
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DDX59-CEPT1 (FusionGDB2 ID:22064) |
Fusion Gene Summary for DDX59-CEPT1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DDX59-CEPT1 | Fusion gene ID: 22064 | Hgene | Tgene | Gene symbol | DDX59 | CEPT1 | Gene ID | 83479 | 10390 |
| Gene name | DEAD-box helicase 59 | choline/ethanolamine phosphotransferase 1 | |
| Synonyms | OFD5|ZNHIT5 | - | |
| Cytomap | 1q32.1 | 1p13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | probable ATP-dependent RNA helicase DDX59DEAD (Asp-Glu-Ala-Asp) box polypeptide 59DEAD box protein 59zinc finger HIT domain-containing protein 5 | choline/ethanolaminephosphotransferase 1 | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | Q5T1V6 | Q9Y6K0 | |
| Ensembl transtripts involved in fusion gene | ENST00000331314, ENST00000367348, ENST00000447706, | ENST00000467362, ENST00000357172, ENST00000545121, | |
| Fusion gene scores | * DoF score | 4 X 4 X 2=32 | 6 X 5 X 4=120 |
| # samples | 4 | 6 | |
| ** MAII score | log2(4/32*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(6/120*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DDX59 [Title/Abstract] AND CEPT1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DDX59(200617567)-CEPT1(111724809), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across DDX59 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CEPT1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SARC | TCGA-DX-A2J0-01A | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
Top |
Fusion Gene ORF analysis for DDX59-CEPT1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000331314 | ENST00000467362 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| 5CDS-3UTR | ENST00000367348 | ENST00000467362 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| 5CDS-3UTR | ENST00000447706 | ENST00000467362 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| In-frame | ENST00000331314 | ENST00000357172 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| In-frame | ENST00000331314 | ENST00000545121 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| In-frame | ENST00000367348 | ENST00000357172 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| In-frame | ENST00000367348 | ENST00000545121 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| In-frame | ENST00000447706 | ENST00000357172 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| In-frame | ENST00000447706 | ENST00000545121 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000447706 | DDX59 | chr1 | 200617567 | - | ENST00000545121 | CEPT1 | chr1 | 111724809 | + | 3077 | 1748 | 152 | 2284 | 710 |
| ENST00000447706 | DDX59 | chr1 | 200617567 | - | ENST00000357172 | CEPT1 | chr1 | 111724809 | + | 3077 | 1748 | 152 | 2284 | 710 |
| ENST00000367348 | DDX59 | chr1 | 200617567 | - | ENST00000545121 | CEPT1 | chr1 | 111724809 | + | 3039 | 1710 | 114 | 2246 | 710 |
| ENST00000367348 | DDX59 | chr1 | 200617567 | - | ENST00000357172 | CEPT1 | chr1 | 111724809 | + | 3039 | 1710 | 114 | 2246 | 710 |
| ENST00000331314 | DDX59 | chr1 | 200617567 | - | ENST00000545121 | CEPT1 | chr1 | 111724809 | + | 3139 | 1810 | 214 | 2346 | 710 |
| ENST00000331314 | DDX59 | chr1 | 200617567 | - | ENST00000357172 | CEPT1 | chr1 | 111724809 | + | 3139 | 1810 | 214 | 2346 | 710 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000447706 | ENST00000545121 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + | 0.000334191 | 0.99966586 |
| ENST00000447706 | ENST00000357172 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + | 0.000334191 | 0.99966586 |
| ENST00000367348 | ENST00000545121 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + | 0.000314441 | 0.9996855 |
| ENST00000367348 | ENST00000357172 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + | 0.000314441 | 0.9996855 |
| ENST00000331314 | ENST00000545121 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + | 0.000325353 | 0.9996747 |
| ENST00000331314 | ENST00000357172 | DDX59 | chr1 | 200617567 | - | CEPT1 | chr1 | 111724809 | + | 0.000325353 | 0.9996747 |
Top |
Fusion Genomic Features for DDX59-CEPT1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DDX59 | chr1 | 200617566 | - | CEPT1 | chr1 | 111724808 | + | 0.000114629 | 0.9998853 |
| DDX59 | chr1 | 200617566 | - | CEPT1 | chr1 | 111724808 | + | 0.000114629 | 0.9998853 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
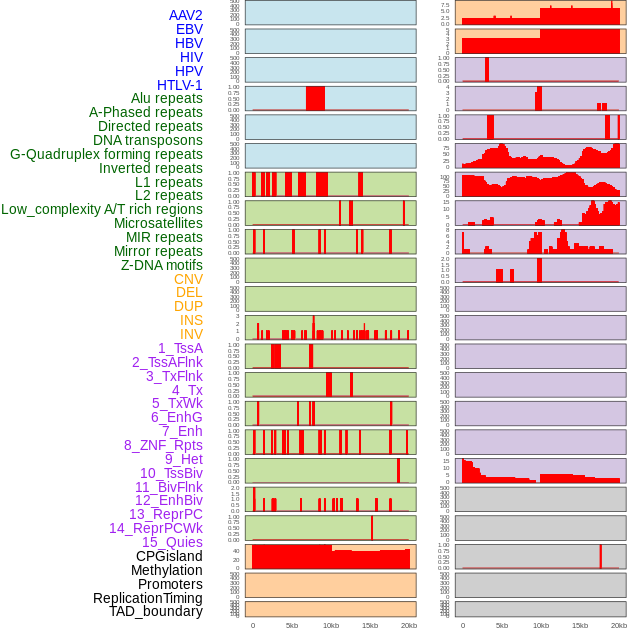 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
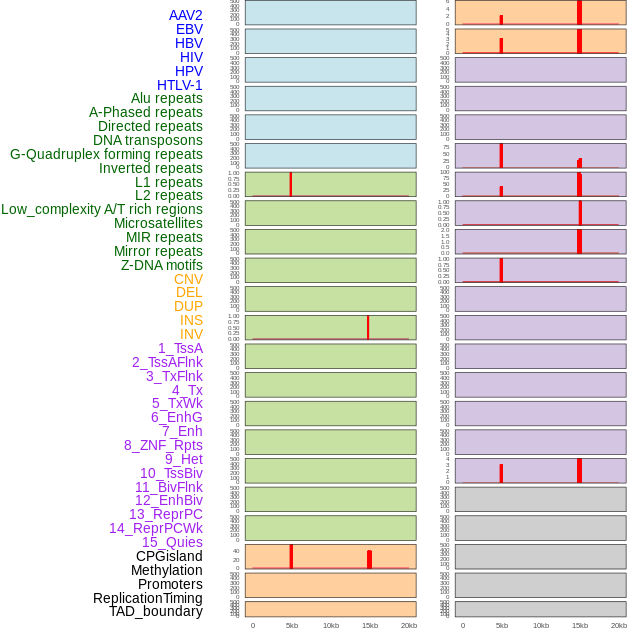 |
Top |
Fusion Protein Features for DDX59-CEPT1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:200617567/chr1:111724809) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DDX59 | CEPT1 |
| FUNCTION: Catalyzes both phosphatidylcholine and phosphatidylethanolamine biosynthesis from CDP-choline and CDP-ethanolamine, respectively. Involved in protein-dependent process of phospholipid transport to distribute phosphatidyl choline to the lumenal surface. Has a higher cholinephosphotransferase activity than ethanolaminephosphotransferase activity. {ECO:0000269|PubMed:10191259, ECO:0000269|PubMed:10893425, ECO:0000269|PubMed:12216837}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000331314 | - | 7 | 8 | 234_405 | 532 | 620.0 | Domain | Helicase ATP-binding |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000447706 | - | 7 | 8 | 234_405 | 532 | 581.0 | Domain | Helicase ATP-binding |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000331314 | - | 7 | 8 | 203_231 | 532 | 620.0 | Motif | Note=Q motif |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000331314 | - | 7 | 8 | 353_356 | 532 | 620.0 | Motif | Note=DEAD box |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000447706 | - | 7 | 8 | 203_231 | 532 | 581.0 | Motif | Note=Q motif |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000447706 | - | 7 | 8 | 353_356 | 532 | 581.0 | Motif | Note=DEAD box |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000331314 | - | 7 | 8 | 247_254 | 532 | 620.0 | Nucleotide binding | ATP |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000447706 | - | 7 | 8 | 247_254 | 532 | 581.0 | Nucleotide binding | ATP |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000331314 | - | 7 | 8 | 104_133 | 532 | 620.0 | Zinc finger | Note=HIT-type |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000447706 | - | 7 | 8 | 104_133 | 532 | 581.0 | Zinc finger | Note=HIT-type |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000357172 | 4 | 9 | 239_259 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000357172 | 4 | 9 | 283_303 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000357172 | 4 | 9 | 317_337 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000357172 | 4 | 9 | 365_385 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000545121 | 4 | 9 | 239_259 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000545121 | 4 | 9 | 283_303 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000545121 | 4 | 9 | 317_337 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000545121 | 4 | 9 | 365_385 | 238 | 417.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000331314 | - | 7 | 8 | 416_579 | 532 | 620.0 | Domain | Helicase C-terminal |
| Hgene | DDX59 | chr1:200617567 | chr1:111724809 | ENST00000447706 | - | 7 | 8 | 416_579 | 532 | 581.0 | Domain | Helicase C-terminal |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000357172 | 4 | 9 | 115_135 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000357172 | 4 | 9 | 186_206 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000357172 | 4 | 9 | 209_229 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000357172 | 4 | 9 | 87_107 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000545121 | 4 | 9 | 115_135 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000545121 | 4 | 9 | 186_206 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000545121 | 4 | 9 | 209_229 | 238 | 417.0 | Transmembrane | Helical | |
| Tgene | CEPT1 | chr1:200617567 | chr1:111724809 | ENST00000545121 | 4 | 9 | 87_107 | 238 | 417.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for DDX59-CEPT1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >22064_22064_1_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000331314_CEPT1_chr1_111724809_ENST00000357172_length(transcript)=3139nt_BP=1810nt AAAGCGGGCTGCGGCCCCCTCCCAAAACCCGGGGAAGTGGATTCTACTCTACGCTCCGCTCCGCTCCGCTCCGCACCACCAACCCCGGGC CGCAGTCCTGACGAGCGGGTCAGGGCTTGTCGGGCGGAAGCCTGGCCTGGAGCCTGGAAGGGGGAGACGGCCCGAGCGGGAGCGGGAGCG GACGCGGCCTCAGTCCTGCGCGGAATATTGAAGGATGTTTGTTCCAAGATCTCTAAAAATCAAGAGGAATGCTAATGATGATGGCAAAAG TTGTGTGGCTAAGATAATTAAACCAGACCCAGAAGACCTTCAGTTGGACAAAAGCAGAGATGTTCCCGTTGATGCTGTAGCTACAGAAGC AGCCACAATAGACAGGCACATCAGCGAATCATGCCCTTTCCCCAGCCCAGGTGGCCAGTTGGCAGAGGTTCATTCAGTAAGTCCCGAGCA GGGTGCGAAGGACAGCCATCCTTCTGAAGAGCCCGTTAAGTCATTTTCCAAAACACAGCGCTGGGCAGAACCAGGGGAACCCATCTGTGT TGTCTGTGGTCGTTATGGAGAGTATATCTGTGATAAGACAGATGAAGATGTGTGTAGTTTGGAGTGTAAAGCGAAACATCTTCTACAAGT TAAGGAAAAGGAAGAGAAATCAAAACTCAGCAATCCACAGAAGGCTGATTCTGAGCCAGAGTCTCCACTGAATGCTTCCTATGTCTACAA AGAGCACCCCTTTATTTTGAACCTTCAGGAAGACCAGATTGAAAATCTTAAACAGCAGCTGGGAATTTTAGTTCAAGGGCAAGAAGTCAC CAGGCCCATTATTGACTTTGAACATTGTAGTCTCCCTGAGGTCTTAAATCACAACTTGAAGAAATCAGGCTATGAGGTGCCAACTCCCAT TCAAATGCAGATGATTCCTGTGGGACTTCTGGGAAGAGACATTCTGGCCAGTGCAGATACTGGCTCAGGAAAAACAGCTGCTTTTCTTCT TCCTGTTATCATGCGAGCTTTATTCGAGAGCAAAACTCCATCTGCGCTCATTCTTACACCAACCAGAGAGTTAGCCATTCAGATAGAGAG ACAAGCTAAAGAATTGATGAGTGGCCTGCCACGCATGAAAACTGTGCTTCTTGTAGGGGGCTTACCCTTACCCCCACAGCTTTATCGTCT GCAACAACATGTTAAGGTTATCATAGCAACCCCTGGGCGACTTCTGGATATAATAAAGCAGAGCTCTGTAGAACTCTGTGGTGTAAAGAT TGTGGTAGTAGATGAAGCTGATACCATGTTAAAGATGGGTTTTCAACAACAAGTGCTTGACATTTTGGAAAACATTCCTAATGATTGTCA GACCATTTTGGTTTCAGCCACAATTCCAACTAGCATAGAACAGCTAGCAAGCCAGCTTCTGCATAATCCTGTGAGAATTATCACTGGAGA AAAGAACCTACCTTGTGCCAATGTACGTCAGATTATTTTGTGGGTAGAAGACCCAGCCAAAAAGAAAAAATTATTTGAAATTTTAAATGA TAAGAAACTCTTTAAGCCTCCAGTGTTAGTATTTGTGGACTGCAAACTAGGAGCAGATCTTTTGAGTGAAGCCGTTCAGAAAATCACAGG GCTGAAAAGCATATCTATACATTCAGAGAAGTCGCAAATAGAAAGGAAAAACATATTGAAGGGATTACTTGAAGGAGACTATGAAGTTGT AGTGAGCACAGGAGTCTTGGGACGAGGCCTAGACTTGATCAGTGTCAGGCTGGTTGTCAATTTTGATATGCCTTCAAGTATGGATGAGTA TGTCCATCAGATTCCAGTGCTGAATATTCAAATGAAAATTTTTCCTGCACTTTGTACTGTAGCAGGGACCATATTTTCCTGTACAAATTA CTTCCGTGTAATCTTCACAGGTGGTGTTGGCAAAAATGGATCAACAATAGCAGGAACAAGTGTCCTTTCTCCTTTTCTCCATATTGGATC AGTGATTACATTAGCTGCAATGATCTACAAGAAATCTGCAGTTCAGCTTTTTGAAAAGCATCCCTGTCTTTATATACTGACATTTGGTTT TGTGTCTGCTAAAATCACTAATAAGCTTGTGGTTGCACACATGACGAAAAGTGAAATGCATTTGCATGACACAGCATTCATAGGTCCGGC ACTTTTGTTTCTGGACCAGTATTTTAACAGCTTTATTGATGAATATATTGTACTTTGGATTGCCCTGGTTTTCTCTTTCTTTGATTTGAT CCGCTACTGTGTCAGTGTTTGCAATCAGATTGCGTCTCACCTGCACATACATGTCTTCAGAATCAAGGTCTCTACAGCTCATTCTAATCA TCATTAATGATGTAATTGGTATATAGGAACATCATGTTTTCTGCAGGAAAGAAAGTAACATATTAAGGAGAATGGGGGTGGATAAGAACA AATATAATTTATAATAATCAATGTTGTATAACTTTTATTCTTTATTATTGGTAACACGCCCTAACTATCCTGTGTGAGAATGGGAATTTC AAGTCCCATCTTGTAAATTGTATATGTTGTCATGCAGGGTTTGGGCCAAGAAAGCATGCAGAAAAAAATGCCATGTGATTGTAATTATCC TGGATTCAGAATAATACTGTGATGGGGAGCCAGATCCGCAGTGGTGGAGAGTTCTAATGTTGACTGTTTGCAGGCCAAAAGATGATTGCT TTATAATTTTAACAAATCATTGTCTTTTAGTAACATCCTTGTTTAGTGTCTTCTCAAGCTTTCTTTACTGAGGAATTCAGCTTGTGACAC AGATACATCCCACTAGCTTGTGAGGTGGAACTAGTAATAAAGACCTTGAATTTGGATTGAAAAGTTTCCTATCTTTACATTGTTGAGGAA GTCCTTTTTTTTTTTTTTTTTTTTTTAATTGCTCAAGAAATGATTCTCTCACAGGCTTGGGAAATCCTGTTAGCATGCAGAATAATGTGG TAACTTTGTCAATTTCCCATTTTATTTTTTTAAATAAATATATGATCTAAAAGCCAACTTTTTCTCAGTTTTACTCAGTGGAAAGATAAA >22064_22064_1_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000331314_CEPT1_chr1_111724809_ENST00000357172_length(amino acids)=710AA_BP=532 MFVPRSLKIKRNANDDGKSCVAKIIKPDPEDLQLDKSRDVPVDAVATEAATIDRHISESCPFPSPGGQLAEVHSVSPEQGAKDSHPSEEP VKSFSKTQRWAEPGEPICVVCGRYGEYICDKTDEDVCSLECKAKHLLQVKEKEEKSKLSNPQKADSEPESPLNASYVYKEHPFILNLQED QIENLKQQLGILVQGQEVTRPIIDFEHCSLPEVLNHNLKKSGYEVPTPIQMQMIPVGLLGRDILASADTGSGKTAAFLLPVIMRALFESK TPSALILTPTRELAIQIERQAKELMSGLPRMKTVLLVGGLPLPPQLYRLQQHVKVIIATPGRLLDIIKQSSVELCGVKIVVVDEADTMLK MGFQQQVLDILENIPNDCQTILVSATIPTSIEQLASQLLHNPVRIITGEKNLPCANVRQIILWVEDPAKKKKLFEILNDKKLFKPPVLVF VDCKLGADLLSEAVQKITGLKSISIHSEKSQIERKNILKGLLEGDYEVVVSTGVLGRGLDLISVRLVVNFDMPSSMDEYVHQIPVLNIQM KIFPALCTVAGTIFSCTNYFRVIFTGGVGKNGSTIAGTSVLSPFLHIGSVITLAAMIYKKSAVQLFEKHPCLYILTFGFVSAKITNKLVV -------------------------------------------------------------- >22064_22064_2_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000331314_CEPT1_chr1_111724809_ENST00000545121_length(transcript)=3139nt_BP=1810nt AAAGCGGGCTGCGGCCCCCTCCCAAAACCCGGGGAAGTGGATTCTACTCTACGCTCCGCTCCGCTCCGCTCCGCACCACCAACCCCGGGC CGCAGTCCTGACGAGCGGGTCAGGGCTTGTCGGGCGGAAGCCTGGCCTGGAGCCTGGAAGGGGGAGACGGCCCGAGCGGGAGCGGGAGCG GACGCGGCCTCAGTCCTGCGCGGAATATTGAAGGATGTTTGTTCCAAGATCTCTAAAAATCAAGAGGAATGCTAATGATGATGGCAAAAG TTGTGTGGCTAAGATAATTAAACCAGACCCAGAAGACCTTCAGTTGGACAAAAGCAGAGATGTTCCCGTTGATGCTGTAGCTACAGAAGC AGCCACAATAGACAGGCACATCAGCGAATCATGCCCTTTCCCCAGCCCAGGTGGCCAGTTGGCAGAGGTTCATTCAGTAAGTCCCGAGCA GGGTGCGAAGGACAGCCATCCTTCTGAAGAGCCCGTTAAGTCATTTTCCAAAACACAGCGCTGGGCAGAACCAGGGGAACCCATCTGTGT TGTCTGTGGTCGTTATGGAGAGTATATCTGTGATAAGACAGATGAAGATGTGTGTAGTTTGGAGTGTAAAGCGAAACATCTTCTACAAGT TAAGGAAAAGGAAGAGAAATCAAAACTCAGCAATCCACAGAAGGCTGATTCTGAGCCAGAGTCTCCACTGAATGCTTCCTATGTCTACAA AGAGCACCCCTTTATTTTGAACCTTCAGGAAGACCAGATTGAAAATCTTAAACAGCAGCTGGGAATTTTAGTTCAAGGGCAAGAAGTCAC CAGGCCCATTATTGACTTTGAACATTGTAGTCTCCCTGAGGTCTTAAATCACAACTTGAAGAAATCAGGCTATGAGGTGCCAACTCCCAT TCAAATGCAGATGATTCCTGTGGGACTTCTGGGAAGAGACATTCTGGCCAGTGCAGATACTGGCTCAGGAAAAACAGCTGCTTTTCTTCT TCCTGTTATCATGCGAGCTTTATTCGAGAGCAAAACTCCATCTGCGCTCATTCTTACACCAACCAGAGAGTTAGCCATTCAGATAGAGAG ACAAGCTAAAGAATTGATGAGTGGCCTGCCACGCATGAAAACTGTGCTTCTTGTAGGGGGCTTACCCTTACCCCCACAGCTTTATCGTCT GCAACAACATGTTAAGGTTATCATAGCAACCCCTGGGCGACTTCTGGATATAATAAAGCAGAGCTCTGTAGAACTCTGTGGTGTAAAGAT TGTGGTAGTAGATGAAGCTGATACCATGTTAAAGATGGGTTTTCAACAACAAGTGCTTGACATTTTGGAAAACATTCCTAATGATTGTCA GACCATTTTGGTTTCAGCCACAATTCCAACTAGCATAGAACAGCTAGCAAGCCAGCTTCTGCATAATCCTGTGAGAATTATCACTGGAGA AAAGAACCTACCTTGTGCCAATGTACGTCAGATTATTTTGTGGGTAGAAGACCCAGCCAAAAAGAAAAAATTATTTGAAATTTTAAATGA TAAGAAACTCTTTAAGCCTCCAGTGTTAGTATTTGTGGACTGCAAACTAGGAGCAGATCTTTTGAGTGAAGCCGTTCAGAAAATCACAGG GCTGAAAAGCATATCTATACATTCAGAGAAGTCGCAAATAGAAAGGAAAAACATATTGAAGGGATTACTTGAAGGAGACTATGAAGTTGT AGTGAGCACAGGAGTCTTGGGACGAGGCCTAGACTTGATCAGTGTCAGGCTGGTTGTCAATTTTGATATGCCTTCAAGTATGGATGAGTA TGTCCATCAGATTCCAGTGCTGAATATTCAAATGAAAATTTTTCCTGCACTTTGTACTGTAGCAGGGACCATATTTTCCTGTACAAATTA CTTCCGTGTAATCTTCACAGGTGGTGTTGGCAAAAATGGATCAACAATAGCAGGAACAAGTGTCCTTTCTCCTTTTCTCCATATTGGATC AGTGATTACATTAGCTGCAATGATCTACAAGAAATCTGCAGTTCAGCTTTTTGAAAAGCATCCCTGTCTTTATATACTGACATTTGGTTT TGTGTCTGCTAAAATCACTAATAAGCTTGTGGTTGCACACATGACGAAAAGTGAAATGCATTTGCATGACACAGCATTCATAGGTCCGGC ACTTTTGTTTCTGGACCAGTATTTTAACAGCTTTATTGATGAATATATTGTACTTTGGATTGCCCTGGTTTTCTCTTTCTTTGATTTGAT CCGCTACTGTGTCAGTGTTTGCAATCAGATTGCGTCTCACCTGCACATACATGTCTTCAGAATCAAGGTCTCTACAGCTCATTCTAATCA TCATTAATGATGTAATTGGTATATAGGAACATCATGTTTTCTGCAGGAAAGAAAGTAACATATTAAGGAGAATGGGGGTGGATAAGAACA AATATAATTTATAATAATCAATGTTGTATAACTTTTATTCTTTATTATTGGTAACACGCCCTAACTATCCTGTGTGAGAATGGGAATTTC AAGTCCCATCTTGTAAATTGTATATGTTGTCATGCAGGGTTTGGGCCAAGAAAGCATGCAGAAAAAAATGCCATGTGATTGTAATTATCC TGGATTCAGAATAATACTGTGATGGGGAGCCAGATCCGCAGTGGTGGAGAGTTCTAATGTTGACTGTTTGCAGGCCAAAAGATGATTGCT TTATAATTTTAACAAATCATTGTCTTTTAGTAACATCCTTGTTTAGTGTCTTCTCAAGCTTTCTTTACTGAGGAATTCAGCTTGTGACAC AGATACATCCCACTAGCTTGTGAGGTGGAACTAGTAATAAAGACCTTGAATTTGGATTGAAAAGTTTCCTATCTTTACATTGTTGAGGAA GTCCTTTTTTTTTTTTTTTTTTTTTTAATTGCTCAAGAAATGATTCTCTCACAGGCTTGGGAAATCCTGTTAGCATGCAGAATAATGTGG TAACTTTGTCAATTTCCCATTTTATTTTTTTAAATAAATATATGATCTAAAAGCCAACTTTTTCTCAGTTTTACTCAGTGGAAAGATAAA >22064_22064_2_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000331314_CEPT1_chr1_111724809_ENST00000545121_length(amino acids)=710AA_BP=532 MFVPRSLKIKRNANDDGKSCVAKIIKPDPEDLQLDKSRDVPVDAVATEAATIDRHISESCPFPSPGGQLAEVHSVSPEQGAKDSHPSEEP VKSFSKTQRWAEPGEPICVVCGRYGEYICDKTDEDVCSLECKAKHLLQVKEKEEKSKLSNPQKADSEPESPLNASYVYKEHPFILNLQED QIENLKQQLGILVQGQEVTRPIIDFEHCSLPEVLNHNLKKSGYEVPTPIQMQMIPVGLLGRDILASADTGSGKTAAFLLPVIMRALFESK TPSALILTPTRELAIQIERQAKELMSGLPRMKTVLLVGGLPLPPQLYRLQQHVKVIIATPGRLLDIIKQSSVELCGVKIVVVDEADTMLK MGFQQQVLDILENIPNDCQTILVSATIPTSIEQLASQLLHNPVRIITGEKNLPCANVRQIILWVEDPAKKKKLFEILNDKKLFKPPVLVF VDCKLGADLLSEAVQKITGLKSISIHSEKSQIERKNILKGLLEGDYEVVVSTGVLGRGLDLISVRLVVNFDMPSSMDEYVHQIPVLNIQM KIFPALCTVAGTIFSCTNYFRVIFTGGVGKNGSTIAGTSVLSPFLHIGSVITLAAMIYKKSAVQLFEKHPCLYILTFGFVSAKITNKLVV -------------------------------------------------------------- >22064_22064_3_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000367348_CEPT1_chr1_111724809_ENST00000357172_length(transcript)=3039nt_BP=1710nt ACGAGCGGGTCAGGGCTTGTCGGGCGGAAGCCTGGCCTGGAGCCTGGAAGGGGGAGACGGCCCGAGCGGGAGCGGGAGCGGACGCGGCCT CAGTCCTGCGCGGAATATTGAAGGATGTTTGTTCCAAGATCTCTAAAAATCAAGAGGAATGCTAATGATGATGGCAAAAGTTGTGTGGCT AAGATAATTAAACCAGACCCAGAAGACCTTCAGTTGGACAAAAGCAGAGATGTTCCCGTTGATGCTGTAGCTACAGAAGCAGCCACAATA GACAGGCACATCAGCGAATCATGCCCTTTCCCCAGCCCAGGTGGCCAGTTGGCAGAGGTTCATTCAGTAAGTCCCGAGCAGGGTGCGAAG GACAGCCATCCTTCTGAAGAGCCCGTTAAGTCATTTTCCAAAACACAGCGCTGGGCAGAACCAGGGGAACCCATCTGTGTTGTCTGTGGT CGTTATGGAGAGTATATCTGTGATAAGACAGATGAAGATGTGTGTAGTTTGGAGTGTAAAGCGAAACATCTTCTACAAGTTAAGGAAAAG GAAGAGAAATCAAAACTCAGCAATCCACAGAAGGCTGATTCTGAGCCAGAGTCTCCACTGAATGCTTCCTATGTCTACAAAGAGCACCCC TTTATTTTGAACCTTCAGGAAGACCAGATTGAAAATCTTAAACAGCAGCTGGGAATTTTAGTTCAAGGGCAAGAAGTCACCAGGCCCATT ATTGACTTTGAACATTGTAGTCTCCCTGAGGTCTTAAATCACAACTTGAAGAAATCAGGCTATGAGGTGCCAACTCCCATTCAAATGCAG ATGATTCCTGTGGGACTTCTGGGAAGAGACATTCTGGCCAGTGCAGATACTGGCTCAGGAAAAACAGCTGCTTTTCTTCTTCCTGTTATC ATGCGAGCTTTATTCGAGAGCAAAACTCCATCTGCGCTCATTCTTACACCAACCAGAGAGTTAGCCATTCAGATAGAGAGACAAGCTAAA GAATTGATGAGTGGCCTGCCACGCATGAAAACTGTGCTTCTTGTAGGGGGCTTACCCTTACCCCCACAGCTTTATCGTCTGCAACAACAT GTTAAGGTTATCATAGCAACCCCTGGGCGACTTCTGGATATAATAAAGCAGAGCTCTGTAGAACTCTGTGGTGTAAAGATTGTGGTAGTA GATGAAGCTGATACCATGTTAAAGATGGGTTTTCAACAACAAGTGCTTGACATTTTGGAAAACATTCCTAATGATTGTCAGACCATTTTG GTTTCAGCCACAATTCCAACTAGCATAGAACAGCTAGCAAGCCAGCTTCTGCATAATCCTGTGAGAATTATCACTGGAGAAAAGAACCTA CCTTGTGCCAATGTACGTCAGATTATTTTGTGGGTAGAAGACCCAGCCAAAAAGAAAAAATTATTTGAAATTTTAAATGATAAGAAACTC TTTAAGCCTCCAGTGTTAGTATTTGTGGACTGCAAACTAGGAGCAGATCTTTTGAGTGAAGCCGTTCAGAAAATCACAGGGCTGAAAAGC ATATCTATACATTCAGAGAAGTCGCAAATAGAAAGGAAAAACATATTGAAGGGATTACTTGAAGGAGACTATGAAGTTGTAGTGAGCACA GGAGTCTTGGGACGAGGCCTAGACTTGATCAGTGTCAGGCTGGTTGTCAATTTTGATATGCCTTCAAGTATGGATGAGTATGTCCATCAG ATTCCAGTGCTGAATATTCAAATGAAAATTTTTCCTGCACTTTGTACTGTAGCAGGGACCATATTTTCCTGTACAAATTACTTCCGTGTA ATCTTCACAGGTGGTGTTGGCAAAAATGGATCAACAATAGCAGGAACAAGTGTCCTTTCTCCTTTTCTCCATATTGGATCAGTGATTACA TTAGCTGCAATGATCTACAAGAAATCTGCAGTTCAGCTTTTTGAAAAGCATCCCTGTCTTTATATACTGACATTTGGTTTTGTGTCTGCT AAAATCACTAATAAGCTTGTGGTTGCACACATGACGAAAAGTGAAATGCATTTGCATGACACAGCATTCATAGGTCCGGCACTTTTGTTT CTGGACCAGTATTTTAACAGCTTTATTGATGAATATATTGTACTTTGGATTGCCCTGGTTTTCTCTTTCTTTGATTTGATCCGCTACTGT GTCAGTGTTTGCAATCAGATTGCGTCTCACCTGCACATACATGTCTTCAGAATCAAGGTCTCTACAGCTCATTCTAATCATCATTAATGA TGTAATTGGTATATAGGAACATCATGTTTTCTGCAGGAAAGAAAGTAACATATTAAGGAGAATGGGGGTGGATAAGAACAAATATAATTT ATAATAATCAATGTTGTATAACTTTTATTCTTTATTATTGGTAACACGCCCTAACTATCCTGTGTGAGAATGGGAATTTCAAGTCCCATC TTGTAAATTGTATATGTTGTCATGCAGGGTTTGGGCCAAGAAAGCATGCAGAAAAAAATGCCATGTGATTGTAATTATCCTGGATTCAGA ATAATACTGTGATGGGGAGCCAGATCCGCAGTGGTGGAGAGTTCTAATGTTGACTGTTTGCAGGCCAAAAGATGATTGCTTTATAATTTT AACAAATCATTGTCTTTTAGTAACATCCTTGTTTAGTGTCTTCTCAAGCTTTCTTTACTGAGGAATTCAGCTTGTGACACAGATACATCC CACTAGCTTGTGAGGTGGAACTAGTAATAAAGACCTTGAATTTGGATTGAAAAGTTTCCTATCTTTACATTGTTGAGGAAGTCCTTTTTT TTTTTTTTTTTTTTTTAATTGCTCAAGAAATGATTCTCTCACAGGCTTGGGAAATCCTGTTAGCATGCAGAATAATGTGGTAACTTTGTC AATTTCCCATTTTATTTTTTTAAATAAATATATGATCTAAAAGCCAACTTTTTCTCAGTTTTACTCAGTGGAAAGATAAACTAAGTTTTA >22064_22064_3_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000367348_CEPT1_chr1_111724809_ENST00000357172_length(amino acids)=710AA_BP=532 MFVPRSLKIKRNANDDGKSCVAKIIKPDPEDLQLDKSRDVPVDAVATEAATIDRHISESCPFPSPGGQLAEVHSVSPEQGAKDSHPSEEP VKSFSKTQRWAEPGEPICVVCGRYGEYICDKTDEDVCSLECKAKHLLQVKEKEEKSKLSNPQKADSEPESPLNASYVYKEHPFILNLQED QIENLKQQLGILVQGQEVTRPIIDFEHCSLPEVLNHNLKKSGYEVPTPIQMQMIPVGLLGRDILASADTGSGKTAAFLLPVIMRALFESK TPSALILTPTRELAIQIERQAKELMSGLPRMKTVLLVGGLPLPPQLYRLQQHVKVIIATPGRLLDIIKQSSVELCGVKIVVVDEADTMLK MGFQQQVLDILENIPNDCQTILVSATIPTSIEQLASQLLHNPVRIITGEKNLPCANVRQIILWVEDPAKKKKLFEILNDKKLFKPPVLVF VDCKLGADLLSEAVQKITGLKSISIHSEKSQIERKNILKGLLEGDYEVVVSTGVLGRGLDLISVRLVVNFDMPSSMDEYVHQIPVLNIQM KIFPALCTVAGTIFSCTNYFRVIFTGGVGKNGSTIAGTSVLSPFLHIGSVITLAAMIYKKSAVQLFEKHPCLYILTFGFVSAKITNKLVV -------------------------------------------------------------- >22064_22064_4_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000367348_CEPT1_chr1_111724809_ENST00000545121_length(transcript)=3039nt_BP=1710nt ACGAGCGGGTCAGGGCTTGTCGGGCGGAAGCCTGGCCTGGAGCCTGGAAGGGGGAGACGGCCCGAGCGGGAGCGGGAGCGGACGCGGCCT CAGTCCTGCGCGGAATATTGAAGGATGTTTGTTCCAAGATCTCTAAAAATCAAGAGGAATGCTAATGATGATGGCAAAAGTTGTGTGGCT AAGATAATTAAACCAGACCCAGAAGACCTTCAGTTGGACAAAAGCAGAGATGTTCCCGTTGATGCTGTAGCTACAGAAGCAGCCACAATA GACAGGCACATCAGCGAATCATGCCCTTTCCCCAGCCCAGGTGGCCAGTTGGCAGAGGTTCATTCAGTAAGTCCCGAGCAGGGTGCGAAG GACAGCCATCCTTCTGAAGAGCCCGTTAAGTCATTTTCCAAAACACAGCGCTGGGCAGAACCAGGGGAACCCATCTGTGTTGTCTGTGGT CGTTATGGAGAGTATATCTGTGATAAGACAGATGAAGATGTGTGTAGTTTGGAGTGTAAAGCGAAACATCTTCTACAAGTTAAGGAAAAG GAAGAGAAATCAAAACTCAGCAATCCACAGAAGGCTGATTCTGAGCCAGAGTCTCCACTGAATGCTTCCTATGTCTACAAAGAGCACCCC TTTATTTTGAACCTTCAGGAAGACCAGATTGAAAATCTTAAACAGCAGCTGGGAATTTTAGTTCAAGGGCAAGAAGTCACCAGGCCCATT ATTGACTTTGAACATTGTAGTCTCCCTGAGGTCTTAAATCACAACTTGAAGAAATCAGGCTATGAGGTGCCAACTCCCATTCAAATGCAG ATGATTCCTGTGGGACTTCTGGGAAGAGACATTCTGGCCAGTGCAGATACTGGCTCAGGAAAAACAGCTGCTTTTCTTCTTCCTGTTATC ATGCGAGCTTTATTCGAGAGCAAAACTCCATCTGCGCTCATTCTTACACCAACCAGAGAGTTAGCCATTCAGATAGAGAGACAAGCTAAA GAATTGATGAGTGGCCTGCCACGCATGAAAACTGTGCTTCTTGTAGGGGGCTTACCCTTACCCCCACAGCTTTATCGTCTGCAACAACAT GTTAAGGTTATCATAGCAACCCCTGGGCGACTTCTGGATATAATAAAGCAGAGCTCTGTAGAACTCTGTGGTGTAAAGATTGTGGTAGTA GATGAAGCTGATACCATGTTAAAGATGGGTTTTCAACAACAAGTGCTTGACATTTTGGAAAACATTCCTAATGATTGTCAGACCATTTTG GTTTCAGCCACAATTCCAACTAGCATAGAACAGCTAGCAAGCCAGCTTCTGCATAATCCTGTGAGAATTATCACTGGAGAAAAGAACCTA CCTTGTGCCAATGTACGTCAGATTATTTTGTGGGTAGAAGACCCAGCCAAAAAGAAAAAATTATTTGAAATTTTAAATGATAAGAAACTC TTTAAGCCTCCAGTGTTAGTATTTGTGGACTGCAAACTAGGAGCAGATCTTTTGAGTGAAGCCGTTCAGAAAATCACAGGGCTGAAAAGC ATATCTATACATTCAGAGAAGTCGCAAATAGAAAGGAAAAACATATTGAAGGGATTACTTGAAGGAGACTATGAAGTTGTAGTGAGCACA GGAGTCTTGGGACGAGGCCTAGACTTGATCAGTGTCAGGCTGGTTGTCAATTTTGATATGCCTTCAAGTATGGATGAGTATGTCCATCAG ATTCCAGTGCTGAATATTCAAATGAAAATTTTTCCTGCACTTTGTACTGTAGCAGGGACCATATTTTCCTGTACAAATTACTTCCGTGTA ATCTTCACAGGTGGTGTTGGCAAAAATGGATCAACAATAGCAGGAACAAGTGTCCTTTCTCCTTTTCTCCATATTGGATCAGTGATTACA TTAGCTGCAATGATCTACAAGAAATCTGCAGTTCAGCTTTTTGAAAAGCATCCCTGTCTTTATATACTGACATTTGGTTTTGTGTCTGCT AAAATCACTAATAAGCTTGTGGTTGCACACATGACGAAAAGTGAAATGCATTTGCATGACACAGCATTCATAGGTCCGGCACTTTTGTTT CTGGACCAGTATTTTAACAGCTTTATTGATGAATATATTGTACTTTGGATTGCCCTGGTTTTCTCTTTCTTTGATTTGATCCGCTACTGT GTCAGTGTTTGCAATCAGATTGCGTCTCACCTGCACATACATGTCTTCAGAATCAAGGTCTCTACAGCTCATTCTAATCATCATTAATGA TGTAATTGGTATATAGGAACATCATGTTTTCTGCAGGAAAGAAAGTAACATATTAAGGAGAATGGGGGTGGATAAGAACAAATATAATTT ATAATAATCAATGTTGTATAACTTTTATTCTTTATTATTGGTAACACGCCCTAACTATCCTGTGTGAGAATGGGAATTTCAAGTCCCATC TTGTAAATTGTATATGTTGTCATGCAGGGTTTGGGCCAAGAAAGCATGCAGAAAAAAATGCCATGTGATTGTAATTATCCTGGATTCAGA ATAATACTGTGATGGGGAGCCAGATCCGCAGTGGTGGAGAGTTCTAATGTTGACTGTTTGCAGGCCAAAAGATGATTGCTTTATAATTTT AACAAATCATTGTCTTTTAGTAACATCCTTGTTTAGTGTCTTCTCAAGCTTTCTTTACTGAGGAATTCAGCTTGTGACACAGATACATCC CACTAGCTTGTGAGGTGGAACTAGTAATAAAGACCTTGAATTTGGATTGAAAAGTTTCCTATCTTTACATTGTTGAGGAAGTCCTTTTTT TTTTTTTTTTTTTTTTAATTGCTCAAGAAATGATTCTCTCACAGGCTTGGGAAATCCTGTTAGCATGCAGAATAATGTGGTAACTTTGTC AATTTCCCATTTTATTTTTTTAAATAAATATATGATCTAAAAGCCAACTTTTTCTCAGTTTTACTCAGTGGAAAGATAAACTAAGTTTTA >22064_22064_4_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000367348_CEPT1_chr1_111724809_ENST00000545121_length(amino acids)=710AA_BP=532 MFVPRSLKIKRNANDDGKSCVAKIIKPDPEDLQLDKSRDVPVDAVATEAATIDRHISESCPFPSPGGQLAEVHSVSPEQGAKDSHPSEEP VKSFSKTQRWAEPGEPICVVCGRYGEYICDKTDEDVCSLECKAKHLLQVKEKEEKSKLSNPQKADSEPESPLNASYVYKEHPFILNLQED QIENLKQQLGILVQGQEVTRPIIDFEHCSLPEVLNHNLKKSGYEVPTPIQMQMIPVGLLGRDILASADTGSGKTAAFLLPVIMRALFESK TPSALILTPTRELAIQIERQAKELMSGLPRMKTVLLVGGLPLPPQLYRLQQHVKVIIATPGRLLDIIKQSSVELCGVKIVVVDEADTMLK MGFQQQVLDILENIPNDCQTILVSATIPTSIEQLASQLLHNPVRIITGEKNLPCANVRQIILWVEDPAKKKKLFEILNDKKLFKPPVLVF VDCKLGADLLSEAVQKITGLKSISIHSEKSQIERKNILKGLLEGDYEVVVSTGVLGRGLDLISVRLVVNFDMPSSMDEYVHQIPVLNIQM KIFPALCTVAGTIFSCTNYFRVIFTGGVGKNGSTIAGTSVLSPFLHIGSVITLAAMIYKKSAVQLFEKHPCLYILTFGFVSAKITNKLVV -------------------------------------------------------------- >22064_22064_5_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000447706_CEPT1_chr1_111724809_ENST00000357172_length(transcript)=3077nt_BP=1748nt GCTCCGCTCCGCACCACCAACCCCGGGCCGCAGTCCTGACGAGCGGGTCAGGGCTTGTCGGGCGGAAGCCTGGCCTGGAGCCTGGAAGGG GGAGACGGCCCGAGCGGGAGCGGGAGCGGACGCGGCCTCAGTCCTGCGCGGAATATTGAAGGATGTTTGTTCCAAGATCTCTAAAAATCA AGAGGAATGCTAATGATGATGGCAAAAGTTGTGTGGCTAAGATAATTAAACCAGACCCAGAAGACCTTCAGTTGGACAAAAGCAGAGATG TTCCCGTTGATGCTGTAGCTACAGAAGCAGCCACAATAGACAGGCACATCAGCGAATCATGCCCTTTCCCCAGCCCAGGTGGCCAGTTGG CAGAGGTTCATTCAGTAAGTCCCGAGCAGGGTGCGAAGGACAGCCATCCTTCTGAAGAGCCCGTTAAGTCATTTTCCAAAACACAGCGCT GGGCAGAACCAGGGGAACCCATCTGTGTTGTCTGTGGTCGTTATGGAGAGTATATCTGTGATAAGACAGATGAAGATGTGTGTAGTTTGG AGTGTAAAGCGAAACATCTTCTACAAGTTAAGGAAAAGGAAGAGAAATCAAAACTCAGCAATCCACAGAAGGCTGATTCTGAGCCAGAGT CTCCACTGAATGCTTCCTATGTCTACAAAGAGCACCCCTTTATTTTGAACCTTCAGGAAGACCAGATTGAAAATCTTAAACAGCAGCTGG GAATTTTAGTTCAAGGGCAAGAAGTCACCAGGCCCATTATTGACTTTGAACATTGTAGTCTCCCTGAGGTCTTAAATCACAACTTGAAGA AATCAGGCTATGAGGTGCCAACTCCCATTCAAATGCAGATGATTCCTGTGGGACTTCTGGGAAGAGACATTCTGGCCAGTGCAGATACTG GCTCAGGAAAAACAGCTGCTTTTCTTCTTCCTGTTATCATGCGAGCTTTATTCGAGAGCAAAACTCCATCTGCGCTCATTCTTACACCAA CCAGAGAGTTAGCCATTCAGATAGAGAGACAAGCTAAAGAATTGATGAGTGGCCTGCCACGCATGAAAACTGTGCTTCTTGTAGGGGGCT TACCCTTACCCCCACAGCTTTATCGTCTGCAACAACATGTTAAGGTTATCATAGCAACCCCTGGGCGACTTCTGGATATAATAAAGCAGA GCTCTGTAGAACTCTGTGGTGTAAAGATTGTGGTAGTAGATGAAGCTGATACCATGTTAAAGATGGGTTTTCAACAACAAGTGCTTGACA TTTTGGAAAACATTCCTAATGATTGTCAGACCATTTTGGTTTCAGCCACAATTCCAACTAGCATAGAACAGCTAGCAAGCCAGCTTCTGC ATAATCCTGTGAGAATTATCACTGGAGAAAAGAACCTACCTTGTGCCAATGTACGTCAGATTATTTTGTGGGTAGAAGACCCAGCCAAAA AGAAAAAATTATTTGAAATTTTAAATGATAAGAAACTCTTTAAGCCTCCAGTGTTAGTATTTGTGGACTGCAAACTAGGAGCAGATCTTT TGAGTGAAGCCGTTCAGAAAATCACAGGGCTGAAAAGCATATCTATACATTCAGAGAAGTCGCAAATAGAAAGGAAAAACATATTGAAGG GATTACTTGAAGGAGACTATGAAGTTGTAGTGAGCACAGGAGTCTTGGGACGAGGCCTAGACTTGATCAGTGTCAGGCTGGTTGTCAATT TTGATATGCCTTCAAGTATGGATGAGTATGTCCATCAGATTCCAGTGCTGAATATTCAAATGAAAATTTTTCCTGCACTTTGTACTGTAG CAGGGACCATATTTTCCTGTACAAATTACTTCCGTGTAATCTTCACAGGTGGTGTTGGCAAAAATGGATCAACAATAGCAGGAACAAGTG TCCTTTCTCCTTTTCTCCATATTGGATCAGTGATTACATTAGCTGCAATGATCTACAAGAAATCTGCAGTTCAGCTTTTTGAAAAGCATC CCTGTCTTTATATACTGACATTTGGTTTTGTGTCTGCTAAAATCACTAATAAGCTTGTGGTTGCACACATGACGAAAAGTGAAATGCATT TGCATGACACAGCATTCATAGGTCCGGCACTTTTGTTTCTGGACCAGTATTTTAACAGCTTTATTGATGAATATATTGTACTTTGGATTG CCCTGGTTTTCTCTTTCTTTGATTTGATCCGCTACTGTGTCAGTGTTTGCAATCAGATTGCGTCTCACCTGCACATACATGTCTTCAGAA TCAAGGTCTCTACAGCTCATTCTAATCATCATTAATGATGTAATTGGTATATAGGAACATCATGTTTTCTGCAGGAAAGAAAGTAACATA TTAAGGAGAATGGGGGTGGATAAGAACAAATATAATTTATAATAATCAATGTTGTATAACTTTTATTCTTTATTATTGGTAACACGCCCT AACTATCCTGTGTGAGAATGGGAATTTCAAGTCCCATCTTGTAAATTGTATATGTTGTCATGCAGGGTTTGGGCCAAGAAAGCATGCAGA AAAAAATGCCATGTGATTGTAATTATCCTGGATTCAGAATAATACTGTGATGGGGAGCCAGATCCGCAGTGGTGGAGAGTTCTAATGTTG ACTGTTTGCAGGCCAAAAGATGATTGCTTTATAATTTTAACAAATCATTGTCTTTTAGTAACATCCTTGTTTAGTGTCTTCTCAAGCTTT CTTTACTGAGGAATTCAGCTTGTGACACAGATACATCCCACTAGCTTGTGAGGTGGAACTAGTAATAAAGACCTTGAATTTGGATTGAAA AGTTTCCTATCTTTACATTGTTGAGGAAGTCCTTTTTTTTTTTTTTTTTTTTTTAATTGCTCAAGAAATGATTCTCTCACAGGCTTGGGA AATCCTGTTAGCATGCAGAATAATGTGGTAACTTTGTCAATTTCCCATTTTATTTTTTTAAATAAATATATGATCTAAAAGCCAACTTTT TCTCAGTTTTACTCAGTGGAAAGATAAACTAAGTTTTAATGTTATTTTTTTAAATTTAAGCAAAATTTATTTCTGTTCTTTAATAAATAA >22064_22064_5_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000447706_CEPT1_chr1_111724809_ENST00000357172_length(amino acids)=710AA_BP=532 MFVPRSLKIKRNANDDGKSCVAKIIKPDPEDLQLDKSRDVPVDAVATEAATIDRHISESCPFPSPGGQLAEVHSVSPEQGAKDSHPSEEP VKSFSKTQRWAEPGEPICVVCGRYGEYICDKTDEDVCSLECKAKHLLQVKEKEEKSKLSNPQKADSEPESPLNASYVYKEHPFILNLQED QIENLKQQLGILVQGQEVTRPIIDFEHCSLPEVLNHNLKKSGYEVPTPIQMQMIPVGLLGRDILASADTGSGKTAAFLLPVIMRALFESK TPSALILTPTRELAIQIERQAKELMSGLPRMKTVLLVGGLPLPPQLYRLQQHVKVIIATPGRLLDIIKQSSVELCGVKIVVVDEADTMLK MGFQQQVLDILENIPNDCQTILVSATIPTSIEQLASQLLHNPVRIITGEKNLPCANVRQIILWVEDPAKKKKLFEILNDKKLFKPPVLVF VDCKLGADLLSEAVQKITGLKSISIHSEKSQIERKNILKGLLEGDYEVVVSTGVLGRGLDLISVRLVVNFDMPSSMDEYVHQIPVLNIQM KIFPALCTVAGTIFSCTNYFRVIFTGGVGKNGSTIAGTSVLSPFLHIGSVITLAAMIYKKSAVQLFEKHPCLYILTFGFVSAKITNKLVV -------------------------------------------------------------- >22064_22064_6_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000447706_CEPT1_chr1_111724809_ENST00000545121_length(transcript)=3077nt_BP=1748nt GCTCCGCTCCGCACCACCAACCCCGGGCCGCAGTCCTGACGAGCGGGTCAGGGCTTGTCGGGCGGAAGCCTGGCCTGGAGCCTGGAAGGG GGAGACGGCCCGAGCGGGAGCGGGAGCGGACGCGGCCTCAGTCCTGCGCGGAATATTGAAGGATGTTTGTTCCAAGATCTCTAAAAATCA AGAGGAATGCTAATGATGATGGCAAAAGTTGTGTGGCTAAGATAATTAAACCAGACCCAGAAGACCTTCAGTTGGACAAAAGCAGAGATG TTCCCGTTGATGCTGTAGCTACAGAAGCAGCCACAATAGACAGGCACATCAGCGAATCATGCCCTTTCCCCAGCCCAGGTGGCCAGTTGG CAGAGGTTCATTCAGTAAGTCCCGAGCAGGGTGCGAAGGACAGCCATCCTTCTGAAGAGCCCGTTAAGTCATTTTCCAAAACACAGCGCT GGGCAGAACCAGGGGAACCCATCTGTGTTGTCTGTGGTCGTTATGGAGAGTATATCTGTGATAAGACAGATGAAGATGTGTGTAGTTTGG AGTGTAAAGCGAAACATCTTCTACAAGTTAAGGAAAAGGAAGAGAAATCAAAACTCAGCAATCCACAGAAGGCTGATTCTGAGCCAGAGT CTCCACTGAATGCTTCCTATGTCTACAAAGAGCACCCCTTTATTTTGAACCTTCAGGAAGACCAGATTGAAAATCTTAAACAGCAGCTGG GAATTTTAGTTCAAGGGCAAGAAGTCACCAGGCCCATTATTGACTTTGAACATTGTAGTCTCCCTGAGGTCTTAAATCACAACTTGAAGA AATCAGGCTATGAGGTGCCAACTCCCATTCAAATGCAGATGATTCCTGTGGGACTTCTGGGAAGAGACATTCTGGCCAGTGCAGATACTG GCTCAGGAAAAACAGCTGCTTTTCTTCTTCCTGTTATCATGCGAGCTTTATTCGAGAGCAAAACTCCATCTGCGCTCATTCTTACACCAA CCAGAGAGTTAGCCATTCAGATAGAGAGACAAGCTAAAGAATTGATGAGTGGCCTGCCACGCATGAAAACTGTGCTTCTTGTAGGGGGCT TACCCTTACCCCCACAGCTTTATCGTCTGCAACAACATGTTAAGGTTATCATAGCAACCCCTGGGCGACTTCTGGATATAATAAAGCAGA GCTCTGTAGAACTCTGTGGTGTAAAGATTGTGGTAGTAGATGAAGCTGATACCATGTTAAAGATGGGTTTTCAACAACAAGTGCTTGACA TTTTGGAAAACATTCCTAATGATTGTCAGACCATTTTGGTTTCAGCCACAATTCCAACTAGCATAGAACAGCTAGCAAGCCAGCTTCTGC ATAATCCTGTGAGAATTATCACTGGAGAAAAGAACCTACCTTGTGCCAATGTACGTCAGATTATTTTGTGGGTAGAAGACCCAGCCAAAA AGAAAAAATTATTTGAAATTTTAAATGATAAGAAACTCTTTAAGCCTCCAGTGTTAGTATTTGTGGACTGCAAACTAGGAGCAGATCTTT TGAGTGAAGCCGTTCAGAAAATCACAGGGCTGAAAAGCATATCTATACATTCAGAGAAGTCGCAAATAGAAAGGAAAAACATATTGAAGG GATTACTTGAAGGAGACTATGAAGTTGTAGTGAGCACAGGAGTCTTGGGACGAGGCCTAGACTTGATCAGTGTCAGGCTGGTTGTCAATT TTGATATGCCTTCAAGTATGGATGAGTATGTCCATCAGATTCCAGTGCTGAATATTCAAATGAAAATTTTTCCTGCACTTTGTACTGTAG CAGGGACCATATTTTCCTGTACAAATTACTTCCGTGTAATCTTCACAGGTGGTGTTGGCAAAAATGGATCAACAATAGCAGGAACAAGTG TCCTTTCTCCTTTTCTCCATATTGGATCAGTGATTACATTAGCTGCAATGATCTACAAGAAATCTGCAGTTCAGCTTTTTGAAAAGCATC CCTGTCTTTATATACTGACATTTGGTTTTGTGTCTGCTAAAATCACTAATAAGCTTGTGGTTGCACACATGACGAAAAGTGAAATGCATT TGCATGACACAGCATTCATAGGTCCGGCACTTTTGTTTCTGGACCAGTATTTTAACAGCTTTATTGATGAATATATTGTACTTTGGATTG CCCTGGTTTTCTCTTTCTTTGATTTGATCCGCTACTGTGTCAGTGTTTGCAATCAGATTGCGTCTCACCTGCACATACATGTCTTCAGAA TCAAGGTCTCTACAGCTCATTCTAATCATCATTAATGATGTAATTGGTATATAGGAACATCATGTTTTCTGCAGGAAAGAAAGTAACATA TTAAGGAGAATGGGGGTGGATAAGAACAAATATAATTTATAATAATCAATGTTGTATAACTTTTATTCTTTATTATTGGTAACACGCCCT AACTATCCTGTGTGAGAATGGGAATTTCAAGTCCCATCTTGTAAATTGTATATGTTGTCATGCAGGGTTTGGGCCAAGAAAGCATGCAGA AAAAAATGCCATGTGATTGTAATTATCCTGGATTCAGAATAATACTGTGATGGGGAGCCAGATCCGCAGTGGTGGAGAGTTCTAATGTTG ACTGTTTGCAGGCCAAAAGATGATTGCTTTATAATTTTAACAAATCATTGTCTTTTAGTAACATCCTTGTTTAGTGTCTTCTCAAGCTTT CTTTACTGAGGAATTCAGCTTGTGACACAGATACATCCCACTAGCTTGTGAGGTGGAACTAGTAATAAAGACCTTGAATTTGGATTGAAA AGTTTCCTATCTTTACATTGTTGAGGAAGTCCTTTTTTTTTTTTTTTTTTTTTTAATTGCTCAAGAAATGATTCTCTCACAGGCTTGGGA AATCCTGTTAGCATGCAGAATAATGTGGTAACTTTGTCAATTTCCCATTTTATTTTTTTAAATAAATATATGATCTAAAAGCCAACTTTT TCTCAGTTTTACTCAGTGGAAAGATAAACTAAGTTTTAATGTTATTTTTTTAAATTTAAGCAAAATTTATTTCTGTTCTTTAATAAATAA >22064_22064_6_DDX59-CEPT1_DDX59_chr1_200617567_ENST00000447706_CEPT1_chr1_111724809_ENST00000545121_length(amino acids)=710AA_BP=532 MFVPRSLKIKRNANDDGKSCVAKIIKPDPEDLQLDKSRDVPVDAVATEAATIDRHISESCPFPSPGGQLAEVHSVSPEQGAKDSHPSEEP VKSFSKTQRWAEPGEPICVVCGRYGEYICDKTDEDVCSLECKAKHLLQVKEKEEKSKLSNPQKADSEPESPLNASYVYKEHPFILNLQED QIENLKQQLGILVQGQEVTRPIIDFEHCSLPEVLNHNLKKSGYEVPTPIQMQMIPVGLLGRDILASADTGSGKTAAFLLPVIMRALFESK TPSALILTPTRELAIQIERQAKELMSGLPRMKTVLLVGGLPLPPQLYRLQQHVKVIIATPGRLLDIIKQSSVELCGVKIVVVDEADTMLK MGFQQQVLDILENIPNDCQTILVSATIPTSIEQLASQLLHNPVRIITGEKNLPCANVRQIILWVEDPAKKKKLFEILNDKKLFKPPVLVF VDCKLGADLLSEAVQKITGLKSISIHSEKSQIERKNILKGLLEGDYEVVVSTGVLGRGLDLISVRLVVNFDMPSSMDEYVHQIPVLNIQM KIFPALCTVAGTIFSCTNYFRVIFTGGVGKNGSTIAGTSVLSPFLHIGSVITLAAMIYKKSAVQLFEKHPCLYILTFGFVSAKITNKLVV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DDX59-CEPT1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DDX59-CEPT1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DDX59-CEPT1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies