
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DAND5-NFIC (FusionGDB2 ID:21319) |
Fusion Gene Summary for DAND5-NFIC |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DAND5-NFIC | Fusion gene ID: 21319 | Hgene | Tgene | Gene symbol | DAND5 | NFIC | Gene ID | 199699 | 4782 |
| Gene name | DAN domain BMP antagonist family member 5 | nuclear factor I C | |
| Synonyms | CER2|CERL2|CKTSF1B3|COCO|CRL2|DANTE|GREM3|SP1 | CTF|CTF5|NF-I|NFI | |
| Cytomap | 19p13.13 | 19p13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | DAN domain family member 5DAN domain family member 5, BMP antagonistDAN domain family, member 5cerberus 2cerberus-like 2cerberus-like protein 2cerl-2cysteine knot superfamily 1, BMP antagonist 3gremlin-3 | nuclear factor 1 C-typeCCAAT-box-binding transcription factorNF-I/CNF1-CTGGCA-binding proteinnuclear factor I/C (CCAAT-binding transcription factor) | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q8N907 | P08651 | |
| Ensembl transtripts involved in fusion gene | ENST00000317060, ENST00000585548, | ENST00000588839, ENST00000341919, ENST00000346156, ENST00000395111, ENST00000443272, ENST00000586919, ENST00000589123, ENST00000590282, | |
| Fusion gene scores | * DoF score | 3 X 3 X 3=27 | 24 X 21 X 9=4536 |
| # samples | 3 | 27 | |
| ** MAII score | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(27/4536*10)=-4.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DAND5 [Title/Abstract] AND NFIC [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DAND5(13080798)-NFIC(3381709), # samples:35 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | NFIC | GO:0000122 | negative regulation of transcription by RNA polymerase II | 19706729 |
| Tgene | NFIC | GO:0045944 | positive regulation of transcription by RNA polymerase II | 1524678|19706729 |
| Fusion gene breakpoints across DAND5 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NFIC (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ACC | TCGA-OR-A5LS | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | CESC | TCGA-Q1-A73R | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | ESCA | TCGA-L5-A893 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-CS-5393 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-DB-A64U | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-DU-7009 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-DU-7300 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-DU-7306 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-DU-8164 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-DU-A6S2 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-EZ-7264 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-F6-A8O3 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HT-7478 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HT-7480 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HT-7485 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HT-7690 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HT-7873 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HT-7875 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HT-7881 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HW-7486 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HW-7491 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HW-7495 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-HW-8322 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-QH-A65R | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-QH-A6CZ | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-QH-A6X8 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-R8-A6ML | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-S9-A7J1 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-S9-A7J2 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-S9-A7J3 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-TM-A84G | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-TM-A84H | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-TM-A84M | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ChimerDB4 | LGG | TCGA-TQ-A7RO | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
Top |
Fusion Gene ORF analysis for DAND5-NFIC |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000317060 | ENST00000588839 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| 5CDS-intron | ENST00000585548 | ENST00000588839 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000317060 | ENST00000341919 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000317060 | ENST00000346156 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000317060 | ENST00000395111 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000317060 | ENST00000443272 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000317060 | ENST00000586919 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000317060 | ENST00000589123 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000317060 | ENST00000590282 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000585548 | ENST00000341919 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000585548 | ENST00000346156 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000585548 | ENST00000395111 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000585548 | ENST00000443272 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000585548 | ENST00000586919 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000585548 | ENST00000589123 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| In-frame | ENST00000585548 | ENST00000590282 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000585548 | DAND5 | chr19 | 13080798 | + | ENST00000589123 | NFIC | chr19 | 3381709 | + | 8455 | 510 | 96 | 2006 | 636 |
| ENST00000585548 | DAND5 | chr19 | 13080798 | + | ENST00000346156 | NFIC | chr19 | 3381709 | + | 2617 | 510 | 96 | 1727 | 543 |
| ENST00000585548 | DAND5 | chr19 | 13080798 | + | ENST00000395111 | NFIC | chr19 | 3381709 | + | 2226 | 510 | 96 | 1799 | 567 |
| ENST00000585548 | DAND5 | chr19 | 13080798 | + | ENST00000586919 | NFIC | chr19 | 3381709 | + | 1728 | 510 | 96 | 1727 | 543 |
| ENST00000585548 | DAND5 | chr19 | 13080798 | + | ENST00000341919 | NFIC | chr19 | 3381709 | + | 1965 | 510 | 96 | 1766 | 556 |
| ENST00000585548 | DAND5 | chr19 | 13080798 | + | ENST00000590282 | NFIC | chr19 | 3381709 | + | 1984 | 510 | 96 | 1799 | 567 |
| ENST00000585548 | DAND5 | chr19 | 13080798 | + | ENST00000443272 | NFIC | chr19 | 3381709 | + | 2145 | 510 | 96 | 2006 | 636 |
| ENST00000317060 | DAND5 | chr19 | 13080798 | + | ENST00000589123 | NFIC | chr19 | 3381709 | + | 8448 | 503 | 89 | 1999 | 636 |
| ENST00000317060 | DAND5 | chr19 | 13080798 | + | ENST00000346156 | NFIC | chr19 | 3381709 | + | 2610 | 503 | 89 | 1720 | 543 |
| ENST00000317060 | DAND5 | chr19 | 13080798 | + | ENST00000395111 | NFIC | chr19 | 3381709 | + | 2219 | 503 | 89 | 1792 | 567 |
| ENST00000317060 | DAND5 | chr19 | 13080798 | + | ENST00000586919 | NFIC | chr19 | 3381709 | + | 1721 | 503 | 89 | 1720 | 544 |
| ENST00000317060 | DAND5 | chr19 | 13080798 | + | ENST00000341919 | NFIC | chr19 | 3381709 | + | 1958 | 503 | 89 | 1759 | 556 |
| ENST00000317060 | DAND5 | chr19 | 13080798 | + | ENST00000590282 | NFIC | chr19 | 3381709 | + | 1977 | 503 | 89 | 1792 | 567 |
| ENST00000317060 | DAND5 | chr19 | 13080798 | + | ENST00000443272 | NFIC | chr19 | 3381709 | + | 2138 | 503 | 89 | 1999 | 636 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000585548 | ENST00000589123 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.018140486 | 0.9818595 |
| ENST00000585548 | ENST00000346156 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.114329584 | 0.8856704 |
| ENST00000585548 | ENST00000395111 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.11035954 | 0.8896405 |
| ENST00000585548 | ENST00000586919 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.13401186 | 0.86598814 |
| ENST00000585548 | ENST00000341919 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.115773864 | 0.8842261 |
| ENST00000585548 | ENST00000590282 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.115104966 | 0.8848951 |
| ENST00000585548 | ENST00000443272 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.09316688 | 0.9068331 |
| ENST00000317060 | ENST00000589123 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.01819588 | 0.98180413 |
| ENST00000317060 | ENST00000346156 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.10801459 | 0.8919854 |
| ENST00000317060 | ENST00000395111 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.099502616 | 0.90049744 |
| ENST00000317060 | ENST00000586919 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.130424 | 0.869576 |
| ENST00000317060 | ENST00000341919 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.11165677 | 0.8883432 |
| ENST00000317060 | ENST00000590282 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.10886025 | 0.8911398 |
| ENST00000317060 | ENST00000443272 | DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 0.08534977 | 0.91465026 |
Top |
Fusion Genomic Features for DAND5-NFIC |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 2.50E-21 | 1 |
| DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 2.50E-21 | 1 |
| DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 2.50E-21 | 1 |
| DAND5 | chr19 | 13080798 | + | NFIC | chr19 | 3381709 | + | 2.50E-21 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
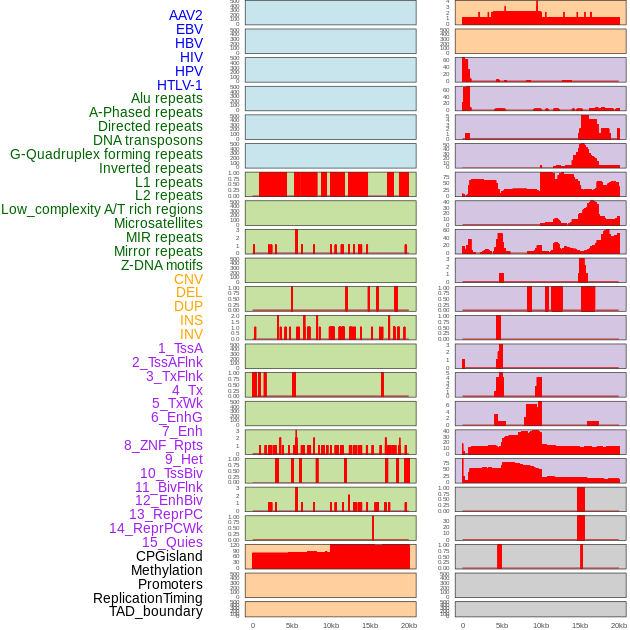 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
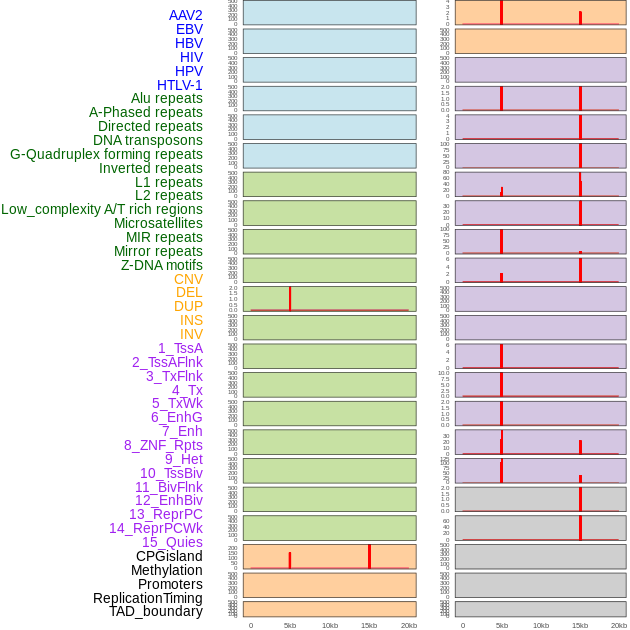 |
Top |
Fusion Protein Features for DAND5-NFIC |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:13080798/chr19:3381709) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DAND5 | NFIC |
| FUNCTION: Seems to play a role in the correct specification of the left-right axis. May antagonize NODAL and BMP4 signaling. Cystine knot-containing proteins play important roles during development, organogenesis, tissue growth and differentiation (By similarity). {ECO:0000250}. | FUNCTION: Recognizes and binds the palindromic sequence 5'-TTGGCNNNNNGCCAA-3' present in viral and cellular promoters and in the origin of replication of adenovirus type 2. These proteins are individually capable of activating transcription and replication. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000346156 | 0 | 9 | 1_195 | 1 | 669.0 | DNA binding | CTF/NF-I | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000395111 | 0 | 10 | 1_195 | 1 | 548.3333333333334 | DNA binding | CTF/NF-I | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000586919 | 0 | 8 | 1_195 | 1 | 407.0 | DNA binding | CTF/NF-I | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000589123 | 0 | 11 | 1_195 | 1 | 500.0 | DNA binding | CTF/NF-I | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000341919 | 0 | 9 | 404_412 | 10 | 429.0 | Motif | 9aaTAD | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000346156 | 0 | 9 | 404_412 | 1 | 669.0 | Motif | 9aaTAD | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000395111 | 0 | 10 | 404_412 | 1 | 548.3333333333334 | Motif | 9aaTAD | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000443272 | 0 | 11 | 404_412 | 10 | 509.0 | Motif | 9aaTAD | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000586919 | 0 | 8 | 404_412 | 1 | 407.0 | Motif | 9aaTAD | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000589123 | 0 | 11 | 404_412 | 1 | 500.0 | Motif | 9aaTAD | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000590282 | 0 | 10 | 404_412 | 10 | 461.6666666666667 | Motif | 9aaTAD |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DAND5 | chr19:13080798 | chr19:3381709 | ENST00000317060 | + | 1 | 2 | 101_186 | 108 | 190.0 | Domain | Note=CTCK |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000341919 | 0 | 9 | 1_195 | 10 | 429.0 | DNA binding | CTF/NF-I | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000443272 | 0 | 11 | 1_195 | 10 | 509.0 | DNA binding | CTF/NF-I | |
| Tgene | NFIC | chr19:13080798 | chr19:3381709 | ENST00000590282 | 0 | 10 | 1_195 | 10 | 461.6666666666667 | DNA binding | CTF/NF-I |
Top |
Fusion Gene Sequence for DAND5-NFIC |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >21319_21319_1_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000341919_length(transcript)=1958nt_BP=503nt ACTCTCCTCCCCCGCTGTGGGTCTACAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAGGCTCAGA TGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGACAAGCAGA TGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCTCCTCGAC CTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGGAGCTGGA AGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACTCTGCCGC TGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTC ACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACG AGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGG ACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGG GCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGC TGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCG TCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACC AGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCC AAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAG CCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACA CGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGT CCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACC ACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCC AGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGG CCTGCGACCCAGCCAGCCAGCAACCTGGACCGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCCAGG AATCCCAGGGGGCAGCACAGCCGGCCCCCGGCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACACCCCTGCCGACTCCCAGCCCG >21319_21319_1_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000341919_length(amino acids)=556AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL -------------------------------------------------------------- >21319_21319_2_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000346156_length(transcript)=2610nt_BP=503nt ACTCTCCTCCCCCGCTGTGGGTCTACAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAGGCTCAGA TGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGACAAGCAGA TGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCTCCTCGAC CTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGGAGCTGGA AGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACTCTGCCGC TGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTC ACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACG AGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGG ACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGG GCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGC TGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCG TCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCA GCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGG CATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGA TGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACA TGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCT CCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTA CGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCA AAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTT TGTGGGATTAGGACCAAGGGATCCTGCGGGCATTTATCAGGCACAGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTC TCCATCGTCCCAGGAATCCCAGGGGGCAGCACAGCCGGCCCCCGGCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACACCCCTGC CGACTCCCAGCCCGGCCAAAAAGACAAAACACATAGACGCACACACTCAGGAGGAAAAGAAAAAACAAAGGCAGAAGAAGAAGAAGAAGA AATAAAAACCCACCCAAGCAAGAAGACAAAAGGTAAAGACGCAACGTTTCCAACTCTCGGGACGCCAAGGCCGCAGGACTGGAGGGCCAG GCCCCGCCACCCCCACGGGAGACCCGGGACAGGGCGTCTTCCTAAGTTATTCATCTCCTCTCCGCCTGCTGCTCGGGAAGGACAGACGCC GGCCGCCCGCCCGCGCCCCGGAGGCCCTGGCTCTGTCCGGAGACCAGGTGAGCACAGCCTGGAGCCTGTGCCCAGGGCCGACAGGCGCGA CACCCAGCAAGGCCACCTCTCCCCGGGCCCCCGCGCCTCTGCCGGACACGGACCGGCCCCTCAGCCCCCACCGAGGACGCAGCCACTGGG GGGAAAGGGAGACACAGCGGACCCCGGCCGGGCAGCGGAGACCGCAGAGGCGGGCAGGGTGGGGCAGGCGAGTGGTGTCGCGGGGGTGCG TGGCGCTTGCGAGCCCTGGCCAGGGGAGGAAGTGAGGCCCAGGCACCTGCTGCCCCTCGAGGGGGCCCTGCCTGCCGCGGGGCCTCCCCA CAAGCCCCTCCCAAAGCGCCGGCCGACTCGCTGTCTCGCTGGGGACTCTTTCAGCCCTCGCGCCCGCCCGTTTGGGAGGAGAAGTCTCTA >21319_21319_2_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000346156_length(amino acids)=543AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHL AYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRL SSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPPTLRPTRPLQTVP -------------------------------------------------------------- >21319_21319_3_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000395111_length(transcript)=2219nt_BP=503nt ACTCTCCTCCCCCGCTGTGGGTCTACAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAGGCTCAGA TGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGACAAGCAGA TGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCTCCTCGAC CTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGGAGCTGGA AGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACTCTGCCGC TGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTC ACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACG AGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGG ACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGG GCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGC TGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCG TCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACC AGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCC AAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAG CCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACA CGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGT CCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACC ACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCC AGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGG CCTGCGACCCAGCCAGCCAGCAACCTGGACCGCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTTTGTGGGATTAGGACCAAG GGATCCTGCGGGCATTTATCAGGCACAGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCCAGGAATC CCAGGGGGCAGCACAGCCGGCCCCCGGCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACACCCCTGCCGACTCCCAGCCCGGCCA AAAAGACAAAACACATAGACGCACACACTCAGGAGGAAAAGAAAAAACAAAGGCAGAAGAAGAAGAAGAAGAAATAAAAACCCACCCAAG CAAGAAGACAAAAGGTAAAGACGCAACGTTTCCAACTCTCGGGACGCCAAGGCCGCAGGACTGGAGGGCCAGGCCCCGCCACCCCCACGG >21319_21319_3_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000395111_length(amino acids)=567AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL -------------------------------------------------------------- >21319_21319_4_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000443272_length(transcript)=2138nt_BP=503nt ACTCTCCTCCCCCGCTGTGGGTCTACAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAGGCTCAGA TGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGACAAGCAGA TGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCTCCTCGAC CTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGGAGCTGGA AGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACTCTGCCGC TGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTC ACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACG AGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGG ACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGG GCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGC TGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCG TCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACC AGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCC AAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAG CCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACA CGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGT CCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACC ACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCC AGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGG CCTGCGACCCAGCCAGCCAGCAACCTGGACCGTTAAATGGAAGTGGTCAGCTCAAAATGCCCAGCCACTGCCTTTCTGCTCAGATGCTGG CACCTCCGCCCCCGGGGCTGCCACGGCTGGCGCTCCCCCCTGCCACCAAACCCGCCACCACCTCCGAGGGAGGAGCCACGTCGCCGACCT CGCCTTCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTTTGTGGGATTAGGACCAAGGGATCCTGCGGGCATTTATCAGGCAC AGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCCAGGAATCCCAGGGGGCAGCACAGCCGGCCCCCG >21319_21319_4_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000443272_length(amino acids)=636AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL ACDPASQQPGPLNGSGQLKMPSHCLSAQMLAPPPPGLPRLALPPATKPATTSEGGATSPTSPSYSPPDTSPANRSFVGLGPRDPAGIYQA -------------------------------------------------------------- >21319_21319_5_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000586919_length(transcript)=1721nt_BP=503nt ACTCTCCTCCCCCGCTGTGGGTCTACAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAGGCTCAGA TGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGACAAGCAGA TGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCTCCTCGAC CTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGGAGCTGGA AGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACTCTGCCGC TGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTC ACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACG AGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGG ACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGG GCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGC TGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCG TCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCA GCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGG CATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGA TGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACA TGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCT CCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTA CGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCA AAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTT >21319_21319_5_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000586919_length(amino acids)=544AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHL AYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRL SSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPPTLRPTRPLQTVP -------------------------------------------------------------- >21319_21319_6_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000589123_length(transcript)=8448nt_BP=503nt ACTCTCCTCCCCCGCTGTGGGTCTACAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAGGCTCAGA TGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGACAAGCAGA TGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCTCCTCGAC CTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGGAGCTGGA AGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACTCTGCCGC TGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTC ACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACG AGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGG ACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGG GCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGC TGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCG TCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACC AGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCC AAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAG CCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACA CGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGT CCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACC ACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCC AGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGG CCTGCGACCCAGCCAGCCAGCAACCTGGACCGTTAAATGGAAGTGGTCAGCTCAAAATGCCCAGCCACTGCCTTTCTGCTCAGATGCTGG CACCTCCGCCCCCGGGGCTGCCACGGCTGGCGCTCCCCCCTGCCACCAAACCCGCCACCACCTCCGAGGGAGGAGCCACGTCGCCGACCT CGCCTTCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTTTGTGGGATTAGGACCAAGGGATCCTGCGGGCATTTATCAGGCAC AGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCCAGGAATCCCAGGGGGCAGCACAGCCGGCCCCCG GCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACACCCCTGCCGACTCCCAGCCCGGCCAAAAAGACAAAACACATAGACGCACAC ACTCAGGAGGAAAAGAAAAAACAAAGGCAGAAGAAGAAGAAGAAGAAATAAAAACCCACCCAAGCAAGAAGACAAAAGGTAAAGACGCAA CGTTTCCAACTCTCGGGACGCCAAGGCCGCAGGACTGGAGGGCCAGGCCCCGCCACCCCCACGGGAGACCCGGGACAGGGCGTCTTCCTA AGTTATTCATCTCCTCTCCGCCTGCTGCTCGGGAAGGACAGACGCCGGCCGCCCGCCCGCGCCCCGGAGGCCCTGGCTCTGTCCGGAGAC CAGGTGAGCACAGCCTGGAGCCTGTGCCCAGGGCCGACAGGCGCGACACCCAGCAAGGCCACCTCTCCCCGGGCCCCCGCGCCTCTGCCG GACACGGACCGGCCCCTCAGCCCCCACCGAGGACGCAGCCACTGGGGGGAAAGGGAGACACAGCGGACCCCGGCCGGGCAGCGGAGACCG CAGAGGCGGGCAGGGTGGGGCAGGCGAGTGGTGTCGCGGGGGTGCGTGGCGCTTGCGAGCCCTGGCCAGGGGAGGAAGTGAGGCCCAGGC ACCTGCTGCCCCTCGAGGGGGCCCTGCCTGCCGCGGGGCCTCCCCACAAGCCCCTCCCAAAGCGCCGGCCGACTCGCTGTCTCGCTGGGG ACTCTTTCAGCCCTCGCGCCCGCCCGTTTGGGAGGAGAAGTCTCTATGCAATTGGCCCCGGCCCCTCCACCCCCCACCCCCGGCATAGGA GGCCCCCCCACCTCGCCCGGCTCACACCCCCAAAGGGAGGGACCCACATTGCACACACTGTAAGAAATGCACTTTCCGAGGAAGGGGATG GGGGAGCCCGGACACCCAGAGCTCCCCGAGTTGGGGGTGCCCGTCTGGAGCGCCCCCGTCAGCCCCTGGCGGTGGGAGGTGAGAGCGAGT GGTTTAAGTGCCTGATTACCACCACCCGCCCCCCCCTTTGTCCAGCTGGGACACGGAATGGCCGCGGGCCTCCTCCCCCTCCCCTCCAGC CTCTCCACCAGCCCCTCCAGTCAACCCTCATCGCCGTGCCCCCCCAGAGCTAGAGAGATGGGGCCCCTGCGTGGCCCGAGGGGCAGAGCT GGGCGTCACTTCGCAAGCGTCCTGCCCTGCCGGGGCGCGGGGGTGGGCTCTGGGGAAGCCGGTGCGCCCCCCACGCCTCCGCTGCCAGTG CCTTACATTCTGGAGCGACCCCCCTCCCTGGTGCCTCCCAGCGAAGGGGGACCGCCGTTTGCACTTTCATCGCCTACCCCGACGCGGGGC CCAGCTGCGGGACGTGCATCACGGCTGGGCCCCCAGAGGAGAGAGGAGGCCGACGCCAGCGGTCCCCGCTCGGAACGGGGAGGGTTTTCG GGGGGTTCGGCGTCGCACCTTGGGGCCCCCCGCAGCCGTGTAGGGGGCCTCCCATCTGCTAAGCGTTTTTCCGTTGAGCCGCTCCAAAAA CACTAAGCTGGGGACGCCAGGTGCCCCCCCACCCCGGCTCCCTGGCCCTATCCACACCTCCACCCCCACCCCAGGATCGCCATCTTTAGG GGAGGCCTGGGAGGGGGTGTTAGGTGTTTTAGGGCCACCGAGCTCAAACACAAGGACCCCTCCCCGGCCCACCCAGCCCAGCCCCAACTG ACCTCCATGCCTAGGGAAAAACTCCCCCCACCACTGCCCCCTCCCCCGACCCAGGCCAAAGCCAGGGCAGGTCTCCGGGTCTCACCTGCT CCTAGCCTCACCCCCCTGCCCCCGAAAACCAGACTCTCCTCCCAAACTAGCCTCAGGAGCTTGGCGAACCCGCTCGCTCCTAAAGAGAAA GACCCAGGACCCTCCCCCATCACCCCCAAGAGAGGTTCGCCATCCTCTGGCCTCGAGCCCTTGGTCCCTCCGTCCGTCTGTCCTCGGGGC CCGCTCCCCCGGTGGCCCTTGGGGATCAAAGCGTGGGCCGCTCTCCGGGAGGGCGGGCGGGGGAGGGGGTGGTCGGGTTGTGCCATTGGG GTGTCCGGAAGCTTCTCAGCCAGGGTGGGGGTCGTGGAGTGGGGGAGGGAGGCCAGCCGGGCTCCAGAGGGGTCAGGGCGCGACGAGAAC CAACTCTTTACCTAACTTTGCATGGTGCTTAGTCAAGGACTCCTGCGACCTGGCTCCCGAGGTCAGCTGGCGGCGCTGACACACATGCAT GGCAGACTATCCCTGGCTCTATCTCCCTGTTCCTCGCCCCCTCCACCCCCCACTTCCTCTTTAAAAAAAAAAAAAAAAAAAAAAAGATAC AAGAAAAACCTTTAAAAAAATTCCATGTTTCCTAATTTGCACGAAATTTTCTACCACAAGATGTGCCTTGCCTTCCGAGAATAAGTATTA CCTTTAAACAATATCAGCGCACACACATAGCTGCATGTTCTGCTCGTGTAGTTTAAAAAAAAAAAGACAAAACAGTGACATGAAATAAAA AATAAAAATTGAAAAGGGATGTATTTCTATTTGTAAAAAAAATAAAATAAAAAATAAGAAAGTGAGAATCTAAAAAAAAAAAAAAAAAAA AAAAAGGAAGAAAAACCACGCTAAAAATCAAGCCACTGAAAACAATTGCCCCCAGGTCTACCCAGCCCCTGGCTGTCCTTGGTCCTGTCT CCCCTCCTGCTGTATTCAGGGGTGCCCCCTGGTGCTCAGCCTCTACCACCCCCAACCCTGCTCTTGGGTACCCAGAGGGGTCATTTCTGA ATCCCTTGCCCAGAGGACAGACCTCCGGGGCCCATCTTGGCCCTGGGAAAGGGCTCTCCTCTCTGATTGGTCCCTAGGCCACGGGCCGGC CCCCAGACACCATTCACCGACCCACTGCAGGCTGTCCTCCAACCATGGGGTGGCCACTCCACCCGCAGCCAGACTCCCCGCTCCCCACTT TTCATGCAGGCTGGCATACCCCTGGCTCAGGGTCAAATGCTGTTCCACACCCACCTCAGAGGCACCCCCTCTCCCCTGCCCCGTGCATCC CCACCCTTCTTGCCAAAGGACCTCTTTTCCCCTATCCAGAGACCACCCCAGGTGGCATTCTCTCCCACCTTCTCCTTTGTCCCCCATCCC CTGTCTCTGTCTTCCAGCTGTGAATATGAAGGGTATCCTGTATGAAACAAAAACAAAACCTGATATATGCAATATCTGTCTGTCTGTCTG TACCCATGGGCCTGGCTCAGCCATTGGAGGCCCAGCCGAGGGTCCGGCAGGGCACAGGGACAGCCAGGTGGCACCGAGTCACAGGCTGTG GTCCGGTGGCTGAGCATGCTGTTGTCTTGTCCTTGATTTTATTTTCTTTTGTTCTTTTTTTTTTTCTTTTCTTTTTGTTTTTAACTCCAG CTTCCTTTGCTTTTTACTTGACCAAAGCTAAGACAATAGCCAGATGGTTAGTGGGGCAGCCAGGCAGGGAGGACCCAGGGCTGGGATTCT CCAACCTTAGGCCATTCCTGCAGCCCTCACCACCTCCAGCCCCTCCAAGCATCTCGTGTAGGGACCCACGCAGATGGTCCCATTCATTCA CTATTGCCCCCAACCCCGGGATTTTGGGTGGTCTCCACAGCCACCATCATACACTCATCCCGTGTTTTCTTCCAAAAAGTCACCTCAGCA GCCTCCCCAGGCGATACAGAGGGAGAGCCCAGACCACCACAGCTGGCCACGACATTGCCCTTAAGTAATATGCATTGGCCAGAGAGCCCG GGCTGGCTGTGCACAGCATTCATGTAGCTGATTTCTAGCTTTTTTTTTTTTTCTGCCCCACTCCTGAGCAAATCTGTCTTGCCAAGGAAC TAGGAGCAACCGGAGGCAAAGGGAGTGGGTGGCCCCATCACTATTGGGACCATCGCGTCCCTGCACAGCCCACACCCGGGGGCCCAGAGT CCTGGGCTGGACGCCACCCTTCTCACCCCGAGCTTGCCTCCTTGGCTCACTTGGCACCTTGGCTGAGTACAGCAGGCAAAAGCCCATACC AGGCAGCATGTTGTGGATGGTTTAGTTCTCCCCGCCTCCCTGTTTCTTGGAAAAGCTACAGGGTCCCTGTAGGGCAAAATTCCCAGGCGC CTTGCTGCAGACAGAGTAAGACAAAAACACCAGGAAGCAGGATTCCGTGCCCATCTCTGCAGTTTGGGTTCACAAAAGGGGGTGCCGTCA TCCCTGGGTGGAGGAGGGAGTGTTGGTTTTTTGTTTTTGTTTTTTTAACATGTATGAAACTGACATCTTCTCAAATCTTGTTCCACCCCC CTCTGGAAGCCCCCATCACCCACCCCTGCTATGGACACCACACCTATGCCAGGCCCCCCCCCCCACCCCAGTCTCATTCTGGGGTCTGCC CATGCTGTGGGAAAGAATAGGGAGGCCTCCCAAATATATGCAAATTGTCCCCATTCCGTGGGGGCACCTGACAATGACCCGGGTGGAGAT GGGGCATGGAGGAGTAGGAAGACCCAGCCCTATTTGACTGGGGAGAGGAGGATCTGGAGTCCTTCATGCCCAGGTCTGGAACCCAGGTTC TGACCCCAGGGCCCCACCCTGGGCTGGACAATCAGATCCCAAAGGAATGCCAAAGGGGACTCGGTTGGGAGAGCCGCTTAGGGGCCAGAC CTGGGTCCCCCTGCAGGTCCCCAGGCAGCAGACAATTCCACCTTCCCTGCCCCAGGACCTTGAGAGACAGCAGCATTCCAGGCACAGACA GACTTGGCTGCACCCCACTGTCCCTTGCAAGACAGGTTCTGGAGCCAGGAGCAACTGTCCAGCCCTCCAGAAGAGACAGCAAGCAGCCCC CCTACCCACTCTGGCCTCCCCAATGGTACTTTGACCTCCAGTGTAGGGCTATACTATACATATATATATATATATATATATATATATATA ATTTTGGAATTTGTTTCTCATAATACAGAATATATAGTGGCTACCTTGTATCTTGGTCTGGATTCTCTCTCTGAGACCCCGGATTTTACT TTCTCTTTGGAGGGCGCTGGGACATACATCTCTCAATCCAGCTTCCTCCGCATCCTCCCATCTTGCCCCATTTCTGCCACGTCAGACACT TCCTGAGAGTCTCACCTTCAAAATGACACCGCTGCCCATCCATTGCTCAATGGTACAGAGTGTGGGGTCAGTCCACCACCCTTGACCTCC CGGCAGGGCAAGGTGAGGAGGCGGACCCAAAGCAGTACCAGCAGGACTTGTTGCCAGTGATACCAAAACAGACTTTTCCCAAGCAGTGCC TCACATGTCTGCTGGTGTGGCTTTGGGATTCTCCTGCCCCACCCCCCCGTCCATGGCAGCCCCCTCCCCAAGGCTTTGCTCACACCTGAG ACAGGAAGGAGGAAGGGGATCCAATAGGAATATGGGCCCCGGAGGGGAAGTCATGCACCCCCAAGCCACCACCCCCCAGCCTTCCACGCA CATCTCCTGGCTGGAAGAGAGCCCTCCAAAAAGGGGACACAGGCTGCCCCGGCCCCTCAACTGCATCCACACCCCATCCTCTCATCTTGG GTCCCAGCCAGGCCCCCCCAAAACCAAAGCCCCCTCAAGTCCTGGGGTCCCAGCCTGTGCCCCCAGCTTCCTGCCCACCCAGCCCTGAGC ATTCTCACACAGAGAAAGAACAAGCAAGGGCTCCAGGGGGACAGGATGGGGCAGGGCATACAGTGGGGGGTGGGGGGGCAGCTGGGAGGA GGGAGGGACAAAACAAAACATTTTCCTTTGGGTTTTTTTTTTCTTTCTTTTTTCTCCCCTTTACTCTTTGGGTGGTGTTGCTTTTCCTTT CCTTTTCCCTTTGAGATTTTTTTGTTGTTGTTTCCTTTTTGTATTTTACTGATATCACCAGGATAGTTTACTCTCCTTCTAGCTTTCTGC TTACCGCACACTGGATAACACACACATACACACCCACAAAAATGCTCATGAACCCAATCCGGAGAAGGTTCCAGCAGGTCCCCCACCCTC CCCTCCTCCTCCTACTTCTCCTCTTGACAGCGAGGACAGGAGGGGGACAAGGGGACACCTGGGCAGACCCGCCGGCTCTCCCCCCACCCC ACCCCGCCCCTCACATCATACTCCAATCATAACCTTGTATATTATGCAGTCATTTTGGTTTTCGCGGACGCGCCTACCTAAGTACCATTT ACAGAAAGTGACTCTGGCTGTCATTATTTTGTTTATTTGTTCCCTATGCAAAAAAAAAATGAAAATGAAAAAAGGGGGATTCCATAAAAG >21319_21319_6_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000589123_length(amino acids)=636AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL ACDPASQQPGPLNGSGQLKMPSHCLSAQMLAPPPPGLPRLALPPATKPATTSEGGATSPTSPSYSPPDTSPANRSFVGLGPRDPAGIYQA -------------------------------------------------------------- >21319_21319_7_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000590282_length(transcript)=1977nt_BP=503nt ACTCTCCTCCCCCGCTGTGGGTCTACAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAGGCTCAGA TGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGACAAGCAGA TGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCTCCTCGAC CTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGGAGCTGGA AGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACTCTGCCGC TGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTC ACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACG AGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGG ACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGG GCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGC TGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCG TCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACC AGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCC AAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAG CCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACA CGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGT CCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACC ACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCC AGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGG CCTGCGACCCAGCCAGCCAGCAACCTGGACCGCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTTTGTGGGATTAGGACCAAG GGATCCTGCGGGCATTTATCAGGCACAGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCCAGGAATC >21319_21319_7_DAND5-NFIC_DAND5_chr19_13080798_ENST00000317060_NFIC_chr19_3381709_ENST00000590282_length(amino acids)=567AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL -------------------------------------------------------------- >21319_21319_8_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000341919_length(transcript)=1965nt_BP=510nt GGGAGACCTGGAAGGAAGCGACTGCACTGATCCAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAG GCTCAGATGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGAC AAGCAGATGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCT CCTCGACCTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGG AGCTGGAAGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACT CTGCCGCTGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTG CTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCG AAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTG CGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGAC CAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGC ATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGC GTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGC TCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAG CTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTG AACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGAC GTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGC ATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACC CAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATC CTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTC TCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCG TCCCAGGAATCCCAGGGGGCAGCACAGCCGGCCCCCGGCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACACCCCTGCCGACTCC >21319_21319_8_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000341919_length(amino acids)=556AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL -------------------------------------------------------------- >21319_21319_9_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000346156_length(transcript)=2617nt_BP=510nt GGGAGACCTGGAAGGAAGCGACTGCACTGATCCAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAG GCTCAGATGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGAC AAGCAGATGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCT CCTCGACCTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGG AGCTGGAAGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACT CTGCCGCTGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTG CTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCG AAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTG CGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGAC CAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGC ATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGC GTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGC GTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGG CACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCG GGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACG GAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCC CGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCAT TTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGAC CCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCCTACTCTCCGCCCGACACGTCCCCTGCAAACC GTTCCTTTGTGGGATTAGGACCAAGGGATCCTGCGGGCATTTATCAGGCACAGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCG CCCCTTCTCCATCGTCCCAGGAATCCCAGGGGGCAGCACAGCCGGCCCCCGGCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACA CCCCTGCCGACTCCCAGCCCGGCCAAAAAGACAAAACACATAGACGCACACACTCAGGAGGAAAAGAAAAAACAAAGGCAGAAGAAGAAG AAGAAGAAATAAAAACCCACCCAAGCAAGAAGACAAAAGGTAAAGACGCAACGTTTCCAACTCTCGGGACGCCAAGGCCGCAGGACTGGA GGGCCAGGCCCCGCCACCCCCACGGGAGACCCGGGACAGGGCGTCTTCCTAAGTTATTCATCTCCTCTCCGCCTGCTGCTCGGGAAGGAC AGACGCCGGCCGCCCGCCCGCGCCCCGGAGGCCCTGGCTCTGTCCGGAGACCAGGTGAGCACAGCCTGGAGCCTGTGCCCAGGGCCGACA GGCGCGACACCCAGCAAGGCCACCTCTCCCCGGGCCCCCGCGCCTCTGCCGGACACGGACCGGCCCCTCAGCCCCCACCGAGGACGCAGC CACTGGGGGGAAAGGGAGACACAGCGGACCCCGGCCGGGCAGCGGAGACCGCAGAGGCGGGCAGGGTGGGGCAGGCGAGTGGTGTCGCGG GGGTGCGTGGCGCTTGCGAGCCCTGGCCAGGGGAGGAAGTGAGGCCCAGGCACCTGCTGCCCCTCGAGGGGGCCCTGCCTGCCGCGGGGC CTCCCCACAAGCCCCTCCCAAAGCGCCGGCCGACTCGCTGTCTCGCTGGGGACTCTTTCAGCCCTCGCGCCCGCCCGTTTGGGAGGAGAA >21319_21319_9_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000346156_length(amino acids)=543AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHL AYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRL SSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPPTLRPTRPLQTVP -------------------------------------------------------------- >21319_21319_10_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000395111_length(transcript)=2226nt_BP=510nt GGGAGACCTGGAAGGAAGCGACTGCACTGATCCAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAG GCTCAGATGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGAC AAGCAGATGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCT CCTCGACCTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGG AGCTGGAAGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACT CTGCCGCTGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTG CTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCG AAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTG CGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGAC CAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGC ATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGC GTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGC TCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAG CTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTG AACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGAC GTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGC ATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACC CAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATC CTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTC TCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTTTGTGGGATTAG GACCAAGGGATCCTGCGGGCATTTATCAGGCACAGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCC AGGAATCCCAGGGGGCAGCACAGCCGGCCCCCGGCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACACCCCTGCCGACTCCCAGC CCGGCCAAAAAGACAAAACACATAGACGCACACACTCAGGAGGAAAAGAAAAAACAAAGGCAGAAGAAGAAGAAGAAGAAATAAAAACCC ACCCAAGCAAGAAGACAAAAGGTAAAGACGCAACGTTTCCAACTCTCGGGACGCCAAGGCCGCAGGACTGGAGGGCCAGGCCCCGCCACC >21319_21319_10_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000395111_length(amino acids)=567AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL -------------------------------------------------------------- >21319_21319_11_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000443272_length(transcript)=2145nt_BP=510nt GGGAGACCTGGAAGGAAGCGACTGCACTGATCCAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAG GCTCAGATGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGAC AAGCAGATGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCT CCTCGACCTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGG AGCTGGAAGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACT CTGCCGCTGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTG CTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCG AAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTG CGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGAC CAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGC ATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGC GTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGC TCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAG CTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTG AACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGAC GTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGC ATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACC CAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATC CTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTC TCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGTTAAATGGAAGTGGTCAGCTCAAAATGCCCAGCCACTGCCTTTCTGCTCAG ATGCTGGCACCTCCGCCCCCGGGGCTGCCACGGCTGGCGCTCCCCCCTGCCACCAAACCCGCCACCACCTCCGAGGGAGGAGCCACGTCG CCGACCTCGCCTTCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTTTGTGGGATTAGGACCAAGGGATCCTGCGGGCATTTAT CAGGCACAGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCCAGGAATCCCAGGGGGCAGCACAGCCG >21319_21319_11_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000443272_length(amino acids)=636AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL ACDPASQQPGPLNGSGQLKMPSHCLSAQMLAPPPPGLPRLALPPATKPATTSEGGATSPTSPSYSPPDTSPANRSFVGLGPRDPAGIYQA -------------------------------------------------------------- >21319_21319_12_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000586919_length(transcript)=1728nt_BP=510nt GGGAGACCTGGAAGGAAGCGACTGCACTGATCCAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAG GCTCAGATGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGAC AAGCAGATGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCT CCTCGACCTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGG AGCTGGAAGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACT CTGCCGCTGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTG CTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCG AAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTG CGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGAC CAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGC ATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGC GTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGC GTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGG CACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCG GGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACG GAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCC CGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCAT TTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGAC CCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCCTACTCTCCGCCCGACACGTCCCCTGCAAACC >21319_21319_12_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000586919_length(amino acids)=543AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHL AYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRL SSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPPTLRPTRPLQTVP -------------------------------------------------------------- >21319_21319_13_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000589123_length(transcript)=8455nt_BP=510nt GGGAGACCTGGAAGGAAGCGACTGCACTGATCCAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAG GCTCAGATGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGAC AAGCAGATGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCT CCTCGACCTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGG AGCTGGAAGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACT CTGCCGCTGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTG CTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCG AAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTG CGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGAC CAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGC ATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGC GTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGC TCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAG CTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTG AACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGAC GTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGC ATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACC CAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATC CTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTC TCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGTTAAATGGAAGTGGTCAGCTCAAAATGCCCAGCCACTGCCTTTCTGCTCAG ATGCTGGCACCTCCGCCCCCGGGGCTGCCACGGCTGGCGCTCCCCCCTGCCACCAAACCCGCCACCACCTCCGAGGGAGGAGCCACGTCG CCGACCTCGCCTTCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTTTGTGGGATTAGGACCAAGGGATCCTGCGGGCATTTAT CAGGCACAGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCCAGGAATCCCAGGGGGCAGCACAGCCG GCCCCCGGCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACACCCCTGCCGACTCCCAGCCCGGCCAAAAAGACAAAACACATAGA CGCACACACTCAGGAGGAAAAGAAAAAACAAAGGCAGAAGAAGAAGAAGAAGAAATAAAAACCCACCCAAGCAAGAAGACAAAAGGTAAA GACGCAACGTTTCCAACTCTCGGGACGCCAAGGCCGCAGGACTGGAGGGCCAGGCCCCGCCACCCCCACGGGAGACCCGGGACAGGGCGT CTTCCTAAGTTATTCATCTCCTCTCCGCCTGCTGCTCGGGAAGGACAGACGCCGGCCGCCCGCCCGCGCCCCGGAGGCCCTGGCTCTGTC CGGAGACCAGGTGAGCACAGCCTGGAGCCTGTGCCCAGGGCCGACAGGCGCGACACCCAGCAAGGCCACCTCTCCCCGGGCCCCCGCGCC TCTGCCGGACACGGACCGGCCCCTCAGCCCCCACCGAGGACGCAGCCACTGGGGGGAAAGGGAGACACAGCGGACCCCGGCCGGGCAGCG GAGACCGCAGAGGCGGGCAGGGTGGGGCAGGCGAGTGGTGTCGCGGGGGTGCGTGGCGCTTGCGAGCCCTGGCCAGGGGAGGAAGTGAGG CCCAGGCACCTGCTGCCCCTCGAGGGGGCCCTGCCTGCCGCGGGGCCTCCCCACAAGCCCCTCCCAAAGCGCCGGCCGACTCGCTGTCTC GCTGGGGACTCTTTCAGCCCTCGCGCCCGCCCGTTTGGGAGGAGAAGTCTCTATGCAATTGGCCCCGGCCCCTCCACCCCCCACCCCCGG CATAGGAGGCCCCCCCACCTCGCCCGGCTCACACCCCCAAAGGGAGGGACCCACATTGCACACACTGTAAGAAATGCACTTTCCGAGGAA GGGGATGGGGGAGCCCGGACACCCAGAGCTCCCCGAGTTGGGGGTGCCCGTCTGGAGCGCCCCCGTCAGCCCCTGGCGGTGGGAGGTGAG AGCGAGTGGTTTAAGTGCCTGATTACCACCACCCGCCCCCCCCTTTGTCCAGCTGGGACACGGAATGGCCGCGGGCCTCCTCCCCCTCCC CTCCAGCCTCTCCACCAGCCCCTCCAGTCAACCCTCATCGCCGTGCCCCCCCAGAGCTAGAGAGATGGGGCCCCTGCGTGGCCCGAGGGG CAGAGCTGGGCGTCACTTCGCAAGCGTCCTGCCCTGCCGGGGCGCGGGGGTGGGCTCTGGGGAAGCCGGTGCGCCCCCCACGCCTCCGCT GCCAGTGCCTTACATTCTGGAGCGACCCCCCTCCCTGGTGCCTCCCAGCGAAGGGGGACCGCCGTTTGCACTTTCATCGCCTACCCCGAC GCGGGGCCCAGCTGCGGGACGTGCATCACGGCTGGGCCCCCAGAGGAGAGAGGAGGCCGACGCCAGCGGTCCCCGCTCGGAACGGGGAGG GTTTTCGGGGGGTTCGGCGTCGCACCTTGGGGCCCCCCGCAGCCGTGTAGGGGGCCTCCCATCTGCTAAGCGTTTTTCCGTTGAGCCGCT CCAAAAACACTAAGCTGGGGACGCCAGGTGCCCCCCCACCCCGGCTCCCTGGCCCTATCCACACCTCCACCCCCACCCCAGGATCGCCAT CTTTAGGGGAGGCCTGGGAGGGGGTGTTAGGTGTTTTAGGGCCACCGAGCTCAAACACAAGGACCCCTCCCCGGCCCACCCAGCCCAGCC CCAACTGACCTCCATGCCTAGGGAAAAACTCCCCCCACCACTGCCCCCTCCCCCGACCCAGGCCAAAGCCAGGGCAGGTCTCCGGGTCTC ACCTGCTCCTAGCCTCACCCCCCTGCCCCCGAAAACCAGACTCTCCTCCCAAACTAGCCTCAGGAGCTTGGCGAACCCGCTCGCTCCTAA AGAGAAAGACCCAGGACCCTCCCCCATCACCCCCAAGAGAGGTTCGCCATCCTCTGGCCTCGAGCCCTTGGTCCCTCCGTCCGTCTGTCC TCGGGGCCCGCTCCCCCGGTGGCCCTTGGGGATCAAAGCGTGGGCCGCTCTCCGGGAGGGCGGGCGGGGGAGGGGGTGGTCGGGTTGTGC CATTGGGGTGTCCGGAAGCTTCTCAGCCAGGGTGGGGGTCGTGGAGTGGGGGAGGGAGGCCAGCCGGGCTCCAGAGGGGTCAGGGCGCGA CGAGAACCAACTCTTTACCTAACTTTGCATGGTGCTTAGTCAAGGACTCCTGCGACCTGGCTCCCGAGGTCAGCTGGCGGCGCTGACACA CATGCATGGCAGACTATCCCTGGCTCTATCTCCCTGTTCCTCGCCCCCTCCACCCCCCACTTCCTCTTTAAAAAAAAAAAAAAAAAAAAA AAGATACAAGAAAAACCTTTAAAAAAATTCCATGTTTCCTAATTTGCACGAAATTTTCTACCACAAGATGTGCCTTGCCTTCCGAGAATA AGTATTACCTTTAAACAATATCAGCGCACACACATAGCTGCATGTTCTGCTCGTGTAGTTTAAAAAAAAAAAGACAAAACAGTGACATGA AATAAAAAATAAAAATTGAAAAGGGATGTATTTCTATTTGTAAAAAAAATAAAATAAAAAATAAGAAAGTGAGAATCTAAAAAAAAAAAA AAAAAAAAAAAAGGAAGAAAAACCACGCTAAAAATCAAGCCACTGAAAACAATTGCCCCCAGGTCTACCCAGCCCCTGGCTGTCCTTGGT CCTGTCTCCCCTCCTGCTGTATTCAGGGGTGCCCCCTGGTGCTCAGCCTCTACCACCCCCAACCCTGCTCTTGGGTACCCAGAGGGGTCA TTTCTGAATCCCTTGCCCAGAGGACAGACCTCCGGGGCCCATCTTGGCCCTGGGAAAGGGCTCTCCTCTCTGATTGGTCCCTAGGCCACG GGCCGGCCCCCAGACACCATTCACCGACCCACTGCAGGCTGTCCTCCAACCATGGGGTGGCCACTCCACCCGCAGCCAGACTCCCCGCTC CCCACTTTTCATGCAGGCTGGCATACCCCTGGCTCAGGGTCAAATGCTGTTCCACACCCACCTCAGAGGCACCCCCTCTCCCCTGCCCCG TGCATCCCCACCCTTCTTGCCAAAGGACCTCTTTTCCCCTATCCAGAGACCACCCCAGGTGGCATTCTCTCCCACCTTCTCCTTTGTCCC CCATCCCCTGTCTCTGTCTTCCAGCTGTGAATATGAAGGGTATCCTGTATGAAACAAAAACAAAACCTGATATATGCAATATCTGTCTGT CTGTCTGTACCCATGGGCCTGGCTCAGCCATTGGAGGCCCAGCCGAGGGTCCGGCAGGGCACAGGGACAGCCAGGTGGCACCGAGTCACA GGCTGTGGTCCGGTGGCTGAGCATGCTGTTGTCTTGTCCTTGATTTTATTTTCTTTTGTTCTTTTTTTTTTTCTTTTCTTTTTGTTTTTA ACTCCAGCTTCCTTTGCTTTTTACTTGACCAAAGCTAAGACAATAGCCAGATGGTTAGTGGGGCAGCCAGGCAGGGAGGACCCAGGGCTG GGATTCTCCAACCTTAGGCCATTCCTGCAGCCCTCACCACCTCCAGCCCCTCCAAGCATCTCGTGTAGGGACCCACGCAGATGGTCCCAT TCATTCACTATTGCCCCCAACCCCGGGATTTTGGGTGGTCTCCACAGCCACCATCATACACTCATCCCGTGTTTTCTTCCAAAAAGTCAC CTCAGCAGCCTCCCCAGGCGATACAGAGGGAGAGCCCAGACCACCACAGCTGGCCACGACATTGCCCTTAAGTAATATGCATTGGCCAGA GAGCCCGGGCTGGCTGTGCACAGCATTCATGTAGCTGATTTCTAGCTTTTTTTTTTTTTCTGCCCCACTCCTGAGCAAATCTGTCTTGCC AAGGAACTAGGAGCAACCGGAGGCAAAGGGAGTGGGTGGCCCCATCACTATTGGGACCATCGCGTCCCTGCACAGCCCACACCCGGGGGC CCAGAGTCCTGGGCTGGACGCCACCCTTCTCACCCCGAGCTTGCCTCCTTGGCTCACTTGGCACCTTGGCTGAGTACAGCAGGCAAAAGC CCATACCAGGCAGCATGTTGTGGATGGTTTAGTTCTCCCCGCCTCCCTGTTTCTTGGAAAAGCTACAGGGTCCCTGTAGGGCAAAATTCC CAGGCGCCTTGCTGCAGACAGAGTAAGACAAAAACACCAGGAAGCAGGATTCCGTGCCCATCTCTGCAGTTTGGGTTCACAAAAGGGGGT GCCGTCATCCCTGGGTGGAGGAGGGAGTGTTGGTTTTTTGTTTTTGTTTTTTTAACATGTATGAAACTGACATCTTCTCAAATCTTGTTC CACCCCCCTCTGGAAGCCCCCATCACCCACCCCTGCTATGGACACCACACCTATGCCAGGCCCCCCCCCCCACCCCAGTCTCATTCTGGG GTCTGCCCATGCTGTGGGAAAGAATAGGGAGGCCTCCCAAATATATGCAAATTGTCCCCATTCCGTGGGGGCACCTGACAATGACCCGGG TGGAGATGGGGCATGGAGGAGTAGGAAGACCCAGCCCTATTTGACTGGGGAGAGGAGGATCTGGAGTCCTTCATGCCCAGGTCTGGAACC CAGGTTCTGACCCCAGGGCCCCACCCTGGGCTGGACAATCAGATCCCAAAGGAATGCCAAAGGGGACTCGGTTGGGAGAGCCGCTTAGGG GCCAGACCTGGGTCCCCCTGCAGGTCCCCAGGCAGCAGACAATTCCACCTTCCCTGCCCCAGGACCTTGAGAGACAGCAGCATTCCAGGC ACAGACAGACTTGGCTGCACCCCACTGTCCCTTGCAAGACAGGTTCTGGAGCCAGGAGCAACTGTCCAGCCCTCCAGAAGAGACAGCAAG CAGCCCCCCTACCCACTCTGGCCTCCCCAATGGTACTTTGACCTCCAGTGTAGGGCTATACTATACATATATATATATATATATATATAT ATATATAATTTTGGAATTTGTTTCTCATAATACAGAATATATAGTGGCTACCTTGTATCTTGGTCTGGATTCTCTCTCTGAGACCCCGGA TTTTACTTTCTCTTTGGAGGGCGCTGGGACATACATCTCTCAATCCAGCTTCCTCCGCATCCTCCCATCTTGCCCCATTTCTGCCACGTC AGACACTTCCTGAGAGTCTCACCTTCAAAATGACACCGCTGCCCATCCATTGCTCAATGGTACAGAGTGTGGGGTCAGTCCACCACCCTT GACCTCCCGGCAGGGCAAGGTGAGGAGGCGGACCCAAAGCAGTACCAGCAGGACTTGTTGCCAGTGATACCAAAACAGACTTTTCCCAAG CAGTGCCTCACATGTCTGCTGGTGTGGCTTTGGGATTCTCCTGCCCCACCCCCCCGTCCATGGCAGCCCCCTCCCCAAGGCTTTGCTCAC ACCTGAGACAGGAAGGAGGAAGGGGATCCAATAGGAATATGGGCCCCGGAGGGGAAGTCATGCACCCCCAAGCCACCACCCCCCAGCCTT CCACGCACATCTCCTGGCTGGAAGAGAGCCCTCCAAAAAGGGGACACAGGCTGCCCCGGCCCCTCAACTGCATCCACACCCCATCCTCTC ATCTTGGGTCCCAGCCAGGCCCCCCCAAAACCAAAGCCCCCTCAAGTCCTGGGGTCCCAGCCTGTGCCCCCAGCTTCCTGCCCACCCAGC CCTGAGCATTCTCACACAGAGAAAGAACAAGCAAGGGCTCCAGGGGGACAGGATGGGGCAGGGCATACAGTGGGGGGTGGGGGGGCAGCT GGGAGGAGGGAGGGACAAAACAAAACATTTTCCTTTGGGTTTTTTTTTTCTTTCTTTTTTCTCCCCTTTACTCTTTGGGTGGTGTTGCTT TTCCTTTCCTTTTCCCTTTGAGATTTTTTTGTTGTTGTTTCCTTTTTGTATTTTACTGATATCACCAGGATAGTTTACTCTCCTTCTAGC TTTCTGCTTACCGCACACTGGATAACACACACATACACACCCACAAAAATGCTCATGAACCCAATCCGGAGAAGGTTCCAGCAGGTCCCC CACCCTCCCCTCCTCCTCCTACTTCTCCTCTTGACAGCGAGGACAGGAGGGGGACAAGGGGACACCTGGGCAGACCCGCCGGCTCTCCCC CCACCCCACCCCGCCCCTCACATCATACTCCAATCATAACCTTGTATATTATGCAGTCATTTTGGTTTTCGCGGACGCGCCTACCTAAGT ACCATTTACAGAAAGTGACTCTGGCTGTCATTATTTTGTTTATTTGTTCCCTATGCAAAAAAAAAATGAAAATGAAAAAAGGGGGATTCC >21319_21319_13_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000589123_length(amino acids)=636AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL ACDPASQQPGPLNGSGQLKMPSHCLSAQMLAPPPPGLPRLALPPATKPATTSEGGATSPTSPSYSPPDTSPANRSFVGLGPRDPAGIYQA -------------------------------------------------------------- >21319_21319_14_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000590282_length(transcript)=1984nt_BP=510nt GGGAGACCTGGAAGGAAGCGACTGCACTGATCCAGAAATGCCTCCCAGGCTATCCAGGAGGGGCCAAGAGATTAAAAGCAGGTTCAGAAG GCTCAGATGCCACTCACCAGACAGCAGGGTCGACTGCTAGTGACCTTGAGCCCAGTCCGGACAGACAGACAGGCAGACAGACGCACGGAC AAGCAGATGCTCCTTGGCCAGCTATCCACTCTTCTGTGCCTGCTTAGCGGGGCCCTGCCTACAGGCTCAGGGAGGCCTGAACCCCAGTCT CCTCGACCTCAGTCCTGGGCTGCAGCCAATCAGACCTGGGCTCTGGGCCCAGGGGCCCTGCCCCCACTGGTGCCAGCTTCTGCCCTTGGG AGCTGGAAGGCCTTCTTGGGCCTGCAGAAAGCCAGGCAGCTGGGGATGGGCAGGCTGCAGCGTGGGCAAGACGAGGTGGCTGCTGTGACT CTGCCGCTGAACCCTCAGGAAGTGATCCAGGGGATGTGTAAGGCTGTGCCCTTCGTTCAGGATGAGTTCCACCCGTTCATCGAGGCCCTG CTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCG AAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTG CGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGAC CAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGC ATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGC GTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGC TCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAG CTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTG AACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGAC GTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGC ATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACC CAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATC CTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTC TCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCCTACTCTCCGCCCGACACGTCCCCTGCAAACCGTTCCTTTGTGGGATTAG GACCAAGGGATCCTGCGGGCATTTATCAGGCACAGTCCTGGTATCTGGGATAGCAAAGGTCTTCTTCCCTCGCCCCTTCTCCATCGTCCC AGGAATCCCAGGGGGCAGCACAGCCGGCCCCCGGCCCACGTTTTCGGTGGAAAATTAGAGTGAACAAGAACACCCCTGCCGACTCCCAGC >21319_21319_14_DAND5-NFIC_DAND5_chr19_13080798_ENST00000585548_NFIC_chr19_3381709_ENST00000590282_length(amino acids)=567AA_BP=137 MPLTRQQGRLLVTLSPVRTDRQADRRTDKQMLLGQLSTLLCLLSGALPTGSGRPEPQSPRPQSWAAANQTWALGPGALPPLVPASALGSW KAFLGLQKARQLGMGRLQRGQDEVAAVTLPLNPQEVIQGMCKAVPFVQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKD EERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIP LESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELI QVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGIS SPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DAND5-NFIC |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DAND5-NFIC |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DAND5-NFIC |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies