
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DOCK5-CDCA2 (FusionGDB2 ID:23806) |
Fusion Gene Summary for DOCK5-CDCA2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DOCK5-CDCA2 | Fusion gene ID: 23806 | Hgene | Tgene | Gene symbol | DOCK5 | CDCA2 | Gene ID | 80005 | 157313 |
| Gene name | dedicator of cytokinesis 5 | cell division cycle associated 2 | |
| Synonyms | - | PPP1R81|Repo-Man | |
| Cytomap | 8p21.2 | 8p21.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | dedicator of cytokinesis protein 5 | cell division cycle-associated protein 2protein phosphatase 1, regulatory subunit 81recruits PP1 onto mitotic chromatin at anaphase protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q69YH5 | |
| Ensembl transtripts involved in fusion gene | ENST00000276440, ENST00000410074, ENST00000481100, | ENST00000380665, ENST00000521098, ENST00000330560, | |
| Fusion gene scores | * DoF score | 6 X 5 X 4=120 | 1 X 3 X 1=3 |
| # samples | 7 | 2 | |
| ** MAII score | log2(7/120*10)=-0.777607578663552 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(2/3*10)=2.73696559416621 | |
| Context | PubMed: DOCK5 [Title/Abstract] AND CDCA2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DOCK5(25101273)-CDCA2(25317755), # samples:1 DOCK5(25101273)-CDCA2(25317756), # samples:1 DOCK5(25101273)-CDCA2(25317900), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across DOCK5 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CDCA2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-BR-8683-01A | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| ChimerDB4 | STAD | TCGA-BR-8683-01A | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| ChimerDB4 | STAD | TCGA-BR-8683 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
Top |
Fusion Gene ORF analysis for DOCK5-CDCA2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000276440 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| 5CDS-5UTR | ENST00000276440 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| 5CDS-5UTR | ENST00000410074 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| 5CDS-5UTR | ENST00000410074 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| 5CDS-5UTR | ENST00000481100 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| 5CDS-5UTR | ENST00000481100 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| 5CDS-intron | ENST00000276440 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| 5CDS-intron | ENST00000276440 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| 5CDS-intron | ENST00000276440 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| 5CDS-intron | ENST00000410074 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| 5CDS-intron | ENST00000410074 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| 5CDS-intron | ENST00000410074 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| 5CDS-intron | ENST00000481100 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| 5CDS-intron | ENST00000481100 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| 5CDS-intron | ENST00000481100 | ENST00000521098 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| Frame-shift | ENST00000276440 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| Frame-shift | ENST00000276440 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| Frame-shift | ENST00000410074 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| Frame-shift | ENST00000410074 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| Frame-shift | ENST00000481100 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317756 | + |
| Frame-shift | ENST00000481100 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + |
| In-frame | ENST00000276440 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| In-frame | ENST00000276440 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| In-frame | ENST00000410074 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| In-frame | ENST00000410074 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| In-frame | ENST00000481100 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| In-frame | ENST00000481100 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000276440 | DOCK5 | chr8 | 25101273 | + | ENST00000330560 | CDCA2 | chr8 | 25317900 | + | 3364 | 171 | 44 | 3181 | 1045 |
| ENST00000276440 | DOCK5 | chr8 | 25101273 | + | ENST00000380665 | CDCA2 | chr8 | 25317900 | + | 3316 | 171 | 187 | 3180 | 997 |
| ENST00000410074 | DOCK5 | chr8 | 25101273 | + | ENST00000330560 | CDCA2 | chr8 | 25317900 | + | 3506 | 313 | 186 | 3323 | 1045 |
| ENST00000410074 | DOCK5 | chr8 | 25101273 | + | ENST00000380665 | CDCA2 | chr8 | 25317900 | + | 3458 | 313 | 329 | 3322 | 997 |
| ENST00000481100 | DOCK5 | chr8 | 25101273 | + | ENST00000330560 | CDCA2 | chr8 | 25317900 | + | 3457 | 264 | 137 | 3274 | 1045 |
| ENST00000481100 | DOCK5 | chr8 | 25101273 | + | ENST00000380665 | CDCA2 | chr8 | 25317900 | + | 3409 | 264 | 280 | 3273 | 997 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000276440 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + | 8.64E-05 | 0.9999136 |
| ENST00000276440 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + | 0.000556449 | 0.9994436 |
| ENST00000410074 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + | 0.000118455 | 0.9998815 |
| ENST00000410074 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + | 0.000623106 | 0.99937695 |
| ENST00000481100 | ENST00000330560 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + | 0.000107716 | 0.99989223 |
| ENST00000481100 | ENST00000380665 | DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317900 | + | 0.000607966 | 0.99939203 |
Top |
Fusion Genomic Features for DOCK5-CDCA2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317899 | + | 0.004510735 | 0.9954893 |
| DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + | 0.000523986 | 0.999476 |
| DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + | 0.000523986 | 0.999476 |
| DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317899 | + | 0.004510735 | 0.9954893 |
| DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + | 0.000523986 | 0.999476 |
| DOCK5 | chr8 | 25101273 | + | CDCA2 | chr8 | 25317755 | + | 0.000523986 | 0.999476 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
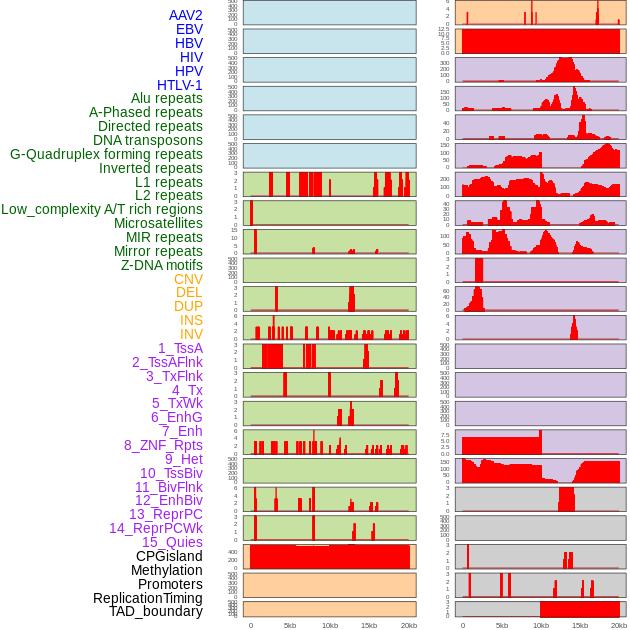 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
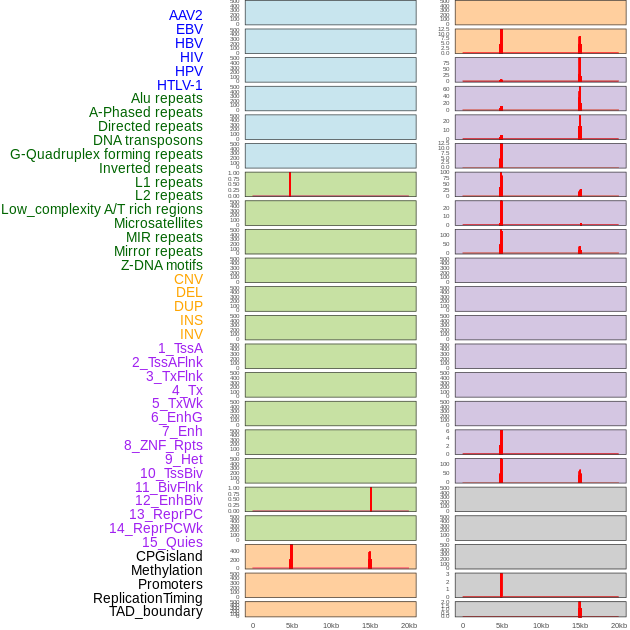 |
Top |
Fusion Protein Features for DOCK5-CDCA2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:25101273/chr8:25317755) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CDCA2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Regulator of chromosome structure during mitosis required for condensin-depleted chromosomes to retain their compact architecture through anaphase. Acts by mediating the recruitment of phopsphatase PP1-gamma subunit (PPP1CC) to chromatin at anaphase and into the following interphase. At anaphase onset, its association with chromatin targets a pool of PPP1CC to dephosphorylate substrates. {ECO:0000269|PubMed:16492807, ECO:0000269|PubMed:16998479}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CDCA2 | chr8:25101273 | chr8:25317900 | ENST00000330560 | 1 | 15 | 533_575 | 20 | 1024.0 | Compositional bias | Note=Lys-rich | |
| Tgene | CDCA2 | chr8:25101273 | chr8:25317900 | ENST00000330560 | 1 | 15 | 389_449 | 20 | 1024.0 | Domain | Note=PP1-binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DOCK5 | chr8:25101273 | chr8:25317900 | ENST00000276440 | + | 2 | 52 | 1782_1855 | 42 | 1871.0 | Compositional bias | Note=Pro-rich |
| Hgene | DOCK5 | chr8:25101273 | chr8:25317900 | ENST00000481100 | + | 2 | 11 | 1782_1855 | 42 | 351.0 | Compositional bias | Note=Pro-rich |
| Hgene | DOCK5 | chr8:25101273 | chr8:25317900 | ENST00000276440 | + | 2 | 52 | 1231_1642 | 42 | 1871.0 | Domain | DOCKER |
| Hgene | DOCK5 | chr8:25101273 | chr8:25317900 | ENST00000276440 | + | 2 | 52 | 443_627 | 42 | 1871.0 | Domain | C2 DOCK-type |
| Hgene | DOCK5 | chr8:25101273 | chr8:25317900 | ENST00000276440 | + | 2 | 52 | 8_69 | 42 | 1871.0 | Domain | SH3 |
| Hgene | DOCK5 | chr8:25101273 | chr8:25317900 | ENST00000481100 | + | 2 | 11 | 1231_1642 | 42 | 351.0 | Domain | DOCKER |
| Hgene | DOCK5 | chr8:25101273 | chr8:25317900 | ENST00000481100 | + | 2 | 11 | 443_627 | 42 | 351.0 | Domain | C2 DOCK-type |
| Hgene | DOCK5 | chr8:25101273 | chr8:25317900 | ENST00000481100 | + | 2 | 11 | 8_69 | 42 | 351.0 | Domain | SH3 |
Top |
Fusion Gene Sequence for DOCK5-CDCA2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >23806_23806_1_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000276440_CDCA2_chr8_25317900_ENST00000330560_length(transcript)=3364nt_BP=171nt TGTAGCAGCCTTAGTCGCCGCCGCCGCGGGGCGAGGTCGCCGCCATGGCCCGCTGGATCCCGACCAAGAGGCAGAAGTACGGGGTTGCGA TCTATAACTACAATGCTTCTCAAGATGTGGAGCTCTCCTTGCAGATCGGTGACACAGTTCACATCCTGGAGATGTACGAGGGAAATGCCT CTTTCATTTTGGGAACTGGGAAGATTGTGACTCCTCAGAAGCATGCCGAATTACCTCCTAATCCTTGCACACCAGATACTTTTAAATCAC CTTTGAACTTTTCCACAGTAACCGTAGAGCAATTGGGAATTACACCTGAAAGCTTTGTTAGGAACTCTGCAGGAAAGTCATCATCCTACC TTAAAAAATGTAGACGACGTTCTGCAGTCGGTGCTCGGGGCTCTCCTGAAACAAACCATCTGATTCGTTTCATTGCTCGGCAGCAAAATA TAAAGAATGCTAGGAAATCTCCTTTGGCACAAGATTCTCCTTCCCAGGGCAGCCCTGCACTGTATCGAAATGTTAACACTTTAAGAGAAC GAATATCAGCCTTCCAGTCAGCTTTTCACTCCATAAAGGAAAATGAGAAAATGACCGGCTGTCTGGAATTCTCAGAGGCAGGAAAAGAGT CCGAGATGACAGACTTGACCAGAAAGGAAGGTCTCAGCGCTTGCCAGCAGTCTGGGTTCCCTGCAGTGTTGTCCTCCAAACGTCGGAGAA TATCCTATCAGAGAGACTCTGATGAAAATCTGACGGATGCTGAAGGAAAAGTAATTGGTCTCCAGATATTCAATATTGATACAGACAGAG CATGTGCAGTTGAAACTTCTGTAGATCTTTCTGAGATATCATCTAAACTTGGTTCAACACAGTCTGGATTTTTAGTTGAAGAGTCTCTTC CCCTTTCAGAGCTCACAGAGACTTCAAATGCACTAAAGGTTGCTGACTGTGTAGTGGGCAAAGGATCAAGTGATGCCGTTTCGCCTGACA CGTTCACAGCAGAAGTGAGCTCAGACGCAGTCCCTGATGTCAGGTCACCAGCTACTCCAGCCTGCAGGAGGGACCTTCCCACCCCCAAGA CCTTTGTACTTCGTTCTGTACTGAAGAAACCCTCTGTTAAGATGTGTCTAGAGAGCTTACAGGAACACTGTAACAACCTCTATGATGATG ATGGGACTCATCCGAGCTTAATCTCAAATCTCCCAAACTGTTGCAAAGAGAAAGAAGCAGAAGATGAAGAAAATTTTGAAGCACCTGCCT TTCTAAATATGAGGAAGAGGAAGAGAGTTACTTTTGGAGAGGACTTAAGCCCGGAAGTGTTTGATGAATCTTTGCCAGCAAATACTCCAT TGCGTAAAGGAGGAACACCTGTTTGTAAAAAAGACTTCAGTGGTCTCAGTTCCCTGCTGCTTGAGCAGTCACCTGTTCCTGAGCCATTAC CTCAACCAGATTTTGATGACAAGGGGGAGAATCTTGAAAACATAGAACCACTTCAAGTATCATTTGCCGTTCTCAGTTCTCCTAATAAAT CATCAATCTCTGAGACCCTTTCAGGCACTGATACCTTTAGTTCTTCAAATAACCATGAGAAAATATCCTCTCCTAAAGTTGGTAGAATAA CAAGGACTTCTAACAGAAGAAATCAATTGGTCAGTGTTGTAGAAGAGAGTGTTTGCAACTTATTGAATACAGAAGTTCAGCCTTGTAAAG AAAAGAAAATTAATAGGAGGAAGTCTCAAGAAACAAAGTGTACAAAGAGAGCACTTCCTAAGAAGAGTCAGGTTTTAAAAAGTTGCAGAA AGAAGAAAGGAAAGGGAAAGAAAAGTGTTCAGAAATCTTTATATGGGGAAAGAGACATTGCTTCTAAGAAGCCCCTCCTCAGTCCTATTC CCGAGCTGCCTGAAGTCCCTGAGATGACACCTTCCATTCCGAGCATCCGAAGACTGGGTTCAGGTTATTTCAGTTCAAATGGCAAACTGG AAGAAGTGAAGACTCCTAAAAATCCAGTGAAAAGAAAGGATCTTTTGCGTCATGACCCAGATTTGCATATGCATCAAGGCTATGATAAAT ATGATGTCTCTGAATTCTGCTCTTATATAAAAAGTTCCTCATCGCTTGGCAATGCTACTTCTGATGAAGATCCAAATACAAATATAATGA ACATTAATGAAAATAAAAATATTCCAAAAGCAAAAAATAAGTCAGAAAGTGAAAATGAACCAAAAGCTGGAACTGACAGTCCTGTTTCTT GTGCTTCTGTAACTGAAGAACGTGTGGCATCAGATAGTCCCAAACCTGCTCTGACCCTGCAGCAGGGTCAAGAATTTTCTGCTGGTGGTC AAAATGCAGAAAACCTTTGTCAGTTCTTTAAAATTTCACCAGATTTAAACATAAAGTGTGAAAGAAAGGATGACTTCTTAGGAGCTGCAG AAGGAAAACTGCAATGCAATCGTTTAATGCCTAATTCACAAAAAGACTGTCATTGTTTAGGAGATGTCTTAATTGAAAATACGAAAGAAT CTAAAAGCCAGAGTGAGGATTTGGGAAGAAAACCCATGGAAAGTAGCAGTGTTGTGAGTTGCAGAGACAGGAAAGATAGAAGACGTTCCA TGTGTTATTCTGATGGTCGAAGTTTACATTTGGAAAAAAATGGAAATCACACACCATCCTCCAGTGTGGGCAGCTCTGTAGAAATTAGTT TAGAAAATTCTGAACTGTTTAAAGATTTGTCTGATGCCATTGAGCAAACCTTTCAGAGGAGAAATAGTGAAACCAAAGTGCGACGTAGCA CGAGGCTACAGAAGGATTTAGAAAACGAAGGTCTTGTATGGATTTCACTTCCACTTCCTTCCACTTCCCAAAAAGCCAAAAGAAGAACAA TATGTACATTTGACAGCAGTGGATTTGAAAGTATGTCTCCCATAAAAGAAACTGTGTCCTCCAGACAAAAACCGCAGATGGCACCTCCCG TCTCAGATCCAGAAAACAGCCAGGGCCCTGCTGCTGGTTCTTCCGATGAACCTGGTAAGAGGAGGAAGAGCTTTTGTATATCTACACTTG CAAATACTAAAGCCACTTCCCAGTTCAAAGGCTACCGGAGAAGATCCTCTCTTAATGGGAAGGGAGAGAGCTCTCTGACTGCCTTGGAAA GGATTGAACATAATGGAGAAAGAAAGCAGTAATTGACATTTCCTGCAGAGTCTGTGGCAAGAGGGAAAGTAACCATCTATGCTGAAATGA TCTGTCTAGTTCCCATTCTCTGTTCAACCTCAGTGTTTCAAAAGTTCCTAATAAATAAACTCATTTGAGTTGAACCTACTTTTATGTAGA >23806_23806_1_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000276440_CDCA2_chr8_25317900_ENST00000330560_length(amino acids)=1045AA_BP=0 MARWIPTKRQKYGVAIYNYNASQDVELSLQIGDTVHILEMYEGNASFILGTGKIVTPQKHAELPPNPCTPDTFKSPLNFSTVTVEQLGIT PESFVRNSAGKSSSYLKKCRRRSAVGARGSPETNHLIRFIARQQNIKNARKSPLAQDSPSQGSPALYRNVNTLRERISAFQSAFHSIKEN EKMTGCLEFSEAGKESEMTDLTRKEGLSACQQSGFPAVLSSKRRRISYQRDSDENLTDAEGKVIGLQIFNIDTDRACAVETSVDLSEISS KLGSTQSGFLVEESLPLSELTETSNALKVADCVVGKGSSDAVSPDTFTAEVSSDAVPDVRSPATPACRRDLPTPKTFVLRSVLKKPSVKM CLESLQEHCNNLYDDDGTHPSLISNLPNCCKEKEAEDEENFEAPAFLNMRKRKRVTFGEDLSPEVFDESLPANTPLRKGGTPVCKKDFSG LSSLLLEQSPVPEPLPQPDFDDKGENLENIEPLQVSFAVLSSPNKSSISETLSGTDTFSSSNNHEKISSPKVGRITRTSNRRNQLVSVVE ESVCNLLNTEVQPCKEKKINRRKSQETKCTKRALPKKSQVLKSCRKKKGKGKKSVQKSLYGERDIASKKPLLSPIPELPEVPEMTPSIPS IRRLGSGYFSSNGKLEEVKTPKNPVKRKDLLRHDPDLHMHQGYDKYDVSEFCSYIKSSSSLGNATSDEDPNTNIMNINENKNIPKAKNKS ESENEPKAGTDSPVSCASVTEERVASDSPKPALTLQQGQEFSAGGQNAENLCQFFKISPDLNIKCERKDDFLGAAEGKLQCNRLMPNSQK DCHCLGDVLIENTKESKSQSEDLGRKPMESSSVVSCRDRKDRRRSMCYSDGRSLHLEKNGNHTPSSSVGSSVEISLENSELFKDLSDAIE QTFQRRNSETKVRRSTRLQKDLENEGLVWISLPLPSTSQKAKRRTICTFDSSGFESMSPIKETVSSRQKPQMAPPVSDPENSQGPAAGSS -------------------------------------------------------------- >23806_23806_2_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000276440_CDCA2_chr8_25317900_ENST00000380665_length(transcript)=3316nt_BP=171nt TGTAGCAGCCTTAGTCGCCGCCGCCGCGGGGCGAGGTCGCCGCCATGGCCCGCTGGATCCCGACCAAGAGGCAGAAGTACGGGGTTGCGA TCTATAACTACAATGCTTCTCAAGATGTGGAGCTCTCCTTGCAGATCGGTGACACAGTTCACATCCTGGAGATGTACGAGGAAATGCCTC TTTCATTTTGGGAACTGGGAAGATTGTGACTCCTCAGAAGCATGCCGAATTACCTCCTAATCCTTGCACACCAGATACTTTTAAATCACC TTTGAACTTTTCCACAGTAACCGTAGAGCAATTGGGAATTACACCTGAAAGCTTTGTTAGGAACTCTGCAGGAAAGTCATCATCCTACCT TAAAAAATGTAGACGACGTTCTGCAGTCGGTGCTCGGGGCTCTCCTGAAACAAACCATCTGATTCGTTTCATTGCTCGGCAGCAAAATAT AAAGAATGCTAGGAAATCTCCTTTGGCACAAGATTCTCCTTCCCAGGGCAGCCCTGCACTGTATCGAAATGTTAACACTTTAAGAGAACG AATATCAGCCTTCCAGTCAGCTTTTCACTCCATAAAGGAAAATGAGAAAATGACCGGCTGTCTGGAATTCTCAGAGGCAGGAAAAGAGTC CGAGATGACAGACTTGACCAGAAAGGAAGGTCTCAGCGCTTGCCAGCAGTCTGGGTTCCCTGCAGTGTTGTCCTCCAAACGTCGGAGAAT ATCCTATCAGAGAGACTCTGATGAAAATCTGACGGATGCTGAAGGAAAAGTAATTGGTCTCCAGATATTCAATATTGATACAGACAGAGC ATGTGCAGTTGAAACTTCTGTAGATCTTTCTGAGATATCATCTAAACTTGGTTCAACACAGTCTGGATTTTTAGTTGAAGAGTCTCTTCC CCTTTCAGAGCTCACAGAGACTTCAAATGCACTAAAGGTTGCTGACTGTGTAGTGGGCAAAGGATCAAGTGATGCCGTTTCGCCTGACAC GTTCACAGCAGAAGTGAGCTCAGACGCAGTCCCTGATGTCAGGTCACCAGCTACTCCAGCCTGCAGGAGGGACCTTCCCACCCCCAAGAC CTTTGTACTTCGTTCTGTACTGAAGAAACCCTCTGTTAAGATGTGTCTAGAGAGCTTACAGGAACACTGTAACAACCTCTATGATGATGA TGGGACTCATCCGAGCTTAATCTCAAATCTCCCAAACTGTTGCAAAGAGAAAGAAGCAGAAGATGAAGAAAATTTTGAAGCACCTGCCTT TCTAAATATGAGGAAGAGGAAGAGAGTTACTTTTGGAGAGGACTTAAGCCCGGAAGTGTTTGATGAATCTTTGCCAGCAAATACTCCATT GCGTAAAGGAGGAACACCTGTTTGTAAAAAAGACTTCAGTGGTCTCAGTTCCCTGCTGCTTGAGCAGTCACCTGTTCCTGAGCCATTACC TCAACCAGATTTTGATGACAAGGGGGAGAATCTTGAAAACATAGAACCACTTCAAGTATCATTTGCCGTTCTCAGTTCTCCTAATAAATC ATCAATCTCTGAGACCCTTTCAGGCACTGATACCTTTAGTTCTTCAAATAACCATGAGAAAATATCCTCTCCTAAAGTTGGTAGAATAAC AAGGACTTCTAACAGAAGAAATCAATTGGTCAGTGTTGTAGAAGAGAGTGTTTGCAACTTATTGAATACAGAAGTTCAGCCTTGTAAAGA AAAGAAAATTAATAGGAGGAAGTCTCAAGAAACAAAGTGTACAAAGAGAGCACTTCCTAAGAAGAGTCAGGTTTTAAAAAGTTGCAGAAA GAAGAAAGGAAAGGGAAAGAAAAGTGTTCAGAAATCTTTATATGGGGAAAGAGACATTGCTTCTAAGAAGCCCCTCCTCAGTCCTATTCC CGAGCTGCCTGAAGTCCCTGAGATGACACCTTCCATTCCGAGCATCCGAAGACTGGGTTCAGGTTATTTCAGTTCAAATGGCAAACTGGA AGAAGTGAAGACTCCTAAAAATCCAGTGAAAAGAAAGGATCTTTTGCGTCATGACCCAGATTTGCATATGCATCAAGGCTATGATAAATA TGATGTCTCTGAATTCTGCTCTTATATAAAAAGTTCCTCATCGCTTGGCAATGCTACTTCTGATGAAGATCCAAATACAAATATAATGAA CATTAATGAAAATAAAAATATTCCAAAAGCAAAAAATAAGTCAGAAAGTGAAAATGAACCAAAAGCTGGAACTGACAGTCCTGTTTCTTG TGCTTCTGTAACTGAAGAACGTGTGGCATCAGATAGTCCCAAACCTGCTCTGACCCTGCAGCAGGGTCAAGAATTTTCTGCTGGTGGTCA AAATGCAGAAAACCTTTGTCAGTTCTTTAAAATTTCACCAGATTTAAACATAAAGTGTGAAAGAAAGGATGACTTCTTAGGAGCTGCAGA AGGAAAACTGCAATGCAATCGTTTAATGCCTAATTCACAAAAAGACTGTCATTGTTTAGGAGATGTCTTAATTGAAAATACGAAAGAATC TAAAAGCCAGAGTGAGGATTTGGGAAGAAAACCCATGGAAAGTAGCAGTGTTGTGAGTTGCAGAGACAGGAAAGATAGAAGACGTTCCAT GTGTTATTCTGATGGTCGAAGTTTACATTTGGAAAAAAATGGAAATCACACACCATCCTCCAGTGTGGGCAGCTCTGTAGAAATTAGTTT AGAAAATTCTGAACTGTTTAAAGATTTGTCTGATGCCATTGAGCAAACCTTTCAGAGGAGAAATAGTGAAACCAAAGTGCGACGTAGCAC GAGGCTACAGAAGGATTTAGAAAACGAAGGTCTTGTATGGATTTCACTTCCACTTCCTTCCACTTCCCAAAAAGCCAAAAGAAGAACAAT ATGTACATTTGACAGCAGTGGATTTGAAAGTATGTCTCCCATAAAAGAAACTGTGTCCTCCAGACAAAAACCGCAGATGGCACCTCCCGT CTCAGATCCAGAAAACAGCCAGGGCCCTGCTGCTGGTTCTTCCGATGAACCTGGTAAGAGGAGGAAGAGCTTTTGTATATCTACACTTGC AAATACTAAAGCCACTTCCCAGTTCAAAGGCTACCGGAGAAGATCCTCTCTTAATGGGAAGGGAGAGAGCTCTCTGACTGCCTTGGAAAG GATTGAACATAATGGAGAAAGAAAGCAGTAATTGACATTTCCTGCAGAGTCTGTGGCAAGAGGGAAAGTAACCATCTATGCTGAAATGAT >23806_23806_2_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000276440_CDCA2_chr8_25317900_ENST00000380665_length(amino acids)=997AA_BP= MGTGKIVTPQKHAELPPNPCTPDTFKSPLNFSTVTVEQLGITPESFVRNSAGKSSSYLKKCRRRSAVGARGSPETNHLIRFIARQQNIKN ARKSPLAQDSPSQGSPALYRNVNTLRERISAFQSAFHSIKENEKMTGCLEFSEAGKESEMTDLTRKEGLSACQQSGFPAVLSSKRRRISY QRDSDENLTDAEGKVIGLQIFNIDTDRACAVETSVDLSEISSKLGSTQSGFLVEESLPLSELTETSNALKVADCVVGKGSSDAVSPDTFT AEVSSDAVPDVRSPATPACRRDLPTPKTFVLRSVLKKPSVKMCLESLQEHCNNLYDDDGTHPSLISNLPNCCKEKEAEDEENFEAPAFLN MRKRKRVTFGEDLSPEVFDESLPANTPLRKGGTPVCKKDFSGLSSLLLEQSPVPEPLPQPDFDDKGENLENIEPLQVSFAVLSSPNKSSI SETLSGTDTFSSSNNHEKISSPKVGRITRTSNRRNQLVSVVEESVCNLLNTEVQPCKEKKINRRKSQETKCTKRALPKKSQVLKSCRKKK GKGKKSVQKSLYGERDIASKKPLLSPIPELPEVPEMTPSIPSIRRLGSGYFSSNGKLEEVKTPKNPVKRKDLLRHDPDLHMHQGYDKYDV SEFCSYIKSSSSLGNATSDEDPNTNIMNINENKNIPKAKNKSESENEPKAGTDSPVSCASVTEERVASDSPKPALTLQQGQEFSAGGQNA ENLCQFFKISPDLNIKCERKDDFLGAAEGKLQCNRLMPNSQKDCHCLGDVLIENTKESKSQSEDLGRKPMESSSVVSCRDRKDRRRSMCY SDGRSLHLEKNGNHTPSSSVGSSVEISLENSELFKDLSDAIEQTFQRRNSETKVRRSTRLQKDLENEGLVWISLPLPSTSQKAKRRTICT FDSSGFESMSPIKETVSSRQKPQMAPPVSDPENSQGPAAGSSDEPGKRRKSFCISTLANTKATSQFKGYRRRSSLNGKGESSLTALERIE -------------------------------------------------------------- >23806_23806_3_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000410074_CDCA2_chr8_25317900_ENST00000330560_length(transcript)=3506nt_BP=313nt GCGGGCGGCGCGGGCACGGGCACGGGCGCGGGCGGCGCGGCGAGGAGGCGGCCCGCGGAGTCCAGCGAAGTTTGGCGGAACATGGCGGAA GCGTCTGGGGCACGCAGGAGCGCGGGGCGGCGGCGGCCGGAGCCCGAGGAGCTGTAGCAGCCTTAGTCGCCGCCGCCGCGGGGCGAGGTC GCCGCCATGGCCCGCTGGATCCCGACCAAGAGGCAGAAGTACGGGGTTGCGATCTATAACTACAATGCTTCTCAAGATGTGGAGCTCTCC TTGCAGATCGGTGACACAGTTCACATCCTGGAGATGTACGAGGGAAATGCCTCTTTCATTTTGGGAACTGGGAAGATTGTGACTCCTCAG AAGCATGCCGAATTACCTCCTAATCCTTGCACACCAGATACTTTTAAATCACCTTTGAACTTTTCCACAGTAACCGTAGAGCAATTGGGA ATTACACCTGAAAGCTTTGTTAGGAACTCTGCAGGAAAGTCATCATCCTACCTTAAAAAATGTAGACGACGTTCTGCAGTCGGTGCTCGG GGCTCTCCTGAAACAAACCATCTGATTCGTTTCATTGCTCGGCAGCAAAATATAAAGAATGCTAGGAAATCTCCTTTGGCACAAGATTCT CCTTCCCAGGGCAGCCCTGCACTGTATCGAAATGTTAACACTTTAAGAGAACGAATATCAGCCTTCCAGTCAGCTTTTCACTCCATAAAG GAAAATGAGAAAATGACCGGCTGTCTGGAATTCTCAGAGGCAGGAAAAGAGTCCGAGATGACAGACTTGACCAGAAAGGAAGGTCTCAGC GCTTGCCAGCAGTCTGGGTTCCCTGCAGTGTTGTCCTCCAAACGTCGGAGAATATCCTATCAGAGAGACTCTGATGAAAATCTGACGGAT GCTGAAGGAAAAGTAATTGGTCTCCAGATATTCAATATTGATACAGACAGAGCATGTGCAGTTGAAACTTCTGTAGATCTTTCTGAGATA TCATCTAAACTTGGTTCAACACAGTCTGGATTTTTAGTTGAAGAGTCTCTTCCCCTTTCAGAGCTCACAGAGACTTCAAATGCACTAAAG GTTGCTGACTGTGTAGTGGGCAAAGGATCAAGTGATGCCGTTTCGCCTGACACGTTCACAGCAGAAGTGAGCTCAGACGCAGTCCCTGAT GTCAGGTCACCAGCTACTCCAGCCTGCAGGAGGGACCTTCCCACCCCCAAGACCTTTGTACTTCGTTCTGTACTGAAGAAACCCTCTGTT AAGATGTGTCTAGAGAGCTTACAGGAACACTGTAACAACCTCTATGATGATGATGGGACTCATCCGAGCTTAATCTCAAATCTCCCAAAC TGTTGCAAAGAGAAAGAAGCAGAAGATGAAGAAAATTTTGAAGCACCTGCCTTTCTAAATATGAGGAAGAGGAAGAGAGTTACTTTTGGA GAGGACTTAAGCCCGGAAGTGTTTGATGAATCTTTGCCAGCAAATACTCCATTGCGTAAAGGAGGAACACCTGTTTGTAAAAAAGACTTC AGTGGTCTCAGTTCCCTGCTGCTTGAGCAGTCACCTGTTCCTGAGCCATTACCTCAACCAGATTTTGATGACAAGGGGGAGAATCTTGAA AACATAGAACCACTTCAAGTATCATTTGCCGTTCTCAGTTCTCCTAATAAATCATCAATCTCTGAGACCCTTTCAGGCACTGATACCTTT AGTTCTTCAAATAACCATGAGAAAATATCCTCTCCTAAAGTTGGTAGAATAACAAGGACTTCTAACAGAAGAAATCAATTGGTCAGTGTT GTAGAAGAGAGTGTTTGCAACTTATTGAATACAGAAGTTCAGCCTTGTAAAGAAAAGAAAATTAATAGGAGGAAGTCTCAAGAAACAAAG TGTACAAAGAGAGCACTTCCTAAGAAGAGTCAGGTTTTAAAAAGTTGCAGAAAGAAGAAAGGAAAGGGAAAGAAAAGTGTTCAGAAATCT TTATATGGGGAAAGAGACATTGCTTCTAAGAAGCCCCTCCTCAGTCCTATTCCCGAGCTGCCTGAAGTCCCTGAGATGACACCTTCCATT CCGAGCATCCGAAGACTGGGTTCAGGTTATTTCAGTTCAAATGGCAAACTGGAAGAAGTGAAGACTCCTAAAAATCCAGTGAAAAGAAAG GATCTTTTGCGTCATGACCCAGATTTGCATATGCATCAAGGCTATGATAAATATGATGTCTCTGAATTCTGCTCTTATATAAAAAGTTCC TCATCGCTTGGCAATGCTACTTCTGATGAAGATCCAAATACAAATATAATGAACATTAATGAAAATAAAAATATTCCAAAAGCAAAAAAT AAGTCAGAAAGTGAAAATGAACCAAAAGCTGGAACTGACAGTCCTGTTTCTTGTGCTTCTGTAACTGAAGAACGTGTGGCATCAGATAGT CCCAAACCTGCTCTGACCCTGCAGCAGGGTCAAGAATTTTCTGCTGGTGGTCAAAATGCAGAAAACCTTTGTCAGTTCTTTAAAATTTCA CCAGATTTAAACATAAAGTGTGAAAGAAAGGATGACTTCTTAGGAGCTGCAGAAGGAAAACTGCAATGCAATCGTTTAATGCCTAATTCA CAAAAAGACTGTCATTGTTTAGGAGATGTCTTAATTGAAAATACGAAAGAATCTAAAAGCCAGAGTGAGGATTTGGGAAGAAAACCCATG GAAAGTAGCAGTGTTGTGAGTTGCAGAGACAGGAAAGATAGAAGACGTTCCATGTGTTATTCTGATGGTCGAAGTTTACATTTGGAAAAA AATGGAAATCACACACCATCCTCCAGTGTGGGCAGCTCTGTAGAAATTAGTTTAGAAAATTCTGAACTGTTTAAAGATTTGTCTGATGCC ATTGAGCAAACCTTTCAGAGGAGAAATAGTGAAACCAAAGTGCGACGTAGCACGAGGCTACAGAAGGATTTAGAAAACGAAGGTCTTGTA TGGATTTCACTTCCACTTCCTTCCACTTCCCAAAAAGCCAAAAGAAGAACAATATGTACATTTGACAGCAGTGGATTTGAAAGTATGTCT CCCATAAAAGAAACTGTGTCCTCCAGACAAAAACCGCAGATGGCACCTCCCGTCTCAGATCCAGAAAACAGCCAGGGCCCTGCTGCTGGT TCTTCCGATGAACCTGGTAAGAGGAGGAAGAGCTTTTGTATATCTACACTTGCAAATACTAAAGCCACTTCCCAGTTCAAAGGCTACCGG AGAAGATCCTCTCTTAATGGGAAGGGAGAGAGCTCTCTGACTGCCTTGGAAAGGATTGAACATAATGGAGAAAGAAAGCAGTAATTGACA TTTCCTGCAGAGTCTGTGGCAAGAGGGAAAGTAACCATCTATGCTGAAATGATCTGTCTAGTTCCCATTCTCTGTTCAACCTCAGTGTTT >23806_23806_3_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000410074_CDCA2_chr8_25317900_ENST00000330560_length(amino acids)=1045AA_BP=0 MARWIPTKRQKYGVAIYNYNASQDVELSLQIGDTVHILEMYEGNASFILGTGKIVTPQKHAELPPNPCTPDTFKSPLNFSTVTVEQLGIT PESFVRNSAGKSSSYLKKCRRRSAVGARGSPETNHLIRFIARQQNIKNARKSPLAQDSPSQGSPALYRNVNTLRERISAFQSAFHSIKEN EKMTGCLEFSEAGKESEMTDLTRKEGLSACQQSGFPAVLSSKRRRISYQRDSDENLTDAEGKVIGLQIFNIDTDRACAVETSVDLSEISS KLGSTQSGFLVEESLPLSELTETSNALKVADCVVGKGSSDAVSPDTFTAEVSSDAVPDVRSPATPACRRDLPTPKTFVLRSVLKKPSVKM CLESLQEHCNNLYDDDGTHPSLISNLPNCCKEKEAEDEENFEAPAFLNMRKRKRVTFGEDLSPEVFDESLPANTPLRKGGTPVCKKDFSG LSSLLLEQSPVPEPLPQPDFDDKGENLENIEPLQVSFAVLSSPNKSSISETLSGTDTFSSSNNHEKISSPKVGRITRTSNRRNQLVSVVE ESVCNLLNTEVQPCKEKKINRRKSQETKCTKRALPKKSQVLKSCRKKKGKGKKSVQKSLYGERDIASKKPLLSPIPELPEVPEMTPSIPS IRRLGSGYFSSNGKLEEVKTPKNPVKRKDLLRHDPDLHMHQGYDKYDVSEFCSYIKSSSSLGNATSDEDPNTNIMNINENKNIPKAKNKS ESENEPKAGTDSPVSCASVTEERVASDSPKPALTLQQGQEFSAGGQNAENLCQFFKISPDLNIKCERKDDFLGAAEGKLQCNRLMPNSQK DCHCLGDVLIENTKESKSQSEDLGRKPMESSSVVSCRDRKDRRRSMCYSDGRSLHLEKNGNHTPSSSVGSSVEISLENSELFKDLSDAIE QTFQRRNSETKVRRSTRLQKDLENEGLVWISLPLPSTSQKAKRRTICTFDSSGFESMSPIKETVSSRQKPQMAPPVSDPENSQGPAAGSS -------------------------------------------------------------- >23806_23806_4_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000410074_CDCA2_chr8_25317900_ENST00000380665_length(transcript)=3458nt_BP=313nt GCGGGCGGCGCGGGCACGGGCACGGGCGCGGGCGGCGCGGCGAGGAGGCGGCCCGCGGAGTCCAGCGAAGTTTGGCGGAACATGGCGGAA GCGTCTGGGGCACGCAGGAGCGCGGGGCGGCGGCGGCCGGAGCCCGAGGAGCTGTAGCAGCCTTAGTCGCCGCCGCCGCGGGGCGAGGTC GCCGCCATGGCCCGCTGGATCCCGACCAAGAGGCAGAAGTACGGGGTTGCGATCTATAACTACAATGCTTCTCAAGATGTGGAGCTCTCC TTGCAGATCGGTGACACAGTTCACATCCTGGAGATGTACGAGGAAATGCCTCTTTCATTTTGGGAACTGGGAAGATTGTGACTCCTCAGA AGCATGCCGAATTACCTCCTAATCCTTGCACACCAGATACTTTTAAATCACCTTTGAACTTTTCCACAGTAACCGTAGAGCAATTGGGAA TTACACCTGAAAGCTTTGTTAGGAACTCTGCAGGAAAGTCATCATCCTACCTTAAAAAATGTAGACGACGTTCTGCAGTCGGTGCTCGGG GCTCTCCTGAAACAAACCATCTGATTCGTTTCATTGCTCGGCAGCAAAATATAAAGAATGCTAGGAAATCTCCTTTGGCACAAGATTCTC CTTCCCAGGGCAGCCCTGCACTGTATCGAAATGTTAACACTTTAAGAGAACGAATATCAGCCTTCCAGTCAGCTTTTCACTCCATAAAGG AAAATGAGAAAATGACCGGCTGTCTGGAATTCTCAGAGGCAGGAAAAGAGTCCGAGATGACAGACTTGACCAGAAAGGAAGGTCTCAGCG CTTGCCAGCAGTCTGGGTTCCCTGCAGTGTTGTCCTCCAAACGTCGGAGAATATCCTATCAGAGAGACTCTGATGAAAATCTGACGGATG CTGAAGGAAAAGTAATTGGTCTCCAGATATTCAATATTGATACAGACAGAGCATGTGCAGTTGAAACTTCTGTAGATCTTTCTGAGATAT CATCTAAACTTGGTTCAACACAGTCTGGATTTTTAGTTGAAGAGTCTCTTCCCCTTTCAGAGCTCACAGAGACTTCAAATGCACTAAAGG TTGCTGACTGTGTAGTGGGCAAAGGATCAAGTGATGCCGTTTCGCCTGACACGTTCACAGCAGAAGTGAGCTCAGACGCAGTCCCTGATG TCAGGTCACCAGCTACTCCAGCCTGCAGGAGGGACCTTCCCACCCCCAAGACCTTTGTACTTCGTTCTGTACTGAAGAAACCCTCTGTTA AGATGTGTCTAGAGAGCTTACAGGAACACTGTAACAACCTCTATGATGATGATGGGACTCATCCGAGCTTAATCTCAAATCTCCCAAACT GTTGCAAAGAGAAAGAAGCAGAAGATGAAGAAAATTTTGAAGCACCTGCCTTTCTAAATATGAGGAAGAGGAAGAGAGTTACTTTTGGAG AGGACTTAAGCCCGGAAGTGTTTGATGAATCTTTGCCAGCAAATACTCCATTGCGTAAAGGAGGAACACCTGTTTGTAAAAAAGACTTCA GTGGTCTCAGTTCCCTGCTGCTTGAGCAGTCACCTGTTCCTGAGCCATTACCTCAACCAGATTTTGATGACAAGGGGGAGAATCTTGAAA ACATAGAACCACTTCAAGTATCATTTGCCGTTCTCAGTTCTCCTAATAAATCATCAATCTCTGAGACCCTTTCAGGCACTGATACCTTTA GTTCTTCAAATAACCATGAGAAAATATCCTCTCCTAAAGTTGGTAGAATAACAAGGACTTCTAACAGAAGAAATCAATTGGTCAGTGTTG TAGAAGAGAGTGTTTGCAACTTATTGAATACAGAAGTTCAGCCTTGTAAAGAAAAGAAAATTAATAGGAGGAAGTCTCAAGAAACAAAGT GTACAAAGAGAGCACTTCCTAAGAAGAGTCAGGTTTTAAAAAGTTGCAGAAAGAAGAAAGGAAAGGGAAAGAAAAGTGTTCAGAAATCTT TATATGGGGAAAGAGACATTGCTTCTAAGAAGCCCCTCCTCAGTCCTATTCCCGAGCTGCCTGAAGTCCCTGAGATGACACCTTCCATTC CGAGCATCCGAAGACTGGGTTCAGGTTATTTCAGTTCAAATGGCAAACTGGAAGAAGTGAAGACTCCTAAAAATCCAGTGAAAAGAAAGG ATCTTTTGCGTCATGACCCAGATTTGCATATGCATCAAGGCTATGATAAATATGATGTCTCTGAATTCTGCTCTTATATAAAAAGTTCCT CATCGCTTGGCAATGCTACTTCTGATGAAGATCCAAATACAAATATAATGAACATTAATGAAAATAAAAATATTCCAAAAGCAAAAAATA AGTCAGAAAGTGAAAATGAACCAAAAGCTGGAACTGACAGTCCTGTTTCTTGTGCTTCTGTAACTGAAGAACGTGTGGCATCAGATAGTC CCAAACCTGCTCTGACCCTGCAGCAGGGTCAAGAATTTTCTGCTGGTGGTCAAAATGCAGAAAACCTTTGTCAGTTCTTTAAAATTTCAC CAGATTTAAACATAAAGTGTGAAAGAAAGGATGACTTCTTAGGAGCTGCAGAAGGAAAACTGCAATGCAATCGTTTAATGCCTAATTCAC AAAAAGACTGTCATTGTTTAGGAGATGTCTTAATTGAAAATACGAAAGAATCTAAAAGCCAGAGTGAGGATTTGGGAAGAAAACCCATGG AAAGTAGCAGTGTTGTGAGTTGCAGAGACAGGAAAGATAGAAGACGTTCCATGTGTTATTCTGATGGTCGAAGTTTACATTTGGAAAAAA ATGGAAATCACACACCATCCTCCAGTGTGGGCAGCTCTGTAGAAATTAGTTTAGAAAATTCTGAACTGTTTAAAGATTTGTCTGATGCCA TTGAGCAAACCTTTCAGAGGAGAAATAGTGAAACCAAAGTGCGACGTAGCACGAGGCTACAGAAGGATTTAGAAAACGAAGGTCTTGTAT GGATTTCACTTCCACTTCCTTCCACTTCCCAAAAAGCCAAAAGAAGAACAATATGTACATTTGACAGCAGTGGATTTGAAAGTATGTCTC CCATAAAAGAAACTGTGTCCTCCAGACAAAAACCGCAGATGGCACCTCCCGTCTCAGATCCAGAAAACAGCCAGGGCCCTGCTGCTGGTT CTTCCGATGAACCTGGTAAGAGGAGGAAGAGCTTTTGTATATCTACACTTGCAAATACTAAAGCCACTTCCCAGTTCAAAGGCTACCGGA GAAGATCCTCTCTTAATGGGAAGGGAGAGAGCTCTCTGACTGCCTTGGAAAGGATTGAACATAATGGAGAAAGAAAGCAGTAATTGACAT TTCCTGCAGAGTCTGTGGCAAGAGGGAAAGTAACCATCTATGCTGAAATGATCTGTCTAGTTCCCATTCTCTGTTCAACCTCAGTGTTTC >23806_23806_4_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000410074_CDCA2_chr8_25317900_ENST00000380665_length(amino acids)=997AA_BP= MGTGKIVTPQKHAELPPNPCTPDTFKSPLNFSTVTVEQLGITPESFVRNSAGKSSSYLKKCRRRSAVGARGSPETNHLIRFIARQQNIKN ARKSPLAQDSPSQGSPALYRNVNTLRERISAFQSAFHSIKENEKMTGCLEFSEAGKESEMTDLTRKEGLSACQQSGFPAVLSSKRRRISY QRDSDENLTDAEGKVIGLQIFNIDTDRACAVETSVDLSEISSKLGSTQSGFLVEESLPLSELTETSNALKVADCVVGKGSSDAVSPDTFT AEVSSDAVPDVRSPATPACRRDLPTPKTFVLRSVLKKPSVKMCLESLQEHCNNLYDDDGTHPSLISNLPNCCKEKEAEDEENFEAPAFLN MRKRKRVTFGEDLSPEVFDESLPANTPLRKGGTPVCKKDFSGLSSLLLEQSPVPEPLPQPDFDDKGENLENIEPLQVSFAVLSSPNKSSI SETLSGTDTFSSSNNHEKISSPKVGRITRTSNRRNQLVSVVEESVCNLLNTEVQPCKEKKINRRKSQETKCTKRALPKKSQVLKSCRKKK GKGKKSVQKSLYGERDIASKKPLLSPIPELPEVPEMTPSIPSIRRLGSGYFSSNGKLEEVKTPKNPVKRKDLLRHDPDLHMHQGYDKYDV SEFCSYIKSSSSLGNATSDEDPNTNIMNINENKNIPKAKNKSESENEPKAGTDSPVSCASVTEERVASDSPKPALTLQQGQEFSAGGQNA ENLCQFFKISPDLNIKCERKDDFLGAAEGKLQCNRLMPNSQKDCHCLGDVLIENTKESKSQSEDLGRKPMESSSVVSCRDRKDRRRSMCY SDGRSLHLEKNGNHTPSSSVGSSVEISLENSELFKDLSDAIEQTFQRRNSETKVRRSTRLQKDLENEGLVWISLPLPSTSQKAKRRTICT FDSSGFESMSPIKETVSSRQKPQMAPPVSDPENSQGPAAGSSDEPGKRRKSFCISTLANTKATSQFKGYRRRSSLNGKGESSLTALERIE -------------------------------------------------------------- >23806_23806_5_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000481100_CDCA2_chr8_25317900_ENST00000330560_length(transcript)=3457nt_BP=264nt GGCCCGCGGAGTCCAGCGAAGTTTGGCGGAACATGGCGGAAGCGTCTGGGGCACGCAGGAGCGCGGGGCGGCGGCGGCCGGAGCCCGAGG AGCTGTAGCAGCCTTAGTCGCCGCCGCCGCGGGGCGAGGTCGCCGCCATGGCCCGCTGGATCCCGACCAAGAGGCAGAAGTACGGGGTTG CGATCTATAACTACAATGCTTCTCAAGATGTGGAGCTCTCCTTGCAGATCGGTGACACAGTTCACATCCTGGAGATGTACGAGGGAAATG CCTCTTTCATTTTGGGAACTGGGAAGATTGTGACTCCTCAGAAGCATGCCGAATTACCTCCTAATCCTTGCACACCAGATACTTTTAAAT CACCTTTGAACTTTTCCACAGTAACCGTAGAGCAATTGGGAATTACACCTGAAAGCTTTGTTAGGAACTCTGCAGGAAAGTCATCATCCT ACCTTAAAAAATGTAGACGACGTTCTGCAGTCGGTGCTCGGGGCTCTCCTGAAACAAACCATCTGATTCGTTTCATTGCTCGGCAGCAAA ATATAAAGAATGCTAGGAAATCTCCTTTGGCACAAGATTCTCCTTCCCAGGGCAGCCCTGCACTGTATCGAAATGTTAACACTTTAAGAG AACGAATATCAGCCTTCCAGTCAGCTTTTCACTCCATAAAGGAAAATGAGAAAATGACCGGCTGTCTGGAATTCTCAGAGGCAGGAAAAG AGTCCGAGATGACAGACTTGACCAGAAAGGAAGGTCTCAGCGCTTGCCAGCAGTCTGGGTTCCCTGCAGTGTTGTCCTCCAAACGTCGGA GAATATCCTATCAGAGAGACTCTGATGAAAATCTGACGGATGCTGAAGGAAAAGTAATTGGTCTCCAGATATTCAATATTGATACAGACA GAGCATGTGCAGTTGAAACTTCTGTAGATCTTTCTGAGATATCATCTAAACTTGGTTCAACACAGTCTGGATTTTTAGTTGAAGAGTCTC TTCCCCTTTCAGAGCTCACAGAGACTTCAAATGCACTAAAGGTTGCTGACTGTGTAGTGGGCAAAGGATCAAGTGATGCCGTTTCGCCTG ACACGTTCACAGCAGAAGTGAGCTCAGACGCAGTCCCTGATGTCAGGTCACCAGCTACTCCAGCCTGCAGGAGGGACCTTCCCACCCCCA AGACCTTTGTACTTCGTTCTGTACTGAAGAAACCCTCTGTTAAGATGTGTCTAGAGAGCTTACAGGAACACTGTAACAACCTCTATGATG ATGATGGGACTCATCCGAGCTTAATCTCAAATCTCCCAAACTGTTGCAAAGAGAAAGAAGCAGAAGATGAAGAAAATTTTGAAGCACCTG CCTTTCTAAATATGAGGAAGAGGAAGAGAGTTACTTTTGGAGAGGACTTAAGCCCGGAAGTGTTTGATGAATCTTTGCCAGCAAATACTC CATTGCGTAAAGGAGGAACACCTGTTTGTAAAAAAGACTTCAGTGGTCTCAGTTCCCTGCTGCTTGAGCAGTCACCTGTTCCTGAGCCAT TACCTCAACCAGATTTTGATGACAAGGGGGAGAATCTTGAAAACATAGAACCACTTCAAGTATCATTTGCCGTTCTCAGTTCTCCTAATA AATCATCAATCTCTGAGACCCTTTCAGGCACTGATACCTTTAGTTCTTCAAATAACCATGAGAAAATATCCTCTCCTAAAGTTGGTAGAA TAACAAGGACTTCTAACAGAAGAAATCAATTGGTCAGTGTTGTAGAAGAGAGTGTTTGCAACTTATTGAATACAGAAGTTCAGCCTTGTA AAGAAAAGAAAATTAATAGGAGGAAGTCTCAAGAAACAAAGTGTACAAAGAGAGCACTTCCTAAGAAGAGTCAGGTTTTAAAAAGTTGCA GAAAGAAGAAAGGAAAGGGAAAGAAAAGTGTTCAGAAATCTTTATATGGGGAAAGAGACATTGCTTCTAAGAAGCCCCTCCTCAGTCCTA TTCCCGAGCTGCCTGAAGTCCCTGAGATGACACCTTCCATTCCGAGCATCCGAAGACTGGGTTCAGGTTATTTCAGTTCAAATGGCAAAC TGGAAGAAGTGAAGACTCCTAAAAATCCAGTGAAAAGAAAGGATCTTTTGCGTCATGACCCAGATTTGCATATGCATCAAGGCTATGATA AATATGATGTCTCTGAATTCTGCTCTTATATAAAAAGTTCCTCATCGCTTGGCAATGCTACTTCTGATGAAGATCCAAATACAAATATAA TGAACATTAATGAAAATAAAAATATTCCAAAAGCAAAAAATAAGTCAGAAAGTGAAAATGAACCAAAAGCTGGAACTGACAGTCCTGTTT CTTGTGCTTCTGTAACTGAAGAACGTGTGGCATCAGATAGTCCCAAACCTGCTCTGACCCTGCAGCAGGGTCAAGAATTTTCTGCTGGTG GTCAAAATGCAGAAAACCTTTGTCAGTTCTTTAAAATTTCACCAGATTTAAACATAAAGTGTGAAAGAAAGGATGACTTCTTAGGAGCTG CAGAAGGAAAACTGCAATGCAATCGTTTAATGCCTAATTCACAAAAAGACTGTCATTGTTTAGGAGATGTCTTAATTGAAAATACGAAAG AATCTAAAAGCCAGAGTGAGGATTTGGGAAGAAAACCCATGGAAAGTAGCAGTGTTGTGAGTTGCAGAGACAGGAAAGATAGAAGACGTT CCATGTGTTATTCTGATGGTCGAAGTTTACATTTGGAAAAAAATGGAAATCACACACCATCCTCCAGTGTGGGCAGCTCTGTAGAAATTA GTTTAGAAAATTCTGAACTGTTTAAAGATTTGTCTGATGCCATTGAGCAAACCTTTCAGAGGAGAAATAGTGAAACCAAAGTGCGACGTA GCACGAGGCTACAGAAGGATTTAGAAAACGAAGGTCTTGTATGGATTTCACTTCCACTTCCTTCCACTTCCCAAAAAGCCAAAAGAAGAA CAATATGTACATTTGACAGCAGTGGATTTGAAAGTATGTCTCCCATAAAAGAAACTGTGTCCTCCAGACAAAAACCGCAGATGGCACCTC CCGTCTCAGATCCAGAAAACAGCCAGGGCCCTGCTGCTGGTTCTTCCGATGAACCTGGTAAGAGGAGGAAGAGCTTTTGTATATCTACAC TTGCAAATACTAAAGCCACTTCCCAGTTCAAAGGCTACCGGAGAAGATCCTCTCTTAATGGGAAGGGAGAGAGCTCTCTGACTGCCTTGG AAAGGATTGAACATAATGGAGAAAGAAAGCAGTAATTGACATTTCCTGCAGAGTCTGTGGCAAGAGGGAAAGTAACCATCTATGCTGAAA TGATCTGTCTAGTTCCCATTCTCTGTTCAACCTCAGTGTTTCAAAAGTTCCTAATAAATAAACTCATTTGAGTTGAACCTACTTTTATGT >23806_23806_5_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000481100_CDCA2_chr8_25317900_ENST00000330560_length(amino acids)=1045AA_BP=0 MARWIPTKRQKYGVAIYNYNASQDVELSLQIGDTVHILEMYEGNASFILGTGKIVTPQKHAELPPNPCTPDTFKSPLNFSTVTVEQLGIT PESFVRNSAGKSSSYLKKCRRRSAVGARGSPETNHLIRFIARQQNIKNARKSPLAQDSPSQGSPALYRNVNTLRERISAFQSAFHSIKEN EKMTGCLEFSEAGKESEMTDLTRKEGLSACQQSGFPAVLSSKRRRISYQRDSDENLTDAEGKVIGLQIFNIDTDRACAVETSVDLSEISS KLGSTQSGFLVEESLPLSELTETSNALKVADCVVGKGSSDAVSPDTFTAEVSSDAVPDVRSPATPACRRDLPTPKTFVLRSVLKKPSVKM CLESLQEHCNNLYDDDGTHPSLISNLPNCCKEKEAEDEENFEAPAFLNMRKRKRVTFGEDLSPEVFDESLPANTPLRKGGTPVCKKDFSG LSSLLLEQSPVPEPLPQPDFDDKGENLENIEPLQVSFAVLSSPNKSSISETLSGTDTFSSSNNHEKISSPKVGRITRTSNRRNQLVSVVE ESVCNLLNTEVQPCKEKKINRRKSQETKCTKRALPKKSQVLKSCRKKKGKGKKSVQKSLYGERDIASKKPLLSPIPELPEVPEMTPSIPS IRRLGSGYFSSNGKLEEVKTPKNPVKRKDLLRHDPDLHMHQGYDKYDVSEFCSYIKSSSSLGNATSDEDPNTNIMNINENKNIPKAKNKS ESENEPKAGTDSPVSCASVTEERVASDSPKPALTLQQGQEFSAGGQNAENLCQFFKISPDLNIKCERKDDFLGAAEGKLQCNRLMPNSQK DCHCLGDVLIENTKESKSQSEDLGRKPMESSSVVSCRDRKDRRRSMCYSDGRSLHLEKNGNHTPSSSVGSSVEISLENSELFKDLSDAIE QTFQRRNSETKVRRSTRLQKDLENEGLVWISLPLPSTSQKAKRRTICTFDSSGFESMSPIKETVSSRQKPQMAPPVSDPENSQGPAAGSS -------------------------------------------------------------- >23806_23806_6_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000481100_CDCA2_chr8_25317900_ENST00000380665_length(transcript)=3409nt_BP=264nt GGCCCGCGGAGTCCAGCGAAGTTTGGCGGAACATGGCGGAAGCGTCTGGGGCACGCAGGAGCGCGGGGCGGCGGCGGCCGGAGCCCGAGG AGCTGTAGCAGCCTTAGTCGCCGCCGCCGCGGGGCGAGGTCGCCGCCATGGCCCGCTGGATCCCGACCAAGAGGCAGAAGTACGGGGTTG CGATCTATAACTACAATGCTTCTCAAGATGTGGAGCTCTCCTTGCAGATCGGTGACACAGTTCACATCCTGGAGATGTACGAGGAAATGC CTCTTTCATTTTGGGAACTGGGAAGATTGTGACTCCTCAGAAGCATGCCGAATTACCTCCTAATCCTTGCACACCAGATACTTTTAAATC ACCTTTGAACTTTTCCACAGTAACCGTAGAGCAATTGGGAATTACACCTGAAAGCTTTGTTAGGAACTCTGCAGGAAAGTCATCATCCTA CCTTAAAAAATGTAGACGACGTTCTGCAGTCGGTGCTCGGGGCTCTCCTGAAACAAACCATCTGATTCGTTTCATTGCTCGGCAGCAAAA TATAAAGAATGCTAGGAAATCTCCTTTGGCACAAGATTCTCCTTCCCAGGGCAGCCCTGCACTGTATCGAAATGTTAACACTTTAAGAGA ACGAATATCAGCCTTCCAGTCAGCTTTTCACTCCATAAAGGAAAATGAGAAAATGACCGGCTGTCTGGAATTCTCAGAGGCAGGAAAAGA GTCCGAGATGACAGACTTGACCAGAAAGGAAGGTCTCAGCGCTTGCCAGCAGTCTGGGTTCCCTGCAGTGTTGTCCTCCAAACGTCGGAG AATATCCTATCAGAGAGACTCTGATGAAAATCTGACGGATGCTGAAGGAAAAGTAATTGGTCTCCAGATATTCAATATTGATACAGACAG AGCATGTGCAGTTGAAACTTCTGTAGATCTTTCTGAGATATCATCTAAACTTGGTTCAACACAGTCTGGATTTTTAGTTGAAGAGTCTCT TCCCCTTTCAGAGCTCACAGAGACTTCAAATGCACTAAAGGTTGCTGACTGTGTAGTGGGCAAAGGATCAAGTGATGCCGTTTCGCCTGA CACGTTCACAGCAGAAGTGAGCTCAGACGCAGTCCCTGATGTCAGGTCACCAGCTACTCCAGCCTGCAGGAGGGACCTTCCCACCCCCAA GACCTTTGTACTTCGTTCTGTACTGAAGAAACCCTCTGTTAAGATGTGTCTAGAGAGCTTACAGGAACACTGTAACAACCTCTATGATGA TGATGGGACTCATCCGAGCTTAATCTCAAATCTCCCAAACTGTTGCAAAGAGAAAGAAGCAGAAGATGAAGAAAATTTTGAAGCACCTGC CTTTCTAAATATGAGGAAGAGGAAGAGAGTTACTTTTGGAGAGGACTTAAGCCCGGAAGTGTTTGATGAATCTTTGCCAGCAAATACTCC ATTGCGTAAAGGAGGAACACCTGTTTGTAAAAAAGACTTCAGTGGTCTCAGTTCCCTGCTGCTTGAGCAGTCACCTGTTCCTGAGCCATT ACCTCAACCAGATTTTGATGACAAGGGGGAGAATCTTGAAAACATAGAACCACTTCAAGTATCATTTGCCGTTCTCAGTTCTCCTAATAA ATCATCAATCTCTGAGACCCTTTCAGGCACTGATACCTTTAGTTCTTCAAATAACCATGAGAAAATATCCTCTCCTAAAGTTGGTAGAAT AACAAGGACTTCTAACAGAAGAAATCAATTGGTCAGTGTTGTAGAAGAGAGTGTTTGCAACTTATTGAATACAGAAGTTCAGCCTTGTAA AGAAAAGAAAATTAATAGGAGGAAGTCTCAAGAAACAAAGTGTACAAAGAGAGCACTTCCTAAGAAGAGTCAGGTTTTAAAAAGTTGCAG AAAGAAGAAAGGAAAGGGAAAGAAAAGTGTTCAGAAATCTTTATATGGGGAAAGAGACATTGCTTCTAAGAAGCCCCTCCTCAGTCCTAT TCCCGAGCTGCCTGAAGTCCCTGAGATGACACCTTCCATTCCGAGCATCCGAAGACTGGGTTCAGGTTATTTCAGTTCAAATGGCAAACT GGAAGAAGTGAAGACTCCTAAAAATCCAGTGAAAAGAAAGGATCTTTTGCGTCATGACCCAGATTTGCATATGCATCAAGGCTATGATAA ATATGATGTCTCTGAATTCTGCTCTTATATAAAAAGTTCCTCATCGCTTGGCAATGCTACTTCTGATGAAGATCCAAATACAAATATAAT GAACATTAATGAAAATAAAAATATTCCAAAAGCAAAAAATAAGTCAGAAAGTGAAAATGAACCAAAAGCTGGAACTGACAGTCCTGTTTC TTGTGCTTCTGTAACTGAAGAACGTGTGGCATCAGATAGTCCCAAACCTGCTCTGACCCTGCAGCAGGGTCAAGAATTTTCTGCTGGTGG TCAAAATGCAGAAAACCTTTGTCAGTTCTTTAAAATTTCACCAGATTTAAACATAAAGTGTGAAAGAAAGGATGACTTCTTAGGAGCTGC AGAAGGAAAACTGCAATGCAATCGTTTAATGCCTAATTCACAAAAAGACTGTCATTGTTTAGGAGATGTCTTAATTGAAAATACGAAAGA ATCTAAAAGCCAGAGTGAGGATTTGGGAAGAAAACCCATGGAAAGTAGCAGTGTTGTGAGTTGCAGAGACAGGAAAGATAGAAGACGTTC CATGTGTTATTCTGATGGTCGAAGTTTACATTTGGAAAAAAATGGAAATCACACACCATCCTCCAGTGTGGGCAGCTCTGTAGAAATTAG TTTAGAAAATTCTGAACTGTTTAAAGATTTGTCTGATGCCATTGAGCAAACCTTTCAGAGGAGAAATAGTGAAACCAAAGTGCGACGTAG CACGAGGCTACAGAAGGATTTAGAAAACGAAGGTCTTGTATGGATTTCACTTCCACTTCCTTCCACTTCCCAAAAAGCCAAAAGAAGAAC AATATGTACATTTGACAGCAGTGGATTTGAAAGTATGTCTCCCATAAAAGAAACTGTGTCCTCCAGACAAAAACCGCAGATGGCACCTCC CGTCTCAGATCCAGAAAACAGCCAGGGCCCTGCTGCTGGTTCTTCCGATGAACCTGGTAAGAGGAGGAAGAGCTTTTGTATATCTACACT TGCAAATACTAAAGCCACTTCCCAGTTCAAAGGCTACCGGAGAAGATCCTCTCTTAATGGGAAGGGAGAGAGCTCTCTGACTGCCTTGGA AAGGATTGAACATAATGGAGAAAGAAAGCAGTAATTGACATTTCCTGCAGAGTCTGTGGCAAGAGGGAAAGTAACCATCTATGCTGAAAT >23806_23806_6_DOCK5-CDCA2_DOCK5_chr8_25101273_ENST00000481100_CDCA2_chr8_25317900_ENST00000380665_length(amino acids)=997AA_BP= MGTGKIVTPQKHAELPPNPCTPDTFKSPLNFSTVTVEQLGITPESFVRNSAGKSSSYLKKCRRRSAVGARGSPETNHLIRFIARQQNIKN ARKSPLAQDSPSQGSPALYRNVNTLRERISAFQSAFHSIKENEKMTGCLEFSEAGKESEMTDLTRKEGLSACQQSGFPAVLSSKRRRISY QRDSDENLTDAEGKVIGLQIFNIDTDRACAVETSVDLSEISSKLGSTQSGFLVEESLPLSELTETSNALKVADCVVGKGSSDAVSPDTFT AEVSSDAVPDVRSPATPACRRDLPTPKTFVLRSVLKKPSVKMCLESLQEHCNNLYDDDGTHPSLISNLPNCCKEKEAEDEENFEAPAFLN MRKRKRVTFGEDLSPEVFDESLPANTPLRKGGTPVCKKDFSGLSSLLLEQSPVPEPLPQPDFDDKGENLENIEPLQVSFAVLSSPNKSSI SETLSGTDTFSSSNNHEKISSPKVGRITRTSNRRNQLVSVVEESVCNLLNTEVQPCKEKKINRRKSQETKCTKRALPKKSQVLKSCRKKK GKGKKSVQKSLYGERDIASKKPLLSPIPELPEVPEMTPSIPSIRRLGSGYFSSNGKLEEVKTPKNPVKRKDLLRHDPDLHMHQGYDKYDV SEFCSYIKSSSSLGNATSDEDPNTNIMNINENKNIPKAKNKSESENEPKAGTDSPVSCASVTEERVASDSPKPALTLQQGQEFSAGGQNA ENLCQFFKISPDLNIKCERKDDFLGAAEGKLQCNRLMPNSQKDCHCLGDVLIENTKESKSQSEDLGRKPMESSSVVSCRDRKDRRRSMCY SDGRSLHLEKNGNHTPSSSVGSSVEISLENSELFKDLSDAIEQTFQRRNSETKVRRSTRLQKDLENEGLVWISLPLPSTSQKAKRRTICT FDSSGFESMSPIKETVSSRQKPQMAPPVSDPENSQGPAAGSSDEPGKRRKSFCISTLANTKATSQFKGYRRRSSLNGKGESSLTALERIE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DOCK5-CDCA2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DOCK5-CDCA2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DOCK5-CDCA2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies