at the omega-1 position displaying the highest catalytic activity for saturated fatty acids (PubMed:10553002, PubMed:18577768). May be involved in the oxidative metabolism of xenobiotics (Probable). {ECO:0000269|PubMed:10553002, ECO:0000269|PubMed:18577768, ECO:0000305|PubMed:9348445}. | FUNCTION: Tethering protein that sequesters GLUT4-containing vesicles in the cytoplasm in the absence of insulin. Modulates the amount of GLUT4 that is available at the cell surface (By similarity). Enhances VCP methylation catalyzed by VCPKMT. {ECO:0000250, ECO:0000269|PubMed:23349634}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ASPSCR1 | chr10:135341076 | chr17:79966913 | ENST00000306729 | 6 | 17 | 386_462 | 311 | 648.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr10:135341076 | chr17:79966913 | ENST00000306739 | 6 | 16 | 386_462 | 311 | 554.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr10:135341076 | chr17:79966913 | ENST00000580534 | 5 | 15 | 386_462 | 234 | 502.0 | Domain | UBX |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CYP2E1 | chr10:135341076 | chr17:79966913 | ENST00000252945 | + | 1 | 9 | 298_303 | 59 | 494.0 | Region | Substrate binding |
| Hgene | CYP2E1 | chr10:135341076 | chr17:79966913 | ENST00000463117 | + | 3 | 11 | 298_303 | 59 | 494.0 | Region | Substrate binding |
Top |
Fusion Gene Sequence for CYP2E1-ASPSCR1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >21056_21056_1_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000252945_ASPSCR1_chr17_79966913_ENST00000306729_length(transcript)=1303nt_BP=210nt CTCCCGGGCTGGCAGCAGGGCCCCAGCGGCACCATGTCTGCCCTCGGAGTCACCGTGGCCCTGCTGGTGTGGGCGGCCTTCCTCCTGCTG GTGTCCATGTGGAGGCAGGTGCACAGCAGCTGGAATCTGCCCCCAGGCCCTTTCCCGCTTCCCATCATCGGGAACCTCTTCCAGTTGGAA TTGAAGAATATTCCCAAGTCCTTCACCCGGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAG CGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGT GAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTG GCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGG AGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAG CCCCAGCTTGGTGACCGGGTGGCTCCATTCACCCTGGGTCCCTCGCTGAAACGGTGCCTGGGACCAGAGCAGAGAACACGCTTGCCAGTG GTAGGAGATGGAGGCGACGTGGACTCTGGGAGGCTTCTTTTTTGGGGTCCATCCAGAGGCCGAGCCTCTCCAAGCACTGGTCAGCCTCCA TGCCACCCAGTCTGCCGACCCTCCTCTCCACCATCCCCTCGTCCGAGCAGTGGCGATCCCTCCCGAGTCAAGGCTGGGCACAAGCACGTG GGGACAGGCCGGGCGAACCTCTTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTG GAGCATGCCATCTCCCCATCTGCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCT GACCCTGCACCTAAGTCTGAGCCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGG AGCCTGGGCAAGGTGCCCAAGTGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGG >21056_21056_1_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000252945_ASPSCR1_chr17_79966913_ENST00000306729_length(amino acids)=395AA_BP=59 MSALGVTVALLVWAAFLLLVSMWRQVHSSWNLPPGPFPLPIIGNLFQLELKNIPKSFTRPVDREPVDREPVVCHPDLEERLQAWPAELPD EFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFY LFITPPKTVLDDHTQTLFQPQLGDRVAPFTLGPSLKRCLGPEQRTRLPVVGDGGDVDSGRLLFWGPSRGRASPSTGQPPCHPVCRPSSPP SPRPSSGDPSRVKAGHKHVGTGRANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAE -------------------------------------------------------------- >21056_21056_2_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000252945_ASPSCR1_chr17_79966913_ENST00000306739_length(transcript)=1023nt_BP=210nt CTCCCGGGCTGGCAGCAGGGCCCCAGCGGCACCATGTCTGCCCTCGGAGTCACCGTGGCCCTGCTGGTGTGGGCGGCCTTCCTCCTGCTG GTGTCCATGTGGAGGCAGGTGCACAGCAGCTGGAATCTGCCCCCAGGCCCTTTCCCGCTTCCCATCATCGGGAACCTCTTCCAGTTGGAA TTGAAGAATATTCCCAAGTCCTTCACCCGGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAG CGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGT GAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTG GCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGG AGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAG GCGAACCTCTTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATC TCCCCATCTGCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCT AAGTCTGAGCCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAG GTGCCCAAGTGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCTCT >21056_21056_2_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000252945_ASPSCR1_chr17_79966913_ENST00000306739_length(amino acids)=301AA_BP=59 MSALGVTVALLVWAAFLLLVSMWRQVHSSWNLPPGPFPLPIIGNLFQLELKNIPKSFTRPVDREPVDREPVVCHPDLEERLQAWPAELPD EFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFY LFITPPKTVLDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAEEGAL -------------------------------------------------------------- >21056_21056_3_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000252945_ASPSCR1_chr17_79966913_ENST00000580534_length(transcript)=1096nt_BP=210nt CTCCCGGGCTGGCAGCAGGGCCCCAGCGGCACCATGTCTGCCCTCGGAGTCACCGTGGCCCTGCTGGTGTGGGCGGCCTTCCTCCTGCTG GTGTCCATGTGGAGGCAGGTGCACAGCAGCTGGAATCTGCCCCCAGGCCCTTTCCCGCTTCCCATCATCGGGAACCTCTTCCAGTTGGAA TTGAAGAATATTCCCAAGTCCTTCACCCGGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAG CGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGT GAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTG GCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGG AGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTGCCTGTCTTCCTTCGGGCGCATGGATGGGCGAGGTCCACGGTGCTTCCTAACA CGTAGGTGCCTTCTCTCCTCAGTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGGCGAACCTCTTCCCG GCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATCTCCCCATCTGCGGCC GATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCTAAGTCTGAGCCAGCT GCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAGGTGCCCAAGTGGCTG AAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCTCTGCCAGCAGGAATAAA >21056_21056_3_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000252945_ASPSCR1_chr17_79966913_ENST00000580534_length(amino acids)=326AA_BP=59 MSALGVTVALLVWAAFLLLVSMWRQVHSSWNLPPGPFPLPIIGNLFQLELKNIPKSFTRPVDREPVDREPVVCHPDLEERLQAWPAELPD EFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFY LCLSSFGRMDGRGPRCFLTRRCLLSSVITPPKTVLDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRA -------------------------------------------------------------- >21056_21056_4_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000463117_ASPSCR1_chr17_79966913_ENST00000306729_length(transcript)=1542nt_BP=449nt ACTTCCGGGTTGTTTGCTCCCGGAGCCATAACCGCAGCTCAGCGTGCGGGCAGAGCCGGCTGACAGGAGACAGGACACAGCACAGAGCCC CGCGCCCTCTGAGGCGGGAGGCTTCGTTCCTGCACCAGCGTGGCTTGCCCTTTGGACGCGGCGAGTTAACTTGAGAAAGTGGAATCGAAT TCCGATGTTGAATTTTCCTTCTGGCCCCATTCATGTGGCAGGTGGTGATTCAGGATTGTCTCCCGGGCTGGCAGCAGGGCCCCAGCGGCA CCATGTCTGCCCTCGGAGTCACCGTGGCCCTGCTGGTGTGGGCGGCCTTCCTCCTGCTGGTGTCCATGTGGAGGCAGGTGCACAGCAGCT GGAATCTGCCCCCAGGCCCTTTCCCGCTTCCCATCATCGGGAACCTCTTCCAGTTGGAATTGAAGAATATTCCCAAGTCCTTCACCCGGC CCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTG ATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGG TGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACG TCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTT ACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGCCCCAGCTTGGTGACCGGGTGGCTCCATTCA CCCTGGGTCCCTCGCTGAAACGGTGCCTGGGACCAGAGCAGAGAACACGCTTGCCAGTGGTAGGAGATGGAGGCGACGTGGACTCTGGGA GGCTTCTTTTTTGGGGTCCATCCAGAGGCCGAGCCTCTCCAAGCACTGGTCAGCCTCCATGCCACCCAGTCTGCCGACCCTCCTCTCCAC CATCCCCTCGTCCGAGCAGTGGCGATCCCTCCCGAGTCAAGGCTGGGCACAAGCACGTGGGGACAGGCCGGGCGAACCTCTTCCCGGCCG CTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATCTCCCCATCTGCGGCCGATG TGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCTAAGTCTGAGCCAGCTGCTG AGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAGGTGCCCAAGTGGCTGAAGC TGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCTCTGCCAGCAGGAATAAAGACT >21056_21056_4_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000463117_ASPSCR1_chr17_79966913_ENST00000306729_length(amino acids)=419AA_BP=83 MAPFMWQVVIQDCLPGWQQGPSGTMSALGVTVALLVWAAFLLLVSMWRQVHSSWNLPPGPFPLPIIGNLFQLELKNIPKSFTRPVDREPV DREPVVCHPDLEERLQAWPAELPDEFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFR PSETVGDLRDFVRSHLGNPELSFYLFITPPKTVLDDHTQTLFQPQLGDRVAPFTLGPSLKRCLGPEQRTRLPVVGDGGDVDSGRLLFWGP SRGRASPSTGQPPCHPVCRPSSPPSPRPSSGDPSRVKAGHKHVGTGRANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYM -------------------------------------------------------------- >21056_21056_5_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000463117_ASPSCR1_chr17_79966913_ENST00000306739_length(transcript)=1262nt_BP=449nt ACTTCCGGGTTGTTTGCTCCCGGAGCCATAACCGCAGCTCAGCGTGCGGGCAGAGCCGGCTGACAGGAGACAGGACACAGCACAGAGCCC CGCGCCCTCTGAGGCGGGAGGCTTCGTTCCTGCACCAGCGTGGCTTGCCCTTTGGACGCGGCGAGTTAACTTGAGAAAGTGGAATCGAAT TCCGATGTTGAATTTTCCTTCTGGCCCCATTCATGTGGCAGGTGGTGATTCAGGATTGTCTCCCGGGCTGGCAGCAGGGCCCCAGCGGCA CCATGTCTGCCCTCGGAGTCACCGTGGCCCTGCTGGTGTGGGCGGCCTTCCTCCTGCTGGTGTCCATGTGGAGGCAGGTGCACAGCAGCT GGAATCTGCCCCCAGGCCCTTTCCCGCTTCCCATCATCGGGAACCTCTTCCAGTTGGAATTGAAGAATATTCCCAAGTCCTTCACCCGGC CCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTG ATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGG TGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACG TCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTT ACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGGCGAACCTCTTCCCGGCCGCTCTGGTGCACT TGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATCTCCCCATCTGCGGCCGATGTGCTGGTGGCCA GGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCTAAGTCTGAGCCAGCTGCTGAGGAGGGGGCGC TGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAGGTGCCCAAGTGGCTGAAGCTGCCGGCCAGCA AGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCTCTGCCAGCAGGAATAAAGACTTGTGCATCCCTC >21056_21056_5_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000463117_ASPSCR1_chr17_79966913_ENST00000306739_length(amino acids)=325AA_BP=83 MAPFMWQVVIQDCLPGWQQGPSGTMSALGVTVALLVWAAFLLLVSMWRQVHSSWNLPPGPFPLPIIGNLFQLELKNIPKSFTRPVDREPV DREPVVCHPDLEERLQAWPAELPDEFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFR PSETVGDLRDFVRSHLGNPELSFYLFITPPKTVLDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAA -------------------------------------------------------------- >21056_21056_6_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000463117_ASPSCR1_chr17_79966913_ENST00000580534_length(transcript)=1335nt_BP=449nt ACTTCCGGGTTGTTTGCTCCCGGAGCCATAACCGCAGCTCAGCGTGCGGGCAGAGCCGGCTGACAGGAGACAGGACACAGCACAGAGCCC CGCGCCCTCTGAGGCGGGAGGCTTCGTTCCTGCACCAGCGTGGCTTGCCCTTTGGACGCGGCGAGTTAACTTGAGAAAGTGGAATCGAAT TCCGATGTTGAATTTTCCTTCTGGCCCCATTCATGTGGCAGGTGGTGATTCAGGATTGTCTCCCGGGCTGGCAGCAGGGCCCCAGCGGCA CCATGTCTGCCCTCGGAGTCACCGTGGCCCTGCTGGTGTGGGCGGCCTTCCTCCTGCTGGTGTCCATGTGGAGGCAGGTGCACAGCAGCT GGAATCTGCCCCCAGGCCCTTTCCCGCTTCCCATCATCGGGAACCTCTTCCAGTTGGAATTGAAGAATATTCCCAAGTCCTTCACCCGGC CCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTG ATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGG TGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACG TCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTT ACCTGTGCCTGTCTTCCTTCGGGCGCATGGATGGGCGAGGTCCACGGTGCTTCCTAACACGTAGGTGCCTTCTCTCCTCAGTCATCACCC CTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGGCGAACCTCTTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGC CGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATCTCCCCATCTGCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGG CCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCTAAGTCTGAGCCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGC CCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAGGTGCCCAAGTGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGC >21056_21056_6_CYP2E1-ASPSCR1_CYP2E1_chr10_135341076_ENST00000463117_ASPSCR1_chr17_79966913_ENST00000580534_length(amino acids)=350AA_BP=83 MAPFMWQVVIQDCLPGWQQGPSGTMSALGVTVALLVWAAFLLLVSMWRQVHSSWNLPPGPFPLPIIGNLFQLELKNIPKSFTRPVDREPV DREPVVCHPDLEERLQAWPAELPDEFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFR PSETVGDLRDFVRSHLGNPELSFYLCLSSFGRMDGRGPRCFLTRRCLLSSVITPPKTVLDDHTQTLFQANLFPAALVHLGAEEPAGVYLE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CYP2E1-ASPSCR1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | ASPSCR1 | chr10:135341076 | chr17:79966913 | ENST00000306729 | 6 | 17 | 317_380 | 311.0 | 648.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr10:135341076 | chr17:79966913 | ENST00000306739 | 6 | 16 | 317_380 | 311.0 | 554.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr10:135341076 | chr17:79966913 | ENST00000580534 | 5 | 15 | 317_380 | 234.0 | 502.0 | GLUT4 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CYP2E1-ASPSCR1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CYP2E1-ASPSCR1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies