
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DCX-PASD1 (FusionGDB2 ID:21738) |
Fusion Gene Summary for DCX-PASD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DCX-PASD1 | Fusion gene ID: 21738 | Hgene | Tgene | Gene symbol | DCX | PASD1 | Gene ID | 1641 | 139135 |
| Gene name | doublecortin | PAS domain containing repressor 1 | |
| Synonyms | DBCN|DC|LISX|SCLH|XLIS | CT63|CT64|OXTES1 | |
| Cytomap | Xq23 | Xq28 | |
| Type of gene | protein-coding | protein-coding | |
| Description | neuronal migration protein doublecortindoublecortexdoublinlis-Xlissencephalin-X | circadian clock protein PASD1PAS domain containing 1cancer/testis antigen 63 | |
| Modification date | 20200313 | 20200315 | |
| UniProtAcc | O43602 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000338081, ENST00000356220, ENST00000356915, ENST00000371993, ENST00000488120, ENST00000496551, | ENST00000370357, | |
| Fusion gene scores | * DoF score | 1 X 2 X 1=2 | 4 X 4 X 4=64 |
| # samples | 1 | 5 | |
| ** MAII score | log2(1/2*10)=2.32192809488736 | log2(5/64*10)=-0.356143810225275 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DCX [Title/Abstract] AND PASD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DCX(110574132)-PASD1(150828185), # samples:2 DCX(110574147)-PASD1(150828185), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | DCX | GO:0001764 | neuron migration | 14741102 |
| Tgene | PASD1 | GO:0042754 | negative regulation of circadian rhythm | 25936801 |
| Tgene | PASD1 | GO:0045892 | negative regulation of transcription, DNA-templated | 25936801 |
| Fusion gene breakpoints across DCX (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PASD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | KIRC | TCGA-CJ-5681-01A | DCX | chrX | 110574132 | - | PASD1 | chrX | 150828185 | + |
| ChimerDB4 | KIRC | TCGA-CJ-5681-01A | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + |
Top |
Fusion Gene ORF analysis for DCX-PASD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000338081 | ENST00000370357 | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + |
| Frame-shift | ENST00000356220 | ENST00000370357 | DCX | chrX | 110574132 | - | PASD1 | chrX | 150828185 | + |
| In-frame | ENST00000356915 | ENST00000370357 | DCX | chrX | 110574132 | - | PASD1 | chrX | 150828185 | + |
| In-frame | ENST00000371993 | ENST00000370357 | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + |
| In-frame | ENST00000488120 | ENST00000370357 | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + |
| intron-3CDS | ENST00000338081 | ENST00000370357 | DCX | chrX | 110574132 | - | PASD1 | chrX | 150828185 | + |
| intron-3CDS | ENST00000356220 | ENST00000370357 | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + |
| intron-3CDS | ENST00000356915 | ENST00000370357 | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + |
| intron-3CDS | ENST00000371993 | ENST00000370357 | DCX | chrX | 110574132 | - | PASD1 | chrX | 150828185 | + |
| intron-3CDS | ENST00000488120 | ENST00000370357 | DCX | chrX | 110574132 | - | PASD1 | chrX | 150828185 | + |
| intron-3CDS | ENST00000496551 | ENST00000370357 | DCX | chrX | 110574132 | - | PASD1 | chrX | 150828185 | + |
| intron-3CDS | ENST00000496551 | ENST00000370357 | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000356915 | DCX | chrX | 110574132 | - | ENST00000370357 | PASD1 | chrX | 150828185 | + | 3210 | 1009 | 907 | 2613 | 568 |
| ENST00000371993 | DCX | chrX | 110574147 | - | ENST00000370357 | PASD1 | chrX | 150828185 | + | 3263 | 1062 | 975 | 2666 | 563 |
| ENST00000488120 | DCX | chrX | 110574147 | - | ENST00000370357 | PASD1 | chrX | 150828185 | + | 3392 | 1191 | 1104 | 2795 | 563 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000356915 | ENST00000370357 | DCX | chrX | 110574132 | - | PASD1 | chrX | 150828185 | + | 0.002395794 | 0.9976042 |
| ENST00000371993 | ENST00000370357 | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + | 0.00214472 | 0.99785525 |
| ENST00000488120 | ENST00000370357 | DCX | chrX | 110574147 | - | PASD1 | chrX | 150828185 | + | 0.002265522 | 0.9977344 |
Top |
Fusion Genomic Features for DCX-PASD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DCX | chrX | 110574131 | - | PASD1 | chrX | 150828184 | + | 5.41E-07 | 0.9999994 |
| DCX | chrX | 110574146 | - | PASD1 | chrX | 150828184 | + | 1.80E-07 | 0.99999976 |
| DCX | chrX | 110574131 | - | PASD1 | chrX | 150828184 | + | 5.41E-07 | 0.9999994 |
| DCX | chrX | 110574146 | - | PASD1 | chrX | 150828184 | + | 1.80E-07 | 0.99999976 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
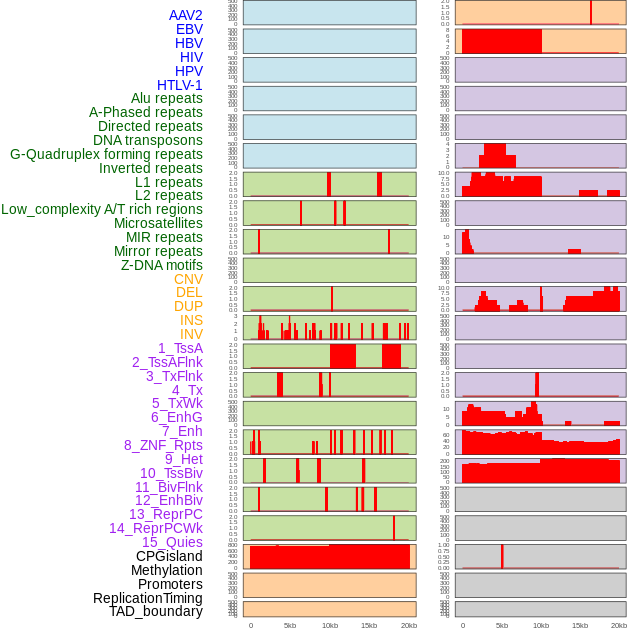 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
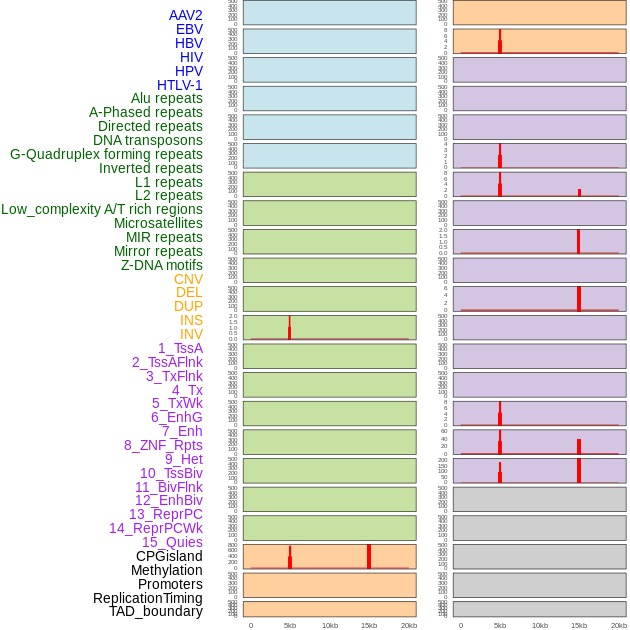 |
Top |
Fusion Protein Features for DCX-PASD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chrX:110574132/chrX:150828185) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DCX | . |
| FUNCTION: Microtubule-associated protein required for initial steps of neuronal dispersion and cortex lamination during cerebral cortex development. May act by competing with the putative neuronal protein kinase DCLK1 in binding to a target protein. May in that way participate in a signaling pathway that is crucial for neuronal interaction before and during migration, possibly as part of a calcium ion-dependent signal transduction pathway. May be part with PAFAH1B1/LIS-1 of overlapping, but distinct, signaling pathways that promote neuronal migration. {ECO:0000269|PubMed:22359282}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000338081 | - | 5 | 7 | 287_365 | 391 | 442.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000356220 | - | 6 | 8 | 180_263 | 315 | 366.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000356220 | - | 6 | 8 | 53_139 | 315 | 366.0 | Domain | Doublecortin 1 |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000356915 | - | 5 | 7 | 180_263 | 315 | 366.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000356915 | - | 5 | 7 | 53_139 | 315 | 366.0 | Domain | Doublecortin 1 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000338081 | - | 5 | 7 | 180_263 | 391 | 442.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000338081 | - | 5 | 7 | 53_139 | 391 | 442.0 | Domain | Doublecortin 1 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000371993 | - | 5 | 7 | 180_263 | 310 | 361.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000371993 | - | 5 | 7 | 53_139 | 310 | 361.0 | Domain | Doublecortin 1 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000488120 | - | 5 | 7 | 180_263 | 310 | 361.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000488120 | - | 5 | 7 | 53_139 | 310 | 361.0 | Domain | Doublecortin 1 |
| Tgene | PASD1 | chrX:110574132 | chrX:150828185 | ENST00000370357 | 8 | 16 | 365_412 | 239 | 774.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PASD1 | chrX:110574132 | chrX:150828185 | ENST00000370357 | 8 | 16 | 475_553 | 239 | 774.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PASD1 | chrX:110574147 | chrX:150828185 | ENST00000370357 | 8 | 16 | 365_412 | 239 | 774.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PASD1 | chrX:110574147 | chrX:150828185 | ENST00000370357 | 8 | 16 | 475_553 | 239 | 774.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PASD1 | chrX:110574132 | chrX:150828185 | ENST00000370357 | 8 | 16 | 508_548 | 239 | 774.0 | Compositional bias | Note=Lys-rich | |
| Tgene | PASD1 | chrX:110574132 | chrX:150828185 | ENST00000370357 | 8 | 16 | 665_668 | 239 | 774.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | PASD1 | chrX:110574147 | chrX:150828185 | ENST00000370357 | 8 | 16 | 508_548 | 239 | 774.0 | Compositional bias | Note=Lys-rich | |
| Tgene | PASD1 | chrX:110574147 | chrX:150828185 | ENST00000370357 | 8 | 16 | 665_668 | 239 | 774.0 | Compositional bias | Note=Poly-Ser |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000338081 | - | 1 | 7 | 287_365 | 0 | 442.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000356220 | - | 6 | 8 | 287_365 | 315 | 366.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000356915 | - | 5 | 7 | 287_365 | 315 | 366.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000371993 | - | 1 | 7 | 287_365 | 0 | 361.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000488120 | - | 1 | 7 | 287_365 | 0 | 361.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000356220 | - | 1 | 8 | 287_365 | 0 | 366.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000356915 | - | 1 | 7 | 287_365 | 0 | 366.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000371993 | - | 5 | 7 | 287_365 | 310 | 361.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000488120 | - | 5 | 7 | 287_365 | 310 | 361.0 | Compositional bias | Note=Pro/Ser-rich |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000338081 | - | 1 | 7 | 180_263 | 0 | 442.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000338081 | - | 1 | 7 | 53_139 | 0 | 442.0 | Domain | Doublecortin 1 |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000371993 | - | 1 | 7 | 180_263 | 0 | 361.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000371993 | - | 1 | 7 | 53_139 | 0 | 361.0 | Domain | Doublecortin 1 |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000488120 | - | 1 | 7 | 180_263 | 0 | 361.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574132 | chrX:150828185 | ENST00000488120 | - | 1 | 7 | 53_139 | 0 | 361.0 | Domain | Doublecortin 1 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000356220 | - | 1 | 8 | 180_263 | 0 | 366.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000356220 | - | 1 | 8 | 53_139 | 0 | 366.0 | Domain | Doublecortin 1 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000356915 | - | 1 | 7 | 180_263 | 0 | 366.0 | Domain | Doublecortin 2 |
| Hgene | DCX | chrX:110574147 | chrX:150828185 | ENST00000356915 | - | 1 | 7 | 53_139 | 0 | 366.0 | Domain | Doublecortin 1 |
| Tgene | PASD1 | chrX:110574132 | chrX:150828185 | ENST00000370357 | 8 | 16 | 229_236 | 239 | 774.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | PASD1 | chrX:110574147 | chrX:150828185 | ENST00000370357 | 8 | 16 | 229_236 | 239 | 774.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | PASD1 | chrX:110574132 | chrX:150828185 | ENST00000370357 | 8 | 16 | 30_102 | 239 | 774.0 | Domain | PAS | |
| Tgene | PASD1 | chrX:110574147 | chrX:150828185 | ENST00000370357 | 8 | 16 | 30_102 | 239 | 774.0 | Domain | PAS |
Top |
Fusion Gene Sequence for DCX-PASD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >21738_21738_1_DCX-PASD1_DCX_chrX_110574132_ENST00000356915_PASD1_chrX_150828185_ENST00000370357_length(transcript)=3210nt_BP=1009nt TTTCTTTCTCTCAGCATCTCCACCCAACCAGCAGAAAACCGGTCTCTGAGGTTCCACCAAAATATGGAACTTGATTTTGGACACTTTGAC GAAAGAGATAAGACATCCAGGAACATGCGAGGCTCCCGGATGAATGGGTTGCCTAGCCCCACTCACAGCGCCCACTGTAGCTTCTACCGA ACCAGAACCTTGCAGGCACTGAGTAATGAGAAGAAAGCCAAGAAGGTACGTTTCTACCGCAATGGGGACCGCTACTTCAAGGGGATTGTG TACGCTGTGTCCTCTGACCGTTTTCGCAGCTTTGACGCCTTGCTGGCTGACCTGACGCGATCTCTGTCTGACAACATCAACCTGCCTCAG GGAGTGCGTTACATTTACACCATTGATGGATCCAGGAAGATCGGAAGCATGGATGAACTGGAGGAAGGGGAAAGCTATGTCTGTTCCTCA GACAACTTCTTTAAAAAGGTGGAGTACACCAAGAATGTCAATCCCAACTGGTCTGTCAACGTAAAAACATCTGCCAATATGAAAGCCCCC CAGTCCTTGGCTAGCAGCAACAGTGCACAGGCCAGGGAGAACAAGGACTTTGTGCGCCCCAAGCTGGTTACCATCATCCGCAGTGGGGTG AAGCCTCGGAAGGCTGTGCGTGTGCTTCTGAACAAGAAGACAGCCCACTCTTTTGAGCAAGTCCTCACTGATATCACAGAAGCCATCAAA CTGGAGACCGGGGTTGTCAAAAAACTCTACACTCTGGATGGAAAACAGGTAACTTGTCTCCATGATTTCTTTGGTGATGATGATGTGTTT ATTGCCTGTGGTCCTGAAAAATTTCGCTATGCTCAGGATGATTTTTCTCTGGATGAAAATGAATGCCGAGTCATGAAGGGAAACCCATCA GCCACAGCTGGCCCAAAGGCATCCCCAACACCTCAGAAGACTTCAGCCAAGAGCCCTGGTCCTATGCGCCGAAGCAAGTCTCCAGCTGAC TCAGGTAACGACCAAGACGGACCAAATTGATATTGCAGAGGTTGAGCAGTATGGACCACAAGAAAACGTTCACATGTTTGTAGATTCTGA TTCAACTTATTGCTCCAGTACAGTTTTCCTGGATACTATGCCTGAATCTCCAGCCTTATCCTTGCAAGACTTTCGAGGTGAGCCTGAGGT GAATCCATTGTACAGGGCAGACCCAGTGGACCTGGAGTTCTCGGTGGATCAGGTGGACTCAGTGGACCAGGAGGGCCCAATGGACCAGCA GGACCCAGAGAACCCAGTTGCCCCGTTGGACCAGGCAGGCCTGATGGATCCAGTGGATCCAGAGGACTCAGTGGACCTGGGGGCTGCTGG CGCAAGTGCTCAGCCATTACAGCCATCATCACCAGTTGCATATGACATCATTAGCCAGGAACTGGAACTGATGAAGAAGTTGAAGGAGCA GCTAGAAGAGAGGACTTGGTTGCTGCATGATGCCATCCAAAACCAGCAGAATGCATTGGAATTGATGATGGATCACCTTCAGAAGCAGCC AAACACATTACGCCACGTTGTCATTCCTGATCTCCAATCTTCGGAGGCAGTGCCCAAGAAACAACAGAAACAACACGCTGGGCAAGTGAA GCGGCCTCTCCCACATCCCAAGGACGTCAAGTGTTTCTGTGGTTTATCTTTATCCAACTCTCTCAAAAACACTGGGGAGCTTCAGGAGCC TTGTGTTGCCTTCAACCAGCAGCAACTGGTGCAGCAAGAACAACACCTGAAGGAGCAGCAGCGGCAGCTGCGGGAGCAGCTGCAACAGCT GAGAGAGCAAAGGAAGGTGCAGAAGCAGAAGAAGATGCAGGAGAAGAAGAAGCTGCAGGAGCAGAAAATGCAGGAGAAGAAGAAGCTGCA GGAGCAGAGGCGGCAAAAGAAGAAGAAGCTACAGGAGCGGAAGAAGTGGCAGGGGCAGATGCTACAGAAAGAGCCAGAGGAGGAGCAGCA GAAGCAGCAGCTGCAAGAGCAGCCACTGAAGCATAATGTCATCGTGGGGAATGAGAGGGTGCAGATATGCCTGCAAAACCCACGTGACGT ATCTGTGCCCCTCTGCAATCACCCTGTTAGATTTTTACAGGCCCAACCCATTGTTCCTGTCCAGAGAGCAGCTGAACAACAGCCCTCTGG CTTCTATCAAGATGAAAACTGTGGGCAACAGGAAGATGAGAGTCAAAGTTTTTATCCTGAGGCGTATCAAGGGCCCCCCGTGAACCAGCT GCCATTGATAGATACCTCAAACTCTGAGGCAATTTCTTCTTCCAGCATTCCTCAGTTTCCCATAACTTCAGACTCAACCATAAGCACCCT GGAGACCCCACAGGATTACATCCGGCTTTGGCAAGAGTTGTCTGATTCACTCGGTCCTGTTGTCCAAGTGAACACTTGGTCTTGCGATGA GCAGGGCACCCTGCACGGCCAACCCACCTACCATCAGGTGCAAGTTTCTGAGGTAGGAGTCGAGGGACCTCCTGATCCACAGGCTTTCCA AGGCCCTGCTGCATACCAGCCAGACCAGATGAGATCTGCGGAGCAGACCAGATTGATGCCTGCAGAGCAACGTGACTCAAATAAGCCGTG CTAACAGTACTTTCATGACCAGTGATGAGGGGAAATGGGGGGAGGGGGCAGGCCAATGAGGTCTGCATGGCCAGGGGACCTTCAAGGTGC GTAAAGTCCCTTGGGGTAGGGTTTAGTGGGTAGAGACTTATTTGTTTCCTGATAGGTTATGTTTGTAATTGTTTGTTAAGCACAGCCTGT TTCTTGGAAGTTATGCTGTAGAGGCAGCCTGTGATCCGTAGTATGCTAGGGTGTGACAGCAGCCAGCCACAGCTGGATCTGATGTCTTGT CTGCCCCGCCCAGCTTTGCATATCCATGTTCTACCACAGGAAGGTGGCCTGCCAAGAGTCTGCTCAAAGTTTTCAACATAAAGAATAAAG AAAAAAAAATGCCAAAGTGCTTTTCAATCTAGTAAATCTAGAGGGTTGTTTTGTCTTAGCCACAAGAATTCCGAGGTCTTGACCCTGATG ATCAACCTGCCTCCCCTCCATAGTCTTGTTGGAGAAGCCCAGAGAGAATGGGACTCCAACTAAGGGAACCTGAAATCAACTCAATGGAGG >21738_21738_1_DCX-PASD1_DCX_chrX_110574132_ENST00000356915_PASD1_chrX_150828185_ENST00000370357_length(amino acids)=568AA_BP=34 MAQRHPQHLRRLQPRALVLCAEASLQLTQVTTKTDQIDIAEVEQYGPQENVHMFVDSDSTYCSSTVFLDTMPESPALSLQDFRGEPEVNP LYRADPVDLEFSVDQVDSVDQEGPMDQQDPENPVAPLDQAGLMDPVDPEDSVDLGAAGASAQPLQPSSPVAYDIISQELELMKKLKEQLE ERTWLLHDAIQNQQNALELMMDHLQKQPNTLRHVVIPDLQSSEAVPKKQQKQHAGQVKRPLPHPKDVKCFCGLSLSNSLKNTGELQEPCV AFNQQQLVQQEQHLKEQQRQLREQLQQLREQRKVQKQKKMQEKKKLQEQKMQEKKKLQEQRRQKKKKLQERKKWQGQMLQKEPEEEQQKQ QLQEQPLKHNVIVGNERVQICLQNPRDVSVPLCNHPVRFLQAQPIVPVQRAAEQQPSGFYQDENCGQQEDESQSFYPEAYQGPPVNQLPL IDTSNSEAISSSSIPQFPITSDSTISTLETPQDYIRLWQELSDSLGPVVQVNTWSCDEQGTLHGQPTYHQVQVSEVGVEGPPDPQAFQGP -------------------------------------------------------------- >21738_21738_2_DCX-PASD1_DCX_chrX_110574147_ENST00000371993_PASD1_chrX_150828185_ENST00000370357_length(transcript)=3263nt_BP=1062nt CACAAGGCAAAGCCTGCTCTCTCTGTCTCTCTGTCTCCTCTTCTCCTTTTTTGCCTTATTCTATCCGATTTTTTCCCTAAGCTTCTACCT GGGATTTTCCTTTGGAAAAGTCTCTGAGGTTCCACCAAAATATGGAACTTGATTTTGGACACTTTGACGAAAGAGATAAGACATCCAGGA ACATGCGAGGCTCCCGGATGAATGGGTTGCCTAGCCCCACTCACAGCGCCCACTGTAGCTTCTACCGAACCAGAACCTTGCAGGCACTGA GTAATGAGAAGAAAGCCAAGAAGGTACGTTTCTACCGCAATGGGGACCGCTACTTCAAGGGGATTGTGTACGCTGTGTCCTCTGACCGTT TTCGCAGCTTTGACGCCTTGCTGGCTGACCTGACGCGATCTCTGTCTGACAACATCAACCTGCCTCAGGGAGTGCGTTACATTTACACCA TTGATGGATCCAGGAAGATCGGAAGCATGGATGAACTGGAGGAAGGGGAAAGCTATGTCTGTTCCTCAGACAACTTCTTTAAAAAGGTGG AGTACACCAAGAATGTCAATCCCAACTGGTCTGTCAACGTAAAAACATCTGCCAATATGAAAGCCCCCCAGTCCTTGGCTAGCAGCAACA GTGCACAGGCCAGGGAGAACAAGGACTTTGTGCGCCCCAAGCTGGTTACCATCATCCGCAGTGGGGTGAAGCCTCGGAAGGCTGTGCGTG TGCTTCTGAACAAGAAGACAGCCCACTCTTTTGAGCAAGTCCTCACTGATATCACAGAAGCCATCAAACTGGAGACCGGGGTTGTCAAAA AACTCTACACTCTGGATGGAAAACAGGTAACTTGTCTCCATGATTTCTTTGGTGATGATGATGTGTTTATTGCCTGTGGTCCTGAAAAAT TTCGCTATGCTCAGGATGATTTTTCTCTGGATGAAAATGAATGCCGAGTCATGAAGGGAAACCCATCAGCCACAGCTGGCCCAAAGGCAT CCCCAACACCTCAGAAGACTTCAGCCAAGAGCCCTGGTCCTATGCGCCGAAGCAAGTCTCCAGCTGACTCAGGACCAAATTGATATTGCA GAGGTTGAGCAGTATGGACCACAAGAAAACGTTCACATGTTTGTAGATTCTGATTCAACTTATTGCTCCAGTACAGTTTTCCTGGATACT ATGCCTGAATCTCCAGCCTTATCCTTGCAAGACTTTCGAGGTGAGCCTGAGGTGAATCCATTGTACAGGGCAGACCCAGTGGACCTGGAG TTCTCGGTGGATCAGGTGGACTCAGTGGACCAGGAGGGCCCAATGGACCAGCAGGACCCAGAGAACCCAGTTGCCCCGTTGGACCAGGCA GGCCTGATGGATCCAGTGGATCCAGAGGACTCAGTGGACCTGGGGGCTGCTGGCGCAAGTGCTCAGCCATTACAGCCATCATCACCAGTT GCATATGACATCATTAGCCAGGAACTGGAACTGATGAAGAAGTTGAAGGAGCAGCTAGAAGAGAGGACTTGGTTGCTGCATGATGCCATC CAAAACCAGCAGAATGCATTGGAATTGATGATGGATCACCTTCAGAAGCAGCCAAACACATTACGCCACGTTGTCATTCCTGATCTCCAA TCTTCGGAGGCAGTGCCCAAGAAACAACAGAAACAACACGCTGGGCAAGTGAAGCGGCCTCTCCCACATCCCAAGGACGTCAAGTGTTTC TGTGGTTTATCTTTATCCAACTCTCTCAAAAACACTGGGGAGCTTCAGGAGCCTTGTGTTGCCTTCAACCAGCAGCAACTGGTGCAGCAA GAACAACACCTGAAGGAGCAGCAGCGGCAGCTGCGGGAGCAGCTGCAACAGCTGAGAGAGCAAAGGAAGGTGCAGAAGCAGAAGAAGATG CAGGAGAAGAAGAAGCTGCAGGAGCAGAAAATGCAGGAGAAGAAGAAGCTGCAGGAGCAGAGGCGGCAAAAGAAGAAGAAGCTACAGGAG CGGAAGAAGTGGCAGGGGCAGATGCTACAGAAAGAGCCAGAGGAGGAGCAGCAGAAGCAGCAGCTGCAAGAGCAGCCACTGAAGCATAAT GTCATCGTGGGGAATGAGAGGGTGCAGATATGCCTGCAAAACCCACGTGACGTATCTGTGCCCCTCTGCAATCACCCTGTTAGATTTTTA CAGGCCCAACCCATTGTTCCTGTCCAGAGAGCAGCTGAACAACAGCCCTCTGGCTTCTATCAAGATGAAAACTGTGGGCAACAGGAAGAT GAGAGTCAAAGTTTTTATCCTGAGGCGTATCAAGGGCCCCCCGTGAACCAGCTGCCATTGATAGATACCTCAAACTCTGAGGCAATTTCT TCTTCCAGCATTCCTCAGTTTCCCATAACTTCAGACTCAACCATAAGCACCCTGGAGACCCCACAGGATTACATCCGGCTTTGGCAAGAG TTGTCTGATTCACTCGGTCCTGTTGTCCAAGTGAACACTTGGTCTTGCGATGAGCAGGGCACCCTGCACGGCCAACCCACCTACCATCAG GTGCAAGTTTCTGAGGTAGGAGTCGAGGGACCTCCTGATCCACAGGCTTTCCAAGGCCCTGCTGCATACCAGCCAGACCAGATGAGATCT GCGGAGCAGACCAGATTGATGCCTGCAGAGCAACGTGACTCAAATAAGCCGTGCTAACAGTACTTTCATGACCAGTGATGAGGGGAAATG GGGGGAGGGGGCAGGCCAATGAGGTCTGCATGGCCAGGGGACCTTCAAGGTGCGTAAAGTCCCTTGGGGTAGGGTTTAGTGGGTAGAGAC TTATTTGTTTCCTGATAGGTTATGTTTGTAATTGTTTGTTAAGCACAGCCTGTTTCTTGGAAGTTATGCTGTAGAGGCAGCCTGTGATCC GTAGTATGCTAGGGTGTGACAGCAGCCAGCCACAGCTGGATCTGATGTCTTGTCTGCCCCGCCCAGCTTTGCATATCCATGTTCTACCAC AGGAAGGTGGCCTGCCAAGAGTCTGCTCAAAGTTTTCAACATAAAGAATAAAGAAAAAAAAATGCCAAAGTGCTTTTCAATCTAGTAAAT CTAGAGGGTTGTTTTGTCTTAGCCACAAGAATTCCGAGGTCTTGACCCTGATGATCAACCTGCCTCCCCTCCATAGTCTTGTTGGAGAAG CCCAGAGAGAATGGGACTCCAACTAAGGGAACCTGAAATCAACTCAATGGAGGCACTTCAGAGCTAAAATAATTATGGCTTCCTTGCTTA >21738_21738_2_DCX-PASD1_DCX_chrX_110574147_ENST00000371993_PASD1_chrX_150828185_ENST00000370357_length(amino acids)=563AA_BP=28 MAQRHPQHLRRLQPRALVLCAEASLQLTQDQIDIAEVEQYGPQENVHMFVDSDSTYCSSTVFLDTMPESPALSLQDFRGEPEVNPLYRAD PVDLEFSVDQVDSVDQEGPMDQQDPENPVAPLDQAGLMDPVDPEDSVDLGAAGASAQPLQPSSPVAYDIISQELELMKKLKEQLEERTWL LHDAIQNQQNALELMMDHLQKQPNTLRHVVIPDLQSSEAVPKKQQKQHAGQVKRPLPHPKDVKCFCGLSLSNSLKNTGELQEPCVAFNQQ QLVQQEQHLKEQQRQLREQLQQLREQRKVQKQKKMQEKKKLQEQKMQEKKKLQEQRRQKKKKLQERKKWQGQMLQKEPEEEQQKQQLQEQ PLKHNVIVGNERVQICLQNPRDVSVPLCNHPVRFLQAQPIVPVQRAAEQQPSGFYQDENCGQQEDESQSFYPEAYQGPPVNQLPLIDTSN SEAISSSSIPQFPITSDSTISTLETPQDYIRLWQELSDSLGPVVQVNTWSCDEQGTLHGQPTYHQVQVSEVGVEGPPDPQAFQGPAAYQP -------------------------------------------------------------- >21738_21738_3_DCX-PASD1_DCX_chrX_110574147_ENST00000488120_PASD1_chrX_150828185_ENST00000370357_length(transcript)=3392nt_BP=1191nt GAAACCTTTCTAGCTGTTAATGCAGCCTGTGAATTTTTTTAAAAGCATGTAATTAATCATAGGAGGTTGGGGGGATTCACTAAGCCTGAG TTACATGGGAGAAGCTGGACAAGGCACTAGGACCTAGAAGGCATCTATCCACCCTGGCAGGAATTTCTTGCTTGGAGCTCAGACAACAAA GGCATAGAGAGATTGGTTTTCTTTCTCTCAGCATCTCCACCCAACCAGCAGAAAACCGGTCTCTGAGGTTCCACCAAAATATGGAACTTG ATTTTGGACACTTTGACGAAAGAGATAAGACATCCAGGAACATGCGAGGCTCCCGGATGAATGGGTTGCCTAGCCCCACTCACAGCGCCC ACTGTAGCTTCTACCGAACCAGAACCTTGCAGGCACTGAGTAATGAGAAGAAAGCCAAGAAGGTACGTTTCTACCGCAATGGGGACCGCT ACTTCAAGGGGATTGTGTACGCTGTGTCCTCTGACCGTTTTCGCAGCTTTGACGCCTTGCTGGCTGACCTGACGCGATCTCTGTCTGACA ACATCAACCTGCCTCAGGGAGTGCGTTACATTTACACCATTGATGGATCCAGGAAGATCGGAAGCATGGATGAACTGGAGGAAGGGGAAA GCTATGTCTGTTCCTCAGACAACTTCTTTAAAAAGGTGGAGTACACCAAGAATGTCAATCCCAACTGGTCTGTCAACGTAAAAACATCTG CCAATATGAAAGCCCCCCAGTCCTTGGCTAGCAGCAACAGTGCACAGGCCAGGGAGAACAAGGACTTTGTGCGCCCCAAGCTGGTTACCA TCATCCGCAGTGGGGTGAAGCCTCGGAAGGCTGTGCGTGTGCTTCTGAACAAGAAGACAGCCCACTCTTTTGAGCAAGTCCTCACTGATA TCACAGAAGCCATCAAACTGGAGACCGGGGTTGTCAAAAAACTCTACACTCTGGATGGAAAACAGGTAACTTGTCTCCATGATTTCTTTG GTGATGATGATGTGTTTATTGCCTGTGGTCCTGAAAAATTTCGCTATGCTCAGGATGATTTTTCTCTGGATGAAAATGAATGCCGAGTCA TGAAGGGAAACCCATCAGCCACAGCTGGCCCAAAGGCATCCCCAACACCTCAGAAGACTTCAGCCAAGAGCCCTGGTCCTATGCGCCGAA GCAAGTCTCCAGCTGACTCAGGACCAAATTGATATTGCAGAGGTTGAGCAGTATGGACCACAAGAAAACGTTCACATGTTTGTAGATTCT GATTCAACTTATTGCTCCAGTACAGTTTTCCTGGATACTATGCCTGAATCTCCAGCCTTATCCTTGCAAGACTTTCGAGGTGAGCCTGAG GTGAATCCATTGTACAGGGCAGACCCAGTGGACCTGGAGTTCTCGGTGGATCAGGTGGACTCAGTGGACCAGGAGGGCCCAATGGACCAG CAGGACCCAGAGAACCCAGTTGCCCCGTTGGACCAGGCAGGCCTGATGGATCCAGTGGATCCAGAGGACTCAGTGGACCTGGGGGCTGCT GGCGCAAGTGCTCAGCCATTACAGCCATCATCACCAGTTGCATATGACATCATTAGCCAGGAACTGGAACTGATGAAGAAGTTGAAGGAG CAGCTAGAAGAGAGGACTTGGTTGCTGCATGATGCCATCCAAAACCAGCAGAATGCATTGGAATTGATGATGGATCACCTTCAGAAGCAG CCAAACACATTACGCCACGTTGTCATTCCTGATCTCCAATCTTCGGAGGCAGTGCCCAAGAAACAACAGAAACAACACGCTGGGCAAGTG AAGCGGCCTCTCCCACATCCCAAGGACGTCAAGTGTTTCTGTGGTTTATCTTTATCCAACTCTCTCAAAAACACTGGGGAGCTTCAGGAG CCTTGTGTTGCCTTCAACCAGCAGCAACTGGTGCAGCAAGAACAACACCTGAAGGAGCAGCAGCGGCAGCTGCGGGAGCAGCTGCAACAG CTGAGAGAGCAAAGGAAGGTGCAGAAGCAGAAGAAGATGCAGGAGAAGAAGAAGCTGCAGGAGCAGAAAATGCAGGAGAAGAAGAAGCTG CAGGAGCAGAGGCGGCAAAAGAAGAAGAAGCTACAGGAGCGGAAGAAGTGGCAGGGGCAGATGCTACAGAAAGAGCCAGAGGAGGAGCAG CAGAAGCAGCAGCTGCAAGAGCAGCCACTGAAGCATAATGTCATCGTGGGGAATGAGAGGGTGCAGATATGCCTGCAAAACCCACGTGAC GTATCTGTGCCCCTCTGCAATCACCCTGTTAGATTTTTACAGGCCCAACCCATTGTTCCTGTCCAGAGAGCAGCTGAACAACAGCCCTCT GGCTTCTATCAAGATGAAAACTGTGGGCAACAGGAAGATGAGAGTCAAAGTTTTTATCCTGAGGCGTATCAAGGGCCCCCCGTGAACCAG CTGCCATTGATAGATACCTCAAACTCTGAGGCAATTTCTTCTTCCAGCATTCCTCAGTTTCCCATAACTTCAGACTCAACCATAAGCACC CTGGAGACCCCACAGGATTACATCCGGCTTTGGCAAGAGTTGTCTGATTCACTCGGTCCTGTTGTCCAAGTGAACACTTGGTCTTGCGAT GAGCAGGGCACCCTGCACGGCCAACCCACCTACCATCAGGTGCAAGTTTCTGAGGTAGGAGTCGAGGGACCTCCTGATCCACAGGCTTTC CAAGGCCCTGCTGCATACCAGCCAGACCAGATGAGATCTGCGGAGCAGACCAGATTGATGCCTGCAGAGCAACGTGACTCAAATAAGCCG TGCTAACAGTACTTTCATGACCAGTGATGAGGGGAAATGGGGGGAGGGGGCAGGCCAATGAGGTCTGCATGGCCAGGGGACCTTCAAGGT GCGTAAAGTCCCTTGGGGTAGGGTTTAGTGGGTAGAGACTTATTTGTTTCCTGATAGGTTATGTTTGTAATTGTTTGTTAAGCACAGCCT GTTTCTTGGAAGTTATGCTGTAGAGGCAGCCTGTGATCCGTAGTATGCTAGGGTGTGACAGCAGCCAGCCACAGCTGGATCTGATGTCTT GTCTGCCCCGCCCAGCTTTGCATATCCATGTTCTACCACAGGAAGGTGGCCTGCCAAGAGTCTGCTCAAAGTTTTCAACATAAAGAATAA AGAAAAAAAAATGCCAAAGTGCTTTTCAATCTAGTAAATCTAGAGGGTTGTTTTGTCTTAGCCACAAGAATTCCGAGGTCTTGACCCTGA TGATCAACCTGCCTCCCCTCCATAGTCTTGTTGGAGAAGCCCAGAGAGAATGGGACTCCAACTAAGGGAACCTGAAATCAACTCAATGGA >21738_21738_3_DCX-PASD1_DCX_chrX_110574147_ENST00000488120_PASD1_chrX_150828185_ENST00000370357_length(amino acids)=563AA_BP=28 MAQRHPQHLRRLQPRALVLCAEASLQLTQDQIDIAEVEQYGPQENVHMFVDSDSTYCSSTVFLDTMPESPALSLQDFRGEPEVNPLYRAD PVDLEFSVDQVDSVDQEGPMDQQDPENPVAPLDQAGLMDPVDPEDSVDLGAAGASAQPLQPSSPVAYDIISQELELMKKLKEQLEERTWL LHDAIQNQQNALELMMDHLQKQPNTLRHVVIPDLQSSEAVPKKQQKQHAGQVKRPLPHPKDVKCFCGLSLSNSLKNTGELQEPCVAFNQQ QLVQQEQHLKEQQRQLREQLQQLREQRKVQKQKKMQEKKKLQEQKMQEKKKLQEQRRQKKKKLQERKKWQGQMLQKEPEEEQQKQQLQEQ PLKHNVIVGNERVQICLQNPRDVSVPLCNHPVRFLQAQPIVPVQRAAEQQPSGFYQDENCGQQEDESQSFYPEAYQGPPVNQLPLIDTSN SEAISSSSIPQFPITSDSTISTLETPQDYIRLWQELSDSLGPVVQVNTWSCDEQGTLHGQPTYHQVQVSEVGVEGPPDPQAFQGPAAYQP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DCX-PASD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DCX-PASD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DCX-PASD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies