
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DAP-CCT5 (FusionGDB2 ID:21336) |
Fusion Gene Summary for DAP-CCT5 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DAP-CCT5 | Fusion gene ID: 21336 | Hgene | Tgene | Gene symbol | DAP | CCT5 | Gene ID | 23549 | 22948 |
| Gene name | aspartyl aminopeptidase | chaperonin containing TCP1 subunit 5 | |
| Synonyms | ASPEP|DAP | CCT-epsilon|CCTE|HEL-S-69|PNAS-102|TCP-1-epsilon | |
| Cytomap | 2q35 | 5p15.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | aspartyl aminopeptidase | T-complex protein 1 subunit epsilonchaperonin containing TCP1, subunit 5 (epsilon)epididymis secretory protein Li 69 | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | P51397 | P48643 | |
| Ensembl transtripts involved in fusion gene | ENST00000510546, ENST00000230895, ENST00000432074, | ENST00000280326, ENST00000503026, ENST00000506600, ENST00000515390, ENST00000515676, | |
| Fusion gene scores | * DoF score | 10 X 8 X 8=640 | 58 X 14 X 17=13804 |
| # samples | 13 | 61 | |
| ** MAII score | log2(13/640*10)=-2.29956028185891 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(61/13804*10)=-4.50013332598527 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DAP [Title/Abstract] AND CCT5 [Title/Abstract] AND fusion [Title/Abstract] | ||
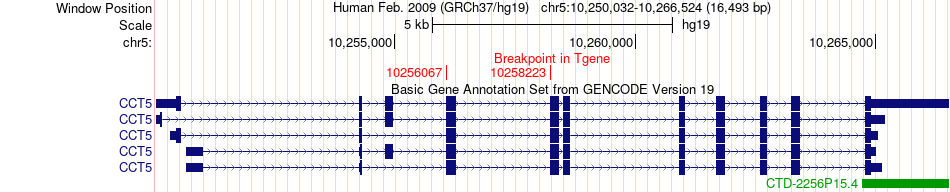
| Most frequent breakpoint | DAP(10748287)-CCT5(10258223), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | DAP-CCT5 seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. DAP-CCT5 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across DAP (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CCT5 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-BT-A20W-01A | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| ChimerDB4 | BLCA | TCGA-BT-A20W-01A | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
Top |
Fusion Gene ORF analysis for DAP-CCT5 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5UTR-3CDS | ENST00000510546 | ENST00000280326 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000280326 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000503026 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000503026 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000506600 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000506600 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000515390 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000515390 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000515676 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| 5UTR-3CDS | ENST00000510546 | ENST00000515676 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| Frame-shift | ENST00000230895 | ENST00000280326 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000230895 | ENST00000503026 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000230895 | ENST00000506600 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000230895 | ENST00000515390 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000230895 | ENST00000515676 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000432074 | ENST00000280326 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000432074 | ENST00000503026 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000432074 | ENST00000506600 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000432074 | ENST00000515390 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| Frame-shift | ENST00000432074 | ENST00000515676 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10256067 | + |
| In-frame | ENST00000230895 | ENST00000280326 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000230895 | ENST00000503026 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000230895 | ENST00000506600 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000230895 | ENST00000515390 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000230895 | ENST00000515676 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000432074 | ENST00000280326 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000432074 | ENST00000503026 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000432074 | ENST00000506600 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000432074 | ENST00000515390 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| In-frame | ENST00000432074 | ENST00000515676 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000230895 | DAP | chr5 | 10748287 | - | ENST00000280326 | CCT5 | chr5 | 10258223 | + | 3081 | 356 | 204 | 1451 | 415 |
| ENST00000230895 | DAP | chr5 | 10748287 | - | ENST00000503026 | CCT5 | chr5 | 10258223 | + | 1747 | 356 | 204 | 1451 | 415 |
| ENST00000230895 | DAP | chr5 | 10748287 | - | ENST00000515390 | CCT5 | chr5 | 10258223 | + | 1594 | 356 | 204 | 1451 | 415 |
| ENST00000230895 | DAP | chr5 | 10748287 | - | ENST00000515676 | CCT5 | chr5 | 10258223 | + | 1571 | 356 | 204 | 1451 | 415 |
| ENST00000230895 | DAP | chr5 | 10748287 | - | ENST00000506600 | CCT5 | chr5 | 10258223 | + | 1680 | 356 | 204 | 1451 | 415 |
| ENST00000432074 | DAP | chr5 | 10748287 | - | ENST00000280326 | CCT5 | chr5 | 10258223 | + | 3037 | 312 | 160 | 1407 | 415 |
| ENST00000432074 | DAP | chr5 | 10748287 | - | ENST00000503026 | CCT5 | chr5 | 10258223 | + | 1703 | 312 | 160 | 1407 | 415 |
| ENST00000432074 | DAP | chr5 | 10748287 | - | ENST00000515390 | CCT5 | chr5 | 10258223 | + | 1550 | 312 | 160 | 1407 | 415 |
| ENST00000432074 | DAP | chr5 | 10748287 | - | ENST00000515676 | CCT5 | chr5 | 10258223 | + | 1527 | 312 | 160 | 1407 | 415 |
| ENST00000432074 | DAP | chr5 | 10748287 | - | ENST00000506600 | CCT5 | chr5 | 10258223 | + | 1636 | 312 | 160 | 1407 | 415 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000230895 | ENST00000280326 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.000787482 | 0.9992125 |
| ENST00000230895 | ENST00000503026 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.00198435 | 0.99801564 |
| ENST00000230895 | ENST00000515390 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.003414117 | 0.99658585 |
| ENST00000230895 | ENST00000515676 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.003909946 | 0.99609 |
| ENST00000230895 | ENST00000506600 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.002509152 | 0.9974909 |
| ENST00000432074 | ENST00000280326 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.000762892 | 0.9992372 |
| ENST00000432074 | ENST00000503026 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.001756948 | 0.9982431 |
| ENST00000432074 | ENST00000515390 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.003039732 | 0.9969602 |
| ENST00000432074 | ENST00000515676 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.003441056 | 0.99655896 |
| ENST00000432074 | ENST00000506600 | DAP | chr5 | 10748287 | - | CCT5 | chr5 | 10258223 | + | 0.002194214 | 0.9978058 |
Top |
Fusion Genomic Features for DAP-CCT5 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DAP | chr5 | 10748286 | - | CCT5 | chr5 | 10258222 | + | 3.91E-09 | 1 |
| DAP | chr5 | 10748286 | - | CCT5 | chr5 | 10256066 | + | 1.45E-09 | 1 |
| DAP | chr5 | 10748286 | - | CCT5 | chr5 | 10258222 | + | 3.91E-09 | 1 |
| DAP | chr5 | 10748286 | - | CCT5 | chr5 | 10256066 | + | 1.45E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for DAP-CCT5 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:10748287/chr5:10258223) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DAP | CCT5 |
| FUNCTION: Negative regulator of autophagy. Involved in mediating interferon-gamma-induced cell death. {ECO:0000269|PubMed:20537536}. | FUNCTION: Component of the chaperonin-containing T-complex (TRiC), a molecular chaperone complex that assists the folding of proteins upon ATP hydrolysis (PubMed:25467444). The TRiC complex mediates the folding of WRAP53/TCAB1, thereby regulating telomere maintenance (PubMed:25467444). As part of the TRiC complex may play a role in the assembly of BBSome, a complex involved in ciliogenesis regulating transports vesicles to the cilia (PubMed:20080638). The TRiC complex plays a role in the folding of actin and tubulin (Probable). {ECO:0000269|PubMed:20080638, ECO:0000269|PubMed:25467444, ECO:0000305}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for DAP-CCT5 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >21336_21336_1_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000280326_length(transcript)=3081nt_BP=356nt GGCTGCGCCACGTCGGCGCGCGGCGGCCGCGCCCCCTTAACGGCAGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCG CGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGCTCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCG GCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGGGAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGT GGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAAAGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTC AACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGTCCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTT ATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAAACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAG ATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATGTCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTG ACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGAGAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAAC CTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTTACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCT GAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCCCAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTT GTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGTCATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGA GGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCACGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTG GTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGTTAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATG AGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTCTGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGA GCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTGTTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAA ACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAATGGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAA TCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCACTTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTAT TTATTGTTACATCCTTTTCCAGACACTGTAGATGCTATAATAAAAATAGCTGTTTGGTAACCATAGTTTCACTTGTTCAAAGCTGTGTAA TCGTGGGGGTACCATCTCAACTGCTTTTGTATTCATTGTATTAAAAGAATCTGTTTAAACAACCTTTATCTTCTCTTCGGGTTTAAGAAA CGTTTATTGTAACAGTAATTAAATGCTGCCTTAATTGAAGGGGTTTGGGTGGATTTTTTTTTCTCAAAATAAGCTGTAGGGACTATTTTA ACAGCTTAAACAGGAGCTCTCAAGATGCACTTTCATATTGAGAGGAATATGGGCTTGATCCTCTTCCTATCTAAATGGGTGGGCCATTTG ATTGTAGAGGGTCCACCACAGAATTATGGGATGCCTTAAGTGCTGTTACTAGGTTGCTCACAGCCTAACCTGGCGTGTTGTTTAGGGCTG ATGGAGACCCATGTGAGCCTTTGCTTTCCTCTGGCCCCGGCCCCACCCTGAACACAGCTCATACACAGAATCAGGACCAGCATGTGCAGA GCTGGCCACCAGCACAGGCTTAGGGCAGTTCAGAACCCACTTGTTTCCCTATCAGAGGGACACAGTGAAGTGGAGGTTAAAGTAAATTAC AGGAAATAAGGGAGAAATCTTGCAGTTACCATGTTCAGATAGAGTGACTGAAATTAATTGTACTTACTAAAGTATTAACTAGCTAACAGT GATGGGCCAAGACGCTCCGAGAACTCTACCGGGATTGTCTGTTCTGACAACCCAGTGAGGCAGATACACTTTCTTACTGCTCACATCTTA CAGGTGAGTACTCATAATTGGCCAGCATCTCACCACCAGCAAGTAGTAGGGCCAGGTCAATCCCAGGCAGTCTGACCCCAGAGTGGCCCA GCTCATCCCCTACTCTGTTATTTGCTTGTTAATGATTCTCTAGATTTTCTAAAATAATGTTTCTTAGCATTGTGATGATAAAGCTCATGA TGAACTTTATCACTAGTTATGCCACCTTAACTAGTCAGATTTCCTAGAATTAGGAAATGGTGACTCTTGTCTAAATTTGGTTAAGTGATG AATTTGGGTTACCGTCTCATGTGAACCTGGAGATTCACCAGTCTTAACTTTTGGGTCATTGTGTTTTCTCTACATTCATGCATTGGATGT TTTGCTAAATAACTCCTGTGGATTTAGGAATGTGTGCTAATAGCAATCTTCCTAATTTTCATGTTTATATGGAACTATGCAGTTGAGTAT TGAAAGCTTTAAACTGAGTTTATTTACAAGGACTGAGTCTAGCCTACAGAGAACATACAGCAGCCTTCTTTGGACCACAGTCTTATCCGA GGGGTCTGTGGTTGTATCAGAAGAGCCACTAAACCAATCCCCCTTTCCAAAATTGAACCTCACAGACGTTCCTGTTTTTTGTGATTGAGA AACTGGTCAATGAACAGGAAGACTTAGAGATGTTTCACAAGCCTTTGATTTTTGTTTCATTTATTTGTAATAAACCTCTTCCACGTGATG >21336_21336_1_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000280326_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_2_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000503026_length(transcript)=1747nt_BP=356nt GGCTGCGCCACGTCGGCGCGCGGCGGCCGCGCCCCCTTAACGGCAGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCG CGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGCTCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCG GCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGGGAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGT GGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAAAGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTC AACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGTCCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTT ATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAAACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAG ATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATGTCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTG ACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGAGAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAAC CTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTTACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCT GAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCCCAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTT GTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGTCATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGA GGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCACGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTG GTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGTTAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATG AGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTCTGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGA GCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTGTTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAA ACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAATGGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAA TCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCACTTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTAT TTATTGTTACATCCTTTTCCAGACACTGTAGATGCTATAATAAAAATAGCTGTTTGGTAACCATAGTTTCACTTGTTCAAAGCTGTGTAA TCGTGGGGGTACCATCTCAACTGCTTTTGTATTCATTGTATTAAAAGAATCTGTTTAAACAACCTTTATCTTCTCTTCGGGTTTAAGAAA >21336_21336_2_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000503026_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_3_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000506600_length(transcript)=1680nt_BP=356nt GGCTGCGCCACGTCGGCGCGCGGCGGCCGCGCCCCCTTAACGGCAGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCG CGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGCTCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCG GCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGGGAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGT GGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAAAGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTC AACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGTCCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTT ATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAAACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAG ATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATGTCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTG ACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGAGAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAAC CTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTTACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCT GAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCCCAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTT GTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGTCATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGA GGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCACGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTG GTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGTTAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATG AGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTCTGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGA GCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTGTTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAA ACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAATGGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAA TCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCACTTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTAT TTATTGTTACATCCTTTTCCAGACACTGTAGATGCTATAATAAAAATAGCTGTTTGGTAACCATAGTTTCACTTGTTCAAAGCTGTGTAA >21336_21336_3_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000506600_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_4_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000515390_length(transcript)=1594nt_BP=356nt GGCTGCGCCACGTCGGCGCGCGGCGGCCGCGCCCCCTTAACGGCAGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCG CGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGCTCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCG GCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGGGAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGT GGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAAAGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTC AACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGTCCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTT ATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAAACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAG ATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATGTCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTG ACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGAGAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAAC CTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTTACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCT GAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCCCAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTT GTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGTCATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGA GGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCACGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTG GTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGTTAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATG AGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTCTGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGA GCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTGTTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAA ACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAATGGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAA TCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCACTTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTAT >21336_21336_4_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000515390_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_5_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000515676_length(transcript)=1571nt_BP=356nt GGCTGCGCCACGTCGGCGCGCGGCGGCCGCGCCCCCTTAACGGCAGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCG CGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGCTCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCG GCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGGGAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGT GGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAAAGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTC AACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGTCCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTT ATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAAACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAG ATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATGTCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTG ACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGAGAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAAC CTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTTACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCT GAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCCCAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTT GTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGTCATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGA GGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCACGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTG GTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGTTAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATG AGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTCTGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGA GCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTGTTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAA ACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAATGGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAA TCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCACTTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTAT >21336_21336_5_DAP-CCT5_DAP_chr5_10748287_ENST00000230895_CCT5_chr5_10258223_ENST00000515676_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_6_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000280326_length(transcript)=3037nt_BP=312nt AGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCGCGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGC TCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCGGCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGG GAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGTGGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAA AGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTCAACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGT CCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTTATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAA ACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAGATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATG TCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTGACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGA GAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAACCTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTT ACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCTGAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCC CAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTTGTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGT CATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGAGGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCA CGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTGGTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGT TAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATGAGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTC TGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGAGCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTG TTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAAACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAAT GGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAATCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCAC TTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTATTTATTGTTACATCCTTTTCCAGACACTGTAGATGCTATAATAAA AATAGCTGTTTGGTAACCATAGTTTCACTTGTTCAAAGCTGTGTAATCGTGGGGGTACCATCTCAACTGCTTTTGTATTCATTGTATTAA AAGAATCTGTTTAAACAACCTTTATCTTCTCTTCGGGTTTAAGAAACGTTTATTGTAACAGTAATTAAATGCTGCCTTAATTGAAGGGGT TTGGGTGGATTTTTTTTTCTCAAAATAAGCTGTAGGGACTATTTTAACAGCTTAAACAGGAGCTCTCAAGATGCACTTTCATATTGAGAG GAATATGGGCTTGATCCTCTTCCTATCTAAATGGGTGGGCCATTTGATTGTAGAGGGTCCACCACAGAATTATGGGATGCCTTAAGTGCT GTTACTAGGTTGCTCACAGCCTAACCTGGCGTGTTGTTTAGGGCTGATGGAGACCCATGTGAGCCTTTGCTTTCCTCTGGCCCCGGCCCC ACCCTGAACACAGCTCATACACAGAATCAGGACCAGCATGTGCAGAGCTGGCCACCAGCACAGGCTTAGGGCAGTTCAGAACCCACTTGT TTCCCTATCAGAGGGACACAGTGAAGTGGAGGTTAAAGTAAATTACAGGAAATAAGGGAGAAATCTTGCAGTTACCATGTTCAGATAGAG TGACTGAAATTAATTGTACTTACTAAAGTATTAACTAGCTAACAGTGATGGGCCAAGACGCTCCGAGAACTCTACCGGGATTGTCTGTTC TGACAACCCAGTGAGGCAGATACACTTTCTTACTGCTCACATCTTACAGGTGAGTACTCATAATTGGCCAGCATCTCACCACCAGCAAGT AGTAGGGCCAGGTCAATCCCAGGCAGTCTGACCCCAGAGTGGCCCAGCTCATCCCCTACTCTGTTATTTGCTTGTTAATGATTCTCTAGA TTTTCTAAAATAATGTTTCTTAGCATTGTGATGATAAAGCTCATGATGAACTTTATCACTAGTTATGCCACCTTAACTAGTCAGATTTCC TAGAATTAGGAAATGGTGACTCTTGTCTAAATTTGGTTAAGTGATGAATTTGGGTTACCGTCTCATGTGAACCTGGAGATTCACCAGTCT TAACTTTTGGGTCATTGTGTTTTCTCTACATTCATGCATTGGATGTTTTGCTAAATAACTCCTGTGGATTTAGGAATGTGTGCTAATAGC AATCTTCCTAATTTTCATGTTTATATGGAACTATGCAGTTGAGTATTGAAAGCTTTAAACTGAGTTTATTTACAAGGACTGAGTCTAGCC TACAGAGAACATACAGCAGCCTTCTTTGGACCACAGTCTTATCCGAGGGGTCTGTGGTTGTATCAGAAGAGCCACTAAACCAATCCCCCT TTCCAAAATTGAACCTCACAGACGTTCCTGTTTTTTGTGATTGAGAAACTGGTCAATGAACAGGAAGACTTAGAGATGTTTCACAAGCCT >21336_21336_6_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000280326_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_7_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000503026_length(transcript)=1703nt_BP=312nt AGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCGCGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGC TCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCGGCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGG GAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGTGGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAA AGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTCAACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGT CCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTTATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAA ACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAGATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATG TCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTGACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGA GAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAACCTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTT ACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCTGAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCC CAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTTGTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGT CATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGAGGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCA CGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTGGTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGT TAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATGAGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTC TGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGAGCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTG TTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAAACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAAT GGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAATCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCAC TTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTATTTATTGTTACATCCTTTTCCAGACACTGTAGATGCTATAATAAA AATAGCTGTTTGGTAACCATAGTTTCACTTGTTCAAAGCTGTGTAATCGTGGGGGTACCATCTCAACTGCTTTTGTATTCATTGTATTAA >21336_21336_7_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000503026_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_8_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000506600_length(transcript)=1636nt_BP=312nt AGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCGCGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGC TCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCGGCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGG GAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGTGGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAA AGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTCAACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGT CCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTTATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAA ACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAGATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATG TCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTGACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGA GAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAACCTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTT ACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCTGAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCC CAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTTGTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGT CATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGAGGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCA CGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTGGTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGT TAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATGAGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTC TGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGAGCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTG TTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAAACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAAT GGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAATCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCAC TTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTATTTATTGTTACATCCTTTTCCAGACACTGTAGATGCTATAATAAA AATAGCTGTTTGGTAACCATAGTTTCACTTGTTCAAAGCTGTGTAATCGTGGGGGTACCATCTCAACTGCTTTTGTATTCATTGTATTAA >21336_21336_8_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000506600_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_9_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000515390_length(transcript)=1550nt_BP=312nt AGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCGCGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGC TCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCGGCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGG GAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGTGGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAA AGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTCAACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGT CCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTTATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAA ACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAGATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATG TCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTGACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGA GAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAACCTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTT ACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCTGAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCC CAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTTGTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGT CATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGAGGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCA CGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTGGTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGT TAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATGAGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTC TGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGAGCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTG TTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAAACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAAT GGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAATCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCAC TTCTGTGATTAAGTAAATGGATGTCTCGTGATGCATCTACAGTTATTTATTGTTACATCCTTTTCCAGACACTGTAGATGCTATAATAAA >21336_21336_9_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000515390_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- >21336_21336_10_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000515676_length(transcript)=1527nt_BP=312nt AGTGGCACTCACCCGGCTCGCGCGGCCCCGGCGCCCCACGCGCGCGCGTCGTTCTCCCGCCCGCTCGCTCCCCGGCGCTCACACCTGAGC TCACTCGCGCACGCCCGCCCGGCCCGAGAACCGCGCCGCCGCCTCGGCCCCGCGGAAGCCCCGCCGCGTCATGTCTTCGCCTCCCGAAGG GAAACTAGAGACTAAAGCTGGACACCCGCCCGCCGTGAAAGCTGGTGGAATGCGAATTGTGCAGAAACACCCACATACAGGAGACACCAA AGAAGAGAAAGACAAGGATGACCAGGAATGGGAAAGCCCCAGGGTCAACAGTTGTCACCGACAGATGGCTGAGATTGCTGTGAATGCCGT CCTCACTGTAGCAGATATGGAGCGGAGAGACGTTGACTTTGAGCTTATCAAAGTAGAAGGCAAAGTGGGCGGCAGGCTGGAGGACACTAA ACTGATTAAGGGCGTGATTGTGGACAAGGATTTCAGTCACCCACAGATGCCAAAAAAAGTGGAAGATGCGAAGATTGCAATTCTCACATG TCCATTTGAACCACCCAAACCAAAAACAAAGCATAAGCTGGATGTGACCTCTGTCGAAGATTATAAAGCCCTTCAGAAATACGAAAAGGA GAAATTTGAAGAGATGATTCAACAAATTAAAGAGACTGGTGCTAACCTAGCAATTTGTCAGTGGGGCTTTGATGATGAAGCAAATCACTT ACTTCTTCAGAACAACTTGCCTGCGGTTCGCTGGGTAGGAGGACCTGAAATTGAGCTGATTGCCATCGCAACAGGAGGGCGGATCGTCCC CAGGTTCTCAGAGCTCACAGCCGAGAAGCTGGGCTTTGCTGGTCTTGTACAGGAGATCTCATTTGGGACAACTAAGGATAAAATGCTGGT CATCGAGCAGTGTAAGAACTCCAGAGCTGTAACCATTTTTATTAGAGGAGGAAATAAGATGATCATTGAGGAGGCGAAACGATCCCTTCA CGATGCTTTGTGTGTCATCCGGAACCTCATCCGCGATAATCGTGTGGTGTATGGAGGAGGGGCTGCTGAGATATCCTGTGCCCTGGCAGT TAGCCAAGAGGCGGATAAGTGCCCCACCTTAGAACAGTATGCCATGAGAGCGTTTGCCGACGCACTGGAGGTCATCCCCATGGCCCTCTC TGAAAACAGTGGCATGAATCCCATCCAGACTATGACCGAAGTCCGAGCCAGACAGGTGAAGGAGATGAACCCTGCTCTTGGCATCGACTG TTTGCACAAGGGGACAAATGATATGAAGCAACAGCATGTCATAGAAACCTTGATTGGCAAAAAGCAACAGATATCTCTTGCAACACAAAT GGTTAGAATGATTTTGAAGATTGATGACATTCGTAAGCCTGGAGAATCTGAAGAATGAAGACATTGAGAAAACTATGTAGCAAGATCCAC >21336_21336_10_DAP-CCT5_DAP_chr5_10748287_ENST00000432074_CCT5_chr5_10258223_ENST00000515676_length(amino acids)=415AA_BP=50 MSSPPEGKLETKAGHPPAVKAGGMRIVQKHPHTGDTKEEKDKDDQEWESPRVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVG GRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGF DDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIE EAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMN -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DAP-CCT5 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DAP-CCT5 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DAP-CCT5 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies