
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DIS3L2-EFHD1 (FusionGDB2 ID:22902) |
Fusion Gene Summary for DIS3L2-EFHD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DIS3L2-EFHD1 | Fusion gene ID: 22902 | Hgene | Tgene | Gene symbol | DIS3L2 | EFHD1 | Gene ID | 129563 | 80303 |
| Gene name | DIS3 like 3'-5' exoribonuclease 2 | EF-hand domain family member D1 | |
| Synonyms | FAM6A|PRLMNS|hDIS3L2 | MST133|MSTP133|PP3051|SWS2 | |
| Cytomap | 2q37.1 | 2q37.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | DIS3-like exonuclease 2DIS3 mitotic control homolog-like 2family with sequence similarity 6, member A | EF-hand domain-containing protein D1EF-hand domain-containing protein 1swiprosin-2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q8IYB7 | Q9BUP0 | |
| Ensembl transtripts involved in fusion gene | ENST00000273009, ENST00000325385, ENST00000409307, ENST00000360410, ENST00000409401, ENST00000470087, | ENST00000409708, ENST00000410095, ENST00000264059, ENST00000409613, | |
| Fusion gene scores | * DoF score | 27 X 9 X 12=2916 | 5 X 6 X 7=210 |
| # samples | 25 | 10 | |
| ** MAII score | log2(25/2916*10)=-3.54399071966485 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/210*10)=-1.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DIS3L2 [Title/Abstract] AND EFHD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DIS3L2(233028342)-EFHD1(233527512), # samples:2 DIS3L2(233075115)-EFHD1(233546295), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | DIS3L2 | GO:0010587 | miRNA catabolic process | 24141620 |
| Fusion gene breakpoints across DIS3L2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
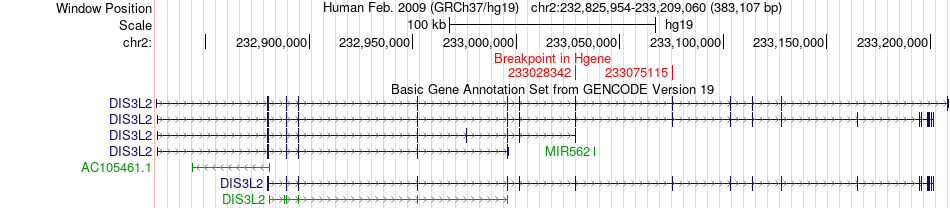 |
| Fusion gene breakpoints across EFHD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PAAD | TCGA-IB-A6UF-01A | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| ChimerDB4 | PAAD | TCGA-IB-A6UF | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| ChimerDB4 | STAD | TCGA-D7-A4YU-01A | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| ChimerDB4 | STAD | TCGA-D7-A4YU | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
Top |
Fusion Gene ORF analysis for DIS3L2-EFHD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000273009 | ENST00000409708 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| 5CDS-5UTR | ENST00000273009 | ENST00000410095 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| 5CDS-5UTR | ENST00000325385 | ENST00000409708 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| 5CDS-5UTR | ENST00000325385 | ENST00000410095 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| 5CDS-5UTR | ENST00000409307 | ENST00000409708 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| 5CDS-5UTR | ENST00000409307 | ENST00000410095 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| Frame-shift | ENST00000273009 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000273009 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| Frame-shift | ENST00000273009 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000273009 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| Frame-shift | ENST00000273009 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000273009 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| Frame-shift | ENST00000325385 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000325385 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| Frame-shift | ENST00000325385 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000325385 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| Frame-shift | ENST00000325385 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000325385 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| Frame-shift | ENST00000409307 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000409307 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| Frame-shift | ENST00000409307 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000409307 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| Frame-shift | ENST00000409307 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| Frame-shift | ENST00000409307 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| In-frame | ENST00000273009 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| In-frame | ENST00000273009 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| In-frame | ENST00000273009 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| In-frame | ENST00000273009 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| In-frame | ENST00000325385 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| In-frame | ENST00000325385 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| In-frame | ENST00000325385 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| In-frame | ENST00000325385 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| In-frame | ENST00000409307 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| In-frame | ENST00000409307 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| In-frame | ENST00000409307 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| In-frame | ENST00000409307 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000360410 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-3CDS | ENST00000360410 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000360410 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000360410 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-3CDS | ENST00000360410 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000360410 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000360410 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000360410 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000360410 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000360410 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000409401 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-3CDS | ENST00000409401 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000409401 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000409401 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-3CDS | ENST00000409401 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000409401 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000409401 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000409401 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000409401 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000409401 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000470087 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-3CDS | ENST00000470087 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000470087 | ENST00000264059 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000470087 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-3CDS | ENST00000470087 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000470087 | ENST00000409613 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000470087 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000470087 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-3CDS | ENST00000470087 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + |
| intron-3CDS | ENST00000470087 | ENST00000410095 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + |
| intron-5UTR | ENST00000360410 | ENST00000409708 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-5UTR | ENST00000360410 | ENST00000410095 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-5UTR | ENST00000409401 | ENST00000409708 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-5UTR | ENST00000409401 | ENST00000410095 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-5UTR | ENST00000470087 | ENST00000409708 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| intron-5UTR | ENST00000470087 | ENST00000410095 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000273009 | DIS3L2 | chr2 | 233028342 | + | ENST00000409613 | EFHD1 | chr2 | 233527512 | + | 2777 | 1738 | 578 | 2155 | 525 |
| ENST00000273009 | DIS3L2 | chr2 | 233028342 | + | ENST00000264059 | EFHD1 | chr2 | 233527512 | + | 3218 | 1738 | 578 | 2155 | 525 |
| ENST00000325385 | DIS3L2 | chr2 | 233028342 | + | ENST00000409613 | EFHD1 | chr2 | 233527512 | + | 2439 | 1400 | 240 | 1817 | 525 |
| ENST00000325385 | DIS3L2 | chr2 | 233028342 | + | ENST00000264059 | EFHD1 | chr2 | 233527512 | + | 2880 | 1400 | 240 | 1817 | 525 |
| ENST00000409307 | DIS3L2 | chr2 | 233028342 | + | ENST00000409613 | EFHD1 | chr2 | 233527512 | + | 2163 | 1124 | 0 | 1541 | 513 |
| ENST00000409307 | DIS3L2 | chr2 | 233028342 | + | ENST00000264059 | EFHD1 | chr2 | 233527512 | + | 2604 | 1124 | 0 | 1541 | 513 |
| ENST00000273009 | DIS3L2 | chr2 | 233075115 | + | ENST00000409708 | EFHD1 | chr2 | 233546295 | + | 3008 | 1818 | 578 | 1843 | 421 |
| ENST00000325385 | DIS3L2 | chr2 | 233075115 | + | ENST00000409708 | EFHD1 | chr2 | 233546295 | + | 2670 | 1480 | 240 | 1505 | 421 |
| ENST00000409307 | DIS3L2 | chr2 | 233075115 | + | ENST00000409708 | EFHD1 | chr2 | 233546295 | + | 2394 | 1204 | 0 | 1229 | 409 |
| ENST00000273009 | DIS3L2 | chr2 | 233075115 | + | ENST00000409708 | EFHD1 | chr2 | 233546294 | + | 3008 | 1818 | 578 | 1843 | 421 |
| ENST00000325385 | DIS3L2 | chr2 | 233075115 | + | ENST00000409708 | EFHD1 | chr2 | 233546294 | + | 2670 | 1480 | 240 | 1505 | 421 |
| ENST00000409307 | DIS3L2 | chr2 | 233075115 | + | ENST00000409708 | EFHD1 | chr2 | 233546294 | + | 2394 | 1204 | 0 | 1229 | 409 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000273009 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + | 0.002030305 | 0.9979697 |
| ENST00000273009 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + | 0.001023702 | 0.99897635 |
| ENST00000325385 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + | 0.001731745 | 0.99826825 |
| ENST00000325385 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + | 0.000855822 | 0.9991442 |
| ENST00000409307 | ENST00000409613 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + | 0.001042298 | 0.99895763 |
| ENST00000409307 | ENST00000264059 | DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527512 | + | 0.00053578 | 0.9994642 |
| ENST00000273009 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + | 0.000835596 | 0.99916446 |
| ENST00000325385 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + | 0.000635065 | 0.9993649 |
| ENST00000409307 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546295 | + | 0.00038714 | 0.99961287 |
| ENST00000273009 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + | 0.000835596 | 0.99916446 |
| ENST00000325385 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + | 0.000635065 | 0.9993649 |
| ENST00000409307 | ENST00000409708 | DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + | 0.00038714 | 0.99961287 |
Top |
Fusion Genomic Features for DIS3L2-EFHD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + | 2.00E-05 | 0.99998 |
| DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + | 2.00E-05 | 0.99998 |
| DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527511 | + | 5.71E-14 | 1 |
| DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527511 | + | 5.71E-14 | 1 |
| DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + | 2.00E-05 | 0.99998 |
| DIS3L2 | chr2 | 233075115 | + | EFHD1 | chr2 | 233546294 | + | 2.00E-05 | 0.99998 |
| DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527511 | + | 5.71E-14 | 1 |
| DIS3L2 | chr2 | 233028342 | + | EFHD1 | chr2 | 233527511 | + | 5.71E-14 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
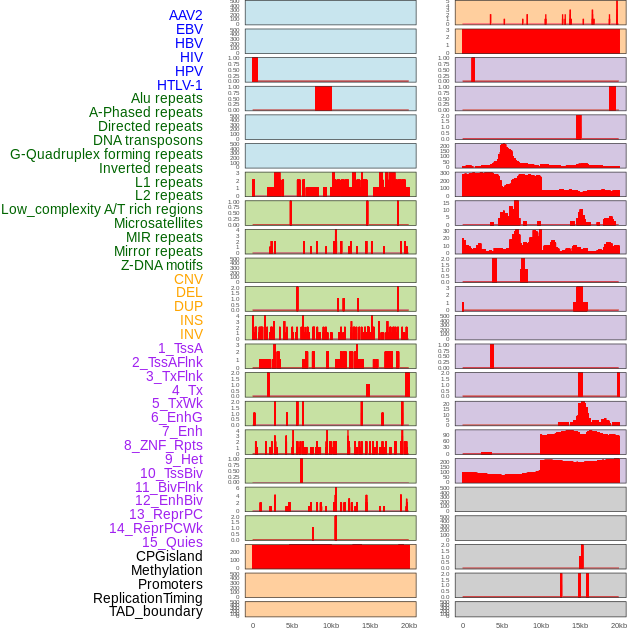 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
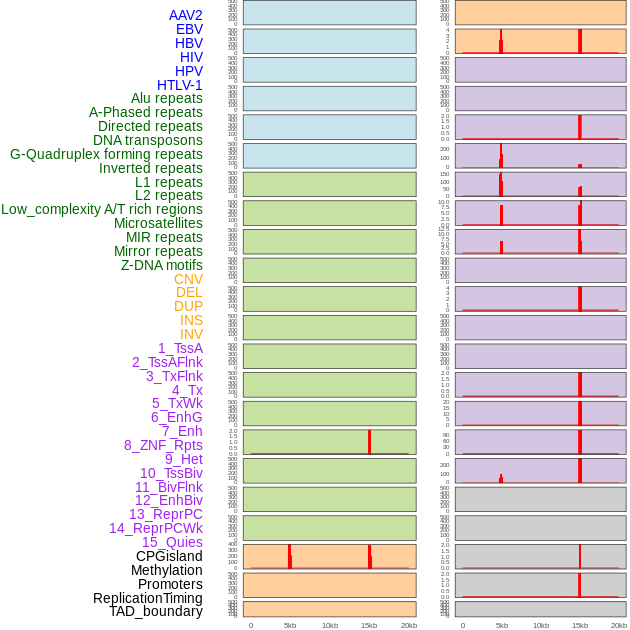 |
Top |
Fusion Protein Features for DIS3L2-EFHD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:233028342/chr2:233527512) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DIS3L2 | EFHD1 |
| FUNCTION: 3'-5'-exoribonuclease that specifically recognizes RNAs polyuridylated at their 3' end and mediates their degradation. Component of an exosome-independent RNA degradation pathway that mediates degradation of both mRNAs and miRNAs that have been polyuridylated by a terminal uridylyltransferase, such as ZCCHC11/TUT4. Mediates degradation of cytoplasmic mRNAs that have been deadenylated and subsequently uridylated at their 3'. Mediates degradation of uridylated pre-let-7 miRNAs, contributing to the maintenance of embryonic stem (ES) cells. Essential for correct mitosis, and negatively regulates cell proliferation. {ECO:0000255|HAMAP-Rule:MF_03045, ECO:0000269|PubMed:23756462, ECO:0000269|PubMed:24141620}. | FUNCTION: Acts as a calcium sensor for mitochondrial flash (mitoflash) activation, an event characterized by stochastic bursts of superoxide production (PubMed:26975899). May play a role in neuronal differentiation (By similarity). {ECO:0000250|UniProtKB:Q9D4J1, ECO:0000269|PubMed:26975899}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | EFHD1 | chr2:233028342 | chr2:233527512 | ENST00000264059 | 0 | 4 | 103_114 | 100 | 240.0 | Calcium binding | 1 | |
| Tgene | EFHD1 | chr2:233028342 | chr2:233527512 | ENST00000264059 | 0 | 4 | 139_150 | 100 | 240.0 | Calcium binding | 2 | |
| Tgene | EFHD1 | chr2:233028342 | chr2:233527512 | ENST00000409613 | 0 | 4 | 103_114 | 4 | 144.0 | Calcium binding | 1 | |
| Tgene | EFHD1 | chr2:233028342 | chr2:233527512 | ENST00000409613 | 0 | 4 | 139_150 | 4 | 144.0 | Calcium binding | 2 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546294 | ENST00000409613 | 2 | 4 | 103_114 | 99 | 144.0 | Calcium binding | 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546294 | ENST00000409613 | 2 | 4 | 139_150 | 99 | 144.0 | Calcium binding | 2 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546295 | ENST00000409613 | 2 | 4 | 103_114 | 99 | 144.0 | Calcium binding | 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546295 | ENST00000409613 | 2 | 4 | 139_150 | 99 | 144.0 | Calcium binding | 2 | |
| Tgene | EFHD1 | chr2:233028342 | chr2:233527512 | ENST00000264059 | 0 | 4 | 126_161 | 100 | 240.0 | Domain | EF-hand 2 | |
| Tgene | EFHD1 | chr2:233028342 | chr2:233527512 | ENST00000409613 | 0 | 4 | 126_161 | 4 | 144.0 | Domain | EF-hand 2 | |
| Tgene | EFHD1 | chr2:233028342 | chr2:233527512 | ENST00000409613 | 0 | 4 | 90_125 | 4 | 144.0 | Domain | EF-hand 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546294 | ENST00000409613 | 2 | 4 | 126_161 | 99 | 144.0 | Domain | EF-hand 2 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546295 | ENST00000409613 | 2 | 4 | 126_161 | 99 | 144.0 | Domain | EF-hand 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546294 | ENST00000264059 | 2 | 4 | 103_114 | 195 | 240.0 | Calcium binding | 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546294 | ENST00000264059 | 2 | 4 | 139_150 | 195 | 240.0 | Calcium binding | 2 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546295 | ENST00000264059 | 2 | 4 | 103_114 | 195 | 240.0 | Calcium binding | 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546295 | ENST00000264059 | 2 | 4 | 139_150 | 195 | 240.0 | Calcium binding | 2 | |
| Tgene | EFHD1 | chr2:233028342 | chr2:233527512 | ENST00000264059 | 0 | 4 | 90_125 | 100 | 240.0 | Domain | EF-hand 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546294 | ENST00000264059 | 2 | 4 | 126_161 | 195 | 240.0 | Domain | EF-hand 2 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546294 | ENST00000264059 | 2 | 4 | 90_125 | 195 | 240.0 | Domain | EF-hand 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546294 | ENST00000409613 | 2 | 4 | 90_125 | 99 | 144.0 | Domain | EF-hand 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546295 | ENST00000264059 | 2 | 4 | 126_161 | 195 | 240.0 | Domain | EF-hand 2 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546295 | ENST00000264059 | 2 | 4 | 90_125 | 195 | 240.0 | Domain | EF-hand 1 | |
| Tgene | EFHD1 | chr2:233075115 | chr2:233546295 | ENST00000409613 | 2 | 4 | 90_125 | 99 | 144.0 | Domain | EF-hand 1 |
Top |
Fusion Gene Sequence for DIS3L2-EFHD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >22902_22902_1_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000273009_EFHD1_chr2_233527512_ENST00000264059_length(transcript)=3218nt_BP=1738nt ATGCGGGGGTTGTCCATCTCTGTATCCCCAGTGCCAGCACTGCACCTCGCCCCAAGCAGTTGTCCAATAAATGAGCAGTGAGTAAATGAA AGAATGAGCAAAGCCTTGTAACAGGAAAGGGGCCGGCGGCGTCTGCCGTGCAAGACCTGGCCCAGTGGAGCAGAGCCTGGAGGTTCAGGA GCCGGGTCTGGAAGGCTCCTTCCGGTGGAAGAGGGGCCCGGAGCCAGCCGGCGCCTGGCACAAGGCGTCTCAGAGGCCGCCCACTGGGAG CCAACCGTTGCAGCCAGTTGTCCCCGCGAGCGAGGCCGGAGAAGGCGCGGCGGCCCCTGGCCTGGCCATTTCGCCCTTGTCGCAGCTGAA CCGCCGACTACGAGCTCCTGCACCGCGCACACACCCCGCGCGCTTCGCTCTCGGCCTCGCCCGGCCACCGTCGCTCTCTAGAACGCCGCG CCCGTGACCCGGAAGAGCATTCTCCTTAGCAACTGCGGGACTGCGGCGGCGCCGGCCTCCGGGGAGAAACGCGAATGACAACAGAGCTGC TCAAGGCGGGAACTCTGAGCTAAGCAGTGGAGGTTTCTCTGGATCTGGAGAGAAGAGTGACCTTGGAGCCAATAATGAGCCATCCTGACT ACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATTGGTGCTTCGCCAGGTGACAAAA AGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGATGTTTCAGAAGGCTTGAAGAGAG GAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCGGATGGTGATCGAGACATTTTTA TTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAGGAGCATTGGAAGGTAGTTAAAC CAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACACCATCTCCCGCAACAGTCCCTGA AAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGACATGGCATCACACAAAATGTGC TGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCGGTTACAAAAGATGAGACCACCT GCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATCTTGGAGAAAAAACATTCTCGAG CAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTTTCTCCCTCAGACCACCGAGTGC CTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAACACACTGTTCATCTGCCGCATTG TGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAAATTGAGCCTGAAACAGAAGGAA TACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGCCTGCCATGGACAATTCCACCAG AGGAGTTCAGCAAGAGAAGGGATTTAAGGTATGACGCTGGGCGGGATGGCTTCATCGACCTGATGGAGCTGAAGCTGATGATGGAGAAGC TGGGGGCCCCCCAGACCCACCTGGGCCTGAAGAGCATGATCAAGGAGGTGGATGAGGACTTCGATGGCAAGCTCAGCTTCCGGGAGTTCC TGCTCATTTTCCACAAGGCCGCGGCAGGGGAGCTGCAGGAGGACAGTGGGCTGATGGCGCTGGCAAAGCTTTCTGAGATCGATGTGGCCC TGGAGGGTGTCAAAGGTGCCAAGAACTTCTTTGAAGCCAAGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAAGCAGAGTTGAAAGCTG AGCAAGATGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAACTTCAATACATAGTCCT GCTGACCTTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACTGCTGTCGGTCCCCTCC CTGAGCCAGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCCCTCCAGGAGGGTCCTG GGGTGGGCCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTATCTTCTCAGCAACCTTC ACTTTGTCCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTCTTTTTGGGTCCTCAGA GAAAATGCCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTTGGTAGGATTCTGCCAG TTGCTTTTGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTCTTCAACAGGAGGAACA GCATGCCACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCCTTAGCATTCCCCCAGT CCCTCCCTCTTCACCTTGCTCCGTCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGTACTACTTCACTGTAAGAACGAA AGAATAGTTAGGATACCAATGAGTAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACAGTAGACCGCTGACGTTCCCAAG TGACAGATCCAGGGCCTTTCAAACATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAACATCTGTTTCAGGGTATCCAGCT GTAGATGTTCTTATCCCCCATACTTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTGTATTTTTAACAAATATATCCTA >22902_22902_1_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000273009_EFHD1_chr2_233527512_ENST00000264059_length(amino acids)=525AA_BP=1 MDLERRVTLEPIMSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPK KFHEAFIPSPDGDRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEA QFDGSDSEDGHGITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKN SELFRKYALFSPSDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFS SEVLECLPQGLPWTIPPEEFSKRRDLRYDAGRDGFIDLMELKLMMEKLGAPQTHLGLKSMIKEVDEDFDGKLSFREFLLIFHKAAAGELQ -------------------------------------------------------------- >22902_22902_2_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000273009_EFHD1_chr2_233527512_ENST00000409613_length(transcript)=2777nt_BP=1738nt ATGCGGGGGTTGTCCATCTCTGTATCCCCAGTGCCAGCACTGCACCTCGCCCCAAGCAGTTGTCCAATAAATGAGCAGTGAGTAAATGAA AGAATGAGCAAAGCCTTGTAACAGGAAAGGGGCCGGCGGCGTCTGCCGTGCAAGACCTGGCCCAGTGGAGCAGAGCCTGGAGGTTCAGGA GCCGGGTCTGGAAGGCTCCTTCCGGTGGAAGAGGGGCCCGGAGCCAGCCGGCGCCTGGCACAAGGCGTCTCAGAGGCCGCCCACTGGGAG CCAACCGTTGCAGCCAGTTGTCCCCGCGAGCGAGGCCGGAGAAGGCGCGGCGGCCCCTGGCCTGGCCATTTCGCCCTTGTCGCAGCTGAA CCGCCGACTACGAGCTCCTGCACCGCGCACACACCCCGCGCGCTTCGCTCTCGGCCTCGCCCGGCCACCGTCGCTCTCTAGAACGCCGCG CCCGTGACCCGGAAGAGCATTCTCCTTAGCAACTGCGGGACTGCGGCGGCGCCGGCCTCCGGGGAGAAACGCGAATGACAACAGAGCTGC TCAAGGCGGGAACTCTGAGCTAAGCAGTGGAGGTTTCTCTGGATCTGGAGAGAAGAGTGACCTTGGAGCCAATAATGAGCCATCCTGACT ACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATTGGTGCTTCGCCAGGTGACAAAA AGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGATGTTTCAGAAGGCTTGAAGAGAG GAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCGGATGGTGATCGAGACATTTTTA TTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAGGAGCATTGGAAGGTAGTTAAAC CAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACACCATCTCCCGCAACAGTCCCTGA AAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGACATGGCATCACACAAAATGTGC TGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCGGTTACAAAAGATGAGACCACCT GCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATCTTGGAGAAAAAACATTCTCGAG CAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTTTCTCCCTCAGACCACCGAGTGC CTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAACACACTGTTCATCTGCCGCATTG TGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAAATTGAGCCTGAAACAGAAGGAA TACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGCCTGCCATGGACAATTCCACCAG AGGAGTTCAGCAAGAGAAGGGATTTAAGGTATGACGCTGGGCGGGATGGCTTCATCGACCTGATGGAGCTGAAGCTGATGATGGAGAAGC TGGGGGCCCCCCAGACCCACCTGGGCCTGAAGAGCATGATCAAGGAGGTGGATGAGGACTTCGATGGCAAGCTCAGCTTCCGGGAGTTCC TGCTCATTTTCCACAAGGCCGCGGCAGGGGAGCTGCAGGAGGACAGTGGGCTGATGGCGCTGGCAAAGCTTTCTGAGATCGATGTGGCCC TGGAGGGTGTCAAAGGTGCCAAGAACTTCTTTGAAGCCAAGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAAGCAGAGTTGAAAGCTG AGCAAGATGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAACTTCAATACATAGTCCT GCTGACCTTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACTGCTGTCGGTCCCCTCC CTGAGCCAGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCCCTCCAGGAGGGTCCTG GGGTGGGCCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTATCTTCTCAGCAACCTTC ACTTTGTCCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTCTTTTTGGGTCCTCAGA GAAAATGCCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTTGGTAGGATTCTGCCAG TTGCTTTTGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTCTTCAACAGGAGGAACA >22902_22902_2_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000273009_EFHD1_chr2_233527512_ENST00000409613_length(amino acids)=525AA_BP=1 MDLERRVTLEPIMSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPK KFHEAFIPSPDGDRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEA QFDGSDSEDGHGITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKN SELFRKYALFSPSDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFS SEVLECLPQGLPWTIPPEEFSKRRDLRYDAGRDGFIDLMELKLMMEKLGAPQTHLGLKSMIKEVDEDFDGKLSFREFLLIFHKAAAGELQ -------------------------------------------------------------- >22902_22902_3_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000325385_EFHD1_chr2_233527512_ENST00000264059_length(transcript)=2880nt_BP=1400nt TTTCGCCCTTGTCGCAGCTGAACCGCCGACTACGAGCTCCTGCACCGCGCACACACCCCGCGCGCTTCGCTCTCGGCCTCGCCCGGCCAC CGTCGCTCTCTAGAACGCCGCGCCCGTGACCCGGAAGAGCATTCTCCTTAGCAACTGCGGGACTGCGGCGGCGCCGGCCTCCGGGGAGAA ACGCGAATGACAACAGAGCTGCTCAAGGCGGGAACTCTGAGCTAAGCAGTGGAGGTTTCTCTGGATCTGGAGAGAAGAGTGACCTTGGAG CCAATAATGAGCCATCCTGACTACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATT GGTGCTTCGCCAGGTGACAAAAAGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGAT GTTTCAGAAGGCTTGAAGAGAGGAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCG GATGGTGATCGAGACATTTTTATTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAG GAGCATTGGAAGGTAGTTAAACCAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACAC CATCTCCCGCAACAGTCCCTGAAAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGA CATGGCATCACACAAAATGTGCTGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCG GTTACAAAAGATGAGACCACCTGCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATC TTGGAGAAAAAACATTCTCGAGCAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTT TCTCCCTCAGACCACCGAGTGCCTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAAC ACACTGTTCATCTGCCGCATTGTGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAA ATTGAGCCTGAAACAGAAGGAATACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGC CTGCCATGGACAATTCCACCAGAGGAGTTCAGCAAGAGAAGGGATTTAAGGTATGACGCTGGGCGGGATGGCTTCATCGACCTGATGGAG CTGAAGCTGATGATGGAGAAGCTGGGGGCCCCCCAGACCCACCTGGGCCTGAAGAGCATGATCAAGGAGGTGGATGAGGACTTCGATGGC AAGCTCAGCTTCCGGGAGTTCCTGCTCATTTTCCACAAGGCCGCGGCAGGGGAGCTGCAGGAGGACAGTGGGCTGATGGCGCTGGCAAAG CTTTCTGAGATCGATGTGGCCCTGGAGGGTGTCAAAGGTGCCAAGAACTTCTTTGAAGCCAAGGTCCAAGCCTTGTCATCGGCCAGTAAG TTTGAAGCAGAGTTGAAAGCTGAGCAAGATGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAG GCCAACTTCAATACATAGTCCTGCTGACCTTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTC ATCACTGCTGTCGGTCCCCTCCCTGAGCCAGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCC AAGCCCCTCCAGGAGGGTCCTGGGGTGGGCCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAAC TTGTATCTTCTCAGCAACCTTCACTTTGTCCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATG TCTGTCTTTTTGGGTCCTCAGAGAAAATGCCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTC ATCTTTGGTAGGATTCTGCCAGTTGCTTTTGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGT CCACTCTTCAACAGGAGGAACAGCATGCCACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCT GGCCCCTTAGCATTCCCCCAGTCCCTCCCTCTTCACCTTGCTCCGTCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGT ACTACTTCACTGTAAGAACGAAAGAATAGTTAGGATACCAATGAGTAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACA GTAGACCGCTGACGTTCCCAAGTGACAGATCCAGGGCCTTTCAAACATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAAC ATCTGTTTCAGGGTATCCAGCTGTAGATGTTCTTATCCCCCATACTTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTG TATTTTTAACAAATATATCCTAATGTCATATTTATTCTCTTTTGTAACTGCTGTCTTTACAATAAAGAAATCATCTGCCTTTCTATCTTA >22902_22902_3_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000325385_EFHD1_chr2_233527512_ENST00000264059_length(amino acids)=525AA_BP=1 MDLERRVTLEPIMSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPK KFHEAFIPSPDGDRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEA QFDGSDSEDGHGITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKN SELFRKYALFSPSDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFS SEVLECLPQGLPWTIPPEEFSKRRDLRYDAGRDGFIDLMELKLMMEKLGAPQTHLGLKSMIKEVDEDFDGKLSFREFLLIFHKAAAGELQ -------------------------------------------------------------- >22902_22902_4_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000325385_EFHD1_chr2_233527512_ENST00000409613_length(transcript)=2439nt_BP=1400nt TTTCGCCCTTGTCGCAGCTGAACCGCCGACTACGAGCTCCTGCACCGCGCACACACCCCGCGCGCTTCGCTCTCGGCCTCGCCCGGCCAC CGTCGCTCTCTAGAACGCCGCGCCCGTGACCCGGAAGAGCATTCTCCTTAGCAACTGCGGGACTGCGGCGGCGCCGGCCTCCGGGGAGAA ACGCGAATGACAACAGAGCTGCTCAAGGCGGGAACTCTGAGCTAAGCAGTGGAGGTTTCTCTGGATCTGGAGAGAAGAGTGACCTTGGAG CCAATAATGAGCCATCCTGACTACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATT GGTGCTTCGCCAGGTGACAAAAAGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGAT GTTTCAGAAGGCTTGAAGAGAGGAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCG GATGGTGATCGAGACATTTTTATTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAG GAGCATTGGAAGGTAGTTAAACCAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACAC CATCTCCCGCAACAGTCCCTGAAAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGA CATGGCATCACACAAAATGTGCTGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCG GTTACAAAAGATGAGACCACCTGCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATC TTGGAGAAAAAACATTCTCGAGCAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTT TCTCCCTCAGACCACCGAGTGCCTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAAC ACACTGTTCATCTGCCGCATTGTGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAA ATTGAGCCTGAAACAGAAGGAATACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGC CTGCCATGGACAATTCCACCAGAGGAGTTCAGCAAGAGAAGGGATTTAAGGTATGACGCTGGGCGGGATGGCTTCATCGACCTGATGGAG CTGAAGCTGATGATGGAGAAGCTGGGGGCCCCCCAGACCCACCTGGGCCTGAAGAGCATGATCAAGGAGGTGGATGAGGACTTCGATGGC AAGCTCAGCTTCCGGGAGTTCCTGCTCATTTTCCACAAGGCCGCGGCAGGGGAGCTGCAGGAGGACAGTGGGCTGATGGCGCTGGCAAAG CTTTCTGAGATCGATGTGGCCCTGGAGGGTGTCAAAGGTGCCAAGAACTTCTTTGAAGCCAAGGTCCAAGCCTTGTCATCGGCCAGTAAG TTTGAAGCAGAGTTGAAAGCTGAGCAAGATGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAG GCCAACTTCAATACATAGTCCTGCTGACCTTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTC ATCACTGCTGTCGGTCCCCTCCCTGAGCCAGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCC AAGCCCCTCCAGGAGGGTCCTGGGGTGGGCCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAAC TTGTATCTTCTCAGCAACCTTCACTTTGTCCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATG TCTGTCTTTTTGGGTCCTCAGAGAAAATGCCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTC ATCTTTGGTAGGATTCTGCCAGTTGCTTTTGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGT CCACTCTTCAACAGGAGGAACAGCATGCCACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCT >22902_22902_4_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000325385_EFHD1_chr2_233527512_ENST00000409613_length(amino acids)=525AA_BP=1 MDLERRVTLEPIMSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPK KFHEAFIPSPDGDRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEA QFDGSDSEDGHGITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKN SELFRKYALFSPSDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFS SEVLECLPQGLPWTIPPEEFSKRRDLRYDAGRDGFIDLMELKLMMEKLGAPQTHLGLKSMIKEVDEDFDGKLSFREFLLIFHKAAAGELQ -------------------------------------------------------------- >22902_22902_5_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000409307_EFHD1_chr2_233527512_ENST00000264059_length(transcript)=2604nt_BP=1124nt ATGAGCCATCCTGACTACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATTGGTGCT TCGCCAGGTGACAAAAAGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGATGTTTCA GAAGGCTTGAAGAGAGGAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCGGATGGT GATCGAGACATTTTTATTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAGGAGCAT TGGAAGGTAGTTAAACCAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACACCATCTC CCGCAACAGTCCCTGAAAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGACATGGC ATCACACAAAATGTGCTGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCGGTTACA AAAGATGAGACCACCTGCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATCTTGGAG AAAAAACATTCTCGAGCAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTTTCTCCC TCAGACCACCGAGTGCCTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAACACACTG TTCATCTGCCGCATTGTGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAAATTGAG CCTGAAACAGAAGGAATACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGCCTGCCA TGGACAATTCCACCAGAGGAGTTCAGCAAGAGAAGGGATTTAAGGTATGACGCTGGGCGGGATGGCTTCATCGACCTGATGGAGCTGAAG CTGATGATGGAGAAGCTGGGGGCCCCCCAGACCCACCTGGGCCTGAAGAGCATGATCAAGGAGGTGGATGAGGACTTCGATGGCAAGCTC AGCTTCCGGGAGTTCCTGCTCATTTTCCACAAGGCCGCGGCAGGGGAGCTGCAGGAGGACAGTGGGCTGATGGCGCTGGCAAAGCTTTCT GAGATCGATGTGGCCCTGGAGGGTGTCAAAGGTGCCAAGAACTTCTTTGAAGCCAAGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAA GCAGAGTTGAAAGCTGAGCAAGATGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAAC TTCAATACATAGTCCTGCTGACCTTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACT GCTGTCGGTCCCCTCCCTGAGCCAGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCC CTCCAGGAGGGTCCTGGGGTGGGCCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTAT CTTCTCAGCAACCTTCACTTTGTCCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTC TTTTTGGGTCCTCAGAGAAAATGCCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTT GGTAGGATTCTGCCAGTTGCTTTTGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTC TTCAACAGGAGGAACAGCATGCCACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCC TTAGCATTCCCCCAGTCCCTCCCTCTTCACCTTGCTCCGTCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGTACTACT TCACTGTAAGAACGAAAGAATAGTTAGGATACCAATGAGTAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACAGTAGAC CGCTGACGTTCCCAAGTGACAGATCCAGGGCCTTTCAAACATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAACATCTGT TTCAGGGTATCCAGCTGTAGATGTTCTTATCCCCCATACTTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTGTATTTT >22902_22902_5_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000409307_EFHD1_chr2_233527512_ENST00000264059_length(amino acids)=513AA_BP=0 MSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPKKFHEAFIPSPDG DRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEAQFDGSDSEDGHG ITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKNSELFRKYALFSP SDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFSSEVLECLPQGLP WTIPPEEFSKRRDLRYDAGRDGFIDLMELKLMMEKLGAPQTHLGLKSMIKEVDEDFDGKLSFREFLLIFHKAAAGELQEDSGLMALAKLS -------------------------------------------------------------- >22902_22902_6_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000409307_EFHD1_chr2_233527512_ENST00000409613_length(transcript)=2163nt_BP=1124nt ATGAGCCATCCTGACTACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATTGGTGCT TCGCCAGGTGACAAAAAGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGATGTTTCA GAAGGCTTGAAGAGAGGAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCGGATGGT GATCGAGACATTTTTATTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAGGAGCAT TGGAAGGTAGTTAAACCAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACACCATCTC CCGCAACAGTCCCTGAAAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGACATGGC ATCACACAAAATGTGCTGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCGGTTACA AAAGATGAGACCACCTGCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATCTTGGAG AAAAAACATTCTCGAGCAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTTTCTCCC TCAGACCACCGAGTGCCTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAACACACTG TTCATCTGCCGCATTGTGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAAATTGAG CCTGAAACAGAAGGAATACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGCCTGCCA TGGACAATTCCACCAGAGGAGTTCAGCAAGAGAAGGGATTTAAGGTATGACGCTGGGCGGGATGGCTTCATCGACCTGATGGAGCTGAAG CTGATGATGGAGAAGCTGGGGGCCCCCCAGACCCACCTGGGCCTGAAGAGCATGATCAAGGAGGTGGATGAGGACTTCGATGGCAAGCTC AGCTTCCGGGAGTTCCTGCTCATTTTCCACAAGGCCGCGGCAGGGGAGCTGCAGGAGGACAGTGGGCTGATGGCGCTGGCAAAGCTTTCT GAGATCGATGTGGCCCTGGAGGGTGTCAAAGGTGCCAAGAACTTCTTTGAAGCCAAGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAA GCAGAGTTGAAAGCTGAGCAAGATGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAAC TTCAATACATAGTCCTGCTGACCTTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACT GCTGTCGGTCCCCTCCCTGAGCCAGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCC CTCCAGGAGGGTCCTGGGGTGGGCCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTAT CTTCTCAGCAACCTTCACTTTGTCCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTC TTTTTGGGTCCTCAGAGAAAATGCCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTT GGTAGGATTCTGCCAGTTGCTTTTGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTC TTCAACAGGAGGAACAGCATGCCACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCC >22902_22902_6_DIS3L2-EFHD1_DIS3L2_chr2_233028342_ENST00000409307_EFHD1_chr2_233527512_ENST00000409613_length(amino acids)=513AA_BP=0 MSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPKKFHEAFIPSPDG DRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEAQFDGSDSEDGHG ITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKNSELFRKYALFSP SDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFSSEVLECLPQGLP WTIPPEEFSKRRDLRYDAGRDGFIDLMELKLMMEKLGAPQTHLGLKSMIKEVDEDFDGKLSFREFLLIFHKAAAGELQEDSGLMALAKLS -------------------------------------------------------------- >22902_22902_7_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000273009_EFHD1_chr2_233546294_ENST00000409708_length(transcript)=3008nt_BP=1818nt ATGCGGGGGTTGTCCATCTCTGTATCCCCAGTGCCAGCACTGCACCTCGCCCCAAGCAGTTGTCCAATAAATGAGCAGTGAGTAAATGAA AGAATGAGCAAAGCCTTGTAACAGGAAAGGGGCCGGCGGCGTCTGCCGTGCAAGACCTGGCCCAGTGGAGCAGAGCCTGGAGGTTCAGGA GCCGGGTCTGGAAGGCTCCTTCCGGTGGAAGAGGGGCCCGGAGCCAGCCGGCGCCTGGCACAAGGCGTCTCAGAGGCCGCCCACTGGGAG CCAACCGTTGCAGCCAGTTGTCCCCGCGAGCGAGGCCGGAGAAGGCGCGGCGGCCCCTGGCCTGGCCATTTCGCCCTTGTCGCAGCTGAA CCGCCGACTACGAGCTCCTGCACCGCGCACACACCCCGCGCGCTTCGCTCTCGGCCTCGCCCGGCCACCGTCGCTCTCTAGAACGCCGCG CCCGTGACCCGGAAGAGCATTCTCCTTAGCAACTGCGGGACTGCGGCGGCGCCGGCCTCCGGGGAGAAACGCGAATGACAACAGAGCTGC TCAAGGCGGGAACTCTGAGCTAAGCAGTGGAGGTTTCTCTGGATCTGGAGAGAAGAGTGACCTTGGAGCCAATAATGAGCCATCCTGACT ACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATTGGTGCTTCGCCAGGTGACAAAA AGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGATGTTTCAGAAGGCTTGAAGAGAG GAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCGGATGGTGATCGAGACATTTTTA TTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAGGAGCATTGGAAGGTAGTTAAAC CAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACACCATCTCCCGCAACAGTCCCTGA AAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGACATGGCATCACACAAAATGTGC TGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCGGTTACAAAAGATGAGACCACCT GCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATCTTGGAGAAAAAACATTCTCGAG CAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTTTCTCCCTCAGACCACCGAGTGC CTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAACACACTGTTCATCTGCCGCATTG TGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAAATTGAGCCTGAAACAGAAGGAA TACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGCCTGCCATGGACAATTCCACCAG AGGAGTTCAGCAAGAGAAGGGATTTAAGAAAAGACTGTATCTTCACCATTGACCCATCAACCGCCCGAGACCTCGATGATGCCCTCTCCT GCAAGCCACTCGCTGACGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAAGCAGAGTTGAAAGCTGAGCAAGATGAGCGGAAGCGGGAG GAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAACTTCAATACATAGTCCTGCTGACCTTGCCCTCTGCCCACA GCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACTGCTGTCGGTCCCCTCCCTGAGCCAGCATCTCCATCCACC ACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCCCTCCAGGAGGGTCCTGGGGTGGGCCAGATGCCTGCCCAC CTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTATCTTCTCAGCAACCTTCACTTTGTCCTTGTCCCTTTACCA TTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTCTTTTTGGGTCCTCAGAGAAAATGCCCATTTTCTCGGAGA ATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTTGGTAGGATTCTGCCAGTTGCTTTTGCATCTTCTGTTCCT GGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTCTTCAACAGGAGGAACAGCATGCCACCATAGTAACACACA TTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCCTTAGCATTCCCCCAGTCCCTCCCTCTTCACCTTGCTCCG TCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGTACTACTTCACTGTAAGAACGAAAGAATAGTTAGGATACCAATGAG TAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACAGTAGACCGCTGACGTTCCCAAGTGACAGATCCAGGGCCTTTCAAA CATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAACATCTGTTTCAGGGTATCCAGCTGTAGATGTTCTTATCCCCCATAC TTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTGTATTTTTAACAAATATATCCTAATGTCATATTTATTCTCTTTTGT >22902_22902_7_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000273009_EFHD1_chr2_233546294_ENST00000409708_length(amino acids)=421AA_BP= MDLERRVTLEPIMSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPK KFHEAFIPSPDGDRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEA QFDGSDSEDGHGITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKN SELFRKYALFSPSDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFS -------------------------------------------------------------- >22902_22902_8_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000273009_EFHD1_chr2_233546295_ENST00000409708_length(transcript)=3008nt_BP=1818nt ATGCGGGGGTTGTCCATCTCTGTATCCCCAGTGCCAGCACTGCACCTCGCCCCAAGCAGTTGTCCAATAAATGAGCAGTGAGTAAATGAA AGAATGAGCAAAGCCTTGTAACAGGAAAGGGGCCGGCGGCGTCTGCCGTGCAAGACCTGGCCCAGTGGAGCAGAGCCTGGAGGTTCAGGA GCCGGGTCTGGAAGGCTCCTTCCGGTGGAAGAGGGGCCCGGAGCCAGCCGGCGCCTGGCACAAGGCGTCTCAGAGGCCGCCCACTGGGAG CCAACCGTTGCAGCCAGTTGTCCCCGCGAGCGAGGCCGGAGAAGGCGCGGCGGCCCCTGGCCTGGCCATTTCGCCCTTGTCGCAGCTGAA CCGCCGACTACGAGCTCCTGCACCGCGCACACACCCCGCGCGCTTCGCTCTCGGCCTCGCCCGGCCACCGTCGCTCTCTAGAACGCCGCG CCCGTGACCCGGAAGAGCATTCTCCTTAGCAACTGCGGGACTGCGGCGGCGCCGGCCTCCGGGGAGAAACGCGAATGACAACAGAGCTGC TCAAGGCGGGAACTCTGAGCTAAGCAGTGGAGGTTTCTCTGGATCTGGAGAGAAGAGTGACCTTGGAGCCAATAATGAGCCATCCTGACT ACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATTGGTGCTTCGCCAGGTGACAAAA AGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGATGTTTCAGAAGGCTTGAAGAGAG GAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCGGATGGTGATCGAGACATTTTTA TTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAGGAGCATTGGAAGGTAGTTAAAC CAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACACCATCTCCCGCAACAGTCCCTGA AAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGACATGGCATCACACAAAATGTGC TGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCGGTTACAAAAGATGAGACCACCT GCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATCTTGGAGAAAAAACATTCTCGAG CAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTTTCTCCCTCAGACCACCGAGTGC CTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAACACACTGTTCATCTGCCGCATTG TGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAAATTGAGCCTGAAACAGAAGGAA TACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGCCTGCCATGGACAATTCCACCAG AGGAGTTCAGCAAGAGAAGGGATTTAAGAAAAGACTGTATCTTCACCATTGACCCATCAACCGCCCGAGACCTCGATGATGCCCTCTCCT GCAAGCCACTCGCTGACGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAAGCAGAGTTGAAAGCTGAGCAAGATGAGCGGAAGCGGGAG GAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAACTTCAATACATAGTCCTGCTGACCTTGCCCTCTGCCCACA GCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACTGCTGTCGGTCCCCTCCCTGAGCCAGCATCTCCATCCACC ACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCCCTCCAGGAGGGTCCTGGGGTGGGCCAGATGCCTGCCCAC CTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTATCTTCTCAGCAACCTTCACTTTGTCCTTGTCCCTTTACCA TTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTCTTTTTGGGTCCTCAGAGAAAATGCCCATTTTCTCGGAGA ATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTTGGTAGGATTCTGCCAGTTGCTTTTGCATCTTCTGTTCCT GGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTCTTCAACAGGAGGAACAGCATGCCACCATAGTAACACACA TTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCCTTAGCATTCCCCCAGTCCCTCCCTCTTCACCTTGCTCCG TCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGTACTACTTCACTGTAAGAACGAAAGAATAGTTAGGATACCAATGAG TAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACAGTAGACCGCTGACGTTCCCAAGTGACAGATCCAGGGCCTTTCAAA CATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAACATCTGTTTCAGGGTATCCAGCTGTAGATGTTCTTATCCCCCATAC TTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTGTATTTTTAACAAATATATCCTAATGTCATATTTATTCTCTTTTGT >22902_22902_8_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000273009_EFHD1_chr2_233546295_ENST00000409708_length(amino acids)=421AA_BP= MDLERRVTLEPIMSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPK KFHEAFIPSPDGDRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEA QFDGSDSEDGHGITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKN SELFRKYALFSPSDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFS -------------------------------------------------------------- >22902_22902_9_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000325385_EFHD1_chr2_233546294_ENST00000409708_length(transcript)=2670nt_BP=1480nt TTTCGCCCTTGTCGCAGCTGAACCGCCGACTACGAGCTCCTGCACCGCGCACACACCCCGCGCGCTTCGCTCTCGGCCTCGCCCGGCCAC CGTCGCTCTCTAGAACGCCGCGCCCGTGACCCGGAAGAGCATTCTCCTTAGCAACTGCGGGACTGCGGCGGCGCCGGCCTCCGGGGAGAA ACGCGAATGACAACAGAGCTGCTCAAGGCGGGAACTCTGAGCTAAGCAGTGGAGGTTTCTCTGGATCTGGAGAGAAGAGTGACCTTGGAG CCAATAATGAGCCATCCTGACTACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATT GGTGCTTCGCCAGGTGACAAAAAGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGAT GTTTCAGAAGGCTTGAAGAGAGGAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCG GATGGTGATCGAGACATTTTTATTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAG GAGCATTGGAAGGTAGTTAAACCAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACAC CATCTCCCGCAACAGTCCCTGAAAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGA CATGGCATCACACAAAATGTGCTGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCG GTTACAAAAGATGAGACCACCTGCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATC TTGGAGAAAAAACATTCTCGAGCAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTT TCTCCCTCAGACCACCGAGTGCCTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAAC ACACTGTTCATCTGCCGCATTGTGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAA ATTGAGCCTGAAACAGAAGGAATACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGC CTGCCATGGACAATTCCACCAGAGGAGTTCAGCAAGAGAAGGGATTTAAGAAAAGACTGTATCTTCACCATTGACCCATCAACCGCCCGA GACCTCGATGATGCCCTCTCCTGCAAGCCACTCGCTGACGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAAGCAGAGTTGAAAGCTGA GCAAGATGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAACTTCAATACATAGTCCTG CTGACCTTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACTGCTGTCGGTCCCCTCCC TGAGCCAGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCCCTCCAGGAGGGTCCTGG GGTGGGCCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTATCTTCTCAGCAACCTTCA CTTTGTCCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTCTTTTTGGGTCCTCAGAG AAAATGCCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTTGGTAGGATTCTGCCAGT TGCTTTTGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTCTTCAACAGGAGGAACAG CATGCCACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCCTTAGCATTCCCCCAGTC CCTCCCTCTTCACCTTGCTCCGTCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGTACTACTTCACTGTAAGAACGAAA GAATAGTTAGGATACCAATGAGTAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACAGTAGACCGCTGACGTTCCCAAGT GACAGATCCAGGGCCTTTCAAACATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAACATCTGTTTCAGGGTATCCAGCTG TAGATGTTCTTATCCCCCATACTTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTGTATTTTTAACAAATATATCCTAA >22902_22902_9_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000325385_EFHD1_chr2_233546294_ENST00000409708_length(amino acids)=421AA_BP= MDLERRVTLEPIMSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPK KFHEAFIPSPDGDRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEA QFDGSDSEDGHGITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKN SELFRKYALFSPSDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFS -------------------------------------------------------------- >22902_22902_10_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000325385_EFHD1_chr2_233546295_ENST00000409708_length(transcript)=2670nt_BP=1480nt TTTCGCCCTTGTCGCAGCTGAACCGCCGACTACGAGCTCCTGCACCGCGCACACACCCCGCGCGCTTCGCTCTCGGCCTCGCCCGGCCAC CGTCGCTCTCTAGAACGCCGCGCCCGTGACCCGGAAGAGCATTCTCCTTAGCAACTGCGGGACTGCGGCGGCGCCGGCCTCCGGGGAGAA ACGCGAATGACAACAGAGCTGCTCAAGGCGGGAACTCTGAGCTAAGCAGTGGAGGTTTCTCTGGATCTGGAGAGAAGAGTGACCTTGGAG CCAATAATGAGCCATCCTGACTACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATT GGTGCTTCGCCAGGTGACAAAAAGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGAT GTTTCAGAAGGCTTGAAGAGAGGAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCG GATGGTGATCGAGACATTTTTATTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAG GAGCATTGGAAGGTAGTTAAACCAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACAC CATCTCCCGCAACAGTCCCTGAAAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGA CATGGCATCACACAAAATGTGCTGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCG GTTACAAAAGATGAGACCACCTGCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATC TTGGAGAAAAAACATTCTCGAGCAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTT TCTCCCTCAGACCACCGAGTGCCTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAAC ACACTGTTCATCTGCCGCATTGTGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAA ATTGAGCCTGAAACAGAAGGAATACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGC CTGCCATGGACAATTCCACCAGAGGAGTTCAGCAAGAGAAGGGATTTAAGAAAAGACTGTATCTTCACCATTGACCCATCAACCGCCCGA GACCTCGATGATGCCCTCTCCTGCAAGCCACTCGCTGACGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAAGCAGAGTTGAAAGCTGA GCAAGATGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAACTTCAATACATAGTCCTG CTGACCTTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACTGCTGTCGGTCCCCTCCC TGAGCCAGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCCCTCCAGGAGGGTCCTGG GGTGGGCCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTATCTTCTCAGCAACCTTCA CTTTGTCCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTCTTTTTGGGTCCTCAGAG AAAATGCCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTTGGTAGGATTCTGCCAGT TGCTTTTGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTCTTCAACAGGAGGAACAG CATGCCACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCCTTAGCATTCCCCCAGTC CCTCCCTCTTCACCTTGCTCCGTCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGTACTACTTCACTGTAAGAACGAAA GAATAGTTAGGATACCAATGAGTAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACAGTAGACCGCTGACGTTCCCAAGT GACAGATCCAGGGCCTTTCAAACATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAACATCTGTTTCAGGGTATCCAGCTG TAGATGTTCTTATCCCCCATACTTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTGTATTTTTAACAAATATATCCTAA >22902_22902_10_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000325385_EFHD1_chr2_233546295_ENST00000409708_length(amino acids)=421AA_BP= MDLERRVTLEPIMSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPK KFHEAFIPSPDGDRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEA QFDGSDSEDGHGITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKN SELFRKYALFSPSDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFS -------------------------------------------------------------- >22902_22902_11_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000409307_EFHD1_chr2_233546294_ENST00000409708_length(transcript)=2394nt_BP=1204nt ATGAGCCATCCTGACTACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATTGGTGCT TCGCCAGGTGACAAAAAGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGATGTTTCA GAAGGCTTGAAGAGAGGAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCGGATGGT GATCGAGACATTTTTATTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAGGAGCAT TGGAAGGTAGTTAAACCAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACACCATCTC CCGCAACAGTCCCTGAAAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGACATGGC ATCACACAAAATGTGCTGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCGGTTACA AAAGATGAGACCACCTGCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATCTTGGAG AAAAAACATTCTCGAGCAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTTTCTCCC TCAGACCACCGAGTGCCTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAACACACTG TTCATCTGCCGCATTGTGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAAATTGAG CCTGAAACAGAAGGAATACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGCCTGCCA TGGACAATTCCACCAGAGGAGTTCAGCAAGAGAAGGGATTTAAGAAAAGACTGTATCTTCACCATTGACCCATCAACCGCCCGAGACCTC GATGATGCCCTCTCCTGCAAGCCACTCGCTGACGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAAGCAGAGTTGAAAGCTGAGCAAGA TGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAACTTCAATACATAGTCCTGCTGACC TTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACTGCTGTCGGTCCCCTCCCTGAGCC AGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCCCTCCAGGAGGGTCCTGGGGTGGG CCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTATCTTCTCAGCAACCTTCACTTTGT CCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTCTTTTTGGGTCCTCAGAGAAAATG CCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTTGGTAGGATTCTGCCAGTTGCTTT TGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTCTTCAACAGGAGGAACAGCATGCC ACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCCTTAGCATTCCCCCAGTCCCTCCC TCTTCACCTTGCTCCGTCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGTACTACTTCACTGTAAGAACGAAAGAATAG TTAGGATACCAATGAGTAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACAGTAGACCGCTGACGTTCCCAAGTGACAGA TCCAGGGCCTTTCAAACATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAACATCTGTTTCAGGGTATCCAGCTGTAGATG TTCTTATCCCCCATACTTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTGTATTTTTAACAAATATATCCTAATGTCAT >22902_22902_11_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000409307_EFHD1_chr2_233546294_ENST00000409708_length(amino acids)=409AA_BP= MSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPKKFHEAFIPSPDG DRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEAQFDGSDSEDGHG ITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKNSELFRKYALFSP SDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFSSEVLECLPQGLP -------------------------------------------------------------- >22902_22902_12_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000409307_EFHD1_chr2_233546295_ENST00000409708_length(transcript)=2394nt_BP=1204nt ATGAGCCATCCTGACTACAGAATGAACCTCCGGCCCCTGGGGACCCCCAGAGGTGTGTCTGCTGTGGCTGGTCCACATGACATTGGTGCT TCGCCAGGTGACAAAAAGTCAAAGAACAGGTCCACACGAGGGAAGAAAAAGAGCATATTTGAAACTTACATGTCCAAGGAGGATGTTTCA GAAGGCTTGAAGAGAGGAACACTCATCCAGGGTGTATTGAGAATTAATCCAAAGAAGTTTCATGAAGCCTTCATTCCTTCCCCGGATGGT GATCGAGACATTTTTATTGATGGGGTTGTTGCTCGTAATAGAGCCTTAAATGGGGATCTGGTGGTCGTGAAACTGCTTCCCGAGGAGCAT TGGAAGGTAGTTAAACCAGAGAGCAATGACAAAGAAACAGAAGCTGCGTATGAATCAGATATCCCCGAGGAGCTCTGTGGACACCATCTC CCGCAACAGTCCCTGAAAAGCTATAATGACAGTCCTGATGTCATTGTAGAGGCTCAGTTTGATGGCAGCGACTCAGAAGATGGACATGGC ATCACACAAAATGTGCTGGTTGATGGTGTTAAGAAACTCTCAGTTTGTGTTTCTGAGAAAGGAAGAGAGGATGGTGATGCACCGGTTACA AAAGATGAGACCACCTGCATTTCACAAGACACAAGAGCTTTATCGGAGAAATCCCTGCAAAGATCAGCAAAGGTGGTTTACATCTTGGAG AAAAAACATTCTCGAGCAGCAACCGGCTTCCTCAAACTCTTGGCTGATAAGAACAGCGAACTGTTTAGGAAATACGCCCTGTTTTCTCCC TCAGACCACCGAGTGCCTAGAATTTATGTGCCTCTCAAGGACTGTCCCCAGGACTTTGTGGCACGGCCTAAAGATTATGCCAACACACTG TTCATCTGCCGCATTGTGGACTGGAAGGAGGACTGCAATTTTGCCCTGGGGCAGCTGGCTAAGAGTCTTGGGCAGGCTGGTGAAATTGAG CCTGAAACAGAAGGAATACTAACAGAGTATGGCGTGGATTTCTCTGATTTCTCTTCAGAAGTTCTAGAATGTCTTCCTCAAGGCCTGCCA TGGACAATTCCACCAGAGGAGTTCAGCAAGAGAAGGGATTTAAGAAAAGACTGTATCTTCACCATTGACCCATCAACCGCCCGAGACCTC GATGATGCCCTCTCCTGCAAGCCACTCGCTGACGGTCCAAGCCTTGTCATCGGCCAGTAAGTTTGAAGCAGAGTTGAAAGCTGAGCAAGA TGAGCGGAAGCGGGAGGAGGAGGAGAGGCGGCTCCGCCAGGCAGCCTTCCAGAAACTCAAGGCCAACTTCAATACATAGTCCTGCTGACC TTGCCCTCTGCCCACAGCTGTGCCTCACAGATGCCCCGAGAAGAGATGACTAGGCATCTTCATCACTGCTGTCGGTCCCCTCCCTGAGCC AGCATCTCCATCCACCACCCCGTGCCAGCTCCCGTGCCAGCCTTCATTCCTCCCAGTGTCCAAGCCCCTCCAGGAGGGTCCTGGGGTGGG CCAGATGCCTGCCCACCTCTGTCTCCTGCCTCTGCTCCTCTGCCCTTCTTATAGCCAGAACTTGTATCTTCTCAGCAACCTTCACTTTGT CCTTGTCCCTTTACCATTCCCCATCAAAGAGTAGTCTGCTATATCAATTTGTGTAGATATGTCTGTCTTTTTGGGTCCTCAGAGAAAATG CCCATTTTCTCGGAGAATTCTCTGCACTCCTCTCTGCTTCACATTCAACTTCCCTGTTCTCATCTTTGGTAGGATTCTGCCAGTTGCTTT TGCATCTTCTGTTCCTGGGTAATGGTGGGTCTTAATGGAGGCTGGGTGGACCACTGCCCGTCCACTCTTCAACAGGAGGAACAGCATGCC ACCATAGTAACACACATTAGAGAAAGGACAGAGGTCTGCTCCTTCCTGCCACCTTTCTCCTGGCCCCTTAGCATTCCCCCAGTCCCTCCC TCTTCACCTTGCTCCGTCTATGTCTTCCCAGCTCAGCCTTTTCCCCACTCTTAAATACTGTACTACTTCACTGTAAGAACGAAAGAATAG TTAGGATACCAATGAGTAAAAGGGTTCCTGTTCACTCTGACTCTGTGCAAATTGTATTACAGTAGACCGCTGACGTTCCCAAGTGACAGA TCCAGGGCCTTTCAAACATCCCCAAAGTCATGGCCATACTCACCATTAGCCAGTTTCTAACATCTGTTTCAGGGTATCCAGCTGTAGATG TTCTTATCCCCCATACTTGTGAGTTCTTGGGGTTGCTCACAAATACTAGGGGTTTTTGTTGTATTTTTAACAAATATATCCTAATGTCAT >22902_22902_12_DIS3L2-EFHD1_DIS3L2_chr2_233075115_ENST00000409307_EFHD1_chr2_233546295_ENST00000409708_length(amino acids)=409AA_BP= MSHPDYRMNLRPLGTPRGVSAVAGPHDIGASPGDKKSKNRSTRGKKKSIFETYMSKEDVSEGLKRGTLIQGVLRINPKKFHEAFIPSPDG DRDIFIDGVVARNRALNGDLVVVKLLPEEHWKVVKPESNDKETEAAYESDIPEELCGHHLPQQSLKSYNDSPDVIVEAQFDGSDSEDGHG ITQNVLVDGVKKLSVCVSEKGREDGDAPVTKDETTCISQDTRALSEKSLQRSAKVVYILEKKHSRAATGFLKLLADKNSELFRKYALFSP SDHRVPRIYVPLKDCPQDFVARPKDYANTLFICRIVDWKEDCNFALGQLAKSLGQAGEIEPETEGILTEYGVDFSDFSSEVLECLPQGLP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DIS3L2-EFHD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DIS3L2-EFHD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DIS3L2-EFHD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies