
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DOLPP1-SPTAN1 (FusionGDB2 ID:23871) |
Fusion Gene Summary for DOLPP1-SPTAN1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DOLPP1-SPTAN1 | Fusion gene ID: 23871 | Hgene | Tgene | Gene symbol | DOLPP1 | SPTAN1 | Gene ID | 57171 | 6709 |
| Gene name | dolichyldiphosphatase 1 | spectrin alpha, non-erythrocytic 1 | |
| Synonyms | LSFR2 | EIEE5|NEAS|SPTA2 | |
| Cytomap | 9q34.11 | 9q34.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | dolichyldiphosphatase 1dolichyl pyrophosphate phosphatase 1linked to Surfeit genes in Fugu rubripes 2 | spectrin alpha chain, non-erythrocytic 1alpha-II spectrinalpha-fodrinepididymis secretory sperm binding proteinfodrin alpha chainspectrin, non-erythroid alpha chainspectrin, non-erythroid alpha subunit | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q86YN1 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000372546, ENST00000406974, ENST00000540102, | ENST00000475367, ENST00000358161, ENST00000372731, ENST00000372739, | |
| Fusion gene scores | * DoF score | 3 X 3 X 2=18 | 21 X 23 X 11=5313 |
| # samples | 3 | 25 | |
| ** MAII score | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(25/5313*10)=-4.40952671281098 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DOLPP1 [Title/Abstract] AND SPTAN1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DOLPP1(131849077)-SPTAN1(131379919), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across DOLPP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SPTAN1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-AC-A62Y-01A | DOLPP1 | chr9 | 131849077 | - | SPTAN1 | chr9 | 131379919 | + |
| ChimerDB4 | BRCA | TCGA-AC-A62Y-01A | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
Top |
Fusion Gene ORF analysis for DOLPP1-SPTAN1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000372546 | ENST00000475367 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| 5CDS-intron | ENST00000406974 | ENST00000475367 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| 5CDS-intron | ENST00000540102 | ENST00000475367 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000372546 | ENST00000358161 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000372546 | ENST00000372731 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000372546 | ENST00000372739 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000406974 | ENST00000358161 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000406974 | ENST00000372731 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000406974 | ENST00000372739 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000540102 | ENST00000358161 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000540102 | ENST00000372731 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| In-frame | ENST00000540102 | ENST00000372739 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000372546 | DOLPP1 | chr9 | 131849077 | + | ENST00000358161 | SPTAN1 | chr9 | 131379919 | + | 3114 | 712 | 2 | 2788 | 928 |
| ENST00000372546 | DOLPP1 | chr9 | 131849077 | + | ENST00000372739 | SPTAN1 | chr9 | 131379919 | + | 3117 | 712 | 2 | 2788 | 928 |
| ENST00000372546 | DOLPP1 | chr9 | 131849077 | + | ENST00000372731 | SPTAN1 | chr9 | 131379919 | + | 3117 | 712 | 2 | 2788 | 928 |
| ENST00000406974 | DOLPP1 | chr9 | 131849077 | + | ENST00000358161 | SPTAN1 | chr9 | 131379919 | + | 2974 | 572 | 21 | 2648 | 875 |
| ENST00000406974 | DOLPP1 | chr9 | 131849077 | + | ENST00000372739 | SPTAN1 | chr9 | 131379919 | + | 2977 | 572 | 21 | 2648 | 875 |
| ENST00000406974 | DOLPP1 | chr9 | 131849077 | + | ENST00000372731 | SPTAN1 | chr9 | 131379919 | + | 2977 | 572 | 21 | 2648 | 875 |
| ENST00000540102 | DOLPP1 | chr9 | 131849077 | + | ENST00000358161 | SPTAN1 | chr9 | 131379919 | + | 2866 | 464 | 207 | 2540 | 777 |
| ENST00000540102 | DOLPP1 | chr9 | 131849077 | + | ENST00000372739 | SPTAN1 | chr9 | 131379919 | + | 2869 | 464 | 207 | 2540 | 777 |
| ENST00000540102 | DOLPP1 | chr9 | 131849077 | + | ENST00000372731 | SPTAN1 | chr9 | 131379919 | + | 2869 | 464 | 207 | 2540 | 777 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000372546 | ENST00000358161 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.007465337 | 0.99253464 |
| ENST00000372546 | ENST00000372739 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.007507177 | 0.99249285 |
| ENST00000372546 | ENST00000372731 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.007507177 | 0.99249285 |
| ENST00000406974 | ENST00000358161 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.01059272 | 0.98940736 |
| ENST00000406974 | ENST00000372739 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.010555279 | 0.9894447 |
| ENST00000406974 | ENST00000372731 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.010555279 | 0.9894447 |
| ENST00000540102 | ENST00000358161 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.014396227 | 0.9856038 |
| ENST00000540102 | ENST00000372739 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.014482725 | 0.9855173 |
| ENST00000540102 | ENST00000372731 | DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379919 | + | 0.014482725 | 0.9855173 |
Top |
Fusion Genomic Features for DOLPP1-SPTAN1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379918 | + | 1.11E-06 | 0.9999989 |
| DOLPP1 | chr9 | 131849077 | + | SPTAN1 | chr9 | 131379918 | + | 1.11E-06 | 0.9999989 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
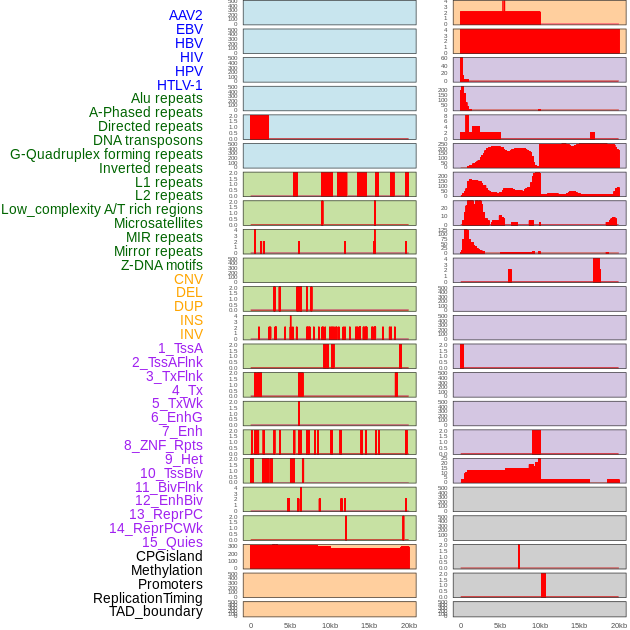 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
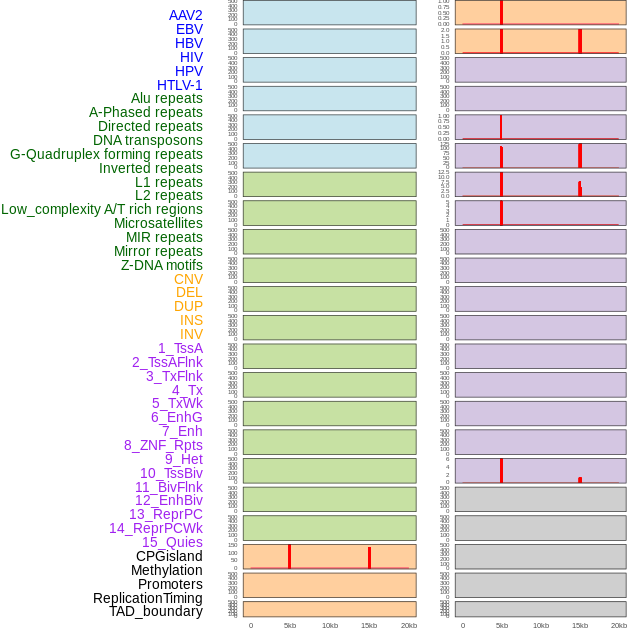 |
Top |
Fusion Protein Features for DOLPP1-SPTAN1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:131849077/chr9:131379919) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DOLPP1 | . |
| FUNCTION: Required for efficient N-glycosylation. Necessary for maintaining optimal levels of dolichol-linked oligosaccharides. Hydrolyzes dolichyl pyrophosphate at a very high rate and dolichyl monophosphate at a much lower rate. Does not act on phosphatidate (By similarity). {ECO:0000250|UniProtKB:Q9JMF7}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DOLPP1 | chr9:131849077 | chr9:131379919 | ENST00000372546 | + | 7 | 8 | 100_120 | 226 | 239.0 | Transmembrane | Helical |
| Hgene | DOLPP1 | chr9:131849077 | chr9:131379919 | ENST00000372546 | + | 7 | 8 | 130_150 | 226 | 239.0 | Transmembrane | Helical |
| Hgene | DOLPP1 | chr9:131849077 | chr9:131379919 | ENST00000372546 | + | 7 | 8 | 162_182 | 226 | 239.0 | Transmembrane | Helical |
| Hgene | DOLPP1 | chr9:131849077 | chr9:131379919 | ENST00000372546 | + | 7 | 8 | 33_53 | 226 | 239.0 | Transmembrane | Helical |
| Hgene | DOLPP1 | chr9:131849077 | chr9:131379919 | ENST00000406974 | + | 6 | 7 | 100_120 | 183 | 196.0 | Transmembrane | Helical |
| Hgene | DOLPP1 | chr9:131849077 | chr9:131379919 | ENST00000406974 | + | 6 | 7 | 130_150 | 183 | 196.0 | Transmembrane | Helical |
| Hgene | DOLPP1 | chr9:131849077 | chr9:131379919 | ENST00000406974 | + | 6 | 7 | 162_182 | 183 | 196.0 | Transmembrane | Helical |
| Hgene | DOLPP1 | chr9:131849077 | chr9:131379919 | ENST00000406974 | + | 6 | 7 | 33_53 | 183 | 196.0 | Transmembrane | Helical |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 2336_2347 | 1780 | 2473.0 | Calcium binding | 1 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 2379_2390 | 1780 | 2473.0 | Calcium binding | 2 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 2336_2347 | 1785 | 2478.0 | Calcium binding | 1 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 2379_2390 | 1785 | 2478.0 | Calcium binding | 2 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 2323_2358 | 1780 | 2473.0 | Domain | EF-hand 1 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 2366_2401 | 1780 | 2473.0 | Domain | EF-hand 2 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 2404_2439 | 1780 | 2473.0 | Domain | EF-hand 3 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 2323_2358 | 1785 | 2478.0 | Domain | EF-hand 1 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 2366_2401 | 1785 | 2478.0 | Domain | EF-hand 2 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 2404_2439 | 1785 | 2478.0 | Domain | EF-hand 3 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1871_1974 | 1780 | 2473.0 | Repeat | Spectrin 17 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1978_2081 | 1780 | 2473.0 | Repeat | Spectrin 18 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 2092_2194 | 1780 | 2473.0 | Repeat | Spectrin 19 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 2206_2310 | 1780 | 2473.0 | Repeat | Spectrin 20 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1871_1974 | 1785 | 2478.0 | Repeat | Spectrin 17 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1978_2081 | 1785 | 2478.0 | Repeat | Spectrin 18 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 2092_2194 | 1785 | 2478.0 | Repeat | Spectrin 19 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 2206_2310 | 1785 | 2478.0 | Repeat | Spectrin 20 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 967_1026 | 1780 | 2473.0 | Domain | SH3 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 967_1026 | 1785 | 2478.0 | Domain | SH3 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1096_1166 | 1780 | 2473.0 | Repeat | Spectrin 10 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1233_1336 | 1780 | 2473.0 | Repeat | Spectrin 11 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1339_1442 | 1780 | 2473.0 | Repeat | Spectrin 12 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1446_1549 | 1780 | 2473.0 | Repeat | Spectrin 13 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 150_251 | 1780 | 2473.0 | Repeat | Spectrin 2 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1552_1656 | 1780 | 2473.0 | Repeat | Spectrin 14 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1659_1762 | 1780 | 2473.0 | Repeat | Spectrin 15 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 1764_1868 | 1780 | 2473.0 | Repeat | Spectrin 16 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 256_358 | 1780 | 2473.0 | Repeat | Spectrin 3 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 361_465 | 1780 | 2473.0 | Repeat | Spectrin 4 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 45_146 | 1780 | 2473.0 | Repeat | Spectrin 1 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 468_570 | 1780 | 2473.0 | Repeat | Spectrin 5 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 574_676 | 1780 | 2473.0 | Repeat | Spectrin 6 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 679_781 | 1780 | 2473.0 | Repeat | Spectrin 7 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 785_888 | 1780 | 2473.0 | Repeat | Spectrin 8 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372731 | 39 | 56 | 891_969 | 1780 | 2473.0 | Repeat | Spectrin 9 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1096_1166 | 1785 | 2478.0 | Repeat | Spectrin 10 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1233_1336 | 1785 | 2478.0 | Repeat | Spectrin 11 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1339_1442 | 1785 | 2478.0 | Repeat | Spectrin 12 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1446_1549 | 1785 | 2478.0 | Repeat | Spectrin 13 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 150_251 | 1785 | 2478.0 | Repeat | Spectrin 2 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1552_1656 | 1785 | 2478.0 | Repeat | Spectrin 14 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1659_1762 | 1785 | 2478.0 | Repeat | Spectrin 15 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 1764_1868 | 1785 | 2478.0 | Repeat | Spectrin 16 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 256_358 | 1785 | 2478.0 | Repeat | Spectrin 3 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 361_465 | 1785 | 2478.0 | Repeat | Spectrin 4 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 45_146 | 1785 | 2478.0 | Repeat | Spectrin 1 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 468_570 | 1785 | 2478.0 | Repeat | Spectrin 5 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 574_676 | 1785 | 2478.0 | Repeat | Spectrin 6 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 679_781 | 1785 | 2478.0 | Repeat | Spectrin 7 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 785_888 | 1785 | 2478.0 | Repeat | Spectrin 8 | |
| Tgene | SPTAN1 | chr9:131849077 | chr9:131379919 | ENST00000372739 | 40 | 57 | 891_969 | 1785 | 2478.0 | Repeat | Spectrin 9 |
Top |
Fusion Gene Sequence for DOLPP1-SPTAN1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >23871_23871_1_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000372546_SPTAN1_chr9_131379919_ENST00000358161_length(transcript)=3114nt_BP=712nt GGCTGCTCGAAGAAGCCCGGTCTCCGGGTAAGATGGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCC ACGTCGAATATCCTGCAGGTGATCTCTCTGGCCACCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCC TCATCATATTTAAGCGGGAGCTGCACACGATCTCCTTCCTTGGGGGCCTGGCACTGAACGAGGGGGTCAACTGGCTGATCAAAAACGTCA TCCAGGAGCCACGGCCCTGTGGAGGCCCCCACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCT TCTCCGTCTATTCCTTCCTTTTCCTGTATTTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCT CCCTGGGACTCCTCGCTGTGGCCTTCCTAGTCTCCTACAGCAGGGTCTACCTGCTGTACCACACCTGGAGCCAGGTGCTCTATGGAGGCA TCGCTGGAGGCCTCATGGCCATCGCCTGGTTCATCTTCACCCAGGAGGTCCTCACCCCGCTGTTCCCCAGGATAGCAGCCTGGCCTGTCT CCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGGTTTGAGTACACGGTAACCCGGGCAGAAGCCAGGGAGAAGA AGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAGAACCTGAGGAAGAAGCACAAGCGGCTGGAAGCAGAACTGG CTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTGTCCGATGACAACACCATCGGGAAAGAGGAGATCCAGCAGC GGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCTGCCCGGGGTCAGCGGCTGGAAGAGTCCTTGGAATATCAGC AGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATGACCCTGGTGGCCAGCGAAGATTATGGCGACACTCTTGCCG CCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACCGTCCACAAGGATCGCGTGAATGATGTCTGCACCAATGGAC AAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAG CTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTG AAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTG GGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCA TCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGA GTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACT TAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCC AGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGG CCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACG ACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGTGCCAGCCCGCTGGGGCGTCCTGTA TGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAA AGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGT GGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGG CCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCT CCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATG GCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCC GGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCC ACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAG CCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAA CCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTG TGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCC >23871_23871_1_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000372546_SPTAN1_chr9_131379919_ENST00000358161_length(amino acids)=928AA_BP=236 LLEEARSPGKMAADGQCSLPASWRPVTLTHVEYPAGDLSGHLLAYLSLSPVFVIVGFVTLIIFKRELHTISFLGGLALNEGVNWLIKNVI QEPRPCGGPHTAVGTKYGMPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRVYLLYHTWSQVLYGGI AGGLMAIAWFIFTQEVLTPLFPRIAAWPVSEFFLIRDTSLIPNVLWFEYTVTRAEAREKKLLVGSEDYGRDLTGVQNLRKKHKRLEAELA AHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLEESLEYQQFVANVEEEEAWINEKMTLVASEDYGDTLAA IQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDENSAFLQFNWKADVVESWIGE KENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRWSQLLANSAARKKKLLEAQS HFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDRQIKSFRVASNPYTWFTMEA LEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRCQPAGASCMVEESGTLESQLEATKRKHQEIRAMRSQLKK IEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHFDKDKSGRLNHQEFKSCLRS LGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVTKEELYQNLTREQADYCVSH -------------------------------------------------------------- >23871_23871_2_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000372546_SPTAN1_chr9_131379919_ENST00000372731_length(transcript)=3117nt_BP=712nt GGCTGCTCGAAGAAGCCCGGTCTCCGGGTAAGATGGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCC ACGTCGAATATCCTGCAGGTGATCTCTCTGGCCACCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCC TCATCATATTTAAGCGGGAGCTGCACACGATCTCCTTCCTTGGGGGCCTGGCACTGAACGAGGGGGTCAACTGGCTGATCAAAAACGTCA TCCAGGAGCCACGGCCCTGTGGAGGCCCCCACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCT TCTCCGTCTATTCCTTCCTTTTCCTGTATTTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCT CCCTGGGACTCCTCGCTGTGGCCTTCCTAGTCTCCTACAGCAGGGTCTACCTGCTGTACCACACCTGGAGCCAGGTGCTCTATGGAGGCA TCGCTGGAGGCCTCATGGCCATCGCCTGGTTCATCTTCACCCAGGAGGTCCTCACCCCGCTGTTCCCCAGGATAGCAGCCTGGCCTGTCT CCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGGTTTGAGTACACGGTAACCCGGGCAGAAGCCAGGGAGAAGA AGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAGAACCTGAGGAAGAAGCACAAGCGGCTGGAAGCAGAACTGG CTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTGTCCGATGACAACACCATCGGGAAAGAGGAGATCCAGCAGC GGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCTGCCCGGGGTCAGCGGCTGGAAGAGTCCTTGGAATATCAGC AGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATGACCCTGGTGGCCAGCGAAGATTATGGCGACACTCTTGCCG CCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACCGTCCACAAGGATCGCGTGAATGATGTCTGCACCAATGGAC AAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAG CTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTG AAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTG GGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCA TCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGA GTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACT TAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCC AGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGG CCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACG ACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGACATACCTCCTCGATGGGTCCTGTA TGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAA AGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGT GGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGG CCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCT CCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATG GCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCC GGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCC ACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAG CCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAA CCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTG TGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCC >23871_23871_2_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000372546_SPTAN1_chr9_131379919_ENST00000372731_length(amino acids)=928AA_BP=236 LLEEARSPGKMAADGQCSLPASWRPVTLTHVEYPAGDLSGHLLAYLSLSPVFVIVGFVTLIIFKRELHTISFLGGLALNEGVNWLIKNVI QEPRPCGGPHTAVGTKYGMPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRVYLLYHTWSQVLYGGI AGGLMAIAWFIFTQEVLTPLFPRIAAWPVSEFFLIRDTSLIPNVLWFEYTVTRAEAREKKLLVGSEDYGRDLTGVQNLRKKHKRLEAELA AHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLEESLEYQQFVANVEEEEAWINEKMTLVASEDYGDTLAA IQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDENSAFLQFNWKADVVESWIGE KENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRWSQLLANSAARKKKLLEAQS HFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDRQIKSFRVASNPYTWFTMEA LEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTYLLDGSCMVEESGTLESQLEATKRKHQEIRAMRSQLKK IEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHFDKDKSGRLNHQEFKSCLRS LGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVTKEELYQNLTREQADYCVSH -------------------------------------------------------------- >23871_23871_3_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000372546_SPTAN1_chr9_131379919_ENST00000372739_length(transcript)=3117nt_BP=712nt GGCTGCTCGAAGAAGCCCGGTCTCCGGGTAAGATGGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCC ACGTCGAATATCCTGCAGGTGATCTCTCTGGCCACCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCC TCATCATATTTAAGCGGGAGCTGCACACGATCTCCTTCCTTGGGGGCCTGGCACTGAACGAGGGGGTCAACTGGCTGATCAAAAACGTCA TCCAGGAGCCACGGCCCTGTGGAGGCCCCCACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCT TCTCCGTCTATTCCTTCCTTTTCCTGTATTTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCT CCCTGGGACTCCTCGCTGTGGCCTTCCTAGTCTCCTACAGCAGGGTCTACCTGCTGTACCACACCTGGAGCCAGGTGCTCTATGGAGGCA TCGCTGGAGGCCTCATGGCCATCGCCTGGTTCATCTTCACCCAGGAGGTCCTCACCCCGCTGTTCCCCAGGATAGCAGCCTGGCCTGTCT CCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGGTTTGAGTACACGGTAACCCGGGCAGAAGCCAGGGAGAAGA AGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAGAACCTGAGGAAGAAGCACAAGCGGCTGGAAGCAGAACTGG CTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTGTCCGATGACAACACCATCGGGAAAGAGGAGATCCAGCAGC GGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCTGCCCGGGGTCAGCGGCTGGAAGAGTCCTTGGAATATCAGC AGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATGACCCTGGTGGCCAGCGAAGATTATGGCGACACTCTTGCCG CCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACCGTCCACAAGGATCGCGTGAATGATGTCTGCACCAATGGAC AAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAG CTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTG AAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTG GGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCA TCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGA GTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACT TAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCC AGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGG CCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACG ACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGACATACCTCCTCGATGGGTCCTGTA TGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAA AGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGT GGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGG CCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCT CCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATG GCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCC GGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCC ACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAG CCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAA CCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTG TGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCC >23871_23871_3_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000372546_SPTAN1_chr9_131379919_ENST00000372739_length(amino acids)=928AA_BP=236 LLEEARSPGKMAADGQCSLPASWRPVTLTHVEYPAGDLSGHLLAYLSLSPVFVIVGFVTLIIFKRELHTISFLGGLALNEGVNWLIKNVI QEPRPCGGPHTAVGTKYGMPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRVYLLYHTWSQVLYGGI AGGLMAIAWFIFTQEVLTPLFPRIAAWPVSEFFLIRDTSLIPNVLWFEYTVTRAEAREKKLLVGSEDYGRDLTGVQNLRKKHKRLEAELA AHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLEESLEYQQFVANVEEEEAWINEKMTLVASEDYGDTLAA IQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDENSAFLQFNWKADVVESWIGE KENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRWSQLLANSAARKKKLLEAQS HFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDRQIKSFRVASNPYTWFTMEA LEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTYLLDGSCMVEESGTLESQLEATKRKHQEIRAMRSQLKK IEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHFDKDKSGRLNHQEFKSCLRS LGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVTKEELYQNLTREQADYCVSH -------------------------------------------------------------- >23871_23871_4_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000406974_SPTAN1_chr9_131379919_ENST00000358161_length(transcript)=2974nt_BP=572nt GAAGCCCGGTCTCCGGGTAAGATGGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCCACGTCGAATAT CCTGCAGGTGATCTCTCTGGCCACCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCCTCATCATATTT AAGCGGGAGCTGCACACGATCTCCTTCCTTGGGGGCCTGGCACTGAACGAGGGGGTCAACTGGCTGATCAAAAACGTCATCCAGGAGCCA CGGCCCTGTGGAGGCCCCCACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCTTCTCCGTCTAT TCCTTCCTTTTCCTGTATTTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCTCCCTGGGACTC CTCGCTGTGGCCTTCCTAGTCTCCTACAGCAGGCCTGTCTCCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGG TTTGAGTACACGGTAACCCGGGCAGAAGCCAGGGAGAAGAAGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAG AACCTGAGGAAGAAGCACAAGCGGCTGGAAGCAGAACTGGCTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTG TCCGATGACAACACCATCGGGAAAGAGGAGATCCAGCAGCGGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCT GCCCGGGGTCAGCGGCTGGAAGAGTCCTTGGAATATCAGCAGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATG ACCCTGGTGGCCAGCGAAGATTATGGCGACACTCTTGCCGCCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACC GTCCACAAGGATCGCGTGAATGATGTCTGCACCAATGGACAAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAG ATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAG TTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCT GTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAA GATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCC AACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCT TCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGC GAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTC CGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAG CTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGG ATCCAAGAGACCAGGTGCCAGCCCGCTGGGGCGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGC AAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAAC AAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAG CAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCT GGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAG TTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACT GAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTAC CAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTC GACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCT GCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCA CTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAG AAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTTTTCATGTAAAAGACAAATAAATGATGACTTC >23871_23871_4_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000406974_SPTAN1_chr9_131379919_ENST00000358161_length(amino acids)=875AA_BP=183 MAADGQCSLPASWRPVTLTHVEYPAGDLSGHLLAYLSLSPVFVIVGFVTLIIFKRELHTISFLGGLALNEGVNWLIKNVIQEPRPCGGPH TAVGTKYGMPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRPVSEFFLIRDTSLIPNVLWFEYTVTR AEAREKKLLVGSEDYGRDLTGVQNLRKKHKRLEAELAAHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLE ESLEYQQFVANVEEEEAWINEKMTLVASEDYGDTLAAIQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGK VSDLEKAAAQRKAKLDENSAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAK HVQSKAIEARHASLMKRWSQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFR SSLSSAQADFNQLAELDRQIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRCQ PAGASCMVEESGTLESQLEATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNT TGVTEEALKEFSMMFKHFDKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSE -------------------------------------------------------------- >23871_23871_5_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000406974_SPTAN1_chr9_131379919_ENST00000372731_length(transcript)=2977nt_BP=572nt GAAGCCCGGTCTCCGGGTAAGATGGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCCACGTCGAATAT CCTGCAGGTGATCTCTCTGGCCACCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCCTCATCATATTT AAGCGGGAGCTGCACACGATCTCCTTCCTTGGGGGCCTGGCACTGAACGAGGGGGTCAACTGGCTGATCAAAAACGTCATCCAGGAGCCA CGGCCCTGTGGAGGCCCCCACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCTTCTCCGTCTAT TCCTTCCTTTTCCTGTATTTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCTCCCTGGGACTC CTCGCTGTGGCCTTCCTAGTCTCCTACAGCAGGCCTGTCTCCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGG TTTGAGTACACGGTAACCCGGGCAGAAGCCAGGGAGAAGAAGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAG AACCTGAGGAAGAAGCACAAGCGGCTGGAAGCAGAACTGGCTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTG TCCGATGACAACACCATCGGGAAAGAGGAGATCCAGCAGCGGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCT GCCCGGGGTCAGCGGCTGGAAGAGTCCTTGGAATATCAGCAGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATG ACCCTGGTGGCCAGCGAAGATTATGGCGACACTCTTGCCGCCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACC GTCCACAAGGATCGCGTGAATGATGTCTGCACCAATGGACAAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAG ATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAG TTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCT GTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAA GATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCC AACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCT TCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGC GAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTC CGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAG CTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGG ATCCAAGAGACCAGGACATACCTCCTCGATGGGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGC AAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAAC AAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAG CAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCT GGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAG TTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACT GAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTAC CAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTC GACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCT GCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCA CTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAG AAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTTTTCATGTAAAAGACAAATAAATGATGACTTC >23871_23871_5_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000406974_SPTAN1_chr9_131379919_ENST00000372731_length(amino acids)=875AA_BP=183 MAADGQCSLPASWRPVTLTHVEYPAGDLSGHLLAYLSLSPVFVIVGFVTLIIFKRELHTISFLGGLALNEGVNWLIKNVIQEPRPCGGPH TAVGTKYGMPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRPVSEFFLIRDTSLIPNVLWFEYTVTR AEAREKKLLVGSEDYGRDLTGVQNLRKKHKRLEAELAAHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLE ESLEYQQFVANVEEEEAWINEKMTLVASEDYGDTLAAIQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGK VSDLEKAAAQRKAKLDENSAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAK HVQSKAIEARHASLMKRWSQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFR SSLSSAQADFNQLAELDRQIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTY LLDGSCMVEESGTLESQLEATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNT TGVTEEALKEFSMMFKHFDKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSE -------------------------------------------------------------- >23871_23871_6_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000406974_SPTAN1_chr9_131379919_ENST00000372739_length(transcript)=2977nt_BP=572nt GAAGCCCGGTCTCCGGGTAAGATGGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCCACGTCGAATAT CCTGCAGGTGATCTCTCTGGCCACCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCCTCATCATATTT AAGCGGGAGCTGCACACGATCTCCTTCCTTGGGGGCCTGGCACTGAACGAGGGGGTCAACTGGCTGATCAAAAACGTCATCCAGGAGCCA CGGCCCTGTGGAGGCCCCCACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCTTCTCCGTCTAT TCCTTCCTTTTCCTGTATTTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCTCCCTGGGACTC CTCGCTGTGGCCTTCCTAGTCTCCTACAGCAGGCCTGTCTCCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGG TTTGAGTACACGGTAACCCGGGCAGAAGCCAGGGAGAAGAAGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAG AACCTGAGGAAGAAGCACAAGCGGCTGGAAGCAGAACTGGCTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTG TCCGATGACAACACCATCGGGAAAGAGGAGATCCAGCAGCGGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCT GCCCGGGGTCAGCGGCTGGAAGAGTCCTTGGAATATCAGCAGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATG ACCCTGGTGGCCAGCGAAGATTATGGCGACACTCTTGCCGCCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACC GTCCACAAGGATCGCGTGAATGATGTCTGCACCAATGGACAAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAG ATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAG TTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCT GTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAA GATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCC AACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCT TCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGC GAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTC CGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAG CTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGG ATCCAAGAGACCAGGACATACCTCCTCGATGGGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGC AAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAAC AAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAG CAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCT GGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAG TTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACT GAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTAC CAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTC GACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCT GCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCA CTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAG AAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTTTTCATGTAAAAGACAAATAAATGATGACTTC >23871_23871_6_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000406974_SPTAN1_chr9_131379919_ENST00000372739_length(amino acids)=875AA_BP=183 MAADGQCSLPASWRPVTLTHVEYPAGDLSGHLLAYLSLSPVFVIVGFVTLIIFKRELHTISFLGGLALNEGVNWLIKNVIQEPRPCGGPH TAVGTKYGMPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRPVSEFFLIRDTSLIPNVLWFEYTVTR AEAREKKLLVGSEDYGRDLTGVQNLRKKHKRLEAELAAHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLE ESLEYQQFVANVEEEEAWINEKMTLVASEDYGDTLAAIQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGK VSDLEKAAAQRKAKLDENSAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAK HVQSKAIEARHASLMKRWSQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFR SSLSSAQADFNQLAELDRQIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTY LLDGSCMVEESGTLESQLEATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNT TGVTEEALKEFSMMFKHFDKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSE -------------------------------------------------------------- >23871_23871_7_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000540102_SPTAN1_chr9_131379919_ENST00000358161_length(transcript)=2866nt_BP=464nt GGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCCACGTCGAATATCCTGCAGGTGATCTCTCTGGCCA CCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCCTCATCATATTTAAGCGGGAGCTGCACACGGCCCC CACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCTTCTCCGTCTATTCCTTCCTTTTCCTGTAT TTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCTCCCTGGGACTCCTCGCTGTGGCCTTCCTA GTCTCCTACAGCAGGCCTGTCTCCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGGTTTGAGTACACGGTAACC CGGGCAGAAGCCAGGGAGAAGAAGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAGAACCTGAGGAAGAAGCAC AAGCGGCTGGAAGCAGAACTGGCTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTGTCCGATGACAACACCATC GGGAAAGAGGAGATCCAGCAGCGGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCTGCCCGGGGTCAGCGGCTG GAAGAGTCCTTGGAATATCAGCAGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATGACCCTGGTGGCCAGCGAA GATTATGGCGACACTCTTGCCGCCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACCGTCCACAAGGATCGCGTG AATGATGTCTGCACCAATGGACAAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGG AAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGAC GTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACC AAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCC AAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAG AAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGG TTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTC CGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCC TACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAA CAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGTGC CAGCCCGCTGGGGCGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGA GCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGC ACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAAC ACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAG GAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGAC ACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGC GAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAA CAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACC CGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGT GTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCC AGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGC >23871_23871_7_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000540102_SPTAN1_chr9_131379919_ENST00000358161_length(amino acids)=777AA_BP=85 MPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRPVSEFFLIRDTSLIPNVLWFEYTVTRAEAREKKL LVGSEDYGRDLTGVQNLRKKHKRLEAELAAHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLEESLEYQQF VANVEEEEAWINEKMTLVASEDYGDTLAAIQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGKVSDLEKAA AQRKAKLDENSAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIE ARHASLMKRWSQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQA DFNQLAELDRQIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRCQPAGASCMV EESGTLESQLEATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEAL KEFSMMFKHFDKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRA -------------------------------------------------------------- >23871_23871_8_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000540102_SPTAN1_chr9_131379919_ENST00000372731_length(transcript)=2869nt_BP=464nt GGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCCACGTCGAATATCCTGCAGGTGATCTCTCTGGCCA CCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCCTCATCATATTTAAGCGGGAGCTGCACACGGCCCC CACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCTTCTCCGTCTATTCCTTCCTTTTCCTGTAT TTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCTCCCTGGGACTCCTCGCTGTGGCCTTCCTA GTCTCCTACAGCAGGCCTGTCTCCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGGTTTGAGTACACGGTAACC CGGGCAGAAGCCAGGGAGAAGAAGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAGAACCTGAGGAAGAAGCAC AAGCGGCTGGAAGCAGAACTGGCTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTGTCCGATGACAACACCATC GGGAAAGAGGAGATCCAGCAGCGGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCTGCCCGGGGTCAGCGGCTG GAAGAGTCCTTGGAATATCAGCAGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATGACCCTGGTGGCCAGCGAA GATTATGGCGACACTCTTGCCGCCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACCGTCCACAAGGATCGCGTG AATGATGTCTGCACCAATGGACAAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGG AAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGAC GTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACC AAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCC AAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAG AAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGG TTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTC CGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCC TACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAA CAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGACA TACCTCCTCGATGGGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGA GCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGC ACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAAC ACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAG GAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGAC ACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGC GAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAA CAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACC CGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGT GTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCC AGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGC >23871_23871_8_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000540102_SPTAN1_chr9_131379919_ENST00000372731_length(amino acids)=777AA_BP=85 MPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRPVSEFFLIRDTSLIPNVLWFEYTVTRAEAREKKL LVGSEDYGRDLTGVQNLRKKHKRLEAELAAHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLEESLEYQQF VANVEEEEAWINEKMTLVASEDYGDTLAAIQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGKVSDLEKAA AQRKAKLDENSAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIE ARHASLMKRWSQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQA DFNQLAELDRQIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTYLLDGSCMV EESGTLESQLEATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEAL KEFSMMFKHFDKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRA -------------------------------------------------------------- >23871_23871_9_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000540102_SPTAN1_chr9_131379919_ENST00000372739_length(transcript)=2869nt_BP=464nt GGCAGCGGACGGACAGTGCTCGCTCCCCGCTTCATGGCGGCCGGTGACCCTCACCCACGTCGAATATCCTGCAGGTGATCTCTCTGGCCA CCTCCTTGCCTACCTGAGCCTCAGCCCTGTATTTGTCATCGTCGGTTTCGTGACCCTCATCATATTTAAGCGGGAGCTGCACACGGCCCC CACACAGCAGTGGGCACCAAGTACGGGATGCCCTCCAGCCATTCCCAGTTTATGTGGTTCTTCTCCGTCTATTCCTTCCTTTTCCTGTAT TTAAGAATGCACCAAACAAACAACGCCAGGTTCCTGGACTTGCTGTGGAGGCACGTGCTCTCCCTGGGACTCCTCGCTGTGGCCTTCCTA GTCTCCTACAGCAGGCCTGTCTCCGAGTTCTTCCTAATCCGAGACACAAGCCTCATTCCCAACGTACTCTGGTTTGAGTACACGGTAACC CGGGCAGAAGCCAGGGAGAAGAAGCTGCTGGTGGGCTCAGAGGACTACGGCCGGGACCTAACCGGCGTGCAGAACCTGAGGAAGAAGCAC AAGCGGCTGGAAGCAGAACTGGCTGCGCATGAGCCGGCTATTCAGGGTGTCCTGGACACTGGCAAGAAGCTGTCCGATGACAACACCATC GGGAAAGAGGAGATCCAGCAGCGGCTGGCGCAGTTTGTGGAGCACTGGAAAGAGCTGAAGCAGCTGGCAGCTGCCCGGGGTCAGCGGCTG GAAGAGTCCTTGGAATATCAGCAGTTTGTAGCCAATGTGGAAGAGGAAGAAGCCTGGATCAATGAGAAAATGACCCTGGTGGCCAGCGAA GATTATGGCGACACTCTTGCCGCCATCCAGGGCTTACTGAAGAAACATGAAGCTTTTGAGACAGACTTCACCGTCCACAAGGATCGCGTG AATGATGTCTGCACCAATGGACAAGACCTCATTAAGAAGAACAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGG AAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGAC GTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACC AAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCC AAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAG AAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGG TTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTC CGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCC TACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAA CAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGACA TACCTCCTCGATGGGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGA GCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGC ACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAAC ACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAG GAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGAC ACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGC GAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAA CAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACC CGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGT GTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCC AGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGC >23871_23871_9_DOLPP1-SPTAN1_DOLPP1_chr9_131849077_ENST00000540102_SPTAN1_chr9_131379919_ENST00000372739_length(amino acids)=777AA_BP=85 MPSSHSQFMWFFSVYSFLFLYLRMHQTNNARFLDLLWRHVLSLGLLAVAFLVSYSRPVSEFFLIRDTSLIPNVLWFEYTVTRAEAREKKL LVGSEDYGRDLTGVQNLRKKHKRLEAELAAHEPAIQGVLDTGKKLSDDNTIGKEEIQQRLAQFVEHWKELKQLAAARGQRLEESLEYQQF VANVEEEEAWINEKMTLVASEDYGDTLAAIQGLLKKHEAFETDFTVHKDRVNDVCTNGQDLIKKNNHHEENISSKMKGLNGKVSDLEKAA AQRKAKLDENSAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIE ARHASLMKRWSQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQA DFNQLAELDRQIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTYLLDGSCMV EESGTLESQLEATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEAL KEFSMMFKHFDKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DOLPP1-SPTAN1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DOLPP1-SPTAN1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DOLPP1-SPTAN1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies