
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ADAP1-MAD1L1 (FusionGDB2 ID:2152) |
Fusion Gene Summary for ADAP1-MAD1L1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ADAP1-MAD1L1 | Fusion gene ID: 2152 | Hgene | Tgene | Gene symbol | ADAP1 | MAD1L1 | Gene ID | 11033 | 8379 |
| Gene name | ArfGAP with dual PH domains 1 | mitotic arrest deficient 1 like 1 | |
| Synonyms | CENTA1|GCS1L|p42IP4 | MAD1|PIG9|TP53I9|TXBP181 | |
| Cytomap | 7p22.3 | 7p22.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | arf-GAP with dual PH domain-containing protein 1centaurin-alphacentaurin-alpha-1cnt-a1putative MAPK-activating protein PM25 | mitotic spindle assembly checkpoint protein MAD1MAD1 mitotic arrest deficient like 1MAD1-like protein 1mitotic arrest deficient 1-like protein 1mitotic checkpoint MAD1 protein homologmitotic-arrest deficient 1, yeast, homolog-like 1tax-binding prote | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O75689 | Q9Y6D9 | |
| Ensembl transtripts involved in fusion gene | ENST00000265846, ENST00000449296, ENST00000539900, ENST00000463358, | ENST00000486340, ENST00000265854, ENST00000399654, ENST00000402746, ENST00000406869, | |
| Fusion gene scores | * DoF score | 13 X 10 X 8=1040 | 23 X 16 X 12=4416 |
| # samples | 18 | 37 | |
| ** MAII score | log2(18/1040*10)=-2.53051471669878 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(37/4416*10)=-3.57714299626186 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ADAP1 [Title/Abstract] AND MAD1L1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ADAP1(966189)-MAD1L1(2108973), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | MAD1L1 | GO:0007094 | mitotic spindle assembly checkpoint | 18981471 |
| Tgene | MAD1L1 | GO:0090235 | regulation of metaphase plate congression | 20133940 |
| Fusion gene breakpoints across ADAP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MAD1L1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-DK-AA6P-01A | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
Top |
Fusion Gene ORF analysis for ADAP1-MAD1L1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000265846 | ENST00000486340 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| 5CDS-intron | ENST00000449296 | ENST00000486340 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| 5CDS-intron | ENST00000539900 | ENST00000486340 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| 5UTR-3CDS | ENST00000463358 | ENST00000265854 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| 5UTR-3CDS | ENST00000463358 | ENST00000399654 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| 5UTR-3CDS | ENST00000463358 | ENST00000402746 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| 5UTR-3CDS | ENST00000463358 | ENST00000406869 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| 5UTR-intron | ENST00000463358 | ENST00000486340 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000265846 | ENST00000265854 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000265846 | ENST00000399654 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000265846 | ENST00000402746 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000265846 | ENST00000406869 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000449296 | ENST00000265854 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000449296 | ENST00000399654 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000449296 | ENST00000402746 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000449296 | ENST00000406869 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000539900 | ENST00000265854 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000539900 | ENST00000399654 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000539900 | ENST00000402746 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| In-frame | ENST00000539900 | ENST00000406869 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000265846 | ADAP1 | chr7 | 966189 | - | ENST00000402746 | MAD1L1 | chr7 | 2108973 | - | 1885 | 525 | 220 | 1608 | 462 |
| ENST00000265846 | ADAP1 | chr7 | 966189 | - | ENST00000399654 | MAD1L1 | chr7 | 2108973 | - | 1885 | 525 | 220 | 1608 | 462 |
| ENST00000265846 | ADAP1 | chr7 | 966189 | - | ENST00000406869 | MAD1L1 | chr7 | 2108973 | - | 1885 | 525 | 220 | 1608 | 462 |
| ENST00000265846 | ADAP1 | chr7 | 966189 | - | ENST00000265854 | MAD1L1 | chr7 | 2108973 | - | 1868 | 525 | 220 | 1608 | 462 |
| ENST00000449296 | ADAP1 | chr7 | 966189 | - | ENST00000402746 | MAD1L1 | chr7 | 2108973 | - | 1613 | 253 | 17 | 1336 | 439 |
| ENST00000449296 | ADAP1 | chr7 | 966189 | - | ENST00000399654 | MAD1L1 | chr7 | 2108973 | - | 1613 | 253 | 17 | 1336 | 439 |
| ENST00000449296 | ADAP1 | chr7 | 966189 | - | ENST00000406869 | MAD1L1 | chr7 | 2108973 | - | 1613 | 253 | 17 | 1336 | 439 |
| ENST00000449296 | ADAP1 | chr7 | 966189 | - | ENST00000265854 | MAD1L1 | chr7 | 2108973 | - | 1596 | 253 | 17 | 1336 | 439 |
| ENST00000539900 | ADAP1 | chr7 | 966189 | - | ENST00000402746 | MAD1L1 | chr7 | 2108973 | - | 1698 | 338 | 0 | 1421 | 473 |
| ENST00000539900 | ADAP1 | chr7 | 966189 | - | ENST00000399654 | MAD1L1 | chr7 | 2108973 | - | 1698 | 338 | 0 | 1421 | 473 |
| ENST00000539900 | ADAP1 | chr7 | 966189 | - | ENST00000406869 | MAD1L1 | chr7 | 2108973 | - | 1698 | 338 | 0 | 1421 | 473 |
| ENST00000539900 | ADAP1 | chr7 | 966189 | - | ENST00000265854 | MAD1L1 | chr7 | 2108973 | - | 1681 | 338 | 0 | 1421 | 473 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000265846 | ENST00000402746 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.008363348 | 0.9916366 |
| ENST00000265846 | ENST00000399654 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.008363348 | 0.9916366 |
| ENST00000265846 | ENST00000406869 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.008363348 | 0.9916366 |
| ENST00000265846 | ENST00000265854 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.007945234 | 0.9920548 |
| ENST00000449296 | ENST00000402746 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.007580563 | 0.9924194 |
| ENST00000449296 | ENST00000399654 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.007580563 | 0.9924194 |
| ENST00000449296 | ENST00000406869 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.007580563 | 0.9924194 |
| ENST00000449296 | ENST00000265854 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.007157714 | 0.9928423 |
| ENST00000539900 | ENST00000402746 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.011006847 | 0.9889931 |
| ENST00000539900 | ENST00000399654 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.011006847 | 0.9889931 |
| ENST00000539900 | ENST00000406869 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.011006847 | 0.9889931 |
| ENST00000539900 | ENST00000265854 | ADAP1 | chr7 | 966189 | - | MAD1L1 | chr7 | 2108973 | - | 0.010617676 | 0.9893824 |
Top |
Fusion Genomic Features for ADAP1-MAD1L1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
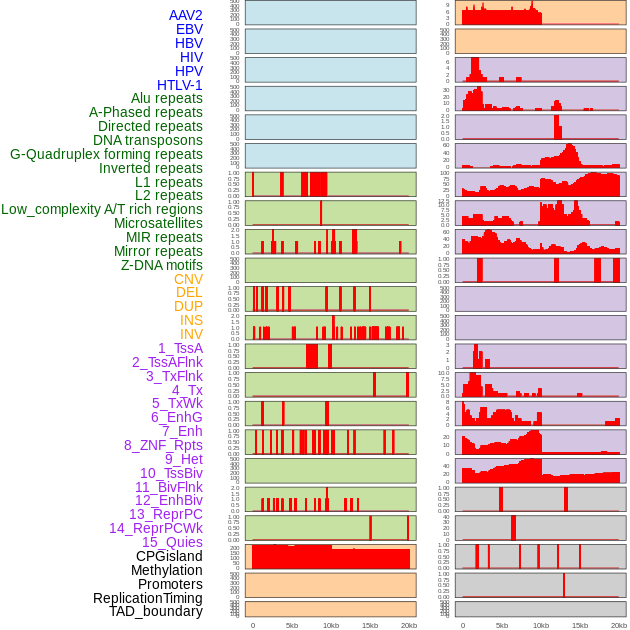 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ADAP1-MAD1L1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:966189/chr7:2108973) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ADAP1 | MAD1L1 |
| FUNCTION: GTPase-activating protein for the ADP ribosylation factor family (Probable). Binds phosphatidylinositol 3,4,5-trisphosphate (PtdInsP3) and inositol 1,3,4,5-tetrakisphosphate (InsP4). {ECO:0000269|PubMed:10448098, ECO:0000303|PubMed:10333475, ECO:0000305}. | FUNCTION: Component of the spindle-assembly checkpoint that prevents the onset of anaphase until all chromosomes are properly aligned at the metaphase plate (PubMed:10049595, PubMed:20133940, PubMed:29162720). Forms a heterotetrameric complex with the closed conformation form of MAD2L1 (C-MAD2) at unattached kinetochores during prometaphase, recruits an open conformation of MAD2L1 (O-MAD2) and promotes the conversion of O-MAD2 to C-MAD2, which ensures mitotic checkpoint signaling (PubMed:29162720). {ECO:0000269|PubMed:10049595, ECO:0000269|PubMed:20133940, ECO:0000269|PubMed:29162720}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ADAP1 | chr7:966189 | chr7:2108973 | ENST00000265846 | - | 3 | 11 | 21_44 | 101 | 375.0 | Zinc finger | C4-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ADAP1 | chr7:966189 | chr7:2108973 | ENST00000265846 | - | 3 | 11 | 129_230 | 101 | 375.0 | Domain | PH 1 |
| Hgene | ADAP1 | chr7:966189 | chr7:2108973 | ENST00000265846 | - | 3 | 11 | 252_356 | 101 | 375.0 | Domain | PH 2 |
| Hgene | ADAP1 | chr7:966189 | chr7:2108973 | ENST00000265846 | - | 3 | 11 | 7_126 | 101 | 375.0 | Domain | Arf-GAP |
| Tgene | MAD1L1 | chr7:966189 | chr7:2108973 | ENST00000265854 | 9 | 18 | 46_632 | 357 | 719.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MAD1L1 | chr7:966189 | chr7:2108973 | ENST00000399654 | 10 | 19 | 46_632 | 357 | 719.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MAD1L1 | chr7:966189 | chr7:2108973 | ENST00000406869 | 10 | 19 | 46_632 | 357 | 719.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for ADAP1-MAD1L1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >2152_2152_1_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000265846_MAD1L1_chr7_2108973_ENST00000265854_length(transcript)=1868nt_BP=525nt CCGGGCCCCGCGCCGGCACTCGCTCAGCGACCGCGGCGGAGACACGAGCGGCGGCGGCGGAGCCCAGAGGGCGGCGGGAATGCGGAACCG GCGCGCGGGCTGAGGCCGCCCGGGATGGCGCAGGGGCGGCGGCGGCGGGCGGCCTGCGCGGGGCCCTAGCGAGCCGGGCTGACGCTCCCG GCCCCGGCCCCGGCATCGGCATCGCGGGCGCATCGCGGCCATGGCCAAGGAGCGGCGCAGGGCGGTCCTGGAGCTGCTGCAGCGGCCGGG GAACGCGCGCTGCGCGGACTGCGGCGCCCCGGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAAT CCACCGGAATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGG GAACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGA GAAGGCCAGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCT GGCCCGGAGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGAC CCCGGCCGAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGA GGCTCAGCTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCA GTCCAGCTCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAG TCGGCTGGAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCT GCACATGAGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGG GCTCCTGCGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGA GCTGAAGAAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTG CTACACGCTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCT CATCTTCAAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCA CCTGCGGCGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTC GGGGGCATAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAG CCCCACAGGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGAC >2152_2152_1_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000265846_MAD1L1_chr7_2108973_ENST00000265854_length(amino acids)=462AA_BP=100 MAKERRRAVLELLQRPGNARCADCGAPDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGNDAARARFESKVP SFYYRPTPSDCHARGLEKARQQLQEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPAEYSPQLTRRMR EAEDMVQKVHSHSAEMEAQLSQALEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRLEEEKRMLEAQL ERRALQGDYDQSRTKVLHMSLNPTSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELKKQVESAELKNQ RLKEVFQTKIQEFRKACYTLTGYQIDITTENQYRLTSLYAEHPGDCLIFKATSPSGSKMQLLETEFSHTVGELIEVHLRRQDSIPAFLSS -------------------------------------------------------------- >2152_2152_2_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000265846_MAD1L1_chr7_2108973_ENST00000399654_length(transcript)=1885nt_BP=525nt CCGGGCCCCGCGCCGGCACTCGCTCAGCGACCGCGGCGGAGACACGAGCGGCGGCGGCGGAGCCCAGAGGGCGGCGGGAATGCGGAACCG GCGCGCGGGCTGAGGCCGCCCGGGATGGCGCAGGGGCGGCGGCGGCGGGCGGCCTGCGCGGGGCCCTAGCGAGCCGGGCTGACGCTCCCG GCCCCGGCCCCGGCATCGGCATCGCGGGCGCATCGCGGCCATGGCCAAGGAGCGGCGCAGGGCGGTCCTGGAGCTGCTGCAGCGGCCGGG GAACGCGCGCTGCGCGGACTGCGGCGCCCCGGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAAT CCACCGGAATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGG GAACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGA GAAGGCCAGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCT GGCCCGGAGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGAC CCCGGCCGAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGA GGCTCAGCTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCA GTCCAGCTCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAG TCGGCTGGAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCT GCACATGAGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGG GCTCCTGCGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGA GCTGAAGAAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTG CTACACGCTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCT CATCTTCAAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCA CCTGCGGCGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTC GGGGGCATAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAG CCCCACAGGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGAC >2152_2152_2_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000265846_MAD1L1_chr7_2108973_ENST00000399654_length(amino acids)=462AA_BP=100 MAKERRRAVLELLQRPGNARCADCGAPDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGNDAARARFESKVP SFYYRPTPSDCHARGLEKARQQLQEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPAEYSPQLTRRMR EAEDMVQKVHSHSAEMEAQLSQALEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRLEEEKRMLEAQL ERRALQGDYDQSRTKVLHMSLNPTSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELKKQVESAELKNQ RLKEVFQTKIQEFRKACYTLTGYQIDITTENQYRLTSLYAEHPGDCLIFKATSPSGSKMQLLETEFSHTVGELIEVHLRRQDSIPAFLSS -------------------------------------------------------------- >2152_2152_3_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000265846_MAD1L1_chr7_2108973_ENST00000402746_length(transcript)=1885nt_BP=525nt CCGGGCCCCGCGCCGGCACTCGCTCAGCGACCGCGGCGGAGACACGAGCGGCGGCGGCGGAGCCCAGAGGGCGGCGGGAATGCGGAACCG GCGCGCGGGCTGAGGCCGCCCGGGATGGCGCAGGGGCGGCGGCGGCGGGCGGCCTGCGCGGGGCCCTAGCGAGCCGGGCTGACGCTCCCG GCCCCGGCCCCGGCATCGGCATCGCGGGCGCATCGCGGCCATGGCCAAGGAGCGGCGCAGGGCGGTCCTGGAGCTGCTGCAGCGGCCGGG GAACGCGCGCTGCGCGGACTGCGGCGCCCCGGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAAT CCACCGGAATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGG GAACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGA GAAGGCCAGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCT GGCCCGGAGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGAC CCCGGCCGAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGA GGCTCAGCTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCA GTCCAGCTCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAG TCGGCTGGAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCT GCACATGAGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGG GCTCCTGCGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGA GCTGAAGAAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTG CTACACGCTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCT CATCTTCAAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCA CCTGCGGCGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTC GGGGGCATAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAG CCCCACAGGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGAC >2152_2152_3_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000265846_MAD1L1_chr7_2108973_ENST00000402746_length(amino acids)=462AA_BP=100 MAKERRRAVLELLQRPGNARCADCGAPDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGNDAARARFESKVP SFYYRPTPSDCHARGLEKARQQLQEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPAEYSPQLTRRMR EAEDMVQKVHSHSAEMEAQLSQALEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRLEEEKRMLEAQL ERRALQGDYDQSRTKVLHMSLNPTSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELKKQVESAELKNQ RLKEVFQTKIQEFRKACYTLTGYQIDITTENQYRLTSLYAEHPGDCLIFKATSPSGSKMQLLETEFSHTVGELIEVHLRRQDSIPAFLSS -------------------------------------------------------------- >2152_2152_4_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000265846_MAD1L1_chr7_2108973_ENST00000406869_length(transcript)=1885nt_BP=525nt CCGGGCCCCGCGCCGGCACTCGCTCAGCGACCGCGGCGGAGACACGAGCGGCGGCGGCGGAGCCCAGAGGGCGGCGGGAATGCGGAACCG GCGCGCGGGCTGAGGCCGCCCGGGATGGCGCAGGGGCGGCGGCGGCGGGCGGCCTGCGCGGGGCCCTAGCGAGCCGGGCTGACGCTCCCG GCCCCGGCCCCGGCATCGGCATCGCGGGCGCATCGCGGCCATGGCCAAGGAGCGGCGCAGGGCGGTCCTGGAGCTGCTGCAGCGGCCGGG GAACGCGCGCTGCGCGGACTGCGGCGCCCCGGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAAT CCACCGGAATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGG GAACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGA GAAGGCCAGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCT GGCCCGGAGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGAC CCCGGCCGAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGA GGCTCAGCTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCA GTCCAGCTCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAG TCGGCTGGAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCT GCACATGAGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGG GCTCCTGCGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGA GCTGAAGAAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTG CTACACGCTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCT CATCTTCAAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCA CCTGCGGCGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTC GGGGGCATAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAG CCCCACAGGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGAC >2152_2152_4_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000265846_MAD1L1_chr7_2108973_ENST00000406869_length(amino acids)=462AA_BP=100 MAKERRRAVLELLQRPGNARCADCGAPDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGNDAARARFESKVP SFYYRPTPSDCHARGLEKARQQLQEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPAEYSPQLTRRMR EAEDMVQKVHSHSAEMEAQLSQALEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRLEEEKRMLEAQL ERRALQGDYDQSRTKVLHMSLNPTSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELKKQVESAELKNQ RLKEVFQTKIQEFRKACYTLTGYQIDITTENQYRLTSLYAEHPGDCLIFKATSPSGSKMQLLETEFSHTVGELIEVHLRRQDSIPAFLSS -------------------------------------------------------------- >2152_2152_5_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000449296_MAD1L1_chr7_2108973_ENST00000265854_length(transcript)=1596nt_BP=253nt TTTCCTTCTCCCTCAGCCTGTTTCGTAAACATGTTCTGGGTCCCTGCAGTGTGTCCCTGCAGAGTCCCCTCAGAGACTCTGTCCTAGCCA CATCTGGGTCTCTCGCTCACCAGCCCATCTCCAGGCCCCCGTGTCTGGCGCCTGTTGGCTCTTTGCTAAATTTCATGGCCTCCCACGGGA ACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGAGA AGGCCAGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCTGG CCCGGAGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGACCC CGGCCGAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGAGG CTCAGCTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCAGT CCAGCTCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAGTC GGCTGGAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCTGC ACATGAGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGGGC TCCTGCGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGAGC TGAAGAAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTGCT ACACGCTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCTCA TCTTCAAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCACC TGCGGCGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTCGG GGGCATAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAGCC CCACAGGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGACCC >2152_2152_5_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000449296_MAD1L1_chr7_2108973_ENST00000265854_length(amino acids)=439AA_BP=77 MFRKHVLGPCSVSLQSPLRDSVLATSGSLAHQPISRPPCLAPVGSLLNFMASHGNDAARARFESKVPSFYYRPTPSDCHARGLEKARQQL QEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPAEYSPQLTRRMREAEDMVQKVHSHSAEMEAQLSQA LEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRLEEEKRMLEAQLERRALQGDYDQSRTKVLHMSLNP TSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELKKQVESAELKNQRLKEVFQTKIQEFRKACYTLTGY -------------------------------------------------------------- >2152_2152_6_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000449296_MAD1L1_chr7_2108973_ENST00000399654_length(transcript)=1613nt_BP=253nt TTTCCTTCTCCCTCAGCCTGTTTCGTAAACATGTTCTGGGTCCCTGCAGTGTGTCCCTGCAGAGTCCCCTCAGAGACTCTGTCCTAGCCA CATCTGGGTCTCTCGCTCACCAGCCCATCTCCAGGCCCCCGTGTCTGGCGCCTGTTGGCTCTTTGCTAAATTTCATGGCCTCCCACGGGA ACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGAGA AGGCCAGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCTGG CCCGGAGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGACCC CGGCCGAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGAGG CTCAGCTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCAGT CCAGCTCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAGTC GGCTGGAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCTGC ACATGAGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGGGC TCCTGCGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGAGC TGAAGAAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTGCT ACACGCTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCTCA TCTTCAAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCACC TGCGGCGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTCGG GGGCATAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAGCC CCACAGGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGACCC >2152_2152_6_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000449296_MAD1L1_chr7_2108973_ENST00000399654_length(amino acids)=439AA_BP=77 MFRKHVLGPCSVSLQSPLRDSVLATSGSLAHQPISRPPCLAPVGSLLNFMASHGNDAARARFESKVPSFYYRPTPSDCHARGLEKARQQL QEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPAEYSPQLTRRMREAEDMVQKVHSHSAEMEAQLSQA LEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRLEEEKRMLEAQLERRALQGDYDQSRTKVLHMSLNP TSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELKKQVESAELKNQRLKEVFQTKIQEFRKACYTLTGY -------------------------------------------------------------- >2152_2152_7_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000449296_MAD1L1_chr7_2108973_ENST00000402746_length(transcript)=1613nt_BP=253nt TTTCCTTCTCCCTCAGCCTGTTTCGTAAACATGTTCTGGGTCCCTGCAGTGTGTCCCTGCAGAGTCCCCTCAGAGACTCTGTCCTAGCCA CATCTGGGTCTCTCGCTCACCAGCCCATCTCCAGGCCCCCGTGTCTGGCGCCTGTTGGCTCTTTGCTAAATTTCATGGCCTCCCACGGGA ACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGAGA AGGCCAGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCTGG CCCGGAGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGACCC CGGCCGAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGAGG CTCAGCTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCAGT CCAGCTCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAGTC GGCTGGAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCTGC ACATGAGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGGGC TCCTGCGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGAGC TGAAGAAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTGCT ACACGCTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCTCA TCTTCAAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCACC TGCGGCGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTCGG GGGCATAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAGCC CCACAGGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGACCC >2152_2152_7_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000449296_MAD1L1_chr7_2108973_ENST00000402746_length(amino acids)=439AA_BP=77 MFRKHVLGPCSVSLQSPLRDSVLATSGSLAHQPISRPPCLAPVGSLLNFMASHGNDAARARFESKVPSFYYRPTPSDCHARGLEKARQQL QEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPAEYSPQLTRRMREAEDMVQKVHSHSAEMEAQLSQA LEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRLEEEKRMLEAQLERRALQGDYDQSRTKVLHMSLNP TSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELKKQVESAELKNQRLKEVFQTKIQEFRKACYTLTGY -------------------------------------------------------------- >2152_2152_8_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000449296_MAD1L1_chr7_2108973_ENST00000406869_length(transcript)=1613nt_BP=253nt TTTCCTTCTCCCTCAGCCTGTTTCGTAAACATGTTCTGGGTCCCTGCAGTGTGTCCCTGCAGAGTCCCCTCAGAGACTCTGTCCTAGCCA CATCTGGGTCTCTCGCTCACCAGCCCATCTCCAGGCCCCCGTGTCTGGCGCCTGTTGGCTCTTTGCTAAATTTCATGGCCTCCCACGGGA ACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGAGA AGGCCAGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCTGG CCCGGAGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGACCC CGGCCGAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGAGG CTCAGCTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCAGT CCAGCTCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAGTC GGCTGGAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCTGC ACATGAGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGGGC TCCTGCGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGAGC TGAAGAAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTGCT ACACGCTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCTCA TCTTCAAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCACC TGCGGCGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTCGG GGGCATAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAGCC CCACAGGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGACCC >2152_2152_8_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000449296_MAD1L1_chr7_2108973_ENST00000406869_length(amino acids)=439AA_BP=77 MFRKHVLGPCSVSLQSPLRDSVLATSGSLAHQPISRPPCLAPVGSLLNFMASHGNDAARARFESKVPSFYYRPTPSDCHARGLEKARQQL QEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPAEYSPQLTRRMREAEDMVQKVHSHSAEMEAQLSQA LEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRLEEEKRMLEAQLERRALQGDYDQSRTKVLHMSLNP TSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELKKQVESAELKNQRLKEVFQTKIQEFRKACYTLTGY -------------------------------------------------------------- >2152_2152_9_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000539900_MAD1L1_chr7_2108973_ENST00000265854_length(transcript)=1681nt_BP=338nt ATGTTCCAGTTTGTTTTCAGCCGGGTGTACTGCATTAACCCTGCAAGAAGAAAATGGAAAGAATTTGAAAAGATGCTGGGGTGTGCAGAG GAAGGGCACGCGAGTCTGGGAAGAGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAATCCACCGG AATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGGGAACGAC GCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGAGAAGGCC AGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCTGGCCCGG AGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGACCCCGGCC GAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGAGGCTCAG CTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCAGTCCAGC TCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAGTCGGCTG GAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCTGCACATG AGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGGGCTCCTG CGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGAGCTGAAG AAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTGCTACACG CTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCTCATCTTC AAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCACCTGCGG CGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTCGGGGGCA TAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAGCCCCACA GGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGACCCCATGC >2152_2152_9_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000539900_MAD1L1_chr7_2108973_ENST00000265854_length(amino acids)=473AA_BP=111 MFQFVFSRVYCINPARRKWKEFEKMLGCAEEGHASLGRDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGND AARARFESKVPSFYYRPTPSDCHARGLEKARQQLQEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPA EYSPQLTRRMREAEDMVQKVHSHSAEMEAQLSQALEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRL EEEKRMLEAQLERRALQGDYDQSRTKVLHMSLNPTSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELK KQVESAELKNQRLKEVFQTKIQEFRKACYTLTGYQIDITTENQYRLTSLYAEHPGDCLIFKATSPSGSKMQLLETEFSHTVGELIEVHLR -------------------------------------------------------------- >2152_2152_10_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000539900_MAD1L1_chr7_2108973_ENST00000399654_length(transcript)=1698nt_BP=338nt ATGTTCCAGTTTGTTTTCAGCCGGGTGTACTGCATTAACCCTGCAAGAAGAAAATGGAAAGAATTTGAAAAGATGCTGGGGTGTGCAGAG GAAGGGCACGCGAGTCTGGGAAGAGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAATCCACCGG AATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGGGAACGAC GCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGAGAAGGCC AGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCTGGCCCGG AGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGACCCCGGCC GAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGAGGCTCAG CTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCAGTCCAGC TCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAGTCGGCTG GAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCTGCACATG AGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGGGCTCCTG CGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGAGCTGAAG AAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTGCTACACG CTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCTCATCTTC AAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCACCTGCGG CGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTCGGGGGCA TAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAGCCCCACA GGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGACCCCATGC >2152_2152_10_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000539900_MAD1L1_chr7_2108973_ENST00000399654_length(amino acids)=473AA_BP=111 MFQFVFSRVYCINPARRKWKEFEKMLGCAEEGHASLGRDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGND AARARFESKVPSFYYRPTPSDCHARGLEKARQQLQEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPA EYSPQLTRRMREAEDMVQKVHSHSAEMEAQLSQALEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRL EEEKRMLEAQLERRALQGDYDQSRTKVLHMSLNPTSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELK KQVESAELKNQRLKEVFQTKIQEFRKACYTLTGYQIDITTENQYRLTSLYAEHPGDCLIFKATSPSGSKMQLLETEFSHTVGELIEVHLR -------------------------------------------------------------- >2152_2152_11_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000539900_MAD1L1_chr7_2108973_ENST00000402746_length(transcript)=1698nt_BP=338nt ATGTTCCAGTTTGTTTTCAGCCGGGTGTACTGCATTAACCCTGCAAGAAGAAAATGGAAAGAATTTGAAAAGATGCTGGGGTGTGCAGAG GAAGGGCACGCGAGTCTGGGAAGAGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAATCCACCGG AATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGGGAACGAC GCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGAGAAGGCC AGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCTGGCCCGG AGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGACCCCGGCC GAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGAGGCTCAG CTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCAGTCCAGC TCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAGTCGGCTG GAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCTGCACATG AGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGGGCTCCTG CGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGAGCTGAAG AAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTGCTACACG CTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCTCATCTTC AAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCACCTGCGG CGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTCGGGGGCA TAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAGCCCCACA GGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGACCCCATGC >2152_2152_11_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000539900_MAD1L1_chr7_2108973_ENST00000402746_length(amino acids)=473AA_BP=111 MFQFVFSRVYCINPARRKWKEFEKMLGCAEEGHASLGRDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGND AARARFESKVPSFYYRPTPSDCHARGLEKARQQLQEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPA EYSPQLTRRMREAEDMVQKVHSHSAEMEAQLSQALEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRL EEEKRMLEAQLERRALQGDYDQSRTKVLHMSLNPTSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELK KQVESAELKNQRLKEVFQTKIQEFRKACYTLTGYQIDITTENQYRLTSLYAEHPGDCLIFKATSPSGSKMQLLETEFSHTVGELIEVHLR -------------------------------------------------------------- >2152_2152_12_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000539900_MAD1L1_chr7_2108973_ENST00000406869_length(transcript)=1698nt_BP=338nt ATGTTCCAGTTTGTTTTCAGCCGGGTGTACTGCATTAACCCTGCAAGAAGAAAATGGAAAGAATTTGAAAAGATGCTGGGGTGTGCAGAG GAAGGGCACGCGAGTCTGGGAAGAGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAATCCACCGG AATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGGGAACGAC GCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCACGCCCGGGGGCTGGAGAAGGCC AGGCAGCAGCTGCAGGAGGAGCTCCGGCAGGTCAGCGGCCAGCTGTTGGAGGAGAGGAAGAAGCGCGAGACCCACGAGGCGCTGGCCCGG AGGCTCCAGAAACGGGTCCTGCTGCTCACCAAGGAGCGGGACGGTATGCGGGCCATCCTGGGGTCCTACGACAGCGAGCTGACCCCGGCC GAGTACTCACCCCAGCTGACGCGGCGCATGCGGGAGGCTGAGGATATGGTGCAGAAGGTGCACAGCCACAGCGCCGAGATGGAGGCTCAG CTGTCGCAGGCCCTGGAGGAGCTGGGAGGCCAGAAACAAAGAGCAGACATGCTGGAGATGGAGCTGAAGATGCTGAAGTCTCAGTCCAGC TCTGCCGAACAGAGCTTCCTGTTCTCCAGGGAGGAGGCGGACACGCTCAGGTTGAAGGTCGAGGAGCTGGAAGGCGAGCGGAGTCGGCTG GAGGAGGAAAAGAGGATGCTGGAGGCACAGCTGGAGCGGCGAGCTCTGCAGGGTGACTATGACCAGAGCAGGACCAAAGTGCTGCACATG AGCCTGAACCCCACCAGTGTGGCCAGGCAGCGCCTGCGCGAGGACCACAGCCAGCTGCAGGCGGAGTGCGAGCGACTGCGCGGGCTCCTG CGCGCCATGGAGAGAGGAGGCACCGTCCCAGCCGACCTTGAGGCTGCCGCCGCGAGTCTGCCATCGTCCAAGGAGGTGGCAGAGCTGAAG AAGCAGGTGGAGAGTGCCGAGCTGAAGAACCAGCGGCTCAAGGAGGTTTTCCAGACCAAGATCCAGGAGTTCCGCAAGGCCTGCTACACG CTCACCGGCTACCAGATCGACATCACCACGGAGAACCAGTACCGGCTGACCTCGCTGTACGCCGAGCACCCAGGCGACTGCCTCATCTTC AAGGCCACCAGCCCCTCGGGTTCCAAGATGCAGCTACTGGAGACAGAGTTCTCACACACCGTGGGCGAGCTCATCGAGGTGCACCTGCGG CGCCAGGACAGCATCCCTGCCTTCCTCAGCTCGCTCACCCTCGAGCTCTTCAGCCGCCAGACCGTGGCGTAGCCTGCAGGCTCGGGGGCA TAGCCGGAGCCACTCTGCTTGGCCTGACCTGCAGGTCCCCTGCCCCGCCAGCCACAGGCTGGGTGCACGTCCTGCCTCTCCAGCCCCACA GGGCAGCAGCATGACTGACAGACACGCTGGGACCTACGTCGGGCTTCCTGCTGGGGCGGCCAGCACCCTCTCCACGTGCAGACCCCATGC >2152_2152_12_ADAP1-MAD1L1_ADAP1_chr7_966189_ENST00000539900_MAD1L1_chr7_2108973_ENST00000406869_length(amino acids)=473AA_BP=111 MFQFVFSRVYCINPARRKWKEFEKMLGCAEEGHASLGRDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGND AARARFESKVPSFYYRPTPSDCHARGLEKARQQLQEELRQVSGQLLEERKKRETHEALARRLQKRVLLLTKERDGMRAILGSYDSELTPA EYSPQLTRRMREAEDMVQKVHSHSAEMEAQLSQALEELGGQKQRADMLEMELKMLKSQSSSAEQSFLFSREEADTLRLKVEELEGERSRL EEEKRMLEAQLERRALQGDYDQSRTKVLHMSLNPTSVARQRLREDHSQLQAECERLRGLLRAMERGGTVPADLEAAAASLPSSKEVAELK KQVESAELKNQRLKEVFQTKIQEFRKACYTLTGYQIDITTENQYRLTSLYAEHPGDCLIFKATSPSGSKMQLLETEFSHTVGELIEVHLR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ADAP1-MAD1L1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ADAP1-MAD1L1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ADAP1-MAD1L1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies