
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DNM2-ANGPTL4 (FusionGDB2 ID:23631) |
Fusion Gene Summary for DNM2-ANGPTL4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DNM2-ANGPTL4 | Fusion gene ID: 23631 | Hgene | Tgene | Gene symbol | DNM2 | ANGPTL4 | Gene ID | 1785 | 51129 |
| Gene name | dynamin 2 | angiopoietin like 4 | |
| Synonyms | CMT2M|CMTDI1|CMTDIB|DI-CMTB|DYN2|DYNII|LCCS5 | ARP4|FIAF|HARP|HFARP|NL2|PGAR|TGQTL|UNQ171|pp1158 | |
| Cytomap | 19p13.2 | 19p13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | dynamin-2dynamin II | angiopoietin-related protein 4PPARG angiopoietin related proteinfasting-induced adipose factorhepatic angiopoietin-related proteinhepatic fibrinogen/angiopoietin-related proteinperoxisome proliferator-activated receptor (PPAR) gamma induced angiopoie | |
| Modification date | 20200329 | 20200322 | |
| UniProtAcc | P50570 | Q9BY76 | |
| Ensembl transtripts involved in fusion gene | ENST00000314646, ENST00000355667, ENST00000359692, ENST00000389253, ENST00000408974, ENST00000585892, ENST00000591819, | ENST00000541807, ENST00000301455, ENST00000393962, | |
| Fusion gene scores | * DoF score | 36 X 17 X 17=10404 | 4 X 4 X 3=48 |
| # samples | 49 | 6 | |
| ** MAII score | log2(49/10404*10)=-4.40821274494042 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/48*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: DNM2 [Title/Abstract] AND ANGPTL4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DNM2(10829079)-ANGPTL4(8438589), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | DNM2-ANGPTL4 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. DNM2-ANGPTL4 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. DNM2-ANGPTL4 seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. DNM2-ANGPTL4 seems lost the major protein functional domain in Tgene partner, which is a tumor suppressor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | DNM2 | GO:1903526 | negative regulation of membrane tubulation | 18388313 |
| Tgene | ANGPTL4 | GO:0043066 | negative regulation of apoptotic process | 10698685 |
| Tgene | ANGPTL4 | GO:0043335 | protein unfolding | 29899144 |
| Tgene | ANGPTL4 | GO:0051005 | negative regulation of lipoprotein lipase activity | 19542565|29899144 |
| Fusion gene breakpoints across DNM2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
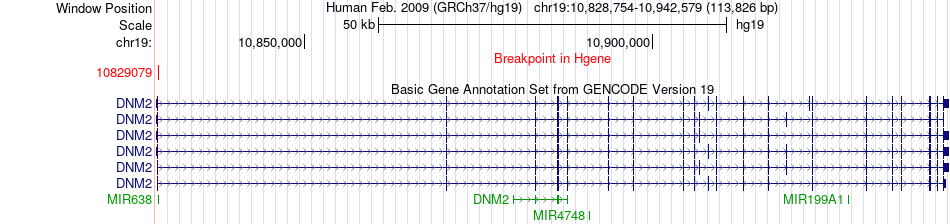 |
| Fusion gene breakpoints across ANGPTL4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LIHC | TCGA-KR-A7K8-01A | DNM2 | chr19 | 10829079 | - | ANGPTL4 | chr19 | 8438589 | + |
| ChimerDB4 | LIHC | TCGA-KR-A7K8-01A | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
Top |
Fusion Gene ORF analysis for DNM2-ANGPTL4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000314646 | ENST00000541807 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| Frame-shift | ENST00000355667 | ENST00000541807 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| Frame-shift | ENST00000359692 | ENST00000541807 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| Frame-shift | ENST00000389253 | ENST00000541807 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| Frame-shift | ENST00000408974 | ENST00000541807 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| Frame-shift | ENST00000585892 | ENST00000541807 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000314646 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000314646 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000355667 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000355667 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000359692 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000359692 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000389253 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000389253 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000408974 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000408974 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000585892 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| In-frame | ENST00000585892 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| intron-3CDS | ENST00000591819 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| intron-3CDS | ENST00000591819 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| intron-3CDS | ENST00000591819 | ENST00000541807 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000585892 | DNM2 | chr19 | 10829079 | + | ENST00000301455 | ANGPTL4 | chr19 | 8438589 | + | 994 | 325 | 722 | 222 | 166 |
| ENST00000585892 | DNM2 | chr19 | 10829079 | + | ENST00000393962 | ANGPTL4 | chr19 | 8438589 | + | 952 | 325 | 722 | 222 | 166 |
| ENST00000314646 | DNM2 | chr19 | 10829079 | + | ENST00000301455 | ANGPTL4 | chr19 | 8438589 | + | 994 | 325 | 722 | 222 | 166 |
| ENST00000314646 | DNM2 | chr19 | 10829079 | + | ENST00000393962 | ANGPTL4 | chr19 | 8438589 | + | 952 | 325 | 722 | 222 | 166 |
| ENST00000359692 | DNM2 | chr19 | 10829079 | + | ENST00000301455 | ANGPTL4 | chr19 | 8438589 | + | 980 | 311 | 708 | 208 | 166 |
| ENST00000359692 | DNM2 | chr19 | 10829079 | + | ENST00000393962 | ANGPTL4 | chr19 | 8438589 | + | 938 | 311 | 708 | 208 | 166 |
| ENST00000389253 | DNM2 | chr19 | 10829079 | + | ENST00000301455 | ANGPTL4 | chr19 | 8438589 | + | 942 | 273 | 670 | 170 | 166 |
| ENST00000389253 | DNM2 | chr19 | 10829079 | + | ENST00000393962 | ANGPTL4 | chr19 | 8438589 | + | 900 | 273 | 670 | 170 | 166 |
| ENST00000355667 | DNM2 | chr19 | 10829079 | + | ENST00000301455 | ANGPTL4 | chr19 | 8438589 | + | 910 | 241 | 638 | 138 | 166 |
| ENST00000355667 | DNM2 | chr19 | 10829079 | + | ENST00000393962 | ANGPTL4 | chr19 | 8438589 | + | 868 | 241 | 638 | 138 | 166 |
| ENST00000408974 | DNM2 | chr19 | 10829079 | + | ENST00000301455 | ANGPTL4 | chr19 | 8438589 | + | 865 | 196 | 593 | 93 | 166 |
| ENST00000408974 | DNM2 | chr19 | 10829079 | + | ENST00000393962 | ANGPTL4 | chr19 | 8438589 | + | 823 | 196 | 593 | 93 | 166 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000585892 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.09391931 | 0.90608066 |
| ENST00000585892 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.0859272 | 0.9140728 |
| ENST00000314646 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.09391931 | 0.90608066 |
| ENST00000314646 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.0859272 | 0.9140728 |
| ENST00000359692 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.09326565 | 0.9067343 |
| ENST00000359692 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.088728085 | 0.9112719 |
| ENST00000389253 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.13065165 | 0.86934835 |
| ENST00000389253 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.10639691 | 0.8936031 |
| ENST00000355667 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.065849975 | 0.93415 |
| ENST00000355667 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.07143659 | 0.92856336 |
| ENST00000408974 | ENST00000301455 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.12291417 | 0.8770858 |
| ENST00000408974 | ENST00000393962 | DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438589 | + | 0.12674887 | 0.8732511 |
Top |
Fusion Genomic Features for DNM2-ANGPTL4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438588 | + | 1.35E-10 | 1 |
| DNM2 | chr19 | 10829079 | + | ANGPTL4 | chr19 | 8438588 | + | 1.35E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
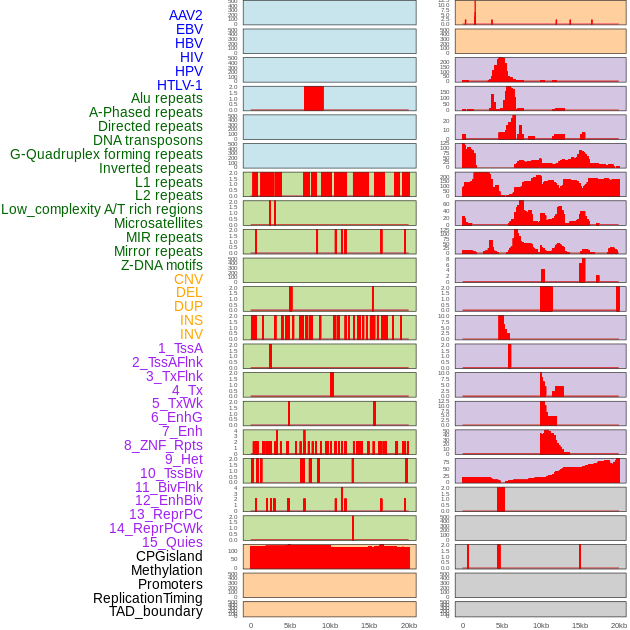 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
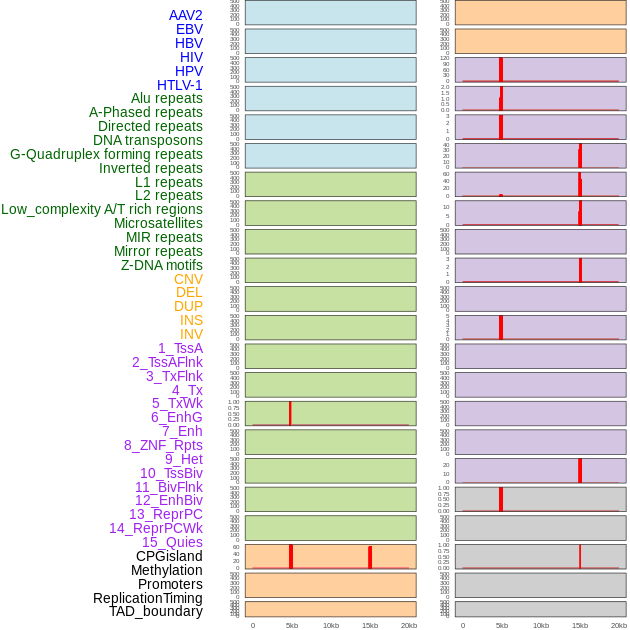 |
Top |
Fusion Protein Features for DNM2-ANGPTL4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:10829079/chr19:8438589) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DNM2 | ANGPTL4 |
| FUNCTION: Microtubule-associated force-producing protein involved in producing microtubule bundles and able to bind and hydrolyze GTP. Plays a role in the regulation of neuron morphology, axon growth and formation of neuronal growth cones (By similarity). Plays an important role in vesicular trafficking processes, in particular endocytosis. Involved in cytokinesis (PubMed:12498685). Regulates maturation of apoptotic cell corpse-containing phagosomes by recruiting PIK3C3 to the phagosome membrane (By similarity). {ECO:0000250|UniProtKB:P39052, ECO:0000250|UniProtKB:P39054, ECO:0000269|PubMed:12498685}. | FUNCTION: Mediates inactivation of the lipoprotein lipase LPL, and thereby plays a role in the regulation of triglyceride clearance from the blood serum and in lipid metabolism (PubMed:19270337, PubMed:21398697, PubMed:27929370, PubMed:29899144). May also play a role in regulating glucose homeostasis and insulin sensitivity (Probable). Inhibits proliferation, migration, and tubule formation of endothelial cells and reduces vascular leakage (PubMed:14583458, PubMed:17068295). Upon heterologous expression, inhibits the adhesion of endothelial cell to the extracellular matrix (ECM), and inhibits the reorganization of the actin cytoskeleton, formation of actin stress fibers and focal adhesions in endothelial cells that have adhered to ANGPTL4-containing ECM (in vitro) (PubMed:17068295). Depending on context, may modulate tumor-related angiogenesis (By similarity). {ECO:0000250|UniProtKB:Q9Z1P8, ECO:0000269|PubMed:14583458, ECO:0000269|PubMed:17068295, ECO:0000269|PubMed:19270337, ECO:0000269|PubMed:21398697, ECO:0000269|PubMed:27929370, ECO:0000269|PubMed:29899144, ECO:0000305|PubMed:29899519}.; FUNCTION: [ANGPTL4 N-terminal chain]: Mediates inactivation of the lipoprotein lipase LPL, and thereby plays an important role in the regulation of triglyceride clearance from the blood serum and in lipid metabolism (PubMed:19270337, PubMed:21398697, PubMed:27929370, PubMed:29899144). Has higher activity in LPL inactivation than the uncleaved protein (PubMed:19270337, PubMed:21398697). {ECO:0000269|PubMed:19270337, ECO:0000269|PubMed:21398697, ECO:0000269|PubMed:27929370, ECO:0000269|PubMed:29899144}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 38_46 | 53 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 38_46 | 53 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 38_46 | 53 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 38_46 | 53 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 38_46 | 53 | 870.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 38_45 | 53 | 871.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 38_45 | 53 | 867.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 38_45 | 53 | 871.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 38_45 | 53 | 867.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 38_45 | 53 | 870.0 | Region | G1 motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 747_866 | 53 | 871.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 747_866 | 53 | 867.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 747_866 | 53 | 871.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 747_866 | 53 | 867.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 747_866 | 53 | 870.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 28_294 | 53 | 871.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 519_625 | 53 | 871.0 | Domain | PH |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 653_744 | 53 | 871.0 | Domain | GED |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 28_294 | 53 | 867.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 519_625 | 53 | 867.0 | Domain | PH |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 653_744 | 53 | 867.0 | Domain | GED |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 28_294 | 53 | 871.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 519_625 | 53 | 871.0 | Domain | PH |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 653_744 | 53 | 871.0 | Domain | GED |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 28_294 | 53 | 867.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 519_625 | 53 | 867.0 | Domain | PH |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 653_744 | 53 | 867.0 | Domain | GED |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 28_294 | 53 | 870.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 519_625 | 53 | 870.0 | Domain | PH |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 653_744 | 53 | 870.0 | Domain | GED |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 205_211 | 53 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 236_239 | 53 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 205_211 | 53 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 236_239 | 53 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 205_211 | 53 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 236_239 | 53 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 205_211 | 53 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 236_239 | 53 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 205_211 | 53 | 870.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 236_239 | 53 | 870.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 136_139 | 53 | 871.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 205_208 | 53 | 871.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 235_238 | 53 | 871.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000355667 | + | 1 | 21 | 64_66 | 53 | 871.0 | Region | G2 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 136_139 | 53 | 867.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 205_208 | 53 | 867.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 235_238 | 53 | 867.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000359692 | + | 1 | 20 | 64_66 | 53 | 867.0 | Region | G2 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 136_139 | 53 | 871.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 205_208 | 53 | 871.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 235_238 | 53 | 871.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000389253 | + | 1 | 21 | 64_66 | 53 | 871.0 | Region | G2 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 136_139 | 53 | 867.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 205_208 | 53 | 867.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 235_238 | 53 | 867.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000408974 | + | 1 | 20 | 64_66 | 53 | 867.0 | Region | G2 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 136_139 | 53 | 870.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 205_208 | 53 | 870.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 235_238 | 53 | 870.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10829079 | chr19:8438589 | ENST00000585892 | + | 1 | 21 | 64_66 | 53 | 870.0 | Region | G2 motif |
| Tgene | ANGPTL4 | chr19:10829079 | chr19:8438589 | ENST00000301455 | 5 | 7 | 100_143 | 346 | 407.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | ANGPTL4 | chr19:10829079 | chr19:8438589 | ENST00000393962 | 4 | 6 | 100_143 | 308 | 369.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | ANGPTL4 | chr19:10829079 | chr19:8438589 | ENST00000301455 | 5 | 7 | 179_401 | 346 | 407.0 | Domain | Fibrinogen C-terminal | |
| Tgene | ANGPTL4 | chr19:10829079 | chr19:8438589 | ENST00000393962 | 4 | 6 | 179_401 | 308 | 369.0 | Domain | Fibrinogen C-terminal |
Top |
Fusion Gene Sequence for DNM2-ANGPTL4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >23631_23631_1_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000314646_ANGPTL4_chr19_8438589_ENST00000301455_length(transcript)=994nt_BP=325nt GAGAACCGGATGAGGCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACG CCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGA TGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTG TAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAAC CTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTAC CCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAA AGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACA GAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCT CAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGC CAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTG TTGTGTGTAGGTCCCCTGGGGACACAAGCAGGCGCCAATGGTATCTGGGCGGAGCTCACAGAGTTCTTGGAATAAAAGCAACCTCAGAAC >23631_23631_1_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000314646_ANGPTL4_chr19_8438589_ENST00000301455_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_2_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000314646_ANGPTL4_chr19_8438589_ENST00000393962_length(transcript)=952nt_BP=325nt GAGAACCGGATGAGGCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACG CCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGA TGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTG TAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAAC CTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTAC CCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAA AGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACA GAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCT CAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGC CAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTG >23631_23631_2_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000314646_ANGPTL4_chr19_8438589_ENST00000393962_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_3_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000355667_ANGPTL4_chr19_8438589_ENST00000301455_length(transcript)=910nt_BP=241nt CAGACGCCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACC GCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGA TCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCAT TCCAACCTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGC TACTACCCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCC CACGAAAGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTG TGGACAGAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGA TATGCTCAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGG GCCAGCCAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTG GTGCTGTTGTGTGTAGGTCCCCTGGGGACACAAGCAGGCGCCAATGGTATCTGGGCGGAGCTCACAGAGTTCTTGGAATAAAAGCAACCT >23631_23631_3_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000355667_ANGPTL4_chr19_8438589_ENST00000301455_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_4_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000355667_ANGPTL4_chr19_8438589_ENST00000393962_length(transcript)=868nt_BP=241nt CAGACGCCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACC GCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGA TCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCAT TCCAACCTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGC TACTACCCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCC CACGAAAGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTG TGGACAGAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGA TATGCTCAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGG GCCAGCCAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTG >23631_23631_4_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000355667_ANGPTL4_chr19_8438589_ENST00000393962_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_5_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000359692_ANGPTL4_chr19_8438589_ENST00000301455_length(transcript)=980nt_BP=311nt GCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACGCCGCGGGGCCAGGT CGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATC CCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAG AGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAACCTCAACGGCCAGTA CTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTACCCGCTGCAGGCCAC CACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAAAGACGGTGACTCTT GGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACAGAGAAGAAGACCAC GACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCTCAGACTCTAGAGGC GTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGCCAGACTGGCCTCAA TGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTGTTGTGTGTAGGTCC >23631_23631_5_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000359692_ANGPTL4_chr19_8438589_ENST00000301455_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_6_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000359692_ANGPTL4_chr19_8438589_ENST00000393962_length(transcript)=938nt_BP=311nt GCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACGCCGCGGGGCCAGGT CGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATC CCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAG AGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAACCTCAACGGCCAGTA CTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTACCCGCTGCAGGCCAC CACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAAAGACGGTGACTCTT GGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACAGAGAAGAAGACCAC GACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCTCAGACTCTAGAGGC GTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGCCAGACTGGCCTCAA TGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTGTTGTGTGTAGGTCC >23631_23631_6_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000359692_ANGPTL4_chr19_8438589_ENST00000393962_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_7_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000389253_ANGPTL4_chr19_8438589_ENST00000301455_length(transcript)=942nt_BP=273nt CCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACGCCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCT CGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCAT CGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGG CCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAACCTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGA AGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTACCCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCT CCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAAAGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCA GGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACAGAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGC ATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCTCAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCC AGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGCCAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGC TTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTGTTGTGTGTAGGTCCCCTGGGGACACAAGCAGGCGCCAATGGTATCTGGGCGG >23631_23631_7_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000389253_ANGPTL4_chr19_8438589_ENST00000301455_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_8_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000389253_ANGPTL4_chr19_8438589_ENST00000393962_length(transcript)=900nt_BP=273nt CCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACGCCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCT CGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCAT CGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGG CCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAACCTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGA AGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTACCCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCT CCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAAAGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCA GGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACAGAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGC ATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCTCAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCC AGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGCCAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGC TTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTGTTGTGTGTAGGTCCCCTGGGGACACAAGCAGGCGCCAATGGTATCTGGGCGG >23631_23631_8_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000389253_ANGPTL4_chr19_8438589_ENST00000393962_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_9_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000408974_ANGPTL4_chr19_8438589_ENST00000301455_length(transcript)=865nt_BP=196nt AGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACG CCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGG AGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAACCTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGG CAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTACCCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCA GCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAAAGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTT CCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACAGAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGT GCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCTCAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCA CTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGCCAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGA CGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTGTTGTGTGTAGGTCCCCTGGGGACACAAGCAGGCGCCAAT >23631_23631_9_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000408974_ANGPTL4_chr19_8438589_ENST00000301455_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_10_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000408974_ANGPTL4_chr19_8438589_ENST00000393962_length(transcript)=823nt_BP=196nt AGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACG CCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGG AGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAACCTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGG CAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTACCCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCA GCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAAAGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTT CCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACAGAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGT GCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCTCAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCA CTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGCCAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGA CGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTGTTGTGTGTAGGTCCCCTGGGGACACAAGCAGGCGCCAAT >23631_23631_10_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000408974_ANGPTL4_chr19_8438589_ENST00000393962_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_11_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000585892_ANGPTL4_chr19_8438589_ENST00000301455_length(transcript)=994nt_BP=325nt GAGAACCGGATGAGGCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACG CCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGA TGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTG TAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAAC CTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTAC CCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAA AGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACA GAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCT CAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGC CAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTG TTGTGTGTAGGTCCCCTGGGGACACAAGCAGGCGCCAATGGTATCTGGGCGGAGCTCACAGAGTTCTTGGAATAAAAGCAACCTCAGAAC >23631_23631_11_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000585892_ANGPTL4_chr19_8438589_ENST00000301455_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- >23631_23631_12_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000585892_ANGPTL4_chr19_8438589_ENST00000393962_length(transcript)=952nt_BP=325nt GAGAACCGGATGAGGCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACG CCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGA TGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTG TAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGAGGCTGGTGGTTTGGCACCTGCAGCCATTCCAAC CTCAACGGCCAGTACTTCCGCTCCATCCCACAGCAGCGGCAGAAGCTTAAGAAGGGAATCTTCTGGAAGACCTGGCGGGGCCGCTACTAC CCGCTGCAGGCCACCACCATGTTGATCCAGCCCATGGCAGCAGAGGCAGCCTCCTAGCGTCCTGGCTGGGCCTGGTCCCAGGCCCACGAA AGACGGTGACTCTTGGCTCTGCCCGAGGATGTGGCCGTTCCCTGCCTGGGCAGGGGCTCCAAGGAGGGGCCATCTGGAAACTTGTGGACA GAGAAGAAGACCACGACTGGAGAAGCCCCCTTTCTGAGTGCAGGGGGGCTGCATGCGTTGCCTCCTGAGATCGAGGCTGCAGGATATGCT CAGACTCTAGAGGCGTGGACCAAGGGGCATGGAGCTTCACTCCTTGCTGGCCAGGGAGTTGGGGACTCAGAGGGACCACTTGGGGCCAGC CAGACTGGCCTCAATGGCGGACTCAGTCACATTGACTGACGGGGACCAGGGCTTGTGTGGGTCGAGAGCGCCCTCATGGTGCTGGTGCTG >23631_23631_12_DNM2-ANGPTL4_DNM2_chr19_10829079_ENST00000585892_ANGPTL4_chr19_8438589_ENST00000393962_length(amino acids)=166AA_BP=1 MSISCSLDLRRQRMQPPCTQKGGFSSRGLLLCPQVSRWPLLGAPAQAGNGHILGQSQESPSFVGLGPGPARTLGGCLCCHGLDQHGGGLQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DNM2-ANGPTL4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DNM2-ANGPTL4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DNM2-ANGPTL4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies