
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:EEF1B2-ABCF2 (FusionGDB2 ID:25158) |
Fusion Gene Summary for EEF1B2-ABCF2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: EEF1B2-ABCF2 | Fusion gene ID: 25158 | Hgene | Tgene | Gene symbol | EEF1B2 | ABCF2 | Gene ID | 1933 | 10061 |
| Gene name | eukaryotic translation elongation factor 1 beta 2 | ATP binding cassette subfamily F member 2 | |
| Synonyms | EEF1B|EEF1B1|EF1B | ABC28|EST133090|HUSSY-18|HUSSY18 | |
| Cytomap | 2q33.3 | 7q36.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | elongation factor 1-betaEF-1-betaeukaryotic translation elongation factor 1 beta 1 | ATP-binding cassette sub-family F member 2ABC-type transport proteinATP-binding cassette, sub-family F (GCN20), member 2iron-inhibited ABC transporter 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P24534 | Q9UG63 | |
| Ensembl transtripts involved in fusion gene | ENST00000236957, ENST00000392221, ENST00000392222, | ENST00000473874, ENST00000222388, ENST00000287844, | |
| Fusion gene scores | * DoF score | 4 X 3 X 3=36 | 5 X 4 X 3=60 |
| # samples | 4 | 6 | |
| ** MAII score | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(6/60*10)=0 | |
| Context | PubMed: EEF1B2 [Title/Abstract] AND ABCF2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | EEF1B2(207026196)-ABCF2(150913115), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across EEF1B2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ABCF2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CG-5721-01A | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
Top |
Fusion Gene ORF analysis for EEF1B2-ABCF2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000236957 | ENST00000473874 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| 5CDS-intron | ENST00000392221 | ENST00000473874 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| 5CDS-intron | ENST00000392222 | ENST00000473874 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| In-frame | ENST00000236957 | ENST00000222388 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| In-frame | ENST00000236957 | ENST00000287844 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| In-frame | ENST00000392221 | ENST00000222388 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| In-frame | ENST00000392221 | ENST00000287844 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| In-frame | ENST00000392222 | ENST00000222388 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| In-frame | ENST00000392222 | ENST00000287844 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000236957 | EEF1B2 | chr2 | 207026196 | + | ENST00000222388 | ABCF2 | chr7 | 150913115 | - | 1252 | 451 | 121 | 1017 | 298 |
| ENST00000236957 | EEF1B2 | chr2 | 207026196 | + | ENST00000287844 | ABCF2 | chr7 | 150913115 | - | 2549 | 451 | 121 | 984 | 287 |
| ENST00000392221 | EEF1B2 | chr2 | 207026196 | + | ENST00000222388 | ABCF2 | chr7 | 150913115 | - | 1289 | 488 | 158 | 1054 | 298 |
| ENST00000392221 | EEF1B2 | chr2 | 207026196 | + | ENST00000287844 | ABCF2 | chr7 | 150913115 | - | 2586 | 488 | 158 | 1021 | 287 |
| ENST00000392222 | EEF1B2 | chr2 | 207026196 | + | ENST00000222388 | ABCF2 | chr7 | 150913115 | - | 1506 | 705 | 375 | 1271 | 298 |
| ENST00000392222 | EEF1B2 | chr2 | 207026196 | + | ENST00000287844 | ABCF2 | chr7 | 150913115 | - | 2803 | 705 | 375 | 1238 | 287 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000236957 | ENST00000222388 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - | 0.00235639 | 0.99764353 |
| ENST00000236957 | ENST00000287844 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - | 0.001743911 | 0.998256 |
| ENST00000392221 | ENST00000222388 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - | 0.002549959 | 0.99745005 |
| ENST00000392221 | ENST00000287844 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - | 0.001731672 | 0.99826825 |
| ENST00000392222 | ENST00000222388 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - | 0.001748388 | 0.9982516 |
| ENST00000392222 | ENST00000287844 | EEF1B2 | chr2 | 207026196 | + | ABCF2 | chr7 | 150913115 | - | 0.001154765 | 0.9988452 |
Top |
Fusion Genomic Features for EEF1B2-ABCF2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
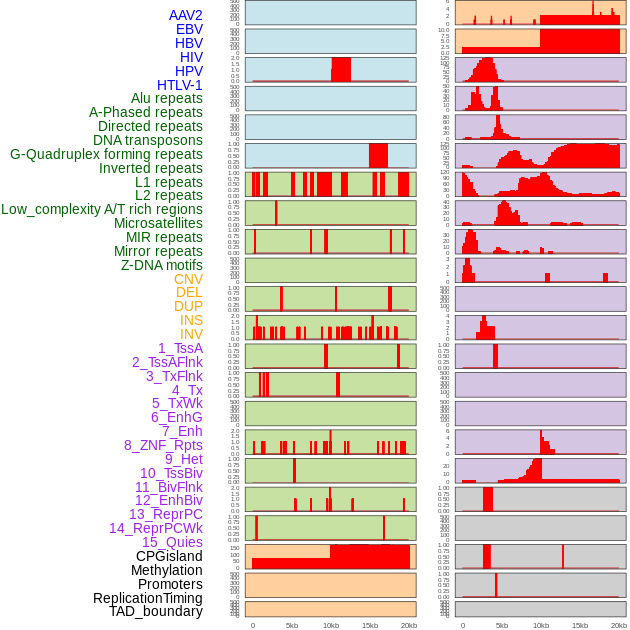 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for EEF1B2-ABCF2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:207026196/chr7:150913115) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| EEF1B2 | ABCF2 |
| FUNCTION: EF-1-beta and EF-1-delta stimulate the exchange of GDP bound to EF-1-alpha to GTP. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EEF1B2 | chr2:207026196 | chr7:150913115 | ENST00000236957 | + | 4 | 7 | 2_84 | 110 | 226.0 | Domain | Note=GST C-terminal |
| Hgene | EEF1B2 | chr2:207026196 | chr7:150913115 | ENST00000392221 | + | 4 | 7 | 2_84 | 110 | 226.0 | Domain | Note=GST C-terminal |
| Hgene | EEF1B2 | chr2:207026196 | chr7:150913115 | ENST00000392222 | + | 3 | 6 | 2_84 | 110 | 226.0 | Domain | Note=GST C-terminal |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ABCF2 | chr2:207026196 | chr7:150913115 | ENST00000287844 | 10 | 15 | 396_613 | 446 | 624.0 | Domain | ABC transporter 2 | |
| Tgene | ABCF2 | chr2:207026196 | chr7:150913115 | ENST00000287844 | 10 | 15 | 86_325 | 446 | 624.0 | Domain | ABC transporter 1 | |
| Tgene | ABCF2 | chr2:207026196 | chr7:150913115 | ENST00000287844 | 10 | 15 | 118_125 | 446 | 624.0 | Nucleotide binding | ATP 1 | |
| Tgene | ABCF2 | chr2:207026196 | chr7:150913115 | ENST00000287844 | 10 | 15 | 430_437 | 446 | 624.0 | Nucleotide binding | ATP 2 |
Top |
Fusion Gene Sequence for EEF1B2-ABCF2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >25158_25158_1_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000236957_ABCF2_chr7_150913115_ENST00000222388_length(transcript)=1252nt_BP=451nt CGCAGTTCCGCCGGAAGTGGCCCCAGCCTCGAGGCCGGGCGTCTTCGGTCATCTCCGGCGCTTCTAGGGCTGGTTCCCGTCATCTTCGGG AGCCGTGGAGCTCTCGGATACAGCCGACACCATGGGTTTCGGAGACCTGAAAAGCCCTGCCGGCCTCCAGGTGCTCAACGATTACCTGGC GGACAAGAGCTACATCGAGGGGTATGTGCCATCACAAGCAGATGTGGCAGTATTTGAAGCCGTGTCCAGCCCACCGCCTGCCGACTTGTG TCATGCCCTACGTTGGTATAATCACATCAAGTCTTACGAAAAGGAAAAGGCCAGCCTGCCAGGAGTGAAGAAAGCTTTGGGCAAATATGG TCCTGCCGATGTGGAAGACACTACAGGAAGTGGAGCTACAGATAGTAAAGATGATGATGACATTGACCTCTTTGGATCTGATGATGAGGA GCTACTACCCACAGATGGCATGATCCGAAAACACTCTCATGTCAAGATAGGGCGTTACCATCAGCATTTACAAGAGCAGCTGGACTTAGA TCTCTCACCTTTGGAGTACATGATGAAGTGCTACCCAGAGATCAAGGAGAAGGAAGAAATGAGGAAGATCATTGGGCGATACGGTCTCAC TGGGAAACAACAGGTGAGCCCAATCCGGAACTTGTCAGACGGGCAGAAGTGCCGAGTGTGTCTGGCCTGGCTGGCCTGGCAGAACCCCCA CATGCTCTTCCTGGATGAACCCACCAATCACCTGGATATCGAGACCATCGACGCCCTGGCAGATGCCATCAATGAGTTTGAGGGTGGTAT GATGCTGGTCAGCCATGACTTCAGACTCATTCAGCAGGTTGCACAGGAAATTTGGGTCTGTGAGAAGCAGACAATCACCAAGTGGCCTGG AGACATCCTGGCTTACAAGGAGCACCTCAAGTCCAAGCTGGTGGATGAGGAGCCCCAGCTCACCAAGAGGACCCACAACGTGTGCACCCT GACATTGGCATCTCTGCCAAGGCCATGAGCATCATGAACTCGTTTGTAAACGACGTGTTTGAGCAGCTGGCGTGTGAGGCTGCCCGGCTG GCCCAGTACTCGGGCCGGACCACCCTGACATCCCGAGAAGTCCAGACGGCTGTGCGTCTGCTGCTGCCTGGGGAGCTGGCCAAGCACGCT >25158_25158_1_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000236957_ABCF2_chr7_150913115_ENST00000222388_length(amino acids)=298AA_BP=110 MGFGDLKSPAGLQVLNDYLADKSYIEGYVPSQADVAVFEAVSSPPPADLCHALRWYNHIKSYEKEKASLPGVKKALGKYGPADVEDTTGS GATDSKDDDDIDLFGSDDEELLPTDGMIRKHSHVKIGRYHQHLQEQLDLDLSPLEYMMKCYPEIKEKEEMRKIIGRYGLTGKQQVSPIRN LSDGQKCRVCLAWLAWQNPHMLFLDEPTNHLDIETIDALADAINEFEGGMMLVSHDFRLIQQVAQEIWVCEKQTITKWPGDILAYKEHLK -------------------------------------------------------------- >25158_25158_2_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000236957_ABCF2_chr7_150913115_ENST00000287844_length(transcript)=2549nt_BP=451nt CGCAGTTCCGCCGGAAGTGGCCCCAGCCTCGAGGCCGGGCGTCTTCGGTCATCTCCGGCGCTTCTAGGGCTGGTTCCCGTCATCTTCGGG AGCCGTGGAGCTCTCGGATACAGCCGACACCATGGGTTTCGGAGACCTGAAAAGCCCTGCCGGCCTCCAGGTGCTCAACGATTACCTGGC GGACAAGAGCTACATCGAGGGGTATGTGCCATCACAAGCAGATGTGGCAGTATTTGAAGCCGTGTCCAGCCCACCGCCTGCCGACTTGTG TCATGCCCTACGTTGGTATAATCACATCAAGTCTTACGAAAAGGAAAAGGCCAGCCTGCCAGGAGTGAAGAAAGCTTTGGGCAAATATGG TCCTGCCGATGTGGAAGACACTACAGGAAGTGGAGCTACAGATAGTAAAGATGATGATGACATTGACCTCTTTGGATCTGATGATGAGGA GCTACTACCCACAGATGGCATGATCCGAAAACACTCTCATGTCAAGATAGGGCGTTACCATCAGCATTTACAAGAGCAGCTGGACTTAGA TCTCTCACCTTTGGAGTACATGATGAAGTGCTACCCAGAGATCAAGGAGAAGGAAGAAATGAGGAAGATCATTGGGCGATACGGTCTCAC TGGGAAACAACAGGTGAGCCCAATCCGGAACTTGTCAGACGGGCAGAAGTGCCGAGTGTGTCTGGCCTGGCTGGCCTGGCAGAACCCCCA CATGCTCTTCCTGGATGAACCCACCAATCACCTGGATATCGAGACCATCGACGCCCTGGCAGATGCCATCAATGAGTTTGAGGGTGGTAT GATGCTGGTCAGCCATGACTTCAGACTCATTCAGCAGGTTGCACAGGAAATTTGGGTCTGTGAGAAGCAGACAATCACCAAGTGGCCTGG AGACATCCTGGCTTACAAGGAGCACCTCAAGTCCAAGCTGGTGGATGAGGAGCCCCAGCTCACCAAGAGGACCCACAACGTGTGAGCCCT CTACCTGGGTTCGGGTCAGGAGCTCCATCTGGGAACTAACAGCTGCTAACCTGACCAGCCGCTCAGGACAGGACCCTGGGGCTACACTCC TGCATTGCTGCAATACTGCTCCCCCAGCCTCTCCCCTGCCCCTCAACCTGCCTTAGCTGCACTCTCTTACCTACAGCTGGACAGTACCTG TCTGTTTCCTGTCCTCCTTCCAGTTACATCTGTCCATGTCTGGACTCGGCTGGCCGTTCCCTCCAGCCCCTTGCTGGTTATCTTACTCTG AGTGTGATGCAGTCAGAGGCACCTGCGGGTTAGCCCAGGGGCCCAAGCCCTGGATTTGGCCTGCGGAGGAGCTTAGGATCCTCGTTTTCT GGGTTTTGGTGATGTTGGAGGAGTACCCCCCAGCCCACCGCCCCGATTCCTTTTTGCTTCTGGTTTGGAGCTCCGGACCAGGACCTTCGT CCTGGTCAGTTTTTAAATAATTATTTAGCAGTGTAACTTTTAGACCTGCGTGACATCTACAAAGCGCCCAATAAAGAAAGAGGAAGCCAC GGTCCCTACCTTCCTTCTCGGGTCTCTGGGGCCTTCTCCTCCCTGCAGTGCCAACATGCACTGCCCACAGCAGGAGCTGGATCCAGCGTC AGTGTGTCGATGGGAACTGAAGACTAGTCCATAGGAGCTGGAAGAACTTTGTCCCTTTACTTCTGATTTGAAATTGTACCTTTTCTCAGG CCTGTGATTCACAGACTTTAACATGAATCAGAATCACCTGGAGGGCTCATGCAATCAGATTGCCAGATCTCGCCTCAGCGTTTCTGGTTC AATAGGTTTTGGGGGAGACCAAGAACGTTAACATTTCTAGCAAGTTTCCAGGTGATGCTGTTGTTGCTGGTCTAGAGACTATTTTGAGAA CCACTGTCCAGGAGCGTGGTTTTCTGATTGTGATCTGAGGTTCTGCCCCAACTGCACAGCAGTTGGGCTGCTTGTTAAAAATGCAGGCCA GGTGCGGTGGCTCACACCTGTAATCCCAGCGCTTTGGGAGGCTGAGGCAGGTGGATCACTTGAGCTCAGGAGTTCAAGACCAGCTTGGGA AACATGGCAAAACCCGTCTTTATGTGCCTGGAATCCCACCTGCTCAGGTGGCTAGGGTGGATGGATCGCTTGAGCCCAGGAGGTGGAGGT TGCAGTGAGCTGAGATTGCACCACTGCATTCCAGCCTGGATGACAGAGCAAAACCCTGTCTCAAAAAAATGCAGACTGGCCAGGCACAGT GGCTCACACCTGTAATCCGACTGTAAGCTCATCACCTTGGGAGGCCACTGTAGGAGGATCAATTGAGCCTAGAAGTTCAAGACCAGCCTG GGCAAAGTAGGGAGACCCCTTCTCTACAAATAGTAATAAAATGAACCGGGCATAGTAGCATGTGCCTGCGGTCCCAGCTGCTCTGATAAG AGGAGGCTCACTTGAGCCCAGGAGGTTGAGGCTGCAGTGAGCAGAGCGTGCCGCTACACTCCAGCCTGATGACAGACCGAGACACTGTCT >25158_25158_2_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000236957_ABCF2_chr7_150913115_ENST00000287844_length(amino acids)=287AA_BP=110 MGFGDLKSPAGLQVLNDYLADKSYIEGYVPSQADVAVFEAVSSPPPADLCHALRWYNHIKSYEKEKASLPGVKKALGKYGPADVEDTTGS GATDSKDDDDIDLFGSDDEELLPTDGMIRKHSHVKIGRYHQHLQEQLDLDLSPLEYMMKCYPEIKEKEEMRKIIGRYGLTGKQQVSPIRN LSDGQKCRVCLAWLAWQNPHMLFLDEPTNHLDIETIDALADAINEFEGGMMLVSHDFRLIQQVAQEIWVCEKQTITKWPGDILAYKEHLK -------------------------------------------------------------- >25158_25158_3_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000392221_ABCF2_chr7_150913115_ENST00000222388_length(transcript)=1289nt_BP=488nt GCCGGAAGTGGCCCCAGCCTCGAGGCCGGGCGTCTTCGGTCATCTCCGGCGCTTCTAGGGCTGGTTCCCGTCATCTTCGGGAGCCGTGGA GCGTGGGGCGCCCACAATTTGCGCGCTCTCTTTCTGCTGCTCCCCAGCTCTCGGATACAGCCGACACCATGGGTTTCGGAGACCTGAAAA GCCCTGCCGGCCTCCAGGTGCTCAACGATTACCTGGCGGACAAGAGCTACATCGAGGGGTATGTGCCATCACAAGCAGATGTGGCAGTAT TTGAAGCCGTGTCCAGCCCACCGCCTGCCGACTTGTGTCATGCCCTACGTTGGTATAATCACATCAAGTCTTACGAAAAGGAAAAGGCCA GCCTGCCAGGAGTGAAGAAAGCTTTGGGCAAATATGGTCCTGCCGATGTGGAAGACACTACAGGAAGTGGAGCTACAGATAGTAAAGATG ATGATGACATTGACCTCTTTGGATCTGATGATGAGGAGCTACTACCCACAGATGGCATGATCCGAAAACACTCTCATGTCAAGATAGGGC GTTACCATCAGCATTTACAAGAGCAGCTGGACTTAGATCTCTCACCTTTGGAGTACATGATGAAGTGCTACCCAGAGATCAAGGAGAAGG AAGAAATGAGGAAGATCATTGGGCGATACGGTCTCACTGGGAAACAACAGGTGAGCCCAATCCGGAACTTGTCAGACGGGCAGAAGTGCC GAGTGTGTCTGGCCTGGCTGGCCTGGCAGAACCCCCACATGCTCTTCCTGGATGAACCCACCAATCACCTGGATATCGAGACCATCGACG CCCTGGCAGATGCCATCAATGAGTTTGAGGGTGGTATGATGCTGGTCAGCCATGACTTCAGACTCATTCAGCAGGTTGCACAGGAAATTT GGGTCTGTGAGAAGCAGACAATCACCAAGTGGCCTGGAGACATCCTGGCTTACAAGGAGCACCTCAAGTCCAAGCTGGTGGATGAGGAGC CCCAGCTCACCAAGAGGACCCACAACGTGTGCACCCTGACATTGGCATCTCTGCCAAGGCCATGAGCATCATGAACTCGTTTGTAAACGA CGTGTTTGAGCAGCTGGCGTGTGAGGCTGCCCGGCTGGCCCAGTACTCGGGCCGGACCACCCTGACATCCCGAGAAGTCCAGACGGCTGT GCGTCTGCTGCTGCCTGGGGAGCTGGCCAAGCACGCTGTGTCTGAGGGCACCAAGGCTGTCACCAAGTACACCAGCTCCAAGTGACCCAG >25158_25158_3_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000392221_ABCF2_chr7_150913115_ENST00000222388_length(amino acids)=298AA_BP=110 MGFGDLKSPAGLQVLNDYLADKSYIEGYVPSQADVAVFEAVSSPPPADLCHALRWYNHIKSYEKEKASLPGVKKALGKYGPADVEDTTGS GATDSKDDDDIDLFGSDDEELLPTDGMIRKHSHVKIGRYHQHLQEQLDLDLSPLEYMMKCYPEIKEKEEMRKIIGRYGLTGKQQVSPIRN LSDGQKCRVCLAWLAWQNPHMLFLDEPTNHLDIETIDALADAINEFEGGMMLVSHDFRLIQQVAQEIWVCEKQTITKWPGDILAYKEHLK -------------------------------------------------------------- >25158_25158_4_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000392221_ABCF2_chr7_150913115_ENST00000287844_length(transcript)=2586nt_BP=488nt GCCGGAAGTGGCCCCAGCCTCGAGGCCGGGCGTCTTCGGTCATCTCCGGCGCTTCTAGGGCTGGTTCCCGTCATCTTCGGGAGCCGTGGA GCGTGGGGCGCCCACAATTTGCGCGCTCTCTTTCTGCTGCTCCCCAGCTCTCGGATACAGCCGACACCATGGGTTTCGGAGACCTGAAAA GCCCTGCCGGCCTCCAGGTGCTCAACGATTACCTGGCGGACAAGAGCTACATCGAGGGGTATGTGCCATCACAAGCAGATGTGGCAGTAT TTGAAGCCGTGTCCAGCCCACCGCCTGCCGACTTGTGTCATGCCCTACGTTGGTATAATCACATCAAGTCTTACGAAAAGGAAAAGGCCA GCCTGCCAGGAGTGAAGAAAGCTTTGGGCAAATATGGTCCTGCCGATGTGGAAGACACTACAGGAAGTGGAGCTACAGATAGTAAAGATG ATGATGACATTGACCTCTTTGGATCTGATGATGAGGAGCTACTACCCACAGATGGCATGATCCGAAAACACTCTCATGTCAAGATAGGGC GTTACCATCAGCATTTACAAGAGCAGCTGGACTTAGATCTCTCACCTTTGGAGTACATGATGAAGTGCTACCCAGAGATCAAGGAGAAGG AAGAAATGAGGAAGATCATTGGGCGATACGGTCTCACTGGGAAACAACAGGTGAGCCCAATCCGGAACTTGTCAGACGGGCAGAAGTGCC GAGTGTGTCTGGCCTGGCTGGCCTGGCAGAACCCCCACATGCTCTTCCTGGATGAACCCACCAATCACCTGGATATCGAGACCATCGACG CCCTGGCAGATGCCATCAATGAGTTTGAGGGTGGTATGATGCTGGTCAGCCATGACTTCAGACTCATTCAGCAGGTTGCACAGGAAATTT GGGTCTGTGAGAAGCAGACAATCACCAAGTGGCCTGGAGACATCCTGGCTTACAAGGAGCACCTCAAGTCCAAGCTGGTGGATGAGGAGC CCCAGCTCACCAAGAGGACCCACAACGTGTGAGCCCTCTACCTGGGTTCGGGTCAGGAGCTCCATCTGGGAACTAACAGCTGCTAACCTG ACCAGCCGCTCAGGACAGGACCCTGGGGCTACACTCCTGCATTGCTGCAATACTGCTCCCCCAGCCTCTCCCCTGCCCCTCAACCTGCCT TAGCTGCACTCTCTTACCTACAGCTGGACAGTACCTGTCTGTTTCCTGTCCTCCTTCCAGTTACATCTGTCCATGTCTGGACTCGGCTGG CCGTTCCCTCCAGCCCCTTGCTGGTTATCTTACTCTGAGTGTGATGCAGTCAGAGGCACCTGCGGGTTAGCCCAGGGGCCCAAGCCCTGG ATTTGGCCTGCGGAGGAGCTTAGGATCCTCGTTTTCTGGGTTTTGGTGATGTTGGAGGAGTACCCCCCAGCCCACCGCCCCGATTCCTTT TTGCTTCTGGTTTGGAGCTCCGGACCAGGACCTTCGTCCTGGTCAGTTTTTAAATAATTATTTAGCAGTGTAACTTTTAGACCTGCGTGA CATCTACAAAGCGCCCAATAAAGAAAGAGGAAGCCACGGTCCCTACCTTCCTTCTCGGGTCTCTGGGGCCTTCTCCTCCCTGCAGTGCCA ACATGCACTGCCCACAGCAGGAGCTGGATCCAGCGTCAGTGTGTCGATGGGAACTGAAGACTAGTCCATAGGAGCTGGAAGAACTTTGTC CCTTTACTTCTGATTTGAAATTGTACCTTTTCTCAGGCCTGTGATTCACAGACTTTAACATGAATCAGAATCACCTGGAGGGCTCATGCA ATCAGATTGCCAGATCTCGCCTCAGCGTTTCTGGTTCAATAGGTTTTGGGGGAGACCAAGAACGTTAACATTTCTAGCAAGTTTCCAGGT GATGCTGTTGTTGCTGGTCTAGAGACTATTTTGAGAACCACTGTCCAGGAGCGTGGTTTTCTGATTGTGATCTGAGGTTCTGCCCCAACT GCACAGCAGTTGGGCTGCTTGTTAAAAATGCAGGCCAGGTGCGGTGGCTCACACCTGTAATCCCAGCGCTTTGGGAGGCTGAGGCAGGTG GATCACTTGAGCTCAGGAGTTCAAGACCAGCTTGGGAAACATGGCAAAACCCGTCTTTATGTGCCTGGAATCCCACCTGCTCAGGTGGCT AGGGTGGATGGATCGCTTGAGCCCAGGAGGTGGAGGTTGCAGTGAGCTGAGATTGCACCACTGCATTCCAGCCTGGATGACAGAGCAAAA CCCTGTCTCAAAAAAATGCAGACTGGCCAGGCACAGTGGCTCACACCTGTAATCCGACTGTAAGCTCATCACCTTGGGAGGCCACTGTAG GAGGATCAATTGAGCCTAGAAGTTCAAGACCAGCCTGGGCAAAGTAGGGAGACCCCTTCTCTACAAATAGTAATAAAATGAACCGGGCAT AGTAGCATGTGCCTGCGGTCCCAGCTGCTCTGATAAGAGGAGGCTCACTTGAGCCCAGGAGGTTGAGGCTGCAGTGAGCAGAGCGTGCCG >25158_25158_4_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000392221_ABCF2_chr7_150913115_ENST00000287844_length(amino acids)=287AA_BP=110 MGFGDLKSPAGLQVLNDYLADKSYIEGYVPSQADVAVFEAVSSPPPADLCHALRWYNHIKSYEKEKASLPGVKKALGKYGPADVEDTTGS GATDSKDDDDIDLFGSDDEELLPTDGMIRKHSHVKIGRYHQHLQEQLDLDLSPLEYMMKCYPEIKEKEEMRKIIGRYGLTGKQQVSPIRN LSDGQKCRVCLAWLAWQNPHMLFLDEPTNHLDIETIDALADAINEFEGGMMLVSHDFRLIQQVAQEIWVCEKQTITKWPGDILAYKEHLK -------------------------------------------------------------- >25158_25158_5_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000392222_ABCF2_chr7_150913115_ENST00000222388_length(transcript)=1506nt_BP=705nt CCCCAGCCTCGAGGCCGGGCGTCTTCGGTCATCTCCGGCGCTTCTAGGGCTGGTTCCCGTCATCTTCGGGAGCCGTGGAGGTACGAACTT AAGACATGCCTATTTTATTAATTTACTTCCAAACGCAACGAAAGGTCCATGGACAATTTGTGGGCCATTTAATTCAGGGCCCCCAATTCG TACGTGGAGAAGTGGGAATGCAAAAGTACTTTGACCTTTAACCTTCGGTCCGGCGCGGTGGAGGGAAACGCCTCCGTCTCTATATAAGGA ATTTTCCGGTCTCTTCGGGTCCTTTTTCCTCTCTTCAGCGTGGGGCGCCCACAATTTGCGCGCTCTCTTTCTGCTGCTCCCCAGCTCTCG GATACAGCCGACACCATGGGTTTCGGAGACCTGAAAAGCCCTGCCGGCCTCCAGGTGCTCAACGATTACCTGGCGGACAAGAGCTACATC GAGGGGTATGTGCCATCACAAGCAGATGTGGCAGTATTTGAAGCCGTGTCCAGCCCACCGCCTGCCGACTTGTGTCATGCCCTACGTTGG TATAATCACATCAAGTCTTACGAAAAGGAAAAGGCCAGCCTGCCAGGAGTGAAGAAAGCTTTGGGCAAATATGGTCCTGCCGATGTGGAA GACACTACAGGAAGTGGAGCTACAGATAGTAAAGATGATGATGACATTGACCTCTTTGGATCTGATGATGAGGAGCTACTACCCACAGAT GGCATGATCCGAAAACACTCTCATGTCAAGATAGGGCGTTACCATCAGCATTTACAAGAGCAGCTGGACTTAGATCTCTCACCTTTGGAG TACATGATGAAGTGCTACCCAGAGATCAAGGAGAAGGAAGAAATGAGGAAGATCATTGGGCGATACGGTCTCACTGGGAAACAACAGGTG AGCCCAATCCGGAACTTGTCAGACGGGCAGAAGTGCCGAGTGTGTCTGGCCTGGCTGGCCTGGCAGAACCCCCACATGCTCTTCCTGGAT GAACCCACCAATCACCTGGATATCGAGACCATCGACGCCCTGGCAGATGCCATCAATGAGTTTGAGGGTGGTATGATGCTGGTCAGCCAT GACTTCAGACTCATTCAGCAGGTTGCACAGGAAATTTGGGTCTGTGAGAAGCAGACAATCACCAAGTGGCCTGGAGACATCCTGGCTTAC AAGGAGCACCTCAAGTCCAAGCTGGTGGATGAGGAGCCCCAGCTCACCAAGAGGACCCACAACGTGTGCACCCTGACATTGGCATCTCTG CCAAGGCCATGAGCATCATGAACTCGTTTGTAAACGACGTGTTTGAGCAGCTGGCGTGTGAGGCTGCCCGGCTGGCCCAGTACTCGGGCC GGACCACCCTGACATCCCGAGAAGTCCAGACGGCTGTGCGTCTGCTGCTGCCTGGGGAGCTGGCCAAGCACGCTGTGTCTGAGGGCACCA >25158_25158_5_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000392222_ABCF2_chr7_150913115_ENST00000222388_length(amino acids)=298AA_BP=110 MGFGDLKSPAGLQVLNDYLADKSYIEGYVPSQADVAVFEAVSSPPPADLCHALRWYNHIKSYEKEKASLPGVKKALGKYGPADVEDTTGS GATDSKDDDDIDLFGSDDEELLPTDGMIRKHSHVKIGRYHQHLQEQLDLDLSPLEYMMKCYPEIKEKEEMRKIIGRYGLTGKQQVSPIRN LSDGQKCRVCLAWLAWQNPHMLFLDEPTNHLDIETIDALADAINEFEGGMMLVSHDFRLIQQVAQEIWVCEKQTITKWPGDILAYKEHLK -------------------------------------------------------------- >25158_25158_6_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000392222_ABCF2_chr7_150913115_ENST00000287844_length(transcript)=2803nt_BP=705nt CCCCAGCCTCGAGGCCGGGCGTCTTCGGTCATCTCCGGCGCTTCTAGGGCTGGTTCCCGTCATCTTCGGGAGCCGTGGAGGTACGAACTT AAGACATGCCTATTTTATTAATTTACTTCCAAACGCAACGAAAGGTCCATGGACAATTTGTGGGCCATTTAATTCAGGGCCCCCAATTCG TACGTGGAGAAGTGGGAATGCAAAAGTACTTTGACCTTTAACCTTCGGTCCGGCGCGGTGGAGGGAAACGCCTCCGTCTCTATATAAGGA ATTTTCCGGTCTCTTCGGGTCCTTTTTCCTCTCTTCAGCGTGGGGCGCCCACAATTTGCGCGCTCTCTTTCTGCTGCTCCCCAGCTCTCG GATACAGCCGACACCATGGGTTTCGGAGACCTGAAAAGCCCTGCCGGCCTCCAGGTGCTCAACGATTACCTGGCGGACAAGAGCTACATC GAGGGGTATGTGCCATCACAAGCAGATGTGGCAGTATTTGAAGCCGTGTCCAGCCCACCGCCTGCCGACTTGTGTCATGCCCTACGTTGG TATAATCACATCAAGTCTTACGAAAAGGAAAAGGCCAGCCTGCCAGGAGTGAAGAAAGCTTTGGGCAAATATGGTCCTGCCGATGTGGAA GACACTACAGGAAGTGGAGCTACAGATAGTAAAGATGATGATGACATTGACCTCTTTGGATCTGATGATGAGGAGCTACTACCCACAGAT GGCATGATCCGAAAACACTCTCATGTCAAGATAGGGCGTTACCATCAGCATTTACAAGAGCAGCTGGACTTAGATCTCTCACCTTTGGAG TACATGATGAAGTGCTACCCAGAGATCAAGGAGAAGGAAGAAATGAGGAAGATCATTGGGCGATACGGTCTCACTGGGAAACAACAGGTG AGCCCAATCCGGAACTTGTCAGACGGGCAGAAGTGCCGAGTGTGTCTGGCCTGGCTGGCCTGGCAGAACCCCCACATGCTCTTCCTGGAT GAACCCACCAATCACCTGGATATCGAGACCATCGACGCCCTGGCAGATGCCATCAATGAGTTTGAGGGTGGTATGATGCTGGTCAGCCAT GACTTCAGACTCATTCAGCAGGTTGCACAGGAAATTTGGGTCTGTGAGAAGCAGACAATCACCAAGTGGCCTGGAGACATCCTGGCTTAC AAGGAGCACCTCAAGTCCAAGCTGGTGGATGAGGAGCCCCAGCTCACCAAGAGGACCCACAACGTGTGAGCCCTCTACCTGGGTTCGGGT CAGGAGCTCCATCTGGGAACTAACAGCTGCTAACCTGACCAGCCGCTCAGGACAGGACCCTGGGGCTACACTCCTGCATTGCTGCAATAC TGCTCCCCCAGCCTCTCCCCTGCCCCTCAACCTGCCTTAGCTGCACTCTCTTACCTACAGCTGGACAGTACCTGTCTGTTTCCTGTCCTC CTTCCAGTTACATCTGTCCATGTCTGGACTCGGCTGGCCGTTCCCTCCAGCCCCTTGCTGGTTATCTTACTCTGAGTGTGATGCAGTCAG AGGCACCTGCGGGTTAGCCCAGGGGCCCAAGCCCTGGATTTGGCCTGCGGAGGAGCTTAGGATCCTCGTTTTCTGGGTTTTGGTGATGTT GGAGGAGTACCCCCCAGCCCACCGCCCCGATTCCTTTTTGCTTCTGGTTTGGAGCTCCGGACCAGGACCTTCGTCCTGGTCAGTTTTTAA ATAATTATTTAGCAGTGTAACTTTTAGACCTGCGTGACATCTACAAAGCGCCCAATAAAGAAAGAGGAAGCCACGGTCCCTACCTTCCTT CTCGGGTCTCTGGGGCCTTCTCCTCCCTGCAGTGCCAACATGCACTGCCCACAGCAGGAGCTGGATCCAGCGTCAGTGTGTCGATGGGAA CTGAAGACTAGTCCATAGGAGCTGGAAGAACTTTGTCCCTTTACTTCTGATTTGAAATTGTACCTTTTCTCAGGCCTGTGATTCACAGAC TTTAACATGAATCAGAATCACCTGGAGGGCTCATGCAATCAGATTGCCAGATCTCGCCTCAGCGTTTCTGGTTCAATAGGTTTTGGGGGA GACCAAGAACGTTAACATTTCTAGCAAGTTTCCAGGTGATGCTGTTGTTGCTGGTCTAGAGACTATTTTGAGAACCACTGTCCAGGAGCG TGGTTTTCTGATTGTGATCTGAGGTTCTGCCCCAACTGCACAGCAGTTGGGCTGCTTGTTAAAAATGCAGGCCAGGTGCGGTGGCTCACA CCTGTAATCCCAGCGCTTTGGGAGGCTGAGGCAGGTGGATCACTTGAGCTCAGGAGTTCAAGACCAGCTTGGGAAACATGGCAAAACCCG TCTTTATGTGCCTGGAATCCCACCTGCTCAGGTGGCTAGGGTGGATGGATCGCTTGAGCCCAGGAGGTGGAGGTTGCAGTGAGCTGAGAT TGCACCACTGCATTCCAGCCTGGATGACAGAGCAAAACCCTGTCTCAAAAAAATGCAGACTGGCCAGGCACAGTGGCTCACACCTGTAAT CCGACTGTAAGCTCATCACCTTGGGAGGCCACTGTAGGAGGATCAATTGAGCCTAGAAGTTCAAGACCAGCCTGGGCAAAGTAGGGAGAC CCCTTCTCTACAAATAGTAATAAAATGAACCGGGCATAGTAGCATGTGCCTGCGGTCCCAGCTGCTCTGATAAGAGGAGGCTCACTTGAG CCCAGGAGGTTGAGGCTGCAGTGAGCAGAGCGTGCCGCTACACTCCAGCCTGATGACAGACCGAGACACTGTCTCAAAAAAATAAAAAAA >25158_25158_6_EEF1B2-ABCF2_EEF1B2_chr2_207026196_ENST00000392222_ABCF2_chr7_150913115_ENST00000287844_length(amino acids)=287AA_BP=110 MGFGDLKSPAGLQVLNDYLADKSYIEGYVPSQADVAVFEAVSSPPPADLCHALRWYNHIKSYEKEKASLPGVKKALGKYGPADVEDTTGS GATDSKDDDDIDLFGSDDEELLPTDGMIRKHSHVKIGRYHQHLQEQLDLDLSPLEYMMKCYPEIKEKEEMRKIIGRYGLTGKQQVSPIRN LSDGQKCRVCLAWLAWQNPHMLFLDEPTNHLDIETIDALADAINEFEGGMMLVSHDFRLIQQVAQEIWVCEKQTITKWPGDILAYKEHLK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for EEF1B2-ABCF2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for EEF1B2-ABCF2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for EEF1B2-ABCF2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies