
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DDT-PAK1 (FusionGDB2 ID:21871) |
Fusion Gene Summary for DDT-PAK1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DDT-PAK1 | Fusion gene ID: 21871 | Hgene | Tgene | Gene symbol | DDT | PAK1 | Gene ID | 100037417 | 5585 |
| Gene name | D-dopachrome tautomerase like | protein kinase N1 | |
| Synonyms | DDT|KB-226F1.2 | DBK|PAK-1|PAK1|PKN|PKN-ALPHA|PRK1|PRKCL1 | |
| Cytomap | 22q11.23 | 19p13.12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | D-dopachrome decarboxylase-like proteinD-dopachrome decarboxylaseD-dopachrome tautomerase-like proteinPhenylpyruvate tautomerase II | serine/threonine-protein kinase N1protease-activated kinase 1protein kinase C-like 1protein kinase C-like PKNprotein kinase C-related kinase 1protein kinase PKN-alphaserine-threonine kinase Nserine/threonine protein kinase N | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000350608, ENST00000398344, ENST00000403754, ENST00000404092, ENST00000430101, | ENST00000525542, ENST00000278568, ENST00000356341, ENST00000528203, ENST00000530617, | |
| Fusion gene scores | * DoF score | 10 X 3 X 6=180 | 22 X 17 X 10=3740 |
| # samples | 10 | 26 | |
| ** MAII score | log2(10/180*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(26/3740*10)=-3.84645474174655 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DDT [Title/Abstract] AND PAK1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DDT(24315957)-PAK1(77066887), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | DDT-PAK1 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. DDT-PAK1 seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. DDT-PAK1 seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PAK1 | GO:0006357 | regulation of transcription by RNA polymerase II | 12514133 |
| Tgene | PAK1 | GO:0006468 | protein phosphorylation | 17332740 |
| Tgene | PAK1 | GO:0035407 | histone H3-T11 phosphorylation | 18066052 |
| Fusion gene breakpoints across DDT (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PAK1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-23-1110-01A | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
Top |
Fusion Gene ORF analysis for DDT-PAK1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000350608 | ENST00000525542 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| 5CDS-intron | ENST00000398344 | ENST00000525542 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| 5CDS-intron | ENST00000403754 | ENST00000525542 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| 5CDS-intron | ENST00000404092 | ENST00000525542 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| 5CDS-intron | ENST00000430101 | ENST00000525542 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000398344 | ENST00000278568 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000398344 | ENST00000356341 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000398344 | ENST00000528203 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000398344 | ENST00000530617 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000403754 | ENST00000278568 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000403754 | ENST00000356341 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000403754 | ENST00000528203 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000403754 | ENST00000530617 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000430101 | ENST00000278568 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000430101 | ENST00000356341 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000430101 | ENST00000528203 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| Frame-shift | ENST00000430101 | ENST00000530617 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| In-frame | ENST00000350608 | ENST00000278568 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| In-frame | ENST00000350608 | ENST00000356341 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| In-frame | ENST00000350608 | ENST00000528203 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| In-frame | ENST00000350608 | ENST00000530617 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| In-frame | ENST00000404092 | ENST00000278568 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| In-frame | ENST00000404092 | ENST00000356341 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| In-frame | ENST00000404092 | ENST00000528203 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| In-frame | ENST00000404092 | ENST00000530617 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000350608 | DDT | chr22 | 24315957 | - | ENST00000356341 | PAK1 | chr11 | 77066887 | - | 3020 | 412 | 517 | 1452 | 311 |
| ENST00000350608 | DDT | chr22 | 24315957 | - | ENST00000530617 | PAK1 | chr11 | 77066887 | - | 2504 | 412 | 517 | 1383 | 288 |
| ENST00000350608 | DDT | chr22 | 24315957 | - | ENST00000278568 | PAK1 | chr11 | 77066887 | - | 1828 | 412 | 517 | 1476 | 319 |
| ENST00000350608 | DDT | chr22 | 24315957 | - | ENST00000528203 | PAK1 | chr11 | 77066887 | - | 1752 | 412 | 517 | 1476 | 319 |
| ENST00000404092 | DDT | chr22 | 24315957 | - | ENST00000356341 | PAK1 | chr11 | 77066887 | - | 3167 | 559 | 664 | 1599 | 311 |
| ENST00000404092 | DDT | chr22 | 24315957 | - | ENST00000530617 | PAK1 | chr11 | 77066887 | - | 2651 | 559 | 664 | 1530 | 288 |
| ENST00000404092 | DDT | chr22 | 24315957 | - | ENST00000278568 | PAK1 | chr11 | 77066887 | - | 1975 | 559 | 664 | 1623 | 319 |
| ENST00000404092 | DDT | chr22 | 24315957 | - | ENST00000528203 | PAK1 | chr11 | 77066887 | - | 1899 | 559 | 664 | 1623 | 319 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000350608 | ENST00000356341 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - | 0.001094045 | 0.9989059 |
| ENST00000350608 | ENST00000530617 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - | 0.00119283 | 0.9988072 |
| ENST00000350608 | ENST00000278568 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - | 0.00174431 | 0.99825567 |
| ENST00000350608 | ENST00000528203 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - | 0.002370515 | 0.99762946 |
| ENST00000404092 | ENST00000356341 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - | 0.001491222 | 0.99850875 |
| ENST00000404092 | ENST00000530617 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - | 0.001708324 | 0.9982917 |
| ENST00000404092 | ENST00000278568 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - | 0.002514997 | 0.9974849 |
| ENST00000404092 | ENST00000528203 | DDT | chr22 | 24315957 | - | PAK1 | chr11 | 77066887 | - | 0.003094172 | 0.99690586 |
Top |
Fusion Genomic Features for DDT-PAK1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
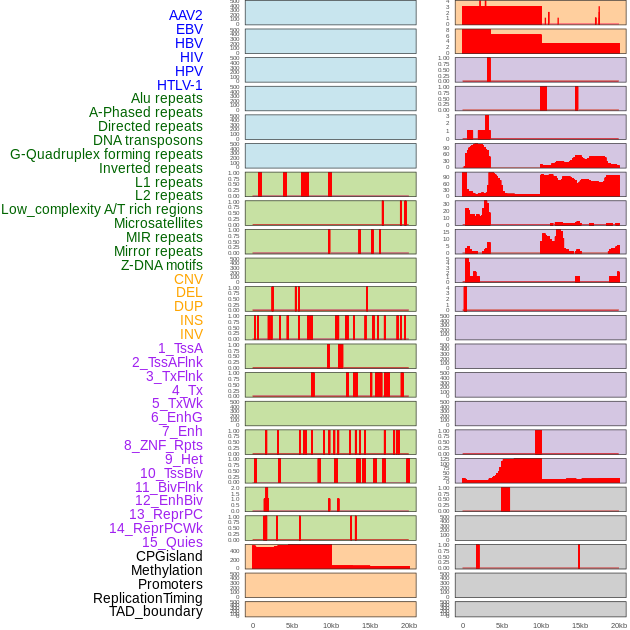
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for DDT-PAK1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:24315957/chr11:77066887) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000278568 | 5 | 16 | 270_521 | 199 | 554.0 | Domain | Protein kinase | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000356341 | 5 | 15 | 270_521 | 199 | 546.0 | Domain | Protein kinase | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000278568 | 5 | 16 | 276_284 | 199 | 554.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000278568 | 5 | 16 | 345_347 | 199 | 554.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000356341 | 5 | 15 | 276_284 | 199 | 546.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000356341 | 5 | 15 | 345_347 | 199 | 546.0 | Nucleotide binding | Note=ATP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000278568 | 5 | 16 | 75_88 | 199 | 554.0 | Domain | CRIB | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000356341 | 5 | 15 | 75_88 | 199 | 546.0 | Domain | CRIB | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000278568 | 5 | 16 | 70_140 | 199 | 554.0 | Region | Note=Autoregulatory region | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000278568 | 5 | 16 | 75_105 | 199 | 554.0 | Region | Note=GTPase-binding | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000356341 | 5 | 15 | 70_140 | 199 | 546.0 | Region | Note=Autoregulatory region | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000356341 | 5 | 15 | 75_105 | 199 | 546.0 | Region | Note=GTPase-binding |
Top |
Fusion Gene Sequence for DDT-PAK1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >21871_21871_1_DDT-PAK1_DDT_chr22_24315957_ENST00000350608_PAK1_chr11_77066887_ENST00000278568_length(transcript)=1828nt_BP=412nt GATCCCGGTGCCAGGGACCCTGCCCAGTTCCAGGCGTCGCCCTGACCCAGAAACGACTGGGCGCCGCCGTCCTGGAAAGGCCCCAGCGCA CGGACATCTGAGGAGCTGTTTCCGTTCCTCTGCCCGCCATGCCGTTCCTGGAGCTGGACACGAATTTGCCCGCCAACCGAGTGCCCGCGG GGCTGGAGAAACGACTCTGCGCCGCCGCTGCCTCCATCCTGGGCAAACCTGCGGACCGCGTGAACGTGACGGTACGGCCGGGCCTGGCCA TGGCGCTGAGCGGGTCCACCGAGCCCTGCGCGCAGCTGTCCATCTCCTCCATCGGCGTAGTGGGCACCGCCGAGGACAACCGCAGCCACA GCGCCCACTTCTTTGAGTTTCTCACCAAGGAGCTAGCCCTGGGCCAGGACCGGTATACACACGGTCTGTGATTGAACCACTTCCTGTCAC TCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTACTGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCA GAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGAGAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACG GTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTACACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAA TCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGAGATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGA CAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGAATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGA TGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCAGGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAG TGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCTAACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAG CACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGTTGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCAT CATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCTCAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCC AGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGC TAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGC CCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGC CAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTA GCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCT AAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTC >21871_21871_1_DDT-PAK1_DDT_chr22_24315957_ENST00000350608_PAK1_chr11_77066887_ENST00000278568_length(amino acids)=319AA_BP= MTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKN PNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQI TPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEM -------------------------------------------------------------- >21871_21871_2_DDT-PAK1_DDT_chr22_24315957_ENST00000350608_PAK1_chr11_77066887_ENST00000356341_length(transcript)=3020nt_BP=412nt GATCCCGGTGCCAGGGACCCTGCCCAGTTCCAGGCGTCGCCCTGACCCAGAAACGACTGGGCGCCGCCGTCCTGGAAAGGCCCCAGCGCA CGGACATCTGAGGAGCTGTTTCCGTTCCTCTGCCCGCCATGCCGTTCCTGGAGCTGGACACGAATTTGCCCGCCAACCGAGTGCCCGCGG GGCTGGAGAAACGACTCTGCGCCGCCGCTGCCTCCATCCTGGGCAAACCTGCGGACCGCGTGAACGTGACGGTACGGCCGGGCCTGGCCA TGGCGCTGAGCGGGTCCACCGAGCCCTGCGCGCAGCTGTCCATCTCCTCCATCGGCGTAGTGGGCACCGCCGAGGACAACCGCAGCCACA GCGCCCACTTCTTTGAGTTTCTCACCAAGGAGCTAGCCCTGGGCCAGGACCGGTATACACACGGTCTGTGATTGAACCACTTCCTGTCAC TCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTACTGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCA GAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGAGAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACG GTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTACACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAA TCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGAGATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGA CAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGAATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGA TGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCAGGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAG TGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCTAACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAG CACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGTTGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCAT CATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCTCAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCC AGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGC TAAAGAGCTGCTACAGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAA GAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGAT GCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAG AGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATT AAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATTCTTGACTA TATAAATTTATGGTTTGATAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACAC CTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCA TGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCC AATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCC TGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTT AGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTG AAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGA TTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTAC ACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTT GTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGAGGTACTACTGCCTCTGCAGCACAAATTTCTATTTCTGTCAATAAAAGGAGAT GAAAATATTCTATTGGAGTATGCCTTTCTTTTTTCTCTTCGTTTTTTCTTTCCTTTTCTAATTTTTTATATGAAATAATGAGTAGTTTCT TCCTGAACCATTTGAGAGTGGTAAGTTGCAGATAGAATGCCCCTTTACCACTATATACCTGAATGTGTATTCTTTCTTTTTAACACTTTT ATTTTAAATATAAATTAAGAGAAATGGGCCAAAACCATTTGTATTGTTTAAAGAATAATTATAAACACACTTGTATCCACCAAATCAAGA >21871_21871_2_DDT-PAK1_DDT_chr22_24315957_ENST00000350608_PAK1_chr11_77066887_ENST00000356341_length(amino acids)=311AA_BP= MTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKN PNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQI TPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEM -------------------------------------------------------------- >21871_21871_3_DDT-PAK1_DDT_chr22_24315957_ENST00000350608_PAK1_chr11_77066887_ENST00000528203_length(transcript)=1752nt_BP=412nt GATCCCGGTGCCAGGGACCCTGCCCAGTTCCAGGCGTCGCCCTGACCCAGAAACGACTGGGCGCCGCCGTCCTGGAAAGGCCCCAGCGCA CGGACATCTGAGGAGCTGTTTCCGTTCCTCTGCCCGCCATGCCGTTCCTGGAGCTGGACACGAATTTGCCCGCCAACCGAGTGCCCGCGG GGCTGGAGAAACGACTCTGCGCCGCCGCTGCCTCCATCCTGGGCAAACCTGCGGACCGCGTGAACGTGACGGTACGGCCGGGCCTGGCCA TGGCGCTGAGCGGGTCCACCGAGCCCTGCGCGCAGCTGTCCATCTCCTCCATCGGCGTAGTGGGCACCGCCGAGGACAACCGCAGCCACA GCGCCCACTTCTTTGAGTTTCTCACCAAGGAGCTAGCCCTGGGCCAGGACCGGTATACACACGGTCTGTGATTGAACCACTTCCTGTCAC TCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTACTGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCA GAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGAGAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACG GTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTACACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAA TCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGAGATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGA CAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGAATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGA TGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCAGGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAG TGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCTAACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAG CACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGTTGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCAT CATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCTCAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCC AGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGC TAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGC CCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGC CAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTA GCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCT >21871_21871_3_DDT-PAK1_DDT_chr22_24315957_ENST00000350608_PAK1_chr11_77066887_ENST00000528203_length(amino acids)=319AA_BP= MTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKN PNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQI TPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEM -------------------------------------------------------------- >21871_21871_4_DDT-PAK1_DDT_chr22_24315957_ENST00000350608_PAK1_chr11_77066887_ENST00000530617_length(transcript)=2504nt_BP=412nt GATCCCGGTGCCAGGGACCCTGCCCAGTTCCAGGCGTCGCCCTGACCCAGAAACGACTGGGCGCCGCCGTCCTGGAAAGGCCCCAGCGCA CGGACATCTGAGGAGCTGTTTCCGTTCCTCTGCCCGCCATGCCGTTCCTGGAGCTGGACACGAATTTGCCCGCCAACCGAGTGCCCGCGG GGCTGGAGAAACGACTCTGCGCCGCCGCTGCCTCCATCCTGGGCAAACCTGCGGACCGCGTGAACGTGACGGTACGGCCGGGCCTGGCCA TGGCGCTGAGCGGGTCCACCGAGCCCTGCGCGCAGCTGTCCATCTCCTCCATCGGCGTAGTGGGCACCGCCGAGGACAACCGCAGCCACA GCGCCCACTTCTTTGAGTTTCTCACCAAGGAGCTAGCCCTGGGCCAGGACCGGTATACACACGGTCTGTGATTGAACCACTTCCTGTCAC TCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTACTGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCA GAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGAGAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACG GTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTACACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAA TCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGAGATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGA CAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGAATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGA TGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCAGGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAG TGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCTAACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAG CACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGTTGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCAT CATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCTCAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCC AGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGC TAAAGAGCTGCTACAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAG ATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCT AGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTGATAATATTA TCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAACTGGAACAG CTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTGATCCTGACA TGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGT GAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAACATTGAGAGG TTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTG TCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATCTTCTAATGG TCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATGATACCCTGC CAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATGTTTGCTACC TCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATTGACTACCTT >21871_21871_4_DDT-PAK1_DDT_chr22_24315957_ENST00000350608_PAK1_chr11_77066887_ENST00000530617_length(amino acids)=288AA_BP= MTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKN PNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQI TPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEM -------------------------------------------------------------- >21871_21871_5_DDT-PAK1_DDT_chr22_24315957_ENST00000404092_PAK1_chr11_77066887_ENST00000278568_length(transcript)=1975nt_BP=559nt ATCCCTTCAAGGCCACTCAGTCCACAGCATTCTCTGGTGGCAGACGCTGCAGGAGGAGCCCATCAGTGCTGGCTGCTGAGTCTTTGAAAG CGGACCCACGGTGGCAGCATGGTGCCCAACACGTGGAGGCTGCAGTGCGGGAGGACCTCTTCCAGGAGGCCCTCCCAGCTGTCCTGAAGG CCAAGGACCTGCCTCCAGTAGAACCTGCTGTTAAAGAGAATCTGAAGACCTTAATGCAGCTTTTCTTGCTAGCTGTTTCCGTTCCTCTGC CCGCCATGCCGTTCCTGGAGCTGGACACGAATTTGCCCGCCAACCGAGTGCCCGCGGGGCTGGAGAAACGACTCTGCGCCGCCGCTGCCT CCATCCTGGGCAAACCTGCGGACCGCGTGAACGTGACGGTACGGCCGGGCCTGGCCATGGCGCTGAGCGGGTCCACCGAGCCCTGCGCGC AGCTGTCCATCTCCTCCATCGGCGTAGTGGGCACCGCCGAGGACAACCGCAGCCACAGCGCCCACTTCTTTGAGTTTCTCACCAAGGAGC TAGCCCTGGGCCAGGACCGGTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTC ACCTACTGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGAT CTTGGAGAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCAC CGTGTACACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTAT TAATGAGATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGT TATGGAATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTG TCTGCAGGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGT CAAGCTAACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACC AGAGGTTGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCC ATACCTCAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTAT CTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTT TCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAG CTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGA AATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGT GTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATG >21871_21871_5_DDT-PAK1_DDT_chr22_24315957_ENST00000404092_PAK1_chr11_77066887_ENST00000278568_length(amino acids)=319AA_BP= MTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKN PNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQI TPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEM -------------------------------------------------------------- >21871_21871_6_DDT-PAK1_DDT_chr22_24315957_ENST00000404092_PAK1_chr11_77066887_ENST00000356341_length(transcript)=3167nt_BP=559nt ATCCCTTCAAGGCCACTCAGTCCACAGCATTCTCTGGTGGCAGACGCTGCAGGAGGAGCCCATCAGTGCTGGCTGCTGAGTCTTTGAAAG CGGACCCACGGTGGCAGCATGGTGCCCAACACGTGGAGGCTGCAGTGCGGGAGGACCTCTTCCAGGAGGCCCTCCCAGCTGTCCTGAAGG CCAAGGACCTGCCTCCAGTAGAACCTGCTGTTAAAGAGAATCTGAAGACCTTAATGCAGCTTTTCTTGCTAGCTGTTTCCGTTCCTCTGC CCGCCATGCCGTTCCTGGAGCTGGACACGAATTTGCCCGCCAACCGAGTGCCCGCGGGGCTGGAGAAACGACTCTGCGCCGCCGCTGCCT CCATCCTGGGCAAACCTGCGGACCGCGTGAACGTGACGGTACGGCCGGGCCTGGCCATGGCGCTGAGCGGGTCCACCGAGCCCTGCGCGC AGCTGTCCATCTCCTCCATCGGCGTAGTGGGCACCGCCGAGGACAACCGCAGCCACAGCGCCCACTTCTTTGAGTTTCTCACCAAGGAGC TAGCCCTGGGCCAGGACCGGTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTC ACCTACTGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGAT CTTGGAGAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCAC CGTGTACACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTAT TAATGAGATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGT TATGGAATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTG TCTGCAGGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGT CAAGCTAACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACC AGAGGTTGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCC ATACCTCAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTAT CTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGCATCAATTCCTGAAGAT TGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCT CATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTC CTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGG CCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTC CGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTGATAATATTATCAATTT GTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGA ATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGA ACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGC TCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTA GGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCT CTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAAT CTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGT GAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCT ATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGC TCTGAGGTACTACTGCCTCTGCAGCACAAATTTCTATTTCTGTCAATAAAAGGAGATGAAAATATTCTATTGGAGTATGCCTTTCTTTTT TCTCTTCGTTTTTTCTTTCCTTTTCTAATTTTTTATATGAAATAATGAGTAGTTTCTTCCTGAACCATTTGAGAGTGGTAAGTTGCAGAT AGAATGCCCCTTTACCACTATATACCTGAATGTGTATTCTTTCTTTTTAACACTTTTATTTTAAATATAAATTAAGAGAAATGGGCCAAA ACCATTTGTATTGTTTAAAGAATAATTATAAACACACTTGTATCCACCAAATCAAGAAATGGAACACTGACAGTAAGAACCTTCTCTATC >21871_21871_6_DDT-PAK1_DDT_chr22_24315957_ENST00000404092_PAK1_chr11_77066887_ENST00000356341_length(amino acids)=311AA_BP= MTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKN PNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQI TPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEM -------------------------------------------------------------- >21871_21871_7_DDT-PAK1_DDT_chr22_24315957_ENST00000404092_PAK1_chr11_77066887_ENST00000528203_length(transcript)=1899nt_BP=559nt ATCCCTTCAAGGCCACTCAGTCCACAGCATTCTCTGGTGGCAGACGCTGCAGGAGGAGCCCATCAGTGCTGGCTGCTGAGTCTTTGAAAG CGGACCCACGGTGGCAGCATGGTGCCCAACACGTGGAGGCTGCAGTGCGGGAGGACCTCTTCCAGGAGGCCCTCCCAGCTGTCCTGAAGG CCAAGGACCTGCCTCCAGTAGAACCTGCTGTTAAAGAGAATCTGAAGACCTTAATGCAGCTTTTCTTGCTAGCTGTTTCCGTTCCTCTGC CCGCCATGCCGTTCCTGGAGCTGGACACGAATTTGCCCGCCAACCGAGTGCCCGCGGGGCTGGAGAAACGACTCTGCGCCGCCGCTGCCT CCATCCTGGGCAAACCTGCGGACCGCGTGAACGTGACGGTACGGCCGGGCCTGGCCATGGCGCTGAGCGGGTCCACCGAGCCCTGCGCGC AGCTGTCCATCTCCTCCATCGGCGTAGTGGGCACCGCCGAGGACAACCGCAGCCACAGCGCCCACTTCTTTGAGTTTCTCACCAAGGAGC TAGCCCTGGGCCAGGACCGGTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTC ACCTACTGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGAT CTTGGAGAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCAC CGTGTACACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTAT TAATGAGATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGT TATGGAATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTG TCTGCAGGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGT CAAGCTAACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACC AGAGGTTGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCC ATACCTCAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTAT CTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTT TCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAG CTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGA AATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGT GTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATG >21871_21871_7_DDT-PAK1_DDT_chr22_24315957_ENST00000404092_PAK1_chr11_77066887_ENST00000528203_length(amino acids)=319AA_BP= MTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKN PNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQI TPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEM -------------------------------------------------------------- >21871_21871_8_DDT-PAK1_DDT_chr22_24315957_ENST00000404092_PAK1_chr11_77066887_ENST00000530617_length(transcript)=2651nt_BP=559nt ATCCCTTCAAGGCCACTCAGTCCACAGCATTCTCTGGTGGCAGACGCTGCAGGAGGAGCCCATCAGTGCTGGCTGCTGAGTCTTTGAAAG CGGACCCACGGTGGCAGCATGGTGCCCAACACGTGGAGGCTGCAGTGCGGGAGGACCTCTTCCAGGAGGCCCTCCCAGCTGTCCTGAAGG CCAAGGACCTGCCTCCAGTAGAACCTGCTGTTAAAGAGAATCTGAAGACCTTAATGCAGCTTTTCTTGCTAGCTGTTTCCGTTCCTCTGC CCGCCATGCCGTTCCTGGAGCTGGACACGAATTTGCCCGCCAACCGAGTGCCCGCGGGGCTGGAGAAACGACTCTGCGCCGCCGCTGCCT CCATCCTGGGCAAACCTGCGGACCGCGTGAACGTGACGGTACGGCCGGGCCTGGCCATGGCGCTGAGCGGGTCCACCGAGCCCTGCGCGC AGCTGTCCATCTCCTCCATCGGCGTAGTGGGCACCGCCGAGGACAACCGCAGCCACAGCGCCCACTTCTTTGAGTTTCTCACCAAGGAGC TAGCCCTGGGCCAGGACCGGTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTC ACCTACTGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGAT CTTGGAGAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCAC CGTGTACACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTAT TAATGAGATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGT TATGGAATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTG TCTGCAGGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGT CAAGCTAACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACC AGAGGTTGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCC ATACCTCAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTAT CTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGCACTCCTCAAGACTTTG ATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCC CAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTC ATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTGATAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGC TTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCA GGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGC TTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATT CCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGT TGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTC AGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCA AATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCAT GGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACT ATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGAGGTACTACTGCCTCTGCAGCA >21871_21871_8_DDT-PAK1_DDT_chr22_24315957_ENST00000404092_PAK1_chr11_77066887_ENST00000530617_length(amino acids)=288AA_BP= MTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKN PNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQI TPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEM -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DDT-PAK1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000278568 | 5 | 16 | 132_270 | 199.0 | 554.0 | CRIPAK | |
| Tgene | PAK1 | chr22:24315957 | chr11:77066887 | ENST00000356341 | 5 | 15 | 132_270 | 199.0 | 546.0 | CRIPAK |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DDT-PAK1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DDT-PAK1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies