
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:EIF4A2-HIF1A (FusionGDB2 ID:25934) |
Fusion Gene Summary for EIF4A2-HIF1A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: EIF4A2-HIF1A | Fusion gene ID: 25934 | Hgene | Tgene | Gene symbol | EIF4A2 | HIF1A | Gene ID | 1974 | 3091 |
| Gene name | eukaryotic translation initiation factor 4A2 | hypoxia inducible factor 1 subunit alpha | |
| Synonyms | BM-010|DDX2B|EIF4A|EIF4F|eIF-4A-II|eIF4A-II | HIF-1-alpha|HIF-1A|HIF-1alpha|HIF1|HIF1-ALPHA|MOP1|PASD8|bHLHe78 | |
| Cytomap | 3q27.3 | 14q23.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | eukaryotic initiation factor 4A-IIATP-dependent RNA helicase eIF4A-2 | hypoxia-inducible factor 1-alphaARNT interacting proteinPAS domain-containing protein 8basic-helix-loop-helix-PAS protein MOP1class E basic helix-loop-helix protein 78hypoxia inducible factor 1 alpha subunithypoxia inducible factor 1, alpha subunit | |
| Modification date | 20200322 | 20200329 | |
| UniProtAcc | Q14240 | Q9NWT6 | |
| Ensembl transtripts involved in fusion gene | ENST00000323963, ENST00000356531, ENST00000440191, | ENST00000557206, ENST00000323441, ENST00000539097, ENST00000557538, ENST00000337138, ENST00000394997, | |
| Fusion gene scores | * DoF score | 21 X 21 X 7=3087 | 7 X 7 X 3=147 |
| # samples | 23 | 7 | |
| ** MAII score | log2(23/3087*10)=-3.74649971667075 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/147*10)=-1.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: EIF4A2 [Title/Abstract] AND HIF1A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | EIF4A2(186505373)-HIF1A(62213652), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | EIF4A2-HIF1A seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. EIF4A2-HIF1A seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. EIF4A2-HIF1A seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. EIF4A2-HIF1A seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. EIF4A2-HIF1A seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. EIF4A2-HIF1A seems lost the major protein functional domain in Tgene partner, which is a transcription factor due to the frame-shifted ORF. EIF4A2-HIF1A seems lost the major protein functional domain in Tgene partner, which is a tumor suppressor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | EIF4A2 | GO:1900260 | negative regulation of RNA-directed 5'-3' RNA polymerase activity | 11922617 |
| Tgene | HIF1A | GO:0001666 | response to hypoxia | 8756616|9887100|11782478|15261140|18419598 |
| Tgene | HIF1A | GO:0006355 | regulation of transcription, DNA-templated | 11782478|15261140 |
| Tgene | HIF1A | GO:0010468 | regulation of gene expression | 18419598 |
| Tgene | HIF1A | GO:0010573 | vascular endothelial growth factor production | 12958148 |
| Tgene | HIF1A | GO:0010575 | positive regulation of vascular endothelial growth factor production | 8756616 |
| Tgene | HIF1A | GO:0010628 | positive regulation of gene expression | 15459207|24244340 |
| Tgene | HIF1A | GO:0032364 | oxygen homeostasis | 16956324 |
| Tgene | HIF1A | GO:0043619 | regulation of transcription from RNA polymerase II promoter in response to oxidative stress | 8089148|8387214 |
| Tgene | HIF1A | GO:0045893 | positive regulation of transcription, DNA-templated | 8089148|9887100|25043030 |
| Tgene | HIF1A | GO:0045944 | positive regulation of transcription by RNA polymerase II | 11573933 |
| Tgene | HIF1A | GO:0046886 | positive regulation of hormone biosynthetic process | 1448077 |
| Tgene | HIF1A | GO:0061419 | positive regulation of transcription from RNA polymerase II promoter in response to hypoxia | 22735262 |
| Tgene | HIF1A | GO:0071456 | cellular response to hypoxia | 11573933|19528298|20889502 |
| Tgene | HIF1A | GO:1902895 | positive regulation of pri-miRNA transcription by RNA polymerase II | 19782034 |
| Tgene | HIF1A | GO:1903377 | negative regulation of oxidative stress-induced neuron intrinsic apoptotic signaling pathway | 24899725 |
| Fusion gene breakpoints across EIF4A2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
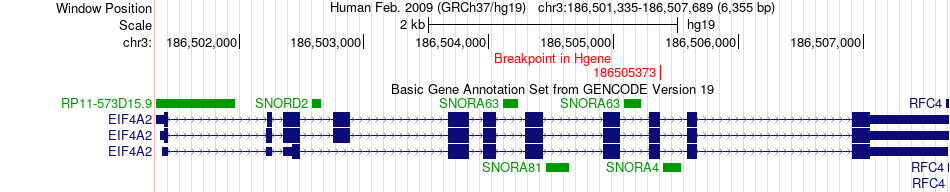 |
| Fusion gene breakpoints across HIF1A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-HU-A4GT-01A | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
Top |
Fusion Gene ORF analysis for EIF4A2-HIF1A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000323963 | ENST00000557206 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| 5CDS-intron | ENST00000356531 | ENST00000557206 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| 5CDS-intron | ENST00000440191 | ENST00000557206 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000323963 | ENST00000323441 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000323963 | ENST00000539097 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000323963 | ENST00000557538 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000356531 | ENST00000323441 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000356531 | ENST00000539097 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000356531 | ENST00000557538 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000440191 | ENST00000323441 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000440191 | ENST00000539097 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| Frame-shift | ENST00000440191 | ENST00000557538 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| In-frame | ENST00000323963 | ENST00000337138 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| In-frame | ENST00000323963 | ENST00000394997 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| In-frame | ENST00000356531 | ENST00000337138 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| In-frame | ENST00000356531 | ENST00000394997 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| In-frame | ENST00000440191 | ENST00000337138 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| In-frame | ENST00000440191 | ENST00000394997 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000323963 | EIF4A2 | chr3 | 186505373 | + | ENST00000394997 | HIF1A | chr14 | 62213652 | + | 2388 | 1063 | 64 | 1068 | 334 |
| ENST00000323963 | EIF4A2 | chr3 | 186505373 | + | ENST00000337138 | HIF1A | chr14 | 62213652 | + | 2388 | 1063 | 64 | 1068 | 334 |
| ENST00000440191 | EIF4A2 | chr3 | 186505373 | + | ENST00000394997 | HIF1A | chr14 | 62213652 | + | 2361 | 1036 | 34 | 1041 | 335 |
| ENST00000440191 | EIF4A2 | chr3 | 186505373 | + | ENST00000337138 | HIF1A | chr14 | 62213652 | + | 2361 | 1036 | 34 | 1041 | 335 |
| ENST00000356531 | EIF4A2 | chr3 | 186505373 | + | ENST00000394997 | HIF1A | chr14 | 62213652 | + | 2201 | 876 | 162 | 881 | 239 |
| ENST00000356531 | EIF4A2 | chr3 | 186505373 | + | ENST00000337138 | HIF1A | chr14 | 62213652 | + | 2201 | 876 | 162 | 881 | 239 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000323963 | ENST00000394997 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + | 0.000245261 | 0.9997547 |
| ENST00000323963 | ENST00000337138 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + | 0.000245261 | 0.9997547 |
| ENST00000440191 | ENST00000394997 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + | 0.000211576 | 0.99978846 |
| ENST00000440191 | ENST00000337138 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + | 0.000211576 | 0.99978846 |
| ENST00000356531 | ENST00000394997 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + | 0.000308458 | 0.9996916 |
| ENST00000356531 | ENST00000337138 | EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213652 | + | 0.000308458 | 0.9996916 |
Top |
Fusion Genomic Features for EIF4A2-HIF1A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213651 | + | 0.002230004 | 0.9977701 |
| EIF4A2 | chr3 | 186505373 | + | HIF1A | chr14 | 62213651 | + | 0.002230004 | 0.9977701 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
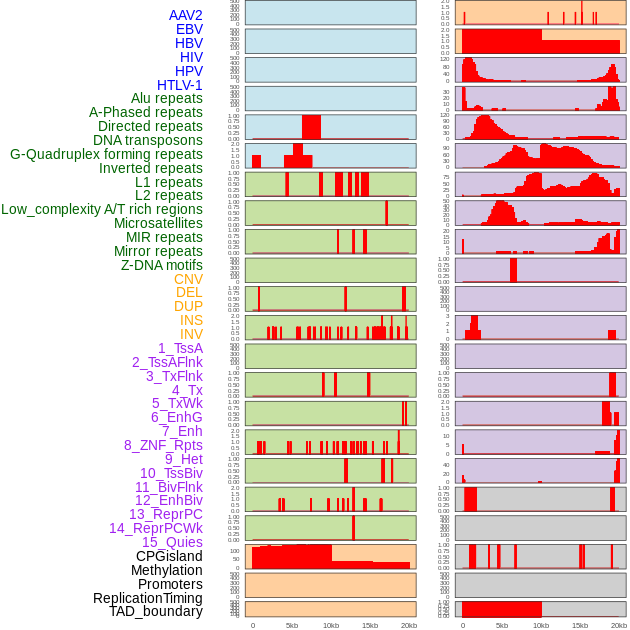 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
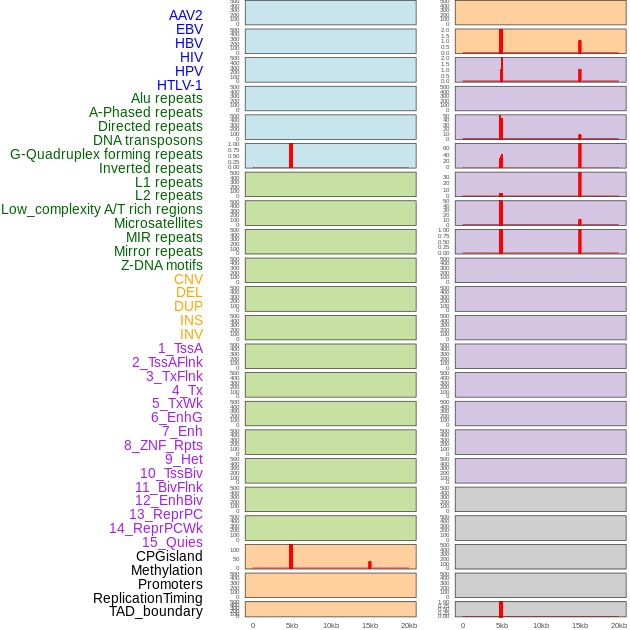 |
Top |
Fusion Protein Features for EIF4A2-HIF1A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:186505373/chr14:62213652) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| EIF4A2 | HIF1A |
| FUNCTION: ATP-dependent RNA helicase which is a subunit of the eIF4F complex involved in cap recognition and is required for mRNA binding to ribosome. In the current model of translation initiation, eIF4A unwinds RNA secondary structures in the 5'-UTR of mRNAs which is necessary to allow efficient binding of the small ribosomal subunit, and subsequent scanning for the initiator codon. | FUNCTION: Hydroxylates HIF-1 alpha at 'Asn-803' in the C-terminal transactivation domain (CAD). Functions as an oxygen sensor and, under normoxic conditions, the hydroxylation prevents interaction of HIF-1 with transcriptional coactivators including Cbp/p300-interacting transactivator. Involved in transcriptional repression through interaction with HIF1A, VHL and histone deacetylases. Hydroxylates specific Asn residues within ankyrin repeat domains (ARD) of NFKB1, NFKBIA, NOTCH1, ASB4, PPP1R12A and several other ARD-containing proteins. Also hydroxylates Asp and His residues within ARDs of ANK1 and TNKS2, respectively. Negatively regulates NOTCH1 activity, accelerating myogenic differentiation. Positively regulates ASB4 activity, promoting vascular differentiation. {ECO:0000269|PubMed:12042299, ECO:0000269|PubMed:12080085, ECO:0000269|PubMed:17003112, ECO:0000269|PubMed:17573339, ECO:0000269|PubMed:18299578, ECO:0000269|PubMed:19245366, ECO:0000269|PubMed:21177872, ECO:0000269|PubMed:21251231}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000323963 | + | 9 | 11 | 64_235 | 333 | 408.0 | Domain | Helicase ATP-binding |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000440191 | + | 9 | 11 | 64_235 | 334 | 409.0 | Domain | Helicase ATP-binding |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000323963 | + | 9 | 11 | 183_186 | 333 | 408.0 | Motif | Note=DEAD box |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000323963 | + | 9 | 11 | 33_61 | 333 | 408.0 | Motif | Note=Q motif |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000440191 | + | 9 | 11 | 183_186 | 334 | 409.0 | Motif | Note=DEAD box |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000440191 | + | 9 | 11 | 33_61 | 334 | 409.0 | Motif | Note=Q motif |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000323963 | + | 9 | 11 | 77_84 | 333 | 408.0 | Nucleotide binding | ATP |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000440191 | + | 9 | 11 | 77_84 | 334 | 409.0 | Nucleotide binding | ATP |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 786_826 | 734 | 736.0 | Region | Note=CTAD | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 786_826 | 776 | 827.0 | Region | Note=CTAD |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000323963 | + | 9 | 11 | 246_407 | 333 | 408.0 | Domain | Helicase C-terminal |
| Hgene | EIF4A2 | chr3:186505373 | chr14:62213652 | ENST00000440191 | + | 9 | 11 | 246_407 | 334 | 409.0 | Domain | Helicase C-terminal |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 615_621 | 734 | 736.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 615_621 | 776 | 827.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 615_621 | 800 | 851.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 17_70 | 734 | 736.0 | Domain | bHLH | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 228_298 | 734 | 736.0 | Domain | PAS 2 | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 302_345 | 734 | 736.0 | Domain | Note=PAC | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 85_158 | 734 | 736.0 | Domain | PAS 1 | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 17_70 | 776 | 827.0 | Domain | bHLH | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 228_298 | 776 | 827.0 | Domain | PAS 2 | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 302_345 | 776 | 827.0 | Domain | Note=PAC | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 85_158 | 776 | 827.0 | Domain | PAS 1 | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 17_70 | 800 | 851.0 | Domain | bHLH | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 228_298 | 800 | 851.0 | Domain | PAS 2 | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 302_345 | 800 | 851.0 | Domain | Note=PAC | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 85_158 | 800 | 851.0 | Domain | PAS 1 | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 718_721 | 734 | 736.0 | Motif | Nuclear localization signal | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 718_721 | 776 | 827.0 | Motif | Nuclear localization signal | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 718_721 | 800 | 851.0 | Motif | Nuclear localization signal | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 170_191 | 734 | 736.0 | Region | Required for heterodimer formation with ARNT | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 21_30 | 734 | 736.0 | Region | DNA-binding | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 380_417 | 734 | 736.0 | Region | Note=N-terminal VHL recognition site | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 401_603 | 734 | 736.0 | Region | Note=ODD | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 531_575 | 734 | 736.0 | Region | Note=NTAD | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 556_572 | 734 | 736.0 | Region | Note=C-terminal VHL recognition site | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 576_785 | 734 | 736.0 | Region | Note=ID | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 170_191 | 776 | 827.0 | Region | Required for heterodimer formation with ARNT | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 21_30 | 776 | 827.0 | Region | DNA-binding | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 380_417 | 776 | 827.0 | Region | Note=N-terminal VHL recognition site | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 401_603 | 776 | 827.0 | Region | Note=ODD | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 531_575 | 776 | 827.0 | Region | Note=NTAD | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 556_572 | 776 | 827.0 | Region | Note=C-terminal VHL recognition site | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 576_785 | 776 | 827.0 | Region | Note=ID | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 170_191 | 800 | 851.0 | Region | Required for heterodimer formation with ARNT | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 21_30 | 800 | 851.0 | Region | DNA-binding | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 380_417 | 800 | 851.0 | Region | Note=N-terminal VHL recognition site | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 401_603 | 800 | 851.0 | Region | Note=ODD | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 531_575 | 800 | 851.0 | Region | Note=NTAD | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 556_572 | 800 | 851.0 | Region | Note=C-terminal VHL recognition site | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 576_785 | 800 | 851.0 | Region | Note=ID | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 786_826 | 800 | 851.0 | Region | Note=CTAD |
Top |
Fusion Gene Sequence for EIF4A2-HIF1A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >25934_25934_1_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000323963_HIF1A_chr14_62213652_ENST00000337138_length(transcript)=2388nt_BP=1063nt TATAAAAAACGGGTGGTTGGGCGCCGCTGTCTTTTCAGTCGGGCGCTGAGTGGTTTTTCGGATCATGTCTGGTGGCTCCGCGGATTATAA CAGAGAACATGGCGGCCCAGAGGGAATGGACCCCGATGGTGTCATCGAGAGCAACTGGAATGAGATTGTTGATAACTTTGATGATATGAA TTTAAAGGAGTCTCTCCTTCGTGGCATCTATGCTTACGGTTTTGAGAAGCCTTCCGCTATTCAGCAGAGAGCTATTATTCCCTGTATTAA AGGGTATGATGTGATTGCTCAAGCTCAGTCAGGTACTGGCAAGACAGCCACATTTGCTATTTCCATCCTGCAACAGTTGGAGATTGAGTT CAAGGAGACCCAAGCACTAGTATTGGCCCCCACCAGAGAACTGGCTCAACAGATCCAAAAGGTAATTCTGGCACTTGGAGACTATATGGG AGCCACTTGTCATGCCTGCATTGGTGGAACAAATGTTCGAAATGAAATGCAAAAACTGCAGGCTGAAGCACCACATATTGTTGTTGGTAC ACCCGGGAGAGTGTTTGATATGTTAAACAGAAGATACCTTTCTCCAAAATGGATCAAAATGTTTGTTTTGGATGAAGCAGATGAAATGTT GAGCCGTGGTTTTAAGGATCAAATCTATGAGATTTTCCAAAAACTAAACACAAGTATTCAGGTTGTGTTGCTTTCTGCCACAATGCCAAC TGATGTGTTGGAAGTGACCAAAAAATTCATGAGAGATCCAATTCGAATTCTGGTGAAAAAGGAAGAATTGACCCTTGAAGGAATCAAACA GTTTTATATTAATGTTGAGAGAGAGGAATGGAAGTTGGATACACTTTGTGACTTGTACGAGACACTGACCATTACACAGGCTGTTATTTT TCTCAATACGAGGCGCAAGGTGGACTGGCTGACTGAGAAGATGCATGCCAGAGACTTCACAGTTTCTGCTCTGCATGGTGACATGGACCA GAAGGAGAGAGATGTTATCATGAGGGAATTCCGGTCAGGGTCAAGTCGTGTTCTGATCACTACTGACTTGTTGATTTAGCATGTAGACTG CTGGGGCAATCAATGGATGAAAGTGGATTACCACAGCTGACCAGTTATGATTGTGAAGTTAATGCTCCTATACAAGGCAGCAGAAACCTA CTGCAGGGTGAAGAATTACTCAGAGCTTTGGATCAAGTTAACTGAGCTTTTTCTTAATTTCATTCCTTTTTTTGGACACTGGTGGCTCAT TACCTAAAGCAGTCTATTTATATTTTCTACATCTAATTTTAGAAGCCTGGCTACAATACTGCACAAACTTGGTTAGTTCAATTTTGATCC CCTTTCTACTTAATTTACATTAATGCTCTTTTTTAGTATGTTCTTTAATGCTGGATCACAGACAGCTCATTTTCTCAGTTTTTTGGTATT TAAACCATTGCATTGCAGTAGCATCATTTTAAAAAATGCACCTTTTTATTTATTTATTTTTGGCTAGGGAGTTTATCCCTTTTTCGAATT ATTTTTAAGAAGATGCCAATATAATTTTTGTAAGAAGGCAGTAACCTTTCATCATGATCATAGGCAGTTGAAAAATTTTTACACCTTTTT TTTCACATTTTACATAAATAATAATGCTTTGCCAGCAGTACGTGGTAGCCACAATTGCACAATATATTTTCTTAAAAAATACCAGCAGTT ACTCATGGAATATATTCTGCGTTTATAAAACTAGTTTTTAAGAAGAAATTTTTTTTGGCCTATGAAATTGTTAAACCTGGAACATGACAT TGTTAATCATATAATAATGATTCTTAAATGCTGTATGGTTTATTATTTAAATGGGTAAAGCCATTTACATAATATAGAAAGATATGCATA TATCTAGAAGGTATGTGGCATTTATTTGGATAAAATTCTCAATTCAGAGAAATCATCTGATGTTTCTATAGTCACTTTGCCAGCTCAAAA GAAAACAATACCCTATGTAGTTGTGGAAGTTTATGCTAATATTGTGTAACTGATATTAAACCTAAATGTTCTGCCTACCCTGTTGGTATA AAGATATTTTGAGCAGACTGTAAACAAGAAAAAAAAAATCATGCATTCTTAGCAAAATTGCCTAGTATGTTAATTTGCTCAAAATACAAT GTTTGATTTTATGCACTTTGTCGCTATTAACATCCTTTTTTTCATGTAGATTTCAATAATTGAGTAATTTTAGAAGCATTATTTTAGGAA TATATAGTTGTCACAGTAAATATCTTGTTTTTTCTATGTACATTGTACAAATTTTTCATTCCTTTTGCTCTTTGTGGTTGGATCTAACAC >25934_25934_1_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000323963_HIF1A_chr14_62213652_ENST00000337138_length(amino acids)=334AA_BP= MSGGSADYNREHGGPEGMDPDGVIESNWNEIVDNFDDMNLKESLLRGIYAYGFEKPSAIQQRAIIPCIKGYDVIAQAQSGTGKTATFAIS ILQQLEIEFKETQALVLAPTRELAQQIQKVILALGDYMGATCHACIGGTNVRNEMQKLQAEAPHIVVGTPGRVFDMLNRRYLSPKWIKMF VLDEADEMLSRGFKDQIYEIFQKLNTSIQVVLLSATMPTDVLEVTKKFMRDPIRILVKKEELTLEGIKQFYINVEREEWKLDTLCDLYET -------------------------------------------------------------- >25934_25934_2_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000323963_HIF1A_chr14_62213652_ENST00000394997_length(transcript)=2388nt_BP=1063nt TATAAAAAACGGGTGGTTGGGCGCCGCTGTCTTTTCAGTCGGGCGCTGAGTGGTTTTTCGGATCATGTCTGGTGGCTCCGCGGATTATAA CAGAGAACATGGCGGCCCAGAGGGAATGGACCCCGATGGTGTCATCGAGAGCAACTGGAATGAGATTGTTGATAACTTTGATGATATGAA TTTAAAGGAGTCTCTCCTTCGTGGCATCTATGCTTACGGTTTTGAGAAGCCTTCCGCTATTCAGCAGAGAGCTATTATTCCCTGTATTAA AGGGTATGATGTGATTGCTCAAGCTCAGTCAGGTACTGGCAAGACAGCCACATTTGCTATTTCCATCCTGCAACAGTTGGAGATTGAGTT CAAGGAGACCCAAGCACTAGTATTGGCCCCCACCAGAGAACTGGCTCAACAGATCCAAAAGGTAATTCTGGCACTTGGAGACTATATGGG AGCCACTTGTCATGCCTGCATTGGTGGAACAAATGTTCGAAATGAAATGCAAAAACTGCAGGCTGAAGCACCACATATTGTTGTTGGTAC ACCCGGGAGAGTGTTTGATATGTTAAACAGAAGATACCTTTCTCCAAAATGGATCAAAATGTTTGTTTTGGATGAAGCAGATGAAATGTT GAGCCGTGGTTTTAAGGATCAAATCTATGAGATTTTCCAAAAACTAAACACAAGTATTCAGGTTGTGTTGCTTTCTGCCACAATGCCAAC TGATGTGTTGGAAGTGACCAAAAAATTCATGAGAGATCCAATTCGAATTCTGGTGAAAAAGGAAGAATTGACCCTTGAAGGAATCAAACA GTTTTATATTAATGTTGAGAGAGAGGAATGGAAGTTGGATACACTTTGTGACTTGTACGAGACACTGACCATTACACAGGCTGTTATTTT TCTCAATACGAGGCGCAAGGTGGACTGGCTGACTGAGAAGATGCATGCCAGAGACTTCACAGTTTCTGCTCTGCATGGTGACATGGACCA GAAGGAGAGAGATGTTATCATGAGGGAATTCCGGTCAGGGTCAAGTCGTGTTCTGATCACTACTGACTTGTTGATTTAGCATGTAGACTG CTGGGGCAATCAATGGATGAAAGTGGATTACCACAGCTGACCAGTTATGATTGTGAAGTTAATGCTCCTATACAAGGCAGCAGAAACCTA CTGCAGGGTGAAGAATTACTCAGAGCTTTGGATCAAGTTAACTGAGCTTTTTCTTAATTTCATTCCTTTTTTTGGACACTGGTGGCTCAT TACCTAAAGCAGTCTATTTATATTTTCTACATCTAATTTTAGAAGCCTGGCTACAATACTGCACAAACTTGGTTAGTTCAATTTTGATCC CCTTTCTACTTAATTTACATTAATGCTCTTTTTTAGTATGTTCTTTAATGCTGGATCACAGACAGCTCATTTTCTCAGTTTTTTGGTATT TAAACCATTGCATTGCAGTAGCATCATTTTAAAAAATGCACCTTTTTATTTATTTATTTTTGGCTAGGGAGTTTATCCCTTTTTCGAATT ATTTTTAAGAAGATGCCAATATAATTTTTGTAAGAAGGCAGTAACCTTTCATCATGATCATAGGCAGTTGAAAAATTTTTACACCTTTTT TTTCACATTTTACATAAATAATAATGCTTTGCCAGCAGTACGTGGTAGCCACAATTGCACAATATATTTTCTTAAAAAATACCAGCAGTT ACTCATGGAATATATTCTGCGTTTATAAAACTAGTTTTTAAGAAGAAATTTTTTTTGGCCTATGAAATTGTTAAACCTGGAACATGACAT TGTTAATCATATAATAATGATTCTTAAATGCTGTATGGTTTATTATTTAAATGGGTAAAGCCATTTACATAATATAGAAAGATATGCATA TATCTAGAAGGTATGTGGCATTTATTTGGATAAAATTCTCAATTCAGAGAAATCATCTGATGTTTCTATAGTCACTTTGCCAGCTCAAAA GAAAACAATACCCTATGTAGTTGTGGAAGTTTATGCTAATATTGTGTAACTGATATTAAACCTAAATGTTCTGCCTACCCTGTTGGTATA AAGATATTTTGAGCAGACTGTAAACAAGAAAAAAAAAATCATGCATTCTTAGCAAAATTGCCTAGTATGTTAATTTGCTCAAAATACAAT GTTTGATTTTATGCACTTTGTCGCTATTAACATCCTTTTTTTCATGTAGATTTCAATAATTGAGTAATTTTAGAAGCATTATTTTAGGAA TATATAGTTGTCACAGTAAATATCTTGTTTTTTCTATGTACATTGTACAAATTTTTCATTCCTTTTGCTCTTTGTGGTTGGATCTAACAC >25934_25934_2_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000323963_HIF1A_chr14_62213652_ENST00000394997_length(amino acids)=334AA_BP= MSGGSADYNREHGGPEGMDPDGVIESNWNEIVDNFDDMNLKESLLRGIYAYGFEKPSAIQQRAIIPCIKGYDVIAQAQSGTGKTATFAIS ILQQLEIEFKETQALVLAPTRELAQQIQKVILALGDYMGATCHACIGGTNVRNEMQKLQAEAPHIVVGTPGRVFDMLNRRYLSPKWIKMF VLDEADEMLSRGFKDQIYEIFQKLNTSIQVVLLSATMPTDVLEVTKKFMRDPIRILVKKEELTLEGIKQFYINVEREEWKLDTLCDLYET -------------------------------------------------------------- >25934_25934_3_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000356531_HIF1A_chr14_62213652_ENST00000337138_length(transcript)=2201nt_BP=876nt TGGTTTTTCGGATCATGTCTGGTGGCTCCGCGGATTATAACAGCAGAGAACATGGCGGCCCAGAGGGAATGGACCCCGATGGTGTCATCG AGAGCAACTGGAATGAGATTGTTGATAACTTTGATGATATGAATTTAAAGGAGTCTCTCCTTCGTGGCATCTATGCTTACGGTTTTGAGA AGCCTTCCGCTATTCAGCAGAGAGCTATTATTCCCTGTATTAAAGATCCAAAAGGTAATTCTGGCACTTGGAGACTATATGGGAGCCACT TGTCATGCCTGCATTGGTGGAACAAATGTTCGAAATGAAATGCAAAAACTGCAGGCTGAAGCACCACATATTGTTGTTGGTACACCCGGG AGAGTGTTTGATATGTTAAACAGAAGATACCTTTCTCCAAAATGGATCAAAATGTTTGTTTTGGATGAAGCAGATGAAATGTTGAGCCGT GGTTTTAAGGATCAAATCTATGAGATTTTCCAAAAACTAAACACAAGTATTCAGGTTGTGTTGCTTTCTGCCACAATGCCAACTGATGTG TTGGAAGTGACCAAAAAATTCATGAGAGATCCAATTCGAATTCTGGTGAAAAAGGAAGAATTGACCCTTGAAGGAATCAAACAGTTTTAT ATTAATGTTGAGAGAGAGGAATGGAAGTTGGATACACTTTGTGACTTGTACGAGACACTGACCATTACACAGGCTGTTATTTTTCTCAAT ACGAGGCGCAAGGTGGACTGGCTGACTGAGAAGATGCATGCCAGAGACTTCACAGTTTCTGCTCTGCATGGTGACATGGACCAGAAGGAG AGAGATGTTATCATGAGGGAATTCCGGTCAGGGTCAAGTCGTGTTCTGATCACTACTGACTTGTTGATTTAGCATGTAGACTGCTGGGGC AATCAATGGATGAAAGTGGATTACCACAGCTGACCAGTTATGATTGTGAAGTTAATGCTCCTATACAAGGCAGCAGAAACCTACTGCAGG GTGAAGAATTACTCAGAGCTTTGGATCAAGTTAACTGAGCTTTTTCTTAATTTCATTCCTTTTTTTGGACACTGGTGGCTCATTACCTAA AGCAGTCTATTTATATTTTCTACATCTAATTTTAGAAGCCTGGCTACAATACTGCACAAACTTGGTTAGTTCAATTTTGATCCCCTTTCT ACTTAATTTACATTAATGCTCTTTTTTAGTATGTTCTTTAATGCTGGATCACAGACAGCTCATTTTCTCAGTTTTTTGGTATTTAAACCA TTGCATTGCAGTAGCATCATTTTAAAAAATGCACCTTTTTATTTATTTATTTTTGGCTAGGGAGTTTATCCCTTTTTCGAATTATTTTTA AGAAGATGCCAATATAATTTTTGTAAGAAGGCAGTAACCTTTCATCATGATCATAGGCAGTTGAAAAATTTTTACACCTTTTTTTTCACA TTTTACATAAATAATAATGCTTTGCCAGCAGTACGTGGTAGCCACAATTGCACAATATATTTTCTTAAAAAATACCAGCAGTTACTCATG GAATATATTCTGCGTTTATAAAACTAGTTTTTAAGAAGAAATTTTTTTTGGCCTATGAAATTGTTAAACCTGGAACATGACATTGTTAAT CATATAATAATGATTCTTAAATGCTGTATGGTTTATTATTTAAATGGGTAAAGCCATTTACATAATATAGAAAGATATGCATATATCTAG AAGGTATGTGGCATTTATTTGGATAAAATTCTCAATTCAGAGAAATCATCTGATGTTTCTATAGTCACTTTGCCAGCTCAAAAGAAAACA ATACCCTATGTAGTTGTGGAAGTTTATGCTAATATTGTGTAACTGATATTAAACCTAAATGTTCTGCCTACCCTGTTGGTATAAAGATAT TTTGAGCAGACTGTAAACAAGAAAAAAAAAATCATGCATTCTTAGCAAAATTGCCTAGTATGTTAATTTGCTCAAAATACAATGTTTGAT TTTATGCACTTTGTCGCTATTAACATCCTTTTTTTCATGTAGATTTCAATAATTGAGTAATTTTAGAAGCATTATTTTAGGAATATATAG TTGTCACAGTAAATATCTTGTTTTTTCTATGTACATTGTACAAATTTTTCATTCCTTTTGCTCTTTGTGGTTGGATCTAACACTAACTGT >25934_25934_3_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000356531_HIF1A_chr14_62213652_ENST00000337138_length(amino acids)=239AA_BP= MLTVLRSLPLFSRELLFPVLKIQKVILALGDYMGATCHACIGGTNVRNEMQKLQAEAPHIVVGTPGRVFDMLNRRYLSPKWIKMFVLDEA DEMLSRGFKDQIYEIFQKLNTSIQVVLLSATMPTDVLEVTKKFMRDPIRILVKKEELTLEGIKQFYINVEREEWKLDTLCDLYETLTITQ -------------------------------------------------------------- >25934_25934_4_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000356531_HIF1A_chr14_62213652_ENST00000394997_length(transcript)=2201nt_BP=876nt TGGTTTTTCGGATCATGTCTGGTGGCTCCGCGGATTATAACAGCAGAGAACATGGCGGCCCAGAGGGAATGGACCCCGATGGTGTCATCG AGAGCAACTGGAATGAGATTGTTGATAACTTTGATGATATGAATTTAAAGGAGTCTCTCCTTCGTGGCATCTATGCTTACGGTTTTGAGA AGCCTTCCGCTATTCAGCAGAGAGCTATTATTCCCTGTATTAAAGATCCAAAAGGTAATTCTGGCACTTGGAGACTATATGGGAGCCACT TGTCATGCCTGCATTGGTGGAACAAATGTTCGAAATGAAATGCAAAAACTGCAGGCTGAAGCACCACATATTGTTGTTGGTACACCCGGG AGAGTGTTTGATATGTTAAACAGAAGATACCTTTCTCCAAAATGGATCAAAATGTTTGTTTTGGATGAAGCAGATGAAATGTTGAGCCGT GGTTTTAAGGATCAAATCTATGAGATTTTCCAAAAACTAAACACAAGTATTCAGGTTGTGTTGCTTTCTGCCACAATGCCAACTGATGTG TTGGAAGTGACCAAAAAATTCATGAGAGATCCAATTCGAATTCTGGTGAAAAAGGAAGAATTGACCCTTGAAGGAATCAAACAGTTTTAT ATTAATGTTGAGAGAGAGGAATGGAAGTTGGATACACTTTGTGACTTGTACGAGACACTGACCATTACACAGGCTGTTATTTTTCTCAAT ACGAGGCGCAAGGTGGACTGGCTGACTGAGAAGATGCATGCCAGAGACTTCACAGTTTCTGCTCTGCATGGTGACATGGACCAGAAGGAG AGAGATGTTATCATGAGGGAATTCCGGTCAGGGTCAAGTCGTGTTCTGATCACTACTGACTTGTTGATTTAGCATGTAGACTGCTGGGGC AATCAATGGATGAAAGTGGATTACCACAGCTGACCAGTTATGATTGTGAAGTTAATGCTCCTATACAAGGCAGCAGAAACCTACTGCAGG GTGAAGAATTACTCAGAGCTTTGGATCAAGTTAACTGAGCTTTTTCTTAATTTCATTCCTTTTTTTGGACACTGGTGGCTCATTACCTAA AGCAGTCTATTTATATTTTCTACATCTAATTTTAGAAGCCTGGCTACAATACTGCACAAACTTGGTTAGTTCAATTTTGATCCCCTTTCT ACTTAATTTACATTAATGCTCTTTTTTAGTATGTTCTTTAATGCTGGATCACAGACAGCTCATTTTCTCAGTTTTTTGGTATTTAAACCA TTGCATTGCAGTAGCATCATTTTAAAAAATGCACCTTTTTATTTATTTATTTTTGGCTAGGGAGTTTATCCCTTTTTCGAATTATTTTTA AGAAGATGCCAATATAATTTTTGTAAGAAGGCAGTAACCTTTCATCATGATCATAGGCAGTTGAAAAATTTTTACACCTTTTTTTTCACA TTTTACATAAATAATAATGCTTTGCCAGCAGTACGTGGTAGCCACAATTGCACAATATATTTTCTTAAAAAATACCAGCAGTTACTCATG GAATATATTCTGCGTTTATAAAACTAGTTTTTAAGAAGAAATTTTTTTTGGCCTATGAAATTGTTAAACCTGGAACATGACATTGTTAAT CATATAATAATGATTCTTAAATGCTGTATGGTTTATTATTTAAATGGGTAAAGCCATTTACATAATATAGAAAGATATGCATATATCTAG AAGGTATGTGGCATTTATTTGGATAAAATTCTCAATTCAGAGAAATCATCTGATGTTTCTATAGTCACTTTGCCAGCTCAAAAGAAAACA ATACCCTATGTAGTTGTGGAAGTTTATGCTAATATTGTGTAACTGATATTAAACCTAAATGTTCTGCCTACCCTGTTGGTATAAAGATAT TTTGAGCAGACTGTAAACAAGAAAAAAAAAATCATGCATTCTTAGCAAAATTGCCTAGTATGTTAATTTGCTCAAAATACAATGTTTGAT TTTATGCACTTTGTCGCTATTAACATCCTTTTTTTCATGTAGATTTCAATAATTGAGTAATTTTAGAAGCATTATTTTAGGAATATATAG TTGTCACAGTAAATATCTTGTTTTTTCTATGTACATTGTACAAATTTTTCATTCCTTTTGCTCTTTGTGGTTGGATCTAACACTAACTGT >25934_25934_4_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000356531_HIF1A_chr14_62213652_ENST00000394997_length(amino acids)=239AA_BP= MLTVLRSLPLFSRELLFPVLKIQKVILALGDYMGATCHACIGGTNVRNEMQKLQAEAPHIVVGTPGRVFDMLNRRYLSPKWIKMFVLDEA DEMLSRGFKDQIYEIFQKLNTSIQVVLLSATMPTDVLEVTKKFMRDPIRILVKKEELTLEGIKQFYINVEREEWKLDTLCDLYETLTITQ -------------------------------------------------------------- >25934_25934_5_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000440191_HIF1A_chr14_62213652_ENST00000337138_length(transcript)=2361nt_BP=1036nt CTTTTCAGTCGGGCGCTGAGTGGTTTTTCGGATCATGTCTGGTGGCTCCGCGGATTATAACAGCAGAGAACATGGCGGCCCAGAGGGAAT GGACCCCGATGGTGTCATCGAGAGCAACTGGAATGAGATTGTTGATAACTTTGATGATATGAATTTAAAGGAGTCTCTCCTTCGTGGCAT CTATGCTTACGGTTTTGAGAAGCCTTCCGCTATTCAGCAGAGAGCTATTATTCCCTGTATTAAAGGGTATGATGTGATTGCTCAAGCTCA GTCAGGTACTGGCAAGACAGCCACATTTGCTATTTCCATCCTGCAACAGTTGGAGATTGAGTTCAAGGAGACCCAAGCACTAGTATTGGC CCCCACCAGAGAACTGGCTCAACAGATCCAAAAGGTAATTCTGGCACTTGGAGACTATATGGGAGCCACTTGTCATGCCTGCATTGGTGG AACAAATGTTCGAAATGAAATGCAAAAACTGCAGGCTGAAGCACCACATATTGTTGTTGGTACACCCGGGAGAGTGTTTGATATGTTAAA CAGAAGATACCTTTCTCCAAAATGGATCAAAATGTTTGTTTTGGATGAAGCAGATGAAATGTTGAGCCGTGGTTTTAAGGATCAAATCTA TGAGATTTTCCAAAAACTAAACACAAGTATTCAGGTTGTGTTGCTTTCTGCCACAATGCCAACTGATGTGTTGGAAGTGACCAAAAAATT CATGAGAGATCCAATTCGAATTCTGGTGAAAAAGGAAGAATTGACCCTTGAAGGAATCAAACAGTTTTATATTAATGTTGAGAGAGAGGA ATGGAAGTTGGATACACTTTGTGACTTGTACGAGACACTGACCATTACACAGGCTGTTATTTTTCTCAATACGAGGCGCAAGGTGGACTG GCTGACTGAGAAGATGCATGCCAGAGACTTCACAGTTTCTGCTCTGCATGGTGACATGGACCAGAAGGAGAGAGATGTTATCATGAGGGA ATTCCGGTCAGGGTCAAGTCGTGTTCTGATCACTACTGACTTGTTGATTTAGCATGTAGACTGCTGGGGCAATCAATGGATGAAAGTGGA TTACCACAGCTGACCAGTTATGATTGTGAAGTTAATGCTCCTATACAAGGCAGCAGAAACCTACTGCAGGGTGAAGAATTACTCAGAGCT TTGGATCAAGTTAACTGAGCTTTTTCTTAATTTCATTCCTTTTTTTGGACACTGGTGGCTCATTACCTAAAGCAGTCTATTTATATTTTC TACATCTAATTTTAGAAGCCTGGCTACAATACTGCACAAACTTGGTTAGTTCAATTTTGATCCCCTTTCTACTTAATTTACATTAATGCT CTTTTTTAGTATGTTCTTTAATGCTGGATCACAGACAGCTCATTTTCTCAGTTTTTTGGTATTTAAACCATTGCATTGCAGTAGCATCAT TTTAAAAAATGCACCTTTTTATTTATTTATTTTTGGCTAGGGAGTTTATCCCTTTTTCGAATTATTTTTAAGAAGATGCCAATATAATTT TTGTAAGAAGGCAGTAACCTTTCATCATGATCATAGGCAGTTGAAAAATTTTTACACCTTTTTTTTCACATTTTACATAAATAATAATGC TTTGCCAGCAGTACGTGGTAGCCACAATTGCACAATATATTTTCTTAAAAAATACCAGCAGTTACTCATGGAATATATTCTGCGTTTATA AAACTAGTTTTTAAGAAGAAATTTTTTTTGGCCTATGAAATTGTTAAACCTGGAACATGACATTGTTAATCATATAATAATGATTCTTAA ATGCTGTATGGTTTATTATTTAAATGGGTAAAGCCATTTACATAATATAGAAAGATATGCATATATCTAGAAGGTATGTGGCATTTATTT GGATAAAATTCTCAATTCAGAGAAATCATCTGATGTTTCTATAGTCACTTTGCCAGCTCAAAAGAAAACAATACCCTATGTAGTTGTGGA AGTTTATGCTAATATTGTGTAACTGATATTAAACCTAAATGTTCTGCCTACCCTGTTGGTATAAAGATATTTTGAGCAGACTGTAAACAA GAAAAAAAAAATCATGCATTCTTAGCAAAATTGCCTAGTATGTTAATTTGCTCAAAATACAATGTTTGATTTTATGCACTTTGTCGCTAT TAACATCCTTTTTTTCATGTAGATTTCAATAATTGAGTAATTTTAGAAGCATTATTTTAGGAATATATAGTTGTCACAGTAAATATCTTG TTTTTTCTATGTACATTGTACAAATTTTTCATTCCTTTTGCTCTTTGTGGTTGGATCTAACACTAACTGTATTGTTTTGTTACATCAAAT >25934_25934_5_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000440191_HIF1A_chr14_62213652_ENST00000337138_length(amino acids)=335AA_BP= MSGGSADYNSREHGGPEGMDPDGVIESNWNEIVDNFDDMNLKESLLRGIYAYGFEKPSAIQQRAIIPCIKGYDVIAQAQSGTGKTATFAI SILQQLEIEFKETQALVLAPTRELAQQIQKVILALGDYMGATCHACIGGTNVRNEMQKLQAEAPHIVVGTPGRVFDMLNRRYLSPKWIKM FVLDEADEMLSRGFKDQIYEIFQKLNTSIQVVLLSATMPTDVLEVTKKFMRDPIRILVKKEELTLEGIKQFYINVEREEWKLDTLCDLYE -------------------------------------------------------------- >25934_25934_6_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000440191_HIF1A_chr14_62213652_ENST00000394997_length(transcript)=2361nt_BP=1036nt CTTTTCAGTCGGGCGCTGAGTGGTTTTTCGGATCATGTCTGGTGGCTCCGCGGATTATAACAGCAGAGAACATGGCGGCCCAGAGGGAAT GGACCCCGATGGTGTCATCGAGAGCAACTGGAATGAGATTGTTGATAACTTTGATGATATGAATTTAAAGGAGTCTCTCCTTCGTGGCAT CTATGCTTACGGTTTTGAGAAGCCTTCCGCTATTCAGCAGAGAGCTATTATTCCCTGTATTAAAGGGTATGATGTGATTGCTCAAGCTCA GTCAGGTACTGGCAAGACAGCCACATTTGCTATTTCCATCCTGCAACAGTTGGAGATTGAGTTCAAGGAGACCCAAGCACTAGTATTGGC CCCCACCAGAGAACTGGCTCAACAGATCCAAAAGGTAATTCTGGCACTTGGAGACTATATGGGAGCCACTTGTCATGCCTGCATTGGTGG AACAAATGTTCGAAATGAAATGCAAAAACTGCAGGCTGAAGCACCACATATTGTTGTTGGTACACCCGGGAGAGTGTTTGATATGTTAAA CAGAAGATACCTTTCTCCAAAATGGATCAAAATGTTTGTTTTGGATGAAGCAGATGAAATGTTGAGCCGTGGTTTTAAGGATCAAATCTA TGAGATTTTCCAAAAACTAAACACAAGTATTCAGGTTGTGTTGCTTTCTGCCACAATGCCAACTGATGTGTTGGAAGTGACCAAAAAATT CATGAGAGATCCAATTCGAATTCTGGTGAAAAAGGAAGAATTGACCCTTGAAGGAATCAAACAGTTTTATATTAATGTTGAGAGAGAGGA ATGGAAGTTGGATACACTTTGTGACTTGTACGAGACACTGACCATTACACAGGCTGTTATTTTTCTCAATACGAGGCGCAAGGTGGACTG GCTGACTGAGAAGATGCATGCCAGAGACTTCACAGTTTCTGCTCTGCATGGTGACATGGACCAGAAGGAGAGAGATGTTATCATGAGGGA ATTCCGGTCAGGGTCAAGTCGTGTTCTGATCACTACTGACTTGTTGATTTAGCATGTAGACTGCTGGGGCAATCAATGGATGAAAGTGGA TTACCACAGCTGACCAGTTATGATTGTGAAGTTAATGCTCCTATACAAGGCAGCAGAAACCTACTGCAGGGTGAAGAATTACTCAGAGCT TTGGATCAAGTTAACTGAGCTTTTTCTTAATTTCATTCCTTTTTTTGGACACTGGTGGCTCATTACCTAAAGCAGTCTATTTATATTTTC TACATCTAATTTTAGAAGCCTGGCTACAATACTGCACAAACTTGGTTAGTTCAATTTTGATCCCCTTTCTACTTAATTTACATTAATGCT CTTTTTTAGTATGTTCTTTAATGCTGGATCACAGACAGCTCATTTTCTCAGTTTTTTGGTATTTAAACCATTGCATTGCAGTAGCATCAT TTTAAAAAATGCACCTTTTTATTTATTTATTTTTGGCTAGGGAGTTTATCCCTTTTTCGAATTATTTTTAAGAAGATGCCAATATAATTT TTGTAAGAAGGCAGTAACCTTTCATCATGATCATAGGCAGTTGAAAAATTTTTACACCTTTTTTTTCACATTTTACATAAATAATAATGC TTTGCCAGCAGTACGTGGTAGCCACAATTGCACAATATATTTTCTTAAAAAATACCAGCAGTTACTCATGGAATATATTCTGCGTTTATA AAACTAGTTTTTAAGAAGAAATTTTTTTTGGCCTATGAAATTGTTAAACCTGGAACATGACATTGTTAATCATATAATAATGATTCTTAA ATGCTGTATGGTTTATTATTTAAATGGGTAAAGCCATTTACATAATATAGAAAGATATGCATATATCTAGAAGGTATGTGGCATTTATTT GGATAAAATTCTCAATTCAGAGAAATCATCTGATGTTTCTATAGTCACTTTGCCAGCTCAAAAGAAAACAATACCCTATGTAGTTGTGGA AGTTTATGCTAATATTGTGTAACTGATATTAAACCTAAATGTTCTGCCTACCCTGTTGGTATAAAGATATTTTGAGCAGACTGTAAACAA GAAAAAAAAAATCATGCATTCTTAGCAAAATTGCCTAGTATGTTAATTTGCTCAAAATACAATGTTTGATTTTATGCACTTTGTCGCTAT TAACATCCTTTTTTTCATGTAGATTTCAATAATTGAGTAATTTTAGAAGCATTATTTTAGGAATATATAGTTGTCACAGTAAATATCTTG TTTTTTCTATGTACATTGTACAAATTTTTCATTCCTTTTGCTCTTTGTGGTTGGATCTAACACTAACTGTATTGTTTTGTTACATCAAAT >25934_25934_6_EIF4A2-HIF1A_EIF4A2_chr3_186505373_ENST00000440191_HIF1A_chr14_62213652_ENST00000394997_length(amino acids)=335AA_BP= MSGGSADYNSREHGGPEGMDPDGVIESNWNEIVDNFDDMNLKESLLRGIYAYGFEKPSAIQQRAIIPCIKGYDVIAQAQSGTGKTATFAI SILQQLEIEFKETQALVLAPTRELAQQIQKVILALGDYMGATCHACIGGTNVRNEMQKLQAEAPHIVVGTPGRVFDMLNRRYLSPKWIKM FVLDEADEMLSRGFKDQIYEIFQKLNTSIQVVLLSATMPTDVLEVTKKFMRDPIRILVKKEELTLEGIKQFYINVEREEWKLDTLCDLYE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for EIF4A2-HIF1A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000323441 | 12 | 14 | 1_401 | 734.0 | 736.0 | TSGA10 | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000337138 | 13 | 15 | 1_401 | 776.3333333333334 | 827.0 | TSGA10 | |
| Tgene | HIF1A | chr3:186505373 | chr14:62213652 | ENST00000539097 | 13 | 15 | 1_401 | 800.3333333333334 | 851.0 | TSGA10 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for EIF4A2-HIF1A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for EIF4A2-HIF1A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies