
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ECE1-SRSF10 (FusionGDB2 ID:24862) |
Fusion Gene Summary for ECE1-SRSF10 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ECE1-SRSF10 | Fusion gene ID: 24862 | Hgene | Tgene | Gene symbol | ECE1 | SRSF10 | Gene ID | 1889 | 10772 |
| Gene name | endothelin converting enzyme 1 | serine and arginine rich splicing factor 10 | |
| Synonyms | ECE | FUSIP1|FUSIP2|NSSR|PPP1R149|SFRS13|SFRS13A|SRp38|SRrp40|TASR|TASR1|TASR2 | |
| Cytomap | 1p36.12 | 1p36.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | endothelin-converting enzyme 1ECE-1 | serine/arginine-rich splicing factor 1040 kDa SR-repressor proteinFUS interacting protein (serine-arginine rich) 1FUS-interacting protein (serine-arginine rich) 2SR splicing factor 10TLS-associated SR proteinTLS-associated protein TASRTLS-associate | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000264205, ENST00000357071, ENST00000374893, ENST00000415912, ENST00000436918, ENST00000528294, | ENST00000341154, ENST00000343255, ENST00000374452, ENST00000374453, ENST00000484146, ENST00000492112, ENST00000374449, ENST00000374457, ENST00000433682, ENST00000344989, ENST00000453840, | |
| Fusion gene scores | * DoF score | 16 X 15 X 9=2160 | 4 X 4 X 2=32 |
| # samples | 18 | 4 | |
| ** MAII score | log2(18/2160*10)=-3.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/32*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: ECE1 [Title/Abstract] AND SRSF10 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ECE1(21573714)-SRSF10(24305307), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ECE1 | GO:0010814 | substance P catabolic process | 18039931 |
| Hgene | ECE1 | GO:0010815 | bradykinin catabolic process | 18039931 |
| Hgene | ECE1 | GO:0010816 | calcitonin catabolic process | 18039931 |
| Hgene | ECE1 | GO:0016485 | protein processing | 7805846 |
| Hgene | ECE1 | GO:0016486 | peptide hormone processing | 7864876 |
| Hgene | ECE1 | GO:0034959 | endothelin maturation | 7805846 |
| Hgene | ECE1 | GO:0042447 | hormone catabolic process | 7864876 |
| Tgene | SRSF10 | GO:0000375 | RNA splicing, via transesterification reactions | 9774382 |
| Tgene | SRSF10 | GO:0000398 | mRNA splicing, via spliceosome | 9774382 |
| Tgene | SRSF10 | GO:0006376 | mRNA splice site selection | 9774382 |
| Tgene | SRSF10 | GO:0048024 | regulation of mRNA splicing, via spliceosome | 26876937 |
| Tgene | SRSF10 | GO:0048025 | negative regulation of mRNA splicing, via spliceosome | 11684676 |
| Fusion gene breakpoints across ECE1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SRSF10 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-09-1673-01A | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
Top |
Fusion Gene ORF analysis for ECE1-SRSF10 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000264205 | ENST00000341154 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000264205 | ENST00000343255 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000264205 | ENST00000374452 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000264205 | ENST00000374453 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000264205 | ENST00000484146 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000264205 | ENST00000492112 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000357071 | ENST00000341154 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000357071 | ENST00000343255 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000357071 | ENST00000374452 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000357071 | ENST00000374453 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000357071 | ENST00000484146 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000357071 | ENST00000492112 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000374893 | ENST00000341154 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000374893 | ENST00000343255 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000374893 | ENST00000374452 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000374893 | ENST00000374453 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000374893 | ENST00000484146 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000374893 | ENST00000492112 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000415912 | ENST00000341154 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000415912 | ENST00000343255 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000415912 | ENST00000374452 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000415912 | ENST00000374453 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000415912 | ENST00000484146 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000415912 | ENST00000492112 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000436918 | ENST00000341154 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000436918 | ENST00000343255 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000436918 | ENST00000374452 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000436918 | ENST00000374453 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000436918 | ENST00000484146 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-5UTR | ENST00000436918 | ENST00000492112 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000264205 | ENST00000374449 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000264205 | ENST00000374457 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000264205 | ENST00000433682 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000357071 | ENST00000374449 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000357071 | ENST00000374457 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000357071 | ENST00000433682 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000374893 | ENST00000374449 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000374893 | ENST00000374457 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000374893 | ENST00000433682 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000415912 | ENST00000374449 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000415912 | ENST00000374457 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000415912 | ENST00000433682 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000436918 | ENST00000374449 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000436918 | ENST00000374457 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5CDS-intron | ENST00000436918 | ENST00000433682 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-3CDS | ENST00000528294 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-3CDS | ENST00000528294 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-5UTR | ENST00000528294 | ENST00000341154 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-5UTR | ENST00000528294 | ENST00000343255 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-5UTR | ENST00000528294 | ENST00000374452 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-5UTR | ENST00000528294 | ENST00000374453 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-5UTR | ENST00000528294 | ENST00000484146 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-5UTR | ENST00000528294 | ENST00000492112 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-intron | ENST00000528294 | ENST00000374449 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-intron | ENST00000528294 | ENST00000374457 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| 5UTR-intron | ENST00000528294 | ENST00000433682 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000264205 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000264205 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000357071 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000357071 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000374893 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000374893 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000415912 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000415912 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000436918 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| In-frame | ENST00000436918 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000415912 | ECE1 | chr1 | 21573714 | - | ENST00000344989 | SRSF10 | chr1 | 24305307 | - | 4587 | 1241 | 126 | 1727 | 533 |
| ENST00000415912 | ECE1 | chr1 | 21573714 | - | ENST00000453840 | SRSF10 | chr1 | 24305307 | - | 2943 | 1241 | 126 | 1724 | 532 |
| ENST00000357071 | ECE1 | chr1 | 21573714 | - | ENST00000344989 | SRSF10 | chr1 | 24305307 | - | 4588 | 1242 | 46 | 1728 | 560 |
| ENST00000357071 | ECE1 | chr1 | 21573714 | - | ENST00000453840 | SRSF10 | chr1 | 24305307 | - | 2944 | 1242 | 46 | 1725 | 559 |
| ENST00000374893 | ECE1 | chr1 | 21573714 | - | ENST00000344989 | SRSF10 | chr1 | 24305307 | - | 4584 | 1238 | 63 | 1724 | 553 |
| ENST00000374893 | ECE1 | chr1 | 21573714 | - | ENST00000453840 | SRSF10 | chr1 | 24305307 | - | 2940 | 1238 | 63 | 1721 | 552 |
| ENST00000436918 | ECE1 | chr1 | 21573714 | - | ENST00000344989 | SRSF10 | chr1 | 24305307 | - | 4559 | 1213 | 38 | 1699 | 553 |
| ENST00000436918 | ECE1 | chr1 | 21573714 | - | ENST00000453840 | SRSF10 | chr1 | 24305307 | - | 2915 | 1213 | 38 | 1696 | 552 |
| ENST00000264205 | ECE1 | chr1 | 21573714 | - | ENST00000344989 | SRSF10 | chr1 | 24305307 | - | 4559 | 1213 | 59 | 1699 | 546 |
| ENST00000264205 | ECE1 | chr1 | 21573714 | - | ENST00000453840 | SRSF10 | chr1 | 24305307 | - | 2915 | 1213 | 59 | 1696 | 545 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000415912 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000452003 | 0.999548 |
| ENST00000415912 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.001060298 | 0.9989397 |
| ENST00000357071 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000214672 | 0.99978536 |
| ENST00000357071 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000512278 | 0.99948764 |
| ENST00000374893 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000147322 | 0.99985266 |
| ENST00000374893 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000347584 | 0.9996524 |
| ENST00000436918 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000147434 | 0.99985254 |
| ENST00000436918 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000344688 | 0.99965537 |
| ENST00000264205 | ENST00000344989 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000179235 | 0.99982077 |
| ENST00000264205 | ENST00000453840 | ECE1 | chr1 | 21573714 | - | SRSF10 | chr1 | 24305307 | - | 0.000397688 | 0.9996024 |
Top |
Fusion Genomic Features for ECE1-SRSF10 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
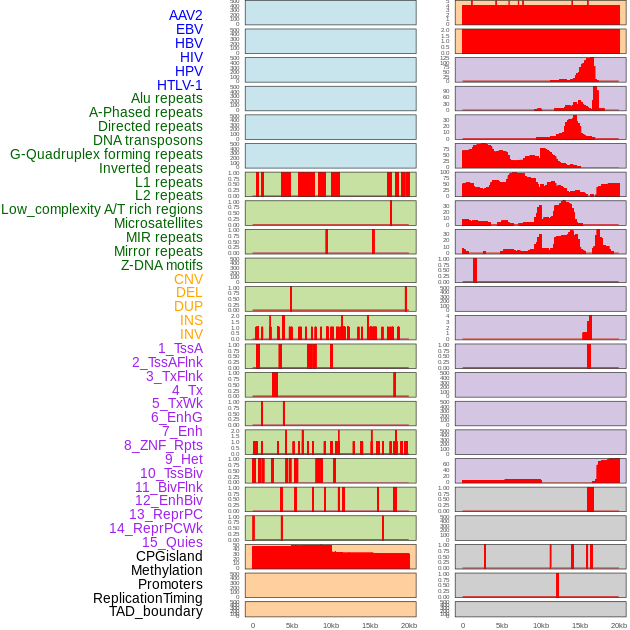 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ECE1-SRSF10 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:21573714/chr1:24305307) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000264205 | - | 8 | 18 | 1_68 | 384 | 768.0 | Topological domain | Cytoplasmic |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000357071 | - | 7 | 17 | 1_68 | 375 | 759.0 | Topological domain | Cytoplasmic |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000374893 | - | 9 | 19 | 1_68 | 387 | 771.0 | Topological domain | Cytoplasmic |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000415912 | - | 9 | 19 | 1_68 | 371 | 755.0 | Topological domain | Cytoplasmic |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000264205 | - | 8 | 18 | 69_89 | 384 | 768.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000357071 | - | 7 | 17 | 69_89 | 375 | 759.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000374893 | - | 9 | 19 | 69_89 | 387 | 771.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000415912 | - | 9 | 19 | 69_89 | 371 | 755.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000343255 | 0 | 6 | 106_260 | 21 | 262.0 | Compositional bias | Note=Arg/Ser-rich (RS domain) | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000344989 | 0 | 6 | 106_260 | 21 | 184.0 | Compositional bias | Note=Arg/Ser-rich (RS domain) | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000374452 | 0 | 6 | 106_260 | 21 | 174.0 | Compositional bias | Note=Arg/Ser-rich (RS domain) | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000453840 | 0 | 6 | 106_260 | 21 | 183.0 | Compositional bias | Note=Arg/Ser-rich (RS domain) | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000484146 | 0 | 5 | 106_260 | 21 | 166.0 | Compositional bias | Note=Arg/Ser-rich (RS domain) | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000492112 | 0 | 6 | 106_260 | 21 | 263.0 | Compositional bias | Note=Arg/Ser-rich (RS domain) |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000264205 | - | 8 | 18 | 98_770 | 384 | 768.0 | Domain | Peptidase M13 |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000357071 | - | 7 | 17 | 98_770 | 375 | 759.0 | Domain | Peptidase M13 |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000374893 | - | 9 | 19 | 98_770 | 387 | 771.0 | Domain | Peptidase M13 |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000415912 | - | 9 | 19 | 98_770 | 371 | 755.0 | Domain | Peptidase M13 |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000264205 | - | 8 | 18 | 90_770 | 384 | 768.0 | Topological domain | Extracellular |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000357071 | - | 7 | 17 | 90_770 | 375 | 759.0 | Topological domain | Extracellular |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000374893 | - | 9 | 19 | 90_770 | 387 | 771.0 | Topological domain | Extracellular |
| Hgene | ECE1 | chr1:21573714 | chr1:24305307 | ENST00000415912 | - | 9 | 19 | 90_770 | 371 | 755.0 | Topological domain | Extracellular |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000343255 | 0 | 6 | 10_88 | 21 | 262.0 | Domain | RRM | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000344989 | 0 | 6 | 10_88 | 21 | 184.0 | Domain | RRM | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000374452 | 0 | 6 | 10_88 | 21 | 174.0 | Domain | RRM | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000453840 | 0 | 6 | 10_88 | 21 | 183.0 | Domain | RRM | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000484146 | 0 | 5 | 10_88 | 21 | 166.0 | Domain | RRM | |
| Tgene | SRSF10 | chr1:21573714 | chr1:24305307 | ENST00000492112 | 0 | 6 | 10_88 | 21 | 263.0 | Domain | RRM |
Top |
Fusion Gene Sequence for ECE1-SRSF10 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >24862_24862_1_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000264205_SRSF10_chr1_24305307_ENST00000344989_length(transcript)=4559nt_BP=1213nt GGGGCGCGGCGGCGGCGGCGCCAGGGTCGGGGCCGCTTCCCCATTCGGGCGCGAGAGCCATGGAGGCGCTGAGGGAGTCCGTGCTGCATT TGGCCTTGCAGATGTCGACGTACAAGCGGGCCACGCTGGACGAGGAGGACCTGGTGGACTCGCTCTCCGAGGGCGACGCATACCCCAACG GCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCAGGTGGAGAAGCGGCTGGTGGTGTTGGTGG TACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAGATCCCCCTCTGTGTGCCTGAGCGAAGCTT GTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGACTTCTTCAGCTACGCCTGTGGGGGCTGGA TCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGAACACAACCAAGCAATCATCAAGCACCTCC TCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGCGTGCATGAACGAGACCAGGATCGAGGAGC TCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCCCTGGGCCAAGGACAACTTCCAGGACACCC TGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGATTCCAAGAACTCCAACAGCAACGTGATCC AGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAACGAGAAGGTGCTGACCGGATATCTGAACT ACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGATGCAGCAGATCTTGGACTTTGAGACGGCAC TGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGTGACGGCAGCCGAGCTGCAGACCTTGGCAC CCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATCCGAGCCTATTGTGGTCTATGACAAGGAAT ACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCGTGAATTTGGTCGTTATGGTCCTATAGTTG ATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATTTGAGGATGTTCGTGATGCTGAAGACGCTT TACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGGGATCGAAAGACACCAAATCAGATGAAAG CCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACGTTCTAGAAGCCGAAGTTATGAAAGGAGGA GATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAACAGTAGACCGACTGGAAGACCACGGCGTAGCAGAA GCCATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACACTTCAAGAAAGATCTGAAAGCGGAAAA AGAACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATACTGTACGAATATTTTGACTCTGGTCTGA AAAGATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAGTAAGCATTTTAGGACAAATAAAAGGAAA TTCAACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGGTAACAGGTCCATAATAAATTATTGGAAA CTAGGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGTCTCAAACTGAATTGGGTGGGAAAAGGTA TGGTCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGGTGCCAGTGTTTTCTGCTTAATCATTTGC TTTGTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTACTCCTTCCCAGGTAAATTCCAATTATATT TGACATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAATATTTATTGAGCCCTTACTGTGGGCAAA TCATTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGCACAATCTAGTGAATCATTACAGTATGGC CTCATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTAATTATAGAACACAATATACGATCAAGGA TAAGTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAATAATGAAAAAATGATTTAATCTGTAATA AACTGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCTCACCAAACACATGCTAGGATATAACCCC CAAAATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATTTTGAGGCAGACAGAGAGCTGTTATCCTA ACTGATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTACATGTACATTTTATAGGGGACATGTTCT GTGTATAGCGAATAAATAACTTTTATAGTATCACAAAATGTTTTGGATTCCTTAGTTTCTTATTAGGATATGATGTTTCTTTACCTATAC ATTGATTTCATCACATTTGATTTTTGTCATCTTTTTTGCCACATACTTAAAATTTTCCATATAAAATTAACTAAAAATCTGGAAGTGGAA TTTAAGCTTTTAATTTGTAGCAATTTTGAAAATATAGCAGAGGTATATTTTCAAGGGAGGTGTGAAATGGAGGTATTATTGTTTGTATTT TATTTTAGAAATTTTGTTTGAACTTGCCCAAGATCACACAGCAAGTGTCAGATCCTAGGTTACAGCCCATAATTTTTCACTTGTTTCATC TTTTGTTACCATGTTTGTTGTTTAATCCAATGGGGAAGTGTTTTTATAGCTTTATTTTCATGGAGATAGTAACATTGATATAATGGGATC TAGAATTTACTTAGAGTCAAAGTGACTAGATTTAATTACAAAAAGTATTTTGTTGTATACCGTTATACACTCATTAACATAGGGGTTCTT ATGGACAGAGGTTCTATGTATTTTTAAAAGAATATGTAGAGGCTATAGACTTTTTTGCCCTCTACCTCCCTTCTCCATTTCCTTTTGAAG TTAAGACATTTAAGGGGGAGAATTAAGGTGCATATTGAGTTGGGGTTTTGTTTAAAAAAAATTAGGTAAATACATATATAACTACAATAA CAACAGTTGGTAGTTCTCTAAAATATTTAATTATGGTAAATCAGAAAAGGCCCTTTAATTTTTGCATCTGTTGAATGAATTGCTTTAGGA TCTCTTCTGTGGTTGTTTCTCTCTATACTGAATGCTGTCAATATTATTGAGCACTTACTGTGCCGAACCATGTGCTTTTCAAATATTTCT ATTTAATCCTAAAAACACTCCTGGGAAATGGGTATTATTCCCATTTTACAGATGAGAAAATTGTCCTTTGTAGAATACCCATCATGTGAT AGCTTCTTGCATATTATGCTATTCATTTCTCACAACCTTACAAGGTAAATGGATAATGTTCCTGGATGAGAGATTAAACGTACTCGAAGA TCTTATGGTTGTGTGGCTCAGAGACTCTAAGCATGGCTTTCCAAATCTCATTCTCTTGTAGAGATTTTCCATTGTATTGCATTTTGACCA TGTTCCTGTTTACAAAACCTAAGATTATATTCTGAAGTATCTGTGACTTGAGTGATAGCTCAGGAATAATCTGAGGGCATTCTATTAGGA AGGAGGACTAGCAAAGCCTATAGTTAGCCTATCCTAGGCATGAACTATTCTCATTTTAGATAGGATGACTTGATAAATAGGATGAAGTGA GCAACCTGTTTGTCTTCGGTTATTGCTATCTACAAGACATTCTGCTAGTCACTGTGGAAAAGTTTCCTTCTCTTGGGTTTTTTCCTCTTC CCCTTCCTCTTAACAGTGTTGGTTATCTTTATTATGTTTCTGTGTATTTGTAACAGCTGTTTCACCCTTGTATTGCATAATGGGGATTTT TCTTGGAATAAAAAGTGAGGCATGTAAATTCATTGAGAACTAACCGTAGTTTGTAAAGAAGTAAAAGGCCTTTGTATCTAGTTTTTTGCA >24862_24862_1_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000264205_SRSF10_chr1_24305307_ENST00000344989_length(amino acids)=546AA_BP=385 MEALRESVLHLALQMSTYKRATLDEEDLVDSLSEGDAYPNGLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAGLVACLAALGIQYQT RSPSVCLSEACVSVTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTASVSEAERKAQVYYR ACMNETRIEELRAKPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSGLGLPSRDYYLNKTE NEKVLTGYLNYMVQLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWLPFLNTIFYPVEINE SEPIVVYDKEYLEQISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQ GDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNSRPTGRPRRSRSHSDNDRPNCSWNTQYSSAY -------------------------------------------------------------- >24862_24862_2_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000264205_SRSF10_chr1_24305307_ENST00000453840_length(transcript)=2915nt_BP=1213nt GGGGCGCGGCGGCGGCGGCGCCAGGGTCGGGGCCGCTTCCCCATTCGGGCGCGAGAGCCATGGAGGCGCTGAGGGAGTCCGTGCTGCATT TGGCCTTGCAGATGTCGACGTACAAGCGGGCCACGCTGGACGAGGAGGACCTGGTGGACTCGCTCTCCGAGGGCGACGCATACCCCAACG GCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCAGGTGGAGAAGCGGCTGGTGGTGTTGGTGG TACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAGATCCCCCTCTGTGTGCCTGAGCGAAGCTT GTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGACTTCTTCAGCTACGCCTGTGGGGGCTGGA TCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGAACACAACCAAGCAATCATCAAGCACCTCC TCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGCGTGCATGAACGAGACCAGGATCGAGGAGC TCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCCCTGGGCCAAGGACAACTTCCAGGACACCC TGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGATTCCAAGAACTCCAACAGCAACGTGATCC AGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAACGAGAAGGTGCTGACCGGATATCTGAACT ACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGATGCAGCAGATCTTGGACTTTGAGACGGCAC TGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGTGACGGCAGCCGAGCTGCAGACCTTGGCAC CCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATCCGAGCCTATTGTGGTCTATGACAAGGAAT ACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCGTGAATTTGGTCGTTATGGTCCTATAGTTG ATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATTTGAGGATGTTCGTGATGCTGAAGACGCTT TACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGGGATCGAAAGACACCAAATCAGATGAAAG CCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACGTTCTAGAAGCCGAAGTTATGAAAGGAGGA GATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAATAGACCGACTGGAAGACCACGGCGTAGCAGAAGCC ATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACACTTCAAGAAAGATCTGAAAGCGGAAAAAGA ACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATACTGTACGAATATTTTGACTCTGGTCTGAAAA GATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAGTAAGCATTTTAGGACAAATAAAAGGAAATTC AACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGGTAACAGGTCCATAATAAATTATTGGAAACTA GGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGTCTCAAACTGAATTGGGTGGGAAAAGGTATGG TCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGGTGCCAGTGTTTTCTGCTTAATCATTTGCTTT GTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTACTCCTTCCCAGGTAAATTCCAATTATATTTGA CATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAATATTTATTGAGCCCTTACTGTGGGCAAATCA TTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGCACAATCTAGTGAATCATTACAGTATGGCCTC ATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTAATTATAGAACACAATATACGATCAAGGATAA GTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAATAATGAAAAAATGATTTAATCTGTAATAAAC TGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCTCACCAAACACATGCTAGGATATAACCCCCAA AATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATTTTGAGGCAGACAGAGAGCTGTTATCCTAACT GATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTACATGTACATTTTATAGGGGACATGTTCTGTG >24862_24862_2_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000264205_SRSF10_chr1_24305307_ENST00000453840_length(amino acids)=545AA_BP=385 MEALRESVLHLALQMSTYKRATLDEEDLVDSLSEGDAYPNGLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAGLVACLAALGIQYQT RSPSVCLSEACVSVTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTASVSEAERKAQVYYR ACMNETRIEELRAKPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSGLGLPSRDYYLNKTE NEKVLTGYLNYMVQLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWLPFLNTIFYPVEINE SEPIVVYDKEYLEQISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQ GDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNRPTGRPRRSRSHSDNDRPNCSWNTQYSSAYY -------------------------------------------------------------- >24862_24862_3_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000357071_SRSF10_chr1_24305307_ENST00000344989_length(transcript)=4588nt_BP=1242nt GACTCTCTGATGTTTGGGAGCAGATCCGAGCAGCTGAGCAGGGTGGCTGTTCCTTTCCTGGATTAGGGCTGAATCTGTGGGAACCAGACC ACCCCTGAGACAGGAGGCAGCCCTGATGCCTCTCCAGGGCCTGGGCCTGCAGCGGAACCCCTTCCTCCAAGGGAAGCGGGGCCCGGGGCT CACGTCTTCCCCGCCCCTCCTGCCTCCTTCCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCA GGTGGAGAAGCGGCTGGTGGTGTTGGTGGTACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAG ATCCCCCTCTGTGTGCCTGAGCGAAGCTTGTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGA CTTCTTCAGCTACGCCTGTGGGGGCTGGATCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGA ACACAACCAAGCAATCATCAAGCACCTCCTCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGC GTGCATGAACGAGACCAGGATCGAGGAGCTCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCC CTGGGCCAAGGACAACTTCCAGGACACCCTGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGA TTCCAAGAACTCCAACAGCAACGTGATCCAGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAA CGAGAAGGTGCTGACCGGATATCTGAACTACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGAT GCAGCAGATCTTGGACTTTGAGACGGCACTGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGT GACGGCAGCCGAGCTGCAGACCTTGGCACCCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATC CGAGCCTATTGTGGTCTATGACAAGGAATACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCG TGAATTTGGTCGTTATGGTCCTATAGTTGATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATT TGAGGATGTTCGTGATGCTGAAGACGCTTTACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGG GGATCGAAAGACACCAAATCAGATGAAAGCCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACG TTCTAGAAGCCGAAGTTATGAAAGGAGGAGATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAACAGTAG ACCGACTGGAAGACCACGGCGTAGCAGAAGCCATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTA CACTTCAAGAAAGATCTGAAAGCGGAAAAAGAACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAAT ACTGTACGAATATTTTGACTCTGGTCTGAAAAGATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAA GTAAGCATTTTAGGACAAATAAAAGGAAATTCAACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGG GTAACAGGTCCATAATAAATTATTGGAAACTAGGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTG TCTCAAACTGAATTGGGTGGGAAAAGGTATGGTCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTG GTGCCAGTGTTTTCTGCTTAATCATTTGCTTTGTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTA CTCCTTCCCAGGTAAATTCCAATTATATTTGACATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAA ATATTTATTGAGCCCTTACTGTGGGCAAATCATTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAG CACAATCTAGTGAATCATTACAGTATGGCCTCATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGT AATTATAGAACACAATATACGATCAAGGATAAGTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAA ATAATGAAAAAATGATTTAATCTGTAATAAACTGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCC TCACCAAACACATGCTAGGATATAACCCCCAAAATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTAT TTTGAGGCAGACAGAGAGCTGTTATCCTAACTGATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTT ACATGTACATTTTATAGGGGACATGTTCTGTGTATAGCGAATAAATAACTTTTATAGTATCACAAAATGTTTTGGATTCCTTAGTTTCTT ATTAGGATATGATGTTTCTTTACCTATACATTGATTTCATCACATTTGATTTTTGTCATCTTTTTTGCCACATACTTAAAATTTTCCATA TAAAATTAACTAAAAATCTGGAAGTGGAATTTAAGCTTTTAATTTGTAGCAATTTTGAAAATATAGCAGAGGTATATTTTCAAGGGAGGT GTGAAATGGAGGTATTATTGTTTGTATTTTATTTTAGAAATTTTGTTTGAACTTGCCCAAGATCACACAGCAAGTGTCAGATCCTAGGTT ACAGCCCATAATTTTTCACTTGTTTCATCTTTTGTTACCATGTTTGTTGTTTAATCCAATGGGGAAGTGTTTTTATAGCTTTATTTTCAT GGAGATAGTAACATTGATATAATGGGATCTAGAATTTACTTAGAGTCAAAGTGACTAGATTTAATTACAAAAAGTATTTTGTTGTATACC GTTATACACTCATTAACATAGGGGTTCTTATGGACAGAGGTTCTATGTATTTTTAAAAGAATATGTAGAGGCTATAGACTTTTTTGCCCT CTACCTCCCTTCTCCATTTCCTTTTGAAGTTAAGACATTTAAGGGGGAGAATTAAGGTGCATATTGAGTTGGGGTTTTGTTTAAAAAAAA TTAGGTAAATACATATATAACTACAATAACAACAGTTGGTAGTTCTCTAAAATATTTAATTATGGTAAATCAGAAAAGGCCCTTTAATTT TTGCATCTGTTGAATGAATTGCTTTAGGATCTCTTCTGTGGTTGTTTCTCTCTATACTGAATGCTGTCAATATTATTGAGCACTTACTGT GCCGAACCATGTGCTTTTCAAATATTTCTATTTAATCCTAAAAACACTCCTGGGAAATGGGTATTATTCCCATTTTACAGATGAGAAAAT TGTCCTTTGTAGAATACCCATCATGTGATAGCTTCTTGCATATTATGCTATTCATTTCTCACAACCTTACAAGGTAAATGGATAATGTTC CTGGATGAGAGATTAAACGTACTCGAAGATCTTATGGTTGTGTGGCTCAGAGACTCTAAGCATGGCTTTCCAAATCTCATTCTCTTGTAG AGATTTTCCATTGTATTGCATTTTGACCATGTTCCTGTTTACAAAACCTAAGATTATATTCTGAAGTATCTGTGACTTGAGTGATAGCTC AGGAATAATCTGAGGGCATTCTATTAGGAAGGAGGACTAGCAAAGCCTATAGTTAGCCTATCCTAGGCATGAACTATTCTCATTTTAGAT AGGATGACTTGATAAATAGGATGAAGTGAGCAACCTGTTTGTCTTCGGTTATTGCTATCTACAAGACATTCTGCTAGTCACTGTGGAAAA GTTTCCTTCTCTTGGGTTTTTTCCTCTTCCCCTTCCTCTTAACAGTGTTGGTTATCTTTATTATGTTTCTGTGTATTTGTAACAGCTGTT TCACCCTTGTATTGCATAATGGGGATTTTTCTTGGAATAAAAAGTGAGGCATGTAAATTCATTGAGAACTAACCGTAGTTTGTAAAGAAG >24862_24862_3_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000357071_SRSF10_chr1_24305307_ENST00000344989_length(amino acids)=560AA_BP=399 MFLSWIRAESVGTRPPLRQEAALMPLQGLGLQRNPFLQGKRGPGLTSSPPLLPPSLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAG LVACLAALGIQYQTRSPSVCLSEACVSVTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTA SVSEAERKAQVYYRACMNETRIEELRAKPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSG LGLPSRDYYLNKTENEKVLTGYLNYMVQLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWL PFLNTIFYPVEINESEPIVVYDKEYLEQISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDR KWICGRQIEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNSRPTGRPRRSRSHSDND -------------------------------------------------------------- >24862_24862_4_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000357071_SRSF10_chr1_24305307_ENST00000453840_length(transcript)=2944nt_BP=1242nt GACTCTCTGATGTTTGGGAGCAGATCCGAGCAGCTGAGCAGGGTGGCTGTTCCTTTCCTGGATTAGGGCTGAATCTGTGGGAACCAGACC ACCCCTGAGACAGGAGGCAGCCCTGATGCCTCTCCAGGGCCTGGGCCTGCAGCGGAACCCCTTCCTCCAAGGGAAGCGGGGCCCGGGGCT CACGTCTTCCCCGCCCCTCCTGCCTCCTTCCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCA GGTGGAGAAGCGGCTGGTGGTGTTGGTGGTACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAG ATCCCCCTCTGTGTGCCTGAGCGAAGCTTGTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGA CTTCTTCAGCTACGCCTGTGGGGGCTGGATCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGA ACACAACCAAGCAATCATCAAGCACCTCCTCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGC GTGCATGAACGAGACCAGGATCGAGGAGCTCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCC CTGGGCCAAGGACAACTTCCAGGACACCCTGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGA TTCCAAGAACTCCAACAGCAACGTGATCCAGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAA CGAGAAGGTGCTGACCGGATATCTGAACTACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGAT GCAGCAGATCTTGGACTTTGAGACGGCACTGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGT GACGGCAGCCGAGCTGCAGACCTTGGCACCCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATC CGAGCCTATTGTGGTCTATGACAAGGAATACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCG TGAATTTGGTCGTTATGGTCCTATAGTTGATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATT TGAGGATGTTCGTGATGCTGAAGACGCTTTACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGG GGATCGAAAGACACCAAATCAGATGAAAGCCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACG TTCTAGAAGCCGAAGTTATGAAAGGAGGAGATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAATAGACC GACTGGAAGACCACGGCGTAGCAGAAGCCATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACAC TTCAAGAAAGATCTGAAAGCGGAAAAAGAACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATACT GTACGAATATTTTGACTCTGGTCTGAAAAGATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAGTA AGCATTTTAGGACAAATAAAAGGAAATTCAACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGGTA ACAGGTCCATAATAAATTATTGGAAACTAGGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGTCT CAAACTGAATTGGGTGGGAAAAGGTATGGTCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGGTG CCAGTGTTTTCTGCTTAATCATTTGCTTTGTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTACTC CTTCCCAGGTAAATTCCAATTATATTTGACATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAATA TTTATTGAGCCCTTACTGTGGGCAAATCATTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGCAC AATCTAGTGAATCATTACAGTATGGCCTCATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTAAT TATAGAACACAATATACGATCAAGGATAAGTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAATA ATGAAAAAATGATTTAATCTGTAATAAACTGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCTCA CCAAACACATGCTAGGATATAACCCCCAAAATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATTTT GAGGCAGACAGAGAGCTGTTATCCTAACTGATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTACA >24862_24862_4_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000357071_SRSF10_chr1_24305307_ENST00000453840_length(amino acids)=559AA_BP=399 MFLSWIRAESVGTRPPLRQEAALMPLQGLGLQRNPFLQGKRGPGLTSSPPLLPPSLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAG LVACLAALGIQYQTRSPSVCLSEACVSVTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTA SVSEAERKAQVYYRACMNETRIEELRAKPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSG LGLPSRDYYLNKTENEKVLTGYLNYMVQLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWL PFLNTIFYPVEINESEPIVVYDKEYLEQISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDR KWICGRQIEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNRPTGRPRRSRSHSDNDR -------------------------------------------------------------- >24862_24862_5_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000374893_SRSF10_chr1_24305307_ENST00000344989_length(transcript)=4584nt_BP=1238nt AGGTGGTGCAACGCCTGGCCCGGCCCATCCCATCCCGGCCACCCGGGCAGCGGGACCAGGCGTCTGGGGCACAGCATGCGGGGCGTGTGG CCGCCCCCGGTGTCCGCCCTGCTGTCGGCGCTGGGGATGTCGACGTACAAGCGGGCCACGCTGGACGAGGAGGACCTGGTGGACTCGCTC TCCGAGGGCGACGCATACCCCAACGGCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCAGGTG GAGAAGCGGCTGGTGGTGTTGGTGGTACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAGATCC CCCTCTGTGTGCCTGAGCGAAGCTTGTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGACTTC TTCAGCTACGCCTGTGGGGGCTGGATCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGAACAC AACCAAGCAATCATCAAGCACCTCCTCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGCGTGC ATGAACGAGACCAGGATCGAGGAGCTCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCCCTGG GCCAAGGACAACTTCCAGGACACCCTGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGATTCC AAGAACTCCAACAGCAACGTGATCCAGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAACGAG AAGGTGCTGACCGGATATCTGAACTACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGATGCAG CAGATCTTGGACTTTGAGACGGCACTGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGTGACG GCAGCCGAGCTGCAGACCTTGGCACCCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATCCGAG CCTATTGTGGTCTATGACAAGGAATACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCGTGAA TTTGGTCGTTATGGTCCTATAGTTGATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATTTGAG GATGTTCGTGATGCTGAAGACGCTTTACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGGGAT CGAAAGACACCAAATCAGATGAAAGCCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACGTTCT AGAAGCCGAAGTTATGAAAGGAGGAGATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAACAGTAGACCG ACTGGAAGACCACGGCGTAGCAGAAGCCATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACACT TCAAGAAAGATCTGAAAGCGGAAAAAGAACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATACTG TACGAATATTTTGACTCTGGTCTGAAAAGATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAGTAA GCATTTTAGGACAAATAAAAGGAAATTCAACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGGTAA CAGGTCCATAATAAATTATTGGAAACTAGGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGTCTC AAACTGAATTGGGTGGGAAAAGGTATGGTCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGGTGC CAGTGTTTTCTGCTTAATCATTTGCTTTGTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTACTCC TTCCCAGGTAAATTCCAATTATATTTGACATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAATAT TTATTGAGCCCTTACTGTGGGCAAATCATTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGCACA ATCTAGTGAATCATTACAGTATGGCCTCATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTAATT ATAGAACACAATATACGATCAAGGATAAGTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAATAA TGAAAAAATGATTTAATCTGTAATAAACTGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCTCAC CAAACACATGCTAGGATATAACCCCCAAAATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATTTTG AGGCAGACAGAGAGCTGTTATCCTAACTGATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTACAT GTACATTTTATAGGGGACATGTTCTGTGTATAGCGAATAAATAACTTTTATAGTATCACAAAATGTTTTGGATTCCTTAGTTTCTTATTA GGATATGATGTTTCTTTACCTATACATTGATTTCATCACATTTGATTTTTGTCATCTTTTTTGCCACATACTTAAAATTTTCCATATAAA ATTAACTAAAAATCTGGAAGTGGAATTTAAGCTTTTAATTTGTAGCAATTTTGAAAATATAGCAGAGGTATATTTTCAAGGGAGGTGTGA AATGGAGGTATTATTGTTTGTATTTTATTTTAGAAATTTTGTTTGAACTTGCCCAAGATCACACAGCAAGTGTCAGATCCTAGGTTACAG CCCATAATTTTTCACTTGTTTCATCTTTTGTTACCATGTTTGTTGTTTAATCCAATGGGGAAGTGTTTTTATAGCTTTATTTTCATGGAG ATAGTAACATTGATATAATGGGATCTAGAATTTACTTAGAGTCAAAGTGACTAGATTTAATTACAAAAAGTATTTTGTTGTATACCGTTA TACACTCATTAACATAGGGGTTCTTATGGACAGAGGTTCTATGTATTTTTAAAAGAATATGTAGAGGCTATAGACTTTTTTGCCCTCTAC CTCCCTTCTCCATTTCCTTTTGAAGTTAAGACATTTAAGGGGGAGAATTAAGGTGCATATTGAGTTGGGGTTTTGTTTAAAAAAAATTAG GTAAATACATATATAACTACAATAACAACAGTTGGTAGTTCTCTAAAATATTTAATTATGGTAAATCAGAAAAGGCCCTTTAATTTTTGC ATCTGTTGAATGAATTGCTTTAGGATCTCTTCTGTGGTTGTTTCTCTCTATACTGAATGCTGTCAATATTATTGAGCACTTACTGTGCCG AACCATGTGCTTTTCAAATATTTCTATTTAATCCTAAAAACACTCCTGGGAAATGGGTATTATTCCCATTTTACAGATGAGAAAATTGTC CTTTGTAGAATACCCATCATGTGATAGCTTCTTGCATATTATGCTATTCATTTCTCACAACCTTACAAGGTAAATGGATAATGTTCCTGG ATGAGAGATTAAACGTACTCGAAGATCTTATGGTTGTGTGGCTCAGAGACTCTAAGCATGGCTTTCCAAATCTCATTCTCTTGTAGAGAT TTTCCATTGTATTGCATTTTGACCATGTTCCTGTTTACAAAACCTAAGATTATATTCTGAAGTATCTGTGACTTGAGTGATAGCTCAGGA ATAATCTGAGGGCATTCTATTAGGAAGGAGGACTAGCAAAGCCTATAGTTAGCCTATCCTAGGCATGAACTATTCTCATTTTAGATAGGA TGACTTGATAAATAGGATGAAGTGAGCAACCTGTTTGTCTTCGGTTATTGCTATCTACAAGACATTCTGCTAGTCACTGTGGAAAAGTTT CCTTCTCTTGGGTTTTTTCCTCTTCCCCTTCCTCTTAACAGTGTTGGTTATCTTTATTATGTTTCTGTGTATTTGTAACAGCTGTTTCAC CCTTGTATTGCATAATGGGGATTTTTCTTGGAATAAAAAGTGAGGCATGTAAATTCATTGAGAACTAACCGTAGTTTGTAAAGAAGTAAA >24862_24862_5_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000374893_SRSF10_chr1_24305307_ENST00000344989_length(amino acids)=553AA_BP=392 MGHSMRGVWPPPVSALLSALGMSTYKRATLDEEDLVDSLSEGDAYPNGLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAGLVACLAA LGIQYQTRSPSVCLSEACVSVTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTASVSEAER KAQVYYRACMNETRIEELRAKPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSGLGLPSRD YYLNKTENEKVLTGYLNYMVQLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWLPFLNTIF YPVEINESEPIVVYDKEYLEQISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQ IEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNSRPTGRPRRSRSHSDNDRPNCSWN -------------------------------------------------------------- >24862_24862_6_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000374893_SRSF10_chr1_24305307_ENST00000453840_length(transcript)=2940nt_BP=1238nt AGGTGGTGCAACGCCTGGCCCGGCCCATCCCATCCCGGCCACCCGGGCAGCGGGACCAGGCGTCTGGGGCACAGCATGCGGGGCGTGTGG CCGCCCCCGGTGTCCGCCCTGCTGTCGGCGCTGGGGATGTCGACGTACAAGCGGGCCACGCTGGACGAGGAGGACCTGGTGGACTCGCTC TCCGAGGGCGACGCATACCCCAACGGCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCAGGTG GAGAAGCGGCTGGTGGTGTTGGTGGTACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAGATCC CCCTCTGTGTGCCTGAGCGAAGCTTGTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGACTTC TTCAGCTACGCCTGTGGGGGCTGGATCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGAACAC AACCAAGCAATCATCAAGCACCTCCTCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGCGTGC ATGAACGAGACCAGGATCGAGGAGCTCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCCCTGG GCCAAGGACAACTTCCAGGACACCCTGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGATTCC AAGAACTCCAACAGCAACGTGATCCAGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAACGAG AAGGTGCTGACCGGATATCTGAACTACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGATGCAG CAGATCTTGGACTTTGAGACGGCACTGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGTGACG GCAGCCGAGCTGCAGACCTTGGCACCCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATCCGAG CCTATTGTGGTCTATGACAAGGAATACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCGTGAA TTTGGTCGTTATGGTCCTATAGTTGATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATTTGAG GATGTTCGTGATGCTGAAGACGCTTTACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGGGAT CGAAAGACACCAAATCAGATGAAAGCCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACGTTCT AGAAGCCGAAGTTATGAAAGGAGGAGATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAATAGACCGACT GGAAGACCACGGCGTAGCAGAAGCCATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACACTTCA AGAAAGATCTGAAAGCGGAAAAAGAACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATACTGTAC GAATATTTTGACTCTGGTCTGAAAAGATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAGTAAGCA TTTTAGGACAAATAAAAGGAAATTCAACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGGTAACAG GTCCATAATAAATTATTGGAAACTAGGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGTCTCAAA CTGAATTGGGTGGGAAAAGGTATGGTCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGGTGCCAG TGTTTTCTGCTTAATCATTTGCTTTGTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTACTCCTTC CCAGGTAAATTCCAATTATATTTGACATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAATATTTA TTGAGCCCTTACTGTGGGCAAATCATTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGCACAATC TAGTGAATCATTACAGTATGGCCTCATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTAATTATA GAACACAATATACGATCAAGGATAAGTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAATAATGA AAAAATGATTTAATCTGTAATAAACTGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCTCACCAA ACACATGCTAGGATATAACCCCCAAAATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATTTTGAGG CAGACAGAGAGCTGTTATCCTAACTGATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTACATGTA >24862_24862_6_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000374893_SRSF10_chr1_24305307_ENST00000453840_length(amino acids)=552AA_BP=392 MGHSMRGVWPPPVSALLSALGMSTYKRATLDEEDLVDSLSEGDAYPNGLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAGLVACLAA LGIQYQTRSPSVCLSEACVSVTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTASVSEAER KAQVYYRACMNETRIEELRAKPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSGLGLPSRD YYLNKTENEKVLTGYLNYMVQLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWLPFLNTIF YPVEINESEPIVVYDKEYLEQISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQ IEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNRPTGRPRRSRSHSDNDRPNCSWNT -------------------------------------------------------------- >24862_24862_7_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000415912_SRSF10_chr1_24305307_ENST00000344989_length(transcript)=4587nt_BP=1241nt GAGCGCGCCGCCTGGGCCAGGCAGCCGAGCCGTCCGAGCAGCTGGGCTGGGAGCAGGGAACCCGGAGCTGGGAATCGGGAGCCGGGCGCG GGGAGCTGCGCGAAGCCGGGGCGGAGCACGCGAGCTATGATGTCGACGTACAAGCGGGCCACGCTGGACGAGGAGGACCTGGTGGACTCG CTCTCCGAGGGCGACGCATACCCCAACGGCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCAG GTGGAGAAGCGGCTGGTGGTGTTGGTGGTACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAGA TCCCCCTCTGTGTGCCTGAGCGAAGCTTGTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGAC TTCTTCAGCTACGCCTGTGGGGGCTGGATCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGAA CACAACCAAGCAATCATCAAGCACCTCCTCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGCG TGCATGAACGAGACCAGGATCGAGGAGCTCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCCC TGGGCCAAGGACAACTTCCAGGACACCCTGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGAT TCCAAGAACTCCAACAGCAACGTGATCCAGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAAC GAGAAGGTGCTGACCGGATATCTGAACTACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGATG CAGCAGATCTTGGACTTTGAGACGGCACTGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGTG ACGGCAGCCGAGCTGCAGACCTTGGCACCCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATCC GAGCCTATTGTGGTCTATGACAAGGAATACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCGT GAATTTGGTCGTTATGGTCCTATAGTTGATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATTT GAGGATGTTCGTGATGCTGAAGACGCTTTACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGG GATCGAAAGACACCAAATCAGATGAAAGCCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACGT TCTAGAAGCCGAAGTTATGAAAGGAGGAGATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAACAGTAGA CCGACTGGAAGACCACGGCGTAGCAGAAGCCATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTAC ACTTCAAGAAAGATCTGAAAGCGGAAAAAGAACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATA CTGTACGAATATTTTGACTCTGGTCTGAAAAGATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAG TAAGCATTTTAGGACAAATAAAAGGAAATTCAACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGG TAACAGGTCCATAATAAATTATTGGAAACTAGGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGT CTCAAACTGAATTGGGTGGGAAAAGGTATGGTCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGG TGCCAGTGTTTTCTGCTTAATCATTTGCTTTGTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTAC TCCTTCCCAGGTAAATTCCAATTATATTTGACATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAA TATTTATTGAGCCCTTACTGTGGGCAAATCATTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGC ACAATCTAGTGAATCATTACAGTATGGCCTCATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTA ATTATAGAACACAATATACGATCAAGGATAAGTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAA TAATGAAAAAATGATTTAATCTGTAATAAACTGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCT CACCAAACACATGCTAGGATATAACCCCCAAAATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATT TTGAGGCAGACAGAGAGCTGTTATCCTAACTGATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTA CATGTACATTTTATAGGGGACATGTTCTGTGTATAGCGAATAAATAACTTTTATAGTATCACAAAATGTTTTGGATTCCTTAGTTTCTTA TTAGGATATGATGTTTCTTTACCTATACATTGATTTCATCACATTTGATTTTTGTCATCTTTTTTGCCACATACTTAAAATTTTCCATAT AAAATTAACTAAAAATCTGGAAGTGGAATTTAAGCTTTTAATTTGTAGCAATTTTGAAAATATAGCAGAGGTATATTTTCAAGGGAGGTG TGAAATGGAGGTATTATTGTTTGTATTTTATTTTAGAAATTTTGTTTGAACTTGCCCAAGATCACACAGCAAGTGTCAGATCCTAGGTTA CAGCCCATAATTTTTCACTTGTTTCATCTTTTGTTACCATGTTTGTTGTTTAATCCAATGGGGAAGTGTTTTTATAGCTTTATTTTCATG GAGATAGTAACATTGATATAATGGGATCTAGAATTTACTTAGAGTCAAAGTGACTAGATTTAATTACAAAAAGTATTTTGTTGTATACCG TTATACACTCATTAACATAGGGGTTCTTATGGACAGAGGTTCTATGTATTTTTAAAAGAATATGTAGAGGCTATAGACTTTTTTGCCCTC TACCTCCCTTCTCCATTTCCTTTTGAAGTTAAGACATTTAAGGGGGAGAATTAAGGTGCATATTGAGTTGGGGTTTTGTTTAAAAAAAAT TAGGTAAATACATATATAACTACAATAACAACAGTTGGTAGTTCTCTAAAATATTTAATTATGGTAAATCAGAAAAGGCCCTTTAATTTT TGCATCTGTTGAATGAATTGCTTTAGGATCTCTTCTGTGGTTGTTTCTCTCTATACTGAATGCTGTCAATATTATTGAGCACTTACTGTG CCGAACCATGTGCTTTTCAAATATTTCTATTTAATCCTAAAAACACTCCTGGGAAATGGGTATTATTCCCATTTTACAGATGAGAAAATT GTCCTTTGTAGAATACCCATCATGTGATAGCTTCTTGCATATTATGCTATTCATTTCTCACAACCTTACAAGGTAAATGGATAATGTTCC TGGATGAGAGATTAAACGTACTCGAAGATCTTATGGTTGTGTGGCTCAGAGACTCTAAGCATGGCTTTCCAAATCTCATTCTCTTGTAGA GATTTTCCATTGTATTGCATTTTGACCATGTTCCTGTTTACAAAACCTAAGATTATATTCTGAAGTATCTGTGACTTGAGTGATAGCTCA GGAATAATCTGAGGGCATTCTATTAGGAAGGAGGACTAGCAAAGCCTATAGTTAGCCTATCCTAGGCATGAACTATTCTCATTTTAGATA GGATGACTTGATAAATAGGATGAAGTGAGCAACCTGTTTGTCTTCGGTTATTGCTATCTACAAGACATTCTGCTAGTCACTGTGGAAAAG TTTCCTTCTCTTGGGTTTTTTCCTCTTCCCCTTCCTCTTAACAGTGTTGGTTATCTTTATTATGTTTCTGTGTATTTGTAACAGCTGTTT CACCCTTGTATTGCATAATGGGGATTTTTCTTGGAATAAAAAGTGAGGCATGTAAATTCATTGAGAACTAACCGTAGTTTGTAAAGAAGT >24862_24862_7_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000415912_SRSF10_chr1_24305307_ENST00000344989_length(amino acids)=533AA_BP=372 MMSTYKRATLDEEDLVDSLSEGDAYPNGLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAGLVACLAALGIQYQTRSPSVCLSEACVS VTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTASVSEAERKAQVYYRACMNETRIEELRA KPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSGLGLPSRDYYLNKTENEKVLTGYLNYMV QLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWLPFLNTIFYPVEINESEPIVVYDKEYLE QISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQGDRKTPNQMKAKE -------------------------------------------------------------- >24862_24862_8_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000415912_SRSF10_chr1_24305307_ENST00000453840_length(transcript)=2943nt_BP=1241nt GAGCGCGCCGCCTGGGCCAGGCAGCCGAGCCGTCCGAGCAGCTGGGCTGGGAGCAGGGAACCCGGAGCTGGGAATCGGGAGCCGGGCGCG GGGAGCTGCGCGAAGCCGGGGCGGAGCACGCGAGCTATGATGTCGACGTACAAGCGGGCCACGCTGGACGAGGAGGACCTGGTGGACTCG CTCTCCGAGGGCGACGCATACCCCAACGGCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCAG GTGGAGAAGCGGCTGGTGGTGTTGGTGGTACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAGA TCCCCCTCTGTGTGCCTGAGCGAAGCTTGTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGAC TTCTTCAGCTACGCCTGTGGGGGCTGGATCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGAA CACAACCAAGCAATCATCAAGCACCTCCTCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGCG TGCATGAACGAGACCAGGATCGAGGAGCTCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCCC TGGGCCAAGGACAACTTCCAGGACACCCTGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGAT TCCAAGAACTCCAACAGCAACGTGATCCAGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAAC GAGAAGGTGCTGACCGGATATCTGAACTACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGATG CAGCAGATCTTGGACTTTGAGACGGCACTGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGTG ACGGCAGCCGAGCTGCAGACCTTGGCACCCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATCC GAGCCTATTGTGGTCTATGACAAGGAATACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCGT GAATTTGGTCGTTATGGTCCTATAGTTGATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATTT GAGGATGTTCGTGATGCTGAAGACGCTTTACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGG GATCGAAAGACACCAAATCAGATGAAAGCCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACGT TCTAGAAGCCGAAGTTATGAAAGGAGGAGATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAATAGACCG ACTGGAAGACCACGGCGTAGCAGAAGCCATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACACT TCAAGAAAGATCTGAAAGCGGAAAAAGAACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATACTG TACGAATATTTTGACTCTGGTCTGAAAAGATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAGTAA GCATTTTAGGACAAATAAAAGGAAATTCAACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGGTAA CAGGTCCATAATAAATTATTGGAAACTAGGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGTCTC AAACTGAATTGGGTGGGAAAAGGTATGGTCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGGTGC CAGTGTTTTCTGCTTAATCATTTGCTTTGTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTACTCC TTCCCAGGTAAATTCCAATTATATTTGACATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAATAT TTATTGAGCCCTTACTGTGGGCAAATCATTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGCACA ATCTAGTGAATCATTACAGTATGGCCTCATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTAATT ATAGAACACAATATACGATCAAGGATAAGTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAATAA TGAAAAAATGATTTAATCTGTAATAAACTGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCTCAC CAAACACATGCTAGGATATAACCCCCAAAATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATTTTG AGGCAGACAGAGAGCTGTTATCCTAACTGATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTACAT >24862_24862_8_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000415912_SRSF10_chr1_24305307_ENST00000453840_length(amino acids)=532AA_BP=372 MMSTYKRATLDEEDLVDSLSEGDAYPNGLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAGLVACLAALGIQYQTRSPSVCLSEACVS VTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTASVSEAERKAQVYYRACMNETRIEELRA KPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSGLGLPSRDYYLNKTENEKVLTGYLNYMV QLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWLPFLNTIFYPVEINESEPIVVYDKEYLE QISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQGDRKTPNQMKAKE -------------------------------------------------------------- >24862_24862_9_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000436918_SRSF10_chr1_24305307_ENST00000344989_length(transcript)=4559nt_BP=1213nt CATCCCATCCCGGCCACCCGGGCAGCGGGACCAGGCGTCTGGGGCACAGCATGCGGGGCGTGTGGCCGCCCCCGGTGTCCGCCCTGCTGT CGGCGCTGGGGATGTCGACGTACAAGCGGGCCACGCTGGACGAGGAGGACCTGGTGGACTCGCTCTCCGAGGGCGACGCATACCCCAACG GCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCAGGTGGAGAAGCGGCTGGTGGTGTTGGTGG TACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAGATCCCCCTCTGTGTGCCTGAGCGAAGCTT GTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGACTTCTTCAGCTACGCCTGTGGGGGCTGGA TCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGAACACAACCAAGCAATCATCAAGCACCTCC TCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGCGTGCATGAACGAGACCAGGATCGAGGAGC TCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCCCTGGGCCAAGGACAACTTCCAGGACACCC TGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGATTCCAAGAACTCCAACAGCAACGTGATCC AGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAACGAGAAGGTGCTGACCGGATATCTGAACT ACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGATGCAGCAGATCTTGGACTTTGAGACGGCAC TGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGTGACGGCAGCCGAGCTGCAGACCTTGGCAC CCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATCCGAGCCTATTGTGGTCTATGACAAGGAAT ACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCGTGAATTTGGTCGTTATGGTCCTATAGTTG ATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATTTGAGGATGTTCGTGATGCTGAAGACGCTT TACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGGGATCGAAAGACACCAAATCAGATGAAAG CCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACGTTCTAGAAGCCGAAGTTATGAAAGGAGGA GATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAACAGTAGACCGACTGGAAGACCACGGCGTAGCAGAA GCCATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACACTTCAAGAAAGATCTGAAAGCGGAAAA AGAACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATACTGTACGAATATTTTGACTCTGGTCTGA AAAGATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAGTAAGCATTTTAGGACAAATAAAAGGAAA TTCAACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGGTAACAGGTCCATAATAAATTATTGGAAA CTAGGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGTCTCAAACTGAATTGGGTGGGAAAAGGTA TGGTCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGGTGCCAGTGTTTTCTGCTTAATCATTTGC TTTGTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTACTCCTTCCCAGGTAAATTCCAATTATATT TGACATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAATATTTATTGAGCCCTTACTGTGGGCAAA TCATTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGCACAATCTAGTGAATCATTACAGTATGGC CTCATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTAATTATAGAACACAATATACGATCAAGGA TAAGTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAATAATGAAAAAATGATTTAATCTGTAATA AACTGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCTCACCAAACACATGCTAGGATATAACCCC CAAAATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATTTTGAGGCAGACAGAGAGCTGTTATCCTA ACTGATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTACATGTACATTTTATAGGGGACATGTTCT GTGTATAGCGAATAAATAACTTTTATAGTATCACAAAATGTTTTGGATTCCTTAGTTTCTTATTAGGATATGATGTTTCTTTACCTATAC ATTGATTTCATCACATTTGATTTTTGTCATCTTTTTTGCCACATACTTAAAATTTTCCATATAAAATTAACTAAAAATCTGGAAGTGGAA TTTAAGCTTTTAATTTGTAGCAATTTTGAAAATATAGCAGAGGTATATTTTCAAGGGAGGTGTGAAATGGAGGTATTATTGTTTGTATTT TATTTTAGAAATTTTGTTTGAACTTGCCCAAGATCACACAGCAAGTGTCAGATCCTAGGTTACAGCCCATAATTTTTCACTTGTTTCATC TTTTGTTACCATGTTTGTTGTTTAATCCAATGGGGAAGTGTTTTTATAGCTTTATTTTCATGGAGATAGTAACATTGATATAATGGGATC TAGAATTTACTTAGAGTCAAAGTGACTAGATTTAATTACAAAAAGTATTTTGTTGTATACCGTTATACACTCATTAACATAGGGGTTCTT ATGGACAGAGGTTCTATGTATTTTTAAAAGAATATGTAGAGGCTATAGACTTTTTTGCCCTCTACCTCCCTTCTCCATTTCCTTTTGAAG TTAAGACATTTAAGGGGGAGAATTAAGGTGCATATTGAGTTGGGGTTTTGTTTAAAAAAAATTAGGTAAATACATATATAACTACAATAA CAACAGTTGGTAGTTCTCTAAAATATTTAATTATGGTAAATCAGAAAAGGCCCTTTAATTTTTGCATCTGTTGAATGAATTGCTTTAGGA TCTCTTCTGTGGTTGTTTCTCTCTATACTGAATGCTGTCAATATTATTGAGCACTTACTGTGCCGAACCATGTGCTTTTCAAATATTTCT ATTTAATCCTAAAAACACTCCTGGGAAATGGGTATTATTCCCATTTTACAGATGAGAAAATTGTCCTTTGTAGAATACCCATCATGTGAT AGCTTCTTGCATATTATGCTATTCATTTCTCACAACCTTACAAGGTAAATGGATAATGTTCCTGGATGAGAGATTAAACGTACTCGAAGA TCTTATGGTTGTGTGGCTCAGAGACTCTAAGCATGGCTTTCCAAATCTCATTCTCTTGTAGAGATTTTCCATTGTATTGCATTTTGACCA TGTTCCTGTTTACAAAACCTAAGATTATATTCTGAAGTATCTGTGACTTGAGTGATAGCTCAGGAATAATCTGAGGGCATTCTATTAGGA AGGAGGACTAGCAAAGCCTATAGTTAGCCTATCCTAGGCATGAACTATTCTCATTTTAGATAGGATGACTTGATAAATAGGATGAAGTGA GCAACCTGTTTGTCTTCGGTTATTGCTATCTACAAGACATTCTGCTAGTCACTGTGGAAAAGTTTCCTTCTCTTGGGTTTTTTCCTCTTC CCCTTCCTCTTAACAGTGTTGGTTATCTTTATTATGTTTCTGTGTATTTGTAACAGCTGTTTCACCCTTGTATTGCATAATGGGGATTTT TCTTGGAATAAAAAGTGAGGCATGTAAATTCATTGAGAACTAACCGTAGTTTGTAAAGAAGTAAAAGGCCTTTGTATCTAGTTTTTTGCA >24862_24862_9_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000436918_SRSF10_chr1_24305307_ENST00000344989_length(amino acids)=553AA_BP=392 MGHSMRGVWPPPVSALLSALGMSTYKRATLDEEDLVDSLSEGDAYPNGLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAGLVACLAA LGIQYQTRSPSVCLSEACVSVTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTASVSEAER KAQVYYRACMNETRIEELRAKPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSGLGLPSRD YYLNKTENEKVLTGYLNYMVQLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWLPFLNTIF YPVEINESEPIVVYDKEYLEQISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQ IEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNSRPTGRPRRSRSHSDNDRPNCSWN -------------------------------------------------------------- >24862_24862_10_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000436918_SRSF10_chr1_24305307_ENST00000453840_length(transcript)=2915nt_BP=1213nt CATCCCATCCCGGCCACCCGGGCAGCGGGACCAGGCGTCTGGGGCACAGCATGCGGGGCGTGTGGCCGCCCCCGGTGTCCGCCCTGCTGT CGGCGCTGGGGATGTCGACGTACAAGCGGGCCACGCTGGACGAGGAGGACCTGGTGGACTCGCTCTCCGAGGGCGACGCATACCCCAACG GCCTGCAGGTGAACTTCCACAGCCCCCGGAGTGGCCAGAGGTGCTGGGCTGCACGGACCCAGGTGGAGAAGCGGCTGGTGGTGTTGGTGG TACTTCTGGCGGCAGGACTGGTGGCCTGCTTGGCAGCACTGGGCATCCAGTACCAGACAAGATCCCCCTCTGTGTGCCTGAGCGAAGCTT GTGTCTCAGTGACCAGCTCCATCTTGAGCTCCATGGACCCCACAGTGGACCCCTGCCATGACTTCTTCAGCTACGCCTGTGGGGGCTGGA TCAAGGCCAACCCAGTCCCTGATGGCCACTCACGCTGGGGGACCTTCAGCAACCTCTGGGAACACAACCAAGCAATCATCAAGCACCTCC TCGAAAACTCCACGGCCAGCGTGAGCGAGGCAGAGAGAAAGGCGCAAGTATACTACCGTGCGTGCATGAACGAGACCAGGATCGAGGAGC TCAGGGCCAAACCTCTAATGGAGTTGATTGAGAGGCTCGGGGGCTGGAACATCACAGGTCCCTGGGCCAAGGACAACTTCCAGGACACCC TGCAGGTGGTCACCGCCCACTACCGCACCTCACCCTTCTTCTCTGTCTATGTCAGTGCCGATTCCAAGAACTCCAACAGCAACGTGATCC AGGTGGACCAGTCTGGCCTGGGCTTGCCCTCGAGAGACTATTACCTGAACAAAACTGAAAACGAGAAGGTGCTGACCGGATATCTGAACT ACATGGTCCAGCTGGGGAAGCTGCTGGGCGGCGGGGACGAGGAGGCCATCCGGCCCCAGATGCAGCAGATCTTGGACTTTGAGACGGCAC TGGCCAACATCACCATCCCACAGGAGAAGCGCCGTGATGAGGAGCTCATCTACCACAAAGTGACGGCAGCCGAGCTGCAGACCTTGGCAC CCGCCATCAACTGGTTGCCTTTTCTCAACACCATCTTCTACCCCGTGGAGATCAATGAATCCGAGCCTATTGTGGTCTATGACAAGGAAT ACCTTGAGCAGATCTCCACTCTCATCAACACCACCGACAGATGGTCTGAAGACTTGCGGCGTGAATTTGGTCGTTATGGTCCTATAGTTG ATGTGTATGTTCCACTTGATTTCTACACTCGCCGTCCAAGAGGATTTGCTTATGTTCAATTTGAGGATGTTCGTGATGCTGAAGACGCTT TACATAATTTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGGGATCGAAAGACACCAAATCAGATGAAAG CCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAGACGTTCTAGAAGCCGAAGTTATGAAAGGAGGA GATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGATCGTATAGTCCTAGAAATAGACCGACTGGAAGACCACGGCGTAGCAGAAGCC ATTCCGACAATGATAGACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACACTTCAAGAAAGATCTGAAAGCGGAAAAAGA ACCAAAGAAGGGCAGTTCAAGCGACCAAAGGGTGGGTGGAAGGTGCTGCAGTATGAATACTGTACGAATATTTTGACTCTGGTCTGAAAA GATAAAAGAATGTTATCGAAAACTACATGGAATAATTGAAGTCCCTTCAAGTTTGAAAGTAAGCATTTTAGGACAAATAAAAGGAAATTC AACTTTGTACTTGTGGAAACTAATCCCTAAATATGAATAGGTTTATATTGATTCATGGGTAACAGGTCCATAATAAATTATTGGAAACTA GGATGTCTGAATATCAAGGAAGACAGCCATAGTCTCTTACAGTGCCTCTGTTGGTCTGTCTCAAACTGAATTGGGTGGGAAAAGGTATGG TCCAATATAAAAGTTCCATTTTTGCCATTATTGGCAAATCTTGCCTTTGTTTATTTTGGTGCCAGTGTTTTCTGCTTAATCATTTGCTTT GTTGGCATCTGTGTTTATTTACTTGTACACCACATGCAGTTTACATCTGTCTTAACTACTCCTTCCCAGGTAAATTCCAATTATATTTGA CATCCAGCTAAGAGGGCCCATCTCTTCTCACCTCTTTCCTAGTCAGTATATTCAGCAAATATTTATTGAGCCCTTACTGTGGGCAAATCA TTGTACTGGATAATTGAGAAAAATAGATAATTCCCTTATTCAGTAAATGTCTACTGAGCACAATCTAGTGAATCATTACAGTATGGCCTC ATTGTTTTGTTTGAGGTGTGTTATTCATAACAATATTTTACACCATTCGTATCAATGTAATTATAGAACACAATATACGATCAAGGATAA GTAATTGTGTGGTTATCTGCCATTTAAAAGTATCCAGTATTTGATCACATTATTATAAATAATGAAAAAATGATTTAATCTGTAATAAAC TGGTTTATTGTGCAGTGACTGTAATATACTAGAGTTATAATAAATTGTTTACTCTGCCTCACCAAACACATGCTAGGATATAACCCCCAA AATAAGTATTTAACTTTGCATTAGGTATAAAGGAGACTGGGTGCTATAATTAGATTATTTTGAGGCAGACAGAGAGCTGTTATCCTAACT GATTTAGTATGTTCTGTAATTGAGAAAATGTTCACCAAATTATACTTTTTAGTGATTTACATGTACATTTTATAGGGGACATGTTCTGTG >24862_24862_10_ECE1-SRSF10_ECE1_chr1_21573714_ENST00000436918_SRSF10_chr1_24305307_ENST00000453840_length(amino acids)=552AA_BP=392 MGHSMRGVWPPPVSALLSALGMSTYKRATLDEEDLVDSLSEGDAYPNGLQVNFHSPRSGQRCWAARTQVEKRLVVLVVLLAAGLVACLAA LGIQYQTRSPSVCLSEACVSVTSSILSSMDPTVDPCHDFFSYACGGWIKANPVPDGHSRWGTFSNLWEHNQAIIKHLLENSTASVSEAER KAQVYYRACMNETRIEELRAKPLMELIERLGGWNITGPWAKDNFQDTLQVVTAHYRTSPFFSVYVSADSKNSNSNVIQVDQSGLGLPSRD YYLNKTENEKVLTGYLNYMVQLGKLLGGGDEEAIRPQMQQILDFETALANITIPQEKRRDEELIYHKVTAAELQTLAPAINWLPFLNTIF YPVEINESEPIVVYDKEYLEQISTLINTTDRWSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQ IEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNRPTGRPRRSRSHSDNDRPNCSWNT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ECE1-SRSF10 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ECE1-SRSF10 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ECE1-SRSF10 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies