
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DSTYK-CSRP1 (FusionGDB2 ID:24327) |
Fusion Gene Summary for DSTYK-CSRP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DSTYK-CSRP1 | Fusion gene ID: 24327 | Hgene | Tgene | Gene symbol | DSTYK | CSRP1 | Gene ID | 25778 | 1465 |
| Gene name | dual serine/threonine and tyrosine protein kinase | cysteine and glycine rich protein 1 | |
| Synonyms | CAKUT1|DustyPK|HDCMD38P|RIP5|RIPK5|SPG23 | CRP|CRP1|CSRP|CYRP|D1S181E|HEL-141|HEL-S-286 | |
| Cytomap | 1q32.1 | 1q32.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | dual serine/threonine and tyrosine protein kinaseRIP-homologous kinasedusty PKdusty protein kinasereceptor-interacting serine/threonine-protein kinase 5sgK496spastic paraplegia 23 (autosomal recessive)sugen kinase 496 | cysteine and glycine-rich protein 1LIM-domain proteincysteine-rich protein 1epididymis luminal protein 141epididymis secretory protein Li 286epididymis secretory sperm binding protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q6XUX3 | P21291 | |
| Ensembl transtripts involved in fusion gene | ENST00000367160, ENST00000367161, ENST00000367162, | ENST00000458271, ENST00000526723, ENST00000531916, ENST00000532460, ENST00000533432, ENST00000340006, ENST00000367306, | |
| Fusion gene scores | * DoF score | 8 X 5 X 7=280 | 7 X 9 X 5=315 |
| # samples | 11 | 11 | |
| ** MAII score | log2(11/280*10)=-1.34792330342031 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/315*10)=-1.51784830486262 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DSTYK [Title/Abstract] AND CSRP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DSTYK(205180399)-CSRP1(201454504), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | DSTYK | GO:0044344 | cellular response to fibroblast growth factor stimulus | 23862974 |
| Fusion gene breakpoints across DSTYK (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CSRP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
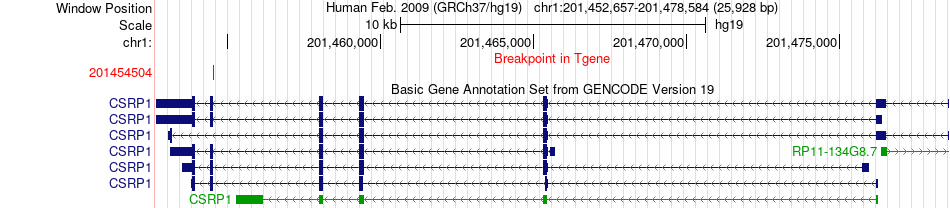 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCS | TCGA-N8-A56S-01A | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| ChimerDB4 | UCS | TCGA-N8-A56S | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| ChimerDB4 | UCS | TCGA-N8-A56S | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
Top |
Fusion Gene ORF analysis for DSTYK-CSRP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000367160 | ENST00000458271 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000458271 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000526723 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000526723 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000531916 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000531916 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000532460 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000532460 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000533432 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367160 | ENST00000533432 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000458271 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000458271 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000526723 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000526723 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000531916 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000531916 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000532460 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000532460 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000533432 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367161 | ENST00000533432 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000458271 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000458271 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000526723 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000526723 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000531916 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000531916 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000532460 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000532460 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000533432 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| 5CDS-intron | ENST00000367162 | ENST00000533432 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367160 | ENST00000340006 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367160 | ENST00000340006 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367160 | ENST00000367306 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367160 | ENST00000367306 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367161 | ENST00000340006 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367161 | ENST00000340006 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367161 | ENST00000367306 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367161 | ENST00000367306 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367162 | ENST00000340006 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367162 | ENST00000340006 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367162 | ENST00000367306 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - |
| In-frame | ENST00000367162 | ENST00000367306 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000367160 | DSTYK | chr1 | 205180399 | - | ENST00000367306 | CSRP1 | chr1 | 201454504 | - | 1683 | 329 | 84 | 665 | 193 |
| ENST00000367160 | DSTYK | chr1 | 205180399 | - | ENST00000340006 | CSRP1 | chr1 | 201454504 | - | 1679 | 329 | 84 | 665 | 193 |
| ENST00000367161 | DSTYK | chr1 | 205180399 | - | ENST00000367306 | CSRP1 | chr1 | 201454504 | - | 1650 | 296 | 51 | 632 | 193 |
| ENST00000367161 | DSTYK | chr1 | 205180399 | - | ENST00000340006 | CSRP1 | chr1 | 201454504 | - | 1646 | 296 | 51 | 632 | 193 |
| ENST00000367162 | DSTYK | chr1 | 205180399 | - | ENST00000367306 | CSRP1 | chr1 | 201454504 | - | 1650 | 296 | 51 | 632 | 193 |
| ENST00000367162 | DSTYK | chr1 | 205180399 | - | ENST00000340006 | CSRP1 | chr1 | 201454504 | - | 1646 | 296 | 51 | 632 | 193 |
| ENST00000367160 | DSTYK | chr1 | 205180398 | - | ENST00000367306 | CSRP1 | chr1 | 201454504 | - | 1683 | 329 | 84 | 665 | 193 |
| ENST00000367160 | DSTYK | chr1 | 205180398 | - | ENST00000340006 | CSRP1 | chr1 | 201454504 | - | 1679 | 329 | 84 | 665 | 193 |
| ENST00000367161 | DSTYK | chr1 | 205180398 | - | ENST00000367306 | CSRP1 | chr1 | 201454504 | - | 1650 | 296 | 51 | 632 | 193 |
| ENST00000367161 | DSTYK | chr1 | 205180398 | - | ENST00000340006 | CSRP1 | chr1 | 201454504 | - | 1646 | 296 | 51 | 632 | 193 |
| ENST00000367162 | DSTYK | chr1 | 205180398 | - | ENST00000367306 | CSRP1 | chr1 | 201454504 | - | 1650 | 296 | 51 | 632 | 193 |
| ENST00000367162 | DSTYK | chr1 | 205180398 | - | ENST00000340006 | CSRP1 | chr1 | 201454504 | - | 1646 | 296 | 51 | 632 | 193 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000367160 | ENST00000367306 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - | 0.576351 | 0.423649 |
| ENST00000367160 | ENST00000340006 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - | 0.5814876 | 0.4185124 |
| ENST00000367161 | ENST00000367306 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - | 0.6122478 | 0.38775215 |
| ENST00000367161 | ENST00000340006 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - | 0.6182326 | 0.3817674 |
| ENST00000367162 | ENST00000367306 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - | 0.6122478 | 0.38775215 |
| ENST00000367162 | ENST00000340006 | DSTYK | chr1 | 205180399 | - | CSRP1 | chr1 | 201454504 | - | 0.6182326 | 0.3817674 |
| ENST00000367160 | ENST00000367306 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - | 0.576351 | 0.423649 |
| ENST00000367160 | ENST00000340006 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - | 0.5814876 | 0.4185124 |
| ENST00000367161 | ENST00000367306 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - | 0.6122478 | 0.38775215 |
| ENST00000367161 | ENST00000340006 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - | 0.6182326 | 0.3817674 |
| ENST00000367162 | ENST00000367306 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - | 0.6122478 | 0.38775215 |
| ENST00000367162 | ENST00000340006 | DSTYK | chr1 | 205180398 | - | CSRP1 | chr1 | 201454504 | - | 0.6182326 | 0.3817674 |
Top |
Fusion Genomic Features for DSTYK-CSRP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
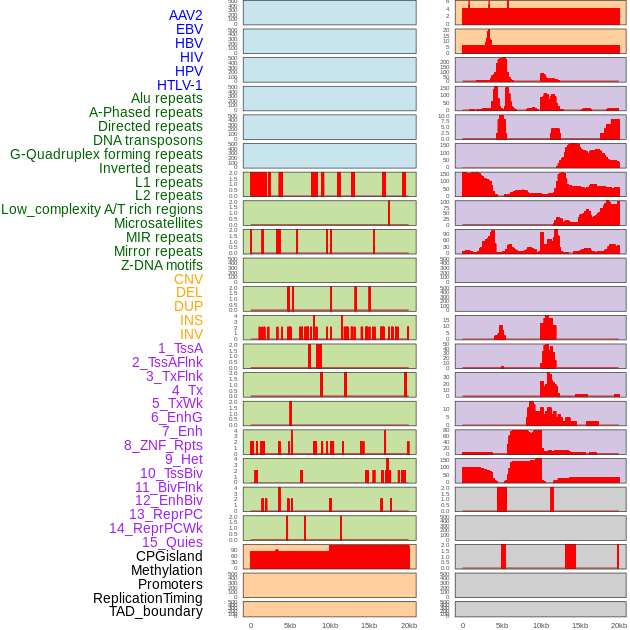 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for DSTYK-CSRP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:205180399/chr1:201454504) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DSTYK | CSRP1 |
| FUNCTION: Acts as a positive regulator of ERK phosphorylation downstream of fibroblast growth factor-receptor activation (PubMed:23862974, PubMed:28157540). Involved in the regulation of both caspase-dependent apoptosis and caspase-independent cell death (PubMed:15178406). In the skin, it plays a predominant role in suppressing caspase-dependent apoptosis in response to UV stress in a range of dermal cell types (PubMed:28157540). {ECO:0000269|PubMed:15178406, ECO:0000269|PubMed:23862974, ECO:0000269|PubMed:28157540}. | FUNCTION: Could play a role in neuronal development. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 15_22 | 88 | 885.0 | Compositional bias | Note=Poly-Gly |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 69_72 | 88 | 885.0 | Compositional bias | Note=Poly-Gly |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 15_22 | 88 | 930.0 | Compositional bias | Note=Poly-Gly |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 69_72 | 88 | 930.0 | Compositional bias | Note=Poly-Gly |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 15_22 | 88 | 885.0 | Compositional bias | Note=Poly-Gly |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 69_72 | 88 | 885.0 | Compositional bias | Note=Poly-Gly |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 15_22 | 88 | 930.0 | Compositional bias | Note=Poly-Gly |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 69_72 | 88 | 930.0 | Compositional bias | Note=Poly-Gly |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000340006 | 3 | 6 | 176_187 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000367306 | 4 | 7 | 176_187 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000532460 | 3 | 6 | 176_187 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000533432 | 3 | 6 | 176_187 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000340006 | 3 | 6 | 176_187 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000367306 | 4 | 7 | 176_187 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000532460 | 3 | 6 | 176_187 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000533432 | 3 | 6 | 176_187 | 137 | 194.0 | Compositional bias | Note=Gly-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 189_215 | 88 | 885.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 395_431 | 88 | 885.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 189_215 | 88 | 930.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 395_431 | 88 | 930.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 189_215 | 88 | 885.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 395_431 | 88 | 885.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 189_215 | 88 | 930.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 395_431 | 88 | 930.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 652_906 | 88 | 885.0 | Domain | Protein kinase |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 652_906 | 88 | 930.0 | Domain | Protein kinase |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 652_906 | 88 | 885.0 | Domain | Protein kinase |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 652_906 | 88 | 930.0 | Domain | Protein kinase |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 658_666 | 88 | 885.0 | Nucleotide binding | ATP |
| Hgene | DSTYK | chr1:205180398 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 658_666 | 88 | 930.0 | Nucleotide binding | ATP |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367161 | - | 1 | 12 | 658_666 | 88 | 885.0 | Nucleotide binding | ATP |
| Hgene | DSTYK | chr1:205180399 | chr1:201454504 | ENST00000367162 | - | 1 | 13 | 658_666 | 88 | 930.0 | Nucleotide binding | ATP |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000340006 | 3 | 6 | 63_78 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000367306 | 4 | 7 | 63_78 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000532460 | 3 | 6 | 63_78 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000533432 | 3 | 6 | 63_78 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000340006 | 3 | 6 | 63_78 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000367306 | 4 | 7 | 63_78 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000532460 | 3 | 6 | 63_78 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000533432 | 3 | 6 | 63_78 | 137 | 194.0 | Compositional bias | Note=Gly-rich | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000340006 | 3 | 6 | 10_61 | 137 | 194.0 | Domain | LIM zinc-binding 1 | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000340006 | 3 | 6 | 119_170 | 137 | 194.0 | Domain | LIM zinc-binding 2 | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000367306 | 4 | 7 | 10_61 | 137 | 194.0 | Domain | LIM zinc-binding 1 | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000367306 | 4 | 7 | 119_170 | 137 | 194.0 | Domain | LIM zinc-binding 2 | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000532460 | 3 | 6 | 10_61 | 137 | 194.0 | Domain | LIM zinc-binding 1 | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000532460 | 3 | 6 | 119_170 | 137 | 194.0 | Domain | LIM zinc-binding 2 | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000533432 | 3 | 6 | 10_61 | 137 | 194.0 | Domain | LIM zinc-binding 1 | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000533432 | 3 | 6 | 119_170 | 137 | 194.0 | Domain | LIM zinc-binding 2 | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000340006 | 3 | 6 | 10_61 | 137 | 194.0 | Domain | LIM zinc-binding 1 | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000340006 | 3 | 6 | 119_170 | 137 | 194.0 | Domain | LIM zinc-binding 2 | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000367306 | 4 | 7 | 10_61 | 137 | 194.0 | Domain | LIM zinc-binding 1 | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000367306 | 4 | 7 | 119_170 | 137 | 194.0 | Domain | LIM zinc-binding 2 | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000532460 | 3 | 6 | 10_61 | 137 | 194.0 | Domain | LIM zinc-binding 1 | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000532460 | 3 | 6 | 119_170 | 137 | 194.0 | Domain | LIM zinc-binding 2 | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000533432 | 3 | 6 | 10_61 | 137 | 194.0 | Domain | LIM zinc-binding 1 | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000533432 | 3 | 6 | 119_170 | 137 | 194.0 | Domain | LIM zinc-binding 2 | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000340006 | 3 | 6 | 64_69 | 137 | 194.0 | Motif | Nuclear localization signal | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000367306 | 4 | 7 | 64_69 | 137 | 194.0 | Motif | Nuclear localization signal | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000532460 | 3 | 6 | 64_69 | 137 | 194.0 | Motif | Nuclear localization signal | |
| Tgene | CSRP1 | chr1:205180398 | chr1:201454504 | ENST00000533432 | 3 | 6 | 64_69 | 137 | 194.0 | Motif | Nuclear localization signal | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000340006 | 3 | 6 | 64_69 | 137 | 194.0 | Motif | Nuclear localization signal | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000367306 | 4 | 7 | 64_69 | 137 | 194.0 | Motif | Nuclear localization signal | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000532460 | 3 | 6 | 64_69 | 137 | 194.0 | Motif | Nuclear localization signal | |
| Tgene | CSRP1 | chr1:205180399 | chr1:201454504 | ENST00000533432 | 3 | 6 | 64_69 | 137 | 194.0 | Motif | Nuclear localization signal |
Top |
Fusion Gene Sequence for DSTYK-CSRP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >24327_24327_1_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367160_CSRP1_chr1_201454504_ENST00000340006_length(transcript)=1679nt_BP=329nt GGGGAGGAGGGAGGCCGGGCCTGCGGCCGGGGACCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGG CAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGGCGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGG ACGGCTGCGACAGAACCTGCGCGAGACCCAGAAGTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGG CGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGATGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCA AGTGTGGCAAAGGCCTTGAGTCAACCACCCTGGCAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCA AGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCTTGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTT TTCATCGCCATTCCATTCCCAGCAGCTTTGGAGACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTG GGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCCTGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGT AGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAGCAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTG CGTGTCCATCATCAGCTGACCAAGACACCTGAGGACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAA GACCAAGATGAGGAGGGGGGAAGGCTGGGTTTTTTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCA GAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTCACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGG CCTCTTGCCTTTGAGTCTTTGTGGAATGGATAGCCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGA TGTTGTTTGATCTTCTCAAACATCTAGTTCCCTGCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGG CTCAAATCTTCATTTATCTCTGGCCTTAACCCTGGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCT GCTTGATCCTCAGATGTGGAGGGAGGTAGGCACTGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCC TTTAACCCAAGACCCTGCCTCTTCCACTCCACCCTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGA ATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCCTCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGC >24327_24327_1_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367160_CSRP1_chr1_201454504_ENST00000340006_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_2_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367160_CSRP1_chr1_201454504_ENST00000367306_length(transcript)=1683nt_BP=329nt GGGGAGGAGGGAGGCCGGGCCTGCGGCCGGGGACCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGG CAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGGCGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGG ACGGCTGCGACAGAACCTGCGCGAGACCCAGAAGTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGG CGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGATGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCA AGTGTGGCAAAGGCCTTGAGTCAACCACCCTGGCAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCA AGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCTTGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTT TTCATCGCCATTCCATTCCCAGCAGCTTTGGAGACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTG GGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCCTGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGT AGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAGCAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTG CGTGTCCATCATCAGCTGACCAAGACACCTGAGGACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAA GACCAAGATGAGGAGGGGGGAAGGCTGGGTTTTTTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCA GAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTCACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGG CCTCTTGCCTTTGAGTCTTTGTGGAATGGATAGCCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGA TGTTGTTTGATCTTCTCAAACATCTAGTTCCCTGCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGG CTCAAATCTTCATTTATCTCTGGCCTTAACCCTGGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCT GCTTGATCCTCAGATGTGGAGGGAGGTAGGCACTGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCC TTTAACCCAAGACCCTGCCTCTTCCACTCCACCCTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGA ATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCCTCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGC >24327_24327_2_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367160_CSRP1_chr1_201454504_ENST00000367306_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_3_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367161_CSRP1_chr1_201454504_ENST00000340006_length(transcript)=1646nt_BP=296nt CCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGGCAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGG CGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGGACGGCTGCGACAGAACCTGCGCGAGACCCAGAA GTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGGCGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGA TGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCAAGTGTGGCAAAGGCCTTGAGTCAACCACCCTGG CAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCAAGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCT TGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTTTTCATCGCCATTCCATTCCCAGCAGCTTTGGAG ACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTGGGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCC TGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGTAGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAG CAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTGCGTGTCCATCATCAGCTGACCAAGACACCTGAG GACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAAGACCAAGATGAGGAGGGGGGAAGGCTGGGTTTT TTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCAGAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTC ACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGGCCTCTTGCCTTTGAGTCTTTGTGGAATGGATAG CCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGATGTTGTTTGATCTTCTCAAACATCTAGTTCCCT GCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGGCTCAAATCTTCATTTATCTCTGGCCTTAACCCT GGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCTGCTTGATCCTCAGATGTGGAGGGAGGTAGGCAC TGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCCTTTAACCCAAGACCCTGCCTCTTCCACTCCACC CTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGAATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCC TCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGCTGCAGGCATGGGCTGTACCCAAGCTGATTTCTC >24327_24327_3_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367161_CSRP1_chr1_201454504_ENST00000340006_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_4_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367161_CSRP1_chr1_201454504_ENST00000367306_length(transcript)=1650nt_BP=296nt CCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGGCAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGG CGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGGACGGCTGCGACAGAACCTGCGCGAGACCCAGAA GTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGGCGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGA TGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCAAGTGTGGCAAAGGCCTTGAGTCAACCACCCTGG CAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCAAGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCT TGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTTTTCATCGCCATTCCATTCCCAGCAGCTTTGGAG ACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTGGGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCC TGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGTAGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAG CAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTGCGTGTCCATCATCAGCTGACCAAGACACCTGAG GACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAAGACCAAGATGAGGAGGGGGGAAGGCTGGGTTTT TTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCAGAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTC ACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGGCCTCTTGCCTTTGAGTCTTTGTGGAATGGATAG CCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGATGTTGTTTGATCTTCTCAAACATCTAGTTCCCT GCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGGCTCAAATCTTCATTTATCTCTGGCCTTAACCCT GGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCTGCTTGATCCTCAGATGTGGAGGGAGGTAGGCAC TGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCCTTTAACCCAAGACCCTGCCTCTTCCACTCCACC CTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGAATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCC TCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGCTGCAGGCATGGGCTGTACCCAAGCTGATTTCTC >24327_24327_4_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367161_CSRP1_chr1_201454504_ENST00000367306_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_5_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367162_CSRP1_chr1_201454504_ENST00000340006_length(transcript)=1646nt_BP=296nt CCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGGCAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGG CGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGGACGGCTGCGACAGAACCTGCGCGAGACCCAGAA GTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGGCGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGA TGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCAAGTGTGGCAAAGGCCTTGAGTCAACCACCCTGG CAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCAAGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCT TGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTTTTCATCGCCATTCCATTCCCAGCAGCTTTGGAG ACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTGGGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCC TGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGTAGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAG CAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTGCGTGTCCATCATCAGCTGACCAAGACACCTGAG GACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAAGACCAAGATGAGGAGGGGGGAAGGCTGGGTTTT TTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCAGAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTC ACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGGCCTCTTGCCTTTGAGTCTTTGTGGAATGGATAG CCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGATGTTGTTTGATCTTCTCAAACATCTAGTTCCCT GCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGGCTCAAATCTTCATTTATCTCTGGCCTTAACCCT GGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCTGCTTGATCCTCAGATGTGGAGGGAGGTAGGCAC TGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCCTTTAACCCAAGACCCTGCCTCTTCCACTCCACC CTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGAATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCC TCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGCTGCAGGCATGGGCTGTACCCAAGCTGATTTCTC >24327_24327_5_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367162_CSRP1_chr1_201454504_ENST00000340006_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_6_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367162_CSRP1_chr1_201454504_ENST00000367306_length(transcript)=1650nt_BP=296nt CCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGGCAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGG CGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGGACGGCTGCGACAGAACCTGCGCGAGACCCAGAA GTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGGCGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGA TGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCAAGTGTGGCAAAGGCCTTGAGTCAACCACCCTGG CAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCAAGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCT TGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTTTTCATCGCCATTCCATTCCCAGCAGCTTTGGAG ACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTGGGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCC TGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGTAGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAG CAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTGCGTGTCCATCATCAGCTGACCAAGACACCTGAG GACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAAGACCAAGATGAGGAGGGGGGAAGGCTGGGTTTT TTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCAGAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTC ACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGGCCTCTTGCCTTTGAGTCTTTGTGGAATGGATAG CCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGATGTTGTTTGATCTTCTCAAACATCTAGTTCCCT GCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGGCTCAAATCTTCATTTATCTCTGGCCTTAACCCT GGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCTGCTTGATCCTCAGATGTGGAGGGAGGTAGGCAC TGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCCTTTAACCCAAGACCCTGCCTCTTCCACTCCACC CTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGAATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCC TCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGCTGCAGGCATGGGCTGTACCCAAGCTGATTTCTC >24327_24327_6_DSTYK-CSRP1_DSTYK_chr1_205180398_ENST00000367162_CSRP1_chr1_201454504_ENST00000367306_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_7_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367160_CSRP1_chr1_201454504_ENST00000340006_length(transcript)=1679nt_BP=329nt GGGGAGGAGGGAGGCCGGGCCTGCGGCCGGGGACCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGG CAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGGCGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGG ACGGCTGCGACAGAACCTGCGCGAGACCCAGAAGTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGG CGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGATGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCA AGTGTGGCAAAGGCCTTGAGTCAACCACCCTGGCAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCA AGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCTTGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTT TTCATCGCCATTCCATTCCCAGCAGCTTTGGAGACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTG GGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCCTGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGT AGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAGCAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTG CGTGTCCATCATCAGCTGACCAAGACACCTGAGGACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAA GACCAAGATGAGGAGGGGGGAAGGCTGGGTTTTTTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCA GAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTCACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGG CCTCTTGCCTTTGAGTCTTTGTGGAATGGATAGCCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGA TGTTGTTTGATCTTCTCAAACATCTAGTTCCCTGCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGG CTCAAATCTTCATTTATCTCTGGCCTTAACCCTGGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCT GCTTGATCCTCAGATGTGGAGGGAGGTAGGCACTGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCC TTTAACCCAAGACCCTGCCTCTTCCACTCCACCCTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGA ATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCCTCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGC >24327_24327_7_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367160_CSRP1_chr1_201454504_ENST00000340006_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_8_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367160_CSRP1_chr1_201454504_ENST00000367306_length(transcript)=1683nt_BP=329nt GGGGAGGAGGGAGGCCGGGCCTGCGGCCGGGGACCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGG CAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGGCGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGG ACGGCTGCGACAGAACCTGCGCGAGACCCAGAAGTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGG CGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGATGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCA AGTGTGGCAAAGGCCTTGAGTCAACCACCCTGGCAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCA AGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCTTGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTT TTCATCGCCATTCCATTCCCAGCAGCTTTGGAGACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTG GGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCCTGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGT AGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAGCAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTG CGTGTCCATCATCAGCTGACCAAGACACCTGAGGACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAA GACCAAGATGAGGAGGGGGGAAGGCTGGGTTTTTTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCA GAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTCACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGG CCTCTTGCCTTTGAGTCTTTGTGGAATGGATAGCCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGA TGTTGTTTGATCTTCTCAAACATCTAGTTCCCTGCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGG CTCAAATCTTCATTTATCTCTGGCCTTAACCCTGGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCT GCTTGATCCTCAGATGTGGAGGGAGGTAGGCACTGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCC TTTAACCCAAGACCCTGCCTCTTCCACTCCACCCTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGA ATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCCTCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGC >24327_24327_8_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367160_CSRP1_chr1_201454504_ENST00000367306_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_9_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367161_CSRP1_chr1_201454504_ENST00000340006_length(transcript)=1646nt_BP=296nt CCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGGCAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGG CGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGGACGGCTGCGACAGAACCTGCGCGAGACCCAGAA GTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGGCGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGA TGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCAAGTGTGGCAAAGGCCTTGAGTCAACCACCCTGG CAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCAAGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCT TGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTTTTCATCGCCATTCCATTCCCAGCAGCTTTGGAG ACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTGGGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCC TGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGTAGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAG CAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTGCGTGTCCATCATCAGCTGACCAAGACACCTGAG GACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAAGACCAAGATGAGGAGGGGGGAAGGCTGGGTTTT TTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCAGAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTC ACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGGCCTCTTGCCTTTGAGTCTTTGTGGAATGGATAG CCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGATGTTGTTTGATCTTCTCAAACATCTAGTTCCCT GCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGGCTCAAATCTTCATTTATCTCTGGCCTTAACCCT GGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCTGCTTGATCCTCAGATGTGGAGGGAGGTAGGCAC TGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCCTTTAACCCAAGACCCTGCCTCTTCCACTCCACC CTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGAATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCC TCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGCTGCAGGCATGGGCTGTACCCAAGCTGATTTCTC >24327_24327_9_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367161_CSRP1_chr1_201454504_ENST00000340006_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_10_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367161_CSRP1_chr1_201454504_ENST00000367306_length(transcript)=1650nt_BP=296nt CCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGGCAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGG CGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGGACGGCTGCGACAGAACCTGCGCGAGACCCAGAA GTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGGCGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGA TGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCAAGTGTGGCAAAGGCCTTGAGTCAACCACCCTGG CAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCAAGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCT TGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTTTTCATCGCCATTCCATTCCCAGCAGCTTTGGAG ACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTGGGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCC TGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGTAGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAG CAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTGCGTGTCCATCATCAGCTGACCAAGACACCTGAG GACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAAGACCAAGATGAGGAGGGGGGAAGGCTGGGTTTT TTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCAGAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTC ACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGGCCTCTTGCCTTTGAGTCTTTGTGGAATGGATAG CCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGATGTTGTTTGATCTTCTCAAACATCTAGTTCCCT GCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGGCTCAAATCTTCATTTATCTCTGGCCTTAACCCT GGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCTGCTTGATCCTCAGATGTGGAGGGAGGTAGGCAC TGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCCTTTAACCCAAGACCCTGCCTCTTCCACTCCACC CTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGAATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCC TCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGCTGCAGGCATGGGCTGTACCCAAGCTGATTTCTC >24327_24327_10_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367161_CSRP1_chr1_201454504_ENST00000367306_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_11_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367162_CSRP1_chr1_201454504_ENST00000340006_length(transcript)=1646nt_BP=296nt CCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGGCAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGG CGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGGACGGCTGCGACAGAACCTGCGCGAGACCCAGAA GTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGGCGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGA TGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCAAGTGTGGCAAAGGCCTTGAGTCAACCACCCTGG CAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCAAGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCT TGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTTTTCATCGCCATTCCATTCCCAGCAGCTTTGGAG ACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTGGGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCC TGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGTAGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAG CAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTGCGTGTCCATCATCAGCTGACCAAGACACCTGAG GACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAAGACCAAGATGAGGAGGGGGGAAGGCTGGGTTTT TTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCAGAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTC ACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGGCCTCTTGCCTTTGAGTCTTTGTGGAATGGATAG CCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGATGTTGTTTGATCTTCTCAAACATCTAGTTCCCT GCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGGCTCAAATCTTCATTTATCTCTGGCCTTAACCCT GGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCTGCTTGATCCTCAGATGTGGAGGGAGGTAGGCAC TGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCCTTTAACCCAAGACCCTGCCTCTTCCACTCCACC CTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGAATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCC TCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGCTGCAGGCATGGGCTGTACCCAAGCTGATTTCTC >24327_24327_11_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367162_CSRP1_chr1_201454504_ENST00000340006_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- >24327_24327_12_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367162_CSRP1_chr1_201454504_ENST00000367306_length(transcript)=1650nt_BP=296nt CCGAGCCGCAAAGACAGAGCGGGCAGAGGCGATGGAGGGCGACGGGGTGCCATGGGGCAGCGAGCCCGTCTCGGGTCCCGGCCCCGGCGG CGGCGGAATGATCCGCGAGCTGTGCCGGGGCTTCGGCCGCTACCGCCGCTACCTGGGACGGCTGCGACAGAACCTGCGCGAGACCCAGAA GTTCTTCCGCGACATCAAGTGCTCCCACAACCACACTTGTCTCTCCTCCCTCACGGGCGGCGGCGGGGCCGAGCGCGGCCCTGCAGGCGA TGTCGCCGAAACCGGGCTGCAGGCGGTCCTGGCATAAGGCCTGCTTTCGATGTGCCAAGTGTGGCAAAGGCCTTGAGTCAACCACCCTGG CAGACAAGGATGGCGAGATTTACTGCAAAGGATGTTATGCTAAAAACTTCGGGCCCAAGGGCTTTGGTTTTGGGCAAGGAGCTGGGGCCT TGGTCCACTCTGAGTGAGGCCACCATCACCCACCACACCCTGCCCACTCCTGCGCTTTTCATCGCCATTCCATTCCCAGCAGCTTTGGAG ACCTCCAGGATTATTTCTCTGTCAGCCCTGCCACATATCACTAATGACTTGAACTTGGGCATCTGGCTCCCTTTGGTTTGGGGGTCTGCC TGAGGTCCCACCCCACTAAAGGGCTCCCCAGGCCTGGGATCTGACACCATCACCAGTAGGAGACCTCAGTGTTTTGGGTCTAGGTGAGAG CAGGCCCCTCTCCCCACACCTCGCCCCACAGAGCTCTGTTCTTAGCCTCCTGTGCTGCGTGTCCATCATCAGCTGACCAAGACACCTGAG GACACATCTTGGCACCCAGAGGAGCAGCAGCAACAGGCTGGAGGGAGAGGGAAGCAAGACCAAGATGAGGAGGGGGGAAGGCTGGGTTTT TTGGATCTCAGAGATTCTCCTCTGTGGGAAAGAGGTTGAGCTTCCTGGTGTCCCTCAGAGTAAGCCTGAGGAGTCCCAGCTTAGGGAGTC ACTATTGGAGGCAGAGAGGCATGCAGGCAGGGTCCTAGGAGCCCCTGCTTCTCCAGGCCTCTTGCCTTTGAGTCTTTGTGGAATGGATAG CCTCCCACTAGGACTGGGAGGAGAATAACCCAGGTCTTAAGGACCCCAAAGTCAGGATGTTGTTTGATCTTCTCAAACATCTAGTTCCCT GCTTGATGGGAGGATCCTAATGAAATACCTGAAACATATATTGGCATTTATCAATGGCTCAAATCTTCATTTATCTCTGGCCTTAACCCT GGCTCCTGAGGCTGCGGCCAGCAGAGCCCAGGCCAGGGCTCTGTTCTTGCCACACCTGCTTGATCCTCAGATGTGGAGGGAGGTAGGCAC TGCCTCAGTCTTCATCCAAACACCTTTCCCTTTGCCCTGAGACCTCAGAATCTTCCCTTTAACCCAAGACCCTGCCTCTTCCACTCCACC CTTCTCCAGGGACCCTTAGATCACATCACTCCACCCCTGCCAGGCCCCAGGTTAGGAATAGTGGTGGGAGGAAGGGGAAAGGGCTGGGCC TCACCGCTCCCAGCAACTGAAAGGACAACACTATCTGGAGCCACCCACTGAAAGGGCTGCAGGCATGGGCTGTACCCAAGCTGATTTCTC >24327_24327_12_DSTYK-CSRP1_DSTYK_chr1_205180399_ENST00000367162_CSRP1_chr1_201454504_ENST00000367306_length(amino acids)=193AA_BP=77 MGQRARLGSRPRRRRNDPRAVPGLRPLPPLPGTAATEPARDPEVLPRHQVLPQPHLSLLPHGRRRGRARPCRRCRRNRAAGGPGIRPAFD VPSVAKALSQPPWQTRMARFTAKDVMLKTSGPRALVLGKELGPWSTLSEATITHHTLPTPALFIAIPFPAALETSRIISLSALPHITNDL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DSTYK-CSRP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DSTYK-CSRP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DSTYK-CSRP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies